bootstrap自助(抽样)法
一,概念

一言以蔽之:从训练集中有放回的均匀抽样——》本质就是有放回抽样;
自助法(bootstrap)是一种通过从数据集中重复抽样来估计统计量分布的非参数方法。它可用于构建假设检验,当对参数模型的假设存在怀疑,或者基于参数模型进行统计推断不可行、计算标准误差需要复杂公式时,自助法可作为替代方案。
说的更严谨点,就是随机可置换抽样(random sampling with replacement)


从总体中获取样本,再从样本中重采样获取重样本,即总体-样本-重样本的处理路线;
注意,从样本到重样本的重采样,通常需要确保重采样的大小和原本样本的大小一致(通常要求重采样的样本大小与原始样本大小相同)——
数据使用完备性,尽可能使用上所有的数据,另外一方面因为最终的目的是为了估计总体中的某个参数,也就是说无论是重样本还是样本,最终目的都是为了估计最上游总体中的某个参数,方法都是基于重样本或者是样本的统计量的估计。
所以一般要求重采样的样本大小与原始样本大小相同,目的是为了保证重采样样本能够尽可能地反映原始样本的分布特征,从而使得基于重采样样本得到的统计量的估计更加准确和可靠。如果重采样样本大小与原始样本大小不同,可能会导致估计结果出现偏差。
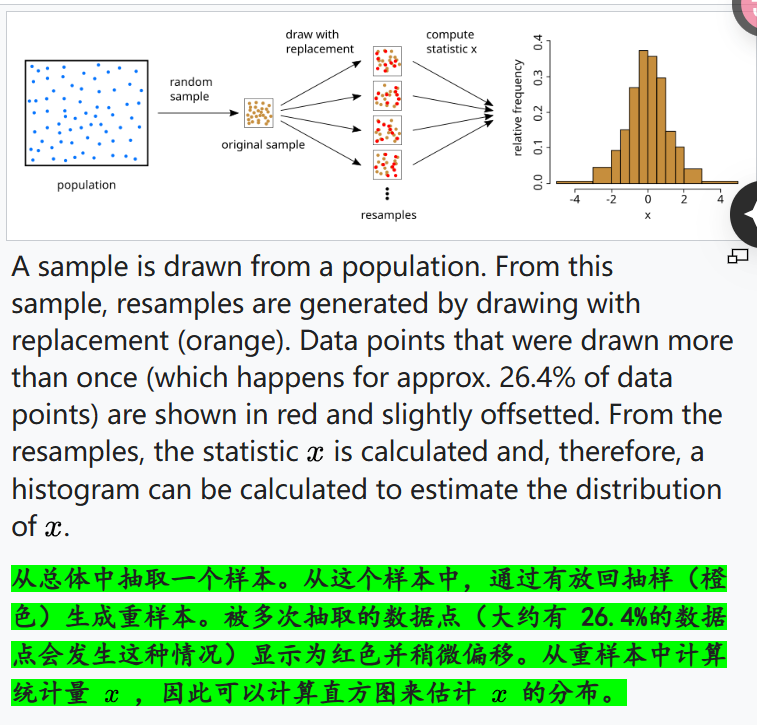
道理其实很简单:如果我的样本比如说是长度为1000的字符序列(比如说是长度为1000的氨基酸序列),那么我每次重采样,就需要从这个长度为1000的字符序列中重新采样生成长度为1000的一个样,这才是一个样;
我可以是采样原始氨基酸序列前100个字符重复10次;或者是重复后200个字符5次;
总之每个字符的选择都是有放回的采样采得的,然后一共采了1000个原始氨基酸序列长度个字符,这样才是一个样;
然后我需要按照这种采样规则采样n次,这就是bootstrap。
如果要严谨一点的、数学一点的定义:





自助法的基本原理

自助法的评估机制


自助法通过模拟重采样数据的经验分布 来近似原始数据的真实分布 ,并利用已知的 来评估推断的准确性。如果 是 的合理近似,那么就可以通过评估 的推断质量来推断 的推断质量。这种方法为在有限样本数据下进行统计推断提供了一种有效的途径。
————》
当然,嵌套了两层的近似,从总体-原始样本-重采样,总会有点概念上的迷惑,比如说近似传递性的证明是否严谨等?
我们需要更清晰地区分总体、样本和重样本,再次对以上内容进行复述;
总体、样本和重样本的定义
- 总体(Population)

- 样本(Sample)

样本分布对总体分布的近似就是一般初学者大一学的概率论中的统计推断、参数估计部分;
我们对于不同的总体,抽样获取的样本,也会有一个对应的分布。
- 重样本(Bootstrap Sample)

自助法的核心逻辑

详细解释
- 类比推断过程


- 评估
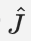 的准确性
的准确性

- 推断
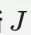 的质量
的质量

总的来说

——》
在这个表述下,我们对近似的传递性,会自然而然的有一个疑问:
我有一个问题,这里是从样本中有放回抽样得到样本分布的一个近似,那么样本分布又可能是总体分布的一个近似,那么这里的重采样获取的经验分布岂不是对总体分布近似的近似?
这种疑问的产生是因为数学严谨性要求自然产生的疑问,某种程度上这么理解是正确的。
自助法(bootstrap)确实是从样本中有放回地抽样,以得到样本分布的一个近似,而这个样本分布本身又是总体分布的一个近似。因此,通过重采样得到的经验分布可以被视为对总体分布的近似的近似。
为了更清楚地解释这一点,我们可以从以下几个方面来理解:
- 样本分布与总体分布:样本分布是根据从总体中抽取的样本数据计算得到的分布,它试图近似总体分布。由于样本量有限,样本分布可能无法完全准确地反映总体分布,但随着样本量的增加,样本分布通常会越来越接近总体分布。
- 重采样与经验分布:在自助法中,我们从原始样本中有放回地抽取多个重采样样本,每个重采样样本的大小与原始样本相同。然后,我们根据每个重采样样本计算出一个经验分布。这个经验分布是基于重采样样本的,因此它是对样本分布的一个近似。
- 近似的近似:由于样本分布本身是总体分布的近似,而经验分布又是样本分布的近似,因此经验分布可以被视为对总体分布的近似的近似。尽管存在这种双重近似,但自助法在很多情况下仍然能够提供对总体分布的可靠估计,特别是当原始样本量较大时。
- 自助法的有效性:自助法的有效性依赖于样本分布与总体分布之间的相似性,以及重采样样本与原始样本之间的相似性。如果样本量足够大,样本分布通常能够较好地近似总体分布,而重采样样本也能够较好地近似原始样本,从而使得经验分布成为对总体分布的一个合理近似。
综上所述,虽然经验分布是总体分布的近似的近似,但自助法通过重采样和利用样本分布的相似性,仍然能够提供对总体分布的有效估计。这种方法在统计学中被广泛使用,特别是在样本量有限或总体分布未知的情况下。

