【机器学习】Logistic 回归
Logistic 回归虽然名字中带有“回归”,但它实际上是一种广泛应用于 二分类问题 的线性分类算法。
Logistic 回归的核心任务是预测一个样本属于正类的概率,而概率必须在 [ 0 , 1 ] 范围内。
Logistic回归 通过将输入特征的线性组合映射到概率空间,输出介于 [0,1] 的概率值,通常以0.5作为阈值进行分类( >0.5 正类 ;<0.5 负类)。
一、Logistic 回归的引入:为什么不用线性回归做分类?
线性回归的输出是一个连续值,形式为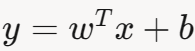 其值域为 ( − ∞ , + ∞ ) 。
其值域为 ( − ∞ , + ∞ ) 。
在二分类问题中,我们通常希望预测类别标签(如0或1),或者表示样本属于某个类别的概率(范围在 [ 0 , 1 ] )。
将线性回归直接用于分类存在以下问题:
-
输出范围不匹配:线性回归的输出可能远大于1或小于0,无法直接解释为概率。例如,预测值 𝑦 = 5或 𝑦 = − 3在分类中没有意义。
-
对离群点敏感:线性回归对离群点非常敏感,少量异常值可能显著改变模型的决策边界,导致分类性能下降。
二、Logistic回归 引入
为了解决上述问题,逻辑回归被提出作为一种专门针对分类问题的算法。
逻辑回归通过以下方式改进:
- 概率输出:使用Sigmoid函数将线性组合 映射到 [0,1],直接输出样本属于正类的概率 P(y=1∣x)。
- 对数损失:采用对数损失作为目标函数,专门优化分类任务的概率预测,更加适合离散标签的场景。
- 非线性映射:Sigmoid函数引入非线性,使得模型能更好地适应分类任务的概率分布特性。
- 鲁棒性:逻辑回归通过概率建模,对离群点的敏感性较低,且决策边界更适合分类任务。
因此,逻辑回归在分类问题中取代线性回归,成为二分类任务的首选算法,同时也可通过扩展(如Softmax回归)处理多分类问题。
三、Logistic回归的数学原理
3.1 模型假设
假设输入特征为 x=[x1,x2,…,xn],权重为 w=[w1,w2,…,wn] ,偏置为 b。
线性组合为:
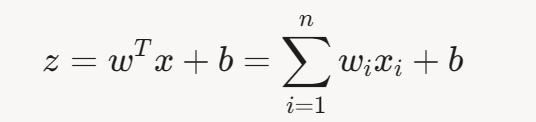
为了将 z 映射到 [ 0 , 1 ] 的概率,使用 Sigmoid函数: 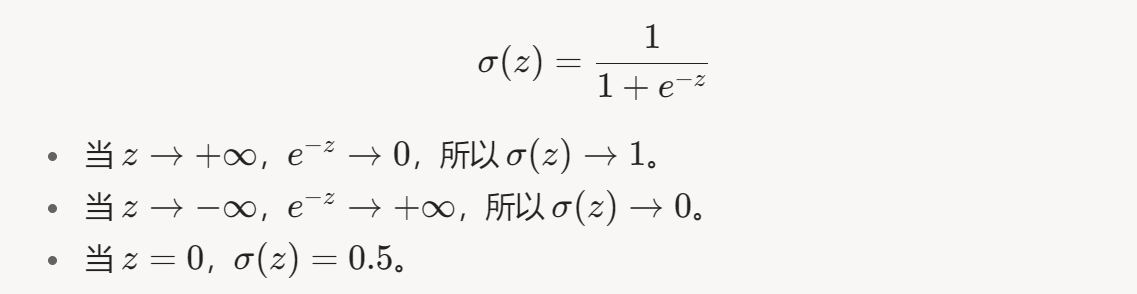
因此,样本属于正类的概率为: 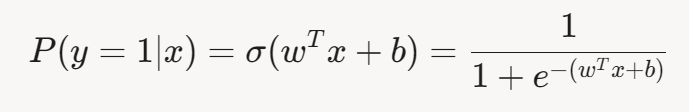
-
y 是真实标签, P(y=1∣x) 表示给定特征 x 时,标签为正类(y=1)的概率。
负类的概率为:
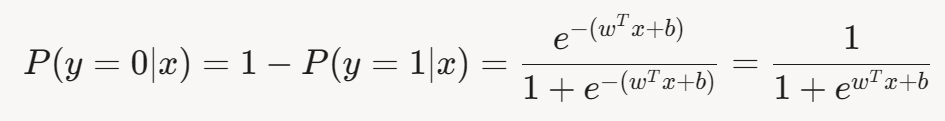
3.2 决策边界
逻辑回归通过概率阈值(通常为0.5)进行分类:
- 若 P(y=1∣x)≥0.5 ,预测 y=1 。
- 若 P(y=1∣x)<0.5,预测 y=0。
当 σ(z)=0.5 时,z=0,因此决策边界为: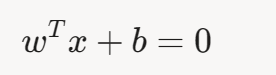
