目标检测任务常用脚本1——将YOLO格式的数据集转换成VOC格式的数据集
在目标检测任务中,不同框架使用的标注格式各不相同。常见的框架中,YOLO 使用 .txt 文件进行标注,而 PASCAL VOC 则使用 .xml 文件。如果你需要将一个 YOLO 格式的数据集转换为 VOC 格式以便适配其他模型,本文提供了一个结构清晰、可维护性强的 Python 脚本。
🧩 输入输出目录结构
✅ 输入目录结构(YOLO 格式)
<YOLO数据集名称>
├── train/
│ ├── images/
│ │ ├── img_000001.bmp
│ │ └── ...
│ └── labels/
│ ├── img_000001.txt
│ └── ...
└── val/├── images/│ ├── img_000100.bmp│ └── ...└── labels/├── img_000100.txt└── ...
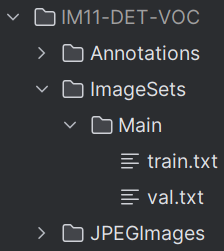
✅ 输出目录结构(VOC 格式)
<VOC格式数据集名称>
├── JPEGImages/ # 转换后的图像文件(.jpg)
├── Annotations/ # 对应的XML标注文件
└── ImageSets/└── Main/├── train.txt└── val.txt
🛠️ 配置参数说明
YOLO_DATASET_ROOT = '' # YOLO格式数据集根目录(输入)
VOC_OUTPUT_DIR = '' # VOC格式输出目录(输出)
CLASS_NAMES = [] # 类别名称列表,示例:['person', 'car', 'dog']
SPLITS = ['train', 'val'] # 数据集划分类型(训练集、验证集等)
VERBOSE = True # 是否输出详细日志
⚠️ 注意:你需要根据自己的项目路径和类别信息填写 YOLO_DATASET_ROOT、VOC_OUTPUT_DIR 和 CLASS_NAMES。
目前脚本默认处理 .bmp 图像并将其转为 .jpg,你可以根据需求修改扩展名以支持 .png、.jpeg 等格式。
完整代码如下:
import os
import xml.etree.ElementTree as ET
from xml.dom import minidom
import cv2# -----------------------------
# 超参数配置(Hyperparameters)
# -----------------------------
YOLO_DATASET_ROOT = '' # YOLO格式数据集根目录(输入)
VOC_OUTPUT_DIR = '' # VOC格式输出目录(输出)
CLASS_NAMES = [] # 类别名称列表,示例:['person', 'car', 'dog']
SPLITS = ['train', 'val'] # 数据集划分类型(训练集、验证集等)
VERBOSE = True # 是否输出详细日志def create_voc_annotation(image_path, label_path, annotations_output_dir):"""根据图像和YOLO标签生成PASCAL VOC格式的XML标注文件。"""image = cv2.imread(image_path)height, width, depth = image.shapeannotation = ET.Element('annotation')# .bmp -> .jpgfilename = os.path.basename(image_path).replace('.bmp', '.jpg')ET.SubElement(annotation, 'folder').text = 'JPEGImages'ET.SubElement(annotation, 'filename').text = filenameET.SubElement(annotation, 'path').text = os.path.join(VOC_OUTPUT_DIR, 'JPEGImages', filename)source = ET.SubElement(annotation, 'source')ET.SubElement(source, 'database').text = 'Custom Dataset'size = ET.SubElement(annotation, 'size')ET.SubElement(size, 'width').text = str(width)ET.SubElement(size, 'height').text = str(height)ET.SubElement(size, 'depth').text = str(depth)ET.SubElement(annotation, 'segmented').text = '0'if os.path.exists(label_path):with open(label_path, 'r') as f:for line in f.readlines():data = line.strip().split()class_id = int(data[0])x_center = float(data[1]) * widthy_center = float(data[2]) * heightbbox_width = float(data[3]) * widthbbox_height = float(data[4]) * heightxmin = int(x_center - bbox_width / 2)ymin = int(y_center - bbox_height / 2)xmax = int(x_center + bbox_width / 2)ymax = int(y_center + bbox_height / 2)obj = ET.SubElement(annotation, 'object')ET.SubElement(obj, 'name').text = CLASS_NAMES[class_id]ET.SubElement(obj, 'pose').text = 'Unspecified'ET.SubElement(obj, 'truncated').text = '0'ET.SubElement(obj, 'difficult').text = '0'bndbox = ET.SubElement(obj, 'bndbox')ET.SubElement(bndbox, 'xmin').text = str(xmin)ET.SubElement(bndbox, 'ymin').text = str(ymin)ET.SubElement(bndbox, 'xmax').text = str(xmax)ET.SubElement(bndbox, 'ymax').text = str(ymax)# 保存XML文件xml_str = minidom.parseString(ET.tostring(annotation)).toprettyxml(indent=" ")xml_filename = filename.replace('.jpg', '.xml')xml_path = os.path.join(annotations_output_dir, xml_filename) # 确保这里只有一层Annotations目录with open(xml_path, "w") as f:f.write(xml_str)if VERBOSE:print(f"✅ 已生成标注文件: {xml_filename}")def convert_dataset(input_dir, output_dir):"""将YOLO格式的数据集转换为VOC格式。包括图像格式转换(.bmp -> .jpg)、生成XML标注文件,并创建ImageSets/Main/train.txt/val.txt。"""print("🔄 开始转换YOLO格式数据集到VOC格式...")if not os.path.exists(output_dir):os.makedirs(output_dir)for split in SPLITS:images_dir = os.path.join(input_dir, split, 'images')labels_dir = os.path.join(input_dir, split, 'labels')output_images_dir = os.path.join(output_dir, 'JPEGImages')output_annotations_dir = os.path.join(output_dir, 'Annotations')output_imagesets_dir = os.path.join(output_dir, 'ImageSets', 'Main')os.makedirs(output_images_dir, exist_ok=True)os.makedirs(output_annotations_dir, exist_ok=True)os.makedirs(output_imagesets_dir, exist_ok=True)set_file_path = os.path.join(output_imagesets_dir, f"{split}.txt")set_file = open(set_file_path, 'w')count = 0for filename in os.listdir(images_dir):if filename.endswith('.bmp'):image_path = os.path.join(images_dir, filename)label_path = os.path.join(labels_dir, filename.replace('.bmp', '.txt'))# 图像转换new_image_name = filename.replace('.bmp', '.jpg')new_image_path = os.path.join(output_images_dir, new_image_name)image = cv2.imread(image_path)cv2.imwrite(new_image_path, image)# 写入ImageSets/Main/train.txt或val.txtbase_name = new_image_name.replace('.jpg', '')set_file.write(f"{base_name}\n")# 生成XML标注文件create_voc_annotation(new_image_path, label_path, output_annotations_dir) # 确保传入的是Annotations目录路径count += 1if VERBOSE and count % 10 == 0:print(f"🖼️ 已处理 {count} 张图片...")set_file.close()print(f"✅ 完成 [{split}] 分割集处理,共处理 {count} 张图片")print("🎉 数据集转换完成!")if __name__ == "__main__":convert_dataset(YOLO_DATASET_ROOT, VOC_OUTPUT_DIR)
转换后效果:
验证生成的VOC数据集中图片质量和数量是否合适可以用下面的脚本:
import os
import cv2
from xml.etree import ElementTree as ET# -----------------------------
# 超参数配置(Hyperparameters)
# -----------------------------
DATASET_ROOT = '' # VOC格式数据集根目录
CLASS_NAMES = [] # 类别列表, 示例: ['car', 'person', 'dog']
VERBOSE = True # 是否输出详细日志def count_images_in_set(imagesets_dir, set_name):"""统计ImageSets/Main目录下指定集合(train/val)的图片数量。"""set_file_path = os.path.join(imagesets_dir, f"{set_name}.txt")if not os.path.exists(set_file_path):print(f"[警告] 找不到 {set_name}.txt 文件,请确认是否生成正确划分文件。")return 0with open(set_file_path, 'r') as f:lines = [line.strip() for line in f.readlines() if line.strip()]return len(lines)def check_images(jpeg_dir):"""检查JPEGImages目录下的所有图片是否都能正常加载。"""