Kafka Go客户端--Sarama
Kafka Go客户端
在Go中里面有三个比较有名气的Go客户端。
- Sarama:用户数量最多,早期这个项目是在Shopify下面,现在挪到了IBM下。
- segmentio/kafka-go:没啥大的缺点。
- confluent-kafka-go:需要启用cgo,跨平台问题比较多,交叉编译也不支持。
Sarama 使用入门:tools
IBM/sarama: Sarama is a Go library for Apache Kafka.
在 Sarama 里面提供了一些简单的命令行工具,可以看做是 Shell脚本提供的功能一个子集。
Consumer和 producer中的用得比较多
1.设置 Go 代理(如果内网无法直连 proxy.golang.org)
export GOPROXY=https://goproxy.cn,direct
export GOSUMDB=sum.golang.google.cn
2.在虚拟机上执行安装命令:
- go install github.com/IBM/sar ama/tools/kafka-console-consumer@latest
- go install github.com/lBM/sarama/tools/kafka-console-producer@latest
3.把可执行文件所在目录加到 PATH(如果还没加)
export PATH=$PATH:$(go env GOBIN)
4.确认可执行文件在哪里
# 查看 GOBIN,如果你没显式设置,就会是空
go env GOBIN# 查看 GOPATH,默认是 $HOME/go(对于 root 用户就是 /root/go)
go env GOPATH#我的是/home/cxz/go/lib:/home/cxz/go/work
5.查看安装结果
ls /home/cxz/go/lib/bin
#应该能够看到kafka-console-consumer kafka-console-producer
6.临时生效
export PATH=$PATH:/home/cxz/go/lib/bin# 然后验证
which kafka-console-consumer
# 应该输出 /home/cxz/go/lib/bin/kafka-console-consumer
7.永久生效
echo 'export PATH=$PATH:/home/cxz/go/lib/bin' >> ~/.bashrc
# 或者,如果你用的是 zsh:
# echo 'export PATH=$PATH:/home/cxz/go/lib/bin' >> ~/.zshrc# 然后重新加载配置
source ~/.bashrc
Sarama 使用入门:发送消息
虚拟机上执行
kafka-console-consumer -topic=test_topic -brokers=192.168.24.101:9094
Goland上执行
package mainimport ("github.com/IBM/sarama""github.com/stretchr/testify/assert""testing"
)var addrs = []string{"192.168.24.101:9094"}func TestSyncProducer(t *testing.T) {//创建一个 Sarama 的配置对象。cfg := sarama.NewConfig()//表示生产者要等待 Kafka 确认消息成功写入后再返回(同步模式)。如果不设置这个,SyncProducer.SendMessage 会一直失败。cfg.Producer.Return.Successes = true //同步的Producer一定要设置//创建一个同步的生产者实例producer, err := sarama.NewSyncProducer(addrs, cfg)assert.NoError(t, err)//构建消息并发送_, _, err = producer.SendMessage(&sarama.ProducerMessage{Topic: "test_topic",//消息数据本体Value: sarama.StringEncoder("hello world ,这是一条使用kafka的消息"),//会在生产者和消费者之间传递,消息头,可传递自定义键值对,比如 trace_id 用于链路追踪。Headers: []sarama.RecordHeader{{Key: []byte("trace_id"),Value: []byte("123456"),},},//只作用于发送过程。元信息,在发送过程中使用,可以用来传递额外信息,发送完成后会原样返回(不会传给消费者)。Metadata: "这是metadata",})assert.NoError(t, err)
}
10.执行结果
Partition: 0
Offset: 0
Key:
Value: hello world ,这是一条使用kafka的消息
使用控制台工具连接Kafka
Sarama 使用入门:指定分区
可以注意到,前面所有的消息都被发送到了 Partition 0 上面。
正常来说,在 Sarama 里面,可以通过指定 config 中的Partitioner来指定最终的目标分区。
常见的方法:
- Random:随机挑一个。
- RoundRobin:轮询。
