【se-res模块学习】结合CIFAR-10分类任务学习
继CIFAR-10图像分类:【Res残差连接学习】结合CIFAR-10任务学习-CSDN博客 再优化
本次训练结果在测试集上的准确率表现可达到90%以上
1.训练模型(MyModel.py)
import torch
import torch.nn as nnclass SENet(nn.Module): # SE-Net模块def __init__(self, channel, reduction=16): # 默认r为16super(SENet, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化层,输出大小1*1self.fc = nn.Sequential(nn.Linear(channel * 2, channel // reduction), # 输入通道数加倍nn.ReLU(),nn.Linear(channel // reduction, channel),nn.Sigmoid(), # 将通道权重输出为0-1)def forward(self, x, previous_features=None):b, c, _, _ = x.size()y_current = self.avg_pool(x).view(b, c) # 当前层的全局平均池化# 将当前特征向量与之前特征向量拼接if previous_features is not None:y_previous = self.avg_pool(previous_features).view(b, c) # 之前特征的全局平均池化y = torch.cat([y_current, y_previous], dim=1) # 拼接else:y = y_current # 如果没有之前的特征,只使用当前特征y = self.fc(y).view(b, c, 1, 1) # 计算通道权重return x * y.expand_as(x) # 对应元素进行逐一相乘class BasicRes(nn.Module):def __init__(self, in_cha, out_cha, stride=1, res=True):super(BasicRes, self).__init__()self.conv01 = nn.Sequential(nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=3, stride=stride, padding=1),nn.BatchNorm2d(out_cha),nn.ReLU(),)self.conv02 = nn.Sequential(nn.Conv2d(in_channels=out_cha, out_channels=out_cha, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(out_cha),)self.se = SENet(out_cha)if res:self.res = resif in_cha != out_cha or stride != 1: # 若x和f(x)维度不匹配:self.shortcut = nn.Sequential(nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=1, stride=stride),nn.BatchNorm2d(out_cha),)else:self.shortcut = nn.Sequential()def forward(self, x):residual = xx = self.conv01(x)features = xx = self.conv02(x)x = self.se(x=x, previous_features=features) # 传递前层的特征图if self.res:x += self.shortcut(residual)return x# 2.训练模型
class cifar10(nn.Module):def __init__(self):super(cifar10, self).__init__()# 初始维度3*32*32self.Stem = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(64),nn.ReLU(),)self.layer01 = BasicRes(in_cha=64, out_cha=64)self.layer02 = BasicRes(in_cha=64, out_cha=64)self.layer11 = BasicRes(in_cha=64, out_cha=128)self.layer12 = BasicRes(in_cha=128, out_cha=128)self.layer21 = BasicRes(in_cha=128, out_cha=256)self.layer22 = BasicRes(in_cha=256, out_cha=256)self.layer31 = BasicRes(in_cha=256, out_cha=512)self.layer32 = BasicRes(in_cha=512, out_cha=512)self.pool_max = nn.MaxPool2d(2)self.pool_avg = nn.AdaptiveAvgPool2d((1, 1)) # b*c*1*1self.fc = nn.Sequential(nn.Dropout(0.4),nn.Linear(512, 128),nn.ReLU(),nn.Linear(128, 10),)def forward(self, x):x = self.Stem(x)x = self.layer01(x)x = self.layer02(x)x = self.pool_max(x)x = self.layer11(x)x = self.layer12(x)x = self.pool_max(x)x = self.layer21(x)x = self.layer22(x)x = self.pool_max(x)x = self.layer31(x)x = self.layer32(x)x = self.pool_max(x)x = self.pool_avg(x).view(x.size()[0], -1)x = self.fc(x)return x
本训练模型结合了 SE 模块和残差学习思想,并且适当修改了SE模块的输入层以更好地捕捉图像中重要的特征。
SENet类:Squeeze-and-Excitation(SE)模块,通过全局平均池化来获取特征图的全局信息,然后通过一系列全连接层生成一个通道权重向量,这部分适当修改了SE模块的输入层可做参考;
BasicRes类:基本残差块实现了一个带有 SE 模块的残差连接,使用两个卷积层用于提取特征,第二个卷积层的输出与第一层特征的输出都传入 SE 模块,用于计算通道权重,从而增强网络对特征的选择性;
cifar10类(主网络结构):
1. Stem(干茎部分):由卷积层、批归一化层和 ReLU 激活组成,负责特征的初步提取,输入是大小为 3x32x32 的图像,输出是 64 个通道。
