量化感知训练与 PyTorch 的哪些事
大家好呀!今天咱们要来聊聊一个超厉害的技术——量化感知训练(Quantization-Aware Training,简称 QAT)
在神经网络的世界里,我们总是想方设法地让模型变得更准确、更高效,毕竟谁不想自己的模型在边缘设备上也能大展身手呢?不过,光靠改变架构、融合多层或者编译模型这些招数,有时候还是不够看的。为了打造又小又准的模型,研究人员们可是想了不少办法,主要有这么三种:
- 模型量化:这个招数的精髓就是把模型的权重从高精度(比如 16 位浮点数)变成低精度(比如 8 位整数),这样一来,模型的内存占用和计算需求就能大大减少啦。
- 模型剪枝:顾名思义,就是把训练好的神经网络里那些不太重要的神经元或者权重给去掉,让模型的结构变得更简单,而且还不怎么影响性能哦。
- 知识蒸馏(也叫“教师-学生训练”):想象一下,有个又大又复杂的模型(教师)特别厉害,它能把一些高级的知识传递给一个更小、更高效的模型(学生)。这个过程就像是教师把自己的“软标签”(也就是对不同类别相似性的高级理解)教给学生,让学生能够更好地泛化,而不是像教师那样只用那种尖锐的 one-hot 编码表示哦。
接下来,咱们就来深入了解一下模型量化到底是个啥,它有哪两种技术,还有怎么用 PyTorch 把它们实现出来。
量化到底是个啥玩意儿?
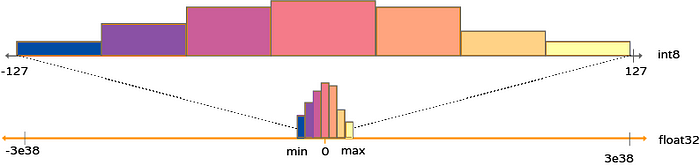
这张图展示了一个从 FP32 到 INT8 的代表性映射
量化可是优化神经网络的杀手锏之一呢!它的原理说起来也挺简单的,就是把神经网络里的模型数据(包括网络参数和激活值)从高精度的浮点数(通常是 16 位)转换成低精度的表示(通常是 8 位整数)。这么做的好处可多了去了,比如说:
- GPU 们现在可以用那种又快又省成本的 8 位核心(Nvidia GPU 的 Tensor Cores 就是这么干的)来计算卷积和矩阵乘法这些操作啦,这样一来,计算吞吐量就能蹭蹭往上涨咯。
- 有些层是带宽受限的(也就是内存受限),它们大部分时间都在忙着读写数据呢。对于这些层来说,减少计算时间并不能减少它们的总体运行时间。不过,要是减少了带宽需求,那可就大不一样啦!
- 模型的内存占用变小了,这意味着模型需要的存储空间少了,参数更新的体积也小了,缓存利用率还能提高呢,总之好处多多呀。
- 最后,把数据从内存搬到计算单元这个过程可是既耗时又耗能的哦。要是把精度从 16 位降到 8 位,那数据量就能减少一半,这样一来,就能节省不少能耗咯。
当然啦,把高精度数字映射到低精度数字的方法可不止一种,比如零点量化、绝对最大值(absmax)量化等等。不过,咱们今天就不深入这些细节啦。要是你对这些感兴趣,可以去瞅瞅 Hao Wu et al. 和 Amir Gholani et al. 写的那两篇技术论文哦。
量化的两种招式