- Hash(默认):根据 key 的哈希值来筛选一个。
- Manual: 根据 Message 中的 partition 字段来选择。
- ConsistentCRC:一致性哈希,用的是 CRC32 算法。
- Custom:实际上不 Custom,而是自定义一部分Hash 的参数,本质上是一个 Hash 的实现。
//默认HashPartitioner 适合: 按用户 ID、订单 ID 等字段分区场景
cfg.Producer.Partitioner = sarama.NewHashPartitioner
//使用 CRC32 算法 计算 Key 的哈希。 适合: 需要高一致性分布的业务,例如日志收集系统
cfg.Producer.Partitioner = sarama.NewConsistentCRCHashPartitioner
//忽略 Key,每条消息随机分配 partition。 适合: 普通消息队列、广播类场景。
cfg.Producer.Partitioner = sarama.NewRandomPartitioner
//需要手动指定 partition(ProducerMessage.Partition 字段)。适合: 明确知道要写哪个 partition,例如做数据分流
cfg.Producer.Partitioner = sarama.NewManualPartitioner
//用于实现你自己的 Partitioner 一般不推荐使用这个空参函数(它会 panic),应实现完整接口。
cfg.Producer.Partitioner = sarama.NewCustomPartitioner()
//允许你使用自定义哈希函数来做 key 分区。 适合: 有特定哈希策略需求时,例如分布要尽可能均匀。
cfg.Producer.Partitioner = sarama.NewCustomHashPartitioner(func() hash.Hash32 {})Topic: "test_topic",
//分区依据
Key: sarama.StringEncoder("user_123"), // 🔑 这里是分区依据
//消息数据本体
Value: sarama.StringEncoder("hello world ,这是一条使用kafka的消息"),
最典型的场景,就是利用Partitioner来保证同一个业务的消息一定发送到同一个分区上,从而保证业 有序。
Sarama 使用入门:异步发送
Sarama有一个异步发送的producer,它的用法稍微复杂一点。
- 把Return.Success和 Errors都设置为true,这是为了后面能够拿到发送结果。
- 初始化异步producer。
- 从producer里面拿到Input的channel,并且发送 一条消息。
- 利用select case,同时**监听Success和Error两个channel,**来获得发送成功与否的信息。
func TestAsyncProducer(t *testing.T) {cfg := sarama.NewConfig()//怎么知道发送是否成功cfg.Producer.Return.Errors = truecfg.Producer.Return.Successes = trueproducer, err := sarama.NewAsyncProducer(addrs, cfg)require.NoError(t, err)messages := producer.Input()go func() {for {messages <- &sarama.ProducerMessage{Topic: "test_topic",//分区依据Key: sarama.StringEncoder("user_123"), // 🔑 这里是分区依据//消息数据本体Value: sarama.StringEncoder("hello world ,这是一条使用kafka的消息"),//会在生产者和消费者之间传递Headers: []sarama.RecordHeader{{Key: []byte("trace_id"),Value: []byte("123456"),},},//只作用于发送过程Metadata: "这是metadata",}}}()errCh := producer.Errors()succCh := producer.Successes()for {//两个都不满足就会阻塞select {case err := <-errCh:t.Log("发送出了问题", err.Err)case <-succCh:t.Log("发送成功")}}
}Sarama 使用入门:acks
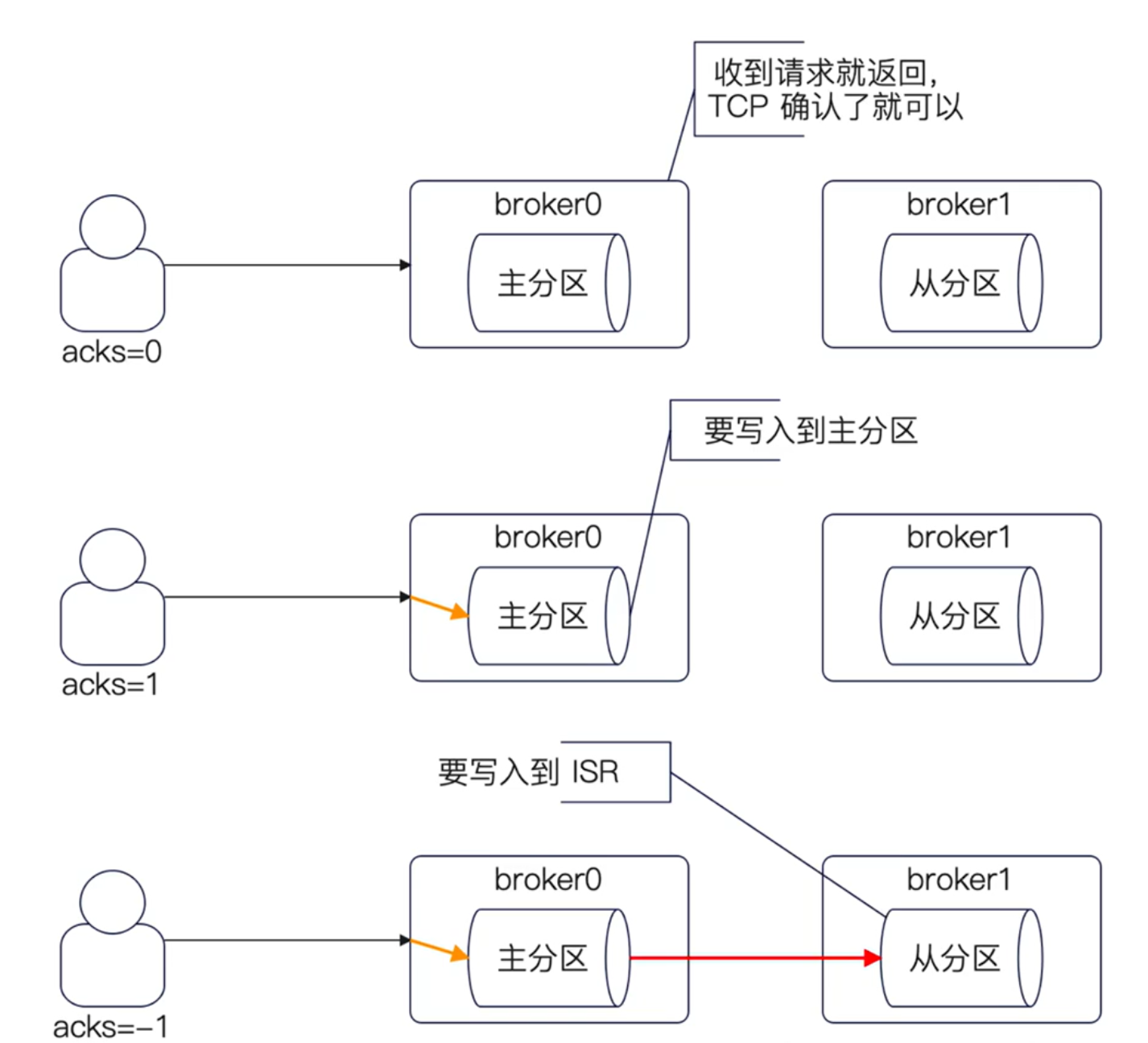
在Kafka里面,生产者在发送数据的时候,有一个很关键的参数,就是 acks。
有三个取值:
- 0:客户端发一次,不需要服务端的确认。
- 1:客户端发送,并且需要服务端写入到主分区。
- -1:客户端发送,并且需要服务端同步到所有的ISR 上。
从上到下,性能变差,但是数据可靠性上升。需要性能,选 0,需要消息不丢失,选-1。
理解acks你就要抓住核心点,谁ack才算数?
- 0:TCP协议返回了ack就可以。
- 1:主分区确认写入了就可以。
- -1:所有的ISR都确认了就可以。
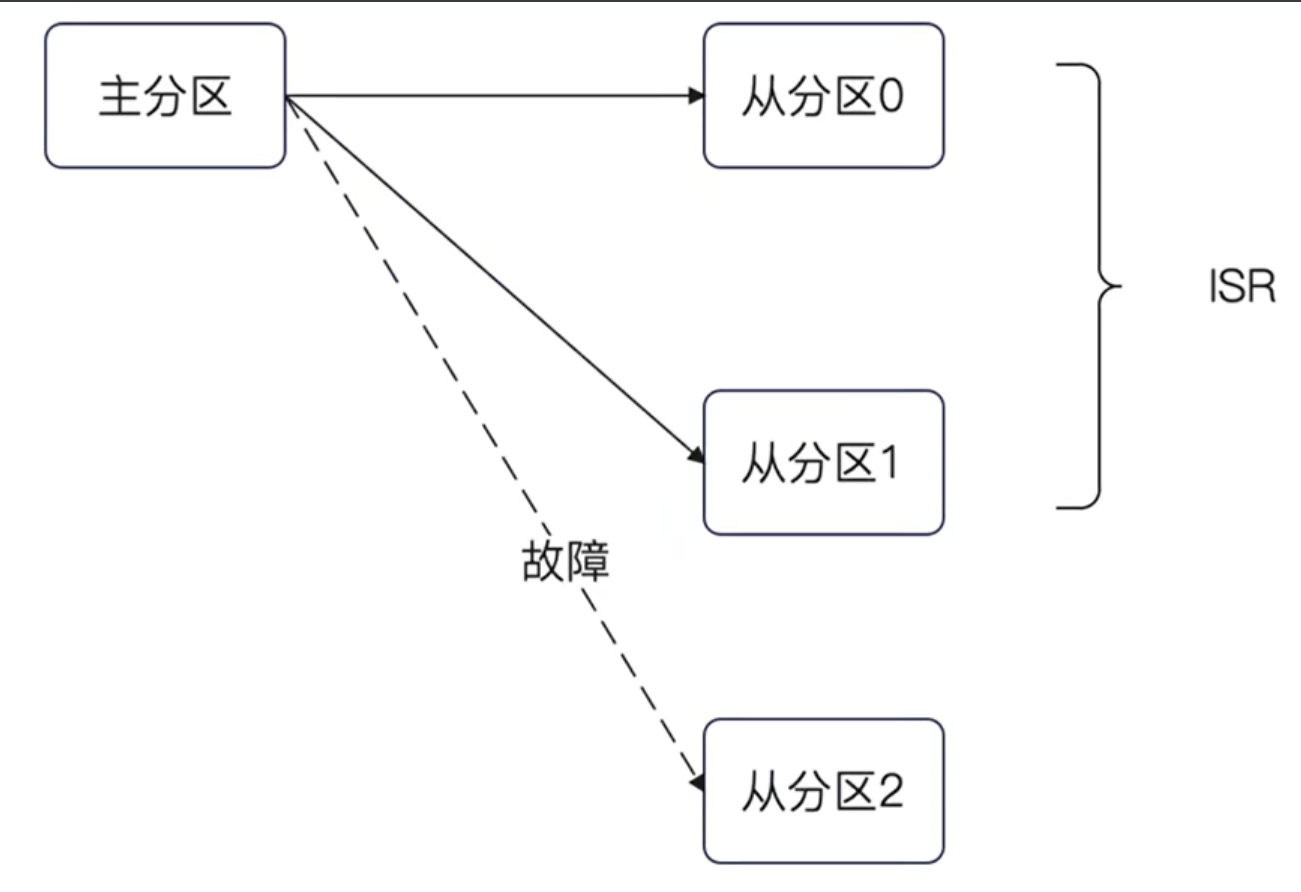
