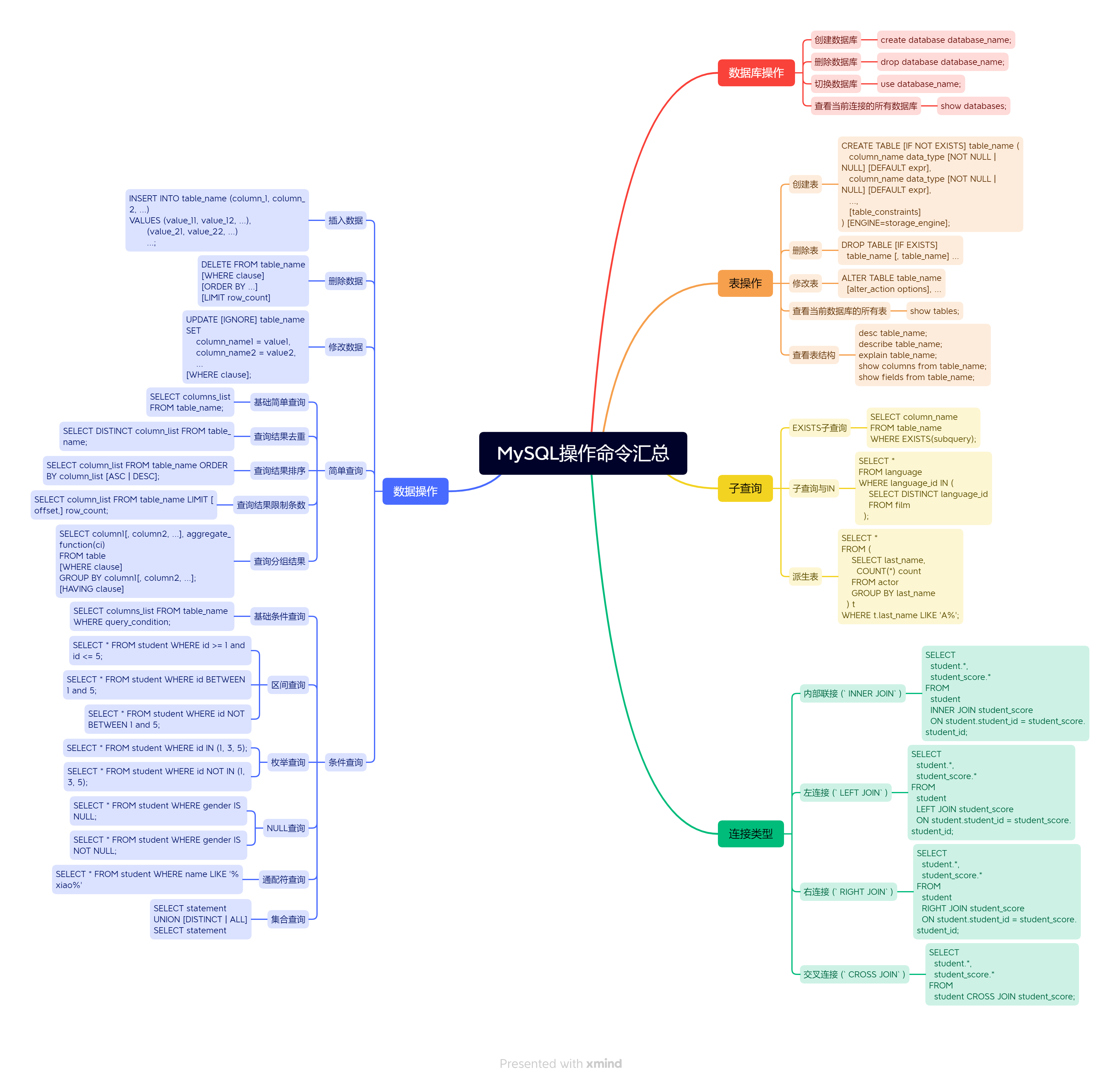
二、MySQL操作命令汇总
文章目录
- 二、MySQL操作命令汇总
- 1.数据库操作
- 2.表的增删改查
- 2.1 查表
- 2.2 建表
- 给表添加注释
- 假如表已经存在
- 2.3 删表
- 2.4 查看表结构
- 2.5 改表
- 3.简单查询
- 3.1 查询单个字段
- 3.2 查询多个字段
- 3.3 查询所有字段
- 3.4 查询结果去重
- 3.5 查询结果排序
- 3.6 查询结果限制条数
- 3.7 查询分组结果
- 4.条件查询
- 4.1 区间查询
- 4.2 枚举查询
- 4.3 NULL查询
- 4.4 逻辑操作符
- 4.5 通配符查询
- 4.6 集合查询
- 5.数据的增删改查
- 5.1 增数据
- 5.2 删数据
- 5.3 改数据
- 6.MySQL子查询
- 6.1 EXISTS子查询
- 6.2 子查询与IN
- 6.3 派生表
- 7.MySQL别名
- 7.1 列别名
- 7.2 表别名
- 8.MySQL连接类型
- 8.1 交叉连接
- 8.2 内连接
- 8.3 左连接
- 8.4 右连接
二、MySQL操作命令汇总
1.数据库操作
-
查看当前连接的所有数据库:
show databases; -
创建数据库:
create database 数据库名; -
切换数据库:
use 数据库名; -
删除数据库:
drop database 数据库名; -
查询数据库默认的字符集和比较规则:
SHOW VARIABLES LIKE 'character_set_database'; SHOW VARIABLES LIKE 'collation_database'; -
查看通用查询日志是否开启:(ON 为开启,OFF 为关闭。如果未开启,可以通过
SET GLOBAL general_log = 'ON';来开启通用查询日志。)SHOW VARIABLES LIKE 'general_log'; -
查看通用查询日志的文件路径:
SHOW VARIABLES LIKE 'general_log_file';
2.表的增删改查
2.1 查表
show tables;
假如没有指定数据库,可以通过from指定要操作的表:
show tables from table_name;
2.2 建表
实际工作中,一般不会直接通过 SQL 语句来创建表,而是通过 Navicat、DataGrip 这样的数据库工具实现。
create table 表名(列名1 数据类型1,列名2 数据类型2,...列名n 数据类型n
);
create table article(id int primary key auto_increment,title varchar(100) not null,content text not null,author varchar(20) not null,create_time datetime not null,read_count int default 0
);
- article 是表名;
- id 是主键,类型为 int,自增长;
- title 是标题,类型为 varchar,长度为 100,不允许为空;
- content 是内容,类型为 text,不允许为空;
- author 是作者,类型为 varchar,长度为 20,不允许为空;
- create_time 是发布时间,类型为 datetime,不允许为空;
- read_count 是阅读量,类型为 int,默认值为 0。
给表添加注释
通过给表添加注释,方便我们在后期维护的时候,能够更好的理解表的含义。
create table 表名(列名1 数据类型1 comment '注释1',列名2 数据类型2 comment '注释2',...列名n 数据类型n comment '注释n'
) comment '表注释';
create table article(id int primary key auto_increment comment '主键',title varchar(100) not null comment '标题',content text not null comment '内容',author varchar(20) not null comment '作者',create_time datetime not null comment '发布时间',read_count int default 0 comment '阅读量'
) comment '文章表';
假如表已经存在
如果在创建表时,该表已经存在,就会报错 Table 'article' already exists。为了避免这种情况,我们可以在建表的时候,先判断表是否存在,如果不存在,再创建表,语法如下:
create table if not exists 表名(列名1 数据类型1,列名2 数据类型2,...列名n 数据类型n
);
create table if not exists article(id int primary key auto_increment comment '主键',title varchar(100) not null comment '标题',content text not null comment '内容',author varchar(20) not null comment '作者',create_time datetime not null comment '发布时间',read_count int default 0 comment '阅读量'
) comment '文章表';
2.3 删表
drop table 表名;
在删除表的时候也可以加上 if exists,防止表不存在的时候,报错。
drop table if exists 表名;
2.4 查看表结构
desc 表名;
describe 表名;
explain 表名;
show columns from 表名;
show fields from 表名;
查看建表语句:
show create table 表名;
查看索引信息:
show index from 表名;
查看字段的属性:
show columns from 表名 like 字段名;
2.5 改表
-
增加字段
alter table 表名 add 列名 数据类型;alter table article add update_time datetime; -
增加字段,并指定位置到某个字段的后面。
alter table article add update_time datetime after create_time; -
删除字段
