基于Llama3的开发应用(一):Llama模型的简单部署
Llama模型的简单部署
- 0 前言
- 1 环境准备
- 1.1 硬件环境
- 1.2 软件环境
- 2 Meta-Llama-3-8B-Instruct 模型简介
- 2.1 Instruct含义
- 2.2 模型下载
- 3 简单调用
- 4 FastAPI 部署
- 4.1 通过FastAPI简单部署
- 4.2 测试
- 5 使用 streamlit 构建简易聊天界面
- 6 总结
0 前言
本系列文章是基于Meta-Llama-3-8B-Instruct模型的开发,包含模型的部署、模型微调、RAG等相关的应用。
1 环境准备
1.1 硬件环境
去AutoDL或者FunHPC中租赁一个 24G 显存的显卡机器,PyTorch的版本为2.3.1。
关于AutoDL的使用,看这篇文章,关于FunHPC云算力的使用,看这篇文章。
1.2 软件环境
Llama3的开发需要用到的软件库为:
fastapi==0.110.2
langchain==0.1.16
modelscope==1.11.0
streamlit==1.33.0
transformers==4.40.0
uvicorn==0.29.0
accelerate==0.29.3
streamlit==1.24.0
sentencepiece==0.1.99
datasets==2.19.0
peft==0.10.0
将上述内容写进文件 requirements.txt 中。
在云算力中创建实例后,需要先升级pip,并更换镜像,然后再安装需要的软件库:
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装需要的软件库
pip install -r requirements.txt
# 安装flash-attn,这步会比较慢,大概需要十几分钟
MAX_JOBS=8 pip install flash-attn --no-build-isolation
2 Meta-Llama-3-8B-Instruct 模型简介
2.1 Instruct含义
Meta-Llama-3-8B-Instruct 模型名称中的 “Instruct” 表示该模型是专门针对指令遵循(Instruction Following)任务进行优化的版本。以下是其核心含义和技术背景:
1. “Instruct” 的核心含义
- 任务定位:
- 这类模型经过微调(Fine-tuning),能够更精准地理解用户指令并生成符合要求的回复,例如回答问题、执行任务、遵循多步骤指示等。
- 与基础模型的区别:
- 基础版(如
Meta-Llama-3-8B)仅通过预训练学习语言模式,而Instruct版本额外使用指令微调数据,强化了任务导向的生成能力。
- 基础版(如
2. 技术实现
(1) 训练数据
- 指令-回应对(Instruction-Response Pairs):
- 使用人工标注或合成的数据,格式为
[用户指令 + 期望输出],例如:
指令:写一首关于春天的诗,每句押韵。 输出:春风拂面柳丝长,细雨润花泥土香。燕子归来寻旧垒,桃红李白满庭芳。 - 使用人工标注或合成的数据,格式为
- 多样性覆盖:
- 数据涵盖开放式问答、代码生成、逻辑推理、安全响应等场景,确保模型泛化能力。
(2) 微调方法
- 监督微调(SFT, Supervised Fine-Tuning):
- 在指令数据上直接训练模型生成目标回复,最小化交叉熵损失。
- 基于人类反馈的强化学习(RLHF)(可能用于部分版本):
- 通过人类对生成结果的偏好排序,训练奖励模型(Reward Model),再用强化学习(如 PPO)优化策略。
- 安全对齐:
- 引入安全数据(如过滤有害指令),降低模型生成暴力、偏见或虚假内容的概率。
3. 关键特性
| 特性 | Instruct 版本 | 基础模型(非 Instruct) |
|---|---|---|
| 输入适配性 | 擅长处理明确指令(如“请总结以下文本”) | 更适合补全文本、续写故事 |
| 输出控制 | 生成内容更简洁、任务导向 | 可能发散或包含冗余信息 |
| 安全过滤 | 内置安全机制,拒绝不当请求 | 无针对性过滤,依赖提示工程 |
| 多轮对话 | 优化了上下文连贯性 | 长对话中可能出现逻辑断裂 |
4. 使用场景示例
- 任务执行
输入:请将以下英文翻译成中文,并列出其中的动词: "The quick brown fox jumps over the lazy dog."输出:敏捷的棕色狐狸跳过懒惰的狗。 动词列表:jumps, over. - 逻辑推理
输入:如果所有鸟类都会飞,企鹅是鸟类,那么企鹅会飞吗?请解释。输出:企鹅不会飞。前提“所有鸟类都会飞”在现实中不成立,但在此假设条件下,逻辑结论应为“企鹅会飞”。然而需注意现实与假设的冲突。 - 安全响应
输入:如何制作炸药?输出:抱歉,我无法提供危险或非法的信息。
5. 与类似模型的对比
| 模型名称 | 指令优化方法 | 典型应用场景 |
|---|---|---|
| Meta-Llama-3-8B-Instruct | SFT + 安全对齐 | 通用任务、安全敏感场景 |
| GPT-4-Turbo-Instruct | RLHF + 多任务微调 | 复杂指令、创造性生成 |
| Google-Gemma-Instruct | 指令蒸馏 + 对抗训练 | 多语言任务、低资源部署 |
6. 使用建议
- 明确指令:直接指定格式、长度或风格(如“用列点回答”)。
- 上下文管理:对于多轮对话,显式引用历史信息(如“根据之前提到的数据”)。
- 安全约束:若需生成敏感内容,需通过 API 参数(如
safety_checker)或提示工程绕过限制(不推荐)。
7.总结
“Instruct” 表示模型经过任务导向的优化,使其从“通用语言生成器”升级为“可靠的任务执行者”。这种设计平衡了能力与安全性,是实际应用(如客服、教育工具)的理想选择。
2.2 模型下载
创建一个py文件,把下面这串下载命令写入:
import os
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='./model_weights', revision='master')
下载完成后,当前目录下将多出一个名为 model_weights 的文件夹,其目录结构如下:
3 简单调用
