19、DeepSeek LLM论文笔记
DeepSeek LLM
- 1. **引言**
- 2、架构
- 3、多步学习率调度器
- 4、缩放定律
- 1.超参数的缩放定律
- 2. 估计最优模型和数据缩放
- 5、GQA分组查询注意力
- 汇总
- deepseek
- DeepSeek LLM 技术文档总结
- 1. **引言**
- 2. **预训练**
- 3. **扩展法则**
- 4. **对齐(Alignment)**
- 5. **评估**
- 6. **局限与未来工作**
- 附录亮点
- 豆包
- 一、研究背景与目标
- 二、预训练技术细节
- 三、缩放定律核心发现
- 四、对齐与微调策略
- 五、评估结果
- 六、结论与未来方向
- 关键问题
- 1. **DeepSeek LLM在缩放定律上的核心创新是什么?**
- 2. **DeepSeek如何处理预训练数据以提升模型性能?**
- 3. **DeepSeek 67B模型在哪些关键任务上超越了LLaMA-2 70B?**
论文:DeepSeek LLM
• 标题:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
• 时间:2024年1月
• 链接:arXiv:2401.02954
• 突破:首次提出分组查询注意力(GQA)降低推理成本,并优化多步学习率调度器提升训练效率,奠定了后续模型的高效训练基础。
1. 引言
- 背景:大型语言模型(LLM)基于解码器Transformer架构,通过自监督预训练和后续对齐技术(如SFT、RLHF)提升性能。闭源模型(如ChatGPT、Claude)推动了社区对开源模型的期待,而LLaMA系列成为开源模型基准。
- 目标:研究扩展法则(Scaling Laws),优化模型与数据规模的分配策略,构建高性能开源LLM,推动AGI发展。

