TCPIP详解 卷1协议 九 广播和本地组播(IGMP 和 MLD)
9.1——广播和本地组播(IGMP 和 MLD)
IPv4可以使用4种IP地址:单播(unicast)、任播(anycast)、组播(multicast)和广播(broadcast)。
IPv6可以使用3种IP地址:单播(unicast)、任播(anycast)、组播(multicast)。
互联网组管理协议(IGMP)[RFC3376]和IPv6组播侦听发现(MLD)[RFC3810]协议,它们用来通知IPv4和IPv6组播路由器子网中哪些组播地址在使用中。
广播和组播为应用程序提供了两种服务:数据分组交付至多个目的地,通过客户端请¢
求/发现服务器。
- 数据分组交付至多个目的地:有许多应用程序将信息交付至多个收件方,例如,互动式会议、邮件或新闻分发至多个收件方。没有广播或组播,这些类型的服务往往倾向于使用现在的TCP(将一个单独的副本交付至每一个目的地,这是非常低效的)。
- 通过客户端请求/发现服务器:使用广播或组播,应用程序可以向一个服务器发送一个请器求,而不用知道任何特定服务器的IP地址。当本地网络环境的信息了解得很少时,这种功能在配置过程中非常有用。例如,一台笔记本电脑可能需要使用DHCP,获取它的初始IP地址,找到其最近的路由器。
虽然广播和组播都可以提供这些重要的功能,但是相对于广播来说,组播一般情况下是更可取的,因为组播只涉及那些支持或使用特定服务或协议的系统,而广播却不是。因此,一个广播请求会影响在广播范围内所有可以到达的主机,而组播只影响那些可能对该请求有兴趣的主机。
一般来说,只有使用 UDP 传输协议的用户应用程序利用广播和组播,此时应用程序发送单个报文到多个收件方才是有意义的。TCP是一个面向连接的协议,这意味着两台主机(由 IP 地址指定)和每台主机上的一个进程(由端口号指定)之间的一个连接。TCP 可以使用单播和任播地址,但是不能使用广播或组播地址。
9.2——广播
广播是指将报文发送到网络中的所有可能的接收者。原理:路由器简单地将它接收到的任意报文副本转离(forward out)除报文到达的接口以外的每个接口。当有多个主机连接到同一个本地局域网时,事情就稍微有点复杂了。在这种情况下,链路层的特点可以使得广播在某种程度上更高效。
考虑在诸如以太网的网络上的一组主机,这种网络在链路层上支持广播。每个以太网帧络包含源和目的MAC地址(48位值),通常情况下,每个IP分组被指定到一个单一的主机,所以使用单播寻址,目的地的唯一MAC地址使用ARP 或IPv6 ND 来确定。当一个帧以这种方式被发送到一个单播目的地时,任意两个主机之间的通信不会打扰网络上的任何其他主播机。对于交换以太网来说,这些都是在交换机和网桥中的站点缓存中发现的地址类型。然而,有些时候,一个主机要向网络(或 VLAN)上的每个其他主机发送一个帧——这称为广播(broadcast)。
9.2.1 使用广播地址
在一个以太网或类似网络中,组播 MAC地址中高位字节的低序位打开。以十六进制表示,这看起来像01:00:00:00:00:00。我们可以认为以太网广播地址ff:ff:ff:ff是以太网组播地址的一种特殊情况。在 IPv4 中,每个子网都有一个本地定向子网广播地址,它是通过将地址中的主机部分全部置 1 形成的,特殊地址 255.255.255.255对应于本地网络(也称为“有限”)广播。
9.2.2 发送广播数据报
一般来说,使用广播的应用程序使用 UDP 协议(或 ICMPv4 协议),然后调用一组普播通API来发送流量。唯一例外的是,当调用API时,一些操作系统会使用一个特殊的标志(SO_BROADCAST),以表示该应用程序确实打算发送广播数据报。例如,在Linux中,当试图发送广播 ping 时,没有使用-b 标志会引起下面的输出:
Linuxt ping 10.0.0.127
Do you want to ping broadcast? Then -b
之所以引起该错误,是因为只有在命令中提供-b 参数时,才能通过 API 提供 SO_BROADCAST标志。这有助于避免意外产生广播流量而造成暂时拥塞网络。
9.3——组播
为了减少在广播中涉及的开销,可以只向那些对它感兴趣的接收方发送流量。这被称为组播(multicasting)。
组播状态(multicast state)信息必须由主机和路由器来保持,以说明哪些接收方对哪类流量有兴趣。在组播 TCP/IP 模型中,接收方通过指明组播地址和可选源列表来表明它们对希望接收的流量的兴趣。这个信息作为主机和路由器中的软状态(soft state)来维持,这意味着它必须定期更新或是超时删除。当超时删除时,组播流量的交付要么停止,要么恢复为广播。
为了使组播工作,希望参与通信的应用程序需要一种机制来发布其意愿的协议实现。然后主机软件可以安排接收与应用程序的条件相匹配的分组。
IP组播在诸如以太网的链路层网络中,起初使用一种基于组寻址工作方式的设计。在这种方法中,每个站点选择它愿意接收流量的组地址,而不考虑发送方。因为对于发送方的身份是不敏感的,所以这种方法有时也被称为任源组播(ASM)。另一种代替方式,它对于发送方的身份是敏感的,被称为特定源组播(SSM),它允许终端站点明确地包含或排除从一组特定发送方发送到一个组播组的流量。SSM 服务模型比 ASM 更容易实现,这主要是因为在广域组播中,确定单个源的位置比确定很多源的位置更容易。然而,在局部区域,支持ASM或SSM的大部分机器是相同的。
9.3.1 将IP组播地址转换为802 MAC/以太网地址
在类似以太网的网络中,使用单播地址时,ARP通常根据目的地的IPv4地址确定其 MAC 地址。在 IPv6 中,ND 起着类似的作用。当我们想要发送组播流量时,什么样的目的地MAC地址应该放置于链路层帧中呢?理想的情况下,我们不必使用协议报文来确定适当的MAC地址,相反,可以只是简单地将一个IP 组播地址直接映射到一些对应的 MAC地址。
为了在链路层网络中有效地承载IP 组播,在 IP 层和链路层帧的数据分组和地址之间应该有一个一对一的映射。IANA拥有IEEE组织唯一标识符(以下简称OUI,或非正式称为以太网地址前缀)00:00:5e。有了它,IANA就被赋予权限去使用以 01:00:5e开始的组(组播)MAC 地址以及以 01:00:5e 开始的单播地址。该前缀被用作以太网地址的高序 24位,这意味着此块包括范围在00:00:5e:00:00:00 到00:00:5e:ff:ff:ff的单播地址,以及范围在01:00:5e:00:00:00 到 01:00:5e:ff:ff:ff 的组播地址。除了IANA 的其他组织也拥有地址块,但只有 IANA 将其空间的一部分用于支持IP 组播。
IANA 分配一半的组地址块用于识别 IEEE 802 LAN 上的 IPv4 组播流量。这意味着,对应到IPv4组播的以太网地址范围为01:00:5e:00:00:00到01:00:5e:7f:ff:ff。
IPV4地址到它们对应的IEEE 802形式的链路层地址的映射如下图所示。