ISR (In Sync Replicas),用通俗易懂的话来说,就是跟上了节奏的从分区。
什么叫做跟上了节奏?就是它和主分区保持了数据同步。
所以,当消息被同步到从分区之后,如果主分区崩溃了那么依旧可以保证在从分区上还有数据。
sarama 使用入门:启动消费者
Sarama的消费者设计不是很直观,稍微有点复杂。
- 首先要初始化一个ConsumerGroup。
- 调用ConsumerGroup上的Consume方法。
- 为 Consume 方法传入一个 ConsumerGroupHandler的辅助方法。
package mainimport ("context""github.com/IBM/sarama""github.com/stretchr/testify/assert""log""testing"
)func TestConsumer(t *testing.T) {cfg := sarama.NewConfig()//正常来说,一个消费者都是归属一个消费者组的//消费者就是你的业务consumerGroup, err := sarama.NewConsumerGroup(addrs, "test_group", cfg)assert.NoError(t, err)err = consumerGroup.Consume(context.Background(), []string{"test_topic"}, testConsumerGroupHandler{})//你消费结束,就会到这里t.Log(err)
}type testConsumerGroupHandler struct {
}func (t testConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {log.Println("Setup session:", session)return nil
}func (t testConsumerGroupHandler) Cleanup(session sarama.ConsumerGroupSession) error {log.Println("Cleanup session:", session)return nil
}func (t testConsumerGroupHandler) ConsumeClaim(//代表的是你和Kafka的会话(从建立连接到连接彻底断掉的那一段时间)session sarama.ConsumerGroupSession,claim sarama.ConsumerGroupClaim) error {msgs := claim.Messages()for msg := range msgs {//var bizMsg MyBizMsg//err := json.Unmarshal(msg.Value, &bizMsg)//if err != nil {// //这就是消费消息出错// //大多数时候就是重试// //记录日志// continue//}log.Println(string(msg.Value))session.MarkMessage(msg, "")}//什么情况下会到这里//msg被人关了,也就是要退出消费逻辑return nil
}type MyBizMsg struct {Name string
}sarama 使用入门:ConsumerGroupHandler
下面的代码就是对ConsumerGroupHandler的实现,关键就是在消费了msg之后,如果消费成功了,要记得提交。
也就是调用MarkMessage方法。
至于 Setup 和 Cleanup 方法反而用得不多。
type testConsumerGroupHandler struct {
}func (t testConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {log.Println("Setup session:", session)return nil
}func (t testConsumerGroupHandler) Cleanup(session sarama.ConsumerGroupSession) error {log.Println("Cleanup session:", session)return nil
}func (t testConsumerGroupHandler) ConsumeClaim(//代表的是你和Kafka的会话(从建立连接到连接彻底断掉的那一段时间)session sarama.ConsumerGroupSession,claim sarama.ConsumerGroupClaim) error {msgs := claim.Messages()for msg := range msgs {//var bizMsg MyBizMsg//err := json.Unmarshal(msg.Value, &bizMsg)//if err != nil {// //这就是消费消息出错// //大多数时候就是重试// //记录日志// continue//}log.Println(string(msg.Value))session.MarkMessage(msg, "")}//什么情况下会到这里//msg被人关了,也就是要退出消费逻辑return nil
}