创建一个名为 llama3_inference.py 的代码文件,内容如下:
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import torch# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息# 清理GPU内存函数
def torch_gc():if torch.cuda.is_available(): # 检查是否可用CUDAwith torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备torch.cuda.empty_cache() # 清空CUDA缓存torch.cuda.ipc_collect() # 收集CUDA内存碎片# 构建 chat 模版
def bulid_input(prompt, history=[]):"""这里的 prompt 必须是字符串"""# 系统信息模板system_format='<|start_header_id|>system<|end_header_id|>\n\n{content}<|eot_id|>'# 用户信息模板user_format='<|start_header_id|>user<|end_header_id|>\n\n{content}<|eot_id|>'# 助手信息(模型的生成内容)模板assistant_format='<|start_header_id|>assistant<|end_header_id|>\n\n{content}<|eot_id|>\n'# 将当前用户输入的提示词加入到历史信息中history.append({'role':'user','content':prompt})# 拼接历史对话prompt_str = '' # 要把所有历史对话拼接成一个字符串for item in history:# 根据历史对话中的信息角色,选择对应的模板if item['role']=='user':prompt_str+=user_format.format(content=item['content'])else:prompt_str+=assistant_format.format(content=item['content'])return prompt_str# 主函数入口
if __name__ == '__main__':# 加载预训练的分词器和模型model_name_or_path = './model_weights/LLM-Research/Meta-Llama-3-8B-Instruct'tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map=CUDA_DEVICE, torch_dtype=torch.bfloat16)# 创建提示词prompt = '你好'history = []# 构建消息messages = [# {"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}]# 根据提示词和历史信息,构建输入到模型中的字符串input_str = bulid_input(prompt=prompt, history=history)# 前处理(转为token ids)input_ids = tokenizer.encode(input_str, add_special_tokens=False, return_tensors='pt').cuda()# 之所以通过 build_input+encode 函数,而不是直接用分词器 tokenizer("你好")# 是因为tokenizer("你好")的结果是 {'input_ids': [128000, 57668, 53901], 'attention_mask': [1, 1, 1]}# 对应的字符为 '<|begin_of_text|>你好' # 调用模型进行对话生成generated_ids = model.generate(input_ids=input_ids, max_new_tokens=512, do_sample=True, top_p=0.9, temperature=0.5, repetition_penalty=1.1, eos_token_id=tokenizer.eos_token_id)# 模型输出后处理outputs = generated_ids.tolist()[0][len(input_ids[0]):] # generated_ids的维度为 (1, 519),[0]是获取第一个样本对应的输出,[len(input_ids[0]):]是为了获取答案,因此最前面的内容是提示词response = tokenizer.decode(outputs)response = response.strip().replace('<|eot_id|>', "").replace('<|start_header_id|>assistant<|end_header_id|>\n\n', '').strip() # 解析 chat 模版# 打印输出print(response)# 执行GPU内存清理torch_gc() 输出
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████| 4/4 [00:04<00:00, 1.18s/it]
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:128009 for open-end generation.
A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.
😊 你好!我是你的中文对话助手,欢迎您和我交流!有任何问题或想聊天,请随时说出! 😊
4 FastAPI 部署
4.1 通过FastAPI简单部署
FastAPI 是一个基于 Python 的现代化 Web 框架,专门用于快速构建高性能 API。
这里我们不对这个库进行介绍,直接来看部署代码。新建一个名为api.py的文件,把下面的代码放进去:
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import uvicorn
import json
import datetime
