Java复习笔记-基础
Java复习笔记
- 一、什么是JDK、JRE、JVM
- 二、Keyword-关键字
- 三、variable-变量
- 浮点数类型-float和double
- 字符类型-char
- 基本数据类型变量间运算规则
- 基本数据类型与 String 的运算
- ++和++
- 四、逻辑运算符
- 五、流程控制语句
- 关于if else 和 switch
- for循环
- while循环
- do while循环
- 六、Array-数组
- 数组的声明和初始化
- 数组在JVM中内存划分:
- 数组的排序算法
- 冒泡排序
Java体系平台
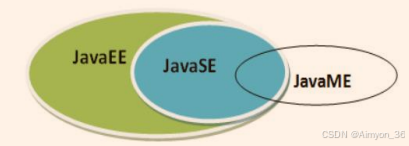
- Java SE(Java Standard Edition)标准版
- 支持面向桌面级应用(如 Windows 下的应用程序)的 Java 平台,即定位个人计算机的应用开发。
- 包括用户界面接口 AWT 及 Swing,网络功能与国际化、图像处理能力以及输入输出支持等。
- 此版本以前称为 J2SE
- Java EE(Java Enterprise Edition)企业版
- 为开发企业环境下的应用程序提供的一套解决方案,即定位在服务器端的Web 应用开发。
- JavaEE 是 JavaSE 的扩展,增加了用于服务器开发的类库。如:Servlet 能够延伸服务器的功能,通过请求-响应的模式来处理客户端的请求;JSP 是一种可以将 Java 程序代码内嵌在网页内的技术。
- 版本以前称为 J2EE
- Java ME(Java Micro Edition)小型版
- 支持 Java 程序运行在移动终端(手机、机顶盒)上的平台,即定位在消费性电子产品的应用开发
- JavaME 是 JavaSE 的内伸,精简了 JavaSE 的核心类库,同时也提供自己的扩展类。增加了适合微小装置的库 javax.microedition.io.*等。
- 此版本以前称为 J2ME
PS : Android 开发不等同于 Java ME 的开发
一、什么是JDK、JRE、JVM
JDK (Java Development Kit):是 Java 程序开发工具包,包含 JRE 和开发人员使用的工具。
JRE (Java Runtime Environment) :是 Java 程序的运行时环境,包含 JVM 和运行时所需要的核心类库。
JDK = JRE + 开发工具集(例如 Javac 编译工具等)
JRE = JVM + Java SE 标准类库
JVM(Java Virtual Machine ,Java 虚拟机):是一个虚拟的计算机,是 Java 程序的运行环境。JVM 具有指令集并使用不同的存储区域,负责执行指令,管理数据、内存、寄存器。

我们编写的 Java 代码,都运行在 JVM 之上。正是因为有了 JVM,才使得 Java程序具备了跨平台性。

使用JVM前后对比
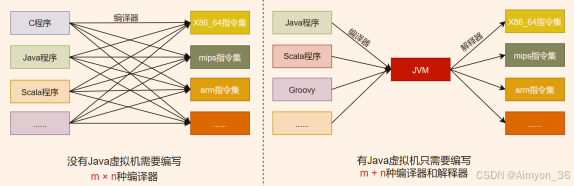
JVM的自动内存管理(内存分配、内存回收)
Java 程序在运行过程中,涉及到运算的数据的分配、存储等都由 JVM 来完成
- Java 消除了程序员回收无用内存空间的职责。提供了一种系统级线程跟踪存储空间的分配情况,在内存空间达到相应阈值时,检查并释放可被释放的存储器空间。
- GC 的自动回收,提高了内存空间的利用效率,也提高了编程人员的效率,很大程度上减少了因为没有释放空间而导致的内存泄漏。
既然JVM能够自动管理内存,是否还存在内存泄漏问题?Yes
JVM 通过 GC 自动回收不可达对象(即没有任何引用指向的对象)的内存,但 GC 无法判断“逻辑上无用但技术上可达”的对象。这就是内存泄漏的根源。
- 长生命周期的对象持有短生命周期对象的引用,例如静态集合存储了一个不在需要的对象,该对象无法回收。
- 未关闭的资源(隐式内存泄漏),例如数据库连接、文件流、。
- 不合理的键对象设计(如 HashMap),例如使用可变对象(如 StringBuilder)作为 HashMap 的键,StringBuilder内容修改后无法通过 get() 访问原值,但键仍被 Map 引用。
只要对象被根引用(如静态变量、线程栈变量)间接引用,GC 就会认为它“存活”。
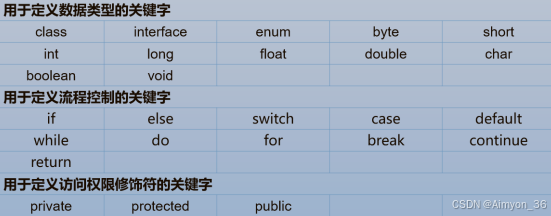
二、Keyword-关键字
定义:被 Java 语言赋予了特殊含义,用做专门用途的字符串(或单词),例如有 class、public 、 static 、 void 等,这些单词已经被 Java 定义好了。
特点:关键字都是小写字母
true,false,null 不在其中,它们看起来像关键字,其实是字面量,表示特殊的布尔值和空值。

三、variable-变量
变量的概念:
- 内存中的一个存储区域,该区域的数据可以在同一类型范围内不断变化
- 变量的构成包含三个要素:数据类型、变量名、存储的值
- Java 中变量声明的格式:数据类型 变量名 = 变量值
变量是程序中不可或缺的组成单位,最基本的存储单元。