所有的 IPv4 组播地址都被包含在从 224.0.0.0 到 239.255.255.255 的地址空间中(以前称为 D 类地址空间)。所有这样的地址在高序位共享一个共同的 4 位序列 1110。因此,有 32-4=28 位可用来编码整个空间,即 2 ^ 28 = 268 435 456 个组播 IPv4 地址(也称为组 ID)。对于 IPv4,IANA 的政策是分配一半的组地址用于支持 IPv4 组播,这意味着所有的 268 435 456 个组播组 ID 需要被映射到只包含 2^23 = 8 388 608个唯一条目的链路层地址空间。因此,映射是非唯一的。即多个IPv4组ID被映射到相同MAC层组地址。具体来说,228/223= 2^5=32 个不同的 IPv4 组播组 ID 被映射到每个组地址。例如,组播地址224.128.64.32(十六进制为 e0.80.40.20)和 224.0.64.32(十六进制为 e0.00.40.20)都被映射到以太网地址 01:00:5e:00:40:20。
对于 IPv6,16 位的 OUI 十六进制前缀是 33:33。这意味着,IPv6 地址的最后 32 位可以用来形成链路层地址。因此,任何以相同的 32 位结束的地址映射到相同的 MAC 地址(见下图)。由于所有的 IPv6 组播地址以 ff 开始,随后的 8 位用于标志和范围信息,这就留下128-16=112 位用于表示 2^112 个组。因此,MAC 层地址的 32 位可用来编码这些组,可能有多达 2112/232 = 2^80 个组映射到相同的 MAC 地址!

9.3.3 发送组播数据报
当发送任意的IP 数据分组时,必须决定使用哪个地址和接口。对于IPv6来说尤其如此,因为IPv6中每个接口有多个地址被认为是正常的。为了帮助确定这一点,我们可以看一下目前主机中的转发表。在Windows或Linux操作系统中,都可以使用netstat命令。
netstat -rn
下面是在 Windows Vista(更高版本使用相同的格式)上 IPv4 和 IPv6 的路由表的输出情况。
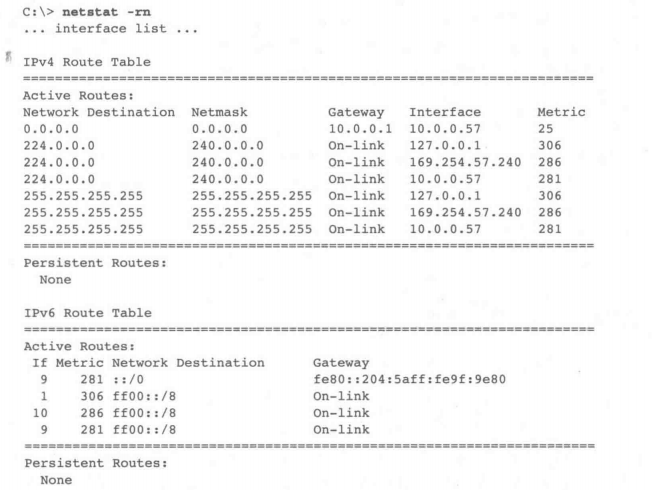
从表中我们可以看到,IPv4 流量的默认路由是使用接口10.0.0.57转向 10.0.0.1。虽然这确实与组播流量匹配,但是有其他更具体的条目。列出的条目224.0.0.0/4(子网掩码240.0.0.0)说明三个不同的接口可以承载传出的组播流量。具有最低跃点数的接口(10.0.0.57,跃点数值为281)最优先选择,所以如果应用程序没有指定,就会使用它。对于IPv6,所有的组播地址以ff开始,没有广播地址,所以接口1、9和10都可以使用。接口9(这恰好是IPv4中的相同接口和IPv6单播流量的默认接口)具有最低跃点数。
9.3.4 接收组播数据报
组播的基本是在主机给定的接口上进程加入或离开一个或多个组播组的概念。(我们使用术语进程(process)代表由操作系统执行的程序,往往代表一个用户。)在一个给定接口上的组播组的成员资格是动态的,它随进程加入或离开组而改变。除了加入或离开组,如果进程希望指定它希望收听或排除的源,就需要额外的方法。这些是支持组播的主机上的任意API的必需部分。组的成员资格与接口相关,因此我们使用限定词“接口”。一个进程可以在多个接口上加入同一组,也可以加入同一接口上的多个组,或是其中的任意组合。
9.3.5 主机地址过滤
为了了解操作系统进程如何为程序已加入的组播组接收组播数据报,每当一个帧因可能会被接收而交给过滤器时,过滤(filtering)就在每个主机的网络接口卡(NIC)上发生。下图说明了这是如何发生的。
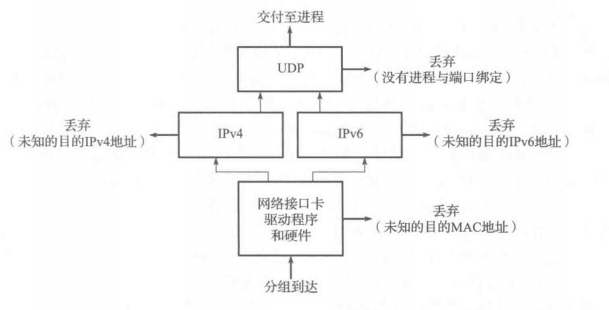
在一个典型的交换式以太网环境中,广播和组播帧沿着在交换机之间形成的一棵生成树在VLAN中的所有段被复制。这样的帧被交付至每台主机上的NIC,它将会检查帧的正确性(使用CRC),并且决定是否接收该帧,并将其交付给设备驱动程序和网络协议栈。通常情况下,NIC只接收目的地址是接口的硬件地址或广播地址的那些帧。然而,当涉及组播帧时,情况就更加复杂了。
NIC往往有两类。一类执行基于组播硬件地址的散列值的过滤,主机软件可以表达对该硬件地址的兴趣,这意味着由于散列冲突,一些不需要的帧总是可以通过。另一类侦听组播地址的一张有限表,这意味着,如果主机需要接收超过表中能够容纳的更多的组播地址的帧,NIC 将进入一种“组播混杂”模式,在这种情况下,所有的组播流量将会交给主机软件。因此,两种类型的接口需要设备驱动程序或高层软件执行检查,以确定接收到的帧是否真的需要。虽然接口进行完善的组播过滤(基于 48 位的硬件地址),但是由于从组播 IPv4 或 IPv6地址到 48 位的硬件地址的映射不是唯一的,过滤还是必需的。尽管存在不完美的地址映射和硬件过滤,组播仍然比广播更高效。
对于支持多条目地址表的NIC来说,将每个接收到的帧的目的地址与该表比较,如果在表中发现该地址,该帧由设备驱动程序接收和处理。此表的条目由设备驱动程序软件和协议栈的其他层(如 IPv4 和 IPv6 的实现)联合管理。实现这种类型过滤器的另一种方法是对目的地址使用散列函数,形成一个到二元向量的索引。当向量中被索引的条目包含一个 1 位时,对应的地址被视为可以接受,并进一步处理该帧。这种做法可以节省 NIC的内存,但因为在散列函数中的冲突,一些不应该接收的帧可能被认为是可以接受的。然而,这不是一个致命的问题,因为栈中较高层也执行过滤,并且当帧不应该被丢弃时,没有帧被丢弃(即,不存在漏报,但有可能存在误报)。
一旦NIC硬件验证一个帧是可以接受的(即CRC是正确的,任何VLAN标签匹配,目的MAC地址与一个或多个NIC表中一个地址条目相匹配),该帧被传递到设备驱动器程序,在此执行另外的过滤。首先,帧类型必须指定一种被支持的协议(例如,IPv4、IPv6、ARP等)。其次,可以执行另外的组播过滤以检查主机是否属于被寻址的组播组(通过目的IP地址说明)。这对于可能产生误报的 NIC 来说是必要的。
然后,设备驱动程序将该帧传递到下一层,例如,如果帧类型指定一个IP 数据报,则为IP 层。基于源和目的 IP 地址,IP 进行更多的过滤,如果一切没有问题,它将该数据报向上传递到下一层(如TCP或UDP)。每次UDP从IP收到一个数据报,它执行基于目的端口号的过滤,有时也基于源端口号。如果当前没有进程正在使用该目的端口,数据报就被丢弃,并生成一个ICMPv4 或 ICMPv6 端口不可达报文。(TCP 基于它的端口号执行类似的过滤。)如果UDP数据报存在校验和错误,UDP默默丢弃它。
9.4——互联网组管理协议(IGMP)和组播侦听发现协议(MLD)
当组播数据报在广域网或是在跨越多个子网的企业中转发时,我们要求,组播路由应该由一个或多个组播路由器启动。这种情况更加复杂,因为为了合理地安排要交付的组播流量,组播路由器需要了解哪些主机对什么组播组感兴趣。它们也执行一个特定的程序,称为反向路径转发(RPF)检查。此过程在到达的组播数据报的源地址上进行路由查找。只有当路由的传出接口与数据报到达的接口相匹配时,数据报才转发。RPF检查对于避免组播回路来说是非常重要的。组播路由在很大程度上是独立于由IP路由器提供的传统的单播路由的。然而,一些组播路由的功能需要IPv6 ND协议来正常地操作。
两个主要的协议用于允许组播路由器了解附近的主机感兴趣的组:IPv4使用的互联网组管理协议(IGMP)和 IPv6 使用的组播侦听发现(MLD)协议。两者都由支持组播的主机和路由器使用,并且协议非常相似。这些协议让LAN(VLAN)上的组播路由器知道哪些主机当前属于哪些组播组。路由器需要此信息,这样它们知道哪些组播数据报转发到哪些接口。在大多数情况下,组播路由器只要求知道至少一个侦听主机通过一个特定接口是可达的,因为链路层组播寻址(假设它支持)允许组播路由器发送链路层组播帧,这些帧将被所有的感兴趣的侦听方接收。这允许一个组播路由器完成其工作,而不用记录每个接口上的单个主机,它们可能只对特定组的组播流量感兴趣。
随着时间的推移,IGMP已经演变了,并且[RFC3376]定义了第3版(到写作的时候最新的版本)。MLD在并行发展,其目前版本(2)在[RFC3810]中定义。IGMPv3 和/或MLDv2 被要求支持 SSM。
IGMP版本 1 是第一个广泛使用的IGMP 版本。版本 2 添加了更迅速地离开组(也被MLDv1 支持)的能力。IGMPv3 和 MLDv2 添加了选择组播流量源的能力,并要求部署 SSM。然而 IGMP 是 IPv4 使用的一个单独的协议,而 MLD 是 ICMPv6的真正的一部分。
下图显示了IPv4(IPv6)具有组播功能的路由器如何使用IGMP(MLD)。这样的路由器关注于确定在它的每个连接的接口上有哪些感兴趣的组播组。这些路由器需要此信息,以避免简单地从每个接口广播出所有的流量。
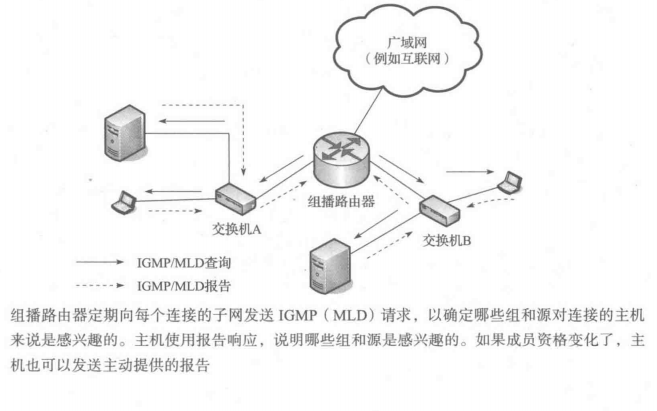
在上图中,我们可以看到IGMP(MLD)查询是如何通过组播路由器发送的。这些被发送到所有主机组播地址 224.0.0.1(IGMP),或所有节点链路范围组播地址 ff02::1(MLD),并且被实现IP组播的每台主机处理。成员资格报告报文由组成员发送以响应查询,但是也可能从一些主机以一种主动提供的方式来发送,这些主机希望通知组播路由器它们的组成员资格和/或对特定源的兴趣已经改变了。IGMPv3报告发送到具有IGMPv3功能的组播路由器地址224.0.0.22,MLDv2报告被发送到相应的MLDv2 侦听IPv6 组播地址 ff02::16。需要注意的是,当组播路由器加入组播组时,组播路由器本身也作为成员。
IGMP 和 MLD 的封装如下图所示。