这张图是我自己画的哦。
量化模型主要有两种方法:
1. 训练后量化(PTQ)
训练后量化(PTQ)是在模型训练完成之后才施展的一种招式。它不需要重新训练模型,而是通过一个小的校准数据集来确定最优的量化参数,从而把模型从高精度转换成低精度。这个过程主要是收集模型激活值的统计信息,然后计算合适的量化参数,尽量减少浮点表示和量化表示之间的差异。
PTQ 可以说是非常节省资源、实现和部署起来也很快呢,特别适合那些没办法重新训练模型的情况。不过,它的缺点也很明显哦,模型的准确性会有所下降,而且需要仔细地校准和调整参数,所以它更适合用来快速原型制作,而不是真正部署到实际场景中。
训练后量化又可以细分为两种小招式:
1.1)动态训练后量化
这个小招式的核心是在推理过程中,根据运行时输入模型的数据分布,实时地调整激活值的范围。
1.2)静态训练后量化
在这个方法里,会多出一个校准步骤。具体来说,就是用一个有代表性的数据集来估计激活值的范围,这个估计过程是在全精度下完成的,目的是尽量减少误差。等到估计完成之后,再把激活值缩放到低精度的数据类型中去。
2. 量化感知训练(QAT)
QAT 可是另一种大招哦!它是在模型训练过程中就模拟量化效果的一种方法。具体来说,就是在训练过程中引入“假量化”操作,这些操作能够模拟低精度对权重和激活值的影响。换句话说,就是带着量化约束来训练模型。模型在训练过程中会用到一种叫做**直通估计器(Straight-Through Estimator,简称 STE)**的技术来计算梯度,这样一来,模型就能更好地适应低精度的环境啦。
QAT 的好处在于,模型在训练过程中就能适应量化带来的噪声,所以最终的量化模型在准确性上通常会比 PTQ 的要好不少。不过,这也意味着 QAT 需要更多的计算资源和时间,因为要重新训练模型,而且实现起来也相对复杂一些。不过,要是你的模型对量化误差比较敏感,那 QAT 绝对是个不错的选择哦!
量化感知训练到底是怎么工作的呢?
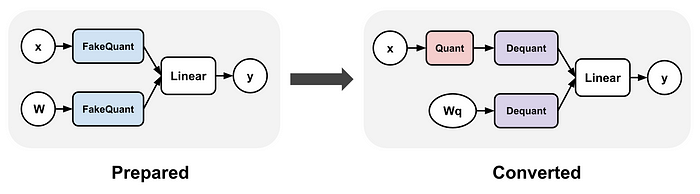
这张图展示了 QAT 在 PyTorch 中的工作原理哦。
从前面的介绍里,咱们已经知道 QAT 的好处啦——和 PTQ 不同,QAT 是在训练过程中插入“假量化”模块的。这样一来,模型就能“看到”量化噪声,并且学会补偿这些噪声,最终得到的量化模型在准确性上就能和全精度模型相当接近啦。QAT 的工作流程大致如下:
- 准备阶段:把敏感层(比如卷积层、线性层、激活层等)替换成带有量化模拟功能的包装器。在 PyTorch 里,这可以通过
prepare_qat或者prepare_qat_fx来完成哦。 - 训练阶段:在每次前向传播过程中,权重和激活值都会被“假量化”——也就是像在 INT8/INT4 中那样进行四舍五入和限制范围。在反向传播过程中,会用到 STE,让梯度就像量化是恒等函数一样流动。
- 转换阶段:训练完成之后,用
convert或者convert_fx把假量化模块换成真正的量化内核。这样一来,模型就准备好进行高效的int8 / int4推理啦。
假量化的数学原理
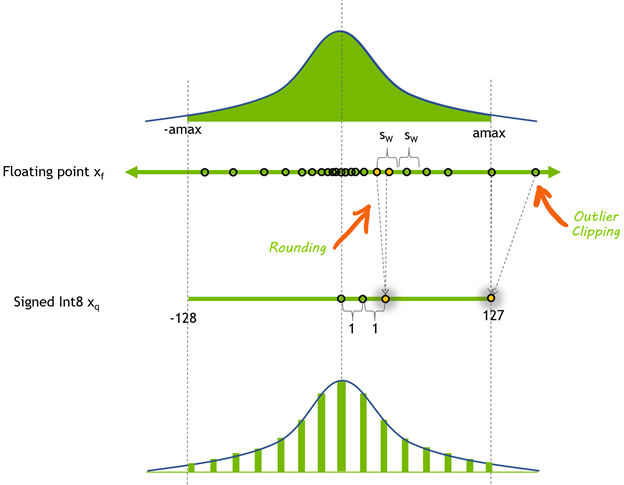
这张图展示了简单的量化过程。
咱们先不深入那些复杂的技巧,简单来说,量化过程是这样的:
假设 x_float 是一个实值激活值。均匀仿射量化使用以下公式:
scale = x max − x min q max − q min \text{scale} = \frac{x_{\text{max}} - x_{\text{min}}}{q_{\text{max}} - q_{\text{min}}} scale=qmax−qminxmax−xmin
zeroPt = round ( q min − x min scale ) \text{zeroPt} = \text{round}\left(\frac{q_{\text{min}} - x_{\text{min}}}{\text{scale}}\right) zeroPt=round(scaleqmin−xmin)
x q = clamp ( round ( x float scale ) + zeroPt , q min , q max ) x_q = \text{clamp}\left(\text{round}\left(\frac{x_{\text{float}}}{\text{scale}}\right) + \text{zeroPt}, q_{\text{min}}, q_{\text{max}}\right) xq=clamp(round(scalexfloat)+zeroPt,qmin,qmax)
x deq = ( x q − zeroPt ) × scale x_{\text{deq}} = (x_q - \text{zeroPt}) \times \text{scale} xdeq=(xq−zeroPt)×scale
在 QAT 中,假量化操作是这样的:
x fake = ( round ( x float scale ) + zeroPt − zeroPt ) × scale x_{\text{fake}} = \left(\text{round}\left(\frac{x_{\text{float}}}{\text{scale}}\right) + \text{zeroPt} - \text{zeroPt}\right) \times \text{scale} xfake=(round(scalexfloat)+zeroPt−zeroPt)×scale
所以,x_fake 仍然是浮点数,但它现在被限制在了 int8 张量会占据的相同离散格点上了。
梯度流动——直通估计器
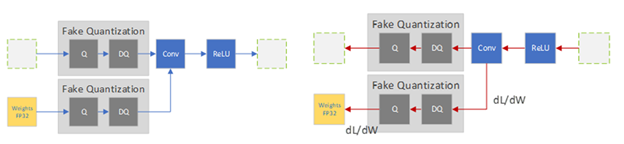
这张图展示了 QAT 假量化操作在训练的前向传播(左边)和反向传播(右边)过程哦,图片来源是 这里。
四舍五入操作是不可微的,所以 PyTorch 用的是:
d L d x float ≈ d L d x fake \frac{dL}{dx_{\text{float}}} \approx \frac{dL}{dx_{\text{fake}}} dxfloatdL≈dxfakedL
在反向传播过程中,直接把假量化模块当作恒等函数来处理梯度,这样优化器就能调整上游的权重,以抵消量化噪声啦。
结果就是,学到的权重会自然地落在整数中心附近,而且调整后的 scale 和 zeroPt 能够最小化总的重构误差哦。
动手实践:用 PyTorch 实现量化
PyTorch 提供了三种不同的量化模式,接下来咱们就来一一看看吧。
1. Eager 模式量化
这是一个还在测试阶段的功能哦。用户需要手动进行融合,并且指定量化和反量化的具体位置。而且,这个模式只支持模块,不支持函数式操作。
下面的代码片段展示了从模型定义到 QAT 准备,再到最终的 int8 转换的每一步哦:
import os, torch, torch.nn as nn, torch.optim as optim# 1. 定义模型,包含 QuantStub 和 DeQuantStub
class QATCNN(nn.Module):def __init__(self):super().__init__()self.quant = torch.quantization.QuantStub() # 量化入口self.conv1 = nn.Conv2d(1, 16, 3, padding=1) # 第一个卷积层self.relu1 = nn.ReLU() # 第一个激活层self.pool = nn.MaxPool2d(2) # 池化层self.conv2 = nn.Conv2d(16, 32, 3, padding=1) # 第二个卷积层self.relu2 = nn.ReLU() # 第二个激活层self.fc = nn.Linear(32*14*14, 10) # 全连接层self.dequant = torch.quantization.DeQuantStub()# 反量化出口def forward(self, x):x = self.quant(x) # 进入量化x = self.pool(self.relu1(self.conv1(x))) # 第一个卷积块x = self.relu2(self.conv2(x)) # 第二个卷积块x = x.flatten(1) # 展平x = self.fc(x) # 全连接层return self.dequant(x) # 退出量化# 2. QAT 准备
model = QATCNN()
model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm') # 设置量化配置
torch.quantization.prepare_qat(model, inplace=True) # 准备 QAT# 3. 简单的训练循环
opt = optim.SGD(model.parameters(), lr=1e-2) # 优化器
crit = nn.CrossEntropyLoss() # 损失函数
for _ in range(3): # 训练 3 个 epochinp = torch.randn(16,1,28,28) # 随机输入tgt = torch.randint(0,10,(16,)) # 随机目标opt.zero_grad() # 清空梯度crit(model(inp), tgt).backward() # 反向传播opt.step() # 更新参数# 4. 转换为真正的 int8 模型