使用变量注意:
- Java 中每个变量必须先声明,后使用。
- 使用变量名来访问这块区域的数据。
- 变量的作用域:其定义所在的一对{ }内。
- 变量只有在其作用域内才有效。出了作用域,变量不可以再被调用。
- 同一个作用域内,不能定义重名的变量。
变量的作用:用于在内存中保存数据。
Java 中变量的数据类型分为两大类:
基本数据类型:包括 整数类型、浮点数类型、字符类型、布尔类型。
引用数据类型:包括数组、 类、接口、枚举、注解、记录
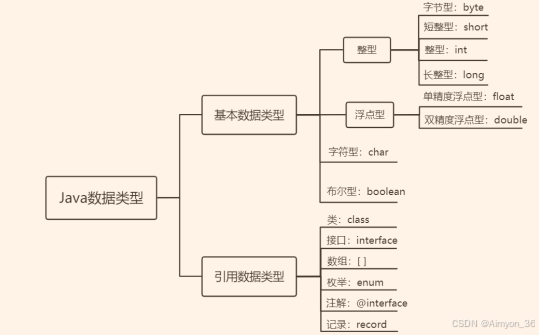
基本数据类型的表示范围:
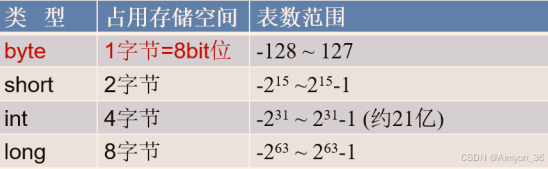

- 定义 long 类型的变量,赋值时需要以"l"或"L"作为后缀。
- Java 程序中变量通常声明为 int 型,除非不足以表示较大的数,才使用 long。
- Java 的整型常量默认为 int 型。
浮点数类型-float和double
float:单精度,尾数可以精确到 7 位有效数字。很多情况下,精度很难满足需求。
double:双精度,精度是 float 的两倍。通常采用此类型。
定义 float 类型的变量,赋值时需要以"f"或"F"作为后缀。
Java 的浮点型常量默认为 double 型。
并不是所有的小数都能可以精确的用二进制浮点数表示。二进制浮点数不能精确的表示 0.1、0.01、0.001 这样 10 的负次幂。浮点类型 float、double 的数据不适合在不容许舍入误差的金融计算领域。如果需要精确数字计算或保留指定位数的精度,需要使用 BigDecimal 类。
//测试 1:(解释见章末企业真题:为什么 0.1 + 0.2 不等于 0.3)
System.out.println(0.1 + 0.2);//0.30000000000000004
//测试 2:
float ff1 = 123123123f;
float ff2 = ff1 + 1;
System.out.println(ff1); //1.2312312E8
System.out.println(ff2); //1.2312312E8
System.out.println(ff1 == ff2); //true
测试1:
计算机使用 二进制(base-2) 存储浮点数,而人类通常使用 十进制(base-10)。十进制小数(如 0.1 和 0.2)在二进制中是 无限循环小数,无法精确存储。
测试2:
float 的精度不足以区分 123123123 和 123123124,导致 ff1 + 1 的计算结果仍然是 ff1。
计算机存储单位:
字节(Byte):是计算机用于计量存储容量的基本单位,一个字节等于 8 bit。
位(bit):是数据存储的最小单位。二进制数系统中,每个 0 或 1 就是一个位,叫做 bit(比特),其中 8 bit 就称为一个字节(Byte)。
转换关系:
8 bit = 1 Byte
1024 Byte = 1 KB
1024 KB = 1 MB
1024 MB = 1 GB
1024 GB = 1 TB
字符类型-char
Java 中的所有字符都使用 Unicode 编码,故一个字符可以存储一个字母,一个汉字,或其他书面语的一个字符。
| 转义字符 | 说明 | Unicode 表示方式 |
|---|---|---|
| \n | 换行符 | \u000a |
| \t | 制表符 | \u0009 |
| " | 双引号 | \u0022 |
| ’ | 单引号 | \u0027 |
| \ | 反斜线 | \u005c |
| \b | 退格符 | \u0008 |
| \r | 回车符 | \u000 |
char 类型是可以进行运算的。因为它都对应有 Unicode 码,可以看做是一个数值。
拓展:Java 虚拟机中没有任何供 boolean 值专用的字节码指令,Java 语言表达所操作的 boolean 值,在编译之后都使用 java 虚拟机中的 int 数据类型来代替:true 用 1 表示,false 用 0 表示。——《java 虚拟机规范 8 版》
基本数据类型变量间运算规则
在 Java 程序中,不同的基本数据类型(只有 7 种,不包含 boolean 类型)变量的值经常需要进行相互转换。
转换的方式有两种:自动类型提升和强制类型转换。
自动类型提升
规则:将取值范围小(或容量小)的类型自动提升为取值范围大(或容量大)的类型 。
基本数据类型的转换规则如图所示:

当把存储范围小的值(常量值、变量的值、表达式计算的结果值)赋值给了存储范围大的变量时:
int i = 'A';//char 自动升级为 int,其实就是把字符的编码值赋值给 i 变量了
double d = 10;//int 自动升级为 double
long num = 1234567; //右边的整数常量值如果在 int 范围呢,编译和运行都可以通过,这里涉及到数据类型转换
//byte bigB = 130;//错误,右边的整数常量值超过 byte 范围
long bigNum = 12345678912L;//右边的整数常量值如果超过 int 范围,必须加 L,显式表示 long 类型。否则编译不通过
当存储范围小的数据类型与存储范围大的数据类型变量一起混合运算时,会按照其中最大的类型运算。
int i = 1;
byte b = 1;
double d = 1.0;
double sum = i + b + d;//混合运算,升级为 double
当 byte,short,char 数据类型的变量进行算术运算时,按照 int 类型处理。
byte b1 = 1;
byte b2 = 2;
byte b3 = b1 + b2;//编译报错,b1 + b2 自动升级为 int
char c1 = '0';
char c2 = 'A';
int i = c1 + c2;//至少需要使用 int 类型来接收
System.out.println(c1 + c2);//113
强制类型转换
规则:将取值范围大(或容量大)的类型强制转换成取值范围小(或容量小)的类型。
自动类型提升是 Java 自动执行的,而强制类型转换是自动类型提升的逆运算,需要我们自己手动执行。
当把存储范围大的值(常量值、变量的值、表达式计算的结果值)强制转换为存储范围小的变量时,可能会损失精度或溢出。
int i = (int)3.14;//损失精度
double d = 1.2;
int num = (int)d;//损失精度
int i = 200;
byte b = (byte)i;//溢出
当某个值想要提升数据类型时,也可以使用强制类型转换。这种情况的强制类型转换是没有风险的,通常省略。
int i = 1;
int j = 2;
double bigger = (double)(i/j);
声明 long 类型变量时,可以出现省略后缀的情况。float 则不同。
long l1 = 123L;
long l2 = 123;//如何理解呢? 此时可以看做是 int 类型的 123 自动类型提升为 long 类型
//long l3 = 123123123123; //报错,因为 123123123123 超出了 int 的范围。
long l4 = 123123123123L;
//float f1 = 12.3; //报错,因为 12.3 看做是 double,不能自动转换为 float
类型
float f2 = 12.3F;
float f3 = (float)12.3;
例题Demo:
1)short s = 5;s = s-2; //判断:no ,s - 2 运算时,short 会被 自动提升为 int(因为 2 是 int) ,没有进行强制转换报错。
2) byte b = 3;b = b + 4; //判断:no , b + 4 转换为int,无法复制给byteb = (byte)(b+4); //判断:yes
3)char c = ‘a’; //'a' 的 ASCII 码是 97int i = 5;float d = .314F;double result = c+i+d; //判断:yes ,char也是可以运算的,结果自动类型转换为double
4) byte b = 5;short s = 3;short t = s + b; //判断:no,运算结果是 int,不能直接赋值给 short。
基本数据类型与 String 的运算
String 不是基本数据类型,属于引用数据类型,使用一对""来表示一个字符串,内部可以包含 0 个、1 个或多个字符。
- 任意八种基本数据类型的数据与 String 类型只能进行连接“+”运算,且结果一定也是 String 类型
System.out.println("" + 1 + 2);//12
int num = 10;
boolean b1 = true;
String s1 = "abc";
String s2 = s1 + num + b1;
System.out.println(s2);//abc10true
- String 类型不能通过强制类型()转换,转为其他的类型
String str = "123";
int num = (int)str;//错误的
int num = Integer.parseInt(str);//正确的,借助包装类的方法才能转
++和++
和其他变量放在一起使用或者和输出语句放在一起使用,前++和后++就产生了不同。
• 变量前++ :变量先自增 1,然后再运算。
• 变量后++ :变量先运算,然后再自增 1。
public class ArithmeticTest4 {
public static void main(String[] args) {
// 其他变量放在一起使用
int x = 3;
//int y = ++x; // y 的值是 4,x 的值是 4,
int y = x++; // y 的值是 3,x 的值是 4
System.out.println(x);
System.out.println(y);
System.out.println("==========");// 和输出语句一起
int z = 5;
//System.out.println(++z);// 输出结果是 6,z 的值也是 6
System.out.println(z++);// 输出结果是 5,z 的值是 6
System.out.println(z);}
}
四、逻辑运算符
运算符说明:
- & 和 &&:表示"且"关系,当符号左右两边布尔值都是 true 时,结果才能为 true。否则,为 false。
- | 和 || :表示"或"关系,当符号两边布尔值有一边为 true 时,结果为true。当两边都为 false 时,结果为 false
