Redis从入门到实战 - 高级篇(上)
一、分布式缓存
1. 单点Redis的问题
数据丢失问题:Redis是内存存储,服务重启可能会丢失数据 -> 实现Redis数据持久化
并发能力问题:单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景 -> 搭建主从集群,实现读写分离
故障恢复问题:如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段 -> 利用Redis哨兵,实现健康检测和自动恢复
存储能力问题:Redis基于内存,单节点能存储的数据量难以满足海量数据需求 -> 搭建分片集群,利用插槽机制实现动态扩容
2. Redis持久化
2.1 RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫作Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件全称RDB文件,默认是保存在当前运行目录。
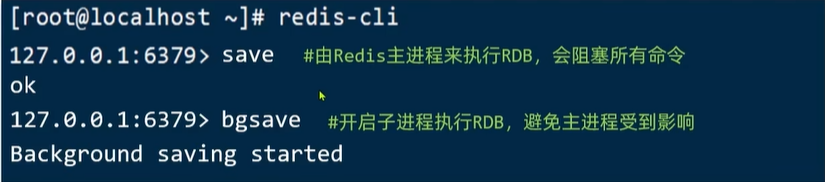
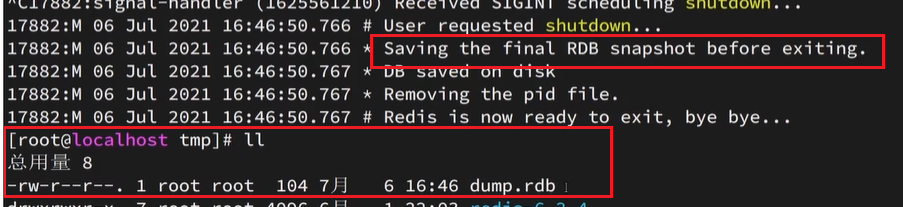
Redis停机时会执行一次RDB。
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:

RDB的其他配置也可以在redis.conf文件中配置

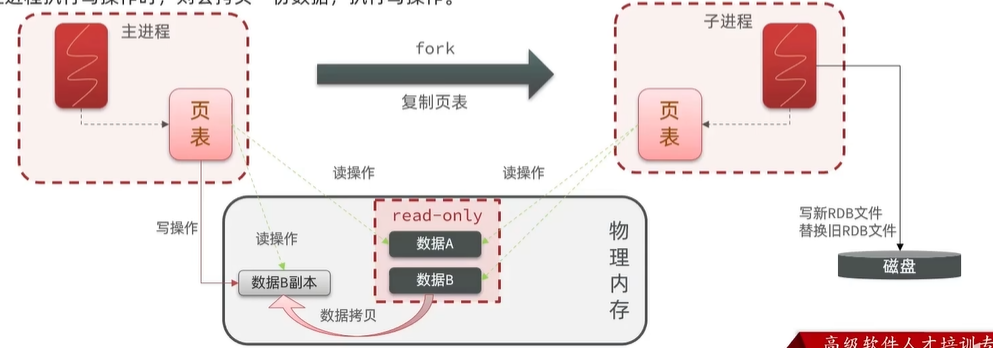
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件。fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内容;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
总结
1. RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
2. RDB会在什么时候执行?save 60 1000 代表什么含义?
- 默认是服务停止时。
- 代表60秒内至少执行1000次修改则触发RDB
3. RDB的缺点?
- RDB的执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
2.2 AOF持久化
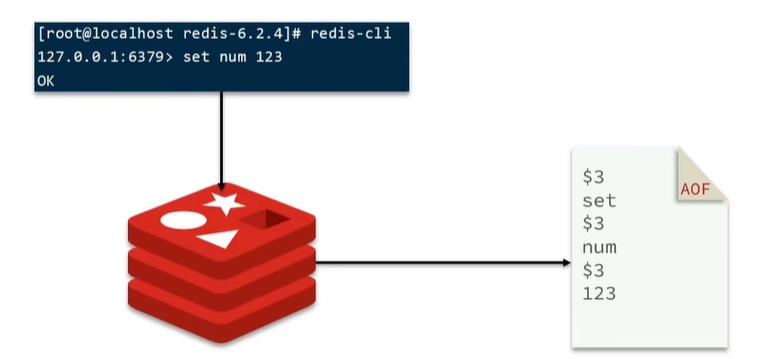
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:

AOF的命令记录的概率也可以通过redis.conf文件来配:

| 配置项 | 刷盘时机 | 优点 | 缺点 |
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgwriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

![]()
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:

RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往结合两者来使用。
| RDB | AOF | |
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源, 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高的场景 |
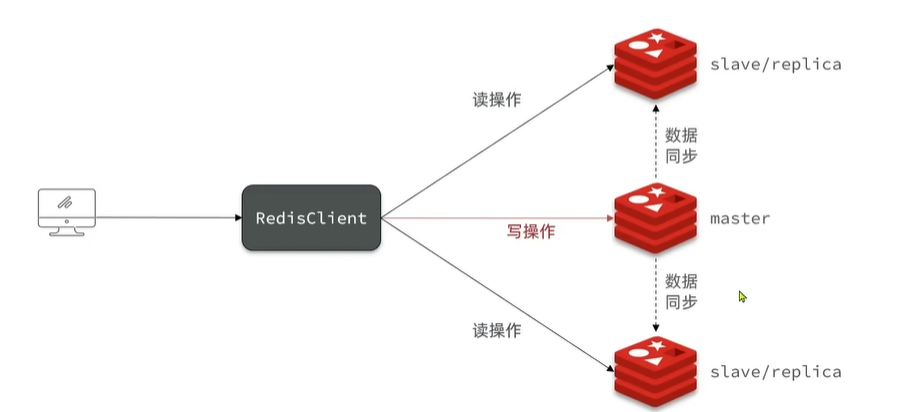
3. Redis主从
3.1 搭建主从架构
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
具体可以参考:Docs
实现步骤:
①将docker-compose.yml文件上传至虚拟机的/root/redis目录下,文件内容如下:
version: "3.2"services:r1:image: rediscontainer_name: r1network_mode: "host"entrypoint: ["redis-server", "--port", "7001"]r2:image: rediscontainer_name: r2network_mode: "host"entrypoint: ["redis-server", "--port", "7002"]r3:image: rediscontainer_name: r3network_mode: "host"entrypoint: ["redis-server", "--port", "7003"]
②执行命令,运行集群
docker compose up -d结果:

查看docker容器,发现都正常启动了:docker ps

由于采用的是host模式,我们看不到端口映射。不过能直接在宿主机通过ps命令查看到redis进程:

③建立集群
虽然我们启动了3个Redis实例,但是他们并没有形成主从关系。我们需要通过命令来配置主从关系:
# Redis5.0以前
slaveof <masterip> <masterport>
# Redis5.0以后
replicaof <masterip> <masterport>有临时和永久两种模式:
- 永久生效:在redis.conf文件中利用slaveof命令指定master节点
- 临时生效:直接利用redis-cli控制台输入slaveof命令,指定master节点
这里测试临时模式,首先连接r2,让其以r1为master
# 连接r2
docker exec -it r2 redis-cli -p 7002
# 认r1主,也就是7001
slaveof 192.168.200.130 7001然后连接r3,让其以r1为master
# 连接r3
docker exec -it r3 redis-cli -p 7003
# 认r1主,也就是7001
slaveof 192.168.200.130 7001然后连接r1,查看集群状态:
# 连接r1
docker exec -it r1 redis-cli -p 7001
# 查看集群状态
info replication结果如下:
127.0.0.1:7001> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.200.130,port=7002,state=online,offset=140,lag=1
slave1:ip=192.168.200.130,port=7003,state=online,offset=140,lag=1
master_failover_state:no-failover
master_replid:16d90568498908b322178ca12078114e6c518b86
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:140
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:140可以看到,当前节点r1:7001的角色是master,有两个slave与其连接:
slave0:port是7002,也就是r2节点
slave1:port是7003,也就是r3节点
④测试
依次在r1、r2、r3节点上执行下面命令:
set num 123get num可以发现,只有在r1节点上可以执行set命令(写操作),其他两个节点只能执行get命令(读操作)。也就是说读写操作已经分离了。
3.2 主从数据同步原理
3.2.1 全量同步
主从第一次同步是全量同步:

问题:master如何判断slave是不是第一次来同步数据?这里会用到两个很重要的概念:
- Replication Id:简称replid,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offsset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
由于我们在执行slaveof命令之前,所有redis节点都是master,有自己的replid和offset。
- 当我们第一次执行slaveof命令,与master建立主从关系时,发送的replid和offset是自己的,与master肯定不一致。
- master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
- master会将自己的replid和offset都发送给这个slave,slave保存这些信息到本地。自此以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。流程如图:
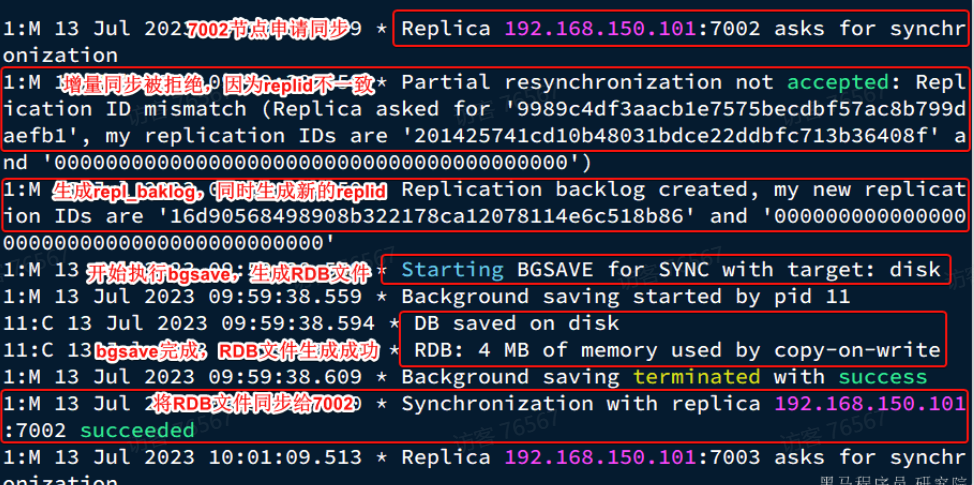
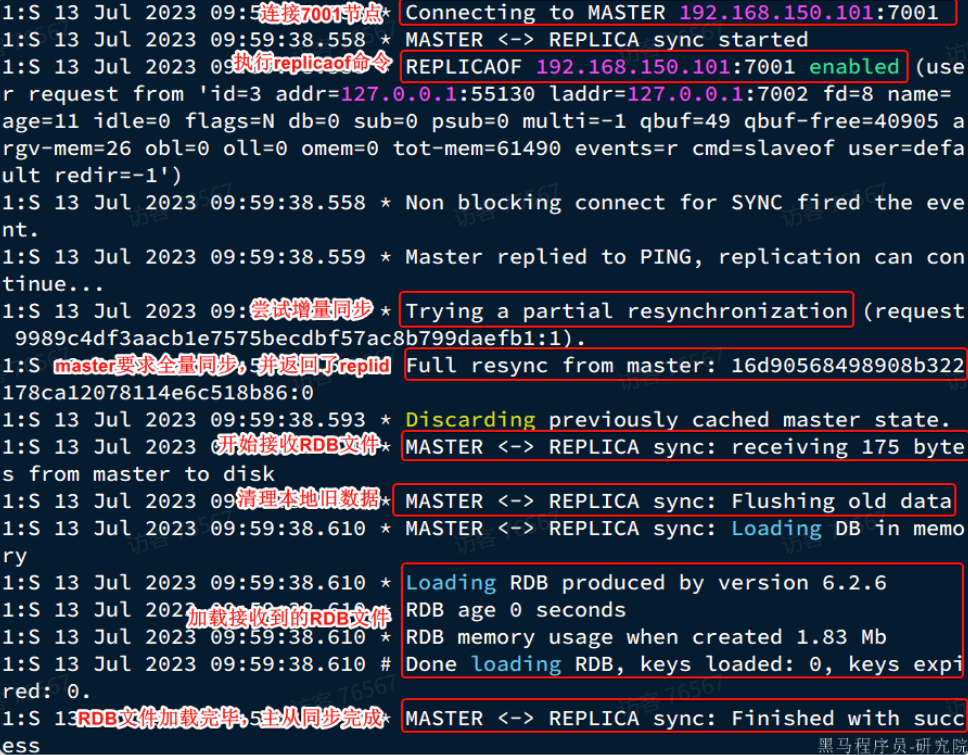
完整的流程描述:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内容数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
查看r1节点的运行日志:
r2节点执行replicaof命令时的日志:
3.2.2 增量同步
主从第一次同步是全量同步,但如果slave重启后同步,则执行增量同步。
全量同步需要先做RDB,然后将RDB文件通过网络传输给slave,成本高。因此除了第一次做全量同步,其他大多数时候slave与master都是做增量同步。
增量同步:只更新slave与master存在差异的部分数据。