此处目的是为了获取均值这个统计量变异性的一个概念,也就是变异性的一个认知,说白了其实就是想构建这个均值的分布,也就是知道这个均值统计量的取值区间,类似于我们光估计出来均值=10不够,我们还想知道10±1或者±多少。
总的来说:自举法是为了推导一些非常复杂的统计量(比如说是协方差或者是分位数)的分布,比如说计算该统计量的标准误(标准误差SE)和置信区间(CI)的方法。


Bootstrapping不提供通用的有限样本保证,它的运用基于很多统计学假设,因此假设的成立与否会影响采样的准确性。(这个也是数学的魅力所在,在定义中的限制,就是显而易见的缺点,需要满足相应的统计学假设)



bootstrap自助法类型:
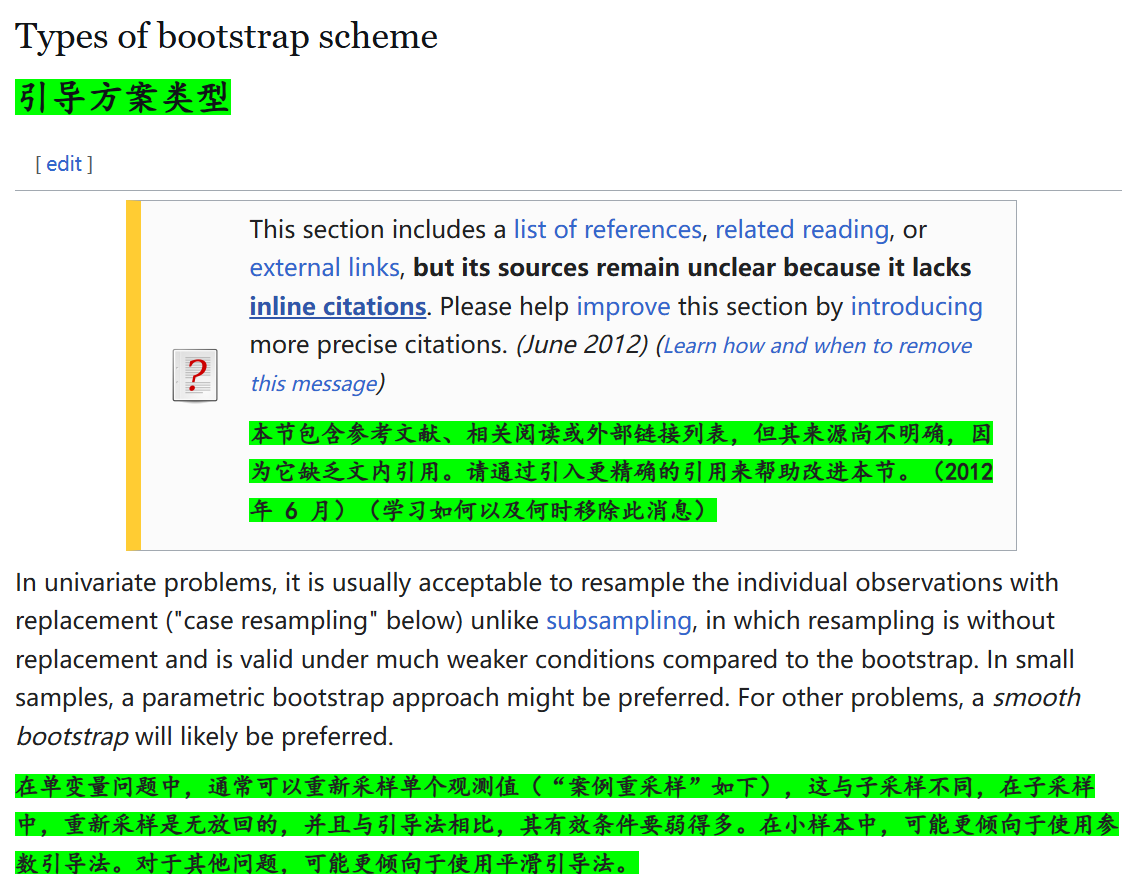

我们可以从排列组合(中学)的隔板法问题中推导出来理论上精确的重采样有多少种组合:




注意这里之所以用2n-1个位置,是因为我们允许某个样本(比如说第i个样本)不被采样到,这是有放回采样的定义自然而然推导获得的是;

参考:https://blog.csdn.net/mingyuli/article/details/81223463

二,实践举例
1,估计样本均值的分布:


2,回归

具体例子:使用重采样估计回归模型的稳健性
假设我们有一个简单的线性回归问题,研究广告投入(解释变量 X)与产品销售额(响应变量 Y)之间的关系。数据集包含100个观测值,每行代表一个时间段的广告投入和对应的销售额。
数据集示例
| 广告投入 X | 销售额 Y |
|---|---|
| 10 | 150 |
| 20 | 200 |
| 30 | 250 |
| … | … |
| 100 | 500 |
使用案例重采样的过程



3,贝叶斯自助法:

4,平滑自举:

5,参数自助法:

6,重采样残差:

7,高斯过程回归自助法:
涉及到随机过程等相关概念




8,野自助法/随机扰动自助法:
处理异方差性(heteroscedasticity)问题,即数据中不同观测值的方差不相等的情况;

9,块自助法**Block bootstrap**




三,拓展
1,统计量的选择

2,自助置信区间——》从自助分布中推导置信区间

我们先讨论理想的构造自助置信区间的方法,或者说应该满足的性质:


偏差、不对称性和置信区间:

场景设定
假设我们有一个班级,班级里学生的数学考试成绩是我们感兴趣的总体。我们想估计这个班级的平均成绩,但只有一部分学生的成绩样本。
1. 偏差(Bias)
假设我们从班级中随机抽取了10个学生的成绩作为样本,样本平均成绩是75分。但实际上,班级的总体平均成绩是80分。这种情况下,样本平均数(75分)和总体平均数(80分)之间的差异(-5分)就是偏差。
用数学公式表示:
[ \text{Bias} = \text{样本估计值} - \text{总体真实值} ]
[ \text{Bias} = 75 - 80 = -5 ]
偏差的来源:
- 样本可能不具有代表性。比如,我们可能不小心抽到了一些成绩较低的学生。
- 样本量太小,导致估计不够准确。
2. 不对称性(Asymmetry)
假设我们用自助法(Bootstrap)来估计班级平均成绩。我们从样本中重复抽样(有放回)1000次,每次抽10个成绩,计算每次抽样的平均值,得到一个自助法分布。
如果这个分布是对称的,比如:
- 一半的自助样本平均值在70分到75分之间,
- 另一半在75分到80分之间,
那么这个分布是对称的。
但如果分布不对称,比如:
- 大多数自助样本平均值集中在70分到75分之间,
- 只有少数在75分到80分之间,
那么这个分布就是不对称的。
不对称性的直观理解:
- 想象一个钟形曲线,如果它左右两边是对称的,那么它就是对称分布;如果它偏向一侧,比如右边更高,左边更低,那么它就是不对称的。
3. 置信区间(Confidence Intervals)
假设我们想估计班级平均成绩的95%置信区间。置信区间是一个范围,我们有95%的信心认为总体平均成绩在这个范围内。
情况1:对称分布
如果自助法分布是对称的,我们可以用百分位数法来计算置信区间。比如,我们取自助样本平均值的第2.5百分位数和第97.5百分位数作为置信区间的上下限。
假设自助样本平均值的分布如下:
- 第2.5百分位数是72分,
- 第97.5百分位数是78分,
那么95%置信区间就是[72, 78]。
情况2:不对称分布
如果自助法分布是不对称的,百分位数法可能不适用。因为百分位数法假设分布是对称的,而不对称分布会导致置信区间估计不准确。
比如,假设自助样本平均值的分布如下:
- 大多数集中在70分到75分之间,
- 只有少数在75分到80分之间,
如果还用百分位数法,可能会得到一个偏向较低值的置信区间,比如[71, 76],但实际上总体平均成绩可能更高。
通俗易懂的总结
- 偏差:样本估计值和总体真实值之间的差异。比如我们用样本平均成绩估计总体平均成绩,但估计值和真实值不一样。
- 不对称性:自助法分布的形状。如果分布左右不对称,说明数据更倾向于一边,这种情况下用百分位数法计算置信区间可能会出问题。
- 置信区间:一个范围,我们有较高信心(如95%)认为总体参数在这个范围内。如果分布对称,可以用百分位数法;如果不对称,可能需要其他方法。
我们一般遇到的都是正态分布或者是t分布等对称分布,如果我们使用自助法抽样获取的某个统计量也符合对称的分布,那么我们其实确实是可以使用百分位数来表征置信区间,注意,此处只是表征。
我想一个很容易被搞混的点,就是很多人容易搞混置信区间的置信指标α,或者说置信水平1-α,
与该置信区间的覆盖度,以及所谓假设检验中经常提及的上下α分位点的概念等。
为什么要考虑分布是否对称呢,F检验的时候用的也是F分布的上下5%分位数区间?(看,这里我们很容易搞混这个概念)。也不对,F分布使用的是上下分位点,分位点实际使用的是概率的覆盖所定义的,并不是分位数所定义的,确实是这样的。
从定义上讲,置信区间所覆盖的范围本质上就是从概率定义的,所以我们很容易将概率频率,再降级为相应的分位数。
我们说上α分位点,或者说下α分位点,但是我们不常说上α分位数或者是下α分位数。
1. 为什么分布的对称性很重要?
在统计推断中,对称性是一个重要的假设,因为它影响置信区间的构建和解释。具体来说:
- 对称分布的优势:
- 如果一个分布是对称的(例如正态分布),那么分布的中位数和均值是相同的,且分布的上下尾部是对称的。这意味着我们可以使用简单的百分位数方法来构建置信区间。例如,对于一个对称分布,95%的置信区间可以通过取分布的2.5%和97.5%百分位数来定义。
- 对称分布使得估计量的偏差(Bias)更容易被识别和校正,因为偏差通常表现为分布中心的偏移。
- 非对称分布的问题:
- 如果分布是非对称的(例如卡方分布或某些自助法分布),使用百分位数方法构建置信区间可能会导致区间估计不准确。因为非对称分布的尾部不对称,简单地取百分位数可能导致区间覆盖概率不正确。
- 非对称分布的置信区间需要更复杂的调整方法,例如使用偏差校正的自助法(Bias-Corrected and Accelerated, BCA)置信区间。
2. F检验中的分位数和分位点
- F检验的背景:
- F检验用于比较两个方差是否相等,或者在方差分析(ANOVA)中检验多个组的均值是否相等。
- F检验的统计量遵循F分布,F分布是非对称的,其形状取决于分子和分母的自由度。
- F分布的分位点:
- 在F检验中,我们通常使用F分布的上下分位点来构建置信区间或临界值。例如,对于一个95%的置信区间,我们会找到F分布的0.025分位点和0.975分位点。
- 这些分位点是通过F分布的概率密度函数(PDF)或累积分布函数(CDF)计算得到的,而不是简单地取分布的百分位数。
- 分位数与分位点的区别:
- 分位数:是指将数据分成具有相等概率的连续区间的点。例如,中位数是50%分位数,它将数据分成两部分,每部分的概率为50%。
- 分位点:是指分布函数的反函数在特定概率值处的取值。例如,F分布的0.025分位点是指F分布的累积分布函数等于0.025时对应的值。
3. 为什么F检验中使用分位点而不是分位数?
- F分布的非对称性:
- F分布是非对称的,因此不能简单地使用百分位数方法来定义置信区间。例如,F分布的0.025分位点和0.975分位点并不对称地分布在分布的中位数周围。
- 使用分位点可以确保置信区间的覆盖概率是正确的,即使分布是非对称的。
- 概率覆盖的定义:
- 在F检验中,我们关心的是置信区间的覆盖概率,即区间包含真实参数的概率。分位点是通过分布的概率密度函数或累积分布函数计算得到的,能够更准确地反映这种概率覆盖。
- 而简单地使用百分位数可能会忽略分布的非对称性,导致区间估计不准确。
总结
- 对称性的重要性:对称分布使得置信区间的构建更简单,因为可以使用百分位数方法。非对称分布则需要更复杂的调整方法。
- F检验中的分位点:F分布是非对称的,因此使用分位点而不是分位数来定义置信区间,以确保覆盖概率的准确性。
3,自助置信区间的构建方法


