【论文阅读】Dip-based Deep Embedded Clustering with k-Estimation

摘要
近年来,聚类与深度学习的结合受到了广泛关注。无监督神经网络,如自编码器,能够自主学习数据集中的关键结构。这一思想可以与聚类目标结合,实现对相关特征的自动学习。然而,这类方法通常基于 k-means 框架,因此继承了诸如聚类呈球形分布等各种假设。另一项常见假设(即使在非 k-means 方法中也存在)是需要预先知道聚类的数量。
本文提出了一种新颖的聚类算法 DipDECK,它能够在优化基于深度学习的聚类目标的同时估计聚类数。此外,方法无需假设聚类仅为球形结构,即可处理复杂的数据集。该算法的核心思路是:在自编码器的嵌入空间中大幅度高估聚类数,并基于 Hartigan 的 Dip 检验(一种用于判断单峰性的统计检验)分析生成的微聚类,从而确定哪些聚类应当合并。
通过大量实验证明了该方法的多种优势:
(1) 在同时学习有利于聚类的表示和聚类数量的情况下,能够取得具有竞争力的效果;
(2) 该方法对参数不敏感,具有稳定的性能表现,并支持更灵活的聚类形状;
(3) 在聚类数量估计方面,DipDECK方法优于相关的现有方法。
引言
在大量未标注数据中发现模式是数据挖掘研究的重要分支之一,其目标是将数据划分为若干组相似的数据点。然而在实际应用中,往往无法事先得知数据中有多少个聚类。
传统聚类算法中已有诸多方法尝试解决这一问题。其中许多方法基于 k-means 框架,例如 X-means [23] 和 Dip-means [16]。也有一些方法,如 PG-Means [8],采用基于期望最大化(EM)的方法,从而在聚类形状上具有更高的灵活性。但这些方法通常会自动继承“高斯分布聚类”的假设。虽然这种假设对部分数据集有效,但对其他数据集则过于严格,从而导致聚类结果不理想。
当然,也存在一些可以自动确定聚类数且不依赖高斯假设的聚类方法。例如著名的基于密度的 DBSCAN [7] 方法,以及一些基于谱聚类的变种 [31]。这些方法不仅可以估计聚类数,还支持任意形状的聚类。但它们以更复杂的参数(如邻域范围、邻居数量)取代了“聚类数量”这一直观参数。最终,聚类数量主要由这些复杂参数所控制,因此实质上只是将一个参数替换为了另外一些参数。
然而,上述所有方法在处理现代高维大数据(如图像、视频和文本)时往往效果不佳。即使运行时间和内存问题可以通过高性能实现来缓解,这些方法依然受到“维度灾难”的制约,因其多数依赖欧几里得距离。面对这类数据集,近年来的趋势是采用深度学习方法进行聚类。
在这类方法中,通常使用自编码器学习有利于聚类的低维表示,以降低维度并提升聚类效率,从而缓解高维带来的问题。因此,理想的方法应能够与深度学习聚类算法集成,在兼容深度学习优势的基础上,自动估计聚类数量。
截至目前,据作者所知,还没有一种基于深度学习的方法能够在聚类的同时估计聚类数量。现有策略仍依赖于传统聚类方法,而这些方法在高维或大规模数据集上扩展性较差。
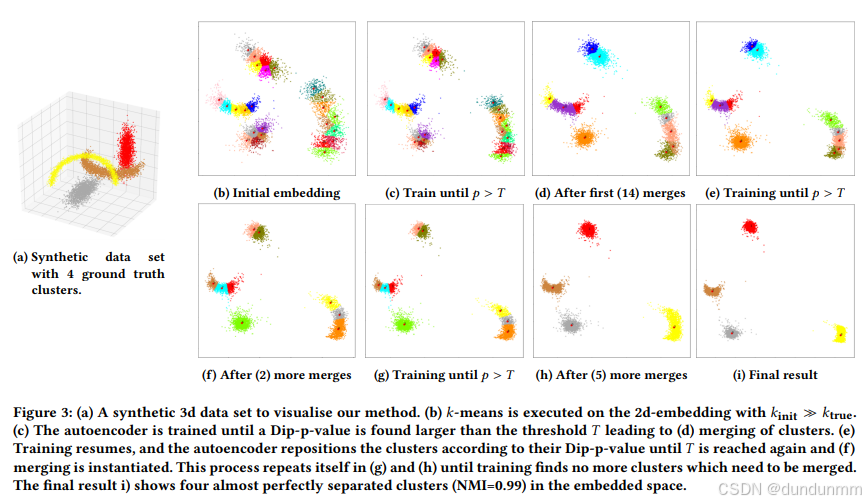
为了解决上述问题,本文提出了一种新算法:DipDECK(Dip-based Deep Embedded Clustering with k-estimation)。该方法能够同时优化聚类数量 𝑘、聚类分配和数据嵌入表示。本文的做法是在自编码器的嵌入空间中先大幅高估聚类数量(记作 𝑘init),再利用 Hartigan 的 Dip 检验(该检验用于一维样本的多峰性判断)来识别具有结构相似性的聚类进行合并。Dip 检验输出的 Dip 值可转换为一个 p 值,表示样本为单峰分布的概率。本文设计了一种聚类损失函数,促使自编码器将 Dip p 值较高的聚类向同一方向靠拢,形成更紧凑的聚类结构,从而支持将多个子聚类合并为一个完整聚类。本文引入的唯一假设是 𝑘 ≤ 𝑘init,这相比于预设固定聚类数的传统方法是一种显著的放宽。图 1 展示了 DipDECK 背后的基本思想:假设图中点为某高维数据集经过自编码器降维后的二维嵌入表示,可通过 Dip 检验识别哪些子聚类结构上相似并进行合并,同时也支持识别非凸形状的聚类。