与ICMP类似,IGMP被认为是IP 层的一部分。还和 ICMP 类似的是,IGMP 报文也在 IPv4 数据报中传输。不像我们已经看到的其他协议,IGMP使用一个固定的为1的TTL值,所以数据分组仅限于本地子网。IGMP数据分组也使用 IPv4 路由器警告选项,并使用 6 位值 0x30 的 DS 字段来代表网间控制。在 IPv6 中,MLD 是 ICMPv6 的一部分,但MLD 的功能和 IGMP 的几乎是相同的,它的封装使用了IPv6的逐跳扩展头部以保持路由器警告选项。在许多情况下,源列表是空的。
IGMP 和 MLD 定义了两组协议处理规则:由组成员的主机执行的和由组播路由器执行的。一般来说,成员主机(我们将其称为“组成员”)的工作是自发地报告对组播组和源的兴趣改变,以及响应定期的查询。组播路由器发送查询,以确定连接链路上的对于任意组或是特定的组播组和源是否有兴趣。路由器也与广域组播协议(如 PIM-SM 和 BIDIR-PIM)交互,将所需的流量带给有兴趣的主机或禁止流量流向不感兴趣的主机。
9.4.1 组成员的IGMP和MLD处理
IGMP和MLD组成员的部分被设计为允许主机指定它们对什么样的组有兴趣,以及从特定源发送的流量是否应该接受或过滤掉。这是通过向一个或多个连接到同一子网的组播路由器(和参与主机)发送报告完成的。报告可以作为接收查询的结果发送,或是因为接收状态的本地改变而自发地发送。IGMP报告采取下图所示的格式。
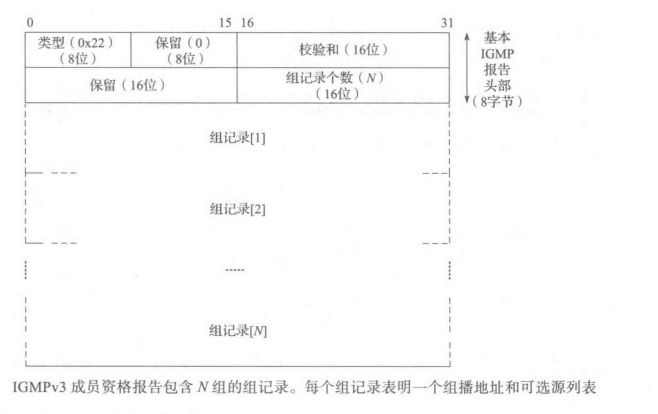
报告报文是相当简单的。它们包含一个组记录向量,其中的每一个提供了有关特定组播组的信息,包括主题组的地址,以及用于建立过滤器的一个可选源列表(参见下图)。