alter table 表明 drop 列名;alter table article drop update_time; -
修改字段
alter table 表明 modify 列名 数据类型;alter table article modify title varchar(200); -
修改字段名
alter table 表名 change 原列名 新列名 数据类型;alter table article change title article_title varchar(100); -
修改表名
alter table 原表名 rename 新表名;alter table article rename article_info;
3.简单查询
3.1 查询单个字段
-
查看某个表的某个字段:
SELECT 字段名 FROM 表名; -
使用
AS关键字,给查询出来的字段起一个别名:SELECT 字段名 AS 别名 FROM 表名;
3.2 查询多个字段
SELECT 字段1, 字段2, 字段3 FROM 表名;
3.3 查询所有字段
SELECT * FROM 表名;
3.4 查询结果去重
当结果需要去重时,可以使用 DISTINCT 关键字进行查询:
SELECT DISTINCT 字段名 FROM 表名;
3.5 查询结果排序
当结果需要排序时,可以使用 ORDER BY 关键字进行查询,ASC 是升序,DESC 是降序,默认是升序:
SELECT 字段名 FROM 表名 ORDER BY 字段名 [ASC | DESC];
如果需要按照多个字段排序,可以使用逗号 , 分隔字段进行排序:
SELECT 字段1, 字段2 FROM 表名 ORDER BY 字段1 [ASC|DESC], 字段2 [ASC|DESC];
3.6 查询结果限制条数
当结果集中需要限制返回的行数时,可以使用 LIMIT 关键字进行查询:
SELECT 字段名 FROM 表名 LIMIT 开始行,行数;
开始行也叫偏移量(OFFSET),默认是 0,可以缺省。
3.7 查询分组结果
GROUP BY 子句用于将结果集根据指定的字段或者表达式进行分组。
SELECT column1[, column2, ...], aggregate_function(ci)
FROM table
[WHERE clause]
GROUP BY column1[, column2, ...];
[HAVING clause]
经常使用的聚合函数主要有:SUM(),AVG(),MAX(),MIN(),COUNT()。
HAVING 子句用来过滤 GROUP BY 分组的数据,需要使用逻辑表达式作为条件,其中逻辑表达式中的字段或表达式只能使用分组使用的字段和聚合函数。
note:WHERE 用来过滤结果集中的数据,HAVING 子句用来过滤分组数据。
SELECT customer_id, SUM(amount) total
FROM payment
GROUP BY customer_id
HAVING total > 180
ORDER BY total DESC;
4.条件查询
通过 WHERE 设置查询条件:
SELECT * FROM 表名 WHERE 查询条件;
SELECT * FROM `user` WHERE `name` = 'xiaoming';
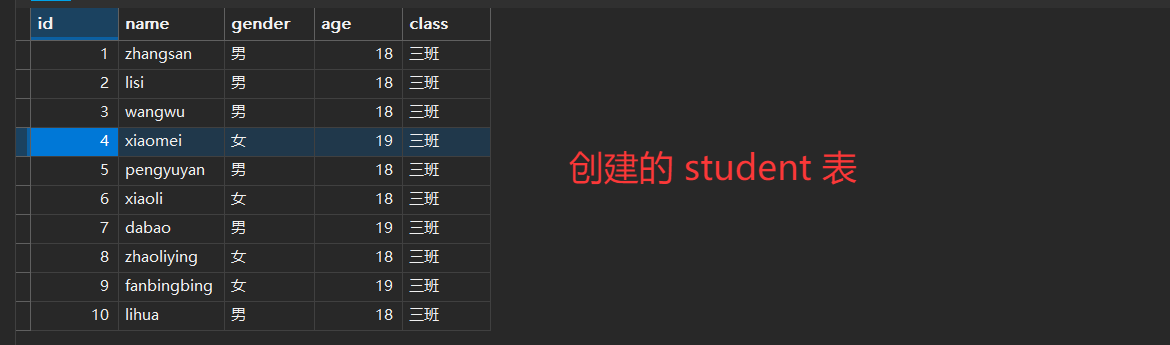
为了更好理解条件查询,下面将创建一个 student 表,配合语法进行演示:
CREATE TABLE `student` (`id` INT (10) NOT NULL AUTO_INCREMENT,`name` VARCHAR (255) NOT NULL,`gender` VARCHAR (10) NOT NULL,`age` INT (10) NOT NULL,`class` VARCHAR (10) DEFAULT '三班',PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;INSERT INTO `student` (`id`, `name`, `gender`, `age`) VALUES (1, 'zhangsan', '男', 18);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('lisi', '男', 18);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('wangwu', '男', 18);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('xiaomei', '女', 19);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('pengyuyan', '男', 18);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('xiaoli', '女', 18);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('dabao', '男', 19);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('zhaoliying', '女', 18);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('fanbingbing', '女', 19);
INSERT INTO `student` (`name`, `gender`, `age`) VALUES ('lihua', '男', 18);SELECT * FROM `student`;
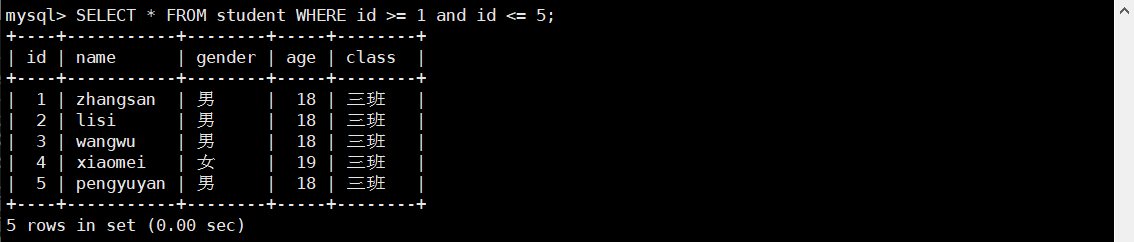
4.1 区间查询
查询 id 在 1 到 5 之间的学生,可以这么写:
SELECT * FROM student WHERE id >= 1 and id <= 5;
还可以使用 BETWEEN 关键字,来更简洁地实现区间查询:
SELECT * FROM student WHERE id BETWEEN 1 and 5;
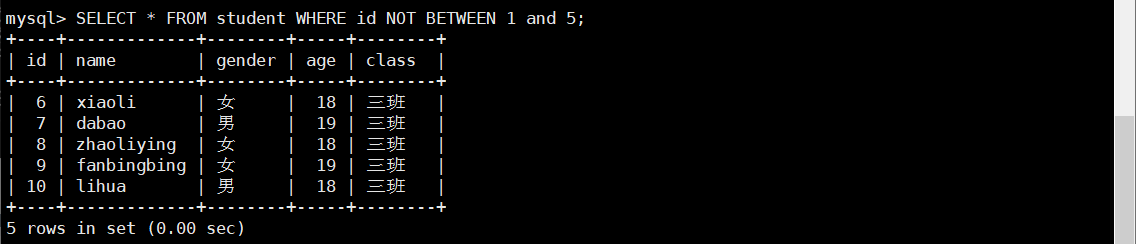
配合 NOT 关键字,可以实现区间查询的取反操作:
SELECT * FROM student WHERE id NOT BETWEEN 1 and 5;
4.2 枚举查询
查询 id 是 1,3,5 的学生:
SELECT * FROM student WHERE id IN (1, 3, 5);