本文的贡献如下:
-
提出了一种新颖的深度聚类方法,无需预先指定聚类数量 𝑘。即便在缺乏该信息的情况下,本文的方法在多个基准数据集上也能取得具有竞争力的聚类效果(如 NMI 指标)。
-
虽然本文的方法在某种程度上引入了 k-means 风格的中心损失项,但在聚类形状方面表现出更大的灵活性。
-
本文首次将 Dip 检验(用于判断一维样本单峰性)引入深度学习聚类方法,以量化数据集中的结构信息。
-
本文在多个数据集上聚类数估计表现优越,因此该方法也可作为独立工具用于估计聚类数,再与其他聚类方法配合使用。
方法
DipDECK(Dip-based Deep Embedded Clustering with 𝑘-estimation)方法利用自编码器(autoencoder)在嵌入空间中同时实现聚类数量的估计与聚类分配的优化。本文中所使用的所有符号已在表1中列出。

自编码器是一种由编码器(encoder)和解码器(decoder)组成的无监督神经网络结构。编码器负责将输入数据映射到一个潜在的、通常是低维的空间中;解码器则尝试将嵌入后的数据重构回原始输入。通过最小化重构损失 Lrec,自编码器可以学习嵌入空间的结构特征。该损失通常采用均方误差(Mean Squared Error)计算,对于一个小批量样本 B,其公式如下:

其中,enc(⋅)表示编码器的输出,dec(⋅) 表示解码器的输出,∥⋅∥表示平方欧氏距离。图2展示了该自编码器结构。
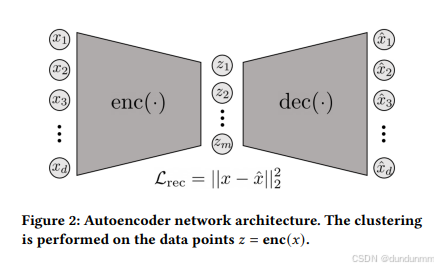
总体而言,该方法依赖于两个主要参数:
-
初始聚类数 kinit,其应远大于实际的预期聚类数量;
-
Dip-p值阈值 T,用于判断两个聚类是否应合并。
在本文的实验中,采用了一个简单的前馈神经网络架构,但在实际应用中也可替换为其他领域相关的网络结构。接下来,在嵌入空间中执行 k-means 聚类(使用 kinit作为聚类数),以获得初始的聚类中心和聚类分配。由于作者希望在嵌入空间中同时优化数据表示和聚类中心的位置,因此本文选取离 k-means 初始中心最近的样本点作为新的聚类中心,具体计算如下:
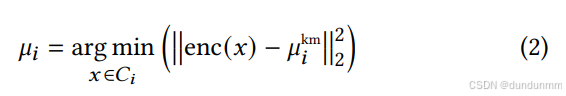
其中,μikm是 k-means 聚类得到的第 i个初始聚类中心。
随后,对嵌入空间中的每对聚类(i,j)应用 Dip 检验以获取它们之间的 Dip 值。由于 Dip 检验的输入必须是一维数据,通过点积将每个样本投影到连接对应两个聚类中心 μi和 μj的直线上,计算如下:
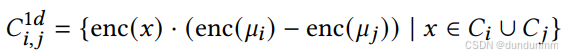
生成的这一维数据集 Ci,j1d可用于计算 Dip 值,进而得到相应的 Dip-p 值。图1形象地展示了这一思想的实现过程。
Dip 检验在某些情况下可能会将两个实际相距较远的聚类识别为单峰分布(unimodal),尤其当它们的样本数量差异较大时。 为了解决这个问题,作者额外计算了一个 第二 Dip 值:该值仅考虑大聚类中靠近小聚类中心的样本点与小聚类的全部样本点。最终,取两个 Dip 值中较大的一个(即 Dip-p 值较小的一个)作为最终判断依据。这样可以确保两个聚类之间的过渡也是单峰的。
此外,作者规定每个聚类与自身之间的 Dip 值设为 0,因此对应的 Dip-p 值为 1。由于 pi,j=pj,i,可以构造一个对称的 Dip-p 值矩阵 P:
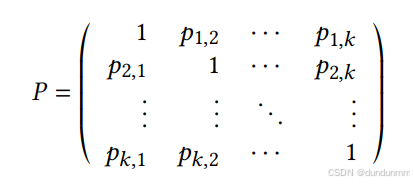
然后,矩阵 P 进行行归一化:将第 i行的每个元素除以该行的总和,得到矩阵 P^。
接下来,开始以 mini-batch 方式优化自编码器。在每个批次 B中,首先对所有样本及聚类中心进行编码,然后使用 k-means 方式更新聚类分配:每个样本被分配到距离其最近的中心。
提出了一个新的聚类目标函数 Lclu:
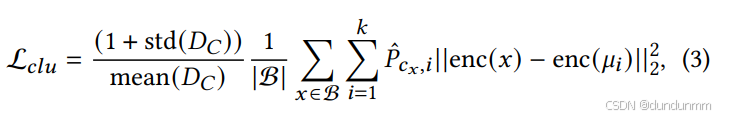
其中,cx是样本 x所属的聚类标签,std(⋅)和 mean(⋅)分别表示标准差和均值。集合 DC表示所有聚类中心之间的欧氏距离:
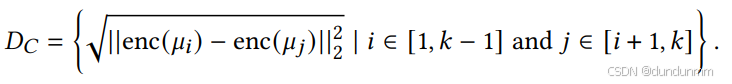
对 P^ 的行归一化保证了式 (3) 内部求和是一个仿射和,即对于一个固定的样本 x,所有权重 P^cx,i的和为 1。
其背后的直觉是:神经网络应当最强烈地将样本 enc(x) 推向它所分配的聚类中心(因为 Dip-p 值最大为 1),但同时也应适度地将其推向其他与其当前聚类形成单峰分布的中心 μi。由于对应的 P^cx,i较大,网络会倾向于缩小它与这些中心之间的距离,以减少损失。
本文对 Lclu中的距离进行归一化,使用 mean(DC)防止自编码器简单通过缩小嵌入空间的尺度来减小损失。然而,如果网络将个别聚类推得很远,mean(DC)仍可能保持较大。为防止这一点,又引入了 std(DC)项。
最后,使用公式 (1) 计算重构损失 Lrec,并将其与聚类损失相加,定义最终的 DipDECK 损失函数:
![]()
每个训练周期结束后,将每个嵌入点重新分配到其最近的聚类中心,以适应自编码器最新的嵌入结构。同时更新聚类中心,此次更新不同于式 (2),不再使用 k-means 中心,而是改用嵌入中心的平均值最近的点作为新的中心:
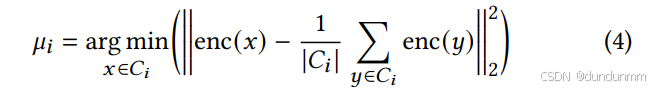
之后,更新 Dip-p 值矩阵 P 和 P^,并启动聚类合并过程。
聚类合并过程(Merging Process)
为合并两个聚类,首先检查 Dip-p 值矩阵 P 中的最大 Dip-p 值是否大于指定的阈值 T。如果是,则将聚类数量减少一个,并将产生该最大 Dip-p 值的两个聚类 i 和 j 合并。
具体而言,为这两个聚类中的所有样本分配相同的标签,并通过以下方式创建一个新的聚类中心:选择最接近旧两个中心加权平均位置的样本点作为新的中心:
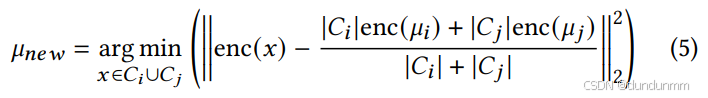
有了新的聚类中心后,即可更新 Dip-p 值矩阵 P 和归一化矩阵 P^。然后,再次检查 P 中的最大 Dip-p 值是否仍大于阈值。如果满足条件,则重复合并过程;如果不再满足,则重置训练轮次(epoch)计数器,并重新开始自编码器的优化过程。
注意:在合并之后的第一个训练轮次中,不会更新批次的标签,以让自编码器有时间适应新的聚类结构,并压缩由于合并而占据较大空间的聚类。
算法 1 展示了整个 DipDECK 聚类流程。