每个组记录中包含一个类型、主题组的地址,以及要包含或是排除的源地址列表。此外,还支持包括辅助数据,但此功能在 IGMPv3 中没有使用。下表显示使用 IGMPv3 报告记录类型可以获得极高的灵活性。MLD 使用相同的值。源列表涉及了包含(include)或排除(exclude)模式。在包含模式中,在列表中的源是流量应该被接收的唯一的源。在排除模式中,在列表中的源是应该被过滤掉的。离开一个组可以表示为使用没有源的包含模式过滤器,一个组的简单加入(即对所有源)可以表示为使用没有源的排除模式滤波器。注意,当使用SSM时,类型 0x02 和 0x04不能使用,因为对于任意组,只有一个单一源是假定的。
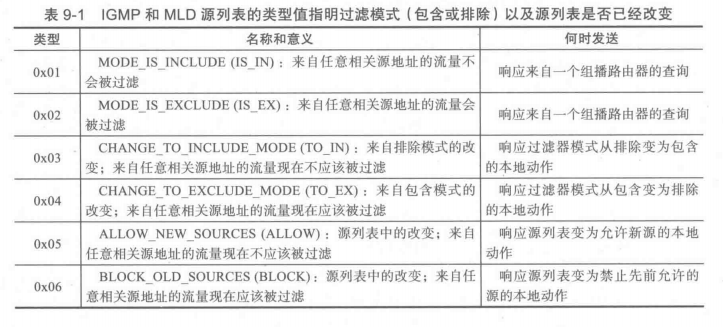
前两种报文类型(0x01,0x02)被称为当前状态记录(current-state record),用于在响应查询中报告当前过滤器的状态。
接下来的两个(0x03,0x04)被称为过滤器模式改变记录滤(filter-mode-change record),这表明从包含模式变为排除模式,或相反。
最后的两个(0x05,0x06)被称为源列表变更记录(source-list-change record),指明在排除或包含模式中正在处理的源的变化。
最后四种类型也被更一般地描述为状态变化记录(state-change record)或状态变化报告(state-change report)。这些作为一些本地状态改变的结果来发送,如一个新的应用程序正在启动或停止,或是一个正运行的应用程序改变了它的组/源兴趣。需要注意的是,IGMP和MLD查询/报告本身从不过滤。MLD报告使用类似于IGMP报告的结构,但是可以容纳更大的地址范围,并使用一个ICMPv6类型代码 143。当接收到一个查询时,组成员没有立即回应。相反,它们设置一个随机的(有界限的)计时器来决定何时响应。在此期间,进程可能会改变它们的组/源兴趣。任何这样的变化可以在计时器到期前一起处理来触发报告。这样一来,一旦计时器到期,多个组的状态可以更容易地被合并成一个单一的报告,节省了开销。
用于IGMP的源地址是发送接口的主要或首选的IPv4地址。对于MLD,源地址是本地链路 IPv6 地址。当主机在启动并尝试确定它自己的 IPv6 地址时,会同时出现一个问题。在此期间,它选择一个潜在的 IPv6 地址来使用并执行重复地址检测(DAD)过程,以确定是否有任何其他的系统已经使用这个地址。因为DAD 涉及组播,一些源地址必须被分配为传出 MLD 报文。[RFC3590]解决了这个问题,它允许未指定的地址(::)在配置过程中被用来作为MLD流量的源 IPv6 地址。
9.4.2 组播路由器的IGMP和MLD处理
在 IGMP 和 MLD 中,组播路由器的工作是为每个组播组、接口和源列表确定是否至少有一个组成员目前在接收相应的流量。这是通过发送查询,以及基于成员发送的报告,建立描述成员存在性的状态来完成的。此状态是软状态,这意味着,如果没有被刷新,在经过一个确定的时间后,它会被清除。为了建立这种状态,组播路由器发送IGMPv3查询,其形式如下图所示。

IGMP查询报文与ICMPv6 MLD查询很相似。
-
最大响应代码:最大响应代码字段是8位而非16位。最大响应代码字段编码查询的接收方在发送报告之前应该延迟的最大时间量,对于128以下的值以100ms为单位编码。对于 127 以上的值,该字段编码如下图所示。

