《Python星球日记》 第46天:决策树与随机森林
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
专栏:《Python星球日记》,限时特价订阅中ing
目录
- 一、前言
- 二、决策树算法原理
- 1. 决策树简介
- 2. 决策树的分裂准则
- (1) 信息熵与信息增益
- (2) 基尼不纯度
- 三、随机森林算法
- 1. 集成学习思想
- 2. 随机森林的优势
- 四、使用Scikit-learn实现决策树与随机森林
- 1. 决策树的实现
- 2. 随机森林的实现
- 3. 随机森林的超参数调优
- 五、实战案例:泰坦尼克生存预测
- 1. 数据加载与探索
- 2. 数据预处理
- 3. 训练决策树和随机森林模型
- 4. 模型评估与特征重要性分析
- 5. 结果分析与讨论
- 六、总结与拓展
- 1. 学习要点回顾
- 2. 实际应用场景
- 3. 拓展学习方向
- 4. 练习挑战
- 七、参考资料
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第45天:KNN 与 SVM 分类器
欢迎来到Python星球的第46天!🪐
一、前言
今天我们将深入机器学习的森林世界,学习两个强大的分类与回归算法:决策树与随机森林。这两种算法凭借其直观性和高效性,在机器学习领域占据着重要地位。无论你是想预测客户行为,还是分析复杂数据模式,这些工具都将成为你数据科学工具箱中的得力助手!
让我们用一张图来直观感受决策树与随机森林的关系:
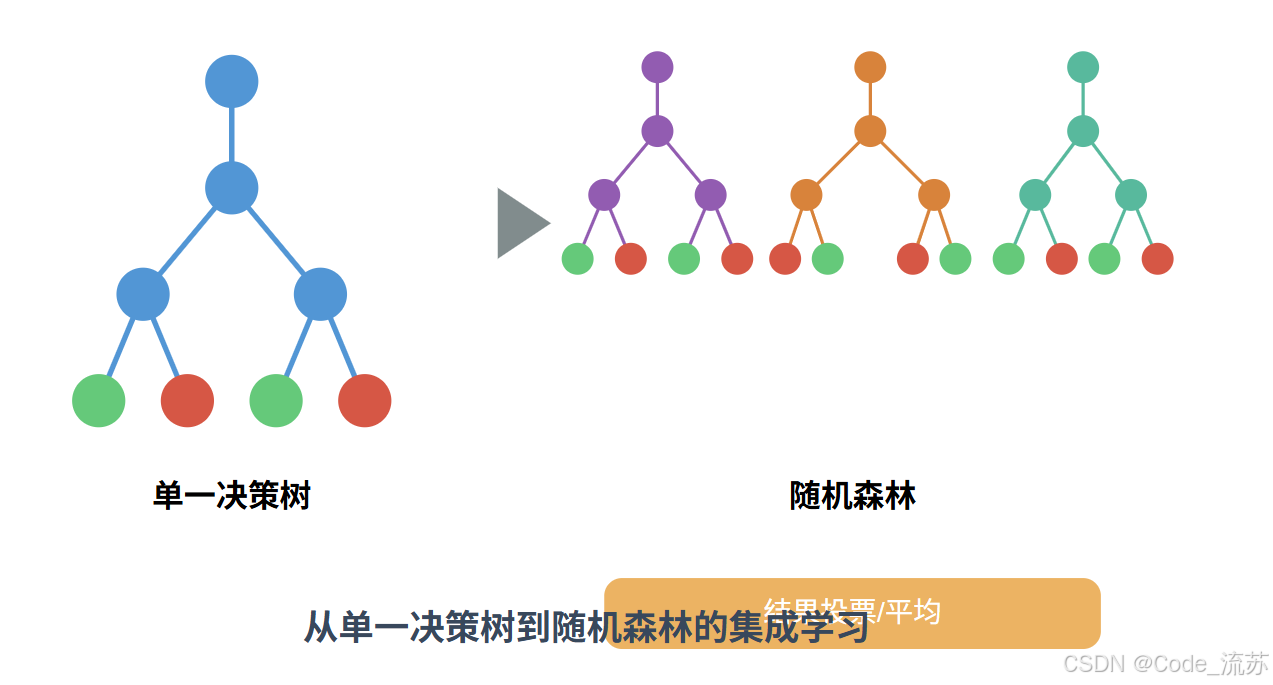
二、决策树算法原理
1. 决策树简介
决策树是一种树形结构的监督学习模型,它通过一系列问题将数据划分为不同类别。就像我们玩"20个问题"猜物品游戏一样,决策树通过提问来缩小可能性范围,最终给出预测结果。
决策树的核心思想可以用以下流程图表示:
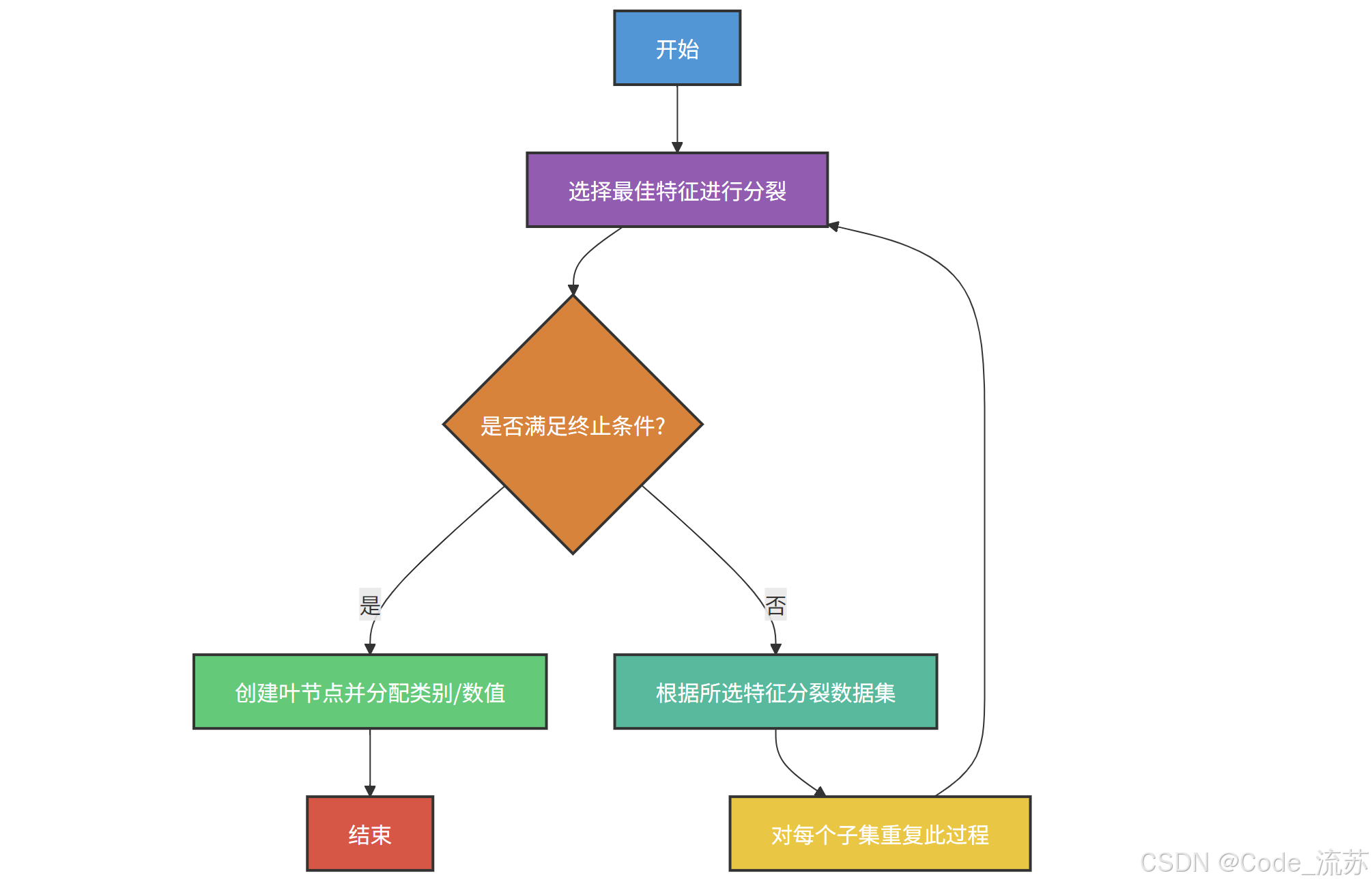
2. 决策树的分裂准则
决策树构建的关键问题是:如何选择最佳特征进行分裂?这就需要用到分裂准则。
(1) 信息熵与信息增益
信息熵(Information Entropy)是衡量数据集不确定性的指标。熵越高,数据的不确定性越大。
对于分类问题,信息熵的计算公式为:
Entropy(S) = -∑(pi * log2(pi))
其中,pi 是类别 i 在数据集中的比例。
信息增益(Information Gain)是父节点的熵与子节点熵的加权平均之间的差值,表示分裂后不确定性的减少程度:
Gain(S, A) = Entropy(S) - ∑((|Sv|/|S|) * Entropy(Sv))
其中,A 是用于分裂的特征,Sv 是特征 A 取值为 v 时的子集。
让我们通过一个视觉化说明来理解信息增益:
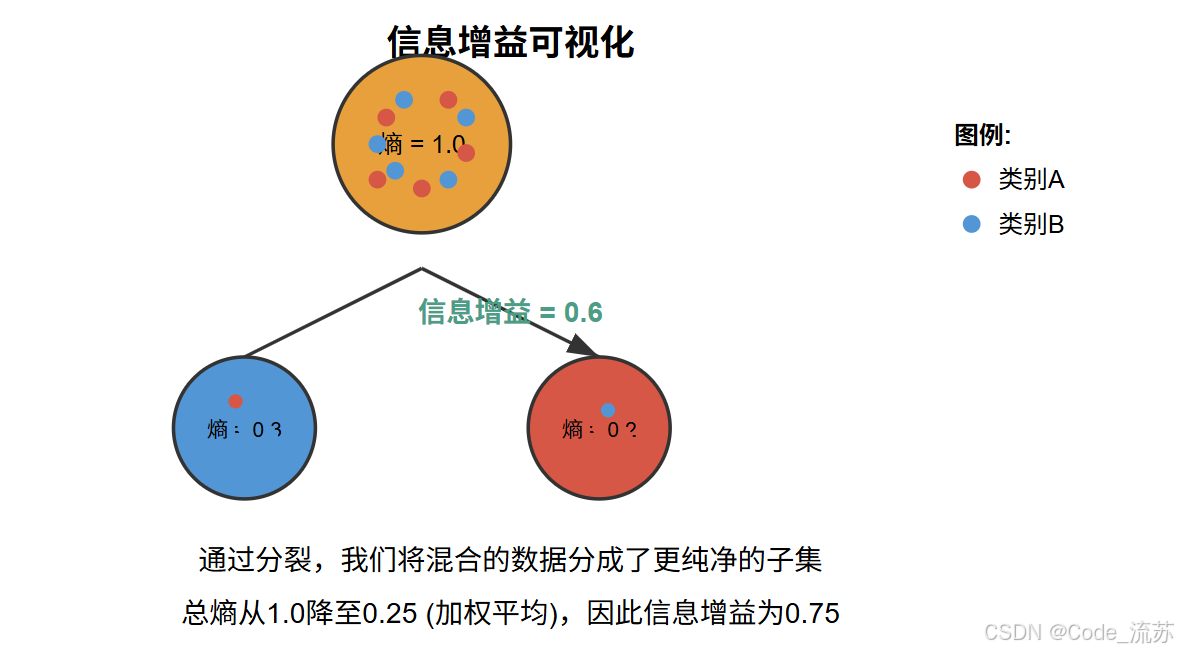
(2) 基尼不纯度
另一个常用的分裂准则是基尼不纯度(Gini Impurity),它衡量随机选择的样本被错误分类的概率。基尼不纯度越小,数据集的纯度越高。
对于分类问题,基尼不纯度的计算公式为:
Gini(S) = 1 - ∑(pi²)
其中,pi 是类别 i 在数据集中的比例。
基尼系数与信息增益的比较:
- 计算效率:基尼系数计算速度更快(不需要计算对数)
- 分裂倾向:信息增益更倾向于创建不平衡的树,基尼系数更倾向于创建平衡的树
- 使用场景:实际应用中差异往往不大,scikit-learn默认使用基尼系数
三、随机森林算法
1. 集成学习思想
集成学习(Ensemble Learning)是一种将多个基学习器(弱分类器)组合成一个更强大的学习器的方法。就像"三个臭皮匠,顶个诸葛亮",多个简单模型的组合往往能获得比单个复杂模型更好的性能。
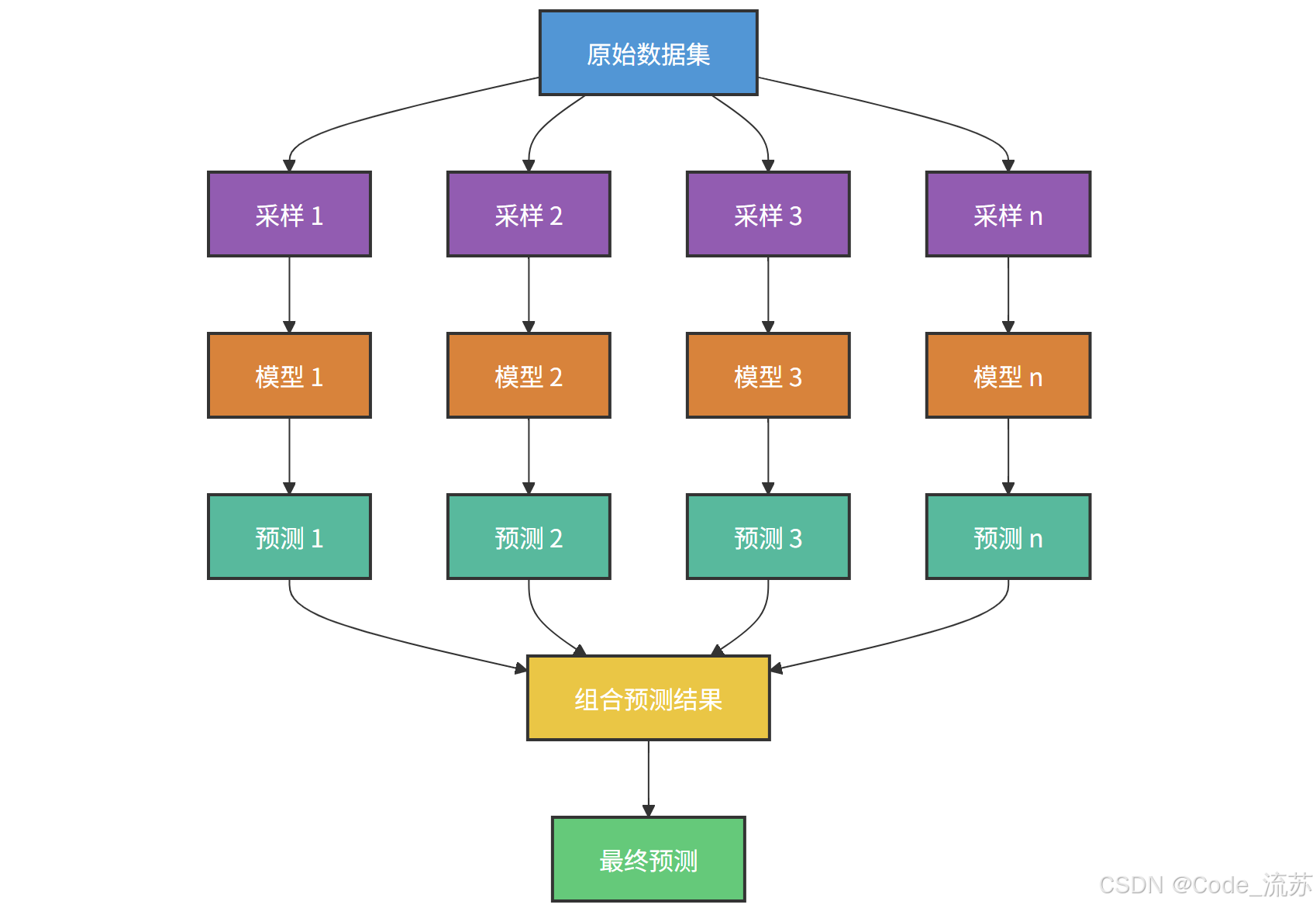
2. 随机森林的优势
随机森林(Random Forest)是一种基于决策树的集成学习方法,它通过构建多棵决策树,并将它们的结果进行整合(分类问题通过投票,回归问题通过平均)来得到最终预测。
随机森林具有以下优势:
- 准确性高:通过集成多个决策树的结果,降低了过拟合风险
- 鲁棒性强:对噪声和异常值不敏感
- 特征重要性:可以评估特征的重要程度
- 无需特征缩放:对特征的尺度不敏感
- 可处理高维数据:能够处理有大量特征的数据集
- 并行计算:各个决策树可以并行训练,提高效率
随机森林通过两种主要的随机性来确保多样性:
- 自助采样(Bootstrap Sampling):随机抽取样本构建每棵树
- 特征随机选择:在每个节点随机选择特征子集来寻找最佳分裂点