这表示特征空间中的一个超平面,用于分隔两个类别。
我理解的逻辑回归实现的是这样一个功能:给定一个样本,经过算法处理最终会得到一个介于0-1之间的值,而这个值实际上就表示了这个样本属于正类的概率,然后刚开始会有一个人为设定的阈值(通常是0.5),如果这个输出概率值大于阈值,那么我们就认为样本属于正类。
四、损失函数
为了训练模型,需要找到使预测最优的权重 w 和偏置 b,通过最小化损失函数实现。
4.1 对数损失
逻辑回归使用对数损失(或二元交叉熵)作为损失函数,衡量预测概率与真实标签的差异。
对于单个样本(x i ,y i ),其中 y i ∈{0,1},预测概率为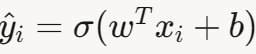
损失为: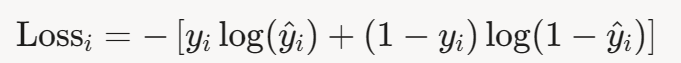 对于包含 m 个样本的数据集,总损失(平均对数损失)为:
对于包含 m 个样本的数据集,总损失(平均对数损失)为:
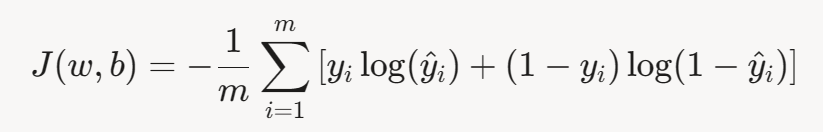
4.2 正则化
为防止过拟合,可在损失函数中加入正则化项:
L2正则化(Ridge)

L1正则化(Lasso)
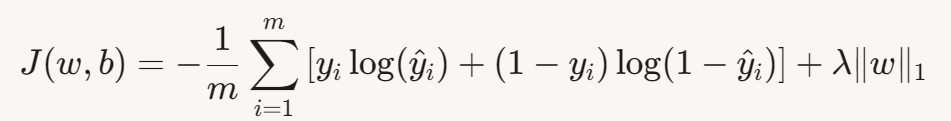
其中, λ 是正则化强度。
五、优化方法
逻辑回归通过最小化损失函数 𝐽 ( 𝑤 , 𝑏 ) 训练模型,优化参数 𝑤 和 𝑏 。
由于损失函数是非线性的,无法直接求解,因此通常使用迭代优化方法,以梯度下降为核心。
本节详细讲解梯度下降的原理、变体、收敛性等。
5.1 损失函数回顾
逻辑回归的损失函数为对数损失:
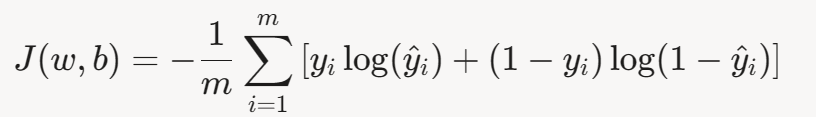
其中![]()
目标是找到 𝑤 和 𝑏 ,使 𝐽 ( 𝑤 , 𝑏 ) 最小。
5.2 梯度下降原理
梯度下降是一种迭代优化算法,通过沿损失函数梯度的反方向更新参数,逐步逼近最小值。
更新规则为:
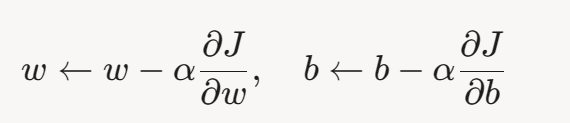
5.2.1 梯度推导
对于单个样本 (x i ,y i ),损失为:
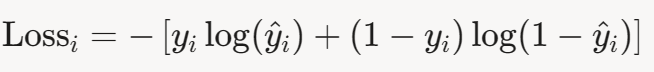
其中![]()
对 𝑤 𝑗 求偏导:
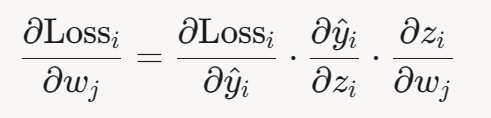
- 第一项:
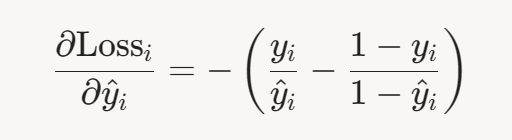
- 第二项(Sigmoid 导数):
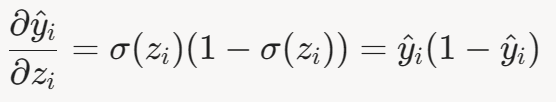
- 第三项:
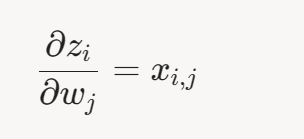
- 合并:
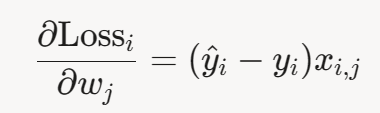
对 𝑏 :
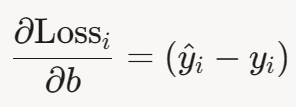
对整个数据集,梯度为:
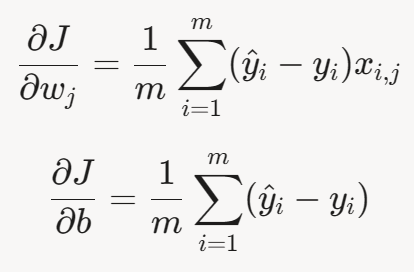
