Ultralytics中的YOLODataset和BaseDataset
YOLODataset 和 BaseDataset 是 Ultralytics YOLO 框架中用于加载和处理数据集的两个关键类。
YOLODataset类(ultralytics/data/dataset.py)继承于 BaseDataset类(ultralytics/data/base.py)
BaseDataset()
BaseDataset 是一个基础数据集类,提供了加载图像、缓存数据、预处理数据等核心功能。它是所有数据集类的父类,为子类提供了通用的数据加载和处理逻辑。
主要功能:
- 图像加载:从指定路径加载图像文件。
- 缓存机制:支持将图像缓存到内存或磁盘,以加速训练。
- 数据预处理:包括图像大小调整、填充等操作。
- 标签处理:加载和更新标签信息。
- 数据增强:通过
build_transforms方法支持数据增强。
关键方法:
get_img_files:从指定路径加载图像文件。load_image:加载单个图像并返回其原始和调整后的尺寸。cache_images:将图像缓存到内存或磁盘。set_rectangle:设置矩形训练模式。get_image_and_label:获取图像和标签信息。build_transforms:构建数据增强和预处理管道(需子类实现)。
YOLODataset()
YOLODataset 继承自 BaseDataset,并在此基础上扩展了 YOLO 特定任务的功能。它支持 YOLO 的目标检测、实例分割、姿态估计和旋转框(OBB)等任务。
主要功能:
- 标签加载:从磁盘或缓存中加载 YOLO 格式的标签。
- 任务支持:根据任务类型(检测、分割、姿态估计、OBB)加载相应的标签。
- 数据增强:扩展了 YOLO 特定的数据增强逻辑(如 Mosaic、MixUp 等)。
- 标签格式处理:将标签转换为 YOLO 训练所需的格式。
关键方法:
cache_labels:缓存标签并检查图像和标签的完整性。get_labels:加载标签并返回 YOLO 训练所需的格式。build_transforms:构建 YOLO 特定的数据增强和预处理管道。update_labels_info:更新标签格式以适应不同任务。collate_fn:将数据样本整理为批次。
YOLODataset 和BaseDataset 的关系
YOLODataset 继承自 BaseDataset,并在此基础上扩展了 YOLO 特定任务的功能。具体关系如下:
class YOLODataset(BaseDataset):def __init__(self, *args, data=None, task="detect", **kwargs):super().__init__(*args, channels=self.data["channels"], **kwargs)
YOLODataset通过super().__init__()调用BaseDataset的初始化方法,继承了BaseDataset的所有属性和方法。YOLODataset在初始化时增加了task参数,用于指定任务类型(检测、分割、姿态估计、OBB)。
方法重写
- 标签加载:
YOLODataset重写了get_labels方法,支持从 YOLO 格式的标签文件中加载数据。- 数据增强:
YOLODataset重写了build_transforms方法,增加了 YOLO 特定的数据增强逻辑(如 Mosaic、MixUp 等)。- 任务支持:
YOLODataset根据任务类型加载相应的标签,并处理成 YOLO 训练所需的格式,update_labels_info。
YOLODataset整体流程
1. 初始化 (__init__)
步骤:
1. 设置任务类型2. 调用父类初始化
- 通过
super().__init__(*args, channels=self.data["channels"], **kwargs)调用父类BaseDataset的初始化函数。- 父类会加载图像文件、标签文件,并进行缓存和预处理。
父类初始化流程:
1. 初始化参数。
2. 加载图像文件 (
get_img_files),返回找到的图像文件路径列表。3. 加载标签文件 (
get_labels),get_labels函数子类YOLODataset进行了复写!所以调用的是子类方法。4. 缓存图像 (
cache_images),以加快训练速度。5. 构建数据增强方法 (
build_transforms)。
2. 缓存标签 (cache_labels)
cache_labels 方法用于缓存标签数据,并检查图像和标签的完整性。
3. 获取标签 (get_labels)
