redis存储结构
一、存储结构
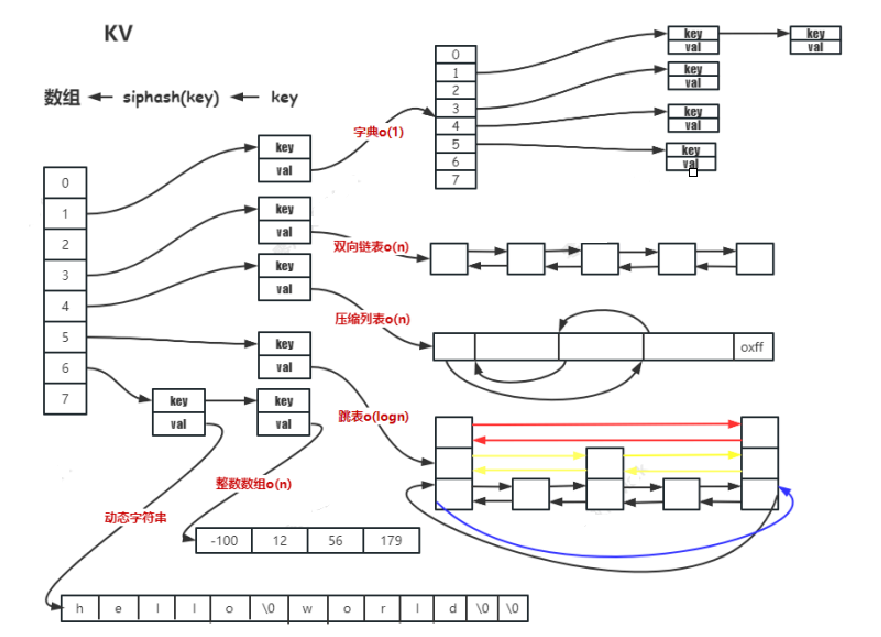
存储转换:
string
- int:字符串长度 ≤ 20 且能转成整数
- raw:字符串长度 > 44
- embstr:字符串长度 ≤ 44
- 附加:CPU 缓存中基本单位为 cacheline 64 字节
list
- quicklist(双向链表)
- ziplist(压缩列表):间接使用
hash
- dict(字典):节点数量 > 512 或字符串长度 > 64
- ziplist(压缩列表):节点数量 ≤ 512(
hash - max - ziplist - entries)且字符串长度 ≤ 64(hash - max - ziplist - value)set
- intset(整数数组):元素都为整数且节点数量 ≤ 512(
set - max - intset - entries)- dict(字典):元素有一个不为整数或数量 > 512
zset
- skiplist(跳表):数量 > 128 或者有一个字符串长度 > 64
- ziplist(压缩列表):子节点数量 ≤ 128(
zset - max - ziplist - entries)且字符串长度 ≤ 64(zset - max - ziplist - value)
二、字典实现
redis 中 KV 组织是通过字典来实现的;hash 结构当节点超过 512 个或者单个字符串长度大于 64 时,hash 结构采用字典实现;
typedef struct dictEntry {void *key;union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next;
} dictEntry;typedef struct dictht {dictEntry **table;unsigned long size;// 数组长度unsigned long sizemask; //size-1unsigned long used;//当前数组当中包含的元素
} dictht;typedef struct dict {dictType *type;void *privdata;dictht ht[2];long rehashidx; /* rehashing not in progress if rehashidx == -1 */int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error)用于安全遍历*/
} dict;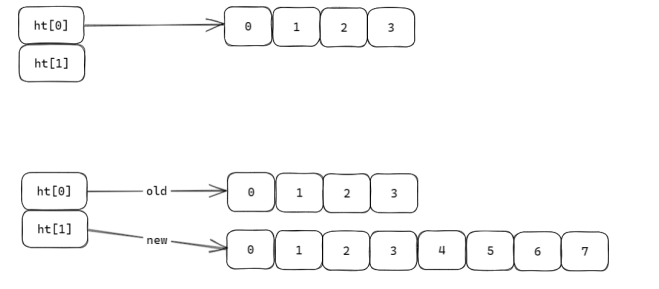
三、冲突
负载因子
负载因子 = used / size ; used 是数组存储元素的个数, size 是数组的长度;
扩容
缩容
四、渐进式rehash
一、什么是渐进式 Rehash?
1. 背景:哈希表扩容的性能问题
Redis 中的哈希表(Hashtable)使用两个底层数组
ht[0]和ht[1],正常情况下数据存储在ht[0]中。当ht[0]中的元素数量过多(达到扩容阈值,如负载因子超过 1),直接一次性将所有元素迁移到更大的ht[1]会带来两个问题:
- 阻塞主线程:迁移大量数据需要大量计算,可能导致 Redis 长时间无法处理其他命令(如读写请求),影响响应速度。
- 内存峰值:一次性创建新表并迁移数据,可能导致短期内内存占用激增。
为解决上述问题,Redis 采用 渐进式 Rehash,将数据迁移拆分成多个小步骤,逐步完成,避免阻塞。
2. 渐进式 Rehash 的核心步骤
初始化
ht[1]:
首先根据扩容规则(如扩容为ht[0]大小的 2 倍)创建ht[1],并记录当前迁移的进度(如当前处理到ht[0]的哪个槽位)。分批次迁移数据:
每次处理客户端的增、删、改、查操作时,除了执行正常命令外,额外迁移ht[0]中 少量槽位(如 100 个) 的数据到ht[1]。
迁移时,对每个槽位中的元素重新计算哈希值(生成 64 位整数),并根据ht[1]的长度取余,映射到新表的槽位中。定时器辅助迁移:
Redis 内部定时器会定期触发 Rehash 任务,每次最多执行 1 毫秒,确保即使没有客户端操作,迁移也能持续进行,避免无限拖延。双表共存阶段:
在迁移过程中,ht[0]和ht[1]同时存在:
- 读操作:同时查询
ht[0]和ht[1](先查ht[1],若不存在再查ht[0])。- 写操作:直接写入
ht[1],并标记ht[0]对应元素为已迁移,避免重复迁移。3. 渐进式 Rehash 的优势
- 无阻塞:将迁移压力分散到多次操作中,避免单次耗时过长,保证 Redis 的响应能力。
- 平滑过渡:客户端几乎感知不到迁移过程,业务无中断。
- 内存可控:分批次迁移,避免内存突然飙升。
二、为什么渐进式 Rehash 时不会发生扩容或缩容?
