HBase进阶之路:从原理到实战的深度探索
目录
一、HBase 核心概念再梳理
1.1 RowKey
1.2 Column Family
1.3 Region
二、架构与运行机制剖析
2.1 架构组件详解
2.1.1 Client
2.1.2 Zookeeper
2.1.3 Master
2.1.4 RegionServer
2.1.5 HDFS
2.2 数据读写流程深度解析
2.2.1 数据写入流程
2.2.2 数据读取流程
三、性能优化实战策略
3.1 写入性能优化
3.1.1 Server 端优化
3.1.2 Client 端优化
3.2 读取性能优化
3.2.1 Server 端优化
3.2.2 Client 端优化
四、高级特性与应用场景
4.1 高级特性揭秘
4.1.1 过滤器(Filter)
4.1.2 计数器(Counter)
4.1.3 与 YARN 集成
4.2 典型应用场景分析
4.2.1 搜索引擎
4.2.2 广告效果和点击流分析
4.2.3 滴滴
五、总结与展望
一、HBase 核心概念再梳理
在深入探索 HBase 进阶知识之前,让我们先来回顾一下 HBase 的核心概念,这些概念是理解 HBase 强大功能的基石。
1.1 RowKey
RowKey 是 HBase 中每一行数据的唯一标识,类似于关系型数据库中的主键。它在 HBase 中起着至关重要的作用,数据在存储时会按照 RowKey 的字典序进行排序,这一特性对于高效的数据检索和范围查询至关重要。例如,在一个存储用户信息的 HBase 表中,可以将用户 ID 作为 RowKey,这样就能快速定位到特定用户的所有相关数据。
1.2 Column Family
列族是一组相关列的集合,是 HBase 数据模型的重要组织单元。在创建表时,需要预先定义列族,且列族一旦确定,后续修改相对困难。每个列族下可以有多个列,这些列可以动态添加。比如在上述用户信息表中,可以定义一个“basic_info”列族,用于存放用户的基本信息,如姓名、年龄、性别等列;再定义一个“contact_info”列族,用于存放用户的联系方式,如电话号码、邮箱等列。列族的设计直接影响着 HBase 的性能,合理的列族划分能够提高数据的读写效率。
1.3 Region
Region 是 HBase 中数据存储和管理的基本单元,一个 HBase 表会被划分为多个 Region。每个 Region 负责存储表中某一段连续 RowKey 范围的数据。当数据不断写入,一个 Region 的大小达到一定阈值时,就会触发 Region Split,将其拆分为两个新的 Region,以保证数据的均衡存储和高效访问。相反,当一些 Region 的数据量过少时,可以进行 Region Merge,将相邻的 Region 合并。例如,在一个拥有海量用户数据的 HBase 表中,通过 Region 的自动拆分和合并机制,能够动态适应数据量的变化,确保系统的高性能运行。
二、架构与运行机制剖析
2.1 架构组件详解
HBase 的架构犹如一座精密构建的大厦,各个组件各司其职,协同工作,共同支撑起整个分布式数据存储系统的高效运行。
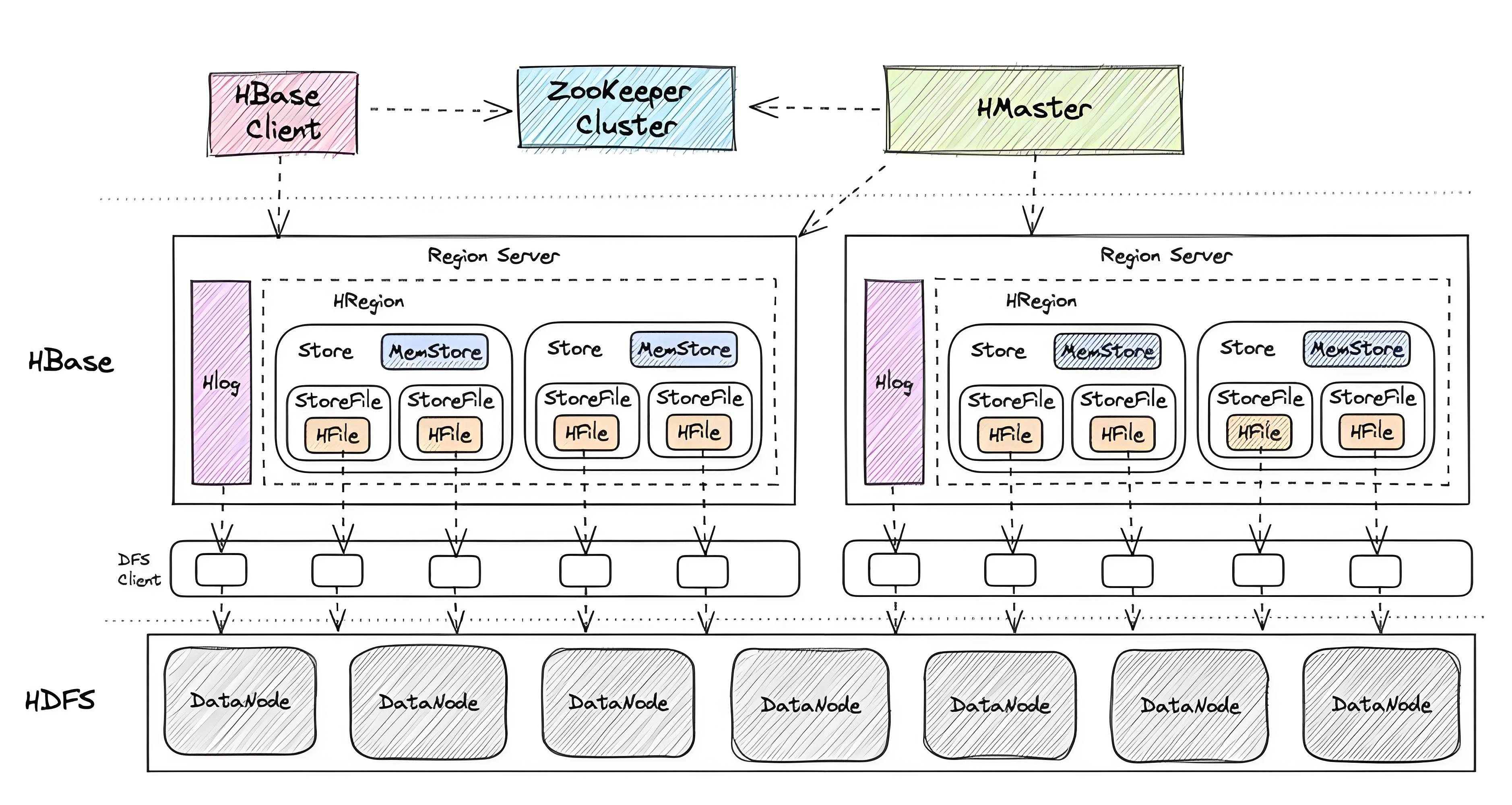
2.1.1 Client
Client 是用户与 HBase 集群交互的桥梁,它提供了访问 HBase 的接口,使得用户能够方便地进行数据的读写、表的管理等操作。Client 在工作时,会先与 Zookeeper 通信,获取元数据信息,从而定位到数据所在的 RegionServer。同时,Client 还维护着 cache,用于缓存元数据和部分数据,以减少网络开销,加快对 HBase 的访问速度。例如,当用户频繁查询某一特定区域的数据时,Client 的 cache 可以快速响应,避免重复从服务器获取相同的数据。
2.1.2 Zookeeper
Zookeeper 在 HBase 架构中扮演着至关重要的协调者角色。它就像是一个智能的指挥中心,负责保证集群中只有一个活跃的 HMaster,防止出现多个主节点导致的混乱情况。Zookeeper 存储了所有 Region 的寻址入口,当 Client 需要访问数据时,首先会通过 Zookeeper 找到数据所在的 Region 位置。此外,Zookeeper 还实时监控着 RegionServer 的状态,一旦发现某个 RegionServer 上线或下线,会立即通知 HMaster,以便 HMaster 及时做出调整,保证集群的稳定运行。
2.1.3 Master
HMaster 是 HBase 集群的管理者,负责整个集群的资源分配和管理工作。它就像一个经验丰富的指挥官,为 RegionServer 分配 Region,确保数据能够均匀地分布在各个 RegionServer 上,实现负载均衡。当 RegionServer 出现故障时,HMaster 会迅速发现,并将故障 RegionServer 上的 Region 重新分配到其他正常的 RegionServer 上,保障数据的可用性。同时,HMaster 还负责处理用户对表的创建、删除、修改等操作,以及管理 HDFS 上的垃圾文件回收工作。
2.1.4 RegionServer
RegionServer 是 HBase 中真正负责数据存储和处理的工作节点,它维护着 Master 分配给它的 Region,处理对这些 Region 的 I/O 请求。当 Client 发起数据读写请求时,RegionServer 会直接响应并进行处理。RegionServer 还负责在 Region 数据量过大时进行拆分,以及对小的 StoreFile 进行合并操作,以优化数据存储和查询性能。例如,当一个 Region 的大小达到设定的阈值时,RegionServer 会将其拆分为两个新的 Region,使得数据分布更加均衡,提高查询效率。
2.1.5 HDFS
HDFS(Hadoop Distributed File System)为 HBase 提供了最终的底层数据存储服务,就像一个巨大的仓库,负责持久化存储 HBase 的数据。HDFS 具有高容错性和高扩展性,能够保证数据的安全性和可靠性。HBase 的数据以 HFile 的形式存储在 HDFS 上,HDFS 的数据多副本机制确保了即使部分节点出现故障,数据也不会丢失,为 HBase 提供了坚实的数据存储基础。
2.2 数据读写流程深度解析
深入了解 HBase 的数据读写流程,有助于我们更好地理解其内部工作机制,从而优化数据操作,提高系统性能。接下来,我们将分别深入探讨HBase的数据写入流程和读取流程,揭示其背后的工作细节和关键机制。
2.2.1 数据写入流程
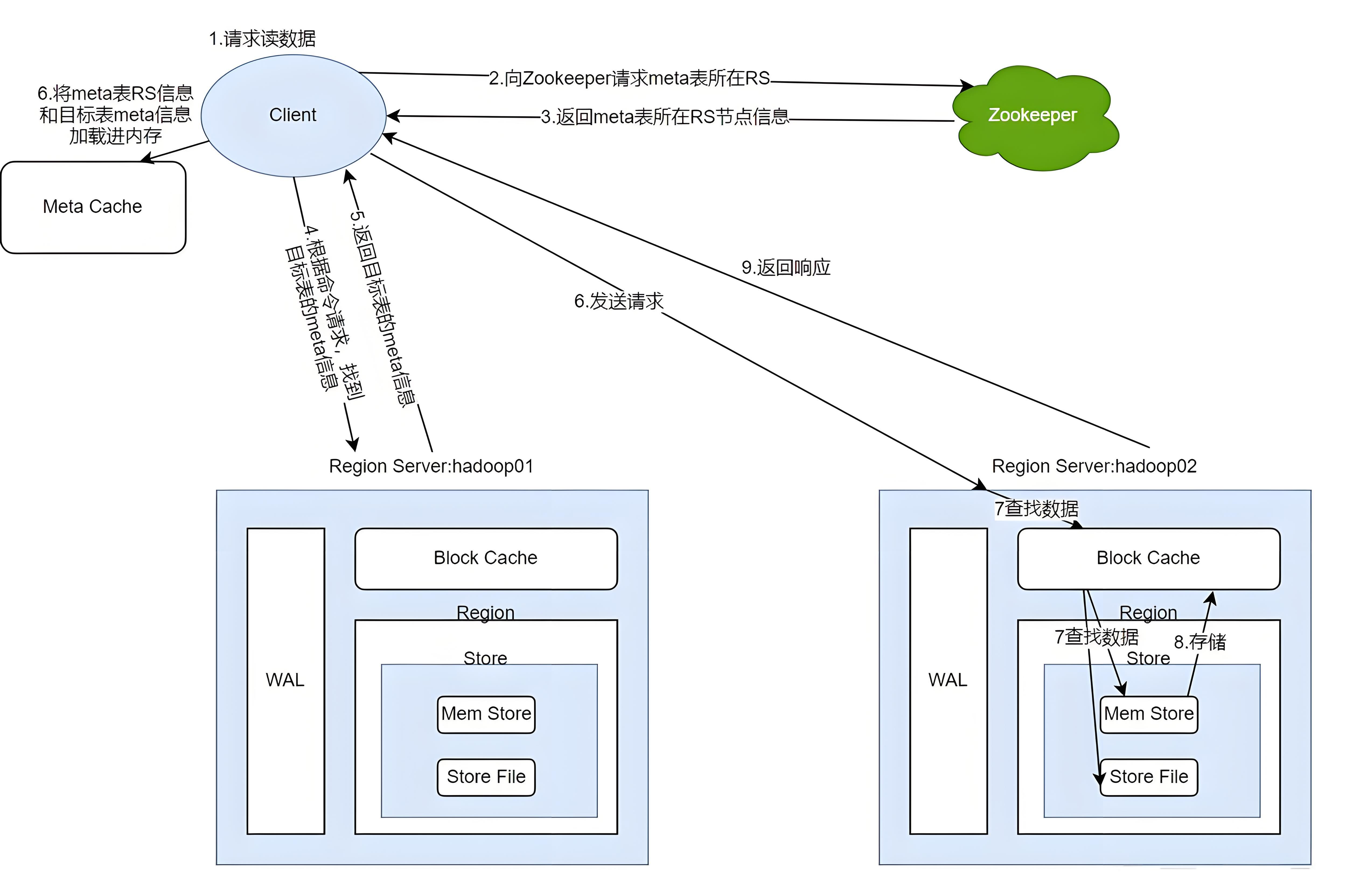