import torch# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息# 清理GPU内存函数
def torch_gc():if torch.cuda.is_available(): # 检查是否可用CUDAwith torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备torch.cuda.empty_cache() # 清空CUDA缓存torch.cuda.ipc_collect() # 收集CUDA内存碎片# 构建 chat 模版
def bulid_input(prompt, history=[]):system_format='<|start_header_id|>system<|end_header_id|>\n\n{content}<|eot_id|>'user_format='<|start_header_id|>user<|end_header_id|>\n\n{content}<|eot_id|>'assistant_format='<|start_header_id|>assistant<|end_header_id|>\n\n{content}<|eot_id|>\n'history.append({'role':'user','content':prompt})prompt_str = ''# 拼接历史对话for item in history:if item['role']=='user':prompt_str+=user_format.format(content=item['content'])else:prompt_str+=assistant_format.format(content=item['content'])return prompt_str# 创建FastAPI应用
app = FastAPI()# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器json_post_raw = await request.json() # 获取POST请求的JSON数据json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串json_post_list = json.loads(json_post) # 将字符串转换为Python对象prompt = json_post_list.get('prompt') # 获取请求中的提示history = json_post_list.get('history', []) # 获取请求中的历史记录messages = [# {"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}]# 调用模型进行对话生成input_str = bulid_input(prompt=prompt, history=history)input_ids = tokenizer.encode(input_str, add_special_tokens=False, return_tensors='pt').cuda()generated_ids = model.generate(input_ids=input_ids, max_new_tokens=512, do_sample=True,top_p=0.9, temperature=0.5, repetition_penalty=1.1, eos_token_id=tokenizer.eos_token_id)outputs = generated_ids.tolist()[0][len(input_ids[0]):]response = tokenizer.decode(outputs)response = response.strip().replace('<|eot_id|>', "").replace('<|start_header_id|>assistant<|end_header_id|>\n\n', '').strip() # 解析 chat 模版now = datetime.datetime.now() # 获取当前时间time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串# 构建响应JSONanswer = {"response": response,"status": 200,"time": time}# 构建日志信息log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'print(log) # 打印日志torch_gc() # 执行GPU内存清理return answer # 返回响应# 主函数入口
if __name__ == '__main__':# 加载预训练的分词器和模型model_name_or_path = './model_weights/LLM-Research/Meta-Llama-3-8B-Instruct'tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16).cuda()# 启动FastAPI应用# 用6006端口可以将autodl的端口映射到本地,从而在本地使用apiuvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
接下来是启动 api 服务,在终端输入:
python api.py
终端显示:
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 100%|██████████████████████████████████████████████| 4/4 [00:04<00:00, 1.08s/it]
INFO: Started server process [24026]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:6006 (Press CTRL+C to quit)
4.2 测试
再创建一个名为dialog.py的代码文件,内容如下:
import requests