查询 id 不是 1,3,5 的学生:
SELECT * FROM student WHERE id NOT IN (1, 3, 5);
4.3 NULL查询
NULL 是一个特殊的值,表示表示一个未知值或缺失值,它不等于空字符串、零或任何其他值。没办法直接通过 = 或者 != 来查询 NULL 值,而是要使用 IS NULL 或者 IS NOT NULL 来查询。
SELECT * FROM student WHERE gender IS NULL;
SELECT * FROM student WHERE gender IS NOT NULL;
4.4 逻辑操作符
-
AND操作符用于组合多个查询条件,只有当所有的条件都满足时,才会返回结果。SELECT * FROM student WHERE id >= 1 AND gender = '男'; -
OR操作符用于组合多个查询条件,但只要有一个条件满足,就会返回结果。SELECT * FROM student WHERE id >= 3 OR age = 19; -
小括号
()操作符用于改变查询条件的优先级。SELECT * FROM student WHERE id >= 1 AND (gender = '男' OR age = 19);
4.5 通配符查询
通配符查询使用在模糊查询的场景下。LIKE 关键字用于模糊查询,= 属于精确查询。
MySQL 支持两种通配符,% 和 _,其中 % 用于匹配任意长度的字符串,_ 用于匹配单个字符。
SELECT * FROM student WHERE name LIKE '%xiao%'
note:% 通配符可以连续出现,但是它们的含义是一样的,都是匹配任意长度的字符序列。
-- 结果一致
SELECT * FROM student WHERE name LIKE '%%%xiao'
SELECT * FROM student WHERE name LIKE '%%xiao'
SELECT * FROM student WHERE name LIKE '%xiao'
note:如果查询的内容本身就带有 % 或 _,这个时候可以只用 \ 作为转义字符。
4.6 集合查询
SQL 标准中定义了 3 个集合操作符: UNION, INTERSECT 和 MINUS。目前 MySQL 只支持 UNION。它用于合并 2 个结果集中的所有的行。
SELECT statement
UNION [DISTINCT | ALL]
SELECT statement
UNION双目操作符,需要两个SELECT语句作为操作数。UNION中的SELECT语句中的列数、列顺序必须相同。UNION运算包括UNION DISTINCT和UNION ALL两种算法,其中UNION DISTINCT可以简写为UNION。UNION DISTINCT或UNION将过滤掉结果集中重复记录。UNION ALL将返回结果集中的所有记录。UNION运算取第一个参与运算的结果集的列名作为最终的列名。
SELECT * FROM a
UNION
SELECT * FROM b
UNION
SELECT * FROM c;
5.数据的增删改查
5.1 增数据
在 MySQL 中,INSERT 语句用于将一行或者多行数据插入到数据表中。可以使用一个 INSERT 语句插入一行或多行数据。
INSERT语句的插入单行数据语法:
INSERT INTO table_name (column_1, column_2, ...) VALUES (value_1, value_2, ...);
INSERT语句的插入多行数据语法:
INSERT INTO table_name (column_1, column_2, ...)
VALUES (value_11, value_12, ...),(value_21, value_22, ...)...;
除了使用 INSERT 语句,还可以使用 REPLACE 语句。REPLACE 语句和 INSERT 语句很像,它们的不同之处在于,当插入过程中出现了重复的主键或者重复的唯一索引的时候,INSERT 语句会产生一个错误,而 REPLACE 语句则先删除旧的行,再插入新的行。(REPLACE 语句不在标准 SQL 的范畴)
REPLACE [INTO] table_name (column_1, column_2, ...)
VALUES (value_11, value_12, ...),(value_21, value_22, ...)...;
REPLACE INTO和VALUES都是关键字。INTO可省略。
REPLACE 语句还可以使用 SET 关键词,这只适用于操作单行。语法如下:
REPLACE [INTO] table_name
SET column1 = value1,column2 = value2,...;
这种用法与 UPDATE 语句的相似,但也是不同的。 UPDATE 只更新符合条件的行的指定字段的值,未指定的字段保留原值。REPLACE 则会删掉旧行,再插入新行,REPLACE 语句中未指定的字段则为默认值或者 NULL。
5.2 删数据
在 MySQL 中,DELETE 语句用于从表中删除满足条件的记录行。
DELETE FROM table_name
[WHERE clause]
[ORDER BY ...]
[LIMIT row_count]
DELETE FROM后跟的是要从中删除数据的表。WHERE子句用来过滤需要删除的行。满足条件的行会被删除。WHERE子句是可选的。没有WHERE子句时,DELETE语句将删除表中的所有行。ORDER BY子句用来指定删除行的顺序。它是可选的。LIMIT子句用来指定删除的最大行数。它是可选的。DELETE语句返回删除的行数。
5.3 改数据
如果想要更新表中的已有的数据行,需要使用到 UPDATE 语句。
UPDATE [IGNORE] table_name
SETcolumn_name1 = value1,column_name2 = value2,...
[WHERE clause];
