深入浅出理解常见的分布式ID解决方案
分布式ID在构建大规模分布式系统时扮演着至关重要的角色,主要用于确保在分布式环境中数据的唯一性和一致性。以下是分布式ID的几个主要作用:
-
确保唯一性:在分布式系统中,可能有成千上万个实例同时请求ID。分布式ID生成系统能保证即使在高并发的情况下也能生成全局唯一的ID,避免数据冲突和覆盖
-
便于水平扩展:分布式系统通常需要水平扩展以支持更多的用户和业务。分布式ID生成机制允许系统在不同的机器、数据中心甚至地理区域中扩展,同时仍然能够生成唯一的ID,无需担心ID冲突
-
提高性能:通过避免依赖中心化的数据库序列生成ID,分布式ID生成机制可以显著提高应用性能。这些机制通常在内存中进行,减少了网络延迟和磁盘I/O,从而加快了ID的生成速度
-
减少系统依赖:分布式ID生成不依赖特定的数据库或存储系统,减少了系统组件之间的耦合。这种独立性使得系统更加健壮,减少了因数据库故障导致的ID生成问题
-
时间有序性:某些分布式ID生成策略(如雪花算法)能够生成大致按时间顺序递增的ID。这对于需要跟踪记录创建顺序或进行时间序列分析的应用来说是一个重要特性
-
支持事务和日志追踪:在复杂的分布式系统中,分布式ID可以用来追踪和管理跨多个系统和组件的事务和日志。每个操作都可以关联一个唯一ID,使得问题定位和性能监控变得更加容易。
-
安全性和隐私保护:通过生成不可预测的唯一ID,分布式ID机制还可以增加系统的安全性,防止恶意用户通过ID预测和访问未授权的数据
UUID
UUID (Universally Unique Identifier),通用唯一识别码。UUID是基于当前时间、计数器(counter)和硬件标识(通常为无线网卡的MAC地址)等数据计算生成的。
UUID由以下几部分的组合:
-
当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。
-
时钟序列。
-
全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
UUID 是由一组32位数的16进制数字所构成,以连字号分隔的五组来显示,形式为 8-4-4-4-12,总共有 36个字符(即三十二个英数字母和四个连字号)。
例如:
aefbbd3a-9cc5-4655-8363-a2a43e6e6c80
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx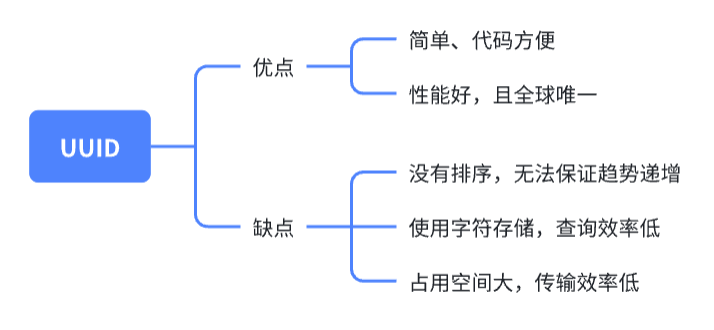
如果需求是只保证唯一性,那么UUID也是可以使用的,但是按照上面的分布式id的要求, UUID其实是不能做成分布式id的,原因如下:
首先分布式id一般都会作为主键,但是按照MySQL官方所推荐的主键要尽量越短越好,UUID每一个都很长,所以不是很推荐。
既然分布式id是主键,然后主键是包含索引的,然后Mysql的索引是通过b+树来实现的,每一次新的UUID数据的插入,为了查询的优化,都会对索引底层的b+树进行修改,因为UUID数据是无序的,所以每一次UUID数据的插入都会对主键生成的b+树进行很大的修改,这一点很不好。
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
自增ID
针对表结构的主键,我们常规的操作是在创建表结构的时候给对应的ID设置 auto_increment.也就是勾选自增选项。
但是这种方式我们清楚在单个数据库的场景中我们是可以这样做的,但如果是在分库分表的环境下,直接利用单个数据库的自增肯定会出现问题。因为ID要唯一,但是分表分库后只能保证一个表中的ID的唯一,而不能保证整体的ID唯一。 上面的情况我们可以通过单独创建主键维护表来处理。
CREATE TABLE `order_id` (`id` bigint NOT NULL AUTO_INCREMENT,`title` char(1) NOT NULL,PRIMARY KEY (`id`),UNIQUE KEY `title` (`title`)
) ENGINE = InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET =utf8;通过更新ID操作来获取ID信息
BEGIN;REPLACE INTO order_id (title) values ('p') ;
SELECT LAST_INSERT_ID();COMMIT;数据库多主模式
单点数据库方式存在明显的性能问题,可以对数据库进行高可用优化,担心一个主节点挂掉没法使用,可以选择做双主模式集群,也就是两个MySQL实例都能单独生产自增的ID。
show variables like '%increment%'我们可以设置主键自增的步长从2开始。

但是这种方案在并发量比较高的情况下,如何保证其拓展性其实会是一个问题。在高并发的情况下无能为力。
号段模式
号段模式是目前分布式ID生成器的主流实现方式之一,号段模式可以理解为数据库批量获取自增ID,每次从数据库中取一个号段范围,例如(1,1000]代表1000个ID,具体的业务服务将本号段生成1~1000的自增ID并加载到内存中。
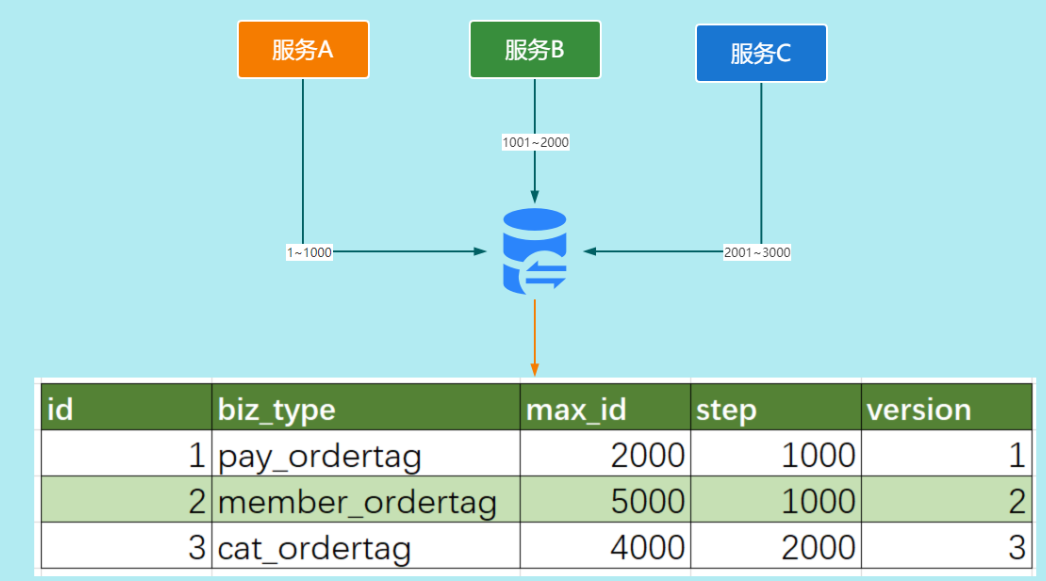
CREATE TABLE id_generator (id int(10) NOT NULL,max_id bigint(20) NOT NULL COMMENT '当前最大id',step int(20) NOT NULL COMMENT '号段的布长',biz_type int(20) NOT NULL COMMENT '业务类型',version int(20) NOT NULL COMMENT '版本号',PRIMARY KEY (`id`)
) biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
但同样也会存在一些缺点比如:服务器重启,单点故障会造成ID不连续。
Redis
基于全局唯一ID的特性,我们可以通过Redis的INCR命令来生成全局唯一ID。