2、架构
| 参数 | 层数(𝑛layers) | 模型维度(𝑑model) | 头数(𝑛heads) | 键值头数(𝑛kv_heads) | 上下文长度(Context Length) | 序列批量大小(Sequence Batch Size) | 学习率(Learning Rate) | 标记(Tokens) |
|---|---|---|---|---|---|---|---|---|
| 7B | 30 | 4096 | 32 | 32 | 4096 | 2304 | 4.2e - 4 | 2.0T |
| 67B | 95 | 8192 | 64 | 8 | 4096 | 4608 | 3.2e - 4 | 2.0T |
表2 | DeepSeek LLM模型家族详细规格。我们根据第3节的研究结果选择超参数。
DeepSeek LLM的微观设计在很大程度上遵循LLaMA(Touvron等人,2023a,b)的设计,采用带有RMSNorm(Zhang和Sennrich,2019)函数的Pre - Norm结构,并使用SwiGLU(Shazeer,2020)作为前馈网络(FFN)的激活函数,中间层维度为 8 3 d m o d e l \frac{8}{3}d_{model} 38dmodel。它还整合了旋转嵌入(Su等人,2024)用于位置编码。为了优化推理成本,67B模型使用分组查询注意力(GQA)(Ainslie等人,2023)代替传统的多头注意力(MHA)。
然而,在宏观设计方面,DeepSeek LLM略有不同。具体来说,DeepSeek LLM 7B是一个30层的网络,而DeepSeek LLM 67B有95层。这些层的调整,在与其他开源模型保持参数一致性的同时,也便于模型管道划分,以优化训练和推理。
与大多数使用分组查询注意力(GQA)的工作不同,我们在网络深度上扩展67B模型的参数,而不是像常见做法那样拓宽FFN层的中间宽度,旨在获得更好的性能。详细的网络规格见表2。
3、多步学习率调度器
- 多步学习率调度器
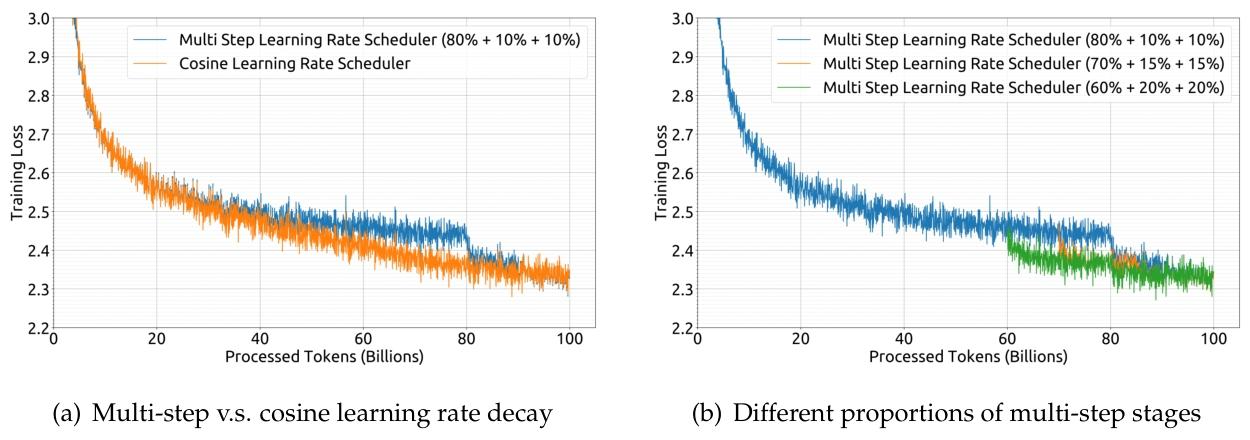
在预训练期间使用多步学习率调度器,而不是典型的余弦调度器。具体来说,模型的学习率在 2000 个预热步骤后达到最大值,然后在处理 80% 的训练 token 后下降到最大值的 31.6%。在 90% 的代币之后,它进一步减少到最大值的 10%。训练阶段的梯度裁剪设置为 1.0。
趋势,使用多步学习率调度器的最终性能与余弦调度器的最终性能基本一致,如图 1(a) 所示。在保持模型大小固定的情况下调整训练规模时,多步学习率调度器允许重复使用第一阶段的训练,为持续训练提供独特的便利。因此,我们选择了多步学习率调度器作为默认设置。我们还在图 1(b) 中演示了调整多步学习率调度器中不同阶段的比例可以产生稍微更好的性能。然而,为了平衡持续训练中的重用率和模型性能,我们选择了上述三个阶段的 80%、10% 和 10% 的分布。
多步学习率调度器的原理是在模型训练过程中,根据预设的阶段节点(如处理一定比例的训练数据或达到特定训练步数),分阶段降低学习率,以平衡训练初期的快速收敛与后期的精细调整,避免过拟合,同时提升训练效率与模型性能。
以文中 DeepSeek LLM 预训练为例:
- 模型先通过 2000 个 warmup 步骤,使学习率达到最大值(设为 η max \eta_{\text{max}} ηmax)。
- 当处理完 80% 的训练 tokens(如总训练量为 2.0 T 2.0T 2.0T,则处理 1.6 T 1.6T 1.6T 后),学习率下降至 η max \eta_{\text{max}} ηmax 的 31.6 % 31.6\% 31.6%,即 0.316 η max 0.316\eta_{\text{max}} 0.316ηmax。
- 当处理完 90% 的 tokens(即 1.8 T 1.8T 1.8T 后),学习率进一步降至 η max \eta_{\text{max}} ηmax 的 10 % 10\% 10%,即 0.1 η max 0.1\eta_{\text{max}} 0.1ηmax。
这种分阶段调整学习率的方式,既允许训练初期模型快速更新参数、捕捉数据特征,又能在后期降低学习率,使参数更新更精细,防止模型在后期训练中因学习率过大而跳过最优解。此外,如文中所述,多步学习率调度器在调整训练规模时,还支持重用第一阶段的训练成果,为持续训练提供了便利,在保证模型性能的同时,提升了训练效率与灵活性。
- warmup(预热)
在深度学习中,warmup(预热)步骤是训练初期通过逐步增加学习率来稳定模型训练过程的策略,避免因初始学习率过大导致模型训练不稳定或发散。其核心步骤如下:-
确定初始学习率
设定一个相对较小的初始学习率(通常是全局目标学习率的一小部分)。例如,若目标学习率为 0.01 0.01 0.01,初始学习率可能设为 0.001 0.001 0.001,让模型在训练初期以较小幅度更新参数,适应数据分布。 -
设定warmup周期
选择一个适当的周期,可用训练轮数(epoch)或批次(batch)数量表示。如设定 5 5 5 个epoch或 1000 1000 1000 个batch作为warmup阶段,确保模型有足够时间“热身”。 -
线性增加学习率
在warmup阶段内,逐步线性增加学习率,直至达到预设的目标学习率。公式为:
l r ( t ) = l r initial + t T × ( l r target − l r initial ) lr(t) = lr_{\text{initial}} + \frac{t}{T} \times (lr_{\text{target}} - lr_{\text{initial}}) lr(t)=lrinitial+Tt×(lrtarget−lrinitial)
其中 t t t 是当前训练步数, T T T 是warmup总步数, l r initial lr_{\text{initial}} lrinitial 是初始学习率, l r target lr_{\text{target}} lrtarget 是目标学习率。例如,warmup共 1000 1000 1000 步,初始学习率 0.001 0.001 0.001,目标学习率 0.01 0.01 0.01,则第 500 500 500 步时学习率为 0.001 + 500 1000 × ( 0.01 − 0.001 ) = 0.0055 0.001 + \frac{500}{1000} \times (0.01 - 0.001) = 0.0055 0.001+1000500×(0.01−0.001)=0.0055。 -
动态调整学习率(warmup结束后)
warmup结束后,可采用其他学习率调度策略(如余弦退火、阶梯衰减等)继续调整学习率。
-
4、缩放定律
1.超参数的缩放定律
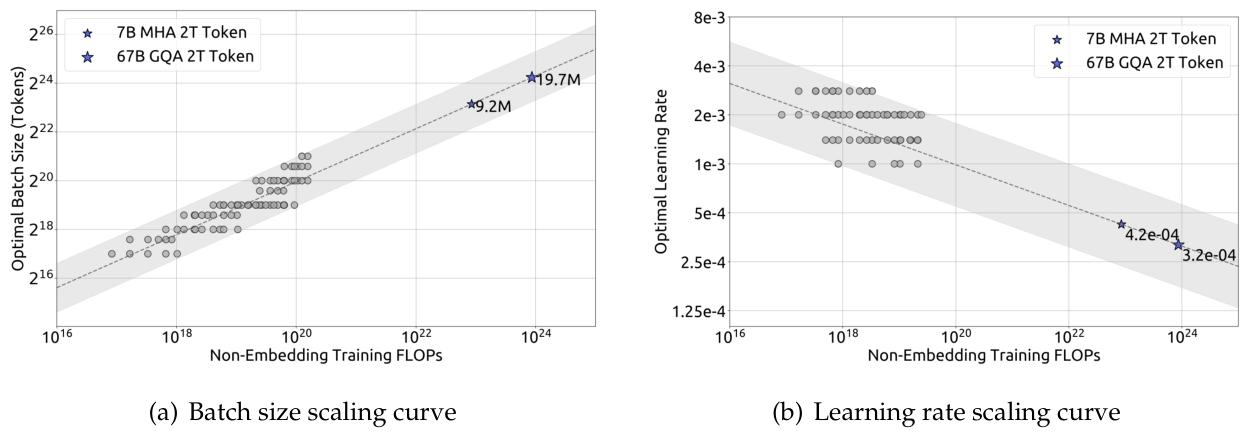
图 3 |批量大小和学习率的缩放曲线。灰色圆圈表示泛化误差超过最小值不超过 0.25% 的模型。虚线表示适合较小模型的幂律。蓝色星号代表 DeepSeek LLM 7B 和 67B。