2. 多个 BasicRes 块:这些块逐层堆叠形成一个深度网络,具体分为三组:第一组:两个BasicRes块(64 通道),后接最大池化层;第二组:两个 BasicRes 块(128 通道),后接最大池化层;第三组:两个 BasicRes 块(256 通道),后接最大池化层;第四组:两个 BasicRes 块(512 通道),后接最大池化层。
3. 全局平均池化和全连接层:最后的特征图经过 Adaptive Avg Pooling 调整为 1x1 的大小,然后展平为一维向量,送入全连接层进行最终分类。
2.训练函数
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import time
from MyModel import cifar10def train_val(train_loader, val_loader, device, model, loss, optimizer, epochs, save_path, scheduler): # 正式训练函数model = model.to(device)plt_train_loss = [] # 训练过程loss值,存储每轮训练的均值plt_train_acc = [] # 训练过程acc值plt_val_loss = [] # 验证过程plt_val_acc = []max_acc = 0 # 以最大准确率来确定训练过程的最优模型for epoch in range(epochs): # 开始训练train_loss = 0.0train_acc = 0.0val_acc = 0.0val_loss = 0.0start_time = time.time()model.train()for index, (images, labels) in enumerate(train_loader):images, labels = images.to(device), labels.to(device)optimizer.zero_grad() # 梯度置0pred = model(images)bat_loss = loss(pred, labels) # CrossEntropyLoss会对输入进行一次softmaxbat_loss.backward() # 回传梯度optimizer.step() # 更新模型参数train_loss += bat_loss.item()# 注意此时的pred结果为64*10的张量pred = pred.argmax(dim=1)train_acc += (pred == labels).sum().item()print("当前为第{}轮训练,批次为{}/{},该批次总loss:{} | 正确acc数量:{}".format(epoch+1, index+1, len(train_data)//config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))# 计算当前Epoch的训练损失和准确率,并存储到对应列表中:plt_train_loss.append(train_loss / train_loader.dataset.__len__())plt_train_acc.append(train_acc / train_loader.dataset.__len__())model.eval() # 模型调为验证模式with torch.no_grad(): # 验证过程不需要梯度回传,无需追踪gradfor index, (images, labels) in enumerate(val_loader):images, labels = images.cuda(), labels.cuda()pred = model(images)bat_loss = loss(pred, labels) # 算交叉熵lossval_loss += bat_loss.item()pred = pred.argmax(dim=1)val_acc += (pred == labels).sum().item()print("当前为第{}轮验证,批次为{}/{},该批次总loss:{} | 正确acc数量:{}".format(epoch+1, index+1, len(val_data)//config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))val_acc = val_acc / val_loader.dataset.__len__()if val_acc > max_acc:max_acc = val_acctorch.save(model, save_path)plt_val_loss.append(val_loss / val_loader.dataset.__len__())plt_val_acc.append(val_acc)print('该轮训练结束,训练结果如下[%03d/%03d] %2.2fsec(s) TrainAcc:%3.6f TrainLoss:%3.6f | valAcc:%3.6f valLoss:%3.6f \n\n'% (epoch+1, epochs, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1]))scheduler.step() # 更新学习率print(f'训练结束,最佳模型的准确率为{max_acc}')plt.plot(plt_train_loss) # 画图plt.plot(plt_val_loss)plt.title('loss')plt.legend(['train', 'val'])plt.show()plt.plot(plt_train_acc)plt.plot(plt_val_acc)plt.title('Accuracy')plt.legend(['train', 'val'])# plt.savefig('./acc.png')plt.show()将真正的训练过程封装为上述函数。
训练模式中使用“训练模型”获取预估值,根据loss和梯度回传不断优化模型内参数,且保存训练过程的loss值。
验证模式无需梯度回传,设置为验证模式以保证模型验证过程的数据完整性,记录验证过程的模型loss值。
最后将整个训练过程和验证过程的loss值和acc值进行可视化展现。
3.训练过程
total_start = time.time()# 1.数据预处理
transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
ori_data = dataset.CIFAR10(root="./Data_CIFAR10",train=True,transform=transform,download=True
)
print(f"各标签的真实含义:{ori_data.class_to_idx}\n")
# print(len(ori_data))
# # 查看某一样本数据
# image, label = ori_data[0]
# print(f"Image shape: {image.shape}, Label: {label}")
# image = image.permute(1, 2, 0).numpy()
# plt.imshow(image)
# plt.title(f'Label: {label}')
# plt.show()config = {"train_size_perc": 0.8,"batch_size": 64,"learning_rate": 0.001,"epochs": 60,"lr_decay_step": 20,"lr_decay_gamma": 0.2, # 衰减系数"save_path": "model_save/NewSe60_0.2_model.pth"
}# 设置训练集和验证集的比例