四、使用Scikit-learn实现决策树与随机森林
1. 决策树的实现
在Scikit-learn中,我们可以使用DecisionTreeClassifier和DecisionTreeRegressor分别实现分类和回归任务。下面是一个基本的分类决策树示例:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='gini', # 使用基尼系数max_depth=3, # 树的最大深度min_samples_split=2, # 分裂内部节点所需的最小样本数random_state=42)# 训练模型
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"决策树准确率: {accuracy:.4f}")
2. 随机森林的实现
随机森林在Scikit-learn中通过RandomForestClassifier和RandomForestRegressor实现:
from sklearn.ensemble import RandomForestClassifier# 创建随机森林分类器
rf_clf = RandomForestClassifier(n_estimators=100, # 树的数量max_depth=3, # 树的最大深度min_samples_split=2, # 分裂内部节点所需的最小样本数random_state=42)# 训练模型
rf_clf.fit(X_train, y_train)# 预测
rf_y_pred = rf_clf.predict(X_test)# 计算准确率
rf_accuracy = accuracy_score(y_test, rf_y_pred)
print(f"随机森林准确率: {rf_accuracy:.4f}")# 特征重要性
feature_importance = rf_clf.feature_importances_
for i, importance in enumerate(feature_importance):print(f"特征 {iris.feature_names[i]}: {importance:.4f}")
3. 随机森林的超参数调优
随机森林有多个重要的超参数,可以通过网格搜索等方法进行调优:
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 5, 10],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}# 创建网格搜索对象
grid_search = GridSearchCV(RandomForestClassifier(random_state=42),param_grid=param_grid,cv=5,scoring='accuracy')# 执行网格搜索
grid_search.fit(X_train, y_train)# 最佳参数
print("最佳参数:", grid_search.best_params_)# 最佳模型
best_rf = grid_search.best_estimator_# 使用最佳模型预测
best_pred = best_rf.predict(X_test)
best_accuracy = accuracy_score(y_test, best_pred)
print(f"调优后的随机森林准确率: {best_accuracy:.4f}")
五、实战案例:泰坦尼克生存预测
接下来,我们将使用泰坦尼克号乘客数据集,构建一个能够预测乘客是否能够在这场灾难中幸存的模型。
1. 数据加载与探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据
titanic_data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')# 查看数据前几行
print(titanic_data.head())# 数据基本信息
print(titanic_data.info())# 统计描述
print(titanic_data.describe())# 检查缺失值
print(titanic_data.isnull().sum())# 查看存活率
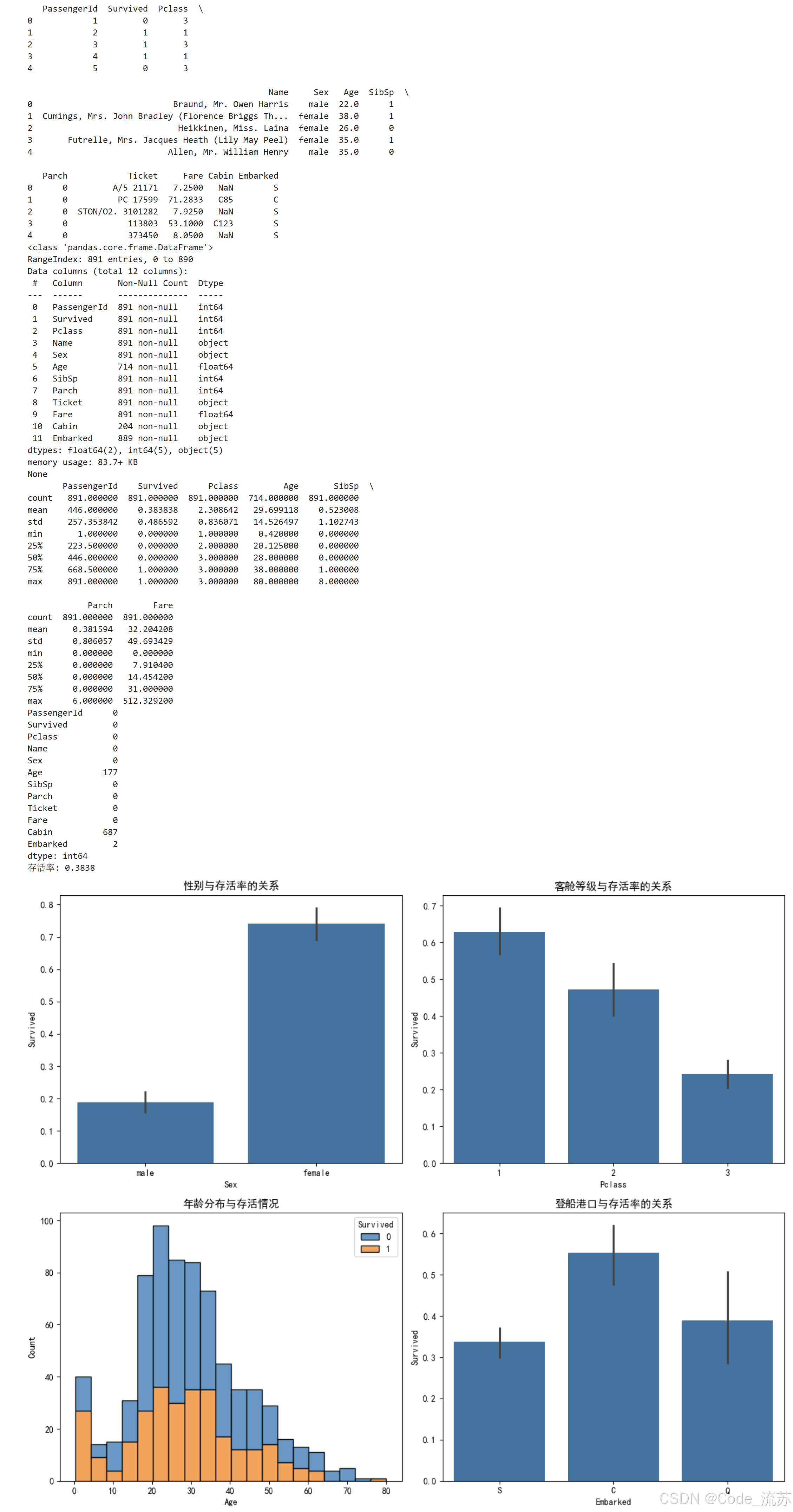
print(f"存活率: {titanic_data['Survived'].mean():.4f}")# 可视化不同特征与存活率的关系
plt.figure(figsize=(12, 10))# 性别与存活率
plt.subplot(2, 2, 1)
sns.barplot(x='Sex', y='Survived', data=titanic_data)
plt.title('性别与存活率的关系')# 客舱等级与存活率
plt.subplot(2, 2, 2)
sns.barplot(x='Pclass', y='Survived', data=titanic_data)
plt.title('客舱等级与存活率的关系')# 年龄分布与存活情况
plt.subplot(2, 2, 3)
sns.histplot(data=titanic_data, x='Age', hue='Survived', multiple='stack')
plt.title('年龄分布与存活情况')# 登船港口与存活率
