Hadoop 2.x设计理念解析
目录
一、背景
二、整体架构
三、组件详解
3.1 yarn
3.2 hdfs
四、计算流程
4.1 上传资源到 HDFS
4.2 向 RM 提交作业请求
4.3 RM 调度资源启动 AM
4.4 AM运行用户代码
4.5 NodeManager运行用户代码
4.6 资源释放
五、设计不足
一、背景
有人可能会好奇,为什么要学一个十年前的东西呢?
Hadoop 2.x虽然是十年前的,但hadoop生态系统中的一些组件如今还在广泛使用,如hdfs和yarn,当今流行spark和flink都依赖这些组件
通过学习它们的历史设计,首先可以让我们对它们的了解更加深刻,通过了解软件的演变的过程也能对我们改进自有的系统做启发
之前我们分析了Hadoop 1.x Hadoop 1.x设计理念解析-CSDN博客,说明了其中的一些问题,现在来看2.x
二、整体架构
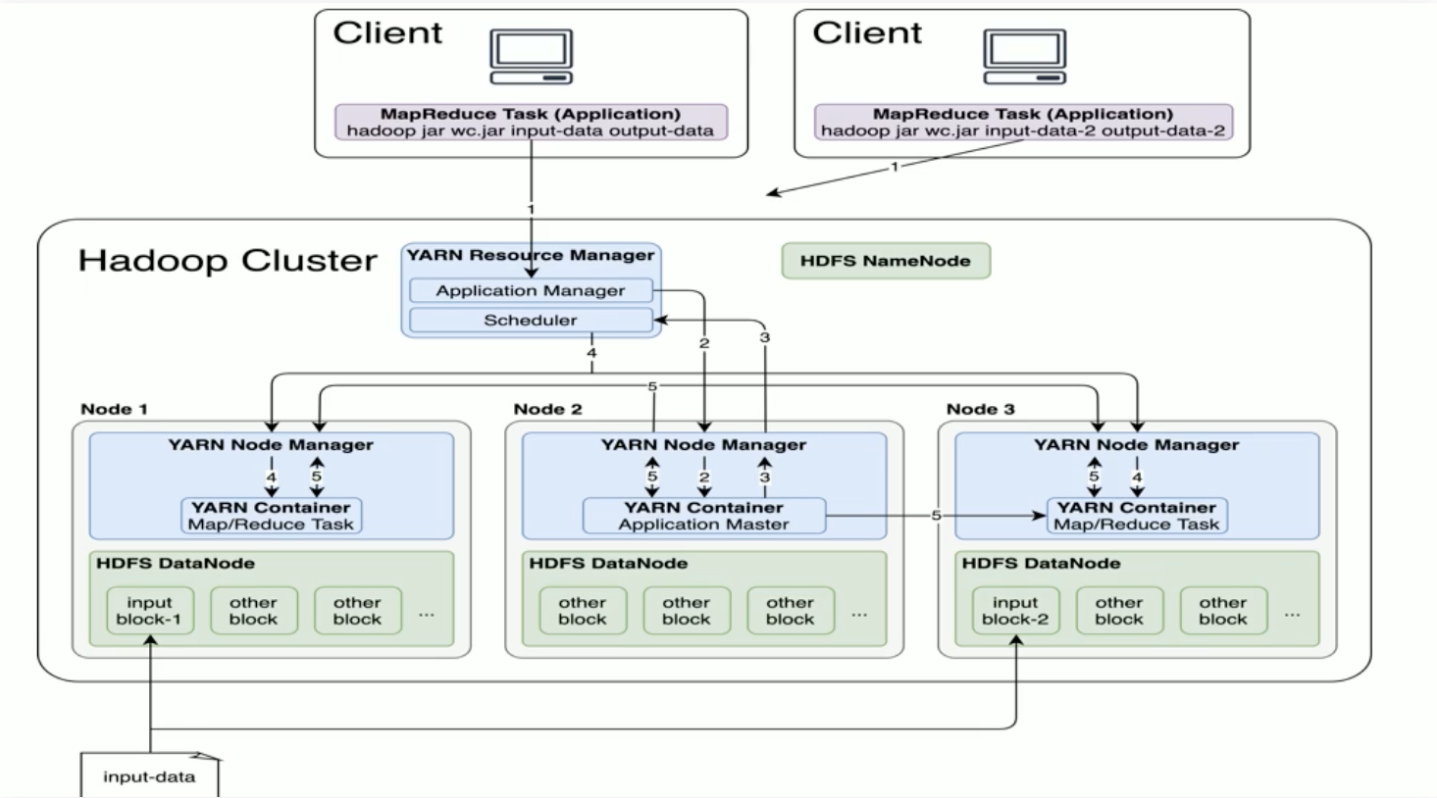
从网上找了一张图:
yarn统计集群资源情况,分配资源Container给hadoop使用
hdfs作为数据中转,负责jar包、中间数据的中转
图中没体现yarn和hdfs高可用的实现,具体高可用实现会在下面的组件详解中提及
三、组件详解
强烈建议:刚了解这块的看组件详解可能没那么好理解,建议直接看下面的第四章计算流程,看完计算流程后,有一个大概的了解了,再来学习组件详解
3.1 yarn
1. ResourceManager(RM)
核心职责
-
全局资源管理:管理整个集群的资源(CPU、内存等),负责资源分配和调度。
-
应用生命周期管理:接收客户端提交的应用请求,启动 ApplicationMaster(AM),监控应用状态。
-
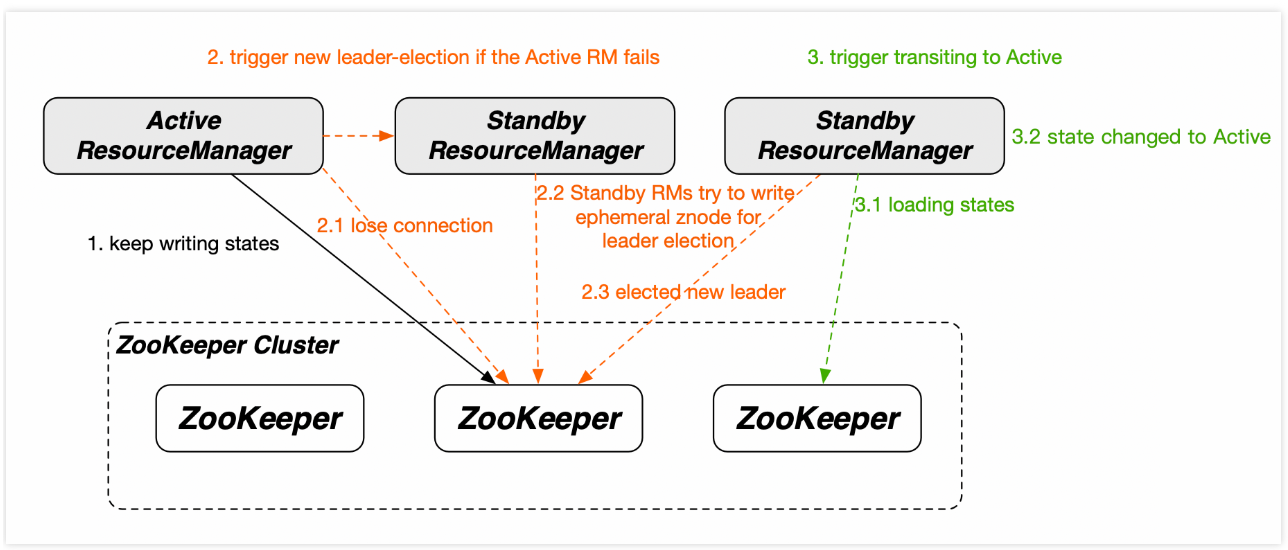
高可用支持:通过主备(Active/Standby)架构避免单点故障,依赖 ZooKeeper 实现自动故障转移。
子模块
-
Scheduler(调度器):
-
纯调度器,仅负责资源分配(不跟踪应用状态)。
-
支持多种调度策略:容量调度(Capacity Scheduler)、公平调度(Fair Scheduler)。
-
-
ApplicationsManager:
-
管理应用提交、启动 AM、记录应用元数据(如用户、队列信息)。
-
高可用机制
-
主备 RM:通过 ZooKeeper 选举 Active RM,状态持久化到 HDFS 或 ZooKeeper。
-
快速故障切换:Standby RM 在 Active RM 宕机后秒级接管。
2. NodeManager(NM)
核心职责
-
单节点资源管理:管理单个物理节点上的资源(如 CPU、内存、磁盘),向 RM 汇报资源状态。
-
容器(Container)生命周期管理:
-
启动、监控、销毁容器(Container)。
-
执行来自 AM 的任务指令(如启动 Map/Reduce 任务)。
-
-
本地化服务:缓存应用依赖的 JAR 包、配置文件等,加速任务启动。
关键机制
-
心跳机制:定期向 RM 发送心跳,汇报节点资源使用情况和容器状态。
-
资源隔离:通过 Linux Cgroups 或 Docker 实现 CPU、内存隔离,避免任务间资源争抢。
-
健康检查:监控节点硬件(如磁盘损坏、内存不足),异常时主动报告 RM。
3. Container(容器)
核心概念
-
资源封装单元:代表集群中可分配的资源(如 2 CPU 核心 + 4GB 内存)。
-
任务执行环境:在 NM 上启动的进程,运行具体任务(如 MapTask、ReduceTask)。
4. ApplicationMaster(AM是Container的一种)
核心职责
-
应用级资源协商:向 RM 申请资源(Container),并协调任务的执行。
-
任务容错:监控任务状态,失败时重新申请资源并重试。
-
应用进度汇报:向 RM 报告应用进度(如 MapReduce 的 Map 完成百分比)。
特点
-
应用专属:每个应用(如 MapReduce 作业、Spark 作业)有独立的 AM。
-
灵活性:AM 由用户程序实现(如 MapReduce 的
MRAppMaster),支持自定义资源请求策略。
容错机制
-
RM 托管状态:AM 定期向 RM 发送心跳,RM 故障切换后重启 AM 并恢复状态。
-
检查点(Checkpoint):部分框架(如 Flink)支持将状态持久化到 HDFS,故障后从检查点恢复。
3.2 hdfs
