【Yolo精读+实践+魔改系列】Yolov3论文超详细精讲(翻译+笔记)


前言
前面咱们已经把 YOLOv1 和 YOLOv2 的老底都给掀了,今天轮到 YOLOv3 登场,这可是 Joseph Redmon 的“封神之作”。讲真,这哥们本来是搞学术的,结果研究的模型被某些军方拿去“整点活”——不是做人是做武器的那种活。于是他一怒之下,宣布退圈,跑路了,2020年告别 CV 界,江湖再无 Redmon,但江湖却一直流传着他留下的神器——YOLOv3。
YOLOv3 是 YOLO 家族里奠基性的“骨架搭建者”,后面那些五花八门的 YOLO(v4、v5、v6……都快出到v∞了)基本都站在它的肩膀上跳舞。那咱们就来看看,它到底在 YOLOv2 的基础上都升级了啥吧!
改进点一:多尺度预测,大小通吃
YOLOv2 一直用一个尺寸的特征图来做目标预测,这就像拿个放大镜找蚂蚁,有点搞笑。而 YOLOv3 摆烂不干了,它直接上了三个不同尺寸的特征图: 13×13、26×26、52×52,分别打击大中小目标。
这就好比带了望远镜、眼镜和放大镜,不管你是小蚊子还是大恐龙,全都别想跑。这个设计也奠定了后面 YOLO 系列的多尺度检测思路,简直是“祖传三件套”。
改进点二:主干换代,肌肉更猛
YOLOv2 用的是 Darknet-19,听起来像个没进化完的宝可梦。而 YOLOv3 直接换装了 Darknet-53,一口气加到了53层,还加了残差连接,ResNet 那一套全学了个遍。
这就像从“老年机”一口气升级到了“满配游戏本”,计算力直接起飞,特征提取能力翻倍,让 YOLO 的眼神变得更加犀利。
改进点三:不搞 softmax,搞起独立判断
YOLOv2 在分类的时候是“你只能选一个类”,就像问你喜欢苹果还是香蕉,非得选一个。但 YOLOv3 说——“为啥不能又喜欢苹果又喜欢香蕉?”
于是它放弃了 softmax,采用 logistic 回归+独立二分类的方式。每个类别都单独判断,谁爱谁就打个1,不爱就打0。这样不仅更灵活,还能处理那种“目标多重身份”的场景,堪称分类界的“社交达人”。
视频讲解:B站 智算学术 (会有一天的延迟)
项目主页:YOLO: Real-Time Object Detection
论文链接:Joseph Redmon - Survival Strategies for the Robot Rebellion
代码链接:GitHub - ultralytics/yolov3: YOLOv3 in PyTorch > ONNX > CoreML > TFLite
500篇经典深度学习论文+视频讲解+论文写作工具+模块缝合 请关注公众号:智算学术 领取
前情回顾
【Yolo精读+实践+魔改系列】Yolov1论文超详细精讲(翻译+笔记)
【Yolo精读+实践+魔改系列】Yolov2论文超详细精讲(翻译+笔记
目录
前言
改进点一:多尺度预测,大小通吃
改进点二:主干换代,肌肉更猛
改进点三:不搞 softmax,搞起独立判断
前情回顾
Abstract—摘要
一、Introduction—引言
二、The Deal—改进的细节
2.1 Bounding Box Prediction—边界框预测
🚀 YOLOv3 vs YOLOv2 的核心区别
🔍 具体解释一些重要差异
👀 YOLOv3 中置信度的具体计算逻辑:
1. 正样本(positive sample)
2. 负样本(negative sample)
3. 被忽略的样本
🧠 一句话总结:
2.2 Class Prediction—类预测(单标签分类改进为多标签分类)
2.3 Predictions Across Scales—跨尺度预测
2.4 Feature Extractor—特征提取
2.5 Training—训练
三、How We Do—我们怎样做
四、Things We Tried That Didn’t Work—那些我们尝试了但没有奏效的方法
五、 What This All Means—这一切意味着什么?
Abstract—摘要
翻译
我们对 YOLO 进行了一些更新!我们在设计上做了一些小改动,使它变得更好。我们还训练了一个新的网络,它非常强大。它比上次的大了一点,但更准确了。不过速度还是很快,不用担心。在 320 × 320 的分辨率下,YOLOv3 在 28.2 mAP 下的运行时间为 22 毫秒,与 SSD 一样精确,但速度快了三倍。当我们使用旧的 .5 IOU mAP 检测指标时,YOLOv3 的表现相当不错。在 Titan X 上,它在 51 毫秒内实现了 57.9 AP50,而 RetinaNet 在 198 毫秒内实现了 57.5 AP50,性能相似,但速度快了 3.8 倍。一如既往,所有代码均可在 Joseph Redmon - Survival Strategies for the Robot Rebellion 在线查阅。
精读
大佬就是大佬,摘要写的这么敷衍!
总结: YOLOv3 进行了设计优化和网络更新,提升了准确率,虽然模型略大,但速度依然很快。在多项指标上优于同类模型,尤其在速度上表现突出。
具体列举:
-
设计优化:对 YOLO 架构进行了小改动以提升性能。
-
新网络训练:新的模型更大但更准确,速度仍然很快。
-
性能指标(320×320 分辨率):
-
YOLOv3:28.2 mAP,运行时间为 22 毫秒。
-
与 SSD 相比:精度相当,但速度快了 3 倍。
-
-
旧版 AP50 指标下(IOU = 0.5):
-
YOLOv3:57.9 AP50,耗时 51 毫秒(Titan X)。