同样使用Redis也有对应的缺点:
-
ID 生成的持久化问题,如果Redis宕机了怎么进行恢复
-
当个节点宕机问题
当然针对故障问题我们可以通过Redis集群来处理,比如我们有三个Redis的Master节点。可以初始化每台Redis的值分别是1,2,3,然后分别把分布式ID的KEY用Hash Tags固定每一个master节点,步长就是master节点的个数。各个Redis生成的ID为:
A:1,4,7 | B:2,5,8 | C:3,6,9
优点:
-
不依赖于数据库,灵活方便,且性能优于数据库
-
数字ID有序,对分页处理和排序都很友好
-
防止了Redis的单机故障
缺点:
-
如果没有Redis数据库,需要安装配置,增加复杂度
-
集群节点确定是3个后,后面调整不是很友好
/*** Redis 分布式ID生成器*/
@Component
public class RedisDistributedId {@Autowiredprivate StringRedisTemplate redisTemplate;private static final long BEGIN_TIMESTAMP = 1659312000l;/*** 生成分布式ID* 符号位 时间戳[31位] 自增序号【32位】* @param item* @return*/public long nextId(String item){// 1.生成时间戳LocalDateTime now = LocalDateTime.now();// 格林威治时间差long nowSecond = now.toEpochSecond(ZoneOffset.UTC);// 我们需要获取的 时间戳 信息long timestamp = nowSecond - BEGIN_TIMESTAMP;// 2.生成序号 --> 从Redis中获取// 当前当前的日期String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));// 获取对应的自增的序号Long increment = redisTemplate.opsForValue().increment("id:" + item + ":" + date);return timestamp << 32 | increment;}}雪花算法
Snowflake,雪花算法是有Twitter开源的分布式ID生成算法,以划分命名空间的方式将64bit位分割成了多个部分,每个部分都有具体的不同含义,在Java中64Bit位的整数是Long类型,所以在Java中Snowflake算法生成的ID就是long来存储的。

第一部分:占用1bit,第一位为符号位,固定为0,二进制中最高位是符号位,1表示负数,0表示正数。ID都是正整数,所以固定为0。
第二部分:41位的时间戳,41bit位可以表示2(41个数,每个数代表的是毫秒,那么雪花算法的时间年限是(2)41)/(1000×60×60×24×365)=69年。时间戳带有自增属性。
第三部分:10bit表示是机器数,即 2^ 10 = 1024台机器,通常不会部署这么多机器。此部分也可拆分成5位datacenterId和5位workerId,datacenterId表示机房ID,workerId表示机器ID。
第四部分:12bit位是自增序列,表示序列号,同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
雪花算法的特点:
-
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
-
对于每一个雪花算法服务,需要先指定 10 位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的 10 位比特位的整数值都行。
优点:
-
高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
-
基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
-
不依赖第三方库或者中间件。
-
算法简单,在内存中进行,效率高。
缺点:
-
依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
值得注意的是:
-
雪花算法每一部分占用的比特位数量并不是固定死的。例如你的业务可能达不到 69 年之久,那么可用减少时间戳占用的位数,雪花算法服务需要部署的节点超过1024 台,那么可将减少的位数补充给机器码用。
-
雪花算法中 41 位比特位不是直接用来存储当前服务器毫秒时间戳的,而是需要当前服务器时间戳减去某一个初始时间戳值,一般可以使用服务上线时间作为初始时间戳值。
-
对于机器码,可根据自身情况做调整,例如机房号,服务器号,业务号,机器 IP 等都是可使用的。对于部署的不同雪花算法服务中,最后计算出来的机器码能区分开来即可。
/*** Twitter_Snowflake* SnowFlake的结构如下(每部分用-分开):* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号* 加起来刚好64位,为一个Long型。* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。* @version 1.0* @Author 振鹏* @Date 2025/5/6 9:58* @注释*/
public class SnowflakeIdWorkerTest {/*** 开始时间截 (2020-11-03,一旦确定不可更改,否则时间被回调,或者改变,可能会造成id重复或冲突)*/private final long twepoch = 1604374294980L;// 定义位数// 机器ID所占的位数private final long workerIdBits = 5L;// 数据中心ID所占的位数private final long datacenterIdBits = 5L;// 支持的最大机器id,结果是31private final long maxWorkerId = -1L ^ (-1L << workerIdBits);// 支持的最大数据标识id,结果是31private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);// 序列在id中占的位数private final long sequenceBits = 12L;// 机器ID向左移12位private final long workerIdShift = sequenceBits;// 数据中心ID向左移17位(12+5)private final long datacenterIdShift = sequenceBits + workerIdBits;/*** 时间截向左移22位(5+5+12)*/private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;// 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)private final long sequenceMask = -1L ^ (-1L << sequenceBits);// 工作机器ID(0~31)private long workerId;// 数据中心ID(0~31)private long datacenterId;// 毫秒内序列(0~4095)private long sequence = 0L;// 上次生成ID的时间截private long lastTimestamp = -1L;//==============================Constructors=====================================/*** 构造函数**/public SnowflakeIdWorkerTest() {this.workerId = 0L;this.datacenterId = 0L;}/*** 构造函数* @param workerId 工作ID (0~31)* @param datacenterId 数据中心ID (0~31)*/public SnowflakeIdWorkerTest(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;}//==============================Methods==/*** 获得下一个ID (该方法是线程安全的)* @return SnowflakeId*/public synchronized long nextId() {long timestamp = timeGen();// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}// 如果是同一时间生成的,则进行序列号自增if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {// 序列号溢出timestamp = tilNextMillis(lastTimestamp);}}// 时间戳改变,毫秒内序列重置else {sequence = 0L;}// 上次生成ID的时间截lastTimestamp = timestamp;//移位并通过或运算拼到一起组成64位的IDreturn ((timestamp - twepoch) << timestampLeftShift)| (datacenterId << datacenterIdShift)| (workerId << workerIdShift)| sequence;}/*** 防止产生的时间回拨* 当时间差距小的时候,等待时间差距,直到时间差距大于阈值,才重新生成id(阻塞线程)* @param lastTimestamp 上次生成ID的时间截* @return 当前时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 返回以毫秒为单位的当前时间* @return 当前时间(毫秒)*/protected long timeGen() {return System.currentTimeMillis();}/*** 随机id生成,使用雪花算法** @return */public static String getSnowId() {SnowflakeIdWorkerTest sf = new SnowflakeIdWorkerTest();String id = String.valueOf(sf.nextId());return id;}public static void main(String[] args) {SnowflakeIdWorkerTest idWorker = new SnowflakeIdWorkerTest(0, 0);for (int i = 0; i < 10; i++) {long id = idWorker.nextId();System.out.println(id);}}
}在生产中如何使用雪花算法来实现分布式ID?
如果发生了时钟回拨,怎么进行解决?
-
回拨时间很短(<=100ms) :直接阻塞100毫秒
-
回拨时间适中(>100ms &<500ms):维护这500毫秒的时间戳最大的ID信息
-
回拨时间比较长(>=500ms & <1000ms):通过分布式ID服务器进行轮询处理
-
回拨时间很长(>=1000ms):直接下线。
当使用雪花算法生成唯一ID时,如果时钟回拨超过500毫秒,可以通过以下几种方式来处理:
-
等待时钟同步:等待系统时钟同步到正确的时间后再继续生成唯一ID。这样虽然会造成一定的延迟,但可以保证生成的唯一ID是正确的。
-
保存历史时间戳:在时钟回拨时,记录下回拨前的时间戳,当时钟同步后,使用回拨前的时间戳来生成唯一ID。这样可以避免重复生成相同的ID。
-
抛出异常或记录日志:如果时钟回拨超过500毫秒,可以抛出异常或记录日志来提示系统管理员或开发人员出现了异常情况,需要及时处理。
百度 UIDgenerator
UidGenerator是百度开源的Java语言实现,基于Snowflake算法的唯一ID生成器。它是分布式的,并克服了雪花算法的并发限制。单个实例的QPS能超过6000000。需要的环境:JDK8+,MySQL(用于分配WorkerId)。