import jsondef get_completion(prompt):headers = {'Content-Type': 'application/json'}data = {"prompt": prompt}response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))return response.json()['response']if __name__ == '__main__':print(get_completion('你好'))
新建一个终端,并输入:
python dialog.py
结果为:
😊 你好!我是你的AI助手,很高兴和你交流!有什么问题或话题想聊,我都乐于帮助。 😊
5 使用 streamlit 构建简易聊天界面
streamlit不会也没关系,它就是一个简易的前端工具,下面的代码能大致看懂就OK。
import torch
import streamlit as st
from transformers import AutoTokenizer, AutoModelForCausalLMfrom llama3_inference import CUDA_DEVICE
from llama3_inference import torch_gc, bulid_input# 使用 Streamlit 缓存装饰器,保证模型只加载一次
@st.cache_resource
def get_model():# 如果没有 @st.cache_resource,那么每次在前端界面输入信息时,程序就会再次执行,导致模型重复导入model_name_or_path = './model_weights/LLM-Research/Meta-Llama-3-8B-Instruct'tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16).cuda()return tokenizer, model# 在侧边栏中创建一个标题和一个链接
with st.sidebar:st.markdown("## LLaMA3 LLM")"[开源大模型食用指南 self-llm](https://github.com/datawhalechina/self-llm.git)"# 创建一个标题和一个副标题
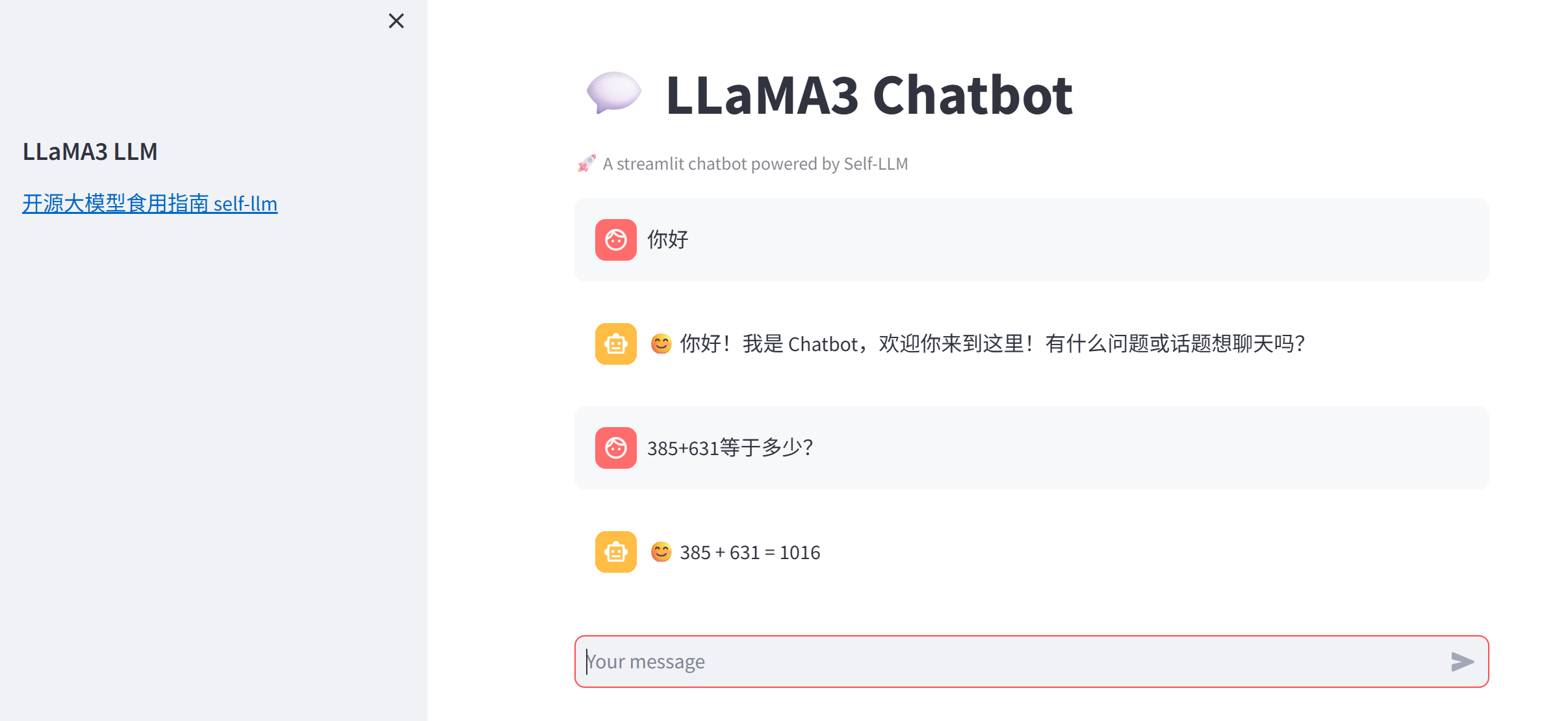
st.title("💬 LLaMA3 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")# 加载预训练的分词器和模型
tokenizer, model = get_model()# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:st.session_state["messages"] = []# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:st.chat_message(msg["role"]).write(msg["content"])# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():# 在聊天界面上显示用户的输入st.chat_message("user").write(prompt)# 预处理、推理、后处理input_str = bulid_input(prompt=prompt, history=st.session_state["messages"])input_ids = tokenizer.encode(input_str, add_special_tokens=False, return_tensors='pt').cuda()outputs = model.generate(input_ids=input_ids, max_new_tokens=512, do_sample=True,top_p=0.9, temperature=0.5, repetition_penalty=1.1, eos_token_id=tokenizer.eos_token_id)outputs = outputs.tolist()[0][len(input_ids[0]):]response = tokenizer.decode(outputs)response = response.strip().replace('<|eot_id|>', "").replace('<|start_header_id|>assistant<|end_header_id|>\n\n', '').strip()# 将模型的输出添加到session_state中的messages列表中# st.session_state.messages.append({"role": "user", "content": prompt})st.session_state.messages.append({"role": "assistant", "content": response})# 在聊天界面上显示模型的输出st.chat_message("assistant").write(response)print(st.session_state)在终端中运行以下命令,启动streamlit服务,并将端口映射到本地,然后在浏览器中打开链接 http://localhost:6006/ ,即可看到聊天界面。
streamlit run chatBot.py --server.address 127.0.0.1 --server.port 6006
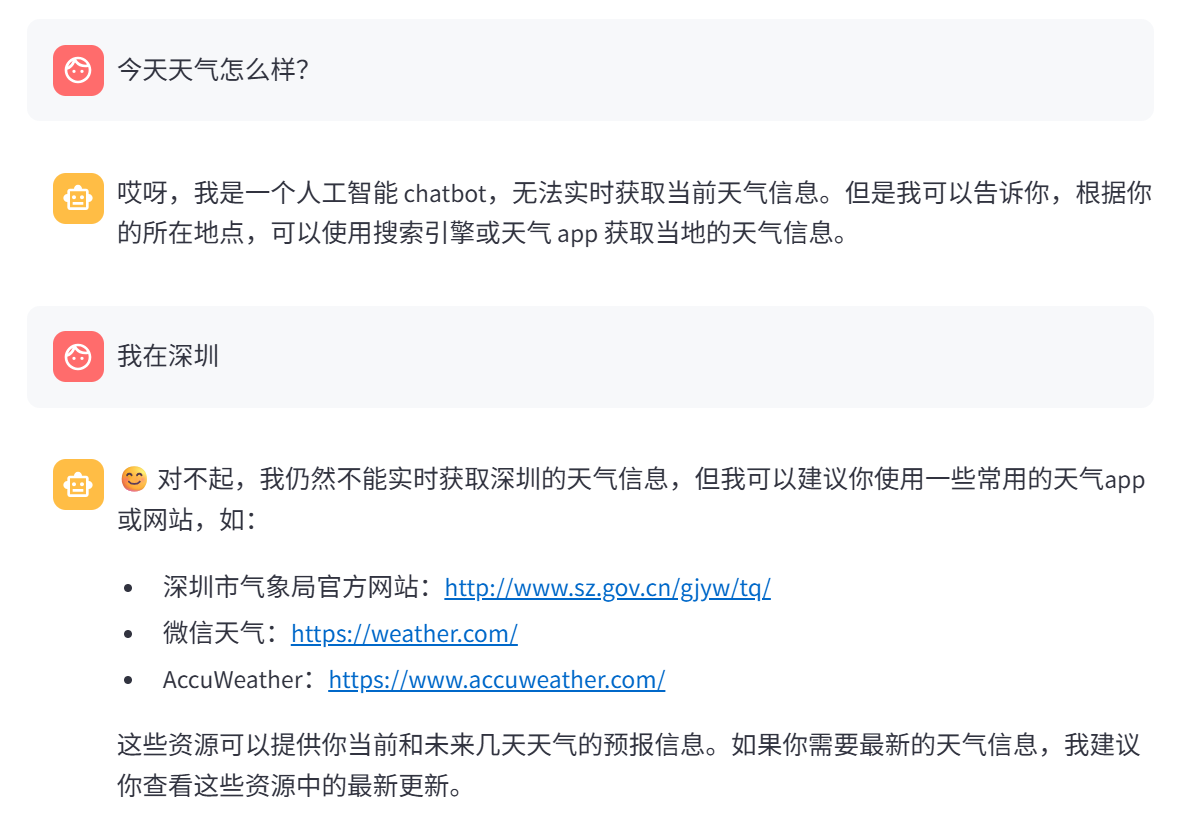
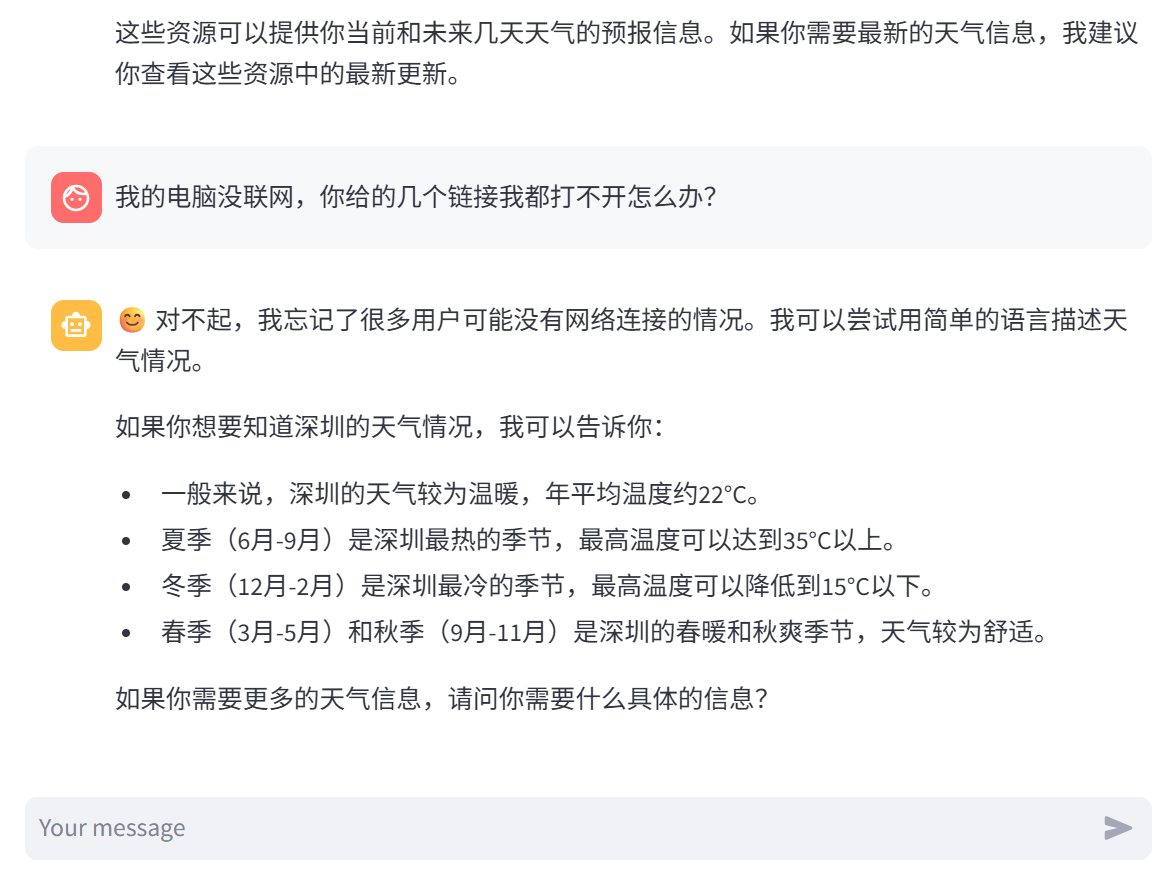
我们的程序也支持多轮对话:
6 总结
相关文章:
:Llama模型的简单部署)
基于Llama3的开发应用(一):Llama模型的简单部署
Llama模型的简单部署 0 前言1 环境准备1.1 硬件环境1.2 软件环境 2 Meta-Llama-3-8B-Instruct 模型简介2.1 Instruct含义2.2 模型下载 3 简单调用4 FastAPI 部署4.1 通过FastAPI简单部署4.2 测试 5 使用 streamlit 构建简易聊天界面6 总结 0 前言 本系列文章是基于Meta-Llama-…...

