Node.js 技术原理分析系列9——Node.js addon一文通
Node.js 是一个开源的、跨平台的JavaScript运行时环境,它允许开发者在服务器端运行JavaScript代码。Node.js 是基于Chrome V8引擎构建的,专为高性能、高并发的网络应用而设计,广泛应用于构建服务器端应用程序、网络应用、命令行工具等。
本系列将分为9篇文章为大家介绍 Node.js 技术原理:从调试能力分析到内置模块新增,从性能分析工具 perf_hooks 的用法到 Chrome DevTools 的性能问题剖析,再到 ABI 稳定的理解、基于 V8 封装 JavaScript 运行时、模块加载方式探究、内置模块外置以及 Node.js addon 的全面解读等主题,每一篇都干货满满。
在上一节中我们探讨了将Node.js内置模块外置的相关内容,在本节中则主要分享《Node.js addon一文通》相关内容,本文内容为本系列第9篇,以下为正文内容。
addon 是什么
addon 这个单词来源于英文的复合名词 add-on,add-on 来自短语 add on,意为附加物,可翻译为插件。
在 Node.js 领域,addon 是一种特殊模块,和普通的 JS 包的区别在于 addon 主要是用 C/C++ 写的,而普通模块是用 JS 写的。
例如我们使用的 npm 库 canvas、node-sass、sqlite3 等,这些就是 addon 模块,我们可以在它们的安装目录中看到里面有 .node 后缀名的文件。
addon 适用场景
addon 的开发和使用,相对纯 JS 模块都比较复杂,一般只有特定场景会使用,包括:
- 性能优化
众所周知,C++相对 JS 有绝对的性能优势。addon 技术使得 Node.js 拥有接近 C++的性能。如果你的 Node.js 工程有一小块业务属于 CPU 密集型计算,可以使用 addon 技术来优化性能。 - 复用现有 C/C++ 库
Node.js 诞生至今已经有 15 年了,开发者通常会将其他成熟语言常用的库,用 JS 再实现一次。
但是有些 CPU 密集型计算的库,不适合用 JS 写,这时就会将原有的成熟的 C++库封装为 addon。例如 sharp、canvas 等。 当然,你也可以仅仅因为不想重复造轮子,而将一个 C++库封装为 addon。 - 需要调用 Node.js 未封装的操作系统能力
如果你的 JS 程序需要调用一些操作系统上面的能力,而这些能力 Node.js 并没有帮你封装成标准库,这时候你就得自己写一个 addon,在 addon 里面用 C/C++ 代码去调相关的操作系统接口。
addon 生命周期介绍
开发者完成 addon 开发后,可以将其发布到各种仓库,供后续自己或其他开发者使用。
不同于纯 JS 模块,addon 模块中有 C/C++代码,必须编译后才能使用。addon 开发者可以只发布 C/C++ 源码,让它在用户 npm install 装包的时候自动进行编译构建;也可以把编译产物也一起发布,让用户侧省去编译构建的步骤。
如下图所示,是 addon 生命周期。
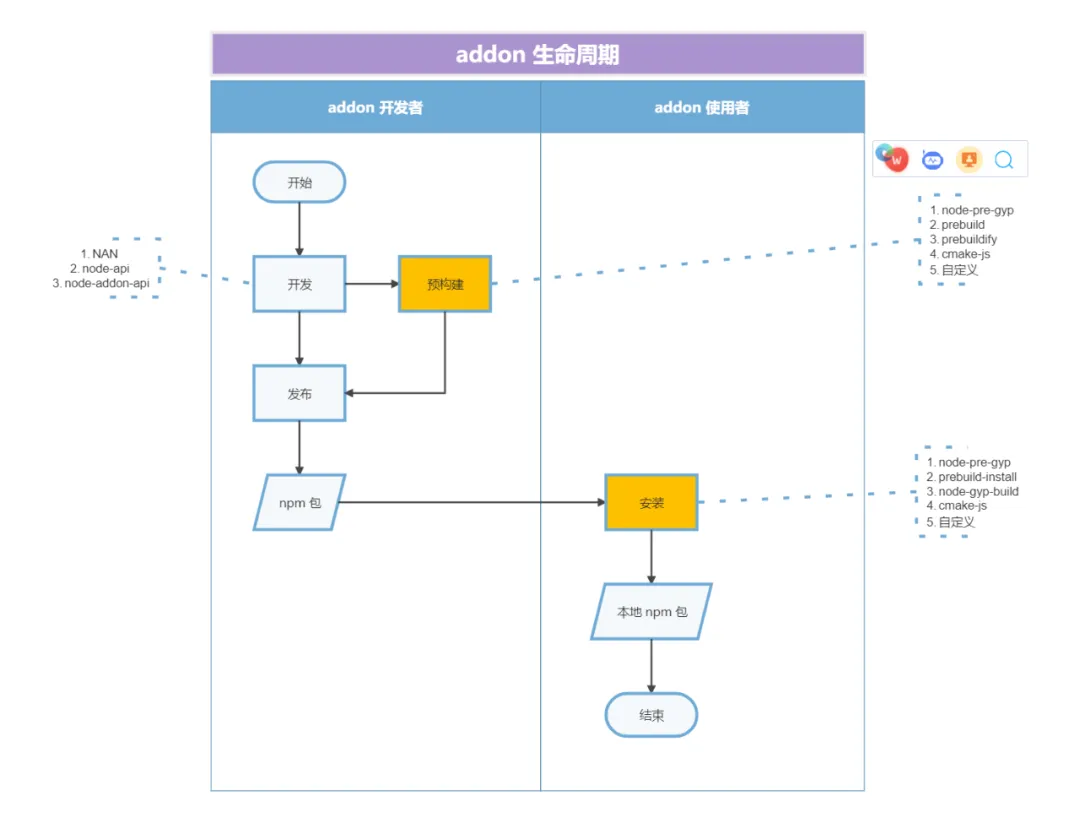
其中,预构建是个可选环节,是否使用取决于 addon 开发者根据特定 addon 自身情况的选择。
开发者可以选择提前编译构建出产物,以备后续随代码发布到 npm 仓库中。
如果没有预构建,addon 会在安装时调用构建工具本地构建。
所以安装没有预构建产物的 addon,需要环境中有必备的构建工具。
addon 工具链介绍
addon 工具链总览
上一节的 addon 业务流程图中,预构建和安装两个环节会用到一些工具,在右侧虚线半框中列出来了。
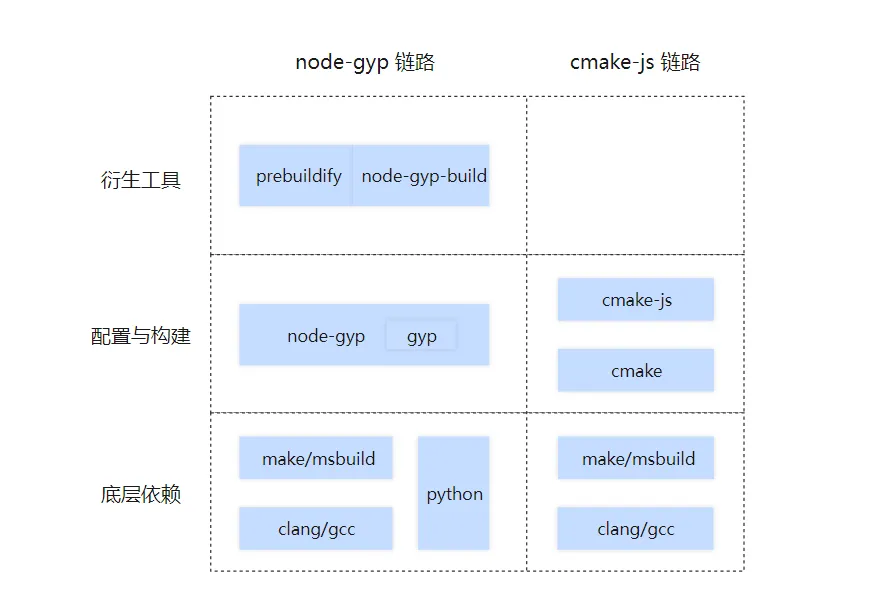
这些工具,可以分到 node-gyp 和 cmake 两条工具链上。如下图:

其中 node-pre-gyp 已废弃,我们不再分析。
prebuild 和 prebuild-install 已经处于不提倡使用状态,以后将会逐渐淘汰,我们也不分析。
所以重点关注的工具还剩 5 个,包括 node-gyp、prebuildify、node-gyp-build、cmake、cmake-js。 这些工具还有 python、make/msbuild、clang/gcc 等底层依赖。
最后 addon 两条构建工具链路中,各个组件间关系概括为下图:
node-gyp-build 工作原理
前文提到的两条工具链中,node-gyp 的市场占有率是 90%以上。而 node-gyp 的相关角色群体中,node-gyp-build 使用者群体是数量最大的,所以本节对 node-gyp-build 进行详细分析,其他则略过。
从前文的 addon 业务流程图可以看出,node-gyp-build 在安装环节起作用。node-gyp-build 就是这个环节的官方推荐工具。
具体业务流程如下图所示:
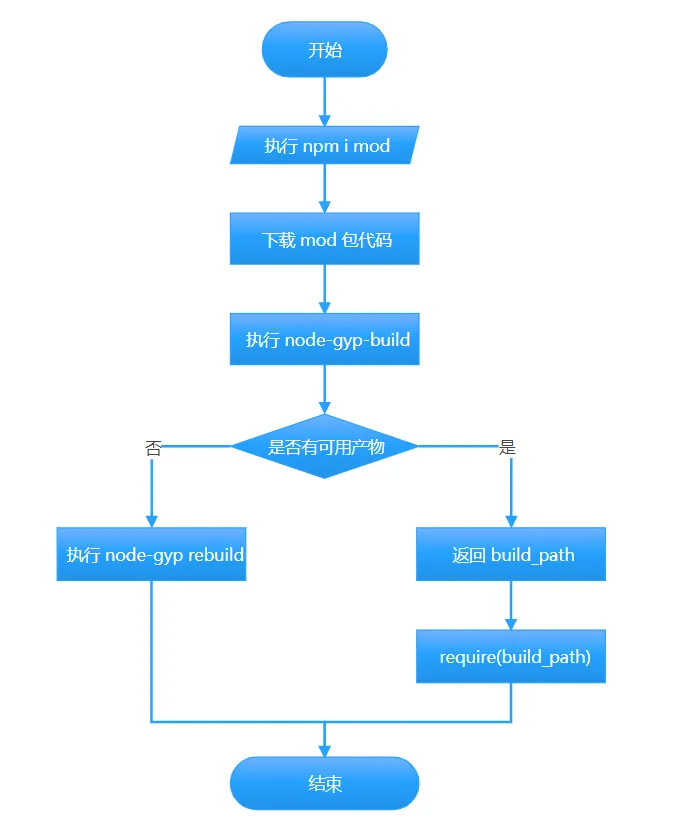
对上图做一下文字描述:
假设我们要在一个 node 工程中,使用一个名称为 mod 的 addon 包。 首先,我们在 node 工程根目录运行npm install mod命令,装包。
接下来是装包详细过程:
-
从 npm 仓库(也可能是其他仓库)下载 mod 包代码。
-
node-gyp-build 命令执行。
-
执行过程中判断下载到的 mod 代码中,是否有可用的预构建产物。
- 如果有,就会用 require 方法加载这个产物。加载成功后,整个装包流程结束。
- 如果没有,就会执行
node-gyp rebuild命令,进行本地构建。 本地构建成功的前提是,环境中有可用的 node-gyp、python、make/msbuild、clang/gcc 等底层依赖。 本地构建成功后,整个装包流程结束。
addon 开发
选择实现方式
如何开发一个 addon 呢?
随着 Node.js 演进,addon 有以下几种实现方式:

当前,直接引用 v8 和使用 NAN 的实现方式已不推荐再用。
node-api 是集成在 Node.js 上的一些 api。它基本消除了 ABI 不稳定造成的影响。参考理解 Node.js 中的 ABI 稳定。
node-addon-api 是一个基于 node-api 实现的 Node.js 三方库,这个库主要是通过封装,简化代码,提升开发体验。这是最常用,也是最推荐的 addon 实现方式。
node-api 原理解析
由于 node-api 几乎是当前的唯一方案(node-addon-api 算是 node-api 的语法糖),所以我们需要重点学习。搞清楚 node-api 原理,就相当于掌握了 addon 开发。
简单来讲,node-api 实际是建立了与 v8 api 之间的映射,或者桥梁。如下图:

下面 是一个 node-addon-api 的例子的核心代码:
#include <napi.h>Napi::String Method(const Napi::CallbackInfo& info) {Napi::Env env = info.Env();return Napi::String::New(env, "world");
}Napi::Object Init(Napi::Env env, Napi::Object exports) {exports.Set(Napi::String::New(env, "hello"),Napi::Function::New(env, Method));return exports;
}NODE_API_MODULE(hello, Init);
我们聚焦到return Napi::String::New(env, "world"),这行代码意思是,返回字符串"world",相当于 js 的return 'world'。
Napi::String::New是 node-addon-api 的字符串类型表示。
运行时,Napi::String::New会被转成 napi_value 类型(node-api 中 string 类型的父类),然后再转成 V8 对应的类型。
addon 开发教程
熟悉了前面介绍的 node-api 原理,想必你已经知道怎么开发 addon。
实际开发的部分细节可以参考这篇文档: https://blog.csdn.net/qq1195566313/article/details/136725679
addon 预构建与发布
前文有提到过,预构建和包安装环节都可能对 addon 进行构建。
推荐使用 prebuildify + node-gyp-build 方案进行构建,即预构建时使用 prebuildify,包安装使时用 node-gyp-build。
预构建需要按操作系统和 cpu 架构,构建不同的产物。
下图是开源 npm 包 bufferutil 的 GitHub Actions 的 workflow 配置文件截图。
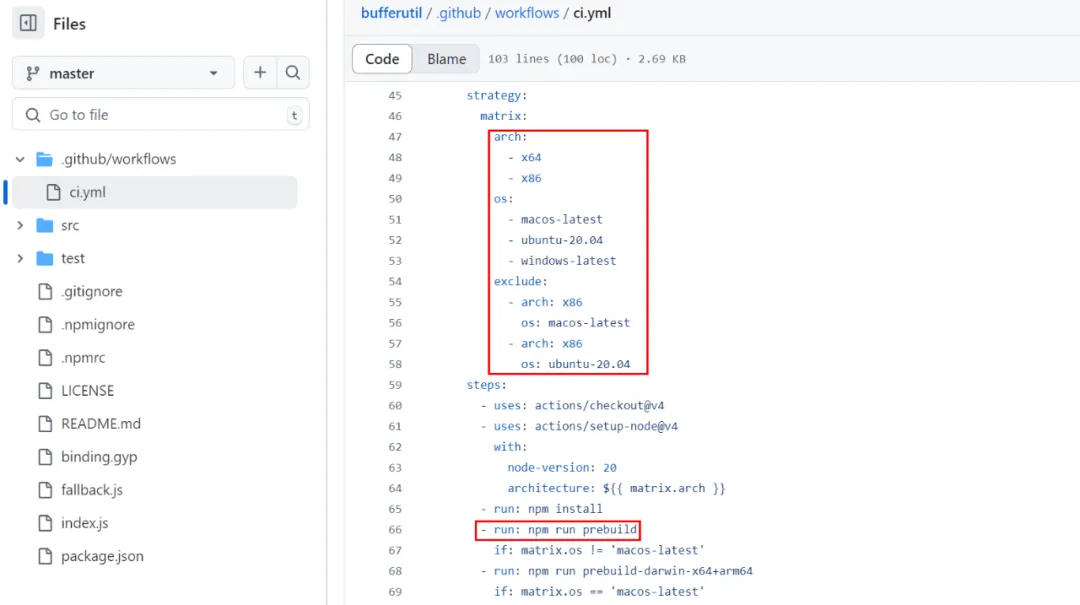
按照截图中的配置,在发布 bufferutil 新版本时,工作流将会创建 4(2×3-2)个虚拟机或容器,分别构建对应的操作系统和 cpu 架构组合的二进制产物。