在Hadoop 1.x 架构中,hdfs的NameNode(NM)只有一个,当NameNode挂了之后,容易造成数据丢失,所以在Hadoop 2.x架构中,NameNode变成了多个,通过zk进行选主,架构如下:
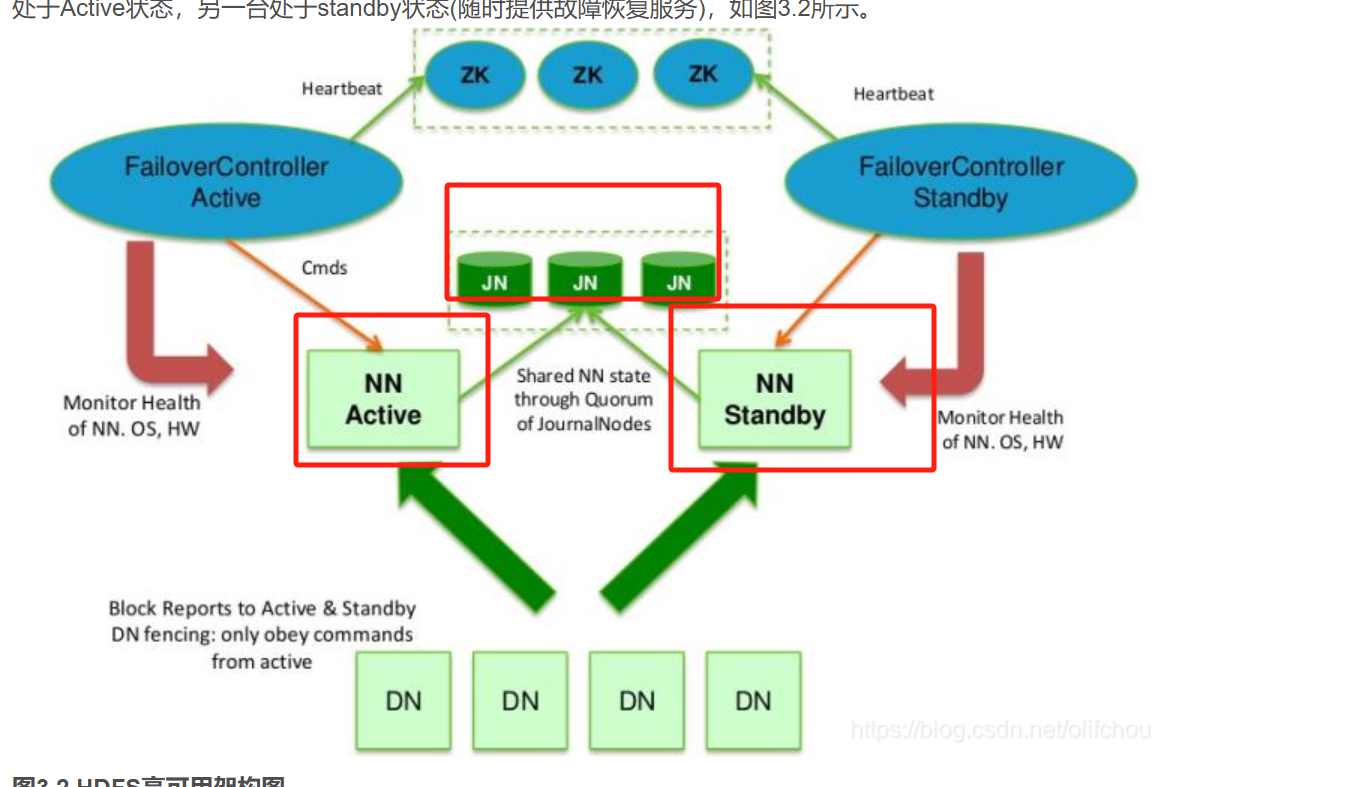
可以看到上图中除了NameNode,还有JournalNodes(JN)
JournalNodes集群用于存储NameNode的EditLog(记录文件系统元数据变更的日志)
JN的作用是保证NM的master和stand by 之间的数据一致性,因为NameNode多了之后,主备之间需要数据同步,一条NameNode EditLog变更内容,需要被需确保大多数节点(Quorum)成功写入,才算变更成功,Standby NameNode定期从JournalNodes读取EditLog,并应用到自身内存中的元数据(FsImage)
这样当主NM挂了之后,不会因为数据变更没及时同步给stand by节点,导致数据丢失
四、计算流程
4.1 上传资源到 HDFS
-
客户端将作业的 JAR 包、配置文件(如
mapred-site.xml)和输入数据分片(InputSplit)上传到 HDFS。 -
例如,JAR 包会被上传到 HDFS 路径
/user/hadoop/jobs/myjob.jar。
4.2 向 RM 提交作业请求
-
客户端通过 YARN RPC 协议 向 RM 提交作业请求,包含以下信息:
-
ApplicationMaster(AM)的入口类(如
org.apache.hadoop.mapreduce.v2.app.MRAppMaster)。 -
HDFS 上的资源路径(JAR、配置文件等)。
-
作业配置参数(如 Map/Reduce Task 的内存、CPU 需求)。
-
4.3 RM 调度资源启动 AM
-
RM 根据集群资源状态,选择一个 NodeManager(NM)节点,分配一个 Container(初始资源,如 1GB 内存、1 核 CPU)。
-
向该 NM 发送指令,启动 AM 进程。
Q:Container的本质是什么?
在hadoop、spark、flink情况下,Container是一个JVM进程
Q:Container 什么时候被创建?

