day22python打卡
复习日
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。
作业:
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
kaggle泰坦里克号人员生还预测![]() https://www.kaggle.com/competitions/titanic/overview
https://www.kaggle.com/competitions/titanic/overview
import numpy as np
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
df = pd.read_csv('./train.csv')
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
print(df.isnull().sum())PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64
import matplotlib.pyplot as plt
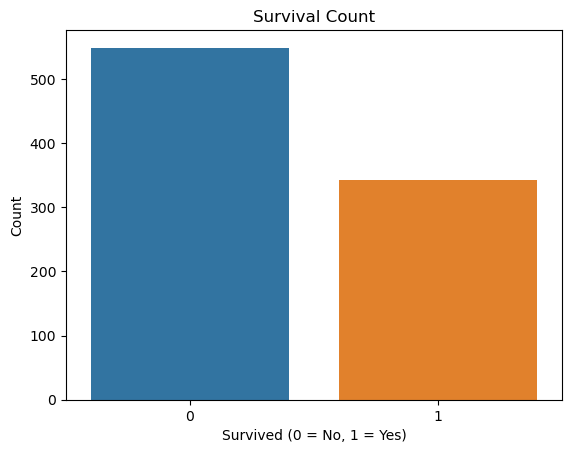
import seaborn as snssns.countplot(x='Survived', data=df)
plt.title('Survival Count')
plt.xlabel('Survived (0 = No, 1 = Yes)')
plt.ylabel('Count')
plt.show()
sns.countplot(x='Survived', hue='Sex', data=df)
plt.title('Survival by Gender')
plt.xlabel('Survived (0 = No, 1 = Yes)')
plt.ylabel('Count')
plt.legend(title='Sex', labels=['Male', 'Female'])
plt.show()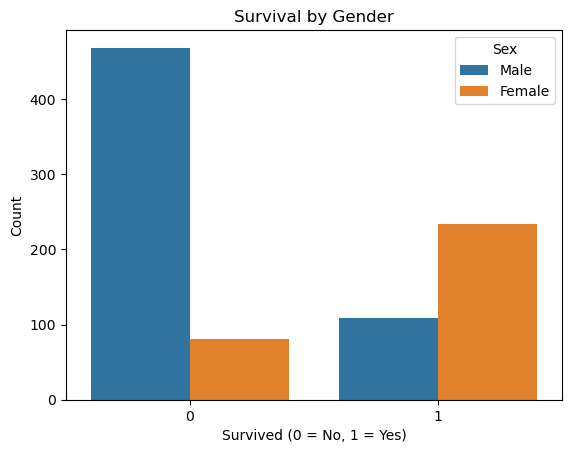
sns.countplot(x='Survived', hue='Pclass', data=df)
plt.title('Survival by Passenger Class')
plt.xlabel('Survived (0 = No, 1 = Yes)')
plt.ylabel('Count')
plt.legend(title='Pclass', labels=['1st Class', '2nd Class', '3rd Class'])
plt.show()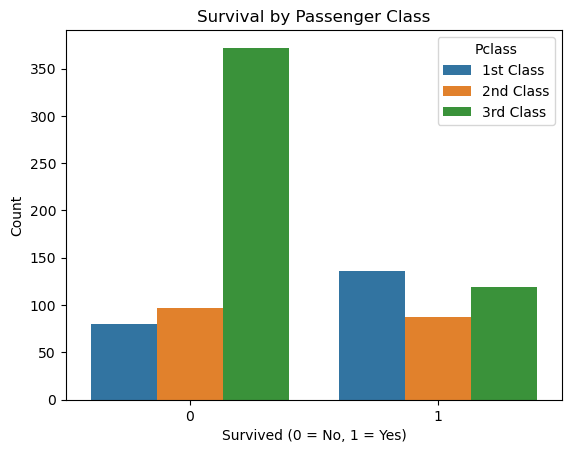
import matplotlib.pyplot as plt
import seaborn as snssns.histplot(df['Age'], kde=True, bins=30)
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()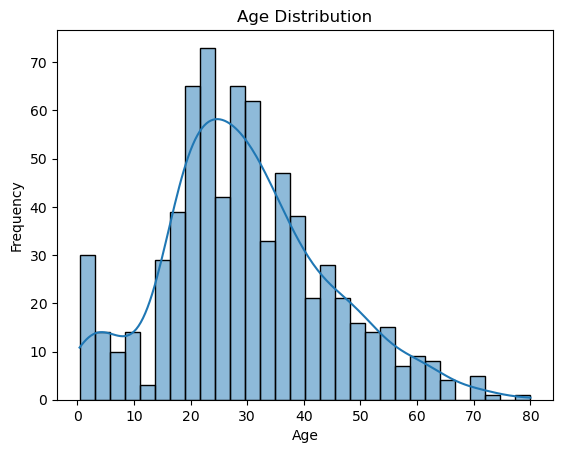
sns.kdeplot(data=df, x='Age', hue='Survived', fill=True)
plt.title('Survival by Age')
plt.xlabel('Age')
plt.ylabel('Density')
plt.legend(title='Survived', labels=['No', 'Yes'])
plt.show()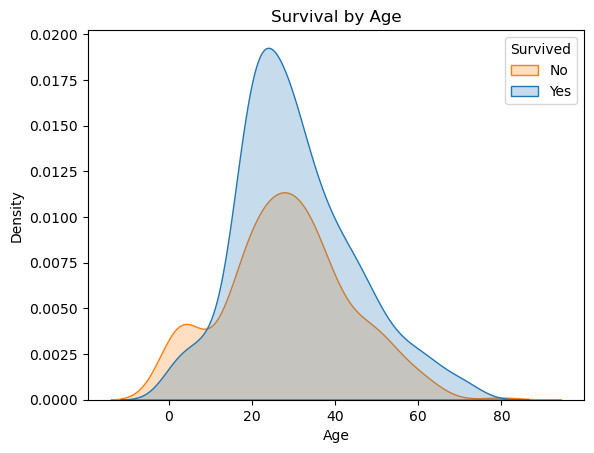
sns.histplot(df['Fare'], kde=True, bins=30)
plt.title('Fare Distribution')
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()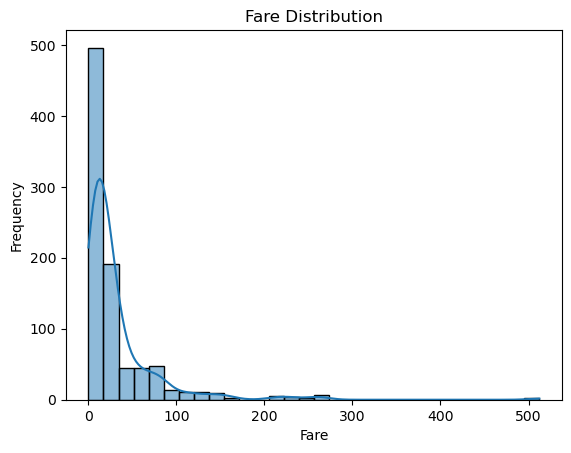
sns.countplot(x='Survived', hue='Embarked', data=df)
plt.title('Survival by Embarkation Port')
plt.xlabel('Survived (0 = No, 1 = Yes)')
plt.ylabel('Count')
plt.legend(title='Embarked', labels=['Cherbourg (C)', 'Queenstown (Q)', 'Southampton (S)'])
plt.show()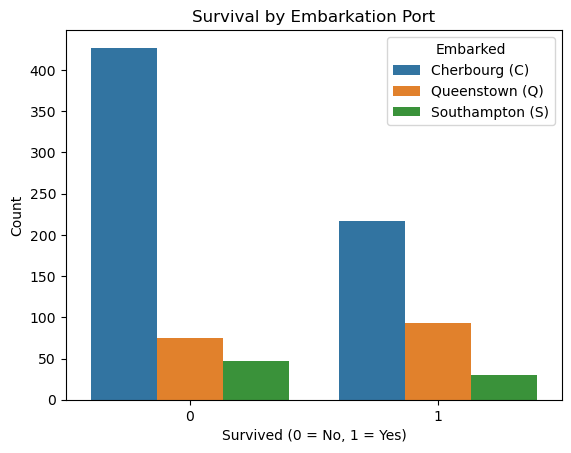
correlation_matrix = df.select_dtypes(include=['number']).corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('Correlation Heatmap')
plt.show()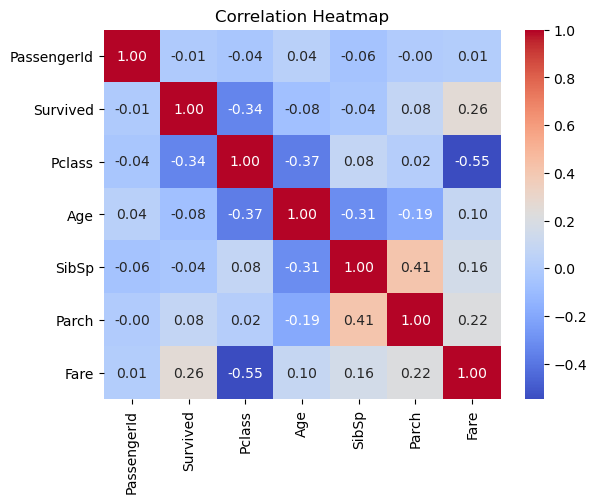
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 373450 8.0500 NaN S
df['Title'] = df['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
rare_titles = ['Lady', 'Countess', 'Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona']
df['Title'] = df['Title'].replace(rare_titles, 'Rare')
df['Title'] = df['Title'].replace({'Mlle': 'Miss', 'Ms': 'Miss', 'Mme': 'Mrs'})
title_mapping = {'Mr': 1, 'Miss': 2, 'Mrs': 3, 'Master': 4, 'Rare': 5}
df['Title'] = df['Title'].map(title_mapping)
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 373450 8.0500 NaN S
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1
df['IsAlone'] = (df['FamilySize'] == 1).astype(int)
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Title FamilySize IsAlone 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 PC 17599 71.2833 C85 C 3 2 0 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 2 1 1 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 113803 53.1000 C123 S 3 2 0 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 373450 8.0500 NaN S 1 1 1