另外,图中的steps:run:npm run prebuild步骤,会运行 bufferutil 根目录下的 package.json 中的定义的 prebuild 命令,如下图:
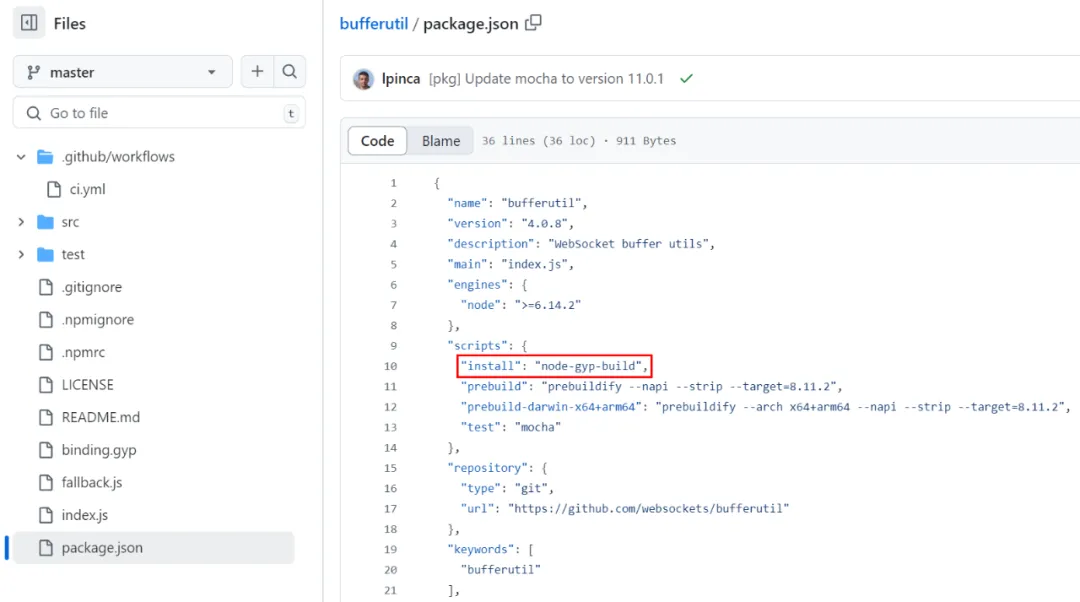
至此,阅读中的你应该了解到了 bufferutil 的正式预构建过程了。
addon 的使用
本节我们来看看 addon 具体使用的相关细节。以推荐的 prebuildify + node-gyp-build 方案为例进行讲解。
本地构建和使用
所谓本地构建,通常用于开发场景的验证和调试。其本质和前文介绍的预构建并无区别,不过操作流程不一样。
当我们开发完一个 addon 时,按以下步骤进行本地构建和使用。
-
安装 prebuildify
最好全局安装,命令如下:npm install prebuildify -g -
本地构建
这里仅给出最简参数配置,更多参数可以查阅 prebuildify 文档。prebuildify --napi -
导入并使用构建产物
导入代码示例:var addon = require('node-gyp-build')(__dirname);console.log(addon.hello()); // 'world'如上所示,
require('node-gyp-build')(__dirname)会从当前目录查找 prebuilds、build 等目录,并从中找到 .node 文件进行加载(require(‘xxx.node’))。
正式使用一个 addon
在介绍 addon 正式使用之前,先得介绍一下 npm scripts 运行机制。
上一节的 package.json 截图中,我们可以看到其中还定义了"install": "node-gyp-build",这一行代码是怎么运作的?它的运行原理涉及 npm scripts 的运行机制。
如下图所示,当 npm install 运行时,package.json 文件中的 scripts 中配置的部分命令也会执行。
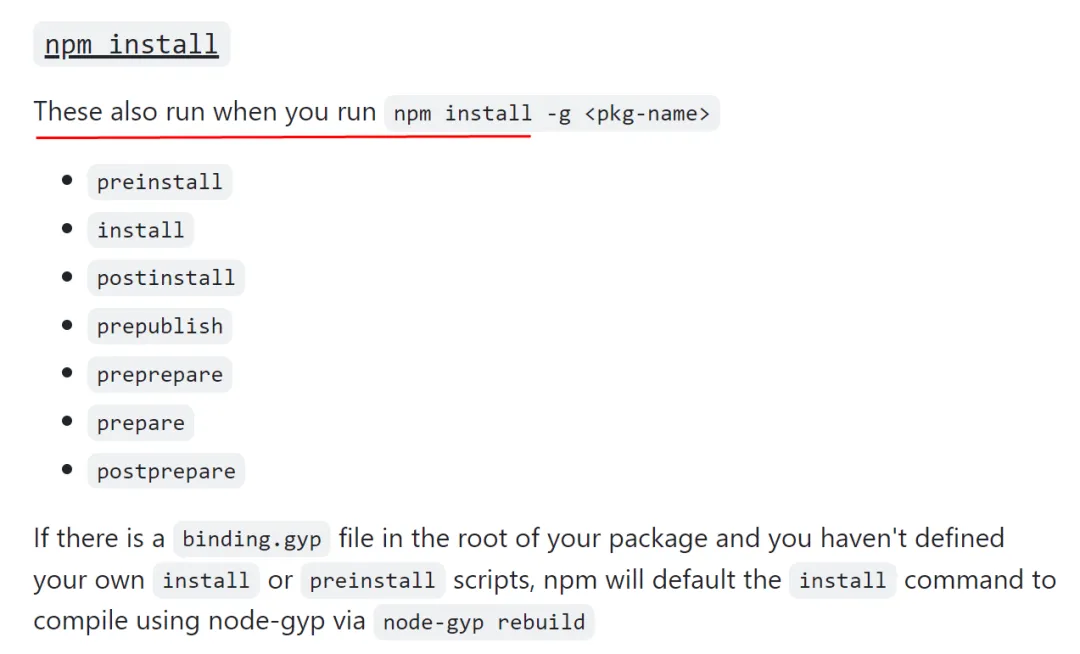
按照 npm scripts 运行机制,npm install 运行时,node-gyp-build 也会运行。
而 node-gype-build 运行时,会先检测是否已经存在可用的构建产物;如果没有,会执行 node-gyp prebuild,本地构建一份。详见前文对 node-gyp-build 工作原理的介绍。
本文开头有说,addon 是特殊模块。特殊模块也是模块,其正式使用时的导入方式与普通模块相同,例如 require(‘bufferutil’)。关于 addon 的加载的特殊性,在Node.js 模块加载方式分析这篇文章有讲解。
小结一下,如何正式使用 addon:
如果有当前环境可用预构建产物(需要预判或尝试),我们只需要将这个 addon 当做普通 npm 包使用即可;
如果没有,那么 npm install 时,会进自动行本地构建。这就要求我们,提前准备好构建环境。以 Linux 环境为例,需要环境中有 node-gyp、python、gcc 或 clang等合适的编译工具、make等构建工具。
常见 addon 统计
为了让大家对 addon 生态有个完整的认识,这里列出一些 GitHub 上最常见的 addon,以供查阅。

