遗传算法求解异构车队VRPTW问题
这里写目录标题
- 染色体编码设计:两种染色体编码方式
- 一、客户排列 + 分割点(Giant Tour + Split)
- 1. 示例编码与解码
- 2. 采用 客户排列 + 分割点 设计的特点
- 3. 编码实现(基于Python)
- 二、使用整体聚类+局部路由(cluster-first+route-second)
- 1. 聚类(Cluster-First)
- 2. 子问题路由优化(Route-Second)
- 2.1 随机键/分段编码 GA
- 2.2 局部搜索/禁忌搜索
- 2.3 多车次分配
- 方法优缺点总结
- 代码实现
- 三、贪心构造(Route‐based Encoding)
染色体编码设计:两种染色体编码方式
一、客户排列 + 分割点(Giant Tour + Split)
1. 示例编码与解码
假设有 5 个客户 (1, 2, 3, 4, 5),有 2 种车型:Type A (容量 50, 1辆, 车A1),Type B (容量 30, 2辆, 车B1, 车B2)。总车辆数 M=3;客户需求:C1(10), C2(25), C3(20), C4(15), C5(30);时间窗等信息省略,但解码时需要检查。
编码:
- 染色体是一个包含 N 个客户ID(例如,1 到 N)和若干个分隔符(例如使用0作为分隔符)的排列。例如:使用0作为分割点编码,一个可能的染色体为:
[3, 1, 0, 5, 2, 0, 4, 0]
解码:
- 从左到右读取染色体,遇到客户ID,将其加入当前正在构建的路线。遇到分隔符 0,表示当前路线结束。
- 据预先定义的顺序(例如,先分配 Type 1 的所有车辆,再分配 Type 2 的所有车辆,以此类推)。
- 在分配时,需要检查该路线分配给特定类型的车辆是否可行(容量限制)。然后,计算该路线的行驶时间和到达时间,检查是否满足所有客户的时间窗要求以及车辆的总行驶时间/距离限制。如果分配给当前考虑的车辆类型不可行,则尝试下一个可用车辆。
- 如果一条路线(两个分隔符之间的客户序列)无法分配给任何可用且合适的车辆,则该染色体代表一个不可行解(在评估适应度时给予惩罚)。
- 所有分隔符都处理完毕后,就得到了一个完整的车辆路径规划方案。
对于染色体[3, 1, 0, 5, 2, 0, 4, 0],解码过程为:
-
读取 3, 1,遇到 0。路线 1:
Depot -> 3 -> 1 -> Depot。总需求 = 20 + 10 = 30。
尝试分配:车 A1 (容量 50):可行。假设时间窗也满足。分配给 A1。 -
读取 5, 2,遇到 0。路线 2:
Depot -> 5 -> 2 -> Depot。总需求 = 30 + 25 = 55。
尝试分配 (这里A1已用,不再考虑):- 车 B1 (容量 30):不可行 (55 > 30)。
- 车 B2 (容量 30):不可行 (55 > 30)。
-
该染色体解码为不可行解,需要在评估适应度时给予惩罚
2. 采用 客户排列 + 分割点 设计的特点
优点:
- 结构相对简单,是 VRP 编码的自然扩展。
- 可以直接应用经典的排列交叉算子(如 OX, CX, PMX)和变异算子(如交换、插入、倒置)。
缺点:
- 解码过程复杂,需要检查容量、时间窗等约束,并进行车辆分配。
容易产生不可行解(特别是容量和时间窗约束严格时),解码时按“先 Type A 再 Type B…”“顺序尝试”车辆,但一旦高容量车型被前面路段消耗,就很难满足后面高需求子路段,更容易判为不可行。建议在分配时使用先将大需求路线配大车、小需求路线配小车的策略,或根据“需求密度”动态选择车辆类型。- 隐式地进行车辆分配,可能不是最高效的方式。分隔符的位置对解的质量影响很大。
3. 编码实现(基于Python)
首先构造数据,生成一些随机的客户点,不妨简化时间窗,设位置都是(0,0),方便求解。
# Using dictionaries for simplicity. Classes could also be used.
def create_customer(id, demand, tw_early=0, tw_late=float('inf'), service_time=0, coords=(0,0)):"""Helper to create customer data."""return {"id": id,"demand": demand,"tw_early": tw_early,"tw_late": tw_late,"service_time": service_time,"coords": coords # Needed for distance/TW calculations}# 1. Define Customers
customers_data = {1: create_customer(1, 10),2: create_customer(2, 25),3: create_customer(3, 20),4: create_customer(4, 15),5: create_customer(5, 30),6: create_customer(6, 10), # Add another customer
}
num_customers = len(customers_data)
再构造异构车队,有3种车型A、B和C,数量分别为1、2和1辆。容量分别为50、30和40,具体如下:
def create_vehicle(id, type, capacity, depot_coords=(0,0)):"""Helper to create vehicle data."""return {"id": id,"type": type,"capacity": capacity,"depot_coords": depot_coords}# 2. Define Vehicles (Multi-type)
vehicles_data = [create_vehicle(id="A1", type="Type A", capacity=50),create_vehicle(id="B1", type="Type B", capacity=30),create_vehicle(id="B2", type="Type B", capacity=30),create_vehicle(id="C1", type="Type C", capacity=40), # Add another type
]
用0表示Split,构造示例染色体:
delimiter_token = 0
example_chromosome = [3, 1, delimiter_token, 6, 4, 2, delimiter_token, 5, delimiter_token]
进行解码:
# 4. Decode the Chromosome
assigned_routes, unserved, issues = decode_chromosome_method1(example_chromosome,customers_data,vehicles_data,delimiter=delimiter_token
)
解码结果为不可行解:
Vehicle: A1 (Type A), Route: Depot -> 3 -> 1 -> Depot, Demand: 30
Vehicle: B1 (Type B), Route: Depot -> 5 -> Depot, Demand: 30
Unserved Customers: {2, 4, 6}
完整代码:
import random
import pandas as pd
from dataclasses import dataclass
from typing import Tuple, overridedef create_vehicle(id, type, capacity, depot_coords=(0, 0)):"""Helper to create vehicle data."""return {"id": id, "type": type, "capacity": capacity, "depot_coords": depot_coords}@dataclass
class Customer:"""Class representing a customer in the VRPTW problem."""id: intcoords: Tuple[float, float] = (0, 0)demand: int = 0tw_early: float = 0tw_late: float = float("inf")service_time: float = 0def __post_init__(self):"""Validate the time window constraints."""if self.tw_early > self.tw_late:raise ValueError("tw_early cannot be greater than tw_late")@overridedef __repr__(self) -> str:return str(self.id)class GeneticAlgorithm:def __init__(self,customers: list[Customer],vehicles: dict,pop_size: int,cx_pc: float,mut_pm: float,) -> None:self.customers = customersself.vehicles = vehiclesself.pop_size = pop_sizeself.cx_pc = cx_pcself.mut_pm = mut_pmself.n_vehicles = len(vehicles)self.delimiter = 0def print_decode_result(self, assigned_routes, unserved, issues):# 5. Print Resultsprint("Decoding Results:")print("-" * 20)if assigned_routes:print("Assigned Routes:")for route_info in assigned_routes:print(f" Vehicle: {route_info['vehicle_id']}shuffled_customers ({route_info['vehicle_type']}), "f"Route: Depot -> {' -> '.join(map(str, route_info['route']))} -> Depot, "f"Demand: {route_info['demand']}")else:print("No routes could be assigned.")if unserved:print(f"\nUnserved Customers: {unserved}")if issues:print("\nFeasibility Issues Encountered During Decoding:")for issue in issues:print(f" - {issue}")def generate_initial_population(self, delimiter=0) -> list[list[Customer]]:"""生成初始种群Args:customers: 客户数据vehicles: 车辆数据pop_size: 种群大小delimiter: 分隔符(默认为0)Returns:list: 包含多个染色体的列表"""all_customer_ids = list(self.customers)population = []for _ in range(self.pop_size):# 1. 随机打乱客户顺序# 将所有客户随机打乱顺序,生成一个新的列表shuffled_customers = random.sample(all_customer_ids, len(all_customer_ids))# 2. 随机分割客户为多个路线,有几辆车最多几条路线num_routes = random.randint(1, min(len(self.vehicles), len(all_customer_ids)))route_boundaries = sorted(random.sample(range(1, len(shuffled_customers)), num_routes - 1))# 3. 