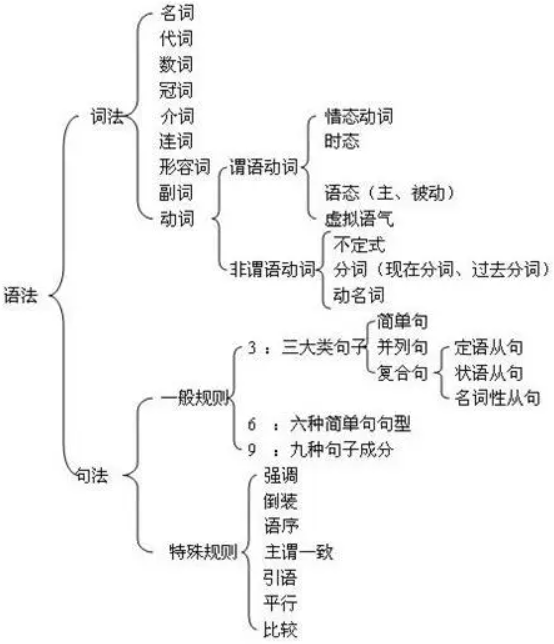
NLP基础
1. 基本概念
自然语言处理(Natural Language Processing,简称NLP)是人工智能和语言学领域的一个分支,它涉及到计算机和人类(自然)语言之间的相互作用。它的主要目标是让计算机能够理解、解释和生成人类语言的数据。NLP结合了计算机科学、人工智能和语言学的技术和理论,旨在填补人与机器之间的交流隔阂。
1.1 自然语言处理的基本介绍
1.1.1 与语言相关的概念
在定义NLP之前,先了解几个相关概念:
-
语言(Language):是人类用于沟通的一种结构化系统,可以包括声音、书写符号或手势。
-
自然语言(Natural Language):是指自然进化中通过使用和重复,无需有意计划或预谋而形成的语言。
-
计算语言学(Computational Linguistics):是语言学和计算机科学之间的跨学科领域,它包括:
a.计算机辅助语言学(Computer-aided Linguistics):利用计算机研究语言的学科,主要为语言学家所实践。
b.自然语言处理(NLP):使计算机能够解决以自然语言表达的数据问题的技术,主要由工程师和计算机科学家实践。
NLP的研究范围广泛,包括但不限于语言理解(让计算机理解输入的语言)、语言生成(让计算机生成人类可以理解的语言)、机器翻译(将一种语言翻译成另一种语言)、情感分析(分析文本中的情绪倾向)、语音识别和语音合成等。
在中文环境下,自然语言处理的定义和应用也与英文环境相似,但需要考虑中文的特殊性,如中文分词、中文语法和语义分析等,因为中文与英文在语言结构上有很大的不同,这对NLP技术的实现提出了特殊的挑战。自然语言处理使计算机不仅能够理解和解析人类的语言,还能在一定程度上模仿人类的语言使用方式,进行有效的沟通和信息交换。
1.1.2 为什么使用NLP
-
每种动物都有自己的语言,机器也是!
-
自然语言处理(NLP)就是在机器语言和人类语言之间沟通的桥梁,以实现人机交流的目的。人类通过语言来交流,猫通过喵喵叫来交流。
-
机器也有自己的语言,那就是数字信息。
-
NLP 就是让机器学会处理我们的语言!

-
人类和机器之间是否可以通过“翻译”的方式来直接交流呢?

1.2 NLP的应用方向
多种多样的NLP研究方向,paperwithcode网站上总结的有308项。
1.2.1 自然语言理解
典型的自然语言理解(NLU)任务包括:
-
情感分析:对给定的文本输入,在给定的选项范围内分析文本的情绪是正面还是负面;
-
文本分类:对给定的文本输入,在给定的选项范围内对文本进行二分类或多分类;
-
信息检索:搜索引擎依托于多种技术,如网络爬虫技术、检索排序技术、网页处理技术、大数据处理技术、自然语言处理技术等,为信息检索用户提供快速、高相关性的信息服务;

-
抽取式阅读理解:对给定的文本输入,用文本中的内容回答问题;

-
语义匹配:对给定的两个文本输入,判断是否相似;
-
自然语言推理:对给定的两个文本输入,判断是蕴涵、矛盾还是无关;
-
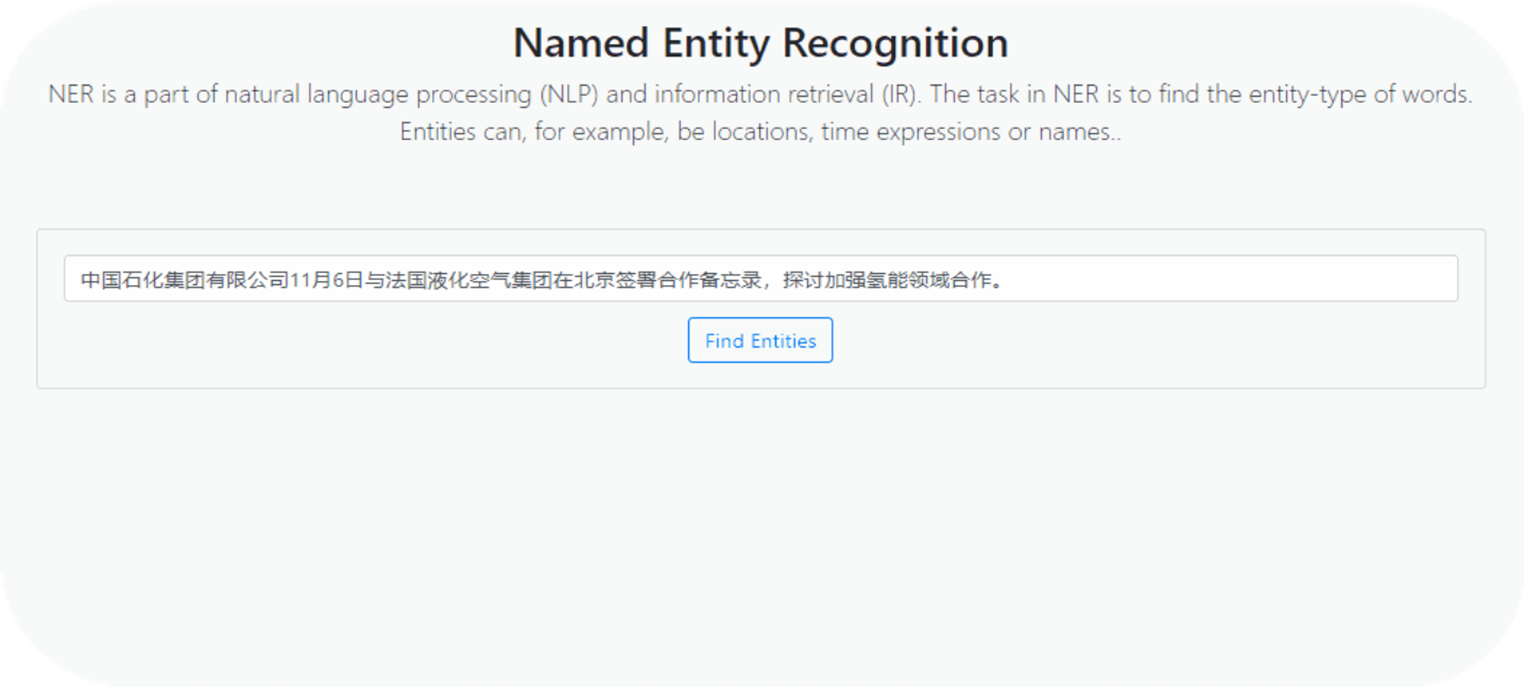
命名实体识别:对给定的文本输入,返回含有命名实体及其对应标签的映射,例如{'糖尿病':'疾病'};
-
文本摘要:对给定的文本输入,用文本中的内容对文本进行摘要。