model.eval() # 切换到评估模式
int8_model = torch.quantization.convert(model) # 转换模型# 5. 查看存储节省
torch.save(model.state_dict(), "fp32.pth") # 保存 FP32 模型
torch.save(int8_model.state_dict(), "int8.pth") # 保存 INT8 模型
mb = lambda p: os.path.getsize(p)/1e6 # 计算文件大小(MB)
print(f"FP32: {mb('fp32.pth'):.2f} MB vs INT8: {mb('int8.pth'):.2f} MB") # 打印大小对比
预期输出:模型大小大约会减少 4 倍,而且在类似 MNIST 的数据上,准确率的损失不会超过 1% 哦。
为啥能行:torch.quantization.prepare_qat 会递归地为每个符合条件的层包装 FakeQuantize 模块,而默认的 FBGEMM qconfig 会选择适合服务器/边缘 CPU 的每张量权重观察器和每通道激活观察器。
2. FX 图模式量化
这是一种自动化的量化工作流哦,目前还在维护阶段。它在 Eager 模式量化的基础上进行了升级,支持函数式操作,并且能够自动完成量化过程。不过,用户可能需要对自己的模型进行一些重构,以确保兼容性。
需要注意的是,由于可能存在符号追踪的问题,这个模式可能并不适用于所有模型。这也意味着,你可能需要对 torch.fx 有一定的了解哦。下面是一个使用这个模式的代码示例:
import torch, torchvision.models as models
from torch.ao.quantization import get_default_qat_qconfig_mapping
from torch.ao.quantization import prepare_qat_fx, convert_fxmodel = models.resnet18(weights=None) # 或者使用预训练模型
model.train()# 一行代码搞定 qconfig 映射
qmap = get_default_qat_qconfig_mapping("fbgemm")
# 图重写
model_prepared = prepare_qat_fx(model, qmap)# 微调几个 epoch
model_prepared.eval()
int8_resnet = convert_fx(model_prepared)
FX 模式是在图级别进行操作的哦:比如 conv2d、batch_norm 和 relu 这些操作会被自动融合,从而生成更精简的内核,在 CPU 上的延迟也会更小哦。
3. PyTorch 2 导出量化
如果你打算把导出的程序部署到 C++ 运行时,那 PT2E(PyTorch 2 Export)就是你的不二之选咯。这是 PyTorch 2.1 中推出的一种全新的全图量化工作流,专门为通过 torch.export 捕获的模型设计的。整个流程只需要几行代码就能搞定哦:
import torch
from torch import nn
from torch._export import capture_pre_autograd_graph
from torch.ao.quantization.quantize_pt2e import (prepare_qat_pt2e, convert_pt2e)
from torch.ao.quantization.quantizer.xnnpack_quantizer import (XNNPACKQuantizer, get_symmetric_quantization_config)class Tiny(nn.Module):def __init__(self): super().__init__(); self.fc=nn.Linear(8,4)def forward(self,x): return self.fc(x)ex_in = (torch.randn(2,8),)
exported = torch.export.export_for_training(Tiny(), ex_in).module()
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
qat_mod = prepare_qat_pt2e(exported, quantizer)# 微调模型 ...
int8_mod = convert_pt2e(qat_mod)
torch.ao.quantization.move_exported_model_to_eval(int8_mod)
最终生成的图可以直接用于 torch::deploy,或者提前编译到移动引擎中哦。
加餐福利:大型语言模型 Int4/Int8 混合演示
虽然这不是一个明确的 API,但 torchao/torchtune 提供了一些用于极致压缩的原型量化器哦:
import torch
from torchtune.models.llama3 import llama3
from torchao.quantization.prototype.qat import Int8DynActInt4WeightQATQuantizermodel = llama3(vocab_size=4096, num_layers=16,num_heads=16, num_kv_heads=4,embed_dim=2048, max_seq_len=2048).cuda()qat_quant = Int8DynActInt4WeightQATQuantizer()
model = qat_quant.prepare(model).train()# 开始微调(类似 Kathy 的微调方式)
optim = torch.optim.AdamW(model.parameters(), 1e-4)
lossf = torch.nn.CrossEntropyLoss()
for _ in range(100):ids = torch.randint(0,4096,(2,128)).cuda()label = torch.randint(0,4096,(2,128)).cuda()loss = lossf(model(ids), label)optim.zero_grad(); loss.backward(); optim.step()model_quant = qat_quant.convert(model)
torch.save(model_quant.state_dict(),"llama3_int4int8.pth")
模型的激活值运行在 int8 上,权重运行在 int4 上,这样在单个 A100 GPU 上就能获得超过 2 倍的速度提升,同时内存占用减少约 60%,而且困惑度的下降不到 0.8 pp 哦。
如果你想了解更多关于使用 torchao 和 torchtune 进行 LLM 量化的信息,我强烈推荐你去读一读 PyTorch 的相关博客哦。
最佳实践
为了让模型在量化后能够最大程度地节省存储空间,同时又不损失太多的准确性,下面这些小贴士你可得记好了哦:
- 先用 PTQ 暖身:如果 PTQ 的准确性损失不到 2%,那么通常只需要进行短暂的 QAT 微调(5-10 个 epoch)就足够啦。
- 进行消融分析:通过消融分析来找出哪些层对量化比较敏感哦。如果量化某一层会导致性能大幅下降,那可以考虑保持该层的权重不变。
- 尽早融合操作:把
Conv + BN + ReLU这些操作尽早融合起来,能够稳定观察器的范围,并且还能显著提高准确性呢。 - 冻结批量归一化统计量:在训练了几轮之后,调用
torch.ao.quantization.disable_observer,然后冻结批量归一化统计量。这样可以防止范围出现振荡哦。 - 监控直方图:使用
torch.ao.quantization.get_observer_state_dict()或者 Netron 来找出异常值哦。 - 调整学习率计划:使用较小的学习率(不超过 1e-3)可以避免在 STE 近似值起作用时出现过度调整的情况哦。
- 每通道权重量化:这比每张量量化要好一倍呢,它已经被设置为卷积操作的默认量化方式了。
- 混合精度:如果准确性还是下降了,可以考虑把第一层和最后一层保持在
fp16,这样会更安全一些哦。 - 硬件检查:对于 x86 架构,使用
FBGEMM;对于 ARM 架构,使用QNNPACK/XNNPACK;选择与之匹配的 qconfig 哦。
总结
模型部署往往需要多管齐下的策略哦——打造出一个准确的模型其实只是第一步,真正难的是如何在大规模场景中进行部署。如果你的模型没办法承受 PTQ 带来的准确性损失,那 QAT 就是你的救星啦。不过,你得记住,在成功部署的过程中,需要考虑很多因素哦,包括目标平台以及它支持的操作等等。PyTorch 的成熟 QAT 工具链在这个时候就派上大用场啦,它能让量化任何模型都变得轻而易举——不管是简单的 CNN,还是拥有十亿参数的语言模型呢。
相关文章:

量化感知训练与 PyTorch 的哪些事
大家好呀!今天咱们要来聊聊一个超厉害的技术——量化感知训练(Quantization-Aware Training,简称 QAT) 在神经网络的世界里,我们总是想方设法地让模型变得更准确、更高效,毕竟谁不想自己的模型在边缘设备上…...

【Mac 从 0 到 1 保姆级配置教程 15】- Python 环境一键安装与配置,就是这么的丝滑
文章目录 前言安装 Python 环境VSCode 配置Python 环境NeoVim 配置 Python 环境(选看)1. Python LSP 配置2. 打开 python 语言支持 最后参考资料系列教程 Mac 从 0 到 1 保姆级配置教程目录,点击即可跳转对应文章: 【Mac 从 0 到 …...
—— CSS实现热搜榜)
前端学习(3)—— CSS实现热搜榜
效果展示 具体的展示效果如下,可以直接在浏览器显示: 页面分为两部分,一部分是 body 标签里的 html 结构,一部分是 style 标签里的CSS代码(页面布局的部分数据直接在代码里显示了) 一,html结…...
)
大数据——解决Matplotlib 字体不足问题(Linux\mac\windows)
1、将下载好的字体文件放到文件夹中 谷歌官方字体 import matplotlib print(matplotlib.matplotlib_fname())cp NotoSansSC-Regular.ttf /data/home/miniconda3/envs/python3128/lib/python3.12/site-packages/matplotlib/mpl-data/fonts/ttf/cp wqy-zenhei.ttc /data/home/m…...
顺序表与单向链表)
嵌入式培训之数据结构学习(二)顺序表与单向链表
目录 一、顺序表 (一)顺序表的基本操作 1、创建顺序表 2、销毁顺序表 3、遍历顺序表 4、尾插,在顺序表的最后插入元素 5、判断表是否满 6、判断表是否空 7、按指定位置插入元素 8、查找元素,根据名字 9、根据名字修改指…...