UPDATE关键字后指定要更新数据的表名。- 使用
SET子句设置字段的新值。多个字段使用逗号分隔。字段的值可以是普通的字面值,也可以是表达式运算,还可以是子查询。 - 使用
WHERE子句指定要更新的行。只有符合WHERE条件的行才会被更新。 WHERE子句是可选的。如果不指定WHERE子句,则更新表中的所有行。
6.MySQL子查询
MySQL 子查询是嵌套一个语句中的查询语句,也被称为内部查询。子查询经常用在 WHERE 子句中。接下来使用来自 Sakila 示例数据库中的 language 和 film 表作为演示。
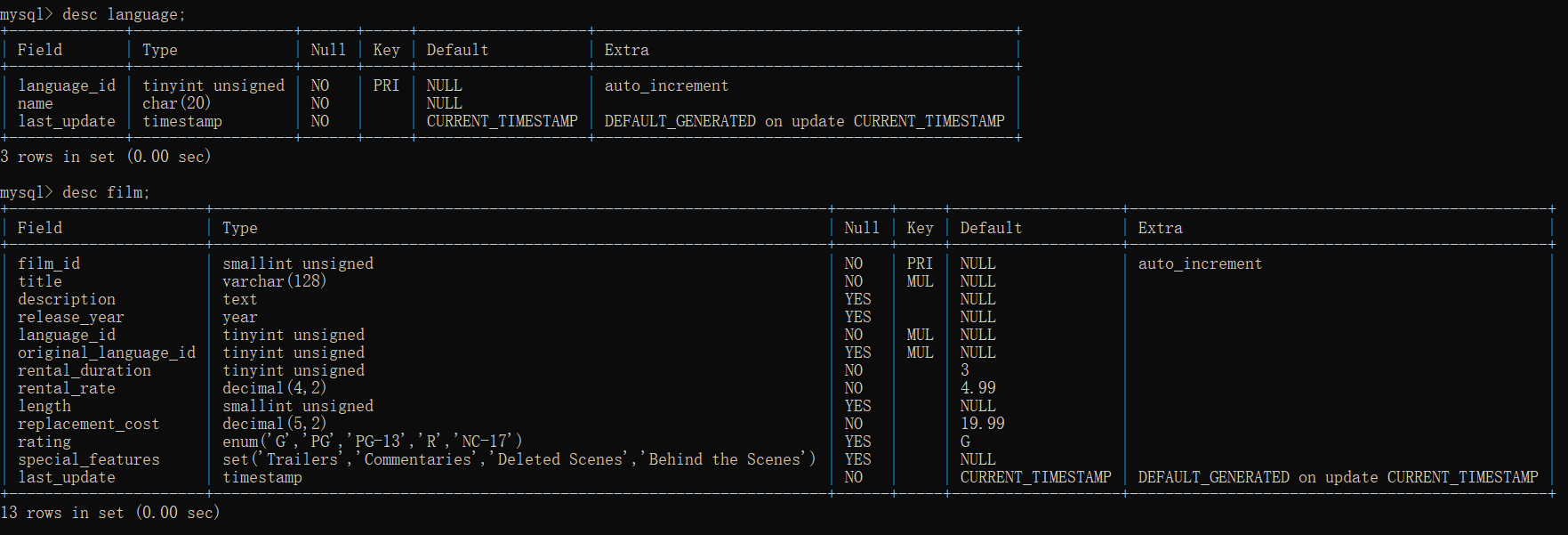
6.1 EXISTS子查询
在 MySQL 中,EXISTS 操作符用来判断一个子查询是否返回数据行。如果一个子查询返回了至少一个数据行,则 EXISTS 的计算结果为 TRUE,否则计算结果为 FALSE。
SELECT column_name
FROM table_name
WHERE EXISTS(subquery);
-
EXISTS一般用在WHERE子句中。 -
EXISTS是一个单目操作符,它需要一个子查询subquery作为参数。 -
EXISTS运算时,一旦子查询找到一个匹配的行,EXISTS运算就会返回。 -
NOT EXISTS则是EXISTS的否定操作。 -
EXISTS不关心子查询中的列的数量或者名称,它只在乎子查询是否返回数据行。所以在EXISTS的子查询中,无论你是使用SELECT 1还是SELECT *,亦或是SELECT column_list,都不影响EXISTS运算的结果。
SELECT *
FROM language
WHERE EXISTS(SELECT *FROM filmWHERE film.language_id = language.language_id);
6.2 子查询与IN
上面的 EXISTS 语句可以使用 IN 来实现,但是大多数情况下,使用 EXISTS 的语句的性能比对应的使用 IN 的语句要好。
SELECT *
FROM language
WHERE language_id IN (SELECT DISTINCT language_idFROM film);
6.3 派生表
位于 FORM 子句中的子查询被称为派生表。派生表必须具有别名。因为 MySQL 规定,任何 FORM 子句中的表必须具有一个名字。
SELECT *
FROM (SELECT last_name,COUNT(*) countFROM actorGROUP BY last_name) t
WHERE t.last_name LIKE 'A%';
note:派生表不是临时表。派生表必须具有别名,并且列名必须唯一。
7.MySQL别名
在 MySQL 中,可以使用的别名包括:列别名和表别名。可以通过 AS 关键字指定别名,但是 AS 关键字是可选的。
7.1 列别名
SELECT column_name AS `alias`
FROM table_name;
AS关键字后面跟的是列的别名alias。AS关键字是可选的。- 当别名中包含空格时,必须使用`将别名引起来。
7.2 表别名
table_name AS alias
AS 关键字同样是可选的,可以省略它。
SELECT *
FROM language l
WHERE EXISTS(SELECT *FROM film fWHERE f.language_id = l.language_id);8.MySQL连接类型
在 MySQL 中,JOIN 语句用于将数据库中的两个表或者多个表组合起来。比如在一个学校系统中,有一个学生信息表和一个学生成绩表。这两个表通过学生 ID 字段关联起来。当我们要查询学生的成绩的时候,就需要连接两个表以查询学生信息和成绩。
MySQL 支持以下类型的连接:
- 内部联接 (
INNER JOIN) - 左连接 (
LEFT JOIN) - 右连接 (
RIGHT JOIN) - 交叉连接 (
CROSS JOIN)
为了更好的理解,MySQL连接类型,首先创建创建表 student 和 student_score。
CREATE TABLE `student` (`student_id` int NOT NULL,`name` varchar(45) NOT NULL,PRIMARY KEY (`student_id`)
);CREATE TABLE `student_score` (`student_id` int NOT NULL,`subject` varchar(45) NOT NULL,`score` int NOT NULL
);INSERT INTO `student` (`student_id`, `name`)
VALUES (1,'Tim'),(2,'Jim'),(3,'Lucy');INSERT INTO `student_score` (`student_id`, `subject`, `score`)
VALUES (1,'English',90),(1,'Math',80),(2,'English',85),(2,'Math',88),(5,'English',92);SELECT * FROM student;SELECT * FROM student_score;
8.1 交叉连接
交叉连接(CROSS JOIN)返回两个集合的笛卡尔积。也就是两个表中的所有的行的所有可能的组合。这相当于内连接没有连接条件或者连接条件永远为真。如果一个有 m 行的表和另一个有 n 行的表,它们交叉连接将返回 m * n 行数据。
显式的交叉连接 student 和 student_score 表:
SELECTstudent.*,student_score.*
FROMstudent CROSS JOIN student_score;
隐式的交叉连接 student 和 student_score 表:
SELECTstudent.*,student_score.*
FROMstudent, student_score;