当 Client 向 HBase 写入数据时,首先会与 Zookeeper 通信,获取 hbase:meta 表所在的 RegionServer 地址。hbase:meta 表记录了所有 Region 的位置信息,通过查询 hbase:meta 表,Client 可以确定要写入的数据所在的 Region,并找到对应的 RegionServer。接着,Client 将数据发送到对应的 RegionServer。RegionServer 接收到数据后,会先将数据写入 WAL(Write Ahead Log),WAL 是一种预写式日志,用于在系统故障时恢复数据,保证数据的持久性。然后,数据会被写入 MemStore,MemStore 是内存中的缓存区域,数据会在 MemStore 中按 RowKey 排序。当 MemStore 中的数据量达到一定阈值(例如默认的 128MB)时,会触发 Flush 操作,将 MemStore 中的数据写入磁盘,生成一个新的 StoreFile 文件。随着数据的不断写入,会产生多个 StoreFile 文件,当 StoreFile 的数量达到一定阈值时,会触发 Compact 操作,将多个小的 StoreFile 合并成一个大的 StoreFile,以减少文件数量,提高查询性能。此外,当一个 Region 中的 StoreFile 大小达到一定阈值时,会触发 Region Split 操作,将该 Region 拆分为两个新的 Region,实现数据的均衡分布。
2.2.2 数据读取流程
Client 发起读请求时,同样先与 Zookeeper 通信,获取 hbase:meta 表的位置信息。通过 hbase:meta 表,Client 找到存储目标数据的 Region 所在的 RegionServer。然后,Client 向该 RegionServer 发送读请求。RegionServer 接收到请求后,会先在 BlockCache 中查找数据,BlockCache 是 RegionServer 中的读缓存,用于缓存热点数据,以提高读取速度。如果在 BlockCache 中未找到数据,则会在 MemStore 中查找。由于 MemStore 中的数据是按 RowKey 排序的,所以可以快速定位到是否存在目标数据。如果 MemStore 中也没有找到数据,最后会在 StoreFile 中查找。StoreFile 存储在磁盘上,读取速度相对较慢,因此从 StoreFile 中读取到数据后,会将数据缓存到 BlockCache 中,以便下次读取时能够更快地获取。在读取过程中,如果数据存在多个版本(HBase 支持数据的多版本存储),会根据时间戳等条件进行版本筛选,返回符合条件的最新版本数据。
三、性能优化实战策略
在 HBase 的实际应用中,性能优化是至关重要的环节。通过合理的优化策略,可以显著提升 HBase 在读写操作上的性能,使其更好地满足各种业务场景的需求。
3.1 写入性能优化
3.1.1 Server 端优化
Region 数量控制:在建表时,若能预估数据量且了解数据特点,进行预分区是关键。例如,当我们知道一个电商订单表未来会有海量数据,且数据按时间分布较为均匀时,提前根据时间范围进行预分区,能充分利用多个服务器的并行处理能力。在预分区后,如果发现部分 Region 负载及请求量不均匀,可对负载高的 Region 进行切分。比如,某一时间段内订单量暴增,导致对应 Region 负载过高,通过切分可缓解压力。之后等待 HBase 自动负载均衡,也可使用命令手动将部分 Region 迁移到其他 RegionServer 节点,以实现资源的充分利用和负载均衡。
根据查询场景确定预分区策略:检查 RowKey 设计和预分区策略,确保写入请求均衡。对于以 get 查询为主的表,使用 hash 预分区策略。假设一个用户信息查询表,以用户 ID 作为 RowKey,通过 hash 预分区,可使查询请求均匀分布到各个 Region,提高查询效率。针对 scan 为主的表,建议采用分段预分区策略。例如,一个按时间序列存储的传感器数据记录表,按时间分段进行预分区,在进行范围查询(scan)时,能快速定位到相应的 Region,提升查询性能。
使用 SSD 存储 WAL:将 WAL 文件存储到 SSD 上,能极大提升写性能。具体配置步骤为:先利用 HDFS Archival Storage 机制,将 HDFS 的部分文件目录配置为 SSD 介质。然后在 hbase - site.xml 中添加配置,如指定 hbase.wal.storage.policy 为 ONE_SSD(将 WAL 的一个副本写入 SSD 介质)或者 ALLSSD(将 WAL 的三个副本全部写入 SSD 介质),默认为 none。
3.1.2 Client 端优化
离线导入使用 Bulkload 方案:Bulkload 是一个 MapReduce 程序,用于离线导入数据,它输出 HFile 文件。在大数据量离线导入场景下,如每月一次的电商历史订单数据导入,使用 Bulkload 方案,其优势在于吞吐量大、效率高,缺点是实时性差,不适合实时数据导入场景。
WAL 相关设置:WAL 的持久化分为四个等级,分别是 SKIP_WAL(只写缓存,不写 HLog 日志,数据有丢失风险)、ASYNC_WAL(异步将数据写入 HLog 日志中)、SYNC_WAL(同步将数据写入日志文件中,但未真正落盘,为默认等级)、FSYNC_WAL(同步将数据写入日志文件并强制落盘)。若业务能忍受小部分数据丢失且追求极限写入速度,可考虑禁用 WAL,但缺点是 RegionServer 宕机时会丢数据,且无法进行跨集群的 replication。用户可根据业务关注点,在 WAL 机制和写入吞吐量之间做出选择,通过客户端设置 WAL 持久化策略,如 put.setDurability (Durability.SYNC_WAL) 来指定持久化等级。
Put 批量提交:HBase 提供单条 put 和批量 put 的 API 接口,使用批量 put 接口可减少客户端到 RegionServer 之间的 RPC 连接数,从而提高写入吞吐量。若对数据实时性要求不高,可开启异步批量提交,通过设置 setAutoFlush (false),让客户端缓存达到阈值(默认 2M)后批量提交给 RegionServer。这样能减少 RPC 调用次数,提高吞吐量,但客户端异常时,缓存数据可能丢失。
控制单条数据大小:KeyValue 大小对写入性能影响巨大。RowKey 最大长度限制为 64KB,但实际应用中一般不超过 100B,因为 RowKey 会按 rowkey + columnFamily + qualifier + timestamp 组成的 cell 被多次冗余存储,过大的 RowKey 会浪费内存和硬盘资源。Value 过大同样会影响性能和 HBase 的响应速度,若 Value 过大,建议拆成多列存储,每次返回需要的值,或者将 Value 存储到 HDFS 上,在 HBase 中存储 url。
