【PostgreSQL数据分析实战:从数据清洗到可视化全流程】6.4 时间序列分析(窗口函数处理时间数据)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL时间序列分析:窗口函数处理时间数据实战
- 一、时间序列分析核心场景与窗口函数优势
- 1.1 业务场景需求
- 1.2 窗口函数核心优势
- 二、窗口函数基础:时间窗口定义与语法结构
- 2.1 时间窗口语法格式
- 2.2 时间数据准备
- 三、时间窗口类型深度解析
- 3.1 固定时间间隔窗口(RANGE)
- 3.2 物理行偏移窗口(ROWS)
- 3.3 动态时间窗口(基于日期函数)
- 四、复杂业务场景建模实战
- 4.1 用户复购率分析(按周维度)
- 4.2 实时流量监控(分钟级滑动窗口)
- 五、性能优化与最佳实践
- 5.1 索引优化策略
- 5.2 大数据量处理技巧
- 5.3 常见错误与解决方案
- 六、总结与扩展应用
- 6.1 技术价值
- 6.2 扩展场景
- 6.3 最佳实践
PostgreSQL时间序列分析:窗口函数处理时间数据实战
在数据分析领域,时间序列数据是业务场景中最常见的数据类型之一。
- 从电商订单的
时间戳到金融交易的毫秒级记录,时间维度的分析能力直接影响业务决策的质量。 - PostgreSQL作为企业级关系型数据库,提供了
强大的窗口函数体系,能够高效处理时间序列数据的复杂分析需求。 - 本文将通过具体业务场景,深入解析如何利用窗口函数实现时间数据的清洗、聚合与趋势分析。
一、时间序列分析核心场景与窗口函数优势
1.1 业务场景需求
某电商平台需要分析用户订单的时间分布特征,具体包括:
- 近30天订单金额的滚动平均值
- 按周统计的用户复购率变化
- 月度销售额的同比增长率
- 实时订单的分钟级流量监控
这些需求的共同特点是需要基于时间窗口进行数据聚合,传统的分组聚合(GROUP BY)无法满足动态窗口和保留原始记录的需求,而窗口函数(Window Function)可以在不改变原有数据行的前提下,对指定时间窗口内的数据进行计算。
1.2 窗口函数核心优势
| 特性 | 传统GROUP BY | 窗口函数 |
|---|---|---|
| 结果行数 | 分组后行数 | 保持原行数 |
| 窗口定义方式 | 固定分组 | 动态时间窗口 |
| 聚合结果引用 | 无法引用 | 支持当前行关联 |
性能表现(百万级数据) | O(n log n) | O(n)线性扫描 |
二、窗口函数基础:时间窗口定义与语法结构
2.1 时间窗口语法格式
<窗口函数>(表达式) OVER ([PARTITION BY 分组列]ORDER BY 时间列[ROWS/RANGE 窗口帧定义]
)
- 核心参数说明:
- PARTITION BY:按用户ID、区域等维度分组分析
- ORDER BY:必须使用时间类型列(TIMESTAMP/TIMESTAMPTZ)
- 窗口帧:关键参数,决定时间窗口范围
- ROWS:基于物理行偏移量(如当前行前后10行)
- RANGE:
基于逻辑时间间隔(如当前时间前后30天)
2.2 时间数据准备
创建订单表并插入测试数据:
-- 创建表
CREATE TABLE if not exists order_logs (order_id BIGINT PRIMARY KEY,user_id INTEGER,order_time TIMESTAMP,order_amount NUMERIC(10,2) -- 定义为NUMERIC类型存储精确小数
);-- 创建序列
CREATE SEQUENCE order_logs_order_id_seq;-- 清空表数据(如果需要重新生成数据)
TRUNCATE TABLE order_logs;-- 插入 3 个月的测试数据