1. 扩缩容的触发条件
Redis 的扩缩容(扩容或缩容)触发时机是:
- 扩容:当
ht[0]的负载因子(元素数 / 数组大小)超过阈值(如 1,或哈希冲突严重时)。- 缩容:当
ht[0]的负载因子过低(如低于 0.1),为节省内存而缩小数组大小。2. 渐进式 Rehash 期间的状态
在渐进式 Rehash 过程中:
- 双表共存:
ht[0]正在迁移数据到ht[1],此时系统的哈希表状态是 “正在迁移”,而非正常的单表状态。- 迁移优先级更高:Redis 规定,必须先完成当前的 Rehash 任务,才能进行下一次扩缩容。
例如:若在迁移过程中,ht[1]的元素数又达到了扩容条件,系统不会立即触发新的扩容,而是等当前ht[0]数据全部迁移到ht[1]后,将ht[1]设为ht[0],再重新评估是否需要扩缩容。3. 避免操作冲突
若在 Rehash 期间允许扩缩容,会导致以下问题:
- 数据不一致:同时操作两个表的迁移和扩缩容,可能引发哈希表结构混乱。
- 逻辑复杂度激增:需要处理多表之间的多层迁移,增加实现难度和 bug 风险。
因此,Redis 设计为:渐进式 Rehash 是一个 “独占” 过程,期间不会触发任何新的扩缩容操作,确保每次仅处理单一的哈希表调整任务,保证稳定性和正确性。
五、scan
scan cursor [MATCH pattern] [COUNT count] [TYPE type]
Redis 的
SCAN命令是一种渐进式遍历键的机制,用于替代KEYS命令(KEYS会阻塞服务器,不适用于生产环境)。它通过游标逐步遍历数据库中的键,不会对服务器性能造成长时间阻塞。以下是其原理和示例:
一、SCAN 机制原理
游标(Cursor)
SCAN使用一个游标cursor来记录遍历的位置。每次调用SCAN,都会返回一个新的游标,用于下一次遍历。当游标为0时,表示遍历结束。哈希表槽位遍历
Redis 的数据库是一个哈希表,SCAN通过遍历哈希表的槽位(slot)来查找键。它采用 高位进位加法 的顺序遍历槽位,这种算法确保在哈希表rehash(扩容或缩容)后,槽位的遍历顺序仍然相邻,从而尽量保证对SCAN开始时已存在的数据 不重复、不遗漏(特殊情况除外,如两次缩容可能导致重复)。参数控制
MATCH pattern:用于筛选符合特定模式的键(如user:*表示以user:开头的键)。COUNT count:提示 Redis 每次遍历的大致数量,但实际返回的键数量可能因哈希表结构而有所不同。数据变更处理
SCAN仅保证对SCAN开始时已存在的数据进行遍历,不保证遍历过程中新增的键会被扫描到。- 扩容或缩容会改变键的映射,但高位进位加法算法能确保对
SCAN开始时已存在的数据的遍历正确性。
二、具体示例
假设 Redis 中有以下键:
user:1、user:2、order:1、order:2、cache:1。示例 1:基本 SCAN 遍历
第一次调用:
SCAN 010和部分键(如["user:1", "order:1"]),表示游标移动到10。第二次调用:
SCAN 10假设返回
0和剩余键(如["user:2", "order:2", "cache:1"]),表示遍历结束(游标回到0)。示例 2:带模式匹配的 SCAN
查找所有以
user:开头的键:SCAN 0 MATCH "user:*"假设返回
10和["user:1", "user:2"],继续用新游标10遍历,直到游标为0。示例 3:带 COUNT 提示的 SCAN
提示每次遍历约
3个键:SCAN 0 COUNT 3Redis 会尽量返回接近
3个键,但实际数量可能因哈希表结构而变化。
三、注意事项
- 不保证顺序:
SCAN返回的键顺序是不确定的,因为它基于哈希表槽位的遍历。- 数据变更影响:若在
SCAN过程中大量新增或删除键,新增键可能不会被遍历,删除键若已被扫描则会被返回(但实际已不存在,需业务层过滤)。- 缩容重复问题:理论上,若在
SCAN过程中发生两次缩容,可能出现重复键(但这种情况极少,属于特殊场景)。
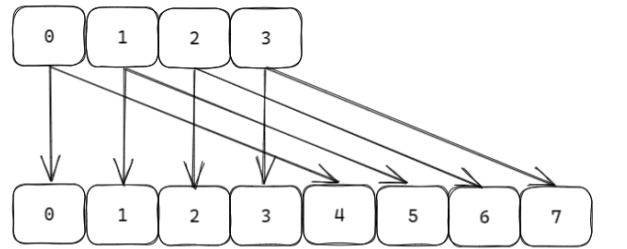
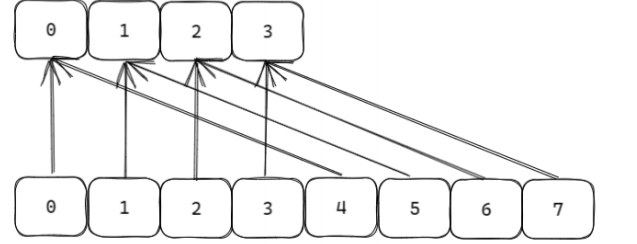
假设场景
- 初始哈希表
ht[0]有4个槽(编号0~3,二进制表示为2位:00, 01, 10, 11)。- 触发扩容后,新表
ht[1]有8个槽(编号0~7,二进制表示为3位)。- 假设
ht[0]的槽0有键A,槽2有键B。扩容后,槽0对应ht[1]的槽0和4(高位为0和1),槽2对应ht[1]的槽2和6(高位为0和1)。高位进位加法的遍历逻辑
ht[0]阶段(4 个槽,2 位二进制)
遍历顺序按高位进位加法:
0(00) →2(10) →1(01) →3(11)。
此时能覆盖ht[0]所有槽。扩容到
ht[1](8 个槽,3 位二进制)
高位进位加法的遍历顺序为:
0(000) →4(100) →2(010) →6(110) →1(001) →5(101) →3(011) →7(111)。
- 原
ht[0]槽0对应ht[1]的0和4,在遍历顺序中是连续的(0 → 4)。- 原
ht[0]槽2对应ht[1]的2和6,在遍历顺序中也是连续的(2 → 6)。这样,
ht[0]中每个槽的数据在ht[1]中对应的新槽会被连续遍历,确保SCAN开始时已存在的键(如A和B)不会遗漏。
六、expire机制
# 只支持对最外层key过期;
expire key seconds
pexpire key milliseconds
ttl key
pttl keyRedis 的
expire机制用于管理键的生命周期,允许为键设置生存时间(TTL),当时间到期后自动删除键,从而节省内存资源。以下是其详细介绍及示例:一、设置过期时间的命令
EXPIRE key seconds:以秒为单位设置键的过期时间。
例如:EXPIRE mykey 60,表示mykey会在 60 秒后过期。PEXPIRE key milliseconds:以毫秒为单位设置过期时间。EXPIREAT key timestamp:使用 UNIX 时间戳(秒)设置过期时间。PEXPIREAT key timestamp:使用 UNIX 时间戳(毫秒)设置过期时间。TTL key/PTTL key:分别以秒、毫秒为单位返回键的剩余生存时间。若键未设置过期时间,返回-1;若键不存在,返回-2。二、过期键的存储
Redis 内部使用一个名为
expires的字典存储键的过期时间。字典的键是数据库中的键,值是对应键的过期时间(以毫秒为单位的 UNIX 时间戳)。例如,设置mykey60 秒后过期,expires字典会记录mykey对应的过期时间戳。三、过期键的删除策略
惰性删除(Lazy Expiration)
当客户端尝试访问一个键时,Redis 会检查该键是否过期。若过期,则删除该键并返回空值。
- 优点:仅在访问时检查,减少不必要的 CPU 开销。
- 缺点:若键长期不被访问,可能导致内存泄漏(过期键一直占用内存)。
定期删除(Periodic Expiration)
Redis 定期随机抽取一部分键,检查其是否过期,若过期则删除。
- 检查频率和每次检查的键数量可通过配置调整(默认每秒检查 10 次,每次检查 20 个键)。
- 若一批检查中发现有过期键,会继续检查下一批,直到无过期键或达到最大检查次数。
- 平衡了 CPU 开销和内存回收效率,避免过期键长时间留存。
四、示例
127.0.0.1:6379> SET mykey "hello" # 创建键值对 OK 127.0.0.1:6379> EXPIRE mykey 10 # 设置 mykey 10 秒后过期 (integer) 1 127.0.0.1:6379> TTL mykey # 查看剩余生存时间(秒) (integer) 8 127.0.0.1:6379> PTTL mykey # 查看剩余生存时间(毫秒) (integer) 7890 # 等待 10 秒后再次操作 127.0.0.1:6379> GET mykey # 键已过期删除,返回 (nil) (nil) 127.0.0.1:6379> TTL mykey # 键不存在,返回 -2 (integer) -2通过
expire机制,Redis 能有效管理过期数据,结合惰性删除和定期删除策略,在性能和内存管理上取得平衡,适用于缓存失效、限时数据等场景(如购物车超时自动清理、验证码有效期控制等)。
七、大KEY
在 redis 实例中形成了很大的对象,比如一个很大的 hash 或很大的 zset,这样的对象在扩容的时 候,会一次性申请更大的一块内存,这会导致卡顿;如果这个大 key 被删除,内存会一次性回收, 卡顿现象会再次产生;
# 每隔0.1秒 执行100条scan命令
redis-cli -h 127.0.0.1 --bigkeys -i 0.1Redis 中的 大 key 指占用内存大、包含元素数量多的键,常见于
hash、zset、list等集合类型。例如一个hash键包含数万甚至数十万字段,或一个zset拥有海量成员。这类大 key 在扩容时需申请大量内存,可能引发卡顿;删除时内存一次性回收,也会导致 Redis 服务停顿,且会使内存波动明显。解决方案
发现大 key
使用redis - cli - h <host> --bigkeys - i <interval>命令(如redis - cli - h 127.0.0.1 --bigkeys - i 0.1,每隔 0.1 秒执行 100 条scan命令),快速定位大 key。拆分大 key
- 对
hash,按业务属性拆分。例如,原大 keyuser:1000(存储某用户所有信息,含 10 万字段),可拆分为user:1000:basic(基础信息)、user:1000:detail(详细信息)等小hash,减少单个键的字段数。- 对