UidGenerator的时间部分只有28位,这就意味着UidGenerator默认只能承受8.5年(2^28-1/86400/365)也可以根据你业务的需求,UidGenerator可以适当调整delta seconds、worker node id和sequence占用位数。
官方地址:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
美团Leaf
世界上没有两片完全相同的树叶。
Leaf 最早期需求是各个业务线的订单ID生成需求。在美团早期,有的业务直接通过DB自增的方式生成ID,有的业务通过redis缓存来生成ID,也有的业务直接用UUID这种方式来生成ID。以上的方式各自有各自的问题,因此我们决定实现一套分布式ID生成服务来满足需求。具体Leaf 设计文档见: leaf 美团分布式ID生成服务
目前Leaf覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM基础上,通过公司RPC方式调用,QPS压测结果近5w/s,TP999 1ms。
Leaf-segment方案:利用数据库自增原理;可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。
Leaf同时支持号段模式和snowflake算法模式,可以切换使用。ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
Leaf的snowflake模式依赖于ZooKeeper,利用zookeeper的顺序节点原理;不同于原始snowflake算法也主要是在workId的生成上,Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
Leaf的号段模式是对直接用数据库自增ID充当分布式ID的一种优化,减少对数据库的频率操作。相当于从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,业务服务将号段在本地生成1~1000的自增ID并加载到内存.。
特性:
1)全局唯一,绝对不会出现重复的ID,且ID整体趋势递增。
2)高可用,服务完全基于分布式架构,即使MySQL宕机,也能容忍一段时间的数据库不可用。
3)高并发低延时,在CentOS 4C8G的虚拟机上,远程调用QPS可达5W+,TP99在1ms内。
4)接入简单,直接通过公司RPC服务或者HTTP调用即可接入。
Leaf采用双buffer的方式,它的服务内部有两个号段缓存区segment。当前号段已消耗10%时,还没能拿到下一个号段,则会另启一个更新线程去更新下一个号段。
简而言之就是Leaf保证了总是会多缓存两个号段,即便哪一时刻数据库挂了,也会保证发号服务可以正常工作一段时间。
滴滴TinyID
由滴滴开发,开源项目链接:GitHub - didi/tinyid: ID Generator id生成器 分布式id生成系统,简单易用、高性能、高可用的id生成系统
Tinyid是在美团(Leaf)的leaf-segment算法基础上升级而来,不仅支持了数据库多主节点模式,还提供了tinyid-client客户端的接入方式,使用起来更加方便。但和美团(Leaf)不同的是,Tinyid只支持号段一种模式不支持雪花模式。Tinyid提供了两种调用方式,一种基于Tinyid-server提供的http方式,另一种Tinyid-client客户端方式。每个服务获取一个号段(1000,2000]、(2000,3000]、(3000,4000]
特性:
1)全局唯一的long型ID
2)趋势递增的id
3)提供 http 和 java-client 方式接入
4)支持批量获取ID
5)支持生成1,3,5,7,9...序列的ID
6)支持多个db的配置
适用场景:只关心ID是数字,趋势递增的系统,可以容忍ID不连续,可以容忍ID的浪费
不适用场景:像类似于订单ID的业务,因生成的ID大部分是连续的,容易被扫库、或者推算出订单量等信息
实战中的分布式ID生成器!保障数据唯一性的核心组件
案例中前置知识点:Redis+Lua实现分布式主键ID方案
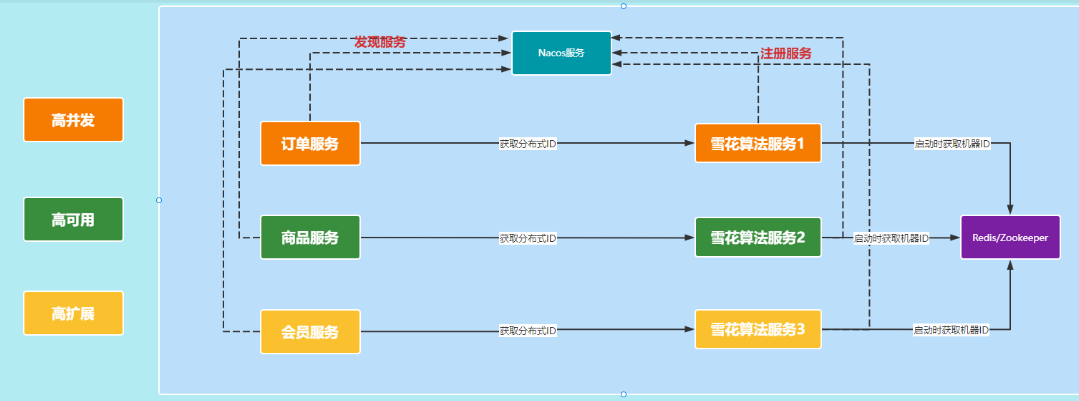
我们了解了分布式ID应用中最出名的雪花算法以后,其中最需要考虑的就是datacenterId 和 workerId 了,datacenterId 表示机房ID,workerId 表示机器ID。而在Mybatis-Plus中,对这两个字段都有进行了配置,但这种配置在k8s的环境下,依然会发生重复问题。
生成的策略与时间戳、mac地址、进程id、自增序列有关。
在k8s集群环境下,如果不是在同一个k8s环境中,mac地址有可能会重复
,java服务进程id都为1,这就造成生成的id会可能重复。所以需要借助第三方来解决redis或zookeeper,因为redis比zookeeper更常用,最终决定用redis来生成
datacenterId和workerId
实战案例中,分布式id生成器对Mybatis-Plus中的雪花算法进行了改造优化,通过依靠redis来配置datacenterId 和 workerId,从而解决这个重复的问题,并且也集成了百度开源的UidGenerator,将依靠数据库自增的方式替换成了依靠redis自增。
-
怎么编写Lua脚本是关键
-
关键的逻辑有一点:workid和dataCenterId的初始化过程都结束
-- 如果work_id不存在,则将值初始化为0
if (redis.call('exists', snowflake_work_id_key) == 0) thenredis.call('set',snowflake_work_id_key,0)snowflake_work_id_flag = true
end
-- 如果data_center_id不存在,则将值初始化为0
if (redis.call('exists', snowflake_data_center_id_key) == 0) thenredis.call('set',snowflake_data_center_id_key,0)snowflake_data_center_id_flag = true
end
-- 如果work_id和data_center_id都是初始化了,那么执行返回初始化的值
if (snowflake_work_id_flag and snowflake_data_center_id_flag) thenreturn json_result
end-- 这是初始化的逻辑。-- redis中work_id的key
local snowflake_work_id_key = KEYS[1]
-- redis中data_center_id的key
local snowflake_data_center_id_key = KEYS[2]
-- worker_id的最大阈值
local max_worker_id = tonumber(ARGV[1])
-- data_center_id的最大阈值
local max_data_center_id = tonumber(ARGV[2])
-- 返回的work_id
local return_worker_id = 0
-- 返回的data_center_id
local return_data_center_id = 0
-- work_id初始化flag
local snowflake_work_id_flag = false
-- data_center_id初始化flag
local snowflake_data_center_id_flag = false
-- 构建并返回JSON字符串
local json_result = string.format('{"%s": %d, "%s": %d}','workId', return_worker_id,'dataCenterId', return_data_center_id)-- 如果work_id不存在,则将值初始化为0
if (redis.call('exists', snowflake_work_id_key) == 0) thenredis.call('set',snowflake_work_id_key,0)snowflake_work_id_flag = true
end
-- 如果data_center_id不存在,则将值初始化为0
if (redis.call('exists', snowflake_data_center_id_key) == 0) thenredis.call('set',snowflake_data_center_id_key,0)snowflake_data_center_id_flag = true
end
-- 如果work_id和data_center_id都是初始化了,那么执行返回初始化的值
if (snowflake_work_id_flag and snowflake_data_center_id_flag) thenreturn json_result
end-- 获得work_id的值
local snowflake_work_id = tonumber(redis.call('get',snowflake_work_id_key))
-- 获得data_center_id的值
local snowflake_data_center_id = tonumber(redis.call('get',snowflake_data_center_id_key))-- 如果work_id的值达到了最大阈值