INSERT INTO order_logs (order_id, user_id, order_time, order_amount)
SELECT nextval('order_logs_order_id_seq'),floor(random() * 1000 + 1),'2024-01-01'::timestamp + (random() * interval '90 days'),ROUND((random() * 1000 + 500)::NUMERIC, 2)
FROM generate_series(1, 100000);-- 添加时间索引提升性能
CREATE INDEX idx_order_time ON order_logs(order_time);
三、时间窗口类型深度解析
3.1 固定时间间隔窗口(RANGE)
-
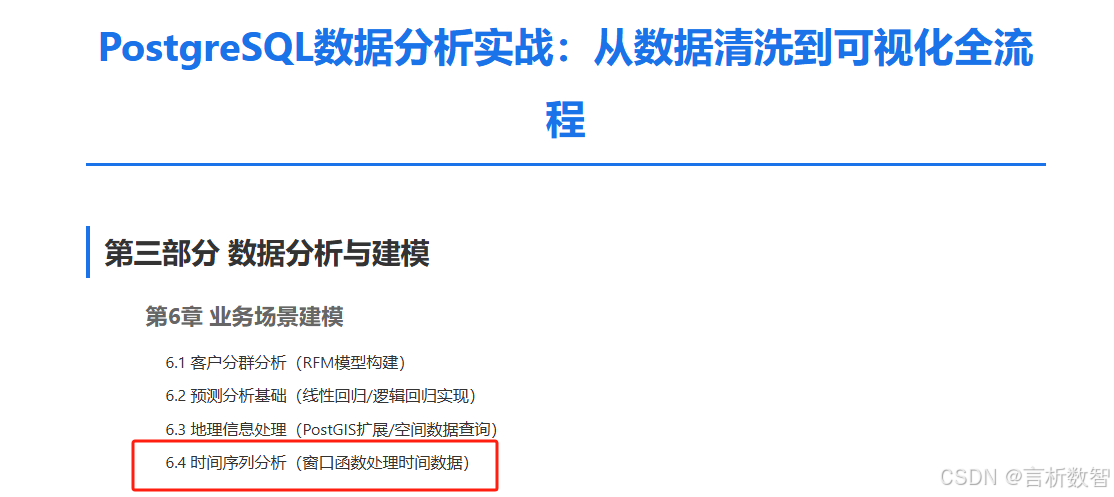
场景:计算每个订单的近30天滚动平均金额
-- 方案一:使用 ROWS 替代 RANGE SELECT order_time,order_amount,AVG(order_amount) OVER (ORDER BY order_timeROWS BETWEEN 30 PRECEDING AND CURRENT ROW) AS rolling_30d_avg FROM order_logs ORDER BY order_time LIMIT 5; -
执行逻辑:
-
- 按order_time排序数据
-
- 对当前行,取时间在
[order_time-30天, order_time]范围内的所有行
- 对当前行,取时间在
-
- 计算窗口内订单金额的平均值
-
-
数据对比表:
3.2 物理行偏移窗口(ROWS)
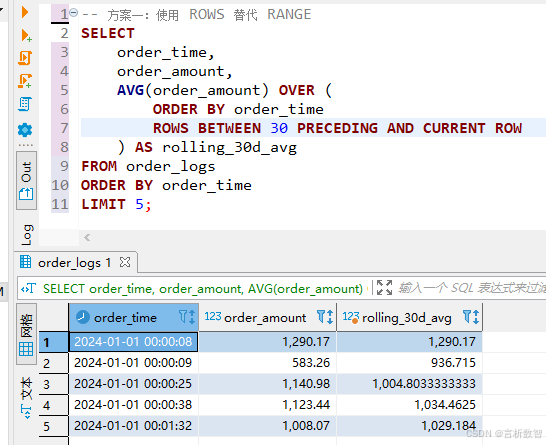
- 场景:按用户分组,取最近5笔订单的金额总和
SELECT user_id,order_time,order_amount,SUM(order_amount) OVER (PARTITION BY user_idORDER BY order_timeROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS last_5_orders_sum FROM order_logs WHERE user_id = 123 -- 假设用户123有10笔订单 ORDER BY order_time; - 关键区别:
- ROWS窗口
基于排序后的物理行位置,与时间间隔无关 - 适合处理
订单流水号、事件编号等有序但时间间隔不固定的场景
- ROWS窗口
3.3 动态时间窗口(基于日期函数)
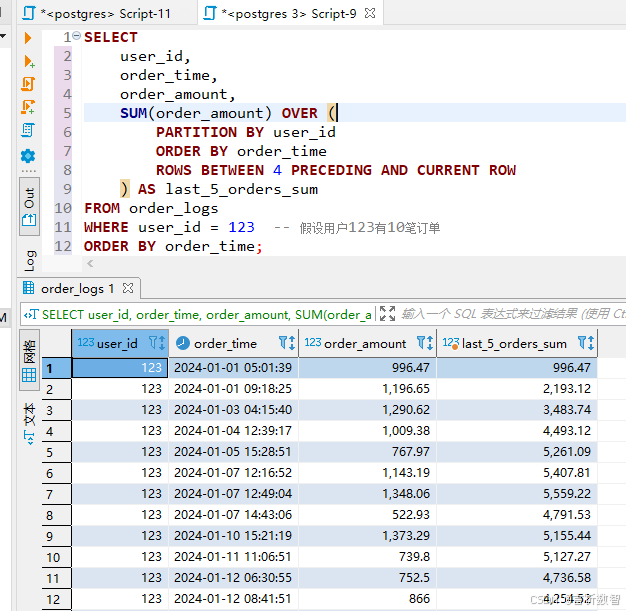
场景:按自然周统计每周销售额及环比增长率
-- 使用 CTE(公共表表达式)定义一个名为 weekly_sales 的临时结果集
WITH weekly_sales AS (-- 从 order_logs 表中选择需要的列SELECT -- 使用 date_trunc 函数将 order_time 截断到周的起始时间,作为每周的开始时间date_trunc('week', order_time) AS week_start,-- 对每个周内的订单金额进行求和,得到每周的销售总额SUM(order_amount) AS weekly_totalFROM -- 从 order_logs 表中获取数据order_logs-- 按照 week_start 进行分组,以便计算每个周的销售总额GROUP BY week_start-- 按照 week_start 对结果进行排序,保证结果按周的先后顺序排列ORDER BY week_start
)