图 3 展示了该流程在一个三维数据集上的应用示例。该数据集中包含四个真实聚类:两个方向任意的“月牙形”聚类,以及两个方向任意的拉长高斯聚类。尽管该数据集在无需自编码器的情况下(例如通过谱聚类)也可能被成功聚类,但它是一个很好的示例,可用于可视化二维嵌入空间中我们的聚类流程。
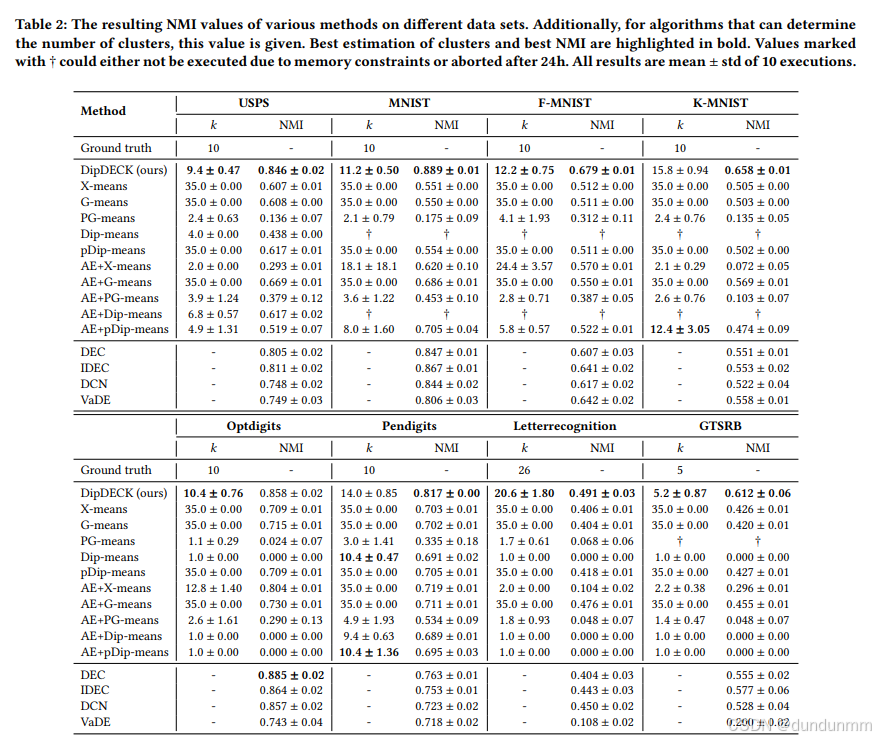
实验
相关文章:

【论文阅读】Dip-based Deep Embedded Clustering with k-Estimation
摘要 近年来,聚类与深度学习的结合受到了广泛关注。无监督神经网络,如自编码器,能够自主学习数据集中的关键结构。这一思想可以与聚类目标结合,实现对相关特征的自动学习。然而,这类方法通常基于 k-means 框架&#x…...