5.2.2 梯度下降步骤
- 初始化 w和 b ,通常为随机值或零向量。
- 计算预测概率
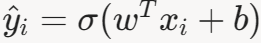 。
。 - 计算梯度
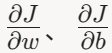 。
。 - 更新参数:
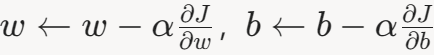 。
。 - 重复直到损失收敛(达到最大迭代次数或损失变化小于阈值)。
5.3 梯度下降变体
梯度下降有多种实现方式,平衡计算效率和稳定性。
5.3.1 批量梯度下降(Batch Gradient Descent)
原理:每次迭代中使用 整个数据集 来计算损失函数的梯度,确保梯度方向准确。
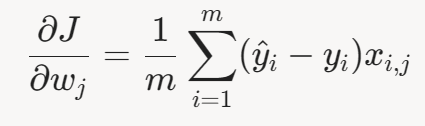
优点:
- 梯度准确:使用所有样本,梯度方向稳定,收敛路径平滑。
- 适合小型数据集:当数据量小(数百到数千样本),计算成本可接受。
缺点:
- 计算成本高,内存需求大(需加载全部数据)。
- 更新慢:每次迭代耗时长,收敛速度慢。
5.3.2 随机梯度下降(Stochastic Gradient Descent, SGD)
原理:每次迭代中随机选择一个样本计算梯度,极大降低单次计算成本。
单样本梯度为:
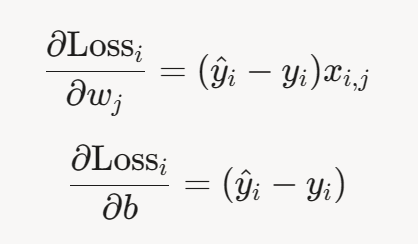
参数更新规则:
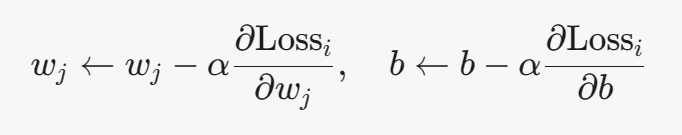
优点
- 计算效率高:单次迭代复杂度为 O(n) O(n) O(n),适合大型数据集。
- 快速更新:频繁更新参数,收敛初期进展快。
- 随机性有益:梯度噪声可能帮助逃离鞍点。
缺点
- 梯度噪声大:单样本梯度不代表整体方向,更新路径震荡,收敛不稳定。
- 收敛慢:接近最小值时,噪声导致难以精确收敛。
5.3.3 小批量梯度下降(Mini-Batch Gradient Descent)
原理:每次迭代使用一小批样本计算梯度
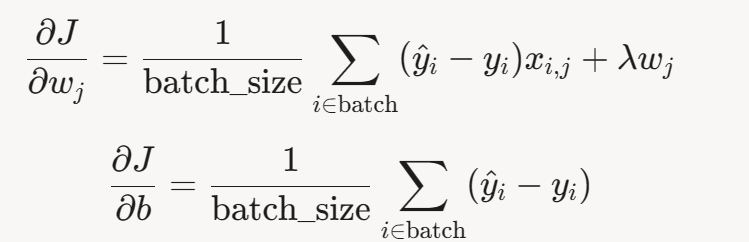
优点
- 效率与稳定平衡:比批量梯度下降快,比 SGD 噪声小。
- 适合大型数据集:分批处理,内存需求适中。
- 支持并行计算:批量计算可利用 GPU 加速。
- 收敛稳定:梯度噪声适中,收敛路径较平滑。
缺点
- 需调参:批量大小影响性能,需实验选择。
- 内存需求:比 SGD 高,需加载批量数据。
- 仍需调学习率:收敛依赖 α \alpha α 和批量大小。
六、Logistic回归应用实例:基于二维数据集的分类实践
6.1 背景与目标
逻辑回归是一种广泛用于二分类问题的机器学习算法。
本实例使用数据集 `Logistic_testSet.txt`(包含 100 个样本,2 个特征 ( x1 ,x2 ),标签 0 或 1),目标是训练模型、优化分类效果,并通过可视化展示决策边界和性能评估。
6.2 数据与预处理
数据集:100 个样本,特征 x1 、x2 表示二维坐标,标签0或1表示类别。