1.2.2 自然语言转换
自然语言转换(NLT)任务包括但不限于:
-
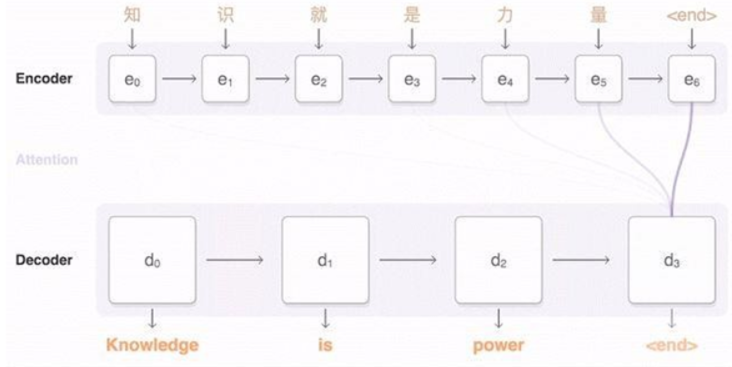
机器翻译:将一种自然语言转换为另一种自然语言,包括从源语言到目标语言的文本或语音的转换;
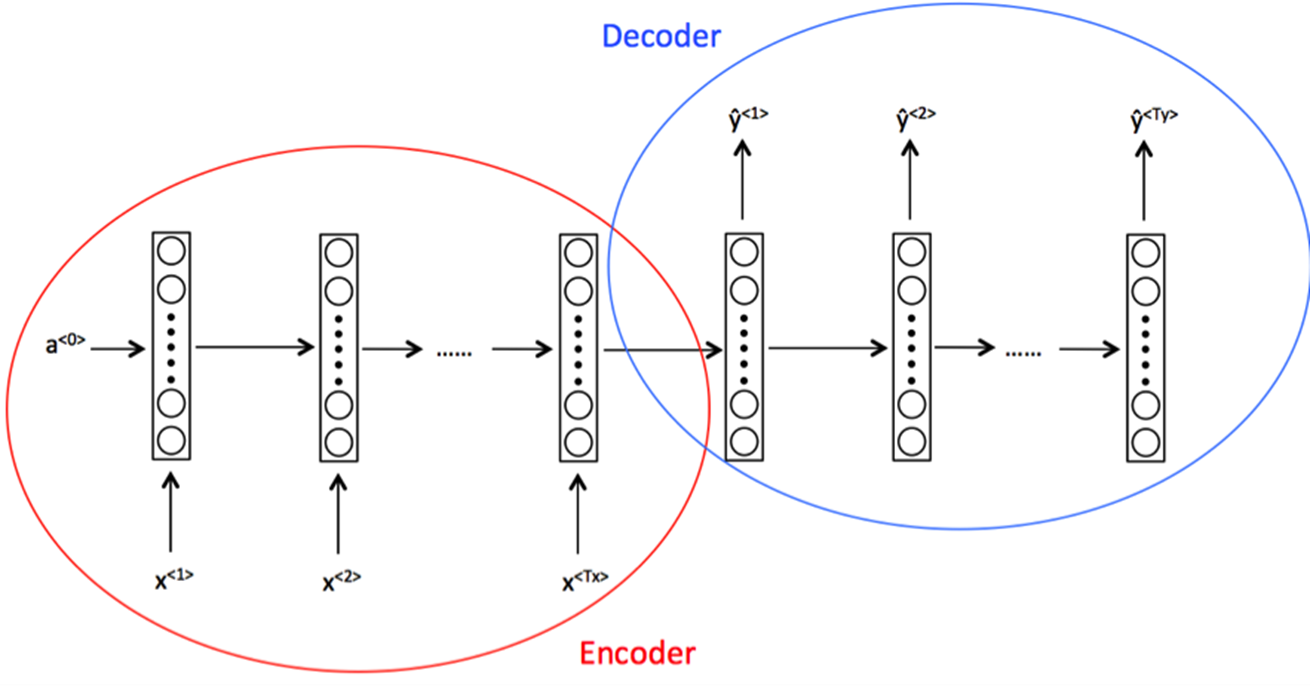
机器学习模型目前常用seq2seq模型来实现,由Encoder和Decoder组成。
-
非抽取式阅读理解:接受给定文本的输入,能够理解自然语言问题,并回答问题;
-
文本风格转换:将文本从一种风格转换为另一种风格,如将正式文本转换为非正式文本;
-
语音识别:将人类的语音转换为文本,用于语音指令、口述文本、会议记录等。
苹果的用户肯定都体验过,就是典型的语音识别,微信里有一个功能是"文字语音转文字" ,也利用了语音识别,最近流行的智能音箱就是以语音识别为核心的产品,比较新款的汽车基本都有语音控制的功能
-
意图改写:对给定的文本输入,将原始文本中的意图或核心信息重新表述,以不同的词汇和句式表达相同的意思,同时保持原意的准确性和完整性;
1.2.3 自然语言生成
自然语言生成(NLG)任务则更为灵活了:
-
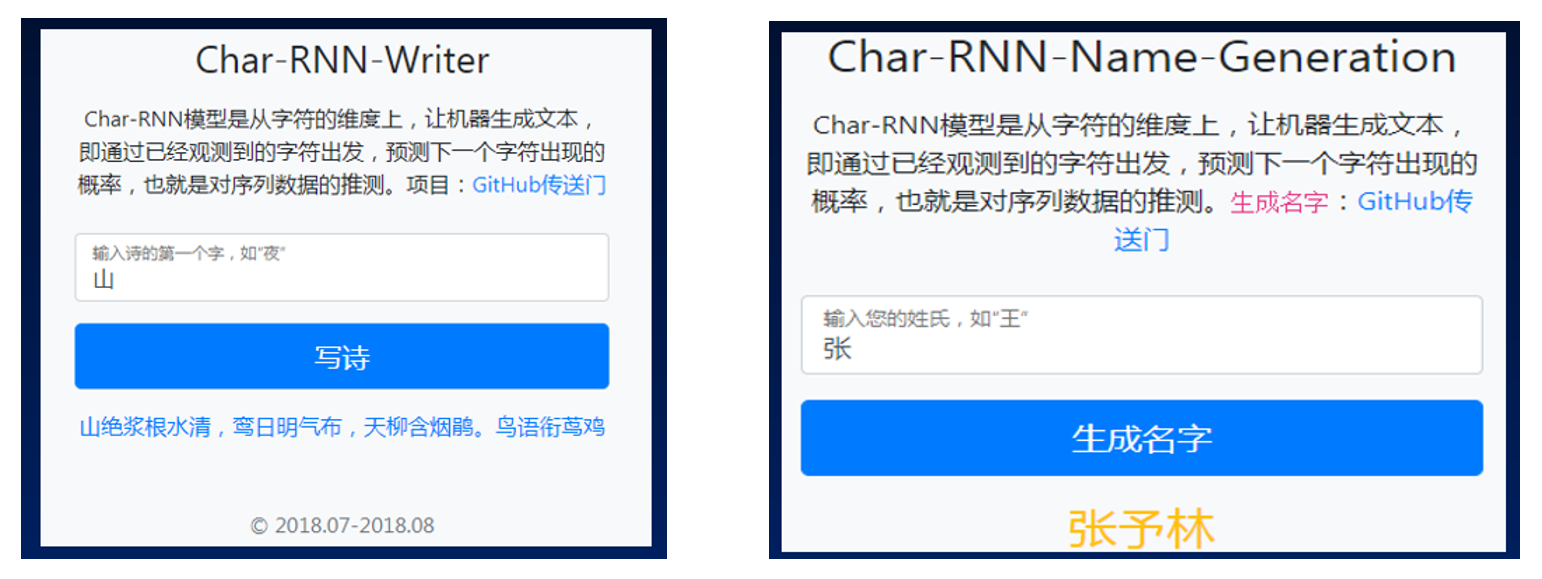
文本生成:根据给定的上下文或提示,自动生成文本,如自动写作、诗歌创作、故事生成等。
GitHub - yanqiangmiffy/char-rnn-writer: 基于Char RNN实现的“作家”应用,可以写诗也可以生成名字,看起来还:ok_hand:
-
语音合成:将文本转换为听起来自然的语音,用于有声书、导航系统、虚拟助手等。
-
聊天机器人:能够与人类实现多轮对话的聊天助手;
-
文本到知识:从文本中提取知识,构建知识图谱或语义网络;
-
语义解析:将自然语言表达转换为形式化的逻辑表示,用于命令解析、查询理解等。
应用方向又可以分为:
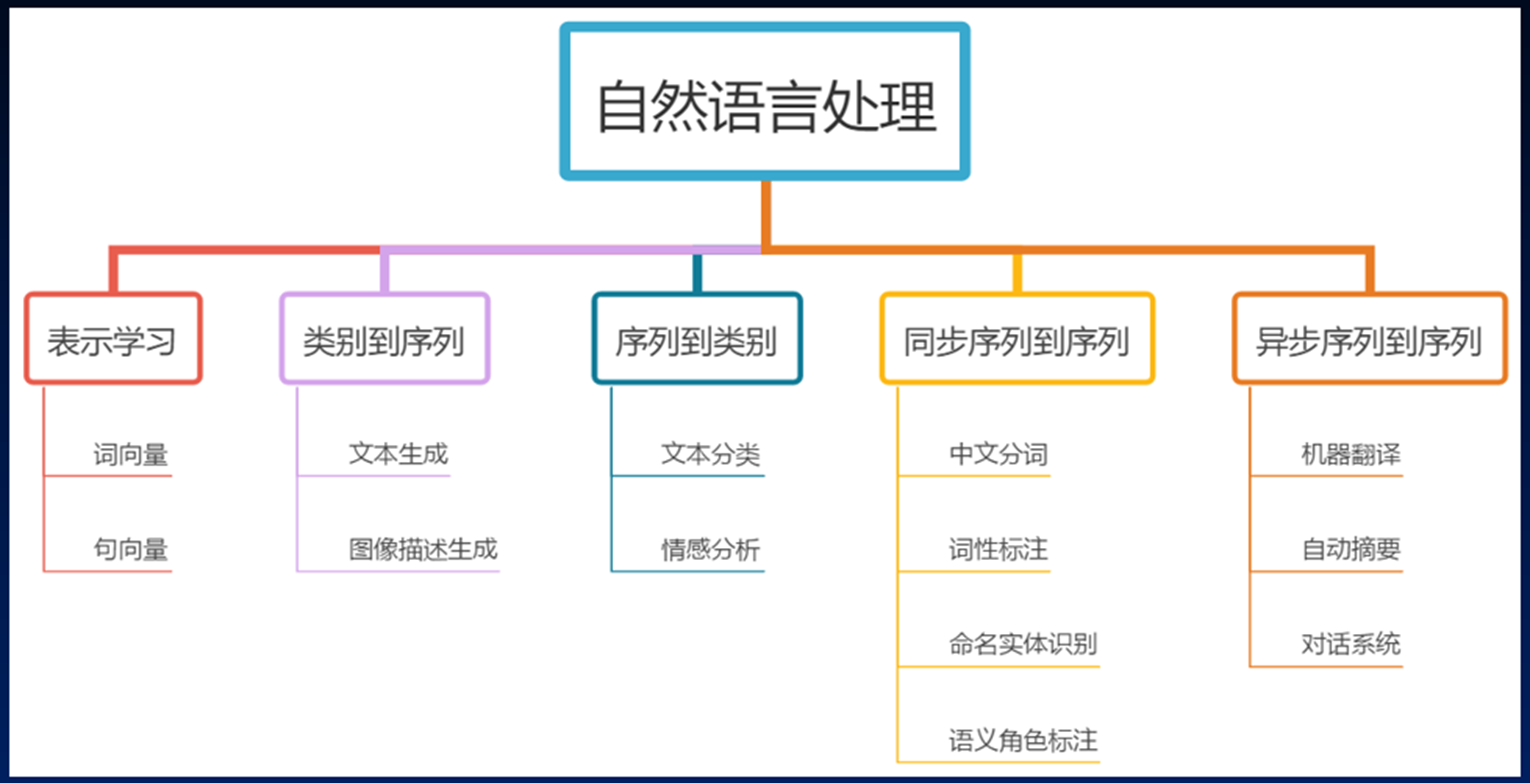
序列到序列(Sequence-to-Sequence, Seq2Seq)问题是指模型将一个输入序列转换为一个输出序列的任务。这类问题可以同步或异步进行,具体取决于输入序列和输出序列的处理方式。
1. 同步序列到序列(Synchronous Seq2Seq)
-
特点:输入序列和输出序列是严格对齐的,即在处理一个输入序列的元素时,模型会即时产生相应的输出序列的元素。
-
典型应用:通常应用在那些输入和输出之间存在一对一对齐关系的任务中。例如,逐词对齐、词性标注(POS tagging)、命名实体识别(NER)。
-
优点:处理速度快,因为输入和输出同步生成,不需要等待整个输入处理完毕。
-
缺点:要求输入和输出严格对齐,不适合处理输入输出之间存在较复杂映射关系的任务。
2. 异步序列到序列(Asynchronous Seq2Seq)
-
特点:输入序列和输出序列之间不需要严格对齐,模型可以在处理完整个输入序列后,再开始生成输出序列。大多数的Seq2Seq模型都是异步的。
-
典型应用:用于需要对整个输入序列进行全局上下文理解后,才能生成输出的任务。例如,机器翻译(句子级别)、文本摘要生成、问答系统等。经典的Seq2Seq模型,如基于RNN或Transformer的模型,通常都属于异步类型。
-
优点:模型可以利用输入序列的全局上下文信息进行更准确的输出生成。
-
缺点:生成速度较慢,因为需要等待整个输入序列处理完毕后才开始生成输出。
数据集
1.3 NLP基础概念
下面总结一些NLP中常用的概念名词,便于理解任务。
(1)词表/词库(Vocabulary):文本数据集中出现的所有单词的集合。
(2)语料库(Corpus):用于NLP任务的文本数据集合,可以是大规模的书籍、文章、网页等。
(3)词嵌入(Word Embedding):将单词映射到低维连续向量空间的技术,用于捕捉单词的语义和语法信息。
(4)停用词(Stop Words):在文本处理中被忽略的常见单词,如"a"、"the"、"is"等,它们通常对文本的意义贡献较 小。
(5)分词(Tokenization):将文本分割成一个个单词或标记的过程,为后续处理提供基本的单位。
(6) 词频(Term Frequency):在给定文档中,某个单词出现的次数。
(7)逆文档频率(Inverse Document Frequency):用于衡量一个单词在整个语料库中的重要性,是将词频取倒数并取 对数的值。
(8) TF-IDF(Term Frequency-Inverse Document Frequency):一种常用的文本特征表示方法,综合考虑了词频和逆文档频率。
(9) 词袋模型(Bag of Words):将文本表示为一个单词的集合,忽略了单词的顺序和语法结构。
(10)N-gram:连续的N个单词构成的序列,用于捕捉文本中的局部特征和上下文信息。
(11)序列:指的是一个按顺序排列的元素集合。这些元素可以是字符、单词、句子,甚至更抽象的结构。序列的每个元素都有特定的顺序和位置,这意味着它们不能随意重排,否则会影响其意义或功能。
序列的常见类型:
-
字符序列:一个字符串就是一个字符序列,每个字符按顺序排列。
例子:"hello"是一个由h、e、l、l、o组成的字符序列。 -
单词序列:一句话可以看作是一个单词序列,每个单词按照一定顺序排列。
例子:"I love NLP"是一个由I、love、NLP组成的单词序列。 -
时序数据:在时间序列中,元素是按时间顺序排列的,常用于预测问题。
例子:股票价格数据可以看作是随时间变化的数值序列。 -
语音序列:在语音处理任务中,语音信号可以被分解为按时间顺序排列的帧序列(特征向量序列)。
-
其他序列:序列还可以表示一些更抽象的结构,比如DNA序列(由碱基组成的序列)、事件序列等。
1.4 NLP的发展历史
1950年代 - 自然语言处理的起点 1954年,乔治城-IBM实验展示了基于规则的机器翻译系统,能够将俄语翻译成英语,标志着NLP的起点。
1990年代 - 统计方法的兴起 随着计算能力的提升,基于统计的语言处理方法成为主流。n元语法、隐马尔科夫模型(HMM)被广泛用于机器翻译、语音识别等任务。
2000年代 - 机器学习的普及 支持向量机(SVM)、朴素贝叶斯等传统机器学习算法被用于文本分类、情感分析等任务,推动了数据驱动方法的发展;以及NNLM 语言模型的提出。
2013年 - 词向量模型Word2Vec的提出 Mikolov等人提出Word2Vec模型,能够将词表示为连续的向量,捕捉词的语义关系,这是词嵌入技术的重大突破。
-
RNN,LSTM等递归神经网络的兴起,甚至在2014年提出了另一种改进的递归神经网络结构,称为门控循环单元(GRU),与LSTM类似,但结构更简单,性能上也表现良好。
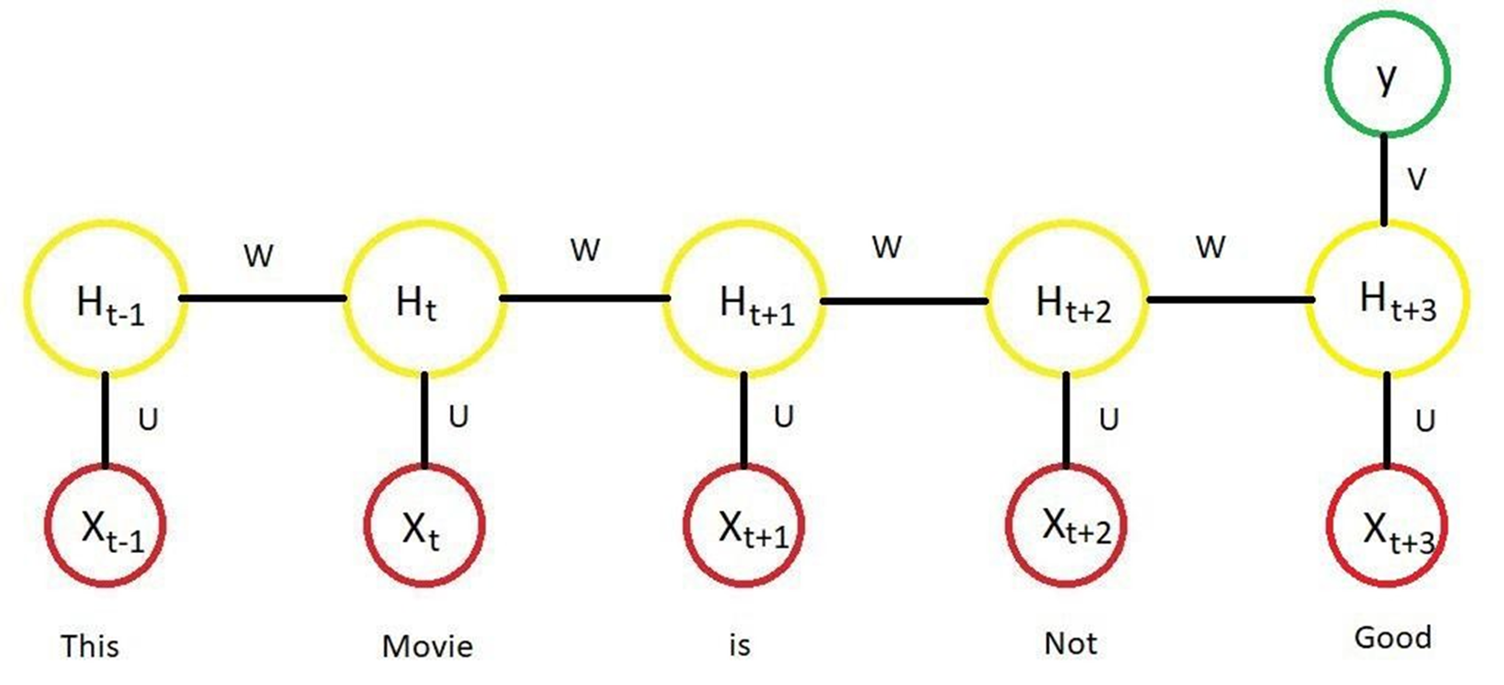
2014年 - Seq2Seq模型用于文本生成和机器翻译 Sutskever等人提出了序列到序列(Seq2Seq)模型,并成功应用于机器翻译、文本摘要等任务,引入了编码器-解码器结构。
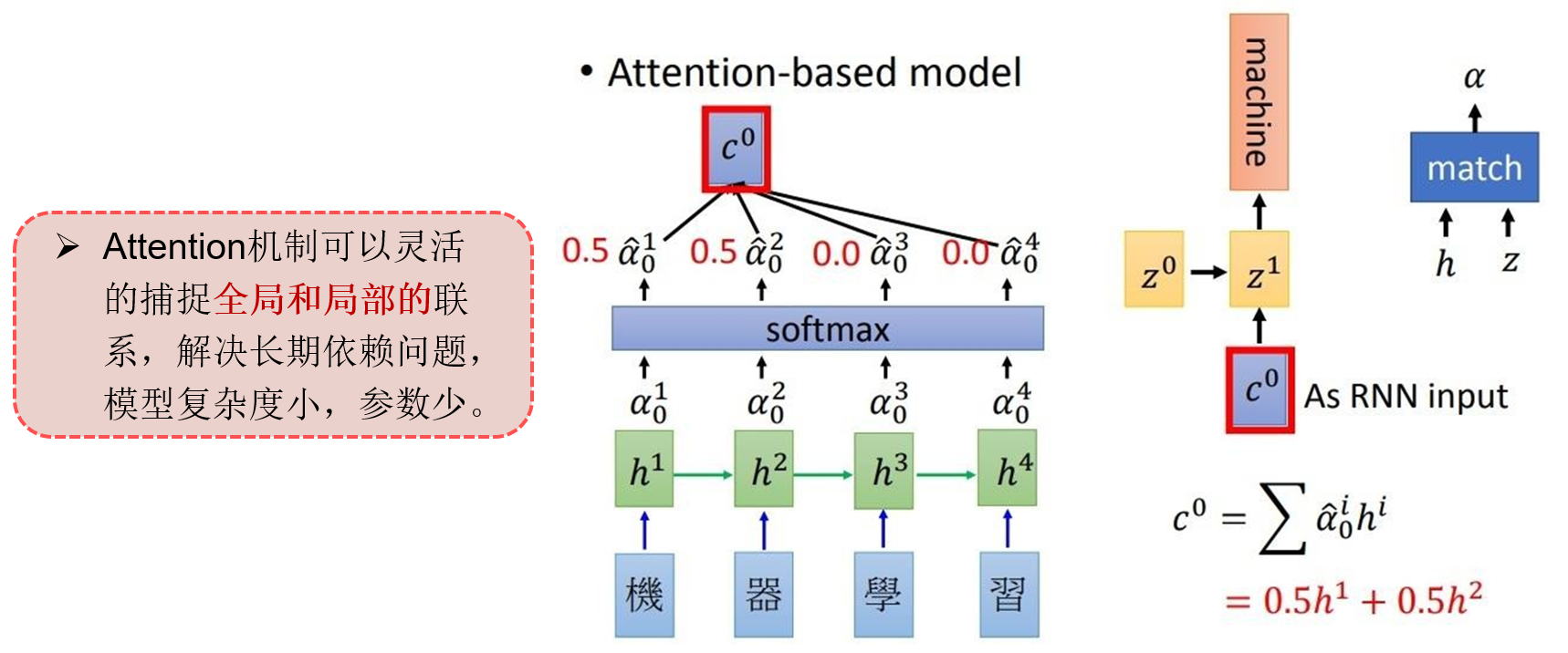
2015年 - 注意力机制(Attention)的提出 Bahdanau等人提出了注意力机制,大幅提升了Seq2Seq模型的效果,使得模型能够更加灵活地处理长序列依赖问题,尤其在机器翻译中取得了突破性进展。
2017年 - Transformer模型的提出 Vaswani等人提出了Transformer模型,完全基于自注意力机制,取代了传统RNN结构,成为后来许多NLP模型的基础。
2018年 - BERT模型的提出 谷歌发布了BERT(Bidirectional Encoder Representations from Transformers),这是第一个双向预训练的语言模型,能够在多个NLP任务中实现最先进的性能。
2020年 - GPT-3的发布 OpenAI发布了GPT-3,一个拥有1750亿参数的大型语言模型,展示了强大的少样本学习和文本生成能力,在对话系统和内容生成等任务中表现优异。
2021年 - 多模态模型的兴起 OpenAI发布了CLIP和DALL·E,将文本和图像结合,实现了跨模态内容理解与生成,进一步扩展了NLP的应用领域。
预训练模型工具包 : https://github.com/huggingface/
1.5 NLP的基本流程
中文NLP的基本流程和英文相比有一些特殊性,主要表现在文本预处理环节。首先,中文文本没有像英文单词那样用空格隔开,因此不能像英文一样直接用最简单的空格和标点符号完成分词,一般需要用分词算法完成分词。其次,中文的编码不是utf-8,而是Unicode,因此在预处理的时候,有编码处理的问题。中文NLP的基本流程由语料获取、语料预处理、文本向量化、模型构建、模型训练和模型评价等六部分组成。
(1)语料获取:在进行NLP之前,人们需要得到文本语料。文本语料的获取一般有以下几种方法。
(1)利用已经建好的数据集或第三方语料库,这样可以省去很多处理成本。
(2)获取网络数据。很多时候要解决的是某种特定领域的应用,仅靠开放语料库无法满足需求,这时就需要通过爬虫技术获取需要的信息。
(3)与第三方合作获取数据。通过购买的方式获取部分需求文本数据。
(2)语料预处理:获取语料后还需要对语料进行预处理,常见的语料预处理如下。
(1)去除数据中非文本内容。大多数情况下,获取的文本数据中存在很多无用的内容,如爬取的一些HTML代码、CSS标签和不需要的标点符号等,这些都需要分步骤去除。少量非文本内容可以直接用 Python的正则表达式删除,复杂的非文本内容可以通过 Python的 Beautiful Soup库去除。
(2)中文分词。常用的中文分词软件有很多,如jieba、FoolNLTK、HanLP、THULAC、NLPIR、LTP等。其中jieba是使用 Python语言编写的,其安装方法很简单,使用“pip install jieba”命令即可完成安装。
(3)词性标注。词性标注指给词语打上词类标签,如名词、动词、形容词等,常用的词性标注方法有基于规则的算法、基于统计的算法等。
(4)去停用词。停用词就是句子中没必要存在的词,去掉停用词后对理解整个句子的语义没有影响。中文文本中存在大量的虚词、代词或者没有特定含义的动词、名词,在文本分析的时候需要去掉。
(3)文本向量化(特征工程):文本数据经过预处理去除数据中非文本内容、中文分词、词性标注和去停用词后,基本上是干净的文本了。但此时还是无法直接将文本用于任务计算,需要通过某些处理手段,预先将文本转化为特征向量。一般可以调用一些模型来对文本进行处理,常用的模型有词袋模型(Bag of Words Model)、独热表示、TF-IDF 表示、n元语法(n-gram)模型和 Word2Vec模型等。
(4)模型构建:文本向量化后,根据文本分析的需求选择合适的模型进行模型构建,同类模型也需要多准备几个备选用于效果对比。过于复杂的模型往往不是最优的选择,模型的复杂度与模型训练时间呈正相关,模型复杂度越高,模型训练时间往往也越长,但结果的精度可能与简单的模型相差无几。NLP中使用的模型包括机器学习模型和深度学习模型两种。常用的机器学习模型有SVM、Naive Bayes、决策树、K-means 等。常用的深度学习模型有TextCNN、RNN、LSTM、GRU、Seq2Seq、transformer等。
(5)模型训练:模型构建完成后,需要进行模型训练,其中包括模型微调等。训练时可先使用小批量数据进行试验,这样可以避免直接使用大批量数据训练导致训练时间过长等问题。在模型训练的过程中要注意两个问题:一个为在训练集上表现很好,但在测试集上表现很差的过拟合问题;另一个为模型不能很好地拟合数据的欠拟合问题。同时;还要避免出现梯度消失和梯度爆炸问题。 仅训练一次的模型往往无法达到理想的精度与效果,还需要进行模型调优迭代,提升模型的性能。模型调优往往是一个复杂、冗长且枯燥的过程,需要多次对模型的参数做出修正;调优的同时需要权衡模型的精度与泛用性,在提高模型精度的同时还需要避免过拟合。在现实生产与生活中,数据的分布会随着时间的推移而改变,有时甚至会变化得很急剧,这种现象称为分布漂移(Distribution Drift)。当一个模型随着时间的推移,在新的数据集中的评价不断下降时,就意味着这个模型无法适应新的数据的变化,此时模型需要进行重新训练。
(6)模型评价:模型训练完成后,还需要对模型的效果进行评价。模型的评价指标指主要有准确率(Accuracy)、精确率(Precision)、召回率、F1值、ROC曲线、AUC线等。针对不同类型的模型,所用的评价指标往往也不同,例如分类模型常用的评价方法有准确率、精确率AUC曲线等。同一种评价方法也往往适用于多种类型的模型。在实际的生产环境中,模型性能评价的侧重点可能会不一样,不同的业务场景对模型的性能有不同的要求,如可能造成经济损失的预测结果会要求模型的精度更高。
2. NLP中的特征工程
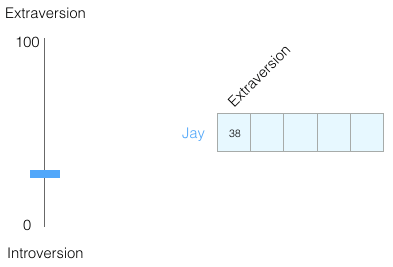
让我们从一个例子开始,了解使用向量来表示事物。您是否知道五个数字(向量)的列表可以代表您的个性?
个性嵌入:你的个性怎么样?
使用0到100的范围表示你的个性(其中0是最内向的,100是最外向的)。
五大人格特质测试,这些测试会问你一个问题列表,然后在很多方面给你打分,内向/外向就是其中之一。