本文是本系列的最后一个章节,恭喜大家完成本系列学习内容,希望你能从本系列中学习到以下技能:
- 提升调试与性能优化能力
- 深入理解模块化与扩展机制
- 探索底层技术与定制化能力
同时欢迎大家一起参与OpenTiny开源共建:朋友你好,一起加入OpenTiny社区吧~
关于OpenTiny
欢迎加入 OpenTiny 开源社区。添加微信小助手:opentiny-official 一起参与交流前端技术~
OpenTiny 官网:https://opentiny.design
OpenTiny 代码仓库:https://github.com/opentiny
TinyVue 源码:https://github.com/opentiny/tiny-vue
TinyEngine 源码:https://github.com/opentiny/tiny-engine
欢迎进入代码仓库 Star🌟TinyEngine、TinyVue、TinyNG、TinyCLI、TinyEditor ~ 如果你也想要共建,可以进入代码仓库,找到 good first issue标签,一起参与开源贡献~
相关文章:

Node.js 技术原理分析系列9——Node.js addon一文通
Node.js 是一个开源的、跨平台的JavaScript运行时环境,它允许开发者在服务器端运行JavaScript代码。Node.js 是基于Chrome V8引擎构建的,专为高性能、高并发的网络应用而设计,广泛应用于构建服务器端应用程序、网络应用、命令行工具等。 本系…...

HBuilderX安卓真机运行安装失败解决汇总
前置方案 1. 确认USB调试和连接模式 (1)开启USB调试:进入手机设置 > 开发者选项 > 确保USB调试已开启(如无开发者选项,连续点击“版本号”激活)。 (2)连接模式:将…...

TensorFlow 2.x入门实战:从零基础到图像分类项目
TensorFlow 2.x入门实战:从零基础到图像分类项目 前言 TensorFlow是Google开发的开源机器学习框架,已成为深度学习领域的重要工具。TensorFlow 2.x版本相比1.x有了重大改进,更加易用且功能强大。本文将带你从零开始学习TensorFlow 2.x&…...

SpringBoot+Dubbo+Zookeeper实现分布式系统步骤
SpringBootDubboZookeeper实现分布式系统 一、分布式系统通俗解释二、环境准备(详细版)1. 软件版本2. 安装Zookeeper(单机模式) 三、完整项目结构(带详细注释)四、手把手代码实现步骤1:创建父工…...

数据中台-常用工具组件:DataX、Flink、Dolphin Scheduler、TensorFlow和PyTorch等
数据实施服务工具组件概览 数据中台的数据实施服务涵盖 数据采集、处理、调度、分析与应用 全流程,以下为关键工具组件及其作用: 工具类型核心功能典型应用场景DataX离线数据采集多源异构数据批量同步数据仓库ODS层数据导入Apache Flink实时计算引擎流…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】电商数据分析案例-9.2 流量转化漏斗分析
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 9.2 流量转化漏斗分析:从数据清洗到可视化全流程实战一、背景与目标二、数据准备与清洗2.1 数据来源与字段说明2.2 数据清洗步骤2.2.1 去除无效数据2.2.2 处理时…...

结合Splash与Scrapy:高效爬取动态JavaScript网站
在当今的Web开发中,JavaScript的广泛应用使得许多网站的内容无法通过传统的请求-响应模式直接获取。为了解决这个问题,Scrapy开发者经常需要集成像Splash这样的JavaScript渲染引擎。本文将详细介绍Splash JS引擎的工作原理,并探讨如何将其与S…...