百分位数法构造置信区间:这个方法实际上是很常用的,首先从代码实践上操作很简单,因为python的numpy或者是R的tidyverse中对于数组/array计算分位数的API很容易调用(也就是调包,自己写函数很简单)。
所以我们说写简单的包或者是函数,调包调库def不是很难,难的是数学严谨性,也就是应用的条件。

当然了,此处还是需要注意前面已经提到的问题,就是当自助分布是对称的,并且以观察到的统计量为中心的时候,这种自助法估计真实总体参数的置信区间(用重采样的分位数去估计推导)才是比较合适的。
1. 估计分位数参数时,自助抽样得到的中位数分布是否对称?
简短回答:
通常情况下,自助法得到的中位数分布并不一定是严格对称的,但是如果原始数据“不是严重偏斜”,当样本量不是特别小的时候,自助分布往往“近似对称且集中在观测中位数附近”。但如果原始数据特别偏斜(比如90%的点都挤在一边),则自助中位数分布也会偏斜,不能保证一定对称。
详细解释与举例:
举例1(数据分布接近对称):
- 假设你的原始数据是
[2, 3, 4, 5, 6],中位数是4。 - 用自助法重复抽样后,每一组都算中位数,得到一大堆“自助中位数”。
- 你会发现这些自助中位数大部分也集中在4的附近,分布近似对称——这时候用百分位法效果好。
举例2(数据强偏斜):
- 如果原始数据是
[1, 1, 1, 1, 10],中位数是1。 - 自助重抽时,大部分样本的中位数仍然是1,只在极少数时候抽到比较多10时,中位数才变成10。这时自助分布极度偏斜(大多数1,个别出现10),就很不对称。
- 如果你直接用bootstrap分布的2.5%和97.5%分位数,得到的置信区间将“严重低估”或者“不能如实反映实际分布的不确定性”。
结论:
自助中位数分布是否对称,取决于原始数据分布。如果样本偏态、不均匀,bootstrap分布也往往偏斜。这时百分位法的置信区间未必可靠,建议使用偏差校正类的改进方法(比如BCa),特别是样本量不大或分位数落在分布的“偏斜端”时。
2. 分位数和概率可以对应吗?分位数区间为何不等于概率置信区间?
这是bootstrap置信区间常见误解。
分位数和概率的基本关系:
- 分位数的定义:第p百分位数就是分布中有p比例数据点小于等于它。比如0.975分位数=97.5%的bootstrap统计量小于它。
- 概率置信区间:在bootstrap自助法里,用p和1-p分位数围出来的区间,在bootstrap分布下,覆盖被估计的统计量的概率大约是(1-2p)。
疑惑来源与本质:
- 理论上,如果自助分布与真实抽样分布等价、对称并以观测统计量为中心,那么用分位数构造置信区间,和直觉上的概率置信区间基本一致。(比如bootstrap均值是对称、集中的)
- 但如果分布偏斜,观测统计量未必正好落在中心,那么用bootstrap分位数构造的区间,实际置信水平和你期望的不完全一致。也就是,置信区间中包含真实参数的概率不再等于你用的百分比。
举个极端例子:
- 你的自助分布大多数“挤在一侧”,那你得到的“95%区间”可能有95%的自助统计量落在区间内,但这个区间对应原参数的实际置信概率可能远低于95%。
为什么会这样?
- 分位数只是把自助统计量本身排序后的排名,不等同于对真实未知参数的概率分布排序。
- 只有分布对称、以观测统计量为中心时,这两者才近似等价。
- 一旦分布偏斜,区间边界和实际参数脱钩;也可能区间包含观测统计量的概率达不到设定的95%等。
总结与建议
- Bootstrap中位数分布是否对称,视原始样本分布和样本量而定,并不保证天然对称,实际常常偏斜,需具体检验。
- 分位数与置信区间的概率只有在分布对称、以观测统计量为中心时才近似等价;一旦偏斜就不准。
- 如果估计分位数参数,且分布明显偏斜,建议使用:
- 偏差校正加加速法(BCa, bias-corrected accelerated)
- 或者用“基本自助法”(basic bootstrap),校准中心和分布形状
一句话总结:
百分位数法的核心假设是bootstrap分布“对称+居中”,否则分位数和真实置信概率不等价,区间易失真。


注:以上结论仅供参考,实际分析时,需要绘制bootstrap自助参数的分布形状


如果是数学一点的表述:

4,与其他重采样方法的关系:我们重点理解其和交叉验证CV的关系

在统计学习也就是机器学习中,经常和bootstrap一起提到的就是cross validation即CV交叉验证(一般是数据集划分+模型验证部分会涉及到)。


上面说的是只是一次抽样中可能产生的偏差,如果一次抽样,抽样样本无限大(也就是N或者是d无限大),我们实际上通过抽样划分出来的数据是有偏差的:也就是说如果我们只是有放回的重采样1次+采样样本量很大,相当于我们只是划分了63.2%的训练集,然后再用这63.2%的数据之外的作为验证集去验证模型,其实就相当于是63.2:36.8的数据集划分了(近似于6:4),
然后我们再不断重复这个重采样也就是划分过程,不断地进行64划分CV。
和CV不同的是,我们每次64划分中的6和4是不定的,也就是变动的
1. 自助法(Bootstrap)的基本原理
自助法是一种基于有放回抽样的统计方法,主要用于估计模型的性能或评估模型的稳健性。它的核心思想是从原始数据集中有放回地抽取样本,生成新的数据集(称为“自助样本集”),并基于这些自助样本集进行分析。
2. .632自助法的具体过程
在.632自助法中,具体步骤如下:
- 生成训练集:从原始数据集(包含d个样本)中,有放回地随机抽取d次,生成一个新的训练集。由于是有放回抽样,某些样本可能会被重复抽取,而有些样本可能一次也没有被抽到。
- 生成验证集:那些在训练集中没有被抽到的样本,自然就形成了验证集(也称为测试集)。根据前面的数学推导,当样本数量足够大时,大约有36.8%的样本会进入验证集,而63.2%的样本会进入训练集。
- 模型训练与验证:使用生成的训练集训练模型,然后在验证集上评估模型的性能。
3. 与交叉验证的区别
- 交叉验证:
- 原理:将原始数据集划分为若干个互不重叠的子集,每次用其中一部分作为验证集,其余部分作为训练集,重复多次,最后取平均性能。
- 优点:充分利用了所有数据,每个样本都有机会被用作验证集。
- 缺点:计算成本较高,尤其是当数据集较大或模型训练时间较长时。
- .632自助法:
- 原理:通过有放回抽样生成训练集和验证集,每次抽样得到的训练集和验证集是随机的。
- 优点:计算成本相对较低,因为每次只需要生成一个训练集和一个验证集,适合大规模数据集。
- 缺点:验证集的样本数量较少(约占36.8%),可能导致验证结果的方差较大。
4. 应用场景
.632自助法常用于以下场景:
- 模型评估:当数据集较大且计算资源有限时,.632自助法可以快速评估模型的性能。
- 模型选择:通过多次自助抽样,比较不同模型的性能,选择最优模型。
- 特征选择:评估特征对模型性能的影响,选择重要特征。
5. 总结
.632自助法是一种利用自助法划分训练集和验证集的方法,它通过有放回抽样生成训练集和验证集,并利用数学推导保证了验证集的样本比例约为36.8%。它与交叉验证不同,更注重计算效率,适合大规模数据集的快速模型评估。
总的来说,两者的异同在于:
交叉验证法
采用无放回的随机采样方式,从数据集D中抽出部分数据作为训练集T,另外一部分作为测试集T’,并重复若干次随即划分过程,以每次划分对应的测试评估的均值作为评估结果(交叉便体现在重复若干次随机划分过程中两个数据集间数据的交叉)。
自助法
采用有放回的随机抽样方法,在保持训练集T与数据集D规模一致的条件下,从数据集D中抽出有重复的数据作为训练集T,剩下没有被抽中的数据作为测试集T’。
相同点:
交叉验证法和自助法都是随机采样法。它们作为人工智能中评估模型的方法,根据一定规则从数据集D中划分训练集和测试(验证)集,从而评价模型在数据集上的表现,便于我们选择合适的模型。
不同点:
正如上面所述,这两种方法最大的不同点在于每次划分过程中每个样本点是否只有一次被划入训练集或测试集的机会。下面将针对这方面详细展开论述:
交叉验证法采用的是无放回的随机采样方式,这种方式可以保持数据分布的一致性条件,并严格划分训练集与测试集的界限,从而增强测试评估的稳定性和可靠性。
自助法主要面向数据集同规模的划分问题。其采用的是有放回的随机抽样方法,可以使得得到的模型更为稳健,解决了交叉验证法中模型选择阶段和最终模型训练阶段的训练集规模差异问题;但训练集T和原始数据集D中数据的分布未必相一致,因此对一些对数据分布敏感的模型选择并不适用。
四,code实现
此处以python实现为主,我们考虑
首先按步骤分解我们的问题:
(1)从原始样本中有放回的抽取一定数量的样本:
因为是随机抽样+有放回,使用numpy中的np.random.choice函数
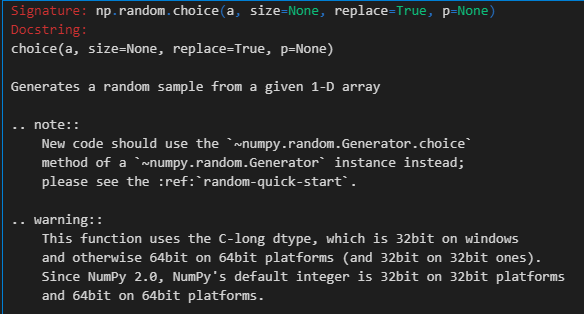
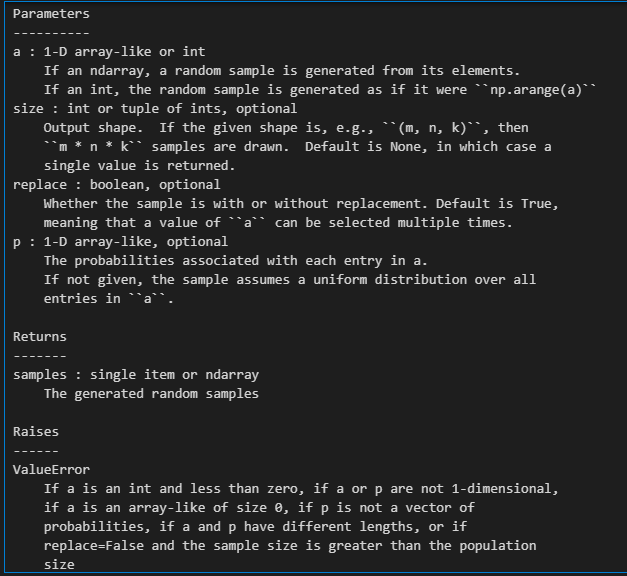
我们只需要关注其中的参数size(一般为原始样本的尺寸size)、replace(True,即有放回抽样);
注意上面只是1次抽样,返回的也是一个ndarray对象;
我们可以通过for循环进行多次抽样:
for iter in range(num_of_bootstrap):
(2)根据抽出的样本计算给定的统计量:
即自助统计量,比如说我们此处以中位数为例,numpy中可以调用median
(3)重复上述抽样操作N次,得到N个统计量,见(1)
(4)构造置信区间,使用百分位数法:
在python中计算一个多维数组的任意百分比分位数,此处的百分位是从小到大排列,只需用np.percentile即可(至于百分位数的问题,还是参考前面的说法)
下面是我的一个草稿代码:
def bootstrap_X(n_bootstrap,sample:list[float],real_param_to_test,alpha=0.05):"""Args:n_bootstrap: 自助法抽样的次数sample: 需要进行自助法抽样的样本数据,此处设置为list浮点数列表类型real_param_to_test: 需要进行置信区间估计(显著性判断)的真实数据,比如说某个待检测样本的均值、方差、中位数、相关系数等alpha: 置信水平,默认值为0.05Fun:1,进行自助法抽样,返回一个包含n_bootstrap次抽样结果的列表;每次抽样计算一个统计量,此处命名为X,可以是均值、方差、中位数、相关系数等,比如说bootstrap_of_median函数,此处统一使用“X”指代2,利用百分位数法构造该参数X(比如说上面X指代median中位数)的置信区间;比如说置信水平为α,则使用(1-α/2)的百分位数和α/2的百分位数来构造置信区间,即α*100/2%和(1-α/2)*100%分位数;3,返回置信区间的下限和上限;4,顺便我们可以判断一下某个真实样本的参数数据(真实数据)是否在置信区间内,即是否显著,即real_param_to_test是否在置信区间内;"""import numpy as npfrom scipy import stats# 注意下面都是以X代称需要估计的统计量bootstrap_X = [] # 存储自助法抽样获取的多次抽样结果,比如说是bootstrap_medianfor i in range(n_bootstrap):bootstrap_sample = np.random.choice(sample,size=len(sample),replace=True)bootstrap_X.append(np.X(bootstrap_sample)) # np.X指代任何python实现中能够计算指标X的api函数,比如说均值用np.mean,中位数用np.median等ci_lower = np.percentile(bootstrap_X, alpha * 100 / 2) # 置信区间下限ci_upper = np.percentile(bootstrap_X, (1 - alpha / 2) * 100) # 置信区间上限# 下面是判断真实数据是否在置信区间内,即是否显著 is_significant = not (ci_lower <= real_param_to_test <= ci_upper)# 或者我们也可以使用# result = False if ci_lower <= observation_param <= ci_upper else Truereturn ci_lower, ci_upper, is_significant# 也可以return result如果是在一个真实的机器学习例子中:
假设我们有样本数据X和标签y,以scikit-learn的分类器为例:
import numpy as np
from sklearn.base import clone
from sklearn.metrics import accuracy_scoredef bootstrap_632(X, y, model, metric=accuracy_score, n_iterations=100):'''.632自助法评估模型性能参数:X, y : 原始样本和标签, X为(n_samples, n_features)的ndarray,y为(n_samples,)的ndarraymodel : 已实现fit/predict接口的sklearn模型metric : 性能度量函数,如accuracy_score等n_iterations : 自助法抽样次数返回:.632自助法估计的得分'''n_samples = X.shape[0]scores_in = [] # 训练集分数scores_out = [] # 留出(测试集)分数for _ in range(n_iterations):# 有放回随机采样训练集索引train_idx = np.random.choice(n_samples, size=n_samples, replace=True)# 检验集为未被选中的样本test_idx = np.setdiff1d(np.arange(n_samples), train_idx)model_ = clone(model)model_.fit(X[train_idx], y[train_idx])# 训练集得分score_in = metric(y[train_idx], model_.predict(X[train_idx]))scores_in.append(score_in)# 检验集得分if len(test_idx) > 0:score_out = metric(y[test_idx], model_.predict(X[test_idx]))else:# 若某次抽样所有样本都被抽中,则检验集为空,跳过score_out = np.nanscores_out.append(score_out)# 取所有非nan的测试集分数平均scores_out = np.array(scores_out)mean_score_in = np.nanmean(scores_in)mean_score_out = np.nanmean(scores_out)# .632法则组合训练集与检验集得分final_score = 0.368 * mean_score_in + 0.632 * mean_score_outreturn final_score# 使用示例
if __name__ == "__main__":from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierX, y = load_iris(return_X_y=True)model = DecisionTreeClassifier(random_state=42)score = bootstrap_632(X, y, model, metric=accuracy_score, n_iterations=300)print(".632自助法评估得分:", score)训练集样本有重复,检验集为未被采样的样本。
每次实验如检验集为空,则该次得分记为NaN,整体均值时跳过。
.632法则最终得分为:
final_score = 0.368 × 训练集得分均值 + 0.632 × 检验集得分均值
metrics可更换为需要的其它评估指标。
参考:
https://en.wikipedia.org/wiki/Bootstrapping_(statistics)
http://taggedwiki.zubiaga.org/new_content/5c318780fb5bb20ff852e11a72b52b5f
https://www.math.pku.edu.cn/teachers/lidf/docs/statcomp/html/_statcompbook/sim-bootstrap.html
相关文章:
法)
bootstrap自助(抽样)法
一,概念 一言以蔽之:从训练集中有放回的均匀抽样——》本质就是有放回抽样; 自助法(bootstrap)是一种通过从数据集中重复抽样来估计统计量分布的非参数方法。它可用于构建假设检验,当对参数模型的假设存在…...

