消息队列作用及RocketMQ详解(1)
目录
1 什么是消息队列
2 为什么要使用消息队列
2.1 异步处理
2.2 解耦
2.3 削峰填谷
3. 如何选择消息队列?
4. RocketMQ
4.1 生产者
4.2 消费者
4.3 主题
4.4 NameSever
4.5 Broker
5. 生产者发送消息
5.1 普通消息发送
5.1.1 同步发送
5.1.2 异步发送
5.2 顺序消息发送
5.3 延迟消息发送
5.4 批量消息发送
5.5 事务消息发送
6 消费者消费消息
6.1 Push消费
6.1.1 集群模式和广播模式
6.1.2 并发消费和顺序消费
6.1.3 消息重试
6.1.4 死信队列
6.2 Pull消费
7.后续
8. 每日一笑
1 什么是消息队列
消息队列(Message Queue,简称MQ)指保存消息的一个容器,其实本质就是一个保存数据的队列。
消息中间件是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的构建。
形象来讲消息队列就是驿站,就是邮政,你只需要告诉送信人员你要将邮箱送至哪个信箱,
甚至在什么时候开始派送(延迟队列),送信人员即可送达目的地。至于取信的人看了信件是什么反应大可以不必太过关注。
2 为什么要使用消息队列
2.1 异步处理
我们使用商城举例,一般商城都会有积分系统,积分额度。当用于下单之后就应该增加对应的积分。
没有使用消息队列的情况:用户A在支付的时候调用订单接口,在订单接口中有两个动作,支付和增加积分,如果支付成功,但是在调用增加积分的时候出现异常了,按照正常来讲应该回滚数据,退回用户支付的金额。这样就会导致订单失败。
使用消息队列的情况:同样的下单行为,支付成功之后向外界发送消息然后返回成功的状态码。即使到时候积分系统崩溃/消息消费失败但是依旧能够正常下单,我们可以在之后人为处理数据/或者给出兜底方案。不至于影响下单系统。
在这种情况下,其实我们是有一个侧重点的,在订单和积分之间我们选择了订单。因为订单才是当前业务的主流程和重中之重。当然在解决了这种场景下的情况之后,我们就需要来解决发送消息能够发送成功,消费者也能够正常消费,这就是消息中间件的高可用了。
2.2 解耦
我们依旧以商城举例,如果我们是XX商城系统的新用户,在注册成功之后是不是就会送我们几张优惠券,或者初始化数据。正常情况我们就需要处理用户信息进行落库,并且发送优惠券,这样会导致我们的这个接口速度越来越慢,业务逻辑也越来越复杂在引入消息队列之后就可以将部分逻辑给拆分出去。同时能够提高接口响应速度。
2.3 削峰填谷
系统A,平常时期的qps大约50个,在中午12点-13点是用户高峰期,qps在10k,大量请求涌入服务器导致服务器挂掉,可以在应用前端加入消息队列,后台系统根据消息队列中的消息信息进行处理。服务器接收到用户的请求后,首先写入消息队列,后台系统根据消息队列中的请求信息,做后续业务处理。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
又比如有大量写库的需求,高峰期qps在10k左右,但是数据库又最多支持2k个,如果直接连接数据库就会导致数据库挂掉。依旧可以接用消息队列,将需要落库的数据写到队列中,高峰期可能会造成队列挤压几十万甚至上百万的数据,但是高峰期一过可能每秒只有几十个落库的需求,然后每秒能够处理2k个数据,挤压的数据也能够很快的处理掉,短暂的积压还是没有任何问题的。
3. 如何选择消息队列?
市场主流的消息队列有:Kafka、RocketMQ、RabbitMQ、ActiveMQ,以下是他们的对比信息。
| 特性 | Kafka | RocketMQ | RabbitMQ | ActiveMQ |
|---|---|---|---|---|
| 单机吞吐量 | 10万级 | 10万级 | 万级 | 10万级 |
| 开发语言 | Scala | Java | Erlang | Java |
| 高可用 | 分布式 | 分布式 | 主从 | 分布式 |
| 消息延迟 | ms级 | ms级 | us级 | ms级 |
| 消息丢失 | 理论上不会丢失 | 理论上不会丢失 | 低 | 低 |
| 消费模式 | 拉取 | 推拉 | 推拉 | |
| 持久化 | 文件 | 内存,文件 | 内存,文件,数据库 | |
| 支持协议 | 自定义协议 | 自定义协议 | AMQP,XMPP, SMTP,STOMP | AMQP,MQTT,OpenWire,STOMP |
| 社区活跃度 | 高 | 中 | 高 | 高 |
| 管理界面 | web console | 好 | 一般 | |
| 部署难度 | 中 | 低 | ||
| 部署方式 | 独立 | 独立 | 独立 | 独立,嵌入 |
| 成熟度 | 成熟 | 比较成熟 | 成熟 | 成熟 |
| 综合评价 | 优点:拥有强大的性能及吞吐量,兼容性很好。 缺点:由于支持消息堆积,导致延迟比较高。 | 优点:性能好,稳定可靠,有活跃的中文社区,特点响应快。 缺点:兼容性较差,但随着影响力的扩大,该问题会有改善。 | 优点:产品成熟,容易部署和使用,拥有灵活的路由配置。 缺点:性能和吞吐量较差,不易进行二次开发。 | 优点:产品成熟,支持协议多,支持多种语言的客户端。 缺点:社区不活跃,存在消息丢失的可能。 |
4. RocketMQ
本文主要讲解RocketMQ
RocketMQ的基础消息模型是一个简单的Pub/Sub模型。即发布-订阅模式,是一种消息范式,消息的发送者(称为发布者、生产者、Producer)会将消息直接发送给特定的接收者(称为订阅者、消费者、Consumer)
举个形象的例子:抖音关注xx博主,博主更新视频后会受到推送消息,如果你没有关注的话就不会收到该推送消息。关注就是消息队列中的订阅,不订阅的话,发布消息你是接收不到的。
消息队列中有三大角色:生产者、消费者、主题
4.1 生产者
负责生产消息(抖音xx博主),一般由业务系统负责生产消息。一个消息生产者会把业务应用系统里产生的消息发送到broker服务器。RocketMQ提供多种发送方式,同步发送、异步发送、顺序发送、单向发送。
4.2 消费者
负责消费消息(自己),一般是后台系统负责异步消费。一个消息消费者会从Broker服务器拉取消息、并将其提供给应用程序。从用户应用的角度而言提供了两种消费形式:拉取式消费、推动式消费。
4.3 主题
表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题(可以理解为类型),是RocketMQ进行消息订阅的基本单位。