构建染色体chromosome = []prev_index = 0for boundary in route_boundaries:chromosome.extend(shuffled_customers[prev_index:boundary])chromosome.append(delimiter)prev_index = boundarychromosome.extend(shuffled_customers[prev_index:])population.append(chromosome)return populationdef decode_chromosome_method1(self, chromosome: list[Customer]):print(chromosome)print(type(chromosome[0]))"""Decodes a single chromosome with delimiters into vehicle routes for MDVRP.Args:chromosome (list): A list of customer IDs and delimiters (e.g., 0).customers (dict): A dictionary where keys are customer IDs and values arecustomer data dictionaries (including 'demand').vehicles (list): A list of vehicle data dictionaries (including 'id', 'type', 'capacity').The order matters for assignment preference.delimiter (int): The value used to separate routes in the chromosome.Returns:tuple: A tuple containing:- assigned_routes (list): A list of dictionaries, each representing anassigned route:{'vehicle_id': id, 'vehicle_type': type,'route': [cust_id1, cust_id2,...],'demand': total_demand}- unassigned_customers (set): A set of customer IDs from the chromosomethat couldn't be assigned to any route/vehicle.- feasibility_issues (list): A list of strings describing problems(e.g., capacity violations found during decode)."""assigned_routes = []unassigned_customers = set(c.id for c in chromosome if c != self.delimiter) # Start assuming all are unassignedfeasibility_issues = []available_vehicle_indices = list(range(len(self.vehicles))) # Indices of vehicles not yet usedassigned_vehicle_ids = set()current_route_customers = []chromosome_ptr = 0while chromosome_ptr < len(chromosome):gene = chromosome[chromosome_ptr]if gene == self.delimiter:if current_route_customers: # End of a potential routeroute_demand = sum(c.demand for c in current_route_customers)assigned_this_route = False# Try to find a suitable *available* vehiclevehicle_idx_to_remove = -1for i, v_idx in enumerate(available_vehicle_indices):vehicle = self.vehicles[v_idx]# 1. Check Capacityif route_demand <= vehicle["capacity"]:# 2. *** Placeholder for Time Window Check ***# This requires coordinates, travel times, service times etc.# route_is_tw_feasible = check_time_windows(current_route_customers, vehicle, customers)route_is_tw_feasible = (True # Assume feasible for this example)if route_is_tw_feasible:# Assign route to this vehicleassigned_routes.append({"vehicle_id": vehicle["id"],"vehicle_type": vehicle["type"],"route": list(current_route_customers), # Use copy"demand": route_demand,})assigned_vehicle_ids.add(vehicle["id"])# Mark customers as assignedfor c in current_route_customers:unassigned_customers.discard(c.id)assigned_this_route = Truevehicle_idx_to_remove = (i # Mark this vehicle index for removal)break # Stop searching for vehicles for this routeif vehicle_idx_to_remove != -1:available_vehicle_indices.pop(vehicle_idx_to_remove) # Remove used vehicle indexif not assigned_this_route:# Route could not be assigned to any available vehiclefeasibility_issues.append(f"Route {current_route_customers} (Demand: {route_demand}) could not be assigned."f" Available vehicles checked: {[self.vehicles[i]['id'] for i in available_vehicle_indices]}")# Customers remain in unassigned_customers set# Reset for next routecurrent_route_customers = []# Else (delimiter found but current_route empty): just move onelse:# It's a customer IDif gene in customers:print("type gene", type(gene))current_route_customers.append(gene)else:feasibility_issues.append(f"Customer ID {gene} not found in customer data.")chromosome_ptr += 1# After loop: Handle any remaining customers if chromosome didn't end with delimiterif current_route_customers:route_demand = sum(c.demand for c in current_route_customers)assigned_this_route = Falsevehicle_idx_to_remove = -1for i, v_idx in enumerate(available_vehicle_indices):vehicle = self.vehicles[v_idx]if route_demand <= vehicle["capacity"]:# Placeholder TW checkroute_is_tw_feasible = Trueif route_is_tw_feasible:assigned_routes.append({"vehicle_id": vehicle["id"],"vehicle_type": vehicle["type"],"route": list(current_route_customers),"demand": route_demand,})assigned_vehicle_ids.add(vehicle["id"])for c in current_route_customers:unassigned_customers.discard(c.id)assigned_this_route = Truevehicle_idx_to_remove = ibreakif vehicle_idx_to_remove != -1:available_vehicle_indices.pop(vehicle_idx_to_remove)if not assigned_this_route:feasibility_issues.append(f"Final Route {current_route_customers} (Demand: {route_demand}) could not be assigned."f" Available vehicles checked: {[self.vehicles[i]['id'] for i in available_vehicle_indices]}")return assigned_routes, unassigned_customers, feasibility_issuesif __name__ == "__main__":# 1. Define Customerscustomers = [# Depot (仓库)Customer(id=0, coords=(0, 0), demand=0, tw_early=0, tw_late=1440, service_time=0),# Customer 1Customer(id=1,coords=(10, 10),demand=50,tw_early=480, # 8:00tw_late=660, # 11:00service_time=15,),# Customer 2Customer(id=2,coords=(20, -15),demand=75,tw_early=540, # 9:00tw_late=720, # 12:00service_time=20,),# Customer 3Customer(id=3,coords=(-15, 25),demand=40,tw_early=600, # 10:00tw_late=780, # 13:00service_time=10,),# Customer 4Customer(id=4,coords=(25, 5),demand=60,tw_early=510, # 8:30tw_late=750, # 12:30service_time=18,),# Customer 5Customer(id=5,coords=(-10, -20),demand=30,tw_early=570, # 9:30tw_late=810, # 13:30service_time=12,),# Customer 6Customer(id=6,coords=(15, -5),demand=85,tw_early=450, # 7:30tw_late=690, # 11:30service_time=25,),# Customer 7Customer(id=7,coords=(-20, 10),demand=55,tw_early=630, # 10:30tw_late=840, # 14:00service_time=16,),# Customer 8Customer(id=8,coords=(0, 25),demand=70,tw_early=510, # 8:30tw_late=720, # 12:00service_time=22,),# Customer 9Customer(id=9,coords=(-25, -15),demand=45,tw_early=480, # 8:00tw_late=750, # 12:30service_time=14,),]# 2. Define Vehicles (Multi-type)vehicles_data = [create_vehicle(id="A1", type="Type A", capacity=50),create_vehicle(id="B1", type="Type B", capacity=30),create_vehicle(id="B2", type="Type B", capacity=30),create_vehicle(id="C1", type="Type C", capacity=40), # Add another type]num_vehicles = len(vehicles_data)ga = GeneticAlgorithm(customers, vehicles_data, 10, 0.8, 0.2)pop = ga.generate_initial_population()n_infeasible_chroms = 0for chrom in pop:assigned_routes, unserved, issues = ga.decode_chromosome_method1(chrom)if unserved:n_infeasible_chroms += 1print(n_infeasible_chroms)运行结果10条染色体均为不可行解,分析原因:
- 初始种群中对客户序列的“随机切割”完全不参考各段需求之和,因而很容易生成需求总和超过任何车辆容量的子路线。
- 启用时间窗约束,随机的客户顺序大概率打乱最优路径时序,生成严重超时的路线。
- 解码时按“先 Type A 再 Type B…”“顺序尝试”车辆,但一旦高容量车型被前面路段消耗,就很难满足后面高需求子路段,更容易判为不可行。
- 可在分配时使用先将大需求路线配大车、小需求路线配小车的策略,或根据“需求密度”动态选择车辆类型。
- 目前对生成的染色体完全无惩罚地放入种群,只在评估时惩罚不可行解,导致一大半染色体从一开始就是垃圾解。
- 可在生成初始种群时,加入简单的“容量剪枝”:
- 随机分割后,若某段需求和大于所有车辆容量最大值,则直接重采样切点。
- 或者采用半启发式:先按客户需求排序,聚簇分块,再在每块内部打乱。
- 可在生成初始种群时,加入简单的“容量剪枝”:
二、使用整体聚类+局部路由(cluster-first+route-second)
(Cluster-First / Route-Second)策略的实现思路分为三大阶段:
1. 聚类(Cluster-First)
1.1 特征选择
- 空间特征:客户坐标 ( x i , y i ) (x_i,y_i) (xi,yi)。
- 需求特征:客户需求量 q i q_i qi。
- 时间窗紧迫度:可以定义紧迫度指数 w i = 1 − t i late − t i early max j ( t j late − t j early ) \displaystyle w_i \;=\; 1 \;-\; \frac{t^{\text{late}}_i - t^{\text{early}}_i}{\max_j (t^{\text{late}}_j - t^{\text{early}}_j)} wi=1−maxj(tjlate−tjearly)tilate−tiearly,越大表示时间窗越紧。
将上述特征组合成向量 f i = ( x i , y i , q i , w i ) \mathbf{f}_i=(x_i,y_i,q_i,w_i) fi=(xi,yi,qi,wi),并标准化。
1.2 聚类算法
-
簇数 K K K:等于可用车辆总数 M M M;或者先按车型分组,再分别对每一车型群做聚类(车型 A 聚为 K A K_A KA 簇,车型 B 聚为 K B K_B KB 簇…)。
-
聚类方式:
-
容量敏感 K-Means
- 在更新簇中心时,引入簇内总需求约束:若某簇聚得太多需求,拆分该簇(或将部分点划到最近的其他簇)。
-
时间窗敏感聚类
- 把紧时间窗客户优先分配到同一簇中,以保证簇内路由更易满足时窗。
-
算法示例(容量敏感 K-Means)
- 初始化:在空间中心附近随机选 K K K 个点作簇中心。
- 分配:按最短欧氏距离把每个客户指派到最近中心;
- 修复:对每个簇,若 ∑ i ∈ C k q i > max v ∈ Type ( k ) cap ( v ) \sum_{i\in C_k} q_i > \max_{v\in \text{Type}(k)} \text{cap}(v) ∑i∈Ckqi>maxv∈Type(k)cap(v),则把簇内最远离中心的一个客户移出,重新指派给下一个最近中心;重复直到所有簇容量可行。
- 更新:重新计算每个簇的中心(加权重可加需求或时间窗紧迫度)。
- 收敛或循环次数足够后停止。
结果:每个簇 C k C_k Ck 对应一辆或一组同类型车辆的潜在服务区。
2. 子问题路由优化(Route-Second)
对每个簇 C k C_k Ck(客户集合)单独生成路由,可选择不同策略:
2.1 随机键/分段编码 GA
-
染色体:仅包含簇内客户的随机键向量,或“客户 + 分隔符”编码,但规模缩小至 ∣ C k ∣ |C_k| ∣Ck∣,容量超载概率大幅下降。
-
解码与本地修复:
- 按键排序或分隔符切分生成路线。
- 若某段超载,则将超载部分的末尾 1–2 个点标记为“待重分配”,插入到同簇剩余车辆的空闲路由中或交给全局修复。
- 时间窗计算精确累积:从仓库出发,依次加上行驶时间+服务时间,并与 [ t early , t late ] [t^{\text{early}},t^{\text{late}}] [tearly,tlate] 比较,若违反可向后平移或重排序。
2.2 局部搜索/禁忌搜索
- 在每个簇内可并行使用局部优化算法,如 2-opt、Or-opt、或基于时间窗的 TSPLTW 变种,进一步精炼每条路线。
2.3 多车次分配
- 若某簇对应多辆同类型车辆(例如簇 C A C_A CA 对应 3 辆 Type A),则对该簇内插入额外的“虚拟分隔符”来分路,也可让子 GA 同时演化“分配+排序”两部分。
方法优缺点总结
| 优点 | 缺点 |
|---|---|
| - 初期大幅剪枝,减少不可行染色体比例 | - 聚类结果质量强依赖初始中心与参数 |
| - 并行化能力强:各簇可独立优化 | - 簇边界客户可能在两个簇之间切换时增加复杂度 |
| - 容量/时窗约束在聚类和本地优化双重保障 | - 全局最优性难保证,需要后期修复和微调 |
代码实现
# %%
import pandas as pd
from sklearn.cluster import KMeans# Define sample customers
data = [{"id": 0, "x": 0, "y": 0, "demand": 0, "tw_early": 0, "tw_late": 1440},{"id": 1, "x": 10, "y": 10, "demand": 50, "tw_early": 480, "tw_late": 660},{"id": 2, "x": 20, "y": -15, "demand": 75, "tw_early": 540, "tw_late": 720},{"id": 3, "x": -15, "y": 25, "demand": 40, "tw_early": 600, "tw_late": 780},{"id": 4, "x": 25, "y": 5, "demand": 60, "tw_early": 510, "tw_late": 750},{"id": 5, "x": -10, "y": -20, "demand": 30, "tw_early": 570, "tw_late": 810},{"id": 6, "x": 15, "y": -5, "demand": 85, "tw_early": 450, "tw_late": 690},{"id": 7, "x": -20, "y": 10, "demand": 55, "tw_early": 630, "tw_late": 840},{"id": 8, "x": 0, "y": 25, "demand": 70, "tw_early": 510, "tw_late": 720},{"id": 9, "x": -25, "y": -15, "demand": 45, "tw_early": 480, "tw_late": 750},
]df = pd.DataFrame(data)# Compute time window tightness index
max_window = (df["tw_late"] - df["tw_early"]).max()
df["tw_tightness"] = 1 - (df["tw_late"] - df["tw_early"]) / max_window# Normalize demand
df["demand_norm"] = (df["demand"] - df["demand"].mean()) / df["demand"].std()# Features: x, y, normalized demand, time window tightness
features = df[["x", "y", "demand_norm", "tw_tightness"]].values# Cluster into 4 clusters (equal to number of vehicles in example)
kmeans = KMeans(n_clusters=4, random_state=42)
df["cluster"] = kmeans.fit_predict(features)
df# %%
from scipy import spatial
customer_coord = [(row['x'], row['y']) for idx, row in df.iterrows()]
distance = spatial.distance.cdist(customer_coord, customer_coord, 'euclidean')
distance# %%
def check_time_windows(seq_ids, vehicle, df, speed=40):t = 0.0last = 0for cid in seq_ids:cust = df[df.id == cid].iloc[0]dist = distance[0][cid]t += dist / speed * 60if t < cust["tw_early"]:t = cust.tw_earlyif t > cust["tw_late"]:return Falset += 0 # cust["service_time"]last = ciddist = distance[last][0]t += dist / speed * 60return True# %%
# Reuse the clustered DataFrame from previous step
data = [{"id": 0, "x": 0, "y": 0, "demand": 0, "tw_early": 0, "tw_late": 1440, "cluster": 3},{"id": 1, "x": 10, "y": 10, "demand": 50, "tw_early": 480, "tw_late": 660, "cluster": 3},{"id": 2, "x": 20, "y": -15, "demand": 75, "tw_early": 540, "tw_late": 720, "cluster": 0},{"id": 3, "x": -15, "y": 25, "demand": 40, "tw_early": 600, "tw_late": 780, "cluster": 1},{"id": 4, "x": 25, "y": 5, "demand": 60, "tw_early": 510, "tw_late": 750, "cluster": 2},{"id": 5, "x": -10, "y": -20, "demand": 30, "tw_early": 570, "tw_late": 810, "cluster": 1},{"id": 6, "x": 15, "y": -5, "demand": 85, "tw_early": 450, "tw_late": 690, "cluster": 0},{"id": 7, "x": -20, "y": 10, "demand": 55, "tw_early": 630, "tw_late": 840, "cluster": 1},{"id": 8, "x": 0, "y": 25, "demand": 70, "tw_early": 510, "tw_late": 720, "cluster": 2},{"id": 9, "x": -25, "y": -15, "demand": 45, "tw_early": 480, "tw_late": 750, "cluster": 2},
]df = pd.DataFrame(data)# Define vehicles with capacities
vehicles = [{"id": "A1", "type": "A", "capacity": 50},{"id": "B1", "type": "B", "capacity": 180},{"id": "B2", "type": "B", "capacity": 180},{"id": "C1", "type": "C", "capacity": 240},
]# Assign each cluster to a vehicle by matching total demand
cluster_groups = df.groupby("cluster")
cluster_to_vehicle = {}
used = set()
chromosome = {}