PyInstaller 打包后 Excel 转 CSV 报错解决方案:“excel file format cannot be determined“
一、问题背景 在使用 Python 开发 Excel 转 CSV 工具时,直接运行脚本(python script.py)可以正常工作,但通过 PyInstaller 打包成可执行文件后,出现以下报错: excel file format cannot be determined, you must specify an engine manually 该问题通常发生在使用pandas…...

鸿蒙 PC 发布之后,想在技术上聊聊它的未来可能
最近鸿蒙 PC 刚发布完,但是发布会没公布太多技术细节,基本上一些细节都是通过自媒体渠道获取,首先可以确定的是,鸿蒙 PC 本身肯定是无法「直接」运行 win 原本的应用,但是可以支持手机上「原生鸿蒙」的应用,…...
)
HarmonyOS 【诗韵悠然】AI古诗词赏析APP开发实战从零到一系列(一、开篇,项目介绍)
诗词,作为中国传统文化的瑰宝,承载着中华民族几千年的思想智慧和审美情趣。然而,在现代社会快节奏的生活压力下,诗词文化却逐渐被忽视,更多的人感到诗词艰涩深奥,难以亲近。与此同时,虽然市场上…...
)
实物工厂零件画图案例(上)
文章目录 滑台气缸安装板旋转气缸安装板张紧调节块长度调节块双轴气缸安装板步进电机安装板梯形丝杆轴承座 简介:案例点击此处下载,这次的这几个案例并没有很大的难度,练习这几个案例最为重要的一点就是知道:当你拿到一个实物的时…...

js中的同步方法及异步方法
目录 1.代码说明 2.async修饰的方法和非async修饰的方法的区别 3.不使用await的场景 4.总结 1.代码说明 const saveTem () > {// 校验处理const res check()if (!res) {return}addTemplateRef.value.openModal() } 这段代码中,check方法返回的是true和fal…...