plt.subplot(2, 2, 4)
sns.barplot(x='Embarked', y='Survived', data=titanic_data)
plt.title('登船港口与存活率的关系')plt.tight_layout()
plt.show()
2. 数据预处理
# 选择特征
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
X = titanic_data[features].copy()
y = titanic_data['Survived']# 处理缺失值
# 年龄缺失值用中位数填充
X['Age'].fillna(X['Age'].median(), inplace=True)
# 登船港口缺失值用最频繁值填充
X['Embarked'].fillna(X['Embarked'].mode()[0], inplace=True)# 类别特征编码
X['Sex'] = X['Sex'].map({'male': 0, 'female': 1})
# 创建登船港口的独热编码
embarked_dummies = pd.get_dummies(X['Embarked'], prefix='Embarked')
X = pd.concat([X, embarked_dummies], axis=1)
X.drop('Embarked', axis=1, inplace=True)# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
3. 训练决策树和随机森林模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
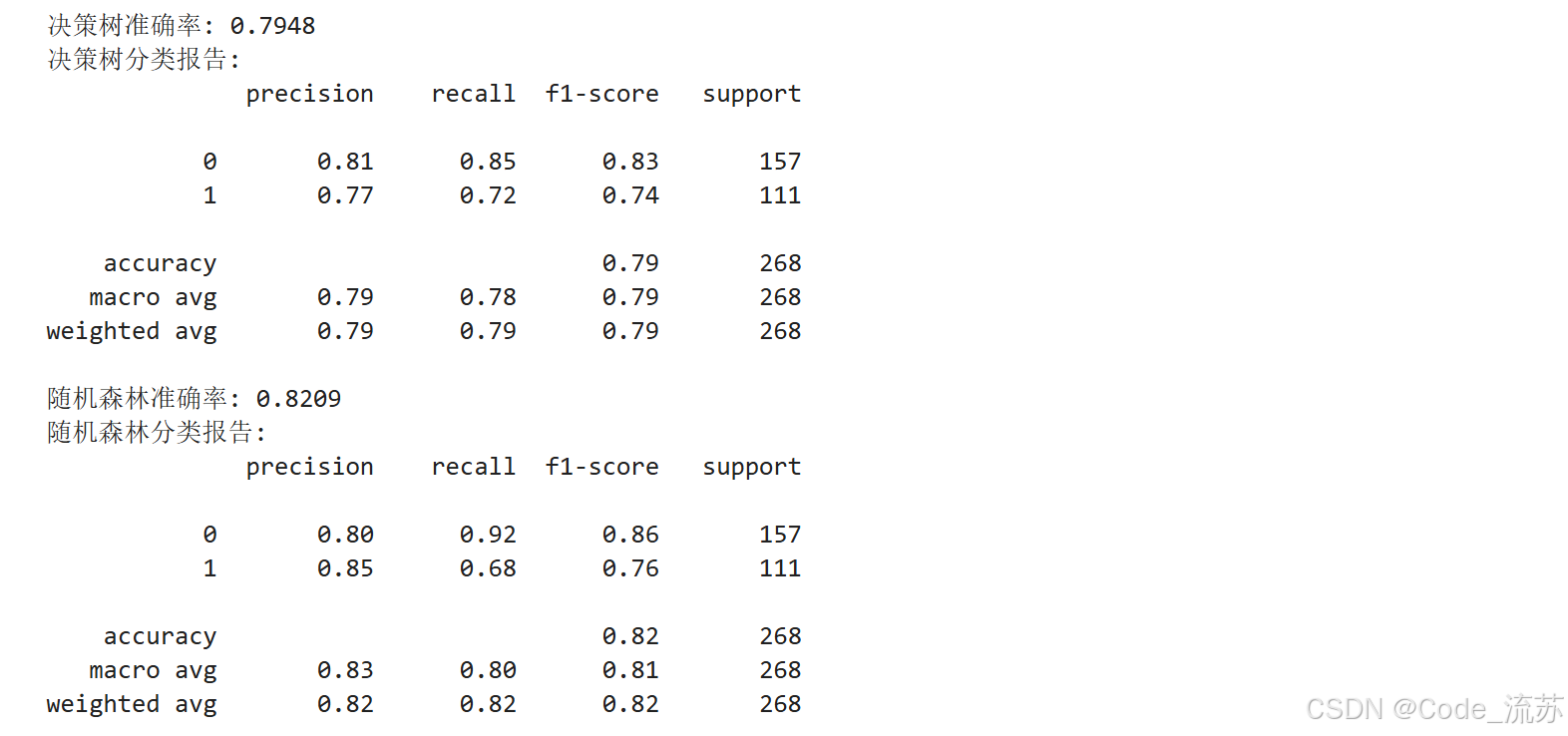
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 训练决策树模型
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)# 决策树预测
dt_y_pred = dt_model.predict(X_test)
dt_accuracy = accuracy_score(y_test, dt_y_pred)
print(f"决策树准确率: {dt_accuracy:.4f}")
print("决策树分类报告:")
print(classification_report(y_test, dt_y_pred))# 训练随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
rf_model.fit(X_train, y_train)# 随机森林预测
rf_y_pred = rf_model.predict(X_test)
rf_accuracy = accuracy_score(y_test, rf_y_pred)
print(f"随机森林准确率: {rf_accuracy:.4f}")
print("随机森林分类报告:")
print(classification_report(y_test, rf_y_pred))
4. 模型评估与特征重要性分析
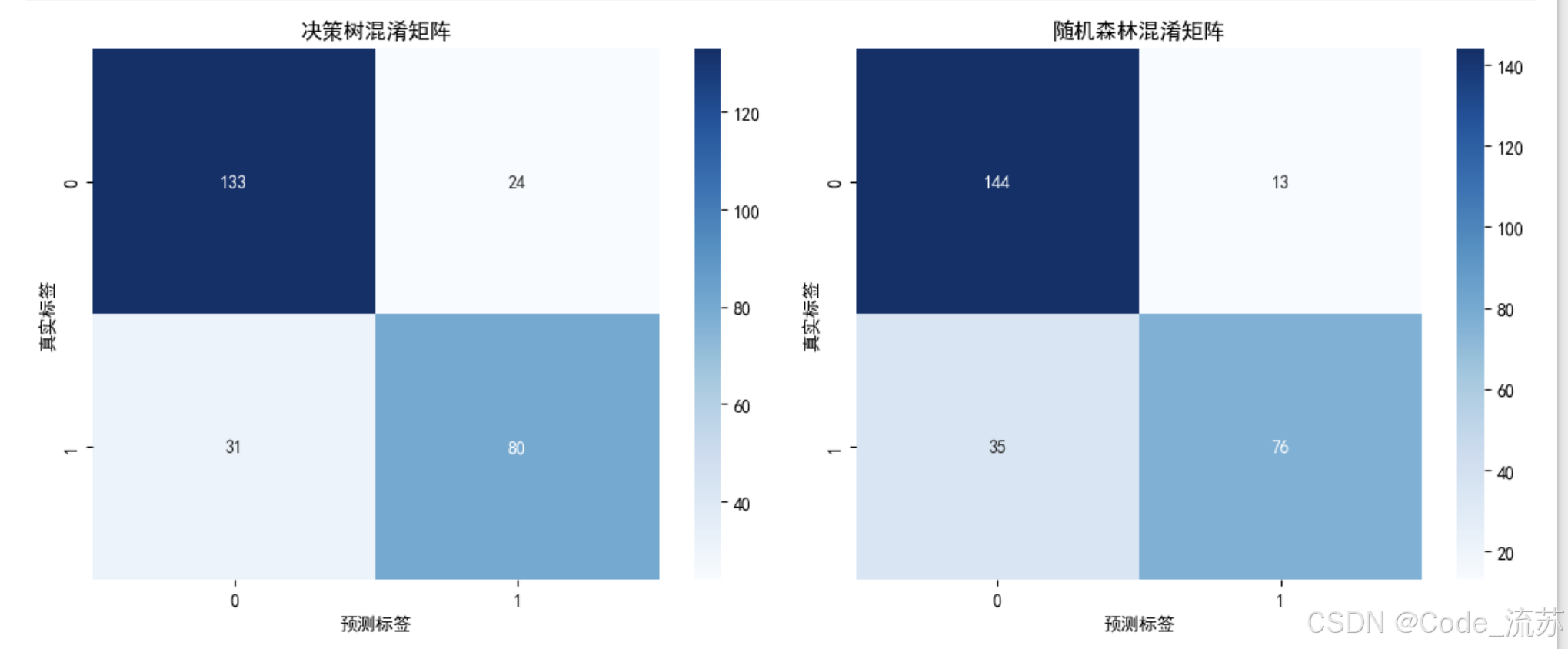
# 混淆矩阵可视化
plt.figure(figsize=(12, 5))plt.subplot(1, 2, 1)
cm = confusion_matrix(y_test, dt_y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('决策树混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')plt.subplot(1, 2, 2)
cm = confusion_matrix(y_test, rf_y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('随机森林混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')plt.tight_layout()
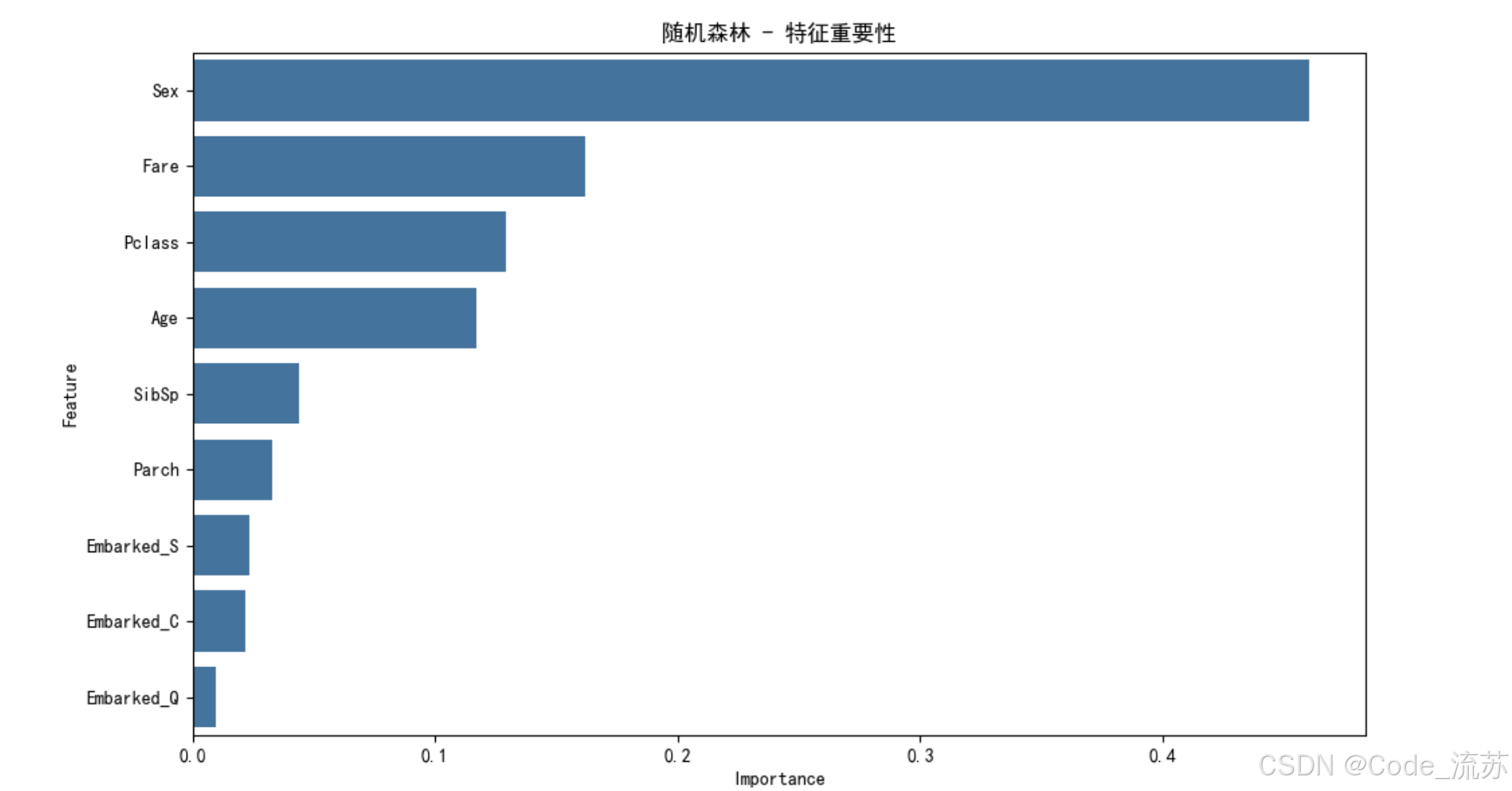
plt.show()# 特征重要性分析
feature_names = X.columns
feature_importance = rf_model.feature_importances_# 创建特征重要性DataFrame
importance_df = pd.DataFrame({'Feature': feature_names,'Importance': feature_importance
})
importance_df = importance_df.sort_values('Importance', ascending=False)# 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('随机森林 - 特征重要性')
plt.tight_layout()
plt.show()print("特征重要性排名:")
for index, row in importance_df.iterrows():print(f"{row['Feature']}: {row['Importance']:.4f}")