for k, group in cluster_groups:total_demand = group["demand"].sum()group = group.sort_values(by=["tw_early", "tw_late"], ascending=True)seq = group[group.id != 0].id.tolist()print(f"cluster{k}: \n", group)print("cluster all cusomters': ", seq)print("total demand: ", total_demand)print()# find smallest vehicle that can cover itfor v in sorted(vehicles, key=lambda x: x["capacity"]):if v["capacity"] >= total_demand and check_time_windows(seq, v, df) and v["id"] not in used:cluster_to_vehicle[k] = v["id"]used.add(v["id"])chromosome[v["id"]] = seqbreakelse:# overflow: assign a default large vehicle or mark for repaircluster_to_vehicle[k] = Noneprint(cluster_to_vehicle)
print("chrom: ", chromosome)
print("vehicle used: ", used)结果为:
cluster0: id x y demand tw_early tw_late cluster
6 6 15 -5 85 450 690 0
2 2 20 -15 75 540 720 0
cluster all cusomters': [6, 2]
total demand: 160cluster1: id x y demand tw_early tw_late cluster
5 5 -10 -20 30 570 810 1
3 3 -15 25 40 600 780 1
7 7 -20 10 55 630 840 1
cluster all cusomters': [5, 3, 7]
total demand: 125cluster2: id x y demand tw_early tw_late cluster
9 9 -25 -15 45 480 750 2
8 8 0 25 70 510 720 2
4 4 25 5 60 510 750 2
cluster all cusomters': [9, 8, 4]
total demand: 175cluster3: id x y demand tw_early tw_late cluster
...{0: 'B1', 1: 'B2', 2: 'C1', 3: 'A1'}
chrom: {'B1': [6, 2], 'B2': [5, 3, 7], 'C1': [9, 8, 4], 'A1': [1]}
vehicle used: {'A1', 'B1', 'B2', 'C1'}
三、贪心构造(Route‐based Encoding)
遍历每一辆车,遍历每个一个客户点,若当前客户点满足时间窗和容量约束,则加入当前车辆。直至遍历结束。这样得到可行解(染色体编码)形式为每辆车对应的客户访问顺序列表,如A1:[c1,c3, c2]表示车辆A1依次访问客户132;A2:[c4]…。
这种“直接编码”可行,但算子设计比传统的“全局序列+解码”要复杂很多(需要自定义交叉和变异算子)。
代码实现:
import collections
from dataclasses import dataclass
from pyexpat import features
from typing import Tuple, List, Dict, override
import math, random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 设置中文字体和解决负号显示问题
plt.rcParams["font.sans-serif"] = ["SimHei", "FangSong"] # 指定默认字体
plt.rcParams["axes.unicode_minus"] = False # 解决保存图像时负号 '-' 显示为方块的问题# 数据结构定义
@dataclass(frozen=True) # 使用frozen=True使类变为不可变的,从而可哈希
class Customer:id: intcoord: Tuple[float, float]demand: inttime_window: Tuple[float, float]service_time: float@overridedef __repr__(self) -> str:return str(self.id)@overridedef __str__(self) -> str:return self.__repr__()def __hash__(self):return hash((self.id, self.coord, self.demand, self.time_window, self.service_time))@dataclass(frozen=True) # 使用frozen=True使类变为不可变的,从而可哈希
class Vehicle:id: strcapacity: inttype: strspeed: float = 1.0@overridedef __repr__(self) -> str:return str(self.id)@overridedef __str__(self) -> str:return self.__repr__()def __hash__(self):return hash((self.id, self.capacity, self.type, self.speed))def read_solomon_data(filename):"""读取Solomon格式的VRPTW数据集"""customers_data = []vehicles_data = []with open(filename, "r") as f:lines = f.readlines()# 读取车辆信息vehicle_info = lines[4].strip().split()num_vehicles = int(vehicle_info[0])capacity = int(vehicle_info[1])# 创建标准车队for i in range(num_vehicles):vehicles_data.append(Vehicle(id=f"V{i+1}", capacity=capacity, type="Standard"))# 跳过表头start_line = 9# 读取客户信息for line in lines[start_line:]:data = line.strip().split()if len(data) >= 7: # 确保数据行完整cust_id = int(data[0])x_coord = float(data[1])y_coord = float(data[2])demand = int(data[3])ready_time = float(data[4])due_time = float(data[5])service_time = float(data[6])if cust_id == 0: # depotdepot = Customer(id=0,coord=(x_coord, y_coord),demand=0,time_window=(ready_time, due_time),service_time=0,)else: # customercustomers_data.append(Customer(id=cust_id,coord=(x_coord, y_coord),demand=demand,time_window=(ready_time, due_time),service_time=service_time,))return depot, customers_data, vehicles_datadef euclidean_time(p1, p2, speed):return math.hypot(p1[0] - p2[0], p1[1] - p2[1]) / speeddef initialize_chrom(customers: list, vehicles, depot):# 可行性检查:车辆总容量 >= 客户总需求total_demand = sum(customer.demand for customer in customers)total_capacity = sum(vehicle.capacity for vehicle in vehicles)if total_capacity < total_demand:raise ValueError(f"车辆总容量{total_capacity} < 客户总需求{total_demand},无法找到可行解")unvisited = set(customers)current_route = [depot]routes = {}available_vehicles = list(vehicles)v = available_vehicles.pop(0)while unvisited:# 找出当前路线可行的下一个客户集feasible = [c for c in unvisited if _time_feasible(current_route, c, v)]if not feasible: # ==[]if len(current_route) > 1:routes[v] = current_route + [depot]# 尝试获取下一辆车if available_vehicles:v = available_vehicles.pop(0)current_route = [depot]else:# 没有更多车辆,结束循环print(f"警告: 车辆不足以服务所有客户。剩余未服务客户: {len(unvisited)}")breakelse: # 如果一辆车无法服务任何客户(即 feasible 为空且 current_route 只有起点)# 尝试下一辆车if available_vehicles:v = available_vehicles.pop(0)else:# 没有更多车辆,结束循环print(f"警告: 车辆不足以服务所有客户。剩余未服务客户: {len(unvisited)}")breakcurrent_route = [depot]continuenext_customer = feasible[np.random.choice(len(feasible))]current_route.append(next_customer)unvisited.remove(next_customer)if len(current_route) > 1:routes[v] = current_route + [depot]return routesdef _time_feasible(route, new_customer, v):"""时间窗检查"""temp_route = route + [new_customer]current_time = 0current_load = 0prev_customer = temp_route[0]# 检查起始点载重current_load += prev_customer.demandif current_load > v.capacity:return Falsefor i in range(1, len(temp_route)):curr_customer = temp_route[i]# 计算旅行时间travel_time = euclidean_time(prev_customer.coord, curr_customer.coord, v.speed)arrival_time = current_time + travel_time# 检查到达时间是否超过最晚时间if arrival_time > curr_customer.time_window[1]:return False# 计算服务开始时间(考虑等待)service_start = max(arrival_time, curr_customer.time_window[0])# 更新当前时间为服务结束时间current_time = service_start + curr_customer.service_time# 更新载重current_load += curr_customer.demandif current_load > v.capacity:return Falseprev_customer = curr_customerreturn Truedef generate_initial_population(customers: list, vehicles, depot, population_size):population = []for _ in range(population_size):chrom = initialize_chrom(customers, vehicles, depot)population.append(chrom)return population# 适应度: 总距离