图:测试结果示例。它可以真正告诉你很多关于你自己的事情,并且在学术、个人和职业成功方面都具有预测能力。 假设我的测试得分为38/100。我们可以用这种方式绘制:
让我们将范围切换到从-1到1:

了解一个人,一个维度的信息不够,所以让我们添加另一个维度 - 测试中另一个特征的得分。
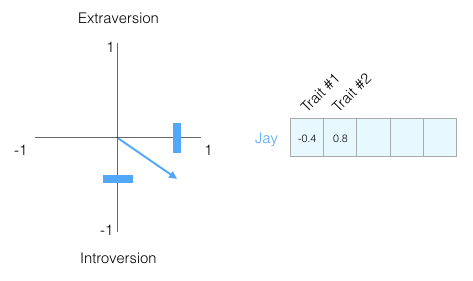
你可能不知道每个维度代表什么,但仍然可以从一个人的个性的向量表示中获得了很多有用的信息。
我们现在可以说这个向量部分代表了我的个性。当你想要将另外两个人与我进行比较时,这种表示的有用性就出现了。在下图中,两个人中哪一个更像我?
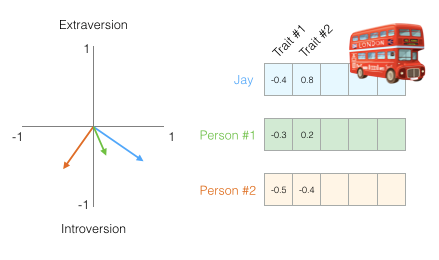
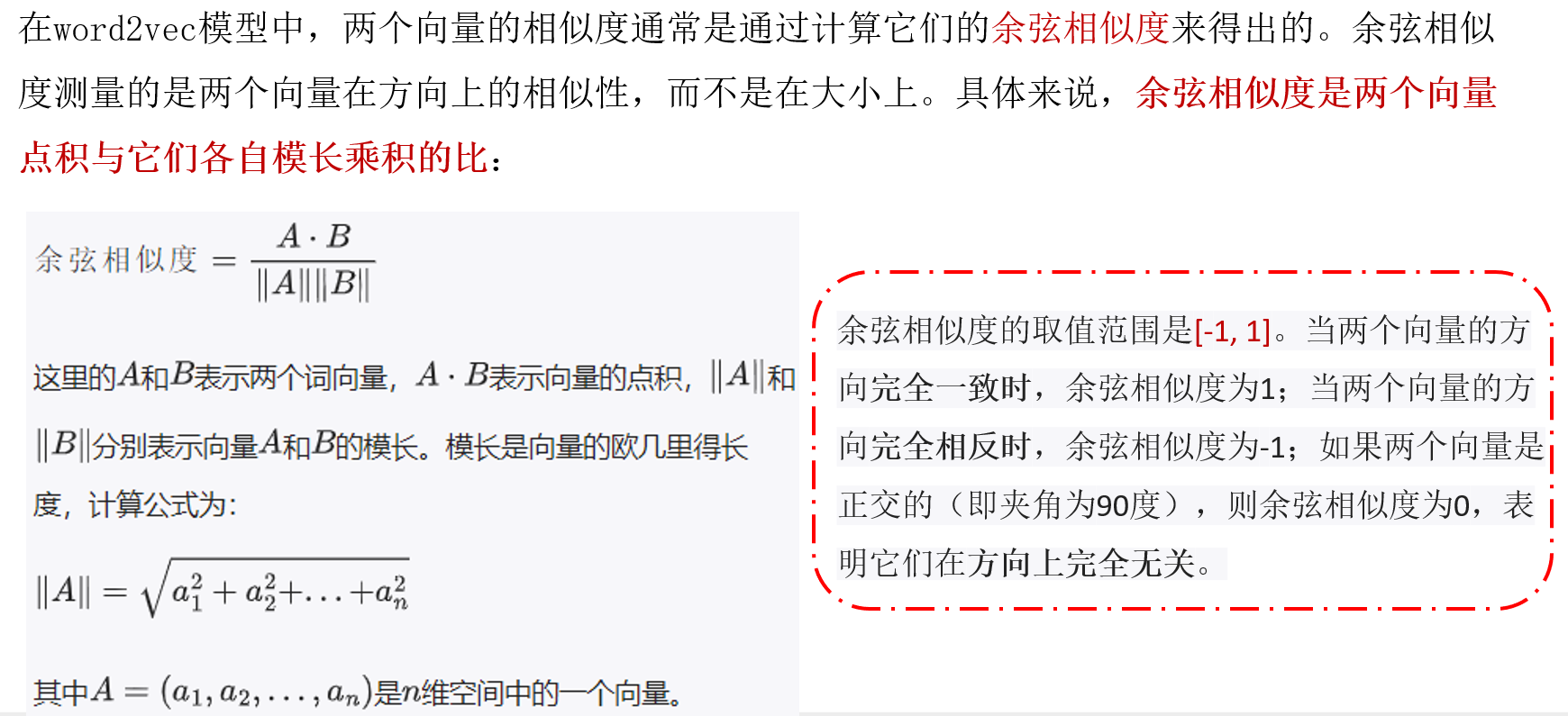
处理向量时,计算相似度得分的常用方法是余弦相似度:

一号人物与我的余弦相似度得分高,所以我们的性格比较相似。
然而,两个方面还不足以捕获有关不同人群的足够信息。几十年的心理学研究已经研究了五个主要特征(以及大量的子特征)。所以我们在比较中使用所有五个维度:

我们没法在二维上绘制出来五个维度,这是机器学习中的常见挑战,我们经常需要在更高维度的空间中思考。但好处是余弦相似度仍然有效。它适用于任意数量的维度:
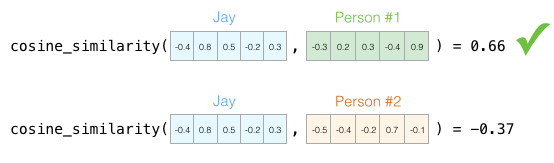
NLP中特征的概念:特征是数据中抽取出来的对结果预测有用的信息。
在自然语言处理(NLP)中,特征工程是指将文本数据转换为适合机器学习模型使用的数值表示的过程。文本是一种非结构化数据,机器学习模型无法直接处理,因此必须通过特征工程来提取有用的信息。
通过特征工程能让机器学习到文本数据中的一些特征,比如词性、语法、相似度等。比如在英文中可以学到。
我希望得到的特征工程训练后的结果,从向量空间里面的分布角度看。

2.1 词向量
词向量(Word Vector)是对词语义或含义的数值向量表示,包括字面意义和隐含意义。 词向量可以捕捉到词的内涵,将这些含义结合起来构成一个稠密的浮点数向量,这个稠密向量支持查询和逻辑推理。
词向量也称为词嵌入,其英文均可用 Word Embedding,是自然语言处理中的一组语言建模和特征学习技术的统称,其中来自词表的单词或短语被映射为实数的向量,这些向量能够体现词语之间的语义关系。从概念上讲,它涉及从每个单词多维的空间到具有更低维度的连续向量空间的数学嵌入。当用作底层输入表示时,单词和短语嵌入已经被证明可以提高 NLP 任务的性能,例如文本分类、命名实体识别、关系抽取等。
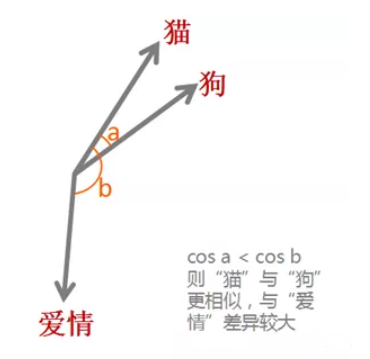
词嵌入实际上是一类技术,单个词在预定义的向量空间中被表示为实数向量,每个单词都映射到一个向量。举个例子,比如在一个文本中包含“猫”“狗”“爱情”等若干单词,而这若干单词映射到向量空间中,“猫”对应的向量为(0.1 0.2 0.3),“狗”对应的向量为(0.2 0.2 0.4),“爱情”对应的映射为(-0.4 -0.5 -0.2)(本数据仅为示意)。像这种将文本X{x1,x2,x3,x4,x5……xn}映射到多维向量空间Y{y1,y2,y3,y4,y5……yn },这个映射的过程就叫做词嵌入。
之所以希望把每个单词都变成一个向量,目的还是为了方便计算,比如“猫”,“狗”,“爱情”三个词。对于我们人而言,我们可以知道“猫”和“狗”表示的都是动物,而“爱情”是表示的一种情感,但是对于机器而言,这三个词都是用0,1表示成二进制的字符串而已,无法对其进行计算。而通过词嵌入这种方式将单词转变为词向量,机器便可对单词进行计算,通过计算不同词向量之间夹角余弦值cosine而得出单词之间的相似性。
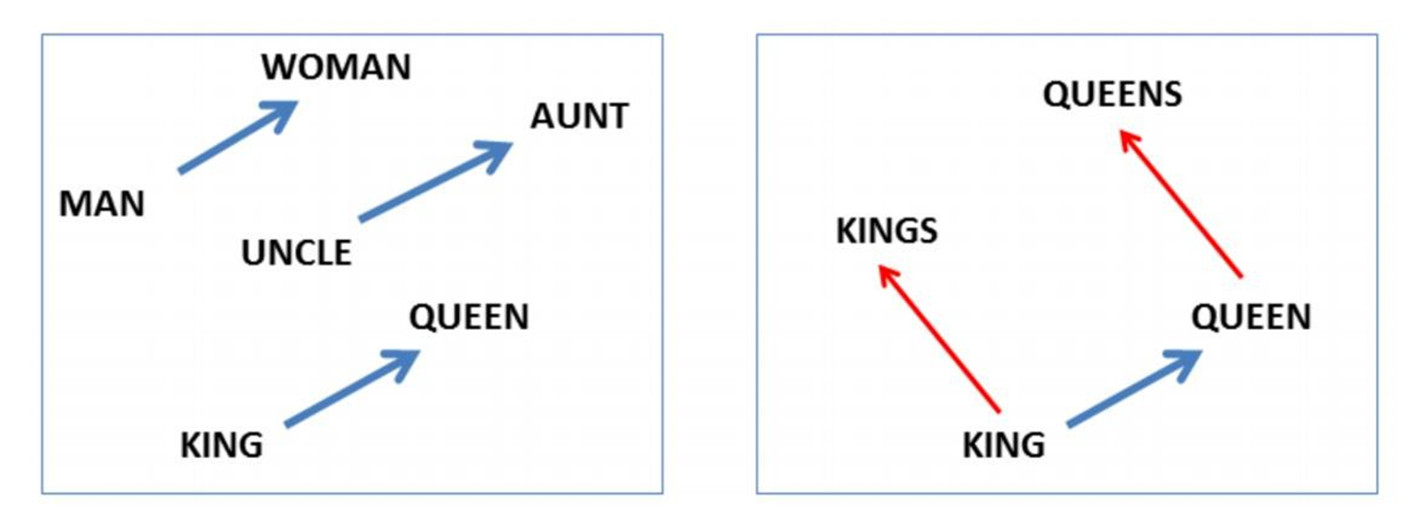
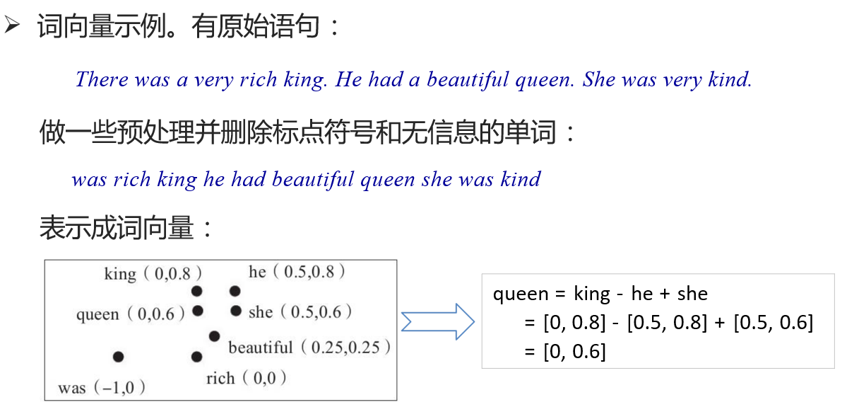
此外,词嵌入还可以做类比,比如:v(“国王”)-v(“男人”)+v(“女人”)≈v(“女王”),v(“中国”)+v(“首都”)≈v(“北京”),当然还可以进行算法推理。有了这些运算,机器也可以像人一样“理解”词汇的意思了。
词向量的发展历程,词向量作为词的分布式表示方法,经过多年研究,产生了非常多的词向量的生成模型。
2.2 传统NLP中的特征工程
2.2.1 独热编码 one - hot
独热编码(One-Hot Encoding) 是一种常见的特征表示方法,通常用于将离散的类别型数据转换为数值型表示,以便输入到机器学习模型中。它的特点是将每个类别表示为一个向量,在该向量中,只有一个元素为1,其余元素全部为0。
One-Hot Encoding 的工作原理,假设你有一个包含以下类别的分类任务:
-
红色(red)
-
绿色(green)
-
蓝色(blue)
要将这些类别转换为 One-Hot 编码,我们会为每个类别创建一个独特的二进制向量:
-
红色:
[1, 0, 0] -
绿色:
[0, 1, 0] -
蓝色:
[0, 0, 1]
例如,如果输入数据是“红色”,在使用 One-Hot 编码后,它将被表示为 [1, 0, 0]。
在NLP当中
-
Time flies like an arrow.
-
Fruit flies like a banana.
构成词库{time, fruit, flies, like, a, an, arrow, banana},banana的one-hot表示就是:[0,0,0,0,0,0,0,1],"like a banana” 的one-hot表示就是:[0,0,0,1,1,0,0,1]。
示例

2.2.2 词频-逆文档频率(TF-IDF)
(1)词频:将文本中的每个单词视为一个特征,并将文本中每个单词的出现次数除以该单词在所有文档中的出现次数,以调整单词的权重。
注意:在计算词频(TF)时,分母是文档中的总词数,而不考虑每个词是否重复。这意味着无论词是否重复,分母始终是文档中所有词的数量总和。

举个例子,如果词 "cat" 在一篇包含 100 个词的文章中出现了 5 次,那么它的词频为:
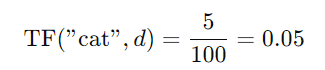
1. 短语,句子或者文档的词频表示就是其组成单词‘one-hot’表示向量的总和。
2. “Fruit flies like time flies a fruit” ,DF表示为:[1,2,2,1,1,0,0,0],TF表示为:[0.14,0.29,0.29,0.14,0.14,0,0,0]
3. 根据词库{time, fruit, flies, like, a, an, arrow, banana}验证上面的表示Fruit flies like a banana.
(2)逆文档频率(Inverse Document Frequency, IDF):逆文档频率用来衡量一个词在整个文档集合(语料库)中的重要性。它的目的是降低那些在很多文档中频繁出现的词的权重,例如“the”、“is”这种常见词,或者低频罕见词tetrafluoroethylene(四氟乙烯)。计算公式如下:

其中,`D` 表示文档集合,`t` 是要计算的词。`+1` 是为了避免分母为 0 的情况。
例如,如果有 1000 篇文档,而词 "cat" 仅在 10 篇文档中出现过,那么它的 IDF 计算如下:
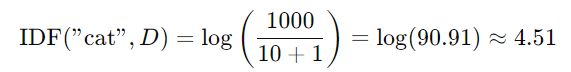
(3)TF-IDF 计算:最终,TF-IDF 是将 TF 和 IDF 相乘得出的结果,公式如下:
![]()
通过这个方法,一个词在特定文档中出现的频率越高(TF高),并且在整个语料库中出现得越少(IDF高),它的 TF-IDF 值就越高。这样可以使模型更加关注那些在某篇文档中特别重要但不常见的词。
特性:

结论:1. 文档频率和样本语义贡献程度呈反相关;
2. 文档频率和逆文档频率呈反相关;
3. 逆文档频率和样本语义贡献度呈正相关。
2.2.3 n-grams
n-grams 是特征工程中的一种技术,它通过将文本中的连续 n 个词(或字符)组合起来,形成一个短语来捕捉文本中的局部上下文信息。n 可以为 1、2、3 等,具体取决于希望捕捉的上下文范围。
什么是 n-grams?
-
1-gram(Unigram):每个单独的词作为一个单位。例如,"I love NLP" 的 1-gram 是
["I", "love", "NLP"]。 -
2-grams(Bigram):相邻的两个词组合成一个短语。例如,"I love NLP" 的 2-grams 是
["I love", "love NLP"]。 -
3-grams(Trigram):相邻的三个词组合成一个短语。例如,"I love NLP" 的 3-grams 是
["I love NLP"]。
n-grams 的作用:使用 n-grams 可以捕捉词之间的局部上下文关系。例如,1-gram 只关心词的独立出现频率,而 bigram 和 trigram 能捕捉到词之间的顺序关系。例如,bigram "love NLP" 表示词 "love" 和 "NLP" 是一起出现的,这种信息在建模中会比仅仅知道 "love" 和 "NLP" 出现频率更有价值。
n-grams 的示例:假设句子为 "I love NLP and machine learning":
-
1-gram(Unigram):
["I", "love", "NLP", "and", "machine", "learning"] -
2-grams(Bigram):
["I love", "love NLP", "NLP and", "and machine", "machine learning"] -
3-grams(Trigram):
["I love NLP", "love NLP and", "NLP and machine", "and machine learning"]
通过这些 n-grams,模型可以捕捉到词与词之间的局部依赖关系。将 n-grams 与 TF-IDF 相结合是文本特征工程中非常常见的做法,它不仅能够捕捉词与词之间的局部关系,还能通过 TF-IDF 来衡量这些短语在整个语料库中的重要性。结合的过程基本上是先生成 n-grams,然后对这些 n-grams 计算 TF-IDF 权重。
结合 n-grams 与 TF-IDF 的步骤:
-
生成 n-grams:首先从文本中生成 n-grams(n 可以是 1, 2, 3 等)。这些 n-grams 就像是词的组合,通常使用
CountVectorizer或类似的工具生成。 -
计算词频 (TF):统计每个 n-gram 在文本中出现的频率。
-
计算逆文档频率 (IDF):计算 n-gram 在所有文档中出现的频率,稀有的 n-grams 会得到较高的权重,而常见的 n-grams 权重较低。
-
计算 TF-IDF:将每个 n-gram 的 TF 和 IDF 相乘,得到 TF-IDF 权重,表示该 n-gram 对特定文本的重要性。
注意:当使用 2-grams 时,I love 和 love NLP 被看作是两个单独的特征,总共有两个特征(总特征数 = 2)。
举例说明:假设我们有以下两个文本:
-
"I love NLP" -
"NLP is fun"
我们的词汇表为 {"I", "love", "NLP", "is", "fun"},并且我们想要计算 2-grams 的 TF-IDF 值。
步骤 1:生成 2-grams
对于 "I love NLP",生成的 2-grams 是:
-
["I love", "love NLP"]
对于 "NLP is fun",生成的 2-grams 是:
-
["NLP is", "is fun"]
所以我们的 n-grams 词汇表为 {"I love", "love NLP", "NLP is", "is fun"}。
步骤 2:计算词频(TF)
在每个文本中,计算每个 2-gram 的出现次数:
-
文本 1 ("I love NLP") 的 2-grams 词频:
-
I love: 1/2 -
love NLP: 1/2
-
-
文本 2 ("NLP is fun") 的 2-grams 词频:
-
NLP is: 1/2 -
is fun: 1/2
-
步骤 3:计算逆文档频率(IDF)

步骤 4:计算 TF-IDF
现在,我们计算每个 2-gram 的 TF-IDF 值:
-
文本 1 ("I love NLP"):
-
I love的 TF = 0.5,IDF = 0.693,所以 TF-IDF(I love) = 0.5×0.693=0.3465 -
love NLP的 TF =0.5,IDF = 0.693,所以 TF-IDF(love NLP) = 0.5×0.693=0.3465
-
-
文本 2 ("NLP is fun"):
-
NLP is的 TF =0.5,IDF = 0.693,所以 TF-IDF(NLP is) = 0.5×0.693=0.3465 -
is fun的 TF =0.5,IDF = 0.693,所以 TF-IDF(is fun) = 0.5×0.693=0.3465
-
传统NLP中的特征工程缺点:

2.3 深度学习中NLP的特征输入
深度学习使用分布式单词表示技术(也称**词嵌入**表示),通过查看所使用的单词的周围单词(即上下文)来学习单词表示。这种表示方式将词表示为一个粘稠的序列,在保留词**上下文信息**同时,避免维度过大导致的计算困难。
2.3.1 稠密编码(特征嵌入)
稠密编码(Dense Encoding),在机器学习和深度学习中,通常指的是将离散或高维稀疏数据转化为低维的连续、密集向量表示。这种编码方式在特征嵌入(Feature Embedding)中尤为常见。
稠密向量表示:不再以one-hot中的一维来表示各个特征,而是把每个核心特征(词,词性,位置等)都嵌入到d维空间中,并用空间中的一个向量表示。通常空间维度d远小于每个特征的样本数(40000的词表,100/200维向量)。嵌入的向量(每个核心特征的向量表示)作为网络参数与神经网络中的其他参数一起被训练。
特征嵌入(Feature Embedding):特征嵌入,也成为词嵌入,是稠密编码的一种表现形式,目的是将离散的类别、对象或其他类型的特征映射到一个连续的向量空间。通过这种方式,嵌入后的向量可以捕捉不同特征之间的语义关系,并且便于在后续的机器学习模型中使用。
特点:
-
低维度:相比稀疏表示(如独热编码),稠密编码的维度更低,能够减少计算和存储成本。
-
语义相似性:嵌入向量之间的距离(如欧氏距离或余弦相似度)可以表示这些对象之间的语义相似性。
-
可微学习:嵌入表示通常通过神经网络进行学习,并且通过反向传播算法进行优化。
2.3.2 词嵌入算法
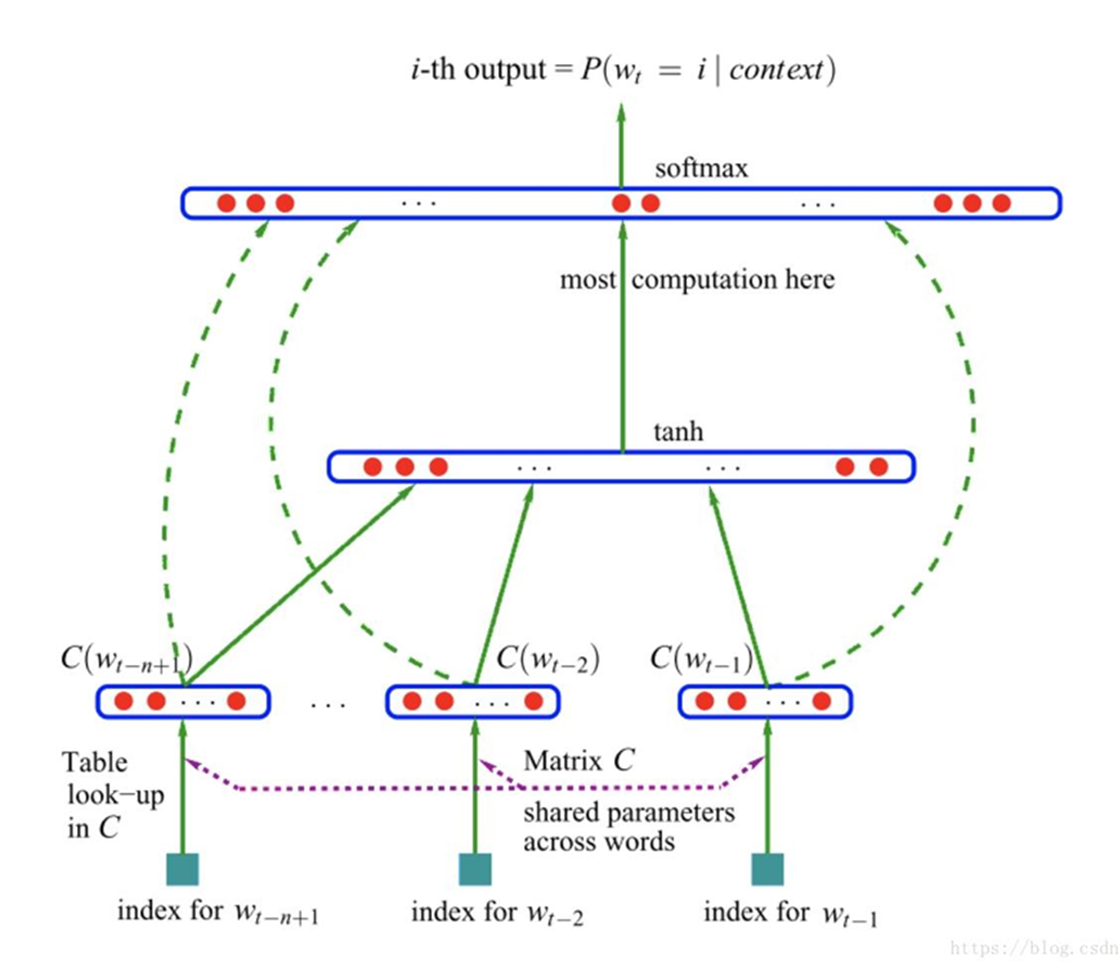
(1)Embedding Layer:由于缺乏更好的名称,Embedding Layer是与特定自然语言处理上的神经网络模型联合学习的单词嵌入。该嵌入方法将清理好的文本中的单词进行one hot编码(独热编码),向量空间的大小或维度被指定为模型的一部分,例如50、100或200维。向量以小的随机数进行初始化。Embedding Layer用于神经网络的前端,并采用反向传播算法进行监督。
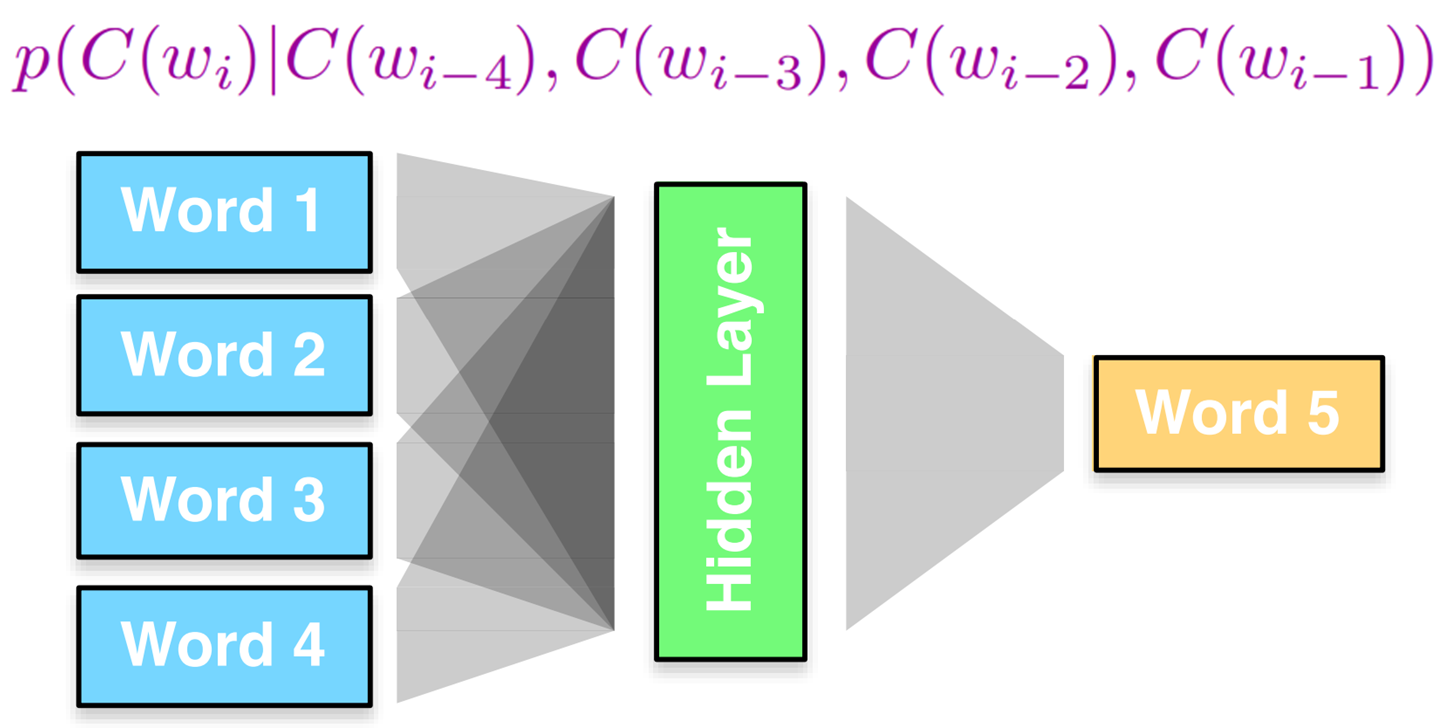
那么怎么得到词向量?
比如我们的目标是希望神经网络发现如下这样的规律:已知一句话的前几个字,预测下一个字是什么,于是有了NNLM 语言模型搭建的网络结构图:
具体怎么实施呢?先用最简单的方法来表示每个词,one-hot 表示为︰dog=(0,0,0,0,1,0,0,0,0,...);cat=(0,0,0,0,0,0,0,1,0,...) ;eat=(0,1,0,0,0,0,0,0,0,...)。
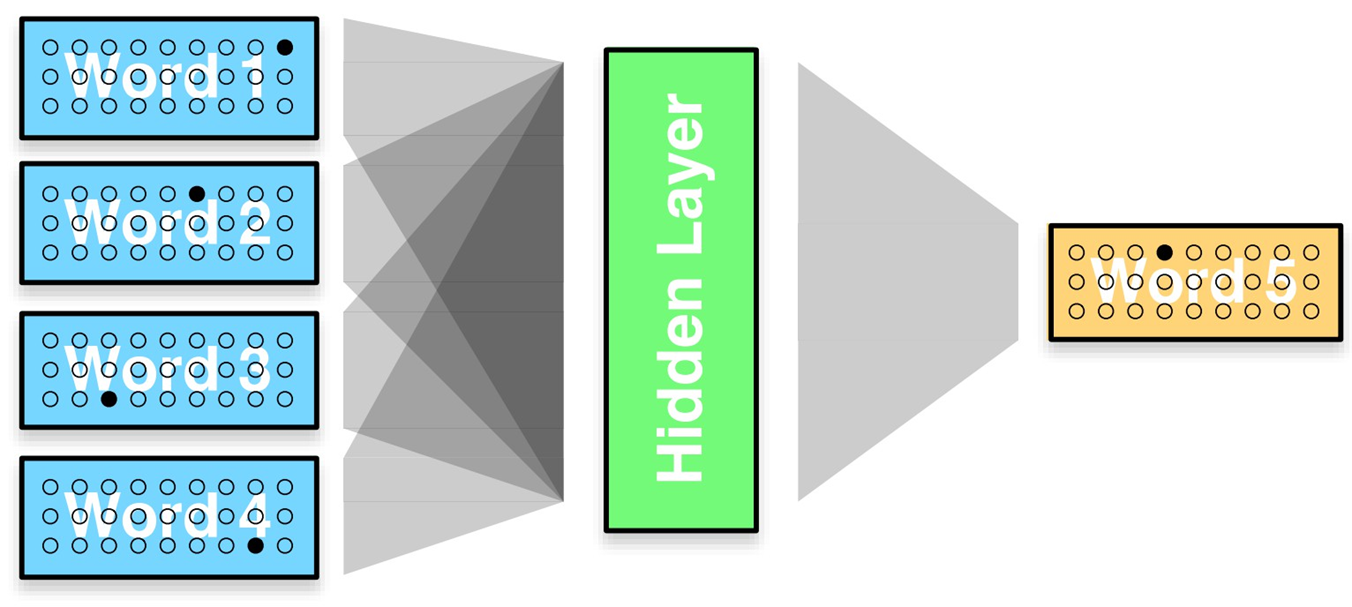
可是 one-hot 表示法有诸多的缺陷,还是稠密的向量表示更好一些,那么怎么转换呢?加一个矩阵映射一下就好!
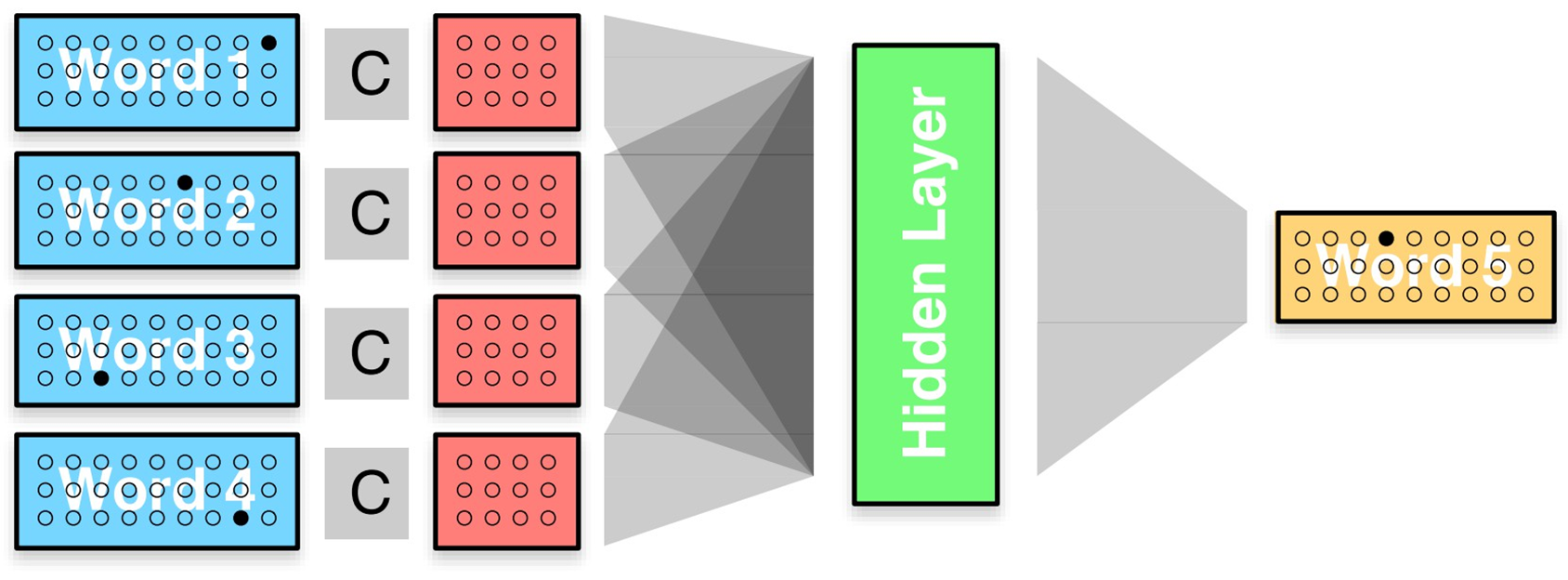
映射之后的向量层如果单独拿出来看,还有办法找到原本的词是什么吗?
One-hot表示法这时候就作为一个索引字典了,可以通过映射矩阵对应到具体的词向量。
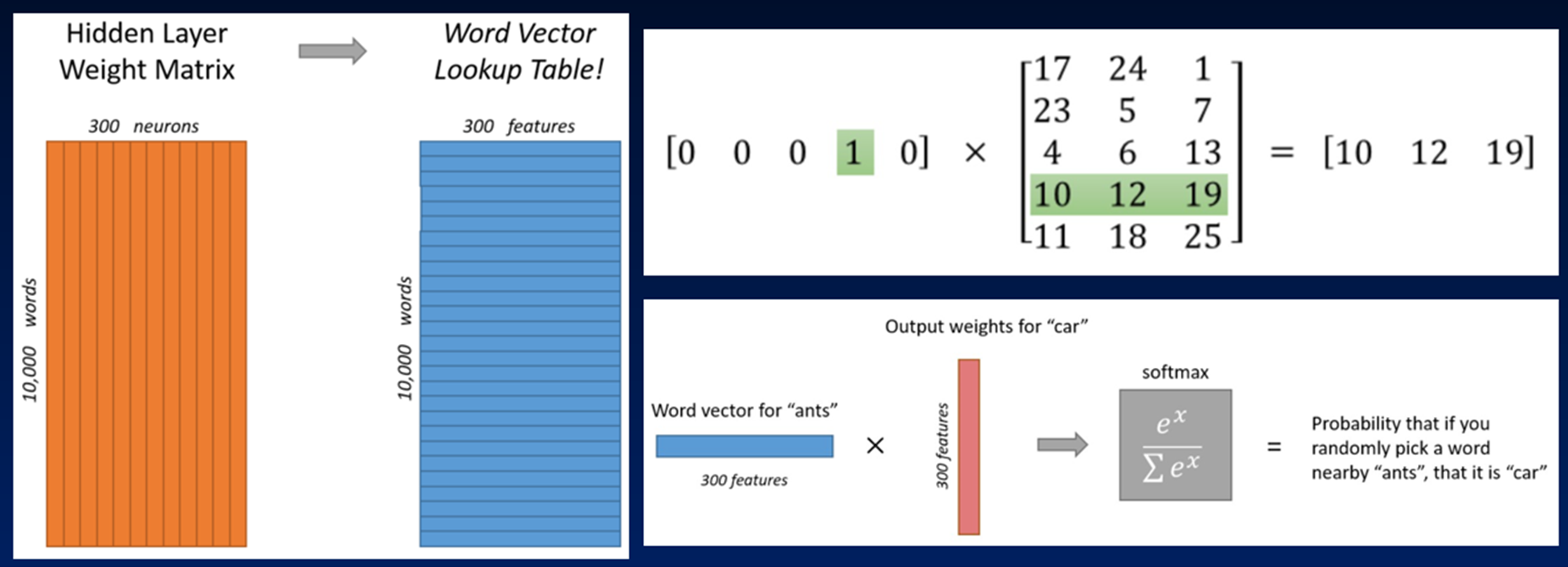
词嵌入层的使用:词嵌入层首先会根据输入的词的数量构建一个词向量矩阵,例如: 我们有 100 个词,每个词希望转换成 128 维度的向量,那么构建的矩阵形状即为: 100*128,输入的每个词都对应了一个该矩阵中的一个向量。
在 PyTorch 中,我们可以使用 nn.Embedding 词嵌入层来实现输入词的向量化。接下来,我们将会学习如何将词转换为词向量,其步骤如下:
-
先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一个唯一的索引;
-
然后使用 nn.Embedding 构建词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。
例如,我们的文本数据为: "北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。",接下来,我们看下如何使用词嵌入层将其进行转换为向量表示,步骤如下:
-
首先,将文本进行分词;
-
然后,根据词构建词表;
-
最后,使用嵌入层将文本转换为向量表示。
nn.Embedding 对象构建时,最主要有两个参数:
-
num_embeddings 表示词的数量
-
embedding_dim 表示用多少维的向量来表示每个词
nn.Embedding(num_embeddings=10, embedding_dim=4)接下来,我们就实现下刚才的需求:
import torch
import torch.nn as nn
import jiebatext = '北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'pass输出的结果:

归纳:
-
Embedding类的本质是一个大小为
(num_embeddings, embedding_dim)的矩阵,每一行是某个词汇的嵌入向量。
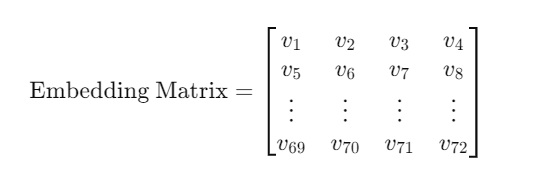
-
通过索引,可以高效地从这个矩阵中提取对应词汇的向量表示,因为
nn.Embedding在内部通过索引直接查找矩阵中的行,这种操作非常快速且方便。
练习:假设现在有语料库sentences = ["i like dog", "i love coffee", "i hate milk", "i do nlp"] 通过词嵌入层算法和NNLM模型得到以下结果 [['i', 'like'], ['i', 'love'], ['i', 'hate'], ['i', 'do']] -> ['dog', 'coffee', 'milk', 'nlp']
说明:
(1) predict = model(input_batch).data.max(1, keepdim=True)[1] 1. model(input_batch):
-
这部分是将
input_batch输入到模型中,经过forward函数计算,得到网络的输出。 -
输出是一个二维张量,形状为
(batch_size, n_class),其中每行代表一个样本的预测得分(未归一化的类别概率),每列对应词汇表中的一个单词类别。2.
.max(1, keepdim=True): -
max是一个 PyTorch 的函数,返回沿指定维度的最大值及其索引。 -
1:表示在第 1 维(即每行)上寻找最大值。第 0 维是批次(样本),第 1 维是类别的得分(对于每个单词的概率分布)。 -
keepdim=True:表示保持原始维度,即结果张量的形状与原来的张量在没有被压缩的维度上保持一致。
返回的结果是一个包含两个元素的元组:
-
第一个元素:每行的最大值(在预测任务中通常是没有用到的)。
-
第二个元素:每行最大值的索引(即预测的类别)。
3.
[1]:通过[1]取出最大值对应的索引,即上一步中返回的最大值的索引部分。这个索引对应预测的类别编号,也就是词汇表中的单词索引。
(2) [number_dict[n.item()] for n in predict.squeeze()] 1. predict.squeeze():
-
predict是模型预测的结果,形状是(batch_size, 1)。predict.squeeze()用于去掉维度为 1 的那一维,使其从(batch_size, 1)变为(batch_size)。 -
squeeze()函数会去掉张量中所有大小为 1 的维度。在这里,predict的维度是(batch_size, 1),经过squeeze()后变成一维张量,形状为(batch_size),即包含batch_size个预测的类别索引。2.
n.item(): -
n是张量中的一个元素(预测的类别索引),n.item()将这个单元素张量转换为普通的 Python 标量类型(整数)。 -
item()是 PyTorch 张量的方法,用于从单个元素的张量中提取值。它确保索引n是一个纯 Python 的整数,可以用于字典查找。3.
number_dict[n.item()]: -
number_dict是一个字典,它将单词索引映射回对应的单词,即{index: word}的映射。 -
number_dict[n.item()]用来通过索引n.item()从字典number_dict中查找对应的单词,将模型预测出的索引转换为实际的单词。
神经语言模型构建完成之后,就是训练参数了,这里的参数包括:
-
词向量矩阵C;
-
神经网络的权重;
-
偏置等参数
训练数据就是大堆大堆的语料库。训练结束之后,语言模型得到了:通过“”去预测第
个词是
的概率,但有点意外收获的是词向量“
”也得到了。换言之,词向量是这个语言模型的副产品。
预训练模型
介绍:通常是一个LM(语言模型)的副产物。模型指的是对事物的数学抽象,那么语言模型指的就是对语言现象的数学抽象。
在自然语言处理(NLP)中,预训练模型是指在大量通用文本数据集上训练好的模型,它可以捕捉到语言的广泛特征,例如词汇、句法、语境相关性等。这些模型训练完成后,可以在特定的下游任务上进行微调(fine-tuning),以适应特定的应用场景,如情感分析、问答系统、文档摘要等。通过这种方式,预训练模型可以显著提高NLP任务的性能,尤其是在标注数据有限的情况下。
预训练模型的核心思想是利用大规模语料库中的无标签文本数据,学习到一般性的语言表示,然后将这些知识迁移到数据量较小的特定任务中。这种方法背后的假设是,语言中存在大量的通用性规律可被学习并用于各种具体任务。
(2)word2vec:word2vec是Google研究团队里的Tomas Mikolov等人于2013年的《Distributed Representations ofWords and Phrases and their Compositionality》以及后续的《Efficient Estimation of Word Representations in Vector Space》两篇文章中提出的一种高效训练词向量的模型,基本出发点是上下文相似的两个词,它们的词向量也应该相似,比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似。