sarama 使用入门:利用context来控制消费者退出
可以利用初始化ConsumerGroup 时候传入的ctx来控制消费者组退出消息。
下图中,我传入了一个超时的context,那么:
start := time.Now()//这里是测试,我们就控制消费10sctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)defer cancel()//开始消费,会在这里阻塞住err = consumerGroup.Consume(ctx, []string{"test_topic"}, testConsumerGroupHandler{})//你消费结束,就会到这里t.Log(err, time.Since(start).String())
下图中,我主动调用了cancel,那么:
start := time.Now()//这里是测试,我们就控制消费5sctx, cancel := context.WithCancel(context.Background())time.AfterFunc(time.Second*5, func() {cancel()})//开始消费,会在这里阻塞住err = consumerGroup.Consume(ctx, []string{"test_topic"}, testConsumerGroupHandler{})//你消费结束,就会到这里t.Log(err, time.Since(start).String())
- 如果超时了
- 如果我主动调用了cancel
以上两种情况,任何一种情况出现了,都会让消费者退出消息。
sarama 使用入门:指定偏移量消费
在部分场景下,我们会希望消费历史消息,或者从某个消息开始消费,那么可以考虑在Setup里面设置偏移量。
关键调用是 ResetOffset。
不过一般建议走离线渠道,操作Kafka集群去重置对应的偏移量。
核心在于,你并不是每次重新部署,重新启动都是要重置这个偏移量的。
只要你的消费者组在这个分区上有过“已提交的 offset”,Kafka 就会优先使用这个提交的 offset,而忽略你在 Setup() 中设置的 offset。
// 在每次 rebalance 或初次连接 Kafka 后调用,用于初始化。
func (t testConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {//执行一些初始化的事情log.Println("Setup")//假设要重置到0var offset int64 = 0//遍历所有的分区partitions := session.Claims()["test_topic"]for _, p := range partitions {session.ResetOffset("test_topic", p, offset, "")//session.ResetOffset("test_topic", p, sarama.OffsetNewest, "")//session.ResetOffset("test_topic", p, sarama.OffsetOldest, "")}return nil
}
sarama使用入门:异步消费,批量提交
正常来说,为了在异步消费失败之后还能继续重试,可以考虑异步消费一批,提交一批。
下图中,ctx.Done分支用来控制凑够一批的超时机制,防止生产者的速率很低,一直凑不够一批。
func (t testConsumerGroupHandler) ConsumeClaim(//代表的是你和Kafka的会话(从建立连接到连接彻底断掉的那一段时间)//可以通过 session 控制 offset 提交,获取消费者信息,并感知退出时机。session sarama.ConsumerGroupSession,//claim 是你获取消息的入口claim sarama.ConsumerGroupClaim) error {msgs := claim.Messages()//设置批量处理的条数const batchSize = 10for {ctx, cancel := context.WithTimeout(context.Background(), time.Second*1)var eg errgroup.Groupvar last *sarama.ConsumerMessagefor i := 0; i < batchSize; i++ {done := falseselect {case <-ctx.Done()://这边表示超时了done = truecase msg, ok := <-msgs:if !ok {cancel()return nil}last = msgmsg1 := msgeg.Go(func() error {//我就在这里消费time.Sleep(time.Second)//你在这里重试log.Println(string(msg1.Value))return nil})}if done {break}}cancel()err := eg.Wait()if err != nil {//这边能怎么办?//记录日志continue}//就这样session.MarkMessage(last, "")}return nil
}
另外一个分支就是读取消息,并且提交到errgroup里面执行。
Sleep是模拟长时间业务执行。
相关文章:

Kafka Go客户端--Sarama
Kafka Go客户端 在Go中里面有三个比较有名气的Go客户端。 Sarama:用户数量最多,早期这个项目是在Shopify下面,现在挪到了IBM下。segmentio/kafka-go:没啥大的缺点。confluent-kafka-go:需要启用cgo,跨平台问题比较多,交叉编译也…...

Python打卡 DAY 24
知识点回顾: 1. 元组 2. 可迭代对象 3. os模块 作业:对自己电脑的不同文件夹利用今天学到的知识操作下,理解下os路径。 OS 模块 import os # os是系统内置模块,无需安装 获取当前工作目录 os.getcwd() # get current working…...

为什么hadoop不用Java的序列化?
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以…...
》)
《类和对象(下)》
引言: 书接上回,如果说类和对象(上)是入门阶段,类和对象(中)是中间阶段,那么这次的类和对象(下)就可以当做类和对象的补充及收尾。 一:再探构造…...

基于STM32、HAL库的TLV320AIC3101IRHBR音频接口芯片驱动程序设计
一、简介: TLV320AIC3101IRHBR 是 Texas Instruments 推出的高性能、低功耗音频编解码器,专为便携式和电池供电设备设计。它集成了立体声 ADC、DAC、麦克风前置放大器、耳机放大器和数字信号处理功能,支持 I2S/PCM 音频接口和 I2C 控制接口,非常适合与 STM32 微控制器配合…...

EDR与XDR如何选择适合您的网络安全解决方案
1. 什么是EDR? 端点检测与响应(EDR) 专注于保护端点设备(如电脑、服务器、移动设备)。通过在端点安装代理软件,EDR实时监控设备活动,检测威胁并快速响应。 EDR核心功能 实时监控:…...

Vue2 elementUI 二次封装命令式表单弹框组件
需求:封装一个表单弹框组件,弹框和表单是两个组件,表单以插槽的形式动态传入弹框组件中。 使用的方式如下: 直接上代码: MyDialog.vue 弹框组件 <template><el-dialog:titletitle:visible.sync"dialo…...

jenkins流水线常规配置教程!
Jenkins流水线是在工作中实现CI/CD常用的工具。以下是一些我在工作和学习中总结出来常用的一些流水线配置:变量需要加双引号括起来 "${main}" 一 引用无账号的凭据 使用变量方式引用,这种方式只适合只由密码,没有用户名的凭证。例…...
:设计原则(一):SRP、OCP、LSP)
设计模式系列(02):设计原则(一):SRP、OCP、LSP
本文为设计模式系列第2篇,聚焦面向对象设计的三大核心原则:单一职责、开放封闭、里氏替换,系统梳理定义、实际业务场景、优缺点、最佳实践与常见误区,适合系统学习与团队协作。 目录 1. 引言2. 单一职责原则(SRP)3. 开放封闭原则(OCP)4. 里氏替换原则(LSP)5. 常见误区…...