5. 结果分析与讨论
通过上述分析,我们可以发现几个有趣的结论:
- 随机森林的准确率通常高于单一决策树,这证实了集成学习的优势。
- 性别(Sex)和客舱等级(Pclass)是最重要的特征,与历史记载"妇女和儿童优先"的救生原则相符。
- 年龄(Age)也是一个重要特征,儿童的生存率较高。
- 客舱票价(Fare)反映了乘客的社会地位,票价高的乘客通常有更多获救机会。
这些发现与泰坦尼克号沉船事件的历史记载高度一致,表明我们的模型成功捕捉到了影响乘客生存的关键因素。
六、总结与拓展
1. 学习要点回顾
在本文中,我们学习了:
- 决策树的原理与分裂准则(信息增益和基尼系数)
- 随机森林的集成学习思想与优势
- 使用Scikit-learn实现决策树和随机森林模型
- 通过泰坦尼克号数据集进行实战演练
2. 实际应用场景
决策树和随机森林在实际中有广泛应用:
- 金融风险评估:预测贷款违约风险
- 医疗诊断:辅助医生进行疾病诊断
- 推荐系统:预测用户偏好
- 图像分类:识别图像中的物体
- 异常检测:识别欺诈交易
3. 拓展学习方向
如果你对决策树和随机森林感兴趣,可以进一步探索:
- 提升法(Boosting):如 AdaBoost, Gradient Boosting, XGBoost 等
- 剪枝技术:防止决策树过拟合的方法
- 特征工程:如何为树模型选择和创建更好的特征
- 不平衡数据处理:处理类别不平衡数据集的策略
4. 练习挑战
- 尝试使用其他数据集(如Iris, Wine等)应用决策树和随机森林
- 实现交叉验证来更准确地评估模型性能
- 对比决策树、随机森林和其他机器学习算法的性能
- 尝试可视化一个简单的决策树结构,理解其决策路径
七、参考资料
- Scikit-learn官方文档:决策树和随机森林
- 《机器学习》,周志华著,清华大学出版社
- 《Python机器学习》,Sebastian Raschka著
- Kaggle泰坦尼克号竞赛:Titanic - Machine Learning from Disaster
在机器学习的旅程中,决策树和随机森林是非常直观且强大的工具。希望通过今天的学习,你已经掌握了这些算法的核心概念和实践技能。理论知识结合实际练习才能真正提升你的数据科学能力。继续探索,在Python星球上的旅程才刚刚开始!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》 第46天:决策树与随机森林
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、前言二…...