[计算机科学#10]:早期的计算机编程方式
【核知坊】:释放青春想象,码动全新视野。 我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!! 内容摘要:1804年,为了在织布机上编织出丰富多彩的…...

JAVA:Spring Boot 集成 Lua 的技术博客
1、简述 在现代开发中,Lua 以其轻量级、高性能以及易嵌入的特点广泛用于脚本扩展、游戏开发以及配置处理场景。将 Lua 与 Spring Boot 集成,可以在 Java 项目中实现动态脚本功能,增强项目的灵活性和动态配置能力。 样例代码: https://gitee.com/lhdxhl/springboot-example…...

代码随想录算法训练营 Day40 动态规划Ⅷ 股票问题
动态规划 题目 121. 买卖股票的最佳时机 - 力扣(LeetCode) 使用二维 dp 数组表示 1. dp[i][0] 表示持有股票的最大金额,dp[i][1] 表示不持有股票的最大金额,表示盈利结果 2. 递推公式由前一天持有金额和是否买股票决定 决定是否…...

【已解决】WORD域相关问题;错误 未找到引用源;复制域出错;交叉引用域到底是个啥
(微软赶紧倒闭 所有交叉引用域,有两个状态:1.锁定。2.手动。可通过编辑->链接查看。 “锁定”状态域的能力: 1. 导出PDF格式稳定(【已解决】WORD导出PDF时,参考文献上标自动被取消/变为正常文本_word…...

小米 MiMo 开源:7B 参数凭什么 “叫板” AI行业巨头?
目录 一、技术革命的起点:小米AI战略的“破局者” 1.1 战略背景:从硬件厂商到AI基础设施提供商 1.2 团队揭秘:“天才少女”罗福莉与小米AI梦之队 二、技术架构解析:7B参数如何实现“推理跃迁” 2.1 核心技术原理 2.2 技术指…...

构建高可用性的LVS-DR群集:实现无缝的负载均衡与故障转移
目录 一、LVS-DR集群 1.LVS-DR工作原理 2.数据包流向分析 3.LVS-DR模式特点 二、直接路由模式(LVS-DR) 1.资源清单 2.配置负载调度器(lvs) 3.配置节点服务器(web1、web2) 4.测试LVS群集 5.使用NFS发布共享资源(nfs上) …...
)
低光图像增强新色彩空间HVI:技术突破与创新解析(HVI: ANewColor Space for Low-light Image Enhancement)
摘要 低光图像增强(LLIE)是计算机视觉领域的关键任务,旨在从受损的低光图像中恢复细节信息。针对现有方法在标准RGB(sRGB)空间易产生色偏与亮度伪影的问题,以及HSV色彩空间转换引发的红/黑噪声问题…...

Abaqus学习笔记
目录 Abaqus介绍 学习资源 编辑Abaqus/CAE abaqus下载安装 abaqus基本操作 Abaqus启动 新建模型 编辑 编辑修改界面背景 编辑编辑结果信息的显示与否 编辑计算结果信息字体设置 编辑允许多绘图状态 单位量纲 视图操作 事前说明 ODB文件 本构关系…...

AquaCrop 模型新视角:多技术助力农业精准水管理
技术点目录 模型原理介绍与数据要求及模型分析数据制备、模型运行与案例实践(界面GUI版本)模型优化与敏感性分析(基于R语言实践)源代码分析(基于FORTRAN)未来气候变化影响分析与案例实践(基于Py…...

从知识图谱到精准决策:基于MCP的招投标货物比对溯源系统实践
前言 从最初对人工智能的懵懂认知,到逐渐踏入Prompt工程的世界,我们一路探索,从私有化部署的实际场景,到对DeepSeek技术的全面解读,再逐步深入到NL2SQL、知识图谱构建、RAG知识库设计,以及ChatBI这些高阶应用。一路走来,我们在AI的领域里一步一个脚印,不断拓展视野和能…...

【平面波导外腔激光器专题系列】1064nm单纵模平面波导外腔激光器
摘要:我们介绍了平面波导外腔二极管激光器 (PW-ECL) 的特性。据我们所知,这是第一款蝶形封装的 1064nm半导体激光器,其可以稳定锁定到外部参考频率。我们从精密实验的角度评估了它的性能,特别是使用碘的超精细吸收线,在…...

C++ 算法学习之旅:从入门到精通的秘籍
在编程的浩瀚宇宙中,C 算法宛如璀璨的星辰,照亮我们前行的道路。作为一名 C 算法小白,或许你和我一样,怀揣着对算法的好奇与憧憬,却又在学习的道路上感到迷茫。别担心,今天我就和大家分享一下如何学习各种基…...

按摩椅上的气囊系统 是现代按摩椅中非常关键的组成部分,它与机芯系统相辅相成,为用户提供全方位、更接近真人按摩的体验
按摩椅上的气囊系统是现代按摩椅中非常关键的组成部分,它与机芯系统相辅相成,为用户提供全方位、更接近真人按摩的体验。 一、按摩椅气囊的产生背景 1. 传统按摩方式的局限 早期的按摩椅主要依赖机械式的“凸轮电机”或简单的机芯滚轮结构,…...