C 语言_基础语法全解析_深度细化版
一、C 语言基本结构 1.1 程序组成部分 一个完整的 C 程序由以下部分组成: 预处理指令:以#开头,在编译前处理 #include <stdio.h> // 引入标准库 #define PI 3.14159 // 定义常量全局变量声明:在所有函数外部定义的变量 int globalVar = 10; // 全局变量函数定义…...

【Linux系列】dd 命令的深度解析与应用实践
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

ETL背景介绍_1:数据孤岛仓库的介绍
1 ETL介绍 1.1 数据孤岛 随着企业内客户数据大量的涌现,单个数据库已不再足够。为了储存这些数据,公司通常会建立多个业务部门组织的数据库来保存数据。比如,随着数据量的增长,公司通常可能会构建数十个独立运行的业务数据库&am…...

【周输入】510周阅读推荐-1
本号一年了,有一定的成长,也有很多读者和点赞。自觉更新仍然远远不够,需要继续努力。 但是还是要坚持2点: 在当前这个时代,信息大爆炸,层次不齐,不追加多, 信息输入可以很多&#x…...

Games101作业四
作业0到作业3的代码 这次是实现 de Casteljau 算法,以及绘制 Bezier 曲线,比上次简单 核心思想就是递归,原理忘了就去看第十一节课,从15:00开始的 GAMES101-现代计算机图形学入门-闫令琪 代码 先实现贝塞尔曲线 cv::Point2f recursive_bezier(const std::…...

从Aurora 架构看数据库计算存储分离架构
单就公有云来说,现在云数据面临的挑战有以下 5 个: 跨 AZ 的可用性与数据安全性。 现在都提多 AZ 部署,亚马逊在全球有 40 多个 AZ, 16 个 Region,基本上每一个 Region 之内的那些关键服务都是跨 3 个 AZ。你要考虑整个…...
:分页)
ElasticSearch深入解析(十一):分页
在Elasticsearch中,常用的分页方案有from size、search_after和scroll三种,适用于不同场景。from size基于偏移量分页,是全局排序后的切片查询,适用于小数据量、浅分页场景,但深度分页性能差,且有默认上限…...

【MySQL】MySQL数据库结构与操作
目录 一. 数据库的概念 二. 数据库的分类 三. 初始MySQL数据库 四. 数据库操作 1)创建数据库 2) 查看数据库 3)选中数据库 4)删除数据库 五. SQL数据类型 1)整型和浮点型 2)字符串类型 3)时间…...

Vue框架的基本介绍
目录 一.Vue 1.概述 2.三大主流框架 3.优点: 二.Vue搭建 三.语法 1.基本框架 2.插值表达式 3.Vue指令 1.v-text: 2.v-html: 编辑3.v-model: 4.v-on: 5.v-show: 6.v-if: 7.v-else: 8.v-bind: 9.v-for: 一.Vue 1.概述 Vue是一款用于构建用户界面的渐进式的…...

Web 架构之攻击应急方案
文章目录 一、引言二、常见 Web 攻击类型及原理2.1 SQL 注入攻击2.2 跨站脚本攻击(XSS)2.3 分布式拒绝服务攻击(DDoS) 三、攻击检测3.1 日志分析3.2 入侵检测系统(IDS)/入侵防御系统(IPS&#x…...
)
xss-labs靶场基础8-10关(记录学习)
前言: 内容: 第八关 关卡资源网站,html编码网站(两个网站,一个是实体编号转义(只对特殊字符有效,字母无效)、实体符号转义) 在线Html实体编码解码-HTML Entity Encodi…...

arctanx 导数 泰勒展开式证明
你提供的推导内容非常清晰,条理分明。下面是对 d d x arctan x 1 1 x 2 \frac{d}{dx} \arctan x \frac{1}{1 x^2} dxdarctanx1x21 的总结与适当补充: ✅ 结论 d d x arctan x 1 1 x 2 \frac{d}{dx} \arctan x \frac{1}{1 x^2} dxda…...
)
基于Java的家政服务平台设计与实现(代码+数据库+LW)
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本家政服务平台就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息&a…...