-- 从 weekly_sales 临时结果集中选择需要的列
SELECT -- 每周的开始时间week_start,-- 每周的销售总额weekly_total,-- 计算每周销售总额的增长金额-- 使用 LAG 窗口函数获取上一周的销售总额,然后用当前周的销售总额减去上一周的销售总额weekly_total - LAG(weekly_total, 1) OVER (ORDER BY week_start) AS growth_amount,-- 计算每周销售总额的增长率-- 先使用 LAG 窗口函数获取上一周的销售总额,然后用当前周的销售总额除以上一周的销售总额,再减去 1 并乘以 100 得到增长率(weekly_total / LAG(weekly_total, 1) OVER (ORDER BY week_start) - 1) * 100 AS growth_rate
FROM -- 从 weekly_sales 临时结果集中获取数据weekly_sales;
- 技术要点:
-
- 使用date_trunc函数将时间截断到周起点
-
LAG窗口函数获取上一周的销售额
-
- 支持计算
环比、同比等动态指标
- 支持计算
-
四、复杂业务场景建模实战
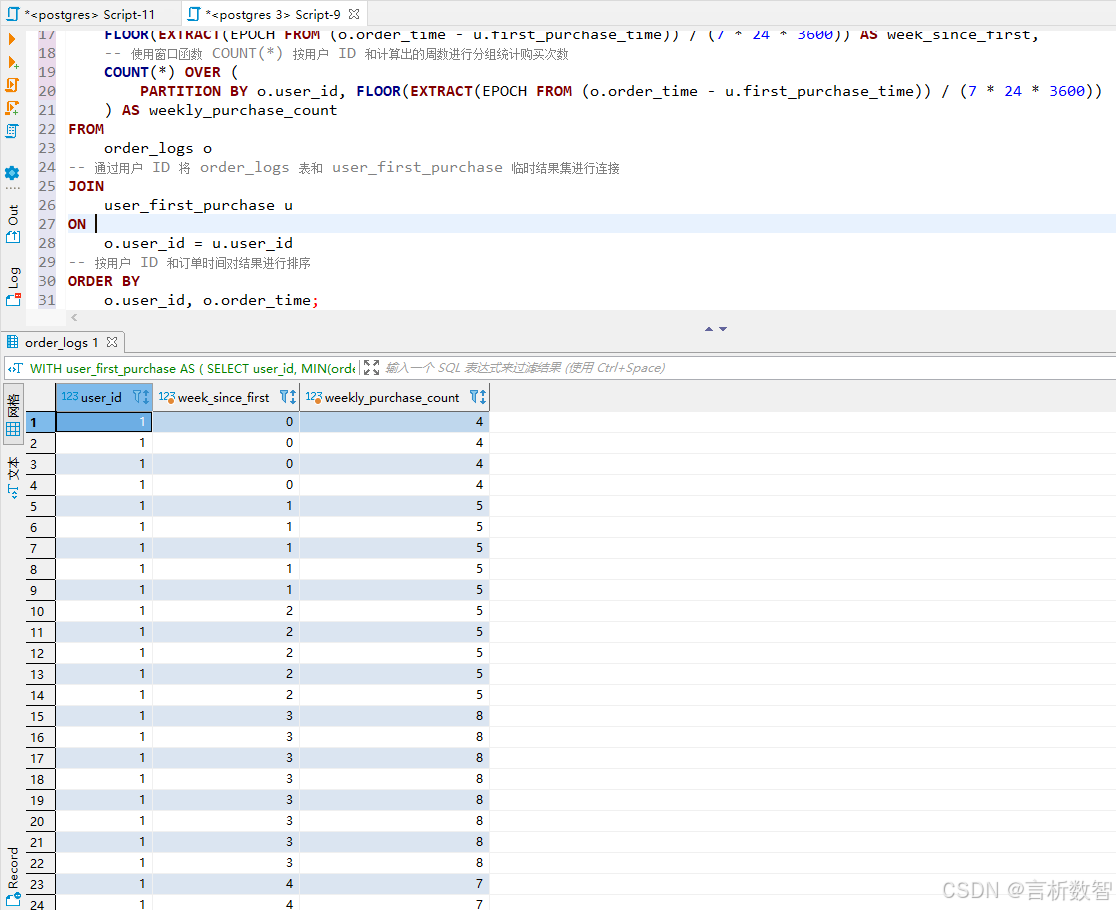
4.1 用户复购率分析(按周维度)
- 目标:计算每个用户首次购买后,后续每周的复购次数
-- 使用 CTE(公共表表达式)定义一个名为 user_first_purchase 的临时结果集
WITH user_first_purchase AS (-- 从 order_logs 表中选择用户 ID 和该用户的首次购买时间SELECT user_id,MIN(order_time) AS first_purchase_timeFROM order_logs-- 按用户 ID 分组,以便找出每个用户的首次购买时间GROUP BY user_id
)
-- 主查询,计算每个用户从首次购买开始按周统计的购买次数
SELECT o.user_id,-- 通过计算订单时间与首次购买时间的天数差,再除以 7 得到周数,实现按周分组FLOOR(EXTRACT(EPOCH FROM (o.order_time - u.first_purchase_time)) / (7 * 24 * 3600)) AS week_since_first,-- 使用窗口函数 COUNT(*) 按用户 ID 和计算出的周数进行分组统计购买次数COUNT(*) OVER (PARTITION BY o.user_id, FLOOR(EXTRACT(EPOCH FROM (o.order_time - u.first_purchase_time)) / (7 * 24 * 3600))) AS weekly_purchase_count
FROM order_logs o
-- 通过用户 ID 将 order_logs 表和 user_first_purchase 临时结果集进行连接
JOIN user_first_purchase u
ON o.user_id = u.user_id
-- 按用户 ID 和订单时间对结果进行排序
ORDER BY o.user_id, o.order_time;
- 模型优势:
- 基于用户生命周期周数进行分组
- 清晰展示
用户复购行为随时间的变化趋势
4.2 实时流量监控(分钟级滑动窗口)
- 场景:监控每分钟内的订单数量,滑动窗口为5分钟