train_size = int(config["train_size_perc"] * len(ori_data)) # 80%用于训练
val_size = len(ori_data) - train_size # 20%用于验证
train_data, val_data = random_split(ori_data, [train_size, val_size])
# print(len(train_data))
# print(len(val_data))train_loader = DataLoader(dataset=train_data, batch_size=config["batch_size"], shuffle=True)
val_loader = DataLoader(dataset=val_data, batch_size=config["batch_size"], shuffle=False)device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")
model = cifar10()
# model = torch.load(config["save_path"]).to(device)
print(f"我的模型框架如下:\n{model}")
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=config["learning_rate"], weight_decay=1e-3) # L2正则化
# optimizer = torch.optim.Adam(model.parameters(), lr=config["learning_rate"]) # 优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=config["lr_decay_step"], gamma=config["lr_decay_gamma"]) # 创建学习率调度器train_val(train_loader, val_loader, device, model, loss, optimizer, config["epochs"], config["save_path"], scheduler)print(f"\n本次训练总耗时为:{(time.time()-total_start) / 60 }min")整个训练过程如上。
数据预处理部分:通过 随机水平翻转、随机裁剪、归一化 实现数据增强;
学习率衰减与优化器选择:使用(AdamW)来更新模型参数减小损失,期间引入L2正则化(weight_decay=1e-3可自行调整);使用 StepLR 学习率调度器,每过一定的训练步数(step_size=20),学习率会下降一个特定的比例(gamma=0.2),有助于动态调整学习率,以提高模型的收敛速度和性能。
4.测试文件
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import time
from MyModel import BasicRes, cifar10total_start = time.time()
# 测试函数
def test(save_path, test_loader, device, loss): # 测试函数best_model = torch.load(save_path).to(device)test_loss = 0.0test_acc = 0.0start_time = time.time()with torch.no_grad():for index, (images, labels) in enumerate(test_loader):images, labels = images.cuda(), labels.cuda()pred = best_model(images)bat_loss = loss(pred, labels) # 算交叉熵losstest_loss += bat_loss.item()pred = pred.argmax(dim=1)test_acc += (pred == labels).sum().item()print("正在最终测试:批次为{}/{},该批次总loss:{} | 正确acc数量:{}".format(index + 1, len(test_data) // config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))print('最终测试结束,测试结果如下:%2.2fsec(s) TestAcc:%.2f%% TestLoss:%.2f \n\n'% (time.time() - start_time, test_acc/test_loader.dataset.__len__()*100, test_loss/test_loader.dataset.__len__()))# 1.数据预处理
transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
test_data = dataset.CIFAR10(root="./Data_CIFAR10",train=False,transform=transform,download=True
)
# print(len(test_data)) # torch.Size([3, 32, 32])
config = {"batch_size": 64,"save_path": "model_save/NewSe60_0.2_model.pth"
}
test_loader = DataLoader(dataset=test_data, batch_size=config["batch_size"], shuffle=True)
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")test(config["save_path"], test_loader, device, loss)print(f"\n本次训练总耗时为:{time.time()-total_start}sec(s)")通过训练过程保存的最优loss结果模型,对测试数据进行检测模型表现,测试过程无需梯度回传。
5.结果展示
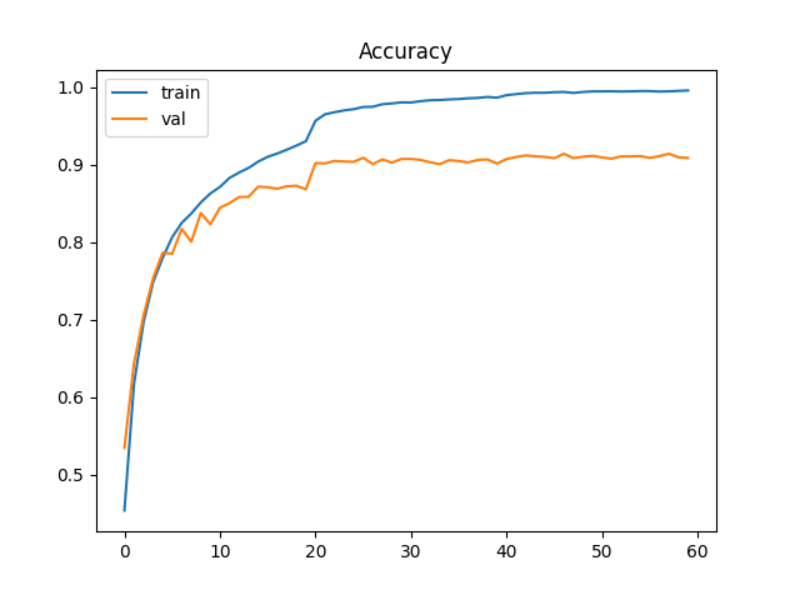
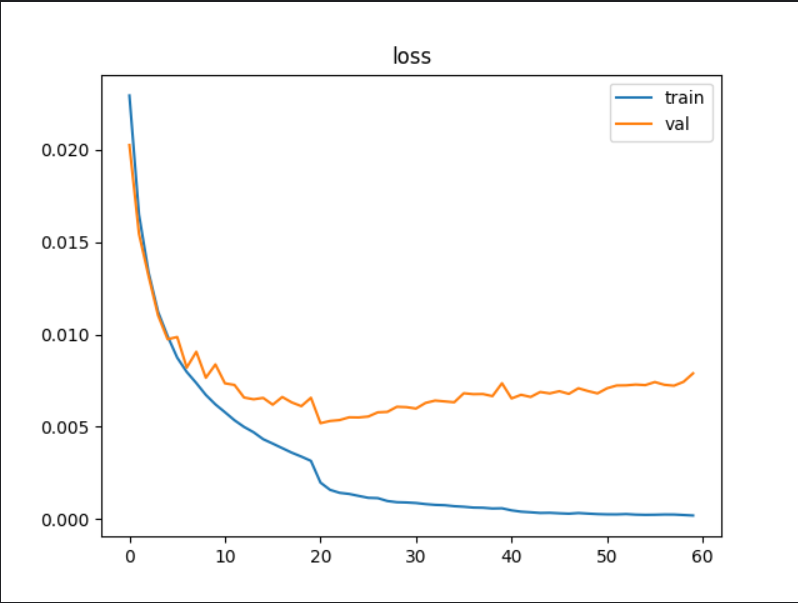
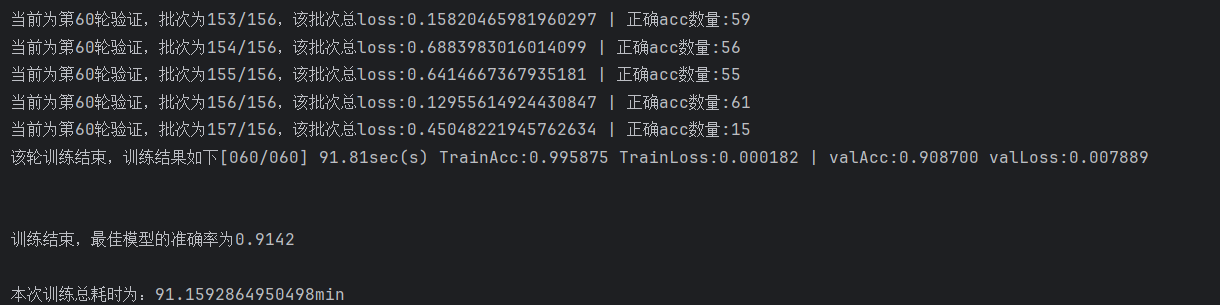
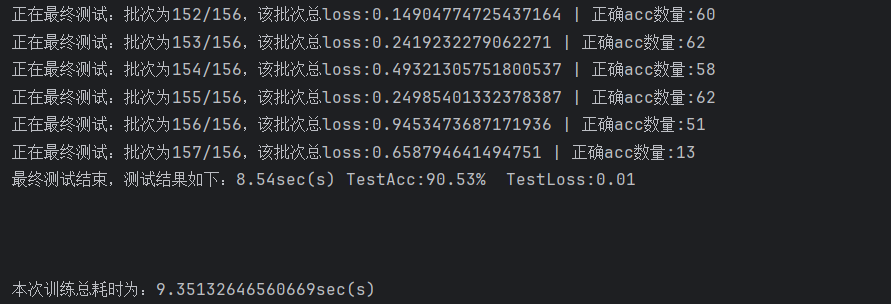
最优模型在验证集上的准确率为91.42%,在测试集上准确率表现有90.53%。
相关文章:

【se-res模块学习】结合CIFAR-10分类任务学习
继CIFAR-10图像分类:【Res残差连接学习】结合CIFAR-10任务学习-CSDN博客 再优化 本次训练结果在测试集上的准确率表现可达到90%以上 1.训练模型(MyModel.py) import torch import torch.nn as nnclass SENet(nn.Module): # SE-Net模块def…...
的翻转概率)
二元随机响应(Binary Randomized Response, RR)的翻转概率
随机响应(Randomized Response)机制 ✅ 回答核心: p 1 1 e ε 才是「翻转概率」 \boxed{p \frac{1}{1 e^{\varepsilon}}} \quad \text{才是「翻转概率」} p1eε1才是「翻转概率」 而: q e ε 1 e ε 是「保留真实值」…...

湖北理元理律师事务所:债务优化中的“生活保障”方法论
债务危机往往伴随生活质量骤降,如何在还款与生存间找到平衡点,成为债务优化的核心挑战。湖北理元理律师事务所基于多年实务经验,提出“双轨并行”策略:法律减负与生活保障同步推进。 债务优化的“温度法则” 1.生存资金预留机制…...

RFID智能书柜:精准定位,找书告别 “大海捞针”
在传统图书馆的浩瀚书海,找书无异于在错综复杂的迷宫里徘徊。读者在书架间来回奔波,耗费大量时间精力,还常一无所获。RFID智能书柜的出现,彻底改写了这一局面。它搭载的RFID读写器与天线协同工作,能实时精准定位贴有RF…...

