Day19 常见的特征筛选算法
常见的特征筛选算法
1. 方差筛选
- 原理 :方差衡量的是数据的离散程度。在特征筛选中,如果某个特征的方差很小,说明该特征在不同样本上的值差异不大,那么它对模型的区分能力可能很弱。方差筛选就是通过设定一个方差阈值,将方差小于该阈值的特征剔除。
- 优点 :计算简单,速度快,不需要依赖模型。
- 缺点 :只考虑了单个特征自身的方差,没有考虑特征与目标变量之间的关系,可能会误删一些有用的特征。
- 应用场景 :适用于快速初步筛选特征,减少数据维度。
2. 皮尔逊相关系数筛选
- 原理 :皮尔逊相关系数用于衡量两个变量之间的线性相关程度,取值范围在 -1 到 1 之间。在特征筛选中,通过计算每个特征与目标变量之间的皮尔逊相关系数,选择相关系数绝对值较大的特征,因为这些特征与目标变量的线性关系更紧密。
- 优点 :可以量化特征与目标变量之间的线性关系,简单易懂。
- 缺点 :只能检测线性关系,对于非线性关系的特征可能会失效。
- 应用场景 :适用于数据呈线性关系的场景。
3. Lasso 筛选
- 原理 :Lasso(Least Absolute Shrinkage and Selection Operator)是一种线性回归模型,在损失函数中加入了 L1 正则化项。L1 正则化会使得部分特征的系数变为 0,从而达到特征选择的目的。
- 优点 :可以同时进行特征选择和模型训练,能够处理高维数据。
- 缺点 :当特征之间存在高度相关性时,Lasso 可能只会选择其中一个特征,而忽略其他相关特征。
- 应用场景 :适用于高维数据和特征选择问题。
4. 树模型重要性
- 原理 :基于树的模型(如随机森林、梯度提升树等)在训练过程中可以计算每个特征的重要性。特征重要性通常根据特征在树的分裂过程中带来的信息增益或基尼系数的减少量来衡量。选择重要性较高的特征可以提高模型的性能。
- 优点 :能够处理非线性关系,不需要对数据进行预处理,并且可以自动考虑特征之间的交互作用。
- 缺点 :计算复杂度较高,不同的树模型可能会得到不同的特征重要性结果。
- 应用场景 :适用于各种类型的数据,特别是非线性数据。
5. SHAP 重要性
- 原理 :SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法。SHAP 值衡量了每个特征对模型预测结果的贡献程度。通过计算每个特征的 SHAP 值的绝对值的均值,可以得到特征的重要性排序。
- 优点 :具有理论上的合理性,能够提供全局和局部的特征重要性解释,适用于各种类型的模型。
- 缺点 :计算复杂度较高,特别是对于大规模数据集和复杂模型。
- 应用场景 :适用于需要深入理解模型预测结果和特征重要性的场景。
6. 递归特征消除(RFE)
- 原理 :递归特征消除是一种迭代的特征选择方法。首先使用全部特征训练一个模型,然后根据模型的系数或特征重要性,剔除最不重要的特征。接着在剩余的特征上重新训练模型,重复这个过程,直到达到预设的特征数量。
- 优点 :可以利用模型的信息进行特征选择,能够找到最优的特征子集。
- 缺点 :计算复杂度较高,需要多次训练模型。
- 应用场景 :适用于对模型性能要求较高,并且有足够计算资源的场景。
下面是根据心脏病数据集来检测一下这几种特征筛选算法。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, Lasso
from sklearn.feature_selection import VarianceThreshold, SelectKBest, f_classif, RFE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import shap
import matplotlib.pyplot as plt# 加载数据
data = pd.read_csv('./csv/heart.csv')
X = data.drop('target', axis=1)
y = data['target']# 数据划分与标准化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 定义逻辑回归模型
model = LogisticRegression(random_state=42)# 原始数据模型精度
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
original_accuracy = accuracy_score(y_test, y_pred)
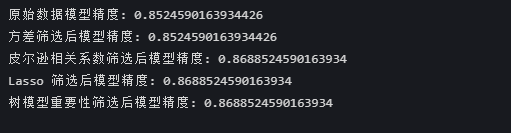
print(f"原始数据模型精度: {original_accuracy}")# 1. 方差筛选
selector_var = VarianceThreshold(threshold=0.1)
X_train_var = selector_var.fit_transform(X_train_scaled)
X_test_var = selector_var.transform(X_test_scaled)
model.fit(X_train_var, y_train)
y_pred_var = model.predict(X_test_var)
var_accuracy = accuracy_score(y_test, y_pred_var)
print(f"方差筛选后模型精度: {var_accuracy}")# 2. 皮尔逊相关系数筛选