-
RetinaNet:57.5 AP50,耗时 198 毫秒。
-
YOLOv3 比 RetinaNet 快 3.8 倍。
-
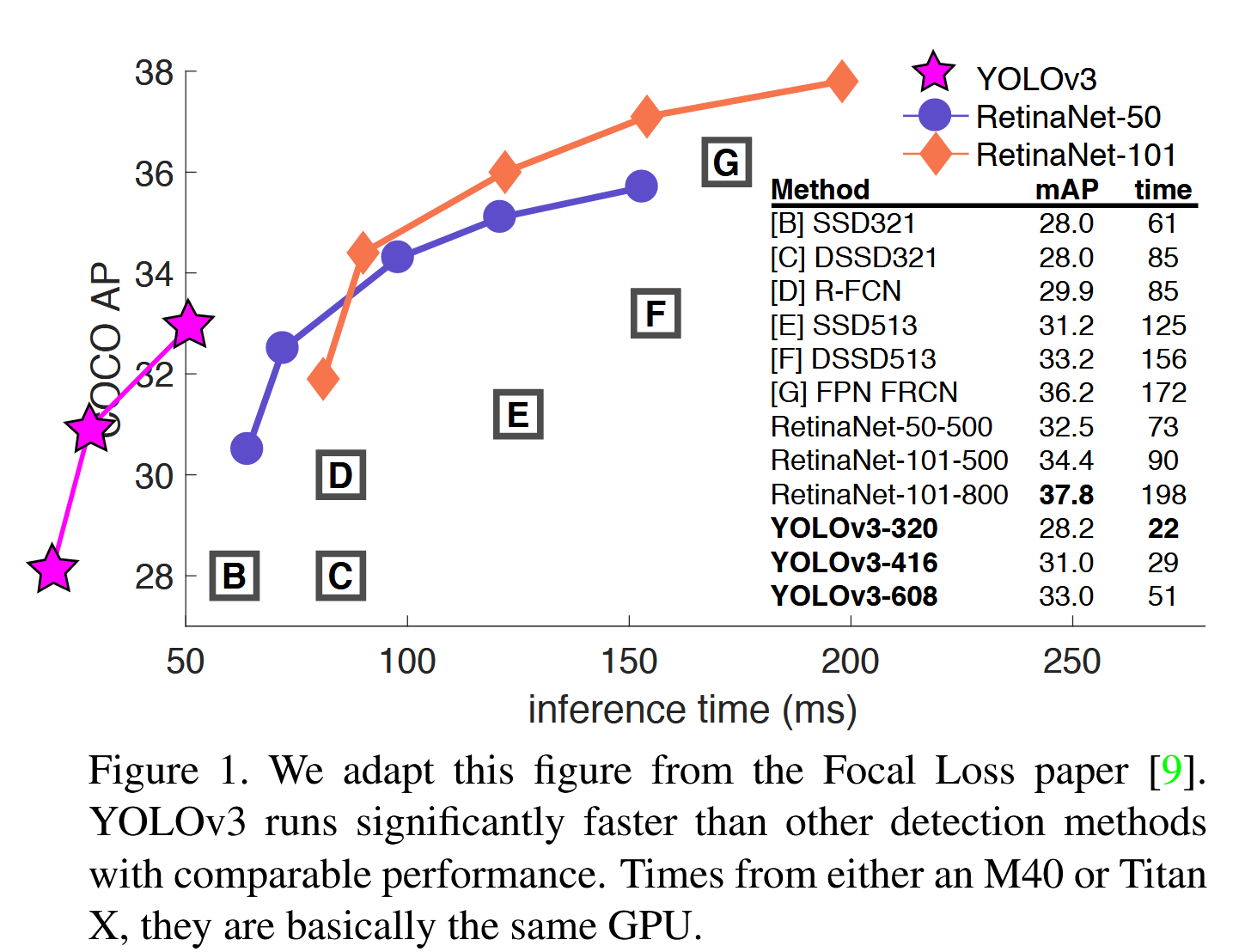
这张图主要突出的是速度,横轴是速度,纵轴是mAP,当纵轴相同时,YOLOv3的速度大大提升
一、Introduction—引言
翻译
有时候,你会在一年里碌碌无为,你知道吗?今年我没做什么研究。在 Twitter 上花了很多时间。玩了一会儿 GANs。去年12我还有点余力;我设法对《YOLO》做了一些改进。不过,说实话,也没什么特别有意思的,只是做了一些让它变得更好的小改动。我还为其他人的研究提供了一些帮助。事实上,这就是我们今天在这里的原因。我们的截稿日期是 [4],我们需要引用我对《YOLO》进行的一些随机更新,但我们没有资料来源。所以,准备好看技术报告吧!技术报告的好处是不需要前言,你们都知道我们为什么在这里。因此,本引言的结尾将为本文的其余部分指明方向。首先,我们会告诉大家 YOLOv3 是怎么回事。然后,我们将告诉大家我们是如何做的。我们还会告诉你我们尝试过的一些行不通的方法。最后,我们将思考这一切意味着什么。
精读
你以为顶会论文的引言会从“深度神经网络的飞速发展”开始?不,YOLOv3 的作者一上来就说: “今年我啥也没干,研究没搞,Twitter 刷到脱发,GAN 玩得像小游戏。”
然后一句话轻描淡写地甩出来:“去年对 YOLO 做了点小更新。” ——这就像是有人跟你说:“我也没啥特长,除了随手把目标检测领域拉高一个量级。”
接下来是名场面:
“我们要引用一下我对 YOLO 的随机更新,但没有资料来源。”
哦豁?学术圈的“你引用我了吗”直接变成“我引用我自己,但懒得写篇正式论文”,于是随手整了一份技术报告,顺便告诉全世界:“技术报告的好处是不需要前言。” 翻译一下就是:“别问,问就是老子写的,我说了算。”
最后一句更是点题收尾:
“首先,我们告诉你 YOLOv3 是怎么回事,然后告诉你我们是怎么做的,接着告诉你哪些方法不行,最后我们来思考这一切意味着啥。”
通俗版总结就是: “先秀肌肉,再讲配方,顺便踩几个坑,最后升华人生。”
二、The Deal—改进的细节
2.1 Bounding Box Prediction—边界框预测
翻译
继 YOLO9000 之后,我们的系统使用维度集群作为锚点来预测边界框[15]。网络会为每个边界框预测 4 个坐标:tx、ty、tw、th。如果单元从图像左上角偏移 (cx,cy),且边界框的先验值为宽和高 pw,ph,则预测结果对应于: bx = σ(tx) + cx
by = σ(ty) + cy
bw = pwetw
bh = pheth 在训练过程中,我们使用平方误差损失总和。如果某个坐标预测的地面实况是 tˆ,我们的梯度就是地面实况值(由地面实况框计算得出)减去我们的预测值:tˆ - t*。通过反演上述公式,可以轻松计算出地面实况值。YOLOv3 使用逻辑回归法为每个边界框预测对象度得分。如果边界框先验值与地面实况对象的重叠程度大于任何其他边界框先验值,则分数应为 1。如果边界框先验值不是最好的,但与地面实况对象的重叠程度超过了某个阈值,我们就会忽略该预测值,具体做法与文献[17]相同。我们使用的阈值是 0.5。与 [17] 不同的是,我们的系统只为每个地面实况对象分配一个边界框先验。如果没有为地面实况对象分配边界框先验,则不会造成坐标或类别预测的损失,只会造成对象性的损失。
精读
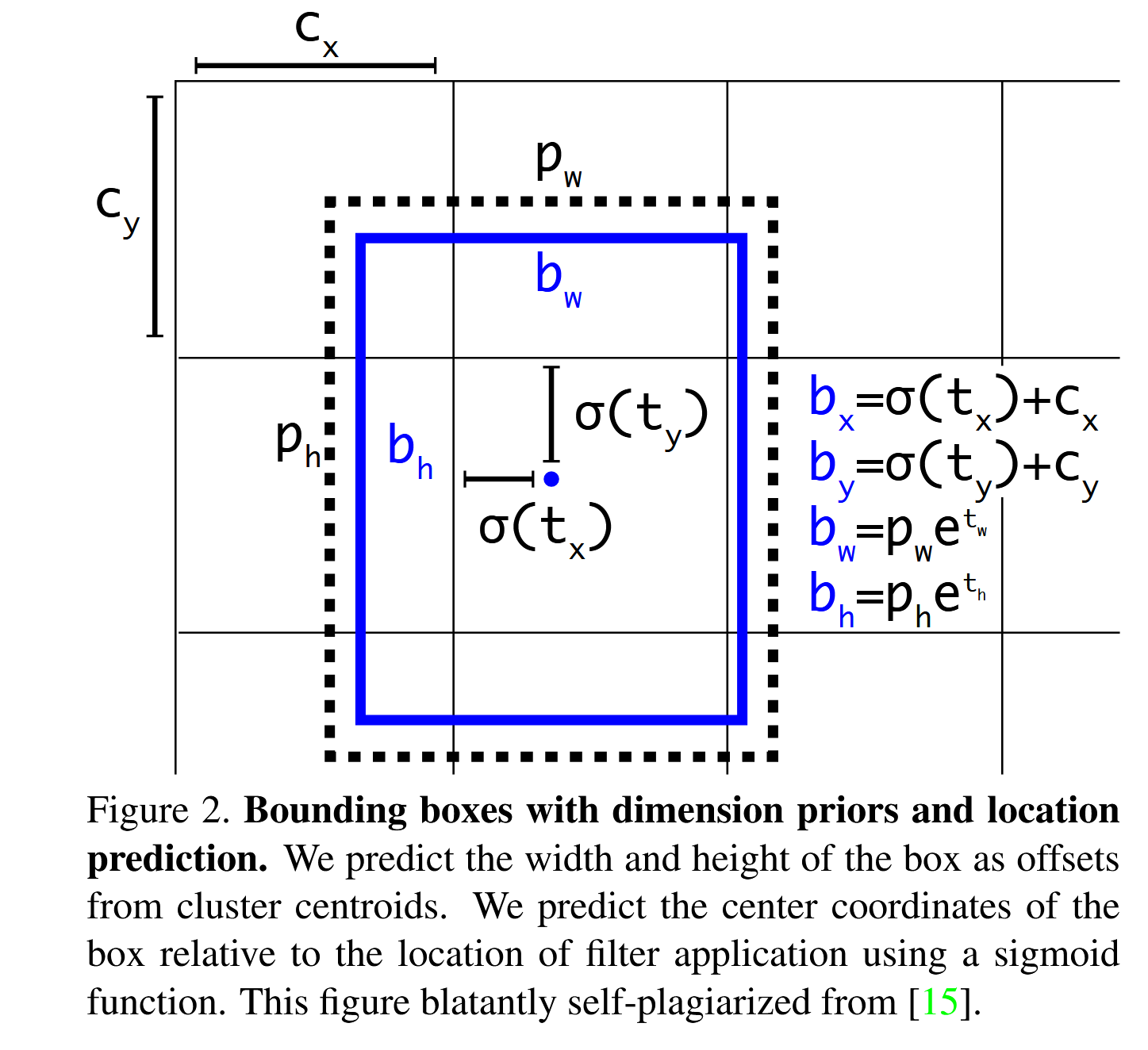
图2 的本质:把预测框的中心点框死在grid cell里面(回看yolov2里面的精读)
🚀 YOLOv3 vs YOLOv2 的核心区别
| 模块 | YOLOv2 | YOLOv3 |
|---|---|---|
| Anchor Boxes 来源 | 使用 k-means 聚类生成 anchors | 同样使用 k-means 维度聚类生成 anchors |
| 坐标预测方式 | 和 YOLOv3 一样,预测的是 tx、ty、tw、th,并通过公式解码为真实框 | ✅ 沿用了 YOLOv2 的预测方式,但细节处理更严谨 |
| Objectness Score(目标置信度)预测方式 | 用逻辑回归(sigmoid)预测是否有物体 | ✅ 相同方式,但引入了更严格的正负样本分配规则 |
| 正样本分配方式 | 一个 ground truth 可以分配给多个 anchors | ✅ YOLOv3 改为每个 ground truth 只分配一个 anchor,更干净利落(防止“一个物体多个预测框抢着报到”的尴尬) |
| 负样本处理 | 设定 IOU 阈值,低于就视为负样本 | ✅ 相似处理,但明确了“非最佳但 IOU>0.5 的 anchor 忽略不训练”这类中间态样本 |
| 损失函数 | 使用 squared error(平方误差)来训练坐标 | ✅ 没变,仍然是平方误差,但训练框选择更细致、更稳定 |
正样本:标注框与预测框IOU最大的即为正例
负样本:除了正例外,与全部标注框的IOU都小于0.5,则为负样本
忽略样本:除正例外,与任意一个标注框的IOU大于阈值0.5,则为忽略样本,不参与任何训练和计算!
🔍 具体解释一些重要差异
-
正样本分配规则变化
-
YOLOv2:一个 GT(ground truth)对象可以匹配多个 anchor(只要 IOU 高)。
-