3.2 读取性能优化
3.2.1 Server 端优化
读请求负载均衡:当数据吞吐量较大且一次查询返回数据量较大时,Rowkey 必须进行散列化处理,同时建表要进行预分区处理。对于以 get 为主的查询场景,将表进行 hash 预分区,使数据均匀分布。比如一个用户行为分析表,按用户 ID 进行 hash 预分区,可使查询请求均匀分布到各个 Region,避免单个 Region 负载过高。对于以 scan 为主的场景,要兼顾业务场景设计 rowkey,在满足查询需求的前提下尽量打散数据并进行负载均衡。例如,一个按地区和时间存储的销售数据表,设计 RowKey 时结合地区和时间信息进行打散,可提高 scan 查询的性能。
BlockCache 策略设置:若 JVM 内存配置量小于 20G,BlockCache 策略选择 LRUBlockCache;否则选择 BucketCache 策略的 offheap 模式。在 heap 模式下,还可根据业务场景的读写比例来配置堆中读写 heap 的比例,默认堆中读写缓存均占 heap 的 40%,即读写均衡。如在一个读多写少的业务场景中,可适当增大 BlockCache 的占比,以提高读性能。
HFile 数量控制:一个 Store 中包含多个 HFile 文件,文件越多,检索所需的 IO 次数越多,读取延迟越高。文件数量通常取决于 minorCompaction 的执行策略,一般与 hbase.hstore.compactionThreshold(表示一个 store 中的文件数超过阈值就应进行合并,默认值为 3 )和 hbase.hstore.compaction.max.size(表示参与合并的文件大小最大是多少,超过此大小的文件不能参与合并 )这两个配置参数有关。可查看 RegionServer 级别以及 Region 级别的 HFile 数量,确认 HFile 文件是否过多,hbase.hstore.compactionThreshold 设置不宜太大,否则会影响合并效果,导致文件数量过多,读取延迟增加。
MajorCompaction 的管理:MajorCompaction 能将一个 store 下的所有文件合并成一个,并在合并过程中处理修改和删除的数据,释放硬盘资源。由于配置文件中默认的 MajorCompaction 定时按表执行,且消耗资源大,对系统性能影响也大。对于读取延迟以及系统性能波动敏感的业务,通常不建议开启自动 MajorCompaction,而是利用脚本定时或手动在业务低峰期触发。比如在电商业务中,凌晨时段业务量低,可在此时间段手动触发 MajorCompaction。对于延迟不敏感的业务,可开启自动 MajorCompaction,但建议限制流量,避免对系统性能造成过大冲击。
3.2.2 Client 端优化
Scan 缓存设置:在 HBase 中,一次 scan 可能返回大量数据,客户端发起 scan 请求时,不会一次性将所有数据加载到本地,而是分成多次 RPC 请求加载。数据加载到本地后存放在 scan 缓存中,默认缓存大小为 100 条数据。在大 scan 场景下,如一次扫描几万甚至几十万行数据时,默认的缓存设置会导致大量的 RPC 请求,增加网络开销和延迟。此时,将 scan 缓存从 100 增大到 500 或者 1000,可以有效减少 RPC 次数,提高读取效率。例如,在进行全表扫描统计用户行为数据时,增大 scan 缓存可显著提升数据读取速度。
批量获取:HBase 分别提供单条 get 和批量 get 的 API 接口,使用批量 get 接口可减少客户端到 RegionServer 之间的 RPC 连接数,提高读取性能。例如,在批量查询多个用户的信息时,使用批量 get 接口,将多个 Get 请求合并成一次 RPC 调用,可大大提高查询效率。但要注意,批量 get 请求要么成功返回所有请求数据,要么抛出异常,在使用时需根据业务需求进行合理处理。
四、高级特性与应用场景
4.1 高级特性揭秘
HBase 作为一款强大的分布式列式存储系统,除了具备基本的数据存储和读写功能外,还拥有一系列高级特性,这些特性极大地拓展了 HBase 的功能边界和应用范围。
4.1.1 过滤器(Filter)
HBase 的过滤器是其强大查询能力的重要体现。过滤器允许用户根据各种条件对数据进行筛选,从而实现更精准的数据查询。它基于 HBase 本身提供的三维有序(行键、列、版本有序)特性,能够高效地完成查询过滤任务。例如,在一个存储用户行为数据的 HBase 表中,我们可以使用 SingleColumnValueFilter 来筛选出特定用户(通过 RowKey 确定)在某一时间段内(通过时间戳列的值过滤)的所有行为记录。过滤器的操作符丰富多样,包括 LESS(小于)、LESS_OR_EQUAL(小于等于)、EQUAL(等于)、NOT_EQUAL(不等于)、GREATER_OR_EQUAL(大于等于)、GREATER(大于)等,比较器也有多种类型,如 BinaryComparator(二进制比较器,按字典序比较 Byte 数据值)、BinaryPrefixComparator(前缀二进制比较器,只比较前缀是否相同)、RegexStringComparator(支持正则表达式的值比较)、SubStringComparator(用于监测一个子串是否存在于值中,且不区分大小写)等。通过不同操作符和比较器的组合,用户可以灵活构建各种复杂的查询条件。
4.1.2 计数器(Counter)
计数器是 HBase 提供的一个非常实用的高级特性,尤其适用于需要实时统计数据的场景。例如,在线广告行业中,需要实时统计广告的点击次数、展示次数等;在社交平台中,需要统计用户的点赞数、评论数等。HBase 的计数器机制是一种原子操作,每次对特定计数器的操作只会锁住一列而不是一行,然后读取数据,再对当前数据做加法操作,最后再写入 HBase 中并释放该列的锁,在操作的过程中用户可以访问这一行的其他数据。这避免了加锁等保证原子性的操作对整行数据的影响,大大提高了系统的并发性能。在 HBase 的 Shell 中,可以使用 incr 命令来操作计数器,如 incr 'counters', '20241001', 'daily:clicks', 1 表示对 counters 表中 RowKey 为 20241001 的记录,在 daily 列族下的 clicks 计数器增加 1。在 Java API 中,也提供了相应的方法来操作计数器,如 Table 的 incrementColumnValue 方法和 increment 方法。
4.1.3 与 YARN 集成