预处理:使用 `StandardScaler` 标准化特征,均值为 0,方差为 1,确保梯度下降收敛。
数据集:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0
6.3 代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, roc_curve, auc, confusion_matrix, ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split# 加载数据集
def load_data(filename):data = np.loadtxt(filename, delimiter='\t')X = data[:, :-1]y = data[:, -1].astype(int)return X, y# 决策边界绘制函数
def plot_decision_boundary(X, y, model, scaler, w, b, filename='decision_boundary_contour_only.png'):X_original = scaler.inverse_transform(X)x_min, x_max = X_original[:, 0].min() - 0.5, X_original[:, 0].max() + 0.5y_min, y_max = X_original[:, 1].min() - 0.5, X_original[:, 1].max() + 0.5xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.005), np.arange(y_min, y_max, 0.005))grid = np.c_[xx.ravel(), yy.ravel()]grid_scaled = scaler.transform(grid)Z = model.predict(grid_scaled).reshape(xx.shape)Z_prob = model.predict_proba(grid_scaled)[:, 1].reshape(xx.shape)plt.figure(figsize=(8, 6))plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)plt.scatter(X_original[y == 0][:, 0], X_original[y == 0][:, 1], c='blue', label='Class 0', marker='o', s=50)plt.scatter(X_original[y == 1][:, 0], X_original[y == 1][:, 1], c='red', label='Class 1', marker='^', s=50)# 绘制 P=0.5 等高线(实线)contour = plt.contour(xx, yy, Z_prob, levels=[0.5], colors='k', linewidths=1.5)plt.clabel(contour, inline=True, fmt={0.5: 