SpringBoot的外部化配置
一、什么是外部化配置 外部化配置是指把应用程序中各种可配置的参数、属性等信息,从代码内部提取出来,放置在外部的配置文件、数据库或配置中心等地方(比如使用.properties、.yml 或.xml 等格式的文件)进行管理。提高应用程序的可…...

Java鼠标事件监听器MouseListener、MouseMotionListener和MouseWheelListener
Java鼠标事件监听器MouseListener、MouseMotionListener和MouseWheelListener java中创建鼠标,键盘的事件行为监听器的几种方法 这里以鼠标点击事件监听器为例,其他也是一样创建。 常用的消息监听器对象 1:点击事件监听器 ActionListener 2:按键事件监…...

第三方支付公司如何代付和入账?
通俗来说,就是企业把钱打到第三方公司账户上,再由第三方公司把钱打入客户指定账户。 那么第三方支付入账流程是怎样的呢? 第一,企业向第三方支付公司指定账户充值打款;第二,企业提交代付银行卡信息后台操…...

.NET8关于ORM的一次思考
文章目录 前言一、思路二、实现ODBC>SqlHelper.cs三、数据对象实体化四、SQL生成SqlBuilder.cs五、参数注入 SqlParameters.cs六、反射 SqlOrm.cs七、自定义数据查询八、总结 前言 琢磨着在.NET8找一个ORM,对比了最新的框架和性能。 框架批量操作性能SQL控制粒…...

LlamaIndex 第八篇 MilvusVectorStore
本指南演示了如何使用 LlamaIndex 和 Milvus 构建一个检索增强生成(RAG)系统。 RAG 系统将检索系统与生成模型相结合,根据给定的提示生成新的文本。该系统首先使用 Milvus 等向量相似性搜索引擎从语料库中检索相关文档,然后使用生…...

记录为什么LIst数组“增删慢“,LinkedList链表“查改快“?
数组(Array) 增删慢:对于数组来说,增加或删除元素的操作可能会比较慢,特别是当你需要在数组的开头或中间进行这些操作时。这是因为这些操作通常需要移动数组中的其他元素以保持连续性。例如,如果你想要在数…...

【论文阅读】Dip-based Deep Embedded Clustering with k-Estimation
摘要 近年来,聚类与深度学习的结合受到了广泛关注。无监督神经网络,如自编码器,能够自主学习数据集中的关键结构。这一思想可以与聚类目标结合,实现对相关特征的自动学习。然而,这类方法通常基于 k-means 框架&#x…...

ARFoundation 图片识别,切换图片克隆不同的追踪模型
场景搭建: 你可以把我的代码发给AI,去理解 using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.XR; using UnityEngine.XR.ARFoundation; using UnityEngine.XR.ARSubsystems; using TMPro; using Unit…...

鸿蒙next播放B站视频横屏后的问题
(此文讨论范围为b站视频链接,且不包括b站直播链接;android/iOS的webview播放b站视频完全没有这么多问题) 1、竖屏播放没问题 从一个竖屏页p1点击进入视频页p2,p2页仍为竖屏; p2页有一Web组件,…...

华为0507机试
题目二 建设基站 有一棵二叉树,每个节点上都住了一户居民。现在要给这棵树上的居民建设基站,每个基站只能覆盖她所在与相邻的节点,请问信号覆盖这棵树最少需要建设多少个基站 #include <bits/stdc.h> using namespace std;const int …...

apache2的默认html修改
使用127.0.0.1的时候,默认打开的是index.html,可以通过配置文件修改成我们想要的html vi /etc/apache2/mods-enabled/dir.conf <IfModule mod_dir.c>DirectoryIndex WS.html index.html index.cgi index.pl index.php index.xhtml index.htm <…...

EXCEL下拉菜单与交替上色设置
Excel/WPS 表格操作教程(双功能整合) 目录 功能一:交替行上色 Excel 操作WPS 操作 功能二:下拉菜单设置 Excel 操作WPS 操作 组合效果示例注意事项 功能一:交替行上色 Excel 操作 选中数据区域 拖动鼠标选择需要设置…...

list基础用法
list基础用法 1.list的访问就不能用下标[]了,用迭代器2.emplace_back()几乎是与push_back()用法一致,但也有差别3.insert(),erase()的用法4.reverse()5.排序6.合并7.unique()(去重)8.splice剪切再粘贴 1.list的访问就不能用下标[]了,用迭代器…...