selector_corr = SelectKBest(score_func=f_classif, k=5)
X_train_corr = selector_corr.fit_transform(X_train_scaled, y_train)
X_test_corr = selector_corr.transform(X_test_scaled)
model.fit(X_train_corr, y_train)
y_pred_corr = model.predict(X_test_corr)
corr_accuracy = accuracy_score(y_test, y_pred_corr)
print(f"皮尔逊相关系数筛选后模型精度: {corr_accuracy}")# 3. Lasso 筛选
lasso = Lasso(alpha=0.01)
lasso.fit(X_train_scaled, y_train)
non_zero_indices = np.where(lasso.coef_ != 0)[0]
X_train_lasso = X_train_scaled[:, non_zero_indices]
X_test_lasso = X_test_scaled[:, non_zero_indices]
model.fit(X_train_lasso, y_train)
y_pred_lasso = model.predict(X_test_lasso)
lasso_accuracy = accuracy_score(y_test, y_pred_lasso)
print(f"Lasso 筛选后模型精度: {lasso_accuracy}")# 4. 树模型重要性筛选
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train_scaled, y_train)
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
top_features = indices[:5]
X_train_tree = X_train_scaled[:, top_features]
X_test_tree = X_test_scaled[:, top_features]
model.fit(X_train_tree, y_train)
y_pred_tree = model.predict(X_test_tree)
tree_accuracy = accuracy_score(y_test, y_pred_tree)
print(f"树模型重要性筛选后模型精度: {tree_accuracy}")# 5. SHAP 重要性筛选
explainer = shap.Explainer(rf)
shap_values = explainer(X_train_scaled)
shap_importance = np.abs(shap_values.values).mean(0)
shap_indices = np.argsort(shap_importance)[::-1]
shap_top_features = shap_indices[:5]
X_train_shap = X_train_scaled[:, shap_top_features]
X_test_shap = X_test_scaled[:, shap_top_features]
model.fit(X_train_shap, y_train)
y_pred_shap = model.predict(X_test_shap)
shap_accuracy = accuracy_score(y_test, y_pred_shap)
print(f"SHAP 重要性筛选后模型精度: {shap_accuracy}")# 6. 递归特征消除(RFE)
rfe = RFE(estimator=model, n_features_to_select=5)
X_train_rfe = rfe.fit_transform(X_train_scaled, y_train)
X_test_rfe = rfe.transform(X_test_scaled)
model.fit(X_train_rfe, y_train)
y_pred_rfe = model.predict(X_test_rfe)
rfe_accuracy = accuracy_score(y_test, y_pred_rfe)
print(f"递归特征消除(RFE)筛选后模型精度: {rfe_accuracy}")# 可视化结果
methods = ['Original', 'Variance', 'Correlation', 'Lasso', 'Tree', 'SHAP', 'RFE']
accuracies = [original_accuracy, var_accuracy, corr_accuracy, lasso_accuracy, tree_accuracy, shap_accuracy, rfe_accuracy]plt.bar(methods, accuracies)
plt.xlabel('Feature Selection Methods')
plt.ylabel('Accuracy')
plt.title('Comparison of Model Accuracies after Feature Selection')
plt.xticks(rotation=45)
plt.show()
总结
可以看到其实这几种算法精度都差不多,后三者的特征筛选后精度略高一点。
相关文章:

Day19 常见的特征筛选算法
常见的特征筛选算法 1. 方差筛选 原理 :方差衡量的是数据的离散程度。在特征筛选中,如果某个特征的方差很小,说明该特征在不同样本上的值差异不大,那么它对模型的区分能力可能很弱。方差筛选就是通过设定一个方差阈值࿰…...

如何使用极狐GitLab 软件包仓库功能托管 terraform?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Terraform 模块库 (BASIC ALL) 基础设施仓库和 Terraform 模块仓库合并到单个 Terraform 模块仓库功能引入于极狐GitLab 15.1…...

15前端项目----用户信息/导航守卫
登录/注册 持久存储用户信息问题 退出登录导航守卫解决问题 持久存储用户信息 本地存储:(在actions中请求成功时) 添加localStorage.setItem(token,result.data.token);获取存储:(在user仓库中,state中tok…...

重定向及基础实验
1.if指令 if (判断条件){ 执行语句; } if的正则表达式 #比较变量和字符串是否相等,相等时if指令认为该条件为true,反之为false ! #比较变量和字符串是否不相等,不相等时if指令认为条件为true,反之为false ~ #区分大小写字符&…...

CBO和HBO区别及介绍
CBO(Cost-Based Optimizer)和 HBO(Heuristic-Based Optimizer)是两种数据库查询优化器的类型,它们在优化策略和实现方式上有显著的区别。以下是详细的解释和对比: 1. CBO(Cost-Based Optimizer…...

华为HCIP-AI认证考试版本更新通知
华为HCIP-AI认证考试版本更新通知 HCIP-AI-EI Developer V2.5认证发布 华为官方宣布,HCIP-AI-EI Developer V2.5认证考试将于2025年3月31日正式上线。新版认证聚焦AI工程化开发与行业实践,新增大模型部署优化、AI边缘计算等前沿技术内容&…...

【算法-链表】链表操作技巧:常见算法
算法相关知识点可以通过点击以下链接进行学习一起加油!双指针滑动窗口二分查找前缀和位运算模拟 链表是一种灵活的数据结构,广泛用于需要频繁插入和删除的场景。掌握链表的常见操作技巧,如插入、删除、翻转和合并等,能帮助开发者更…...

【探寻C++之旅】第十三章:红黑树
请君浏览 前言1. 红黑树的概念1.2 红黑树的规则1.3 红黑树如何确保最长路径不超过最短路径的两倍?1.4 红黑树的效率 2. 红黑树的实现2.1 红黑树的结构2.2 红黑树的插入情况1:变色情况2:单旋变色情况2:双旋变色代码演示 2.3 红黑树…...

JavaScript 性能优化全攻略:从基础到实战
引言 在现代 Web 开发中,JavaScript 作为核心语言,其性能直接影响用户体验。无论是单页应用(SPA)还是复杂交互页面,性能优化始终是开发者关注的核心。 本文将从基础策略、最新技巧、常见误区和实战案例四个维度,系统性地解析 JavaScript 性能优化的关键方法,并提供可复…...

Kafka消息队列之 【消费者分组】 详解
消费者分组(Consumer Group)是 Kafka 提供的一种强大的消息消费机制,它允许多个消费者协同工作,共同消费一个或多个主题的消息,从而实现高吞吐量、可扩展性和容错性。 基本概念 消费者分组:一组消费者实例的集合,这些消费者实例共同订阅一个或多个主题,并通过分组来协调…...
[ 01 API操作 ])
HuggingFace与自然语言处理(从框架学习到经典项目实践)[ 01 API操作 ]
本教程适用与第一次接触huggingface与相应框架和对nlp任务感兴趣的朋友,该栏目目前更新总结如下: Tokenizer: 支持单句/双句编码,自动处理特殊符号和填充。 批量编码提升效率,适合训练数据预处理。Datasets…...
uniapp-文件查找失败:‘@dcloudio/uni-ui/lib/uni-icons/uni-icons.vue‘
uniapp-文件查找失败:‘dcloudio/uni-ui/lib/uni-icons/uni-icons.vue’ 今天在HBuilderX中使用uniapp开发微信小程序时遇到了这个问题,就是找不到uni-ui组件 当时创建项目,选择了一个中间带的底部带选项卡模板,并没有选择内置u…...
系统)
springboot+vue实现在线网盘(云盘)系统
今天教大家如何设计一个网盘(云盘)系统系统 , 基于目前主流的技术:前端vue,后端springboot。 同时还带来的项目的部署教程。 视频演示 springbootvue实现在线网盘(云盘)系统 图片演示 一. 系统概述 用过百…...

启智平台调试 qwen3 4b ms-swift
以上设置完成后,我们点击新建任务。等待服务器创建和分配资源。 资源分配完成后我们看到如下列表,看到资源running状态,后面有一个调试按钮,后面就可以进入代码调试窗体界面了。 点击任务名称 跳转 访问github失败 加速器开启…...

