Python打卡 DAY 18
知识点回顾:
1. 推断簇含义的2个思路:先选特征和后选特征
2. 通过可视化图形借助ai定义簇的含义
3. 科研逻辑闭环:通过精度判断特征工程价值
作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。
# 先运行之前预处理好的代码
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('D:\python学习\学习资源(代码)\python60-days-challenge-master\python60-days-challenge-master\heart.csv') #读取数据from sklearn.model_selection import train_test_split
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签
# # 按照8:2划分训练集和测试集
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# X_scaledimport numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 k 下的指标
k_range = range(2, 11) # 测试k从 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42) kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 轮廓系数: {silhouette:.3f}, 惯性: {kmeans.inertia_:.2f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")selected_k = 3 # 示例值,根据图表调整# 使用选择的k进行kmeans聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())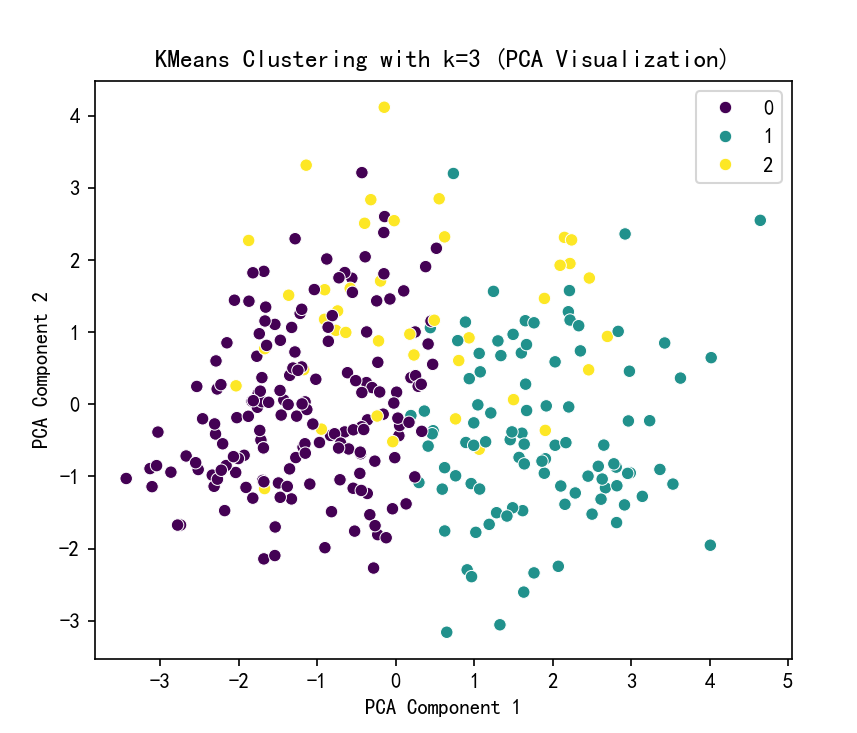