def fitness(sol: Dict[Vehicle, List[Customer]], depot: Customer) -> float:dist = 0.0for v, route in sol.items():prev = depotfor node in route[1:]:dist += math.hypot(prev.coord[0] - node.coord[0], prev.coord[1] - node.coord[1])prev = nodereturn dist# 锦标赛选择
def tournament_selection(pop, scores, k=3):sample = random.sample(list(zip(pop, scores)), k)return min(sample, key=lambda x: x[1])[0]# 路线为基因的交叉: 保持每车映射,交换两辆车的子路径
def crossover(p1: Dict[Vehicle, List[Customer]],p2: Dict[Vehicle, List[Customer]],depot: Customer,vehicles: List[Vehicle],
) -> Dict[Vehicle, List[Customer]]:# 初始化child为完整字典child = {v: list(p1.get(v, [depot, depot])) for v in vehicles}# 随机选两辆车v1, v2 = random.sample(vehicles, 2)# 交换子路径(去掉端点)r1 = child[v1][1:-1]r2 = child[v2][1:-1]child[v1] = [depot] + r2 + [depot]child[v2] = [depot] + r1 + [depot]# 修复: 确保所有客户唯一出现all_custs = set(sum([route[1:-1] for route in child.values()], []))missing = set(sum([route[1:-1] for route in p1.values()], [])) - all_custsfor c in missing:for v in vehicles:route = child[v]for pos in range(1, len(route)):tmp = route[:pos] + [c] + route[pos:]if _time_feasible([depot] + tmp[1:-1] + [depot], c, v):child[v] = [depot] + tmp[1:-1] + [depot]breakif c in child[v]:breakreturn child# 变异: 随机跨车交换
def mutation(sol: Dict[Vehicle, List[Customer]],depot: Customer,vehicles: List[Vehicle],mutation_rate=0.1,
) -> Dict[Vehicle, List[Customer]]:child = {v: list(route) for v, route in sol.items()}if random.random() < mutation_rate:v1, v2 = random.sample(vehicles, 2)if len(child[v1]) > 2 and len(child[v2]) > 2:i = random.randint(1, len(child[v1]) - 2)j = random.randint(1, len(child[v2]) - 2)child[v1][i], child[v2][j] = child[v2][j], child[v1][i]return child# 遗传算法主程序
def genetic_algorithm(customers, vehicles, depot, population_size=50, generations=100, mutation_rate=0.1
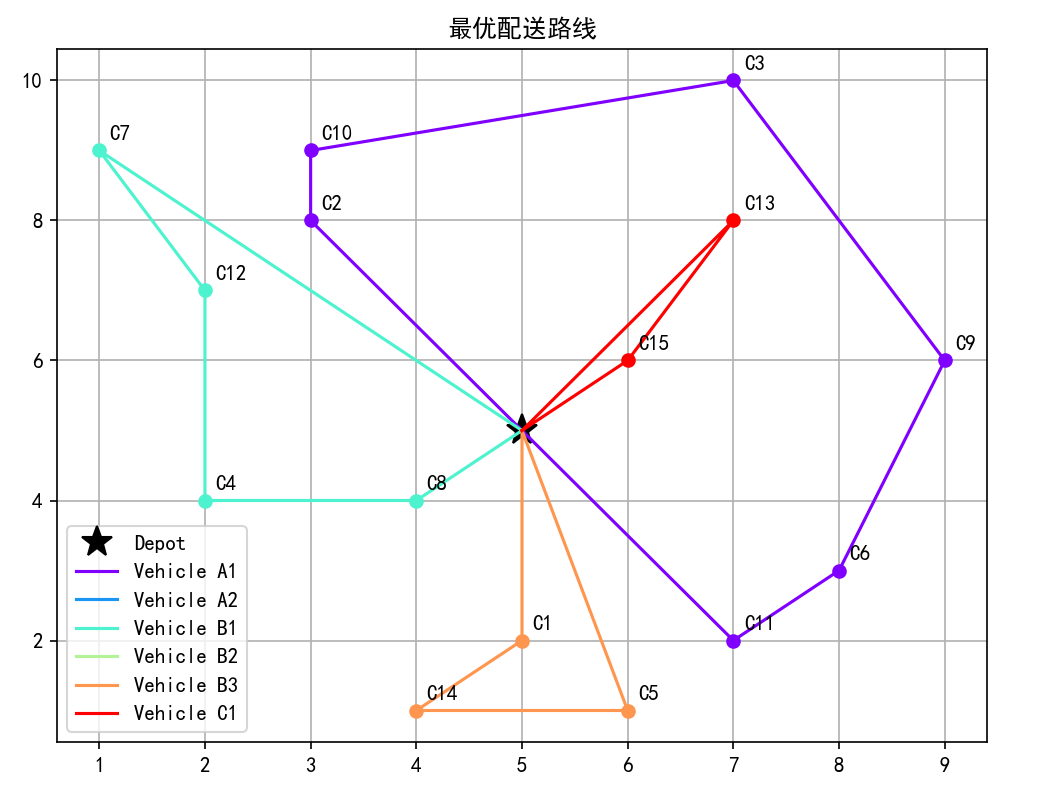
):pop = generate_initial_population(customers, vehicles, depot, population_size)for p in pop:print(p)best, best_score = None, float("inf")for gen in range(1, generations + 1):scores = [fitness(ind, depot) for ind in pop]for ind, sc in zip(pop, scores):if sc < best_score:best, best_score = ind, scnew_pop = []while len(new_pop) < population_size:p1 = tournament_selection(pop, scores)p2 = tournament_selection(pop, scores)child = crossover(p1, p2, depot, vehicles)child = mutation(child, depot, vehicles, mutation_rate)new_pop.append(child)pop = new_popprint(f"Generation {gen}/{generations}, Best Distance: {best_score:.2f}")return best, best_scoredef plot_solution(solution, depot, title="Vehicle Routing Solution"):"""绘制路线图"""plt.figure(figsize=(10, 10))# 绘制仓库plt.plot(depot.coord[0], depot.coord[1], "k*", markersize=15, label="Depot")# 为每个车辆分配不同的颜色colors = plt.cm.rainbow(np.linspace(0, 1, len(solution)))# 绘制每条路径for (vehicle, route), color in zip(solution.items(), colors):route_x = [p.coord[0] for p in route]route_y = [p.coord[1] for p in route]# 绘制路径线plt.plot(route_x, route_y, "-", color=color, label=f"Vehicle {vehicle}")# 绘制客户点plt.plot(route_x[1:-1], route_y[1:-1], "o", color=color)# 添加客户点编号for customer in route[1:-1]:plt.annotate(f"C{customer.id}",(customer.coord[0], customer.coord[1]),xytext=(5, 5),textcoords="offset points",)plt.title(title)plt.legend()plt.grid(True)plt.show()if __name__ == "__main__":# depot, customers, vehicles = read_solomon_data("c101.txt")# print(vehicles)# print(customers)# 运行遗传算法求解VRPTW问题# 示例:1个 depot + 9个客户depot = Customer(id=0, coord=(5, 5), demand=0, time_window=(0, 1e6), service_time=0)customers = [Customer(id=1, coord=(5, 2), demand=10, time_window=(100, 500), service_time=10),Customer(id=2, coord=(3, 8), demand=20, time_window=(200, 600), service_time=12),Customer(id=3, coord=(7, 10), demand=15, time_window=(150, 550), service_time=8),Customer(id=4, coord=(2, 4), demand=25, time_window=(300, 700), service_time=15),Customer(id=5, coord=(6, 1), demand=10, time_window=(100, 400), service_time=5),Customer(id=6, coord=(8, 3), demand=30, time_window=(250, 650), service_time=20),Customer(id=7, coord=(1, 9), demand=5, time_window=(100, 300), service_time=7),Customer(id=8, coord=(4, 4), demand=20, time_window=(200, 600), service_time=10),Customer(id=9, coord=(9, 6), demand=15, time_window=(150, 550), service_time=12),Customer(id=10, coord=(3, 9), demand=12, time_window=(120, 480), service_time=8),Customer(id=11, coord=(7, 2), demand=18, time_window=(180, 520), service_time=15),Customer(id=12, coord=(2, 7), demand=22, time_window=(220, 580), service_time=10),Customer(id=13, coord=(7, 8), demand=8, time_window=(130, 450), service_time=6),Customer(id=14, coord=(4, 1), demand=16, time_window=(160, 490), service_time=12),Customer(id=15, coord=(6, 6), demand=25, time_window=(240, 620), service_time=18),]vehicles = [Vehicle(id="A1", capacity=80, type="A", speed=30),Vehicle(id="A2", capacity=80, type="A", speed=30),Vehicle(id="B1", capacity=50, type="B", speed=30),Vehicle(id="B2", capacity=50, type="B", speed=30),Vehicle(id="B3", capacity=50, type="B", speed=30),Vehicle(id="C1", capacity=100, type="C", speed=30),]# chrom = initialize_chrom(customers, vehicles, depot)# for v, r in chrom.items():# print(v, r)# 运行遗传算法求解best_solution, best_fitness = genetic_algorithm(customers=customers,vehicles=vehicles,depot=depot,population_size=50,generations=300,mutation_rate=0.2,)# 打印最优解结果print("\n最优解:")print(f"总成本: {best_fitness}")for vehicle, route in best_solution.items():print(f"车辆 {vehicle}: {route}")# 可视化最优路径plot_solution(best_solution, depot, title="最优配送路线")运行结果:
Generation 294/300, Best Distance: 53.48
Generation 295/300, Best Distance: 53.48
Generation 296/300, Best Distance: 53.48
Generation 297/300, Best Distance: 53.48
Generation 298/300, Best Distance: 53.48
Generation 299/300, Best Distance: 53.48
Generation 300/300, Best Distance: 53.48最优解:
总成本: 53.483123146779576
车辆 A1: [0, 2, 10, 3, 9, 6, 11, 0]
车辆 A2: [0, 0]
车辆 B1: [0, 8, 4, 12, 7, 0]
车辆 B2: [0, 0]
车辆 B3: [0, 1, 14, 5, 0]
车辆 C1: [0, 13, 15, 0]
最优路径可视化:
相关文章:

遗传算法求解异构车队VRPTW问题
这里写目录标题 染色体编码设计:两种染色体编码方式一、客户排列 分割点(Giant Tour Split)1. 示例编码与解码2. 采用 客户排列 分割点 设计的特点3. 编码实现(基于Python) 二、使用整体聚类局部路由(cl…...

区块链内容创作全攻略:海报、白皮书与视频的视觉化革命
区块链内容创作全攻略:海报、白皮书与视频的视觉化革命 ——2025年去中心化叙事的技术密码与商业实践 一、区块链海报设计:视觉叙事与用户心智占领 区块链海报需在3秒内抓住观众注意力,同时传递技术内核与商业价值。核心设计法则包括&#x…...

windows的rancherDesktop修改镜像源
您好!要在Windows系统上的Rancher Desktop中修改Docker镜像源(即设置registry mirror),您需要根据Rancher Desktop使用的容器运行时(containerd或dockerd)进行配置。用户提到“allowed-image”没有效果&…...
——工业4.0讲解)
从零开始了解数据采集(二十四)——工业4.0讲解
在全球制造业加速变革的今天,“工业4.0”成为了一个炙手可热的词汇。从德国的概念提出,到我国的积极实践,这场技术与产业的深度融合正推动制造业迈向智能化、数字化的新时代。对于企业而言,这是一次不可多得的机遇,更是…...