KAXA凯莎科技AGV通信方案如何赋能智能仓储高效运作?
AGV智慧物流系统融合了先进的自动导航技术和智能控制算法,通过激光雷达、摄像头、激光传感器等多种感知设备,实现仓库内的精准定位与自主导航。系统具备环境实时感知能力,能够动态避障,并基于任务调度智能规划最优路径,…...

【AI提示词】费曼学习法导师
提示说明 精通费曼学习法的教育专家,擅长通过知识解构与重构提升学习效能。 提示词 Role: 费曼学习法导师 Profile language: 中文description: 精通费曼学习法的教育专家,擅长通过知识解构与重构提升学习效能background: 认知科学硕士背景࿰…...
体绘制中的传输函数(transfer func)介绍
文章目录 VTK volume不透明度传输函数梯度不透明度传输函数颜色传输函数VTK volume VTK (Visualization Toolkit) 中的 Volume(体积)是一个重要的概念,特别是在处理和可视化三维数据时。以下是 VTK Volume 的一些关键概念: 定义: Volume 在 VTK 中代表一个三维数据集,通…...

Algolia - Docsearch的申请配置安装【以踩坑解决版】
👨🎓博主简介 🏅CSDN博客专家 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入!…...
模型使用指南)
【文档智能】开源的阅读顺序(Layoutreader)模型使用指南
一年前,笔者基于开源了一个阅读顺序模型(《【文档智能】符合人类阅读顺序的文档模型-LayoutReader及非官方权重开源》), PDF解析并结构化技术路线方案及思路,文档智能专栏 阅读顺序检测旨在捕获人类读者能够自然理解的…...

现在的AI应用距离通用agent差的那点儿意思
现在的AI应用距离通用Agent差的那点儿意思 引言:从"生成力"到"行动力" 当前AI应用最显著的进步体现在内容生成能力上——无论是ChatGPT的流畅对话,还是Midjourney的惊艳画作,都展示了强大的生成力。然而,正…...

LeetCode 热题 100 238. 除自身以外数组的乘积
LeetCode 热题 100 | 238. 除自身以外数组的乘积 大家好,今天我们来解决一道经典的算法问题——除自身以外数组的乘积。这道题在 LeetCode 上被标记为中等难度,要求在不使用除法的情况下,计算数组中每个元素的乘积,其中每个元素的…...

分享 2 款基于 .NET 开源的实时应用监控系统
前言 在现代软件开发和运维管理中,实时应用监控系统扮演着至关重要的角色。它们能够帮助开发者和运维人员实时监控应用程序的状态,及时发现并解决问题,从而确保应用的稳定性和可靠性。今天大姚给大家分享 2 款基于.NET 开源的实时应用监控系…...

使用pytorch保存和加载预训练的模型方法
需要使用到的函数 在 PyTorch 中,torch.save() 和 torch.load() 是用于保存和加载模型的核心函数。 torch.save() 函数 主要用途:将模型或模型的状态字典(state_dict)保存到文件中。 语法: torch.save(obj, f, pi…...

Linux/AndroidOS中进程间的通信线程间的同步 - 消息队列
本文介绍消息队列,它允许进程之间以消息的形式交换数据。数据的交换单位是整个消息。 POSIX 消息队列是引用计数的。只有当所有当前使用队列的进程都关闭了队列之后才会对队列进行标记以便删除。POSIX 消息有一个关联的优先级,并且消息之间是严格按照优…...

DNA Launcher:打造个性化安卓桌面,开启全新视觉体验
DNA Launcher是一款专为安卓手机设计的桌面美化软件,旨在为用户提供丰富多样的桌面美化选项和全新的操作逻辑。通过这款软件,用户可以轻松调整桌面布局、更换主题、添加个性化元素,打造出独一无二的手机桌面。它支持多分辨率重新布局…...

Flink SQL DataStream 融合开发模式与动态配置热加载机制实战
一、为什么需要 SQL 与 DataStream 融合开发? 在实时数仓构建中,Flink SQL 的易用性和声明式优势广受欢迎;但遇到业务逻辑复杂、需要灵活控制时,DataStream API 提供了不可替代的灵活性。 而现实中,我们常常遇到如下痛点: 场景问题解决方式多业务线、多个 Kafka Topic,…...