考虑到参数空间的冗余,我们将泛化误差超过最小值不超过 0.25% 的模型使用的参数视为近最优超参数。然后,我们根据计算预算 c 拟合了批量大小 B 和学习率 n 。如图 3 所示的拟合结果显示,最佳批量大小 B 随着计算预算 c 的增加而逐渐增加,而最佳学习率 η 逐渐降低。这与放大模型时批量大小和学习率的直观经验设置一致。此外,所有近最优超参数都位于宽频带范围内,这表明在此区间内选择近最优参数相对容易。我们拟合的 batch size 和 learning rate 的最终公式如下:
η o p t = 0.3118 ⋅ C − 0.1250 B o p t = 0.2920 ⋅ C 0.3271 \begin{aligned} & \eta_{opt }=0.3118 \cdot C^{-0.1250} \\ & B_{opt }=0.2920 \cdot C^{0.3271} \end{aligned} ηopt=0.3118⋅C−0.1250Bopt=0.2920⋅C0.3271
我们将泛化误差超过最小值不超过 0.25% 的模型使用的参数视为近最优超参数。
注意:此处计算误差时,“超过最小值不超过0.25%” 指的是 绝对误差不超过最小值的0.25%,即:
允许误差 = 最小误差 × ( 1 + 0.25 % ) \text{允许误差} = \text{最小误差} \times (1 + 0.25\%) 允许误差=最小误差×(1+0.25%)
若最小误差为 E min E_{\text{min}} Emin,则合格误差范围为 [ E min , E min × 1.0025 ] [E_{\text{min}}, E_{\text{min}} \times 1.0025] [Emin,Emin×1.0025]。
实际意义
- 参数空间冗余:在大规模训练中,不同超参数组合可能达到相近的泛化性能(如 B = 256 , η = 0.0001 B=256, \eta=0.0001 B=256,η=0.0001 和 B = 512 , η = 0.0001 B=512, \eta=0.0001 B=512,η=0.0001),无需追求唯一最优解。
- 计算效率:筛选近似最优参数可大幅减少搜索成本,尤其在计算预算有限时(如 C = 1 0 17 → 2 × 1 0 19 C=10^{17} \to 2 \times 10^{19} C=1017→2×1019),避免穷举所有可能的参数组合。
举例:
-
- 实验设置
- 计算预算:固定为 C = 1 0 18 C = 10^{18} C=1018
- 超参数范围:
- 批量大小 B B B:[128, 256, 512, 1024, 2048]
- 学习率 η \eta η:[0.001, 0.0005, 0.0001, 0.00005]
-
- 泛化误差结果
批量大小 B B B 学习率 η \eta η 测试集损失(泛化误差) 128 0.001 0.350(最小值) 128 0.0005 0.352(+0.57%) 256 0.0005 0.351(+0.28%) 256 0.0001 0.350(最小值) 512 0.0001 0.350(最小值) 1024 0.00005 0.353(+0.86%) -
- 筛选近似最优超参数
- 理论最小误差:0.350(由3组参数组合达到)
- 允许误差范围:最小值的 0.25 % 0.25\% 0.25% 以内,即 0.350 × ( 1 + 0.25 % ) = 0.350875 0.350 \times (1 + 0.25\%) = 0.350875 0.350×(1+0.25%)=0.350875
- 符合条件的参数:
- ( B = 128 , η = 0.001 ) (B=128, \eta=0.001) (B=128,η=0.001):误差0.350(等于最小值,最优)
- ( B = 256 , η = 0.0005 ) (B=256, \eta=0.0005) (B=256,η=0.0005):误差0.351(0.351 ≤ 0.350875? 不,0.351 - 0.350 = 0.001,即0.28% > 0.25%,不符合)
- ( B = 256 , η = 0.0001 ) (B=256, \eta=0.0001) (B=256,η=0.0001):误差0.350(符合)
- ( B = 512 , η = 0.0001 ) (B=512, \eta=0.0001) (B=512,η=0.0001):误差0.350(符合)
2. 估计最优模型和数据缩放
非嵌入参数 N 1 N_1 N1:仅包含 非嵌入层的模型参数,即排除词嵌入(Token Embedding)层的参数,主要计算 Transformer 核心层(如注意力层、前馈网络)的参数。
完整参数 N 2 N_2 N2:包含 所有模型参数,包括词嵌入层和核心层参数,即模型的总参数数量。
DeepSeek 的改进:非嵌入 FLOPs/代币 M M M
- 定义:纳入 注意力机制和前馈网络的计算,排除词嵌入和词汇表计算,公式为:
M = 72 ⋅ n layer ⋅ d model 2 + 12 ⋅ n layer ⋅ d model ⋅ l seq M = 72 \cdot n_{\text{layer}} \cdot d_{\text{model}}^2 + 12 \cdot n_{\text{layer}} \cdot d_{\text{model}} \cdot l_{\text{seq}} M=72⋅nlayer⋅dmodel2+12⋅nlayer⋅dmodel⋅lseq
其中 l seq l_{\text{seq}} lseq 为序列长度(如 4096),显式包含注意力计算(与序列长度相关)。
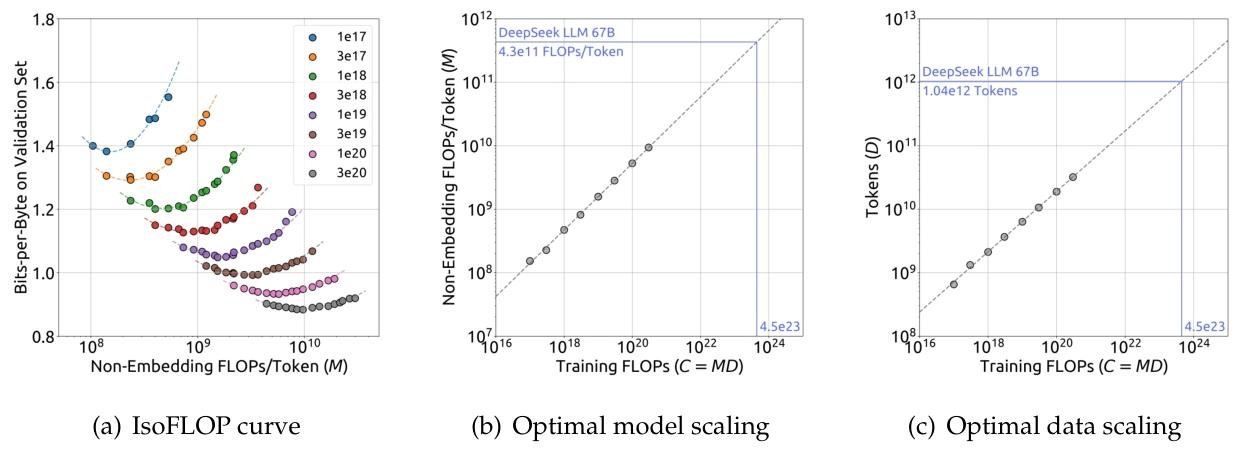
图 4 |IsoFLOP 曲线和最优模型/数据分配。IsoFLOP 曲线中的指标是验证集上的每字节位数。最优模型/数据缩放曲线中的虚线表示适合较小模型的幂律(灰色圆圈)。
图 4 演示了 IsoFLOP 曲线和模型 / 数据缩放曲线,它们是通过使用每个计算预算的最佳模型 / 数据分配进行拟合的。最优非嵌入 FLOPs/token M o p t M_{opt} Mopt 和最优 tokens D o p t D_{opt } Dopt 的具体公式如下:
M o p t = M b a s e ⋅ C a , M b a s e = 0.1715 , a = 0.5243 D o p t = D b a s e ⋅ C b , D b a s e = 5.8316 , b = 0.4757 \begin{array}{lll} M_{opt }=M_{base } \cdot C^{a}, & M_{base }=0.1715, & a=0.5243 \\ D_{opt }=D_{base } \cdot C^{b}, & D_{base }=5.8316, & b=0.4757 \end{array} Mopt=Mbase⋅Ca,Dopt=Dbase⋅Cb,Mbase=0.1715,Dbase=5.8316,a=0.5243b=0.4757
5、GQA分组查询注意力