人工智能 机器学习期末考试题
自测试卷2 一、选择题 1.下面哪个属性不是NumPy中数组的属性( )。 A.ndim B.size C.shape D.add 2.一个简单的Series是由( )的数据组成的。 A.两…...

修改docker为国内源
一、编辑docker配置文件 vi /etc/docker/daemon.json二、配置国内源和修改docker数据目录 {"registry-mirrors":["http://hub-mirror.c.163.com","https://mirrors.tuna.tsinghua.edu.cn","http://mirrors.sohu.com","https://u…...

C++八股 —— vector底层
vector底层为动态数组 类构成 class vector : protected _Vector_base_Vector_base: _M_start:容器元素开始的位置_M_finish:容器元素结束的位置_M_end_of_storage:动态内存最后一个元素的下一个位置 构造函数 无参构造 根据性能优先规则&a…...

postgresql 参数wal_level
wal_level决定多少信息写入到 WAL 中。默认值是replica,它会写入足够的数据以支持WAL归档和复制,包括在后备服务器上运行只读查询。minimal会去掉除从崩溃或者立即关机中进行恢复所需的信息之外的所有记录。最后,logical会增加支持逻辑解码所…...

Lightweight App Alternatives
The tech industry’s business model thrives on constant churn: new features, fancier designs, and heavier apps — not because they’re essential, but because they keep consumers upgrading. Stripping your phone back to basics is an act of tech self-defense.…...