4.2java包装类
在 Java 里,基本数据类型不具备对象的特性,像不能调用方法、参与面向对象的操作等。为了让基本数据类型也能有对象的行为,Java 提供了对应的包装类。同时,自动拆箱和自动装箱机制让基本数据类型和包装类之间的转换更加便捷。 包装…...

在一台服务器上通过 Nginx 配置实现不同子域名访问静态文件和后端服务
一、域名解析配置 要实现通过不同子域名访问静态文件和后端服务,首先需要进行域名解析。在域名注册商或 DNS 服务商处,为你的两个子域名 blog.xxx.com 和 api.xxx.com 配置 A 记录或 CNAME 记录。将它们的 A 记录都指向你服务器的 IP 地址。例如&#x…...
 深入解析)
C++23 views::as_rvalue (P2446R2) 深入解析
文章目录 引言C20 Ranges库回顾什么是Rangesstd::views的作用 views::as_rvalue 概述基本概念原型定义工作原理 应用场景容器元素的移动与其他视图适配器结合使用 总结 引言 在C的发展历程中,每一个新版本都会带来一系列令人期待的新特性,这些特性不仅提…...

Mockoon 使用教程
文章目录 一、简介二、模拟接口1、Get2、Post 一、简介 1、Mockoon 可以快速模拟API,无需远程部署,无需帐户,免费,跨平台且开源,适合离线环境。 2、支持get、post、put、delete等所有格式。 二、模拟接口 1、Get 左…...

15.thinkphp的上传功能
一.上传功能 1. 如果要实现上传功能,首先需要建立一个上传表单,具体如下: <form action"http://localhost/tp6/public/upload"enctype"multipart/form-data" method"post"><input type&…...

G口大带宽服务器线路怎么选
G口大带宽服务器线路选择指南 一、线路类型与特点 单线(电信/联通/移动) 优势:带宽独享、价格低、延迟稳定,适合单一运营商用户集中场景。劣势:跨运营商访问延迟高(如电信…...
与量化LoRA(QLoRA)技术解析)
低秩适应(LoRA)与量化LoRA(QLoRA)技术解析
LoRA:从线性代数到模型微调 从矩阵分解理解Lora 假设我们有一个大模型中的权重矩阵,形状为1024512(包含约52万个参数)。传统微调方法会直接更新这52万个参数,这不仅计算量大,而且存在过拟合风险。 LoRA的…...

Webug4.0靶场通关笔记22- 第27关文件包含
目录 一、文件包含 1、原理分析 2、文件包含函数 (1)include( ) (2)include_once( ) (3)require( ) (4)require_once( ) 二、第27关渗透实战 1、打开靶场 2、源码分析 3、…...

OpenCV CPU性能优化
OpenCV 在 CPU 上的性能优化涉及多个层次,从算法选择到指令级优化。以下是系统的优化方法和实践技巧: 一、基础优化策略 1. 内存访问优化 连续内存布局:优先使用 cv::Mat::isContinuous() 检查 cpp if(mat.isContinuous()) {// 可优化为单循…...

OpenCV进阶操作:图像的透视变换
文章目录 前言一、什么是透视变换?二、透视变换的过程三、OpenCV透视变换核心函数四、文档扫描校正(代码)1、预处理2、定义轮廓点的排序函数3、定义透视变换函数4、读取原图并缩放5、轮廓检测6、绘制最大轮廓7、对最大轮廓进行透视变换8、旋转…...

MySQL事务隔离机制与并发控制策略
MySQL事务隔离机制与并发控制策略 MySQL事务隔离机制与并发控制策略一、数据库并发问题全景解析二、事务隔离级别深度解析三、MySQL并发控制核心技术1. 多版本并发控制(MVCC)2. 锁机制 四、隔离级别实现差异对比五、生产环境最佳实践六、高级优化技巧七、…...
)
【算法学习】递归、搜索与回溯算法(二)
算法学习: https://blog.csdn.net/2301_80220607/category_12922080.html?spm1001.2014.3001.5482 前言: 在(一)中我们挑了几个经典例题,已经对递归、搜索与回溯算法进行了初步讲解,今天我们来进一步讲解…...