YOLOv3:一个 GT 只会被分配给最匹配的一个 anchor,其余即便 IOU 也高,最多“忽略”,不会训练。
➤ 这样做的好处是减少重复预测、加快收敛。
-
-
忽略机制(ignore prediction)
-
YOLOv3 引入“灰色地带”:如果某个 anchor 虽然不是最好的(不是最大 IOU 的),但 IOU 超过 0.5,就既不是正样本也不是负样本,不训练、不更新权重。
-
YOLOv2 没有明确处理这类中间样本,可能会干扰训练。
-
-
损失的处理更清晰
-
YOLOv3 更明确地指出:如果一个 anchor 没有被分配给任何 GT,则不需要计算坐标和类别损失,只计算 objectness 这一项的损失。
-
举例
假设某个特征图位置有 N 个 anchor(比如常见的 3 个),而一张图上有 M 个标注框(GT box):
-
遍历每个 anchor,计算它与图中每一个 ground truth box 的 IOU。
-
找到 IOU 最大的那个 GT,看它是不是当前 anchor 的最佳匹配。
-
判断是否满足以下几种情况:
-
如果这个 anchor 是某个 GT 的“最佳匹配 anchor”(IOU 最大),那它被标为正样本,用于训练这个 GT 的类别、坐标、objectness。
-
如果不是最佳,但和某个 GT 的 IOU > 阈值(通常 0.5),则忽略掉这个 anchor,不作为正负样本,不计算 loss(防止干扰)。
-
如果 IOU 全部都很小(比如 < 0.5),说明它没有匹配到任何目标,就被标为负样本,训练它的 objectness 为 0。
-
每个 anchor 对应一个边界框预测,而每个边界框都会预测一个“置信度分数(objectness score)”,这个值衡量该框中是否包含某个物体。
👀 YOLOv3 中置信度的具体计算逻辑:
1. 正样本(positive sample)
如果某个 anchor 匹配到了 ground truth(是最佳匹配):
-
objectness score = 1 → 网络训练时希望该 anchor 的 objectness 接近 1,因为它确实对准了一个真实物体。
2. 负样本(negative sample)
如果某个 anchor 与所有 GT 的 IOU 都小(比如都小于 0.5):
-
objectness score = 0 → 说明这个框不包含任何物体,网络要学会预测为没有目标。
3. 被忽略的样本
如果 anchor 和某个 GT 的 IOU > 0.5,但不是“最佳匹配 anchor”:
-
不计算 objectness loss,即不训练这个 anchor 的置信度值 → 这样可以避免让“还算合理但不是最好的匹配”对训练造成误导。
🧠 一句话总结:
YOLOv3 沿用了 YOLOv2 的 anchor 机制和回归方式,但是一个标注框只有一个anchor,并且负样本也要参与损失函数的计算
注意:这里的正负样本和忽略样本是针对特定的标注框而言的。
2.2 Class Prediction—类预测(单标签分类改进为多标签分类)
翻译
每个边框使用多标签分类法预测边框可能包含的类别。我们没有使用软最大值,因为我们发现软最大值并不能带来良好的性能,相反,我们只使用了独立的逻辑分类器。在训练过程中,我们使用二元交叉熵损失来预测类别。当我们进入更复杂的领域(如开放图像数据集 [7])时,这种方法会有所帮助。在这个数据集中,有许多重叠的标签(如 “女人 ”和 “人”)。使用 softmax 方法需要假设每个方框只有一个类别,而实际情况往往并非如此。多标签方法能更好地模拟数据。
精读
改进点:
每个边框由只能预测一个类别,改为能够预测多个类别(一个边框对应一个objectness,一个objectness对应多个类别)
在YOLOv3 的训练中,使用Binary Cross Entropy ( BCE, 二元交叉熵) 来进行类别预测。
多标签分类问题:可以独立地预测每个标签的概率。
多类分类问题(互斥类别):通常使用 Softmax,因为它可以处理类别之间的排斥关系,并且概率和为 1。
2.3 Predictions Across Scales—跨尺度预测
翻译
YOLOv3 可预测 3 种不同尺度的方框。我们的系统使用与特征金字塔网络[8]类似的概念从这些尺度上提取特征。我们从基础特征提取器中添加了几个卷积层。最后一个卷积层预测一个 3-D 张量,编码边界框、对象性和类别预测。在 COCO [10] 的实验中,我们在每个尺度上预测 3 个边框,因此张量为 N × N × [3 ∗ (4 + 1 + 80)],包含 4 个边框偏移、1 个对象性预测和 80 个类别预测。我们还从网络的较早层获取一个特征图,并使用连接法将其与上采样特征图合并。通过这种方法,我们可以从上采样特征中获得更有意义的语义信息,并从早期特征图中获得更精细的信息。然后,我们再添加几个卷积层来处理这个合并的特征图,最终预测出一个类似的张量,尽管现在的张量是原来的两倍。我们再进行一次同样的设计,以预测最终尺度的方框。因此,我们对第三个尺度的预测得益于所有先前的计算以及网络早期的精细特征。我们仍然使用 K 均值聚类来确定边界框先验。我们只是任意选择了 9 个聚类和 3 个尺度,然后在各个尺度之间平均分配聚类。COCO 数据集的 9 个聚类分别是 (10 × 13), (16 × 30), (33 × 23), (30 × 61), (62 × 45), (59 × 119), (116 × 90), (156 × 198), (373 × 326).
精读