df['Age'] = df['Age'].fillna(df.groupby(['Pclass', 'Sex'])['Age'].transform('median'))
df['AgeBin'] = pd.cut(df['Age'], bins=[0, 12, 18, 35, 60, 80], labels=[0, 1, 2, 3, 4])
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Title FamilySize IsAlone AgeBin 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 0 2 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 PC 17599 71.2833 C85 C 3 2 0 3 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 2 1 1 2 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 113803 53.1000 C123 S 3 2 0 2 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 373450 8.0500 NaN S 1 1 1 2
df['FareBin'] = pd.qcut(df['Fare'], q=4, labels=[0, 1, 2, 3])
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Title FamilySize IsAlone AgeBin FareBin 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 0 2 0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 PC 17599 71.2833 C85 C 3 2 0 3 3 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 2 1 1 2 1 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 113803 53.1000 C123 S 3 2 0 2 3 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 373450 8.0500 NaN S 1 1 1 2 1
df = df.dropna(subset=['Embarked'])
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Title FamilySize IsAlone AgeBin FareBin 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 0 2 0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 PC 17599 71.2833 C85 C 3 2 0 3 3 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 2 1 1 2 1 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 113803 53.1000 C123 S 3 2 0 2 3 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 373450 8.0500 NaN S 1 1 1 2 1
df['HasCabin'] = df['Cabin'].notna().astype(int)
df['Deck'] = df['Cabin'].fillna('U').str[0]
deck_counts = df['Deck'].value_counts()
rare_decks = deck_counts[deck_counts < 10].index
df['Deck'] = df['Deck'].replace(rare_decks, 'Other')
deck_dummies = pd.get_dummies(df['Deck'], prefix='Deck')
df = pd.concat([df, deck_dummies], axis=1)
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Title FamilySize IsAlone AgeBin FareBin HasCabin Deck Deck_A Deck_B Deck_C Deck_D Deck_E Deck_F Deck_Other Deck_U 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 0 2 0 0 U 0 0 0 0 0 0 0 1 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 PC 17599 71.2833 C85 C 3 2 0 3 3 1 C 0 0 1 0 0 0 0 0 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 2 1 1 2 1 0 U 0 0 0 0 0 0 0 1 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 113803 53.1000 C123 S 3 2 0 2 3 1 C 0 0 1 0 0 0 0 0 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 373450 8.0500 NaN S 1 1 1 2 1 0 U 0 0 0 0 0 0 0 1
df['Ticket'] = df['Ticket'].fillna('')
parts = df['Ticket'].str.split()
df['TicketPrefix'] = parts.str[:-1].str.join(' ')
df['TicketNumber'] = parts.str[-1].where(parts.str[-1].str.isnumeric(), None)
df['HasTicketPrefix'] = (df['TicketPrefix'] != '').astype(int)
prefix_counts = df['TicketPrefix'].value_counts()
top = prefix_counts.nlargest(10).index
df['TicketPrefix2'] = df['TicketPrefix'].where(df['TicketPrefix'].isin(top), 'Other')
prefix_dummies = pd.get_dummies(df['TicketPrefix2'], prefix='TktPre')
df['TicketNumber'] = df['TicketNumber'].astype(float).fillna(0)
df['TicketNum_qbin'] = pd.qcut(df['TicketNumber'], 10, labels=False)
sizes = df.groupby('Ticket')['PassengerId'].transform('count')
df['TicketGroupSize'] = sizes
df['IsGroupTicket'] = (sizes > 1).astype(int)
df = pd.concat([df, prefix_dummies], axis=1)