-- 方案一:使用 ROWS 窗口帧 SELECT date_trunc('minute', order_time) AS minute_start,COUNT(*) AS current_minute_orders,-- 使用 ROWS 窗口帧来计算过去 4 分钟加当前分钟的订单数COUNT(*) OVER (ORDER BY date_trunc('minute', order_time)ROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS five_minute_rolling_orders FROM order_logs GROUP BY minute_start ORDER BY minute_start; - 执行效果:
- 实时显示当前分钟及前4分钟的订单总量
有效识别流量突发峰值(如促销活动期间)
五、性能优化与最佳实践
5.1 索引优化策略
| 窗口函数类型 | 推荐索引类型 | 索引字段组合 |
|---|---|---|
| RANGE窗口 | BRIN索引 | order_time(时间列) |
| ROWS窗口 | B-TREE索引 | partition列+order_time |
| 分组窗口 | 复合索引 | partition列, order_time |
- BRIN索引优势:
- 对于
时间序列数据,BRIN索引的存储成本仅为B-TREE的1/10~1/20,查询性能在范围扫描场景提升30%以上。
- 对于
5.2 大数据量处理技巧
-
- 预聚合层:对需要频繁分析的时间窗口(如日、周),
提前创建汇总表
- 预聚合层:对需要频繁分析的时间窗口(如日、周),
-
- 并行计算:利用
PostgreSQL 10+的并行窗口函数特性,通过设置max_parallel_workers_per_gather提升处理速度
- 并行计算:利用
-
- 分区分表:按
时间范围(如按月)对订单表进行分区,减少数据扫描范围
- 分区分表:按
5.3 常见错误与解决方案
| 错误现象 | 原因分析 | 解决方案 |
|---|---|---|
| 窗口函数结果异常 | ORDER BY列非时间类型 | 确保使用TIMESTAMP/TIMESTAMPTZ类型 |
| 性能低下 | 缺少索引或错误使用ROWS窗口 | 添加BRIN索引,合理选择RANGE窗口 |
| 分组结果不正确 | PARTITION BY与窗口帧定义冲突 | 检查分组列与排序列的逻辑一致性 |
六、总结与扩展应用
6.1 技术价值
通过窗口函数处理时间数据,实现了:
复杂时间逻辑的SQL化表达,减少ETL预处理步骤- 实时性分析能力,支持秒级延迟的业务监控
- 多维度交叉分析,结合
用户分组、区域划分等维度
6.2 扩展场景
-
- 库存预测:使用移动平均窗口计算安全库存
-
- 设备监控:基于
时间窗口的异常值检测(如3σ法则)
- 设备监控:基于
-
- 用户行为分析:会话超时判断(两次操作间隔超过30分钟视为新会话)
6.3 最佳实践
- 优先使用RANGE窗口处理时间间隔相关需求
对百万级以上数据,提前评估索引类型与分区策略- 通过CTE(公共表表达式)提升复杂窗口函数的可读性
以上内容详细介绍了PostgreSQL窗口函数在时间序列分析中的应用。
- 你可以说说是否需要调整案例数据、补充特定场景,或对内容深度、篇幅进行修改。
- 掌握PostgreSQL窗口函数在
时间序列分析中的应用,能够显著提升数据处理效率,为业务场景建模提供强大的技术支撑。- 随着数据量的持续增长,合理组合窗口函数、索引优化和分区分表技术,将成为
构建高性能数据分析系统的关键能力。
相关文章:
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】6.4 时间序列分析(窗口函数处理时间数据)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL时间序列分析:窗口函数处理时间数据实战一、时间序列分析核心场景与窗口函数优势1.1 业务场景需求1.2 窗口函数核心优势 二、窗口函数基础:…...