print(X.columns)
x1= X.drop('KMeans_Cluster',axis=1) # 删除聚类标签列
y1 = X['KMeans_Cluster']
# 构建随机森林,用shap重要性来筛选重要性
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林模型
model.fit(x1, y1) # 训练模型,此时无需在意准确率 直接全部数据用来训练了shap.initjs() # 初始化JavaScript环境,用于SHAP值的可视化
explainer = shap.TreeExplainer(model) # 创建一个TreeExplainer对象,用于解释模型的输出
shap_values = explainer.shap_values(x1) # 计算SHAP值,用于解释模型的预测结果
shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:,:,0],x1,plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance Bar Plot")
print(plt.show())
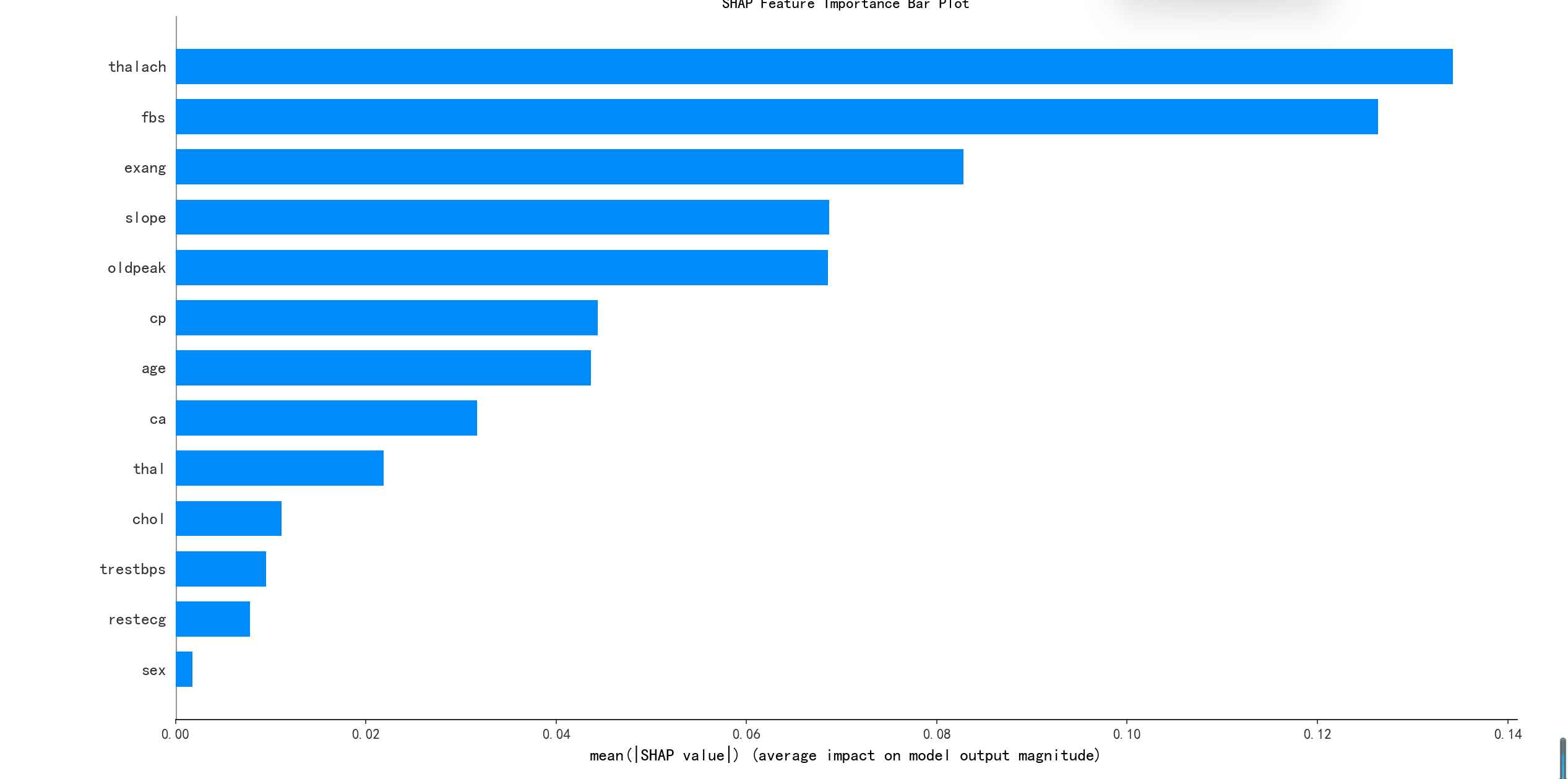
# 此时判断一下这几个特征是离散型还是连续型
import pandas as pd
selected_features = ['thalach', 'fbs','exang', 'slope','oldpeak']for feature in selected_features:unique_count = X[feature].nunique() # 唯一值指的是在某一列或某个特征中,不重复出现的值# 连续型变量通常有很多唯一值,而离散型变量的唯一值较少print(f'{feature} 的唯一值数量: {unique_count}')if unique_count < 10: # 这里 10 是一个经验阈值,可以根据实际情况调整print(f'{feature} 可能是离散型变量')else:print(f'{feature} 可能是连续型变量')