df.drop(columns=['Ticket','TicketPrefix','TicketPrefix2'], inplace=True)
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Fare Cabin Embarked Title FamilySize IsAlone AgeBin FareBin HasCabin Deck Deck_A Deck_B Deck_C Deck_D Deck_E Deck_F Deck_Other Deck_U TicketNumber HasTicketPrefix TicketNum_qbin TicketGroupSize IsGroupTicket TktPre_ TktPre_A/5 TktPre_A/5. TktPre_C.A. TktPre_CA. TktPre_Other TktPre_PC TktPre_SOTON/O.Q. TktPre_SOTON/OQ TktPre_STON/O 2. TktPre_W./C. 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 7.2500 NaN S 1 2 0 2 0 0 U 0 0 0 0 0 0 0 1 21171.0 1 3 1 0 0 1 0 0 0 0 0 0 0 0 0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 71.2833 C85 C 3 2 0 3 3 1 C 0 0 1 0 0 0 0 0 17599.0 1 3 1 0 0 0 0 0 0 0 1 0 0 0 0 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 7.9250 NaN S 2 1 1 2 1 0 U 0 0 0 0 0 0 0 1 3101282.0 1 9 1 0 0 0 0 0 0 1 0 0 0 0 0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 53.1000 C123 S 3 2 0 2 3 1 C 0 0 1 0 0 0 0 0 113803.0 0 5 2 1 1 0 0 0 0 0 0 0 0 0 0 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 8.0500 NaN S 1 1 1 2 1 0 U 0 0 0 0 0 0 0 1 373450.0 0 9 1 0 1 0 0 0 0 0 0 0 0 0 0
mapping = {**dict.fromkeys(list("AB"),"Upper"),**dict.fromkeys(list("CDE"),"Middle"),"F":"Lower","U":"None"}
df["DeckGroup"] = df["Cabin"].fillna("U").str[0].map(mapping)
df = pd.concat([df, pd.get_dummies(df["DeckGroup"], prefix="Deck")], axis=1)
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Fare Cabin Embarked Title FamilySize IsAlone AgeBin FareBin HasCabin Deck Deck_A Deck_B Deck_C Deck_D Deck_E Deck_F Deck_Other Deck_U TicketNumber HasTicketPrefix TicketNum_qbin TicketGroupSize IsGroupTicket TktPre_ TktPre_A/5 TktPre_A/5. TktPre_C.A. TktPre_CA. TktPre_Other TktPre_PC TktPre_SOTON/O.Q. TktPre_SOTON/OQ TktPre_STON/O 2. TktPre_W./C. 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 7.2500 NaN S 1 2 0 2 0 0 U 0 0 0 0 0 0 0 1 21171.0 1 3 1 0 0 1 0 0 0 0 0 0 0 0 0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 71.2833 C85 C 3 2 0 3 3 1 C 0 0 1 0 0 0 0 0 17599.0 1 3 1 0 0 0 0 0 0 0 1 0 0 0 0 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 7.9250 NaN S 2 1 1 2 1 0 U 0 0 0 0 0 0 0 1 3101282.0 1 9 1 0 0 0 0 0 0 1 0 0 0 0 0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 53.1000 C123 S 3 2 0 2 3 1 C 0 0 1 0 0 0 0 0 113803.0 0 5 2 1 1 0 0 0 0 0 0 0 0 0 0 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 8.0500 NaN S 1 1 1 2 1 0 U 0 0 0 0 0 0 0 1 373450.0 0 9 1 0 1 0 0 0 0 0 0 0 0 0 0
print(df.columns.tolist())['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked', 'Title', 'FamilySize', 'IsAlone', 'AgeBin', 'FareBin', 'HasCabin', 'Deck', 'Deck_A', 'Deck_B', 'Deck_C', 'Deck_D', 'Deck_E', 'Deck_F', 'Deck_Other', 'Deck_U', 'TicketNumber', 'HasTicketPrefix', 'TicketNum_qbin', 'TicketGroupSize', 'IsGroupTicket', 'TktPre_', 'TktPre_A/5', 'TktPre_A/5.', 'TktPre_C.A.', 'TktPre_CA.', 'TktPre_Other', 'TktPre_PC', 'TktPre_SOTON/O.Q.', 'TktPre_SOTON/OQ', 'TktPre_STON/O 2.', 'TktPre_W./C.', 'DeckGroup', 'Deck_Lower', 'Deck_Middle', 'Deck_None', 'Deck_Upper']
to_drop = ['PassengerId', 'Name', 'Cabin', 'Deck', 'TicketNumber', 'Age', 'Fare','Deck_A','Deck_B','Deck_C','Deck_D','Deck_E','Deck_F','Deck_Other','Deck_U','TktPre_','TktPre_A/5','TktPre_A/5.','TktPre_C.A.','TktPre_CA.','TktPre_SOTON/O.Q.','TktPre_SOTON/OQ','TktPre_STON/O 2.','TktPre_W./C.'
]
df_model = df.drop(columns=to_drop)