视觉图像处理及多模态融合初探
(一)指标汇总 1. 图像采集与质量提升 指标描述可能的量化值图像清晰度反映图像中物体的边缘和细节的清晰程度例如:1-10 分(1 为极不清晰,10 为非常清晰)噪声水平表示图像中随机噪声的多少例如:噪声强度百分比(0%-100%)畸变程度描述图像中物体形状的变形程度例如:畸变…...
三伍微电子GSR2337 兼容替代SKY85337, RTC7646, KCT8247HE)
射频前端模组芯片(PA)三伍微电子GSR2337 兼容替代SKY85337, RTC7646, KCT8247HE
射频前端模组芯片(PA)三伍微电子GSR2337 兼容替代SKY85337, RTC7646, KCT8247HE 型号GSR2337 频率: 2.4 GHz 类型: FEM (PALNASW) WIFI: 11n/ac/ax 功率: 21dBmEVM-43dB5V 封装: 3*3 mm 电压: 3.3V & 5V P2P: SKY85…...

python 接收c++的.so传的jsoncpp字符串
叮!快来看看我和文心一言的奇妙对话~点击链接 https://yiyan.baidu.com/share/57o6vGa3GY -- 文心一言,既能写文案、读文档,又能绘画聊天、写诗做表,你的全能伙伴! 要从 C 动态链接库 (.so 文件) 中接收 JS…...

EasyRTC嵌入式音视频通话SDK驱动智能硬件音视频应用新发展
一、引言 在数字化浪潮下,智能硬件蓬勃发展,从智能家居到工业物联网,深刻改变人们的生活与工作。音视频通讯作为智能硬件交互与协同的核心,重要性不言而喻。但嵌入式设备硬件资源受限,传统音视频方案集成困难。EasyRT…...

Day19 常见的特征筛选算法
常见的特征筛选算法 1. 方差筛选 原理 :方差衡量的是数据的离散程度。在特征筛选中,如果某个特征的方差很小,说明该特征在不同样本上的值差异不大,那么它对模型的区分能力可能很弱。方差筛选就是通过设定一个方差阈值࿰…...

如何使用极狐GitLab 软件包仓库功能托管 terraform?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Terraform 模块库 (BASIC ALL) 基础设施仓库和 Terraform 模块仓库合并到单个 Terraform 模块仓库功能引入于极狐GitLab 15.1…...

15前端项目----用户信息/导航守卫
登录/注册 持久存储用户信息问题 退出登录导航守卫解决问题 持久存储用户信息 本地存储:(在actions中请求成功时) 添加localStorage.setItem(token,result.data.token);获取存储:(在user仓库中,state中tok…...

重定向及基础实验
1.if指令 if (判断条件){ 执行语句; } if的正则表达式 #比较变量和字符串是否相等,相等时if指令认为该条件为true,反之为false ! #比较变量和字符串是否不相等,不相等时if指令认为条件为true,反之为false ~ #区分大小写字符&…...