print("[检查] 验证图像是否可读...")error_images = []for filename in os.listdir(jpeg_dir):if filename.lower().endswith(('.jpg', '.jpeg', '.png')):image_path = os.path.join(jpeg_dir, filename)try:img = cv2.imread(image_path)if img is None:raise ValueError("无法加载图像")except Exception as e:error_images.append(filename)if VERBOSE:print(f" ❌ 图像加载失败: {filename} | 原因: {str(e)}")return error_imagesdef validate_annotations(annotations_dir, jpeg_dir):"""验证Annotations目录下的XML标注文件是否与对应的图片匹配。"""print("[检查] 验证XML标注文件是否有效...")error_annotations = []for filename in os.listdir(annotations_dir):if filename.endswith('.xml'):xml_path = os.path.join(annotations_dir, filename)try:tree = ET.parse(xml_path)root = tree.getroot()jpg_filename = root.find('filename').textif not os.path.exists(os.path.join(jpeg_dir, jpg_filename)):raise FileNotFoundError(f"找不到对应的图像:{jpg_filename}")except Exception as e:error_annotations.append(filename)if VERBOSE:print(f" ❌ 标注文件异常: {filename} | 原因: {str(e)}")return error_annotationsdef verify_imagesets(imagesets_dir, jpeg_dir):"""确保ImageSets/Main中列出的所有图像都存在于JPEGImages中。"""print("[检查] 验证ImageSets/Main中列出的图像是否存在...")missing_files = []for set_name in ['train', 'val']:set_file_path = os.path.join(imagesets_dir, f"{set_name}.txt")if not os.path.exists(set_file_path):continuewith open(set_file_path, 'r') as f:for line in f:img_id = line.strip()if not img_id:continueimg_path = os.path.join(jpeg_dir, f"{img_id}.jpg")if not os.path.exists(img_path):missing_files.append(f"{img_id}.jpg")if VERBOSE:print(f" ❌ 图像缺失: {img_id}.jpg")return missing_filesdef main():print("🔍 开始验证VOC格式数据集...\n")# 构建路径jpeg_dir = os.path.join(DATASET_ROOT, 'JPEGImages')annotations_dir = os.path.join(DATASET_ROOT, 'Annotations')imagesets_dir = os.path.join(DATASET_ROOT, 'ImageSets', 'Main')# 检查是否存在必要目录for dir_path in [jpeg_dir, annotations_dir, imagesets_dir]:if not os.path.exists(dir_path):print(f"[错误] 必要目录不存在: {dir_path}")exit(1)# 1. 检查图像是否可读error_images = check_images(jpeg_dir)if error_images:print(f"⚠️ 共发现 {len(error_images)} 张图片加载失败:")for img in error_images:print(f" - {img}")else:print("✅ 所有图像均可正常加载。\n")# 2. 检查XML标注文件是否有效error_annotations = validate_annotations(annotations_dir, jpeg_dir)if error_annotations:print(f"⚠️ 共发现 {len(error_annotations)} 个无效或不匹配的XML标注文件:")for ann in error_annotations:print(f" - {ann}")else:print("✅ 所有XML标注文件均有效且与对应图像匹配。\n")# 3. 检查ImageSets/Main中引用的图像是否存在missing_files = verify_imagesets(imagesets_dir, jpeg_dir)if missing_files:print(f"⚠️ 共发现 {len(missing_files)} 张图像在ImageSets中被引用但实际不存在:")for img in missing_files:print(f" - {img}")else:print("✅ ImageSets/Main中引用的所有图像均存在。\n")# 4. 输出训练集和验证集的图像数量train_count = count_images_in_set(imagesets_dir, 'train')val_count = count_images_in_set(imagesets_dir, 'val')total_count = train_count + val_countprint("📊 数据集统计:")print(f" - 训练集: {train_count} 张")print(f" - 验证集: {val_count} 张")print(f" - 总数: {total_count} 张\n")print("🎉 验证完成!")if __name__ == "__main__":main()
验证效果为:

相关文章:

目标检测任务常用脚本1——将YOLO格式的数据集转换成VOC格式的数据集
在目标检测任务中,不同框架使用的标注格式各不相同。常见的框架中,YOLO 使用 .txt 文件进行标注,而 PASCAL VOC 则使用 .xml 文件。如果你需要将一个 YOLO 格式的数据集转换为 VOC 格式以便适配其他模型,本文提供了一个结构清晰、…...

2025深圳杯D题法医物证多人身份鉴定问题四万字思路
Word版论文思路和千行Python代码下载:https://www.jdmm.cc/file/2712074/ 引言 法医遗传学中的混合生物样本分析,特别是短串联重复序列(Short Tandem Repeat, STR)分型结果的解读,是现代刑事侦查和身份鉴定领域的核心…...

利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析
利用自适应双向对比重建网络与精细通道注意机制实现图像去雾化技术的PyTorch代码解析 漫谈图像去雾化的挑战 在计算机视觉领域,图像复原一直是研究热点。其中,图像去雾化技术尤其具有实际应用价值。然而,复杂的气象条件和多种因素干扰使得这…...

Focal Loss 原理详解及 PyTorch 代码实现
Focal Loss 原理详解及 PyTorch 代码实现 介绍一、Focal Loss 背景二、代码逐行解析1. 类定义与初始化 三、核心参数作用四、使用示例五、应用场景六、总结 介绍 一、Focal Loss 背景 Focal Loss 是为解决类别不平衡问题设计的损失函数,通过引入 gamma 参数降低易…...

VScode 的插件本地更改后怎么生效
首先 vscode 的插件安装地址为 C:\Users\%USERNAME%\.vscode\extensions 找到你的插件包进行更改 想要打印日志,用下面方法 vscode.window.showErrorMessage(console.log "${name}" exists.); 打印结果 找到插件,点击卸载 然后点击重新启动 …...

这类物种组织heatmap有点东西
如果想知道研究对象(人、小鼠、拟南芥、恒河猴等)某个时候各个器官的fMRI信号强度、炎症程度等指标的差异,gganatogram可以以热图的形式轻松满足你的需求。 数据准备 以男性为例,数据包含四列, 每列详细介绍 org…...

通讯录程序
假设通讯录可以存放100个人的信息(人的信息:姓名、年龄、性别、地址、电话) 功能:1>增加联系人 2>删除指定联系人 3>查找指定联系人信息 4>修改指定联系人信息 5>显示所有联系人信息 6>排序(…...

无需翻墙!3D 优质前端模板分享
开发网站时,无需撰写 HTML、CSS 和 JavaScript 代码,直接调用模板内现成的组件,通过拖拽组合、修改参数,几天内即可完成核心页面开发,开发速度提升高达 70% 以上。让开发者更专注于业务逻辑优化与功能创新,…...
,它允许您使用简单的 UI 在 5 分钟或更短的时间内创建 AI 代理)
Shinkai开源程序 是一个双击安装 AI 管理器(本地和远程),它允许您使用简单的 UI 在 5 分钟或更短的时间内创建 AI 代理
一、软件介绍 文末提供程序和源码下载 Shinkai 开源应用程序在 Web 浏览器中解锁了一流 LLM (AI) 支持的全部功能/自动化。它允许创建多个代理,每个代理都连接到本地或第三方LLMs(例如 OpenAI GPT),这些…...

vscode不能跳转到同一个工作区的其他文件夹
明白了,你说的“第二种情况”是指: 你先打开的是项目文件夹(比如 MyProject),然后通过 VS Code 的“添加文件夹到工作区”功能,把 ThirdPartyLib 文件夹添加进来。 结果,项目代码里 #include “…...

containerd 之使用 ctr 和 runc 进行底层容器操作与管理
containerd 是目前业界标准的容器运行时,它负责容器生命周期的方方面面,如镜像管理、容器执行、存储和网络等。而 ctr 是 containerd 自带的命令行工具,虽然不如 Docker CLI 用户友好,但它提供了直接与 containerd API 交互的能力…...