此编码提供了一个可能的范围(16)(8)=128到(31)(1024)=31744(即约13秒到53 分钟)。使用较小最大响应代码字段的值允许调节离开延迟(从最后一个组成员离开的时间到相应的流量不再被转发所经过的时间)。增加该字段的值(通过提高更长报告周期的可能性),会减少由成员生成的IGMP报文流量负载。
-
S:用于容错
-
QRV:编码发送方将使用的最大重传次数。
-
QQIC:编码定期查询间隔。并使用和最大响应代码字段相同的方法进行编码(即从0到 31 744 的范围)。
-
组地址:当组播路由器希望了解所有组播组的兴趣时,组地址(Group Address)字段被设置为0(这样的查询被称为一般查询。一般查询使用为0的组地址,并被发送到所有主机组播地址 224.0.0.1。)。
有三种查询报文的变体可以由组播路由器发送:一般查询(general query),特定组查询(group-specific query),特定组和源查询(group-and-source-specific query)。第一种形式被组播路由器用于更新任意组播组的信息,对于这样的查询,组列表是空的。特定组查询与一般查询类似,但对于识别的组是特定的。最后一类本质上是一个包含一组源的特定组查询。特定的查询被发送到主题组的目的 IP 地址,与之形成对照,一般查询被发送到所有系统的组播地址(对于IPv4)或IPv6中的链路范围内的所有节点组播地址(ff02::1)。
发送特定查询响应状态变化报告,以证明它适用于路由器采取一些措施(例如,在构造一个过滤器之前,确保没有兴趣仍然在特定的组中)。当接收过滤器模式改变记录或源列表改变记录时,组播路由器安排增加新的流量源,并且能够过滤掉来自特定源的流量。在组播路由器准备开始过滤前面正流动的流量时,它首先使用特定组查询以及特定组和源查询。如果这些查询没有引起任何报告,路由器开始过滤相应的流量。因为这种变化可以显著地影响组播流量的流动,状态变化报告和特定查询被重传。
9.4.4 轻量级IGMPv3和MLDv2
正如我们已经看到的那样,主机维护对它们的应用和系统软件感兴趣的组播组的过滤器状态。对于IGMPv3 或 MLDv2,它们也维护被排除或包含的源列表。为了了解什么流量需要被转发到链路上以便有兴趣的主机收到,组播路由器维护类似的状态。反过来也是如此:一个组播路由器可以停止转发在每个接收方的排除列表中的主机发送的组播流量。实践经验证明,应用程序很少需要屏蔽特定源,并且支持此功能也比较复杂。然而,主机往往希望包含一个与一个组相关联的特定源,尤其是当 SSM 在使用时。因此,简化版的 IGMPv3 和MLDv2 已在[RFC5790]中定义,分别称为轻量级 IGMPv3(LW-IGMPv3)和轻量级 MLDv2(LW-MLDv2)。
LW-IGMPv3 和LW-MLDv2是其正本的子集。它们支持ASM和SSM,并使用与IGMPv3 和 MLDv2 兼容的报文格式,但它们缺少特定阻塞源的功能。相反,唯一支持的排除模式是没有列出源的情况,它对应于所有版本的IGMP 或MLD 中的传统的组加入。对于组播路由器,这意味着唯一需要的状态是记录哪些组感兴趣,以及哪些源感兴趣。它不需要记录任何不期望的单个源。
下表显示了IGMPv3 和 MLDv2的轻量级变体中使用的报文类型的修改。在此表中,空集符号({})表示一个空的源地址列表。例如,TO_EX({})表示一个0x04类型的报文,说明它改变为没有相关源的EXCLUDE模式。符号(*,G)表示与任何源相关联的组G,符号(S,G)表示与特定源 S 相关联的组 G。
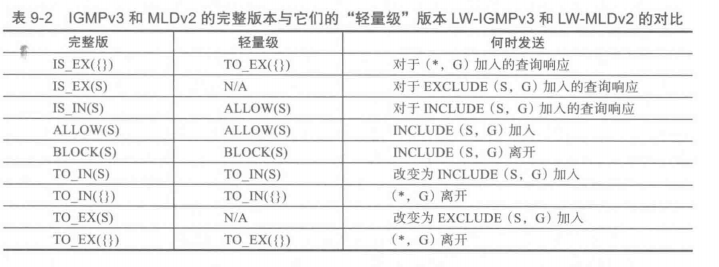
比较表9-2与表9-1中的值。显而易见,没有使用非空排除模式,状态指示符类型已被删除。此外,当前状态记录(IS_EX和IS_EN)已对兼容的主机删除。轻量级组播路由器仍然应该能够接收这样的报文,但对待它们就好像它们总是包含一个空源列表。
9.4.5 IGMP 和 MLD 健壮性
对于 IGMP 和 MLD 协议的健壮性和可靠性有两个主要的问题。IGMP 或 MLD 的失效,可以导致不需要的组播流量的分配,或没有能力交付期望的组播流量。由IGMP和MLD处理的失败类型包含组播路由器的失效和协议报文的丢失。
通过允许多个组播路由器在同一链路上运行,可以处理组播路由器潜在的失效故障。正如前面提到的,在这样的配置中,具有最小IP 地址的路由器被选为“查询器”。查询器负责发送一般和特定查询来确定该子网中主机的当前状态。其他(非查询器)路由器监控协议报文,因为它们也是组成员或组播混杂侦听器,并且假如当前查询器失效了,不同的路由器能够作为查询器介人。为了使其正常工作,所有连接到相同链路的组播路由器需要协调它们的查询、响应和它们的一些配置信息(主要是计时器)。
多个组播路由器实现的第一种类型的协调是查询器选举。每个组播路由器可以侦听其他的查询。当一个组播路由器启动时,它认为自己是查询器,并发送一般查询以确定在子网中哪些组是活跃的。当一个路由器收到另一个路由器的组播查询时,它比较源IP 地址和它自己的。如果在所接收的查询中的源 IP 地址小于它自己的,接收路由器进入备用模式。因此,具有最小IP地址的路由器被认为是获胜者,并成为单一的查询器,负责向它连接的子网中发送查询。备用的路由器设置计时器,如果它们在一个指定的时间(称为其他查询器出现(other-querier-present)计时器)内没有看到更多的查询,它们再次成为查询器。
查询组播路由器定期发送一般查询,以确定哪些组和主机是同一个子网的主机感兴趣的。这些查询被发送的频率由查询器的查询间隔、可配置计时器参数决定。当多个组播路由器在同一子网中运行时,当前查询器的时间间隔被所有其他路由器接受。在这种方式中,如果当前查询器失效,到替代组播路由器的切换不会干扰定期查询速率。
有理由相信,一个组(或源)不再感兴趣的组播路由器发送一个特定的优先查询以停止相应组播流量的转发(或通知组播路由协议)。这些查询以不同于一般查询的时间间隔(称为最后成员查询时间(Last Member Query Time,LMQT)发送。LMQT通常比查询间隔要小(短),并管理离开延迟。当多个组播路由器在同一个子网运行时,可能同时出现一个问题,主机希望离开组(或丢弃源),并且协议信息会丢失。
为了帮助防止丢失协议报文,有些报文被重传多次(由 QRV 查询器鲁棒性变量决定)。QRV值在包含于查询中的QRV字段中编码,非查询路由器采用查询器的QRV作为自己的。如果查询器发生改变,这再次帮助保持了稳定性。重传中保护的报文类型包括状态改变报告和特定查询。其他报文(当前状态报告)通常不会导致转发状态的变化,而是只涉及通过调整计时器刷新软状态,所以使用重传无法保护它们。当重传发生时,报告的重传间隔在0和一个称为主动报告间隔的可配置参数之间随机选择,查询的重传间隔是周期性的(基于LMQT的间隔)。预计更容易出现丢失的链路(如无线链路),可能需要以生成额外的流量为代价,增加鲁棒性变量以增强分组丢失的健壮性。
当处理特定查询时,为了帮助组播路由器保持同步,查询报文中S位字段表明路由器端(计时器)处理应被抑制。当一个特定的查询由查询器发送时,应该安排一个重传次数(QRV)。在发送的第一个查询中,S 位字段被清除。基于重传或这种查询的接收,组播路由器会为随后的重传降低它的计时器到LMQT。此时,为感兴趣的主机提供一个报告,指出它对一个组或源的持续的兴趣,这是可能的。如果没有报文丢失,该报告使每个组播路由器重置它的计时器为普通值,并保持不变。然而,预定的重传不会被放弃。相反,特定查询的重传被发送时,S 位字段被设置,这将导致接收路由器不会降低它们的计时器到 LMQT。
在收到表示有兴趣的报告之后,仍保持查询重传的原因,是为了使跨越所有组播路由器的组的超时时间是一致的。然后,S位字段的目的是为了让特定的查询被(重新)发送,也为了避免降低计时器到 LMQT,因为一个表示兴趣的合法的报告可能已经被接受了,即使它或初始查询被非查询器路由器丢失了。没有这种能力,重传的特定查询会导致非查询器路由器不正确地降低它们的计时器(因为已经收到一个表明兴趣的合法报告)。
9.4.6 IGMP和MLD计数器和变量
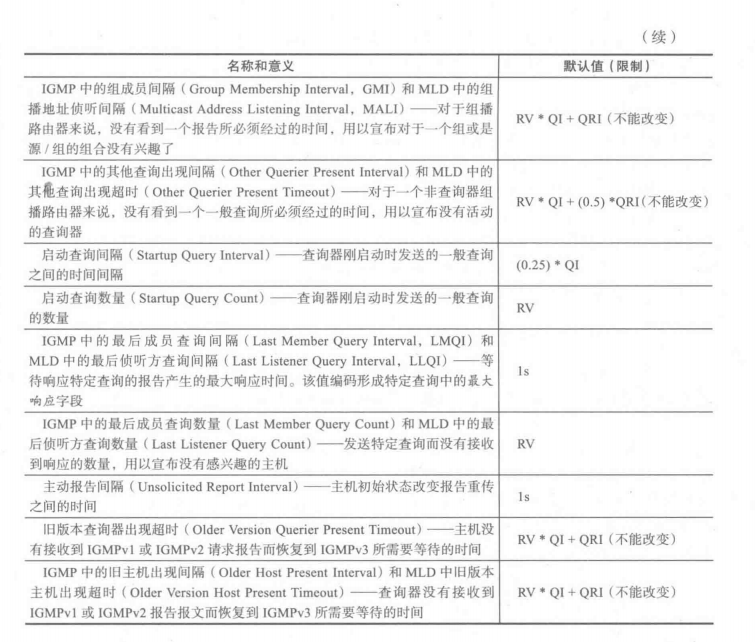
IGMP 和 MLD 是软状态的协议,它们也处理路由器的失效、协议报文的丢失以及与早期协议版本的互操作性。很多设备是基于触发状态改变和协议动作的计时器来启用这些功能的。下表总结了 IGMP 和 MLD 使用的所有的配置参数和状态变量。在下表中,很显然,MLD 和 IGMP共享大部分的计时器和配置参数,虽然在某些情况下术语是不同的。那些表示为“不能改变”的一些值是根据其他值设置的,不能独立变化。