在基于主题的系统中,消息被发布到主题或命名通道上。消费者将收到其订阅主题上的所有消息,生产者负责定义订阅者所订阅的消息类别。这是一个基础的概念模型,而在实际的应用中,结构会更复杂。例如为了支持高并发和水平扩展,中间的消息主题需要进行分区,同一个Topic会有多个生产者,同一个信息会有多个消费者,消费者之间要进行负载均衡等。
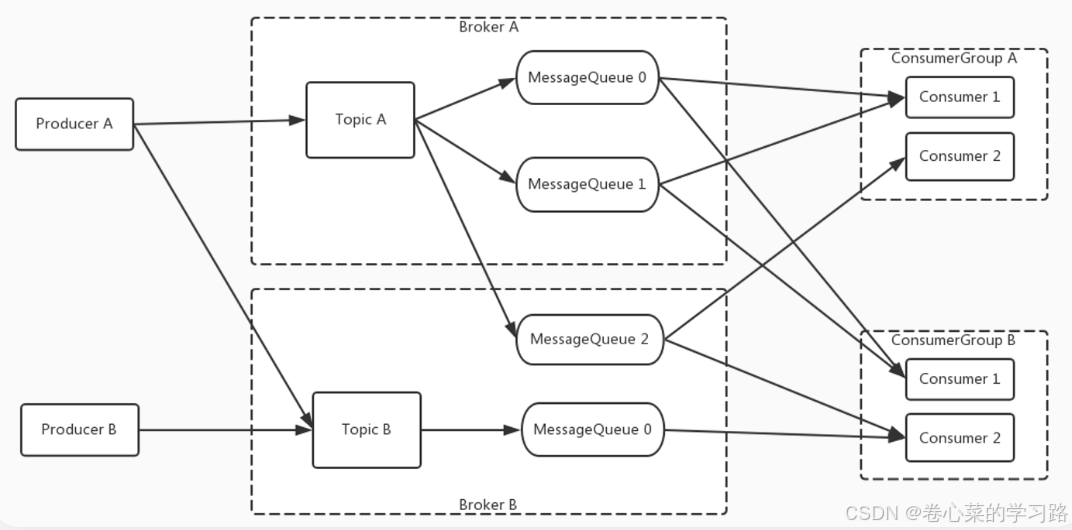
-
为了消息写入能力的水平扩展,RocketMQ 对 Topic进行了分区,这种操作被称为队列(MessageQueue)。
-
为了消费能力的水平扩展,ConsumerGroup的概念应运而生。
- 相同的ConsumerGroup下的消费者主要有两种负载均衡模式,即广播模式,和集群模式(图中是最常用的集群模式)。
- 在集群模式下,同一个 ConsumerGroup 中的 Consumer 实例是负载均衡消费,如图中 ConsumerGroupA 订阅 TopicA,TopicA 对应 3个队列,则 GroupA 中的 Consumer1 消费的是 MessageQueue 0和 MessageQueue 1的消息,Consumer2是消费的是MessageQueue2的消息。
- 在广播模式下,同一个 ConsumerGroup 中的每个 Consumer 实例都处理全部的队列。需要注意的是,广播模式下因为每个 Consumer 实例都需要处理全部的消息,因此这种模式仅推荐在通知推送、配置同步类小流量场景使用。
RocketMQ部署模型:
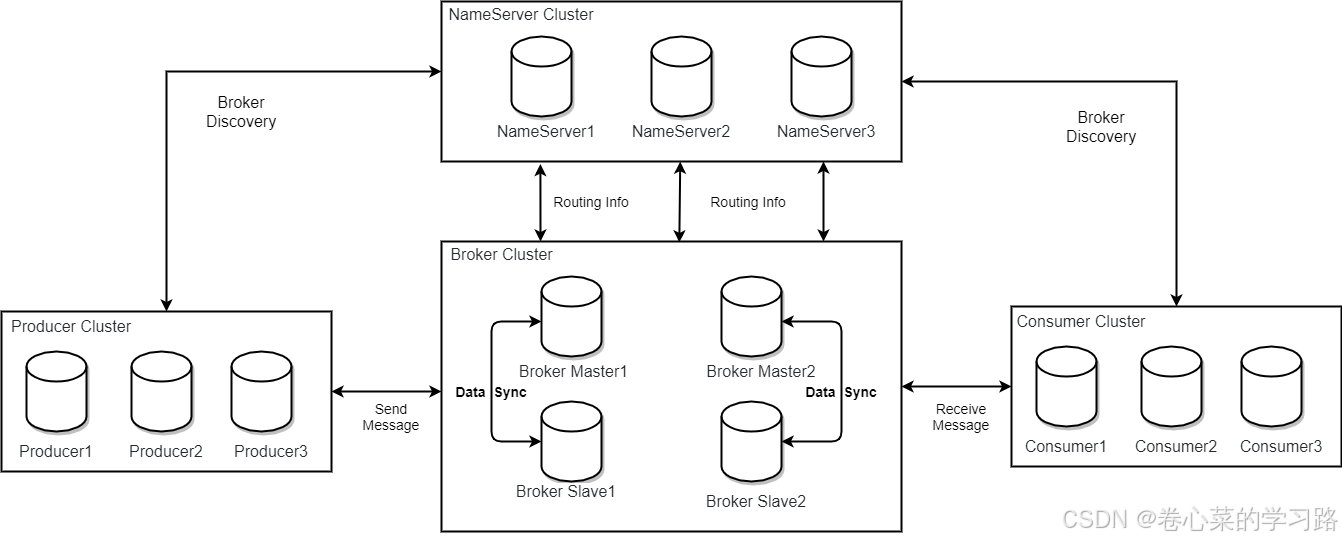
每个 Broker 与 NameServer 集群中的所有节点建立长连接,定时注册 Topic 信息到所有 NameServer。
Producer 与 NameServer 集群中的其中一个节点建立长连接,定期从 NameServer 获取Topic路由信息,并向提供 Topic 服务的 Master 建立长连接,且定时向 Master 发送心跳。Producer 完全无状态。
Consumer 与 NameServer 集群中的其中一个节点建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Master、Slave 建立长连接,且定时向 Master、Slave发送心跳。Consumer 既可以从 Master 订阅消息,也可以从Slave订阅消息。
4.4 NameSever
NameServer是一个简单的 Topic 路由注册中心,支持 Topic、Broker 的动态注册与发现(类似于SpringCloud的服务注册中心)。
主要包括两个功能:
- Broker管理,NameServer接受Broker集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查Broker是否还存活;
- 路由信息管理,每个NameServer将保存关于 Broker 集群的整个路由信息和用于客户端查询的队列信息。Producer和Consumer通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费。
NameServer通常会有多个实例部署,各实例间相互不进行信息通讯。Broker是向每一台NameServer注册自己的路由信息,所以每一个NameServer实例上面都保存一份完整的路由信息。当某个NameServer因某种原因下线了,客户端仍然可以向其它NameServer获取路由信息。
4.5 Broker
Broker主要负责消息的存储、投递和查询以及服务高可用保证。
5. 生产者发送消息
5.1 普通消息发送
5.1.1 同步发送
同步发送是最常用的方式,是指消息发送方发出一条消息后,会在收到服务端同步响应之后才发下一条消息的通讯方式,可靠的同步传输被广泛应用于各种场景,如重要的通知消息、短消息通知等。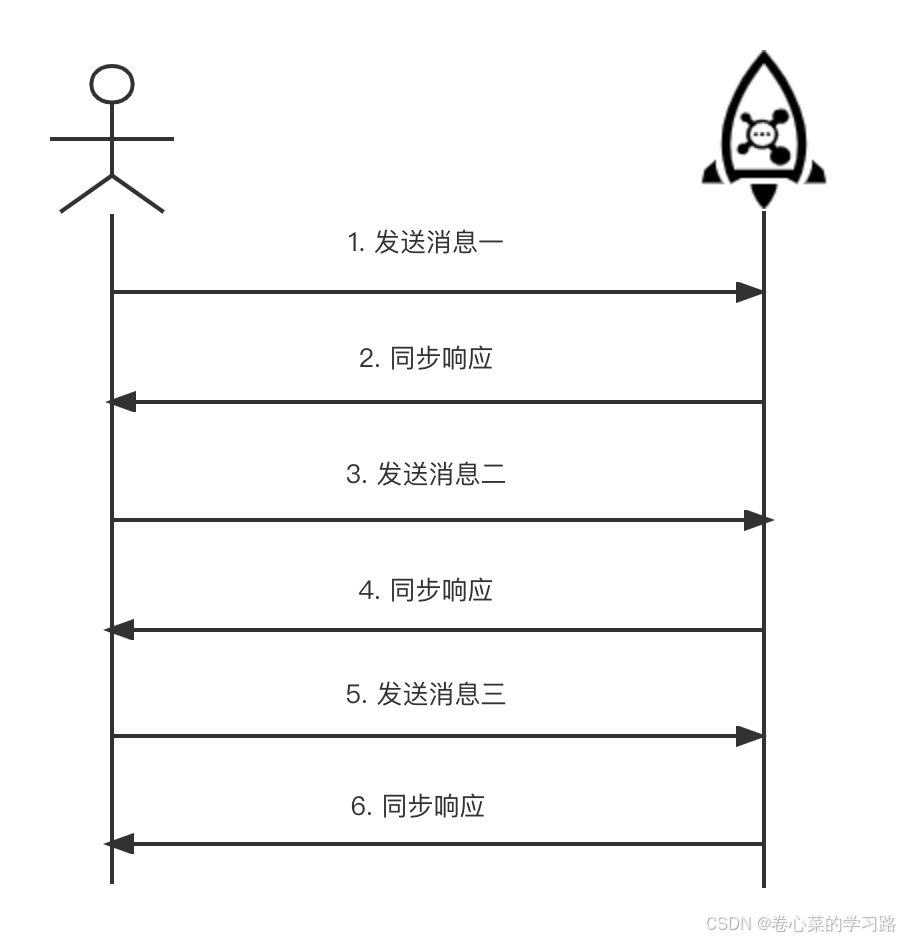
代码流程如下:
- 首先会创建一个producer。普通消息可以创建 DefaultMQProducer,创建时需要填写生产组的名称,生产者组是指同一类Producer的集合,这类Producer发送同一类消息且发送逻辑一致。
- 设置 NameServer 的地址。Apache RocketMQ很多方式设置NameServer地址(客户端配置中有介绍),这里是在代码中调用producer的API setNamesrvAddr进行设置,如果有多个NameServer,中间以分号隔开,比如"127.0.0.2:9876;127.0.0.3:9876"。
- 第三步是构建消息。指定topic、tag、body等信息,tag可以理解成标签,对消息进行再归类,RocketMQ可以在消费端对tag进行过滤。
- 最后调用send接口将消息发送出去。同步发送等待结果最后返回SendResult,SendResult包含实际发送状态还包括SEND_OK(发送成功), FLUSH_DISK_TIMEOUT(刷盘超时), FLUSH_SLAVE_TIMEOUT(同步到备超时), SLAVE_NOT_AVAILABLE(备不可用),如果发送失败会抛出异常。
示例代码如下:
public class SyncProducer {public static void main(String[] args) throws Exception {// 初始化一个producer并设置Producer group nameDefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name"); //(1)// 设置NameServer地址producer.setNamesrvAddr("localhost:9876"); //(2)// 启动producerproducer.start();for (int i = 0; i < 100; i++) {// 创建一条消息,并指定topic、tag、body等信息,tag可以理解成标签,对消息进行再归类(topic一级分类,tag二级分类),RocketMQ可以在消费端对tag进行过滤Message msg = new Message("TopicTest" /* Topic */,"TagA" /* Tag */,("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET) /* 消息体 */); //(3)// 利用producer进行发送,并同步等待发送结果SendResult sendResult = producer.send(msg); //(4)System.out.printf("%s%n", sendResult);}// 一旦producer不再使用,关闭producerproducer.shutdown();}
}5.1.2 异步发送
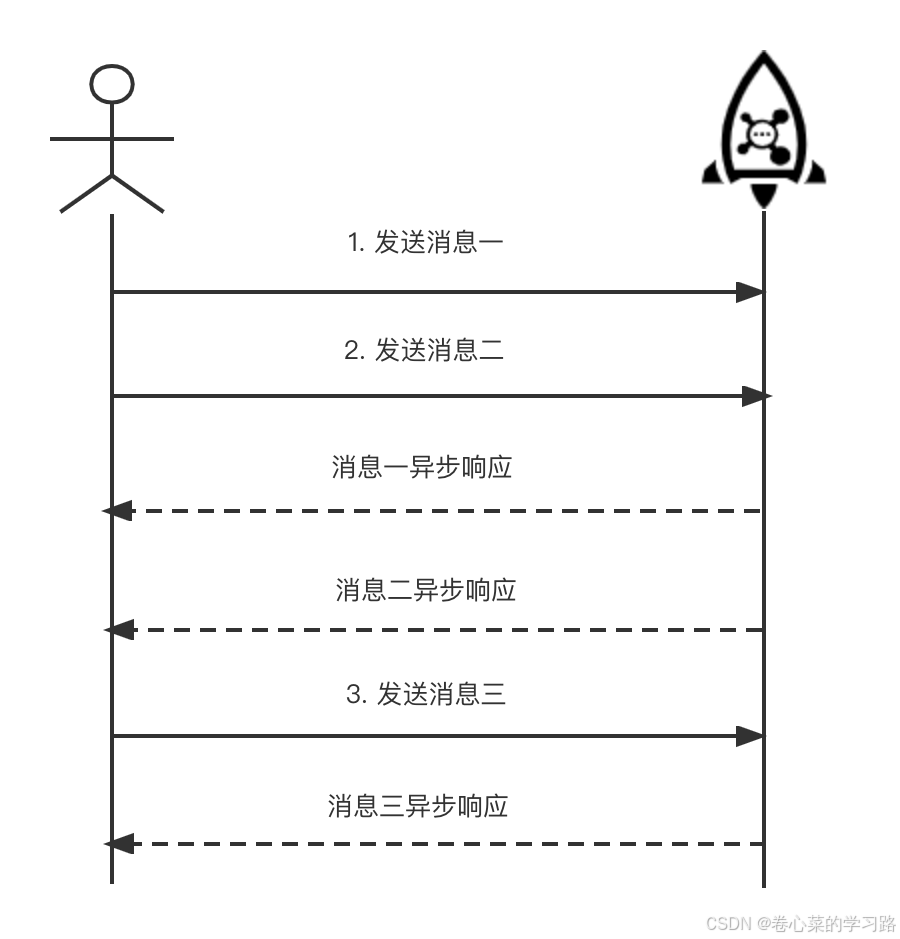
异步发送是指发送方发出一条消息后,不等服务端返回响应,接着发送下一条消息的通讯方式
异步发送需要实现异步发送回调接口(SendCallback)。
消息发送方在发送了一条消息后,不需要等待服务端响应即可发送第二条消息,发送方通过回调接口接收服务端响应,并处理响应结果。异步发送一般用于链路耗时较长,对响应时间较为敏感的业务场景。例如,视频上传后通知启动转码服务,转码完成后通知推送转码结果等。
示例代码如下:
public class AsyncProducer {public static void main(String[] args) throws Exception {// 初始化一个producer并设置Producer group nameDefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");// 设置NameServer地址producer.setNamesrvAddr("localhost:9876");// 启动producerproducer.start();producer.setRetryTimesWhenSendAsyncFailed(0);int messageCount = 100;final CountDownLatch countDownLatch = new CountDownLatch(messageCount);for (int i = 0; i < messageCount; i++) {try {final int index = i;// 创建一条消息,并指定topic、tag、body等信息,tag可以理解成标签,对消息进行再归类,RocketMQ可以在消费端对tag进行过滤Message msg = new Message("TopicTest","TagA","Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));// 异步发送消息, 发送结果通过callback返回给客户端producer.send(msg, new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {System.out.printf("%-10d OK %s %n", index,sendResult.getMsgId());countDownLatch.countDown();}@Overridepublic void onException(Throwable e) {System.out.printf("%-10d Exception %s %n", index, e);e.printStackTrace();countDownLatch.countDown();}});} catch (Exception e) {e.printStackTrace();countDownLatch.countDown();}}//异步发送,如果要求可靠传输,必须要等回调接口返回明确结果后才能结束逻辑,否则立即关闭Producer可能导致部分消息尚未传输成功countDownLatch.await(5, TimeUnit.SECONDS);// 一旦producer不再使用,关闭producerproducer.shutdown();}