IMU 技术概述
IMU(惯性测量单元,Inertial Measurement Unit)是一种通过传感器组合测量物体运动状态和姿态的核心设备,广泛应用于导航、控制、智能设备等领域。以下从原理、组成、应用和发展趋势展开说明: 一、核心定义与本质 IMU …...

talk-centos6之间实现
在 CentOS 6.4 上配置和使用 talk 工具,需要注意系统版本较老,很多配置可能不同于现代系统。我会提供 详细步骤 自动化脚本,帮你在两台 CentOS 6.4 机器上实现局域网聊天。 ⸻ 🧱 一、系统准备 假设你有两台主机: …...

hivesql是什么数据库?
HiveSQL并非指一种独立的数据库,而是指基于Apache Hive的SQL查询语言接口,Hive本身是一个构建在Hadoop生态系统之上的数据仓库基础设施。 以下是对HiveSQL及其相关概念的详细解释: 一、Hive概述 定义: Hive是由Facebook开发&…...
python开发经验)
(1)python开发经验
文章目录 1 安装包格式说明2 PySide支持Windows7 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 安装包格式说明 PySide下载地址 进入下载地址后有多种安装包,怎么选择: …...

[论文翻译]PPA: Preference Profiling Attack Against Federated Learning
文章目录 摘要一、介绍1、最先进的攻击方式2、PPA3、贡献 二、背景和相关工作1、联邦学习2、成员推理攻击3、属性推理攻击4、GAN攻击5、联邦学习中的隐私推理攻击 三、PPA1、威胁模型与攻击目标(1)威胁模型(2)攻击目标 2、PPA 概述…...

北三短报文数传终端:筑牢水利防汛“智慧防线”,守护江河安澜
3月15日我国正式入汛,较以往偏早17天。据水利部预警显示,今年我国极端暴雨洪涝事件趋多趋频趋强,叠加台风北上影响内陆的可能性,灾害风险偏高,防汛形势严峻复杂。面对加快推进“三道防线”建设,提升“四预”…...
简介)
函数加密(Functional Encryption)简介
1. 引言 函数加密(FE)可以被看作是公钥加密(PKE)的一种推广,它允许对第三方的解密能力进行更细粒度的控制。 在公钥加密中,公钥 p k \mathit{pk} pk 用于将某个值 x x x 加密为密文 c t \mathit{ct} c…...

思维链实现 方式解析
思维链的实现方式 思维链的实现方式除了提示词先后顺序外,还有以下几种: 增加详细的中间步骤提示:通过提供问题解决过程中的详细中间步骤提示,引导模型逐步推导和思考。例如,在解决数学证明题时,提示词可以具体到每一步需要运用的定理、公式以及推理的方向,帮助模型构建…...

深入学习Zookeeper的知识体系
目录 1、介绍 1.1、CAP 理论 1.2、BASE 理论 1.3、一致性协议ZAB 1、介绍 2、角色 3、ZXID和myid 4、 历史队列 5、协议模式 6、崩溃恢复模式 7、脑裂问题 2、zookeeper 2.1、开源项目 2.2、功能 2.3、选举机制 3、数据模型 3.1、介绍 3.2、znode分类 4、监听…...

电商平台一站式安全防护架构设计与落地实践
引言:安全即业务,防御即增长 国际权威机构 Forrester 最新报告指出,2024 年全球电商平台因安全防护不足导致的直接营收损失高达 $180 亿,而采用一体化防护方案的头部企业客户留存率提升 32%。本文基于 10 万 节点防护实战数据&a…...

【Pandas】pandas DataFrame cummin
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.any(*[, axis, bool_only, skipna])用于判断…...

奇妙小博客
import matplotlib.pyplot as plt# 定义顶点坐标 A [0, 0] B [6, 1] C [4, 6] P [4, 3]# 绘制三角形 ABC plt.plot([A[0], B[0], C[0], A[0]], [A[1], B[1], C[1], A[1]], b-, labelTriangle ABC) # 绘制点 P plt.scatter(P[0], P[1], colorr, labelPoint P(4,3))# 标注顶点…...

嵌入式学习笔记 - HAL_ADC_ConfigChannel函数解析
贴函数原型: 一 首先配置规则通道序列 其实所有的配置函数都是在对寄存器进行操作,要想看懂Hal库底层函数驱动就先把寄存器如何配置看懂,以下是配置规则通道寄存器的介绍,以ADC_SQR3为例,也就是通道序列1到序列6&…...