【Pandas】pandas DataFrame expanding
Pandas2.2 DataFrame Function application, GroupBy & window 方法描述DataFrame.apply(func[, axis, raw, …])用于沿 DataFrame 的轴(行或列)应用一个函数DataFrame.map(func[, na_action])用于对 DataFrame 的每个元素应用一个函数DataFrame.a…...

【SpringCloud GateWay】Connection prematurely closed BEFORE response 报错分析与解决方案
一、背景 今天业务方调用我们的网关服务报错: Connection prematurely closed BEFORE response二、原因分析 三、解决方案 第一步: 增加 SCG 服务的JVM启动参数,调整连接获取策略。 将连接池获取策略由默认的 FIFO(先进先出)变更为 LIFO(…...

【行业】一些名词
名词 分布式应用架构(分布式计算技术的应用和工具)中间件 中间件(Middleware)主流中间件技术1.通信类2.数据类3. **协调与治理类中间件**4. 监控与可观测性中间件5.**流处理与批处理**中间件6.云原生中间件 数据库Redismogodb 分布…...

深度学习模型的部署实践与Web框架选择
引言 在深度学习项目的完整生命周期中,模型训练只是第一步,将训练好的模型部署到生产环境才能真正发挥其价值。本文将详细介绍模型部署的核心概念、常见部署方式以及三种主流Python Web框架的对比分析,帮助开发者选择最适合自己项目的技术方…...

【笔记】当个自由的书籍收集者从canvas得到png转pdf
最近有点迷各种古书,然后从 www.shuge.org 下载了各种高清的印本,快成db狂魔了…上面也有人在各种平台上分享,不胜感激…只是有些平台可以免费看但是没法下载… 反正你都canvas了,撸下来自己珍藏… 于是让qwen写了一段代码&#…...
详细教程)
Ubuntu 配置网络接口端点(静态 IP 地址)详细教程
在 Ubuntu 系统中,配置网络接口端点通常指的是为您的有线或无线网卡设置一个固定的 IP 地址、子网掩码、网关以及 DNS 服务器。这对于服务器或者需要稳定网络标识的设备来说非常重要。 使用 Netplan (Ubuntu 17.10 及更高版本的默认方式)使用 ifupdown (通过 /etc/…...

JavaScript ES6+ 最佳实践
1. 变量声明:从 var 到 let/const 问题代码:var 存在变量提升,只有函数作用域,没有块级作用域,容易导致变量污染。 // 变量提升导致意外行为 console.log(num); // undefined 而非报错 var num 10;// 没有块级作用域…...

华为昇腾在智慧矿山机器人的应用及其技术解决方案
一、智慧矿山机器人的核心应用场景 1. 井下智能巡检机器人 搭载昇腾AI芯片的巡检机器人可实现 全自主导航与多模态感知,通过激光雷达视觉SLAM技术实时构建井下三维地图,精准识别巷道变形、设备漏油等异常状态47。结合昇腾边缘计算能力…...
)
发那科机器人3(机器人编程基础)
发那科机器人(机器人编程基础) 一、机器人编程基础1、程序构成2、程序创建3、程序修改4、程序操作5、程序的停止与恢复6、执行程序7、测试运转8、自动运转一、机器人编程基础 1、程序构成 什么是程序? 程序指的是由用户编写的一系列机器人指令以及其他附带信息构成,使机器…...