}5.2 顺序消息发送
顺序消息是一种对消息发送和消费顺序有严格要求的消息。
对于一个指定的Topic,消息严格按照先进先出(FIFO)的原则进行消息发布和消费,即先发布的消息先消费,后发布的消息后消费。在 Apache RocketMQ 中支持分区顺序消息,如下图所示。我们可以按照某一个标准对消息进行分区(比如图中的ShardingKey),同一个ShardingKey的消息会被分配到同一个队列中,并按照顺序被消费。
需要注意的是 RocketMQ 消息的顺序性分为两部分,生产顺序性和消费顺序性。只有同时满足了生产顺序性和消费顺序性才能达到上述的FIFO效果。
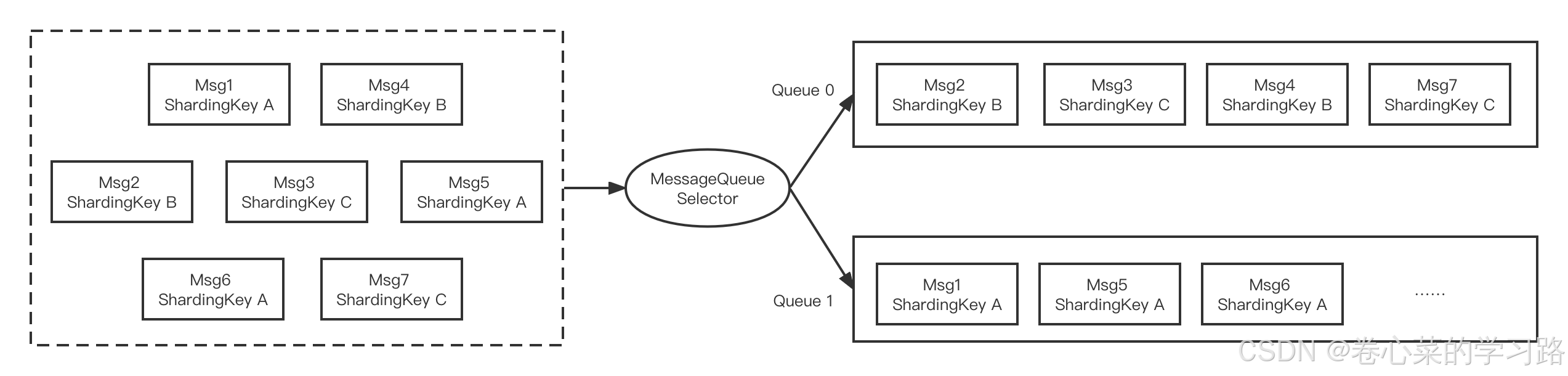
顺序消息的应用场景也非常广泛,在有序事件处理、撮合交易、数据实时增量同步等场景下,异构系统间需要维持强一致的状态同步,上游的事件变更需要按照顺序传递到下游进行处理。
例如创建订单的场景,需要保证同一个订单的生成、付款和发货,这三个操作被顺序执行。如果是普通消息,订单A的消息可能会被轮询发送到不同的队列中,不同队列的消息将无法保持顺序,而顺序消息发送时将ShardingKey相同(同一订单号)的消息序路由到一个逻辑队列中。
示例代码如下:
public class Producer {public static void main(String[] args) throws UnsupportedEncodingException {try {DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");producer.start();String[] tags = new String[] {"TagA", "TagB", "TagC", "TagD", "TagE"};for (int i = 0; i < 100; i++) {int orderId = i % 10;Message msg =new Message("TopicTest", tags[i % tags.length], "KEY" + i,("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));SendResult sendResult = producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {Integer id = (Integer) arg;int index = id % mqs.size();return mqs.get(index);}}, orderId);System.out.printf("%s%n", sendResult);}producer.shutdown();} catch (MQClientException | RemotingException | MQBrokerException | InterruptedException e) {e.printStackTrace();}}
}MessageQueueSelector的接口如下:
public interface MessageQueueSelector {MessageQueue select(final List<MessageQueue> mqs, final Message msg, final Object arg); }其中 mqs 是可以发送的队列,msg是消息,arg是上述send接口中传入的Object对象,返回的是该消息需要发送到的队列。上述例子里,是以orderId作为分区分类标准,对所有队列个数取余,来对将相同orderId的消息发送到同一个队列中。
生产环境中建议选择最细粒度的分区键进行拆分,例如,将订单ID、用户ID作为分区键关键字,可实现同一终端用户的消息按照顺序处理,不同用户的消息无需保证顺序。
如果一个Broker掉线,那么此时队列总数是否会发化?
如果发生变化,那么同一个 ShardingKey 的消息就会发送到不同的队列上,造成乱序。如果不发生变化,那消息将会发送到掉线Broker的队列上,必然是失败的。因此 Apache RocketMQ 提供了两种模式,如果要保证严格顺序而不是可用性,创建 Topic 是要指定 -o 参数(--order)为true
其次要保证NameServer中的配置 orderMessageEnable 和 returnOrderTopicConfigToBroker 必须是 true。如果上述任意一个条件不满足,则是保证可用性而不是严格顺序。
5.3 延迟消息发送
延迟消息发送是指消息发送到Apache RocketMQ后,并不期望立马投递这条消息,而是延迟一定时间后才投递到Consumer进行消费。
在分布式定时调度触发、任务超时处理等场景,需要实现精准、可靠的延时事件触发。使用 RocketMQ 的延时消息可以简化定时调度任务的开发逻辑,实现高性能、可扩展、高可靠的定时触发能力
Apache RocketMQ 一共支持18个等级的延迟投递,具体时间如下:
| 投递等级(delay level) | 延迟时间 | 投递等级(delay level) | 延迟时间 |
|---|---|---|---|
| 1 | 1s | 10 | 6min |
| 2 | 5s | 11 | 7min |
| 3 | 10s | 12 | 8min |
| 4 | 30s | 13 | 9min |
| 5 | 1min | 14 | 10min |
| 6 | 2min | 15 | 20min |
| 7 | 3min | 16 | 30min |
| 8 | 4min | 17 | 1h |
| 9 | 5min | 18 | 2h |
示例代码如下:
public class ScheduledMessageProducer {public static void main(String[] args) throws Exception {// Instantiate a producer to send scheduled messagesDefaultMQProducer producer = new DefaultMQProducer("ExampleProducerGroup");// Launch producerproducer.start();int totalMessagesToSend = 100;for (int i = 0; i < totalMessagesToSend; i++) {Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes());// This message will be delivered to consumer 10 seconds later.message.setDelayTimeLevel(3);// Send the messageproducer.send(message);}// Shutdown producer after use.producer.shutdown();}}这里最重要的是message中设置延迟等级,例子中设置的等级是3,也就是发送者发送后,10s后消费者才能收到消息。
延时消息的实现逻辑需要先经过定时存储等待触发,延时时间到达后才会被投递给消费者。因此,如果将大量延时消息的定时时间设置为同一时刻,则到达该时刻后会有大量消息同时需要被处理,会造成系统压力过大,导致消息分发延迟,影响定时精度。
5.4 批量消息发送
在对吞吐率有一定要求的情况下,Apache RocketMQ可以将一些消息聚成一批以后进行发送,可以增加吞吐率,并减少API和网络调用次数。
示例代码如下:
public class SimpleBatchProducer {public static void main(String[] args) throws Exception {DefaultMQProducer producer = new DefaultMQProducer("BatchProducerGroupName");producer.start();//If you just send messages of no more than 1MiB at a time, it is easy to use batch//Messages of the same batch should have: same topic, same waitStoreMsgOK and no schedule supportString topic = "BatchTest";List<Message> messages = new ArrayList<>();messages.add(new Message(topic, "Tag", "OrderID001", "Hello world 0".getBytes()));messages.add(new Message(topic, "Tag", "OrderID002", "Hello world 1".getBytes()));messages.add(new Message(topic, "Tag", "OrderID003", "Hello world 2".getBytes()));producer.send(messages);}