if (snowflake_work_id == max_worker_id) then-- 如果data_center_id的值也达到了最大阈值if (snowflake_data_center_id == max_data_center_id) then-- 将work_id的值初始化为0redis.call('set',snowflake_work_id_key,0)-- 将data_center_id的值初始化为0redis.call('set',snowflake_data_center_id_key,0)else-- 如果data_center_id的值没有达到最大值,将进行自增,并将自增的结果返回return_data_center_id = redis.call('incr',snowflake_data_center_id_key)end
else-- 如果work_id的值没有达到最大值,将进行自增,并将自增的结果返回return_worker_id = redis.call('incr',snowflake_work_id_key)
end
return string.format('{"%s": %d, "%s": %d}','workId', return_worker_id,'dataCenterId', return_data_center_id)-
怎么执行?
在MyBatisPlus中实现雪花算法,我们需要实现一个接口
/*** Id生成器接口*/
public interface IdentifierGenerator {/*** 判断是否分配 ID** @param idValue 主键值* @return true 分配 false 无需分配*/default boolean assignId(Object idValue) {return StringUtils.checkValNull(idValue);}/*** 生成Id** @param entity 实体* @return id*/Number nextId(Object entity);/*** 生成uuid** @param entity 实体* @return uuid*/default String nextUUID(Object entity) {return IdWorker.get32UUID();}
}本案例中没有这么做,我们是考虑后续可能存在一些新的可替代方案
为了脱离框架依赖,如果以后出现了比Mybatis-Plus更高效的持久化框架,可以更加方便的去替换。
所以选择直接将Mybatis-Plus的雪花算法移植到组件中,并进行了优化。
-
IdGeneratorAutoConfig
public class IdGeneratorAutoConfig {@Beanpublic WorkAndDataCenterIdHandler workAndDataCenterIdHandler(StringRedisTemplate stringRedisTemplate){return new WorkAndDataCenterIdHandler(stringRedisTemplate);}@Beanpublic WorkDataCenterId workDataCenterId(WorkAndDataCenterIdHandler workAndDataCenterIdHandler){return workAndDataCenterIdHandler.getWorkAndDataCenterId();}@Beanpublic SnowflakeIdGenerator snowflakeIdGenerator(WorkDataCenterId workDataCenterId){return new SnowflakeIdGenerator(workDataCenterId);}
}// 定义返回的类型
@Data
public class WorkDataCenterId {private Long workId;private Long dataCenterId;
}-
WorkAndDataCenterIdHandler是执行lua脚本的执行器,执行完脚本后获得了WorkDataCenterId的实体,包好了workId和dataCenterId -
WorkDataCenterId在注入到spring上下文的过程中,就调用了WorkAndDataCenterIdHandler#getWorkAndDataCenterId方法在redis中加载workId和dataCenterId -
加载的过程就是我们上面所列出来Lua脚本。
@Slf4j
public class WorkAndDataCenterIdHandler {private final String SNOWFLAKE_WORK_ID_KEY = "snowflake_work_id";private final String SNOWFLAKE_DATA_CENTER_ID_key = "snowflake_data_center_id";public final List<String> keys = Stream.of(SNOWFLAKE_WORK_ID_KEY,SNOWFLAKE_DATA_CENTER_ID_key).collect(Collectors.toList());private StringRedisTemplate stringRedisTemplate;private DefaultRedisScript<String> redisScript;public WorkAndDataCenterIdHandler(StringRedisTemplate stringRedisTemplate){this.stringRedisTemplate = stringRedisTemplate;try {redisScript = new DefaultRedisScript<>();redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/workAndDataCenterId.lua")));redisScript.setResultType(String.class);} catch (Exception e) {log.error("redisScript init lua error",e);}}public WorkDataCenterId getWorkAndDataCenterId(){WorkDataCenterId workDataCenterId = new WorkDataCenterId();try {String[] data = new String[2];data[0] = String.valueOf(IdGeneratorConstant.MAX_WORKER_ID);data[1] = String.valueOf(IdGeneratorConstant.MAX_DATA_CENTER_ID);String result = stringRedisTemplate.execute(redisScript, keys, data);workDataCenterId = JSON.parseObject(result,WorkDataCenterId.class);}catch (Exception e) {log.error("getWorkAndDataCenterId error",e);}return workDataCenterId;}
}![]()
当创建SnowflakeIdGenerator时,将WorkDataCenterId注入进去
public SnowflakeIdGenerator(WorkDataCenterId workDataCenterId) {if (Objects.nonNull(workDataCenterId.getDataCenterId())) {this.workerId = workDataCenterId.getWorkId();this.datacenterId = workDataCenterId.getDataCenterId();}else {this.datacenterId = getDatacenterId(maxDatacenterId);workerId = getMaxWorkerId(datacenterId, maxWorkerId);}
}SnowflakeIdGenerator
@Slf4j
public class SnowflakeIdGenerator {/*** 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)*/private static final long BASIS_TIME = 1288834974657L;/*** 机器标识位数*/private final long workerIdBits = 5L;private final long datacenterIdBits = 5L;private final long maxWorkerId = -1L ^ (-1L << workerIdBits);private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);/*** 毫秒内自增位*/private final long sequenceBits = 12L;private final long workerIdShift = sequenceBits;private final long datacenterIdShift = sequenceBits + workerIdBits;/*** 时间戳左移动位*/private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private final long sequenceMask = -1L ^ (-1L << sequenceBits);private