注意:repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
问题:master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步的repl_baklog文件了。这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令及offset,包括master当前的offset,和slave已经拷贝到的offset:
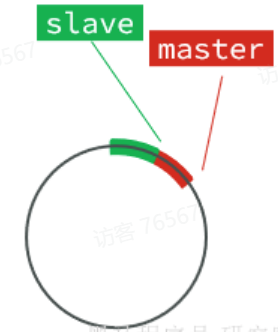
slave与master的offset之间的差异,就是slave需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset:
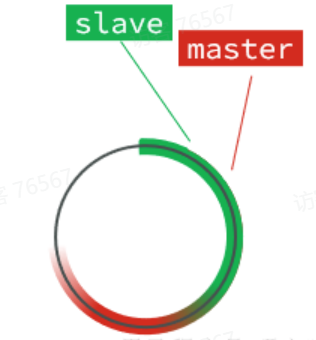
直到数组被填满:
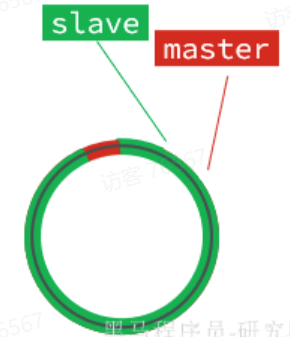
此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分:
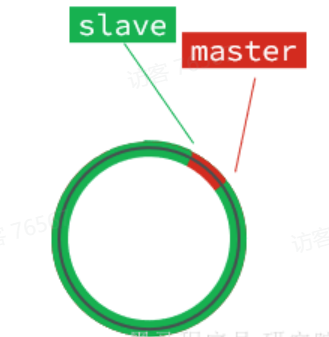
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:
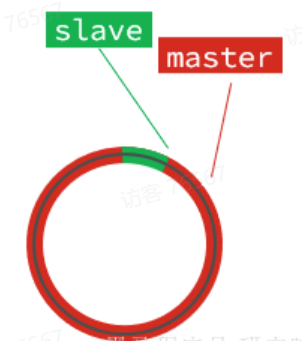
如果master继续写入新数据,master的offset就会覆盖repl_baklog中旧的数据,直到将slave现在的offset也覆盖:
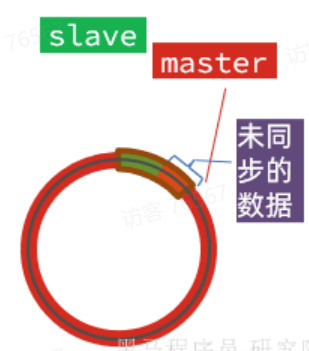
棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于repl_baklog做增量同步,只能再次全量同步。
3.2.3 主从同步优化
主从同步可以保证主从数据的一致性,非常重要。可以从以下几个方面来优化Redis主从集群:
- 在master中配置repl_diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
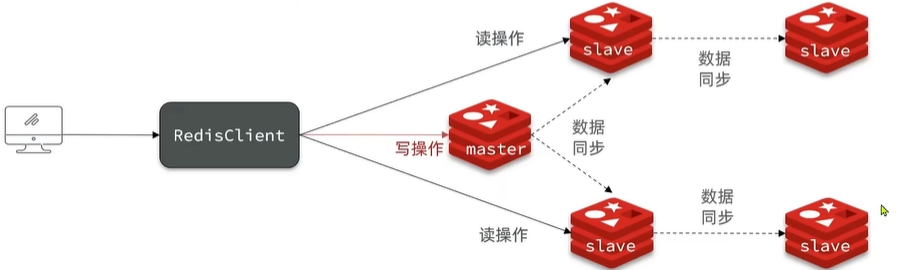
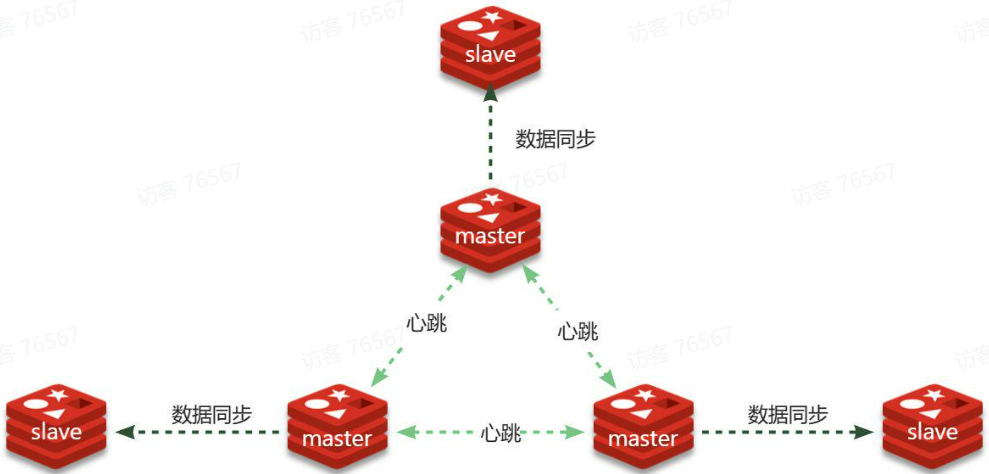
- 限制一个master上slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力。
主-从-从架构图:
总结:
1. 简述全量同步和增量同步的区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
2. 什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
3. 什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
4. Redis哨兵
思考:slave节点宕机恢复后可以找master节点同步数据,那master节点宕机怎么办?
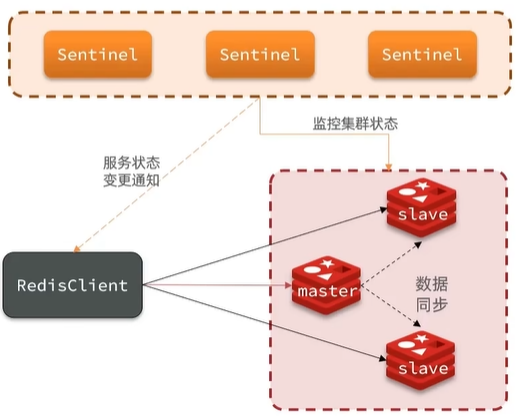
Redis提供了哨兵(Sentinel)机制来监控主从集群监控状态,实现集群的自动故障恢复,确保集群的高可用性。哨兵的结构和作用如下:
- 监控:Sentinel会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
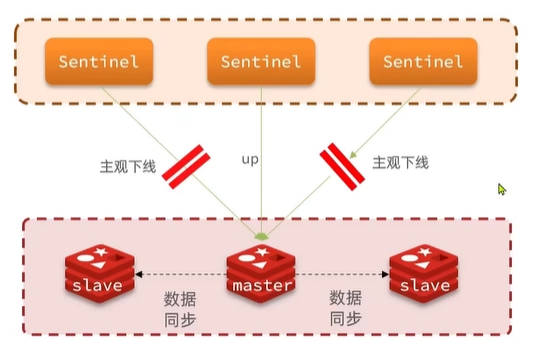
4.1 服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果某个sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)是Sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
4.2 选举新的master
一旦发现master故障,sentinel需要在slave中选择一个作为新的master,选举依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds*10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-priority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后判断slave节点的运行id大小,越小优先级越高(通过info server可以查看run_id)
对应的官方文档:High availability with Redis Sentinel | Docs
问题:当选出一个新的master后,该如何实现身份切换?
- 在多个sentinel中选举一个leader
- 由leader执行failover
4.3 选举leader
首先,Sentinel集群要选出一个执行failoover的Sentinel节点,可以成为leader。要成为leader要满足两个条件:
- 最先获得超过半数的投票
- 获得的投票数不小于quorum值
而sentinel投票的原则有两条:
- 优先投票给目前得票最多的
- 如果目前没有任何节点的票,就投给自己
比如有3个sentinel节点,s1、s2、s3,假如s2先投票:
- 此时发现没有任何人在投票,那就投给自己。s2先得1票
- 接着s1和s3开始投票,发现目前s2票最多,于是也投给s2,s2得3票
- s2成为leader,开始故障转移
不难看出,谁先投票,谁就会成为leader,那什么时候会触发投票呢?答案是第一个确认master客观下线的人会立刻发起投票,一定会成为leader。
4.4 如何实现故障转移
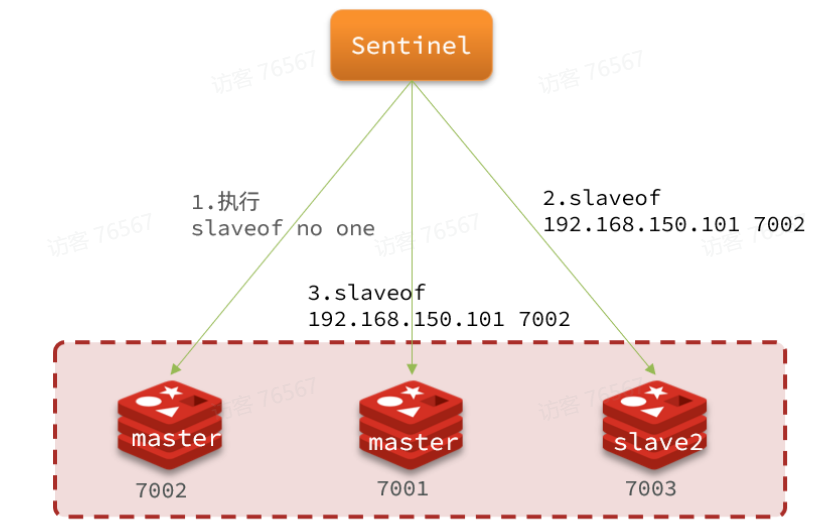
当选中了其中一个slave为新的master后(例如slave1),故障的转移步骤如下:
sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
sentinel给所有其它slave发送slaveof 192.168.200.130 7002命令,让这些slave成为新的master的从节点,开始从新的master上同步数据。
最后,sentinel将故障节点标记为slave,当故障节点恢复后自动成为新的master的slave节点
总结:
1. Sentinel的三个作用是什么?
- 监控
- 故障转移
- 通知
2. Sentinel如何判断一个redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没有响应则认为是主观下线
- 如果大多数sentinel都认为实例主观下线,则判定服务客观下线
3. 故障转移步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行 slaveof 新master
- 修改故障节点配置,添加slaveof 新master
4.5 搭建哨兵集群
①首先停掉之前的redis集群
# 老版本DockerCompose
docker-compose down# 新版本Docker
docker compose down②在虚拟机的/root/redis目录下新建3个文件夹:s1、s2、s3:

将sentinel.conf文件分别拷贝一份到3个文件夹中,文件内容如下:
sentinel announce-ip "192.168.200.130"
sentinel monitor hmaster 192.168.200.130 7001 2
sentinel down-after-milliseconds hmaster 5000
sentinel failover-timeout hmaster 60000说明:
- sentinel announce-ip "192.168.200.130":声明当前sentinel的ip
- sentinel monitor hmaster 192.168.200.130 7001 2:指定集群的主节点信息
- hmaster:主节点名称,自定义,任意写
- 192.168.200.130 7001:主节点的ip和端口
- 2:认定master客观下线时的quorum值
- sentinel down-after-milliseconds hmaster 5000:声明master节点超时多久后被标记主观下线
- sentinel failover-timeout hmaster 60000:在第一次故障转移失败后多久再次重试
③接着修改之前的docker-compose.yaml文件,内容如下:
version: "3.2"services:r1:image: rediscontainer_name: r1network_mode: "host"entrypoint: ["redis-server", "--port", "7001"]r2:image: rediscontainer_name: r2network_mode: "host"entrypoint: ["redis-server", "--port", "7002", "--slaveof", "192.168.200.130", "7001"]r3:image: rediscontainer_name: r3network_mode: "host"entrypoint: ["redis-server", "--port", "7003", "--slaveof", "192.168.200.130", "7001"]s1:image: rediscontainer_name: s1volumes:- /root/redis/s1:/etc/redisnetwork_mode: "host"entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27001"]s2:image: rediscontainer_name: s2volumes:- /root/redis/s2:/etc/redisnetwork_mode: "host"entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27002"]s3:image: rediscontainer_name: s3volumes:- /root/redis/s3:/etc/redisnetwork_mode: "host"entrypoint: ["redis-sentinel", "/etc/redis/sentinel.conf", "--port", "27003"]直接运行命令,启动集群:
docker-compose up -d运行结果:
以s1节点为例,查看其运行日志:
# Sentinel ID is 8e91bd24ea8e5eb2aee38f1cf796dcb26bb88acf
# +monitor master hmaster 192.168.200.130 7001 quorum 2
* +slave slave 192.168.200.130:7003 192.168.200.130 7003 @ hmaster 192.168.200.130 7001
* +sentinel sentinel 5bafeb97fc16a82b431c339f67b015a51dad5e4f 192.168.200.130 27002 @ hmaster 192.168.200.130 7001
* +sentinel sentinel 56546568a2f7977da36abd3d2d7324c6c3f06b8d 192.168.200.130 27003 @ hmaster 192.168.200.130 7001
* +slave slave 192.168.200.130:7002 192.168.200.130 7002 @ hmaster 192.168.200.130 7001可以看到sentinel已经联系到了7001这个节点,并且与其它几个哨兵也建立了链接。哨兵信息如下:
-
27001:Sentinel ID是8e91bd24ea8e5eb2aee38f1cf796dcb26bb88acf -
27002:Sentinel ID是5bafeb97fc16a82b431c339f67b015a51dad5e4f -
27003:Sentinel ID是56546568a2f7977da36abd3d2d7324c6c3f06b8d
当7001宕机时:


4.6 RedisTemplate的哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
①首先,引入课前资料提供的Demo工程:
②在pom文件中引入redis的starter依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>③在配置文件application.yml中指定sentinel相关信息
spring:redis:sentinel:master: hmaster # 指定master名称nodes: # 指定redis-sentinel集群信息- 192.168.200.130:27001- 192.168.200.130:27002- 192.168.200.130:27003④配置主从读写分离
@SpringBootApplication
public class RedisDemoApplication {public static void main(String[] args) {SpringApplication.run(RedisDemoApplication.class, args);}@Beanpublic LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);}
}这里的ReadFrom是配置Redis的读取策略,是一个枚举,包括下面选择:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA_PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
5. Redis分片集群
5.1 搭建分片集群
主从和哨兵可以解决高可用、高并发读的问题,但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端可以访问集群任意节点,最终都会被转发到正确节点
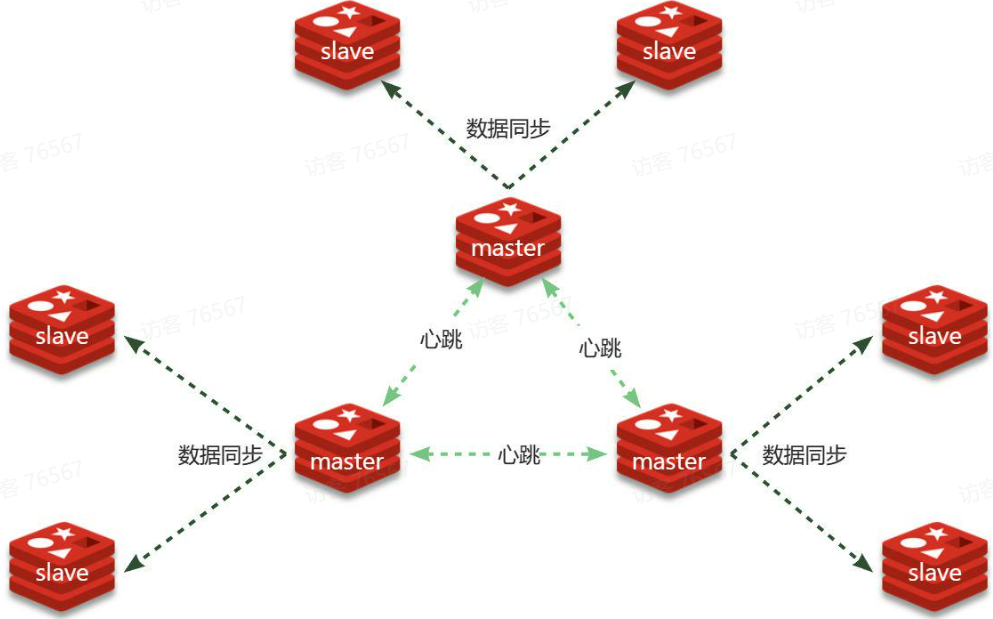
分片集群特征:
- 集群中有多个master,每个master保存不同分片数据,解决海量数据存储问题
- 每个master都可以有多个slave节点,确保高可用
- master之间通过ping监测彼此健康状态,类似哨兵作用
- 客户端请求可以访问集群任意节点,最终都会被转发到数据所在节点
分片集群搭建步骤:
Redis分片集群最少也需要3个master节点,由于我们的机器性能有限,只给每个master配置1个slave,形成最小的分片集群:
计划部署的节点信息如下:
| 容器名 | 角色 | IP | 映射端口 |
| r1 | master | 192.168.200.130 | 7001 |
| r2 | master | 192.168.200.130 | 7002 |
| r3 | master | 192.168.200.130 | 7003 |
| r4 | slave | 192.168.200.130 | 7004 |
| r5 | slave | 192.168.200.130 | 7005 |
| r6 | slave | 192.168.200.130 | 7006 |
分片集群中的Redis节点必须开启集群模式,一般在配置文件中添加下面参数:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes- cluster-enabled:是否开启集群模式
- cluster-config-file:集群模式的配置文件名称,无需手动创建,由集群自动维护
- cluster-node-timeout:集群中节点之间心跳超时时间
一般搭建部署集群肯定是给每个节点都配置上述参数,不过考虑到我们用docker-compose部署,因此可以直接在启动命令中指定参数。
①在虚拟机的/root目录下新建redis-cluster目录,在其中新建一个docker-compose,yaml文件,内容如下:
version: "3.2"services:r1:image: rediscontainer_name: r1network_mode: "host"entrypoint: ["redis-server", "--port", "7001", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r2:image: rediscontainer_name: r2network_mode: "host"entrypoint: ["redis-server", "--port", "7002", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r3:image: rediscontainer_name: r3network_mode: "host"entrypoint: ["redis-server", "--port", "7003", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r4:image: rediscontainer_name: r4network_mode: "host"entrypoint: ["redis-server", "--port", "7004", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r5:image: rediscontainer_name: r5network_mode: "host"entrypoint: ["redis-server", "--port", "7005", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]r6:image: rediscontainer_name: r6network_mode: "host"entrypoint: ["redis-server", "--port", "7006", "--cluster-enabled", "yes", "--cluster-config-file", "node.conf"]注:使用Dokcer部署Redis集群,network模式必须采用host
②进入/root/redis-cluster目录,启动redis:
cd redis-cluster
docker-compose up -d启动成功后可以通过命令查看启动进程:
ps -ef | grep redis
# 结果:
root 4822 4743 0 14:29 ? 00:00:02 redis-server *:7002 [cluster]
root 4827 4745 0 14:29 ? 00:00:01 redis-server *:7005 [cluster]
root 4897 4778 0 14:29 ? 00:00:01 redis-server *:7004 [cluster]
root 4903 4759 0 14:29 ? 00:00:01 redis-server *:7006 [cluster]
root 4905 4775 0 14:29 ? 00:00:02 redis-server *:7001 [cluster]
root 4912 4732 0 14:29 ? 00:00:01 redis-server *:7003 [cluster]可以发现每个redis节点都以cluster模式运行,不过节点与节点之间并未建立连接。
②使用命令创建集群
# 进入任意节点容器
docker exec -it r1 bash
# 然后,执行命令
redis-cli --cluster create --cluster-replicas 1 \
192.168.200.130:7001 192.168.200.130:7002 192.168.200.130:7003 \
192.168.200.130:7004 192.168.200.130:7005 192.168.200.130:7006- redis-cli --cluster:代表集群操作命令
- create:代表是创建集群
- --cluster-replicas 1:指定集群中每个master的副本个数为1
- 此时节点总数 ÷ (replicas + 1)得到的就是master的数量n。因此节点列表中的前n个节点就是master,其他节点都是slave节点,随机分配到不同master。
可以通过命令查看集群状态:
redis-cli -p 7001 cluster nodes5.2 散列插槽
Redis会把每个master节点映射到0~16383共16384个插槽(hash slot)上。数据key不是与节点绑定,而是与插槽绑定。Redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且"{}"中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含"{}",整个key都是有效部分
例如:key是num,那么就根据num计算;如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
问题1:Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
问题2:如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
5.3 故障转移
分配集群的节点之间会互相通过ping的方式做心跳监测,超时未回应的节点会被标记为下线状态。当发现master下线时,会将这个master的某个slave提升为master。
我们先打开一个控制台窗口,利用命令监测集群状态:
watch docker exec -it r1 redis-cli -p 7001 cluster nodes命令前面的watch可以每隔一段时间刷新执行结果,方便实时监控集群状态变化。
接着,利用命令让某个master节点休眠。比如这里我们让7002节点休眠,打开一个新的ssh控制台,输入下面命令:
docker exec -it r2 redis-cli -p 7002 DEBUG sleep 30可以观察到,集群发现7002宕机,标记为下线:


过了一段时间后,7002原本的slave节点7006变成了master:

而7002被标记为slave,而且其master正好是7006,主从地位互换。
数据迁移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
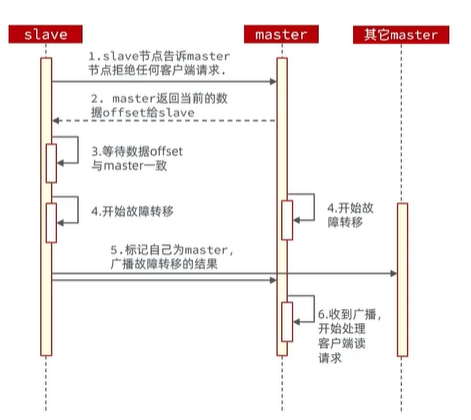
手动的failover支持三种不同模式:
- 缺省:默认的流程,如图1~6步
- force:省略了对offset的一致性校验
- takeover:直接执行第5步,忽略数据一致性、忽略master状态和其他master的意见
5.4 RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
①引入redis的starter依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>②配置分片集群地址。与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:redis:cluster:nodes: # 指定分片集群中的每一个节点信息- 192.168.200.130:7001- 192.168.200.130:7002- 192.168.200.130:7003- 192.168.200.130:8001- 192.168.200.130:8002- 192.168.200.130:8003③配置读写分离
@Beanpublic LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);}相关文章:
)
Redis从入门到实战 - 高级篇(上)
一、分布式缓存 1. 单点Redis的问题 数据丢失问题:Redis是内存存储,服务重启可能会丢失数据 -> 实现Redis数据持久化 并发能力问题:单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景 -> 搭建主从集群&…...

常见的卷积神经网络列举
经典的卷积神经网络(CNN)在深度学习发展史上具有重要地位,以下是一些里程碑式的模型及其核心贡献: 1. LeNet-5(1998) 提出者:Yann LeCun特点: 首个成功应用于手写数字识别ÿ…...

Linux如何安装AppImage程序
Linux如何安装AppImage程序 文章目录 Linux如何安装AppImage程序 在 Linux 中,.AppImage 是一种便携式的应用程序格式,无需安装即可运行。 1.赋予该文件可执行权限 可以使用下列命令,赋予可执行权限 # 举个例子 chmod x /path/to/MyApp.App…...

人工智能如何进行课堂管理?
人工智能如何协助老师课堂管理? 第一步:在腾讯元宝对话框中输入:如何协助老师进行课堂管理,通过提问,我们了解了老师高效备课可以从哪些方面入手,提高效率。 第二步:编辑问题进行提问…...

如何理解参照权
在管理学和组织行为学中,“参照权力”(Referent Power)是一种非常重要的权力来源,它属于非强制性权力的一种,主要基于个人特质和人际关系。以下是对参照权力的详细解释: 一、定义 参照权力是指一个人由于…...

从一次被抄袭经历谈起:iOS App 安全保护实战
如何保护 iOS App 的最后一道防线:那些你可能忽略的混淆技巧 如果你曾认真反编译过别人的 .ipa 文件,很可能会有这种感受:“哇,这代码也太干净了吧。” 类名像 UserManager,方法名是 getUserToken,甚至资源…...

从交互说明文档,到页面流程图设计全过程
依据交互说明文档绘制页面流程图,能够将抽象的交互逻辑转化为可视化、结构化的表达,为开发、测试及团队协作提供清晰指引。接下来,我们以外卖 App 订单确认页为例,详细拆解从交互说明文档到完整页面流程图的设计全过程。 一、交互…...

fedora系统详解详细版本
Fedora 系统详解:从起源到实践的深度解析 一、Fedora 概述:开源社区的技术先锋 Fedora 是由 Fedora 项目社区 开发、Red Hat 公司赞助 的 Linux 发行版,以 自由开源、技术前沿 和 稳定性平衡 著称。它是 Red Hat Enterprise Linuxÿ…...
)
2025-05-07-FFmpeg视频裁剪(尺寸调整,画面比例不变)
原比例如图 原比例如图裁剪后的比例 代码: 方法一:极速 ffmpeg -i input.mp4 -vf "crop1080:750:0:345" -c:v libx264 -preset ultrafast -c:a copy output.mp4关键参数说明: vf “crop宽:高❌y”:定义裁剪区域。 …...

RISC-V JTAG:开启MCU 芯片调试之旅
在当今电子科技飞速发展的时代, MCU 芯片成为众多企业追求技术突破与创新的关键领域。而芯片的调试过程则是确保其性能与可靠性的重要环节。本文以国科安芯自研 AS32A601为例,旨在详细记录基于 RISC-V 架构的 MCU 芯片JTAG 调试过程及操作,为…...

51单片机快速成长路径
作为在嵌入式领域深耕18年的工程师,分享一条经过工业验证的51单片机快速成长路径,全程干货无注水: 一、突破认知误区(新手必看) 不要纠结于「汇编还是C」:现代开发90%场景用C,掌握指针和内存管…...

idea左侧项目资源管理器不见了处理
使用idea误触导致,侧边栏和功能栏没了,如何打开? 1.打开文件(File) 2. 打开设置(Settings) 3.选择Appearance&Behavior--->Appearance划到最下面,开启显示工具栏和左侧并排布…...

给小白的AI Agent 基本技术点分析与讲解
引言:重塑交互与自动化边界的 AI Agent 在人工智能技术飞速发展的浪潮中,AI Agent(智能体)概念的兴起标志着自动化和人机交互正迈向一个全新的阶段。传统的软件系统通常被设计来执行精确预设的指令序列,它们强大且高效…...