'P=0.5'}, colors='k')plt.xlabel('Feature 1 (x1)')plt.ylabel('Feature 2 (x2)')plt.title('Logistic Regression Decision Boundary')plt.legend()plt.grid(True)plt.savefig(filename, dpi=300, bbox_inches='tight')plt.show()# ROC 曲线绘制函数
def plot_roc_curve(y_true, y_scores, filename='roc_curve_final.png'):fpr, tpr, thresholds = roc_curve(y_true, y_scores)roc_auc = auc(fpr, tpr)optimal_idx = np.argmax(tpr - fpr)optimal_threshold = thresholds[optimal_idx]optimal_tpr = tpr[optimal_idx]optimal_fpr = fpr[optimal_idx]plt.figure(figsize=(8, 6))plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.scatter(optimal_fpr, optimal_tpr, c='red', s=100, label=f'Optimal threshold = {optimal_threshold:.2f}')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver Operating Characteristic (ROC) Curve')plt.legend(loc="lower right")plt.grid(True)plt.savefig(filename, dpi=300, bbox_inches='tight')plt.show()return roc_auc, optimal_threshold# 绘制混淆矩阵
def plot_confusion_matrix(y_true, y_pred, filename='confusion_matrix.png'):cm = confusion_matrix(y_true, y_pred)disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['Class 0', 'Class 1'])disp.plot(cmap=plt.cm.Blues)plt.title('Confusion Matrix (Test Set)')plt.savefig(filename, dpi=300, bbox_inches='tight')plt.show()# 主程序