与大多数使用分组查询注意力(GQA)的工作不同,我们在网络深度上扩展67B模型的参数,而不是像常见做法那样拓宽FFN层的中间宽度,旨在获得更好的性能。详细的网络规格见表2。
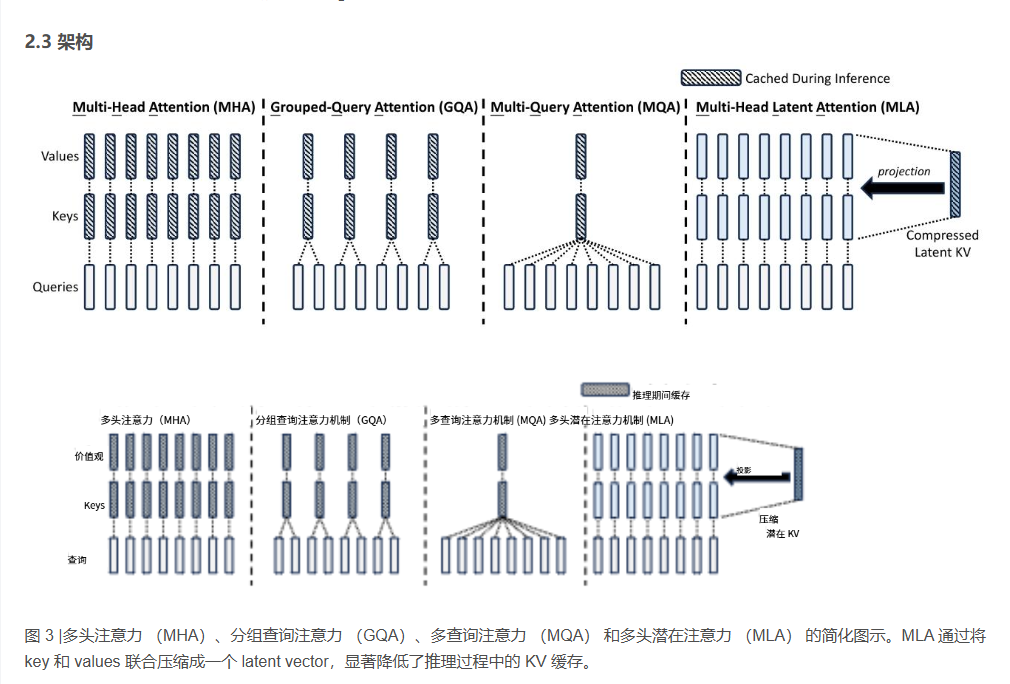
参考: 论文DeepSeek-V2
我们用我们提出的多头潜在注意力 (MLA) 和 DeepSeekMoE 优化了 Transformer 框架(Vaswani et al., 2017)中的注意力模块和前馈网络 (FFN)。(1) 在注意力机制的背景下,多头注意力 (MHA) 的键值 (KV) 缓存(Vaswani et al., 2017)对 LLM 的推理效率构成了重大障碍。已经探索了各种方法来解决这个问题,包括分组查询注意力 (GQA) (Ainslie et al., 2023) 和多查询注意力 (MQA) (Shazeer, 2019)。但是,这些方法在尝试减少 KV 缓存时通常会牺牲性能。为了实现两全其美的效果,我们引入了 MLA,这是一种配备了低秩键值联合压缩的注意力机制。从经验上讲,MLA 实现了优于 MHA 的性能,同时显著降低了推理过程中的 KV 缓存,从而提高了推理效率。(2) 对于前馈网络 (FFN),我们遵循 DeepSeekMoE 架构 (Dai et al., 2024),该架构采用细粒度的专家分割和共享的专家隔离,以提高专家专业化的潜力。与 GShard 等传统 MoE 架构相比,DeepSeekMoE 架构表现出巨大的优势(Lepikhin et al., 2021),使我们能够以经济的成本训练强大的模型。由于我们在训练期间采用专家并行性,因此我们还设计了补充机制来控制通信开销并确保负载平衡。通过结合这两种技术,DeepSeek-V2 同时具有强大的性能(图 1(a))、经济的训练成本和高效的推理吞吐量(图 1(b))。
汇总
deepseek
DeepSeek LLM 技术文档总结
1. 引言
- 背景:大型语言模型(LLM)基于解码器Transformer架构,通过自监督预训练和后续对齐技术(如SFT、RLHF)提升性能。闭源模型(如ChatGPT、Claude)推动了社区对开源模型的期待,而LLaMA系列成为开源模型基准。
- 目标:研究扩展法则(Scaling Laws),优化模型与数据规模的分配策略,构建高性能开源LLM,推动AGI发展。
2. 预训练
- 数据:
- 包含2万亿中英文令牌,采用去重、过滤、混合三阶段处理。
- 去重策略覆盖91个Common Crawl转储,去重率达89.8%(表1)。
- 分词器采用BBPE,词汇量100,015,支持中英混合语料。
- 架构:
- 基于LLaMA,采用RMSNorm、SwiGLU激活函数和旋转位置编码。
- 67B模型使用分组查询注意力(GQA),通过增加网络深度(95层)而非宽度优化性能(表2)。
- 超参数:
- 使用AdamW优化器(β1=0.9,β2=0.95),多步学习率调度器(峰值后分阶段降至10%)。
- 批量大小和学习率随模型规模调整(如7B模型学习率4.2e-4,67B模型3.2e-4)。
- 基础设施:
- 采用HAI-LLM框架,集成数据并行、张量并行、流水线并行,结合Flash Attention和ZeRO-1优化内存与计算效率。
3. 扩展法则
- 核心发现:
- 超参数扩展规律:批量大小和学率与计算预算(C)呈幂律关系(图2-3)。
- 模型与数据分配:引入非嵌入FLOPs/令牌(M)替代参数数量(N),提出最优分配公式:
M opt ∝ C 0.524 , D opt ∝ C 0.476 M_{\text{opt}} \propto C^{0.524}, \quad D_{\text{opt}} \propto C^{0.476} Mopt∝C0.524,Dopt∝C0.476
- 数据质量影响:高质量数据(如OpenWebText2)更倾向于扩展模型规模(表4)。
- 验证:小规模实验可预测大模型性能(图5),7B和67B模型表现符合预期。
4. 对齐(Alignment)
- 监督微调(SFT):
- 数据:150万中英文指令数据(46.6%数学,22.2%代码)。
- 策略:7B模型分两阶段(全数据微调 + 去除数学/代码数据),减少重复响应(表12)。
- 直接偏好优化(DPO):
- 偏好数据覆盖帮助性和安全性,进一步提升开放域生成能力(表7, 8)。
- DPO后模型在MT-Bench评分达8.76,接近GPT-4(表8)。
5. 评估
- 公开基准测试:
- 基础模型:DeepSeek 67B在代码(HumanEval 42.7%)、数学(GSM8K 63.4%)和中文任务(C-Eval 66.1%)显著优于LLaMA-2 70B(表5)。
- 聊天模型:经SFT和DPO后,67B模型在中文AlignBench总分6.69,超越GPT-3.5(表7)。
- 开放域评估:
- 中文AlignBench(GPT-4评分)显示模型在推理、语言任务中表现优异(表7)。
- 英文MT-Bench多轮对话评分8.76,接近GPT-4(表8)。
- 安全评估:
- 通过2,400项人工构建的安全测试(覆盖歧视、侵权、非法行为等类别),安全回答率超97%(表10-11)。
6. 局限与未来工作
- 局限:知识更新滞后、中文数据覆盖不足、幻觉问题。
- 未来方向:
- 发布代码智能和MoE技术报告。
- 构建更大规模数据集,强化数学、代码能力。
- 探索强化学习提升复杂推理能力。
附录亮点
- 数据质量影响:不同数据集下扩展策略差异显著(表4)。
- 分阶段微调:两阶段微调平衡性能与重复率(表12)。
- 安全分类体系:覆盖民族歧视、知识产权、违法违规等10类安全风险(表10)。
DeepSeek LLM通过系统性扩展法则研究和高效训练框架,构建了高性能开源模型,为AGI发展提供了重要参考。
豆包
一、研究背景与目标
-
行业现状