print(df.head())PassengerId Survived Pclass Name Sex Age SibSp Parch Fare Cabin Embarked Title FamilySize IsAlone AgeBin FareBin HasCabin Deck Deck_A Deck_B Deck_C Deck_D Deck_E Deck_F Deck_Other Deck_U TicketNumber HasTicketPrefix TicketNum_qbin TicketGroupSize IsGroupTicket TktPre_ TktPre_A/5 TktPre_A/5. TktPre_C.A. TktPre_CA. TktPre_Other TktPre_PC TktPre_SOTON/O.Q. TktPre_SOTON/OQ TktPre_STON/O 2. TktPre_W./C. DeckGroup Deck_Lower Deck_Middle Deck_None Deck_Upper 0 1 0 3 Braund, Mr. Owen Harris 0 22.0 1 0 7.2500 NaN S 1 2 0 2 0 0 U 0 0 0 0 0 0 0 1 21171.0 1 3 1 0 0 1 0 0 0 0 0 0 0 0 0 None 0 0 1 0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 1 38.0 1 0 71.2833 C85 C 3 2 0 3 3 1 C 0 0 1 0 0 0 0 0 17599.0 1 3 1 0 0 0 0 0 0 0 1 0 0 0 0 Middle 0 1 0 0 2 3 1 3 Heikkinen, Miss. Laina 1 26.0 0 0 7.9250 NaN S 2 1 1 2 1 0 U 0 0 0 0 0 0 0 1 3101282.0 1 9 1 0 0 0 0 0 0 1 0 0 0 0 0 None 0 0 1 0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 1 35.0 1 0 53.1000 C123 S 3 2 0 2 3 1 C 0 0 1 0 0 0 0 0 113803.0 0 5 2 1 1 0 0 0 0 0 0 0 0 0 0 Middle 0 1 0 0 4 5 0 3 Allen, Mr. William Henry 0 35.0 0 0 8.0500 NaN S 1 1 1 2 1 0 U 0 0 0 0 0 0 0 1 373450.0 0 9 1 0 1 0 0 0 0 0 0 0 0 0 0 None 0 0 1 0
from sklearn.model_selection import train_test_split
X = df.drop(columns=['Survived'])
y = df['Survived']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y
)
drop_cols = ['Name','Cabin','Deck','DeckGroup','Embarked']
X_train = X_train.drop(columns=drop_cols)
X_val = X_val.drop(columns=drop_cols)
for col in ['AgeBin','FareBin']:X_train[col] = X_train[col].cat.codesX_val[col] = X_val[col].cat.codes
allowed = ['int64','float64','bool']
print(X_train.dtypes[~X_train.dtypes.isin(allowed)])Age float64 Fare float64 IsAlone int32 AgeBin int8 FareBin int8 HasCabin int32 Deck_A uint8 Deck_B uint8 Deck_C uint8 Deck_D uint8 Deck_E uint8 Deck_F uint8 Deck_Other uint8 Deck_U uint8 TicketNumber float64 HasTicketPrefix int32 IsGroupTicket int32 TktPre_ uint8 TktPre_A/5 uint8 TktPre_A/5. uint8 TktPre_C.A. uint8 TktPre_CA. uint8 TktPre_Other uint8 TktPre_PC uint8 TktPre_SOTON/O.Q. uint8 TktPre_SOTON/OQ uint8 TktPre_STON/O 2. uint8 TktPre_W./C. uint8 Deck_Lower uint8 Deck_Middle uint8 Deck_None uint8 Deck_Upper uint8 dtype: object
from xgboost import XGBClassifier
xgb_model = XGBClassifier(random_state=42,use_label_encoder=False,eval_metric='logloss',enable_categorical=False
)
xgb_model.fit(X_train, y_train)XGBClassifier(base_score=None, booster=None, callbacks=None,colsample_bylevel=None, colsample_bynode=None,colsample_bytree=None, device=None, early_stopping_rounds=None,enable_categorical=False, eval_metric='logloss',feature_types=None, gamma=None, grow_policy=None,importance_type=None, interaction_constraints=None,learning_rate=None, max_bin=None, max_cat_threshold=None,max_cat_to_onehot=None, max_delta_step=None, max_depth=None,max_leaves=None, min_child_weight=None, missing=nan,monotone_constraints=None, multi_strategy=None, n_estimators=None,n_jobs=None, num_parallel_tree=None, random_state=42, ...)
from sklearn.metrics import accuracy_score, classification_reporty_pred = xgb_model.predict(X_val)
acc = accuracy_score(y_val, y_pred)
print(f"XGBoost Accuracy: {acc:.4f}")
print(classification_report(y_val, y_pred))XGBoost Accuracy: 0.8146precision recall f1-score support0 0.83 0.88 0.85 1101 0.79 0.71 0.74 68accuracy 0.81 178macro avg 0.81 0.79 0.80 178 weighted avg 0.81 0.81 0.81 178
浙大疏锦行
相关文章:

day22python打卡
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测https://www.kaggle.com/competitions/titanic/…...

前端项目打包部署流程j
1.打包前端项目(运行build这个文件) 2.打包完成后,控制台如下所示:(没有报错即代表成功) 3.左侧出现dist文件夹 4.准备好我们下载的nginx(可以到官网下载一个),然后在一个没有中文路径下的文件夹里面解压。 5.在继承终端内打开我们的项目,找到前面打包好…...

k8s的flannel生产实战与常见问题排查
关于 Kubernetes Flannel 插件的详细教程及生产环境实战指南,涵盖核心概念、安装配置、常见问题排查与优化策略 Flannel通信流程 一、Flannel 概述 Flannel 是 Kubernetes 最常用的 CNI(Container Network Interface)插件之一,…...

Linux `uname` 指令终极指南
Linux `uname` 指令终极指南 一、核心功能解析1. 命令语法2. 基础输出示例二、选项详解与使用场景三、实战应用技巧1. 系统信息快速获取2. 硬件平台验证3. 内核版本比较四、高级调优方法1. 内核编译优化2. 驱动模块管理3. 安全补丁验证五、系统诊断与排查1. 虚拟化环境检测2. 内…...

wget、curl 命令使用场景与命令实践
一、wget 常见场景与命令 定位:专注于 文件下载,支持递归下载、断点续传,适合批量或自动化下载任务。 1. 基础下载 # 下载文件到当前目录(自动命名) wget https://example.com/file.zip# 指定保存文件名 wget -O cu…...

RAII是什么?
RAII(Resource Acquisition Is Initialization,资源获取即初始化)是C编程中的一项非常重要且经典的设计思想,也是现代C资源管理的基石。它主要解决资源的自动管理与释放问题,从而帮助程序员避免资源泄漏、悬空指针等常…...