YARN(Yet Another Resource Negotiator)是 Hadoop 生态系统的资源管理器,负责分配和调度集群资源。HBase 与 YARN 的集成,使得 HBase 能够充分利用 YARN 的资源调度和管理优势,实现更高效的数据存储和访问。具体来说,YARN 负责为 HBase 分配和调度资源,根据 HBase 的资源需求动态调整资源分配,实现负载均衡,确保 HBase 的高可靠性。当 HBase 集群中的某个 RegionServer 出现故障时,YARN 可以自动重新调度任务,保证数据的高可用性。在配置 HBase 与 YARN 集成时,需要在 HBase 和 YARN 的配置文件中设置相关参数。在 hbase - site.xml 中,需要设置 hbase.cluster.distributed 为 true,表示 HBase 以分布式模式运行 ;设置 hbase.master.yarn.resource.memory - mb 和 hbase.regionserver.yarn.resource.memory - mb 来指定 HBase Master 和 RegionServer 所需的内存资源。在 yarn - site.xml 中,需要设置 yarn.app.classpath.content 和 yarn.app.classpath.content.additional,将 HBase 的类路径添加到 YARN 的应用类路径中。通过这些配置,HBase 可以作为 YARN 的应用类型,在 YARN 的管理下高效运行。
4.2 典型应用场景分析
HBase 凭借其高可靠性、高性能、高扩展性以及面向列存储等特性,在众多领域有着广泛而深入的应用,能够很好地满足不同业务场景对数据存储和处理的需求。
4.2.1 搜索引擎
在搜索引擎领域,HBase 主要用于存储倒排索引和全文检索的数据。倒排索引是搜索引擎中的一种关键索引技术,它将文档中的关键词映射到包含该关键词的文档集合,以及关键词在文档中的位置信息。HBase 的列式存储特性使其能够高效地存储和查询大量的关键词和文档位置信息,支持高并发访问。以常见的网络搜索为例,网络爬虫持续不断地从网络上抓取新页面,并将页面内容存储到 HBase 中。然后,利用 MapReduce 在整张表上计算并生成索引,为网络搜索做准备。当用户发起搜索请求时,搜索引擎查询建立好的索引列表,获取文档索引后,再从 HBase 中获取所需的文档内容,最后将搜索结果提交给用户。在这个过程中,HBase 的分布式和可扩展性使得它能够适应大规模的搜索引擎系统,处理海量的网页数据。
4.2.2 广告效果和点击流分析
在线广告是互联网产品的重要收入来源,精准投放广告需要对用户交互数据进行详细的捕获和分析。HBase 非常适合收集这种以连续流形式出现、且容易按用户划分的用户交互数据。它可以增量捕获第一手点击流和用户交互数据,然后用不同处理方式来处理数据。在电商和广告监控行业,HBase 已经得到了广泛应用。淘宝的实时个性化推荐服务,中间推荐结果存储在 HBase 中,广告相关的用户建模数据也存储在 HBase 中。通过对这些数据的分析,企业可以建立更优的广告投放模型,提高广告投放效果,获得更多的收入。例如,根据用户的浏览历史、点击行为等数据,分析用户的兴趣偏好,从而向用户精准投放符合其兴趣的广告。
4.2.3 滴滴
在滴滴的业务场景中,HBase 有着多种应用。对于一些对 HBase 简单操作,如 Scan 和 Get,有着不同的应用衍生。Scan 操作可以应用于时序和报表场景。在轨迹设计中,将业务 ID、时间戳和轨迹位置作为整体建立时序,通过 Scan 操作可以获取一段时间内的轨迹数据。在资产管理中,将资产 ID、时间戳、资产状态等信息建立时序,用于资产状态的跟踪和管理。在报表场景中,Scan 操作通过 phoenix 使用标准的 SQL 操作 Hbase 做联机事务处理,以用户历史行为、历史事件及历史订单为需求进行详细设计,生成各种报表。Get 操作则应用于 HBase 中存储的语音和滴滴发票等小文件,根据 ID 获取实体属性。在实时计算中,多个数据流需要合并时,ID 即为 HBase 中的 rowkey,通过 Get 操作获取相关数据进行 join 操作。此外,互联网公司需求变化快速,介入业务方众多,HBase 通过动态列帮助实现这类需求。在图和 Coprocessor 方面也有应用,例如接入 JanusGraph 用于图数据处理,Coprocessor 主要应用于 Phoenix 和 GeoMesa。HBase 在滴滴主要存放统计结果、报表类数据,这些数据主要是运营、运力情况、收入等结果,通常需要配合 Phoenix 进行 SQL 查询,数据量较小,对查询的灵活性要求高,延迟要求一般。
五、总结与展望
通过对 HBase 进阶知识的深入探索,我们全面回顾了 RowKey、Column Family 和 Region 等核心概念,这些概念构成了 HBase 数据模型的基础,理解它们是高效使用 HBase 的关键。在架构与运行机制方面,详细剖析了 Client、Zookeeper、Master、RegionServer 和 HDFS 等组件的协同工作原理,以及数据读写的具体流程,这为我们优化 HBase 性能和解决实际问题提供了理论依据。
在性能优化实战策略中,从写入和读取两个维度给出了丰富的优化方案。写入性能优化涵盖了 Server 端的 Region 数量控制、预分区策略选择、WAL 存储优化,以及 Client 端的 Bulkload 方案、WAL 设置、Put 批量提交和单条数据大小控制等;读取性能优化则包括 Server 端的读请求负载均衡、BlockCache 策略设置、HFile 数量控制、MajorCompaction 管理,以及 Client 端的 Scan 缓存设置和批量获取等策略。这些优化策略能够显著提升 HBase 在不同业务场景下的性能表现。
此外,还介绍了 HBase 的高级特性,如过滤器、计数器和与 YARN 集成,以及在搜索引擎、广告效果和点击流分析、滴滴等典型应用场景中的应用。这些高级特性拓展了 HBase 的功能边界,使其能够满足更多复杂业务场景的需求。
展望未来,随着大数据技术的不断发展,HBase 有望在更多领域发挥重要作用。随着物联网、人工智能等技术的兴起,数据量将持续爆发式增长,HBase 凭借其高扩展性和高性能,将在处理海量数据方面展现出更大的优势。在未来,HBase 可能会在性能、功能和易用性等方面不断演进。在性能上,可能会进一步优化存储结构和算法,以提高读写速度和资源利用率;在功能上,可能会增加更多高级特性,如更强大的数据分析功能、与其他大数据组件的深度融合等;在易用性上,可能会提供更简洁的操作接口和管理工具,降低用户的使用门槛。
对于广大技术爱好者和从业者来说,HBase 是一个充满挑战与机遇的领域。希望大家能够基于本文所介绍的知识,继续深入探索 HBase 的奥秘,在实际项目中不断实践和优化,充分发挥 HBase 的优势,为大数据应用的发展贡献自己的力量。
相关文章:

HBase进阶之路:从原理到实战的深度探索
目录 一、HBase 核心概念再梳理 1.1 RowKey 1.2 Column Family 1.3 Region 二、架构与运行机制剖析 2.1 架构组件详解 2.1.1 Client 2.1.2 Zookeeper 2.1.3 Master 2.1.4 RegionServer 2.1.5 HDFS 2.2 数据读写流程深度解析 2.2.1 数据写入流程 2.2.2 数据读取流…...

使用 AddressSanitizer 检测栈内存越界错误
一、概述 在 C/C 编程中,栈内存越界 是一种常见而危险的内存错误,通常发生在局部变量数组被访问时索引越界。由于栈空间的结构特点,越界写入可能覆盖返回地址或其他局部变量,导致不可预测的行为甚至程序崩溃。传统的调试手段难以定…...

【技巧】离线安装docker镜像的方法
回到目录 【技巧】离线安装docker镜像的方法 0. 为什么需要离线安装? 第一、 由于docker hub被墙,所以 拉取镜像需要配置国内镜像源 第二、有一些特殊行业服务器无法接入互联网,需要手工安装镜像 1. 可以正常拉取镜像服务器操作 服务器…...

vue实现与后台springboot传递数据【传值/取值 Axios 】
vue实现与后台springboot传递数据【传值/取值】 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是node.js和vue的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每…...

