【 Redis | 实战篇 缓存 】
目录
前言:
1.认识缓存
2.添加Redis缓存
2.1.根据id查询商铺缓存
2.2.优化根据id查询商铺缓存
3.缓存更新策略
3.1.三种策略
3.2.策略选择
3.3.主动更新的方案
3.4. Cache Aside的模式选择
3.5.最佳实践方案
4.缓存三大问题
4.1.缓存穿透
4.1.1.介绍
4.1.2.解决方案
4.1.3.实现
4.2.缓存雪崩
4.2.1.介绍
4.2.2.解决方案
4.3.缓存击穿
4.3.1.介绍
4.3.2.解决方案
4.3.3.实现
4.4.封装缓存工具
前言:
了解什么是缓存,怎么缓存,缓存的更新策略,缓存的三大问题及解决方案(缓存穿透,缓存雪崩,缓存击穿)
1.认识缓存
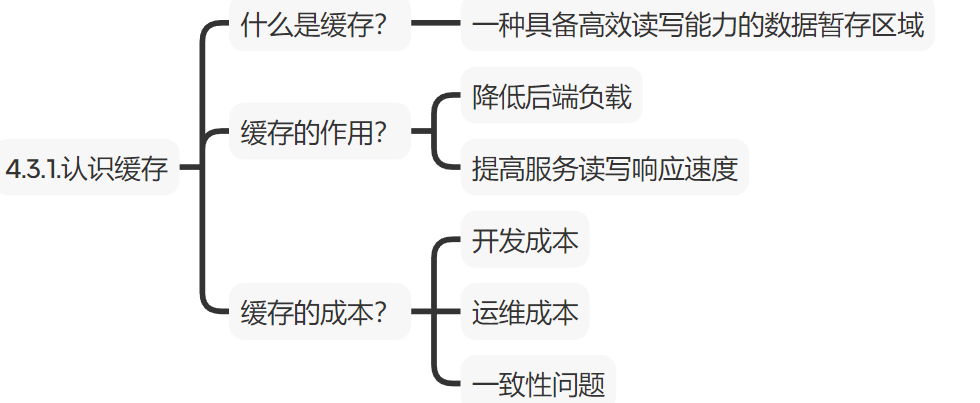
1.1.缓存的介绍
缓存就是数据交换的缓冲区,是储存数据的临时地方( 一种具备高效读写能力的数据暂存区域)
1.2.缓存的作用
-
降低后端负载
-
提高读写速率,降低响应时间
1.3.缓存的成本
-
1.开发成本 (代码维护成本)
-
2.运维成本
-
3.数据一致性成本
图:
2.添加Redis缓存
2.1.根据id查询商铺缓存
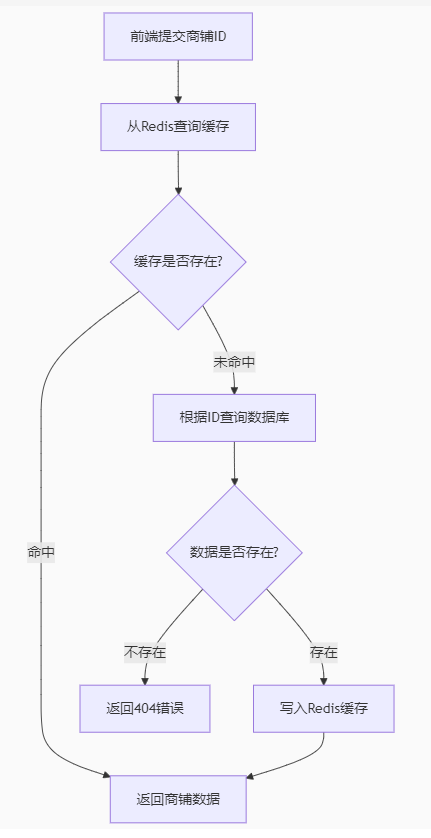
步骤:
前端提交商铺id
==》从Redis中查询缓存
==》判断缓存是否存在(是否命中)
==》命中返回商铺数据
-------------------
==》未命中
==》根据id查询数据库
==》判断数据是否存在
==》不存在返回404,存在将数据写入Redis
==》返回商铺数据
@Autowiredprivate StringRedisTemplate stringRedisTemplate;
@Overridepublic Result queryShopById(Long id) {Shop shop = queryShopPenetrate(id);if (shop == null){return Result.fail("商铺不存在");}//6.返回商铺数据return Result.ok(shop);}public Shop queryShopPenetrate(Long id) {//1.查询RedisString key = RedisConstants.CACHE_SHOP_KEY + id;String strShop = stringRedisTemplate.opsForValue().get(key);//2.判断是否存在if (StrUtil.isNotBlank(strShop)) {//存在直接返回Shop shop = JSONUtil.toBean(strShop, Shop.class);return shop;}//3.不存在,查询数据库Shop shop = getById(id);//4.判断是否存在if (shop == null) {return null;}//5.存在,存入RedisString jsonStr = JSONUtil.toJsonStr(shop);stringRedisTemplate.opsForValue().set(key, jsonStr);return shop;}解释:
- 1.由于商铺信息一般不进行修改,而用户却需要频繁的访问这些数据,如果突然有大量用户同时访问该数据,那么数据库的压力会很大,因此我们需要增加用户访问速度和降低对数据库的压力,所以我们使用Redis来进行缓存(基于内存,读写速度更快,降低数据库的压力)
- 2.用户点击商铺,前端返回对应id,那么后端接收到id在Redis查询(没有数据Redis会返回null),因此我们需要判断其是否命中,缓存存在直接返回缓存数据即可,不存在没有数据,那么我们需要查询数据库,再次判断数据是否存在,没有存在那么就是根本就没有这个商铺的信息直接返回错误信息,数据存在,我们需要先将数据写入Redis以便以后访问再返回数据给前端
2.2.优化根据id查询商铺缓存
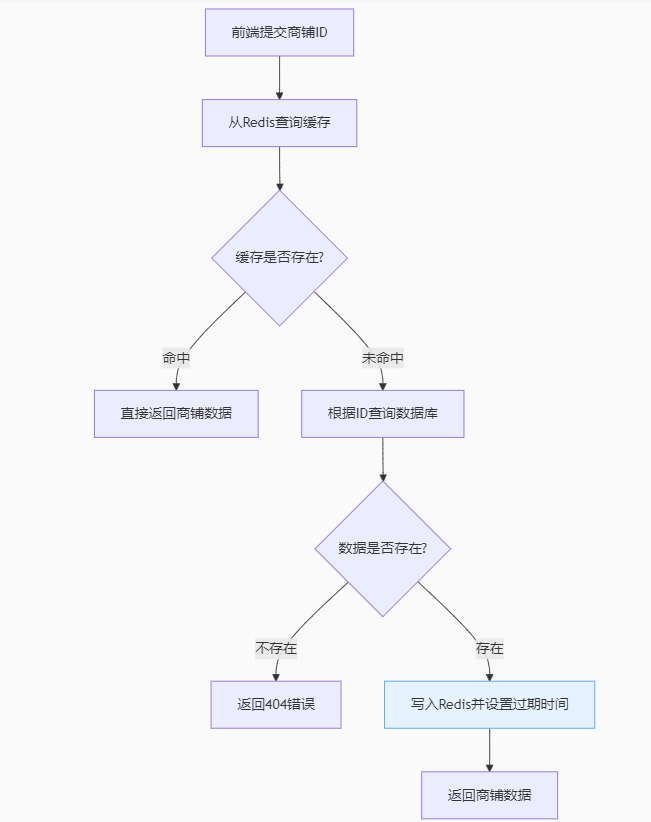
步骤:
前端提交商铺id
==》从Redis中查询缓存
==》判断缓存是否存在(是否命中)
==》命中返回商铺数据
----------------------------
==》未命中
==》根据id查询数据库
==》判断数据是否存在
==》不存在返回404,存在将数据写入Redis,并且设置过期时间(过期淘汰)
==》返回商铺数据
@Autowiredprivate StringRedisTemplate stringRedisTemplate;
@Overridepublic Result queryShopById(Long id) {Shop shop = queryShopPenetrate(id);if (shop == null){return Result.fail("商铺不存在");}//6.返回商铺数据return Result.ok(shop);}public Shop queryShopPenetrate(Long id) {//1.查询RedisString key = RedisConstants.CACHE_SHOP_KEY + id;String strShop = stringRedisTemplate.opsForValue().get(key);//2.判断是否存在if (StrUtil.isNotBlank(strShop)) {//存在直接返回Shop shop = JSONUtil.toBean(strShop, Shop.class);return shop;}//3.不存在,查询数据库Shop shop = getById(id);//4.判断是否存在if (shop == null) {return null;}//5.存在,存入RedisString jsonStr = JSONUtil.toJsonStr(shop);stringRedisTemplate.opsForValue().set(key, jsonStr, RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);return shop;}解释:为什么要设置过期时间,要保证缓存数据定时更新
3.缓存更新策略
3.1.三种策略
1.内存淘汰:Redis自带的内存淘汰机制,不需要自己维护,当Redis内存不足时会自动的淘汰(清理)部分数据,等下次查询时更新缓存即可
------------------
特性:一致性差 ,没有维护成本
2.过期淘汰:给缓存数据添加过期时间(利用expire命令设置),到期自动删除缓存,等下次查询时更新缓存即可
--------------------
特性:一致性一般,维护成本低
3.主动更新:自己编写业务逻辑,在修改数据库的同时更新缓存(主动完成数据库和缓存的同时更新)
----------------------
特性:一致性好,维护成本高
图:

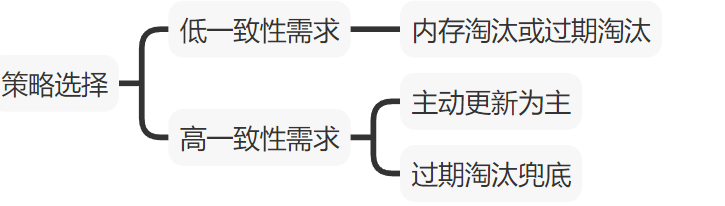
3.2.策略选择
要求数据低一致性
- 内存淘汰或过期淘汰
要求数据高一致性
- 主动更新为主,过期淘汰兜底
图:
3.3.主动更新的方案
方案一:Cache Aside
介绍:由缓存调用者在更新数据库的同时更新缓存
-----------------
特性:一致性良好,实现难度一般
方案二:Read/Write Through
介绍:缓存与数据库集成为一个服务,由服务保证两者的一致性,对外暴露API接口 ,调用者调用API即可,无需知道自己操作的是数据库还是缓存,不关心一致性问题
------------------
特性:一致性优秀,实现复杂,性能一般
方案三:Write Back
介绍:调用者只操作缓存,由其他线程来异步将缓存数据持久化到数据库,保证最终一致
-------------------
特性:一致性差,性能好,实现复杂
图:

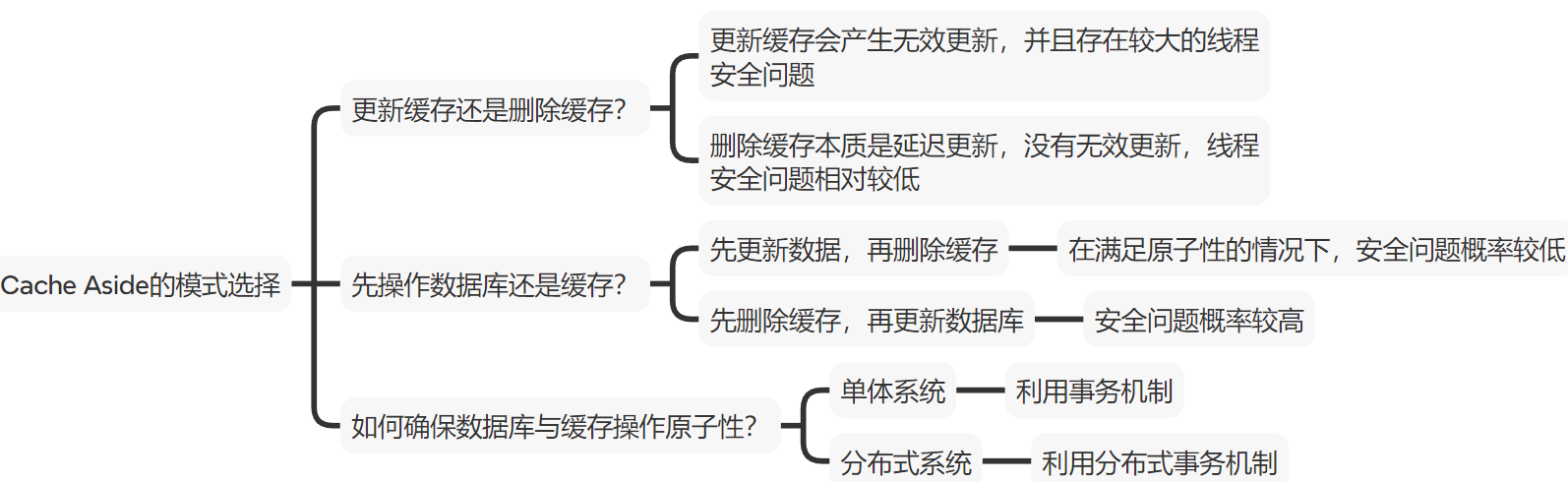
3.4. Cache Aside的模式选择
1.该模式就是开发人员手动进行数据库与缓存的代码实现
2.思考更新缓存还是删除缓存:当数据库内的数据发生改变时,那么Redis缓存是不是也需要修改(保存数据一致性),那么我们是去更新缓存,还是直接删除缓存,等要使用该数据时(此时缓存无数据,查询数据库再写入)才进行写入缓存
更新缓存:是不是每次更新数据库时都需要进行更新缓存(无效操作较大且复杂),存在较大的线程安全问题
----------------------
解释:在一个极短的时间内数据库进行了多次的更新操作,那么缓存是不是也需要进行相同次操作,但其实数据库最后一次修改时缓存更新才是有效的
删除缓存:删除缓存的本质就是延迟更新,没有无效更新,线程安全问题相对较低
-----------------------
解释: 在一个极短的时间内数据库进行了多次的更新操作,而缓存在第一次更新操作时就进行了删除缓存,不管后面有多少次更新操作都影响不到缓存,一直等到用户点击,查询数据库时(用到数据时)才会进行缓存更新
3.思考在写操作时是先操作数据库还是缓存
先删除缓存,再更新数据库 :安全问题概率高
----------------------------
解释:
前提:假设数据库与Redis现在存的数据是100
----------------------------
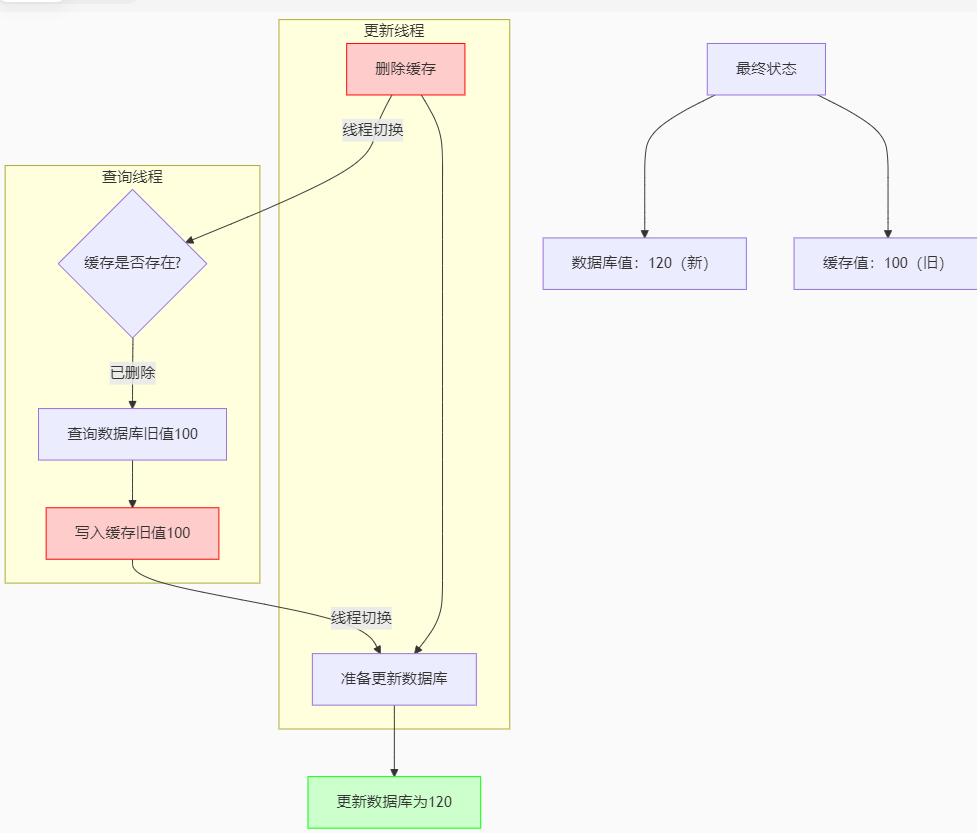
反例:当数据库进行更新时,将数据100更新为120而在更新的同时进行了查询操作
==》线程1先执行
==》线程1删除缓存(100)
==》线程2抢到执行权
==》线程2执行查询数据操作
==》线程2查询缓存没有数据(无)
==》线程2查询数据库(100)
==》线程2再将数据写入Redis缓存中(100)
==》线程2执行完,线程1执行
==》线程1更新数据库(120)
------------------------------
那么下次查询数据时由于缓存有数据,并不会更新缓存,我们发现缓存数据为100,数据库数据为120,数据不一致
先更新数据,再删除缓存: 在满足原子性的情况下,安全问题较低
--------------------------
解释:(也有反例,不过概率很低)
前提:假设数据库存的数据是100,Redis没有存数据
-------------------------
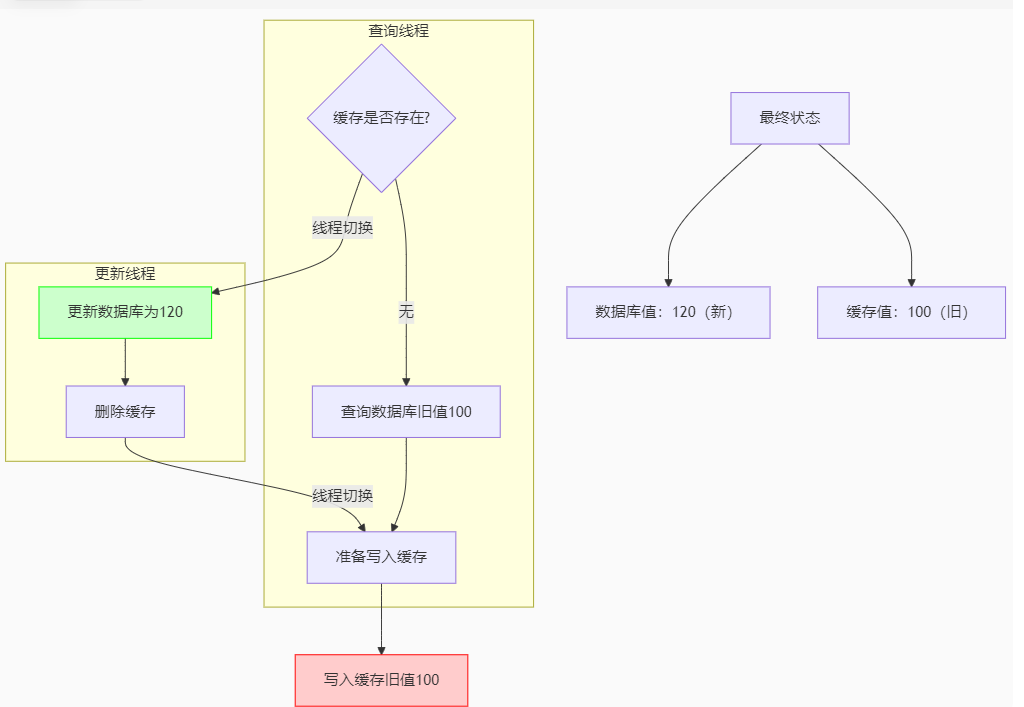
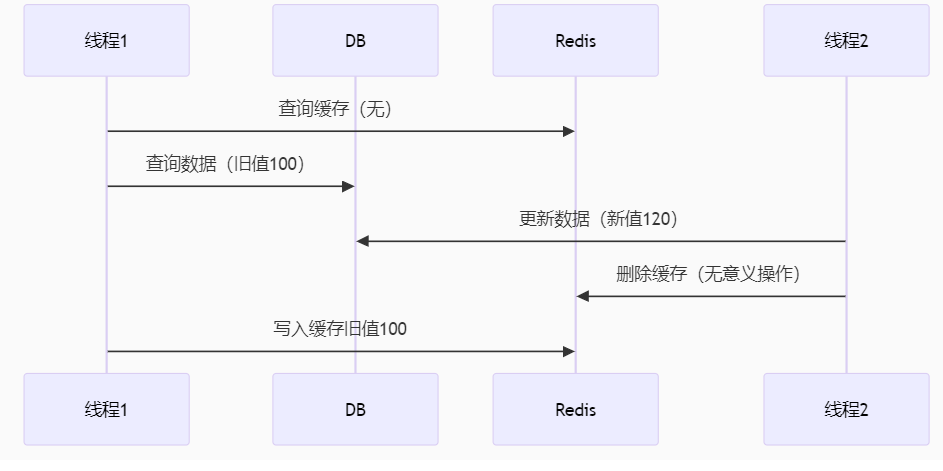
反例:在查询数据库的同时进行了更新数据库操作将100更新为120
==》线程1先执行
==》线程1查询缓存(无),不存在
==》线程1查询数据库(100)
==》线程2抢到执行权
==》线程2更新数据库(120)
==》线程2删除缓存
==》线程2执行完,线程1执行
==》线程1将数据100写入缓存(100)
--------------------------
那么下次查询数据时由于缓存有数据,并不会更新缓存,我们发现缓存数据为100,数据库数据为120,数据依旧不一致
-------------------------
注意:为什么这种概率极低呢,因为缓存的读写是基于内存的,而数据库读写基于硬盘,缓存的操作远远快于数据库操作,因此在线程1写入缓存之前,线程2要想抢到执行权来进行数据库查询的操作的概率极低
4. 如何保证数据库与缓存操作原子性
-
单体系统:利用事务机制
-
分布式系统:利用分布式事务机制
图:
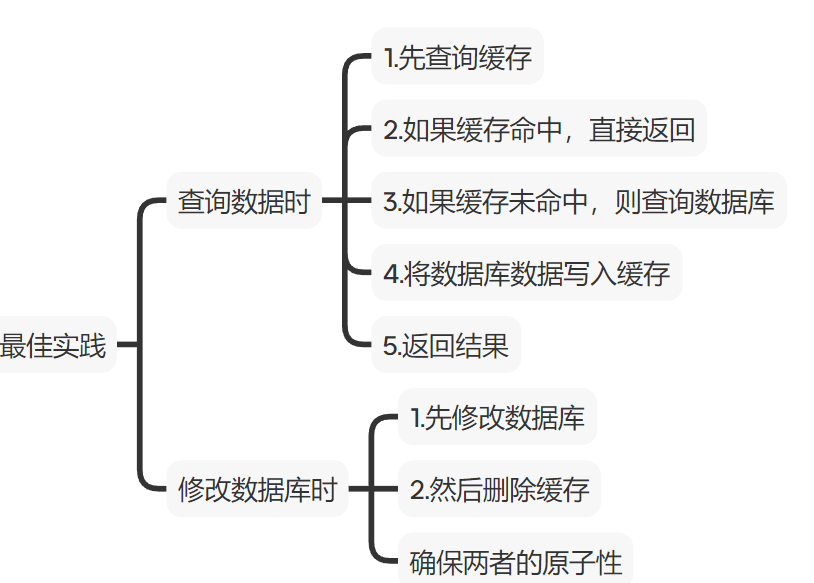
3.5.最佳实践方案
1.低一致性需求:使用Redis自带的内存淘汰机制
2.高一致性需求:主动更新,并以超时剔除作为兜底方案
读操作:
- 缓存命中直接返回
- 没命中查询数据库,并写入缓存,设置超时时间
例子:
前端提交商铺id
==》从Redis中查询缓存
==》判断缓存是否存在(是否命中)
==》命中返回商铺数据
------------------------
==》未命中
==》根据id查询数据库
==》判断数据是否存在
==》不存在返回404,存在将数据写入Redis,并且设置过期时间(过期淘汰)
==》返回商铺数据
@Autowiredprivate StringRedisTemplate stringRedisTemplate;
@Overridepublic Result queryShopById(Long id) {Shop shop = queryShopPenetrate(id);if (shop == null){return Result.fail("商铺不存在");}//6.返回商铺数据return Result.ok(shop);}public Shop queryShopPenetrate(Long id) {//1.查询RedisString key = RedisConstants.CACHE_SHOP_KEY + id;String strShop = stringRedisTemplate.opsForValue().get(key);//2.判断是否存在if (StrUtil.isNotBlank(strShop)) {//存在直接返回Shop shop = JSONUtil.toBean(strShop, Shop.class);return shop;}//3.不存在,查询数据库Shop shop = getById(id);//4.判断是否存在if (shop == null) {return null;}//5.存在,存入RedisString jsonStr = JSONUtil.toJsonStr(shop);stringRedisTemplate.opsForValue().set(key, jsonStr, RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);return shop;}写操作:
- 先写数据库,然后再删除缓存
- 确保数据库与缓存操作的原子性
例子:
@Override@Transactionalpublic Result updateShop(Shop shop) {//1.判断商铺是否存在Long id = shop.getId();String key = RedisConstants.CACHE_SHOP_KEY + id;if (id == null) {return Result.fail("商铺不存在");}//2.先更新数据库updateById(shop);//3.删除RedisstringRedisTemplate.delete(key);return Result.ok();}图:
4.缓存三大问题
4.1.缓存穿透
4.1.1.介绍
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求最终都会打到数据库中
例子:数据库和Redis缓存中都没有数据,但是用户一直频繁访问发出请求,导致大量请求直接打到数据库上,导致数据库崩塌
4.1.2.解决方案
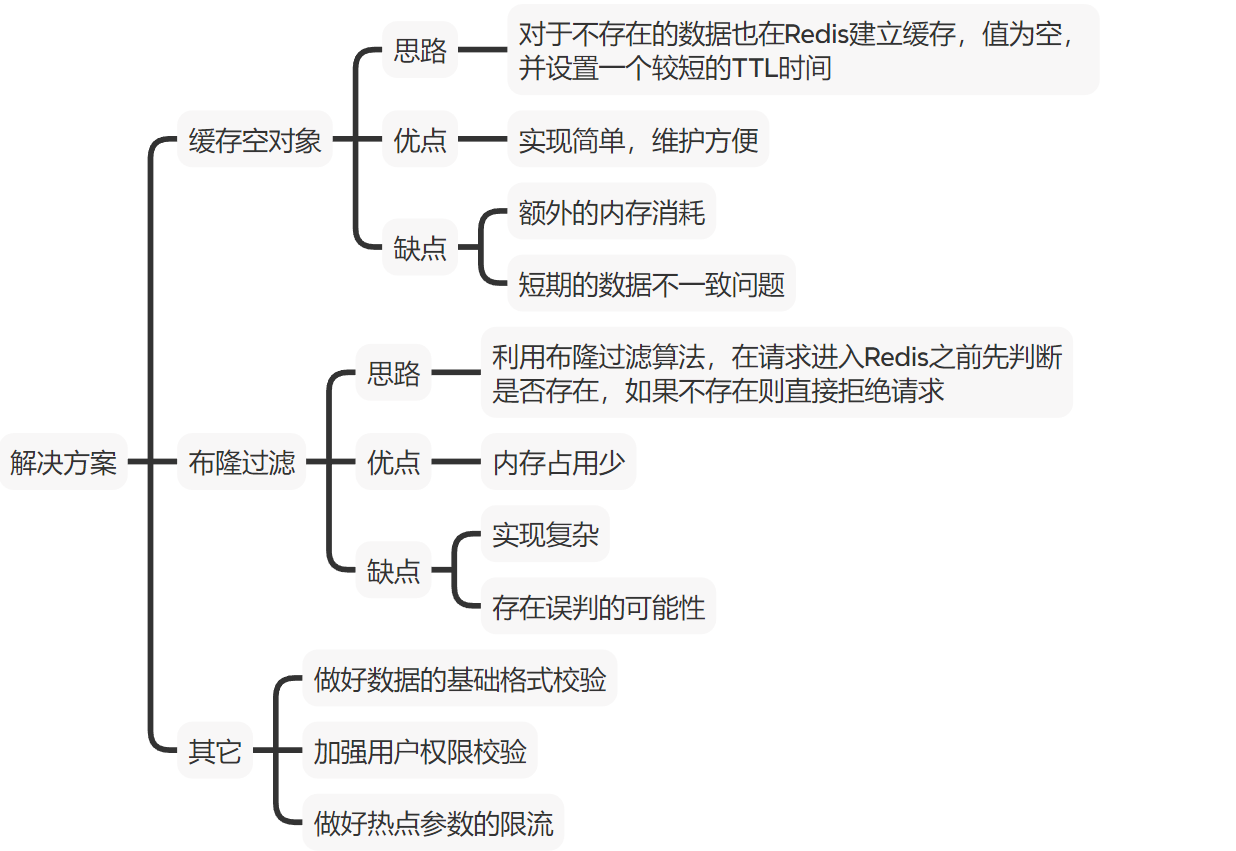
方案一:缓存空对象
- 思路:对不存在的数据也在Redis中建立缓存值,值为空,并且设置一个较短的时间
- 优点:实现简单,维护方便
- 缺点:有额外的内存消耗,短期的数据不一致问题
解释:为什么要设置一个有过期时间的缓存空值,不是用户频繁请求吗,那么我们就给它一个值,防止压力数据库,不过这样会造成数据不一致问题,就是当数据设置空值后,正好数据库添加了相应的数据,那么此时数据将不一致(不过由于我们设置的是较短的过期时间,所以数据不一致时间存在时间不会太久),由于你设置了空值(不必要值),那么会造成内存的消耗
方案二:布隆过滤
- 思路:利用布隆过滤算法,在请求进入Redis之前先判断是否存在,如果不存在则直接拒绝请求
- 优点:内存占用少
- 缺点:实现复杂,存在误判的可能性
解释:本质就是将数据库,Redis中的数据基于一种哈希算法计算出哈希值,再转化成二进制,最终存入过滤器中(1就是存在值,0就是不存在值)
注意:基于哈希算法,那么就会出现哈希冲突问题,导致过滤器判断存在数据可能数据库/Redis中并没有数据(不存在数据就一定不存在,存在有可能不存在)
方案三:细节
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
4.1.3.实现
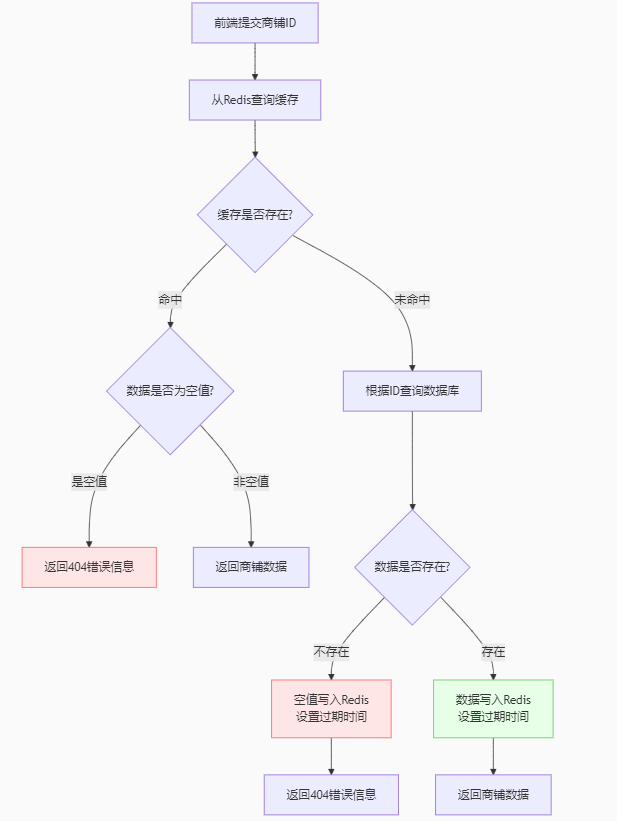
步骤:
前端提交商铺id
==》从Redis中查询缓存
==》判断缓存是否存在(是否命中)
==》命中
==》判断数据是否为空值
==》空值直接返回错误信息,不为空返回商铺数据
------------------------
==》未命中
==》根据id查询数据库
==》判断数据是否存在
==》不存在将空值(设置过期时间)存入Redis,存在将数据写入Redis,并且设置过期时间(过期淘汰)
==》返回商铺数据
@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Overridepublic Result queryShopById(Long id) {//缓存穿透Shop shop = queryShopPenetrate(id);if (shop == null){return Result.fail("商铺不存在");}//6.返回商铺数据return Result.ok(shop);}//穿透public Shop queryShopPenetrate(Long id) {//1.查询RedisString key = RedisConstants.CACHE_SHOP_KEY + id;String strShop = stringRedisTemplate.opsForValue().get(key);//2.判断是否存在if (StrUtil.isNotBlank(strShop)) {//存在直接返回Shop shop = JSONUtil.toBean(strShop, Shop.class);return shop;}if (strShop != null) {return null;}//3.不存在,查询数据库Shop shop = getById(id);//4.判断是否存在if (shop == null) {stringRedisTemplate.opsForValue().set(key, "", RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}//5.存在,存入RedisString jsonStr = JSONUtil.toJsonStr(shop);stringRedisTemplate.opsForValue().set(key, jsonStr, RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);return shop;}图:
4.2.缓存雪崩
4.2.1.介绍
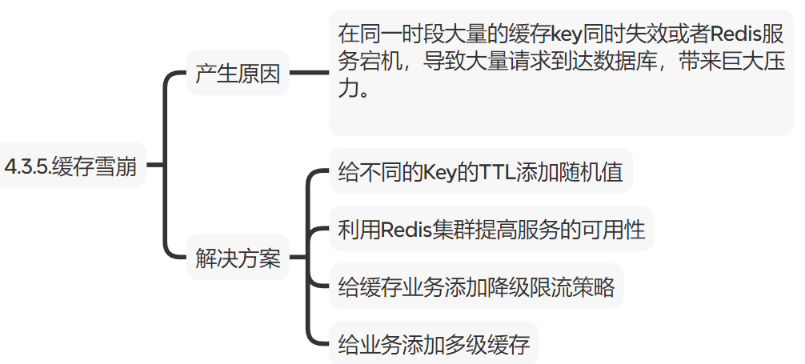
缓存雪崩是在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
4.2.2.解决方案
-
给不同的Key的过期时间添加随机值
-
利用Redis集群提高服务的可用性
-
给缓存业务添加降级限流策略
-
给业务添加多级缓存
解释:
给不同的Key的过期时间添加随机值:避免key同时失效
利用Redis集群提高服务的可用性:利用集群,主从,哨兵机制(主机宕机,从来代主实现并且从与主的数据一致)
给缓存业务添加降级限流策略:当整个机房都挂了(Redis都掉了),出现了超大故障时,直接返回拒绝服务,避免请求压力到数据库
给业务添加多级缓存:1.浏览器缓存静态数据 2.nginx缓存数据 3.jvm内部本地缓存 4.Redis缓存 5.数据库储存
图:
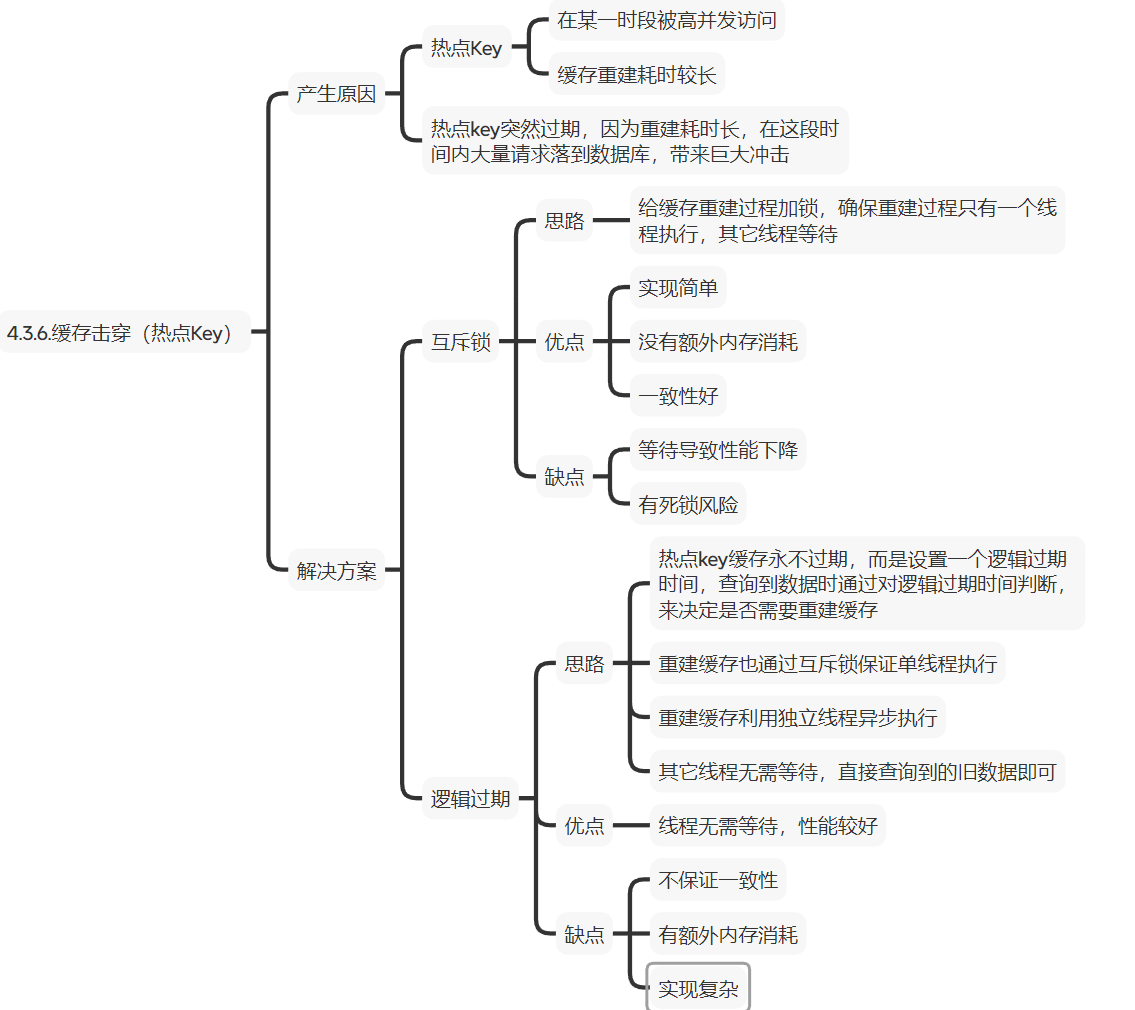
4.3.缓存击穿
4.3.1.介绍
缓存击穿就是热点key问题:就是一个被高并发访问(访问频率高)并且缓存重建业务较复杂(查询数据库业务复杂,耗时长)的key突然失效了,那么无数的请求访问会在一瞬间给数据库带来巨大冲击
4.3.2.解决方案
方案一:互斥锁
- 思路:给缓存重建过程加锁,确保重建过程只有一个线程执行,其他线程等待它执行完成
- 优点:实现简单,没有额外的内存消耗,一致性好
- 缺点:等待导致性能下降,有死锁风险
解释:基于Redis中的命令setnx来实现锁,由于setnx命令是key有值就不赋值,没有才创建key并且赋值,利用这个特性实现自定义锁(只有第一个人可以成功写入数据,其他人就不能),而由于多个线程同时访问时都需要等待(如果重建时间久)那么性能将会减低
方案二:逻辑过期
- 思路:热点key缓存永不过期,而是设置一个逻辑过期时间,查询到数据时通过对逻辑过期时间判断,来决定是否需要重建缓存
- 优点:线程无需等待,性能较好
- 缺点:不保证一致性,有额外内存消耗,实现复杂
解释:由于是热点key那么在一段时间(活动时间内),key应该不会去修改(活动之前就会缓存好key),那么我们也不需要进行key的自动删除(设置真正的过期时间),设置逻辑时间,根据实际时间与逻辑时间对比,那么我们就可以知道key是否过期,来进行对应操作
4.3.3.实现
方案一:互斥锁
步骤:
前端提交商铺id
==》线程1从Redis中查询缓存
==》线程1判断缓存是否存在(是否命中)
==》命中
==》线程1判断数据是否为空值
==》空值直接返回错误信息,不为空返回商铺数据
------------------------
==》未命中
==》线程1尝试获取互斥锁
==》线程1判断是否获取到锁
==》线程1获取到锁
==》线程1再次检查缓存是否存在
==》缓存存在直接返回缓存,不存在查询
==》线程1根据id查询数据库
==》线程1判断数据是否存在
==》线程1不存在将空值(设置过期时间)存入Redis,存在将数据写入Redis,并且设置过期时间(过期淘汰)
==》线程1释放锁
==》线程1返回商铺数据
--------------------------
==》线程2在线程1还未释放锁时也执行查询操作
==》线程2尝试获取锁
==》线程2判断是否获取到锁
==》线程2未获取到锁
==》线程2休眠一段时间并且返回到查询Redis缓存操作阶段
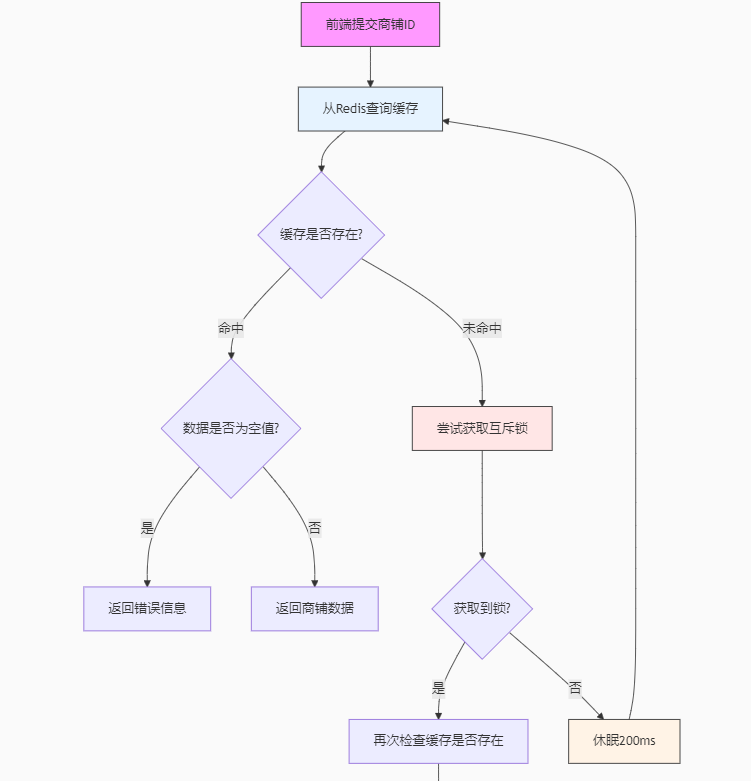
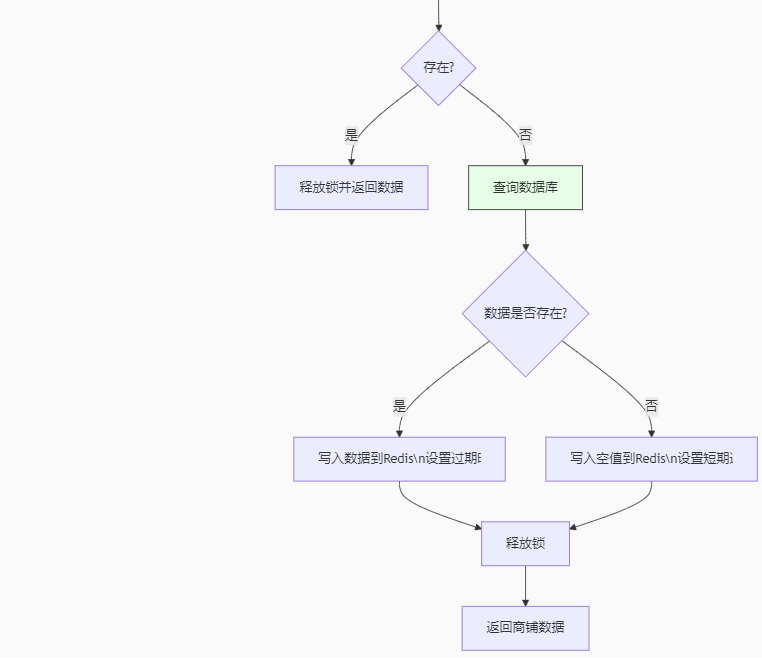
@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Overridepublic Result queryShopById(Long id) {//互斥锁缓存击穿Shop shop = queryShopBreakdown(id);if (shop == null){return Result.fail("商铺不存在");}//返回商铺数据return Result.ok(shop);}//基于互斥锁,击穿public Shop queryShopBreakdown(Long id) {//1.查询RedisString key = RedisConstants.CACHE_SHOP_KEY + id;String strShop = stringRedisTemplate.opsForValue().get(key);//2.判断是否存在if (StrUtil.isNotBlank(strShop)) {//存在直接返回Shop shop = JSONUtil.toBean(strShop, Shop.class);return shop;}if (strShop != null) {return null;}//获取锁String lockKey = RedisConstants.LOCK_SHOP_KEY + id;Shop shop = null;try {Boolean lock = lock(lockKey);if(!lock){//获取锁失败,递归Thread.sleep(50);return queryShopBreakdown(id);}//获取锁,再次查询缓存strShop = stringRedisTemplate.opsForValue().get(key);//判断缓存是否存在if (StrUtil.isNotBlank(strShop)) {//存在直接返回Shop shop = JSONUtil.toBean(strShop, Shop.class);return shop;}if (strShop != null) {return null;}//3.不存在,查询数据库shop = getById(id);//4.判断是否存在if (shop == null) {stringRedisTemplate.opsForValue().set(key, "", RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}//5.存在,存入RedisString jsonStr = JSONUtil.toJsonStr(shop);stringRedisTemplate.opsForValue().set(key, jsonStr, RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);} catch (InterruptedException e) {throw new RuntimeException(e);} finally {//移除锁removeLock(lockKey);}return shop;}//获取锁public Boolean lock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", RedisConstants.LOCK_SHOP_TTL, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);}//释放锁public void removeLock(String key) {stringRedisTemplate.delete(key);}解释:就是当第一个线程获取到锁后并且还没有释放锁,而其本质就是利用命令setnx来建立key赋值并且设置过期时间,在没有线程获取到锁时(没有线程赋值key)那么此时setnx命令是可以执行成功的,执行成功返回对应数字(成功返回1,不成功返回0)根据数字判断是否成功赋值从而判断是否获取到锁。
那么其他线程获取不到锁那就说明锁未释放(删除key),线程就一直等待直到第一个线程释放锁
注意:我们在删除锁时(没有删除)或者是程序出错了,导致锁没有释放,那么就会出现死锁,因此我们预估业务执行时间,给锁设置一个过期时间防止出现该问题
当线程拿到锁时,我们还需要查询Redis来判断缓存是否存在,可能会出现在线程拿到锁之前正好有一个线程刚好释放了锁(已经完成了写入缓存的操作),那么为了效率我们要再次判断缓存是否存在
方案二:逻辑过期
步骤:
前端提交商铺id
==》线程1从Redis中查询缓存
==》线程1判断缓存是否存在(是否命中)
==》未命中
==》直接返回空值
------------------------
==》命中
==》线程1判断缓存是否过期(逻辑时间)
==》过期
==》线程1尝试获取互斥锁
==》线程1判断是否获取到锁
==》线程1获取到锁
==》线程1开启新线程2
==》线程1直接返回旧商铺数据
-------------------------
==》线程2再次检查缓存是否过期
==》缓存没有过期直接返回缓存,过期查询
==》线程2根据id查询数据库
==》线程2判断数据是否存在
==》线程2不存在将空值(设置过期时间)存入Redis,存在将数据(设置逻辑过期时间)写入Redis
==》线程2释放锁
--------------------------
==》线程1未获取到锁
==》线程1直接返回旧商铺数据
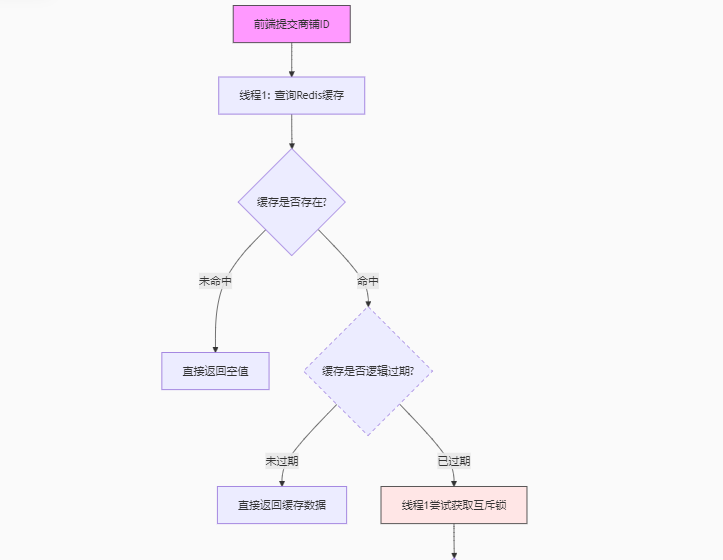
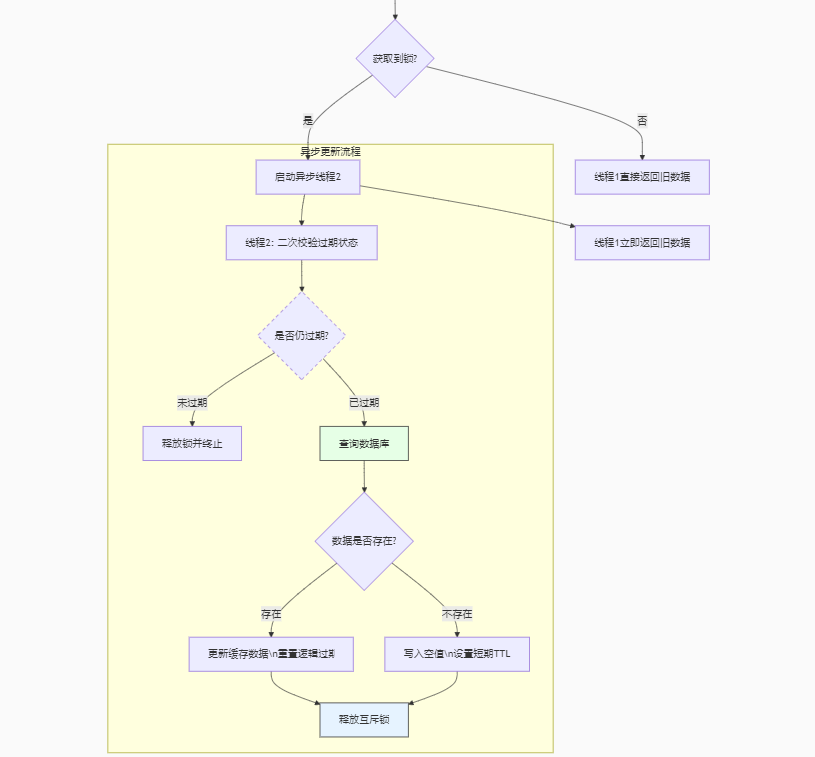