get_labels 方法用于从缓存或磁盘加载标签数据,并准备用于训练。
下面是YOLODataset复写的函数。
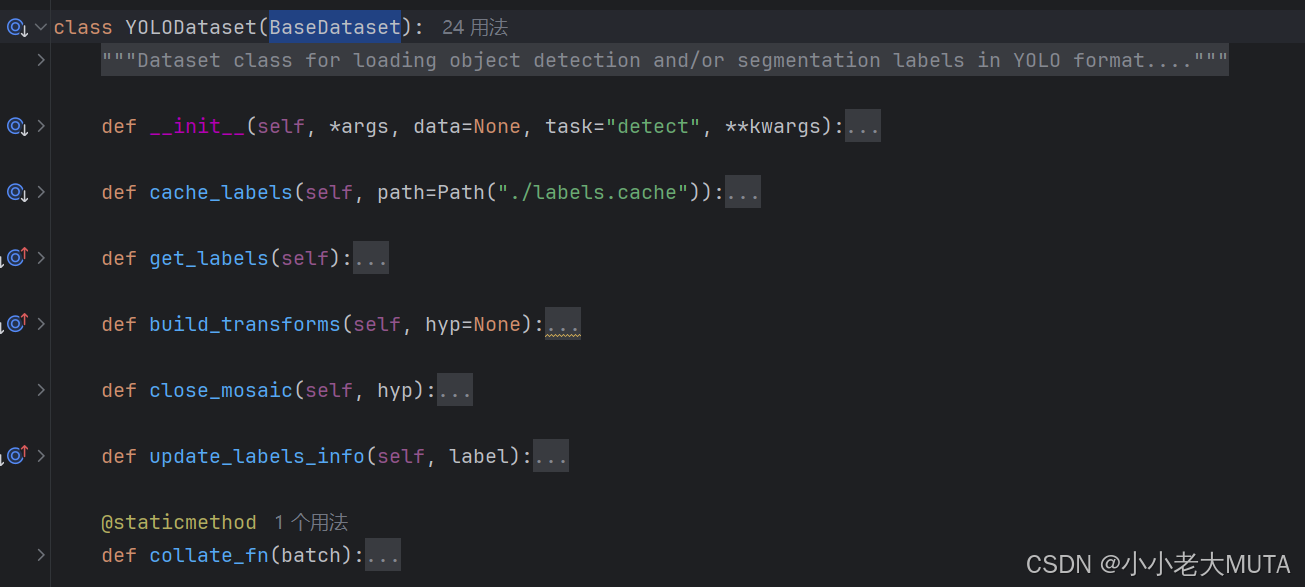
def get_labels(self):"""Returns dictionary of labels for YOLO training.This method loads labels from disk or cache, verifies their integrity, and prepares them for training.Returns:(List[dict]): List of label dictionaries, each containing information about an image and its annotations."""self.label_files = img2label_paths(self.im_files)cache_path = Path(self.label_files[0]).parent.with_suffix(".cache")try:cache, exists = load_dataset_cache_file(cache_path), True # attempt to load a *.cache fileassert cache["version"] == DATASET_CACHE_VERSION # matches current versionassert cache["hash"] == get_hash(self.label_files + self.im_files) # identical hashexcept (FileNotFoundError, AssertionError, AttributeError):cache, exists = self.cache_labels(cache_path), False # run cache ops# Display cachenf, nm, ne, nc, n = cache.pop("results") # found, missing, empty, corrupt, totalif exists and LOCAL_RANK in {-1, 0}:d = f"Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt"TQDM(None, desc=self.prefix + d, total=n, initial=n) # display resultsif cache["msgs"]:LOGGER.info("\n".join(cache["msgs"])) # display warnings# Read cache[cache.pop(k) for k in ("hash", "version", "msgs")] # remove itemslabels = cache["labels"]if not labels:LOGGER.warning(f"No images found in {cache_path}, training may not work correctly. {HELP_URL}")self.im_files = [lb["im_file"] for lb in labels] # update im_files# Check if the dataset is all boxes or all segmentslengths = ((len(lb["cls"]), len(lb["bboxes"]), len(lb["segments"])) for lb in labels)len_cls, len_boxes, len_segments = (sum(x) for x in zip(*lengths))if len_segments and len_boxes != len_segments:LOGGER.warning(f"Box and segment counts should be equal, but got len(segments) = {len_segments}, "f"len(boxes) = {len_boxes}. To resolve this only boxes will be used and all segments will be removed. ""To avoid this please supply either a detect or segment dataset, not a detect-segment mixed dataset.")for lb in labels:lb["segments"] = []if len_cls == 0:LOGGER.warning(f"No labels found in {cache_path}, training may not work correctly. {HELP_URL}")return labels方法流程:
1. 获取标签文件路径:调用img2label_paths方法,根据图像文件路径生成对应的标签文件路径。self.label_files = img2label_paths(self.im_files)2. 加载缓存文件:尝试从缓存文件加载标签数据。
cache, exists = load_dataset_cache_file(cache_path), True3. 验证缓存文件:检查缓存文件的版本和哈希值是否匹配。
assert cache["version"] == DATASET_CACHE_VERSION assert cache["hash"] == get_hash(self.label_files + self.im_files)4. 更新图像文件列表:从缓存中提取图像文件路径,并更新
self.im_files。self.im_files = [lb["im_file"] for lb in labels]5. 检查标签完整性:检查标签数据是否完整(如边界框和分割掩码的数量是否一致)。
if len_segments and len_boxes != len_segments:LOGGER.warning("Box and segment counts should be equal...")6. 返回标签数据:返回处理后的标签数据,供训练使用。
return labels
get_labels方法的主要功能包括:
- 加载标签文件:从磁盘或缓存中加载标签数据。
- 验证标签完整性:检查标签数据是否有效(如是否存在、是否损坏等)。
- 准备标签数据:将标签数据转换为模型训练所需的格式。
- 返回标签数据:返回处理后的标签数据,供训练使用。
get_labels 方法的返回值是一个包含标签数据的列表,列表中的每个元素是一个字典,表示一张图像的标签信息。每个字典的键值对如下:
| 键名 | 描述 |
|---|---|
im_file | 图像文件的路径。 |
shape | 图像的原始尺寸(高度、宽度)。 |
cls | 目标的类别索引,形状为 (n, 1),其中 n 是目标的数量。 |
bboxes | 目标的边界框,形状为 (n, 4),格式为 [x_center, y_center, width, height]。 |
segments | 目标的分割掩码(如果任务为分割),形状为 (n, k, 2),其中 k 是点的数量。 |
keypoints | 目标的关键点(如果任务为姿态估计),形状为 (n, k, 3),其中 k 是点的数量。 |
normalized | 布尔值,表示边界框和关键点是否已归一化。 |
bbox_format | 边界框的格式(如 "xywh")。 |
输出示例:
[{"im_file": "path/to/images/image1.jpg","shape": (640, 640),"cls": [[0], [1]], # 两个目标,类别分别为 0 和 1"bboxes": [[0.5, 0.5, 0.2, 0.3], [0.7, 0.8, 0.1, 0.1]], # 两个目标的边界框"segments": [], # 分割掩码(如果任务为分割)"keypoints": [], # 关键点(如果任务为姿态估计)"normalized": True,"bbox_format": "xywh"},{"im_file": "path/to/images/image2.jpg","shape": (640, 640),"cls": [[0]], # 一个目标,类别为 0"bboxes": [[0.3, 0.4, 0.1, 0.2]], # 一个目标的边界框"segments": [], # 分割掩码(如果任务为分割)"keypoints": [], # 关键点(如果任务为姿态估计)"normalized": True,"bbox_format": "xywh"}
]
4. 构建数据增强 (
build_transforms)
build_transforms 方法用于构建数据增强和预处理管道。
5. 更新标签信息 (update_labels_info)
update_labels_info 方法用于更新标签数据的格式,以支持不同任务(如目标检测、分割等)。
6. 数据加载与训练