Git日志信息
Git日志信息 1. log log 命令用于查看 git 的各种日志信息,在使用 log 后,git 会进入 vim 模式,此时退出日志模式需要按下 q 键。可以通过小箭头来浏览未显示出来的内容。 1.1 查看日志信息 git log git log --prettyoneline #美观输出日…...
Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载)
Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载
Linux操作系统从入门到实战(六)Linux开发工具(上)详细介绍什么是软件包管理器,Linux下如何进行软件和软件包的安装、升级与卸载 前言一、 软件包管理器1.1 传统安装方式的麻烦:从源代码说起1.2 软件包&…...

Java中的策略模式和模板方法模式
文章目录 1. 策略模式(Strategy Pattern)案例:支付方式选择 2. 模板方法模式(Template Method Pattern)案例:制作饮料流程 3. 策略模式 vs 模板方法模式4.总结 在Java中,策略模式和模板方法模式…...

C#里WPF使用触发器实现鼠标点击响应
在WPF里创建了一个自定义的用户控件, 要想在这个控件里实现鼠标的点击事件响应, 就需要添加事件触发器交互定义,如下代码: <ListView x:Name="ListViewMenu" ItemsSource="{Binding Path=SubItems}" Foreground="White" ScrollViewer.Ho…...

tensorflow-cpu
python3.8~3.12安装tensorflow-cpu 准备 创建并进入目录 mkdir tf-cpu cd tf-cpu编写测试代码 test_tensorflow.py import tensorflow as tf# 检查TensorFlow版本 print("\nTensorFlow version:", tf.__version__,end\n\n)# 创建一个简单的计算图并运行它 tensor …...

【AI提示词】PEST分析
提示说明 市场分析师专注于为企业、产品或国家提供PEST分析支持,以制定精准的市场战略。 提示词 # Role: PEST分析## Profile - language: 中文 - description: 市场分析师专注于为企业、产品或国家提供PEST分析支持,以制定精准的市场战略 - backgrou…...

42、在.NET 中能够将⾮静态的⽅法覆写成静态⽅法吗?
在.NET中,不能将非静态方法(实例方法)直接覆写(Override)为静态方法(Static Method)。以下是关键原因和解释: 1. 方法绑定的本质区别 实例方法:属于对象的实例…...
】第三章:嵌入式系统软件基础知识——①软件及操作系统基础)
【嵌入式系统设计师(软考中级)】第三章:嵌入式系统软件基础知识——①软件及操作系统基础
文章目录 1. 嵌入式系统软件基础知识1.1 嵌入式软件分类1.2 嵌入式系统初始化1.3 无操作系统支持的嵌入式软件体系结构1.4 有操作系统支持的嵌入式软件体系结构1.5 嵌入式支撑软件 2. 嵌入式操作系统基础知识2.1 嵌入式操作系统基本概念2.2 处理器管理2.2.1 多道程序2.2.2 分区…...

cs224w课程学习笔记-第11课
cs224w课程学习笔记-第11课 知识图谱嵌入 前言一、知识图谱1、知识图谱特点2、关系类型 二、知识图谱嵌入1、嵌入核心思想2、嵌入模型2.1 嵌入模型transE1)、核心思想2)、训练步骤3)、模型表征能力 2.2 嵌入模型TransR2.3 DistMult嵌入模型1)、核心思想2)、表征能力 2.4 complE…...

