深度学习Y7周:YOLOv8训练自己数据集
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、配置环境
1.官网下载源码
2.安装需要环境
二、准备好自己的数据
目录结构:
·主目录
·data
·images(存放图片)
·annotations(放置.xml文件)
·imagesets
·main(会在该文件夹内自动生成train.txt、val.txt、test.txt、trainval.txt文件, 存放训练集、验证集、测试集图片的名字)
·split_train_val.py(划分训练集、验证集与测试集)
·voc_label.py(获取划分训练集、验证集与测试集路径)
·ab.yaml(数据集及数据类别声明文件)
·trainByK.py(代码运行文件)
1.运行split_train_val.py文件
文件代码:
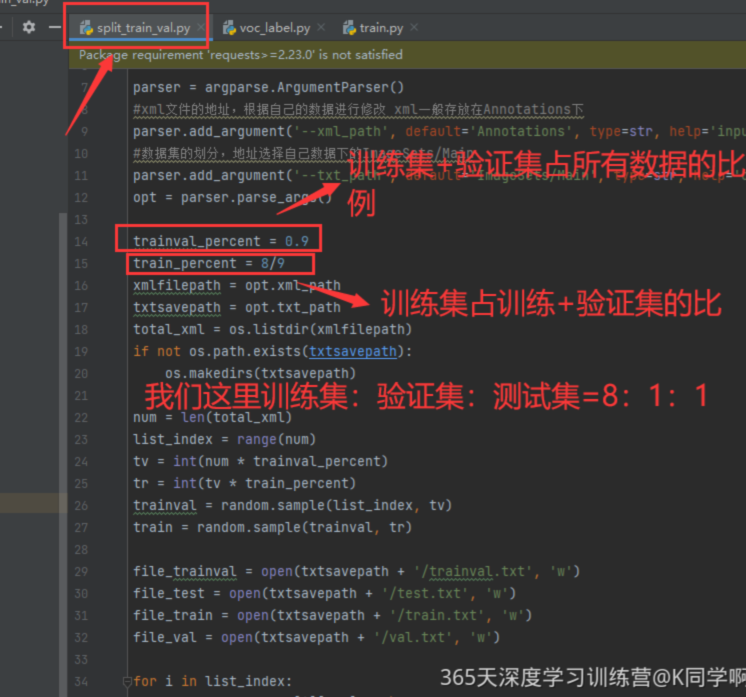
import os,random,argparseparser=argparse.ArgumentParser()# 添加命令行参数,用于指定XML文件的路径,默认为‘Annotation'文件夹
parser.add_argument('--xml_path',default='Annotations',type=str,help='input xml label path')#添加命令行参数,用于指定输出txt标签文件的路径,默认为'ImageSets/Main'文件
parser.add_argument('--txt_path',default='ImageSets/Main',type=str,help='output txt label path')#解析命令行参数
opt=parser.parse_args()#定义训练验证集和测试集的划分比例
trainval_percent=1.0 # 使用全部数据
train_percent=0.9 # 训练集占训练验证集的90%# 设置XML文件夹的路径,根据命令行参数指定
xmlfilepath=opt.xml_path# 设置输出txt标签文件的路径,根据命令行参数指定
txtsavepath=opt.txt_path# 获取XML文件夹中的所有XML文件列表
total_xml=os.listdir(xmlfilepath)# 如果输出txt标签文件的文件夹不存在,创建它
if not os.path.exists(txtsavepath):os.makedirs(txtsavepath)# 获取XML文件的总数
num=len(total_xml)# 创建一个包含所有XML文件索引的列表
list_index=range(num)# 计算训练验证集的数量
tv=int(num*trainval_percent)# 计算训练集的数量
tr=int(tv*train_percent)# 从所有XML文件索引中随机选择出训练验证集的索引
trainval=random.sample(list_index,tv)# 从训练验证集的索引中随机选择出训练集的索引
train=random.sample(trainval,tr)# 打开要写入的训练验证集、测试集、训练集、验证集的txt文件
file_trainval=open(txtsavepath+'/trainval.txt','w')
file_test=open(txtsavepath+'/test.txt','w')
file_train=open(txtsavepath+'/train.txt','w')
file_val=open(txtsavepath+'/val.txt','w')#遍历所有XML文件的索引
for i in list_index:name = total_xml[i][:-4] + '\n' #获取XML文件的名称(去掉后缀.xml),并添加换行符#如果该索引在训练验证集中if i in trainval:file_trainval.write(name) #写入训练验证集txt文件if i in train:file_train.write(name)else:file_val.write(name)else:file_test.write(name)file_trainval.close()
file_train.close()
file_val.close()
file_test.close()运行后得到四个文件:
注:如何修改数据集中训练集、验证集、测试集的比例?
2.运行voc_label.py文件(将label格式转换为VOC格式)
文件代码:
#-*- coding:utf-8 -*-import xml.etree.ElementTree as ET
import os
from os import getcwd#定义数据集的名称
sets =['train','val','test']#请根据您的数据集修改这些类别名称
# classes =['Banana','Snake fruit','Dragon fruit','Pineapple']
classes = ["banana","snake fruit","dragon fruit","pineapple"]#获取当前工作目录的绝对路径
abs_path = os.getcwd()
print(abs_path)#定义一个函数,将边界框的坐标从绝对值转换为相对于图像大小的比例