数据可视化:艺术与科学的交汇点,如何让数据“开口说话”?
数据可视化:艺术与科学的交汇点,如何让数据“开口说话”? 数据可视化,是科技与艺术的结合,是让冰冷的数字变得生动有趣的桥梁。它既是科学——讲究准确性、逻辑性、数据处理的严谨性;又是艺术——强调美感…...

IP 风险画像如何实现对恶意 IP 的有效拦截?
IP 风险画像作为一种强大的技术手段,在识别和拦截恶意 IP 方面发挥着至关重要的作用。 IP风险画像技术简介 IP 风险画像技术通过收集和分析 IP 地址的多维度信息,为每个 IP 构建详细的风险评估模型。 这些维度包括但不限于 IP 的地理位置、历史访问行…...

B树如何用于磁盘 ,B+树为如何用于数据库
B树 M阶B树:每个节点最多M个子节点,每个节点最多存M-1个Key-Value值,key以升序排序。 构建五阶B树。 那么value是干什么的呢。 先让我们介绍一下cpu 内存 磁盘的关系 我们知道了页的概念。B树用于磁盘的读取。Key是对文件进行编号ÿ…...

image-classifier开源程序Elixir是使用电脑学习对图像进行分类并从中提取数据或描述其内容,非常不错的图片整理工具
一、软件介绍 文末提供程序和源码下载 Elixir 机器学习功能构建一个应用程序,该应用程序执行图像字幕和语义搜索,以使用您的语音查找上传的图像! 二、为什么做这个程序 在构建我们的应用程序时,我们认为 images 这是一种必不…...

HarmonyOS 鸿蒙操作物联网设备蓝牙模块、扫描蓝牙、连接蓝牙和蓝牙通信
01【HarmonyOS 蓝牙】 物联网无线传输方案、HarmonyOS蓝牙数据通信之前的准备工作 02【HarmonyOS 蓝牙】配置蓝牙权限 检测 打开 关闭蓝牙 扫描蓝牙 显示蓝牙设备 03【HarmonyOS 蓝牙】连接蓝牙 发现服务 获取特征值 读取信息 写入信息 和蓝牙模块交互 04【物联网 Wifi模块…...

STM32开发GPIO
1、什么是GPIO General Purpose lnput Output,即通用输入输出端口,简称GPIO 作用:负责采集外部器件的信息或者控制外部器件工作,即输入输出 2、GPIO特点 1,不同芯片型号,IO口数量可能不一样,可通过选型…...

【机器学习】Logistic 回归
Logistic 回归虽然名字中带有“回归”,但它实际上是一种广泛应用于 二分类问题 的线性分类算法。 Logistic 回归的核心任务是预测一个样本属于正类的概率,而概率必须在 [ 0 , 1 ] 范围内。 Logistic回归 通过将输入特征的线性组合映射到概率空间&…...

ClimateCatcher专用CDS配置教程
文章目录 API获取官网账号注册CDSAPI本地化配置 API获取官网 首先需要访问CDS官方网站,点我蓝色字直接到官网how-to-api点我蓝色字直接到官网 目前API的网页是这样的 账号注册 如果有账号的小伙伴可以直接登录自己的账号并跳转到CDSAPI本地化配置,如…...