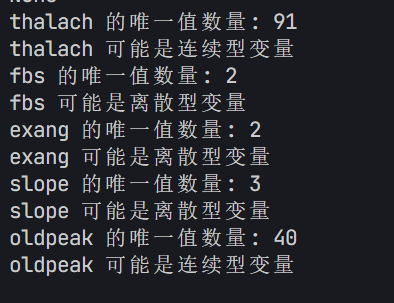
# X["Purpose_debt consolidation"].value_counts() # 统计每个唯一值的出现次数
import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
print(plt.show())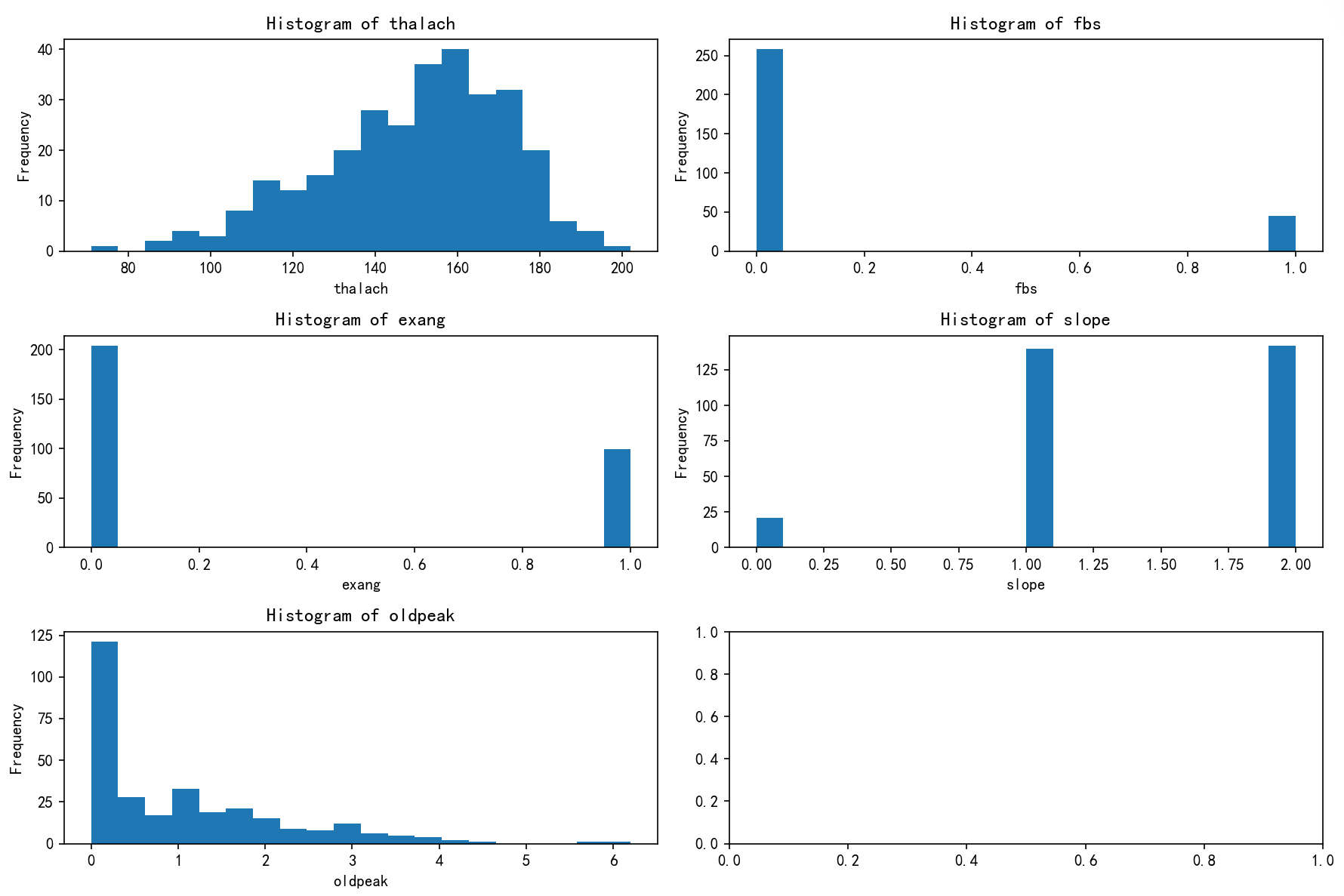
# 绘制出每个簇对应的这四个特征的分布图
X[['KMeans_Cluster']].value_counts()# 分别筛选出每个簇的数据
X_cluster0 = X[X['KMeans_Cluster'] == 0]
X_cluster1 = X[X['KMeans_Cluster'] == 1]
X_cluster2 = X[X['KMeans_Cluster'] == 2]# 先绘制簇0的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster0[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
print(plt.show())
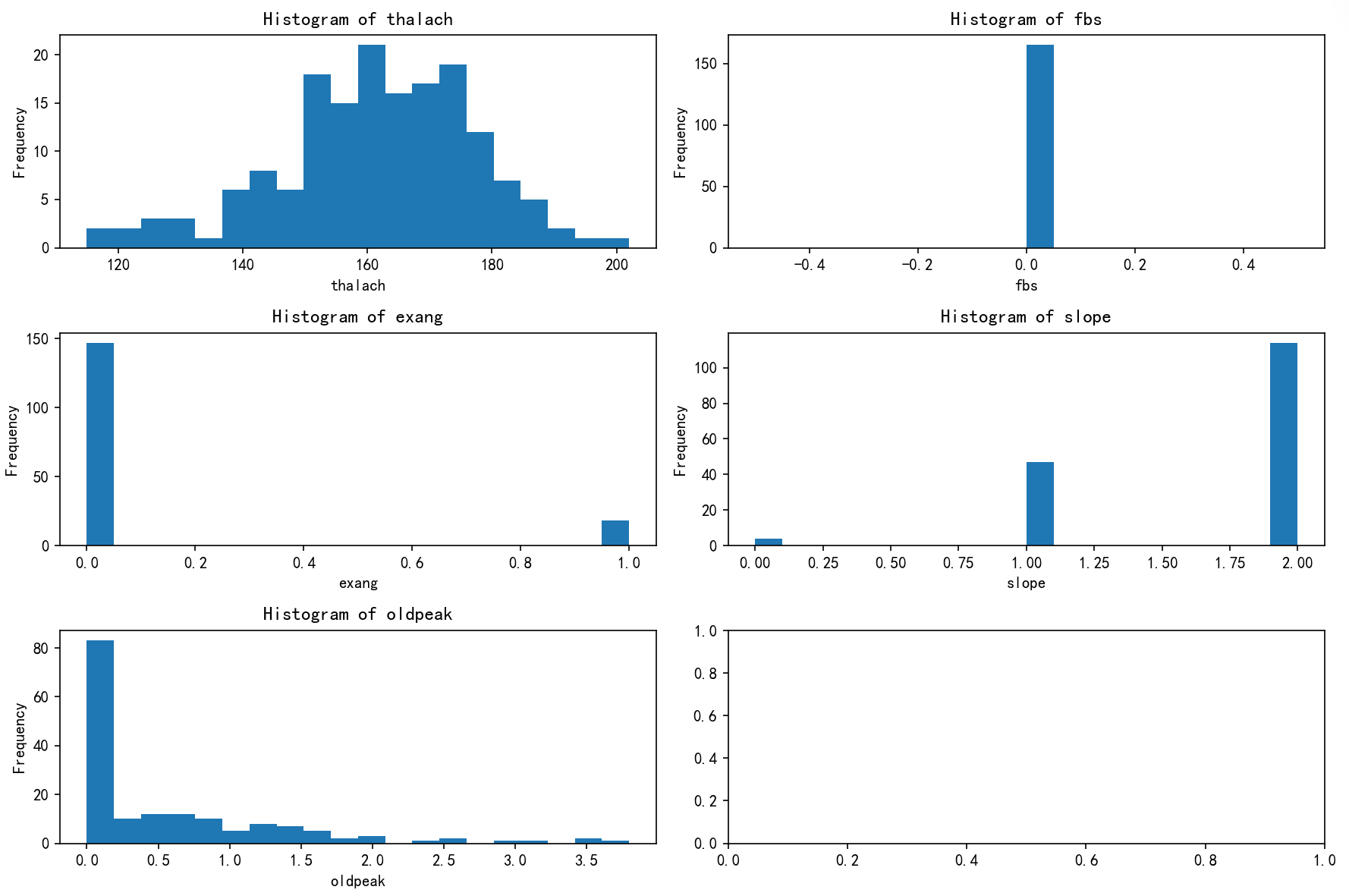
# 先绘制簇1的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster1[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
print(plt.show())
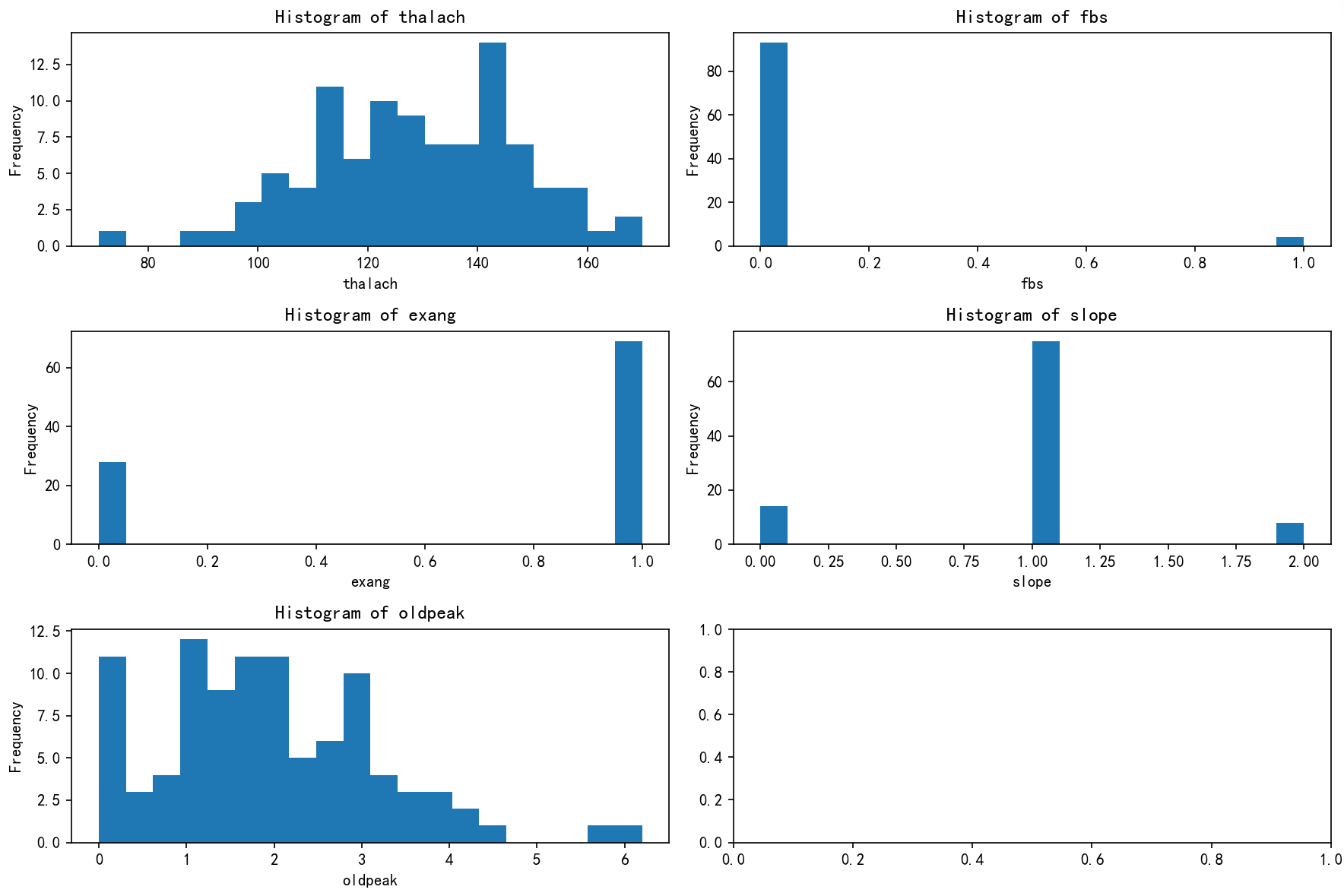