def convert(size,box):dw = 1./(size[0]) #计算图像宽度的倒数dh = 1./(size[1]) #计算图像高度的倒数x = (box[0]+box[1])/2.0-1 #计算中心点的x坐标y = (box[2]+box[3])/2.0-1 # 计算中心点的y坐标w= box[1]- box[0] # 计算边界框的宽度h = box[3] - box[2] # 计算边界框的高度x = x * dw # 缩放x坐标w = w * dw # 缩放宽度y = y * dh # 缩放y坐标h=h*dh #缩放高度return x, y, w, h# 定义一个函数,将标注文件从XML格式转换为YOLO格式
def convert_annotation(image_id):in_file = open('./Annotations/%s.xml' % (image_id),encoding='UTF-8') # 打开XML标注文件out_file = open('./labels/%s.txt'%(image_id),'w') # 打开要写入的YOL0格式标签文件tree =ET.parse(in_file) #解析XML文件root = tree.getroot()filename = root.find('filename').text # 获取图像文件名filenameFormat=filename.split(".")[1] # 获取文件格式size = root.find('size') # 获取图像尺寸信息w= int(size.find('width').text) # 获取图像宽度h=int(size.find('height').text) #获取图像高度for obj in root.iter('object'):difficult = obj.find('difficult').text # 获取对象的难度标志cls= obj.find('name').text #获取对象的类别名称if cls not in classes or int(difficult)== 1:continuecls_id = classes.index(cls) # 获取类别的索引xmlbox = obj.find('bndbox') # 获取边界框坐标信息b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1,b2,b3,b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb=(b1,b2,b3,b4)bb=convert((w,h),b) #调用convert函数,将边界框坐标转换为Y0OLO格式out_file.write(str(cls_id)+" "+" ".join([str(a) for a in bb])+'\n') #写入YOLO格式标签文件return filenameFormat#获取当前工作目录
wd = getcwd()#遍历每个数据集(train、val、test)
for image_set in sets:#如果labels目录不存在,创建它if not os.path.exists('./labels/'):os.makedirs('./labels/')#从数据集文件中获取图像ID列表image_ids = open('./ImageSets/Main/%s.txt'%(image_set)).read().strip().split()#打开要写入的文件,写入图像的文件路径和格式list_file =open('./%s.txt'%(image_set),'w')for image_id in image_ids:filenameFormat=convert_annotation(image_id)list_file.write(abs_path +'/images/%s.%s\n'%(image_id,filenameFormat)) #注意你的图片格式,如果是.jpg记得修改list_file.close()
运行voc_label.py,获得三个文件
3.创建ab.yaml文件
train:D:\learn\data\train.txt #绝对路径
val:D:\learn\data\val.txt #绝对路径nc: 4 # number of classesnames: ["banana", "snake fruit", "dragon fruit", "pineapple"]
三、开始用自己数据集训练模型
自建train.py文件运行
from ultralytics import YOLOif __name__ == '__main__':model = YOLO("yolov8s.pt")model.train(data=r"D:\learn\ultralytics-main\data\ab.yaml",seed=0,epoches=10,batch=4,workes=2)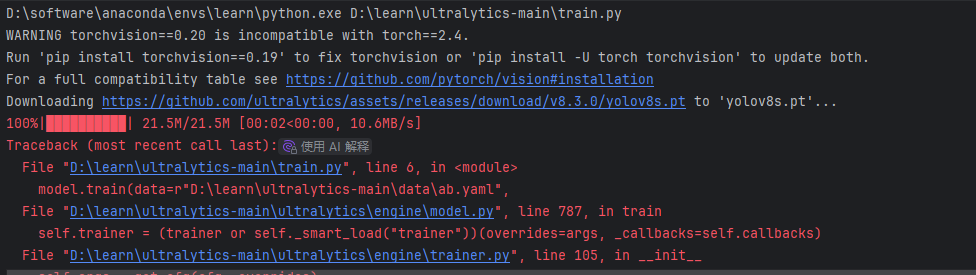
修改了很久,可能环境方面出了问题,依旧连接不到我的数据文件夹里。
四、训练参数设置(defalult.yaml)
# Ultralytics YOLO 🚀, AGPL-3.0 许可证,由K同学啊注解
# 默认的训练设置和超参数,用于中度增强 COCO 训练task: detect # (str) YOLO 任务,例如 detect、segment、classify、pose
mode: train # (str) YOLO 模式,例如 train、val、predict、export、track、benchmark# 训练设置 -------------------------------------------------------------------------------------------------------