ARFoundation 图片识别,切换图片克隆不同的追踪模型
场景搭建: 你可以把我的代码发给AI,去理解 using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.XR; using UnityEngine.XR.ARFoundation; using UnityEngine.XR.ARSubsystems; using TMPro; using Unit…...

鸿蒙next播放B站视频横屏后的问题
(此文讨论范围为b站视频链接,且不包括b站直播链接;android/iOS的webview播放b站视频完全没有这么多问题) 1、竖屏播放没问题 从一个竖屏页p1点击进入视频页p2,p2页仍为竖屏; p2页有一Web组件,…...

华为0507机试
题目二 建设基站 有一棵二叉树,每个节点上都住了一户居民。现在要给这棵树上的居民建设基站,每个基站只能覆盖她所在与相邻的节点,请问信号覆盖这棵树最少需要建设多少个基站 #include <bits/stdc.h> using namespace std;const int …...

apache2的默认html修改
使用127.0.0.1的时候,默认打开的是index.html,可以通过配置文件修改成我们想要的html vi /etc/apache2/mods-enabled/dir.conf <IfModule mod_dir.c>DirectoryIndex WS.html index.html index.cgi index.pl index.php index.xhtml index.htm <…...

EXCEL下拉菜单与交替上色设置
Excel/WPS 表格操作教程(双功能整合) 目录 功能一:交替行上色 Excel 操作WPS 操作 功能二:下拉菜单设置 Excel 操作WPS 操作 组合效果示例注意事项 功能一:交替行上色 Excel 操作 选中数据区域 拖动鼠标选择需要设置…...

list基础用法
list基础用法 1.list的访问就不能用下标[]了,用迭代器2.emplace_back()几乎是与push_back()用法一致,但也有差别3.insert(),erase()的用法4.reverse()5.排序6.合并7.unique()(去重)8.splice剪切再粘贴 1.list的访问就不能用下标[]了,用迭代器…...

鸿蒙PC版体验_画面超级流畅_具备terminal_无法安装windows、linux软件--纯血鸿蒙HarmonyOS5.0工作笔记017
鸿蒙NEXT和开源鸿蒙OpenHarmony现在已经开发实现统一,使用鸿蒙ArkTS开发的应用,可以直接 在开源鸿蒙上. 鸿蒙的terminal是使用的linux的语法,但是有很多命令,目前还不能使用,常用的ifconfig等是可以用的. 鸿蒙终于出来PC版了,虽然,不像Windows以及mac等,开放的命令那么多,但…...
)
Spring 集成 SM4(国密对称加密)
Spring 集成 SM4(国密对称加密)算法 主要用于保护敏感数据,如身份证、手机号、密码等。 下面是完整集成步骤(含工具类 使用示例),采用 Java 实现(可用于 Spring Boot)。 一、依赖引…...

deepseek梳理java高级开发工程师微服务面试题
Java微服务高级面试题与答案 一、微服务架构设计 1. 服务拆分原则 Q1:微服务拆分时有哪些核心原则?如何解决拆分后的分布式事务问题? 答案: 服务拆分五大原则: 1. 单一职责原则(SRP)- 每个…...

人事管理系统8
员工管理(分页查询、查看详情页、修改): 1. 分页查询 Staff.java 中加入部门名和岗位名两个属性以及对应的 get 和 set 方法。这两个属性没有数据库字段对应, 仅供前端显示用: private String departname; //部门名属…...

Stapi知识框架
一、Stapi 基础认知 1. 框架定位 自动化API开发框架:专注于快速生成RESTful API 约定优于配置:通过标准化约定减少样板代码 企业级应用支持:适合构建中大型API服务 代码生成导向:显著提升开发效率 2. 核心特性 自动CRUD端点…...
)
第三章 初始化配置(一)
我们首先介绍配置Logback的方法,并提供了许多示例配置脚本。在后面的章节中,我们将介绍Logback所依赖的配置框架Joran。 初始化配置 在应用程序代码中插入日志请求需要大量的规划和努力。观察表明,大约4%的代码用于记录。因此,即…...

WebGIS 开发中的数据安全与隐私保护:急需掌握的要点
在 WebGIS 开发中,数据安全与隐私保护是绝对不能忽视的问题!随着地理信息系统的广泛应用,越来越多的敏感数据被存储和传输,比如个人位置信息、企业地理资产等。一旦这些数据泄露,后果不堪设想。然而,很多开…...