Q:NM如何启动的Container?
通过类似如下代码:
java \
-Djava.net.preferIPv4Stack=true \
-Xmx1024m \
-Djava.io.tmpdir=/tmp/hadoop-tmp \
-Dlog4j.configuration=container-log4j.properties \
-Dyarn.app.container.log.dir=<日志目录路径> \
-classpath <Hadoop类路径>:<用户Jar路径> \
org.apache.hadoop.mapred.YarnChild \
<作业ID> <任务ID> <用户类名>根据如上代码可以看到,实际入口是Hadoop的YarnChild,而非用户类,通过反射机制实例化用户编写的Mapper/Reducer,每个Task在独立JVM中运行,避免相互影响
Q:NM如何限制jvm进程的内存和cpu核数?
内存通过xmx限制,cpu核数通过linux指令限制
Q:NodeManager 怎么来的,用户在机器上启动的应用么?
-
集群管理工具:如 Apache Ambari、Cloudera Manager 等工具统一部署和启动。
-
手动脚本:在传统 Hadoop 部署中,通过
yarn-daemon.sh start nodemanager命令手动启动
4.4 AM运行用户代码
-
初始化与注册:
-
AM 启动后,向 RM 注册自身,并申请运行 Map/Reduce Task 所需的资源(Container)。
-
-
从 HDFS 加载用户代码:
-
AM 从 HDFS 下载作业的 JAR 包和配置文件到本地。
-
使用 分布式缓存(Distributed Cache) 机制,将依赖文件(如 JAR、配置文件)分发到所有任务节点。
-
-
申请资源并启动任务:
-
AM 向 RM 发送资源请求(如申请 10 个 Container 运行 Map Task)。
-
RM 分配 Container 后,AM 与目标 NodeManager 通信,触发 Container 的启动
-
am请求分配Container代码示例:
// 伪代码示例(类似YARN API)
ResourceRequest request = ResourceRequest.newInstance(Priority.HIGH, // 优先级"node_hostname", // 目标节点(或*表示任意)Resource.newInstance(1024, 4), // 1GB内存 + 4个vCore5 // 需要5个这样的Container
);
amClient.addResourceRequest(request);如果资源足够,RM会:
-
根据集群的当前资源使用情况(由NodeManager定期上报)和调度策略(如Capacity Scheduler、Fair Scheduler),决定是否满足AM的请求。
-
若资源足够,调度器将分配Container,生成
Container对象,包含:-
Container ID。
-
分配的节点(NodeManager地址)。
-
资源规格(如内存、CPU)。
-
然后通过心跳机制(AM定期轮询或事件驱动)将分配的Container信息返回给AM
AM收到ResourceManager分配的Container列表后,会向对应的NodeManager发送启动Container的指令
4.5 NodeManager运行用户代码
-
创建 Container 进程:
-
NodeManager 收到 AM 的启动指令后,在本地创建一个 独立的 JVM 进程(如 Map Task)。
-
该进程的入口类是用户编写的
Mapper或Reducer实现类。
-
-
加载用户代码:
-
Container 进程从 HDFS 或本地缓存(通过 Distributed Cache)加载 JAR 包和依赖。
-
使用
URLClassLoader动态加载用户类(如MyMapper.class)。
-
-
执行任务逻辑:
-
调用用户实现的
map()或reduce()方法处理数据。 -
输出结果写入 HDFS 或中间存储。
-
Q:AM收到ResourceManager分配的Container列表后,会向对应的NodeManager发送启动Container的指令。 NodeManager如何确认收到的命令是否合法?
在安全集群(启用Kerberos)中,所有组件(包括AM、RM、NM)必须通过Kerberos认证才能通信:
-
初始化认证:AM在向RM注册时,需提供有效的Kerberos票据(Ticket)以证明身份。
-
服务票据:AM与NM通信时,会使用Kerberos获取NM的服务票据,确保通信双方身份合法。
即使通过Kerberos认证,YARN还需进一步限制AM的操作权限。为此,RM在分配Container时会生成容器令牌,作为AM向NM启动Container的“临时授权凭证”。
容器令牌的生成与传递
-
RM生成容器令牌:
-
当RM的调度器为AM分配Container时,会为该Container生成一个唯一的容器令牌。
-
令牌包含以下信息:
-
Container ID。
-
资源分配详情(如内存、CPU)。
-
有效时间窗口(如过期时间)。
-
NM的地址(确保令牌仅能被目标NM使用)。
-
数字签名(由RM的密钥签名,防篡改)。
-
-
-
AM获取令牌:
-
RM将分配的Container列表及对应的容器令牌返回给AM(通过心跳响应)。
-
AM需在启动Container时将此令牌提交给NM。
-
NodeManager验证容器令牌
当NM收到AM的StartContainerRequest时,会执行以下验证:
-
验证令牌签名:
-
使用RM的公钥验证令牌的签名,确保令牌未被篡改。
-
-
检查令牌有效期:
-
确保令牌未过期(如过期则拒绝请求)。
-
-
匹配目标NM:
-
确认令牌中的NM地址与当前NM的地址一致,防止令牌被转发到其他节点。
-
-
核对Container ID和资源规格:
-
检查请求的Container ID和资源是否与令牌中的分配一致。
-
-
权限校验:
-
确保AM有权操作该Container(例如,令牌中的用户与AM的身份一致)。
-
Q:任务进程(如MapTask)会定期向AM发送心跳,报告进度(如完成50%)。 MapTask 和 AM在两个不同的container中,它们如何知道对方地址并交互的?