zset,按范围或时间拆分。如一个存储全年数据的zset,可按月份拆分为多个zset(zset:202401、zset:202402等)。优化设计避免大 key
- 写入时控制集合大小,如分页存储数据。
- 定期清理无用元素,避免集合无限增长。
一、为什么拆分前后存储量一样却能解决大 key 问题?
虽然拆分前后数据总量未变,但拆分后单个键(小 key)的元素数量和内存占用显著减少,核心优势体现在操作的 粒度和压力分散 上:
- 操作粒度变小:大 key 操作(如扩容、删除)需一次性处理大量元素,耗时久且占用资源集中。拆分后,每个小 key 的操作仅涉及少量元素,耗时短,对 Redis 性能影响小。
- 压力分散:大 key 操作可能导致内存申请或释放的 “瞬间峰值”,拆分后,这些操作的压力分散到多个小 key 上,避免 Redis 因单次操作压力过大而卡顿。例如,删除一个包含 10 万字段的大 hash 会瞬间回收大量内存,可能阻塞 Redis;但拆分为 10 个小 hash 后,每次删除仅回收少量内存,压力分散。
二、为什么大 key 会出现问题?
- 扩容卡顿:
大 key(如大 hash、大 zset)在扩容时需申请一块远大于当前大小的连续内存。例如,一个已用 1GB 内存的大 hash 扩容,可能需申请 2GB 内存,这一过程会阻塞 Redis,直到内存分配完成。- 删除卡顿:
删除大 key 时,内存会被一次性回收,产生大量 “空闲内存块”,可能导致 Redis 主进程暂停(类似 “stop-the-world” 现象),影响服务响应。- 内存管理低效:
大 key 易导致内存碎片化,后续分配内存时,虽有总空闲内存,但缺乏连续大块内存,影响新数据写入,甚至触发频繁扩容。
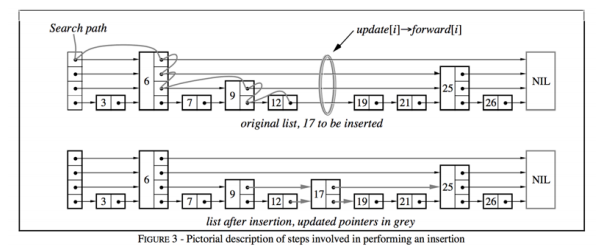
八、跳表
一、跳表的作用与特性
跳表是一种 多层有序链表结构,主要用于实现有序集合(如 Redis 中的有序集合类型),支持高效的范围查询(如
zrange、zrevrange)。其设计目标是在节点间建立直接连接,确保增删改操作后结构依然有序,同时维持较低的时间复杂度。二、理想跳表
- 结构特点:
每隔一个节点生成一个层级节点,模拟二叉树结构。例如,底层链表包含所有节点,上一层级每隔一个节点抽取一个形成高层链表,以此类推。这种结构使得搜索时间复杂度达到 O(log2n),通过 “空间换时间” 提升查询效率。- 操作问题:
若对理想跳表直接进行删除或增加操作,容易破坏其结构,重构代价巨大。因此,引入概率方法优化。- 概率优化:
从每个节点出发,每增加一个节点都有 21 的概率增加一个层级,41 的概率增加两个层级,81 的概率增加三个层级,以此类推。当数据量足够大(如 128 个节点时),通过概率构造的跳表趋近于理想跳表。此时,若删除节点,无需重构跳表结构,时间复杂度为 (1−w1)∗O(log2n)(w 为平均层级宽度)。三、Redis 跳表的优化
- 结构扁平化:
为节约内存,Redis 牺牲少许时间复杂度,使跳表结构更扁平(类似将二叉堆改为四叉堆),减少层级数量。- 层级限制:
Redis 限制跳表的最高层级为 32,避免层级过多导致内存浪费。- 使用条件:
当节点数量大于 128 或有一个字符串长度大于 64 时,Redis 会使用跳表。这种设计在内存占用和操作效率间取得平衡。四、与其他结构的对比
- 有序数组:通过二分查找可获得 O(log2n) 的时间复杂度,但增删操作代价高(需移动大量元素)。
- 平衡二叉树:也能达到 O(log2n) 的时间复杂度,但实现复杂,插入、删除时需频繁调整树结构(如旋转操作)。
- B+ 树:时间复杂度为 h∗O(log2n)(h 为树高),但存在复杂的节点分裂操作,实现难度大。
跳表则通过链表层级结构,在保证接近上述结构时间复杂度的同时,简化了增删改操作的实现,尤其适合 Redis 对有序集合的操作需求。
数据结构:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {sds ele;double score; // WRN: score 只能是浮点数struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span; // 用于 zrank} level[];
} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length; // zcardint level; // 最高层
} zskiplist;typedef struct zset {dict *dict; // 帮助快速索引到节点zskiplist *zsl;
} zset;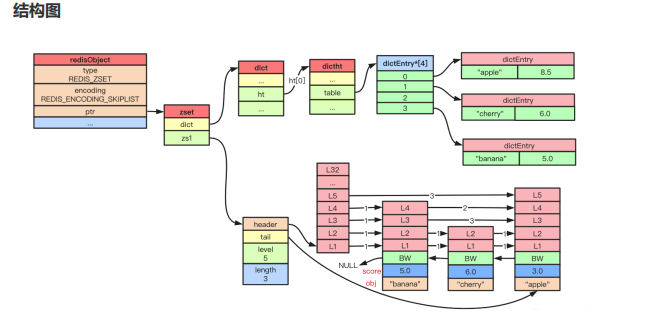
0voice · GitHub
相关文章:

redis存储结构
一、存储结构 存储转换: string int:字符串长度 ≤ 20 且能转成整数raw:字符串长度 > 44embstr:字符串长度 ≤ 44附加:CPU 缓存中基本单位为 cacheline 64 字节 list quicklist(双向链表)zi…...

wordpress自学笔记 第三节 独立站产品和类目的三种展示方式
wordpress自学笔记 摘自 超详细WordPress搭建独立站商城教程-第三节 独立站产品和类目的三种展示方式,2025 WordPress搭建独立站教程#WordPress建站教程https://www.bilibili.com/video/BV1rwcteuETZ?spm_id_from333.788.videopod.sections&vd_sourcea0af3b…...
)
Python 自动化脚本开发秘籍:从入门到实战进阶(6/10)
摘要:本文详细介绍了 Python 自动化脚本开发的全流程,从基础的环境搭建到复杂的实战场景应用,再到进阶的代码优化与性能提升。涵盖数据处理、文件操作、网络交互、Web 测试等核心内容,结合实战案例,助力读者从入门到进…...
)
封装和分用(网络原理)
UDP/TCP协议知识及相关机制 优质好文推荐👆👆 我们如果想要了解封装与分用,先需要了解TCP/IP五层协议~~ 该图的右边就是TCP/IP五层协议~~需要先理解一下各层是什么含义~ 应用层:直接为用户应用程序提供网络服务和通信协议。它定…...