model: # (str, 可选) 模型文件路径,例如 yolov8n.pt、yolov8n.yaml
data: #./paper_data/ab.yaml # (str, 可选) 数据文件路径,例如 coco128.yamlepochs: 100 # (int) 训练的轮次数
patience: 50 # (int) 提前停止训练的等待周期数,如果没有明显的改进
batch: 1 # (int) 每批处理的图像数量(-1 表示自动批处理)
imgsz: 640 # (int | list) 输入图像的大小,以像素为单位,用于训练和验证模式,或以列表[w,h]形式用于预测和导出模式
save: True # (bool) 保存训练检查点和预测结果
save_period: -1 # (int) 每隔 x 个周期保存一个检查点(如果 < 1 则禁用)
cache: False # (bool) 使用缓存加载数据(True/ram、disk 或 False)
device: 0 # (int | str | list, 可选) 运行模型的设备,例如 cuda device=0 或 device=0,1,2,3 或 device=cpu
workers: 4 # (int) 数据加载的工作线程数(每个 DDP 会有一个)
project: # (str, 可选) 项目名称
name: # (str, 可选) 实验名称,结果保存在 'project/name' 目录下
exist_ok: False # (bool) 是否覆盖现有的实验
pretrained: True # (bool | str) 是否使用预训练模型(True 或加载权重的模型路径字符串)
optimizer: auto # (str) 优化器选择,选项=[SGD、Adam、Adamax、AdamW、NAdam、RAdam、RMSProp、auto]
verbose: True # (bool) 是否打印详细输出
seed: 0 # (int) 随机种子,用于可重复性
deterministic: True # (bool) 是否启用确定性模式
single_cls: False # (bool) 是否将多类数据训练为单一类别
rect: False # (bool) 如果模式='train',则进行矩形训练;如果模式='val',则进行矩形验证
cos_lr: False # (bool) 是否使用余弦学习率调度器
close_mosaic: 10 # (int) 在最后几个周期内禁用马赛克增强(0 表示禁用)
resume: False # (bool) 是否从上次检查点恢复训练
amp: True # (bool) 是否启用自动混合精度(AMP)训练,选项=[True, False],True 表示运行 AMP 检查
fraction: 1.0 # (float) 训练集数据分数(默认为 1.0,使用训练集中的所有图像)
profile: False # (bool) 在训练期间记录 ONNX 和 TensorRT 速度以供记录器使用
freeze: None # (int | list, 可选) 冻结前 n 层,或在训练期间冻结的层索引列表
# 分割
overlap_mask: True # (bool) 训练期间是否允许蒙版重叠(仅适用于分割训练)
mask_ratio: 4 # (int) 蒙版下采样比率(仅适用于分割训练)
# 分类
dropout: 0.0 # (float) 是否使用 dropout 正则化(仅适用于分类训练)# 验证/测试设置 ----------------------------------------------------------------------------------------------------
val: True # (bool) 训练期间是否进行验证/测试
split: val # (str) 用于验证的数据集分割,例如 'val'、'test' 或 'train'
save_json: False # (bool) 是否将结果保存为 JSON 文件
save_hybrid: False # (bool) 是否保存标签的混合版本(标签 + 额外的预测)
conf: # (float, 可选) 用于检测的对象置信度阈值(默认 0.25 用于预测,0.001 用于验证)
iou: 0.7 # (float) NMS 的交并比(IoU)阈值
max_det: 300 # (int) 每张图像的最大检测数
half: False # (bool) 是否使用半精度(FP16)
dnn: False # (bool) 是否使用 OpenCV DNN 进行 ONNX 推理
plots: True # (bool) 在训练/验证期间保存图形# 预测设置 --------------------------------------------------------------------------------------------------
source: # (str, 可选) 图像或视频的源目录
show: False # (bool) 如果可能的话是否显示结果
save_txt: False # (bool) 是否将结果保存为 .txt 文件
save_conf: False # (bool) 是否保存带有置信度分数的结果
save_crop: False # (bool) 是否保存裁剪后的带有结果的图像
show_labels: True # (bool) 是否在图形中显示对象标签