综合实验二之删除/boot目录,进行系统修复
实验三、删除/boot目录,进行系统修复 在 Linux 系统中,/boot 目录是一个至关重要的系统目录,主要用于存放系统启动时所需的核心文件和配置信息。 /boot 目录的主要作用: 存放内核文件(Kernel) vmlinuz&…...

postgresql主从集群一键搭建脚本分享
脚本1: cat pg_ms_install.sh #!/bin/bash # 基础环境配置(保持不变) setenforce 0 >/dev/null 2>&1 || true sed -i "s/SELINUXenforcing/SELINUXdisabled/" /etc/selinux/config systemctl stop firewalld >/dev/n…...

融合一致性与差异性约束的光场深度估计
摘要:光场图像深度估计是光场三维重建、目标检测、跟踪等应用中十分关键的技术。虽然光场图像的重聚焦特性为深度估计提供了非常有用的信息,但是在处理遮挡区域、边缘区域、噪声干扰等情况时,光场图像深度估计仍然存在很大的挑战。因此&#…...

转运机器人可以绕障吗?
在工业物流场景中,障碍物动态分布、路径突发拥堵是常态。传统AGV依赖固定轨道或磁条,面对复杂环境时往往“束手无策”。转运机器人可以绕障吗?富唯智能用技术创新给出答案——搭载激光SLAM导航与多传感器融合技术,其转运机器人不仅…...

【Web前端开发】CSS基础
2.CSS 2.1CSS概念 CSS是一组样式设置的规则,称为层叠样式表,用于控制页面的外观样式。 使用CSS能够对网页中元素位置的排版进行像素控制,实现美化页面的效果,也能够做到页面的样式和结构分离。 2.2基本语法 通常都是ÿ…...

【物流开单专用软件】佳易王物流管理系统:常见的物流信息系统以及软件程序实操教程 #物流软件定制#物流软件开发#物流软件推荐
一、概述 软件试用版资源文件下载方法: 【进入头像主页第一篇文章最后 卡片按钮 可点击了解详细资料 或左上角本博客主页 右侧按钮了解具体资料信息】 本实例以 佳易王物流管理系统 为例说明,其他版本可参考本实例。试用版软件资源可到文章最…...

力扣-94.二叉树的中序遍历
题目描述 给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。 class Solution { public:void inorder(TreeNode* root, vector<int>& res){//C这里&一定要加if(!root)return;inorder(root->left,res);res.push_back(root->val);inorder(ro…...

对基于再生龙制作的Linux系统的硬盘进行扩容
背景 公司一个仪器产品是基于x86核心板开发的,因此制作系统镜像时用的再生龙软件,好处是制作的系统镜像比ARM平台那种raw image小很多,缺点是操作有点麻烦。 最近客户反馈512GB的SSD硬盘容量不够,因此公司决定升级成1TB的&#x…...