MySQL数据库容灾设计案例与SQL实现
MySQL数据库容灾设计案例与SQL实现 一、主从复制容灾方案 1. 配置主从复制 -- 在主库执行(创建复制账号) CREATE USER repl_user% IDENTIFIED BY SecurePass123!; GRANT REPLICATION SLAVE ON *.* TO repl_user%;-- 查看主库状态(记录File…...

各类有关NBA数据统计数据集大合集
这些数据我已上传大家在CSDN上直接搜索就可以! 一、【2022-2023 NBA球员统计】数据集 关键词: 篮球 描述: 语境 该数据集每场比赛包含2022-2023常规赛NBA球员统计数据。 请注意,由团队更改产生了重复的球员名称。 * [2021-2022 NBA播放器统计]&#…...

【基于 LangChain 的异步天气查询5】多轮对话天气智能助手
目录 项目概述 1. 天气查询功能 2. 多轮对话与聊天 3. 语音输入与输出 4. 历史记录管理 5. 项目结构 6. 核心功能流程 7. 项目特色 🗂️ 项目目录结构 📄 chat_runnable.py 📄 main.py 📄 history_manager.py 📄 weather_runnable.py 📄 tools.py �…...

图片转ICO图标工具
图片转ICO图标 可批量操作 下载地址: 链接:https://pan.quark.cn/s/6312c565ec98 这个工具是一个批量图片转ICO图标的神器,有了它,以后再也不用为ICO格式的转换烦恼!而且这个软件特别小巧,完全不用安装。…...

istio in action之服务网格和istio组件
微服务和服务网格 微服务 微服务将大系统拆解成一个个独立的、小型的服务单元。每个服务可以独立部署、快速迭代,团队可以自主决策,大大降低了变更风险。当然,微服务不是万能药,它需要强大的自动化和DevOps实践作为支撑。而Isti…...

5 从众效应
引言 有一个成语叫做三人成虎,意思是说,有三个人谎报市上有老虎,听者就信以为真。这种人在社会群体中,容易不加分析地接受大多数人认同的观点或行为的心理倾向,被称为从众效应。 从众效应(Bandwagon Effec…...

超市销售管理系统 - 需求分析阶段报告
1. 系统概述 超市销售管理系统是为中小型超市设计的信息化管理解决方案,旨在通过信息化手段实现商品管理、销售处理、库存管理、会员管理等核心业务流程的数字化,提高超市运营效率和服务质量,同时为管理者提供决策支持数据。 2. 业务需求分…...

懒人美食帮SpringBoot订餐系统开发实现
概述 快速构建一个订餐系统,今天,我们将通过”懒人美食帮”这个基于SpringBoot的订餐系统项目,为大家详细解析从用户登录到多角色权限管理的完整实现方案。本教程特别适合想要学习企业级应用开发的初学者。 主要内容 1. 用户系统设计与实现…...

【计算机视觉】基于Python的相机标定项目Camera-Calibration深度解析
基于Python的相机标定项目Camera-Calibration深度解析 1. 项目概述技术核心 2. 技术原理与数学模型2.1 相机模型2.2 畸变模型 3. 实战指南:项目运行与标定流程3.1 环境配置3.2 数据准备3.3 执行步骤3.4 结果验证 4. 常见问题与解决方案4.1 角点检测失败4.2 标定结果…...

彩票假设学习笔记
彩票假设 文章目录 彩票假设一、基本概念1. 核心观点2. 关键要素 二、彩票假设的用途三、训练流程四、意义和局限性1. 意义2. 局限性 五、总结 一、基本概念 彩票假设(Lottery Ticket Hypothesis)是由 Jonathan Frankle 和 Michael Carbin 在 2019 年的…...
》阅读笔记:p18-p31)
《算法导论(第4版)》阅读笔记:p18-p31
《算法导论(第4版)》学习第 11 天,p18-p31 总结,总计 4 页。 一、技术总结 1. Fourier transform(傅里叶变换) In mathematics, the Fourier transform (FT) is an integral transform that takes a function as input then outputs another function…...

编程技能:字符串函数02,strcpy
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数01,引言 回到目录 …...

UOJ 164【清华集训2015】V Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),另有序列 h h h,初始时 h a ha ha. 有 m m m 个操作分五种: add ( l , r , v ) \operatorname{add}(l,r,v) add(l,r,v):…...

数据库备份与策略【全量备份、增量备份、日志恢复】
数据库备份策略与SQL语句实现 一、基础备份SQL语句 1. 全量备份(逻辑备份) -- 备份单个数据库 mysqldump -u [username] -p[password] --single-transaction --routines --triggers --events --master-data2 [database_name] > backup.sql-- 备份…...

基于单片机的电子法频率计
一、电子计数法测频率原理 通过门控控制闸门开关,闸门时间T自己设定,计数器计数脉冲个数N(也就是待测信号),N个脉冲的时间间隔为δt,倒数即为信号的频率f,由此 δtT/N fN/T——信号频率 根据公式,如果考虑…...

day22python打卡
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测https://www.kaggle.com/competitions/titanic/…...

前端项目打包部署流程j
1.打包前端项目(运行build这个文件) 2.打包完成后,控制台如下所示:(没有报错即代表成功) 3.左侧出现dist文件夹 4.准备好我们下载的nginx(可以到官网下载一个),然后在一个没有中文路径下的文件夹里面解压。 5.在继承终端内打开我们的项目,找到前面打包好…...

k8s的flannel生产实战与常见问题排查
关于 Kubernetes Flannel 插件的详细教程及生产环境实战指南,涵盖核心概念、安装配置、常见问题排查与优化策略 Flannel通信流程 一、Flannel 概述 Flannel 是 Kubernetes 最常用的 CNI(Container Network Interface)插件之一,…...