- 闭源模型(如ChatGPT、Claude)推动技术进步,开源模型(如LLaMA系列)成为基准,但现有缩放定律(如Chinchilla、GPT-3)结论不一致,缺乏对超参数和数据质量的深入分析。
- 开源社区聚焦固定规模模型(7B、70B),忽视缩放规律研究,而该研究对AGI发展至关重要。
-
核心目标
- 探索语言模型缩放定律,优化模型/数据资源分配策略。
- 构建高性能开源模型(DeepSeek LLM 7B/67B),覆盖中英文,提升代码、数学、推理能力。
二、预训练技术细节
-
数据处理
- 规模与构成:2万亿代币,中英文为主,涵盖Common Crawl、学术、代码等领域。
- 处理流程:
- 去重:跨91个Common Crawl转储,去重率达89.8%,减少冗余。
- 过滤:基于语言和语义评估,提升数据质量。
- 重组:平衡数据分布,增加代码、数学等领域占比。
- 分词器:BBPE算法,100015个常规代币+15个特殊代币,词汇表大小102400。
-
模型架构
- 基础设计:类LLaMA架构,Pre-Norm层、RMSNorm归一化、SwiGLU激活函数,旋转位置编码(Rotary Embedding)。
- 差异化设计:
- 7B模型:30层,多头注意力(MHA),序列长度4096。
- 67B模型:95层,分组查询注意力(GQA),减少推理成本,参数集中在深度而非宽度。
-
超参数与训练
- 优化器:AdamW(β1=0.9,β2=0.95,权重衰减0.1),多步学习率调度器(分三阶段衰减),优于余弦调度器。
- 批量大小:7B为2304,67B为4608,随模型规模增加而增大。
- 基础设施:HAI-LLM框架,支持数据/张量/流水线并行,FlashAttention优化显存,ZeRO-1分片优化器状态。
三、缩放定律核心发现
-
超参数缩放规律
- 批量大小(B)与计算预算(C)呈幂律关系:B=0.2920·C0.3271**,学习率(η)负相关:**η=0.3118·C-0.1250。
- 最优参数范围较宽,允许灵活调整以平衡性能和效率。
-
模型与数据最优分配
- 提出**非嵌入FLOPs/代币(M)**替代传统参数表示,更准确计算计算预算(C=M·D),减少小模型估算误差(最高50%降低至10%以内)。
- 最优缩放指数:模型缩放a=0.5243,数据缩放b=0.4757,高质量数据(如OpenWebText2)需更多预算分配给模型(a提升至0.578)。
四、对齐与微调策略
-
监督微调(SFT)
- 数据:150万指令实例,70%为数学/代码任务,30%为通用语言任务。
- 策略:
- 7B模型:4轮微调,两阶段法(先全数据后去数学/代码),重复率从2.0%降至1.4%。
- 67B模型:2轮微调,避免过拟合,直接优化对话逻辑。
-
直接偏好优化(DPO)
- 构建中英文偏好数据,优化对话流畅度和安全性,对基准测试影响小(如MMLU仅下降0.2%),但开放生成能力显著提升。
五、评估结果
-
基准测试对比(关键指标)
任务/模型 DeepSeek 67B Base LLaMA-2 70B 优势点 MATH(4-shot) 18.7% 13.5% 数学推理 HumanEval(0-shot) 42.7% 28.7% 代码生成 CMMLU(5-shot) 70.8% 53.1% 中文多任务 - 对话模型(67B Chat):GSM8K(84.1% vs LLaMA-2 70B的58.4%),MBPP(57.4% vs 45.6%),超越GPT-3.5在中英文开放域任务。
-
开放域与安全性评估
- 中文:AlignBench总分6.69,基础语言任务(7.60)和推理任务(5.77)领先,DPO后进一步提升。
- 英文:MT-Bench得分8.35(接近GPT-3.5的8.39),DPO后达8.76,仅次GPT-4。
- 安全性:2400+测试案例,安全回答率超95%,Do-Not-Answer得分97.8,高于ChatGPT(97.7)和GPT-4(96.5)。
六、结论与未来方向
-
核心贡献
- 校准缩放定律,提出M指标优化资源分配,验证数据质量对缩放策略的影响。
- 开源高性能模型,推动中英文大模型研究,代码/数学能力达SOTA。
-
局限与计划
- 局限:知识截止至2023年5月,多语言能力较弱,复杂逻辑推理待提升。
- 未来:发布代码智能和MoE技术报告,构建更大数据集(目标提升数学/代码能力),探索强化学习对齐。
关键问题
1. DeepSeek LLM在缩放定律上的核心创新是什么?
答案:提出以**非嵌入FLOPs/代币(M)**替代传统模型参数表示,更准确计算计算预算(C=M·D),解决了小模型估算误差问题(误差从50%降至10%以内)。同时发现数据质量影响最优分配策略,高质量数据需更多预算分配给模型缩放(如OpenWebText2的模型缩放指数a=0.578,高于低质量数据的a=0.45)。
2. DeepSeek如何处理预训练数据以提升模型性能?
答案:采用三步数据处理法:
- 去重:跨91个Common Crawl转储,去重率达89.8%,减少冗余数据干扰;
- 过滤:通过语言和语义评估,剔除低质量文档,提升信息密度;
- 重组:平衡数据分布,增加代码、数学等领域占比,构建多样化语料。
此外,使用BBPE分词器,将数字拆分为单个字符,优化中英文处理能力。
3. DeepSeek 67B模型在哪些关键任务上超越了LLaMA-2 70B?
答案:
- 代码生成:HumanEval(42.7% vs 28.7%)、MBPP(57.4% vs 45.6%),支持Python等多语言代码补全;
- 数学推理:MATH(18.7% vs 13.5%)、GSM8K(63.4% vs 58.4%),擅长代数和逻辑问题;
- 中文任务:CMMLU(70.8% vs 53.1%)、CHID(92.1% vs 55.5%),在中文理解和文化任务上优势显著。
相关文章:

19、DeepSeek LLM论文笔记
DeepSeek LLM 1. **引言**2、架构3、多步学习率调度器4、缩放定律1.超参数的缩放定律2. 估计最优模型和数据缩放 5、GQA分组查询注意力汇总deepseekDeepSeek LLM 技术文档总结1. **引言**2. **预训练**3. **扩展法则**4. **对齐(Alignment)**5. **评估*…...

基于LLM的6G空天地一体化网络自进化安全框架
摘要 最近出现的6G空天地一体化网络(SAGINs)整合了卫星、空中网络和地面通信,为各种移动应用提供普遍覆盖。然而,SAGINs的高度动态、开放和异构的性质带来了严重的安全问题。构建SAGINs的防御体系面临两个初步挑战:1)…...

【Mac 从 0 到 1 保姆级配置教程 12】- 安装配置万能的编辑器 VSCode 以及常用插件
文章目录 前言安装 VSCode基础配置常用插件1. 通用开发工具2. 编程语言支持3. 数据库工具4. 主题与界面美化5. 效率工具6. Markdown 工具7. 容器开发8. AI 辅助编程9. 团队协作 最后系列教程 Mac 从 0 到 1 保姆级配置教程目录,点击即可跳转对应文章: 【…...

数据库与SQL核心技术解析:从基础到JDBC编程实战
数据库技术作为现代信息系统的核心,贯穿于数据存储、查询优化、事务管理等关键环节。本文将系统讲解数据库基础知识、SQL语言核心操作、索引与事务机制,并结合Java数据库编程(JDBC)实践,助你构建完整的数据库技术体系。…...
)
JUC并发编程(上)
一、JUC学习准备 核心知识点:进程、线程、并发(共享模型、非共享模型)、并行 预备知识: 基于JDK8,对函数式编程、lambda有一定了解 采用了slf4j打印日志 采用了lombok简化java bean编写 二、进程与线程 进程和线程概念 两者对比…...

postgres--MVCC
PostgreSQL 的 MVCC(Multi-Version Concurrency Control,多版本并发控制) 是其实现高并发和高性能的核心机制,支持多个事务同时读写数据库而无需加锁阻塞。它的核心思想是通过保留数据的多个版本来避免读写冲突,从而提…...

nanodet配置文件分析
以下是针对 NanoDet-Plus-M-1.5x_416 配置文件的逐模块解析,以及调整参数的作用和影响范围: 1. 模型架构(model) Backbone(骨干网络) backbone:name: ShuffleNetV2model_size: 1.5x # 控制网络宽度&…...

【Linux网络】HTTP
应用层协议 HTTP 前置知识 我们上网的所有行为都是在做IO,(我的数据给别人,别人的数据给我)图片。视频,音频,文本等等,都是资源答复前需要先确认我要的资源在哪台服务器上(网络IP&…...
)
Unity中AssetBundle使用整理(一)
一、AssetBundle 概述 AssetBundle 是 Unity 用于存储和加载游戏资源(如模型、纹理、预制体、音频等)的一种文件格式。它允许开发者将游戏资源打包成独立的文件,在运行时动态加载,从而实现资源的按需加载、更新以及减小初始安装包…...

CMOS内存的地址空间在主内存空间中吗?
CMOS内存(即CMOS RAM)的地址空间不位于主内存地址空间(如0x00000-0xFFFFF)内,而是通过独立的I/O端口地址进行访问,具体如下: 1. CMOS内存的物理存储与地址机制 CMOS RAM芯片通常集成在主板…...

大模型应用中常说的Rerank是什么技术?
Rerank技术详解 一、定义与基本原理 Rerank(重排序)是一种在信息检索系统中用于优化搜索结果排序的技术,其核心目标是通过二次评估和排序候选文档,提升结果的相关性和准确性。其运作机制通常分为两阶段: 初步检索:使用传统方法(如BM25关键词匹配或Embedding向量检索)…...

Python-MCPInspector调试
Python-MCPInspector调试 使用FastMCP开发MCPServer,熟悉【McpServer编码过程】【MCPInspector调试方法】-> 可以这样理解:只编写一个McpServer,然后使用MCPInspector作为McpClient进行McpServer的调试 1-核心知识点 1-熟悉【McpServer编…...