【日常】AI 工作流
AI 工作流 名称使用场景产品形态其他ChatGPT网页LLMGemini可以生成一份深度研究的文档并保存到Google Docs网页LLM白嫖了一年会员Kimi日常网页LLMDeepSeek深度思考网页LLMGrok3Deep Research 深度搜索网页LLMQwen3网页LLM元宝可免费使用DS的深度思考(满血DS R1版&a…...

问题及解决02-处理后的图像在坐标轴外显示
一、问题 在使用matlab的appdesigner工具来设计界面,可以通过点击处理按钮来处理图像,并将处理后的图像显示在坐标轴上,但是图像超出了指定的坐标轴,即处理后的图像在坐标轴外显示。 问题图如下图所示。 原来的坐标轴如下图所…...

Spark基础介绍
Spark是一种基于内存的快速、通用、可拓展的大数据分析计算引擎。 起源阶段 Spark 最初是在 2009 年由加州大学伯克利分校的 AMP 实验室开发。当时,Hadoop 在大数据处理领域占据主导地位,但 MapReduce 在某些复杂计算场景下,如迭代计算和交互…...

Oracles数据库通过存储过程调用飞书接口推送群组消息
在Oracle数据库中,可以通过存储过程调用外部接口来实现推送消息的功能。以下是一个示例,展示如何通过存储过程调用飞书接口推送群组消息。 创建存储过程 首先,创建一个存储过程,用于调用飞书接口。该存储过程使用UTL_HTTP包来发送HTTP请求。 CREATE OR REPLACE PROCEDUR…...

ubuntu22.04编译PX4无人机仿真实践
克隆PX4源码,并且更新子模块 git clone https://github.com/PX4/PX4-Autopilot.git --recursive git submodule update --init --recursive # 强制同步所有子模块 接着安装相关依赖: bash ./PX4-Autopilot/Tools/setup/ubuntu.sh 运行以下命令进行编译: cd ~/PX4-Autop…...

MySQL基础入门:MySQL简介与环境搭建
引言 在数字化转型浪潮中,MySQL作为数据存储的"基石引擎",支撑着从电商交易到金融风控的各类核心业务。其高并发处理能力、灵活的架构设计及跨平台兼容性,使其成为开发者技术栈中的"常青树"。本章节将通过历史溯源、技术…...
深蓝学院动力学kinodynamic A* 3D算法理论解读(附C++代码))
无人机避障——(运动规划部分)深蓝学院动力学kinodynamic A* 3D算法理论解读(附C++代码)
开源代码链接:GitHub - Perishell/motion-planning 效果展示: ROS 节点展示全局规划和轨迹生成部分: Kinodynamic A*代码主体: int KinoAstar::search(Eigen::Vector3d start_pt, Eigen::Vector3d start_vel,Eigen::Vector3d en…...

电脑声音小怎么调大 查看声音调整方法
电脑是我们工作学习经常需要用到的工具,同时电脑也可以播放音乐、视频、游戏等,享受声音的效果。但是,有些电脑的声音很小,即使把音量调到最大,也听不清楚,这让我们很苦恼。那么,电脑声音小怎么…...

无人机信号监测系统技术解析
一、模块技术要点 1. 天线阵列与信号接收模块 多频段自适应切换:采用天线阵列模块,根据复杂地形和不同频段自动切换合适的天线,提升信号接收灵敏度。 双天线测向技术:通过双天线的RSSI(信号接收强度)差值…...

Excel的详细使用指南
### **一、Excel基础操作** #### **1. 界面与基本概念** - **工作簿(Workbook)**:一个Excel文件(扩展名.xlsx)。 - **工作表(Worksheet)**:工作簿中的单个表格(默认名…...

基于SSM实现的健身房系统功能实现十六
一、前言介绍: 1.1 项目摘要 随着社会的快速发展和人们健康意识的不断提升,健身行业也在迅速扩展。越来越多的人加入到健身行列,健身房的数量也在不断增加。这种趋势使得健身房的管理变得越来越复杂,传统的手工或部分自动化的管…...
)
序列化和反序列化(hadoop)
1.先将上一个博客的Student复制粘贴后面加上H 在StudentH中敲下面代码 package com.example.sei; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; //学生类,姓名,年龄 //支…...