9.4.7 IGMP 和 MLD 探听
IGMP 和 MLD 管理路由器之间 IP 组播流量的流动。为了进一步优化流量流动,对于第2层交换机(即通常不会处理第 3 层IGMP或MLD 报文)来说,通过查看在第 3 层的信息了解它对特定的组播流量流动是否有兴趣,这是可能的。该功能通过称为IGMP(MLD)探听[RFC4541]的交换机特征指明,并且被很多交换机供应商支持。没有IGMP探听,交换机通常沿着所有交换机形成的生成树的所有分支广播它来发送链路层流量。这是一种浪费,如我们前面描述的原因。IGMP(MLD)感知的(有时也把IGMP探听称为IGS)交换机监控主机和组播路由器之间的IGMP(MLD)流量,并且能记录哪些端口需要哪些特定的组播流动,这和组播路由器的做法很相似。这样做能够实质地影响在一个交换网络中正在被承载的不需要的组播流量的数量。
有几个细节使得IGMP/MLD探听的直接实现变得复杂。在IGMPv3和MLDv2中,生成报告响应查询。然而,在这些协议的早期版本中,一台主机生成的报告,被相同链路上的其他组成员侦听,导致了其他成员抑制它们的报告。如果IGS交换机要将报告转发到所有连接的接口上,这可能会导致一个问题,因为在一些LAN(VLAN)段上的主机和组成员可能没有被通知。因此,支持早期版本的 IGMP 和 MLD的IGS交换机避免向所有的接口广播报告。相反,它们只向最近的组播路由器转发报告。如果使用组播路由器发现(MRD),确定组播路由器的位置就变得更简单了。
实现探听时的另一个值得关注的问题是IGMP和 MLD之间的报文格式上的差异。由于MLD被封装为ICMPv6的一部分,而不是自己单独的协议,因此MLD探听交换机必须处理ICMPv6信息,并小心地从其他报文中分离出MLD报文。尤其是,由于ICMPv6用于其他各种功能,其他的 ICMPv6 流量必须被允许自由流动。
所有的接口广播报告。相反,它们只向最近的组播路由器转发报告。如果使用组播路由器发现(MRD),确定组播路由器的位置就变得更简单了。
实现探听时的另一个值得关注的问题是IGMP和 MLD之间的报文格式上的差异。由于MLD被封装为ICMPv6的一部分,而不是自己单独的协议,因此MLD探听交换机必须处理ICMPv6信息,并小心地从其他报文中分离出MLD报文。尤其是,由于ICMPv6用于其他各种功能,其他的 ICMPv6 流量必须被允许自由流动。
其他非标准的专有协议已经被实现,可以进一步优化通过第2层设备运载的IP组播流量。例如,思科提出了路由器端口组管理协议(Router-port Group Management Protocol,RGMP)[RFC3488]。在RGMP中采用了一种机制,这样主机不仅报告它们的组和感兴趣的源(如在IGMP/MLD中),而且组播路由器也这样做。该信息用来优化组播路由器(不仅仅是主机)之间的组播流量在第 2 层的转发。
相关文章:
)
TCPIP详解 卷1协议 九 广播和本地组播(IGMP 和 MLD)
9.1——广播和本地组播(IGMP 和 MLD) IPv4可以使用4种IP地址:单播(unicast)、任播(anycast)、组播(multicast)和广播(broadcast)。 IPv6可以使用…...

全球变暖-bfs
1.不沉的就是4个方向没有海,一个大岛屿有一个不沉就行了,其余染色就好了 2.第一个bfs来统计总岛屿个数 3.第二个来统计不沉岛屿个数 4.一减就ac啦 #include<bits/stdc.h> using namespace std; #define N 100011 typedef long long ll; typede…...

DDD领域驱动开发
1. 现象: 软件设计质量最高的时候是第一次设计的那个版本(通常是因为第一次设计时,业务技术沟通最充分,从业务技术整体视角出发设计系统)。当第一个版本设计上线以后就开始各种需求变更,这常常又会打乱原有的设计。 2…...

【HarmonyOS 5】鸿蒙App Linking详解
【HarmonyOS 5】鸿蒙App Linking详解 一、前言 HarmonyOS 的 App Linking 功能为开发者提供了一个强大的工具,通过创建跨平台的深度聚合链接,实现用户在不同场景下的无缝跳转,极大地提升了用户转化率和应用的可用性。 其安全性、智能路由和…...

Android Studio 中 build、assemble、assembleDebug 和 assembleRelease 构建 aar 的区别
上一篇:Tasks中没有build选项的解决办法 概述: 在构建 aar 包时通常会在下面的选项中进行构建,但是对于如何构建,选择哪种方式构建我还是处于懵逼状态,所以我整理了一下几种构建方式的区别以及如何选择。 1. build…...

【爬虫】12306查票
城市代码: 没有加密,关键部分: 完整代码: import json import requests with open(rE:\学习文件夹(关于爬虫)\项目实战\12306\城市代码.json,r,encodingutf-8) as f:city_codef.read() city json.loads(c…...

火山RTC 7 获得远端裸数据
一、获得远端裸数据 1、获得h264数据 1)、远端编码后视频数据监测器 /*** locale zh* type callback* region 视频管理* brief 远端编码后视频数据监测器<br>* 注意:回调函数是在 SDK 内部线程(非 UI 线程)同步抛出来的&a…...