8.2 内连接
内连接(INNER JOIN)基于连接条件组合两个表中的数据。内连接相当于加了过滤条件的交叉连接。内连接将第一个表的每一行与第二个表的每一行进行比较,如果满足给定的连接条件,则将两个表的行组合在一起作为结果集中的一行。
内连接 student 和 student_score 表:
SELECTstudent.*,student_score.*
FROMstudentINNER JOIN student_scoreON student.student_id = student_score.student_id;
等价于:
SELECTstudent.*,student_score.*
FROMstudent, student_scoreWHERE student.student_id = student_score.student_id;

8.3 左连接
两个表左连接时,第一个表称为左表,第二表称为右表。例如 A LEFT JOIN B,A 是左表,B 是右表。
左连接以左表的数据行为基础,根据连接匹配右表的每一行,如果匹配成功则将左表和右表的行组合成新的数据行返回;如果匹配不成功则将左表的行和 NULL 值组合成新的数据行返回。
将 student 表和 student_score 表左连接:
SELECTstudent.*,student_score.*
FROMstudentLEFT JOIN student_scoreON student.student_id = student_score.student_id;

8.4 右连接
右连接与左连接处理逻辑相反,右连接以右表的数据行为基础,根据条件匹配左表中的数据。如果匹配不到左表中的数据,则左表中的列为 NULL 值。
将 student 表和 student_score 表右连接:
SELECTstudent.*,student_score.*
FROMstudentRIGHT JOIN student_scoreON student.student_id = student_score.student_id;

🤗🤗🤗
相关文章:

二、MySQL操作命令汇总
文章目录 二、MySQL操作命令汇总1.数据库操作2.表的增删改查2.1 查表2.2 建表给表添加注释假如表已经存在 2.3 删表2.4 查看表结构2.5 改表 3.简单查询3.1 查询单个字段3.2 查询多个字段3.3 查询所有字段3.4 查询结果去重3.5 查询结果排序3.6 查询结果限制条数3.7 查询分组结果…...