在训练过程中,YOLODataset 会通过 __getitem__ 方法加载数据,并应用数据增强和预处理。
数据打包流程(collate_fn)
在 YOLODataset 中,数据打包的过程是通过 collate_fn 方法实现的。collate_fn 方法将多个样本(每张图像及其标签)打包成一个批次,以便输入到模型中进行训练。
collate_fn 方法的主要功能是将多个样本的数据(如图像、标签、边界框等)打包成一个批次。
1. 初始化批次字典:创建一个空字典
new_batch,用于存储批次数据。new_batch = {}2. 排序样本数据:确保每个样本的键值顺序一致,以便后续处理。
batch = [dict(sorted(b.items())) for b in batch]3. 提取样本键值:获取所有样本的键(如
img、bboxes、cls等),并将对应的值打包成列表。keys = batch[0].keys() values = list(zip(*[list(b.values()) for b in batch]))4. 处理不同类型的数据:根据数据类型(如图像、边界框、类别等),使用不同的方式将数据打包成张量。
for i, k in enumerate(keys):value = values[i]if k in {"img", "text_feats"}:value = torch.stack(value, 0) # 图像数据直接堆叠elif k == "visuals":value = torch.nn.utils.rnn.pad_sequence(value, batch_first=True) # 填充序列elif k in {"masks", "keypoints", "bboxes", "cls", "segments", "obb"}:value = torch.cat(value, 0) # 标签数据拼接new_batch[k] = value5. 处理批次索引:为每个样本添加批次索引,以便在训练过程中区分不同样本。
new_batch["batch_idx"] = list(new_batch["batch_idx"]) for i in range(len(new_batch["batch_idx"])):new_batch["batch_idx"][i] += i # 添加目标图像索引 new_batch["batch_idx"] = torch.cat(new_batch["batch_idx"], 0)6. 返回批次数据:返回打包好的批次数据。
return new_batch
DataLoader中读取一批次数据的具体内容
在使用 DataLoader 加载数据时,collate_fn 方法会自动将多个样本打包成一个批次。以下是 DataLoader 中读取一批次数据的具体内容。
| 字段名 | 描述 |
|---|---|
img | 图像数据,形状为 (batch_size, channels, height, width)。 |
bboxes | 边界框数据,形状为 (total_objects, 4),格式为 [x_center, y_center, width, height]。 |
cls | 类别数据,形状为 (total_objects, 1)。 |
segments | 分割掩码数据,形状为 (total_objects, k, 2),其中 k 是点的数量。 |
keypoints | 关键点数据,形状为 (total_objects, k, 3),其中 k 是点的数量。 |
batch_idx | 批次索引,形状为 (total_objects,),用于区分不同样本的目标。 |
从 DataLoader 中读取一批次数据的示例输出:
{"img": tensor([[[[0.5, 0.5, 0.2, 0.3], [0.7, 0.8, 0.1, 0.1]], # 图像数据[[0.3, 0.4, 0.1, 0.2], [0.6, 0.7, 0.2, 0.1]]]),"bboxes": tensor([[0.5, 0.5, 0.2, 0.3], [0.7, 0.8, 0.1, 0.1], # 边界框数据[0.3, 0.4, 0.1, 0.2], [0.6, 0.7, 0.2, 0.1]]),"cls": tensor([[0], [1], [0], [1]]), # 类别数据"segments": tensor([], dtype=torch.float32), # 分割掩码数据"keypoints": tensor([], dtype=torch.float32), # 关键点数据"batch_idx": tensor([0, 0, 1, 1]) # 批次索引
}
相关文章:

Ultralytics中的YOLODataset和BaseDataset
YOLODataset 和 BaseDataset 是 Ultralytics YOLO 框架中用于加载和处理数据集的两个关键类。 YOLODataset类(ultralytics/data/dataset.py)继承于 BaseDataset类(ultralytics/data/base.py) BaseDataset() BaseDataset 是一个…...

Mac 使用 Charles代理生成https服务
在Mac电脑上使用Charles软件通过代理生成HTTPS服务,让手机访问电脑的开发地址,可按以下步骤操作: 一、Charles软件设置 安装与启动Charles:从Charles官网下载并安装Charles软件,之后启动它。开启代理服务 点击菜单栏…...

【PostgreSQL】数据库主从库备份与高可用部署
文章目录 一、架构设计原理二、部署清单示例2.1 StatefulSet配置片段2.2 Service配置三、配置详解3.1 主节点postgresql.conf3.2 从节点配置四、初始化流程4.1 创建复制用户4.2 配置pg_hba.conf五、故障转移示例5.1 自动切换脚本5.2 手动提升从节点六、监控与维护6.1 关键监控指…...

ERP进销存系统源码,SaaS模式多租户ERP管理系统,SpringBoot、Vue、UniAPP技术框架
SaaS ERP管理系统源码,覆盖了整个生产企业所有部门的管理:采购、销售、仓库、生产、财务、质量、OA: ERP源码技术架构:SpringBootVueElementUIUniAPP ERP系统功能清单: 流程处理中心:待审批任务、已审批任…...

Decode rpc invocation failed: null -> DecodeableRpcInvocation
DecodeableRpcInvocation 异常情况解决方法 错误警告官方FAQ 异常情况 记录一下Dubbo调用异常 java.util.concurrent.ExecutionException: org.apache.dubbo.remoting.TimeoutException: Waiting server-side response timeout by scan timer. start time: 2025-05-07 22:09:5…...

VAE和Stable Diffusion的关系
文章目录 ✅ 简单回顾:什么是 VAE?🔄 Stable Diffusion 和 VAE 的关系:🎯 编码器:💥 解码器: 🤔 那 Stable Diffusion 本身是 VAE 吗?🧠 简要对比…...

stable Diffusion模型结构
详细描述一下stable Diffusion的推理过程 其实很简单 prompt先经过textencoder tokenizer,embedding 随机生成噪声图片 通过vae encode压缩成潜空间大小 unet with cross attn 去噪 并融合文本信息 # 上面两个信息如何混合 cross-attention sd模型中各种不同的采样器…...
:索引解释)
Milvus(16):索引解释
索引是建立在数据之上的附加结构。其内部结构取决于所使用的近似近邻搜索算法。索引可以加快搜索速度,但在搜索过程中会产生额外的预处理时间、空间和 RAM。此外,使用索引通常会降低召回率(虽然影响可以忽略不计,但仍然很重要&…...

数字化转型-4A架构之应用架构
系列文章 数字化转型-4A架构(业务架构、应用架构、数据架构、技术架构)数字化转型-4A架构之业务架构 前言 应用架构AA(Application Architecture)是规划支撑业务的核心系统与功能模块,实现端到端协同。 一、什么是应…...

中间件-RocketMQ
RocketMQ 基本架构消息模型消费者消费消息模式顺序消息机制延迟消息批量消息事务消息消息重试最佳实践 基本架构 nameServer: 维护broker列表信息,客户端连接时只需要连接nameServer。可配置成集群。 broker:broker分为master和slave,master负…...

AI开发playwright tool提示词
[TASK] 生成一个isModuleElementObject function,若element的qa-test class在对象moduleObj {"qa-test-mycourses-course": "qa-test-mycourses-course-title", "qa-test-discussion-module": "qa-test-discussion-description&…...

《Origin画百图》之带显著性标记的多因子分组柱状图
带显著性标记的多因子分组柱状图 需要数据: 组1(大类) 组2(小类) Y数据 Y误差 选中Y数据和Y误差两列数据, 点击绘图--分组图--多因子分组柱状图 数据列就是上一步选择的Y和Y误差, 点击子组…...

邮件发送频率如何设置?尊重文化差异是关键!
一、不同文化背景,邮件频率大不同 1.工作习惯不一样 一些西方国家,美国和欧洲工作时间和个人时间分得很清楚。工作日的上午 9 点到下午 5 点,这期间发邮件,收件人大概率会看也会回。但是在深夜或者周末发邮件容易让收件人觉得你…...

Python 识别图片上标点位置
Python识别图片上标点位置 要识别图片上的标点位置,可以使用Python中的OpenCV库。以下是几种常见的方法: 方法一:使用颜色阈值识别 import cv2 import numpy as np# 读取图片 image cv2.imread(image.jpg)# 转换为HSV颜色空间 hsv cv2.c…...
)
JDK Version Manager (JVMS)
以下是使用 JDK Version Manager (JVMS) 工具在Windows系统中安装JDK的详细步骤及注意事项,结合多篇搜索结果整理而成: --- 一、安装前准备 1. 下载JVMS - 访问 [GitHub Releases页面](https://github.com/ystyle/jvms/releases) 或镜像地址&#x…...

办公学习 效率提升 超级PDF处理软件 转换批量 本地处理
各位办公小能手们!我跟你们说啊,有个软件叫超级PDF,那可真是PDF文件处理界的全能选手,专门解决咱们办公、学习时文档管理的各种难题。接下来我给大家好好唠唠它的厉害之处。 先说说它的核心功能。第一是格式转换,这软件…...