C 语言数据结构基石:揭开数组名的面纱与计算数组大小
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 在前面的文章中,我们已经学习了 C 语言一维数组的定义和初始化。我们知道数组是用来存储一系列相同类型数据的集合,并通过下标来访问每个元素。但是,除了通过下标访问单个元素,数组名本身在 C 语言中也…...

Java高频面试之并发编程-15
hello啊,各位观众姥爷们!!!本baby今天又来报道了!哈哈哈哈哈嗝🐶 面试官:as-if-serial 是什么?单线程的程序一定是顺序执行的吗? as-if-serial 规则 定义: …...

MySQL数据库迁移SQL语句指南
MySQL数据库迁移SQL语句指南 一、基础迁移方法 1. 使用mysqldump进行全量迁移 -- 导出源数据库(在命令行执行) mysqldump -u [源用户名] -p[源密码] --single-transaction --routines --triggers --events --master-data2 [数据库名] > migration…...

Vue:生命周期钩子
深入理解 Vue 的钩子函数(生命周期函数) Vue 的钩子函数(生命周期函数)是 Vue 实例在不同阶段自动调用的函数。可以在 Vue 实例的创建、更新、销毁等阶段插入自己的逻辑。 钩子函数的作用 想象一下,Vue 实例的生命周…...
)
深入理解设计模式之原型模式(Prototype Pattern)
一、为什么需要原型模式? 在传统对象创建方式中,我们通过new关键字直接调用构造函数创建实例。但当遇到以下场景时: 对象初始化需要消耗大量资源(如数据库连接)需要创建的对象与现有实例高度相似希望屏蔽对象创建的复…...

K8S cgroups详解
以下是 Kubernetes 中 cgroups(Control Groups) 的详细解析,涵盖其核心原理、在 Kubernetes 中的具体应用及实践操作: 一、cgroups 基础概念 1. 是什么? cgroups 是 Linux 内核提供的 资源隔离与控制机制,…...

ARMV8 RK3399 u-boot TPL启动流程分析 --start.S
上电后运行的第一支文件:arch/arm/cpu/armv8/start.S CONFIG_ENABLE_ARM_SOC_BOOT0_HOOK1 #include <asm/arch/boot0.h> 跳转到 arch/arm/include/asm/arch-rockchip/boot0.h CONFIG_SPL_BUILD1 b 1f ROCKCHIP_EARLYRETURN_TO_BROMno TINY_FRAMEWORKno …...

【网络原理】数据链路层
目录 一. 以太网 二. 以太网数据帧 三. MAC地址 四. MTU 五. ARP协议 六. DNS 一. 以太网 以太网是一种基于有线或无线介质的计算机网络技术,定义了物理层和数据链路层的协议,用于在局域网中传输数据帧。 二. 以太网数据帧 1)目标地址 …...

保姆级教程|YOLO11改进】【卷积篇】【4】使用RFAConv感受野注意力卷积,重塑空间特征提取,助力高效提点
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

虚幻引擎5-Unreal Engine笔记之常用核心类的继承关系
虚幻引擎5-Unreal Engine笔记之常用核心类的继承关系 code review! 文章目录 虚幻引擎5-Unreal Engine笔记之常用核心类的继承关系1.UE5中常用核心类的继承关系1.1.简化版1.2.plantuml图1.3.plantuml代码1.4.关于大写字母U和A2.1.组件和类的关系,组件也是类吗&…...

力扣2680题解
记录 2025.5.9 题目: 思路: 1.计算初始或值:首先计算数组中所有元素的按位或结果 allOr,这表示在不进行任何左移操作时数组的或值。 2.计算固定或值:在计算 allOr 的同时,计算一个 fixed 值,…...
多层级可信时间同步服务)
搭建基于chrony+OpenSSL(NTS协议)多层级可信时间同步服务
1、时间同步服务的层级概念 在绝大多数IT工程师实际工作过程中,针对于局域网的时间同步,遇到最多的场景是根据实际的需求,搭建一个简单的NTP时间同步服务以时间对局域网中的服务器、网络设备、个人电脑等基础设施实现同步授时功能。虽然这样…...

虚拟内存:深入解析与性能优化
文章目录 虚拟内存的概念虚拟内存的实现方式虚拟内存的页面置换算法虚拟内存的性能影响结论 在现代计算机系统中,虚拟内存(Virtual Memory)是一种至关重要的技术,它极大地提高了系统的多任务处理能力和内存利用率。本文将深入探讨…...

元数据和主数据
元数据和主数据是数据管理中的两个关键概念,其核心区别如下: 1. 定义与本质 元数据(Metadata) “关于数据的数据”,用于描述数据的属性、结构、来源、用途等上下文信息。 示例:数据库表的字段名称、数据类型…...

JavaScript事件处理全解析:从基础到最佳实践
在现代Web开发中,事件处理是构建交互式应用的核心技术。JavaScript提供了多种事件绑定方式,每种方法都有其适用场景和特点。本文将深入探讨7种主流的事件绑定方法,通过代码示例和原理分析,帮助开发者选择最合适的解决方案。 一、…...

高级数据结构:线段树
线段树概述 线段树是一种处理区间问题的优越算法,也是算法竞赛的常客。 线段树的特点是,类似于一棵二叉树,将一个序列分解成多个区间并储存在二叉树上。 例如,把区间 [ 1 , 10 ] [1,10] [1,10]作为树的根节点,然后把…...

精讲C++四大核心特性:内联函数加速原理、auto智能推导、范围for循环与空指针进阶
前引:在C语言长达三十余年的演进历程中,每一次标准更新都在试图平衡性能与抽象、控制与安全之间的微妙关系。从C11引入的"现代C"范式开始,开发者得以在保留底层控制能力的同时,借助语言特性大幅提升代码的可维护性与安全…...

用ffmpeg压缩视频参数建议
注意:代码中的斜杠\可以删除 一、基础压缩命令(画质优先) ffmpeg -i input.mp4 \-c:v libx264 -preset slow -crf 23 \ # H.264编码,平衡速度与质量-c:a aac -b:a 128k \ # 音频压缩-vf "scaleif(gt(a,16/9),1920,-2):if(…...
--vue页面代码的构成和新建页面)
uni-app学习笔记(二)--vue页面代码的构成和新建页面
vue页面的构成 一.template 模板区,主要放html布局,注意,如果是开发uni-app,模板区不要放div,h1等标签了,用了在小程序和app端起不到作用。具体应该使用哪些组件,可在uni-app官网上查看:组件-…...