配置Hadoop集群环境-使用脚本命令实现集群文件同步
(一)Hadoop的运行模式 hadoop一共有如下三种运行方式: 1. 本地运行。数据存储在linux本地,测试偶尔用一下。我们上一节课使用的就是本地运行模式hadoop100。 2. 伪分布式。在一台机器上模拟出 Hadoop 分布式系统的各个组件&…...
部署FastGPT)
Linux系统(OpenEuler22.03-LTS)部署FastGPT
在 openEuler 22.03 LTS 系统上通过 Docker Compose 安装 FastGPT 的步骤如下: 官方参考文档:https://doc.fastgpt.cn/docs/development/docker/ 1. 安装 Docker 和 Docker Compose 可以参考我之前离线安装Docker的文章:openEuler 22.03 LT…...

FastExcel 本地开发和Linux上上传Resource文件的差异性
不能直接通过路径来获取 这个是一个下载导出文件的操作 GetMapping(value "/export/all") public void exportAll(HttpServletResponse response, LaylineListReq req) throws IOException {// 从类路径下获取 Excel 文件资源ClassPathResource classPathResource…...

Excel学习笔记
在excel表格中,某列的数据最大,则整行都红色底色标出,怎么实现? 更改x值,excel图表上动态显示 该值的Y值且动态显示十字交叉线 为了实现如下图所示的效果,需要做出几个辅助列就行。 step1:先写…...

数据中台-数仓分层结构【Doris】
数据仓库采用Doris进行搭建,并分为ODS/DWD/DWM/DWS/ADS等层级结构进行分层数据存储。Doris是百度开源的MPP数据库,可有效支撑大数据量的数据计算和分布式扩展存储。 数据仓库分层架构设计目标 解耦与复用性:通过分层隔离原始数据与业务逻辑&a…...

使用Jmeter对AI模型服务进行压力测试
一、JMeter介绍 Apache JMeter 是一款开源的性能测试工具,主要用于评估Web应用程序的负载和性能。它支持多种类型的测试,包括但不限于: 负载测试:模拟大量用户访问系统以检测其在高负载下的表现。性能测试:评估系统在…...

测试用例管理平台哪些好用?9款主流测试平台对比
在当今软件开发领域,测试用例管理平台已成为提升产品质量和团队协同效率的关键工具。本文将围绕“测试用例管理平台”这一核心关键词,全面解析市面上9款主流产品,帮助企业管理者和测试团队快速了解各平台的核心优势和适用场景,从而…...

C++函数传值与传引用对比分析
在C编程中,函数参数传递的方式直接影响程序的性能、内存管理以及代码逻辑的正确性。传值(Pass by Value)和传引用(Pass by Reference)是两种最常用的参数传递方式,它们各有优缺点,适用于不同的场…...

【se-res模块学习】结合CIFAR-10分类任务学习
继CIFAR-10图像分类:【Res残差连接学习】结合CIFAR-10任务学习-CSDN博客 再优化 本次训练结果在测试集上的准确率表现可达到90%以上 1.训练模型(MyModel.py) import torch import torch.nn as nnclass SENet(nn.Module): # SE-Net模块def…...
的翻转概率)
二元随机响应(Binary Randomized Response, RR)的翻转概率
随机响应(Randomized Response)机制 ✅ 回答核心: p 1 1 e ε 才是「翻转概率」 \boxed{p \frac{1}{1 e^{\varepsilon}}} \quad \text{才是「翻转概率」} p1eε1才是「翻转概率」 而: q e ε 1 e ε 是「保留真实值」…...

湖北理元理律师事务所:债务优化中的“生活保障”方法论
债务危机往往伴随生活质量骤降,如何在还款与生存间找到平衡点,成为债务优化的核心挑战。湖北理元理律师事务所基于多年实务经验,提出“双轨并行”策略:法律减负与生活保障同步推进。 债务优化的“温度法则” 1.生存资金预留机制…...

RFID智能书柜:精准定位,找书告别 “大海捞针”
在传统图书馆的浩瀚书海,找书无异于在错综复杂的迷宫里徘徊。读者在书架间来回奔波,耗费大量时间精力,还常一无所获。RFID智能书柜的出现,彻底改写了这一局面。它搭载的RFID读写器与天线协同工作,能实时精准定位贴有RF…...

视觉图像处理及多模态融合初探
(一)指标汇总 1. 图像采集与质量提升 指标描述可能的量化值图像清晰度反映图像中物体的边缘和细节的清晰程度例如:1-10 分(1 为极不清晰,10 为非常清晰)噪声水平表示图像中随机噪声的多少例如:噪声强度百分比(0%-100%)畸变程度描述图像中物体形状的变形程度例如:畸变…...
三伍微电子GSR2337 兼容替代SKY85337, RTC7646, KCT8247HE)
射频前端模组芯片(PA)三伍微电子GSR2337 兼容替代SKY85337, RTC7646, KCT8247HE
射频前端模组芯片(PA)三伍微电子GSR2337 兼容替代SKY85337, RTC7646, KCT8247HE 型号GSR2337 频率: 2.4 GHz 类型: FEM (PALNASW) WIFI: 11n/ac/ax 功率: 21dBmEVM-43dB5V 封装: 3*3 mm 电压: 3.3V & 5V P2P: SKY85…...

python 接收c++的.so传的jsoncpp字符串
叮!快来看看我和文心一言的奇妙对话~点击链接 https://yiyan.baidu.com/share/57o6vGa3GY -- 文心一言,既能写文案、读文档,又能绘画聊天、写诗做表,你的全能伙伴! 要从 C 动态链接库 (.so 文件) 中接收 JS…...