请求参数:Header 参数,Body 参数,Path 参数,Query 参数分别是什么意思,什么样的,分别通过哪个注解获取其中的信息
在API开发中(如Spring Boot),请求参数可以通过不同方式传递,对应不同的注解获取。以下是 Header参数、Body参数、Path参数、Query参数 的区别及对应的注解: Header 参数 • 含义:通过HTTP请求头&#x…...

【Web/HarmonyOS】采用ArkTS+Web组件开发网页嵌套的全屏应用
文章目录 1、简介2、效果3、在ArkTs上全屏Web3.1、创建ArkTS应用3.2、修改模块化配置(module.json5)3.3、修改系统栏控制(ArkTS代码) 4、双网页嵌套Web实现5、ArkTSWeb技术架构的演进 1、简介 在鸿蒙应用开发领域,技术…...
做题记录 hot100(34,215,912,121))
Leetcode (力扣)做题记录 hot100(34,215,912,121)
力扣第34题:在排序数组中查找第一个数和最后一个数 34. 在排序数组中查找元素的第一个和最后一个位置 - 力扣(LeetCode) class Solution {public int[] searchRange(int[] nums, int target) {int left 0;int right nums.length - 1;int[…...

Babylon.js学习之路《三、创建你的第一个 3D 场景:立方体、球体与平面》
文章目录 1. 引言:从零构建一个 3D 场景1.1 目标与成果预览1.2 前置条件 2. 初始化 Babylon.js 场景2.1 创建 HTML 骨架2.2 初始化引擎与场景 3. 创建基础几何体3.1 立方体(Box)3.2 球体(Sphere)3.3 平面(P…...

Go 语言即时通讯系统开发日志-day1:从简单消息收发 Demo 起步
Go语言即时通讯系统开发日志day1,主要模拟实现的一个简单的发送消息和接受消息的小demo,因为也才刚学习go语言的语法,对go的json、net/http库了解不多,所以了解了一下go语言的encoding/json库和net/http库,以及websock…...

AAAI-2025 | 中科院无人机导航新突破!FELA:基于细粒度对齐的无人机视觉对话导航
作者:Yifei Su, Dong An, Kehan Chen, Weichen Yu, Baiyang Ning, Yonggen Ling, Yan Huang, Liang Wang 单位:中国科学院大学人工智能学院,中科院自动化研究所模式识别与智能系统实验室,穆罕默德本扎耶德人工智能大学࿰…...

中科院无人机导航物流配送的智能变革!LogisticsVLN:基于无人机视觉语言导航的低空终端配送系统
作者:Xinyuan Zhang, Yonglin Tian, Fei Lin, Yue Liu, Jing Ma, Kornlia Sra Szatmry, Fei-Yue Wang 单位:中国科学院大学人工智能学院,中科院自动化研究所多模态人工智能系统国家重点实验室,澳门科技大学创新工程学院工程科学系…...

IP协议、以太网包头及UNIX域套接字
IP协议、以太网包头及UNIX域套接字 IP包头结构 IP协议是互联网的核心协议之一,其包头包含了丰富的信息来控制数据包的传输。让我们详细解析IPv4包头结构: 4位版本号(version):标识IP协议版本,IPv4值为4 4位首部长度(header len…...

普林斯顿数学三剑客读本分析。
这几天看了普斯林顿数学三剑客,主要看了微积分、概率论前半部分,数学分析看了目录,大体略读了一下。怎么说呢,整体上来看,是很不错的,适合平常性阅读,配套结合国内教材习题来深入还是很不错的。…...

Matlab 模糊pid的液压舵机伺服系统
1、内容简介 Matlab 235-模糊pid的液压舵机伺服系统 可以交流、咨询、答疑 2、内容说明 略 舵机是轮船,客机等机器控制系统的重要组成部分,是客机,战斗机等飞行器操作系统的关键部件,也是一种超高的精度的位置伺服系统ÿ…...
)
Linux基础命令之目录管理——了解各种操作文件目录的命令,万字教学,超详细!!!(1)
文章目录 前言1、Linux文件系统1.1 核心特点1.2 重要目录结构1.3 文件类型1.4 文件和目录的命名规则1.5 文件与目录的定位方式 2、查看目录或文件的详细信息(ls)2.1 基本语法2.2 常用操作2.3 高级用法 3、切换目录(cd)3.1 常用操作…...

中国黄土高原中部XF剖面磁化率和粒度数据
时间分辨率:1000年 < x空间分辨率为:空共享方式:申请获取数据大小;35.75 KB数据时间范围:743-0 ka元数据更新时间:2023-08-15 数据集摘要 该数据集包括中国黄土高原中部XF剖面磁化率和粒度数据。将所有…...

tabs切换#
1、html <el-tabs v-model"tabValue" tab-change"handleTabClick"><el-tab-pane label"集群" name"1"></el-tab-pane><el-tab-pane label"节点" name"2"></el-tab-pane></el-ta…...

免费Office图片音频高效提取利器
软件介绍 今天要给大家介绍一款非常好用的Office文档图片及音频提取工具,它不仅好用,而且完全免费,没有任何广告。 软件概况 这款名为Office File Picture Extractor(PPT图片提取)的软件,大小仅有4MB。打…...

迁移 Visual Studio Code 设置和扩展到 VSCodium
本文同步发布在个人博客 迁移 Visual Studio Code 设置和扩展到 VSCodium - 萑澈的寒舍https://hs.cnies.org/archives/vscodium-migrateVisual Studio Code(以下简称 VS Code)无疑是当下最常用的代码编辑器。尽管微软的 VS Code 源代码采用 MIT 协议开…...

1.7 方向导数
(底层逻辑演进脉络)从"单车道"到"全路网"的导数进化史: 一、偏导数奠基(1.6核心) 诞生背景:多元函数分析需求 当变量间存在耦合关系时(如房价面积单价装修成本)…...

深入理解目标检测中的关键指标及其计算方法
深入理解目标检测中的关键指标及其计算方法 在目标检测领域,评估模型性能时,我们通常会关注几个关键指标,这些指标帮助我们量化模型的准确性和有效性。本文将详细介绍这些常见指标及其计算方法,帮助你更好地理解和评估目标检测模…...

Ollama+OpenWebUI+docker完整版部署,附带软件下载链接,配置+中文汉化+docker源,适合内网部署,可以局域网使用
前言: 因为想到有些环境可能没法使用外网的大模型,所以可能需要内网部署,看了一下ollama适合小型的部署,所以就尝试了一下,觉得docker稍微简单一点,就做这个教程的,本文中重要的内容都会给下载…...

【Redis实战篇】分布式锁-Redisson
1. 分布式锁-redisson功能介绍 基于setnx实现的分布式锁存在下面的问题: 重入问题: 重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都…...

构造二叉树
一、由中序和后序遍历序列构造二叉树 106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode) /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* …...

vue3: pdf.js 3.4.120 using javascript
npm install pdfjs-dist3.4.120 项目结构: pdfjsViewer.vue <template><div><div v-if"loading" class"flex justify-center items-center py-8"><div class"animate-spin rounded-full h-12 w-12 border-b-2 borde…...

编译原理AST以Babel为例进行解读、Webpack中自定义loader与plugin
AST树详解 编译原理 主要研究如何将高级编程语言的源代码转换为机器能理解的目标代码(通常是二进制代码或中间代码)。编译器的底层实现通常包含多个阶段,包括词法分析、语法分析、语义分析和代码生成。 一、AST的核心概念与作用 AST&#…...