show_conf: True # (bool) 是否在图形中显示对象置信度分数
vid_stride: 1 # (int) 视频帧率跨度
stream_buffer: False # (bool) 是否缓存所有流式帧(True)或返回最新的帧(False)
line_width: # (int, 可选) 边界框的线宽,如果缺失则自动设置
visualize: False # (bool) 是否可视化模型特征
augment: False # (bool) 是否对预测源应用图像增强
agnostic_nms: False # (bool) 是否进行类别无关的 NMS
classes: # (int | list[int], 可选) 按类别筛选结果,例如 classes=0,或 classes=[0,2,3]
retina_masks: False # (bool) 是否使用高分辨率分割蒙版
boxes: True # (bool) 在分割预测中显示边界框# 导出设置 ------------------------------------------------------------------------------------------------------
format: torchscript # (str) 导出格式,可选项请查看 https://docs.ultralytics.com/modes/export/#export-formats
keras: False # (bool) 是否使用 Kera=s
optimize: False # (bool) TorchScript:优化为移动设备
int8: False # (bool) CoreML/TF INT8 量化
dynamic: False # (bool) ONNX/TF/TensorRT:动态轴
simplify: False # (bool) ONNX:简化模型
opset: # (int, 可选) ONNX:opset 版本
workspace: 4 # (int) TensorRT:工作空间大小(GB)
nms: False # (bool) CoreML:添加 NMS# 超参数 ------------------------------------------------------------------------------------------------------
lr0: 0.01 # (float) 初始学习率(例如,SGD=1E-2,Adam=1E-3)
lrf: 0.01 # (float) 最终学习率(lr0 * lrf)
momentum: 0.937 # (float) SGD 动量/Adam beta1
weight_decay: 0.0005 # (float) 优化器权重衰减 5e-4
warmup_epochs: 3.0 # (float) 预热周期数(分数也可以)
warmup_momentum: 0.8 # (float) 预热初始动量
warmup_bias_lr: 0.1 # (float) 预热初始偏置 lr
box: 7.5 # (float) 目标框损失增益
cls: 0.5 # (float) 类别损失增益(与像素一起缩放)
dfl: 1.5 # (float) DFL 损失增益
pose: 12.0 # (float) 姿势损失增益
kobj: 1.0 # (float) 关键点 obj 损失增益
label_smoothing: 0.0 # (float) 标签平滑化(分数)
nbs: 64 # (int) 名义批次大小
hsv_h: 0.015 # (float) 图像 HSV-Hue 增强(分数)
hsv_s: 0.7 # (float) 图像 HSV-Saturation 增强(分数)
hsv_v: 0.4 # (float) 图像 HSV-Value 增强(分数)
degrees: 0.0 # (float) 图像旋转(+/- 度)
translate: 0.1 # (float) 图像平移(+/- 分数)
scale: 0.5 # (float) 图像缩放(+/- 增益)
shear: 0.0 # (float) 图像剪切(+/- 度)
perspective: 0.0 # (float) 图像透视变换(+/- 分数),范围 0-0.001
flipud: 0.0 # (float) 图像上下翻转(概率)
fliplr: 0.5 # (float) 图像左右翻转(概率)
mosaic: 1.0 # (float) 图像马赛克增强(概率)
mixup: 0.0 # (float) 图像混合增强(概率)
copy_paste: 0.0 # (float) 段复制粘贴(概率)# 自定义 config.yaml ---------------------------------------------------------------------------------------------------
cfg: # (str, 可选) 用于覆盖默认.yaml 的自定义配置# 跟踪器设置 ------------------------------------------------------------------------------------------------------
tracker: botsort.yaml # (str) 跟踪器类型,选项=[botsort.yaml, bytetrack.yaml]五、总结
阅读代码能力比之前强了,但是还是缺少连接所有知识的能力。有的时候总会忘记之前出现问题的解决办法,导致实验无法进行。
相关文章:

深度学习Y7周:YOLOv8训练自己数据集
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 一、配置环境 1.官网下载源码 2.安装需要环境 二、准备好自己的数据 目录结构: 主目录 data images(存放图片) annotati…...
(题目+回答))
2025年渗透测试面试题总结-某服面试经验分享(附回答)(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 1. 协议类型 2. OSI七层模型 3. 网络层协议 4. HTTP请求头 5. 常见端口 6. 中间件解析漏洞 7. CS…...

手写Promise的静态方法
最近对promise原理的理解,手写下其中的静态方法。 手写Promise的静态方法 1. Promise.resolve2. Promise.reject3. Promise.all4. Promise.any5. Promise.race6. Promise.allSettled 1. Promise.resolve 首先就是resolve方法,它会接收一个值࿰…...

Python Cookbook-7.8 使用 Berkeley DB 数据库
任务 你想将一些数据做持久化处理,而且也想体验一下BerkeleyDB数据库的简洁和高效。 解决方案 如果以前在你的计算机中安装过 BerkeleyDB,Python标准库附带的bsddb包(以及可选的 bsddb3,用于访间Berkeley DBrelease 3.2数据库)可以被用来作…...

云手机虚拟地址技术的运营场景
云手机虚拟地址技术通过模拟地理位置(GPS/IP地址)与设备指纹,结合云端虚拟化能力,在多个商业场景中实现突破性应用。以下是其核心运营场景及技术实现路径的深度解析: 一、跨境电商与区域化运营 本地化合规与流量突破 目…...
)
操作符详解(2)
目录 9 结构成员访问操作符 9.1.2 结构体变量的定义和初始化 9.2 结构体成员的直接访问 10 操作符的属性:优先级、结合性 10.1 优先级 11 表达式求值 11.1 整型提升 11.2 算术转换 11.3 问题表达式解析 11.3.1 表达式1 11.3.2 表达式2 11.3.3 表达式3 1…...

责任链设计模式
一、核心接口定义 MyAbstractChainHandler<T> 接口继承自 Ordered 接口,用于实现链式处理逻辑。 import org.springframework.core.Ordered;public interface MyAbstractChainHandler<T> extends Ordered {void handle(T requestParam);String getCha…...

【银河麒麟高级服务器操作系统】服务器外挂存储ioerror分析及处理分享
更多银河麒麟操作系统产品及技术讨论,欢迎加入银河麒麟操作系统官方论坛 forum.kylinos.cn 了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:product.kylinos.cn 开发者专区:developer.kylinos.cn 文档中心&a…...

麒麟信安举办特种行业核心代理商中级技术认证培训班
近日,麒麟信安举办为期一周的特种行业核心代理商中级技术认证培训班,吸引了众多来自各地代理商公司的技术骨干踊跃参与。 此次培训班旨在赋能合作伙伴,助力其深入理解并熟练运用麒麟信安产品的核心优势,进一步提升在特种行业中的业…...

非对称加密:为什么RSA让“公开传密”成为可能
在1977年之前,加密世界遵循一个铁律:想要安全通信,必须先秘密交换密钥。无论是凯撒密码还是二战时的恩尼格玛机,都依赖发送方和接收方预先共享同一把“钥匙”。但RSA算法的出现颠覆了这一规则——它让陌生人可以在完全公开的环境下…...

阿里云ddos云防护服务器有哪些功能?ddos防御手段有哪些??
阿里云ddos云防护服务器有哪些功能?ddos防御手段有哪些?? DDoS(分布式拒绝服务)云防护服务器通过多种技术和策略来抵御大规模网络攻击,确保服务的高可用性。以下是其主要功能和防御手段的详细说明: 一、D…...

如何防止域名DNS被劫持?
防止域名DNS被劫持需要综合技术手段和管理措施,以下是一份详细的防护方案: --- ### **一、基础防护措施** 1. **选择可靠的域名注册商和DNS服务商** - 优先选择支持DNSSEC、提供多因素认证(MFA)的知名服务商(如Cl…...

桥隧坡灾害监测报警:用科技筑起生命安全的“智能防线”
.2024年,梅大高速茶阳路段高边坡塌方事件造成重大伤亡,举国痛心。这场悲剧再次敲响警钟:桥梁、隧道、边坡等高风险区域的实时监测与精准报警,已成为交通安全的生命线。如何用技术手段在灾害发生前“抢跑”,第一时间阻断…...