Java反射详细介绍
的反射(Reflection)是一种强大的机制,允许程序在运行时动态获取类的信息、操作类的成员(属性、方法、构造器),甚至修改类的行为。它是框架开发(如 Spring、MyBatis)、单元测试工具&a…...
)
2025年土木建筑与水利工程国际会议(ICCHE 2025)
2025 International Conference on Civil and Hydraulic Engineering (ICCHE 2025) (一)会议信息 会议简称:ICCHE 2025 大会地点:中国银川 投稿邮箱:icchesub-paper.com 收录检索:提交Ei Compendex,CPCI,C…...

适应性神经树:当深度学习遇上决策树的“生长法则”
1st author: Ryutaro Tanno video: Video from London ML meetup paper: Adaptive Neural Trees ICML 2019 code: rtanno21609/AdaptiveNeuralTrees: Adaptive Neural Trees 背景 在机器学习领域,神经网络(NNs)凭借其强大的表示学习能力&…...
使用教程第十四讲)
IBM BAW(原BPM升级版)使用教程第十四讲
续前篇! 一、流程设计中的编程 在 IBM Business Automation Workflow (BAW) 中,编程部分涵盖了多种技术、工具和策略,帮助用户定制和扩展流程。BAW 主要通过脚本、集成、服务和自定义代码来实现流程的灵活性和定制化。下面将详细讲解 BAW …...

【计算机网络 第8版】谢希仁编著 第四章网络层 题型总结3 SDN OpenFlow
SDN OpenFlow题型 这题其实,认真看书P196-197的例子也不难理解。我个人认为所谓防自学设计主要就是你没看懂这张图的时候就是天书,你知道怎么读这张图的时候就很简单。不过我相信这个用心一点应该也都是能懂的。 题目 4.66-4.69 4-66 我最大的一个问题…...

【React中函数组件和类组件区别】
在 React 中,函数组件和类组件是两种构建组件的方式,它们在多个方面存在区别,以下详细介绍: 1. 语法和定义 类组件:使用 ES6 的类(class)语法定义,继承自 React.Component。需要通过 this.props 来访问传递给组件的属性(props),并且通常要实现 render 方法返回 JSX…...

多线程代码案例-1 单例模式
单例模式 单例模式是开发中常见的设计模式。 设计模式,是我们在编写代码时候的一种软性的规定,也就是说,我们遵守了设计模式,代码的下限就有了一定的保证。设计模式有很多种,在不同的语言中,也有不同的设计…...

langChain存储文档片段,并进行相似性检索
https://python.langchain.ac.cn/docs/how_to/document_loader_pdf/#vector-search-over-pdfs 这段代码展示了如何使用LangChain框架中的InMemoryVectorStore和OpenAIEmbeddings来存储文档片段,并基于提供的查询进行相似性搜索。下面是对每一行代码的详细解释&…...

MQTT协议技术详解:深入理解物联网通信基础
MQTT协议技术详解:深入理解物联网通信基础 1. MQTT协议概述 MQTT (Message Queuing Telemetry Transport) 是一种轻量级的发布/订阅消息传输协议,专为资源受限设备和低带宽、高延迟或不可靠网络环境设计。作为物联网通信的核心协议之一,MQTT…...

python中的进程锁与线程锁
在Python中,线程和进程使用锁的机制有所不同,需分别通过threading和multiprocessing模块实现。以下是具体用法及注意事项: 一、线程锁(Thread Lock) 基本用法 线程锁用于多线程环境下保护共享资源,防止数据…...
)
导出导入Excel文件(详解-基于EasyExcel)
前言: 近期由于工作的需要,根据需求需要导出导入Excel模板。于是自学了一下下,在此记录并分享!! EasyExcel: 首先我要在这里非常感谢阿里的大佬们!封装这么好用的Excel相关的API,真…...

仿正点原子驱动BMP280气压传感器实例
文章目录 前言 一、寄存器头文件定义 二、设备树文件中添加节点 三、驱动文件编写 四、编写驱动测试文件并编译测试 总结 前言 本文驱动开发仿照正点原子的iic驱动实现,同时附上bmp280的数据手册,可访问下面的链接: BMP280_Bosch(博世…...
)
Java 反射机制(Reflection)
一、理论说明 1. 反射的定义 Java 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为 Jav…...