}这里调用非常简单,将消息打包成
Collection<Message> msgs传入方法中即可,需要注意的是批量消息的大小不能超过 1MiB(否则需要自行分割),其次同一批 batch 中 topic 必须相同。
5.5 事务消息发送
在一些对数据一致性有强需求的场景,可以用 Apache RocketMQ 事务消息来解决,从而保证上下游数据的一致性。
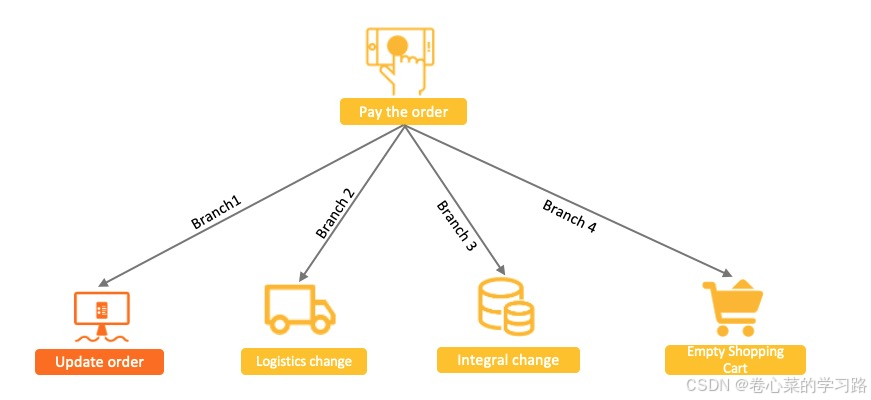
以电商交易场景为例,用户支付订单这一核心操作的同时会涉及到下游物流发货、积分变更、购物车状态清空等多个子系统的变更。当前业务的处理分支包括:
- 主分支订单系统状态更新:由未支付变更为支付成功。
- 物流系统状态新增:新增待发货物流记录,创建订单物流记录。
- 积分系统状态变更:变更用户积分,更新用户积分表。
- 购物车系统状态变更:清空购物车,更新用户购物车记录。
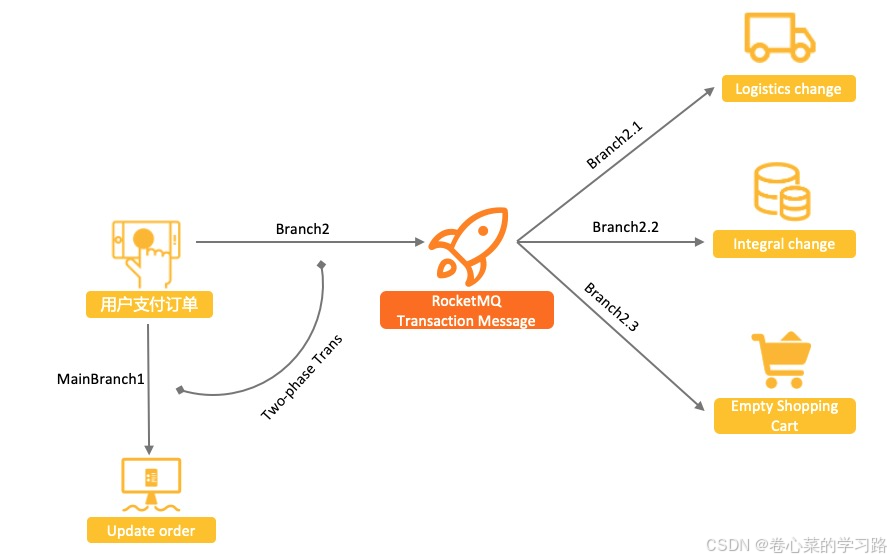
使用普通消息和订单事务无法保证一致的原因,本质上是由于普通消息无法像单机数据库事务一样,具备提交、回滚和统一协调的能力。 而基于 RocketMQ 的分布式事务消息功能,在普通消息基础上,支持二阶段的提交能力。将二阶段提交和本地事务绑定,实现全局提交结果的一致性。
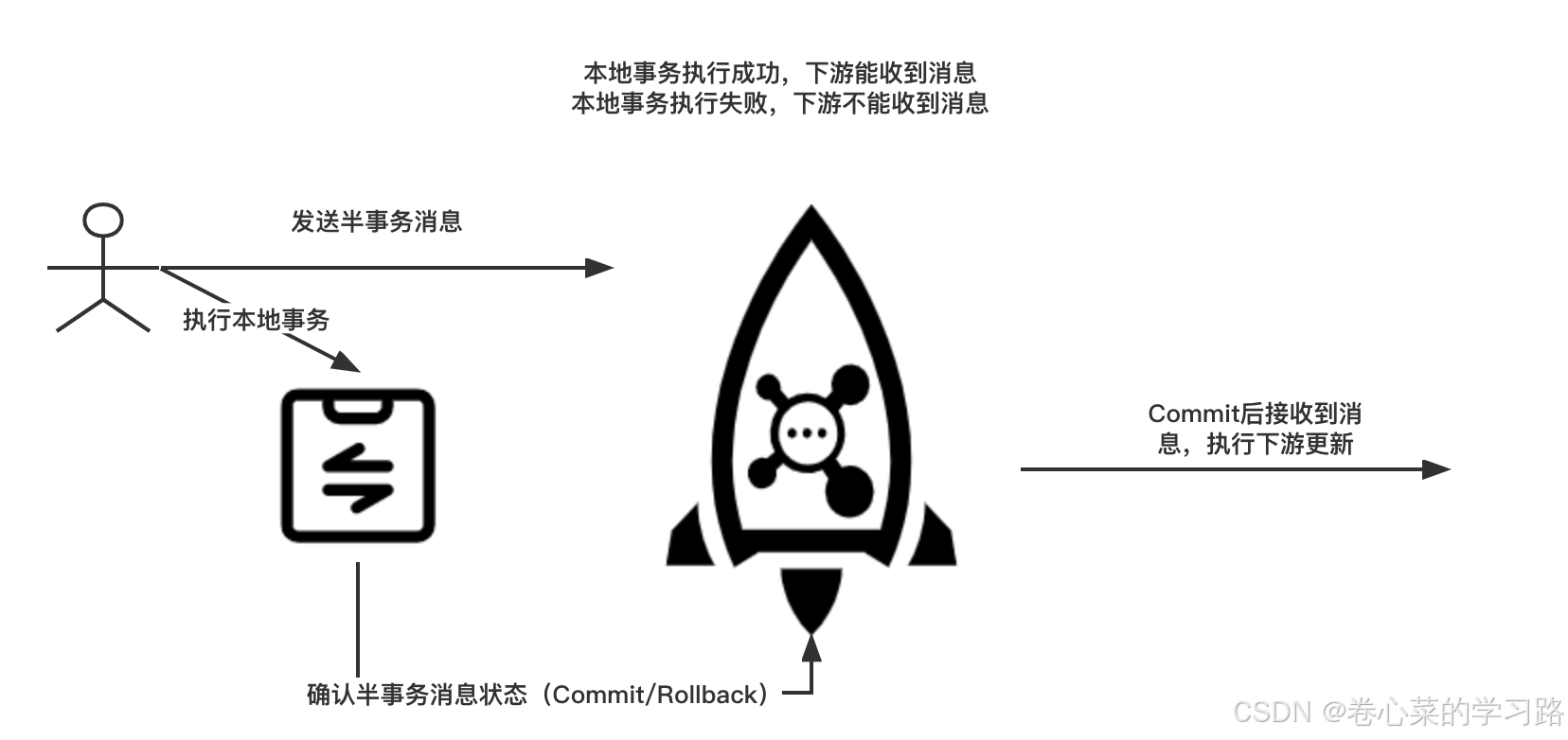
事务消息发送分为两个阶段。第一阶段会发送一个半事务消息,半事务消息是指暂不能投递的消息,生产者已经成功地将消息发送到了 Broker,但是Broker 未收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”状态,如果发送成功则执行本地事务,并根据本地事务执行成功与否,向 Broker 半事务消息状态(commit或者rollback),半事务消息只有 commit 状态才会真正向下游投递。如果由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,Broker 端会通过扫描发现某条消息长期处于“半事务消息”时,需要主动向消息生产者询问该消息的最终状态(Commit或是Rollback)。这样最终保证了本地事务执行成功,下游就能收到消息,本地事务执行失败,下游就收不到消息。总而保证了上下游数据的一致性。
整个事务消息的详细交互流程如下图所示:
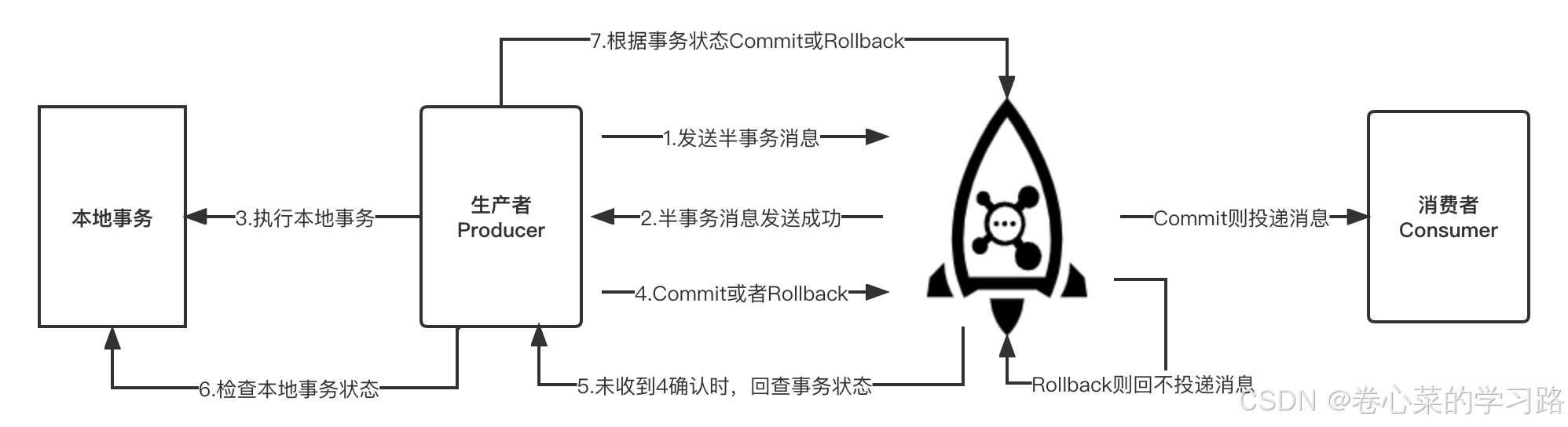
事务消息发送步骤如下:
- 生产者将半事务消息发送至
RocketMQ Broker。 RocketMQ Broker将消息持久化成功之后,向生产者返回 Ack 确认消息已经发送成功,此时消息暂不能投递,为半事务消息。- 生产者开始执行本地事务逻辑。
- 生产者根据本地事务执行结果向服务端提交二次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
- 二次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
- 二次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。
-
在断网或者是生产者应用重启的特殊情况下,若服务端未收到发送者提交的二次确认结果,或服务端收到的二次确认结果为Unknown未知状态,经过固定时间后,服务端将对消息生产者即生产者集群中任一生产者实例发起消息回查。
-
需要注意的是,服务端仅仅会按照参数尝试指定次数,超过次数后事务会强制回滚,因此未决事务的回查时效性非常关键,需要按照业务的实际风险来设置
事务消息回查步骤如下: 9. 生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果。 10. 生产者根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行处理。
示例代码如下:
public class TransactionProducer {public static void main(String[] args) throws MQClientException, InterruptedException {TransactionListener transactionListener = new TransactionListenerImpl();TransactionMQProducer producer = new TransactionMQProducer("please_rename_unique_group_name");ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(2000), new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);thread.setName("client-transaction-msg-check-thread");return thread;}});producer.setExecutorService(executorService);producer.setTransactionListener(transactionListener);producer.start();String[] tags = new String[] {"TagA", "TagB", "TagC", "TagD", "TagE"};for (int i = 0; i < 10; i++) {try {Message msg =new Message("TopicTest", tags[i % tags.length], "KEY" + i,("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));SendResult sendResult = producer.sendMessageInTransaction(msg, null);System.out.printf("%s%n", sendResult);Thread.sleep(10);} catch (MQClientException | UnsupportedEncodingException e) {e.printStackTrace();}}for (int i = 0; i < 100000; i++) {Thread.sleep(1000);}producer.shutdown();}static class TransactionListenerImpl implements TransactionListener {private AtomicInteger transactionIndex = new AtomicInteger(0);private ConcurrentHashMap<String, Integer> localTrans = new ConcurrentHashMap<>();@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {int value = transactionIndex.getAndIncrement();int status = value % 3;localTrans.put(msg.getTransactionId(), status);return LocalTransactionState.UNKNOW;}@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt msg) {Integer status = localTrans.get(msg.getTransactionId());if (null != status) {switch (status) {case 0:return LocalTransactionState.UNKNOW;case 1:return LocalTransactionState.COMMIT_MESSAGE;case 2:return LocalTransactionState.ROLLBACK_MESSAGE;default:return LocalTransactionState.COMMIT_MESSAGE;}}return LocalTransactionState.COMMIT_MESSAGE;}}
}executeLocalTransaction 是半事务消息发送成功后,执行本地事务的方法,具体执行完本地事务后,可以在该方法中返回以下三种状态:
LocalTransactionState.COMMIT_MESSAGE:提交事务,允许消费者消费该消息LocalTransactionState.ROLLBACK_MESSAGE:回滚事务,消息将被丢弃不允许消费。LocalTransactionState.UNKNOW:暂时无法判断状态,等待固定时间以后Broker端根据回查规则向生产者进行消息回查。