C语言 ——— 函数栈帧的创建和销毁
目录 寄存器 mian 函数是被谁调用的 通过汇编了解函数栈帧的创建和销毁 转汇编后(Add函数之前的部分) 转汇编后(进入Add函数之前的部分) 转汇编后(正式进入Add函数的部分) 编辑 总结 局部变量…...
)
2025年真实面试问题汇总(二)
jdbc的事务是怎么开启的 在JDBC中,事务的管理是通过Connection对象控制的。以下是开启和管理事务的详细步骤: 1. 关闭自动提交模式 默认情况下,JDBC连接处于自动提交模式(auto-commit true),即每条SQL语…...

【用「概率思维」重新理解生活】
用「概率思维」重新理解生活:为什么你总想找的「确定答案」并不存在? 第1层:生活真相——所有结果都是「综合得分」 现象:我们总想找到“孩子生病是因为着凉”或“伴侣生气是因为那句话”的单一答案现实:每个结果背后…...

Redis——线程模型·
为什么Redis是单线程却仍能有10w/秒的吞吐量? 内存操作:Redis大部分操作都在内存中完成,并且采用了高效的数据结构,因此Redis的性能瓶颈可能是机器的内存或者带宽,而非CPU,既然CPU不是瓶颈,自然…...
)
APS排程系统(Advanced Planning and Scheduling,高级计划与排程系统)
APS排程系统(Advanced Planning and Scheduling,高级计划与排程系统)是一种基于供应链管理和约束理论的智能生产管理工具,旨在通过动态优化资源分配和生产流程,解决制造业中的复杂计划问题。以下是其核心要点解析&…...

首个窗口级无人机配送VLN系统!中科院LogisticsVLN:基于MLLM实现精准投递
导读 随着智能物流需求日益增长,特别是“最后一公里”配送场景的精细化,传统地面机器人逐渐暴露出适应性差、精度不足等瓶颈。为此,本文提出了LogisticsVLN系统——一个基于多模态大语言模型的无人机视觉语言导航框架,专为窗户级别…...

仓颉Magic亮相GOSIM AI Paris 2025:掀起开源AI框架新热潮
巴黎,2025年5月6日——由全球开源创新组织GOSIM联合CSDN、1ms.ai共同主办的 GOSIM AI Paris 2025 大会今日在法国巴黎盛大开幕。GOSIM 作为开源人工智能领域最具影响力的年度峰会之一,本届大会以“开放、协作、突破”为核心,汇聚了来自华为、…...
的差异)
《Effective Python》第2章 字符串和切片操作——深入理解Python 中的字符数据类型(bytes 与 str)的差异
引言 本篇博客基于学习《Effective Python》第三版 Chapter 2: Strings and Slicing 中的 Item 10: Know the Differences Between bytes and str 的总结与延伸。在 Python 编程中,字符串处理是几乎每个开发者都会频繁接触的基础操作。然而,Python 中的…...

windows 强行终止进程,根据端口号
步骤1:以管理员身份启动终端 右键点击开始菜单 → 选择 终端(管理员) 或 Windows PowerShell(管理员)。 步骤2:检测端口占用状态 # 查询指定端口(示例为1806) netst…...

PHP-FPM 调优配置建议
1、动态模式 pm dynamic; 最大子进程数(根据服务器内存调整) pm.max_children 100 //每个PHP-FPM进程大约占用30-50MB内存(ThinkPHP框架本身有一定内存开销)安全值:8GB内存 / 50MB ≈ 160,保守设置为100 ; 启动时创建的进程数&…...

我喜欢的vscode几个插件和主题
主题 Monokaione Monokai Python 语义高光支持 自定义颜色为 self 将 class , def 颜色更改为红色 为装饰器修复奇怪的颜色 适用于魔法功能的椂光 Python One Dark 这个主题只在python中效果最好。 我为我个人使用做了这个主题,但任何人都可以使用它。 插件 1.Pylance Pylanc…...
)
openharmony 地图开发(高德sdk调用)
1.显示地图 2.利用sdk完成搜索功能,以列表形式展示,并提供定位和寻路按钮 3.利用sdk完成寻路,并显示路线信息和画出路线,路线和信息各自点击后可联动到对方信息显示 4.调用sdk 开始导航 商务合作:...