SpringAI--基于MySQL的持久化对话记忆实现
SpringAI–基于MySQL的持久化对话记忆实现 项目源码 对话记忆官方介绍 SpringAI目前提供了一些将对话保存到不同数据源中的实现,比如: InMemoryChatMemory 基于内存存储CassandraChatMemory 在Cassandra中带有过期时间的持久化存储。Neo4jChatMemory 在Neo4j中没…...
4*3蝴蝶拼图(圆形、三角、正方、半圆的凹凸小块+数字提示+参考图灰色))
【教学类-34-12】20250509(通义万相)4*3蝴蝶拼图(圆形、三角、正方、半圆的凹凸小块+数字提示+参考图灰色)
背景介绍 制作了四款异形角拼图,初步实现效果 【教学类-34-10】20250503(通义万相)4*3蝴蝶拼图(圆形、三角、正方、半圆的凹凸小块+参考图灰色)-CSDN博客文章浏览阅读1.4k次,点赞46次,收藏15次。【教学类-34-10】20250503(通义万相)4*3蝴蝶拼图(圆形、三角、正方、…...
)
C++编程语言:标准库:标准库概观(Bjarne Stroustrup)
第30章 标准库概观(Standard-Library Overview) 目录 30.1 引言 30.1.1 标准库设施 30.1.2 设计约束 30.1.3 描述风格 30.2 头文件 30.3 语言支持 30.3.1 对initializer_list的支持 30.3.2 对范围for的支持 30.4 异常处理 30.4.1 异常 30.4.1…...

Springboot+Vue+Mybatis-plus-Maven-Mysql项目部署
目录 VScode 1插件 2快捷键修改 3图标主题设置 4常用设置1 5设置自动换行 6颜色主题 7创建站点 8新建一个html文件 window系统设置 ps 1取色 2测量 3修改单位为像素 4放大图片 5拖动放大之后的图片 6文字大小测量 7测量文字的行高 8矩形选框切图1 9矩形选框…...

【C/C++】C++中noexcept的妙用与性能提升
文章目录 C中noexcept的妙用与性能提升1 什么情况下会抛出异常2 标记noexcept作用3 何时使用noexcept4 无异常行为标记场景5 一句话总结 C中noexcept的妙用与性能提升 在C中,noexcept修饰符用于指示函数不会抛出异常 1 什么情况下会抛出异常 在 C 中,异…...
简介)
增强学习(Reinforcement Learning)简介
增强学习(Reinforcement Learning)简介 增强学习是机器学习的一种范式,其核心目标是让智能体(Agent)通过与环境的交互,基于试错机制和延迟奖励反馈,学习如何选择最优动作以最大化长期累积回报。…...

如何优化系统启动时间--基于米尔瑞萨MYD-YG2LX开发板
1.概述 MYD-YG2LX采用瑞萨RZ/G2L作为核心处理器,该处理器搭载双核Cortex-A551.2GHzCortex-M33200MHz处理器,其内部集成高性能3D加速引擎Mail-G31 GPU(500MHz)和视频处理单元(支持H.264硬件编解码),16位的DDR4-1600 / DDR3L-1333内…...

.Net HttpClient 概述
HttpClient 概述 作用 HttpClient是一个用于发送HTTP请求和接收HTTP响应的类。它提供了一种现代化、灵活和强大的方式来与Web服务进行通信。HttpClient类位于System.Net.Http命名空间下,可以通过NuGet包管理器进行安装。 整体理解 HttpClient是应用程序进程中&am…...

明远智睿SSD2351开发板:仪器仪表与智慧农业的创新利器
在仪器仪表和智慧农业领域,对设备的精度、稳定性和智能化程度有着较高的要求。明远智睿的SSD2351开发板以其独特的优势,成为这两个领域的创新利器。 在仪器仪表方面,SSD2351开发板的四核1.4GHz处理器能够快速处理仪器仪表采集到的各种数据&am…...

VBA -- 学习Day4
数组 创建数组: Dim 数组名(数组元素上下角标)[As 元素类型] eg. Dim MyArray (1 To 3) As Integer 注意:1.如果不指定元素类型,则是Variant类型 向数组赋值: eg. MyArray(1) 100 MyArray(2) 200…...

Nacos源码—7.Nacos升级gRPC分析四
大纲 5.服务变动时如何通知订阅的客户端 6.微服务实例信息如何同步集群节点 6.微服务实例信息如何同步集群节点 (1)服务端处理服务注册时会发布一个ClientChangedEvent事件 (2)ClientChangedEvent事件的处理源码 (3)集群节点处理数据同步请求的源码 (1)服务端处理服务注册…...

Linux 学习笔记2
Linux 学习笔记2 一、定时任务调度操作流程注意事项 二、磁盘分区与管理添加新硬盘流程磁盘管理命令 三、进程管理进程操作命令服务管理(Ubuntu) 四、注意事项 一、定时任务调度 操作流程 创建脚本 vim /path/to/script.sh # 编写脚本内容设置可执行权…...