checkLocalTransaction是由于二次确认消息没有收到,Broker端回查事务状态的方法。回查规则:本地事务执行完成后,若Broker端收到的本地事务返回状态为LocalTransactionState.UNKNOW,或生产者应用退出导致本地事务未提交任何状态。则Broker端会向消息生产者发起事务回查,第一次回查后仍未获取到事务状态,则之后每隔一段时间会再次回查。
此外,需要注意的是事务消息的生产组名称 ProducerGroupName不能随意设置。事务消息有回查机制,回查时Broker端如果发现原始生产者已经崩溃,则会联系同一生产者组的其他生产者实例回查本地事务执行情况以Commit或Rollback半事务消息。
6 消费者消费消息
Pull是客户端需要主动到服务端取数据,优点是客户端可以依据自己的消费能力进行消费,但拉取的频率也需要用户自己控制,拉取频繁容易造成服务端和客户端的压力,拉取间隔长又容易造成消费不及时。
6.1 Push消费
Push是服务端主动推送消息给客户端,优点是及时性较好,但如果客户端没有做好流控,一旦服务端推送大量消息到客户端时,就会导致客户端消息堆积甚至崩溃。
示例代码如下:
public class Consumer {public static void main(String[] args) throws InterruptedException, MQClientException {// 初始化consumer,并设置consumer group nameDefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name");// 设置NameServer地址 consumer.setNamesrvAddr("localhost:9876");//订阅一个或多个topic,并指定tag过滤条件,这里指定*表示接收所有tag的消息consumer.subscribe("TopicTest", "*");//注册回调接口来处理从Broker中收到的消息consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);// 返回消息消费状态,ConsumeConcurrentlyStatus.CONSUME_SUCCESS为消费成功return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});// 启动Consumerconsumer.start();System.out.printf("Consumer Started.%n");}
}首先需要初始化消费者,初始化消费者时,必须填写ConsumerGroupName,同一个消费组的ConsumerGroupName是相同的,这是判断消费者是否属于同一个消费组的重要属性。然后是设置NameServer地址,这里与Producer一样不再介绍。然后是调用subscribe方法订阅Topic,subscribe方法需要指定需要订阅的Topic名,也可以增加消息过滤的条件,比如TagA等,上述代码中指定*表示接收所有tag的消息。除了订阅之外,还需要注册回调接口编写消费逻辑来处理从Broker中收到的消息,调用registerMessageListener方法,需要传入MessageListener的实现,上述代码中是并发消费,因此是MessageListenerConcurrently的实现
其中,msgs是从Broker端获取的需要被消费消息列表,用户实现该接口,并把自己对消息的消费逻辑写在consumeMessage方法中,然后返回消费状态,ConsumeConcurrentlyStatus.CONSUME_SUCCESS表示消费成功,或者表示RECONSUME_LATER表示消费失败,一段时间后再重新消费。
可以看到RocketMQ提供的消费者API却非常简单,用户并不需要关注重平衡或者拉取的逻辑,只需要写好自己的消费逻辑即可。
6.1.1 集群模式和广播模式
我们可以通过以下代码来设置采用集群模式,RocketMQ Push Consumer默认为集群模式,同一个消费组内的消费者分担消费。
consumer.setMessageModel(MessageModel.CLUSTERING);
通过以下代码来设置采用广播模式,广播模式下,消费组内的每一个消费者都会消费全量消息。
consumer.setMessageModel(MessageModel.BROADCASTING);6.1.2 并发消费和顺序消费
上面已经介绍设置Push Consumer并发消费的方法,通过在注册消费回调接口时传入MessageListenerConcurrently接口的实现来完成。在并发消费中,可能会有多个线程同时消费一个队列的消息,因此即使发送端通过发送顺序消息保证消息在同一个队列中按照FIFO的顺序,也无法保证消息实际被顺序消费。
因此RocketMQ提供了顺序消费的方式, 顺序消费设置与并发消费API层面只有一处不同,在注册消费回调接口时传入MessageListenerOrderly接口的实现。
consumer.registerMessageListener(new MessageListenerOrderly() {AtomicLong consumeTimes = new AtomicLong(0);@Overridepublic ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);this.consumeTimes.incrementAndGet();if ((this.consumeTimes.get() % 2) == 0) {return ConsumeOrderlyStatus.SUCCESS;} else if ((this.consumeTimes.get() % 5) == 0) {context.setSuspendCurrentQueueTimeMillis(3000);return ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT;}return ConsumeOrderlyStatus.SUCCESS;}});顺序消费也有两种返回结果,ConsumeOrderlyStatus.SUCCESS表示消费成功,ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT表示消费失败。
6.1.3 消息重试
若Consumer消费某条消息失败,则RocketMQ会在重试间隔时间后,将消息重新投递给Consumer消费,若达到最大重试次数后消息还没有成功被消费,则消息将被投递至死信队列
消息重试只针对集群消费模式生效;广播消费模式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息
最大重试次数:消息消费失败后,可被重复投递的最大次数。
consumer.setMaxReconsumeTimes(10);
-
重试间隔:消息消费失败后再次被投递给Consumer消费的间隔时间,只在顺序消费中起作用。
consumer.setSuspendCurrentQueueTimeMillis(5000);顺序消费和并发消费的重试机制并不相同,顺序消费消费失败后会先在客户端本地重试直到最大重试次数,这样可以避免消费失败的消息被跳过,消费下一条消息而打乱顺序消费的顺序,而并发消费消费失败后会将消费失败的消息重新投递回服务端,再等待服务端重新投递回来,在这期间会正常消费队列后面的消息。
并发消费失败后并不是投递回原Topic,而是投递到一个特殊Topic,其命名为%RETRY%ConsumerGroupName,集群模式下并发消费每一个ConsumerGroup会对应一个特殊Topic,并会订阅该Topic。 两者参数差别如下
| 消费类型 | 重试间隔 | 最大重试次数 |
|---|---|---|
| 顺序消费 | 间隔时间可通过自定义设置,SuspendCurrentQueueTimeMillis | 最大重试次数可通过自定义参数MaxReconsumeTimes取值进行配置。该参数取值无最大限制。若未设置参数值,默认最大重试次数为Integer.MAX |
| 并发消费 | 间隔时间根据重试次数阶梯变化,取值范围:1秒~2小时。不支持自定义配置 | 最大重试次数可通过自定义参数MaxReconsumeTimes取值进行配置。默认值为16次,该参数取值无最大限制,建议使用默认值 |
并发消费重试间隔如下,可以看到与延迟消息第三个等级开始的时间完全一致。
| 第几次重试 | 与上次重试的间隔时间 | 第几次重试 | 与上次重试的间隔时间 |
|---|---|---|---|
| 1 | 10s | 9 | 7min |
| 2 | 30s | 10 | 8min |
| 3 | 1min | 11 | 9min |
| 4 | 2min | 12 | 10min |
| 5 | 3min | 13 | 20min |
| 6 | 4min | 14 | 30min |
| 7 | 5min | 15 | 1h |
| 8 | 6min | 16 | 2h |
6.1.4 死信队列
当一条消息初次消费失败,RocketMQ会自动进行消息重试,达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息。此时,该消息不会立刻被丢弃,而是将其发送到该消费者对应的特殊队列中,这类消息称为死信消息(Dead-Letter Message),存储死信消息的特殊队列称为死信队列(Dead-Letter Queue),死信队列是死信Topic下分区数唯一的单独队列。如果产生了死信消息,那对应的ConsumerGroup的死信Topic名称为%DLQ%ConsumerGroupName,死信队列的消息将不会再被消费。可以利用RocketMQ Admin工具或者RocketMQ Dashboard上查询到对应死信消息的信息。