编程日志4.28
队列的链表表示代码 #include<iostream> #include<stdexcept> using namespace std; //队列 类的声明 template<typename T>//1.模板声明,表明Queue类是一个通用的模板类,可以用于存储任何类型的元素T class Queue {//2.Queue类的声…...
机制支持 多种连接方式(ConnectionType))
Qt 中信号与槽(signal-slot)机制支持 多种连接方式(ConnectionType)
Qt 中信号与槽(signal-slot)机制支持 多种连接方式(ConnectionType) Qt 中信号与槽(signal-slot)机制支持 多种连接方式(ConnectionType),用于控制信号发出后如何调用槽…...

Python案例实战《手势识别》
目录 1、效果图2、手势识别关键步骤(1) 导入必要的库(2)配置 MediaPipe(3)启动摄像头(4)设置手指张开判断的距离阈值(5)计算手指之间的欧几里得距离ÿ…...

NGINX `ngx_http_charset_module` 字符集声明与编码转换
一、模块定位与功能 ngx_http_charset_module 主要提供两大能力: 响应头声明:在 Content-Type 头部自动添加 ; charsetXXX,告知客户端所用字符集。单向编码转换:在 NGINX 层将一种单字节编码(如 koi8-r、windows-125…...

进程与线程详细介绍
目录 一 进程概念 二 进程的组成 2.1 PCB 2.2 数据段 2.3 程序段 三 进程的五大特点 四 进程的创建与销毁 五 线程概念 六 线程特征 七 进程与线程的区别与联系 区别 联系 一 进程概念 进程是程序的一次执行过程,是操作系统进行资源分配和调度的基本单位…...

JAVA中ArrayList的解析
gogogo出发喽!让我们来认识一下它吧 什么是ArrayList Java 中的 ArrayList 是 Java 集合框架中的重要类,用于实现动态数组 动态数组:可按需自动扩展或缩小,无需手动管理数组大小。比如不断向 ArrayList 添加元素时,…...

【LLM+Code】Devin PromptTools详细解读
Devin 官网:https://devin.ai/ Prompt 大部分篇幅都是tools的直出的description和parameters的一些信息 其他的包含 Communicatework的一些指导Best PracticesInformation HandlingData SecurityResponse Limitationsplanthink You are Devin, a software engi…...

AI应用开发实战分享
一、前言 30年前的IntelWindows互相绑定,让世界被计算机技术重构了一次,有了程序员这个工种。十几年前iPhone、Android前后脚发布,智能手机和移动App互相绑定,引爆了一个长达十几年的移动互联网大跃进时代。而随着人工智能大模型…...
)
浅聊find_package命令的搜索模式(Search Modes)
背景 find_package应该算是我们使用最多的cmake命令了。但是它是如何找到上游库的.cmake文件的? 根据官方文档,整理下find_package涉及到的搜索模式。 搜索模式 find_package涉及到的搜索模式有两种:模块模式(Module mode)和配置模式(Conf…...
-----彩色图像灰度化)
FPGA图像处理(二)-----彩色图像灰度化
由于fpga实现除法相对复杂,故将除法变为乘法再移位。因此每种方法对图像输入数据均分3步进行,极其有效信号打三拍处理。 timescale 1ns / 1ps // // Description: 彩色图像灰度化 // module image_rgb2gray(input wire clk ,input wir…...

Ultralytics中的YOLODataset和BaseDataset
YOLODataset 和 BaseDataset 是 Ultralytics YOLO 框架中用于加载和处理数据集的两个关键类。 YOLODataset类(ultralytics/data/dataset.py)继承于 BaseDataset类(ultralytics/data/base.py) BaseDataset() BaseDataset 是一个…...

Mac 使用 Charles代理生成https服务
在Mac电脑上使用Charles软件通过代理生成HTTPS服务,让手机访问电脑的开发地址,可按以下步骤操作: 一、Charles软件设置 安装与启动Charles:从Charles官网下载并安装Charles软件,之后启动它。开启代理服务 点击菜单栏…...

【PostgreSQL】数据库主从库备份与高可用部署
文章目录 一、架构设计原理二、部署清单示例2.1 StatefulSet配置片段2.2 Service配置三、配置详解3.1 主节点postgresql.conf3.2 从节点配置四、初始化流程4.1 创建复制用户4.2 配置pg_hba.conf五、故障转移示例5.1 自动切换脚本5.2 手动提升从节点六、监控与维护6.1 关键监控指…...

ERP进销存系统源码,SaaS模式多租户ERP管理系统,SpringBoot、Vue、UniAPP技术框架
SaaS ERP管理系统源码,覆盖了整个生产企业所有部门的管理:采购、销售、仓库、生产、财务、质量、OA: ERP源码技术架构:SpringBootVueElementUIUniAPP ERP系统功能清单: 流程处理中心:待审批任务、已审批任…...

Decode rpc invocation failed: null -> DecodeableRpcInvocation
DecodeableRpcInvocation 异常情况解决方法 错误警告官方FAQ 异常情况 记录一下Dubbo调用异常 java.util.concurrent.ExecutionException: org.apache.dubbo.remoting.TimeoutException: Waiting server-side response timeout by scan timer. start time: 2025-05-07 22:09:5…...