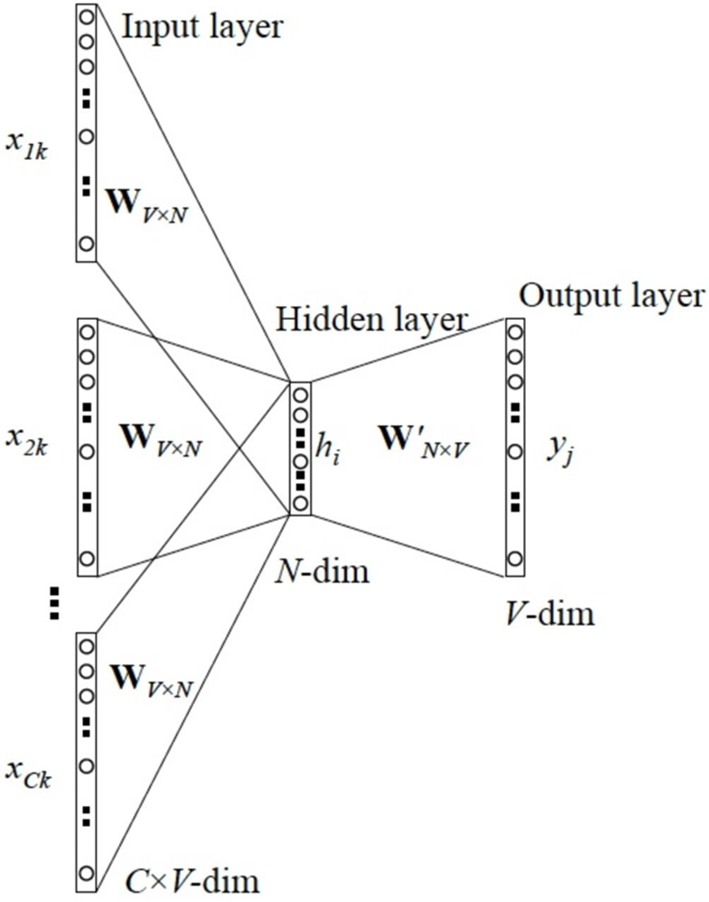
word2vec一般分为CBOW(Continuous Bag-of-Words)与 Skip-Gram 两种模型:
1、CBOW:根据**中心词周围的词来预测中心词**,有negative sample和Huffman两种加速算法;
2、Skip-Gram:根据**中心词来预测周围词**;
二者的结构十分相似,理解了CBOW,对于Skip-Gram也就基本理解了。论文里面的原图如下,左边CBOW,右边skip-gram。
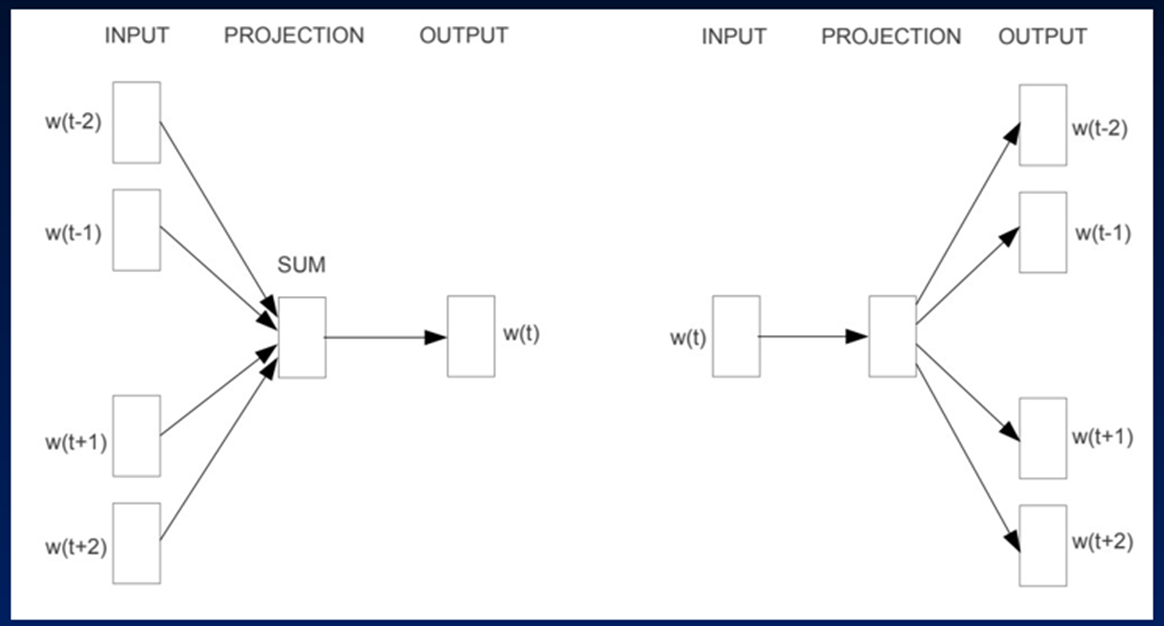
1. Skip-gram 模型:
Skip-gram 模型是一种根据目标单词来预测上下文单词的模型。具体来说,给定一个中心单词,Skip-gram 模型的任务是预测在它周围窗口大小为 n 内的上下文单词。
Skip-gram 模型的优点是:由于它是基于目标单词来预测上下文单词的,因此它可以利用目标单词的语义和语法特征来预测上下文单词;模型能够生成更多的训练数据,因此可以更好地训练低频词汇的表示;Skip-gram 模型在处理大规模语料库时效果比 CBOW 模型更好。
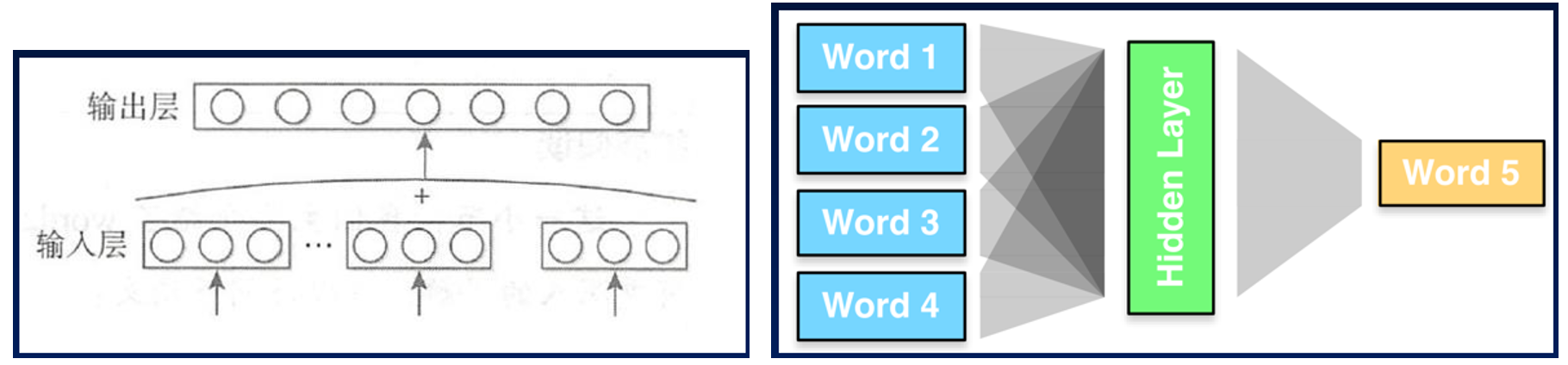
2. CBOW模型:
连续词袋模型(CBOW)是一种根据上下文单词来预测目标单词的模型。具体来说,给定一个窗口大小为 n 的上下文单词序列,连续词袋模型的任务是预测中间的目标单词。
CBOW模型∶使用文本的中间词作为目标词(标签),去掉了隐藏层。用上下文各词的词向量的均值代替NNLM拼接起来的词向量。
连续词袋模型的优点是:由于它是基于上下文单词来预测目标单词的,因此它可以利用上下文单词的信息来推断目标单词的语义和语法特征;模型参数较少,训练速度相对较快。CBOW对小型数据库比较合适。
输入∶上下文的语义表示;
输出∶中间词是哪个词。
3. gensim API调用:
Word2vec是一个用来产生词向量的模型。是一个将单词转换成向量形式的工具。
通过转换,可以把对[文本内容](https://so.csdn.net/so/search?q=文本内容&spm=1001.2101.3001.7020)的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。
| 参数 | 说明 |
|---|---|
| sentences | 可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或lineSentence构建。 |
| vector_size | word向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好。推荐值为几十到几百。 |
| alpha | 学习率 |
| window | 表示当前词与预测词在一个句子中的最大距离是多少。 |
| min_count | 可以对字典做截断。词频少于min_count次数的单词会被丢弃掉,默认值为5。 |
| max_vocab_size | 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。 |
| sample | 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5) |
| seed | 用于随机数发生器。与初始化词向量有关。 |
| workers | 参数控制训练的并行数。 |
| sg | 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。 |
| hs | 如果为1则会采用hierarchica·softmax技巧。如果设置为0(default),则negative sampling会被使用。 |
| negative | 如果>0,则会采用negative samping,用于设置多少个noise words。 |
| cbow_mean | 如果为0,则采用上下文词向量的和,如果为1(default)则采用均值。只有使用CBOW的时候才起作用。 |
| hashfxn | hash函数来初始化权重。默认使用python的hash函数。 |
| epochs | 迭代次数,默认为5。 |
| trim_rule | 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RULE_DISCARD,utils。RULE_KEEP或者utils。RULE_DEFAULT的函数。 |
| sorted_vocab | 如果为1(default),则在分配word index 的时候会先对单词基于频率降序排序。 |
| batch_words | 每一批的传递给线程的单词的数量,默认为10000 |
| min_alpha | 随着训练的进行,学习率线性下降到min_alpha |
常用方法
model.wv: 这个对象包含了所有单词的词嵌入向量。常用的方法有:
-
model.wv[word]:返回某个特定单词的向量。 -
model.wv.most_similar(word):获取与某个单词最相似的词。 -
model.wv.similarity(word1, word2):计算两个词之间的相似度。
model.save("word2vec.model");
model = Word2Vec.load("word2vec.model"),保存和加载模型
相关文章:

NLP基础
1. 基本概念 自然语言处理(Natural Language Processing,简称NLP)是人工智能和语言学领域的一个分支,它涉及到计算机和人类(自然)语言之间的相互作用。它的主要目标是让计算机能够理解、解释和生成人类语言…...

[AI Tools] Dify 工具插件上传指南:如何将插件发布到官方市场
Dify 作为开源的 LLM 应用开发平台,不仅支持本地化插件开发,也提供了插件市场机制,让开发者能够将自己构建的插件发布并供他人使用。本文将详细介绍如何将你开发的 Dify Tools 插件上传至官方插件市场,包括 README 编写、插件打包、仓库 PR 等核心步骤。 一、准备 README 文…...

Qt读写XML文档
XML 结构与概念简介 XML(可扩展标记语言) 是一种用于存储和传输结构化数据的标记语言。其核心特性包括: 1、树状结构:XML 数据以层次化的树形结构组织,包含一个根元素(Root Element)ÿ…...

htmlUnit和Selenium的区别以及使用BrowserMobProxy捕获网络请求
1. Selenium:浏览器自动化之王 核心定位: 跨平台、跨语言的浏览器操控框架,通过驱动真实浏览器实现像素级用户行为模拟。 技术架构: 核心特性: 支持所有主流浏览器(含移动端模拟) 精…...
)
C#黑魔法:鸭子类型(Duck Typing)
C#黑魔法:鸭子类型(Duck Typing) 如果它走起路来像鸭子,叫起来像鸭子,那么它就是鸭子。 鸭子类型,主要应用于动态语言类型,比如JS、Python等,核心理念为:关注对象的行为(方法或属性…...

2025 年数维杯数学建模B题完整论文代码模型
《2025 年数维杯数学建模B题完整论文代码模型》 B题完整论文 一、赛事背景与题目总览 2025 年第十届数维杯大学生数学建模挑战赛的 B 题聚焦于“马拉松经济的高质量发展思路探索”。近年来,我国马拉松赛事如同一颗颗璀璨的星星,在城市的天空中闪耀&am…...

C++23 中的 views::chunk:深入探索与应用
文章目录 一、views::chunk 的背景与动机二、views::chunk 的基本用法语法与参数示例代码 三、views::chunk 的高级用法处理不完整块与 views::drop 和 views::take 结合 四、性能分析五、应用场景1. 批量处理数据2. 分页显示3. 并行处理 六、与其他范围适配器的组合1. 与 view…...

库室指静脉人脸门禁机 LK-BM-S10C/JR
1、采用大于等于四核处理器,主频大于1G; 2、内存≥4G DDR3;存储≥8G 3、核心模块采用国产工业级处理芯片和嵌入式Android实时多任务系统,采用模块化设计,模块间通过标准接口相连; 4、大于等于10英寸电容屏…...

低成本自动化改造的18个技术锚点深度解析
执行摘要 本文旨在深入剖析四项关键的低成本自动化技术,这些技术为工业转型提供了显著的运营和经济效益。文章将提供实用且深入的指导,涵盖老旧设备联网、AGV车队优化、空压机系统智能能耗管控以及此类项目投资回报率(ROI)的严谨…...

线程中常用的方法
知识点详细说明 Java线程的核心方法集中在Thread类和Object类中,以下是新增整合后的常用方法分类解析: 1. 线程生命周期控制 方法作用注意事项start()启动新线程,JVM调用run()方法多次调用会抛出IllegalThreadStateException(线程状态不可逆)。run()线程的任务逻辑直接调…...