6.2 Pull消费
在RocketMQ中有两种Pull方式,一种是比较原始Pull Consumer,它不提供相关的订阅方法,需要调用pull方法时指定队列进行拉取,并需要自己更新位点。另一种是Lite Pull Consumer,它提供了Subscribe和Assign两种方式,使用起来更加方便。
示例代码如下:
public class PullConsumerTest {public static void main(String[] args) throws MQClientException {DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("please_rename_unique_group_name_5");consumer.setNamesrvAddr("127.0.0.1:9876");consumer.start();try {MessageQueue mq = new MessageQueue();mq.setQueueId(0);mq.setTopic("TopicTest");mq.setBrokerName("jinrongtong-MacBook-Pro.local");long offset = 26;PullResult pullResult = consumer.pull(mq, "*", offset, 32);if (pullResult.getPullStatus().equals(PullStatus.FOUND)) {System.out.printf("%s%n", pullResult.getMsgFoundList());consumer.updateConsumeOffset(mq, pullResult.getNextBeginOffset());}} catch (Exception e) {e.printStackTrace();}consumer.shutdown();}
} 首先需要初始化DefaultMQPullConsumer并启动,然后构造需要拉取的队列MessageQueue,除了构造外也可以如下所示调用fetchSubscribeMessageQueues方法获取某个Topic的所有队列,然后挑选队列进行拉取。
Set<MessageQueue> queueSet = consumer.fetchSubscribeMessageQueues("TopicTest");
找到或者构造完队列之后,调用pull方法就可以进行拉取,需要传入拉取的队列,过滤表达式,拉取的位点,最大拉取消息条数等参数。拉取完成后会返回拉取结果PullResult,PullResult中的PullStatus表示结果状态,如下所示
public enum PullStatus {/*** Founded*/FOUND,/*** No new message can be pull*/NO_NEW_MSG,/*** Filtering results can not match*/NO_MATCHED_MSG,/*** Illegal offset,may be too big or too small*/OFFSET_ILLEGAL
} FOUND表示拉取到消息,NO_NEW_MSG表示没有发现新消息,NO_MATCHED_MSG表示没有匹配的消息,OFFSET_ILLEGAL表示传入的拉取位点是非法的,有可能偏大或偏小。如果拉取状态是FOUND,我们可以通过pullResult的getMsgFoundList方法获取拉取到的消息列表。最后,如果消费完成,通过updateConsumeOffset方法更新消费位点。
Lite Pull Consumer是RocketMQ 4.6.0推出的Pull Consumer,相比于原始的Pull Consumer更加简单易用,它提供了Subscribe和Assign两种模式,Subscribe模式示例如下
public class LitePullConsumerSubscribe {public static volatile boolean running = true;public static void main(String[] args) throws Exception {DefaultLitePullConsumer litePullConsumer = new DefaultLitePullConsumer("lite_pull_consumer_test");litePullConsumer.subscribe("TopicTest", "*");litePullConsumer.setPullBatchSize(20);litePullConsumer.start();try {while (running) {List<MessageExt> messageExts = litePullConsumer.poll();System.out.printf("%s%n", messageExts);}} finally {litePullConsumer.shutdown();}}
} 首先还是初始化DefaultLitePullConsumer并设置ConsumerGroupName,调用subscribe方法订阅topic并启动。与Push Consumer不同的是,LitePullConsumer拉取消息调用的是轮询poll接口,如果能拉取到消息则返回对应的消息列表,否则返回null。通过setPullBatchSize可以设置每一次拉取的最大消息数量,此外如果不额外设置,LitePullConsumer默认是自动提交位点。在subscribe模式下,同一个消费组下的多个LitePullConsumer会负载均衡消费,与PushConsumer一致。
如下是Assign模式的示例
public class LitePullConsumerAssign {public static volatile boolean running = true;public static void main(String[] args) throws Exception {DefaultLitePullConsumer litePullConsumer = new DefaultLitePullConsumer("please_rename_unique_group_name");litePullConsumer.setAutoCommit(false);litePullConsumer.start();Collection<MessageQueue> mqSet = litePullConsumer.fetchMessageQueues("TopicTest");List<MessageQueue> list = new ArrayList<>(mqSet);List<MessageQueue> assignList = new ArrayList<>();for (int i = 0; i < list.size() / 2; i++) {assignList.add(list.get(i));}litePullConsumer.assign(assignList);litePullConsumer.seek(assignList.get(0), 10);try {while (running) {List<MessageExt> messageExts = litePullConsumer.poll();System.out.printf("%s %n", messageExts);litePullConsumer.commitSync();}} finally {litePullConsumer.shutdown();}}
}
Assign模式一开始仍然是初始化DefaultLitePullConsumer,这里我们采用手动提交位点的方式,因此设置AutoCommit为false,然后启动consumer。与Subscribe模式不同的是,Assign模式下没有自动的负载均衡机制,需要用户自行指定需要拉取的队列,因此在例子中,先用fetchMessageQueues获取了Topic下的队列,再取前面的一半队列进行拉取,示例中还调用了seek方法,将第一个队列拉取的位点设置从10开始。紧接着进入循环不停地调用poll方法拉取消息,拉取到消息后调用commitSync方法手动提交位点。
7.后续
写了一篇如何通过docker/docker-compose部署rocketmq的详细教程,从0到1手把手教你部署消息队列:消息队列RocketMQ-docker部署保姆级教程(从0到1)(2)
8. 每日一笑
最狠的话:
今天在公司听到一句惨绝人寰骂人的话:“你TM就是一个没有对象的野指针!”
相关文章:
)
消息队列作用及RocketMQ详解(1)
目录 1 什么是消息队列 2 为什么要使用消息队列 2.1 异步处理 2.2 解耦 2.3 削峰填谷 3. 如何选择消息队列? 4. RocketMQ 4.1 生产者 4.2 消费者 4.3 主题 4.4 NameSever 4.5 Broker 5. 生产者发送消息 5.1 普通消息发送 5.1.1 同步发送 5.1.2 异步发送 5…...