大模型MCP_MCP从流式SSE到流式HTTP_1.8.0支持流式HTTP交互_介绍_从应用到最优--人工智能工作笔记0245
从最开始的大模型时代,到现在MCP,大模型技术,人工智能技术迭代真的非常快 之前的大模型更像一个大脑,能帮大家出点子,然后告诉你思路,你去解决问题,但是 一直不能自己解决问题,后来出来了通用的manus智能体,声称可以解决很多问题.直接操作 一个自带的电脑,但是也有局限性,还…...

docker大镜像优化实战
在 Docker 镜像优化方面,有许多实战技巧可以显著减小镜像体积、提高构建效率和运行时性能。以下是一些实用的优化策略和具体操作方法: 1. 选择合适的基础镜像 策略 使用 Alpine 版本:Alpine 镜像通常只有 5-10MB,比 Ubuntu/Deb…...
应用层安全协议)
【25软考网工】第六章(5)应用层安全协议
博客主页:christine-rr-CSDN博客 专栏主页:软考中级网络工程师笔记 大家好,我是christine-rr !目前《软考中级网络工程师》专栏已经更新三十篇文章了,每篇笔记都包含详细的知识点,希望能帮助到你ÿ…...
及其在时间序列中的应用)
RevIN(Reversible Instance Normalization)及其在时间序列中的应用
详细介绍 RevIN(Reversible Instance Normalization)及其在时间序列中的应用 1. RevIN 的定义与背景 RevIN(可逆实例归一化)是一种专门为时间序列预测设计的归一化方法,旨在处理非平稳数据(non-stationar…...

JSON 和 cJSON 库入门教程
第一部分:了解 JSON (JavaScript Object Notation) 什么是 JSON? JSON 是一种轻量级的数据交换格式。它易于人阅读和编写,同时也易于机器解析和生成。 JSON 基于 JavaScript 编程语言的一个子集,但它是一种独立于语言的文本格式…...

Unity 2D 行走动画示例工程手动构建教程-AI变成配额前端UI-完美游戏开发流程
🎮 Unity 2D 行走动画示例工程手动构建教程 ✅ 1. 新建 Unity 项目 打开 Unity Hub: 创建一个新项目,模板选择:2D Core项目名:WalkAnimationDemo ✅ 2. 创建文件夹结构 在 Assets/ 目录下新建以下文件夹:…...

[Java][Leetcode middle] 45. 跳跃游戏 II
这题没做出来,看的答案解析 可以理解为希望采用最少得跳槽次数跳到最高级别的公司。 下标i为公司本身的职级,每个公司可以提供本身等级nums[i]的职级提升。 每次从这些选择中选择自己能够达到最大职级的公司跳槽。 public int jump(int[] nums) {if(nu…...

leetcode 3335. 字符串转换后的长度 I
给你一个字符串 s 和一个整数 t,表示要执行的 转换 次数。每次 转换 需要根据以下规则替换字符串 s 中的每个字符: 如果字符是 z,则将其替换为字符串 "ab"。否则,将其替换为字母表中的下一个字符。例如,a 替…...

Leetcode 3542. Minimum Operations to Convert All Elements to Zero
Leetcode 3542. Minimum Operations to Convert All Elements to Zero 1. 解题思路2. 代码实现 题目链接:3542. Minimum Operations to Convert All Elements to Zero 1. 解题思路 这一题的处理方法其实还是挺好想明白的,其实就是从小到大依次处理各个…...

如何使用C51的Timer0实现定时功能
在C51单片机中,使用定时器0(Timer0)实现定时功能需要以下步骤: 1. 定时器基础知识 时钟源:C51的定时器时钟来源于晶振(如12MHz)。机器周期:1个机器周期 12个时钟周期(1…...

Day1 时间复杂度
一 概念 在 C 中,时间复杂度是衡量算法运行时间随输入规模增长的趋势的关键指标,用于评估算法的效率。它通过 大 O 表示法(Big O Notation) 描述,关注的是输入规模 n 趋近于无穷大时,算法时间增长的主导因…...

PostgreSQL 配置设置函数
PostgreSQL 配置设置函数 PostgreSQL 提供了一组配置设置函数(Configuration Settings Functions),用于查询和修改数据库服务器的运行时配置参数。这些函数为数据库管理员提供了动态管理数据库配置的能力,无需重启数据库服务。 …...
 罗国正)
美学心得(第二百七十六集) 罗国正
美学心得(第二百七十六集) 罗国正 (2025年4月) 3275、人类将迎来真、善、美快速发展的时期,人‐机合一的天人合一(可简称为“天人机合一”)的境界已渐露头角,在优秀的人群中迅猛地…...

描述性统计工具 - AxureMost 落葵网
描述性统计工具是用于汇总和分析数据,以更好地了解数据特征的工具1。以下是一些常见的描述性统计工具简介: 描述性统计工具 Excel 基本统计函数:提供了丰富的函数用于计算描述性统计量。例如,AVERAGE 函数用于计算平均值…...

mybatis中${}和#{}的区别
先测试,再说结论 userService.selectStudentByClssIds(10000, "wzh or 11");List<StudentEntity> selectStudentByClssIds(Param("stuId") int stuId, Param("field") String field);<select id"selectStudentByClssI…...
)
【OpenCV】网络模型推理的简单流程分析(readNetFromONNX、setInput和forward等)
目录 1.模型读取(readNetFromONNX())1.1 初始化解析函数(parseOperatorSet())1.2 提取张量(getGraphTensors())1.3 节点处理(handleNode()) 2.数据准备(blobFromImage() …...