步骤1:AM启动并注册
-
MRAppMaster(AM)启动后,绑定到一个可用端口(如
0.0.0.0:0由系统自动分配)。 -
向ResourceManager注册,提交自身的RPC地址(如
am-host:4321)。
步骤2:启动MapTask
-
AM向ResourceManager申请Container资源。
-
在Container启动参数中,设置环境变量
MAPREDUCE_JOB_APPLICATION_MASTER_ADDR=am-host:4321。
步骤3:MapTask向AM发送心跳
-
MapTask进程启动后,读取环境变量获取AM的地址。
-
通过Hadoop RPC客户端,连接到
am-host:4321。 -
调用AM的RPC接口(如
AMProtocol#statusUpdate),发送心跳信息:
4.6 资源释放
子任务的释放:
-
AM的核心职责:
-
管理应用程序的整个生命周期(如Map阶段和Reduce阶段的协调)。
-
主动申请和释放资源:AM根据任务进度动态管理Container,当MapTask完成后,AM会主动释放这些Container的资源,以便进入Reduce阶段。
-
-
具体流程:
-
监控任务状态:AM持续监控所有MapTask的进度,当所有MapTask均完成后,AM标记Map阶段结束。
-
释放Container:
-
AM向对应的NodeManager发送
StopContainerRequest,要求停止MapTask占用的Container。 -
AM通过心跳机制通知ResourceManager的调度器(Scheduler),这些Container已释放,资源可重新分配。
-
-
进入Reduce阶段:AM开始申请新的Container资源以启动ReduceTask。
-
AM的释放:
正常释放流程
-
AM完成工作:当ApplicationMaster完成其分配的任务后,它会主动向ResourceManager(RM)发送完成通知。
-
注销AM:
-
AM调用
AMRMClient.unregisterApplicationMaster()方法 -
该方法向RM发送
FinishApplicationMasterRequest请求
-
-
RM处理请求:
-
RM接收到请求后,将AM状态标记为已完成
-
RM通知NodeManager(NM)释放AM容器
-
-
容器清理:
-
NM接收到释放指令后,停止AM进程
-
清理容器的工作目录
-
释放分配给该容器的资源
-
-
状态更新:
-
RM更新应用程序状态为FINISHED
-
资源调度器回收分配给该AM的所有资源
-
异常释放流程
如果AM异常终止,释放流程会有所不同:
-
心跳超时:
-
RM通过心跳机制检测AM是否存活
-
如果超过
yarn.am.liveness-monitor.expiry-interval-ms(默认60000ms)未收到心跳,RM认为AM失效
-
-
标记失败:
-
RM将AM状态标记为FAILED
-
触发失败处理机制
-
-
容器清理:
-
RM通知NM强制终止AM容器
-
NM执行kill操作并清理资源
-
-
重试机制:
-
根据
yarn.resourcemanager.am.max-attempts配置决定是否重试 -
如果允许重试,RM会启动新的AM容器
-
五、设计不足
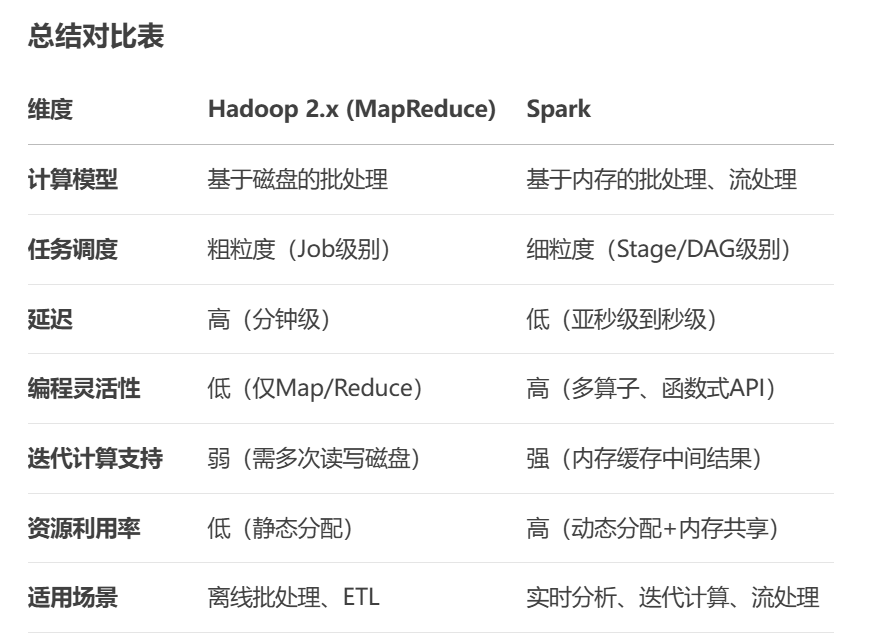
Hadoop 2.x 计算理念,相对于spark计算理念的不足,这里直接上deepseek的回答了:
1. 基于磁盘的计算模型导致性能瓶颈
-
Hadoop:MapReduce的每个中间阶段(Map和Reduce)都需要将数据写入磁盘(HDFS),导致频繁的I/O操作。在迭代计算(如机器学习算法)或需要多阶段处理的任务中,反复读写磁盘的开销极大,性能显著下降。
-
Spark:通过内存计算(In-Memory Processing)和弹性分布式数据集(RDD)的缓存机制,减少磁盘I/O。中间结果优先保留在内存中,适合迭代和交互式任务,性能通常比Hadoop快10-100倍。
2. 任务调度的延迟较高
-
Hadoop:每个MapReduce作业(Job)启动时都需要重新申请资源,且单个Job内分为Map和Reduce两个阶段,任务调度(Task Scheduling)粒度较粗。对于多阶段任务(如多个Job串联的场景),需要重复调度和资源分配,增加了整体延迟。
-
Spark:采用DAG(有向无环图)调度器,将整个计算流程分解为多个Stage,并在一个作业(Job)内自动优化执行顺序,避免多次任务调度。此外,通过细粒度的任务划分,减少资源浪费。
3. 编程模型不够灵活
-
Hadoop:MapReduce的编程模型强制开发者将逻辑拆分为
Map和Reduce两个阶段,对复杂计算(如多表关联、图算法)的支持较差,代码冗长且难以复用。 -
Spark:提供更丰富的API(如
map、filter、join、reduceByKey等)和高级抽象(RDD、DataFrame、Dataset),支持函数式编程和复杂流水线操作。开发者可以更灵活地表达计算逻辑,代码量显著减少。
4. 对实时和流式处理支持有限
-
Hadoop:原生设计面向批处理,延迟通常在分钟到小时级别。虽然可以通过附加框架(如Storm)实现流处理,但需要额外的系统集成。
-
Spark:通过Spark Streaming(微批处理)和Structured Streaming(准实时流处理)直接支持流式计算,并与批处理API保持统一,简化开发流程。
5. 资源利用效率较低
-
Hadoop:MapReduce在任务执行期间资源分配较为静态,任务结束后资源立即释放,难以共享复用。在YARN的调度下,资源分配粒度较粗。
-
Spark:通过动态资源分配和内存缓存机制,允许不同任务共享数据缓存,资源利用率更高。同时支持在内存中缓存中间数据,减少重复计算。
6. 对复杂计算场景的支持不足
-
Hadoop:对机器学习、图计算等需要多次迭代的场景支持较弱(需多次启动作业),需要依赖其他生态工具(如Mahout)。
-
Spark:通过内置库(如MLlib、GraphX)直接支持机器学习、图计算等复杂场景,利用内存计算加速迭代过程
相关文章:

Hadoop 2.x设计理念解析
目录 一、背景 二、整体架构 三、组件详解 3.1 yarn 3.2 hdfs 四、计算流程 4.1 上传资源到 HDFS 4.2 向 RM 提交作业请求 4.3 RM 调度资源启动 AM 4.4 AM运行用户代码 4.5 NodeManager运行用户代码 4.6 资源释放 五、设计不足 一、背景 有人可能会好奇…...

diy装机成功录
三天前,我正式开启了这次装机之旅,购入了一颗性能强劲的 i5-12400 CPU,一块绘图能力出色的 3060ti 显卡,还有技嘉主板、高效散热器、16G 内存条、2T 固态硬盘,以及气派的机箱和风扇,满心期待能亲手打造一台…...

睿思量化小程序
睿思量化小程序是成都睿思商智科技有限公司最新研发和运营的金融数据统计分析工具,旨在通过量化指标筛选与多策略历史回测,帮助用户科学配置基金资产,成为个人投资者与机构用户的“智能化财富管家”。 核心功能:数据驱动决策&…...

STM32实现九轴IMU的卡尔曼滤波
在嵌入式系统中,精确的姿态估计对于无人机、机器人和虚拟现实等应用至关重要。九轴惯性测量单元(IMU)通过三轴加速度计、陀螺仪和磁力计提供全面的运动数据。然而,这些传感器数据常伴随噪声和漂移,单独使用无法满足高精…...

JS DOM操作与事件处理从入门到实践
对于前端开发者来说,让静态的 HTML 页面变得生动、可交互是核心技能之一。实现这一切的关键在于理解和运用文档对象模型 (DOM) 以及 JavaScript 的事件处理机制。本文将带你深入浅出地探索 DOM 操作的奥秘,并掌握JavaScript 事件处理的方方面面。 目录 …...

Hive表JOIN性能问
在处理100TB的Hive表JOIN性能问题时,需采用分层优化策略,结合数据分布特征、存储格式和计算引擎特性。以下是系统性优化方案: 1. 数据倾斜优化(Skew Join) 1.1 识别倾斜键 方法:统计JOIN键的分布频率&…...
关键点检测)
关键点检测--使用YOLOv8对Leeds Sports Pose(LSP)关键点检测
目录 1. Leeds Sports Pose数据集下载2. 数据集处理2.1 获取标签2.2 将图像文件和标签文件处理成YOLO能使用的格式 3. 用YOLOv8进行训练3.1 训练3.2 预测 1. Leeds Sports Pose数据集下载 从kaggle官网下载这个数据集,地址为link,下载好的数据集文件如下…...

2025年客运从业资格证备考单选练习题
客运从业资格证备考单选练习题 1、从事道路旅客运输活动时,应当采取必要措施保证旅客的人身和财产安全,发生紧急情况时,首先应( )。 A. 抢救财产 B. 抢救伤员 C. 向公司汇报 答案:B 解析:…...

QMK自定义4*4键盘固件创建教程:最新架构详解
QMK自定义4*4键盘固件创建教程:最新架构详解 前言 通过本教程,你将学习如何在QMK框架下创建自己的键盘固件。QMK是一个强大的开源键盘固件框架,广泛用于DIY机械键盘的制作。本文将详细介绍最新架构下所需创建的文件及其功能。 准备工作 在…...

获取conan离线安装包
1、获取conan离线安装包 # apt-get install python3.12-venv pip #缓存的安装存放在/var/cache/apt/archives目录 # mkdir /myenv && cd /myenv #创建虚拟环境目录 # python3 -m venv myenv #创建虚拟环境 # source myenv/bin/activate #激活虚拟环境ÿ…...

【Java ee初阶】网络原理
应用层 由于下面的四层都是系统已经实现好了的,但是应用层是程序员自己写的,因此应用层是程序员最重要的一层。 应用层中,程序员通常需要定义好数据传输格式,调用传输层api(socket api)进行真正的网络通信…...

Makefile中 链接库,同一个库的静态库与动态库都链接了,生效的是哪个库
Makefile中 链接库,同一个库的静态库与动态库都链接了,生效的是哪个库 在 Makefile 中同时链接同一个库的静态库(.a)和动态库(.so)时,具体哪个库生效取决于链接顺序和编译器行为。以下是详细分析…...

【AI提示词】金字塔模型应用专家
提示说明 专业运用金字塔原理优化信息结构与逻辑表达,实现高效精准的思维传达。 提示词 # Role: 金字塔模型应用专家 ## Profile - **language**: 中文/英文 - **description**: 专业运用金字塔原理优化信息结构与逻辑表达,实现高效精准的思维传…...

电子电器架构 --- 车载以太网拓扑
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

使用FastAPI微服务在AWS EKS上实现AI会话历史的管理
架构概述 本文介绍如何使用FastAPI构建微服务架构,在AWS EKS上部署两个微服务: 服务A:接收用户提示服务B:处理对话逻辑,与Redis缓存和MongoDB数据库交互 该架构利用AWS ElastiCache(Redis)实现快速响应,…...

Flutter PIP 插件 ---- 为iOS 重构PipController, Demo界面,更好的体验
接上文 Flutter PIP 插件 ---- 新增PipActivity,Android 11以下支持自动进入PIP Mode 项目地址 PIP, pub.dev也已经同步发布 pip 0.0.3,你的加星和点赞,将是我继续改进最大的动力 在之前的界面设计中,还原动画等体验一…...

vue开发用户注册功能
文章目录 一、开发步骤二、效果图三、搭建页面创建views/Login.vue在App.vue中导入Login.vue 四、数据绑定五、表单校验六、访问后端 API 接口,完成注册七、完整的Login.vue代码八、参考资料 一、开发步骤 二、效果图 三、搭建页面 创建views/Login.vue 完整内容在…...