# 先绘制簇2的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster2[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
print(plt.show())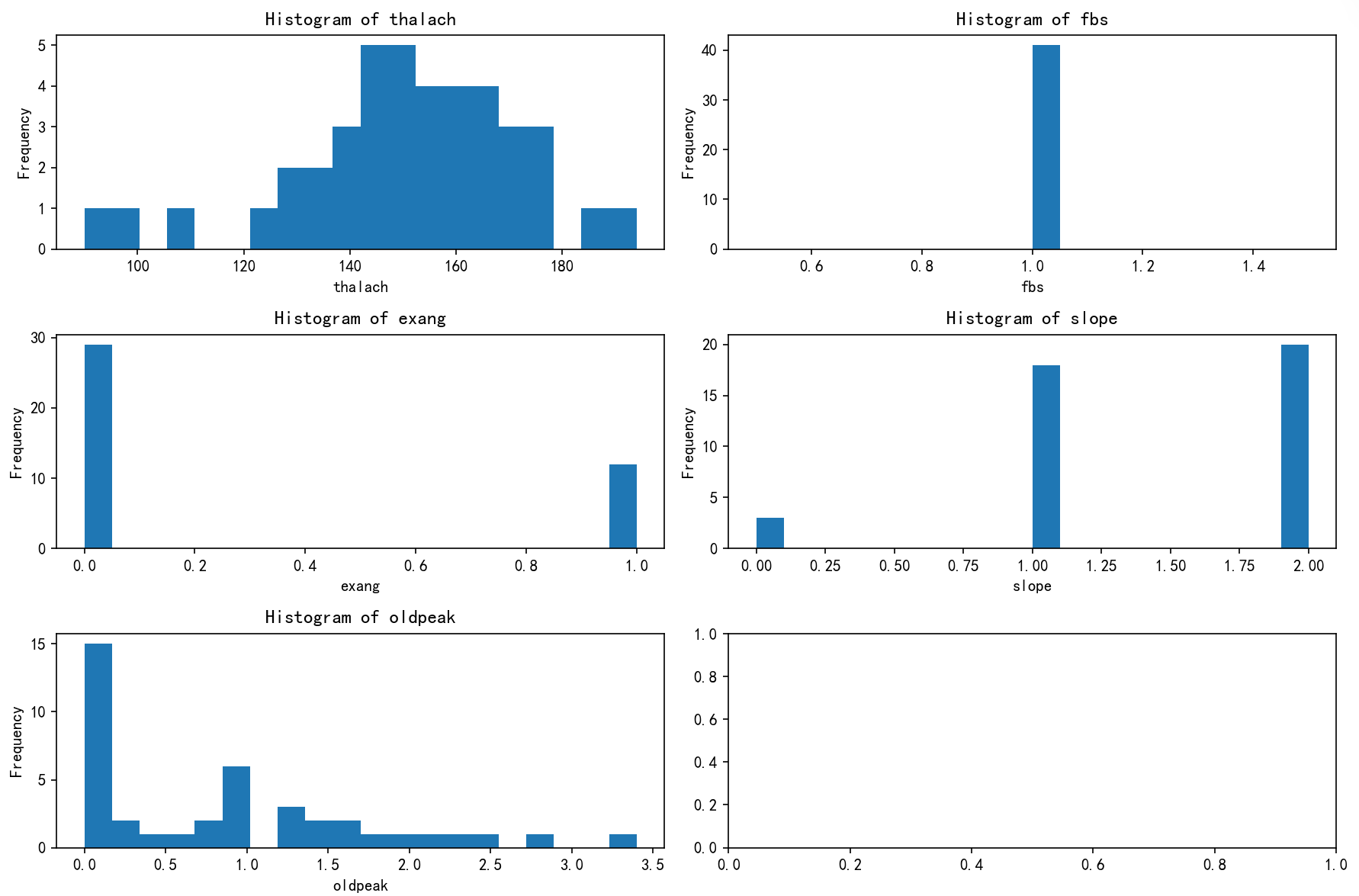
三个簇的总结与定义
簇0
- Thalach(最大心率):集中在140-170,偏高,说明具有较强的运动耐力和心脏功能。
- Fbs(空腹血糖):绝大多数为0,血糖水平正常或偏低。
- Exang(运动后胸痛):多为0(无胸痛),心血管风险较低。
- Slope(心电图坡度):多为1和2,表示不同心电活动状态。
- Oldpeak(旧峰值):大都在0.5以下,说明心肌缺血低,心脏健康状态较好。
总结与定义:
健康状态较佳的群体,心脏功能良好,血糖正常,无运动诱发胸痛,心肌缺血风险较低。
簇1
- Thalach(最大心率):主要在120-150,偏中等偏低。
- Fbs(空腹血糖):大部分偏高(非0),提示血糖略高或可能有糖尿病前期。
- Exang(运动后胸痛):主要为1,表示存在运动诱发的胸痛,心血管风险增加。
- Slope(心电图坡度):多为1,反映心电活动状态。
- Oldpeak(旧峰值):多在1.0-2.0,说明存在一定的心肌缺血。
总结与定义:
潜在风险群体,心脏负荷较大,血糖偏高,有运动诱发胸痛,存在心肌缺血风险。
簇2
- Thalach(最大心率):偏高,集中在140-160。
- Fbs(空腹血糖):为1,提示血糖略高或可能有糖尿病前期。
- Exang(运动后胸痛):多为0,少为1,存在运动诱发胸痛。
- Slope(心电图坡度):多为2,显示心电变化较为显著。
- Oldpeak(旧峰值):多在1及以下,心肌缺血不太严重。
总结与定义:
高风险群体,心电变化明显,心肌缺血不太严重,血糖可能偏高,需密切监控和干预。
总体概述:
- 簇0:健康、心脏功能良好、血糖正常、无显著心肌缺血。
- 簇1:存在潜在心血管风险,血糖偏高,运动引发胸痛,心肌缺血迹象明显。
- 簇2:高风险群体,心电变化明显,血糖可能偏高,需重点关注。
@浙大疏锦行
相关文章:

Python打卡 DAY 18
聚类后的分析:推断簇的类型 知识点回顾: 1. 推断簇含义的2个思路:先选特征和后选特征 2. 通过可视化图形借助ai定义簇的含义 3. 科研逻辑闭环:通过精度判断特征工程价值 作业:参考示例代码对心脏病数据集采取类似操作ÿ…...

C++面向对象 继承
格式 class 子类:继承方式 父类 {};//子类 又称为派生类 //父类 又称为基类 三种继承方式 继承中的同名成员处理 继承中的同名静态成员处理 包含子对象的派生类构造函数 作用: 包含子对象的派生类构造函数用于在创建派生类对象时&…...

Docker容器网络架构深度解析与技术实践指南——基于Linux内核特性的企业级容器网络实现
第1章 容器网络基础架构 1 Linux网络命名空间实现原理 1.1内核级隔离机制深度解析 1.1.1进程隔离的底层实现 通过clone()系统调用创建新进程时,设置CLONE_NEWNET标志位将触发内核执行以下操作: 内核源码示例(linux-6.8.0/kernel/fork.c&a…...

【上位机——MFC】对象和控件绑定
对象和控件绑定 将控件窗口和类对象绑定具有两大作用 如果和数据类对象绑定,对象和控件可以进行数据交换。 如果和控件类对象绑定,对象就可以代表整个控件。 与数据类型对象绑定的使用 数据类型对象和控件可实现数据交互重写父类成员虚函数DoDataExch…...