K8S常见问题汇总
一、 驱逐 master 节点上的所有 Pod 这会“清空”一个节点(包括 master)上的所有可驱逐的 Pod: kubectl drain <master-node-name> --ignore-daemonsets --delete-emptydir-data--ignore-daemonsets:保留 DaemonSet 类型的…...
)
ideal创建Springboot项目(Maven,yml)
以下是使用 IntelliJ IDEA 创建基于 Maven 的 Spring Boot 项目并使用 YAML 配置文件的详细步骤: 一、创建 Spring Boot 项目 启动项目创建向导 打开 IntelliJ IDEA,点击“File”->“New”->“Project”。 在弹出的“New Project”窗口中&#…...
)
解决:‘java‘ 不是内部或外部命令,也不是可运行的程序-Java环境变量配置(含JDK8、JDK21安装包一站式配置)
在使用命令行运行 .jar 文件时,很多用户会遇到如下错误提示: java 不是内部或外部命令,也不是可运行的程序或批处理文件。 这个报错表明系统无法识别 java 命令,通常是由于 Java 没有正确安装,或是系统环境变量没有配…...

android.app.Fragment和androidx.fragment:fragment的区别
android.app.Fragment 与 androidx.fragment.app.Fragment 的区别 这两个 Fragment 实现代表了 Android 碎片化开发的两个时代,以下是它们的核心区别: 一、起源与演变 android.app.Fragmentandroidx.fragment.app.Fragment引入时间Android 3.0 (API 1…...
3 - 串口)
OrangePi Zero 3学习笔记(Android篇)3 - 串口
目录 1. 找到串口号 2. 修改串口权限 3. 串口类 3.1 serialport.hpp 3.2 serialport.cpp 3.2.1 构造函数 3.2.2 Open函数 3.2.3 Close函数 3.2.4 Write函数 3.2.5 Read函数 3.2.6 SetFlowCtrl函数 4. 测试程序 5. 编译 6. 运行验证 除了默认的UART用于shell&…...

Node.js 技术原理分析系列9——Node.js addon一文通
Node.js 是一个开源的、跨平台的JavaScript运行时环境,它允许开发者在服务器端运行JavaScript代码。Node.js 是基于Chrome V8引擎构建的,专为高性能、高并发的网络应用而设计,广泛应用于构建服务器端应用程序、网络应用、命令行工具等。 本系…...

HBuilderX安卓真机运行安装失败解决汇总
前置方案 1. 确认USB调试和连接模式 (1)开启USB调试:进入手机设置 > 开发者选项 > 确保USB调试已开启(如无开发者选项,连续点击“版本号”激活)。 (2)连接模式:将…...

TensorFlow 2.x入门实战:从零基础到图像分类项目
TensorFlow 2.x入门实战:从零基础到图像分类项目 前言 TensorFlow是Google开发的开源机器学习框架,已成为深度学习领域的重要工具。TensorFlow 2.x版本相比1.x有了重大改进,更加易用且功能强大。本文将带你从零开始学习TensorFlow 2.x&…...

SpringBoot+Dubbo+Zookeeper实现分布式系统步骤
SpringBootDubboZookeeper实现分布式系统 一、分布式系统通俗解释二、环境准备(详细版)1. 软件版本2. 安装Zookeeper(单机模式) 三、完整项目结构(带详细注释)四、手把手代码实现步骤1:创建父工…...

数据中台-常用工具组件:DataX、Flink、Dolphin Scheduler、TensorFlow和PyTorch等
数据实施服务工具组件概览 数据中台的数据实施服务涵盖 数据采集、处理、调度、分析与应用 全流程,以下为关键工具组件及其作用: 工具类型核心功能典型应用场景DataX离线数据采集多源异构数据批量同步数据仓库ODS层数据导入Apache Flink实时计算引擎流…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】电商数据分析案例-9.2 流量转化漏斗分析
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 9.2 流量转化漏斗分析:从数据清洗到可视化全流程实战一、背景与目标二、数据准备与清洗2.1 数据来源与字段说明2.2 数据清洗步骤2.2.1 去除无效数据2.2.2 处理时…...

结合Splash与Scrapy:高效爬取动态JavaScript网站
在当今的Web开发中,JavaScript的广泛应用使得许多网站的内容无法通过传统的请求-响应模式直接获取。为了解决这个问题,Scrapy开发者经常需要集成像Splash这样的JavaScript渲染引擎。本文将详细介绍Splash JS引擎的工作原理,并探讨如何将其与S…...

[计算机科学#10]:早期的计算机编程方式
【核知坊】:释放青春想象,码动全新视野。 我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!! 内容摘要:1804年,为了在织布机上编织出丰富多彩的…...