@Autowiredprivate StringRedisTemplate stringRedisTemplate;private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);@Overridepublic Result queryShopById(Long id) {//逻辑Shop shop = queryExpireTime(id);if (shop == null){return Result.fail("商铺不存在");}//返回商铺数据return Result.ok(shop);}//逻辑public Shop queryExpireTime(Long id) {//1.查询RedisString key = RedisConstants.CACHE_SHOP_KEY + id;String strShop = stringRedisTemplate.opsForValue().get(key);//一定存在//2.判断是否存在if (StrUtil.isBlank(strShop)) {//不存在直接返回return null;}//3.存在,判断过期时间RedisData redisData = JSONUtil.toBean(strShop, RedisData.class);LocalDateTime expireTime = redisData.getExpireTime();JSONObject data = (JSONObject) redisData.getData();Shop shop = JSONUtil.toBean(data, Shop.class);if(expireTime.isAfter(LocalDateTime.now())){//没有过期,直接返回return shop;}//4.过期//获取锁String lockKey = RedisConstants.LOCK_SHOP_KEY + id;Boolean lock = lock(lockKey);if(lock){//获取锁//再次判断缓存是否过期strShop = stringRedisTemplate.opsForValue().get(key);//一定存在//判断缓存是否存在if (StrUtil.isBlank(strShop)) {//不存在直接返回return null;}//存在,判断过期时间RedisData redisData = JSONUtil.toBean(strShop, RedisData.class);LocalDateTime expireTime = redisData.getExpireTime();JSONObject data = (JSONObject) redisData.getData();Shop shop = JSONUtil.toBean(data, Shop.class);if(expireTime.isAfter(LocalDateTime.now())){//没有过期,直接返回return shop;}//过期,开启线程CACHE_REBUILD_EXECUTOR.submit(() ->{try {this.expireTime(id,20L);} catch (Exception e) {throw new RuntimeException(e);} finally {//释放锁removeLock(lockKey);}});}//没有获取锁return shop;}//存入逻辑Redispublic void expireTime(Long id,Long expire){//根据id查询数据库Shop shop = getById(id);//存入RedisRedisData redisData = new RedisData();redisData.setExpireTime(LocalDateTime.now().plusSeconds(expire));redisData.setData(shop);stringRedisTemplate.opsForValue().set(RedisConstants.CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(redisData));}
解释:由于是热点key问题(key不会过期),你想一般在活动开始之前这些key是不是就需要准备好(已经缓存好了),所以说明什么,key一定是存在的(不存在,那么该key不是属于该活动返回空值就行),那么我们可以将之前设置给key的过期时间改为逻辑时间(key在活动时间内一定存在,逻辑时间就是活动时间),我们之后只需要判断活动是否已经结束就行(将逻辑时间与实际时间对比),未过期直接返回数据
过期,线程1获取锁,没有获取到说明已经有线程在执行,那么线程1也不需要等待直接返回一个旧的数据(只要锁没有释放,其他线程无需等待直接返回旧的数据),获取到锁,线程1开启一个新的线程2来执行重建缓存操作,而线程1还是直接返回旧的数据
注意:获取到锁成功后还需要判断Redis缓存是否过期,可能在线程拿到锁之前正好有另外一个线程刚好重建了缓存(更新了逻辑时间),那么我们需要再次判断避免重复构建
细节:由于之前实体类你没有单独设置一个逻辑时间属性,那么此时你需要用到该属性该怎么办
方法一:创建一个新的实体类写入时间属性,让原先实体类来继承
缺点:修改了原先实体类数据,并且以后每次需要实现逻辑时间属性时你都需要继承该类,过于繁琐
方法二:创建一个新实体类,写入时间属性并且写入Object类型属性,将原先的实体类数据封装到Object中即可
优点:实现了复用性,不需要修改原先实体类数据
总结:组合优先于继承
图:
4.4.封装缓存工具
实现:
import cn.hutool.core.util.BooleanUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.hmdp.entity.RedisData;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;@Slf4j
@Component
public class CacheUtils {//注入private final StringRedisTemplate stringRedisTemplate;public CacheUtils(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}//线程池private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);//穿透,写入Redisprivate void set(Long time, TimeUnit unit, String key, Object value) {String jsonStr = JSONUtil.toJsonStr(value);stringRedisTemplate.opsForValue().set(key, jsonStr, time, unit);}//击穿,写入Redisprivate void setTime(Long time, TimeUnit unit, String key, Object value) {RedisData redisData = new RedisData();redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));redisData.setData(value);stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(redisData));}//穿透public <R,ID> R queryPenetrate(String keyPrefix, ID id, Class<R> type, Function<ID,R> function,Long time,TimeUnit unit) {//1.查询RedisString key = keyPrefix + id;String JSON = stringRedisTemplate.opsForValue().get(key);//2.判断是否存在if (StrUtil.isNotBlank(JSON)) {//存在直接返回return JSONUtil.toBean(JSON, type);}if (JSON != null) {return null;}//3.不存在,查询数据库R r = function.apply(id);//4.判断是否存在if (r == null) {set(RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES, key, "");return null;}//5.存在,存入Redisthis.set(time, unit, key, r);return r;}//逻辑击穿public <R,ID> R queryExpireTime(String keyPrefix, String lockPrefix,ID id, Class<R> type, Function<ID,R> function,Long time,TimeUnit unit) {//1.查询RedisString key = keyPrefix + id;String JSON = stringRedisTemplate.opsForValue().get(key);//一定存在//2.判断是否存在if (StrUtil.isBlank(JSON)) {//不存在直接返回return null;}//3.存在,判断过期时间RedisData redisData = JSONUtil.toBean(JSON, RedisData.class);LocalDateTime expireTime = redisData.getExpireTime();JSONObject data = (JSONObject) redisData.getData();R r = JSONUtil.toBean(data, type);if(expireTime.isAfter(LocalDateTime.now())){//没有过期,直接返回return r;}//4.过期//获取锁String lockKey = lockPrefix + id;Boolean lock = lock(lockKey);if(lock){//获取锁//开启线程CACHE_REBUILD_EXECUTOR.submit(() ->{try {//根据id查询数据库R r1 = function.apply(id);//存入Redisthis.setTime(time,unit,key,r1);} catch (Exception e) {throw new RuntimeException(e);} finally {//释放锁removeLock(lockKey);}});}//没有获取锁return r;}//获取锁public Boolean lock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", RedisConstants.LOCK_SHOP_TTL, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);}//释放锁public void removeLock(String key) {stringRedisTemplate.delete(key);}
}解释:由于是封装工具,那么我们需要做到多样性,方法传参时不能定义死,采用泛型来实现复用性,由于使用的是mybatis-plus工具(需要查询数据库)而我们的实体类不能确定,因此需要传参Class以及泛型函数
相关文章:

【 Redis | 实战篇 缓存 】
目录 前言: 1.认识缓存 2.添加Redis缓存 2.1.根据id查询商铺缓存 2.2.优化根据id查询商铺缓存 3.缓存更新策略 3.1.三种策略 3.2.策略选择 3.3.主动更新的方案 3.4. Cache Aside的模式选择 3.5.最佳实践方案 4.缓存三大问题 4.1.缓存穿透 4.1.1.介绍 …...
)
数字果园管理系统的设计与实现(Tensorflow的害虫识别结合高德API的害虫定位与Websocket的在线聊天室)
文章目录 技术栈主要功能害虫识别与定位害虫识别的实现训练与测试评估代码模型转化为TFLite预测脚本PredictController预测控制器害虫识别过程展示 害虫定位实现害虫定位代码害虫定位过程展示 专家咨询功能在线咨询聊天室主要前端代码如下主要后端代码如下 技术栈 Spring Boot…...
)
信息检索(包含源码)
实验目的 掌握逻辑回归模型在二分类问题中的应用方法熟悉机器学习模型评估指标PR曲线(精确率-召回率曲线)和ROC曲线(受试者工作特征曲线)的绘制与分析学习使用Python的scikit-learn库进行数据预处理、模型训练与评估理解特征选择…...
)
【金仓数据库征文】金仓数据库KingbaseES: 技术优势与实践指南(包含安装)
目录 前言 引言 一 : 关于KingbaseES,他有那些优势呢? 核心特性 典型应用场景 政务信息化 金融核心系统: 能源通信行业: 企业级信息系统: 二: 下载安装KingbaseES 三:目录一览表: 四:常用SQL语句 创建表: 修改表结构…...