- ! :表示"非"关系,当变量布尔值为 true 时,结果为 false。当变量布尔值为 false 时,结果为 true。
- ^ :当符号左右两边布尔值不同时,结果为 true。当两边布尔值相同时,结果为 false。
区分“&”和“&&”:
- 相同点:如果符号左边是 true,则二者都执行符号右边的操作
- 不同点:
- & : 如果符号左边是 false,则继续执行符号右边的操作
- && :如果符号左边是 false,则不再继续执行符号右边的操作
建议:开发中,推荐使用 &&
区分“|”和“||”:
- 相同点:如果符号左边是 false,则二者都执行符号右边的操作
- 不同点:
- | : 如果符号左边是 true,则继续执行符号右边的操作
- || :如果符号左边是 true,则不再继续执行符号右边的操作
建议:开发中,推荐使用 ||
编码与解码:
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。
字符编码(Character Encoding):就是一套自然语言的字符与二进制数之间的对应规则。
字符集:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
五、流程控制语句
关于if else 和 switch
凡是使用 switch-case 的结构都可以转换为 if-else 结构。反之,不成立。
-
开发经验:如果既可以使用 switch-case,又可以使用 if-else,建议使用 switchcase。因为效率稍高。
- if-else 语句优势
- if 语句的条件是一个布尔类型值,if 条件表达式为 true 则进入分支,可以用于范围的判断,也可以用于等值的判断,使用范围更广。
- switch 语句的条件是一个常量值(byte,short,int,char,枚举,String),只能判断某个变量或表达式的结果是否等于某个常量值,使用场景较狭窄。
- switch 语句优势
- 当条件是判断某个变量或表达式是否等于某个固定的常量值时,使用 if 和 switch 都可以,习惯上使用 switch 更多。因为效率稍高。当条件是区间范围的判断时,只能使用 if 语句。
- 使用 switch 可以利用穿透性,同时执行多个分支,而 if…else 没有穿透性。
- if-else 语句优势
在Java中,switch-case结构通常比等价的if-else链更高效,主要原因如下:
-
跳表实现机制
switch-case:现代JVM通常使用跳表(jump table)或哈希表实现,时间复杂度接近O(1)if-else:需要按顺序逐个检查条件,时间复杂度为O(n)
-
编译器优化
对于密集的case值,编译器会生成tableswitch指令,直接通过索引跳转对于稀疏的case值,使用lookupswitch指令,性能仍优于if-else
-
分支预测优势
switch-case的分支模式更规律,CPU的分支预测器能更有效地预测 -
字节码差异
if-else会生成一系列条件跳转指令switch-case生成专门的switch指令,处理更高效
注意事项
- 当case数量很少时(如少于5个),性能差异可能不明显
- Java 7+支持String的switch,但会先转换为hashcode比较
- 对于枚举类型,switch-case同样高效
for循环
语法格式:
for (①初始化部分; ②循环条件部分; ④迭代部分){③循环体部分;
}
执行过程:①-②-③-④-②-③-④-②-③-④-.....-②int num = 1;
for(System.out.println("a");num < 3; System.out.println("c"),num++){System.out.println("b");
}
输出结果:
a
b
c
b
c
for循环中,初始化部分只执行一次。
while循环
语法格式:
①初始化部分
while(②循环条件部分){③循环体部分;④迭代部分;
}
执行过程:①-②-③-④-②-③-④-②-③-④-...-②
while(循环条件)中循环条件必须是 boolean 类型。
• 注意不要忘记声明④迭代部分。否则,循环将不能结束,变成死循环。
• for 循环和 while 循环可以相互转换。二者没有性能上的差别。实际开发中,根据具体结构的情况,选择哪个格式更合适、美观。
• for 循环与 while 循环的区别:初始化条件部分的作用域不同。
do while循环
语法格式:
①初始化部分;
do{
③循环体部分
④迭代部分
}while(②循环条件部分);
执行过程:①-③-④-②-③-④-②-③-④-...-②
• 结尾 while(循环条件)中循环条件必须是 boolean 类型
• do{}while();最后有一个分号
• do-while 结构的循环体语句是至少会执行一次,这个和 for 和 while 是不一样的
• 循环的三个结构 for、while、do-while 三者是可以相互转换的。
三种循环结构都具有四个要素:
- 循环变量的初始化条件
- 循环条件
- 循环体语句块
- 循环变量的修改的迭代表达式
从循环次数角度分析
- do-while 循环至少执行一次循环体语句。
- for 和 while 循环先判断循环条件语句是否成立,然后决定是否执行循环体。
如何选择
- 遍历有明显的循环次数(范围)的需求,选择 for 循环
- 遍历没有明显的循环次数(范围)的需求,选择 while 循环
- 如果循环体语句块至少执行一次,可以考虑使用 do-while 循环
- 本质上:三种循环之间完全可以互相转换,都能实现循环的功能
六、Array-数组
数组(Array):是多个相同类型数据按一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行统一管理。
数组中的概念:
- 数组名
- 下标(或索引)
- 元素
- 数组的长度
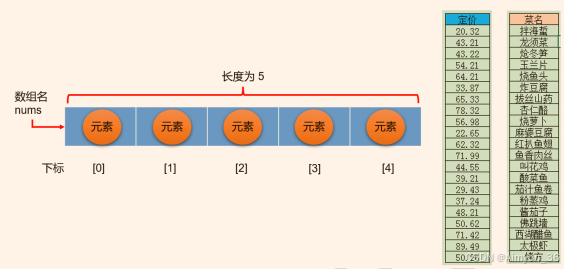
数组的特点:
- 数组本身是引用数据类型,而数组中的元素可以是任何数据类型,包括基本数据类型和引用数据类型。
- 创建数组对象会在内存中开辟一整块连续的空间。占据的空间的大小,取决于数组的长度和数组中元素的类型。