Java复习笔记-基础
Java复习笔记 一、什么是JDK、JRE、JVM二、Keyword-关键字三、variable-变量浮点数类型-float和double字符类型-char基本数据类型变量间运算规则基本数据类型与 String 的运算和 四、逻辑运算符五、流程控制语句关于if else 和 switchfor循环while循环do while循环 六、Array-数…...

用递归实现各种排列
为了满足字典序的输出,我采用了逐位递归的方法(每一位的所能取到的最小值都大于前一位) 1,指数型排列 #include<bits/stdc.h> using ll long long int; using namespace std; int a[10];void printp(int m) {for (int h …...

基于Stable Diffusion XL模型进行文本生成图像的训练
基于Stable Diffusion XL模型进行文本生成图像的训练 flyfish export MODEL_NAME"stabilityai/stable-diffusion-xl-base-1.0" export VAE_NAME"madebyollin/sdxl-vae-fp16-fix" export DATASET_NAME"lambdalabs/naruto-blip-captions"acceler…...

SHA系列算法
SHA1系列算法 SHA(Secure Hash Algorithm,安全散列算法)是一组加密哈希算法,用于确保数据完整性和提供消息摘要功能。SHA算法由美国国家安全局(NSA)设计,并由国家标准与技术研究院(…...

985高校查重率“隐性阈值”:低于5%可能被重点审查!
你是不是也以为: “查重率越低越好,最好压到1%、0%,导师看了都感动哭🥹” 但是你不知道的是——在985/211等重点高校,查重率太低反而可能引起导师和学术办公室的“特别关注”! 今天就来扒一扒这个查重圈“…...

基于vue3+QuillEditor的深度定制
需求: 项目需求一个深度定制的富文本编辑器,要求能够定制表格,能够从素材库插入图片,以及其他个性化操作。我这里就基于vue3+ QuillEditor深度定制的角度,解析一下QuillEditor富文本编辑器的功能扩展功能的需求。 一、扩展工具栏 根据需求,我们需要扩展工具栏,实现自…...

Redis 8.0正式发布,再次开源为哪般?
Redis 8.0 已经于 2025 年 5 月 1 日正式发布,除了一些新功能和性能改进之外,一个非常重要的改变就是新增了开源的 AGPLv3 协议支持,再次回归开源社区。 为什么说再次呢?这个需要从 2024 年 3 月份 Redis 7.4 说起,因为…...

静态BFD配置
AR2配置 int g0/0/0 ip add 10.10.10.2 quit bfd quit bfd 1 bind peer-ip 10.10.10.1 source-ip 10.10.10.2 auto commit AR1配置 int g0/0/0 ip add 10.10.10.1 int g0/0/1 ip add 10.10.11.1 quit bfd quit bfd 1 bind peer-ip 10.0.12.2 source-ip 10.0.12.1 auto co…...

[python] 函数1-函数基础
一 函数使用 1.1 基本用法 def 函数名() 函数体 函数返回值: 返回调用的结果 def myPyFirstFunc():print("hello python") myPyFirstFunc()1.2 函数参数 def 函数名(形参a,形参b) 函数体 def add(a,b):return a b print(add(1,2)) print(add(1,4)) 二 函…...

【并发编程】MySQL锁及单机锁实现
目录 一、MySQL锁机制 1.1 按锁粒度划分 1.2 按锁功能划分 1.3 InnoDB锁实现机制 (1)记录锁(Record Lock) (2) 间隙锁(Gap Lock) (3) 临键锁(Next-Key Lock) (4) 插入意向锁(Insert Intention Lock) 二、基于 JVM 本地锁实现,保证线程安全 2.1 线程不安全的分析 2.1…...

C++ | 常用语法笔记
判断数字还是字母 1.笨办法,使用直接判断办法 if(c > 0 && c < 9) cout << "c是数字" << endl; if(c > a && c < z) cout << "c是小写字母" << endl; if(c > A && c< Z) …...

浅谈 Shell 脚本编程中引号的妙用
在 Shell 脚本编程中,引号的使用是一项基础却至关重要的技能。无论是单引号、双引号还是不加引号,它们都会显著影响 Shell 对字符串、变量、特殊字符以及命令的解析方式。理解这些差异不仅能帮助开发者编写更健壮的脚本,还能避免因误解引发的…...

DeFi开发系统软件开发:技术架构与生态重构
DeFi开发系统软件开发:技术架构与生态重构 ——2025年去中心化金融开发的范式革新与实践指南 一、技术架构演进:从单一链到多链混合引擎 现代DeFi系统开发已从单一公链架构转向“跨链互操作混合模式”,结合中心化效率与去中心化安全双重优势…...

Spring AI 集成 DeepSeek V3 模型开发指南
Spring AI 集成 DeepSeek V3 模型开发指南 前言 在人工智能飞速发展的当下,大语言模型不断推陈出新,DeepSeek AI 推出的开源 DeepSeek V3 模型凭借其卓越的推理和问题解决能力备受瞩目。与此同时,Spring AI 作为一个强大的框架,…...

C++:扫雷游戏
一.扫雷游戏项目设计 1.文件结构设计 首先我们要先定义三个文件 ①test.c //文件中写游戏的测试逻辑 ②game.c //文件中写游戏中函数的实现等 ③game.h //文件中写游戏需要的数据类型和函数声明等 2.扫雷游戏的主体结构 使⽤控制台实现经典的扫雷游戏 •游戏可以通过菜单…...

【写作格式】写论文时常见格式问题
写作格式 1.图片总是乱跑,怎么固定图片2.一键更新引用3.交叉引用[1][2][3]怎么变为[1,2,3]4.目录灰色底纹怎么消除5.word保存为pdf提取标题为书签 1.图片总是乱跑,怎么固定图片 遇到的问题 解决方法 第一步:图片格式——>环绕文字——&g…...

Android平台FFmpeg视频解码全流程指南
本文将详细介绍在Android平台上使用FFmpeg进行高效视频解码的实现方案,采用面向对象的设计思想。 一、架构设计 1.1 整体架构 采用三层架构设计: • 应用层:提供用户接口和UI展示 • 业务逻辑层:管理解码流程和状态 • Native…...

C31-形参与实参的区别
一 形参与实参 实参:调用函数时传递的实际值,可以是变量、常量或表达式,如"add(3,a)"中的’3’与’a’形参:函数定义中声明的参数变量,用于接收实参的值,如"int add(intx,inty)"中的’x’与’y’ C语言默认通过值传递参数,形参与实参是独立的变量,仅数据…...

自学嵌入式 day 16-c语言-第10章 指针
14 指针函数 返回值是指针的函数。 (1)动态内存分配 ①使用方式: #include<stdlib.h> void *malloc(size_t size) ②返回连续的内存空间的首元素地址,内存空间未被初始化,申请的是堆区的空间。 ③内存空间申请…...

DataWorks快速入门
文章目录 一、DataWorks简介1、概念2、功能3、优势 二、DataWorks使用1、创建工作空间2、绑定计算资源3、数据开发 三、DataWorks节点类型1、MaxCompute SQL节点①创建非分区表并插入数据②创建分区表并插入数据③查询表数据 2、离线同步节点3、PYODPS 3节点①判断表是否存在②…...

AtCoder Beginner Contest 404 A-E 题解
还是ABC好打~比ARC好打多了( 题解部分 A - Not Found 给定你一个长度最大25的字符串,任意输出一个未出现过的小写字母 签到题,map或者数组下标查询一下就好 #include<bits/stdc.h>using namespace std;#define int long long #def…...

WiFi出现感叹号上不了网怎么办 轻松恢复网络
在日常生活中,WiFi已成为不可或缺的一部分。然而,有时我们会遇到WiFi图标上出现了感叹号,无法上网。无论是办公、学习还是娱乐,这种情况都会严重影响体验。这种情况该怎么解决呢?本期驱动哥就给各位介绍几种简单的解决…...