5.10-套接字通信 - C++
套接字通信 1.1 通信效率问题 服务器端 单线程 / 单进程 无法使用,不支持多客户端 多线程 / 多进程 写程序优先考虑多线程:什么时候考虑多进程? 启动了一个可执行程序 A ,要在 A 中启动一个可执行程序 B 支持多客户端连接 IO 多…...

【Linux】Linux内核的网络协议之socket理解
1. Socket(套接字) 的本质 它是应用程序与网络协议栈之间的编程接口(API),用于实现网络通信。 Socket 并不是一个物理设备,而是一个抽象层为应用程序提供统一的网络操作接口(如 send()、recv()…...

仿函数和函数对象
1. 概念解读:什么是“函数”和“函数对象”? 核心概念一句话总结 仿函数(Functor) 函数对象(Function Object) 它们本质是一个对象(Object),但可以像函数(Fu…...

Kubernetes控制平面组件:Kubelet 之 Static 静态 Pod
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

Django 项目的 models 目录中,__init__.py 文件的作用
在 Django 项目的models/init.py文件中,这些导入语句的主要作用是将各个模型类从不同的模块中导入到models包的命名空间中。这样做有以下几个目的: 简化导入路径 当你需要在项目的其他地方使用这些模型时,可以直接从models包导入,…...

学习日志04 java
PTA上的练习复盘 java01 编程题作业感悟: 可以用ai指导自己怎么调试,但是不要把调代码这过程里面的精华交给ai,就是自己去修正错误不能让ai代劳!~~~ 1 scanner.close() Scanner *** new Scanner(System.in); ***.close(); …...

vue-pdf-embed预览PDF
一、vue-pdf-embed 链接:Yarn 1、安装插件 npm install vue-pdf-embed 2、文件中引入(分页效果已实现,样式请自行修改) <template><div class"download-pdf-preview" style"height: 450px; border:1…...

C++GO语言微服务之Dockerfile docker-compose
目录 01 01-知识点概述 02 02-dockerfile复习 03 03-环境变量ENV的使用 04 04-WORKDIR的使用 05 05-USER和ARG的使用 06 06-ONBUILD的使用 07 07-dockerfile的缓存相关的参数 08 08-dockerfile的编写 09 09-测试-没成功-好像是网不行 01 10-docker-compose介绍 02 11…...
)
【漫话机器学习系列】255.独立同分布(Independent and Identically Distributed,简称 IID)
深入理解独立同分布(IID):机器学习与统计学的基石 在机器学习、深度学习、统计建模等领域,我们经常会遇到一个重要假设:独立同分布(Independent and Identically Distributed,简称 IID…...

树莓派4 yolo 11l.pt性能优化后的版本
树莓派4 使用 Picamera2 拍摄图像,然后通过 YOLO11l.pt 进行目标检测,并在实时视频流中显示结果。但当前的代码在运行时可能会比较卡顿,主要原因包括: picam2.capture_array() 是一个较慢的操作;YOLO 推理可能耗时较长…...

AD22 快速定义PCB板框与DXF导入定义
自行定义板框 1. 初步评估:选中所有的器件,选中‘在矩形区域排列’ 将元件放好后,可以再将元件紧凑一下 2. 设置原点,并在下方选中机械一层 从原点出发,点击快捷键PL 画框线 3. 对线条长度取整,且最好是5…...
)
LInux系统文件与目录管理(二)
提示:第二部分对第一部分收尾 文章目录 常见的命令如下一、文件查看命令1. more命令2.less命令3.head命令4.tail命令5.nl命令(了解)6.创建目录命令7.创建文件命令>: 覆盖重定向>>: 追加重定向 8.touch命令9.echo命令10.文件或目录复…...

Redisson在业务处理中失败后的应对策略:保障分布式系统的可靠性
分布式系统中的数据一致性与高可用性一直是开发者面临的难题。作为Redis官方推荐的Java客户端,Redisson凭借其强大的分布式能力成为解决这些问题的利器。但在实际业务场景中,网络抖动、资源竞争、节点故障等问题可能导致操作失败,本文将深入探…...

windows下docker 运行 ros2humble arm64
目前要想运行arm版ros humble 目前最好的解决方案是使用qemu模拟。 1.拉取 ubuntu22.04 docker pull ubuntu:22.04 --platformarm642.安装小鱼ros2 humble wget http://fishros.com/install -O fishros && . fishros3.安装eqmu docker run --rm --privileged multia…...

表的增删改查 -- 2
目录 3、查询(R) 3.7、条件查询:where 3.8、分页查询:limit 3.9、查询总结 4、修改(U) 5、删除(D) 3、查询(R) 3.7、条件查询:where selec…...

Linux系统管理与编程20:Apache
兰生幽谷,不为莫服而不芳; 君子行义,不为莫知而止休。 做好网络和yum配置,用前面dns规划的www的IP进行。 #!/bin/bash #----------------------------------------------------------- # File Name: myWeb.sh # Version: 1.0 # …...

dfs 第一次加训 详解 下
目录 P1706 全排列问题 思路 B3618 寻找团伙 思路 B3621 枚举元组 思路 B3622 枚举子集(递归实现指数型枚举) 思路 B3623 枚举排列(递归实现排列型枚举) B3625 迷宫寻路 思路 P6183 [USACO10MAR] The Rock Game S 总结…...
文件)
vue2/3 中使用 @vue-office/docx 在网页中预览(docx、excel、pdf)文件
1. 安装依赖: #docx文档预览组件npm install vue-office/docx vue-demi0.14.6#excel文档预览组件npm install vue-office/excel vue-demi0.14.6#pdf文档预览组件npm install vue-office/pdf vue-demi0.14.6 vue2.6版本或以下还需要额外安装 vue/composition-api …...

Excel表的导入与导出
Excel表的导入与导出 根据excel表来建立所需的数据库表格 <dependency><groupId>com.auth0</groupId><artifactId>java-jwt</artifactId><version>3.10.3</version></dependency><dependency><groupId>cn.hutool&…...

Redis 中常见的数据类型有哪些?
Redis 常见的数据类型包括 5 种基础类型(String、Hash、List、Set、Zset)和 3 种特殊类型(HyperLogLog、Bitmap、Geospatial)。以下是详细说明: 一、5 种基础数据类型 1. 字符串(String) 特点…...
)
消息队列如何保证消息可靠性(kafka以及RabbitMQ)
目录 RabbitMQ保证消息可靠性 生产者丢失消息 MQ丢失消息 消费端丢失了数据 Kakfa的消息可靠性 生产者的消息可靠性 Kakfa的消息可靠性 消费者的消息可靠性 RabbitMQ保证消息可靠性 生产者丢失消息 1.事务消息保证 生产者在发送消息之前,开启事务消息随后生…...