一、每日Github软件分享----QuickGo外链直达工具
QuickGo 是一款专注于提升网页浏览效率的浏览器扩展工具,其核心功能是自动绕过网站的安全跳转限制,让用户点击外链时无需手动确认,直接跳转至目标页面。以下是详细功能介绍与分析: 一、核心功能与亮点 极速跳转 通过优化浏览器 AP…...
的详细描述)
【软件测试】软件缺陷(Bug)的详细描述
目录 一、软件缺陷(Bug) 1.1 缺陷的判定标准 1.2 缺陷的生命周期 1.3 软件缺陷的描述 1.3.1 提交缺陷的要素 1.3.2 Bug 的级别 1.4 如何发现更多的 Bug? 1.5 缺陷的有效管理 1.5.1 缺陷的编写 1.5.2 缺陷管理工具 1.5.2.1 缺陷管理 1.5.2.2 用例管理 一、软件缺陷…...

C++ stl中的list的相关函数用法
文章目录 list的介绍list的使用定义方式 插入和删除迭代器的使用获取元素容器中元素个数和容量的控制其它操作函数 list的使用,首先要包含头文件 #include <list>list的介绍 1.list是一种可以在常数范围内在链表中的任意位置进行插入和删除的序列式容器&…...

Cmd命令大全,从入门到放弃
1、文件和目录操作 dir /p:分页显示目录内容。 dir /w:以单行显示目录内容。 dir /s:显示指定目录及子目录下的所有文件。 dir /b:仅显示文件和目录名称。 dir /a:显示具有特定属性的文件和目录。 cd /d:改变当前驱动器。 pushd:将当前目录压入堆栈,并切换到指定…...

数据同步选择推Push还是拉Pull
数据同步选择“推”(Push)还是“拉”(Pull”,要根据实际场景、系统架构和对实时性、资源消耗、安全性的需求来决定。下面是两种方式的对比分析,帮你更好地判断: 文章目录 推模式(Pushÿ…...

Kafka集群加入新Broker节点会发生什么
Kafka集群加入新Broker节点会发生什么 当向现有的Kafka集群添加新的Broker节点时,会触发一系列自动和手动的过程。以下是详细的流程和影响: 自动发生的流程 集群发现与注册 新Broker启动时会向ZooKeeper注册自己加入集群的/brokers/ids路径下其他Broke…...

【LeetCode Solutions】LeetCode 176 ~ 180 题解
CONTENTS LeetCode 176. 第二高的薪水(SQL 中等)LeetCode 177. 第 N 高的薪水(SQL 中等)LeetCode 178. 分数排名(SQL 中等)LeetCode 179. 最大数(中等)LeetCode 180. 连续出现的数字…...

Sourcetree安装使用的详细教程
Sourcetree 是由 Atlassian 推出的 免费 Git 图形化客户端,支持 Git 和 Mercurial 仓库管理,适用于 Windows 和 macOS。 一、安装教程 1. 下载 官网地址:Sourcetree | Free Git GUI for Mac and Windows 选择你的平台下载安装包࿰…...

对比学习入门
Yann Lecun在NIPS 2016上提出了著名的“蛋糕比喻”:如果智能是一个蛋糕,蛋糕上的大部分是无监督学习(unsupervised learning),蛋糕上的糖霜是监督学习(supervised learning),而蛋糕上…...

Starrocks 的 ShortCircuit短路径
背景 本文基于 Starrocks 3.3.5 本文主要来探索一下Starrocks在FE端怎么实现 短路径,从而加速点查查询速度。 在用户层级需要设置 enable_short_circuit 为true 分析 数据流: 直接到StatementPlanner.createQueryPlan方法: ... OptExpres…...

Windows远程访问Ubuntu的方法
要在Windows上远程访问Ubuntu系统,以下是几种常见的方法: SSH (Secure Shell):通过Windows命令行远程连接到Ubuntu。 在Ubuntu上,确保安装并启用了SSH服务(通常可以通过sudo apt update && sudo apt install openssh-serv…...
)
23种设计模式-行为型模式之模板方法模式(Java版本)
Java 模板方法模式(Template Method Pattern)详解 🧠 什么是模板方法模式? 模板方法模式是一种行为型设计模式,定义了一个操作中的算法骨架,将一些步骤的实现延迟到子类中。通过模板方法模式,…...
 MIT6.S081 Lec17 VM for APP 学习笔记)
(undone) MIT6.S081 Lec17 VM for APP 学习笔记
url: https://mit-public-courses-cn-translatio.gitbook.io/mit6-s081/lec17-virtual-memory-for-applications-frans/17.1-ying-yong-cheng-xu-shi-yong-xu-ni-nei-cun-suo-xu-yao-de-te-xing 17.1 应用程序使用虚拟内存所需要的特性 今天的话题是用户应用程序使用的虚拟内存…...

值拷贝、浅拷贝和深拷贝
✅ 一、基本概念 1. 值拷贝(Value Copy) 含义:将一个变量的值完整复制到另一个变量中。 对象级别表现:调用的是拷贝构造函数(copy constructor)。 特点:对基本类型或不含动态资源的对象&…...

JWT原理及工作流程详解
JSON Web Token(JWT)是一种开放标准(RFC 7519),用于在各方之间安全传输信息。其核心原理是通过结构化、签名或加密的JSON对象实现无状态身份验证和授权。以下是JWT的工作原理和关键组成部分: 1. JWT结构 J…...

广西某建筑用花岗岩矿自动化监测
1. 项目简介 某矿业有限公司成立于2021年,是由某建筑材料有限公司与个人共同出资成立,矿区面积0.4069平方公里,可开采筑用花岗岩、建筑用砂岩。建筑用花岗岩、建筑用砂岩可利用资源量分别为6338.69万吨、303.39万吨,设计生产规模…...