应急响应基础模拟靶机-security2
PS:杰克创建的流量包(result.pcap)在root目录下,请根据已有信息进行分析 1、首个攻击者扫描端口使用的工具是? 2、后个攻击者使用的漏洞扫描工具是? 3、攻击者上传webshell的绝对路径及User-agent是什么? 4、攻击者反弹shell的…...

【C/C++】const关键词及拓展
✅ C 中的 const 关键字 学习笔记 💡 关键词:常量、编译时常量、性能优化、安全性、C11/C14/C17/C20 特性 🧠 一、const —— 常量修饰符 1.1 定义 const 是 “constant” 的缩写。表示一个变量一旦被初始化,其值就不能再改变。…...

什么是电路耦合以及如何解耦合
耦合(Coupling)是指两个或多个电路之间通过物理连接或电磁场交互产生的能量或信号传递现象。其本质是不同电路模块之间相互影响的机制,可能表现为信号传输、噪声干扰或能量传递。 一、解耦合的核心目标 电源噪声抑制:隔离开关电…...
)
【软件测试】基于项目驱动的功能测试报告(持续更新)
目录 一、项目的介绍 1.1 项目背景 二、测试目标 2.1 用户服务模块 2.1.1 用户注册模块 2.1.1.1 测试点 2.1.1.2 边界值分析法(等价类+边界值) 2.1.1.2.1 有效等价类 2.1.1.2.2 无效等价类 2.1.1.2.3 边界值 2.1.1.2.4 测试用例设计 2.1.2 用户登录 2.1.2.1 测试…...

Java面试常见技术问题解析
Java面试常见技术问题 1. Java基础 1.1 Java的特点是什么? Java是一种面向对象的编程语言,具有跨平台性、健壮性、安全性、多线程支持等特点。 1.2 什么是面向对象? 面向对象是一种编程范式,通过类和对象来组织代码ÿ…...

弹性Reasoning!通过RL训练控制推理预算,提升模型的推理能力和效率!
摘要:大型推理模型(LRMs)通过生成扩展的思维链(CoT)在复杂任务上取得了显著进展。然而,它们不受控制的输出长度对于实际部署构成了重大挑战,在实际部署中,对令牌、延迟或计算的推理时…...

Spyglass:在batch/shell模式下运行目标的顶层是什么?
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 除了可以在图形用户界面(GUI)中运行目标外,使用Batch模式或Shell模式也可以运行目标,如下面的命令所示。 % spyglass -project test.prj -ba…...

新手在使用宝塔Linux部署前后端分离项目时可能会出现的问题以及解决方案
常见问题与解决方案 1. 环境配置错误 问题:未正确安装Node.js/Python/JDK等运行时环境解决: 通过宝塔面板的软件商店安装所需环境验证版本: node -v # 查看Node.js版本 python3 --version # 查看Python3版本2. 端口未正确开放 问题&am…...
2025最新(十七))
信息系统项目管理师-软考高级(软考高项)2025最新(十七)
个人笔记整理---仅供参考 第十七章项目干系人管理 17.1管理基础 17.2项目干系人管理过程 17.3识别干系人 17.4规划干系人参与 17.5管理人干系人参与 17.6监督干系人参与...

AI日报 · 2025年05月11日|传闻 OpenAI 考虑推出 ChatGPT “永久”订阅模式
1、Anthropic API 集成网页搜索功能,赋能 Claude 模型实时信息获取与研究能力 Anthropic 公司近日宣布,为其应用程序接口(API)引入了网页搜索工具,显著增强了旗下 Claude 系列模型获取和利用实时信息的能力。这一更新…...

【和春笋一起学C++】数组名作为函数参数实例
接上篇文章《【和春笋一起学C】函数——C的编程模块》,当使用数组名作为函数形参时,数组名会退化为指针,实际传递的是数组首元素的地址。 数组名在大多数情况下会退化为指针,以下两种情况除外: 当使用sizeof运算符时&a…...
)
多智体具身人工智能:进展与未来方向(上)
25年5月来自北理工、南大、西安交大、浙大和同济大学的论文“Multi-Agent Embodied AI: Advances And Future Directions”。 具身人工智能(Embodied AI)在智能时代先进技术的应用中扮演着关键角色。在智能时代,人工智能系统与物理实体相融合…...

C++类和对象--初阶
C类和对象—初阶 01. 面向对象与面向过程深度对比 面向过程:以过程为中心,关心问题解决的步骤。执行效率高,适合简单问题,内存占用小。但是代码复杂性高,维护成本高。 线性流程:点餐 → 烹饪 → 上菜 → …...

sunset:Solstice靶场
sunset:Solstice https://www.vulnhub.com/entry/sunset-solstice,499/ 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.244 3ÿ…...

1247. 后缀表达式
面白i题 ahh 我这朱脑子是写不出来的。大牛分析: 我的ac代码: #include<iostream> using namespace std; int ma-1e91,mi1e91; long long sum; long long sum1; int main(){int n,m; scanf("%d%d",&n,&m);for(int i0;i<(nm…...