- 数组中的元素在内存中是依次紧密排列的,有序的。
- 数组,一旦初始化完成,其长度就是确定的。数组的长度一旦确定,就不能修改。
- 我们可以直接通过下标(或索引)的方式调用指定位置的元素,速度很快。
- 数组名中引用的是这块连续空间的首地址。
基本数据类型元素的数组:每个元素位置存储基本数据类型的值
引用数据类型元素的数组:每个元素位置存储对象(本质是存储对象的首地址)
一维数组:存储一组数据。
二维数组:存储多组数据,相当于二维表,一行代表一组数据,只是这里的二维表每一行长度不要求一样。
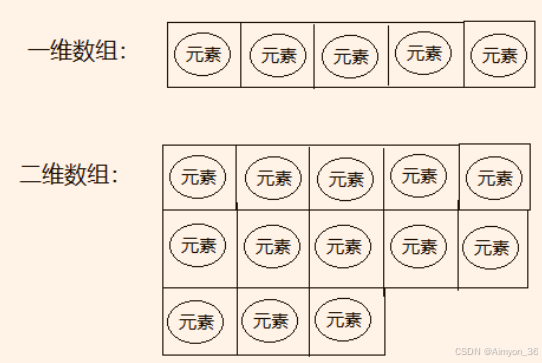
二维数组相当于一维数组中存储了多个一维数组的引用。
数组的声明和初始化
// TODO 一维数组的声明String[] stringArray;//int[] intArray;// TODO 数组的静态初始化int[] intArray = new int[]{1,2,3};stringArray = new String[]{"aimyon","zutomayo","milet"};// TODO 数组的动态初始化Double[] doubleArray = new Double[4];doubleArray[0] = 3.14;
推荐使用的数组声明方式: 数组类型[] 数组名;
静态初始化
如果数组变量的初始化和数组元素的赋值操作同时进行,那就称为静态初始化。
静态初始化,本质是用静态数据(编译时已知)为数组初始化。此时数组的长度由静态数据的个数决定。
数据类型[] 数组名 = new 数据类型[]{元素 1,元素 2,元素 3,...};
or
数据类型[] 数组名;
数组名 = new 数据类型[]{元素 1,元素 2,元素 3,...};
new:关键字,创建数组使用的关键字。因为数组本身是引用数据类型,所以要用 new 创建数组实体。
动态初始化
数组变量的初始化和数组元素的赋值操作分开进行,即为动态初始化。
动态初始化中,只确定了元素的个数(即数组的长度),而元素值此时只是默认值,还并未真正赋自己期望的值。真正期望的数据需要后续单独一个一个赋值。
数组存储的元素的数据类型[] 数组名字 = new 数组存储的元素的数据类型[长度];
or
数组存储的数据类型[] 数组名字;
数组名字 = new 数组存储的数据类型[长度];
[长度]:数组的长度,表示数组容器中可以最多存储多少个元素。 数组有定长特性,长度一旦指定,不可更改。
数组元素默认值:
数组是引用类型,当我们使用动态初始化方式创建数组时,元素值只是默认值。
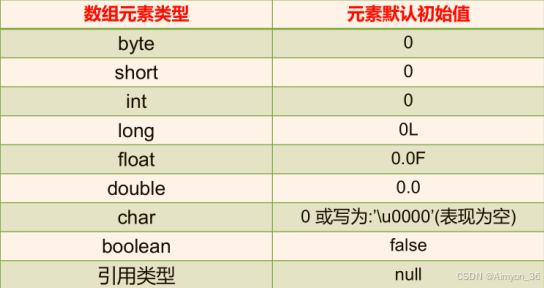
对于基本数据类型而言,默认初始化值各有不同。对于引用数据类型而言,默认初始化值为 null(注意与 0 不同!)
String是引用类型,为null
数组在JVM中内存划分:
为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
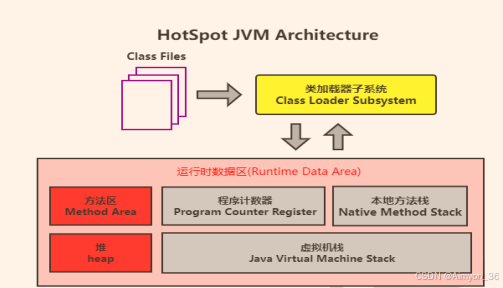
| 区域名称 | 作用 | 资源释放 |
|---|---|---|
| 虚拟机栈 | 线程私有(每个线程有自己的栈),用于存储正在执行的每个 Java 方法的局部变量表等。局部变量表存放了编译期可知长度的各种基本数据类型、对象引用,方法执行完,自动释放。 | 方法结束自动出栈 |
| 堆内存 | 所有线程共享,存储对象(包括数组对象),new 来创建的,都存储在堆内存。(引用对象) | 由 GC 回收 |
| 方法区(永久代/元空间) | 所有线程共享,存储已被虚拟机加载的类信息、常量、(静态变量)、即时编译器编译后的代码等数据。 | 类卸载时释放 |
| 本地方法栈 | 线程私有,当程序中调用了 native 的本地方法时,本地方法执行期间的内存区域 | 随方法结束释放 |
| 程序计数器 | 线程私有(类似JVM栈),程序计数器是 CPU 中的寄存器,它包含每一个线程下一条要执行的指令的地址 | 不回收,没有内存泄漏隐患 |
简单理解:
元空间:运行java程序时,JVM加载.class字节码文件到元空间中存储。(类的存储位置,随类的卸载释放资源)
堆内存:完全二叉树,存储代码中的引用对象。
本地方法栈:线程私有栈,存储非java编写的方法状态
虚拟机栈:线程私有栈,存储用java编写的方法状态。
为什么要用两个栈存储方法状态?
安全隔离:Java 字节码和本地代码的执行环境不同,分开栈可以避免互相干扰。
性能优化:本地方法可能直接操作硬件或系统资源,需要独立的调用约定(如寄存器使用)。
ps: 开发者广泛称虚拟机栈为方法栈。
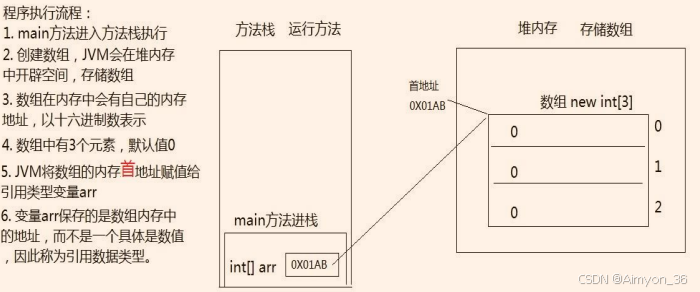
为什么数组的下标从0开始?
因为第一个元素距离数组首地址间隔 0 个单元格。
int[] x, y[];
//x 是一维数组,y 是二维数组
数组的排序算法
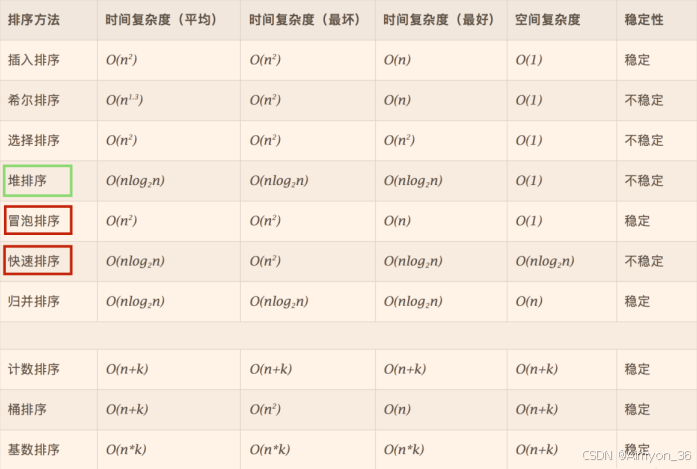
衡量排序算法的优劣:
时间复杂度:分析关键字的比较次数和记录的移动次数
- 常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!)<O(nn)
空间复杂度:分析排序算法中需要多少辅助内存
- 一个算法的空间复杂度 S(n)定义为该算法所耗费的存储空间,它也是问题规模 n 的函数。
稳定性:若两个记录 A 和 B 的关键字值相等,但排序后 A、B 的先后次序保持不变,则称这种排序算法是稳定的。
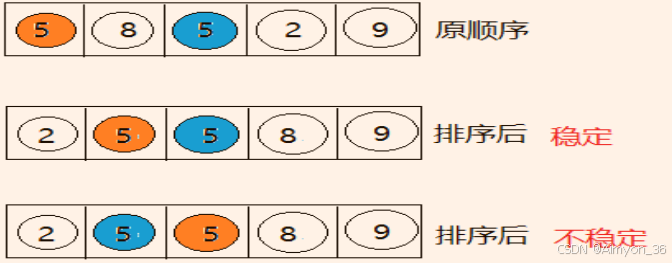
排序算法分类:内部排序和外部排序
- 内部排序:整个排序过程不需要借助于外部存储器(如磁盘等),所有排序操作都在内存中完成。
- 外部排序:参与排序的数据非常多,数据量非常大,计算机无法把整个排序过程放在内存中完成,必须借助于外部存储器(如磁盘)。外部排序最常见的是多路归并排序。可以认为外部排序是由多次内部排序组成。
十大内部排序算法:
冒泡排序
排序思想:
比较相邻的元素。如果第一个比第二个大(升序),就交换他们两个。对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较为止。