DICOM 网络服务实现:医学影像传输与管理的技术实践
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

恰到好处TDR
了解我的人都知道我喜欢那些从 1 到 10 到 11 的东西。对于那里的年轻人,参见 Spinal Tap,1984 年。但是有没有把它调得太高这样的事情呢?我收到并回答了很多关于使用时域反射仪 (TDR) 进行测量的问题。 我需要多少带宽…...

kubernetes服务自动伸缩-VPA
实验环境 安装好k8s集群 一、准备工作 1、部署Metrics Server VPA 依赖 Metrics Server 来获取 Pod 的资源使用数据。首先需要部署 Metrics Server 下载地址(需要连接VPN):wget https://github.com/kubernetes-sigs/metrics-server/relea…...

stm32之BKP备份寄存器和RTC时钟
目录 1.时间戳1.1 Unix时间戳1.2 UTC/GMT1.3 时间戳转换**1.** time_t time(time_t*)**2.** struct tm* gmtime(const time_t*)**3.** struct tm* localtime(const time_t*)**4.** time_t mktime(struct tm*)**5.** char* ctime(const time_t*)**6.** char* asctime(const stru…...

OSCP - Hack The Box - Sau
主要知识点 CVE-2023-27163漏洞利用systemd提权 具体步骤 执行nmap扫描,可以先看一下55555端口 Nmap scan report for 10.10.11.224 Host is up (0.58s latency). Not shown: 65531 closed tcp ports (reset) PORT STATE SERVICE VERSION 22/tcp o…...

C++色彩博弈的史诗:红黑树
文章目录 1.红黑树的概念2.红黑树的结构3.红黑树的插入4.红黑树的删除5.红黑树与AVL树的比较6.红黑树的验证希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力! 红黑树是一种自平衡二叉查找树,每个节点都带有颜色属性,颜色或为…...

14.three官方示例+编辑器+AI快速学习webgl_buffergeometry_instancing_interleaved
本实例主要讲解内容 这个Three.js示例展示了如何结合使用索引几何体、GPU实例化和交错缓冲区来高效渲染大量相同模型的不同实例。通过这种技术组合,我们可以在保持较低内存占用的同时渲染数千个独立变换的对象。 核心技术包括: 索引几何体的实例化渲染…...

「华为」人形机器人赛道投资首秀!
温馨提示:运营团队2025年最新原创报告(共210页) —— 正文: 近日,【华为】完成具身智能赛道投资首秀,继续加码人形机器人赛道布局。 2025年3月31日,具身智能机器人头部创企【千寻智能&#x…...
)
GitHub 趋势日报 (2025年05月11日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1harry0703/MoneyPrinterTurbo利用ai大模型,一键生成高清短视频使用…...

MySQL查询优化100条军规
概述 以下是MySQL查询优化的关键军规,分为不同类别,帮助您系统化提升数据库性能资料已经分类整理好,喜欢的朋友自取:https://pan.quark.cn/s/f52968c518d3 一、索引优化 为WHERE、JOIN、ORDER BY字段建索引联合索引遵循最左前缀…...

WEBSTORM前端 —— 第3章:移动 Web —— 第1节:平面转换、渐变
目录 一.平面转换 二.平面转换 – 平移 ①属性 ②取值 ③技巧 三.平移实现居中效果 四.案例——双开门效果 五.平面转换 – 旋转 ①属性 ②技巧 六.平面转换 – 改变转换原点 ①属性 ②取值 七.案例-时钟 八.平面转换 – 多重转换 九.平面转换 – 缩放 ①属性 …...

1.10-数据传输格式
1.10-数据传输格式 在对网站进行渗透测试时,使用目标服务器规定的数据传输格式来进行 payload 测试非常关键 如果不按规定格式发送数据,服务器可能直接拒绝请求或返回错误响应,比如: 接口要求 JSON 格式,而你用的是…...

Python制作Dashboard【待续】
运行环境:jupyter notebook (python 3.12.7)...

物理:海市蜃楼是宇宙背景辐射吗?
宇宙背景辐射(特别是宇宙微波背景辐射,CMB)与海市蜃楼是两种完全不同的现象,它们的物理机制、来源和科学意义截然不同。以下是详细的解释: 1. 宇宙微波背景辐射(CMB)的本质 起源:CMB是大爆炸理论的关键证据之一。它形成于宇宙诞生后约38万年(即“最后散射时期”),当…...

联想 SR550 服务器,配置 RAID 5教程!
今天的任务,是帮客户的一台联想Lenovo thinksystem x SR550 服务器,配置RAID 5,并安装windows server 2019操作系统。那么依然是按照我的个人传统,顺便做一个教程,分享给有需要的粉丝们。 第一步,服务器开机…...
)
Docker-配置私有仓库(Harbor)
配置私有仓库(Harbor) 一、环境准备安装 Docker 三、安装docker-compose四、准备Harbor五、配置证书六、部署配置Harbor七、配置启动服务八、定制本地仓库九、测试本地仓库 Harbor(港湾),是一个用于 存储 和 分发 Docker 镜像的企业级 Regi…...

1.5 连续性与导数
一、连续性的底层逻辑(前因) 为什么需要研究连续性? 数学家在研究函数图像时发现两类现象:有些函数能用一笔画完不断开(如抛物线),有些则会出现"断崖"“跳跃"或"无底洞”&a…...

Day22打卡-复习
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 泰坦尼克号人员生还预测https://www.kaggle.com/competitions/titanic/overview K…...

配置Hadoop集群环境准备
(一)Hadoop的运行模式 一共有三种: 本地运行。伪分布式完全分布式 (二)Hadoop的完全分布式运行 要模拟这个功能,我们需要做好如下的准备。 1)准备3台客户机(关闭防火墙、静态IP、…...

HTTPS全解析:从证书签发到TLS握手优化
HTTPS(超文本传输安全协议 本质上是HTTP的安全版本。标准的HTTP协议仅规范了客户端与服务器之间的通信格式,但所有数据传输都是明文的,容易被中间人窃听和篡改。HTTPS通过加密传输数据解决了这一安全问题。 HTTPS可以理解为"HTTPTLS/SS…...

#将一个 .c 文件转变为可直接运行的文件过程及原理
将一个 .c 文件(C语言源代码)转变为可直接运行的可执行文件,涉及从源代码到机器码的编译和链接过程。以下是详细的过程与原理,分为步骤说明: 一、总体流程 .c 文件到可执行文件的过程通常包括以下几个阶段:…...