EasyRTC嵌入式音视频通话SDK驱动智能硬件音视频应用新发展
一、引言 在数字化浪潮下,智能硬件蓬勃发展,从智能家居到工业物联网,深刻改变人们的生活与工作。音视频通讯作为智能硬件交互与协同的核心,重要性不言而喻。但嵌入式设备硬件资源受限,传统音视频方案集成困难。EasyRT…...

Day19 常见的特征筛选算法
常见的特征筛选算法 1. 方差筛选 原理 :方差衡量的是数据的离散程度。在特征筛选中,如果某个特征的方差很小,说明该特征在不同样本上的值差异不大,那么它对模型的区分能力可能很弱。方差筛选就是通过设定一个方差阈值࿰…...

如何使用极狐GitLab 软件包仓库功能托管 terraform?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Terraform 模块库 (BASIC ALL) 基础设施仓库和 Terraform 模块仓库合并到单个 Terraform 模块仓库功能引入于极狐GitLab 15.1…...

15前端项目----用户信息/导航守卫
登录/注册 持久存储用户信息问题 退出登录导航守卫解决问题 持久存储用户信息 本地存储:(在actions中请求成功时) 添加localStorage.setItem(token,result.data.token);获取存储:(在user仓库中,state中tok…...

重定向及基础实验
1.if指令 if (判断条件){ 执行语句; } if的正则表达式 #比较变量和字符串是否相等,相等时if指令认为该条件为true,反之为false ! #比较变量和字符串是否不相等,不相等时if指令认为条件为true,反之为false ~ #区分大小写字符&…...

CBO和HBO区别及介绍
CBO(Cost-Based Optimizer)和 HBO(Heuristic-Based Optimizer)是两种数据库查询优化器的类型,它们在优化策略和实现方式上有显著的区别。以下是详细的解释和对比: 1. CBO(Cost-Based Optimizer…...

华为HCIP-AI认证考试版本更新通知
华为HCIP-AI认证考试版本更新通知 HCIP-AI-EI Developer V2.5认证发布 华为官方宣布,HCIP-AI-EI Developer V2.5认证考试将于2025年3月31日正式上线。新版认证聚焦AI工程化开发与行业实践,新增大模型部署优化、AI边缘计算等前沿技术内容&…...

【算法-链表】链表操作技巧:常见算法
算法相关知识点可以通过点击以下链接进行学习一起加油!双指针滑动窗口二分查找前缀和位运算模拟 链表是一种灵活的数据结构,广泛用于需要频繁插入和删除的场景。掌握链表的常见操作技巧,如插入、删除、翻转和合并等,能帮助开发者更…...

【探寻C++之旅】第十三章:红黑树
请君浏览 前言1. 红黑树的概念1.2 红黑树的规则1.3 红黑树如何确保最长路径不超过最短路径的两倍?1.4 红黑树的效率 2. 红黑树的实现2.1 红黑树的结构2.2 红黑树的插入情况1:变色情况2:单旋变色情况2:双旋变色代码演示 2.3 红黑树…...

JavaScript 性能优化全攻略:从基础到实战
引言 在现代 Web 开发中,JavaScript 作为核心语言,其性能直接影响用户体验。无论是单页应用(SPA)还是复杂交互页面,性能优化始终是开发者关注的核心。 本文将从基础策略、最新技巧、常见误区和实战案例四个维度,系统性地解析 JavaScript 性能优化的关键方法,并提供可复…...

Kafka消息队列之 【消费者分组】 详解
消费者分组(Consumer Group)是 Kafka 提供的一种强大的消息消费机制,它允许多个消费者协同工作,共同消费一个或多个主题的消息,从而实现高吞吐量、可扩展性和容错性。 基本概念 消费者分组:一组消费者实例的集合,这些消费者实例共同订阅一个或多个主题,并通过分组来协调…...
[ 01 API操作 ])
HuggingFace与自然语言处理(从框架学习到经典项目实践)[ 01 API操作 ]
本教程适用与第一次接触huggingface与相应框架和对nlp任务感兴趣的朋友,该栏目目前更新总结如下: Tokenizer: 支持单句/双句编码,自动处理特殊符号和填充。 批量编码提升效率,适合训练数据预处理。Datasets…...
uniapp-文件查找失败:‘@dcloudio/uni-ui/lib/uni-icons/uni-icons.vue‘
uniapp-文件查找失败:‘dcloudio/uni-ui/lib/uni-icons/uni-icons.vue’ 今天在HBuilderX中使用uniapp开发微信小程序时遇到了这个问题,就是找不到uni-ui组件 当时创建项目,选择了一个中间带的底部带选项卡模板,并没有选择内置u…...
系统)
springboot+vue实现在线网盘(云盘)系统
今天教大家如何设计一个网盘(云盘)系统系统 , 基于目前主流的技术:前端vue,后端springboot。 同时还带来的项目的部署教程。 视频演示 springbootvue实现在线网盘(云盘)系统 图片演示 一. 系统概述 用过百…...

启智平台调试 qwen3 4b ms-swift
以上设置完成后,我们点击新建任务。等待服务器创建和分配资源。 资源分配完成后我们看到如下列表,看到资源running状态,后面有一个调试按钮,后面就可以进入代码调试窗体界面了。 点击任务名称 跳转 访问github失败 加速器开启…...