public static void main(String[] args) {int[] intArray = new int[]{1,11,10,22,5,6,7,8};for (int i = 0; i < intArray.length - 1; i++) {boolean flag = true;//假设数组已经是有序的for (int j = 0; j < intArray.length - 1 - i; j++) {//希望的是 intArray[j] < intArray[j+1]if (intArray[j] > intArray[j + 1]) {//交换 intArray[j]与 intArray[j+1]int temp = intArray[j];intArray[j] = intArray[j + 1];intArray[j + 1] = temp;flag = false;}}if (flag) {break;}}}
每轮结束后,数组末尾的 i 个元素已是最大值且有序,无需再比较,且每次内循环的便利都会对数组进行遍历,如果存在一次遍历没有发生交换,即证明已经有序。
相关文章:

Java复习笔记-基础
Java复习笔记 一、什么是JDK、JRE、JVM二、Keyword-关键字三、variable-变量浮点数类型-float和double字符类型-char基本数据类型变量间运算规则基本数据类型与 String 的运算和 四、逻辑运算符五、流程控制语句关于if else 和 switchfor循环while循环do while循环 六、Array-数…...

用递归实现各种排列
为了满足字典序的输出,我采用了逐位递归的方法(每一位的所能取到的最小值都大于前一位) 1,指数型排列 #include<bits/stdc.h> using ll long long int; using namespace std; int a[10];void printp(int m) {for (int h …...

基于Stable Diffusion XL模型进行文本生成图像的训练
基于Stable Diffusion XL模型进行文本生成图像的训练 flyfish export MODEL_NAME"stabilityai/stable-diffusion-xl-base-1.0" export VAE_NAME"madebyollin/sdxl-vae-fp16-fix" export DATASET_NAME"lambdalabs/naruto-blip-captions"acceler…...

SHA系列算法
SHA1系列算法 SHA(Secure Hash Algorithm,安全散列算法)是一组加密哈希算法,用于确保数据完整性和提供消息摘要功能。SHA算法由美国国家安全局(NSA)设计,并由国家标准与技术研究院(…...

985高校查重率“隐性阈值”:低于5%可能被重点审查!
你是不是也以为: “查重率越低越好,最好压到1%、0%,导师看了都感动哭🥹” 但是你不知道的是——在985/211等重点高校,查重率太低反而可能引起导师和学术办公室的“特别关注”! 今天就来扒一扒这个查重圈“…...

基于vue3+QuillEditor的深度定制
需求: 项目需求一个深度定制的富文本编辑器,要求能够定制表格,能够从素材库插入图片,以及其他个性化操作。我这里就基于vue3+ QuillEditor深度定制的角度,解析一下QuillEditor富文本编辑器的功能扩展功能的需求。 一、扩展工具栏 根据需求,我们需要扩展工具栏,实现自…...

Redis 8.0正式发布,再次开源为哪般?
Redis 8.0 已经于 2025 年 5 月 1 日正式发布,除了一些新功能和性能改进之外,一个非常重要的改变就是新增了开源的 AGPLv3 协议支持,再次回归开源社区。 为什么说再次呢?这个需要从 2024 年 3 月份 Redis 7.4 说起,因为…...

静态BFD配置
AR2配置 int g0/0/0 ip add 10.10.10.2 quit bfd quit bfd 1 bind peer-ip 10.10.10.1 source-ip 10.10.10.2 auto commit AR1配置 int g0/0/0 ip add 10.10.10.1 int g0/0/1 ip add 10.10.11.1 quit bfd quit bfd 1 bind peer-ip 10.0.12.2 source-ip 10.0.12.1 auto co…...

[python] 函数1-函数基础
一 函数使用 1.1 基本用法 def 函数名() 函数体 函数返回值: 返回调用的结果 def myPyFirstFunc():print("hello python") myPyFirstFunc()1.2 函数参数 def 函数名(形参a,形参b) 函数体 def add(a,b):return a b print(add(1,2)) print(add(1,4)) 二 函…...

【并发编程】MySQL锁及单机锁实现
目录 一、MySQL锁机制 1.1 按锁粒度划分 1.2 按锁功能划分 1.3 InnoDB锁实现机制 (1)记录锁(Record Lock) (2) 间隙锁(Gap Lock) (3) 临键锁(Next-Key Lock) (4) 插入意向锁(Insert Intention Lock) 二、基于 JVM 本地锁实现,保证线程安全 2.1 线程不安全的分析 2.1…...

C++ | 常用语法笔记
判断数字还是字母 1.笨办法,使用直接判断办法 if(c > 0 && c < 9) cout << "c是数字" << endl; if(c > a && c < z) cout << "c是小写字母" << endl; if(c > A && c< Z) …...

浅谈 Shell 脚本编程中引号的妙用
在 Shell 脚本编程中,引号的使用是一项基础却至关重要的技能。无论是单引号、双引号还是不加引号,它们都会显著影响 Shell 对字符串、变量、特殊字符以及命令的解析方式。理解这些差异不仅能帮助开发者编写更健壮的脚本,还能避免因误解引发的…...

DeFi开发系统软件开发:技术架构与生态重构
DeFi开发系统软件开发:技术架构与生态重构 ——2025年去中心化金融开发的范式革新与实践指南 一、技术架构演进:从单一链到多链混合引擎 现代DeFi系统开发已从单一公链架构转向“跨链互操作混合模式”,结合中心化效率与去中心化安全双重优势…...

Spring AI 集成 DeepSeek V3 模型开发指南
Spring AI 集成 DeepSeek V3 模型开发指南 前言 在人工智能飞速发展的当下,大语言模型不断推陈出新,DeepSeek AI 推出的开源 DeepSeek V3 模型凭借其卓越的推理和问题解决能力备受瞩目。与此同时,Spring AI 作为一个强大的框架,…...