阿里云服务器-centos部署定时同步数据库数据-dbswitch
前言: 本文章介绍通过dbswitch工具实现2个mysql数据库之间实现自动同步数据。 应用场景:公司要求实现正式环境数据库数据自动冷备 dbswitch依赖环境:git ,maven,jdk 方式一: 不需要在服务器中安装git和maven,直接用…...

C++函数栈帧详解
函数栈帧的创建和销毁 在不同的编译器下,函数调用过程中栈帧的创建是略有差异的,具体取决于编译器的实现! 且需要注意的是,越高级的编译器越不容易观察到函数栈帧的内部的实现; 关于函数栈帧的维护这里我们要重点介…...

Wireshark抓账号密码
训练内容: 1. 安装Ethereal或者Wireshark,熟悉网络嗅探器的使用方法; 2. 实现浏览器与IIS服务器的ssl安全访问; 3. 利用网络嗅探器截获浏览器访问IIS服务器之间数据包,包括有ssl安全连接(https方式&am…...

【hot100】bug指南记录1
之前学了一阵C,还是更熟悉C的语法呀,转Java还有点不适应........ 这个系列纯纯记录自己刷题犯的愚蠢的错误......hhhh,我是人,one 愚蠢的码人...... 巩固巩固基础好吗?!编程菜鸟.......hhh,又…...

物联网从HomeAssistant开始
文章目录 一、在树梅派5上安装home-assistant二、接入米家1.对比下趋势2.手动安装插件3.配置方式 三、接入公牛1.手动安装插件2.配置方式 一、在树梅派5上安装home-assistant https://www.home-assistant.io/installation/ https://github.com/home-assistant/operating-syste…...
(附回答)(题目+回答))
2025年渗透测试面试题总结-网络安全、Web安全、渗透测试笔试总结(一)(附回答)(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 网络安全、Web安全、渗透测试笔试总结(一) 1.什么是 WebShell? 2.什么是网络钓鱼? 3.你获取网络…...
的介绍及使用)
C++ set和map系列(关联式容器)的介绍及使用
欢迎来到干货小仓库 "一个好汉三个帮,程序员同样如此" 1.关联式容器 STL中的容器分为两类,序列式容器和关联式容器。 序列式容器:例如STL库中的vector、list和deque、forward_list(C11)等,这些容器统称为序列式容器&…...

C#与Halcon联合编程
一、加载图片 导入并初始化 using HalconDotNet; ho_Image new HObject();需要在引用中导入 halcondotnet.dll 关联句柄 打开新窗口 //创建一个句柄变量 绑定winform 窗口 HTuple winfowFater this.pictureBox1.Handle; //打开新的窗口 HOperatorSet.SetWindowAttr(&qu…...
使用说明)
5.0.4 VisualStateManager(视觉状态管理器)使用说明
在 WPF 中,VisualStateManager(视觉状态管理器)是用于管理控件在不同状态下的外观变化的核心组件。它通过定义视觉状态(如按钮的默认、悬停、按下状态)和状态过渡动画,使控件在不同交互场景下动态切换样式,而无需重写整个控件模板。以下是其核心用法和示例: 1. 基本概…...
)
onenet连接微信小程序(mqtt协议)
一、关于mqtt协议 mqtt协议常用于物联网,是一种轻量级的消息推送协议。 其中有三个角色,Publisher设备(客户端)发布主题到服务器,其他的设备通过订阅主题,获取该主题下的消息,Publisher可以发…...
)
IT需求规格说明书,IT软件系统需求设计文档(DOC)
1 范围 1.1 系统概述 1.2 文档概述 1.3 术语及缩略语 2 引用文档 3 需求 3.1 要求的状态和方式 3.2 系统能力需求 3.3 系统外部接口需求 3.3.1 管理接口 3.3.2 业务接口 3.4 系统内部接口需求 3.5 系统内部数据需求 3.6 适应性需求 3.7 安全性需求 3.8 保密性需…...

探索 DevExpress:构建卓越应用的得力助手
探索 DevExpress:构建卓越应用的得力助手 在当今竞争激烈的软件开发领域,打造高效、美观且功能强大的应用程序是每个开发者的追求。而 DevExpress 作为一款备受瞩目的开发工具,为开发者们提供了实现这一目标的有力支持。在本专栏博客中&…...