-
支持三种不同尺度的边框预测:借鉴 FPN(特征金字塔网络)思想,从多个尺度提取信息,当输入图像尺寸为416x416大小时,经过DarkNet-53的主干网络后,生成三个不同的特征图分别为 13x13x(80+5)x3,26x26x(80+5)x3,52x52x(80+5)x3
-
为啥要用三个不同的特征图来目标检测呢? 因为在yolov1和yolov2中,都存在对于图片中的小物体不能够准确的进行检测,当使用三个不同的特诊图来进行检测后,分别可以检测,大 中 小的三类物体,13x13x255 的特征图因为感受野比较大,可以检测大的物体,26x26x255可以检测中等物体,52x52x255 可以检测小物体
-
YOLOv3每个尺度的特征图上使用3个anchor box。
每个尺度上预测 3 个 anchor box。每个 anchor 对应 4 个边框回归量 + 1 个对象性得分 + 80 个类别。
输出张量维度为:N×N×[3×(4+1+80)]=N×N×255 举例:对于 52×52 尺度,张量为 52 × 52 × 255。
| 分配尺度 | Anchor 编号 | Anchor 尺寸 (px) | 特征图大小 (COCO 输入 416×416) | 感受野大小 (估算) |
|---|---|---|---|---|
| 小目标 | Anchor 1 | 10 × 13 | 52 × 52 | ≈ 30–60 px |
| 小目标 | Anchor 2 | 16 × 30 | 52 × 52 | ≈ 30–60 px |
| 小目标 | Anchor 3 | 33 × 23 | 52 × 52 | ≈ 30–60 px |
| 中目标 | Anchor 4 | 30 × 61 | 26 × 26 | ≈ 60–120 px |
| 中目标 | Anchor 5 | 62 × 45 | 26 × 26 | ≈ 60–120 px |
| 中目标 | Anchor 6 | 59 × 119 | 26 × 26 | ≈ 60–120 px |
| 大目标 | Anchor 7 | 116 × 90 | 13 × 13 | ≈ 120–320 px |
| 大目标 | Anchor 8 | 156 × 198 | 13 × 13 | ≈ 120–320 px |
| 大目标 | Anchor 9 | 373 × 326 | 13 × 13 | ≈ 120–320 px |
-
yoloV3网络的整体架构
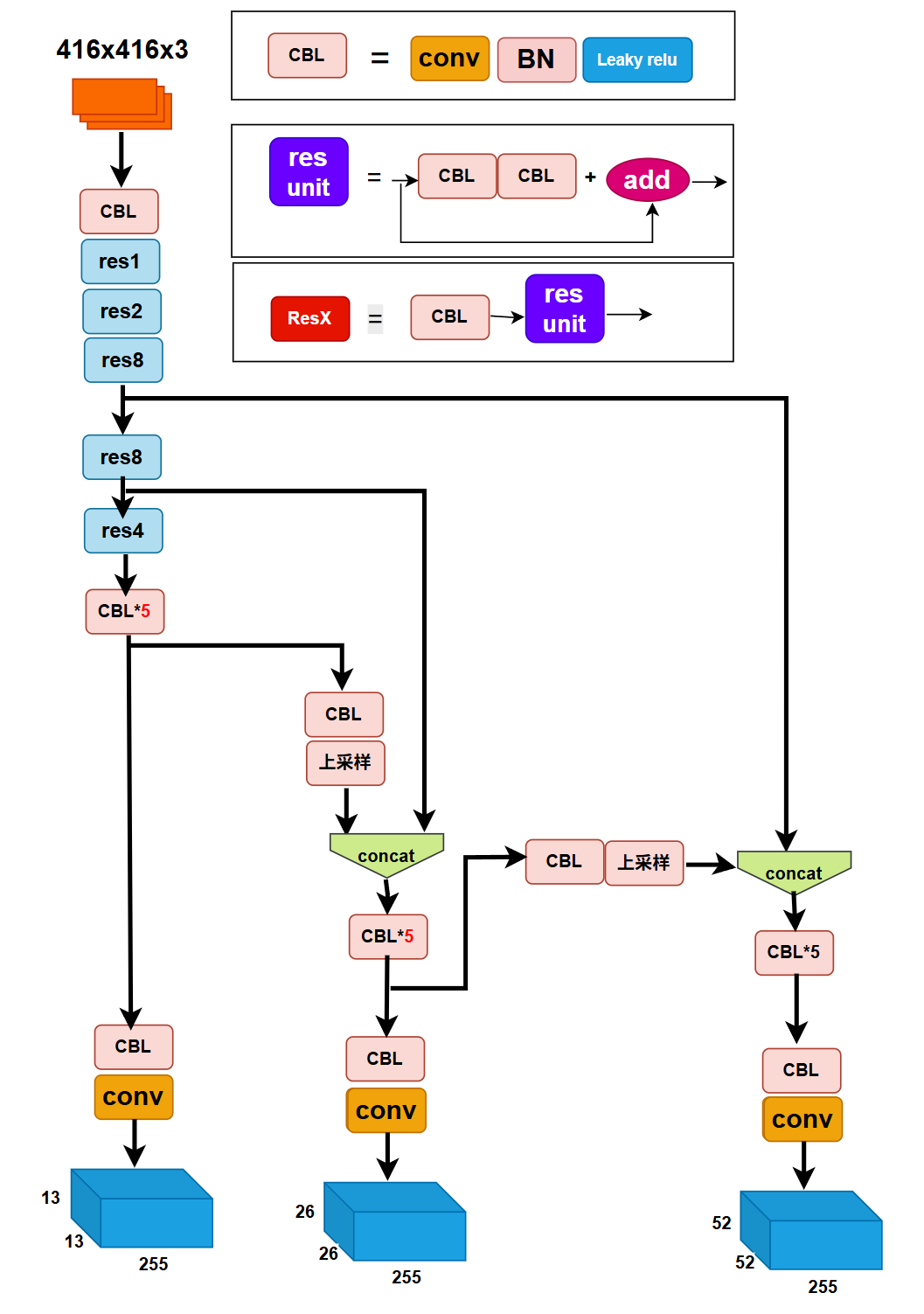
YOLOv3 一共会输出三个不同尺度的特征图,分别对应于输入图像下采样了 32 倍、16 倍和 8 倍 的结果。这些特征图都来自主干网络 Darknet-53 的输出,不过后面又加上了 YOLO 专属的“YOLO block”来进一步处理。
具体流程是这样的:
-
第一张特征图:输入图像经过 Darknet-53 的全卷积结构后,先通过一系列 1×1 和 3×3 的卷积操作,生成第一张特征图,用于检测大目标(下采样 32 倍)。
-
第二张特征图:在前一张特征图的基础上,先用 1×1 卷积进行通道调整,再通过上采样(比如用最近邻插值)恢复一部分空间分辨率。然后,它会与 Darknet-53 中间层提取出的特征图进行特征拼接(concatenation),结合高层语义和底层细节,接着继续卷积处理生成第二张特征图(下采样 16 倍),适合检测中等目标。
-
第三张特征图:再次重复类似操作,对第二张特征图进行上采样,再拼接更浅层的特征图,最终生成下采样 8 倍的第三张特征图,用于检测小目标。
2.4 Feature Extractor—特征提取
翻译
我们使用一种新的网络来进行特征提取。我们的新网络是 YOLOv2、Darknet-19 和新式残差网络之间的混合方法。我们的网络使用连续的 3 × 3 和 1 × 1 卷积层,但现在也有一些捷径连接,而且明显更大。它有 53 个卷积层,所以我们称它为.... 等等..... Darknet-53!
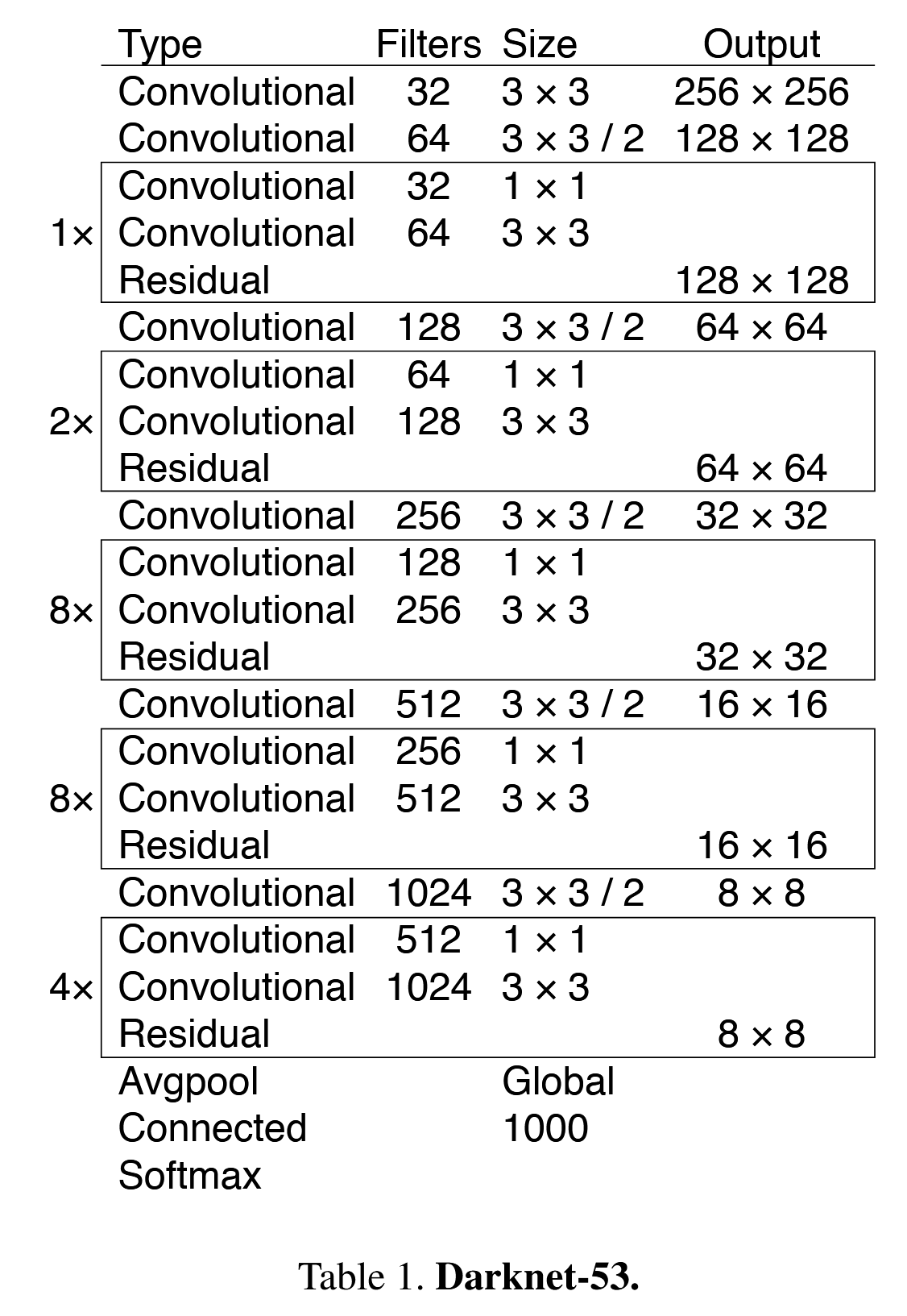
这个新网络比 Darknet19 强大得多,但仍然比 ResNet-101 或 ResNet-152 更有效率。以下是一些 ImageNet 结果:

每个网络都使用相同的设置进行训练,并在 256 × 256 的单作物精度下进行测试。运行时间在 Titan X 上以 256 × 256 进行测量。因此,Darknet-53 与最先进的分类器性能相当,但浮点运算更少,速度更快。Darknet-53 优于 ResNet-101,速度快 1.5 倍。Darknet-53 的性能与 ResNet-152 相似,快 2 倍。Darknet-53 还实现了最高的每秒浮点运算速度。这意味着该网络结构能更好地利用 GPU,使其评估效率更高,因此速度更快。这主要是因为 ResNets 的层数太多,效率不高。
精读
Darknet-53 是在 Darknet-19 的基础上通过加入 ResNet 残差连接进行改进的模型。改进内容如下:
-
去除最大池化层:Darknet-53 不再使用最大池化层,而是采用了步长为 2 的卷积层进行下采样,从而减少了计算量并提高了网络的效率。
-
防止过拟合:每个卷积层后都加上了 Batch Normalization(BN)层和 Leaky ReLU 激活函数,这样能够加速训练并减少过拟合。
-
引入残差连接:通过使用残差网络结构,Darknet-53 在更深的网络层中仍能有效地提取特征,同时避免了梯度消失或爆炸的问题。
-
多尺度特征融合:通过将网络的中间层与某些后期层的上采样结果进行张量拼接,Darknet-53 达到了多尺度特征融合,提高了模型对不同尺度的感知能力。
Darknet-53 在性能上与当前最先进的分类器相媲美,但它在浮点运算上更少,速度更快。此外,Darknet-53 的高效设计使得它在使用 GPU 计算时能够实现更高的运算效率,表现出更快的推理速度。
2.5 Training—训练
翻译
我们仍然在完整图像上进行训练,没有硬性负挖掘或其他任何东西。我们使用多尺度训练、大量数据增强、批量归一化等所有标准方法。我们使用 Darknet 神经网络框架进行训练和测试 [14]。
精读
训练方式:在完整图像上进行训练,未使用硬性负样本挖掘或其他特殊方法。
标准方法:采用了多尺度训练、大量数据增强、批量归一化等标准的训练方法。
使用的框架:使用了 Darknet 神经网络框架进行训练和测试。
三、How We Do—我们怎样做
翻译
YOLOv3 相当不错!见表 3。在 COCOs 怪异的平均 AP 指标方面,它与 SSD 变体相当,但速度快了 3 倍。不过,在这一指标上,它与 RetinaNet 等其他机型仍有相当大的差距。然而,当我们使用 IOU= .5 时的 mAP(或图表中的 AP50)这一 “老 ”检测指标时,YOLOv3 就显得非常强大。它几乎与 RetinaNet 不相上下,远远超过 SSD 变体。这表明 YOLOv3 是一个非常强大的检测器,擅长为物体生成像样的方框。然而,随着 IOU 临界值的增加,性能会明显下降,这表明 YOLOv3 难以使方框与物体完美对齐。过去,YOLO 在处理小物体时非常吃力。但是,现在我们看到这一趋势发生了逆转。通过新的多尺度预测,我们发现 YOLOv3 的 APS 性能相对较高。但是,它在中型和大型天体上的性能相对较差。我们需要进行更多的调查来找出原因。当我们在 AP50 指标上绘制精确度与速度的对比图时(见图 5),我们发现 YOLOv3 与其他检测系统相比具有显著优势。也就是说,它更快更好。
精读
YOLOv3与其他模型比较:
-
在 COCO 数据集上,YOLOv3 在 mAP(平均精度)方面表现良好,和 SSD 变体相当,但速度是 SSD 的 3 倍。
-
然而,与 RetinaNet 等其他模型相比,YOLOv3 在 mAP 上仍有差距。
AP50(IoU=0.5)性能:
-
在 AP50(IoU=0.5)这一老的检测指标上,YOLOv3 显示出强大的性能,几乎与 RetinaNet 不相上下,明显超过 SSD 变体。
-
这表明 YOLOv3 擅长为物体生成准确的边界框。
随着IoU增大,性能下降:
-
当 IoU 阈值提高时,YOLOv3 的性能显著下降,表明它在精确对齐边界框和物体方面存在困难。
小物体的检测改进:
-
YOLOv3 过去在处理小物体时效果较差,但通过 多尺度预测 技术,YOLOv3 的 APS(小物体检测性能) 得到了显著提高。
中型和大型物体的检测问题:
-
尽管小物体的检测性能有了改进,但 YOLOv3 在 中型和大型物体 的检测性能相对较差,需要进一步研究原因。
速度与精度的对比:
-
在 AP50 指标上进行精度与速度的对比时,YOLOv3 展现了 显著的优势,即在保持高精度的同时,速度也非常快。
四、Things We Tried That Didn’t Work—那些我们尝试了但没有奏效的方法
翻译
在开发 YOLOv3 的过程中,我们尝试了很多方法。很多都没有成功。以下是我们能记住的东西。 锚点框 x、y 偏移预测。我们尝试过使用普通的锚点框预测机制,即使用线性激活法将 x、y 偏移量预测为框宽或框高的倍数。我们发现这种方法会降低模型的稳定性,而且效果不佳。 线性 x、y 预测代替逻辑预测。我们尝试使用线性激活来直接预测 x、y 偏移量,而不是使用逻辑激活。这导致 mAP 下降了几个百分点。病灶损失。我们尝试使用焦点损失。它使我们的 mAP 下降了约 2 个点。YOLOv3 可能已经能够很好地解决焦点损失试图解决的问题,因为它具有独立的对象性预测和条件类别预测。因此,对于大多数示例而言,类别预测不会造成损失?还是其他什么原因?我们还不能完全确定。Faster RCNN 在训练过程中使用了两个 IOU 阈值。如果预测结果与地面实况重叠 0.7,则作为正例;重叠 [0.3 - 0.7] 则忽略不计;小于 0.3 的所有地面实况对象均为负例。我们尝试过类似的策略,但效果不佳。我们很喜欢目前的方案,它似乎至少处于局部最优状态。其中一些技术最终可能会产生好的结果,也许它们只是需要一些调整来稳定训练。
精读
作者的失败尝试
锚点框 x、y 偏移预测:
-
尝试使用普通的锚点框预测机制,通过线性激活预测 x、y 偏移量作为框宽或框高的倍数。
-
结果发现该方法会降低模型的稳定性,且效果不佳。
线性 x、y 预测代替逻辑预测:
-
尝试用线性激活直接预测 x、y 偏移量,而非使用逻辑激活。
-
这种方法导致 mAP 降低了几个百分点。
焦点损失(Focal Loss):
-
尝试使用焦点损失(focal loss),但该方法使 mAP 降低了约 2 个点。
-
认为 YOLOv3 可能已经能很好地处理焦点损失想要解决的问题,因为它具有独立的对象性预测和条件类别预测。
Faster RCNN 的 IOU 阈值策略:
-
Faster RCNN 在训练过程中使用了两个 IOU 阈值:与地面实况重叠大于 0.7 为正例,重叠在 0.3 到 0.7 之间的为忽略,重叠小于 0.3 的为负例。
-
尝试了类似的策略,但效果不佳。
当前方案的效果:
-
目前使用的方案表现最好,似乎至少处于局部最优状态。
其他尝试的技术:
-
一些尝试过的技术可能最终能产生好的结果,只是需要进一步调整以稳定训练。
五、 What This All Means—这一切意味着什么?
翻译
YOLOv3 是一款优秀的探测器。速度快,精度高。在 0.5 至 0.95 IOU 的 COCO 平均 AP 指标上,它并不出色。但在 0.5 IOU 的旧检测指标上,它却非常出色。我们为什么要转换指标呢?最初的 COCO 论文中只有这样一句隐晦的话 “一旦评估服务器完成,将添加对评估指标的全面讨论"。Russakovsky 等人报告说,人类很难区分 0.3 和 0.5 的欠条!“训练人类目视检查 IOU 为 0.3 的边界框,并将其与 IOU 为 0.5 的边界框区分开来,难度之大令人吃惊。[18]如果人类很难分辨两者的区别,那么这又有多大关系呢?但也许更好的问题是:"既然我们有了这些探测器,我们该拿它们怎么办?很多从事这项研究的人都在谷歌和脸书工作。我想,至少我们知道这项技术掌握在可靠的人手里,而且绝对不会被用来收集你的个人信息,然后卖到.... 等等,你是说这正是它的用途?是的。我很希望大多数使用计算机视觉的人都是在用它做快乐的好事,比如计算国家公园里斑马的数量[13],或者追踪在家里游荡的猫[19]。但是,计算机视觉已经被用于令人质疑的用途,作为研究人员,我们有责任至少考虑一下我们的工作可能造成的危害,并想办法减轻这种危害。这是我们欠世界的。最后,请不要@我。(因为我终于退出了 Twitter)。
精读
作者就一句话:我希望世界和平
相关文章:
)
【Yolo精读+实践+魔改系列】Yolov3论文超详细精讲(翻译+笔记)
前言 前面咱们已经把 YOLOv1 和 YOLOv2 的老底都给掀了,今天轮到 YOLOv3 登场,这可是 Joseph Redmon 的“封神之作”。讲真,这哥们本来是搞学术的,结果研究的模型被某些军方拿去“整点活”——不是做人是做武器的那种活。于是他一…...