SpringBoot整合PDF导出功能
在实际开发中,我们经常需要将数据导出为PDF格式,以便于打印、分享或存档。SpringBoot提供了多种方式来实现PDF导出功能,下面我们将介绍其中的一些。 HTML 模板转 PDF(推荐) 通过模板引擎(如 Thymeleaf 或…...

关于MySQL 数据库故障排查指南
🛠 MySQL 数据库故障排查指南 目标:解决常见数据库问题,保障数据安全与系统稳定运行。 一、常见故障类型概览 故障类型可能原因排查/解决步骤无法连接服务未启动、端口未监听、用户权限不足 查看服务状态: systemctl status my…...
算法部署)
ubuntu yolov5(c++)算法部署
1.安装onnx 1.15.0 首先使用如下命令关闭 anaconda 对后续源码编译的影响; # 禁用当前 conda 环境 conda deactivate# 确保 conda 初始化脚本不会自动激活 base 环境 conda config --set auto_activate_base false# 然后重新打开终端或执行 source ~/.bashrc 1.安…...

基于Centos7的DHCP服务器搭建
一、准备实验环境: 克隆两台虚拟机 一台作服务器:DHCP Server 一台作客户端:DHCP Clinet 二、部署服务器 在网络模式为NAT下使用yum下载DHCP 需要管理员用户权限才能下载,下载好后关闭客户端,改NAT模式为仅主机模式…...

《开源先锋Apache软件基金会:历史沿革、顶级项目与行业影响》
1. Apache软件基金会概述 Apache软件基金会(Apache Software Foundation, ASF) 是全球最大的开源软件组织之一,成立于1999年,是一个非营利性机构,致力于为公共利益提供开源软件。ASF以“社区主导、共识决策”为核心原…...

Java数据结构——Queue
Queue 队列的概念队列的使用offer和poll方法add和remove方法 设计循环队列队列实现栈栈实现队列 前面所说的Stack是 先入后出的原则,那有没有 先入先出的原则的结构呢?这就是本篇博客所讲的Queue序列就是这个原则 队列的概念 只允许在一段进行插入数据…...

仓储车间安全革命:AI叉车防撞装置系统如何化解操作风险
在现代物流体系中,仓储承担着货物储存、保管、分拣和配送等重要任务。但现代仓储行业的安全现状却不容乐观,诸多痛点严重制约着其发展,其中叉车作业的安全问题尤为突出。相关数据显示,全球范围内,每年因叉车事故导致的…...

深入 FaaS 核心:函数是如何“活”起来的?
深入 FaaS 核心:函数是如何“活”起来的? 在上一篇《你好,Serverless!告别服务器运维的烦恼》中,我们认识了 Serverless 的基本概念,并知道了 FaaS (Function as a Service) 是其核心计算单元,就像一个个“随叫随到”的专业工具人。 那么,这些“工具人”到底是如何被“…...

vue2 两种路由跳转方式
第一种方式:path跳转 第二中写法:用name跳转 路由传参 动态路由传参 案例 通过${} 动态路由传参 动态路由使用params来进行接收 name 传参 总结 传的什么用什么接受...

手机上使用的记录笔记的软件推荐哪一款
在快节奏的生活中,一款好用的手机笔记软件就像随身携带的“外挂大脑”,能帮我们高效记录生活点滴、工作计划和灵感创意。今天,就来给大家详细对比一下Pendo、敬业签、MIGi日历记事本这三款热门笔记软件。 一、Pendo笔记:智能日程…...

SpringBoot 讯飞星火AI WebFlux流式接口返回 异步返回 对接AI大模型 人工智能接口返回
介绍 用于构建基于 WebFlux 的响应式 Web 应用程序。集成了 Spring WebFlux 模块,支持响应式编程模型,构建非阻塞、异步的 Web 应用。WebFlux 使用了非阻塞的异步模型,能够更好地处理高并发请求。适合需要实时数据推送的应用场景。 WebClie…...
)
Python学习笔记--Django的安装和简单使用(一)
一.简介 Django 是一个用于构建 Web 应用程序的高级 Python Web 框架。Django 提供了一套强大的工具和约定,使得开发者能够快速构建功能齐全且易于维护的网站。Django 遵守 BSD 版权,初次发布于 2005 年 7 月, 并于 2008 年 9 月发布了第一个正式版本 1…...