[特殊字符] 深入解析:Go 与 Rust 中的数组与动态集合结构
在 Go 和 Rust 这两种现代语言中,数组和动态集合(如切片或 Vec)是处理数据的基础工具。虽然它们都提供了高效的内存访问能力,但设计理念却截然不同: Go 更注重灵活性和性能,允许开发者直接操作底层指针和容…...

C25-数组应用及练习
第一题 题目: 代码 #include <stdio.h> int main() {//数组及相关数据定义int arr[10];int i;//基于循环的数组数据输入for(i0;i<10;i){arr[i]i;}//基于循环的数组数据输出for(i9;i>0;i--){printf("%d ",arr[i]);}return 0; }结果 第二题 题目 代码 …...
技术)
Soft Mask(软遮罩)技术
一、概述 Soft Mask是一种技术或工具,主要用于实现平滑的边缘遮罩效果。它在不同的应用领域有不同的实现和定义 1.在Unity UI设计中 SoftMask是一款专为Unity设计的高级遮罩工具,它突破了传统Mask的限制,提供了更为灵活和细腻的UI遮罩解决方案…...

683SJBH基于J2EE的广州旅游管理系统
第1章 绪论 课题背景 自互联网internet成为一种革命性的大众媒体以来,其发展速度之快令人惊叹。而作为世界最大朝阳产业的旅游,当它与电子商务这一新兴模式相结合时,其潜藏的商业价值表露无遗。根据CNN(美国有线电视新闻网&…...

关于STM32 SPI收发数据异常
问题描述: STM32主板做SPI从机,另一块linux主板做主机,通信的时候发现从机可以正确接收到主机数据,但是主机接收从机数据时一直不对,是随机值。 问题原因: 刚发现问题的时候,用逻辑分析仪抓包…...
及解决方案)
雅努斯问题(Janus Problem)及解决方案
一、雅努斯简介 雅努斯(Janus)是罗马神话中的门神,也是罗马人的保护神。他具有前后两个面孔或四方四个面孔,象征开始。雅努斯被认为是起源神,执掌着开始和入门,也执掌着出口和结束,因此他又被成…...

ACE-Step:扩散自编码文生音乐基座模型快速了解
ACE-Step 模型速读 一、模型概述 ACE-Step 是一款由 ACE Studio 和 StepFun 开发的新型开源音乐生成基础模型。它通过整合基于扩散的生成方式、Sana 的深度压缩自编码器(DCAE)以及轻量级线性变换器,在音乐生成速度、音乐连贯性和可控性等方…...

【论文阅读】在调制分类中针对对抗性攻击的混合训练时和运行时防御
A Hybrid Training-Time and Run-Time Defense Against Adversarial Attacks in Modulation Classification 摘要 在深度学习在包括计算机视觉和自然语言处理在内的许多应用中的卓越性能的推动下,最近的几项研究侧重于应用深度神经网络来设计未来几代无线网络。然而,最近的…...

HDMI布局布线
1 HDMI简介 高清多媒体接口(High Definition Multimedia Interface),简称:HDMI,是一种全数字化视频和声音发送接口,可以发送未压缩的音频及视频信号。随着技术的不断提升,HDMI的传输速率也不断的提升,HDMI2.0最大传输速率可达14.4Gbit/s,HDMI2.1最大传输数据速率可达42.6Gbit/s…...
的可信数据空间建设指引)
国家信息中心:基于区块链和区块链服务网络(BSN)的可信数据空间建设指引
推荐语: 可信数据空间包含场景应用、生态主体、数据资源、规则机制、技术系统五大部分。《基于区块链和区块链服务网络(BSN)的可信数据空间建设指引》聚焦可信数据空间的单个数据空间中的场景应用、数据资源、规则机制及技术系统四大核心要点…...
)
分区器(1)
1. 需求分析 在分布式计算中,Map任务通常会产生大量的中间结果,这些结果需要被分配到不同的Reducer任务中进行进一步处理。分区器的作用是根据一定的规则将中间结果分配到不同的分区(Partition),从而确保数据能够被正…...

设计一个分布式系统:要求全局消息顺序,如何使用Kafka实现?
一、高吞吐低延迟 Kafka 集群设计要点 1. 分区策略优化 // 计算合理分区数公式(动态调整) int numPartitions max(Tp, Tc) / min(Tp, Tc) // Tp生产者吞吐量 Tc消费者吞吐量建议初始按业务键(如订单ID)哈希分区单分区吞吐建议…...
)
大模型工具与案例:云服务器部署dify(1)
如果您可以装wsl,可以在本机部署参考windows安装dify-江鸟阁长 因为笔者的windows电脑不可以安装wsl,所以本文会带大家在linux云服务器上部署。目前很多厂家都推出了一键部署,但是价格也有差 阿里云 通用型服务器 70rmb/月 华为云比较便宜&a…...

屏蔽力 | 在复杂世界中从内耗到成长的转变之道
注:本文为“屏蔽力”相关文章合辑。 略作重排,未全整理。 世上的事再复杂,不外乎这三种 原创 小鹿 读者 2022 年 12 月 02 日 18 : 27 甘肃 文 / 小鹿 在这世上,每天都有大事小事、琐事烦事。我们总为世事奔波忙碌,…...
2025最新(十一))
信息系统项目管理师-软考高级(软考高项)2025最新(十一)
个人笔记整理---仅供参考 第十一章项目成本管理 11.1管理基础 11.2项目成本管理过程 11.3规划成本管理 11.4估算成本 11.5制定预算 11.6控制成本...

大数据技术全景解析:Spark、Hadoop、Hive与SQL的协作与实战
引言:当数据成为新时代的“石油” 在数字经济时代,数据量以每年50%的速度爆发式增长。如何高效存储、处理和分析PB级数据,成为企业竞争力的核心命题。本文将通过通俗类比场景化拆解,带你深入理解四大关键技术:Hadoop、…...

Linux 驱动开发步骤及 SPI 设备驱动移植示例
Linux 驱动开发的一般步骤 硬件了解:深入研究目标硬件设备的工作原理、寄存器映射、电气特性、中断机制等。例如,若开发网卡驱动,需清楚网卡如何与网络介质交互、数据包的收发流程、硬件缓冲区的管理等。只有透彻理解硬件,才能编…...

直播数据大屏是什么?企业应如何构建直播数据大屏?
目录 一、直播数据大屏是什么? 1. 定义 2. 特点 编辑二、企业如何构建直播数据大屏? (一)明确需求和目标 (二)数据采集和整合 (三)选择合适的可视化工具 (四&a…...