代码随想录算法训练营第三十九天
LeetCode题目: 115. 不同的子序列583. 两个字符串的删除操作72. 编辑距离 其他: 今日总结 往期打卡 115. 不同的子序列 跳转: 115. 不同的子序列 学习: 代码随想录公开讲解 问题: 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数。 测试用例保…...

InternVL3: 利用AI处理文本、图像、视频、OCR和数据分析
InternVL3推动了视觉-语言理解、推理和感知的边界。 在其前身InternVL 2.5的基础上,这个新版本引入了工具使用、GUI代理操作、3D视觉和工业图像分析方面的突破性能力。 让我们来分析一下是什么让InternVL3成为游戏规则的改变者 — 以及今天你如何开始尝试使用它。 InternVL…...
)
力扣刷题Day 48:盛最多水的容器(283)
1.题目描述 2.思路 学习了Krahets佬的双指针思路,初始化两个边界作为容器边界,然后逐个向数组内遍历,直到左右两指针相遇。 3.代码(Python3) class Solution:def maxArea(self, height: List[int]) -> int:left,…...

基于单应性矩阵变换的图像拼接融合
单应性矩阵变换 单应性矩阵是一个 3x3 的可逆矩阵,它描述了两个平面之间的投影变换关系。在图像领域,单应性矩阵可以将一幅图像中的点映射到另一幅图像中的对应点,前提是这两幅图像是从不同视角拍摄的同一平面场景。 常见的应用场景&#x…...

《驱动开发硬核特训 · 专题篇》:深入理解 I2C 子系统
关键词:i2c_adapter、i2c_client、i2c_driver、i2c-core、platform_driver、设备树匹配、驱动模型 本文目标:通过实际代码一步步讲清楚 I2C 子系统的结构与运行机制,让你不再混淆 platform_driver 与 i2c_driver 的职责。 🧩 一、…...

Spark缓存-cache
一、RDD持久化 1.什么时候该使用持久化(缓存) 2. RDD cache & persist 缓存 3. RDD CheckPoint 检查点 4. cache & persist & checkpoint 的特点和区别 特点 区别 二、cache & persist 的持久化级别及策略选择 Spark的几种持久化…...

tails os系统详解
一、起源与发展背景 1. 项目初衷与历史 创立时间:Tails 项目始于 2004 年,最初名为 “Anonymous Live CD”,2009 年正式更名为 “Tails”(The Amnesic Incognito Live System,“健忘的匿名实时系统”)。核…...

[洛谷刷题9]
P2376 [USACO09OCT] Allowance G(贪心) https://www.luogu.com.cn/problem/P2376 题目描述 作为创造产奶纪录的回报,Farmer John 决定开始每个星期给Bessie 一点零花钱。 FJ 有一些硬币,一共有 N ( 1 ≤ N ≤ 20 ) N (1 \le …...

数据挖掘入门-二手车交易价格预测
一、二手车交易价格预测 1-1 项目背景 随着二手车市场的快速发展,二手车交易价格的预测成为了一个热门研究领域。精准的价格预测不仅能帮助买卖双方做出更明智的决策,还能促进市场的透明度和公平性。对于买家来说,了解合理的市场价格可以避免…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】金融风控分析案例-10.4 模型部署与定期评估
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 10.4 模型部署与定期评估10.4.1 模型部署架构设计1.1 模型存储方案1.2 实时预测接口 10.4.2 定期评估体系构建2.1 评估指标体系2.2 自动化评估流程2.3 模型衰退预警 10.4.3 …...

构建可信数据空间需要突破技术、规则和生态三大关键
构建可信数据空间需要突破技术、规则和生态三大关键:技术上要解决"可用不可见"的隐私计算难题,规则上要建立动态确权和跨境流动的治理框架,生态上要形成多方协同的标准体系。他强调,只有实现技术可控、规则可信、生态协…...

阳光学院【2020下】计算机网络原理-A卷-试卷-期末考试试卷
一、单选题(共25分,每空1分) 1.ICMP协议工作在TCP/IP参考模型的 ( ) A.主机-网络 B.网络互联层 C.传输层 D.应用层 2.下列关于交换技术的说法中,错误的是 ( ) A.电路交换适用于突发式通信 B.报文交换不能满足实时通信 C.报文…...
函数用法)
python: union()函数用法
在 Python 中,union() 是集合(set)类型的内置方法,用于返回两个或多个集合的并集(即所有元素的合集,自动去重)。以下是它的用法详解: 1. 基本语法 python 复制 下载 set.union(*…...