运维体系架构规划
运维体系架构规划是一个系统性工程,旨在构建高效、稳定、安全的运维体系,保障业务系统的持续运行。下面从规划目标、核心模块、实施步骤等方面进行详细阐述: 一、规划目标 高可用性:确保业务系统 724 小时不间断运行,…...

C++结构体介绍
结构体的定义 在C中,结构体(struct)是一种用户定义的数据类型,允许将不同类型的数据组合在一起。结构体的定义使用struct关键字,后跟结构体名称和一对花括号{},花括号内包含成员变量的声明。 struct Pers…...

RoPE长度外推:外插内插
RoPE:假定 α \alpha α是定值 其中一半位置是用cos表示的 cos ( k α − 2 i d ) \cos(k\alpha^{-\frac{2i}{d}}) cos(kα−d2i)(另一半是sin)(d是词嵌入维度) 当太长如何解决: 1 直接不管—外插 缺点:超过一定长度性能急剧下降。(较大时,对应的很多位置编码…...

牛客练习赛138-题解
牛客练习赛138-题解 https://ac.nowcoder.com/acm/contest/109081#question A-小s的签到题 题目描述 给定一个比赛榜单: 第一行是 n 个不同的大写字母,代表题号第二行是 n 个形如a/b的字符串,表示每道题的通过人数和提交人数 找到通过人…...

MySQL高可用方案全攻略:选型指南与AI运维实践
MySQL高可用方案全攻略:选型指南与AI运维实践 引言:当数据库成为业务生命线 在数字化时代,数据库就是企业的"心脏"。一次数据库宕机可能导致: 电商网站每秒损失上万元订单游戏公司遭遇玩家大规模流失金融系统引发连锁反应本文将为你揭秘: MySQL主流高可用方案…...
、包(Package)和模块(Module)解析】)
【库(Library)、包(Package)和模块(Module)解析】
在Python中,**库(Library)、包(Package)和模块(Module)**是代码组织的不同层级,而import语句的导入行为与它们密切相关。以下是详细对比和解释: 📦 1. 核心概…...

记录一次使用thinkphp使用PhpSpreadsheet扩展导出数据,解决身份证号码等信息科学计数法问题处理
PhpSpreadsheet官网 PhpSpreadsheet安装 composer require phpoffice/phpspreadsheet使用composer安装时一定要下载php对应的版本,下载之前使用php -v检查当前php版本 简单使用 <?php require vendor/autoload.php;use PhpOffice\PhpSpreadsheet\Spreadshee…...

为什么业务总是被攻击?使用游戏盾解决方案
业务频繁遭受攻击的核心原因在于攻防资源不对等,攻击者利用技术漏洞、利益驱动及企业防护短板发起攻击,而游戏盾通过针对性架构设计实现高效防御。以下是具体分析与解决方案: 一、业务被攻击的根源 利益驱动攻击 勒索与数…...

4.1【LLaMA-Factory 实战】医疗领域大模型:从数据到部署的全流程实践
【LLaMA-Factory实战】医疗领域大模型:从数据到部署的全流程实践 一、引言 在医疗AI领域,构建专业的疾病诊断助手需要解决数据稀缺、知识专业性强、安全合规等多重挑战。本文基于LLaMA-Factory框架,详细介绍如何从0到1打造一个垂直领域的医…...

二维旋转矩阵:让图形动起来的数学魔法 ✨
大家好!今天我们要聊一个超酷的数学工具——旋转矩阵。它就像数学中的"旋转魔法",能让图形在平面上优雅地转圈圈。别被"矩阵"这个词吓到,其实它就是一个数字表格,但功能超级强大! 一、什么是旋转…...

go语言封装、继承与多态:
1.封装: 封装是通过将数据和操作数据的方法绑定在一起来实现的。在Go语言中,封装通过结构体(struct)和方法(method)来实现。结构体的字段可以通过大小写来控制访问权限。 package stutype Person struct …...

golang -- 如何获取变量类型
目录 前言获取变量类型一、fmt.Printf二、类型断言三、类型选择四、反射 reflect.TypeOf五、reflect.Value的Type()方法 前言 在学习反射的时候,对reflect包中获取变量类型的函数很迷惑 比如下面这个 用Type获取变量类型的方法(在下面提到) …...
)
Missashe考研日记-day36(改版说明)
Missashe考研日记-day36 改版说明 经过一天的思考、纠结和尝试,博主决定对更新内容进行改版,如下:1.不再每天都发一篇日记,改为一周发一篇包含一周七天学习进度的周记,但为了标题和以前相同(强迫症&#…...

opencv中的图像特征提取
图像的特征,一般是指图像所表达出的该图像的特有属性,其实就是事物的图像特征,由于图像获得的多样性(拍摄器材、角度等),事物的图像特征有时并不特别突出或与无关物体混杂在一起,因此图像的特征…...

一文了解氨基酸的分类、代谢和应用
氨基酸(Amino acids)是在分子中含有氨基和羧基的一类化合物。氨基酸是生命的基石,人类所有的疾病与健康状况都与氨基酸有直接或间接的关系。氨基酸失衡可引起肝硬化、神经系统感染性疾病、糖尿病、免疫性疾病、心血管疾病、肾病、肿瘤等各类疾…...

Linux 系统安装Minio详细教程
一、🔍 MinIO 简介 MinIO 是一个高性能的对象存储服务,兼容 Amazon S3 接口,适用于大数据、AI、云原生等场景,支持分布式部署和高可用性,可作为轻量级的私有云对象存储解决方案。 二、📦 安装准备 ✅ 系…...

排序算法-归并排序
归并排序是一种分治算法(Divide and Conquer)。对于给定的一组数据,利用递归与分治技术将数据序列划分成为越来越小的半子表,在对半子表排序后,再用递归方法将排好序的半子表合并成为越来越大的有序序列。 核心思想 分…...
相同,为某个对象设置disabled属性)
js 两个数组中的指定参数(id)相同,为某个对象设置disabled属性
在JavaScript中,如果想要比较两个数组并根据它们的id属性来设置某个对象的disabled属性为true,你可以使用几种不同的方法。这里我将介绍几种常用的方法: 方法1:使用循环和条件判断 const array1 [{ id: 1, name: Item 1 },{ id…...

【Java基础】——集合篇
目标: 1.每个集合用的场景 2.每个集合的底层 一.概述 二. 三.Collection 1.通用方法 其中,contains方法,它的底层一定调用了equals方法进行比对,而且一定重写了equals方法,如果不重写equals方法,就是调用…...

小红书视频无水印下载方法
下载小红书(RED/Xiaohongshu)视频并去除水印可以通过以下几种方法实现,但请注意尊重原创作者版权,下载内容仅限个人使用,避免侵权行为。 方法一:使用在线解析工具(推荐) 复制视频链…...

代发考试战报:思科华为HCIP HCSE CCNP 考试通过
CCNP 300-410考试通过战报,HCIP云计算通过,HCIP数通 H12-821考试通过,H12-831考试通过,HCSP金融 H19-611考试通过,HCSE金融 H21-293 考试通过 报名考试一定要找正规报名,避免后续考试成绩被取消࿰…...

辉芒微离线烧录器“文件格式错误”问题解决
最近在使用辉芒微离线烧录器烧录程序时,提示“文件格式错误”,记录一下解决方法。 一、问题现象 经过多次尝试和排查,发现以下几种情况: 情况一:使用离线烧录器导入固件1(boot程序),…...

系统的从零开始学习电子的相关知识,该如何规划?
一、基础理论奠基(6-12个月) 1.1 数学与物理基础 核心内容: 微积分与线性代数(高频电路建模必备)复变函数与概率论(信号处理与通信系统基础)电磁场基础(麦克斯韦方程组的物理意义&…...

网络研讨会开发注册中, 5月15日特励达力科,“了解以太网”
在线研讨会主题 Understanding Ethernet - from basics to testing & optimization 了解以太网 - 从基础知识到测试和优化 注册链接# https://register.gotowebinar.com/register/2823468241337063262 时间 北京时间 2025 年 5 月 15 日 星期四 下午 3:30 - 4:30 适宜…...

LSTM的简单模型
好的,我来用通俗易懂的语言解释一下这个 LSTMTagger 类是如何工作的。 1️⃣ 类的目的 这个 LSTMTagger 类是一个用于自然语言处理(NLP)任务的模型,目的是标注输入的句子,通常用于词性标注(例如ÿ…...

聊聊Spring AI autoconfigure模块的拆分
序 本文主要研究一下Spring AI autoconfigure模块的拆分 v1.0.0-M6版本 (base) ➜ spring-ai-spring-boot-autoconfigure git:(v1.0.0-M6) tree -L 9 . ├── pom.xml ├── src │ ├── main │ │ ├── java │ │ │ └── org │ │ │ └…...
---绘制和刷写)
LVGL源码学习之渲染、更新过程(3)---绘制和刷写
LVGL版本:8.1 往期回顾: LVGL源码学习之渲染、更新过程(1)---标记和激活 LVGL源码学习之渲染、更新过程(2)---无效区域的处理 前文提到,在处理完无效区域后,会得到一个个需要重新绘制的对象,这些对象将在DRAW事件中…...

CTF-DAY11
[NSSRound#16 Basic]了解过PHP特性吗 题目: <?php error_reporting(0); highlight_file(__FILE__); include("rce.php"); $checker_1 FALSE; $checker_2 FALSE; $checker_3 FALSE; $checker_4 FALSE; $num $_GET[num]; if (preg_match("/…...

手动修改uart16550的FIFO深度?
参考:修改AXI UART D16550 FIFO深度的过程记录 - lmore - 博客园...

Unity按钮事件冒泡
今天unity写程序时,我做了一个透明按钮,没图片,只绑了点击事件,把子对象文字组件也删了,空留一个透明按钮,此时运行时点击按钮是没有反应的,网上的教程说必须指定target graphic(目标…...
:Llama模型的简单部署)
基于Llama3的开发应用(一):Llama模型的简单部署
Llama模型的简单部署 0 前言1 环境准备1.1 硬件环境1.2 软件环境 2 Meta-Llama-3-8B-Instruct 模型简介2.1 Instruct含义2.2 模型下载 3 简单调用4 FastAPI 部署4.1 通过FastAPI简单部署4.2 测试 5 使用 streamlit 构建简易聊天界面6 总结 0 前言 本系列文章是基于Meta-Llama-…...

人工智能 机器学习期末考试题
自测试卷2 一、选择题 1.下面哪个属性不是NumPy中数组的属性( )。 A.ndim B.size C.shape D.add 2.一个简单的Series是由( )的数据组成的。 A.两…...

修改docker为国内源
一、编辑docker配置文件 vi /etc/docker/daemon.json二、配置国内源和修改docker数据目录 {"registry-mirrors":["http://hub-mirror.c.163.com","https://mirrors.tuna.tsinghua.edu.cn","http://mirrors.sohu.com","https://u…...

C++八股 —— vector底层
vector底层为动态数组 类构成 class vector : protected _Vector_base_Vector_base: _M_start:容器元素开始的位置_M_finish:容器元素结束的位置_M_end_of_storage:动态内存最后一个元素的下一个位置 构造函数 无参构造 根据性能优先规则&a…...

postgresql 参数wal_level
wal_level决定多少信息写入到 WAL 中。默认值是replica,它会写入足够的数据以支持WAL归档和复制,包括在后备服务器上运行只读查询。minimal会去掉除从崩溃或者立即关机中进行恢复所需的信息之外的所有记录。最后,logical会增加支持逻辑解码所…...

Lightweight App Alternatives
The tech industry’s business model thrives on constant churn: new features, fancier designs, and heavier apps — not because they’re essential, but because they keep consumers upgrading. Stripping your phone back to basics is an act of tech self-defense.…...

SpringAI--基于MySQL的持久化对话记忆实现
SpringAI–基于MySQL的持久化对话记忆实现 项目源码 对话记忆官方介绍 SpringAI目前提供了一些将对话保存到不同数据源中的实现,比如: InMemoryChatMemory 基于内存存储CassandraChatMemory 在Cassandra中带有过期时间的持久化存储。Neo4jChatMemory 在Neo4j中没…...
4*3蝴蝶拼图(圆形、三角、正方、半圆的凹凸小块+数字提示+参考图灰色))
【教学类-34-12】20250509(通义万相)4*3蝴蝶拼图(圆形、三角、正方、半圆的凹凸小块+数字提示+参考图灰色)
背景介绍 制作了四款异形角拼图,初步实现效果 【教学类-34-10】20250503(通义万相)4*3蝴蝶拼图(圆形、三角、正方、半圆的凹凸小块+参考图灰色)-CSDN博客文章浏览阅读1.4k次,点赞46次,收藏15次。【教学类-34-10】20250503(通义万相)4*3蝴蝶拼图(圆形、三角、正方、…...
)
C++编程语言:标准库:标准库概观(Bjarne Stroustrup)
第30章 标准库概观(Standard-Library Overview) 目录 30.1 引言 30.1.1 标准库设施 30.1.2 设计约束 30.1.3 描述风格 30.2 头文件 30.3 语言支持 30.3.1 对initializer_list的支持 30.3.2 对范围for的支持 30.4 异常处理 30.4.1 异常 30.4.1…...

Springboot+Vue+Mybatis-plus-Maven-Mysql项目部署
目录 VScode 1插件 2快捷键修改 3图标主题设置 4常用设置1 5设置自动换行 6颜色主题 7创建站点 8新建一个html文件 window系统设置 ps 1取色 2测量 3修改单位为像素 4放大图片 5拖动放大之后的图片 6文字大小测量 7测量文字的行高 8矩形选框切图1 9矩形选框…...