牛客周赛 Round 92
目录 A-小红的签到题 代码 B-小红的模拟 代码 C-小红的方神题 代码 D-小红的数学题 代码 无注释版 有注释版 E-小红的ds题 代码 无注释版 有注释版 A-小红的签到题 代码 #include<bits/stdc.h> using namespace std; int main(){int n;cin>>n;cha…...

面试题:C++虚函数可以是内联函数吗?
目录 1.引言 2.示例 3.总结 1.引言 为什么C的虚函数和内联函数这两个看似矛盾的特性能否共存?这个问题实际上触及了C编译期优化与运行时多态性之间的微妙平衡。我发现这个问题不仅是面试中的常见陷阱,更是理解C深层机制很好的一个点。 虚函数可以被声…...

蚁群算法赋能生鲜配送:MATLAB 实现多约束路径优化
在生鲜农产品配送中,如何平衡运输效率与成本控制始终是行业难题。本文聚焦多目标路径优化,通过 MATLAB 实现蚁群算法,解决包含载重限制、时间窗约束、冷藏货损成本的复杂配送问题。代码完整复现了从数据生成到路径优化的全流程,助…...

前苹果首席设计官回顾了其在苹果的设计生涯、公司文化、标志性产品的背后故事
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

《基于 Kubernetes 的 WordPress 高可用部署实践:从 MariaDB 到 Nginx 反向代理》
手把手教你用 Kubernetes 部署高可用 WordPress 博客 本实验通过 Kubernetes 容器编排平台,完整部署了一个高可用的 WordPress 网站架构,包含 MariaDB 数据库、WordPress 应用和 Nginx 反向代理三大核心组件。实验涵盖了从基础环境准备到最终服务暴露的…...

文件上传总结
攻击与绕过方式 一、条件竞争 攻击原理:在上传文件的同时利用代码逻辑中的时序问题(如 unlink() 删除操作)触发条件竞争,从而实现上传恶意文件并绕过限制。 示例测试源码: 以下为测试文件上传功能的 PHP 源码ÿ…...

在文档里如何引用在线SVG甘特图
在文档里如何引用在线SVG甘特图 介绍 本文将详细介绍如何快速创建一个功能强大的在线甘特图,并将其嵌入到其他文档(如 Notion、Wiki、Qiita、GitHub、Obsidian、Email 等)中。只要目标工具支持引用网络图片,你就可以轻松实现这一…...

Spring AI 与 Groq 的深度集成:解锁高效 AI 推理新体验
Spring AI 与 Groq 的深度集成:解锁高效 AI 推理新体验 前言 在人工智能飞速发展的当下,AI 推理的效率和性能成为开发者关注的焦点。Groq 作为一款基于 LPU™ 的超快速 AI 推理引擎,凭借其强大的性能,能够支持各类 AI 模型&…...

101alpha---第10
rank(((0 < ts_arg_min(ts_delta(close, 1), 4)) ? ts_delta(close, 1) : ((ts_arg_max(ts_delta(close, 1), 4) < 0) ? ts_delta(close, 1) : (-1 * ts_delta(close, 1))))) alpha 那么我们来看具体含义 吧 rank(((0 < ts_arg_min(ts_delta(close, 1), 4)) ? …...

vim中的查找
在 Vim 中,使用 n 键可以按正向(向下)继续查找下一个匹配项。若要反向(向上)查找,可以使用以下方法: 1. 使用 N 键反向查找 在查找命令(如 /keyword)后,按下…...

什么是IP专线?企业数字化转型的关键网络基础设施
为什么企业需要IP专线? 在当今数字化浪潮席卷全球的背景下,企业网络需求正经历着前所未有的变革。传统网络架构已难以满足现代企业对高效、安全、灵活网络服务的需求,IP专线正是在这一背景下应运而生的关键网络解决方案。 专线服务本质上是…...
)
Linux环境基础开发工具的使用(yum、vim、gcc、g++、gdb、make/Makefile)
目录 Linux软件包管理器 - yum Linux下载软件的方式 认识yum 查找软件包 安装软件包 如何实现本地机器和云服务器之间的文件互传 卸载软件 Linux编辑器 - vim vim的基本概念 vim下各模式的切换 vim命令模式各命令汇总 vim底行模式各命令汇总 Linux编译器 - gcc/g …...

5.11 - 5.12 JDBC+Mybatis+StringBoot项目配置文件
JDBC: 预编译SQL优点:安全,性能更高。 在cmd里面输入java-jar就可以运行jar包。 Mybatis: 持久层框架。用于简化JDBC的开发。 数据库连接池里面放置的是一个一个Connection连接对象。(连接池中的连接可以复用&#…...

判断一个数组有没有重复值
要判断一个数组是否包含重复值,你可以使用多种方法。以下是一些常用的方法: 方法 1:使用 Set Set 是一种集合数据结构,它只存储唯一的值。因此,你可以将数组转换为 Set,然后比较 Set 的大小与数组的长度。…...

51c大模型~合集127
我自己的原文哦~ https://blog.51cto.com/whaosoft/13905076 #Executor-Workers架构 图解Vllm V1系列2 本文详细介绍了vllm v1的Executor-Workers架构,包括Executor的四种类型(mp、ray、uni、external_launcher)及其适用场景ÿ…...

Spring急速入门
Spring 是 企业级开发的一站式框架,核心是 IOC(控制反转) 和 AOP(面向切面编程) 一、Spring 核心:IOC 理论 1. 什么是 IOC? IOC(Inversion of Control,控制反转&…...

#在 CentOS 7 中手动编译安装软件操作及原理
在 CentOS 7 中,手动编译安装软件(即从源代码编译安装)是一种高度灵活的方式,适用于需要定制化软件功能、优化性能或安装官方仓库未提供的软件版本的场景。以下是针对手动编译安装的详细说明,包括原理、步骤、注意事项…...
)
【Kubernetes】初识基础理论(第一篇)
前言 单机容器编排: docker-compose 容器集群编排: docker swarm、mesosmarathon、kubernetes 应用编排: ansible 一、Kubernetes概述 Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的…...
)
配置集群(yarn)
在配置 YARN 集群前,要先完成以下准备工作: 集群环境规划:明确各节点的角色,如 ResourceManager、NodeManager 等。网络环境搭建:保证各个节点之间能够通过网络互通。时间同步设置:安装 NTP 服务࿰…...

按钮导航组件 | 纯血鸿蒙组件库AUI
摘要: 按钮导航组件(A_ButtonNav):可设置导航数据(含文本及路由),可设置按钮颜色、导航标题及导航子标题。 一、组件调用方式 1.1.极简调用: 用 A_ButtonNav 调用“按钮导航组件”,只需要给属性 data (导…...

自适应主从复制模拟器的构建与研究
自适应主从复制模拟器的构建与研究 摘要: 本文旨在构建一个自适应主从复制模拟器,深入研究主从复制原理及优化方法。从研究者视角出发,详细阐述模拟器的设计、实现与实验过程,通过表格、图表及代码等辅助手段,逐步探讨如何在不同网络条件和负载下,自动调整主从复制参数和…...