基础框架搭建流程指南
一、搭建前准备阶段 1. 明确需求目标 确定业务场景类型(Web/APP/微服务等) 分析核心功能与非功能性需求(性能/安全性/扩展性) 预估用户量级与并发压力 2. 技术选型决策 开发语言选择(Java/Python/Go等)…...

Vue.js 全局导航守卫:深度解析与应用
在 Vue.js 开发中,导航守卫是一项极为重要的功能,它为开发者提供了对路由导航过程进行控制的能力。其中,全局导航守卫更是在整个应用的路由切换过程中发挥着关键作用。本文将深入探讨全局导航守卫的分类、作用以及参数等方面内容。 一、全局…...

微服务架构实战:从服务拆分到RestTemplate远程调用
微服务架构实战:从服务拆分到RestTemplate远程调用 一 . 服务拆分1.1 服务拆分注意事项1.2 导入服务拆分 Demo1.3 小结 二 . 服务间调用2.1 注册 RestTemplate2.2 实现远程调用2.3 小结 三 . 提供方和消费方 在分布式系统设计中,微服务架构因其灵活性、可…...
)
10.二叉搜索树中第k小的元素(medium)
1.题目链接: 230. 二叉搜索树中第 K 小的元素 - 力扣(LeetCode)230. 二叉搜索树中第 K 小的元素 - 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数…...

八股文-js篇
八股文-js篇 1. 延迟执行js的方式2. js的数据类型3. null 和 undefined的区别4. 和 的区别5. js微任务和宏任务6. js作用域7. js对象9. JS作用域this指向原型8. js判断数组9. slice作用、splice是否会改变原数组10. js数组去重11. 找出数组最大值12. 给字符串新增方法实现功能…...

Nipype使用:从安装配置到sMRI处理
Nipype使用:从安装配置到sMRI处理 Nipype使用:从安装配置到sMRI处理一、Nipype及其依赖工具安装配置1.1 Nipype安装1.2 依赖工具安装与配置1.2.1 FreeSurfer1.2.2 ANTS1.2.3 FSL1.2.4 dcm2nii/MRIConvert 1.3 环境变量配置 二、Nipype进行sMRI预处理2.1 …...

常用的rerank模型有哪些?都有什么优势?
常用的Rerank模型分类及优势分析 重排序(Rerank)模型在信息检索、推荐系统、问答系统等场景中发挥关键作用,通过优化初步检索结果提升最终输出的相关性。以下是当前主流的Rerank模型分类及其核心优势的详细分析: 一、基于大语言模型(LLM)的Rerank模型 代表性模型: Ran…...

LLM框架
LLM(Large Language Model,大型语言模型)框架是一类用于开发、部署和优化大型语言模型的工具和平台。它们在自然语言处理(NLP)和人工智能(AI)领域中发挥着重要作用,帮助开发者高效地…...

SaaS场快订首页的前端搭建【持续更新】
文章目录 一、创建页面二、配置路由三、写接口文件(api)1.定位的接口函数(腾讯地图api)实现代码: 2.获取场馆分类的数据3.获取附近场馆列表的数据 四、开发首页页面1.顶部区域2.搜索框3.场馆分类4.附近场馆列表 五、难…...
(详解-思路-脚本))
2025第九届御网杯网络安全大赛线上赛 区域赛WP (MISC和Crypto)(详解-思路-脚本)
芜湖~ 御网杯线上分是越来越精细 区域赛都有了 然后不过多评价 整体不算难 以下是我自己的一些思路和解析 有什么问题或者建议随时都可以联系我 目录 芜湖~ MISC #被折叠的显影图纸 #光隙中的寄生密钥 #ez_xor #套娃 #easy_misc #ez_pictre Crypto #easy签到题 …...

HTTP/1.1 host虚拟主机详解
一、核心需求:为什么需要虚拟主机? 在互联网上,我们常常希望在一台物理服务器(它通常只有一个公网 IP 地址)上运行多个独立的网站,每个网站都有自己独特的域名(例如 www.a-site.com, www.b-s…...

低代码开发:开启软件开发的新篇章
摘要 低代码开发作为一种新兴的软件开发方式,正在迅速改变传统软件开发的模式和效率。它通过可视化界面和预设的模板,使非专业开发者也能够快速构建应用程序,极大地降低了开发门槛和成本。本文将深入探讨低代码开发的定义、优势、应用场景以及…...

HVV蓝队初级面试总结
一、技术面: 1-SQL注入原理 1-WEB应用程序对用户输入的数据 2-没有过滤或者过滤的不严谨 3-并且把用户输入的数据当作SQL 语司 4-带入到数据中去执行2-SQL注入分类 1-回显型 2-无回显型/盲注1-联合查询注入unionselect 2-堆叠注入; 3-报错注入upda…...

C++八股——函数对象
文章目录 一、仿函数二、Lambda表达式三、bind四、function 一、仿函数 仿函数:重载了操作符()的类,也叫函数对象 特征:可以有状态,通过类的成员变量来存储;(有状态的函数对象称之为闭包) 样…...