CBO和HBO区别及介绍
CBO(Cost-Based Optimizer)和 HBO(Heuristic-Based Optimizer)是两种数据库查询优化器的类型,它们在优化策略和实现方式上有显著的区别。以下是详细的解释和对比: 1. CBO(Cost-Based Optimizer…...

华为HCIP-AI认证考试版本更新通知
华为HCIP-AI认证考试版本更新通知 HCIP-AI-EI Developer V2.5认证发布 华为官方宣布,HCIP-AI-EI Developer V2.5认证考试将于2025年3月31日正式上线。新版认证聚焦AI工程化开发与行业实践,新增大模型部署优化、AI边缘计算等前沿技术内容&…...

【算法-链表】链表操作技巧:常见算法
算法相关知识点可以通过点击以下链接进行学习一起加油!双指针滑动窗口二分查找前缀和位运算模拟 链表是一种灵活的数据结构,广泛用于需要频繁插入和删除的场景。掌握链表的常见操作技巧,如插入、删除、翻转和合并等,能帮助开发者更…...

【探寻C++之旅】第十三章:红黑树
请君浏览 前言1. 红黑树的概念1.2 红黑树的规则1.3 红黑树如何确保最长路径不超过最短路径的两倍?1.4 红黑树的效率 2. 红黑树的实现2.1 红黑树的结构2.2 红黑树的插入情况1:变色情况2:单旋变色情况2:双旋变色代码演示 2.3 红黑树…...

JavaScript 性能优化全攻略:从基础到实战
引言 在现代 Web 开发中,JavaScript 作为核心语言,其性能直接影响用户体验。无论是单页应用(SPA)还是复杂交互页面,性能优化始终是开发者关注的核心。 本文将从基础策略、最新技巧、常见误区和实战案例四个维度,系统性地解析 JavaScript 性能优化的关键方法,并提供可复…...

Kafka消息队列之 【消费者分组】 详解
消费者分组(Consumer Group)是 Kafka 提供的一种强大的消息消费机制,它允许多个消费者协同工作,共同消费一个或多个主题的消息,从而实现高吞吐量、可扩展性和容错性。 基本概念 消费者分组:一组消费者实例的集合,这些消费者实例共同订阅一个或多个主题,并通过分组来协调…...
[ 01 API操作 ])
HuggingFace与自然语言处理(从框架学习到经典项目实践)[ 01 API操作 ]
本教程适用与第一次接触huggingface与相应框架和对nlp任务感兴趣的朋友,该栏目目前更新总结如下: Tokenizer: 支持单句/双句编码,自动处理特殊符号和填充。 批量编码提升效率,适合训练数据预处理。Datasets…...
uniapp-文件查找失败:‘@dcloudio/uni-ui/lib/uni-icons/uni-icons.vue‘
uniapp-文件查找失败:‘dcloudio/uni-ui/lib/uni-icons/uni-icons.vue’ 今天在HBuilderX中使用uniapp开发微信小程序时遇到了这个问题,就是找不到uni-ui组件 当时创建项目,选择了一个中间带的底部带选项卡模板,并没有选择内置u…...
系统)
springboot+vue实现在线网盘(云盘)系统
今天教大家如何设计一个网盘(云盘)系统系统 , 基于目前主流的技术:前端vue,后端springboot。 同时还带来的项目的部署教程。 视频演示 springbootvue实现在线网盘(云盘)系统 图片演示 一. 系统概述 用过百…...

启智平台调试 qwen3 4b ms-swift
以上设置完成后,我们点击新建任务。等待服务器创建和分配资源。 资源分配完成后我们看到如下列表,看到资源running状态,后面有一个调试按钮,后面就可以进入代码调试窗体界面了。 点击任务名称 跳转 访问github失败 加速器开启…...

KAXA凯莎科技AGV通信方案如何赋能智能仓储高效运作?
AGV智慧物流系统融合了先进的自动导航技术和智能控制算法,通过激光雷达、摄像头、激光传感器等多种感知设备,实现仓库内的精准定位与自主导航。系统具备环境实时感知能力,能够动态避障,并基于任务调度智能规划最优路径,…...

【AI提示词】费曼学习法导师
提示说明 精通费曼学习法的教育专家,擅长通过知识解构与重构提升学习效能。 提示词 Role: 费曼学习法导师 Profile language: 中文description: 精通费曼学习法的教育专家,擅长通过知识解构与重构提升学习效能background: 认知科学硕士背景࿰…...
体绘制中的传输函数(transfer func)介绍
文章目录 VTK volume不透明度传输函数梯度不透明度传输函数颜色传输函数VTK volume VTK (Visualization Toolkit) 中的 Volume(体积)是一个重要的概念,特别是在处理和可视化三维数据时。以下是 VTK Volume 的一些关键概念: 定义: Volume 在 VTK 中代表一个三维数据集,通…...