M0芯片的基础篇Timer
一、计数器的原理 加法计数器 减法计数器 触发中断 最短计时时间 时钟周期决定 16bit 65535 最长计时时间 时间周期和最大计数值决定 二、syscfg配置 timg:通用定时器 tima:高级定时器 timx:不论是高级定时器还是通用定时器都是一样…...
)
vue教程(vuepress版)
Vue 完全指南 项目介绍 这是一个系统化的 Vue.js 学习教程,采用循序渐进的方式,帮助开发者从零开始掌握 Vue 开发技能。 教程特点 循序渐进: 从 Vue 基础概念开始,逐步深入到高级特性,适合不同层次的开发者学习实战驱动: 结合…...

【嵌入式开发-USB】
嵌入式开发-USB ■ USB简介 ■ USB简介...

【前端】webstorm运行程序浏览器报network error
是浏览器阻止了链接,先把能正常访问的链接搜索,禁止访问的时候,高级,强制访问,再运行项目生成的网址就可以了。...

国内led显示屏厂家以及售后 消费对比与选择
国内led显示屏的厂家有很多,虽然让消费者在选择的时候有了多种的机会,可是在质量方面的鉴别上也是无从下手。对此为了方便消费者作出选择,下面为您推荐一些品牌厂家。 1、强力巨彩 是全球比较有名气的LED显示屏厂家的制造商,总厂房…...

【Go】优化文件下载处理:从多级复制到零拷贝流式处理
在开发音频处理服务过程中,我们面临一个常见需求:从网络下载音频文件并保存到本地。这个看似简单的操作,实际上有很多优化空间。本文将分享一个逐步优化的过程,展示如何从一个基础实现逐步改进到高效的流式下载方案。 初始实现&a…...
:深入理解 I2C 总线驱动模型(以 at24 EEPROM 为例))
驱动开发硬核特训 · Day 30(上篇):深入理解 I2C 总线驱动模型(以 at24 EEPROM 为例)
作者:嵌入式Jerry 视频教程请关注 B 站:“嵌入式Jerry” 一、写在前面 在上一阶段我们已经深入理解了字符设备驱动与设备模型之间的结合方式、sysfs 的创建方式以及平台驱动模型的实际运用。今天我们迈入总线驱动模型的世界,聚焦于 I2C 总线…...

LaTeX印刷体 字符与数学符号的总结
1. 希腊字母(Greek Letters) 名称小写 LaTeX大写 LaTeX显示效果Alpha\alphaAαα, AABeta\betaBββ, BBGamma\gamma\Gammaγγ, ΓΓDelta\delta\Deltaδδ, ΔΔTheta\theta\Thetaθθ, ΘΘPi\pi\Piππ, ΠΠSigma\sigma\Sigmaσσ, ΣΣOmega\omeg…...

关键字where
C# 中的 where 关键字主要用在泛型约束(Generic Constraints)中,目的是对泛型类型参数限制其必须满足的条件,从而保证类型参数具备特定的能力或特性,增强类型安全和代码可读性。 约束写法说明适用场景举例C#版本要求w…...

vite 代理 websocket
🛡️一、WebSocket 基本概念 名称全称含义使用场景ws://WebSocket非加密的 WebSocket 连接开发环境、内网通信wss://WebSocket Secure加密的 WebSocket 连接(基于 TLS/SSL)生产环境、公网通信 🛡️二、安全性对比 特性ws://wss…...

深入理解操作系统:从基础概念到核心管理
在计算机系统中,操作系统是至关重要的组成部分,它如同计算机的“大管家”,统筹协调着系统的各项资源与工作流程。接下来,就让我们深入了解操作系统的奥秘。 一、操作系统概述 操作系统能有效组织和管理系统中的软/硬件资源&…...
)
手撕基于AMQP协议的简易消息队列-1(项目介绍与开发环境的搭建)
项目绍 码云仓库:MessageQueues: 仿Rabbit实现消息队列 文章概要 本文将介绍从零搭建一个简易消息队列的方法,目的是了解并学习消息队列的底层原理与逻辑,编写一个独立的服务器程序。从搭建开发环境开始,到编写一些工作组件&am…...

C++ 模板方法模式详解与实例
模板方法模式概念 模板方法模式(Template Method Pattern)属于行为型设计模式,其核心思想是在一个抽象类中定义一个算法的骨架,而将一些步骤延迟到子类中实现。这样可以使得子类在不改变算法结构的情况下,重新定义算法中的某些步骤。它通过继承机制,实现代码复用和行为…...

北京丰台人和中医院,收费贵吗?
北京丰台人和中医院,收费贵吗? 北京丰台人和中医院属于平价医院,百姓医院,收费不贵,北京丰台人和中医院35年专业看肝病,之所以能够在肝病感染者中赢得广泛好评,离不开其严谨的医疗流程、专业的…...

21、魔法传送阵——React 19 文件上传优化
一、魔法传送阵的核心法则 1.量子切割术(分片上传) const sliceFile (file) > {const chunks [];let start 0;const CHUNK_SIZE 2 * 1024 * 1024; // 2MB分片while (start < file.size) {chunks.push({id: ${file.name}-${start},data: file.s…...

Windows命令行软件管理器:Chocolatey
文章目录 Windows命令行软件管理器:Chocolatey1.Chocolatey使用1.1 安装1.2 常用命令1.3 使用流程 2.常用shell命令汇总 Windows命令行软件管理器:Chocolatey Chocolatey 是一款强大的 Windows 命令行软件管理器,目前在 GitHub 上已斩获 10.…...
)
【MySQL】第二弹——MySQL表的增删改查(CRUD)
文章目录 🎓一. CRUD🎓二. 新增(Create)🎓三. 查询(Rertieve)📖1. 全列查询📖2. 指定列查询📖3. 查询带有表达式📖4. 起别名查询(as )📖 5. 去重查询(distinct)📖6. 排序…...

Windows环境,Python实现对本机处于监听状态的端口,打印出端口,进程ID,程序名称
1、pip install tabulate 2、代码实现 #!/usr/bin/env python # -*- coding: utf-8 -*-""" Windows端口监听程序 显示本机处于监听状态的端口,进程ID和程序名称 """import subprocess import re import os import sys from tabulat…...

什么是变量提升?
变量提升(Hoisting) 是 JavaScript 引擎在代码执行前的一个特殊行为,它会将变量声明和函数声明自动移动到当前作用域的顶部。但需要注意的是,只有声明会被提升,赋值操作不会提升。 核心概念 变量声明提升&…...

Java大师成长计划之第15天:Java线程基础
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在现代软件开发中,多线程…...

中小企业设备预测性维护:从技术原理到中讯烛龙实践落地指南
在工业 4.0 与智能制造浪潮的推动下,中小企业正面临设备管理模式的深刻变革。传统的事后维修与预防性维护策略,因缺乏数据驱动与智能决策能力,已难以满足企业降本增效的核心诉求。据 Gartner 统计,非计划停机导致的生产损失平均每…...

mysql 复习
mysql定义与架构 数据库是按照数据结构来组织、存储和管理数据的仓库,方便我们增删查改。MySQL有客户端和服务器端,基于网络服务的,3306端口处于监听状态。 数据库的存储介质有以下两种: 磁盘,比如MySQL就是一种磁盘…...

高低比率策略
本策略的核心在于运用技术指标结合基本规则进行交易决策,旨在通过高低比率策略捕捉市场的超买和超卖信号,以此指导交易行为。 一、交易逻辑思路 1. 指标计算: - 本策略首先通过EMA(指数移动平均)计算快线和慢线的值&am…...

python线上学习进度报告
一、mooc学习 二、python123学习...