final long workerId;/*** 数据标识 ID 部分*/private final long datacenterId;/*** 并发控制*/private long sequence = 0L;/*** 上次生产 ID 时间戳*/private long lastTimestamp = -1L;/*** IP 地址*/private InetAddress inetAddress;public SnowflakeIdGenerator(WorkDataCenterId workDataCenterId) {if (Objects.nonNull(workDataCenterId.getDataCenterId())) {this.workerId = workDataCenterId.getWorkId();this.datacenterId = workDataCenterId.getDataCenterId();}else {this.datacenterId = getDatacenterId(maxDatacenterId);workerId = getMaxWorkerId(datacenterId, maxWorkerId);}}public SnowflakeIdGenerator(InetAddress inetAddress) {this.inetAddress = inetAddress;this.datacenterId = getDatacenterId(maxDatacenterId);this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);initLog();}private void initLog() {if (log.isDebugEnabled()) {log.debug("Initialization SnowflakeIdGenerator datacenterId:" + this.datacenterId + " workerId:" + this.workerId);}}/*** 有参构造器** @param workerId 工作机器 ID* @param datacenterId 序列号*/public SnowflakeIdGenerator(long workerId, long datacenterId) {Assert.isFalse(workerId > maxWorkerId || workerId < 0,String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));Assert.isFalse(datacenterId > maxDatacenterId || datacenterId < 0,String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));this.workerId = workerId;this.datacenterId = datacenterId;initLog();}/*** 获取 maxWorkerId*/protected long getMaxWorkerId(long datacenterId, long maxWorkerId) {StringBuilder mpid = new StringBuilder();mpid.append(datacenterId);String name = ManagementFactory.getRuntimeMXBean().getName();if (StringUtils.isNotBlank(name)) {/** GET jvmPid*/mpid.append(name.split("@")[0]);}/** MAC + PID 的 hashcode 获取16个低位*/return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);}/*** 数据标识id部分*/protected long getDatacenterId(long maxDatacenterId) {long id = 0L;try {if (null == this.inetAddress) {this.inetAddress = InetAddress.getLocalHost();}NetworkInterface network = NetworkInterface.getByInetAddress(this.inetAddress);if (null == network) {id = 1L;} else {byte[] mac = network.getHardwareAddress();if (null != mac) {id = ((0x000000FF & (long) mac[mac.length - 2]) | (0x0000FF00 & (((long) mac[mac.length - 1]) << 8))) >> 6;id = id % (maxDatacenterId + 1);}}} catch (Exception e) {log.warn(" getDatacenterId: " + e.getMessage());}return id;}public long getBase(){int five = 5;long timestamp = timeGen();//闰秒if (timestamp < lastTimestamp) {long offset = lastTimestamp - timestamp;if (offset <= five) {try {wait(offset << 1);timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));}} catch (Exception e) {throw new RuntimeException(e);}} else {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset));}}if (lastTimestamp == timestamp) {// 相同毫秒内,序列号自增sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {// 同一毫秒的序列数已经达到最大timestamp = tilNextMillis(lastTimestamp);}} else {// 不同毫秒内,序列号置为 1 - 2 随机数sequence = ThreadLocalRandom.current().nextLong(1, 3);}lastTimestamp = timestamp;return timestamp;}/*** 获取分布式id** @return id*/public synchronized long nextId() {long timestamp = getBase();// 时间戳部分 | 数据中心部分 | 机器标识部分 | 序列号部分return ((timestamp - BASIS_TIME) << timestampLeftShift)| (datacenterId << datacenterIdShift)| (workerId << workerIdShift)| sequence;}/*** 获取订单编号** @return orderNumber*/public synchronized long getOrderNumber(long userId,long tableCount) {long timestamp = getBase();long sequenceShift = log2N(tableCount);// 时间戳部分 | 数据中心部分 | 机器标识部分 | 序列号部分 | 用户id基因return ((timestamp - BASIS_TIME) << timestampLeftShift)| (datacenterId << datacenterIdShift)| (workerId << workerIdShift)| (sequence << sequenceShift)| (userId % tableCount);}protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}protected long timeGen() {return SystemClock.now();}/*** 反解id的时间戳部分*/public static long parseIdTimestamp(long id) {return (id>>22)+ BASIS_TIME;}/*** 求log2(N)* */public long log2N(long count) {return (long)(Math.log(count)/ Math.log(2));}public long getMaxWorkerId() {return maxWorkerId;}public long getMaxDatacenterId() {return maxDatacenterId;}
}总结
-
在构建
SnowflakeIdGenerator时,如果通过lua执行加载获取workDataCenterId失败,则还采取Mybiats-plus的生成策略 -
nextId方法就是获取分布式id的方法,其内部getBase()是更新时间戳的部分,由 时间戳部分 | 数据中心部分 | 机器标识部分 | 序列号部分 这四个部分组成 -
getOrderNumber方法是生成订单编号,使用了基因替换法,来解决在分库分表情况下,使用订单id和用户id查询订单时的全路由问题。
相关文章:

深入浅出理解常见的分布式ID解决方案
分布式ID在构建大规模分布式系统时扮演着至关重要的角色,主要用于确保在分布式环境中数据的唯一性和一致性。以下是分布式ID的几个主要作用: 确保唯一性:在分布式系统中,可能有成千上万个实例同时请求ID。分布式ID生成系统能保证即…...

mac 使用 Docker 安装向量数据库Milvus独立版的保姆级别教程
Milvus 特点:开源的云原生向量数据库,支持多种索引类型和GPU加速,能够在亿级向量规模下实现低延迟高吞吐。具有灵活的部署选项和强大的社区支持。 适用场景:适合处理超大规模数据和高性能需求的应用,如图像搜索、推荐…...

Ubuntu日志文件清空的三种方式
清空Ubuntu日志文件可以通过三种方式: 使用命令行清空日志文件:可以使用以下命令清空特定日志文件,例如清空syslog文件: sudo truncate -s 0 /var/log/syslog使用编辑器清空日志文件:可以使用文本编辑器如Nano或Vi来…...
)
文章记单词 | 第68篇(六级)
一,单词释义 differentiate:英 [ˌdɪfəˈrenʃieɪt] 美 [ˌdɪfəˈrenʃieɪt] ,动词,意为 “区分;辨别;使有差别;使不同;表明… 间的差别;构成… 间差别的原因”。…...
:基础篇)
Postman最佳平替, API测试工具Bruno实用教程(一):基础篇
序言 在前文【github星标超3万!Postman最强平替Bruno你用了吗?】中,我们介绍了目前目前Github上广受关注的新锐接口测试工具Bruno,给厌倦了Postman必须在线使用限制的同学提供了一个很好的替代选择。 Bruno的核心优势,官网重点给出了如下几点: 承诺开源和可扩展,并且专…...
的深度研究与未来发展趋势-分析报告)
LabVIEW 与 NI 硬件(PXI, CompactRIO, DAQ, RF, Vision)的深度研究与未来发展趋势-分析报告
LabVIEW 与 NI 硬件(PXI, CompactRIO, DAQ, RF, Vision)的深度研究与未来发展趋势 引言 本报告旨在对 National Instruments (NI) 的 LabVIEW 软件平台及其核心硬件产品线,包括 PXI、CompactRIO、DAQ、RF 和 Vision 系列,进行深…...

上海雏鸟科技再赴越南,助力10518架无人机刷新吉尼斯记录
近日,上海雏鸟科技携手深圳大漠大、河南豆丁智能在越南胡志明市,使用10518架无人机刷新了“最多无人机同时起飞”的世界吉尼斯记录。本次无人机灯光秀表演以越南南部解放50周年为背景突出了越南历史与民族文化的主题,是一场融合了技术与艺术的…...

在云环境中部署Redis服务与自建Redis服务有啥不同?
云服务 Redis概述 常见的云服务Redis提供商有(阿里云 Redis、华为云 Redis、AWS ElastiCache for Redis等)。这些云提供商负责底层基础设施的部署、配置、维护、操作系统的管理、补丁升级、硬件故障处理等大部分繁琐的运维工作。我们只需要通过控制台或…...

C++类对象的隐式类型转换和编译器返回值优化
文章目录 前言1. 隐式类型转换1.1 单参数的隐式类型转换1.2 多参数的隐式类型转换1.3 explicit关键字 2. 编译器的优化2.1 普通构造优化2.2 函数传参优化2.3 函数返回优化 前言 在类与对象的学习过程中,一定会对隐式类型转换这个词不陌生。对于内置类型而言&#x…...

西门子 PLC 串口转网口模块
在工业自动化领域,高效稳定的通信是保障生产顺畅运行的关键。三格电子西门子 PLC 串口转网口模块,型号涵盖 SG-S7-200-ETH、SG-S7-200-ETH (2P)、SG-S7-300-ETH、SG-S7-300-ETH (2P) 网口扩展与协议支持:该系列模块专为西门子 S7-200/300 PL…...

MATLAB制作直方图
一、什么是直方图? 直方图(Histogram)是一种用于显示数据分布的图形工具。它通过将数据分成若干个区间,统计每个区间内数据的数量或频率,从而形成类似柱状图的形式。它能帮助我们直观了解数据的集中程度、分布形状、离…...
)
Linux NVIDIA 显卡驱动安装指南(适用于 RHEL/CentOS)
📌 一、禁用 Nouveau 开源驱动 NVIDIA 闭源驱动与开源的 nouveau 驱动冲突,需先禁用: if [ ! -f /etc/modprobe.d/blacklist-nouveau.conf ]; thenecho -e "blacklist nouveau\noptions nouveau modeset0" | sudo tee /etc/modpr…...