Spring Boot 注解详细解析:解锁高效开发的密钥
一、引言 Spring Boot 以其快速开发、自动配置等特性,成为构建 Java 应用程序的热门框架。而注解在 Spring Boot 中扮演着至关重要的角色,它们如同魔法指令,简化了配置流程,增强了代码的可读性与可维护性。本文将深入剖析 Spring…...
)
【速写】KV-cache与解码的再探讨(以束搜索实现为例)
文章目录 1 Beam Search 解码算法实现2 实现带KV Cache的Beam Search解码3 关于在带kv-cache的情况下的use_cache参数 1 Beam Search 解码算法实现 下面是一个使用PyTorch实现的beam search解码算法: 几个小细节: 束搜索可以加入length_penalty&#…...

ElasticSearch聚合操作案例
1、根据color分组统计销售数量 只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于 SQL中的count。 在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用 _key元数据,根据分组后的字段数…...

微信小程序单双周选择排序有效果图
效果图 .wxml <view class"group-box"><label class"radio" wx:for"{{[单周,双周,全选]}}" wx:key"index" bind:tap"radioChange"data-index"{{index}}"><radio checked"{{index zcTem.ind…...

保持Word中插入图片的清晰度
大家有没有遇到这个问题,原本绘制的高清晰度图片,插入word后就变模糊了。先说原因,word默认启动了自动压缩图片功能,分享一下如何关闭这项功能,保持Word中插入图片的清晰度。 ①在Word文档中,点击左上角的…...

Matlab 基于GUI的汽车巡航模糊pid控制
1、内容简介 Matlab 225-基于GUI的汽车巡航模糊pid控制 可以交流、咨询、答疑 2、内容说明 略 依据比例—积分—微分控制的基本原理,我们利用MATLAB软件中SMULINK建立一个简单的PID控制器模型,利用这个模型在模糊控制过程中对PID控制参数进行在线的实时…...
应用层协议-HTTPS)
(网络)应用层协议-HTTPS
1.HTTPS是什么? HTTPS是应用层的一种协议,是在HTTP的基础上进行了加密层的处理。 HTTP协议的内容都是按照文本的形式进行传输的,所以呢就很容易被别人知道传输的是什么。 我们在了解了TCP/IP之后是知道我们的数据在传输的过程中是通过路由器进…...

Browserless 快速上手
要将你提供的 HTML 模板和数据结构转换为可以用于 Browserless /pdf 接口的 JSON 请求体(且能正确渲染为 PDF),需要满足以下几点: ✅ 最终目标格式(这是能用的格式): json 复制编辑 { "h…...

JWT的介绍与在Fastapi框架中的应用
什么是JWT JWT (JSON Web Token) 是一个开放标准 ( RFC 7519 ),它定义了一种紧凑且自包含的方式,用于在各方之间安全地以 JSON 对象的形式传输信息。由于这些信息经过数字签名,因此可以被验证和信任。JWT 可以使用密钥(采用HMAC算…...

Html5新特性_js 给元素自定义属性_json 详解_浅克隆与深克隆
文章目录 1. html5新特性2.用 js 给元素自定义属性3.json3.1 json与普通对象的区别3.2 json对象与 js对象的转化 4.浅克隆和深克隆 1. html5新特性 html5中引入了新的特性(新的标签),下面的新标签是新的结构标签,不过不太常用 h…...

一般纯软工程学习路径
基础 阶段一:基本熟悉工具链代码托管流程和配置 代码托管基本 1. 成见和管理代码库(组) 2. 成员配置和权限配置 代码迁移 1. 手工迁移 2. 脚本自动化迁移 代码提交 1. SSH key配置 2. 代码提交commit message 管理需求单 MR合并请求 1. 合并请…...

ES6基础特性
1.定时器 ——延时定时器 setTimeout(function()>{ },2000) ——间隔执行定时器 setInterval(function()>{ },2000) *定时器方法都返回唯一标识编号id&…...

SSTI记录
SSTI(Server-Side Template Injection,服务器段模板注入) 当前使用的一些框架,如python的flask、php的tp、java的spring,都采用成熟的MVC模式,用户的输入会先进入到Controller控制器,然后根据请求的类型和请求的指令发…...
 爬虫基础入门)
Go语言爬虫系列教程(一) 爬虫基础入门
Go爬虫基础入门 1. 网络爬虫概念介绍 1.1 什么是网络爬虫 网络爬虫(Web Crawler),又称网页蜘蛛、网络机器人,是一种按照一定规则自动抓取互联网信息的程序或脚本。其核心功能是模拟人类浏览网页的行为,通过发送网络…...

c/c++爬虫总结
GitHub 开源 C/C 网页爬虫探究:协议、实现与测试 网页爬虫,作为一种自动化获取网络信息的强大工具,在搜索引擎、数据挖掘、市场分析等领域扮演着至关重要的角色。对于希望深入理解网络工作原理和数据提取技术的 C/C 开发者,尤其是…...

【HarmonyOS 5】鸿蒙碰一碰分享功能开发指南
【HarmonyOS 5】鸿蒙碰一碰分享功能开发指南 一、前言 碰一碰分享的定义 在 HarmonyOS NEXT 系统中,华为分享推出的碰一碰分享功能,为用户带来了便捷高效的跨端分享体验。开发者通过简单的代码实现,就能调用系统 API 拉起分享卡片模板&…...

vue H5解决安卓手机软键盘弹出,页面高度被顶起
开发中安卓机上遇到的软键盘弹出导致布局问题 直接上代码_ 在这里插入代码片 <div class"container"><div class"appContainer" :style"{height:isKeyboardOpen? Heights :inherit}"><p class"name"><!-- 绑定…...
)
【pypi镜像源】使用devpi实现python镜像源代理(缓存加速,私有仓库,版本控制)
【pypi镜像源】使用devpi实现python镜像源代理(缓存加速,私有仓库,版本控制) 文章目录 1、背景与目标2、devpi-server 服务端搭建3、devpi 镜像源使用 1、背景与目标 背景1(访问速度优化): 直…...

Spring Bean有哪几种配置方式?
大家好,我是锋哥。今天分享关于【Spring Bean有哪几种配置方式?】面试题。希望对大家有帮助; Spring Bean有哪几种配置方式? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Spring Bean的配置方式主要有三种ÿ…...

无人机信号线被电磁干扰导致停机
问题描述: 无人机飞控和电调之间使用PWM信号控制时候,无人机可以正常起飞,但是在空中悬停的时候会出现某一个电机停机,经排查电调没有启动过流过压等保护,定位到电调和飞控之间的信号线被干扰问题。 信号线被干扰&am…...