【Python从入门到精通】--‘@‘符号的作用
在Python中,符号主要有三种用途:装饰器(Decorator)、矩阵乘法运算符(Python 3.5)以及类型提示中的修饰符(如typing)。 目录 1.--装饰器(Decorator) 2.--矩…...
)
git命令积累(个人学习)
如何将docx文件不上传? 创建或编辑 .gitignore 文件 打开 .gitignore 文件,添加以下内容来忽略所有 .docx 文件: *.docx清除已追踪的 .docx 文件 git rm --cached "*.docx"这将从 Git 仓库中删除 .docx 文件,但不会删…...

【人工智能核心技术全景解读】从机器学习到深度学习实战
目录 🌍 前言🏛️ 技术背景与价值💔 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...
: use of undeclared identifier ‘pthread_getname_np‘)
android-ndk开发(10): use of undeclared identifier ‘pthread_getname_np‘
1. 报错描述 使用 pthread 获取线程名字, 用到 pthread_getname_np 函数。 交叉编译到 Android NDK 时链接报错 test_pthread.cpp:19:5: error: use of undeclared identifier pthread_getname_np19 | pthread_getname_np(thread_id, thread_name, sizeof(thr…...

CAP理论:分布式系统的权衡
CAP理论:分布式系统的权衡 引言一、CAP理论的核心定义二、CAP的权衡逻辑:如何选择?三、CAP的常见误区与澄清四、CAP的实际应用场景与技术实现五、现代分布式系统对CAP的突破与演进六、CAP理论的设计建议总结 引言 在分布式系统的设计与实践中…...