C++:扫雷游戏
一.扫雷游戏项目设计 1.文件结构设计 首先我们要先定义三个文件 ①test.c //文件中写游戏的测试逻辑 ②game.c //文件中写游戏中函数的实现等 ③game.h //文件中写游戏需要的数据类型和函数声明等 2.扫雷游戏的主体结构 使⽤控制台实现经典的扫雷游戏 •游戏可以通过菜单…...

【写作格式】写论文时常见格式问题
写作格式 1.图片总是乱跑,怎么固定图片2.一键更新引用3.交叉引用[1][2][3]怎么变为[1,2,3]4.目录灰色底纹怎么消除5.word保存为pdf提取标题为书签 1.图片总是乱跑,怎么固定图片 遇到的问题 解决方法 第一步:图片格式——>环绕文字——&g…...

Android平台FFmpeg视频解码全流程指南
本文将详细介绍在Android平台上使用FFmpeg进行高效视频解码的实现方案,采用面向对象的设计思想。 一、架构设计 1.1 整体架构 采用三层架构设计: • 应用层:提供用户接口和UI展示 • 业务逻辑层:管理解码流程和状态 • Native…...

C31-形参与实参的区别
一 形参与实参 实参:调用函数时传递的实际值,可以是变量、常量或表达式,如"add(3,a)"中的’3’与’a’形参:函数定义中声明的参数变量,用于接收实参的值,如"int add(intx,inty)"中的’x’与’y’ C语言默认通过值传递参数,形参与实参是独立的变量,仅数据…...

自学嵌入式 day 16-c语言-第10章 指针
14 指针函数 返回值是指针的函数。 (1)动态内存分配 ①使用方式: #include<stdlib.h> void *malloc(size_t size) ②返回连续的内存空间的首元素地址,内存空间未被初始化,申请的是堆区的空间。 ③内存空间申请…...

DataWorks快速入门
文章目录 一、DataWorks简介1、概念2、功能3、优势 二、DataWorks使用1、创建工作空间2、绑定计算资源3、数据开发 三、DataWorks节点类型1、MaxCompute SQL节点①创建非分区表并插入数据②创建分区表并插入数据③查询表数据 2、离线同步节点3、PYODPS 3节点①判断表是否存在②…...

AtCoder Beginner Contest 404 A-E 题解
还是ABC好打~比ARC好打多了( 题解部分 A - Not Found 给定你一个长度最大25的字符串,任意输出一个未出现过的小写字母 签到题,map或者数组下标查询一下就好 #include<bits/stdc.h>using namespace std;#define int long long #def…...

WiFi出现感叹号上不了网怎么办 轻松恢复网络
在日常生活中,WiFi已成为不可或缺的一部分。然而,有时我们会遇到WiFi图标上出现了感叹号,无法上网。无论是办公、学习还是娱乐,这种情况都会严重影响体验。这种情况该怎么解决呢?本期驱动哥就给各位介绍几种简单的解决…...

M0芯片的基础篇Timer
一、计数器的原理 加法计数器 减法计数器 触发中断 最短计时时间 时钟周期决定 16bit 65535 最长计时时间 时间周期和最大计数值决定 二、syscfg配置 timg:通用定时器 tima:高级定时器 timx:不论是高级定时器还是通用定时器都是一样…...
)
vue教程(vuepress版)
Vue 完全指南 项目介绍 这是一个系统化的 Vue.js 学习教程,采用循序渐进的方式,帮助开发者从零开始掌握 Vue 开发技能。 教程特点 循序渐进: 从 Vue 基础概念开始,逐步深入到高级特性,适合不同层次的开发者学习实战驱动: 结合…...

【嵌入式开发-USB】
嵌入式开发-USB ■ USB简介 ■ USB简介...

【前端】webstorm运行程序浏览器报network error
是浏览器阻止了链接,先把能正常访问的链接搜索,禁止访问的时候,高级,强制访问,再运行项目生成的网址就可以了。...

国内led显示屏厂家以及售后 消费对比与选择
国内led显示屏的厂家有很多,虽然让消费者在选择的时候有了多种的机会,可是在质量方面的鉴别上也是无从下手。对此为了方便消费者作出选择,下面为您推荐一些品牌厂家。 1、强力巨彩 是全球比较有名气的LED显示屏厂家的制造商,总厂房…...

【Go】优化文件下载处理:从多级复制到零拷贝流式处理
在开发音频处理服务过程中,我们面临一个常见需求:从网络下载音频文件并保存到本地。这个看似简单的操作,实际上有很多优化空间。本文将分享一个逐步优化的过程,展示如何从一个基础实现逐步改进到高效的流式下载方案。 初始实现&a…...
:深入理解 I2C 总线驱动模型(以 at24 EEPROM 为例))
驱动开发硬核特训 · Day 30(上篇):深入理解 I2C 总线驱动模型(以 at24 EEPROM 为例)
作者:嵌入式Jerry 视频教程请关注 B 站:“嵌入式Jerry” 一、写在前面 在上一阶段我们已经深入理解了字符设备驱动与设备模型之间的结合方式、sysfs 的创建方式以及平台驱动模型的实际运用。今天我们迈入总线驱动模型的世界,聚焦于 I2C 总线…...

LaTeX印刷体 字符与数学符号的总结
1. 希腊字母(Greek Letters) 名称小写 LaTeX大写 LaTeX显示效果Alpha\alphaAαα, AABeta\betaBββ, BBGamma\gamma\Gammaγγ, ΓΓDelta\delta\Deltaδδ, ΔΔTheta\theta\Thetaθθ, ΘΘPi\pi\Piππ, ΠΠSigma\sigma\Sigmaσσ, ΣΣOmega\omeg…...

关键字where
C# 中的 where 关键字主要用在泛型约束(Generic Constraints)中,目的是对泛型类型参数限制其必须满足的条件,从而保证类型参数具备特定的能力或特性,增强类型安全和代码可读性。 约束写法说明适用场景举例C#版本要求w…...

vite 代理 websocket
🛡️一、WebSocket 基本概念 名称全称含义使用场景ws://WebSocket非加密的 WebSocket 连接开发环境、内网通信wss://WebSocket Secure加密的 WebSocket 连接(基于 TLS/SSL)生产环境、公网通信 🛡️二、安全性对比 特性ws://wss…...