2014年写的一个文档《基于大数据应用的综合健康服务平台研发及应用示范》
项目目标与任务 项目目标与任务需求分析 当今社会已经处于高度信息化的时代,作为关系民生的重要领域,医疗行业的信息化直接涉及临床服务、社会保障、医学研究和大众健康等环节,对提升医疗服务水平,强化管理职能,改善…...
)
Python初学者笔记第十一期 -- (字符串编程练习题)
第20节课 【字符串编程练习题】 练习01 回文字符串 输入一个字符串,判断其是否是回文字符串。 # 思路1 # s1 "黄山落叶松叶落山黄" # s2 s1[::-1] # 反转 # print(s2) # print(s1 s2)# 思路2 def is_palindrome(s):l 0r len(s) - 1while l < r…...

[量化交易Backtrader] - 如何规避过拟合
一、回测中的过拟合:隐藏在数据背后的陷阱 过拟合发生在模型过度适应历史数据,以至于在新数据上表现不佳。这就像是为历史数据量身定制了一件衣服,却在新的数据集上穿不进去。 (一)过拟合的常见表现 曲线过于完美 当在回测报告中看到策略的净值曲线如同一条完美的上升直…...

前端日常 · 移动端网页调试
前端日常 移动端网页调试技巧集锦:5个工具 实战思路 在移动端开发中,调试网页内容常常不是“写完就跑”的顺滑体验。尤其当页面跑在 App WebView 里时,不同系统版本、设备特性、浏览器行为都可能带来各种“只有你遇得到”的玄学 Bug。本篇…...
)
SQLite数据库加密(Java语言、python语言)
1. 背景与需求 SQLite 是一种轻量级的关系型数据库,广泛应用于嵌入式设备、移动应用、桌面应用等场景。为了保护数据的隐私与安全,SQLite 提供了加密功能(通过 SQLCipher 扩展)。在 Java 中,可以使用 sqlite-jdbc 驱动与 SQLCipher 集成来实现 SQLite 数据库的加密。 本…...
)
【前端基础】6、CSS的文本属性(text相关)
目录内容 text-decoration:设置文本装饰线text-transform:文本中文字的大小写转换text-indent:首行缩进text-align:设置文本对齐方式 一、text-decoration:设置文本装饰线 常见值: None:没有…...

Kafka生产者send方法详解
Kafka生产者send方法详解 1. send方法的工作原理 1.1 基本流程 #mermaid-svg-EXvKiyf8oSlenrxK {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-EXvKiyf8oSlenrxK .error-icon{fill:#552222;}#mermaid-svg-EXvKiyf…...

RPA与After Effects 2024深度融合:自动化影视特效全链路革命
文章目录 一、RPA在影视后期中的核心应用场景1. 跨平台数据自动化采集与预处理2. 动态数据驱动动画:从Excel到AE的无缝衔接 二、After Effects 2024自动化增强技术1. Python脚本深度集成:批量生成三维动画2. 实时渲染优化:智能调度与多分辨率…...

【Python 实战】---- 使用Python批量将 .ncm 格式的音频文件转换为 .mp3 格式
1. 前言 .ncm 格式是网易云音乐专属的加密音频格式,用于保护版权。这种格式无法直接播放,需要解密后才能转换为常见的音频格式。本文将介绍如何使用 Python 批量将 .ncm 格式的音频文件转换为 .mp3 格式。 2. 安装 ncmdump ncmdump 是一个专门用于解密 .ncm 文件的工具。它…...

【上位机——MFC】序列化机制
相关类 CFile-文件操作类,封装了关于文件读写等操作 CFile::Open CFile::Write/Read CFile::Close CFile::SeekToBegin / SeekToEnd / Seek 代码示例 #include <afxwin.h> #include <iostream>using namespace std;void File() {CFile file;file.Ope…...

同步 / 异步、阻塞 / 非阻塞
前言 同步异步,在计算机科学中是一个非常重要的概念。作为一位软件开发工程师,我们每天都在和同步和异步打交道。 同步 同步-阻塞,顾名思义,就是同步和阻塞。调用方法后,必须等到结果返回,才能继续执行别…...

Java学习手册:ORM 框架性能优化
一、优化实体类设计 减少实体类属性 :仅保留必要的字段,避免持久化过多数据。例如,对于一个用户实体类,如果某些信息(如详细地址)不是经常使用,可以将其拆分到单独的实体类中。使用合适的数据类…...

标量/向量/矩阵/张量/范数详解及其在机器学习中的应用
标量(Scalar)、向量(Vector)、矩阵(Matrix)、张量(Tensor)与范数(Norm)详解及其在机器学习中的应用 1. 标量(Scalar) 定义࿱…...

Android学习总结之网络篇补充
一、TCP/IP 五层模型(字节跳动 / 腾讯高频题) 面试真题 1:TCP/IP 五层模型与 OSI 七层模型的区别是什么?各层的核心协议有哪些? 常见错误:混淆五层模型与七层模型的层次对应,遗漏关键协议&…...

金融企业如何借力运维监控强化合规性建设?
日前,国家金融监督管理总局网站公布行政处罚信息,认定某银行存在多项违规并对其进行罚款。其中,国家金融监督管理总局认定该银行主要违规内容包括: 一、部分重要信息系统识别不全面,灾备建设和灾难恢复能力不符合监管要…...

食品行业EDI:General Mills EDI需求分析
General Mills 是全球知名的食品制造企业致力于生产和销售各类食品和消费品牌,涵盖早餐谷物、零食、乳制品、烘焙产品和宠物食品等多个领域。其旗下拥有众多家喻户晓的品牌,如 Cheerios、Nature Valley、Yoplait、Hagen-Dazs 和 Blue Buffalo。General M…...

C语言初阶--数组
1.一维数组的创建和初始化 1.1数组的创建 数组是一组相同类型元素的集合。 数组的创建方式: type_t arr_name [const_n]; //type_t 数组的元素类型 //const_n 常量表达式,指定数组的大小#include <stdio.h> int main() {int arr[10]; //数组…...

如何做界面自动化工具选择?
在2025年的技术环境中,UI自动化测试工具的选择需综合考虑工具的功能特性、适用场景、维护成本以及与团队技术栈的匹配度。以下从不同维度对当前主流的UI自动化工具进行分类推荐,并结合实际应用场景提供选型建议: 一、AI驱动的智能测试工具 …...

点云采集学习个人记录
Eagle LiDAR Scanner使用 3DMakerpro Eagle 发布:基于 LiDAR 的空间 3D 扫描仪 --- 3DMakerpro Eagle Launch: LiDAR-based Spatial 3D Scanner (3dwithus.com) RayStudio 工作流程教程 https://store.3dmakerpro.com/blogs/school/raystudio-workflow-tutorial…...

css识别\n换行
在CSS中,\n 通常不会被识别为换行符。如果你希望在CSS中实现换行效果,可以使用以下几种方法: 使用 white-space 属性: 设置 white-space: pre 或 white-space: pre-wrap,这样文本中的换行符 \n 会被保留并显示为换行。…...