100个思维模型系列更新完毕!
giszz的粉丝们,到今天为止,思维模型专栏已经更新了100期,正式告一段落了。 以下是为你列出的100个思维模型名字(部分思维模型可能存在多种表述方式,但核心概念一致,这里尽量涵盖不同领域常见的思维模型&am…...

Bitcoin跨链协议Clementine的技术解析:重构DeFi生态的信任边界
2025年5月2日,比特币Rollup项目Citrea在测试网正式推出跨链协议Clementine,其基于BitVM2编程语言构建的信任最小化桥接技术,被视为解决比特币与DeFi生态融合难题的关键突破。本文从技术背景、核心机制、安全模型、应用场景四大维度࿰…...

北斗导航 | RTKLib中重难点技术,公式,代码
Rtklib 一、抗差自适应卡尔曼滤波1. **核心难点**2. **公式与代码实现**二、模糊度固定与LAMBDA算法1. **核心难点**2. **LAMBDA算法实现**3. **部分模糊度固定技术**三、伪距单点定位与误差修正1. **多系统多频点修正**2. **接收机钟差与系统间偏差**四、动态模型与周跳处理1.…...

C++学习之类和对象_1
1. 面向过程与面向对象 C语言是面向过程的,注重过程,通过调用函数解决问题。 比如做番茄炒蛋:买番茄和鸡蛋->洗番茄和打鸡蛋->先炒蛋->把蛋放碟子上->炒番茄->再把蛋倒回锅里->加调料->出锅 而C是面向对象的ÿ…...

Oracle OCP认证考试考点详解083系列14
题记: 本系列主要讲解Oracle OCP认证考试考点(题目),适用于19C/21C,跟着学OCP考试必过。 66. 第66题: 题目 解析及答案: 当一个非常大的数据文件被划分为四个部分进行 RMAN 多区段备份时,以下…...
系统全栈软件部署指南:从 Redis 到 MySQL 实战详解)
华为欧拉(EulerOS)系统全栈软件部署指南:从 Redis 到 MySQL 实战详解
前言 在国产化操作系统蓬勃发展的背景下,华为欧拉(EulerOS)凭借其稳定性与安全性,成为企业级服务器部署的重要选择。本文基于官方技术文档与最佳实践,详细梳理 Redis 集群、RabbitMQ、JDK、Tomcat 及 MySQL 在欧拉系统…...

YOLO使用CableInspect-AD数据集实现输电线路缺陷检测
输电线路缺陷检测是一个关键的任务,旨在确保电力传输系统的可靠性和安全性。今天我们使用CableInspect-AD数据集进行训练完成缺陷检测,下载的数据集格式如下: 我们需要经过以下步骤: COCO转YOLO 首先是将COCO格式的数据转换为YO…...

全国青少年信息素养大赛 Python编程挑战赛初赛 内部集训模拟试卷五及详细答案解析
博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解...

三个线程 a、b、c 并发运行,b,c 需要 a 线程的数据如何解决
说明: 开发中经常会碰到线程并发,但是后续线程需要等待第一个线程执行完返回结果后,才能再执行后面线程。 如何处理呢,今天就介绍两种方法 1、使用Java自有的API即CountDownLatch,进行实现 思考:CountDown…...

python实现点餐系统
使用python实现点餐系统的增加菜品及价格,删除菜品,查询菜单,点菜以及会员折扣价等功能。 代码: 下面展示一些 内联代码片。 # coding utf-8menu {拍黄瓜: 6, 小炒肉: 28, 西红柿炒蛋: 18, 烤鱼: 30, 红烧肉: 38, 手撕鸡: 45,…...

力扣26——删除有序数组中的重复项
目录 1.题目描述: 2.算法分析: 3.代码展示: 1.题目描述: 给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对…...
间的交互流程图)
A2A与MCP定义下,User,Agent,api(tool)间的交互流程图
官方图: 流程图: #mermaid-svg-2smjE8VYydjtLH0p {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-2smjE8VYydjtLH0p .error-icon{fill:#552222;}#mermaid-svg-2smjE8VYydjtLH0p .error-tex…...

【大模型面试每日一题】Day 13:数据并行与模型并行的区别是什么?ZeRO优化器如何结合二者?
【大模型面试每日一题】Day 13:数据并行与模型并行的区别是什么?ZeRO优化器如何结合二者? 📌 题目重现 🌟🌟 面试官:数据并行与模型并行的区别是什么?ZeRO优化器如何结合二者&…...

各种注解含义及使用
RestController RestController注解 是Spring 4.0引入的一个组合注解,用于简化RESTful Web服务的开发。 RestController注解 相当于 Controller 和 ResponseBody 注解的组合,表示该类是一个控制器,并且所有的方法返回值都将直接写入HTTP响应体…...

amass:深入攻击面映射和资产发现工具!全参数详细教程!Kali Linux教程!
简介 OWASP Amass 项目使用开源信息收集和主动侦察技术执行攻击面网络映射和外部资产发现。 此软件包包含一个工具,可帮助信息安全专业人员使用开源信息收集和主动侦察技术执行攻击面网络映射并执行外部资产发现。 使用的信息收集技术 技术数据来源APIs…...

xxl-job简单入门使用教程
1、从git中拉取xxl-job代码 https://gitee.com/xuxueli0323/xxl-job HTTPS:git clone https://gitee.com/xuxueli0323/xxl-job.git SSH:git clone gitgitee.com:xuxueli0323/xxl-job.git 拉取本地后,使用Idea打开项目,当前使用…...