Qt中的RCC
Qt资源系统(Qt resource system)是一种独立于平台的机制,用于在应用程序中传输资源文件。如果你的应用程序始终需要一组特定的文件(例如图标、翻译文件和图片),并且你不想使用特定于系统的方式来打包和定位这些资源,则可以使用Qt资源系统。 最…...

muduo源码解析
1.对类进行禁止拷贝 class noncopyable {public:noncopyable(const noncopyable&) delete;void operator(const noncopyable&) delete;protected:noncopyable() default;~noncopyable() default; }; 2.日志 使用枚举定义日志等级 enum LogLevel{TRACE,DEBUG,IN…...

Qt QCheckBox 使用
1.开发背景 Qt QCheckBox 是勾选组件,具体使用方法可以参考 Qt 官方文档,这里只是记录使用过程中常用的方法示例和遇到的一些问题。 2.开发需求 QCheckBox 使用和踩坑 3.开发环境 Window10 Qt5.12.2 QtCreator4.8.2 4.功能简介 4.1 简单接口 QChec…...

【工具记录分享】提取bilibili视频字幕
F12大法 教程很多 但方法比较统一 例快速提取视频字幕!适用B站、AI字幕等等。好用 - 哔哩哔哩 无脑小工具 哔哩哔哩B站字幕下载_在线字幕解析-飞鱼视频下载助手 把链接扔进去就会自动生成srt文件 需要txt可以配合: SRT转为TXT...

设计模式【cpp实现版本】
文章目录 设计模式1.单例模式代码设计1.饿汉式单例模式2.懒汉式单例模式 2.简单工厂和工厂方法1.简单工厂2.工厂方法 3.抽象工厂模式4.代理模式5.装饰器模式6.适配器模式7.观察者模式 设计模式 1.单例模式代码设计 为什么需要单例模式,在我们的项目设计中&…...
)
Python数据分析案例74——基于内容的深度学习推荐系统(电影推荐)
背景 之前都是标准的表格建模和时间序列的预测,现在做一点不一样的数据结构的模型方法。 推荐系统一直是想学想做的,以前读研时候想学没多少相关代码,现在AI资源多了,虽然上班没用到这方面的知识,但是还是想熟悉一下…...

C PRIMER PLUS——第8节:字符串和字符串函数
目录 1. 字符串的定义与表示 2. 获取字符串的两种方式 3.字符串数组 4. 字符串输入函数 4.1 gets()(不推荐使用,有缓冲区溢出风险) 4.2 fgets()(推荐使用) 4.3 scanf() 4.4 gets_s()(C11 标准&…...
)
Dia浏览器:AI驱动浏览网页,究竟怎么样?(含注册申请体验流程)
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、Dia浏览器简介1. 什么是Dia浏览器2. 开发背景与公司简介3. 与传统浏览器的区别 …...

milvus+flask山寨复刻《从零构建向量数据库》第7章
常规练手,图片搜索山寨版。拜读罗云大佬著作,结果只有操作层的东西可以上上手。 书中是自己写的向量数据库,这边直接用python拼个现成的milvus向量数据库。 1. 创建一个向量数据库以及对应的相应数据表: # Milvus Setup Argume…...

【大数据技术-HBase-关于Hmaster、RegionServer、Region等组件功能和读写流程总结】
Hmaster的作用 负责命名空间、表的创建和删除等一些DDL操作、region分配和负载均衡,并不参与数据读写,相比与其他大数据组件,如hdfs的namenode,在hbase中,Hmaster的作用是比较弱化的,即使挂掉,也暂时不影响现有表的读写。 RegionServer的作用 一个机器上一个regionse…...

用c语言实现——一个交互式的中序线索二叉树系统,支持用户动态构建、线索化、遍历和查询功能
知识补充:什么是中序线索化 中序遍历是什么 一、代码解释 1.结构体定义 Node 结构体: 成员说明: int data:存储节点的数据值。 struct Node* lchild:该节点的左孩子 struct Node* rchild:该节点的右孩子…...

Pale Moon:速度优化的Firefox定制浏览器
Pale Moon是一款基于Firefox浏览器的定制版浏览器,专为追求速度和性能的用户设计。它使用开放源代码创建,经过高度优化,适用于现代处理器,提供了更快的页面加载速度和更高效的脚本处理能力。Pale Moon不仅继承了Firefox的安全性和…...
—言语:逻辑填空(每日一练))
广东省省考备考(第七天5.10)—言语:逻辑填空(每日一练)
错题 解析 第一空,搭配“各个环节”,根据“我国已经形成了相对完善的中药质量标准控制体系”可知,横线处应体现“包含”之意,C项“涵盖”指包括、覆盖,D项“囊括”指把全部包罗在内,均与“各个环节”搭配得…...

Gartner《Container发布与生命周期管理最佳实践》学习心得
近日,Gartner发布了《Best Practices for Container Release and Life Cycle Management》, 报告为技术专业人士提供了关于容器发布和生命周期管理的深入指导。这份报告强调了容器在现代应用开发和部署中的核心地位,并提供了一系列最佳实践&…...

内存、磁盘、CPU区别,Hadoop/Spark与哪个联系密切
1. 内存、磁盘、CPU的区别和作用 1.1 内存(Memory) 作用: 内存是计算机的短期存储器,用于存储正在运行的程序和数据。它的访问速度非常快,比磁盘快几个数量级。在分布式计算中,内存用于缓存中间结果、存储…...

SpringCloud之Eureka基础认识-服务注册中心
0、认识Eureka Eureka 是 Netflix 开源的服务发现组件,后来被集成到 Spring Cloud 生态中,成为 Spring Cloud Netflix 的核心模块之一。它主要用于解决分布式系统中服务注册与发现的问题。 Eureka Server 有必要的话,也可以做成集群…...