【软件设计师:软件工程】11.项目管理
一、项目管理内容 项目管理是通过规划、组织、协调资源,在有限时间与预算内实现特定目标的过程,核心是平衡范围、时间、成本、质量四大要素,确保项目成功交付。 1.核心内容 项目启动目标定义:明确项目范围、交付成果及成功标准。可行性分析:评估技术、经济与风险可行性…...

遗传算法求解异构车队VRPTW问题
这里写目录标题 染色体编码设计:两种染色体编码方式一、客户排列 分割点(Giant Tour Split)1. 示例编码与解码2. 采用 客户排列 分割点 设计的特点3. 编码实现(基于Python) 二、使用整体聚类局部路由(cl…...

区块链内容创作全攻略:海报、白皮书与视频的视觉化革命
区块链内容创作全攻略:海报、白皮书与视频的视觉化革命 ——2025年去中心化叙事的技术密码与商业实践 一、区块链海报设计:视觉叙事与用户心智占领 区块链海报需在3秒内抓住观众注意力,同时传递技术内核与商业价值。核心设计法则包括&#x…...

windows的rancherDesktop修改镜像源
您好!要在Windows系统上的Rancher Desktop中修改Docker镜像源(即设置registry mirror),您需要根据Rancher Desktop使用的容器运行时(containerd或dockerd)进行配置。用户提到“allowed-image”没有效果&…...
——工业4.0讲解)
从零开始了解数据采集(二十四)——工业4.0讲解
在全球制造业加速变革的今天,“工业4.0”成为了一个炙手可热的词汇。从德国的概念提出,到我国的积极实践,这场技术与产业的深度融合正推动制造业迈向智能化、数字化的新时代。对于企业而言,这是一次不可多得的机遇,更是…...

Java复习笔记-基础
Java复习笔记 一、什么是JDK、JRE、JVM二、Keyword-关键字三、variable-变量浮点数类型-float和double字符类型-char基本数据类型变量间运算规则基本数据类型与 String 的运算和 四、逻辑运算符五、流程控制语句关于if else 和 switchfor循环while循环do while循环 六、Array-数…...

用递归实现各种排列
为了满足字典序的输出,我采用了逐位递归的方法(每一位的所能取到的最小值都大于前一位) 1,指数型排列 #include<bits/stdc.h> using ll long long int; using namespace std; int a[10];void printp(int m) {for (int h …...

基于Stable Diffusion XL模型进行文本生成图像的训练
基于Stable Diffusion XL模型进行文本生成图像的训练 flyfish export MODEL_NAME"stabilityai/stable-diffusion-xl-base-1.0" export VAE_NAME"madebyollin/sdxl-vae-fp16-fix" export DATASET_NAME"lambdalabs/naruto-blip-captions"acceler…...

SHA系列算法
SHA1系列算法 SHA(Secure Hash Algorithm,安全散列算法)是一组加密哈希算法,用于确保数据完整性和提供消息摘要功能。SHA算法由美国国家安全局(NSA)设计,并由国家标准与技术研究院(…...

985高校查重率“隐性阈值”:低于5%可能被重点审查!
你是不是也以为: “查重率越低越好,最好压到1%、0%,导师看了都感动哭🥹” 但是你不知道的是——在985/211等重点高校,查重率太低反而可能引起导师和学术办公室的“特别关注”! 今天就来扒一扒这个查重圈“…...

基于vue3+QuillEditor的深度定制
需求: 项目需求一个深度定制的富文本编辑器,要求能够定制表格,能够从素材库插入图片,以及其他个性化操作。我这里就基于vue3+ QuillEditor深度定制的角度,解析一下QuillEditor富文本编辑器的功能扩展功能的需求。 一、扩展工具栏 根据需求,我们需要扩展工具栏,实现自…...

Redis 8.0正式发布,再次开源为哪般?
Redis 8.0 已经于 2025 年 5 月 1 日正式发布,除了一些新功能和性能改进之外,一个非常重要的改变就是新增了开源的 AGPLv3 协议支持,再次回归开源社区。 为什么说再次呢?这个需要从 2024 年 3 月份 Redis 7.4 说起,因为…...

静态BFD配置
AR2配置 int g0/0/0 ip add 10.10.10.2 quit bfd quit bfd 1 bind peer-ip 10.10.10.1 source-ip 10.10.10.2 auto commit AR1配置 int g0/0/0 ip add 10.10.10.1 int g0/0/1 ip add 10.10.11.1 quit bfd quit bfd 1 bind peer-ip 10.0.12.2 source-ip 10.0.12.1 auto co…...

[python] 函数1-函数基础
一 函数使用 1.1 基本用法 def 函数名() 函数体 函数返回值: 返回调用的结果 def myPyFirstFunc():print("hello python") myPyFirstFunc()1.2 函数参数 def 函数名(形参a,形参b) 函数体 def add(a,b):return a b print(add(1,2)) print(add(1,4)) 二 函…...

【并发编程】MySQL锁及单机锁实现
目录 一、MySQL锁机制 1.1 按锁粒度划分 1.2 按锁功能划分 1.3 InnoDB锁实现机制 (1)记录锁(Record Lock) (2) 间隙锁(Gap Lock) (3) 临键锁(Next-Key Lock) (4) 插入意向锁(Insert Intention Lock) 二、基于 JVM 本地锁实现,保证线程安全 2.1 线程不安全的分析 2.1…...

C++ | 常用语法笔记
判断数字还是字母 1.笨办法,使用直接判断办法 if(c > 0 && c < 9) cout << "c是数字" << endl; if(c > a && c < z) cout << "c是小写字母" << endl; if(c > A && c< Z) …...

浅谈 Shell 脚本编程中引号的妙用
在 Shell 脚本编程中,引号的使用是一项基础却至关重要的技能。无论是单引号、双引号还是不加引号,它们都会显著影响 Shell 对字符串、变量、特殊字符以及命令的解析方式。理解这些差异不仅能帮助开发者编写更健壮的脚本,还能避免因误解引发的…...

DeFi开发系统软件开发:技术架构与生态重构
DeFi开发系统软件开发:技术架构与生态重构 ——2025年去中心化金融开发的范式革新与实践指南 一、技术架构演进:从单一链到多链混合引擎 现代DeFi系统开发已从单一公链架构转向“跨链互操作混合模式”,结合中心化效率与去中心化安全双重优势…...

Spring AI 集成 DeepSeek V3 模型开发指南
Spring AI 集成 DeepSeek V3 模型开发指南 前言 在人工智能飞速发展的当下,大语言模型不断推陈出新,DeepSeek AI 推出的开源 DeepSeek V3 模型凭借其卓越的推理和问题解决能力备受瞩目。与此同时,Spring AI 作为一个强大的框架,…...

C++:扫雷游戏
一.扫雷游戏项目设计 1.文件结构设计 首先我们要先定义三个文件 ①test.c //文件中写游戏的测试逻辑 ②game.c //文件中写游戏中函数的实现等 ③game.h //文件中写游戏需要的数据类型和函数声明等 2.扫雷游戏的主体结构 使⽤控制台实现经典的扫雷游戏 •游戏可以通过菜单…...

【写作格式】写论文时常见格式问题
写作格式 1.图片总是乱跑,怎么固定图片2.一键更新引用3.交叉引用[1][2][3]怎么变为[1,2,3]4.目录灰色底纹怎么消除5.word保存为pdf提取标题为书签 1.图片总是乱跑,怎么固定图片 遇到的问题 解决方法 第一步:图片格式——>环绕文字——&g…...

Android平台FFmpeg视频解码全流程指南
本文将详细介绍在Android平台上使用FFmpeg进行高效视频解码的实现方案,采用面向对象的设计思想。 一、架构设计 1.1 整体架构 采用三层架构设计: • 应用层:提供用户接口和UI展示 • 业务逻辑层:管理解码流程和状态 • Native…...