机器语言程序、汇编语言程序、硬件描述语言程序、编译程序、解释程序和链接程序
程序类型定义与核心特征处理对象 / 输入输出结果所属领域典型例子 / 作用机器语言程序由二进制指令(0/1 序列)构成,可被 CPU 直接执行,与硬件架构强绑定。无(直接执行)无(直接运行)低…...

智能语音助手的未来:从交互到融合
摘要 随着人工智能技术的不断进步,智能语音助手已经成为我们生活中不可或缺的一部分。从简单的语音指令到复杂的多模态交互,语音助手正在经历一场深刻的变革。本文将探讨智能语音助手的发展历程、当前的技术瓶颈以及未来的发展方向,特别是其在…...

Redis从基础到高阶应用:核心命令解析与延迟队列、事务消息实战设计
Redis基础知识 #切换数据库 bd:0>select 2 "OK" bd:2>dbsize "0" #清空数据库 bd:0>flushdb "OK" #设置值 bd:0>set name "lyt" "OK" #查看所有key bd:0>keys *1) "name" #获取key bd:0>get …...

操作系统原理实验报告
操作系统原理课程的实验报告汇总 实验三:线程的创建与撤销 实验环境:计算机一台,内装有VC、office等软件 实验日期:2024.4.11 实验要求: 1.理解:Windows系统调用的基本概念,进程与线程的基…...

Python爬虫实战:研究nodejs aes加密
1. 引言 1.1 研究背景与意义 在当今数字化时代,Web 数据的价值日益凸显。通过爬虫技术获取公开数据并进行分析,能够为企业决策、学术研究等提供有力支持。然而,为了保护数据安全和隐私,许多网站采用了加密技术对数据进行保护,其中 AES 加密是一种常见且安全的加密算法。…...
)
线程的一些事(2)
在java中,线程的终止,是一种“软性”操作,必须要对应的线程配合,才能把终止落实下去 然而,系统原生的api其实还提供了,强制终止线程的操作,无论线程执行到哪,都能强行把这个线程干掉…...

基于 PostgreSQL 的 ABP vNext + ShardingCore 分库分表实战
🚀 基于 PostgreSQL 的 ABP vNext ShardingCore 分库分表实战 📑 目录 🚀 基于 PostgreSQL 的 ABP vNext ShardingCore 分库分表实战✨ 背景介绍🧱 技术选型🛠️ 环境准备✅ Docker Compose(多库 & 读…...

御网杯2025 Web,Msic,密码 WP
Web YWB_Web_xff 审计代码,发现需要$cip2.2.2.1 使用burpsuite抓包,添加X-Forwarded-For:2.2.2.1 然后得到flag YWB_Web_未授权访问 更加题目描述知道需要admin登录,但是现在是guest。 使用burpsuite抓包 发现cookie里面存在userÿ…...

tensorflow 1.x
简介 TensorFlow:2015年谷歌,支持python、C,底层是C,主要用python。支持CNN、RNN等算法,分CPU TensorFlow/GPU TensorFlow。 TensorBoard:训练中的可视化。 快捷键:shiftenter执行命令,Tab键进…...

[ERTS2012] 航天器星载软件形式化模型驱动研发 —— 对 Scade 语言本身的影响
在《从ERTS学习SCADE发展》中提到,在 ERTS 会议中,Scade团队会在该会议中介绍与Scade相关的工作。在 ERTS 2012 中,Scade 团队介绍了使用Scade作为主要工具,应用在航天器星载软件开发中的相关话题。原材料可参考 《Formal Model D…...

Spring Boot 集成 Flink CDC 实现 MySQL 到 Kafka 实时同步
Spring Boot 集成 Flink CDC 实现 MySQL 到 Kafka 实时同步 📌 项目背景 在大数据实时处理场景中,数据库变更数据的捕获与传输是关键环节。Flink CDC 提供了从 MySQL 等数据库中实时捕获数据变更的能力,并通过 Apache Flink 引擎实现流式处理。 本项目使用 Spring Boot …...
)
软件体系结构(Software Architecture)
文章目录 1. 分层架构(Layered Architecture)核心逻辑代码示例(伪代码)典型场景优缺点 2. 客户端-服务器(Client-Server)核心逻辑典型交互流程应用场景代码示例(RESTful API)优缺点 …...

RS485和RS232 通信配置
RS232 目前硬件上支持RS232的有以下板卡: LubanCat-5IO底板(含有RS232x2) 7.1. 引脚定义 具体的引脚定义可以参考背面的丝印 LubanCat-5IO底板 引脚定义图 7.2. 跳帽配置 LubanCat-5IO底板 鲁班买5IO底板上的RS485和RS232是共用同一组…...

【高数上册笔记篇02】:数列与函数极限
【参考资料】 同济大学《高等数学》教材樊顺厚老师B站《高等数学精讲》系列课程 (注:本笔记为个人数学复习资料,旨在通过系统化整理替代厚重教材,便于随时查阅与巩固知识要点) 仅用于个人数学复习,因为课…...
和小端序(Little-Endian))
【网络安全】——大端序(Big-Endian)和小端序(Little-Endian)
字节序(Endianness)是计算机系统中多字节数据(如整数、浮点数)在内存中存储或传输时,字节排列顺序的规则。它分为两种类型:大端序(Big-Endian)和小端序…...

机器学习极简入门:从基础概念到行业应用
有监督学习(supervised learning) 让模型学习的数据包含正确答案(标签)的方法,最终模型可以对无标签的数据进行正确处理和预测,可以分为分类与回归两大类 分类问题主要是为了“尽可能分开整个数据而画线”…...

MIT XV6 - 1.5 Lab: Xv6 and Unix utilities - xargs
接上文 MIT XV6 - 1.4 Lab: Xv6 and Unix utilities - find xargs 继续实验,实验介绍和要求如下 (原文链接 译文链接) : Write a simple version of the UNIX xargs program for xv6: its arguments describe a command to run, it reads lines from the standard …...

Springboot整合Swagger3
Springboot整合Swagger3、常用注解解释、访问Swagger地址出现404、403、拒绝访问等问题_swagger3注解-CSDN博客...

经典音乐播放器——完美歌词 Poweramp Music Player 3 build
—————【下 载 地 址】——————— 【本章单下载】:https://drive.uc.cn/s/d6c480bc47604 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/HPQywvPc7iLZu1k0ODFcWMt2n0d?fromfrom_copylink —————【下 载 地 址】——————— 本…...