鸿蒙PC版体验_画面超级流畅_具备terminal_无法安装windows、linux软件--纯血鸿蒙HarmonyOS5.0工作笔记017
鸿蒙NEXT和开源鸿蒙OpenHarmony现在已经开发实现统一,使用鸿蒙ArkTS开发的应用,可以直接 在开源鸿蒙上. 鸿蒙的terminal是使用的linux的语法,但是有很多命令,目前还不能使用,常用的ifconfig等是可以用的. 鸿蒙终于出来PC版了,虽然,不像Windows以及mac等,开放的命令那么多,但…...
)
Spring 集成 SM4(国密对称加密)
Spring 集成 SM4(国密对称加密)算法 主要用于保护敏感数据,如身份证、手机号、密码等。 下面是完整集成步骤(含工具类 使用示例),采用 Java 实现(可用于 Spring Boot)。 一、依赖引…...

deepseek梳理java高级开发工程师微服务面试题
Java微服务高级面试题与答案 一、微服务架构设计 1. 服务拆分原则 Q1:微服务拆分时有哪些核心原则?如何解决拆分后的分布式事务问题? 答案: 服务拆分五大原则: 1. 单一职责原则(SRP)- 每个…...

人事管理系统8
员工管理(分页查询、查看详情页、修改): 1. 分页查询 Staff.java 中加入部门名和岗位名两个属性以及对应的 get 和 set 方法。这两个属性没有数据库字段对应, 仅供前端显示用: private String departname; //部门名属…...

Stapi知识框架
一、Stapi 基础认知 1. 框架定位 自动化API开发框架:专注于快速生成RESTful API 约定优于配置:通过标准化约定减少样板代码 企业级应用支持:适合构建中大型API服务 代码生成导向:显著提升开发效率 2. 核心特性 自动CRUD端点…...
)
第三章 初始化配置(一)
我们首先介绍配置Logback的方法,并提供了许多示例配置脚本。在后面的章节中,我们将介绍Logback所依赖的配置框架Joran。 初始化配置 在应用程序代码中插入日志请求需要大量的规划和努力。观察表明,大约4%的代码用于记录。因此,即…...

WebGIS 开发中的数据安全与隐私保护:急需掌握的要点
在 WebGIS 开发中,数据安全与隐私保护是绝对不能忽视的问题!随着地理信息系统的广泛应用,越来越多的敏感数据被存储和传输,比如个人位置信息、企业地理资产等。一旦这些数据泄露,后果不堪设想。然而,很多开…...

C语言 ——— 函数栈帧的创建和销毁
目录 寄存器 mian 函数是被谁调用的 通过汇编了解函数栈帧的创建和销毁 转汇编后(Add函数之前的部分) 转汇编后(进入Add函数之前的部分) 转汇编后(正式进入Add函数的部分) 编辑 总结 局部变量…...
)
2025年真实面试问题汇总(二)
jdbc的事务是怎么开启的 在JDBC中,事务的管理是通过Connection对象控制的。以下是开启和管理事务的详细步骤: 1. 关闭自动提交模式 默认情况下,JDBC连接处于自动提交模式(auto-commit true),即每条SQL语…...

【用「概率思维」重新理解生活】
用「概率思维」重新理解生活:为什么你总想找的「确定答案」并不存在? 第1层:生活真相——所有结果都是「综合得分」 现象:我们总想找到“孩子生病是因为着凉”或“伴侣生气是因为那句话”的单一答案现实:每个结果背后…...

Redis——线程模型·
为什么Redis是单线程却仍能有10w/秒的吞吐量? 内存操作:Redis大部分操作都在内存中完成,并且采用了高效的数据结构,因此Redis的性能瓶颈可能是机器的内存或者带宽,而非CPU,既然CPU不是瓶颈,自然…...
)
APS排程系统(Advanced Planning and Scheduling,高级计划与排程系统)
APS排程系统(Advanced Planning and Scheduling,高级计划与排程系统)是一种基于供应链管理和约束理论的智能生产管理工具,旨在通过动态优化资源分配和生产流程,解决制造业中的复杂计划问题。以下是其核心要点解析&…...

首个窗口级无人机配送VLN系统!中科院LogisticsVLN:基于MLLM实现精准投递
导读 随着智能物流需求日益增长,特别是“最后一公里”配送场景的精细化,传统地面机器人逐渐暴露出适应性差、精度不足等瓶颈。为此,本文提出了LogisticsVLN系统——一个基于多模态大语言模型的无人机视觉语言导航框架,专为窗户级别…...

仓颉Magic亮相GOSIM AI Paris 2025:掀起开源AI框架新热潮
巴黎,2025年5月6日——由全球开源创新组织GOSIM联合CSDN、1ms.ai共同主办的 GOSIM AI Paris 2025 大会今日在法国巴黎盛大开幕。GOSIM 作为开源人工智能领域最具影响力的年度峰会之一,本届大会以“开放、协作、突破”为核心,汇聚了来自华为、…...