Ubuntu20.04安装使用ROS-PlotJuggler
Ubuntu20.04安装使用ROS-PlotJuggler 安装PlotJuggler使用Plotjuggler 写在前面,先确保安装了ROS-Noetic,如果没有安装,可通过以下程序一键安装: wget http://fishros.com/install -O fishros && . fishros安装PlotJuggl…...

Go语言八股之并发详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 非常期待和您一起在这个小…...

紫光同创FPGA实现HSSTHP光口视频传输+图像缩放,基于Aurora 8b/10b编解码架构,提供3套PDS工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目紫光同创FPGA相关方案推荐我这里已有的 GT 高速接口解决方案Xilinx系列FPGA实现GTP光口视频传输方案推荐Xilinx系列FPGA实现GTX光口视频传输方案推荐Xilinx系列FPGA实…...

怎样避免住宅IP被平台识别
要有效避免住宅IP被平台识别,需从IP质量选择、环境参数伪装、行为模式模拟、技术细节处理等多维度构建防御体系。以下是基于行业实践的综合性解决方案: 一、确保住宅IP的高纯净度 选择真实家庭网络IP 验证IP是否归属真实家庭宽带(非机房IP伪装…...
Java的JDK、JRE、JVM三者间的关系)
(1-1)Java的JDK、JRE、JVM三者间的关系
目录 1.JVM (Java 虚拟机) 2. JRE (Java运行时环境) 3. JDK(Java开发工具包) 1.JVM (Java 虚拟机) JVM可看作程序的自行引擎,将字节码转化为特定平台上的机器代码执行 功能: 加载并执行字节码文件:JVM从 .class文件中加载字节码…...
:从理论到实践)
机器学习之嵌入(Embeddings):从理论到实践
机器学习之嵌入(Embeddings):从理论到实践 摘要 本文深入探讨了机器学习中嵌入(Embeddings)的概念和应用。通过具体的实例和可视化展示,我们将了解嵌入如何将高维数据转换为低维表示,以及这种转换在推荐系统、自然语言处理等领域的实际应用…...
)
【漫话机器学习系列】245.权重衰减(Weight Decay)
权重衰减(Weight Decay)详解 | L2正则化的奥秘 在深度学习和机器学习模型训练中,我们常常面临 过拟合(Overfitting) 的问题。 为了提高模型在未见数据上的泛化能力,正则化(Regularization&…...
 配合gem5)
DSENT (Design Space Exploration of Networks Tool) 配合gem5
概述 DSENT是一种建模工具,旨在快速探索电子和新兴的片上光电网络(NoC)的设计空间。它为各种网络组件提供分析和参数化模型,并可在一系列技术假设下移植。给定架构级参数,DSENT从电气和光学构建块分层构建指定的模型,并输出详细的功率和面积估计。 版本 当前:0.91(2…...

汽车加气站操作工考试知识点总结
汽车加气站操作工考试知识点总结 加气站基本知识 了解加气站类型(CNG、LNG、LPG等)及其特点。 熟悉加气站的主要设备,如储气瓶组、压缩机、加气机、卸气柱、安全阀等。 掌握加气站工艺流程,包括卸气、储气、加压、加气等环节。…...

云蝠智能大模型语音交互智能体赋能电视台民意调研回访:重构媒体数据采集新范式
一、行业痛点与技术挑战 在媒体融合加速推进的背景下,电视台传统民意调研回访面临三大核心挑战: 人工成本高企:某省级卫视调研部门数据显示,人工外呼日均触达量仅 300-500 人次,人力成本占比超过 60%。数据质量参差&…...

数据可视化与数据编辑器:直观呈现数据价值
在当今数字化时代,数据可视化已成为企业洞察数据价值的关键手段。它与数据编辑器紧密结合,不仅能将复杂的数据转化为直观的图形、图表,以一种更加易懂的方式展现数据的规律、趋势和关系,还能借助数据编辑器随时对原始数据进行调整…...
)
ESP32蓝牙开发笔记(十四)
在 ESP32 的 BLE 开发中,esp_ble_gatts_add_char 是用于向 GATT 服务中添加特征(Characteristic)的核心函数。以下是该函数的详细说明、参数解析及示例代码: 函数原型 esp_err_t esp_ble_gatts_add_char(uint16_t service_handle…...

idea连接mongodb配置schemas
1. idea连接mongodb配置显示的schemas 默认展示 Default databse, 可以在此设置...