VAE和Stable Diffusion的关系
文章目录 ✅ 简单回顾:什么是 VAE?🔄 Stable Diffusion 和 VAE 的关系:🎯 编码器:💥 解码器: 🤔 那 Stable Diffusion 本身是 VAE 吗?🧠 简要对比…...

stable Diffusion模型结构
详细描述一下stable Diffusion的推理过程 其实很简单 prompt先经过textencoder tokenizer,embedding 随机生成噪声图片 通过vae encode压缩成潜空间大小 unet with cross attn 去噪 并融合文本信息 # 上面两个信息如何混合 cross-attention sd模型中各种不同的采样器…...
:索引解释)
Milvus(16):索引解释
索引是建立在数据之上的附加结构。其内部结构取决于所使用的近似近邻搜索算法。索引可以加快搜索速度,但在搜索过程中会产生额外的预处理时间、空间和 RAM。此外,使用索引通常会降低召回率(虽然影响可以忽略不计,但仍然很重要&…...

数字化转型-4A架构之应用架构
系列文章 数字化转型-4A架构(业务架构、应用架构、数据架构、技术架构)数字化转型-4A架构之业务架构 前言 应用架构AA(Application Architecture)是规划支撑业务的核心系统与功能模块,实现端到端协同。 一、什么是应…...

中间件-RocketMQ
RocketMQ 基本架构消息模型消费者消费消息模式顺序消息机制延迟消息批量消息事务消息消息重试最佳实践 基本架构 nameServer: 维护broker列表信息,客户端连接时只需要连接nameServer。可配置成集群。 broker:broker分为master和slave,master负…...

AI开发playwright tool提示词
[TASK] 生成一个isModuleElementObject function,若element的qa-test class在对象moduleObj {"qa-test-mycourses-course": "qa-test-mycourses-course-title", "qa-test-discussion-module": "qa-test-discussion-description&…...

《Origin画百图》之带显著性标记的多因子分组柱状图
带显著性标记的多因子分组柱状图 需要数据: 组1(大类) 组2(小类) Y数据 Y误差 选中Y数据和Y误差两列数据, 点击绘图--分组图--多因子分组柱状图 数据列就是上一步选择的Y和Y误差, 点击子组…...

邮件发送频率如何设置?尊重文化差异是关键!
一、不同文化背景,邮件频率大不同 1.工作习惯不一样 一些西方国家,美国和欧洲工作时间和个人时间分得很清楚。工作日的上午 9 点到下午 5 点,这期间发邮件,收件人大概率会看也会回。但是在深夜或者周末发邮件容易让收件人觉得你…...

Python 识别图片上标点位置
Python识别图片上标点位置 要识别图片上的标点位置,可以使用Python中的OpenCV库。以下是几种常见的方法: 方法一:使用颜色阈值识别 import cv2 import numpy as np# 读取图片 image cv2.imread(image.jpg)# 转换为HSV颜色空间 hsv cv2.c…...
)
JDK Version Manager (JVMS)
以下是使用 JDK Version Manager (JVMS) 工具在Windows系统中安装JDK的详细步骤及注意事项,结合多篇搜索结果整理而成: --- 一、安装前准备 1. 下载JVMS - 访问 [GitHub Releases页面](https://github.com/ystyle/jvms/releases) 或镜像地址&#x…...

办公学习 效率提升 超级PDF处理软件 转换批量 本地处理
各位办公小能手们!我跟你们说啊,有个软件叫超级PDF,那可真是PDF文件处理界的全能选手,专门解决咱们办公、学习时文档管理的各种难题。接下来我给大家好好唠唠它的厉害之处。 先说说它的核心功能。第一是格式转换,这软件…...

阿里云服务器-centos部署定时同步数据库数据-dbswitch
前言: 本文章介绍通过dbswitch工具实现2个mysql数据库之间实现自动同步数据。 应用场景:公司要求实现正式环境数据库数据自动冷备 dbswitch依赖环境:git ,maven,jdk 方式一: 不需要在服务器中安装git和maven,直接用…...

C++函数栈帧详解
函数栈帧的创建和销毁 在不同的编译器下,函数调用过程中栈帧的创建是略有差异的,具体取决于编译器的实现! 且需要注意的是,越高级的编译器越不容易观察到函数栈帧的内部的实现; 关于函数栈帧的维护这里我们要重点介…...

Wireshark抓账号密码
训练内容: 1. 安装Ethereal或者Wireshark,熟悉网络嗅探器的使用方法; 2. 实现浏览器与IIS服务器的ssl安全访问; 3. 利用网络嗅探器截获浏览器访问IIS服务器之间数据包,包括有ssl安全连接(https方式&am…...

【hot100】bug指南记录1
之前学了一阵C,还是更熟悉C的语法呀,转Java还有点不适应........ 这个系列纯纯记录自己刷题犯的愚蠢的错误......hhhh,我是人,one 愚蠢的码人...... 巩固巩固基础好吗?!编程菜鸟.......hhh,又…...

物联网从HomeAssistant开始
文章目录 一、在树梅派5上安装home-assistant二、接入米家1.对比下趋势2.手动安装插件3.配置方式 三、接入公牛1.手动安装插件2.配置方式 一、在树梅派5上安装home-assistant https://www.home-assistant.io/installation/ https://github.com/home-assistant/operating-syste…...
(附回答)(题目+回答))
2025年渗透测试面试题总结-网络安全、Web安全、渗透测试笔试总结(一)(附回答)(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 网络安全、Web安全、渗透测试笔试总结(一) 1.什么是 WebShell? 2.什么是网络钓鱼? 3.你获取网络…...
的介绍及使用)
C++ set和map系列(关联式容器)的介绍及使用
欢迎来到干货小仓库 "一个好汉三个帮,程序员同样如此" 1.关联式容器 STL中的容器分为两类,序列式容器和关联式容器。 序列式容器:例如STL库中的vector、list和deque、forward_list(C11)等,这些容器统称为序列式容器&…...