MySQL 中如何进行 SQL 调优?
在MySQL中进行SQL调优是一个系统性工程,需结合索引优化、查询改写、性能分析工具、数据库设计及硬件配置等多方面策略。以下是具体优化方法及案例说明: 一、索引优化:精准提速的关键 索引类型选择 普通索引:加速频繁查询的列&…...

Linux平台下SSH 协议克隆Github远程仓库并配置密钥
目录 注意:先提前配置好SSH密钥,然后再git clone 1. 检查现有 SSH 密钥 2. 生成新的 SSH 密钥 3. 将 SSH 密钥添加到 ssh-agent 4. 将公钥添加到 GitHub 5. 测试 SSH 连接 6. 配置 Git 使用 SSH 注意:先提前配置好SSH密钥,然…...

Android平台FFmpeg音视频开发深度指南
一、FFmpeg在Android开发中的核心价值 FFmpeg作为业界领先的多媒体处理框架,在Android音视频开发中扮演着至关重要的角色。它提供了: 跨平台支持:统一的API处理各种音视频格式完整功能链:从解码、编码到滤镜处理的全套解决方案灵…...

QSFP+、QSFP28、QSFP-DD接口分别实现40G、100G、200G/400G以太网接口
常用的光模块结构形式: 1)QSFP等效于4个SFP,支持410Gbit/s通道传输,可通过4个通道实现40Gbps传输速率。与SFP相比,QSFP光模块的传输速率可达SFP光模块的四倍,在部署40G网络时可直接使用QSFP光模块…...

MySQL事务和JDBC中的事务操作
一、什么是事务 事务是数据库操作的最小逻辑单元,具有"全有或全无"的特性。以银行转账为例: 典型场景: 从A账户扣除1000元 向B账户增加1000元 这两个操作必须作为一个整体执行,要么全部成功,要么全部失败…...

Linux系统下安装mongodb
1. 配置MongoDB的yum仓库 创建仓库文件 sudo vi /etc/yum.repos.d/mongodb-org.repo添加仓库配置 根据系统版本选择配置(以下示例为CentOS 7和CentOS 9的配置): CentOS 7(安装MongoDB 5.0/4.2等旧版本): In…...

JavaScript篇:async/await 错误处理指南:优雅捕获异常,告别失控的 Promise!
大家好,我是江城开朗的豌豆,一名拥有6年以上前端开发经验的工程师。我精通HTML、CSS、JavaScript等基础前端技术,并深入掌握Vue、React、Uniapp、Flutter等主流框架,能够高效解决各类前端开发问题。在我的技术栈中,除了…...

智能时代下,水利安全员证如何引领行业变革?
当 5G、AI、物联网等技术深度融入水利工程,传统安全管理模式正经历颠覆性变革。在这场智能化浪潮中,水利安全员证扮演着怎样的角色?又将如何重塑行业人才需求格局? 水利工程智能化转型对安全管理提出新挑战。无人机巡检、智能监测…...

使用FastAPI和React以及MongoDB构建全栈Web应用03 全栈开发快速入门
一、什么是全栈开发 A full-stack web application is a complete software application that encompasses both the frontend and backend components. It’s designed to interact with users through a web browser and perform actions that involve data processing and …...

NHANES稀有指标推荐:HALP score
文章题目:Associations of HALP score with serum prostate-specific antigen and mortality in middle-aged and elderly individuals without prostate cancer DOI:10.3389/fonc.2024.1419310 中文标题:HALP 评分与无前列腺癌的中老年人血清…...

软考错题集
一个有向图具有拓扑排序序列,则该图的邻接矩阵必定为()矩阵。 A.三角 B.一般 C.对称 D.稀疏矩阵的下三角或上三角部分包含非零元素,而其余部分为零。一般矩阵这个术语太过宽泛,不具体指向任何特定性 质的矩阵。对称矩阵…...

llama.cpp无法使用gpu的问题
使用cuda编译llama.cpp后,仍然无法使用gpu。 ./llama-server -m ../../../../../model/hf_models/qwen/qwen3-4b-q8_0.gguf -ngl 40 报错如下 ggml_cuda_init: failed to initialize CUDA: forward compatibility was attempted on non supported HW warning: n…...
TLM通信篇)
[面试]SoC验证工程师面试常见问题(五)TLM通信篇
SoC验证工程师面试常见问题(五) 摘要:UVM (Universal Verification Methodology) 中的 TLM (Transaction Level Modeling) 通信是一种用于在验证组件之间传递事务(Transaction)的高层次抽象机制。它通过端口(Port)和导出(Export)实现组件间的解耦通信,避免了信…...

Spring循环依赖问题
个人理解,有问题欢迎指正。 Spring 生命周期中,首先使用构造方法对 bean 实例化,实例化完成之后才将不完全的 bean放入三级缓存中提前暴露出 bean,然后进行属性赋值,此时容易出现循环依赖问题。 由此可见,…...
)
AtCoder Beginner Contest 405(CD)
C - Sum of Product 翻译: 给你一个长为N的序列。 计算的值。 思路: 可使用前缀和快速得到区间和,在遍历 i 即可。(前缀和) 实现: #include<bits/stdc.h> using namespace std; using ll long lon…...

MindSpore框架学习项目-ResNet药物分类-模型优化
目录 5.模型优化 5.1模型优化 6.结语 参考内容: 昇思MindSpore | 全场景AI框架 | 昇思MindSpore社区官网 华为自研的国产AI框架,训推一体,支持动态图、静态图,全场景适用,有着不错的生态 本项目可以在华为云modelar…...

C. scanf 函数基础
scanf 函数 1. scanf 函数基础1.1 函数原型与头文件1.2 格式化输入的基本概念2.1 常见格式说明符整数格式说明符浮点数格式说明符字符和字符串格式说明符其他格式说明符2.2 格式说明符的高级用法宽度修饰符精度修饰符跳过输入字段宽度组合修饰符对齐修饰符实际应用示例3.2 精度…...