每日Prompt:发光线条解剖图
提示词 一幅数字插画,描绘了一个 [SUBJECT],其结构由一组发光、干净且纯净的蓝色线条勾勒而成。画面设定在深色背景之上,以突出 [SUBJECT] 的形态与特征。某个特定部位,如 [PART],通过红色光晕加以强调,以…...

从新手到高手:全面解析 AI 时代的「魔法咒语」——Prompt
引言:AI 时代的「语言炼金术」 在人工智能技术突飞猛进的今天,我们正在经历一场堪比工业革命的生产力变革。从聊天机器人到图像生成,从数据分析到自动化写作,AI 模型正在重塑人类与信息交互的方式。而在这一切背后,隐…...

【SpringBoot】集成kafka之生产者、消费者、幂等性处理和消息积压
目录 配置文件 application.properties启动类 ApplicationKafka 配置Message 消息实体类MessageRepository 消息处理消息积压监控服务Kafka消息消费者服务Kafka消息生产者服务API控制器提供测试接口关键特性说明生产环境建议 配置文件 application.properties # 应用配置 serv…...

[SAP] 通过事务码Tcode获取程序名
如何通过事务码查找对应的程序名? 方法一:直接运行事务码,跳转至功能详情页面,点击【系统】|【状态】即可获取对应事务码的程序名 从上面可以了解到自定义的事务码"ZMM01"对应的程序名为"ZYT36_ZMM001_01"&a…...

蓝桥杯12届国B 纯质数
题目描述 如果一个正整数只有 1 和它本身两个约数,则称为一个质数(又称素数)。 前几个质数是:2,3,5,7,11,13,17,19,23,29,31,37,⋅⋅⋅ 。 如果一个质数的所有十进制数位都是质数,我们称它为纯质数。例如࿱…...

国产大模型「五强争霸」,决战AGI!
来源 | 新智元 DeepSeek的横空出世,已经彻底改变了全球的AI局势。 从此,不仅中美大模型竞争格局改变,国产大模型的产业版图,也被一举打破! 纵观中国基础大模型的市场,可以看到,如今的基础大模…...

C++修炼:继承
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 欢迎点赞,关注&am…...

Mysql新增
插入一个记录需要的时间由下列因素组成,其中的数字表示大约比例: 连接:(3)发送查询给服务器:(2)分析查询:(2)插入记录:(1x记录大小)插入索引:(1x索引&#x…...
成功举办!)
华秋2025电子设计与制造技术研讨会(华东站)成功举办!
“探索科技前沿,共筑创新未来”——华秋“2025电子设计与制造技术研讨会第一站:华东站”在江苏苏州圆满落幕。 随着电子信息产业的持续增长和数字化经济的加速转型,数字化电子供应链的作用愈发显著。本届研讨聚焦EDA设计、DFM软件分析、多层…...

[学习] RTKLib详解:qzslex.c、rcvraw.c与solution.c
RTKLib详解:qzslex.c、rcvraw.c与solution.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详解…...

【Ubuntu】neovim Lazyvim安装与卸载
安装neovim # 下载 AppImage wget https://github.com/neovim/neovim/releases/latest/download/nvim-linux-x86_64.appimage# 添加执行权限 chmod ux nvim-linux-x86_64.appimage# 移动到系统路径,重命名为 nvim sudo mv nvim-linux-x86_64.appimage /usr/local/b…...
 绪论)
数据结构(一) 绪论
一. 时间复杂度: (1)定义: 时间复杂度是衡量算法执行时间随输入规模(通常用n表示)增长的变化趋势的指标,时间复杂度用O符号表示 用于描述算法在最坏情况下或平均情况下的时间需求 时间复杂度关注的是操作次数的增长率,而非具体执行时间 常见的时间复杂度由小到大依次…...

数据库事务并发问题
目录 脏读 幻读 不可重复读 三者的区别 脏读、幻读和不可重复读是在数据库并发操作中可能出现的问题,以下是对它们的详细介绍: 脏读 定义:指一个事务读取了另一个未提交事务修改的数据。示例:事务 A 修改了一条数据…...