Kotlin-类和对象
文章目录 类主构造函数次要构造函数总结 对象初始化 类的继承成员函数属性覆盖(重写)智能转换 类的扩展 类 class Student { }这是一个类,表示学生,怎么才能给这个类添加一些属性(姓名,年龄…)呢? 主构造函数 我们需要指定类的构造函数。构造函数也是函数的一种,但是它专门…...

LVS+keepalived实战案例
目录 部署LVS 安装软件 创建VIP 创建保存规则文件 给RS添加规则 验证规则 部署RS端 安装软件 页面内容 添加VIP 配置系统ARP 传输到rs-2 客户端测试 查看规则文件 实现keepalived 编辑配置文件 传输文件给backup 修改backup的配置文件 开启keepalived服务 …...

可视化+智能补全:用Database Tool重塑数据库工作流
一、插件概述 Database Tool是JetBrains系列IDE(IntelliJ IDEA、PyCharm等)内置的数据库管理插件。它提供了从数据库连接到查询优化的全流程支持,让开发者无需离开IDE即可完成数据库相关工作。 核心价值: 统一工作环境…...

【认知思维】沉没成本谬误:为何难以放弃已投入的资源
什么是沉没成本谬误 沉没成本谬误(Sunk Cost Fallacy)是指人们倾向于根据过去已经投入的资源(时间、金钱、精力等)而非未来收益来做决策的一种认知偏差。简单来说,它反映了"我已经投入这么多,不能就这…...

Linux 系统安全基线检查:入侵防范测试标准与漏洞修复方法
Linux 系统安全基线检查:入侵防范测试标准与漏洞修复方法 在 Linux 系统的安全管理中,入侵防范是至关重要的环节。通过对系统进行安全基线检查,可以有效识别潜在的安全漏洞,并采取相应的修复措施,从而降低被入侵的风险…...
)
【HT周赛】T3.二维平面 题解(分块:矩形chkmax,求矩形和)
题意 需要维护 n n n \times n nn 平面上的整点,每个点 ( x , y ) (x, y) (x,y) 有权值 V ( x , y ) V(x, y) V(x,y),初始都为 0 0 0。 同时给定 n n n 次修改操作,每次修改给出 x 1 , x 2 , y 1 , y 2 , v x_1, x_2, y_1, y_2, v x…...

目标检测任务常用脚本1——将YOLO格式的数据集转换成VOC格式的数据集
在目标检测任务中,不同框架使用的标注格式各不相同。常见的框架中,YOLO 使用 .txt 文件进行标注,而 PASCAL VOC 则使用 .xml 文件。如果你需要将一个 YOLO 格式的数据集转换为 VOC 格式以便适配其他模型,本文提供了一个结构清晰、…...

2025深圳杯D题法医物证多人身份鉴定问题四万字思路
Word版论文思路和千行Python代码下载:https://www.jdmm.cc/file/2712074/ 引言 法医遗传学中的混合生物样本分析,特别是短串联重复序列(Short Tandem Repeat, STR)分型结果的解读,是现代刑事侦查和身份鉴定领域的核心…...

利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析
利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析 漫谈图像去雾化的挑战 在计算机视觉领域,图像复原一直是研究热点。其中,图像去雾化技术尤其具有实际应用价值。然而,复杂的气象条件和多种因素干扰使得这…...

Focal Loss 原理详解及 PyTorch 代码实现
Focal Loss 原理详解及 PyTorch 代码实现 介绍一、Focal Loss 背景二、代码逐行解析1. 类定义与初始化 三、核心参数作用四、使用示例五、应用场景六、总结 介绍 一、Focal Loss 背景 Focal Loss 是为解决类别不平衡问题设计的损失函数,通过引入 gamma 参数降低易…...

VScode 的插件本地更改后怎么生效
首先 vscode 的插件安装地址为 C:\Users\%USERNAME%\.vscode\extensions 找到你的插件包进行更改 想要打印日志,用下面方法 vscode.window.showErrorMessage(console.log "${name}" exists.); 打印结果 找到插件,点击卸载 然后点击重新启动 …...

这类物种组织heatmap有点东西
如果想知道研究对象(人、小鼠、拟南芥、恒河猴等)某个时候各个器官的fMRI信号强度、炎症程度等指标的差异,gganatogram可以以热图的形式轻松满足你的需求。 数据准备 以男性为例,数据包含四列, 每列详细介绍 org…...