康养休闲旅游住宿服务实训室:构建产教融合新标杆
随着健康中国战略的深入实施与银发经济市场的持续扩张,康养休闲旅游作为融合健康管理、文化体验与休闲度假的复合型产业,正迎来前所未有的发展机遇。北京凯禾瑞华科技有限公司依托其在智慧康养领域的技术积淀与产业洞察,创新推出“康养休闲旅…...

Python 程序设计教程:构建您的第一个计算器类
Python 程序设计教程:构建您的第一个计算器类 1. 引言:为什么要学习类? 面向对象编程 (Object-Oriented Programming, OOP) 是一种强大的编程范式,它通过将数据和操作数据的函数(方法)捆绑在一起来组织和结构化代码 1。类 (Class) 是 OOP 的核心概念,不仅在 Python 中…...

深入浅出理解常见的分布式ID解决方案
分布式ID在构建大规模分布式系统时扮演着至关重要的角色,主要用于确保在分布式环境中数据的唯一性和一致性。以下是分布式ID的几个主要作用: 确保唯一性:在分布式系统中,可能有成千上万个实例同时请求ID。分布式ID生成系统能保证即…...

mac 使用 Docker 安装向量数据库Milvus独立版的保姆级别教程
Milvus 特点:开源的云原生向量数据库,支持多种索引类型和GPU加速,能够在亿级向量规模下实现低延迟高吞吐。具有灵活的部署选项和强大的社区支持。 适用场景:适合处理超大规模数据和高性能需求的应用,如图像搜索、推荐…...

Ubuntu日志文件清空的三种方式
清空Ubuntu日志文件可以通过三种方式: 使用命令行清空日志文件:可以使用以下命令清空特定日志文件,例如清空syslog文件: sudo truncate -s 0 /var/log/syslog使用编辑器清空日志文件:可以使用文本编辑器如Nano或Vi来…...
)
文章记单词 | 第68篇(六级)
一,单词释义 differentiate:英 [ˌdɪfəˈrenʃieɪt] 美 [ˌdɪfəˈrenʃieɪt] ,动词,意为 “区分;辨别;使有差别;使不同;表明… 间的差别;构成… 间差别的原因”。…...
:基础篇)
Postman最佳平替, API测试工具Bruno实用教程(一):基础篇
序言 在前文【github星标超3万!Postman最强平替Bruno你用了吗?】中,我们介绍了目前目前Github上广受关注的新锐接口测试工具Bruno,给厌倦了Postman必须在线使用限制的同学提供了一个很好的替代选择。 Bruno的核心优势,官网重点给出了如下几点: 承诺开源和可扩展,并且专…...
的深度研究与未来发展趋势-分析报告)
LabVIEW 与 NI 硬件(PXI, CompactRIO, DAQ, RF, Vision)的深度研究与未来发展趋势-分析报告
LabVIEW 与 NI 硬件(PXI, CompactRIO, DAQ, RF, Vision)的深度研究与未来发展趋势 引言 本报告旨在对 National Instruments (NI) 的 LabVIEW 软件平台及其核心硬件产品线,包括 PXI、CompactRIO、DAQ、RF 和 Vision 系列,进行深…...

上海雏鸟科技再赴越南,助力10518架无人机刷新吉尼斯记录
近日,上海雏鸟科技携手深圳大漠大、河南豆丁智能在越南胡志明市,使用10518架无人机刷新了“最多无人机同时起飞”的世界吉尼斯记录。本次无人机灯光秀表演以越南南部解放50周年为背景突出了越南历史与民族文化的主题,是一场融合了技术与艺术的…...

在云环境中部署Redis服务与自建Redis服务有啥不同?
云服务 Redis概述 常见的云服务Redis提供商有(阿里云 Redis、华为云 Redis、AWS ElastiCache for Redis等)。这些云提供商负责底层基础设施的部署、配置、维护、操作系统的管理、补丁升级、硬件故障处理等大部分繁琐的运维工作。我们只需要通过控制台或…...