微机控制电液伺服拉扭疲劳试验系统
微机控制电液伺服拉扭疲劳试验系统,主要用于测定金属材料及其构件在正弦波、三角波、方波、梯形波、斜波、程序块波谱状态下进行: 拉压扭复合疲劳; 单纯的扭转疲劳试验; 拉压扭复合疲劳作用下材料的断裂韧性试验; 拉压…...

ElementUI 表格el-table自适应高度设置
el-table表格占满页面剩余的全部高度空间 首先,el-table父节点要使用flex布局和超出隐藏(overflow: hidden),设置样式如下: .list{flex: 1;display: flex;flex-direction: column;overflow: hidden; }其次࿰…...
:原理、实践与高级技巧)
深入探索Linux命名管道(FIFO):原理、实践与高级技巧
引言:跨越进程的“文件桥梁” 在Linux的进程间通信(IPC)机制中,命名管道(Named Pipe,FIFO) 是一个看似简单却功能强大的工具。它不仅保留了匿名管道的流式数据传输特性,还通过文件系…...

光伏政策“430”“531”安科瑞光储充为新能源提供解决方案有哪些?
简婷 安科瑞电气股份有限公司 上海嘉定 201801 一、政策节点“430”与“531”的含义 2025年分布式光伏行业的两大核心节点——“4月30日”(430)和“5月31日”(531),分别对应《分布式光伏发电开发建设管理办法》实施…...

VScode一直处于循环“正在重新激活终端“问题的解决方法
方法一: 键盘使用 “ctrlshiftp” 调出快捷命令,也可以按F1,并输入“>Python: Clear Cache and Reload Window ”,回车。清除 VSCode 先前的缓存内容,如下图所示。 方法二: 键盘使用 ” ctrl ,"…...

CAN报文逆向工程
在没有DBC文件的情况下解析CAN报文获取物理信息需要逆向工程和系统分析。以下是详细步骤: 1. 数据采集与基础分析 采集原始数据: 使用CAN分析工具(如PCAN-Explorer、SavvyCAN或USB-CAN适配器配套软件)记录车辆在不同状态下的CAN数…...

文件包含漏洞学习
理论 什么是文件包含漏洞 就是允许攻击者包含并执行非预期的文件。也就是通过PHP函数引入文件时,传入的文件名(或者文件内容)没有经过合理的验证,从而操作了预想之外的文件,就可能导致意外的文件泄漏甚至恶意代码注入…...

Linux基本操作——网络操作文件下载
6.网络操作文件下载 (1)在VMware Workstation中配置固定IP 配置固定IP需要的两个大步骤 VMware Workstation中的配置 步骤概述:配置IP地址、网关和网段(IP地址范围) Linux系统中的配置 步骤概述:手动修改…...

【ARM AMBA AHB 入门 3.1 -- AHB控制信号】
文章目录 AHB控制信号传送状态HTRANS[1:0]批量传送HBURST[2:0]传送方向HWRITE传送大小HSIZE[2:0]保护控制HPROT[3:0]响应信号 HRESP[1:0] AHB控制信号 传送状态HTRANS[1:0] 在AHB总线上, Master (M) 的传送状态可由HTRANS[1:0]来表示,这两位所代表的意…...

Amazing晶焱科技:系统级 EOS 测试方法 - System Level EOS Testing Method
系统上常见的EOS测试端口以AC电源、电话线(RJ11)、同轴电缆(coaxial cable)以及以太网络(RJ45)最常见,这些端口因有机会布线至户外的关系,受到EOS/Surge冲击的几率也大大提升。因此电…...

基于DR模式的LVS集群案例
一.环境描述 如上图所示,后端是一个NFS服务器实现共享文件,调度器是一个高可用的环境, 这是基于LVS的DR模式实现的一个负载均衡集群。 keepalived在于LVS结合使用的时候,会自动实现很多功能。 比如,第一点我们可以修…...

Spark jdbc写入崖山等国产数据库失败问题
随着互联网、信息产业的大发展、以及地缘政治的变化,网络安全风险日益增长,网络安全关乎国家安全。因此很多的企业,开始了国产替代的脚步,从服务器芯片,操作系统,到数据库,中间件,逐步实现信息技术自主可控,规避外部技术制裁和风险。 就数据库而言,目前很多的国产数据…...
 是提示工程的新王者)
Chain-of-Draft (CoD) 是提示工程的新王者
图像由 DALLE 3 生成 推理型大模型,是当前 AI 研究的热门话题。 我们从最早的 GPT-1 一路走到现在像 Grok-3 这样的高级推理模型。 这段旅程可以说非常精彩,过程中也发现了很多重要的推理方法。 其中之一就是 Chain-of-Thought(CoT࿰…...

隐私计算技术及其在数据安全中的应用:守护数据隐私的新范式
前言 在数字化时代,数据已成为企业和组织的核心资产。然而,数据的收集、存储和使用过程中面临着诸多隐私和安全问题。随着法律法规对数据隐私的监管日益严格,企业和组织需要在数据利用与隐私保护之间找到平衡。隐私计算技术作为一种新兴的数据…...

使用Milvus向量数据库构建具有长期记忆的对话机器人
一、申请Milvus试用版 快速创建Milvus实例_向量检索服务 Milvus 版(Milvus)-阿里云帮助中心 二、配置 pip3 install pymilvus tqdm dashscope 由于在下文使用的时候需要用到Milvus的公网地址,而公网地址需要我们手动开启,参考下面这篇文章开启公网地…...

[Es_1] 介绍 | 特点 | 图算法 | Trie | FST
编程就是一门不断试错的艺术。不要害怕犯错,实践才会出真知。 什么是ElasticSearch? Elasticsearch是一个分布式的免费开源搜索和分析引擎 适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。 Elasticsearch在Apache Luc…...

企业安装加密软件有什么好处
企业安装加密软件可以有效保护敏感数据安全,防止信息泄露,并满足合规要求。以下是其主要好处及具体应用场景: 1. 防止数据泄露,保护核心资产 文件加密:对敏感文件(如财务数据、客户信息、设计图纸ÿ…...

【MVCP】基于解纠缠表示学习和跨模态-上下文关联挖掘的多模态情感分析
多处可看出与同专栏下的DCCMCI很像 abstract 多模态情感分析旨在从多模态数据中提取用户表达的情感信息,包括语言、声学和视觉线索。 然而,多模态数据的异质性导致了模态分布的差异,从而影响了模型有效整合多模态互补性和冗余性的能力。此外,现有的方法通常在获得表征后直…...
)
2025软考【系统架构设计师】:两周极限冲刺攻略(附知识点解析+答题技巧)
距离2025上半年“系统架构设计师”考试已经只剩最后两周了,还没有准备好的小伙伴赶紧行动起来。为了帮助大家更好的冲刺学习,特此提供一份考前冲刺攻略。本指南包括考情分析、答题技巧、注意事项三个部分,可以参考此指南进行最后的复习要领&a…...