基于STM32、HAL库的BMP390L气压传感器 驱动程序设计
一、简介: BMP390L 是 Bosch Sensortec 生产的一款高精度气压传感器,专为需要精确测量气压和海拔高度的应用场景设计。BMP390L 具有更低的功耗、更高的精度和更快的响应速度。 二、硬件接口: BMP390L 引脚STM32L4XX 引脚说明VDD3.3V电源GNDGND地SCLPB6 (I2C1 SCL)I2C 时钟线…...
)
QMK键盘固件中LED锁定指示灯的配置与使用详解(实操部分+拓展)
QMK键盘固件中LED锁定指示灯的配置与使用详解 大家好!今天就跟大家一起探索QMK固件中LED锁定指示灯的配置与使用。无论你是键盘DIY新手还是老司机,相信这篇教程都能帮你解锁新技能! 一、基础配置:定义LED引脚 在QMK固件中配置LED锁定指示灯非常简单,只需在config.h文件…...
))
【日撸 Java 三百行】Day 12(顺序表(二))
目录 Day 12:顺序表(二) 一、顺序表的方法 1. 顺序查找 拓展:顺序查找中的哨兵思想 2. 插入 3. 删除 二、代码及测试 拓展: 小结 Day 12:顺序表(二) Task: 今天…...

Python爬虫实战:研究ajax异步渲染加密
一、引言 在当今数字化时代,数据已成为推动各行业发展的核心驱动力。网络爬虫作为一种高效的数据采集工具,能够从互联网上自动获取大量有价值的信息。然而,随着 Web 技术的不断发展,越来越多的网站采用了 AJAX(Asynchronous JavaScript and XML)异步渲染技术来提升用户体…...

Golang企业级商城高并发微服务实战
Golang企业级商城高并发微服务实战包含内容介绍: 从零开始讲了百万级单体高并发架构、千万级微服务架构,其中包含Rpc实现微服务、微服务的跨语言调用jsonrpc和protobuf、protobuf的安装、protobuf高级语法、protobuf结合Grpc实现微服务实战、微服务服务…...

从经典力扣题发掘DFS与记忆化搜索的本质 -从矩阵最长递增路径入手 一步步探究dfs思维优化与编程深度思考
1引子: DFS和递归法的一道经典例题矩阵最长递增子序列这个题写完之后脑袋产生了许多突发奇想: 1 第一个堆栈代码段这些底层C语言内部管理的工具它是怎么进行内存分配的?能不能深究? 2 第二个这个DFS和计划数组存储的思路到底抽象…...

我开源了一个免费在线工具!UIED Tools
UIED Tools - 免费在线工具集合 最近更新:修改了文档说明,优化了项目结构介绍 这是设计师转开发的第一个开源项目,bug和代码规范可能有些欠缺。 这是一个功能丰富的免费在线工具集合网站,集成了多种实用工具,包括 AI …...
)
geoserver发布arcgis瓦片地图服务(最新版本)
第一步:下载geoserver服务,进入bin目录启动 需要提前安装好JDK环境,1.8及以上版本 安装完成,页面访问端口,进入控制台界面,默认用户名密码admin/geoserver 第二步:下载地图 破解版全能电子地图下载器&…...
)
RN 鸿蒙混合开发实践(踩坑)
#三方框架# #React Native # 1 。环境配置; 安装 DevEco 开发工具; Node 版本16; hdc环境配置 hdc 是 OpenHarmony 为开发人员提供的用于调试的命令行工具,鸿蒙 React Native 工程使用 hdc 进行真机调试。hdc 工具通过 OpenHa…...
)
2025年阿里云ACP大数据分析师认证模拟试题(附答案解析)
这篇文章的内容是阿里云ACP大数据分析师认证考试的模拟试题。 所有模拟试题由AI自动生成,主要为了练习和巩固知识,并非所谓的 “题库”,考试中如果出现同样试题那真是纯属巧合。 1、ABC公司现有大量的图片和视频信息,以下哪种产…...

go语言实现IP归属地查询
效果: 实现代码main.go package mainimport ("encoding/json""fmt""io/ioutil""net/http""os" )type AreaData struct {Continent string json:"continent"Country string json:"country"ZipCode …...

Qt中解决UI线程阻塞导致弹窗无法显示的两种方法
在Qt应用程序开发中,我们经常会遇到这样的问题:当执行一个耗时操作时,整个界面会卡住,无法响应任何用户操作,甚至连一个简单的提示弹窗都无法正常显示。本文将介绍两种解决这个问题的方法,并通过完整的代码示例进行说明。 问题描述 先来看一个常见的错误示例: #inclu…...

位运算题目:黑板异或游戏
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法思路和算法代码复杂度分析 题目 标题和出处 标题:黑板异或游戏 出处:810. 黑板异或游戏 难度 8 级 题目描述 要求 给定一个整数数组 nums \texttt{nums} nums,表示写在黑板…...

LegoGPT,卡内基梅隆大学推出的乐高积木设计模型
LegoGPT 是由卡内基梅隆大学开发的一款创新性乐高积木设计模型,能够根据用户的文本提示生成结构稳固、可组装的乐高模型。该模型基于自回归语言模型和大规模乐高设计数据集进行训练,用户只需输入简单的文字描述,LegoGPT 就能逐步构建出物理稳…...

深度 |国产操作系统“破茧而出”:鸿蒙电脑填补自主生态空白
真心为国内能有像华为这样的技术型公司而自豪,一步步突围技术封锁。从这篇信息,可以给软件从业者一个启示:鸿蒙生态将是一个新的机会,值得好好把握。 鸿蒙电脑正成为中国电子信息技术新坐标。 超10亿鸿蒙生态设备、2800家鸿蒙智…...

【Python】Python常用数据类型判断方法详解
在Python编程中,准确判断数据类型是处理逻辑分支、类型转换和异常处理的基础。本文结合核心方法与实践场景,系统介绍type()、isinstance()等常用判断方式,并分析其适用性与最佳实践。 一、直接类型判断方法 type()函数 • 功能:返回对象的精确类型,适用于简单类型判断。 •…...