MySQL的函数
函数其实就是方法,就是别人封装好的东西 熟能生巧,加油!!!完整代码在最后。 一、聚合函数 - group_concat() 就是对数据进行分组然后合并 二、数学函数 函数很多,大家至少看一遍,有一个大概印…...
)
苍穹外卖(订单状态定时处理、来单提醒和客户催单)
订单状态定时处理、来单提醒和客户催单 Spring Task cron表达式 入门案例 ①导入maven坐标 spring-context(已存在) ②启动类添加注解 EnableScheduling 开启任务调度 ③自定义定时任务类 订单状态定时处理 需求分析 代码开发 自定义定…...

SpringBoot应急物资供应管理系统开发设计
概述 基于SpringBoot的应急物资供应管理系统功能完善,采用了现代化的开发框架,非常适合学习或直接应用于实际项目。 主要内容 5.1 管理员功能模块 管理员可通过登录界面进入系统,使用用户名、密码和角色信息进行身份验证。登录后…...
与过滤器(filters))
spring cloud gateway 断言(Predicates)与过滤器(filters)
断言 在 Spring Cloud Gateway 中,内置的断言(Predicates)用于对请求进行条件匹配。Spring Cloud Gateway 提供了多种内置断言,可以根据请求的路径、头部、方法等条件来决定是否将请求路由到特定的处理器。 内置断言 基于路径 …...
-04-(11-2))
MySQL-数据查询(多表连接JOIN)-04-(11-2)
学生表 学号 姓名 班级 课程编号 课程名称 是否结课 create table xs( xs_id int auto_increment primary key, xs_xm varchar(30), xs_bj varchar(30), xs_kcbh varchar(30), xs_kcmc varchar(30), xs_sfjk varchar(30) );insert xs values(1,张三,24大数据技术,1001,MYS…...

解决leetcode第3537题填充特殊网格
3537.填充特殊网格 难度:中等 问题描述: 给你一个非负整数N,表示一个x的网格。你需要用从0到-1的整数填充网格,使其成为一个特殊网格。一个网格当且仅当满足以下所有条件时,才能称之为特殊网格: 右上角…...

C++_MD5算法
文章目录 概要代码应用 概要 MD5算法在数据加密、一致性哈希、安全性验证等技术中有广泛的应用。 MD5算法的原理可简要的叙述为:MD5码以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法…...

深入理解C++ Lambda表达式:从基础到高级应用
在现代C编程中,Lambda表达式已经成为不可或缺的特性之一。自C11引入以来,Lambda极大地改变了我们编写函数对象和回调的方式,使代码更加简洁、表达力更强。本文将全面探讨C Lambda表达式的各个方面,从基础语法到高级应用场景&#…...

蓝桥杯 20. 倍数问题
倍数问题 原题目链接 题目描述 众所周知,小葱同学擅长计算,尤其擅长判断一个数是否是另一个数的倍数。但当面对多个数时,他就比较苦恼了。 现在小葱给了你 n 个数,希望你从中找出三个数,使得这三个数的 和是 K 的倍…...
)
2025最新出版 Microsoft Project由入门到精通(二)
目录 项目五部曲 第一步:先设置项目的信息和日历 项目的开始结束日期 项目的日历 默认日历改为全年无休(除法定节假日) 六天工作制/七天工作制设置方法 七天工作制的设置方法 全年无休工作制的设置方法 大小周交替日历设置方法&…...

从人体姿态到机械臂轨迹:基于深度学习的Kinova远程操控系统架构解析
在工业自动化、医疗辅助、灾难救援与太空探索等前沿领域,Kinova轻型机械臂凭借7自由度关节设计和出色负载能力脱颖而出。它能精准完成物体抓取、复杂装配和精细操作等任务。然而,实现人类操作者对Kinova机械臂的直观高效远程控制一直是技术难题。传统远程…...

【ABAP】定时任务DEBUG方法
事物码SM37 执行后,选中作业名,在输入框输入“JDBG”,进入调试模式(提前在需要的调试的程序设置断点)...
)
DDPM(Denoising Diffusion Probabilistic Models,去噪扩散概率模型)
简介 DDPM即去噪扩散概率模型(Denoising Diffusion Probabilistic Models),是一种生成式模型,在图像生成、视频生成等领域有广泛应用。以下是其详细介绍: 原理 DDPM的核心思想是通过在数据上逐步添加噪声来破坏数据…...

C26-冒泡排序法
一 算法步骤 外层循环:控制遍历轮数(共n-1轮,n为数组长度)内层循环:每轮比较相邻的元素,若顺序错误则交换,将当前一轮最大(最小)的元素移至末尾 二 实例 代码 #include <stdio.h> int main() {//数组及相关数据定义int arr[4]{12,4,78,23};int i;int j;int temp;int …...

CentOS 7.9 安装详解:手动分区完全指南
CentOS 7.9 安装详解:手动分区完全指南 为什么需要手动分区?CentOS 7.9 基本分区说明1. /boot/efi 分区2. /boot 分区3. swap 交换分区4. / (根) 分区 可选分区(进阶设置)5. /home 分区6. /var 分区7. /tmp 分区 分区方案建议标准…...
--- GPT3: Language Models are Few-Shot Learners)
大模型系列(五)--- GPT3: Language Models are Few-Shot Learners
论文链接: Language Models are Few-Shot Learners 点评: GPT3把参数规模扩大到1750亿,且在少样本场景下性能优异。对于所有任务,GPT-3均未进行任何梯度更新或微调,仅通过纯文本交互形式接收任务描述和少量示例。然而&…...