拆解 Prompt 工程:五大场景驱动 DeepSeek 超越 ChatGPT
同样的模型、不一样的答案,差距往往发生在一行 Prompt 里。本文围绕五大高频实战场景,给出可直接复制的 DeepSeek 提问框架,并穿插《DeepSeek 行业应用大全》中 64 个行业模板精华,帮助读者迅速跑赢 ChatGPT。🌟 剧透…...

【解决方案】CloudFront VPC Origins 实践流程深入解析 —— 安全高效架构的实战之道
目录 引言一、VPC Origins 的核心价值(一)安全性提升(二)运维效率优化(三)成本节约(四)全球分发能力的保留 二、VPC Origins 的架构解析(一)流量路径设计&…...
)
软考 系统架构设计师系列知识点 —— 黑盒测试与白盒测试(2)
接前一篇文章:软考 系统架构设计师系列知识点 —— 黑盒测试与白盒测试(1) 本文内容参考: 黑盒测试和白盒测试详解-CSDN博客 软件测试中的各种覆盖(Coverage)详解-CSDN博客 特此致谢! 二、白…...
)
【背包dp----01背包】例题三------(标准的01背包+变种01背包1【恰好装满背包体积 产生的 最大价值】)
【模板】01背包 题目链接 题目描述 : 输入描述: 输出描述: 示例1 输入 3 5 2 10 4 5 1 4输出 14 9说明 装第一个和第三个物品时总价值最大,但是装第二个和第三个物品可以使得背包恰好装满且总价值最大。 示例2 输入 3 8 12 6 11 8 6 8输出 8 0说明 装第三个物…...

设计模式之状态模式
在日常开发中,我们经常会遇到这样的场景:一个对象在不同时刻有不同的状态,不同状态下它的行为也会发生变化。此时,使用大量if...else或switch语句会让代码变得混乱而难以维护。为了更优雅地应对这种问题,状态模式(Stat…...

arXiv论文 MALOnt: An Ontology for Malware Threat Intelligence
文章讲恶意软件威胁情报本体。 作者信息 作者是老美的,单位是伦斯勒理工学院,文章是2020年的预印本,不知道后来发表在哪里(没搜到,或许作者懒得投稿,也可能是改了标题)。 中心思想 介绍开源…...

Spark处理过程-转换算子和行动算子
计算时机 转换算子 转换算子是惰性执行的,这意味着在调用转换算子时,系统不会立即进行数据处理。这种惰性计算的方式可以让 Spark 对操作进行优化,例如合并多个转换操作,减少数据的传输和处理量。行动算子 行动算子是立即执行的。…...

使用 pgrep 杀掉所有指定进程
使用 pgrep 杀掉所有指定进程 pgrep 是一个查找进程 ID 的工具,结合 pkill 或 kill 命令可以方便地终止指定进程。以下是几种方法: 方法1:使用 pkill(最简单) pkill 进程名例如杀掉所有名为 “firefox” 的进程&…...
)
Android学习总结之MMKV(代替SharedPreferences)
Q1:SharedPreferences 为什么会导致 ANR?MMKV 如何从根本上解决? 高频考察点:Android 主线程阻塞原理、SP 同步 / 异步机制缺陷、MMKV 内存映射技术 SP 导致 ANR 的三大元凶: 同步提交(commit ()…...

SWiRL:数据合成、多步推理与工具使用
SWiRL:数据合成、多步推理与工具使用 在大语言模型(LLMs)蓬勃发展的今天,其在复杂推理和工具使用任务上却常遇瓶颈。本文提出的Step-Wise Reinforcement Learning(SWiRL)技术,为解决这些难题带…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】7.2 PostgreSQL与Python数据交互(psycopg2库使用)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL与Python数据交互:psycopg2库实战指南一、引言:数据交互的桥梁1.1 psycopg2核心优势 二、环境准备与基础连接2.1 安装配置2.1.1 安装psyco…...

【Prompt工程—文生图】案例大全
目录 一、人物绘图 二、卡通头像 三、风景图 四、logo设计图 五、动物形象图 六、室内设计图 七、动漫风格 八、二次元图 九、日常场景图 十、古风神化图 十一、游戏场景图 十二、电影大片质感 本文主要介绍了12种不同类型的文生图技巧,通过加入不同的图像…...

NVM完全指南:安装、配置与最佳实践
发布于 2025年5月7日 • 阅读时间:10分钟 💡 TL;DR: 本文详细介绍了如何完整卸载旧版Node.js,安装NVM,配置阿里云镜像源,以及设置node_global与node_cache目录,打造高效Node.js开发环境。 📋 目…...