通讯录程序
假设通讯录可以存放100个人的信息(人的信息:姓名、年龄、性别、地址、电话) 功能:1>增加联系人 2>删除指定联系人 3>查找指定联系人信息 4>修改指定联系人信息 5>显示所有联系人信息 6>排序(…...

无需翻墙!3D 优质前端模板分享
开发网站时,无需撰写 HTML、CSS 和 JavaScript 代码,直接调用模板内现成的组件,通过拖拽组合、修改参数,几天内即可完成核心页面开发,开发速度提升高达 70% 以上。让开发者更专注于业务逻辑优化与功能创新,…...
,它允许您使用简单的 UI 在 5 分钟或更短的时间内创建 AI 代理)
Shinkai开源程序 是一个双击安装 AI 管理器(本地和远程),它允许您使用简单的 UI 在 5 分钟或更短的时间内创建 AI 代理
一、软件介绍 文末提供程序和源码下载 Shinkai 开源应用程序在 Web 浏览器中解锁了一流 LLM (AI) 支持的全部功能/自动化。它允许创建多个代理,每个代理都连接到本地或第三方LLMs(例如 OpenAI GPT),这些…...

vscode不能跳转到同一个工作区的其他文件夹
明白了,你说的“第二种情况”是指: 你先打开的是项目文件夹(比如 MyProject),然后通过 VS Code 的“添加文件夹到工作区”功能,把 ThirdPartyLib 文件夹添加进来。 结果,项目代码里 #include “…...

containerd 之使用 ctr 和 runc 进行底层容器操作与管理
containerd 是目前业界标准的容器运行时,它负责容器生命周期的方方面面,如镜像管理、容器执行、存储和网络等。而 ctr 是 containerd 自带的命令行工具,虽然不如 Docker CLI 用户友好,但它提供了直接与 containerd API 交互的能力…...

IMU 技术概述
IMU(惯性测量单元,Inertial Measurement Unit)是一种通过传感器组合测量物体运动状态和姿态的核心设备,广泛应用于导航、控制、智能设备等领域。以下从原理、组成、应用和发展趋势展开说明: 一、核心定义与本质 IMU …...

talk-centos6之间实现
在 CentOS 6.4 上配置和使用 talk 工具,需要注意系统版本较老,很多配置可能不同于现代系统。我会提供 详细步骤 自动化脚本,帮你在两台 CentOS 6.4 机器上实现局域网聊天。 ⸻ 🧱 一、系统准备 假设你有两台主机: …...

hivesql是什么数据库?
HiveSQL并非指一种独立的数据库,而是指基于Apache Hive的SQL查询语言接口,Hive本身是一个构建在Hadoop生态系统之上的数据仓库基础设施。 以下是对HiveSQL及其相关概念的详细解释: 一、Hive概述 定义: Hive是由Facebook开发&…...
python开发经验)
(1)python开发经验
文章目录 1 安装包格式说明2 PySide支持Windows7 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 安装包格式说明 PySide下载地址 进入下载地址后有多种安装包,怎么选择: …...

[论文翻译]PPA: Preference Profiling Attack Against Federated Learning
文章目录 摘要一、介绍1、最先进的攻击方式2、PPA3、贡献 二、背景和相关工作1、联邦学习2、成员推理攻击3、属性推理攻击4、GAN攻击5、联邦学习中的隐私推理攻击 三、PPA1、威胁模型与攻击目标(1)威胁模型(2)攻击目标 2、PPA 概述…...

北三短报文数传终端:筑牢水利防汛“智慧防线”,守护江河安澜
3月15日我国正式入汛,较以往偏早17天。据水利部预警显示,今年我国极端暴雨洪涝事件趋多趋频趋强,叠加台风北上影响内陆的可能性,灾害风险偏高,防汛形势严峻复杂。面对加快推进“三道防线”建设,提升“四预”…...
简介)
函数加密(Functional Encryption)简介
1. 引言 函数加密(FE)可以被看作是公钥加密(PKE)的一种推广,它允许对第三方的解密能力进行更细粒度的控制。 在公钥加密中,公钥 p k \mathit{pk} pk 用于将某个值 x x x 加密为密文 c t \mathit{ct} c…...