RWA开发全解析:技术架构、合规路径与未来趋势
RWA开发全解析:技术架构、合规路径与未来趋势 ——2025年真实世界资产代币化的创新逻辑与实践指南 一、RWA的核心定义与爆发逻辑 1. 什么是RWA? RWA(Real World Asset Tokenization)是通过区块链技术将现实资产(房地…...
)
消息队列作用及RocketMQ详解(1)
目录 1 什么是消息队列 2 为什么要使用消息队列 2.1 异步处理 2.2 解耦 2.3 削峰填谷 3. 如何选择消息队列? 4. RocketMQ 4.1 生产者 4.2 消费者 4.3 主题 4.4 NameSever 4.5 Broker 5. 生产者发送消息 5.1 普通消息发送 5.1.1 同步发送 5.1.2 异步发送 5…...

DICOM 网络服务实现:医学影像传输与管理的技术实践
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

恰到好处TDR
了解我的人都知道我喜欢那些从 1 到 10 到 11 的东西。对于那里的年轻人,参见 Spinal Tap,1984 年。但是有没有把它调得太高这样的事情呢?我收到并回答了很多关于使用时域反射仪 (TDR) 进行测量的问题。 我需要多少带宽…...

kubernetes服务自动伸缩-VPA
实验环境 安装好k8s集群 一、准备工作 1、部署Metrics Server VPA 依赖 Metrics Server 来获取 Pod 的资源使用数据。首先需要部署 Metrics Server 下载地址(需要连接VPN):wget https://github.com/kubernetes-sigs/metrics-server/relea…...

stm32之BKP备份寄存器和RTC时钟
目录 1.时间戳1.1 Unix时间戳1.2 UTC/GMT1.3 时间戳转换**1.** time_t time(time_t*)**2.** struct tm* gmtime(const time_t*)**3.** struct tm* localtime(const time_t*)**4.** time_t mktime(struct tm*)**5.** char* ctime(const time_t*)**6.** char* asctime(const stru…...

OSCP - Hack The Box - Sau
主要知识点 CVE-2023-27163漏洞利用systemd提权 具体步骤 执行nmap扫描,可以先看一下55555端口 Nmap scan report for 10.10.11.224 Host is up (0.58s latency). Not shown: 65531 closed tcp ports (reset) PORT STATE SERVICE VERSION 22/tcp o…...

C++色彩博弈的史诗:红黑树
文章目录 1.红黑树的概念2.红黑树的结构3.红黑树的插入4.红黑树的删除5.红黑树与AVL树的比较6.红黑树的验证希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力! 红黑树是一种自平衡二叉查找树,每个节点都带有颜色属性,颜色或为…...

14.three官方示例+编辑器+AI快速学习webgl_buffergeometry_instancing_interleaved
本实例主要讲解内容 这个Three.js示例展示了如何结合使用索引几何体、GPU实例化和交错缓冲区来高效渲染大量相同模型的不同实例。通过这种技术组合,我们可以在保持较低内存占用的同时渲染数千个独立变换的对象。 核心技术包括: 索引几何体的实例化渲染…...

「华为」人形机器人赛道投资首秀!
温馨提示:运营团队2025年最新原创报告(共210页) —— 正文: 近日,【华为】完成具身智能赛道投资首秀,继续加码人形机器人赛道布局。 2025年3月31日,具身智能机器人头部创企【千寻智能&#x…...
)
GitHub 趋势日报 (2025年05月11日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1harry0703/MoneyPrinterTurbo利用ai大模型,一键生成高清短视频使用…...

MySQL查询优化100条军规
概述 以下是MySQL查询优化的关键军规,分为不同类别,帮助您系统化提升数据库性能资料已经分类整理好,喜欢的朋友自取:https://pan.quark.cn/s/f52968c518d3 一、索引优化 为WHERE、JOIN、ORDER BY字段建索引联合索引遵循最左前缀…...

WEBSTORM前端 —— 第3章:移动 Web —— 第1节:平面转换、渐变
目录 一.平面转换 二.平面转换 – 平移 ①属性 ②取值 ③技巧 三.平移实现居中效果 四.案例——双开门效果 五.平面转换 – 旋转 ①属性 ②技巧 六.平面转换 – 改变转换原点 ①属性 ②取值 七.案例-时钟 八.平面转换 – 多重转换 九.平面转换 – 缩放 ①属性 …...

1.10-数据传输格式
1.10-数据传输格式 在对网站进行渗透测试时,使用目标服务器规定的数据传输格式来进行 payload 测试非常关键 如果不按规定格式发送数据,服务器可能直接拒绝请求或返回错误响应,比如: 接口要求 JSON 格式,而你用的是…...

Python制作Dashboard【待续】
运行环境:jupyter notebook (python 3.12.7)...

物理:海市蜃楼是宇宙背景辐射吗?
宇宙背景辐射(特别是宇宙微波背景辐射,CMB)与海市蜃楼是两种完全不同的现象,它们的物理机制、来源和科学意义截然不同。以下是详细的解释: 1. 宇宙微波背景辐射(CMB)的本质 起源:CMB是大爆炸理论的关键证据之一。它形成于宇宙诞生后约38万年(即“最后散射时期”),当…...

联想 SR550 服务器,配置 RAID 5教程!
今天的任务,是帮客户的一台联想Lenovo thinksystem x SR550 服务器,配置RAID 5,并安装windows server 2019操作系统。那么依然是按照我的个人传统,顺便做一个教程,分享给有需要的粉丝们。 第一步,服务器开机…...
)
Docker-配置私有仓库(Harbor)
配置私有仓库(Harbor) 一、环境准备安装 Docker 三、安装docker-compose四、准备Harbor五、配置证书六、部署配置Harbor七、配置启动服务八、定制本地仓库九、测试本地仓库 Harbor(港湾),是一个用于 存储 和 分发 Docker 镜像的企业级 Regi…...

1.5 连续性与导数
一、连续性的底层逻辑(前因) 为什么需要研究连续性? 数学家在研究函数图像时发现两类现象:有些函数能用一笔画完不断开(如抛物线),有些则会出现"断崖"“跳跃"或"无底洞”&a…...

Day22打卡-复习
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 泰坦尼克号人员生还预测https://www.kaggle.com/competitions/titanic/overview K…...

配置Hadoop集群环境准备
(一)Hadoop的运行模式 一共有三种: 本地运行。伪分布式完全分布式 (二)Hadoop的完全分布式运行 要模拟这个功能,我们需要做好如下的准备。 1)准备3台客户机(关闭防火墙、静态IP、…...