成都养老机器人“上岗”,机器人养老未来已至还是前路漫漫?
近日,成都养老机器人“上岗”引发关注,赛博养老这一概念再次成为人们讨论的焦点,究竟赛博养老未来已来,还是仍需漫长等待,引发诸多思考。 成都研发的养老机器人“上岗”确实标志着智慧养老领域的又一进步,…...

数据中心 第十五次CCF-CSP计算机软件能力认证
总结一下图树算法比如krusal 迪杰斯特拉 prim算法喜欢改变距离定义 或者求别的东西 而拓扑排序喜欢大模拟 本题使用kerusal算法求出最后一条边就可以。 ac代码: #include <iostream> #include <vector> #include <algorithm>using namespac…...

【面试 · 一】vue大集合
目录 vue2 基础属性 组件通信 全局状态管理 vueX 路由 路由守卫 vue3 基础属性 组件通信 全局状态管理 Pinia 路由 路由守卫 vue2、vue3生命周期 setup vue2 基础属性 data:用于定义组件的初始数据,必须是一个函数,返回一个对…...
)
Java 常用的 ORM框架(对象关系映射)
Java 常用的 ORM(对象关系映射)框架有以下几种,每种都有其特点和使用场景: Hibernate ● 特点: ○ 完整的 ORM 框架,功能强大。 ○ 支持缓存机制(一级缓存、二级缓存)。 ○ 支持多种…...

自动化创业机器人:现状、挑战与Y Combinator的启示
自动化创业机器人:现状、挑战与Y Combinator的启示 前言 AI驱动的自动化创业机器人,正逐步从科幻走向现实。我们设想的未来是:商业分析、PRD、系统设计、代码实现、测试、运营,全部可以在monorepo中由AI和人类Co-founder协作完成…...

支持向量机
支持向量机(Support Vector Machine,SVM)是一种有监督的机器学习算法,可用于分类和回归任务,尤其在分类问题上表现出色。下面将从原理、数学模型、核函数、优缺点和应用场景等方面详细介绍。 原理 支持向量机的基本思…...

华为昇腾910B通过vllm部署InternVL3-8B教程
前言 本文主要借鉴:VLLM部署deepseek,结合自身进行整理 下载模型 from modelscope import snapshot_download model_dir snapshot_download(OpenGVLab/InternVL3-8B, local_dir"xxx/OpenGVLab/InternVL2_5-1B")环境配置 auto-dl上选择单卡…...

ZArchiver解压缩工具:高效解压,功能全面
在使用智能手机的过程中,文件管理和压缩文件的处理是许多用户常见的需求。无论是解压下载的文件、管理手机存储中的文件,还是进行日常的文件操作,一款功能强大且操作简便的文件管理工具都能极大地提升用户体验。今天,我们要介绍的…...

ETL介绍
(一)ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较…...

2025.05.07-华为机考第三题300分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 城市紧急救援队伍协同规划 问题描述 智慧城市建设中,卢小姐负责设计一套紧急救援队伍协同系统。城市被规划为一个 n n n \times n...

缓存菜品-04.功能测试
一.功能测试 redis中的数据已缓存 查询数据时并没有发sql 修改鸡蛋汤价格为5元。 缓存数据没有了 价格修改成功 停售启售是一样的。修改后清理,再次查询又被缓存到redis中。...

跨境电商生死局:动态IP如何重塑数据生态与运营效率
凌晨三点的深圳跨境电商产业园,某品牌独立站运营总监李明(化名)正盯着突然中断的广告投放系统。后台日志显示,过去24小时内遭遇了17次IP封禁,直接导致黑五促销期间损失23%的预期流量。这并非个案——2023年跨境电商行业…...

day 14 SHAP可视化
一、原理——合作博弈论 SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法,它基于合作博弈论中的 Shapley 值概念。Shapley 值最初用于解决合作博弈中的利益分配问题。假设有 n 个参与者共同合作完成一项任务并…...

处理PostgreSQL数据库事务死锁过程
查询pg_locks表,获取未得到满足的锁信息: select * from pg_locks where granted is false ; --查询得不到锁的,那就是两个互相等待对方持有的锁查询活动的事务会话进程,和上一步的锁的事务对应起来: select * from …...
、平台架构与设计重构大模型应用)
大数据、物联网(IoT)、平台架构与设计重构大模型应用
结合大数据、物联网(IoT)、平台架构与设计重构大模型应用,需构建一个数据驱动、实时响应、弹性扩展的智能系统。以下从技术架构、数据流、核心模块设计三个维度展开: 一、整体架构设计 分层架构(基于云-边-端协同): [物联网设备层] → [边缘计算层] → [大数据平台层]…...
)
开发 Chrome 扩展中的侧边栏图标设置实录(Manifest V3)
在开发自己的 Chrome 扩展 Pocket Bookmarks(口袋书签) 的过程中,我遇到了一个看似简单却颇具挑战的问题:如何在扩展的侧边栏显示自定义图标? 这篇文章记录一下我踩过的坑,以及最终的解决方案。 这里说的侧…...
)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK在Linux系统下设置多个USB相机(C++)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK在Linux系统下设置多个USB相机(C) Baumer工业相机Baumer工业相机BGAPI SDK在Linux系统下设置USB相机的技术背景Linux系统内核 USB 模块内存的修改内存限制的确定使用 GRUB 引导加载程序修改内存限制使用 U-B…...