BK精密电源操作软件 9130BA系列和手侧user manual
BK精密电源操作软件 9130BA系列和手侧user manual...

MATLAB的cvpartition函数用法
1. 函数作用 cvpartition 将数据集划分为训练集和测试集,支持多种交叉验证方法,包括: Hold-Out验证:单次划分(如70%训练,30%测试)K折交叉验证:数据分为K个子集,依次用其…...

含铜废水回收的好处体现
一、环境保护:减少污染,守护生态安全 降低重金属污染 含铜废水若直接排放,铜离子会通过食物链富集,对水生生物和人体造成毒性影响(如肝肾损伤)。回收处理可去除废水中90%以上的铜离子,显著降低…...

C++20新特新——02特性的补充
虽然上节我们介绍了不少关于协程的特点,但是大家可能对协程还是不是很了解,没关系,这里我们再对其进行补充,详细讲解一下; 一、协程函数与普通函数的区别 这里我们再回归到问题:普通函数和协程在这方面的…...

【c++】 我的世界
太久没更新小游戏了 给个赞和收藏吧,求求了 要游戏的请私聊我 #include <iostream> #include <vector>// 定义世界大小 const int WORLD_WIDTH 20; const int WORLD_HEIGHT 10;// 定义方块类型 enum BlockType {AIR,GRASS,DIRT,STONE };// 定义世界…...
)
Redis从入门到实战 - 高级篇(上)
一、分布式缓存 1. 单点Redis的问题 数据丢失问题:Redis是内存存储,服务重启可能会丢失数据 -> 实现Redis数据持久化 并发能力问题:单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景 -> 搭建主从集群&…...

常见的卷积神经网络列举
经典的卷积神经网络(CNN)在深度学习发展史上具有重要地位,以下是一些里程碑式的模型及其核心贡献: 1. LeNet-5(1998) 提出者:Yann LeCun特点: 首个成功应用于手写数字识别ÿ…...

Linux如何安装AppImage程序
Linux如何安装AppImage程序 文章目录 Linux如何安装AppImage程序 在 Linux 中,.AppImage 是一种便携式的应用程序格式,无需安装即可运行。 1.赋予该文件可执行权限 可以使用下列命令,赋予可执行权限 # 举个例子 chmod x /path/to/MyApp.App…...

人工智能如何进行课堂管理?
人工智能如何协助老师课堂管理? 第一步:在腾讯元宝对话框中输入:如何协助老师进行课堂管理,通过提问,我们了解了老师高效备课可以从哪些方面入手,提高效率。 第二步:编辑问题进行提问…...

如何理解参照权
在管理学和组织行为学中,“参照权力”(Referent Power)是一种非常重要的权力来源,它属于非强制性权力的一种,主要基于个人特质和人际关系。以下是对参照权力的详细解释: 一、定义 参照权力是指一个人由于…...

从一次被抄袭经历谈起:iOS App 安全保护实战
如何保护 iOS App 的最后一道防线:那些你可能忽略的混淆技巧 如果你曾认真反编译过别人的 .ipa 文件,很可能会有这种感受:“哇,这代码也太干净了吧。” 类名像 UserManager,方法名是 getUserToken,甚至资源…...

从交互说明文档,到页面流程图设计全过程
依据交互说明文档绘制页面流程图,能够将抽象的交互逻辑转化为可视化、结构化的表达,为开发、测试及团队协作提供清晰指引。接下来,我们以外卖 App 订单确认页为例,详细拆解从交互说明文档到完整页面流程图的设计全过程。 一、交互…...

fedora系统详解详细版本
Fedora 系统详解:从起源到实践的深度解析 一、Fedora 概述:开源社区的技术先锋 Fedora 是由 Fedora 项目社区 开发、Red Hat 公司赞助 的 Linux 发行版,以 自由开源、技术前沿 和 稳定性平衡 著称。它是 Red Hat Enterprise Linuxÿ…...
)
2025-05-07-FFmpeg视频裁剪(尺寸调整,画面比例不变)
原比例如图 原比例如图裁剪后的比例 代码: 方法一:极速 ffmpeg -i input.mp4 -vf "crop1080:750:0:345" -c:v libx264 -preset ultrafast -c:a copy output.mp4关键参数说明: vf “crop宽:高❌y”:定义裁剪区域。 …...

RISC-V JTAG:开启MCU 芯片调试之旅
在当今电子科技飞速发展的时代, MCU 芯片成为众多企业追求技术突破与创新的关键领域。而芯片的调试过程则是确保其性能与可靠性的重要环节。本文以国科安芯自研 AS32A601为例,旨在详细记录基于 RISC-V 架构的 MCU 芯片JTAG 调试过程及操作,为…...

51单片机快速成长路径
作为在嵌入式领域深耕18年的工程师,分享一条经过工业验证的51单片机快速成长路径,全程干货无注水: 一、突破认知误区(新手必看) 不要纠结于「汇编还是C」:现代开发90%场景用C,掌握指针和内存管…...

idea左侧项目资源管理器不见了处理
使用idea误触导致,侧边栏和功能栏没了,如何打开? 1.打开文件(File) 2. 打开设置(Settings) 3.选择Appearance&Behavior--->Appearance划到最下面,开启显示工具栏和左侧并排布…...