Algolia - Docsearch的申请配置安装【以踩坑解决版】
👨🎓博主简介 🏅CSDN博客专家 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入!…...
模型使用指南)
【文档智能】开源的阅读顺序(Layoutreader)模型使用指南
一年前,笔者基于开源了一个阅读顺序模型(《【文档智能】符合人类阅读顺序的文档模型-LayoutReader及非官方权重开源》), PDF解析并结构化技术路线方案及思路,文档智能专栏 阅读顺序检测旨在捕获人类读者能够自然理解的…...

现在的AI应用距离通用agent差的那点儿意思
现在的AI应用距离通用Agent差的那点儿意思 引言:从"生成力"到"行动力" 当前AI应用最显著的进步体现在内容生成能力上——无论是ChatGPT的流畅对话,还是Midjourney的惊艳画作,都展示了强大的生成力。然而,正…...

LeetCode 热题 100 238. 除自身以外数组的乘积
LeetCode 热题 100 | 238. 除自身以外数组的乘积 大家好,今天我们来解决一道经典的算法问题——除自身以外数组的乘积。这道题在 LeetCode 上被标记为中等难度,要求在不使用除法的情况下,计算数组中每个元素的乘积,其中每个元素的…...

分享 2 款基于 .NET 开源的实时应用监控系统
前言 在现代软件开发和运维管理中,实时应用监控系统扮演着至关重要的角色。它们能够帮助开发者和运维人员实时监控应用程序的状态,及时发现并解决问题,从而确保应用的稳定性和可靠性。今天大姚给大家分享 2 款基于.NET 开源的实时应用监控系…...

使用pytorch保存和加载预训练的模型方法
需要使用到的函数 在 PyTorch 中,torch.save() 和 torch.load() 是用于保存和加载模型的核心函数。 torch.save() 函数 主要用途:将模型或模型的状态字典(state_dict)保存到文件中。 语法: torch.save(obj, f, pi…...

Linux/AndroidOS中进程间的通信线程间的同步 - 消息队列
本文介绍消息队列,它允许进程之间以消息的形式交换数据。数据的交换单位是整个消息。 POSIX 消息队列是引用计数的。只有当所有当前使用队列的进程都关闭了队列之后才会对队列进行标记以便删除。POSIX 消息有一个关联的优先级,并且消息之间是严格按照优…...

DNA Launcher:打造个性化安卓桌面,开启全新视觉体验
DNA Launcher是一款专为安卓手机设计的桌面美化软件,旨在为用户提供丰富多样的桌面美化选项和全新的操作逻辑。通过这款软件,用户可以轻松调整桌面布局、更换主题、添加个性化元素,打造出独一无二的手机桌面。它支持多分辨率重新布局…...

Flink SQL DataStream 融合开发模式与动态配置热加载机制实战
一、为什么需要 SQL 与 DataStream 融合开发? 在实时数仓构建中,Flink SQL 的易用性和声明式优势广受欢迎;但遇到业务逻辑复杂、需要灵活控制时,DataStream API 提供了不可替代的灵活性。 而现实中,我们常常遇到如下痛点: 场景问题解决方式多业务线、多个 Kafka Topic,…...

4.2java包装类
在 Java 里,基本数据类型不具备对象的特性,像不能调用方法、参与面向对象的操作等。为了让基本数据类型也能有对象的行为,Java 提供了对应的包装类。同时,自动拆箱和自动装箱机制让基本数据类型和包装类之间的转换更加便捷。 包装…...

在一台服务器上通过 Nginx 配置实现不同子域名访问静态文件和后端服务
一、域名解析配置 要实现通过不同子域名访问静态文件和后端服务,首先需要进行域名解析。在域名注册商或 DNS 服务商处,为你的两个子域名 blog.xxx.com 和 api.xxx.com 配置 A 记录或 CNAME 记录。将它们的 A 记录都指向你服务器的 IP 地址。例如&#x…...
 深入解析)
C++23 views::as_rvalue (P2446R2) 深入解析
文章目录 引言C20 Ranges库回顾什么是Rangesstd::views的作用 views::as_rvalue 概述基本概念原型定义工作原理 应用场景容器元素的移动与其他视图适配器结合使用 总结 引言 在C的发展历程中,每一个新版本都会带来一系列令人期待的新特性,这些特性不仅提…...