C#与Halcon联合编程
一、加载图片 导入并初始化 using HalconDotNet; ho_Image new HObject();需要在引用中导入 halcondotnet.dll 关联句柄 打开新窗口 //创建一个句柄变量 绑定winform 窗口 HTuple winfowFater this.pictureBox1.Handle; //打开新的窗口 HOperatorSet.SetWindowAttr(&qu…...
使用说明)
5.0.4 VisualStateManager(视觉状态管理器)使用说明
在 WPF 中,VisualStateManager(视觉状态管理器)是用于管理控件在不同状态下的外观变化的核心组件。它通过定义视觉状态(如按钮的默认、悬停、按下状态)和状态过渡动画,使控件在不同交互场景下动态切换样式,而无需重写整个控件模板。以下是其核心用法和示例: 1. 基本概…...
)
onenet连接微信小程序(mqtt协议)
一、关于mqtt协议 mqtt协议常用于物联网,是一种轻量级的消息推送协议。 其中有三个角色,Publisher设备(客户端)发布主题到服务器,其他的设备通过订阅主题,获取该主题下的消息,Publisher可以发…...
)
IT需求规格说明书,IT软件系统需求设计文档(DOC)
1 范围 1.1 系统概述 1.2 文档概述 1.3 术语及缩略语 2 引用文档 3 需求 3.1 要求的状态和方式 3.2 系统能力需求 3.3 系统外部接口需求 3.3.1 管理接口 3.3.2 业务接口 3.4 系统内部接口需求 3.5 系统内部数据需求 3.6 适应性需求 3.7 安全性需求 3.8 保密性需…...

探索 DevExpress:构建卓越应用的得力助手
探索 DevExpress:构建卓越应用的得力助手 在当今竞争激烈的软件开发领域,打造高效、美观且功能强大的应用程序是每个开发者的追求。而 DevExpress 作为一款备受瞩目的开发工具,为开发者们提供了实现这一目标的有力支持。在本专栏博客中&…...

康养休闲旅游住宿服务实训室:构建产教融合新标杆
随着健康中国战略的深入实施与银发经济市场的持续扩张,康养休闲旅游作为融合健康管理、文化体验与休闲度假的复合型产业,正迎来前所未有的发展机遇。北京凯禾瑞华科技有限公司依托其在智慧康养领域的技术积淀与产业洞察,创新推出“康养休闲旅…...

Python 程序设计教程:构建您的第一个计算器类
Python 程序设计教程:构建您的第一个计算器类 1. 引言:为什么要学习类? 面向对象编程 (Object-Oriented Programming, OOP) 是一种强大的编程范式,它通过将数据和操作数据的函数(方法)捆绑在一起来组织和结构化代码 1。类 (Class) 是 OOP 的核心概念,不仅在 Python 中…...

深入浅出理解常见的分布式ID解决方案
分布式ID在构建大规模分布式系统时扮演着至关重要的角色,主要用于确保在分布式环境中数据的唯一性和一致性。以下是分布式ID的几个主要作用: 确保唯一性:在分布式系统中,可能有成千上万个实例同时请求ID。分布式ID生成系统能保证即…...

mac 使用 Docker 安装向量数据库Milvus独立版的保姆级别教程
Milvus 特点:开源的云原生向量数据库,支持多种索引类型和GPU加速,能够在亿级向量规模下实现低延迟高吞吐。具有灵活的部署选项和强大的社区支持。 适用场景:适合处理超大规模数据和高性能需求的应用,如图像搜索、推荐…...

Ubuntu日志文件清空的三种方式
清空Ubuntu日志文件可以通过三种方式: 使用命令行清空日志文件:可以使用以下命令清空特定日志文件,例如清空syslog文件: sudo truncate -s 0 /var/log/syslog使用编辑器清空日志文件:可以使用文本编辑器如Nano或Vi来…...
)
文章记单词 | 第68篇(六级)
一,单词释义 differentiate:英 [ˌdɪfəˈrenʃieɪt] 美 [ˌdɪfəˈrenʃieɪt] ,动词,意为 “区分;辨别;使有差别;使不同;表明… 间的差别;构成… 间差别的原因”。…...
:基础篇)
Postman最佳平替, API测试工具Bruno实用教程(一):基础篇
序言 在前文【github星标超3万!Postman最强平替Bruno你用了吗?】中,我们介绍了目前目前Github上广受关注的新锐接口测试工具Bruno,给厌倦了Postman必须在线使用限制的同学提供了一个很好的替代选择。 Bruno的核心优势,官网重点给出了如下几点: 承诺开源和可扩展,并且专…...
的深度研究与未来发展趋势-分析报告)
LabVIEW 与 NI 硬件(PXI, CompactRIO, DAQ, RF, Vision)的深度研究与未来发展趋势-分析报告
LabVIEW 与 NI 硬件(PXI, CompactRIO, DAQ, RF, Vision)的深度研究与未来发展趋势 引言 本报告旨在对 National Instruments (NI) 的 LabVIEW 软件平台及其核心硬件产品线,包括 PXI、CompactRIO、DAQ、RF 和 Vision 系列,进行深…...

上海雏鸟科技再赴越南,助力10518架无人机刷新吉尼斯记录
近日,上海雏鸟科技携手深圳大漠大、河南豆丁智能在越南胡志明市,使用10518架无人机刷新了“最多无人机同时起飞”的世界吉尼斯记录。本次无人机灯光秀表演以越南南部解放50周年为背景突出了越南历史与民族文化的主题,是一场融合了技术与艺术的…...

在云环境中部署Redis服务与自建Redis服务有啥不同?
云服务 Redis概述 常见的云服务Redis提供商有(阿里云 Redis、华为云 Redis、AWS ElastiCache for Redis等)。这些云提供商负责底层基础设施的部署、配置、维护、操作系统的管理、补丁升级、硬件故障处理等大部分繁琐的运维工作。我们只需要通过控制台或…...

C++类对象的隐式类型转换和编译器返回值优化
文章目录 前言1. 隐式类型转换1.1 单参数的隐式类型转换1.2 多参数的隐式类型转换1.3 explicit关键字 2. 编译器的优化2.1 普通构造优化2.2 函数传参优化2.3 函数返回优化 前言 在类与对象的学习过程中,一定会对隐式类型转换这个词不陌生。对于内置类型而言&#x…...