Java数据结构——二叉树
二叉树 树的概念二叉树满二叉树和完全二叉树二叉树的性质二叉树的遍历 题目练习前序遍历中序遍历后序遍历 前言 已经知道了数据结构中的线性结构,那有没有非线性结构呢? 当然有就像我们文件夹,一个文件夹中有有另一个文件夹,这就是…...
--- 版本2)
用go从零构建写一个RPC(仿gRPC,tRPC)--- 版本2
在版本1中,虽然系统能够满足基本需求,但随着连接数的增加和处理请求的复杂度上升,性能瓶颈逐渐显现。为了进一步提升系统的稳定性、并发处理能力以及资源的高效利用,版本2引入了三个重要功能:客户端连接池、服务器长连…...

drf 使用jwt
安装jwt pip install pyJwt 添加登录url path("jwt/login",views.JwtLoginView.as_view(),namejwt-login),path("jwt/order",views.JwtOrderView.as_view(),namejwt-order), 创建视图 from django.contrib.auth import authenticateimport jwt from jw…...

202536 | KafKa生产者分区写入策略+消费者分区分配策略
KafKa生产者分区写入策略 1. 轮询分区策略(Round-Robin Partitioning) 轮询分区策略 是 Kafka 默认的分配策略,当消息没有指定 key 时,Kafka 会采用轮询的方式将消息均匀地分配到各个分区。 工作原理: 每次生产者发…...

《自动驾驶封闭测试场地建设技术要求》 GB/T 43119-2023——解读
目录 一、标准框架与核心内容 二、重点技术要求 三、实施要点与建议 四、实施时间与参考依据 原文链接:国家标准|GB/T 43119-2023 (发布:2023-09-07;实施:2024-01-01) 一、标准框架与核心内容 适用范围…...
内附思维导图 通俗易懂)
【C++ Qt】容器类(GroupBox、TabWidget)内附思维导图 通俗易懂
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” ✍️绪论: 本章主要介绍了 Qt 中 QGroupBox 与 QTabWidget 控件。QGroupBox 是带标题的分组框,能容纳其他控件,有标题、对齐方式、是否…...

【SpringBoot】从环境准备到创建SpringBoot项目的全面解析.
本篇博客给大家带来的是SpringBoot的知识点, 包括Idea的干净卸载… 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要…...

基于ESP32控制的机器人摄像头车
DIY Wi-Fi 控制的机器人摄像头车:从零开始的智能探索之旅 在当今科技飞速发展的时代,机器人技术已经逐渐走进了我们的生活。今天,我将带你一起探索如何制作一个 Wi-Fi 控制的机器人摄像头车,它不仅可以远程操控,还能通…...

Excel图表 vs 专业可视化工具:差距有多大?内容摘要
你是不是还在用 Excel 做图表,觉得它已经够用了?但你知道吗,Excel 和专业的可视化工具之间其实有着巨大的差距!Excel 是办公必备,但它的图表功能真的能满足复杂的数据展示需求吗?而那些听起来高大上的专业可…...

Nacos源码—7.Nacos升级gRPC分析三
大纲 5.服务变动时如何通知订阅的客户端 6.微服务实例信息如何同步集群节点 5.服务变动时如何通知订阅的客户端 (1)服务注册和服务订阅时发布的客户端注册和订阅事件的处理 (2)延迟任务的执行引擎源码 (3)处理客户端注册和订阅事件时发布的服务变动和服务订阅事件的处理 (…...

量化学习DAY2-开始批量提交alpha!
量化学习第二天笔记 一、World Quant平台的Alpha概念 在World Quant平台中,alpha本质上是一个数学公式,它是**operator(操作)与Data(数据)**的组合。 (一)Data相关 Data…...

【Qwen3_ 4b lora xinli 】 task完成实践记录
task 我需要 基于llamafactory框架选取基本上相同的数据集用lora微调Qwen3_ 4b两次并保存lora参数然后分别合并这两个lora参数到基座模型。再换个数据集上接着进行微调。并且保存新的lora参数,然后我们匹配这里面的特征值和特征向量,如果这两个新的lora…...
)
文旅田园康养小镇规划设计方案PPT(85页)
1. 项目背景与定位 背景:位于长三角经济圈,依托安吉丰富的自然与文化资源,旨在打造集康养、度假、文化体验于一体的综合小镇。 定位:成为浙北地区知名的康养旅游目的地,融合“一溪两岸”规划理念,实现全面…...

[Windows] 能同时打开多个图片的图像游览器JWSEE v2.0
[Windows] 能同时打开多个图片的图像游览器JWSEE 链接:https://pan.xunlei.com/s/VOPpO86Hu3dalYLaZ1ivcTGIA1?pwdhckf# 十多年前收藏的能同时打开多个图片的图像游览器JWSEE v2.0,官网已没有下载资源。 JWSEE v2.0是乌鲁木齐金维图文信息科技有限公司…...

低成本自动化改造技术锚点深度解析
执行摘要 本文旨在深入剖析四项关键的低成本自动化技术,这些技术为工业转型提供了显著的运营和经济效益。文章将提供实用且深入的指导,涵盖老旧设备联网、AGV车队优化、空压机系统智能能耗管控以及此类项目投资回报率(ROI)的严谨…...

23盘古石决赛
一,流量分析 1. 计算流量包文件的SHA256值是?[答案:字母小写][★☆☆☆☆] 答案:2d689add281b477c82b18af8ab857ef5be6badf253db1c1923528dd73b3d61a9 解压出来流量包计算 2. 流量包长度在“640 - 1279”之间的的数据包总共有多少…...

C语言—指针3
1. 数组名的理解 观察以下代码 可以观察到pa指向的地址与数组首元素地址相同,那么可以说明数组就是首元素地址吗? 这种说法是不严谨的,观察以下代码: 程序输出的结果为16,此时的arr表示的是整个数组的大小。 观察以…...

操作系统 第2章节 进程,线程和作业
一:多道程序设计 1-多道程设计的目的 for:提高吞吐量(作业道数/处理时间),我们可以从提高资源的利用率出发 2-单道程序设计缺点: 设备的利用率低,内存的利用率低,处理机的利用率低 比如CPU去访问内存,CPU空转.内存等待CPU访问也是没有任何操作的.要是有多个东西要去访问不冲…...