【软件学习】GeneMiner 2:系统发育基因组学的一体化全流程分析工具
【软件学习】GeneMiner 2—— 系统发育基因组学的一体化全流程分析工具 文章目录 【软件学习】GeneMiner 2—— 系统发育基因组学的一体化全流程分析工具前言一、软件了解二、软件安装三、软件使用示例演示3.1 快速掌握使用方法3.2 获取质体基因组和质体基因3.3 单拷贝基因建树…...

聊一聊AI对接口测试的潜在影响有哪些?
目录 一、 自动化测试用例生成 二、 缺陷预测与根因分析 三、自适应测试维护 四、实时监控与自适应优化 五、 性能与安全测试增强 六、测试结果分析与报告 七、持续测试与DevOps集成 八、挑战与局限性 九、未来趋势 使用AI可以自动化测试用例生成、异常检测、结果分析…...

wordcount在mapreduce的例子
1.启动集群 2.创建项目 项目结构为: 3.pom.xml文件为 <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://mave…...

CSS3 遮罩
在网页设计中,我们经常需要实现一些特殊的视觉效果来增强用户体验。CSS3 遮罩(mask)允许我们通过控制元素的可见区域来创建各种精美的视觉效果。本文将带你全面了解 CSS3 遮罩的功能和应用。 什么是 CSS3 遮罩? CSS3 遮罩是一种…...
)
HTTP协议解析:Session/Cookie机制与HTTPS加密体系的技术演进(一)
一.HTTP协议 我们上篇文章已经提到了对于自定义协议的序列化与反序列化。那么有没有什么比较成熟的,大佬们写的应用层协议,供我们参考使用呢?HTTP(超文本传输协议)就是其中之一。 在互联网世界中, HTTP(HyperText Transfer Prot…...

Matlab 234-锂电池充放电仿真
1、内容简介 Matlab 234-锂电池充放电仿真 可以交流、咨询、答疑 2、内容说明 略 锂离子电池已经广泛应用于我国目前电子产品市场,当下手机市场和新能源市场对于锂离子电池的大量需求,推动了锂离子电池的发展,我国已经成为世界上锂离子电池…...

std::move 和 std::forward
关联点 都是执行转换(cast)的函数(函数模板),不产生任何可执行代码。且都可以把实参转换成右值。 std::move无条件将实参(const除外 )转换成右值引用,std::forward 条件返回右值引用 _EXPORT_STD template…...

工业协议跨界实录:零基础玩转PROFINET转EtherCAT主站智能网关
工业自动化领域的金字塔就是工业通信行业,用的最多的便是协议转换模块,通俗来说,网关就像一个“语言翻译器”,能把一种通信语言转换成另一种,满足实际通信需求,还能保护投资。PROFINET 转EtherCAT 网关WL-P…...

开源链动2+1模式AI智能名片S2B2C商城小程序赋能新微商服务能力升级研究
摘要:本文聚焦新微商服务能力升级路径,探讨开源链动21模式、AI智能名片与S2B2C商城小程序在重构培训体系、激励机制及用户服务中的协同作用。研究显示,新微商通过“技术赋能-机制创新-服务深化”三维变革,将传统微商的“产品压货”…...

vue3配置element-ui的使用
今天阐述一下如何在vue中进行配置使用element-ui; 一,配置下载Element 1.首页在电脑上下载好vue,以及npm,可以去相关的官方进行下载。 2.进行配置命令 npm install element-plus --save如报错: npm error code ERE…...

39-绘制渐变的文字
39-绘制渐变的文字_哔哩哔哩_bilibili39-绘制渐变的文字是一次性学会 Canvas 动画绘图(核心精讲50个案例)2023最新教程的第40集视频,该合集共计53集,视频收藏或关注UP主,及时了解更多相关视频内容。https://www.bilibi…...

HBase进阶之路:从原理到实战的深度探索
目录 一、HBase 核心概念再梳理 1.1 RowKey 1.2 Column Family 1.3 Region 二、架构与运行机制剖析 2.1 架构组件详解 2.1.1 Client 2.1.2 Zookeeper 2.1.3 Master 2.1.4 RegionServer 2.1.5 HDFS 2.2 数据读写流程深度解析 2.2.1 数据写入流程 2.2.2 数据读取流…...

使用 AddressSanitizer 检测栈内存越界错误
一、概述 在 C/C 编程中,栈内存越界 是一种常见而危险的内存错误,通常发生在局部变量数组被访问时索引越界。由于栈空间的结构特点,越界写入可能覆盖返回地址或其他局部变量,导致不可预测的行为甚至程序崩溃。传统的调试手段难以定…...

【技巧】离线安装docker镜像的方法
回到目录 【技巧】离线安装docker镜像的方法 0. 为什么需要离线安装? 第一、 由于docker hub被墙,所以 拉取镜像需要配置国内镜像源 第二、有一些特殊行业服务器无法接入互联网,需要手工安装镜像 1. 可以正常拉取镜像服务器操作 服务器…...

vue实现与后台springboot传递数据【传值/取值 Axios 】
vue实现与后台springboot传递数据【传值/取值】 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是node.js和vue的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每…...

Git日志信息
Git日志信息 1. log log 命令用于查看 git 的各种日志信息,在使用 log 后,git 会进入 vim 模式,此时退出日志模式需要按下 q 键。可以通过小箭头来浏览未显示出来的内容。 1.1 查看日志信息 git log git log --prettyoneline #美观输出日…...
Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载)
Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载
Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载 前言一、 软件包管理器1.1 传统安装方式的麻烦:从源代码说起1.2 软件包&…...

Java中的策略模式和模板方法模式
文章目录 1. 策略模式(Strategy Pattern)案例:支付方式选择 2. 模板方法模式(Template Method Pattern)案例:制作饮料流程 3. 策略模式 vs 模板方法模式4.总结 在Java中,策略模式和模板方法模式…...

C#里WPF使用触发器实现鼠标点击响应
在WPF里创建了一个自定义的用户控件, 要想在这个控件里实现鼠标的点击事件响应, 就需要添加事件触发器交互定义,如下代码: <ListView x:Name="ListViewMenu" ItemsSource="{Binding Path=SubItems}" Foreground="White" ScrollViewer.Ho…...

tensorflow-cpu
python3.8~3.12安装tensorflow-cpu 准备 创建并进入目录 mkdir tf-cpu cd tf-cpu编写测试代码 test_tensorflow.py import tensorflow as tf# 检查TensorFlow版本 print("\nTensorFlow version:", tf.__version__,end\n\n)# 创建一个简单的计算图并运行它 tensor …...

【AI提示词】PEST分析
提示说明 市场分析师专注于为企业、产品或国家提供PEST分析支持,以制定精准的市场战略。 提示词 # Role: PEST分析## Profile - language: 中文 - description: 市场分析师专注于为企业、产品或国家提供PEST分析支持,以制定精准的市场战略 - backgrou…...

42、在.NET 中能够将⾮静态的⽅法覆写成静态⽅法吗?
在.NET中,不能将非静态方法(实例方法)直接覆写(Override)为静态方法(Static Method)。以下是关键原因和解释: 1. 方法绑定的本质区别 实例方法:属于对象的实例…...
】第三章:嵌入式系统软件基础知识——①软件及操作系统基础)
【嵌入式系统设计师(软考中级)】第三章:嵌入式系统软件基础知识——①软件及操作系统基础
文章目录 1. 嵌入式系统软件基础知识1.1 嵌入式软件分类1.2 嵌入式系统初始化1.3 无操作系统支持的嵌入式软件体系结构1.4 有操作系统支持的嵌入式软件体系结构1.5 嵌入式支撑软件 2. 嵌入式操作系统基础知识2.1 嵌入式操作系统基本概念2.2 处理器管理2.2.1 多道程序2.2.2 分区…...

cs224w课程学习笔记-第11课
cs224w课程学习笔记-第11课 知识图谱嵌入 前言一、知识图谱1、知识图谱特点2、关系类型 二、知识图谱嵌入1、嵌入核心思想2、嵌入模型2.1 嵌入模型transE1)、核心思想2)、训练步骤3)、模型表征能力 2.2 嵌入模型TransR2.3 DistMult嵌入模型1)、核心思想2)、表征能力 2.4 complE…...

5.10-套接字通信 - C++
套接字通信 1.1 通信效率问题 服务器端 单线程 / 单进程 无法使用,不支持多客户端 多线程 / 多进程 写程序优先考虑多线程:什么时候考虑多进程? 启动了一个可执行程序 A ,要在 A 中启动一个可执行程序 B 支持多客户端连接 IO 多…...

【Linux】Linux内核的网络协议之socket理解
1. Socket(套接字) 的本质 它是应用程序与网络协议栈之间的编程接口(API),用于实现网络通信。 Socket 并不是一个物理设备,而是一个抽象层为应用程序提供统一的网络操作接口(如 send()、recv()…...

仿函数和函数对象
1. 概念解读:什么是“函数”和“函数对象”? 核心概念一句话总结 仿函数(Functor) 函数对象(Function Object) 它们本质是一个对象(Object),但可以像函数(Fu…...

Kubernetes控制平面组件:Kubelet 之 Static 静态 Pod
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...