Linux `uname` 指令终极指南
Linux `uname` 指令终极指南 一、核心功能解析1. 命令语法2. 基础输出示例二、选项详解与使用场景三、实战应用技巧1. 系统信息快速获取2. 硬件平台验证3. 内核版本比较四、高级调优方法1. 内核编译优化2. 驱动模块管理3. 安全补丁验证五、系统诊断与排查1. 虚拟化环境检测2. 内…...

wget、curl 命令使用场景与命令实践
一、wget 常见场景与命令 定位:专注于 文件下载,支持递归下载、断点续传,适合批量或自动化下载任务。 1. 基础下载 # 下载文件到当前目录(自动命名) wget https://example.com/file.zip# 指定保存文件名 wget -O cu…...

RAII是什么?
RAII(Resource Acquisition Is Initialization,资源获取即初始化)是C编程中的一项非常重要且经典的设计思想,也是现代C资源管理的基石。它主要解决资源的自动管理与释放问题,从而帮助程序员避免资源泄漏、悬空指针等常…...

应急响应基础模拟靶机-security2
PS:杰克创建的流量包(result.pcap)在root目录下,请根据已有信息进行分析 1、首个攻击者扫描端口使用的工具是? 2、后个攻击者使用的漏洞扫描工具是? 3、攻击者上传webshell的绝对路径及User-agent是什么? 4、攻击者反弹shell的…...

【C/C++】const关键词及拓展
✅ C 中的 const 关键字 学习笔记 💡 关键词:常量、编译时常量、性能优化、安全性、C11/C14/C17/C20 特性 🧠 一、const —— 常量修饰符 1.1 定义 const 是 “constant” 的缩写。表示一个变量一旦被初始化,其值就不能再改变。…...

什么是电路耦合以及如何解耦合
耦合(Coupling)是指两个或多个电路之间通过物理连接或电磁场交互产生的能量或信号传递现象。其本质是不同电路模块之间相互影响的机制,可能表现为信号传输、噪声干扰或能量传递。 一、解耦合的核心目标 电源噪声抑制:隔离开关电…...
)
【软件测试】基于项目驱动的功能测试报告(持续更新)
目录 一、项目的介绍 1.1 项目背景 二、测试目标 2.1 用户服务模块 2.1.1 用户注册模块 2.1.1.1 测试点 2.1.1.2 边界值分析法(等价类+边界值) 2.1.1.2.1 有效等价类 2.1.1.2.2 无效等价类 2.1.1.2.3 边界值 2.1.1.2.4 测试用例设计 2.1.2 用户登录 2.1.2.1 测试…...

Java面试常见技术问题解析
Java面试常见技术问题 1. Java基础 1.1 Java的特点是什么? Java是一种面向对象的编程语言,具有跨平台性、健壮性、安全性、多线程支持等特点。 1.2 什么是面向对象? 面向对象是一种编程范式,通过类和对象来组织代码ÿ…...

弹性Reasoning!通过RL训练控制推理预算,提升模型的推理能力和效率!
摘要:大型推理模型(LRMs)通过生成扩展的思维链(CoT)在复杂任务上取得了显著进展。然而,它们不受控制的输出长度对于实际部署构成了重大挑战,在实际部署中,对令牌、延迟或计算的推理时…...

Spyglass:在batch/shell模式下运行目标的顶层是什么?
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 除了可以在图形用户界面(GUI)中运行目标外,使用Batch模式或Shell模式也可以运行目标,如下面的命令所示。 % spyglass -project test.prj -ba…...

新手在使用宝塔Linux部署前后端分离项目时可能会出现的问题以及解决方案
常见问题与解决方案 1. 环境配置错误 问题:未正确安装Node.js/Python/JDK等运行时环境解决: 通过宝塔面板的软件商店安装所需环境验证版本: node -v # 查看Node.js版本 python3 --version # 查看Python3版本2. 端口未正确开放 问题&am…...
2025最新(十七))
信息系统项目管理师-软考高级(软考高项)2025最新(十七)
个人笔记整理---仅供参考 第十七章项目干系人管理 17.1管理基础 17.2项目干系人管理过程 17.3识别干系人 17.4规划干系人参与 17.5管理人干系人参与 17.6监督干系人参与...

AI日报 · 2025年05月11日|传闻 OpenAI 考虑推出 ChatGPT “永久”订阅模式
1、Anthropic API 集成网页搜索功能,赋能 Claude 模型实时信息获取与研究能力 Anthropic 公司近日宣布,为其应用程序接口(API)引入了网页搜索工具,显著增强了旗下 Claude 系列模型获取和利用实时信息的能力。这一更新…...