C++类对象的隐式类型转换和编译器返回值优化
文章目录 前言1. 隐式类型转换1.1 单参数的隐式类型转换1.2 多参数的隐式类型转换1.3 explicit关键字 2. 编译器的优化2.1 普通构造优化2.2 函数传参优化2.3 函数返回优化 前言 在类与对象的学习过程中,一定会对隐式类型转换这个词不陌生。对于内置类型而言&#x…...

西门子 PLC 串口转网口模块
在工业自动化领域,高效稳定的通信是保障生产顺畅运行的关键。三格电子西门子 PLC 串口转网口模块,型号涵盖 SG-S7-200-ETH、SG-S7-200-ETH (2P)、SG-S7-300-ETH、SG-S7-300-ETH (2P) 网口扩展与协议支持:该系列模块专为西门子 S7-200/300 PL…...

MATLAB制作直方图
一、什么是直方图? 直方图(Histogram)是一种用于显示数据分布的图形工具。它通过将数据分成若干个区间,统计每个区间内数据的数量或频率,从而形成类似柱状图的形式。它能帮助我们直观了解数据的集中程度、分布形状、离…...
)
Linux NVIDIA 显卡驱动安装指南(适用于 RHEL/CentOS)
📌 一、禁用 Nouveau 开源驱动 NVIDIA 闭源驱动与开源的 nouveau 驱动冲突,需先禁用: if [ ! -f /etc/modprobe.d/blacklist-nouveau.conf ]; thenecho -e "blacklist nouveau\noptions nouveau modeset0" | sudo tee /etc/modpr…...

微机控制电液伺服拉扭疲劳试验系统
微机控制电液伺服拉扭疲劳试验系统,主要用于测定金属材料及其构件在正弦波、三角波、方波、梯形波、斜波、程序块波谱状态下进行: 拉压扭复合疲劳; 单纯的扭转疲劳试验; 拉压扭复合疲劳作用下材料的断裂韧性试验; 拉压…...

ElementUI 表格el-table自适应高度设置
el-table表格占满页面剩余的全部高度空间 首先,el-table父节点要使用flex布局和超出隐藏(overflow: hidden),设置样式如下: .list{flex: 1;display: flex;flex-direction: column;overflow: hidden; }其次࿰…...
:原理、实践与高级技巧)
深入探索Linux命名管道(FIFO):原理、实践与高级技巧
引言:跨越进程的“文件桥梁” 在Linux的进程间通信(IPC)机制中,命名管道(Named Pipe,FIFO) 是一个看似简单却功能强大的工具。它不仅保留了匿名管道的流式数据传输特性,还通过文件系…...

光伏政策“430”“531”安科瑞光储充为新能源提供解决方案有哪些?
简婷 安科瑞电气股份有限公司 上海嘉定 201801 一、政策节点“430”与“531”的含义 2025年分布式光伏行业的两大核心节点——“4月30日”(430)和“5月31日”(531),分别对应《分布式光伏发电开发建设管理办法》实施…...

VScode一直处于循环“正在重新激活终端“问题的解决方法
方法一: 键盘使用 “ctrlshiftp” 调出快捷命令,也可以按F1,并输入“>Python: Clear Cache and Reload Window ”,回车。清除 VSCode 先前的缓存内容,如下图所示。 方法二: 键盘使用 ” ctrl ,"…...

CAN报文逆向工程
在没有DBC文件的情况下解析CAN报文获取物理信息需要逆向工程和系统分析。以下是详细步骤: 1. 数据采集与基础分析 采集原始数据: 使用CAN分析工具(如PCAN-Explorer、SavvyCAN或USB-CAN适配器配套软件)记录车辆在不同状态下的CAN数…...

文件包含漏洞学习
理论 什么是文件包含漏洞 就是允许攻击者包含并执行非预期的文件。也就是通过PHP函数引入文件时,传入的文件名(或者文件内容)没有经过合理的验证,从而操作了预想之外的文件,就可能导致意外的文件泄漏甚至恶意代码注入…...

Linux基本操作——网络操作文件下载
6.网络操作文件下载 (1)在VMware Workstation中配置固定IP 配置固定IP需要的两个大步骤 VMware Workstation中的配置 步骤概述:配置IP地址、网关和网段(IP地址范围) Linux系统中的配置 步骤概述:手动修改…...