企业该如何选择合适的DDOS防护?
在互联网行业当中,大型的网络游戏和网络视频企业会经常受到DDOS攻击和CC攻击,这些网络攻击会导致服务器崩溃或者是网络中断,给企业造成巨大的经济损失,所以企业通常会配备合适的DDOS防护来进行防御,但是,对…...

CPU-GPU-NPU-TPU 概念
1.CPU 中央处理器(Central Processing Unit,简称CPU)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。CPU自产生以来,在逻辑结构、运行效率以及功能外延上取得了巨大发展。 2.GPU GPU࿰…...

DELL R770 服务器,更换OCP模块!
今天接到客户报修电话,说有一台 DELL PowerEdge R770服务器,网卡出现了故障,需要更换OCP模块。顺便做一个教程,分享给有需要的小伙伴们。 这一期的教程,听起来好像很高大上,很多小伙伴可能不知道OCP是什么…...

go.mod没有自动缓存问题
今天在安装Gin框架的时候遇到了一个问题 在Terminal运行下面命令安装时,包已经被下载安装到了GoPath中的bkg/mod go get -u github.com/gin-gonic/gin但是由于使用的是Go Modules,GPT以及大多数人给的说法是 运行完这个依赖包会被自动同步更新到go.mod…...
算法)
黑电平校正(Black Level Correction, BLC)算法
黑电平校正(Black Level Correction, BLC)算法 黑电平校正(BLC)是图像传感器(如CMOS/CCD)信号处理中的一个重要步骤,主要用于消除传感器暗电流(Dark Current)导致的基线…...

Ubuntu 安装 Keepalived
Keepalived 是什么 Keepalived 是一个用于实现高可用性(High Availability, HA)的服务,是一款基于 VRRP 协议的高可用软件,常用于主备切换和虚拟IP漂移,在服务故障时自动实现故障转移。 Keepalived 的核心功能 功能说…...

基于SpringBoot和PostGIS的应急运输事件影响分析-以1.31侧翻事故为例
目录 前言 一、技术实现路径 1、需要使用的数据 2、空间分析方法 二、相关模块设计与实现 1、运输路线重现开发 2、事故点影响范围实现 3、WebGIS可视化实现 三、讨论 1、界面结果展示 2、影响范围分析 四、总结 前言 在交通运输发达的当今社会,应急运输…...

ABP-Book Store Application中文讲解 - 前期准备 - Part 2:创建Acme.BookStore + Angular
ABP-Book Store Application中文讲解-汇总-CSDN博客 因为本系列文章使用的.NET8 SDK,此处仅介绍如何使用abp cli .NET 8 SDK SQL sevrer 2014创建Angular模板的Acme.BookStore。 目录 1. ABP cli创建项目 1.1 打开cmd.exe 1.2 创建项目 2. ABP Studio创建项…...

grpc到底是啥! ! !!
一、什么是RPC(Remote Procedure Call) 简单理解: RPC是一种让程序可以像调用本地函数一样去调用远程机器上的函数或方法。它的目标:让分布式系统中的不同计算机可以透明地互相通信,实现远程服务调用的封装。 举个例…...

ES6入门---第三单元 模块五:Map和WeakMap
map: users.map((user) 遍历 类似 json, 但是json的键(key)只能是字符串 map的key可以是任意类型 使用: let map new Map(); map.set(key,value); 设置一个值 map.get(key) 获取一个值 map.delete(key) 删除一项 map.has(key) 判断有没有 map.clear…...

【C++】【数据结构】【API列表】标准库数据结构
标准库数据结构 unordered_set 头文件:#include <unordered_set> 特性: 唯一性:所有元素唯一,重复插入无效无序性:元素存储顺序不固定自定义类型:若存储自定义类型需提供哈希函数和相等比较器 …...

三、Hadoop1.X及其组件的深度剖析
作者:IvanCodes 日期:2025年5月7日 专栏:Hadoop教程 一、Hadoop 1.X 概述 (一)概念 Hadoop 是 Apache 开发的分布式系统基础架构,用 Java 编写,为集群处理大型数据集提供编程模型,…...

stm32常见错误
1.使用LCD屏幕时,只用st-link时,亮度很暗,需要用usb数据线额外给屏幕供电; 2.移植freertos到f103c8t6芯片时,工程没有错误,但单片机没有反应; 需要将堆的大小改成10*1024; 3.在找已经…...

《Python星球日记》 第46天:决策树与随机森林
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、前言二…...

【Pandas】pandas DataFrame expanding
Pandas2.2 DataFrame Function application, GroupBy & window 方法描述DataFrame.apply(func[, axis, raw, …])用于沿 DataFrame 的轴(行或列)应用一个函数DataFrame.map(func[, na_action])用于对 DataFrame 的每个元素应用一个函数DataFrame.a…...

【SpringCloud GateWay】Connection prematurely closed BEFORE response 报错分析与解决方案
一、背景 今天业务方调用我们的网关服务报错: Connection prematurely closed BEFORE response二、原因分析 三、解决方案 第一步: 增加 SCG 服务的JVM启动参数,调整连接获取策略。 将连接池获取策略由默认的 FIFO(先进先出)变更为 LIFO(…...

【行业】一些名词
名词 分布式应用架构(分布式计算技术的应用和工具)中间件 中间件(Middleware)主流中间件技术1.通信类2.数据类3. **协调与治理类中间件**4. 监控与可观测性中间件5.**流处理与批处理**中间件6.云原生中间件 数据库Redismogodb 分布…...

深度学习模型的部署实践与Web框架选择
引言 在深度学习项目的完整生命周期中,模型训练只是第一步,将训练好的模型部署到生产环境才能真正发挥其价值。本文将详细介绍模型部署的核心概念、常见部署方式以及三种主流Python Web框架的对比分析,帮助开发者选择最适合自己项目的技术方…...

【笔记】当个自由的书籍收集者从canvas得到png转pdf
最近有点迷各种古书,然后从 www.shuge.org 下载了各种高清的印本,快成db狂魔了…上面也有人在各种平台上分享,不胜感激…只是有些平台可以免费看但是没法下载… 反正你都canvas了,撸下来自己珍藏… 于是让qwen写了一段代码&#…...