C31-形参与实参的区别
一 形参与实参 实参:调用函数时传递的实际值,可以是变量、常量或表达式,如"add(3,a)"中的’3’与’a’形参:函数定义中声明的参数变量,用于接收实参的值,如"int add(intx,inty)"中的’x’与’y’ C语言默认通过值传递参数,形参与实参是独立的变量,仅数据…...

自学嵌入式 day 16-c语言-第10章 指针
14 指针函数 返回值是指针的函数。 (1)动态内存分配 ①使用方式: #include<stdlib.h> void *malloc(size_t size) ②返回连续的内存空间的首元素地址,内存空间未被初始化,申请的是堆区的空间。 ③内存空间申请…...

DataWorks快速入门
文章目录 一、DataWorks简介1、概念2、功能3、优势 二、DataWorks使用1、创建工作空间2、绑定计算资源3、数据开发 三、DataWorks节点类型1、MaxCompute SQL节点①创建非分区表并插入数据②创建分区表并插入数据③查询表数据 2、离线同步节点3、PYODPS 3节点①判断表是否存在②…...

AtCoder Beginner Contest 404 A-E 题解
还是ABC好打~比ARC好打多了( 题解部分 A - Not Found 给定你一个长度最大25的字符串,任意输出一个未出现过的小写字母 签到题,map或者数组下标查询一下就好 #include<bits/stdc.h>using namespace std;#define int long long #def…...

WiFi出现感叹号上不了网怎么办 轻松恢复网络
在日常生活中,WiFi已成为不可或缺的一部分。然而,有时我们会遇到WiFi图标上出现了感叹号,无法上网。无论是办公、学习还是娱乐,这种情况都会严重影响体验。这种情况该怎么解决呢?本期驱动哥就给各位介绍几种简单的解决…...

M0芯片的基础篇Timer
一、计数器的原理 加法计数器 减法计数器 触发中断 最短计时时间 时钟周期决定 16bit 65535 最长计时时间 时间周期和最大计数值决定 二、syscfg配置 timg:通用定时器 tima:高级定时器 timx:不论是高级定时器还是通用定时器都是一样…...
)
vue教程(vuepress版)
Vue 完全指南 项目介绍 这是一个系统化的 Vue.js 学习教程,采用循序渐进的方式,帮助开发者从零开始掌握 Vue 开发技能。 教程特点 循序渐进: 从 Vue 基础概念开始,逐步深入到高级特性,适合不同层次的开发者学习实战驱动: 结合…...

【嵌入式开发-USB】
嵌入式开发-USB ■ USB简介 ■ USB简介...

【前端】webstorm运行程序浏览器报network error
是浏览器阻止了链接,先把能正常访问的链接搜索,禁止访问的时候,高级,强制访问,再运行项目生成的网址就可以了。...

国内led显示屏厂家以及售后 消费对比与选择
国内led显示屏的厂家有很多,虽然让消费者在选择的时候有了多种的机会,可是在质量方面的鉴别上也是无从下手。对此为了方便消费者作出选择,下面为您推荐一些品牌厂家。 1、强力巨彩 是全球比较有名气的LED显示屏厂家的制造商,总厂房…...

【Go】优化文件下载处理:从多级复制到零拷贝流式处理
在开发音频处理服务过程中,我们面临一个常见需求:从网络下载音频文件并保存到本地。这个看似简单的操作,实际上有很多优化空间。本文将分享一个逐步优化的过程,展示如何从一个基础实现逐步改进到高效的流式下载方案。 初始实现&a…...
:深入理解 I2C 总线驱动模型(以 at24 EEPROM 为例))
驱动开发硬核特训 · Day 30(上篇):深入理解 I2C 总线驱动模型(以 at24 EEPROM 为例)
作者:嵌入式Jerry 视频教程请关注 B 站:“嵌入式Jerry” 一、写在前面 在上一阶段我们已经深入理解了字符设备驱动与设备模型之间的结合方式、sysfs 的创建方式以及平台驱动模型的实际运用。今天我们迈入总线驱动模型的世界,聚焦于 I2C 总线…...

LaTeX印刷体 字符与数学符号的总结
1. 希腊字母(Greek Letters) 名称小写 LaTeX大写 LaTeX显示效果Alpha\alphaAαα, AABeta\betaBββ, BBGamma\gamma\Gammaγγ, ΓΓDelta\delta\Deltaδδ, ΔΔTheta\theta\Thetaθθ, ΘΘPi\pi\Piππ, ΠΠSigma\sigma\Sigmaσσ, ΣΣOmega\omeg…...

关键字where
C# 中的 where 关键字主要用在泛型约束(Generic Constraints)中,目的是对泛型类型参数限制其必须满足的条件,从而保证类型参数具备特定的能力或特性,增强类型安全和代码可读性。 约束写法说明适用场景举例C#版本要求w…...

vite 代理 websocket
🛡️一、WebSocket 基本概念 名称全称含义使用场景ws://WebSocket非加密的 WebSocket 连接开发环境、内网通信wss://WebSocket Secure加密的 WebSocket 连接(基于 TLS/SSL)生产环境、公网通信 🛡️二、安全性对比 特性ws://wss…...

深入理解操作系统:从基础概念到核心管理
在计算机系统中,操作系统是至关重要的组成部分,它如同计算机的“大管家”,统筹协调着系统的各项资源与工作流程。接下来,就让我们深入了解操作系统的奥秘。 一、操作系统概述 操作系统能有效组织和管理系统中的软/硬件资源&…...
)
手撕基于AMQP协议的简易消息队列-1(项目介绍与开发环境的搭建)
项目绍 码云仓库:MessageQueues: 仿Rabbit实现消息队列 文章概要 本文将介绍从零搭建一个简易消息队列的方法,目的是了解并学习消息队列的底层原理与逻辑,编写一个独立的服务器程序。从搭建开发环境开始,到编写一些工作组件&am…...

C++ 模板方法模式详解与实例
模板方法模式概念 模板方法模式(Template Method Pattern)属于行为型设计模式,其核心思想是在一个抽象类中定义一个算法的骨架,而将一些步骤延迟到子类中实现。这样可以使得子类在不改变算法结构的情况下,重新定义算法中的某些步骤。它通过继承机制,实现代码复用和行为…...

北京丰台人和中医院,收费贵吗?
北京丰台人和中医院,收费贵吗? 北京丰台人和中医院属于平价医院,百姓医院,收费不贵,北京丰台人和中医院35年专业看肝病,之所以能够在肝病感染者中赢得广泛好评,离不开其严谨的医疗流程、专业的…...

21、魔法传送阵——React 19 文件上传优化
一、魔法传送阵的核心法则 1.量子切割术(分片上传) const sliceFile (file) > {const chunks [];let start 0;const CHUNK_SIZE 2 * 1024 * 1024; // 2MB分片while (start < file.size) {chunks.push({id: ${file.name}-${start},data: file.s…...

Windows命令行软件管理器:Chocolatey
文章目录 Windows命令行软件管理器:Chocolatey1.Chocolatey使用1.1 安装1.2 常用命令1.3 使用流程 2.常用shell命令汇总 Windows命令行软件管理器:Chocolatey Chocolatey 是一款强大的 Windows 命令行软件管理器,目前在 GitHub 上已斩获 10.…...
)
【MySQL】第二弹——MySQL表的增删改查(CRUD)
文章目录 🎓一. CRUD🎓二. 新增(Create)🎓三. 查询(Rertieve)📖1. 全列查询📖2. 指定列查询📖3. 查询带有表达式📖4. 起别名查询(as )📖 5. 去重查询(distinct)📖6. 排序…...