Typora自动对其脚注序号
欢迎转载,但请标明出处和引用本文地址 Markdown中的脚注 脚注引用:[^2] 脚注定义:[^2]: xxxxxxx 问题:脚注需要 使用者自己定义排序。写作过程中,在文章最前面引用脚注序号,需要递增其后所有的脚注引用&…...

【Android】cmd命令
Android中cmd命令可以用来向binder服务发送命令,来进行相关调试, 其实现原理是调用binder服务的command接口 frameworks/native/cmds/cmd/cmd.cpp 209 Vector<String16> args; 210 for (int i2; i<argc; i) { 211 args.add(Stri…...

【入门】打印字母塔
描述 输入行数N,打印图形. 输入描述 输入只有一行,包括1个整数。(N<15) 输出描述 输出有N行. #include <bits/stdc.h> using namespace std; int main() { char t;int n,f;cin>>n;for(int i1;i<n;i){tchar(65i);for(int j1;j<n-i;j){cout…...

基于OpenCV的人脸识别:LBPH算法
文章目录 引言一、概述二、代码实现1. 代码整体结构2. 导入库解析3. 训练数据准备4. 标签系统5. 待识别图像加载6. LBPH识别器创建7. 模型训练8. 预测执行9. 结果输出 三、 LBPH算法原理解析四、关键点解析五、改进方向总结 引言 人脸识别是计算机视觉领域的一个重要应用&…...

opencascade.js stp vite webpack 调试笔记
Hello, World! | OpenCascade.js cnpm install opencascade.js cnpm install vite-plugin-wasm --save-dev 当你不知道文件写哪的时候trae还是有点用的 ‘’‘ import { defineConfig } from vite; import wasm from vite-plugin-wasm; import rollupWasm from rollup/plugi…...

使用go开发安卓程序
因为使用传统的安卓开发方式对于非专业人士来说比较繁琐,所以这里想用go简单的开发一下安卓程序。go支持安卓的项目就叫gomobile,有写安卓库文件和安卓程序两种方式,写安卓程序只能使用OPENGL画图。 一、安装步骤 参考文档:用Go…...

嵌入式中屏幕的通信方式
LCD屏通信方式详解 LCD屏(液晶显示屏)的通信方式直接影响其数据传输效率、显示刷新速度及硬件设计复杂度。根据应用场景和需求,LCD屏的通信方式主要分为以下三类,每种方式在协议类型、数据速率、硬件成本及适用场景上存在显著差异…...

常见的 DCGM 设备级别指标及其含义
前言 在大规模 GPU 集群运维与性能调优中,精准、全面地了解每块显卡的运行状态和健康状况至关重要。NVIDIA 数据中心 GPU 管理 (DCGM) 提供了一系列关键指标,用于监控显存错误、硬件利用率、温度、能耗以及互联带宽等多维度信息。通过对这些指标的持续采…...

基于zernike 拟合生成包裹训练数据-可自定义拟合的项数
可以看到拟合误差其实还是有很多的,但是这个主要是包裹噪声产生的,用到了github 上的zernike 库,直接pip install 一下安装就可以了 import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot3d import Axes3D import matpl…...

基于多层权重博弈与广播机制的仿生类脑 AI 决策框架
Layered Weighted Consensus and Broadcasting AI Architecture (LWCBA) 前言 本框架模仿人脑的工作机制,模拟人脑对条件反射,本能,道德伦理,理性分析,等事件处理及决策博弈机制。 基本原则和特点 底层-中层-高层的…...
)
欧拉路与欧拉回路(模板)
欧拉路得判别法: 欧拉回路:我们先记录一下所有点得度数,然后拿并查集判断一下连通性,如果有解得话,我们从奇数个得点开始遍历,一直遍历到不能遍历为止,然后逆序输出得路径就是欧拉回路 P7771 【…...

HttpServletResponse的理解
HttpServletResponse 是 Java Servlet API 提供的一个接口 常用方法 方法用途setContentType(String type)设置响应内容类型(如 "application/json"、"text/html")setStatus(int sc)设置响应状态码(如 200、404&#x…...

用一张网记住局域网核心概念:从拓扑结构到传输介质的具象化理解
标题: 用一张网记住局域网核心概念:从拓扑结构到传输介质的具象化理解 摘要: 本文通过"一张网"的类比,将计算机网络中抽象的局域网技术概念转化为日常生活中可感知的网结与绳子模型,帮助读者轻松理解网络拓…...

Linux 进程控制 基础IO
Linux 进程控制学习笔记 本节重点 学习进程创建:fork() / vfork()学习进程等待学习进程程序替换:exec 函数族,微型 shell 实现原理学习进程终止:认识 $? 一、进程创建 1. fork() 函数初识 在 Linux 中,fork() 函…...

三、Hive DDL数据库操作
在 Apache Hive 中,数据库 (Database),有时也被称为模式 (Schema),是组织和管理 表及其他对象的基本命名空间单元。熟练掌握数据库层面的数据定义语言 (DDL) 操作,是构建清晰、有序的 Hive 数据仓库的第一步。本篇笔记将详细梳理 …...