数字化转型-4A架构之数据架构
系列文章 数字化转型-4A架构(业务架构、应用架构、数据架构、技术架构) 数字化转型-4A架构之业务架构 数字化转型-4A架构之应用架构 数据架构 Data Architecture(DA) 1. 定义 数据架构,是组织管理数据资产的科学之…...

Java中的反射
目录 什么是反射 反射的核心作用 反射的核心类 反射的基本使用 获取Class对象 创建对象 操作字段(Field) 调用方法(Method) 反射的应用场景 反射的优缺点 优点 缺点 示例:完整反射操作 总结 什么是反射 …...

LINUX CFS算法解析
文章目录 1. Linux调度器的发展历程2. CFS设计思想3. CFS核心数据结构3.1 调度实体(sched_entity)3.2 CFS运行队列(cfs_rq)3.3 任务结构体中的调度相关字段 4. 优先级与权重4.1 优先级范围4.2 权重映射表 (prio_to_weight[])优先级计算4.3.1. static_prio (静态优先级)4.3.2. n…...

内网渗透——红日靶场三
目录 一、前期准备 二、外网探测 1.使用nmap进行扫描 2.网站信息收集 3.漏洞复现(CVE-2021-23132) 4.disable_function绕过 5.反弹shell(也,并不是) 6.SSH登录 7.权限提升(脏牛漏洞) 8.信息收集 9.上线msf 三…...

The 2024 ICPC Kunming Invitational Contest G. Be Positive
https://codeforces.com/gym/105386/problem/G 题目: 结论: 从0开始每四个相邻数的异或值为0 代码: #include<bits/stdc.h> using namespace std; #define int long long void solve() {int n;cin >> n;if(n1||n%40){cout &…...

CommunityToolkit.Mvvm详解
属性可视化 给一个属性添加ObservableProperty就可以可视化了 [ObservableProperty] private string currentNameInfo;[ObservableProperty] private string currentClassInfo;[ObservableProperty] private string currentPhoneInfo;xaml中只需要绑定大写的属性就可以了 &l…...

密码学--AES
一、实验目的 1、完成AES算法中1轮加密和解密操作 2、掌握AES的4个基本处理步骤 3、理解对称加密算法的“对称”思想 二、实验内容 1、题目内容描述 (1)利用C语言实现字节代换和逆向字节代换,字节查S盒代换 (2)利…...

操作系统的初步了解
目录 引言:什么是操作系统? 一、设计操作系统的目的 二、操作系统是做什么的: 操作系统主要有四大核心任务: 1. 管理硬件 2. 运行软件 3. 存储数据 4. 提供用户界面 如何理解操作系统的管理呢? 1. 什么是操作…...

边缘计算:技术概念与应用详解
引言 随着物联网(IoT)、5G 和人工智能(AI)的快速发展,传统的云计算架构在处理海量数据和实时计算需求时逐渐显现出瓶颈。边缘计算(Edge Computing)作为一种新兴的计算范式,通过将计…...

C++进阶--红黑树的实现
文章目录 红黑树的实现红黑树的概念红黑树的规则红黑树的效率 红黑树的实现红黑树的结构红黑树的插入变色单旋(变色)双旋(变色) 红黑树的查找红黑树的验证 总结:结语 很高兴和大家见面,给生活加点impetus&a…...

[C++类和对象]类和对象的引入
面向过程和面向对象 C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用来逐步解决问题 C是基于面向对象的,关注的是对象,将一件事情分成不同的对象,靠对象之间完成交互 类的引入 C语言结构体中只能定义变量,在C中,结构体不仅仅可以定义变量,而且可以定义函…...

YOLOv12云端GPU谷歌免费版训练模型
1.效果 2.打开 https://colab.research.google.com/?utm_sourcescs-index 3.上传代码 4.解压 !unzip /content/yolov12-main.zip -d /content/yolov12-main 5.进入yolov12-main目录 %cd /content/yolov12-main/yolov12-main 6.安装依赖库 !pip install -r requirements.…...

课程审核流程揭秘:确保内容合规与用户体验
业务流程 为什么课程审核通过才可以发布呢? 这样做为了防止课程信息有违规情况,课程信息不完善对网站用户体验也不好,课程审核不仅起到监督作用,也是 帮助教学机构规范使用平台的手段。 如果流程复杂用工作流 说明如下ÿ…...

【LangChain高级系列】LangGraph第一课
前言 我们今天直接通过一个langgraph的基础案例,来深入探索langgraph的核心概念和工作原理。 基本认识 LangGraph是一个用于构建具有LLMs的有状态、多角色应用程序的库,用于创建代理和多代理工作流。与其他LLM框架相比,它提供了以下核心优…...

ATH12K 驱动框架
ATH12K 驱动框架 ath12k驱动框架及模块交互逻辑详解1. 总体架构2. 关键数据结构2.1 核心数据结构2.2 虚拟接口数据结构3. 硬件抽象层(HAL)4. 无线管理接口(WMI)5. 主机目标通信(HTC)6. 数据路径(DP)6.1 发送路径(TX)6.2 接收路径(RX)7. 多链路操作(MLO)8. 初始化和工作流程8.1 …...

CMA认证对象?CMA评审依据,CMA认证好处
CMA认证对象 CMA(中国计量认证,China Metrology Accreditation)的认证对象主要是第三方检测机构和实验室,包括: 独立检测机构:如环境监测站、产品质量检验所、食品药品检测机构等。 企业内部实验室&#…...

依赖关系-根据依赖关系求候选码
关系模式R(U, F), U{},F是R的函数依赖集,可以将属性分为4类: L: 仅出现在依赖集F左侧的属性 R: 仅出现在依赖集F右侧的属性 LR: 在依赖集F左右侧都出现的属性 NLR: 在依赖集F左右侧都未出现的属性 结论1: 若X是L类…...

解决应用程序在JAR包中运行时无法读取类路径下文件的问题
问题情景 java应用程序在IDE运行正常,打成jar包后执行却发生异常: java.io.FileNotFoundException: class path resource [cert/sync_signer_pri_test.key] cannot be resolved to absolute file path because it does not reside in the file system:…...

第十六届蓝桥杯B组第二题
当时在考场的时候这一道题目 无论我是使用JAVA的大数(BIGTHGER)还是赛后 使用PY 都是没有运行出来 今天也是突发奇想在B站上面搜一搜 看了才知道这也是需要一定的数学思维 通过转换 设X来把运算式精简化 避免运行超时 下面则是代码 public class lanba…...

龙虎榜——20250509
上证指数今天缩量,整体跌多涨少,走势处于日线短期的高位~ 深证指数今天缩量小级别震荡,大盘股表现更好~ 2025年5月9日龙虎榜行业方向分析 一、核心行业方向 军工航天 • 代表个股:航天南湖、天箭科技、襄阳轴承。 • 驱动逻辑…...

node提示node:events:495 throw er解决方法
前言 之前开发的时候喜欢使用高版本,追求新的东西,然后回头运行一下之前的项目提示如下 项目技术栈:node egg 报错 node:events:495 throw er; // Unhandled error event ^ Error: ENOENT: no such file or directory, scandir F:\my\gi…...
4 - eudev编译(获取libudev.so))
OrangePi Zero 3学习笔记(Android篇)4 - eudev编译(获取libudev.so)
目录 1. Ubuntu中编译 2. NDK环境配置 3. 编译 4. 安装 这部分主要是为了得到libudev(因为原来的libudev已经不更新了),eudev的下载地址如下: https://github.com/gentoo/eudev 相应的代码最好是在Ubuntu中先编译通过&#…...

[AI ][Dify] Dify Tool 插件调试流程详解
在使用 Dify 进行插件开发时,调试是必不可少的环节。Dify 提供了远程服务调试的能力,让开发者可以快速验证插件功能和交互逻辑。本文将详细介绍如何配置环境变量进行插件调试,并成功在插件市场中加载调试状态的插件。 一、调试环境配置 在 Dify 的插件调试过程中,我们需要…...

learning ray之ray强化学习/超参调优和数据处理
之前我们掌握了Ray Core的基本编程,我们已经学会了如何使用Ray API。现在,让我们将这些知识应用到一个更实际的场景中——构建一个强化学习项目,并且利用Ray来加速它。 我们的目标是,通过Ray的任务和Actor,将一个简单…...

gpu硬件,gpu驱动,cuda,CUDA Toolkit,cudatoolkit,cudnn,nvcc概念解析
组件角色依赖关系GPU硬件无CUDA编程模型/平台需NVIDIA GPU和驱动CUDA Toolkit开发工具包(含NVCC、库等)需匹配GPU驱动和CUDA版本cuDNN深度学习加速库需CUDA ToolkitNVCCCUDA代码编译器包含在CUDA Toolkit中 GPU硬件: 硬件层面的图形处理器&…...

【C/C++】范围for循环
📘 C 范围 for 循环详解(Range-based for loop) 一、什么是范围 for 循环? 范围 for 循环(Range-based for loop) 是 C11 引入的一种简化容器/数组遍历的方式。它通过自动调用容器的 begin() 和 end() 方法…...
)
嵌入式开发学习(第二阶段 C语言基础)
C语言:第4天笔记 内容提要 流程控制 C语句数据的输入与输出 流程控制 C语句 定义 C程序是以函数为基础单位的。一个函数的执行部分是由若干条语句构成的。C语言都是用来完成一定操作的任务。C语句必须依赖于函数存在。 C程序结构 C语句分类 1.控制语句 作…...

大物重修之浅显知识点
第一章 质点运动学 例1 知识点公式如下: 例2 例3 例4 例5 例6 第四章 刚体的转动 例1 例2 例3 例4 例5 例6 第五章 简谐振动 例1 例2 例3 第六章 机械波 第八章 热力学基础 第九章 静电场 第十一章 恒定磁场…...