《Python星球日记》 第45天:KNN 与 SVM 分类器
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、KNN 原理与距离计算1. KNN 的基本原理2. 距离计算方法3. K值的选择二、SVM 的支持向量与核技…...

STM32基础教程——硬件SPI
目录 前言 SPI硬件电路 SPI部分特征 SPI框图 SPI数据收发过程 W25Q64 技术实现 接线图 代码实现 技术要点 引脚操作 SPI初始化 SPI起始信号 SPI终止信号 SPI字节交换 宏替换W25Q64操作指令 W25Q64写使能 忙等待 读取设备ID号和制造商ID 页写入 数…...

系统架构-云原生架构设计
内涵 基于云原生技术,旨在将云应用中的非业务代码部分进行最大化的剥离,让云设施接管应用中原有的大量非功能特性。 云原生的代码包括三部分:业务代码、三方软件、处理非功能特性的代码 具备云原生架构的应用可以最大程度利用云服务和提升…...

ROS2: 服务通信
目录 服务通信模型服务通信的C实现服务端客户端 关键函数说明 服务通信模型 服务通信模型如上图所示,分为服务端和客户端,客户端根据需要向服务端发送请求(Request),服务端处理请求,并向客户端发回响应&…...
·棒球1号位)
贵州省棒球运动发展中长期规划(2024-2035)·棒球1号位
贵州省棒球运动发展中长期规划(2024-2035) Guizhou Province Baseball Development Medium & Long-Term Plan (2024-2035) 一、战略定位 | Strategic Positioning 立足贵州山地特色与民族文化,借鉴洛杉矶"社区棒球"模式&…...

深度学习中的autograd与jacobian
1. autograd 对于一个很简单的例子,如下图所示,对于一个神经元z,接收数据x作为输入,经过激活函数,获得激活后的结果,最后利用损失函数获得损失,然后梯度反向回传。 上图右侧即梯度反向回传的过…...

Ubuntu 使用dotfiles个性化配置模板
dotfiles 什么是dotfilercm软件手动修改/生成dotfile启动脚本 .bash_profile按键绑定 .inputrc别名 .alias其他dotfiles 从github克隆从Github库中下载代码让dotfile文件生效 GUN stow管理初始化目录结构使用Stow 参考文章 什么是dotfile 每个人都有自己用电脑的习惯ÿ…...
——FFT)
VIVADO IP核整理(二)——FFT
目录 IP 核配置IP 核接口s_axis_config_tdata 配置输入输出端口描述 仿真 参考:FFT IP核 详细介绍 参考:官方文档介绍 IP 核配置 在 IP Catalog 中搜索:Fast Fourier Transform 按照上图所示进行配置,下文对配置内容进行详述。 …...

Excel处理控件Aspose.Cells教程:压缩Excel文件完整指南
Excel 电子表格是管理、分析和可视化数据的有效工具,但随着文件复杂度的增加,它们很快就会变得臃肿。无论是由于数据集庞大、嵌入图片、格式过多还是隐藏工作表,Excel 文件的大小都可能迅速膨胀,导致打开速度变慢、难以通过电子邮…...
)
AKS 网络深入探究:Kubenet、Azure-CNI 和 Azure-CNI(overlay)
Kubernetes 网络使您能够配置 Kubernetes 网络内的通信。部署 AKS 集群时,有三种网络模型需要考虑: Kubenet 网络 KubeNet 是 AKS 中的基础网络插件。它可以被形象地比喻成大城市的地铁系统。地铁可能无法直接连接所有可能的地点(例如您的服…...

angular的cdk组件库
目录 一、虚拟滚动 一、虚拟滚动 <!-- itemSize相当于每个项目的高度为30px --><!-- 需要给虚拟滚动设置宽高,否则无法正常显示 --> <cdk-virtual-scroll-viewport [itemSize]"40" class"view_scroll"><div class"m…...
)
unity 使用蓝牙通讯(PC版,非安卓)
BlueTooth in pc with unity 最近接到的需求是在unity里面开发蓝牙功能,其实一开始我并不慌,因为据我所知,unity有丰富的插件可以使用,但是问题随之而来 1.unity里面无法直接与蓝牙通讯(后来找到了开启runtime一类的东西,但是我找了半天也没找到在哪里可以打开) 2.引入dll通过d…...

Feign 重试策略调整:优化微服务通信的稳定性
在微服务架构中,服务之间的通信是常见的场景。然而,网络问题、服务不稳定或临时故障都可能导致通信失败。Feign 是一个流行的声明式 REST 客户端,广泛用于微服务间的通信。通过合理调整 Feign 的重试策略,可以显著提高系统的稳定性…...

Nacos源码—5.Nacos配置中心实现分析一
大纲 1.关于Nacos配置中心的几个问题 2.Nacos如何整合SpringBoot读取远程配置 3.Nacos加载读取远程配置数据的源码分析 4.客户端如何感知远程配置数据的变更 5.集群架构下节点间如何同步配置数据 1.关于Nacos配置中心的几个问题 问题一:SpringBoot项目启动时如…...

【spring】Spring、Spring MVC、Spring Boot、Spring Cloud?
这些都是 Spring 家族的重要组成部分,但它们各自定位不同、功能层级不同,可以用一张表格和简要说明来帮你快速理解: 一、四者概念和区别表格 名称功能定位主要用途/核心功能是否依赖其他部分Spring基础框架(核心)IOC、…...

RDD的处理过程
1. 创建RDD 通过SparkContext的parallelize方法从本地集合创建RDD。 从外部存储(如HDFS、本地文件系统)加载数据创建RDD。 通过对已有RDD进行转换操作生成新的RDD。 2. 转换操作(Transformation) 对RDD进行操作(如…...

Vue3 中当组件嵌套层级较深导致 ref 无法直接获取子组件实例时,可以通过 provide/inject + 回调函数的方式实现子组件方法传递到父组件
需求:vue3中使用defineExposeref调用子组件方法报错不是一个function 思路:由于组件嵌套层级太深导致ref失效,通过provide/inject 回调函数来实现多层穿透 1. 父组件提供「方法注册函数」 父组件通过 provide 提供一个用于接收子组件方法…...

如何在Ubuntu上安装NVIDIA显卡驱动?
作者:算力魔方创始人/英特尔创新大使刘力 一,前言 对于使用NVIDIA显卡的Ubuntu用户来说,正确安装显卡驱动是获得最佳图形性能的关键。与Windows系统不同,Linux系统通常不会自动安装专有显卡驱动。本文将详细介绍在Ubuntu系统上安…...

Linux 修改bond后网关不生效的问题
1.前言 bond原本是OK的,但是某个同事变更后,发现网关路由存在问题 #查看路由,默认网关信息,发现没有配置的网关信息 ip route show #排查/etc/sysconfig/network-script/下面的ifcfg-* 文件没有问题 1.重启network 服务 systemct…...

chili调试笔记13 工程图模块 mesh渲染 mesh共享边显示实现
把模型投影到工程图要用什么模块当工程图的画板,最后要导出dxf的 three是怎么读取他的3d数据的 mesh不是三角形吗怎么渲染出四边形面的 我想看到三角形的边怎么设置 ai让我干嘛我就干嘛 static getAllEdges(face: { positions: Float32Array; indices: Uint16Array …...