深入理解操作系统:从基础概念到核心管理
在计算机系统中,操作系统是至关重要的组成部分,它如同计算机的“大管家”,统筹协调着系统的各项资源与工作流程。接下来,就让我们深入了解操作系统的奥秘。 一、操作系统概述 操作系统能有效组织和管理系统中的软/硬件资源&…...
)
手撕基于AMQP协议的简易消息队列-1(项目介绍与开发环境的搭建)
项目绍 码云仓库:MessageQueues: 仿Rabbit实现消息队列 文章概要 本文将介绍从零搭建一个简易消息队列的方法,目的是了解并学习消息队列的底层原理与逻辑,编写一个独立的服务器程序。从搭建开发环境开始,到编写一些工作组件&am…...

C++ 模板方法模式详解与实例
模板方法模式概念 模板方法模式(Template Method Pattern)属于行为型设计模式,其核心思想是在一个抽象类中定义一个算法的骨架,而将一些步骤延迟到子类中实现。这样可以使得子类在不改变算法结构的情况下,重新定义算法中的某些步骤。它通过继承机制,实现代码复用和行为…...

北京丰台人和中医院,收费贵吗?
北京丰台人和中医院,收费贵吗? 北京丰台人和中医院属于平价医院,百姓医院,收费不贵,北京丰台人和中医院35年专业看肝病,之所以能够在肝病感染者中赢得广泛好评,离不开其严谨的医疗流程、专业的…...

21、魔法传送阵——React 19 文件上传优化
一、魔法传送阵的核心法则 1.量子切割术(分片上传) const sliceFile (file) > {const chunks [];let start 0;const CHUNK_SIZE 2 * 1024 * 1024; // 2MB分片while (start < file.size) {chunks.push({id: ${file.name}-${start},data: file.s…...

Windows命令行软件管理器:Chocolatey
文章目录 Windows命令行软件管理器:Chocolatey1.Chocolatey使用1.1 安装1.2 常用命令1.3 使用流程 2.常用shell命令汇总 Windows命令行软件管理器:Chocolatey Chocolatey 是一款强大的 Windows 命令行软件管理器,目前在 GitHub 上已斩获 10.…...
)
【MySQL】第二弹——MySQL表的增删改查(CRUD)
文章目录 🎓一. CRUD🎓二. 新增(Create)🎓三. 查询(Rertieve)📖1. 全列查询📖2. 指定列查询📖3. 查询带有表达式📖4. 起别名查询(as )📖 5. 去重查询(distinct)📖6. 排序…...

Windows环境,Python实现对本机处于监听状态的端口,打印出端口,进程ID,程序名称
1、pip install tabulate 2、代码实现 #!/usr/bin/env python # -*- coding: utf-8 -*-""" Windows端口监听程序 显示本机处于监听状态的端口,进程ID和程序名称 """import subprocess import re import os import sys from tabulat…...

什么是变量提升?
变量提升(Hoisting) 是 JavaScript 引擎在代码执行前的一个特殊行为,它会将变量声明和函数声明自动移动到当前作用域的顶部。但需要注意的是,只有声明会被提升,赋值操作不会提升。 核心概念 变量声明提升&…...

Java大师成长计划之第15天:Java线程基础
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在现代软件开发中,多线程…...

中小企业设备预测性维护:从技术原理到中讯烛龙实践落地指南
在工业 4.0 与智能制造浪潮的推动下,中小企业正面临设备管理模式的深刻变革。传统的事后维修与预防性维护策略,因缺乏数据驱动与智能决策能力,已难以满足企业降本增效的核心诉求。据 Gartner 统计,非计划停机导致的生产损失平均每…...

mysql 复习
mysql定义与架构 数据库是按照数据结构来组织、存储和管理数据的仓库,方便我们增删查改。MySQL有客户端和服务器端,基于网络服务的,3306端口处于监听状态。 数据库的存储介质有以下两种: 磁盘,比如MySQL就是一种磁盘…...

高低比率策略
本策略的核心在于运用技术指标结合基本规则进行交易决策,旨在通过高低比率策略捕捉市场的超买和超卖信号,以此指导交易行为。 一、交易逻辑思路 1. 指标计算: - 本策略首先通过EMA(指数移动平均)计算快线和慢线的值&am…...

python线上学习进度报告
一、mooc学习 二、python123学习...

深入剖析ThreadLocal:原理、应用与最佳实践
深入剖析ThreadLocal:原理、应用与最佳实践 一、ThreadLocal的本质与价值 1.1 什么是ThreadLocal? ThreadLocal是Java提供的线程本地变量机制,允许每个线程拥有独立的变量副本,实现线程间的数据隔离。它通过“空间换时间”的方式…...

nginx 配置后端健康检查模块
nginx自带的针对后端节点健康检查的功能比较简单,通过默认自带的ngx_http_proxy_module 模块和ngx_http_upstream_module模块中的参数来完成,当后端节点出现故障时,自动切换到健康节点来提供访问。但是nginx不能事先知道后端节点状态是否健康,后端即使有不健康节点,负载均…...

路由交换实验
案例一:实施和配置RIPV2 1.给AR1配置接口 查看R1接口配置情况 2.配置三台路由的RIP协议,版本为version2 ,关闭自动汇总,通告所有的直连接口 案例二:配置多区域的OSPF协议 1.配置R1的接口IP地址参数 2.配置r2,r3的接口参…...
是什么?简易理解版)
主成分分析(PCA)是什么?简易理解版
文章目录 一、PCA的本质与核心价值二、数据中的"重要方向":理解变异性三、主成分的数学基础四、荷载向量的深入理解五、PCA的计算过程详解5.1 数据预处理5.2 计算协方差矩阵5.3 特征分解5.4 主成分得分计算 六、PCA的实际应用解读七、PCA的工具与实现7.1 …...