JAVA:Spring Boot 集成 Lua 的技术博客
1、简述 在现代开发中,Lua 以其轻量级、高性能以及易嵌入的特点广泛用于脚本扩展、游戏开发以及配置处理场景。将 Lua 与 Spring Boot 集成,可以在 Java 项目中实现动态脚本功能,增强项目的灵活性和动态配置能力。 样例代码: https://gitee.com/lhdxhl/springboot-example…...

代码随想录算法训练营 Day40 动态规划Ⅷ 股票问题
动态规划 题目 121. 买卖股票的最佳时机 - 力扣(LeetCode) 使用二维 dp 数组表示 1. dp[i][0] 表示持有股票的最大金额,dp[i][1] 表示不持有股票的最大金额,表示盈利结果 2. 递推公式由前一天持有金额和是否买股票决定 决定是否…...

【已解决】WORD域相关问题;错误 未找到引用源;复制域出错;交叉引用域到底是个啥
(微软赶紧倒闭 所有交叉引用域,有两个状态:1.锁定。2.手动。可通过编辑->链接查看。 “锁定”状态域的能力: 1. 导出PDF格式稳定(【已解决】WORD导出PDF时,参考文献上标自动被取消/变为正常文本_word…...

小米 MiMo 开源:7B 参数凭什么 “叫板” AI行业巨头?
目录 一、技术革命的起点:小米AI战略的“破局者” 1.1 战略背景:从硬件厂商到AI基础设施提供商 1.2 团队揭秘:“天才少女”罗福莉与小米AI梦之队 二、技术架构解析:7B参数如何实现“推理跃迁” 2.1 核心技术原理 2.2 技术指…...

构建高可用性的LVS-DR群集:实现无缝的负载均衡与故障转移
目录 一、LVS-DR集群 1.LVS-DR工作原理 2.数据包流向分析 3.LVS-DR模式特点 二、直接路由模式(LVS-DR) 1.资源清单 2.配置负载调度器(lvs) 3.配置节点服务器(web1、web2) 4.测试LVS群集 5.使用NFS发布共享资源(nfs上) …...
)
低光图像增强新色彩空间HVI:技术突破与创新解析(HVI: ANewColor Space for Low-light Image Enhancement)
摘要 低光图像增强(LLIE)是计算机视觉领域的关键任务,旨在从受损的低光图像中恢复细节信息。针对现有方法在标准RGB(sRGB)空间易产生色偏与亮度伪影的问题,以及HSV色彩空间转换引发的红/黑噪声问题…...

Abaqus学习笔记
目录 Abaqus介绍 学习资源 编辑Abaqus/CAE abaqus下载安装 abaqus基本操作 Abaqus启动 新建模型 编辑 编辑修改界面背景 编辑编辑结果信息的显示与否 编辑计算结果信息字体设置 编辑允许多绘图状态 单位量纲 视图操作 事前说明 ODB文件 本构关系…...

AquaCrop 模型新视角:多技术助力农业精准水管理
技术点目录 模型原理介绍与数据要求及模型分析数据制备、模型运行与案例实践(界面GUI版本)模型优化与敏感性分析(基于R语言实践)源代码分析(基于FORTRAN)未来气候变化影响分析与案例实践(基于Py…...

从知识图谱到精准决策:基于MCP的招投标货物比对溯源系统实践
前言 从最初对人工智能的懵懂认知,到逐渐踏入Prompt工程的世界,我们一路探索,从私有化部署的实际场景,到对DeepSeek技术的全面解读,再逐步深入到NL2SQL、知识图谱构建、RAG知识库设计,以及ChatBI这些高阶应用。一路走来,我们在AI的领域里一步一个脚印,不断拓展视野和能…...

【平面波导外腔激光器专题系列】1064nm单纵模平面波导外腔激光器
摘要:我们介绍了平面波导外腔二极管激光器 (PW-ECL) 的特性。据我们所知,这是第一款蝶形封装的 1064nm半导体激光器,其可以稳定锁定到外部参考频率。我们从精密实验的角度评估了它的性能,特别是使用碘的超精细吸收线,在…...

C++ 算法学习之旅:从入门到精通的秘籍
在编程的浩瀚宇宙中,C 算法宛如璀璨的星辰,照亮我们前行的道路。作为一名 C 算法小白,或许你和我一样,怀揣着对算法的好奇与憧憬,却又在学习的道路上感到迷茫。别担心,今天我就和大家分享一下如何学习各种基…...

按摩椅上的气囊系统 是现代按摩椅中非常关键的组成部分,它与机芯系统相辅相成,为用户提供全方位、更接近真人按摩的体验
按摩椅上的气囊系统是现代按摩椅中非常关键的组成部分,它与机芯系统相辅相成,为用户提供全方位、更接近真人按摩的体验。 一、按摩椅气囊的产生背景 1. 传统按摩方式的局限 早期的按摩椅主要依赖机械式的“凸轮电机”或简单的机芯滚轮结构,…...