Vue与Python的深度整合:构建现代Web应用的全栈范式
在前后端分离架构成为行业标准的今天,Vue.js与Python的组合为全栈开发提供了高效且灵活的技术方案。这种组合不仅继承了Vue组件化开发的敏捷性,更借助Python后端框架(如Django/Flask)的强大生态,实现了从原型设计到生产…...

移动二维矩阵
1、题目描述 小红获得了一个 n行 m 列的二维字符矩阵,现在她要对这个字符矩阵进行向左循环移位。 向左循环移位规则如下:每一行的每一个字母(除了第一个字母)都向左边移动一位。第一行第一个的字母移动到最后一行的最后一个位置,其它行的第一…...
)
RabbitMq学习(第一天)
文章目录 1、mq(消息队列)概述2、RabbitMQ环境搭建3、java基于AMQP协议操作RabbitMQ4、基于Spring AMQP操作RabbitMQ5、代码中创建队列与交换机①、配置类创建②、基于RabbitListener注解创建 6、RabbitMQ详解①、work模型②、交换机1、Fanout(广播)交换机2、Direct(定向)交换机…...

基于RK3568多功能车载定位导航智能信息终端
基于安卓系统开发集成5G和4G模块,GPS/BD双模定位模块(高精度差分惯导)、WIFI模块,蓝 牙模块,RFID模块,音频播放,视频信号输入(AHD或CVBS)模块等多功能车载定位导航智能信…...

Facebook的元宇宙新次元:社交互动如何改变?
科技的浪潮正将我们推向一个全新的时代——元宇宙时代。Facebook,这个全球最大的社交网络平台,已经宣布将公司名称更改为 Meta,全面拥抱元宇宙概念。那么,元宇宙究竟是什么?它将如何改变我们的社交互动方式呢ÿ…...

【上位机——MFC】对话框
对话框的使用 1.添加对话框资源 2.定义一个自己的对话框类(CMyDlg),管理对话框资源,派生自CDialog或CDialogEx均可 对话框架构 #include <afxwin.h> #include "resource.h"class CMyDlg :public CDialog {DECLARE_MESSAGE_MAP() publi…...
)
【信息系统项目管理师】法律法规与标准规范——历年考题(2024年-2020年)
手机端浏览☞【信息系统项目管理师】法律法规与标准规范——历年考题(2024年-2020年) 2024年上半年综合知识【占比分值3′】 42、关于招标投标的描述,不正确的是(属于同一集团组织成员的投标人可以按照该组织要求协同投标…...

【HarmonyOS 5】鸿蒙Web组件和内嵌网页双向通信DEMO示例
【HarmonyOS 5】鸿蒙Web组件和内嵌网页双向通信DEMO示例 一、前言 在 ArkUI 开发中,Web 组件(Web)允许开发者在应用内嵌入网页,实现混合开发场景。 本文将通过完整 DEMO,详解如何通过WebviewController实现 ArkUI 与内嵌网页的双向通信,涵盖 ArkUI 调用网页 JS、网页调…...

var、let、const的区别
1. var 在ES5中,顶层对象的属性和全局变量是等价的,用var声明的变量即是全局变量,也是顶层变量,在浏览器中顶层对象指的是window对象,在node中顶层对象指的是global对象。 console.log(a) // undefined var a 1 cons…...

计算机视觉注意力机制【一】常用注意力机制整理
在做目标检测项目,尤其是基于 YOLOv5 或 YOLOv7 的改进实验时,我发现不同注意力机制对模型性能的提升确实有明显影响,比如提高小目标检测能力、增强特征表达等。但每次找代码都得翻论文、找 GitHub,效率很低。所以我干脆把常见的注…...

交替序列长度的最大值
1、题目描述 给出n个正整数,你可以随意从中挑选一些数字组成 一段序列S,该序列满足以下两个条件: 1.奇偶交替排列:例如:"奇,偶,奇,偶,奇.…" 或者 "偶&a…...
(来自针对Claude的分析))
追踪大型语言模型的思想(下)(来自针对Claude的分析)
多步推理 正如我们上面所讨论的,语言模型回答复杂问题的一种方式就是简单地记住答案。例如,如果问“达拉斯所在州的首府是哪里?”,一个“机械”的模型可以直接学会输出“奥斯汀”,而无需知道德克萨斯州,达拉…...

嵌入式通信协议总览篇:万物互联的基石
嵌入式系统的世界,是靠协议“说话”的世界。 在你设计一个智能设备、构建一个工业控制系统、开发一款 IoT 网关时,一个核心问题始终绕不开:**这些设备之间如何“对话”?**答案就是——通信协议。 本篇作为系列第一章,将带你全面理解嵌入式通信协议的全貌,为后续深入学习…...

Android 连接德佟打印机全实例+踩坑
文章目录 1. sdk下载2. 开始开发2.1 打印之前准备工作2.2 打印机是否连接检测2.3 打印框架设计 最近有个需求是要连接 德佟打印机 进行打印相关事宜, 现在就遇到的问题简单阐述一下。 1. sdk下载 我们首先需要在官网下载对应的SDK,地址为:https://www.d…...

TikTok 矩阵运营新手实操保姆级教程 2.0 版本
在当下这个全球化的数字浪潮中,TikTok 这片充满机遇的流量蓝海,正吸引着无数创业者和品牌方争相角逐。而要想在这激烈的竞争中脱颖而出,TikTok 矩阵运营无疑是至关重要的制胜法宝。今天,就给大家送上这份超实用的新手实操教程&…...

WordPress:Locoy.php火车头采集
<?php /* 模块参数列表: post_title 必选 标题 post_content 必选 内容 tag 可选 标签 post_category 可选 分类 post_date 可选 时间 post_excerpt 可选 摘要 post_author 可选 作者 category_description 可选 分类信息 post_cate_meta[name] 可选 自定义分…...

C++ 有哪些标准版本
目录 1.主要分为以下几个版本C98(ISO/IEC 14882:1998) 第一个国际标准C03(ISO/IEC 14882:2003)小幅度修订C11(ISO/IEC 14882:2011)一次重大更新C14(ISO/IEC 14882:2014)增量改进C17&…...

二、MySQL操作命令汇总
文章目录 二、MySQL操作命令汇总1.数据库操作2.表的增删改查2.1 查表2.2 建表给表添加注释假如表已经存在 2.3 删表2.4 查看表结构2.5 改表 3.简单查询3.1 查询单个字段3.2 查询多个字段3.3 查询所有字段3.4 查询结果去重3.5 查询结果排序3.6 查询结果限制条数3.7 查询分组结果…...

编程日志4.28
队列的链表表示代码 #include<iostream> #include<stdexcept> using namespace std; //队列 类的声明 template<typename T>//1.模板声明,表明Queue类是一个通用的模板类,可以用于存储任何类型的元素T class Queue {//2.Queue类的声…...