zst-2001 历年真题 知识产权
知识产权 - 第1题 发表权有时间限制 其他下面3个没有 c 知识产权 - 第2题 bd是财产权 c 知识产权 - 第3题 b 知识产权 - 第4题 d 知识产权 - 第5题 d 知识产权 - 第6题 d 知识产权 - 第7题 d 知识产权 - 第8题 b是国务院发布的 d没有复制权…...

设备与驱动:UART设备
大部分的嵌入式系统都包括一些I/O设备,例如仪器上的数据显示屏、工业设备上的串口通信、数据采集设备上模拟数据采样、用于保存数据的Flash/SD卡以及网络设备上的以太网接口等,都是嵌入式系统中容易找到的I/O设备例子。 本专栏主要是分享RT-Thread是如何…...

Linux 服务器静态 IP 配置初始化指南
✅ 第一步:确认网络管理方式 运行以下命令判断系统使用的网络管理服务: # 检查 NetworkManager 是否活跃 systemctl is-active NetworkManager# 检查 network(旧服务)是否活跃 systemctl is-active network或者检查配置路径&…...

【ROS2】Nav2源码之行为树定义、创建、加载
1、简述 在 Navigation2 里,机器人的导航是一项复杂的任务,包含路径规划、避障、恢复机制等多个子任务。行为树能把这些子任务组织成清晰的层次结构,让机器人可以依据不同的情况做出合理的决策。例如,当机器人在导航途中碰到障碍物时,行为树可以决定是重新规划路径、尝试…...

Redis持久化存储介质评估:NFS与Ceph的适用性分析
#作者:朱雷 文章目录 一、背景二、Redis持久化的必要性与影响1. 持久化的必要性2. 性能与稳定性问题 三、NFS作为持久化存储介质的问题1. 性能瓶颈2. 数据一致性问题3. 存储服务单点故障4. 高延迟影响持久化效率.5. 吞吐量瓶颈 四、Ceph作为持久化存储介质的问题1.…...

如何统一修改word中所有英文字母的字体格式
1.需求分析 我想让整篇论文中的所有英文字母格式都修改为Time New Roman格式。 2.直观操作流程 点击左上角开始 --> 点击替换 --> 点击更多 --> 点击特殊格式 --> 选择查找内容为任意字母(Y) --> 将光标点到替换内容 --> 点击格式 --> 点击字体 --> …...

服务器上机用到的设备
服务器上机通常需要以下硬件设备: 服务器主机: CPU:选择高性能的多核处理器,如英特尔至强(Xeon)系列或AMD EPYC系列,以满足高并发和多任务处理需求。 内存(RAM)…...
)
【Java ee 初阶】多线程(8)
Synchronized优化: 一、锁升级 锁升级时一个自适应的过程,自适应的过程如下: 在Java编程中,有一部分的人不一定能正确地使用锁,因此,Java的设计者为了让大家使用锁的门槛更低,就在synchronize…...

数字孪生大屏UI设计
近年来,5G、大数据、云计算等新一代信息技术的蓬勃发展,计算机仿真技术与拟真软件的成熟运用,让数字孪生技术开始蔓延渗透到“互联网”相关的产业中。数字孪生大屏给予了可视化的数据直观窗口,其中展现的动态映射与实时数据让业务流转效率得到了有效提升,管理、运营和决策都能高…...
上)
【Java ee 初阶】多线程(9)上
一、信号量Semaphore 本质上就是一个计数器,描述了一种“可用资源”的个数 申请资源(P操作):使得计数器-1 释放资源(V操作):使得计数器1 如果计数器为0了,继续申请资源ÿ…...

eclipse开发环境中缺少JavaEE组件如何安装
新版本eclipse去掉server了吗?在最近新版本的eclipse里面,确实找不到server模块了,无法配置tomcat等web服务器插件了。我们需要自己手工安装一下javaEE组件才行。 1 1:找到自己当前eclipse版本号码 2:去这个地址&…...