配置Hadoop集群环境-使用脚本命令实现集群文件同步
(一)Hadoop的运行模式 hadoop一共有如下三种运行方式: 1. 本地运行。数据存储在linux本地,测试偶尔用一下。我们上一节课使用的就是本地运行模式hadoop100。 2. 伪分布式。在一台机器上模拟出 Hadoop 分布式系统的各个组件&…...
部署FastGPT)
Linux系统(OpenEuler22.03-LTS)部署FastGPT
在 openEuler 22.03 LTS 系统上通过 Docker Compose 安装 FastGPT 的步骤如下: 官方参考文档:https://doc.fastgpt.cn/docs/development/docker/ 1. 安装 Docker 和 Docker Compose 可以参考我之前离线安装Docker的文章:openEuler 22.03 LT…...

FastExcel 本地开发和Linux上上传Resource文件的差异性
不能直接通过路径来获取 这个是一个下载导出文件的操作 GetMapping(value "/export/all") public void exportAll(HttpServletResponse response, LaylineListReq req) throws IOException {// 从类路径下获取 Excel 文件资源ClassPathResource classPathResource…...

Excel学习笔记
在excel表格中,某列的数据最大,则整行都红色底色标出,怎么实现? 更改x值,excel图表上动态显示 该值的Y值且动态显示十字交叉线 为了实现如下图所示的效果,需要做出几个辅助列就行。 step1:先写…...

数据中台-数仓分层结构【Doris】
数据仓库采用Doris进行搭建,并分为ODS/DWD/DWM/DWS/ADS等层级结构进行分层数据存储。Doris是百度开源的MPP数据库,可有效支撑大数据量的数据计算和分布式扩展存储。 数据仓库分层架构设计目标 解耦与复用性:通过分层隔离原始数据与业务逻辑&a…...

使用Jmeter对AI模型服务进行压力测试
一、JMeter介绍 Apache JMeter 是一款开源的性能测试工具,主要用于评估Web应用程序的负载和性能。它支持多种类型的测试,包括但不限于: 负载测试:模拟大量用户访问系统以检测其在高负载下的表现。性能测试:评估系统在…...

测试用例管理平台哪些好用?9款主流测试平台对比
在当今软件开发领域,测试用例管理平台已成为提升产品质量和团队协同效率的关键工具。本文将围绕“测试用例管理平台”这一核心关键词,全面解析市面上9款主流产品,帮助企业管理者和测试团队快速了解各平台的核心优势和适用场景,从而…...

C++函数传值与传引用对比分析
在C编程中,函数参数传递的方式直接影响程序的性能、内存管理以及代码逻辑的正确性。传值(Pass by Value)和传引用(Pass by Reference)是两种最常用的参数传递方式,它们各有优缺点,适用于不同的场…...

【se-res模块学习】结合CIFAR-10分类任务学习
继CIFAR-10图像分类:【Res残差连接学习】结合CIFAR-10任务学习-CSDN博客 再优化 本次训练结果在测试集上的准确率表现可达到90%以上 1.训练模型(MyModel.py) import torch import torch.nn as nnclass SENet(nn.Module): # SE-Net模块def…...
的翻转概率)
二元随机响应(Binary Randomized Response, RR)的翻转概率
随机响应(Randomized Response)机制 ✅ 回答核心: p 1 1 e ε 才是「翻转概率」 \boxed{p \frac{1}{1 e^{\varepsilon}}} \quad \text{才是「翻转概率」} p1eε1才是「翻转概率」 而: q e ε 1 e ε 是「保留真实值」…...

湖北理元理律师事务所:债务优化中的“生活保障”方法论
债务危机往往伴随生活质量骤降,如何在还款与生存间找到平衡点,成为债务优化的核心挑战。湖北理元理律师事务所基于多年实务经验,提出“双轨并行”策略:法律减负与生活保障同步推进。 债务优化的“温度法则” 1.生存资金预留机制…...

RFID智能书柜:精准定位,找书告别 “大海捞针”
在传统图书馆的浩瀚书海,找书无异于在错综复杂的迷宫里徘徊。读者在书架间来回奔波,耗费大量时间精力,还常一无所获。RFID智能书柜的出现,彻底改写了这一局面。它搭载的RFID读写器与天线协同工作,能实时精准定位贴有RF…...