【和春笋一起学C++】数组名作为函数参数实例
接上篇文章《【和春笋一起学C】函数——C的编程模块》,当使用数组名作为函数形参时,数组名会退化为指针,实际传递的是数组首元素的地址。 数组名在大多数情况下会退化为指针,以下两种情况除外: 当使用sizeof运算符时&a…...
)
多智体具身人工智能:进展与未来方向(上)
25年5月来自北理工、南大、西安交大、浙大和同济大学的论文“Multi-Agent Embodied AI: Advances And Future Directions”。 具身人工智能(Embodied AI)在智能时代先进技术的应用中扮演着关键角色。在智能时代,人工智能系统与物理实体相融合…...

C++类和对象--初阶
C类和对象—初阶 01. 面向对象与面向过程深度对比 面向过程:以过程为中心,关心问题解决的步骤。执行效率高,适合简单问题,内存占用小。但是代码复杂性高,维护成本高。 线性流程:点餐 → 烹饪 → 上菜 → …...

sunset:Solstice靶场
sunset:Solstice https://www.vulnhub.com/entry/sunset-solstice,499/ 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.244 3ÿ…...

1247. 后缀表达式
面白i题 ahh 我这朱脑子是写不出来的。大牛分析: 我的ac代码: #include<iostream> using namespace std; int ma-1e91,mi1e91; long long sum; long long sum1; int main(){int n,m; scanf("%d%d",&n,&m);for(int i0;i<(nm…...

基础框架搭建流程指南
一、搭建前准备阶段 1. 明确需求目标 确定业务场景类型(Web/APP/微服务等) 分析核心功能与非功能性需求(性能/安全性/扩展性) 预估用户量级与并发压力 2. 技术选型决策 开发语言选择(Java/Python/Go等)…...

Vue.js 全局导航守卫:深度解析与应用
在 Vue.js 开发中,导航守卫是一项极为重要的功能,它为开发者提供了对路由导航过程进行控制的能力。其中,全局导航守卫更是在整个应用的路由切换过程中发挥着关键作用。本文将深入探讨全局导航守卫的分类、作用以及参数等方面内容。 一、全局…...

微服务架构实战:从服务拆分到RestTemplate远程调用
微服务架构实战:从服务拆分到RestTemplate远程调用 一 . 服务拆分1.1 服务拆分注意事项1.2 导入服务拆分 Demo1.3 小结 二 . 服务间调用2.1 注册 RestTemplate2.2 实现远程调用2.3 小结 三 . 提供方和消费方 在分布式系统设计中,微服务架构因其灵活性、可…...
)
10.二叉搜索树中第k小的元素(medium)
1.题目链接: 230. 二叉搜索树中第 K 小的元素 - 力扣(LeetCode)230. 二叉搜索树中第 K 小的元素 - 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数…...

八股文-js篇
八股文-js篇 1. 延迟执行js的方式2. js的数据类型3. null 和 undefined的区别4. 和 的区别5. js微任务和宏任务6. js作用域7. js对象9. JS作用域this指向原型8. js判断数组9. slice作用、splice是否会改变原数组10. js数组去重11. 找出数组最大值12. 给字符串新增方法实现功能…...

Nipype使用:从安装配置到sMRI处理
Nipype使用:从安装配置到sMRI处理 Nipype使用:从安装配置到sMRI处理一、Nipype及其依赖工具安装配置1.1 Nipype安装1.2 依赖工具安装与配置1.2.1 FreeSurfer1.2.2 ANTS1.2.3 FSL1.2.4 dcm2nii/MRIConvert 1.3 环境变量配置 二、Nipype进行sMRI预处理2.1 …...

常用的rerank模型有哪些?都有什么优势?
常用的Rerank模型分类及优势分析 重排序(Rerank)模型在信息检索、推荐系统、问答系统等场景中发挥关键作用,通过优化初步检索结果提升最终输出的相关性。以下是当前主流的Rerank模型分类及其核心优势的详细分析: 一、基于大语言模型(LLM)的Rerank模型 代表性模型: Ran…...

LLM框架
LLM(Large Language Model,大型语言模型)框架是一类用于开发、部署和优化大型语言模型的工具和平台。它们在自然语言处理(NLP)和人工智能(AI)领域中发挥着重要作用,帮助开发者高效地…...

SaaS场快订首页的前端搭建【持续更新】
文章目录 一、创建页面二、配置路由三、写接口文件(api)1.定位的接口函数(腾讯地图api)实现代码: 2.获取场馆分类的数据3.获取附近场馆列表的数据 四、开发首页页面1.顶部区域2.搜索框3.场馆分类4.附近场馆列表 五、难…...
(详解-思路-脚本))
2025第九届御网杯网络安全大赛线上赛 区域赛WP (MISC和Crypto)(详解-思路-脚本)
芜湖~ 御网杯线上分是越来越精细 区域赛都有了 然后不过多评价 整体不算难 以下是我自己的一些思路和解析 有什么问题或者建议随时都可以联系我 目录 芜湖~ MISC #被折叠的显影图纸 #光隙中的寄生密钥 #ez_xor #套娃 #easy_misc #ez_pictre Crypto #easy签到题 …...