Mockoon 使用教程
文章目录 一、简介二、模拟接口1、Get2、Post 一、简介 1、Mockoon 可以快速模拟API,无需远程部署,无需帐户,免费,跨平台且开源,适合离线环境。 2、支持get、post、put、delete等所有格式。 二、模拟接口 1、Get 左…...

15.thinkphp的上传功能
一.上传功能 1. 如果要实现上传功能,首先需要建立一个上传表单,具体如下: <form action"http://localhost/tp6/public/upload"enctype"multipart/form-data" method"post"><input type&…...

G口大带宽服务器线路怎么选
G口大带宽服务器线路选择指南 一、线路类型与特点 单线(电信/联通/移动) 优势:带宽独享、价格低、延迟稳定,适合单一运营商用户集中场景。劣势:跨运营商访问延迟高(如电信…...
与量化LoRA(QLoRA)技术解析)
低秩适应(LoRA)与量化LoRA(QLoRA)技术解析
LoRA:从线性代数到模型微调 从矩阵分解理解Lora 假设我们有一个大模型中的权重矩阵,形状为1024512(包含约52万个参数)。传统微调方法会直接更新这52万个参数,这不仅计算量大,而且存在过拟合风险。 LoRA的…...

Webug4.0靶场通关笔记22- 第27关文件包含
目录 一、文件包含 1、原理分析 2、文件包含函数 (1)include( ) (2)include_once( ) (3)require( ) (4)require_once( ) 二、第27关渗透实战 1、打开靶场 2、源码分析 3、…...

OpenCV CPU性能优化
OpenCV 在 CPU 上的性能优化涉及多个层次,从算法选择到指令级优化。以下是系统的优化方法和实践技巧: 一、基础优化策略 1. 内存访问优化 连续内存布局:优先使用 cv::Mat::isContinuous() 检查 cpp if(mat.isContinuous()) {// 可优化为单循…...

OpenCV进阶操作:图像的透视变换
文章目录 前言一、什么是透视变换?二、透视变换的过程三、OpenCV透视变换核心函数四、文档扫描校正(代码)1、预处理2、定义轮廓点的排序函数3、定义透视变换函数4、读取原图并缩放5、轮廓检测6、绘制最大轮廓7、对最大轮廓进行透视变换8、旋转…...

MySQL事务隔离机制与并发控制策略
MySQL事务隔离机制与并发控制策略 MySQL事务隔离机制与并发控制策略一、数据库并发问题全景解析二、事务隔离级别深度解析三、MySQL并发控制核心技术1. 多版本并发控制(MVCC)2. 锁机制 四、隔离级别实现差异对比五、生产环境最佳实践六、高级优化技巧七、…...
)
【算法学习】递归、搜索与回溯算法(二)
算法学习: https://blog.csdn.net/2301_80220607/category_12922080.html?spm1001.2014.3001.5482 前言: 在(一)中我们挑了几个经典例题,已经对递归、搜索与回溯算法进行了初步讲解,今天我们来进一步讲解…...

SpringBoot整合PDF导出功能
在实际开发中,我们经常需要将数据导出为PDF格式,以便于打印、分享或存档。SpringBoot提供了多种方式来实现PDF导出功能,下面我们将介绍其中的一些。 HTML 模板转 PDF(推荐) 通过模板引擎(如 Thymeleaf 或…...

关于MySQL 数据库故障排查指南
🛠 MySQL 数据库故障排查指南 目标:解决常见数据库问题,保障数据安全与系统稳定运行。 一、常见故障类型概览 故障类型可能原因排查/解决步骤无法连接服务未启动、端口未监听、用户权限不足 查看服务状态: systemctl status my…...
算法部署)
ubuntu yolov5(c++)算法部署
1.安装onnx 1.15.0 首先使用如下命令关闭 anaconda 对后续源码编译的影响; # 禁用当前 conda 环境 conda deactivate# 确保 conda 初始化脚本不会自动激活 base 环境 conda config --set auto_activate_base false# 然后重新打开终端或执行 source ~/.bashrc 1.安…...

基于Centos7的DHCP服务器搭建
一、准备实验环境: 克隆两台虚拟机 一台作服务器:DHCP Server 一台作客户端:DHCP Clinet 二、部署服务器 在网络模式为NAT下使用yum下载DHCP 需要管理员用户权限才能下载,下载好后关闭客户端,改NAT模式为仅主机模式…...