def main():filename = 'Logistic_testSet.txt'X, y = load_data(filename)scaler = StandardScaler()X_scaled = scaler.fit_transform(X)X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)model = LogisticRegression(solver='lbfgs', max_iter=2000, C=0.5, random_state=42)model.fit(X_train, y_train)y_pred_train = model.predict(X_train)y_pred_test = model.predict(X_test)train_accuracy = accuracy_score(y_train, y_pred_train)test_accuracy = accuracy_score(y_test, y_pred_test)print(f"训练集准确率: {train_accuracy:.4f}")print(f"测试集准确率: {test_accuracy:.4f}")print(f"权重 w: {model.coef_}")print(f"偏置 b: {model.intercept_}")y_scores = model.predict_proba(X_test)[:, 1]roc_auc, optimal_threshold = plot_roc_curve(y_test, y_scores, 'roc_curve_final.png')print(f"测试集 AUC: {roc_auc:.4f}")print(f"最优阈值: {optimal_threshold:.4f}")y_pred_optimal = (y_scores >= optimal_threshold).astype(int)optimal_accuracy = accuracy_score(y_test, y_pred_optimal)print(f"使用最优阈值的测试集准确率: {optimal_accuracy:.4f}")plot_confusion_matrix(y_test, y_pred_optimal, 'confusion_matrix.png')plot_decision_boundary(X_scaled, y, model, scaler, model.coef_, model.intercept_,'decision_boundary_contour_only.png')if __name__ == "__main__":main()6.4 结果分析
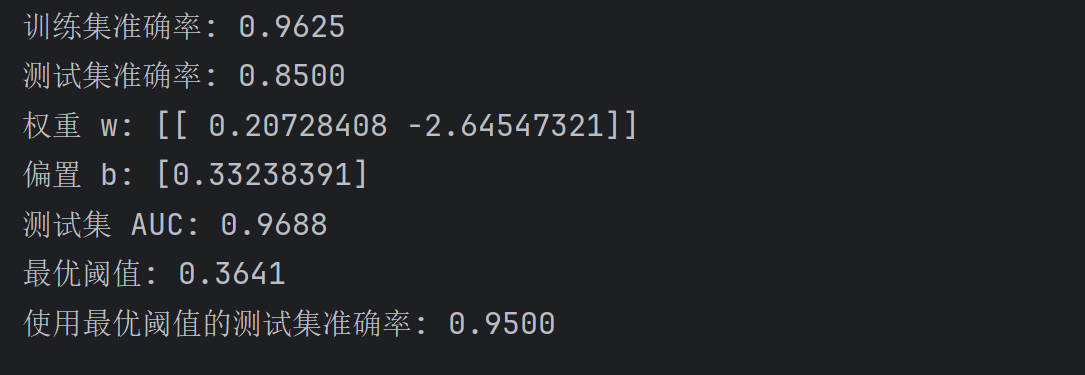
6.4.1 决策边界
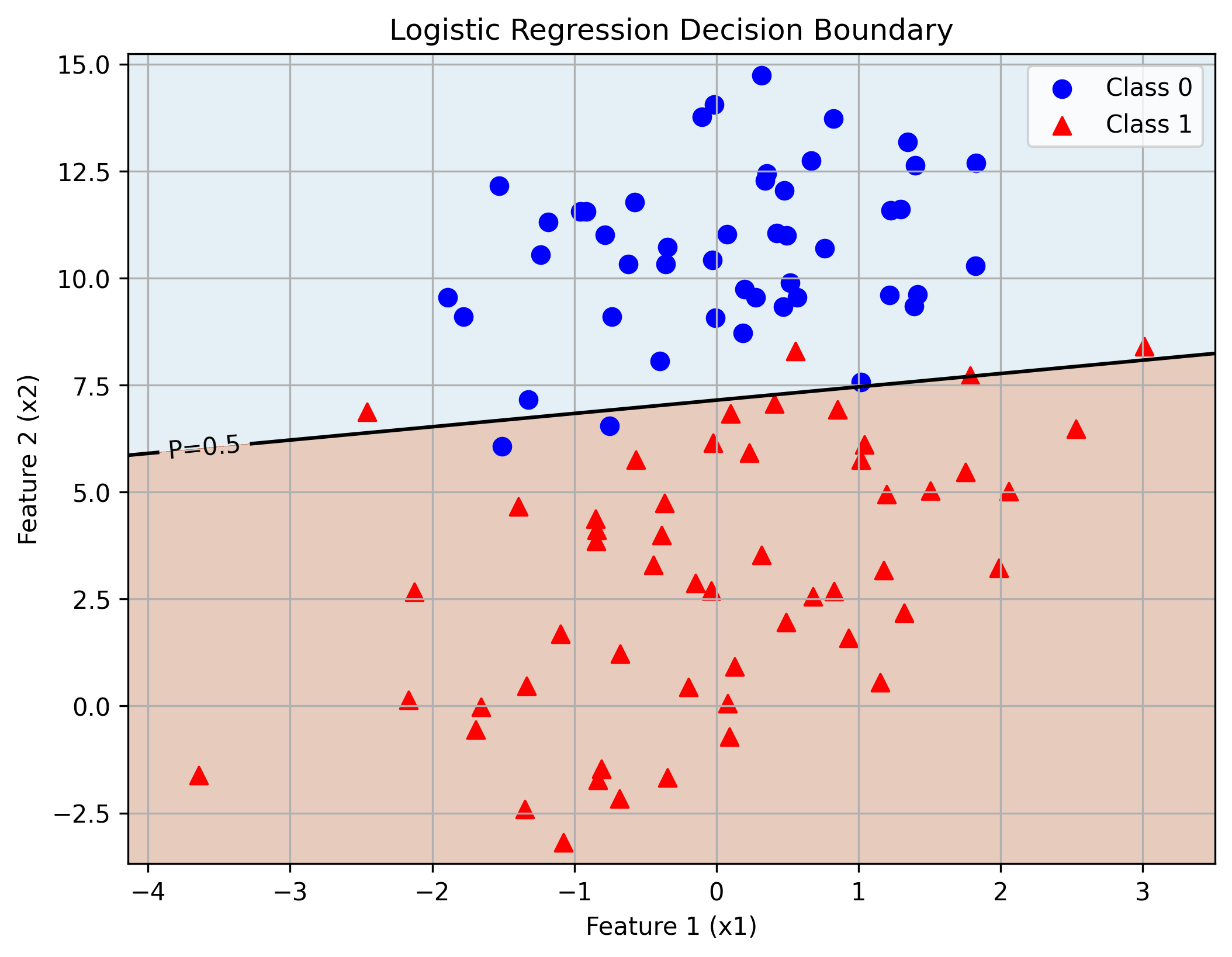
不难发现:
- 蓝色圆点(Class 0)和红色三角形(Class 1)分布清晰。
- 决策边界(黑色实线)为 P(y=1) = 0.5 等高线,基于网格点预测概率绘制。
- 数据近似线性可分,少量误分类点。
6.4.2 ROC 曲线
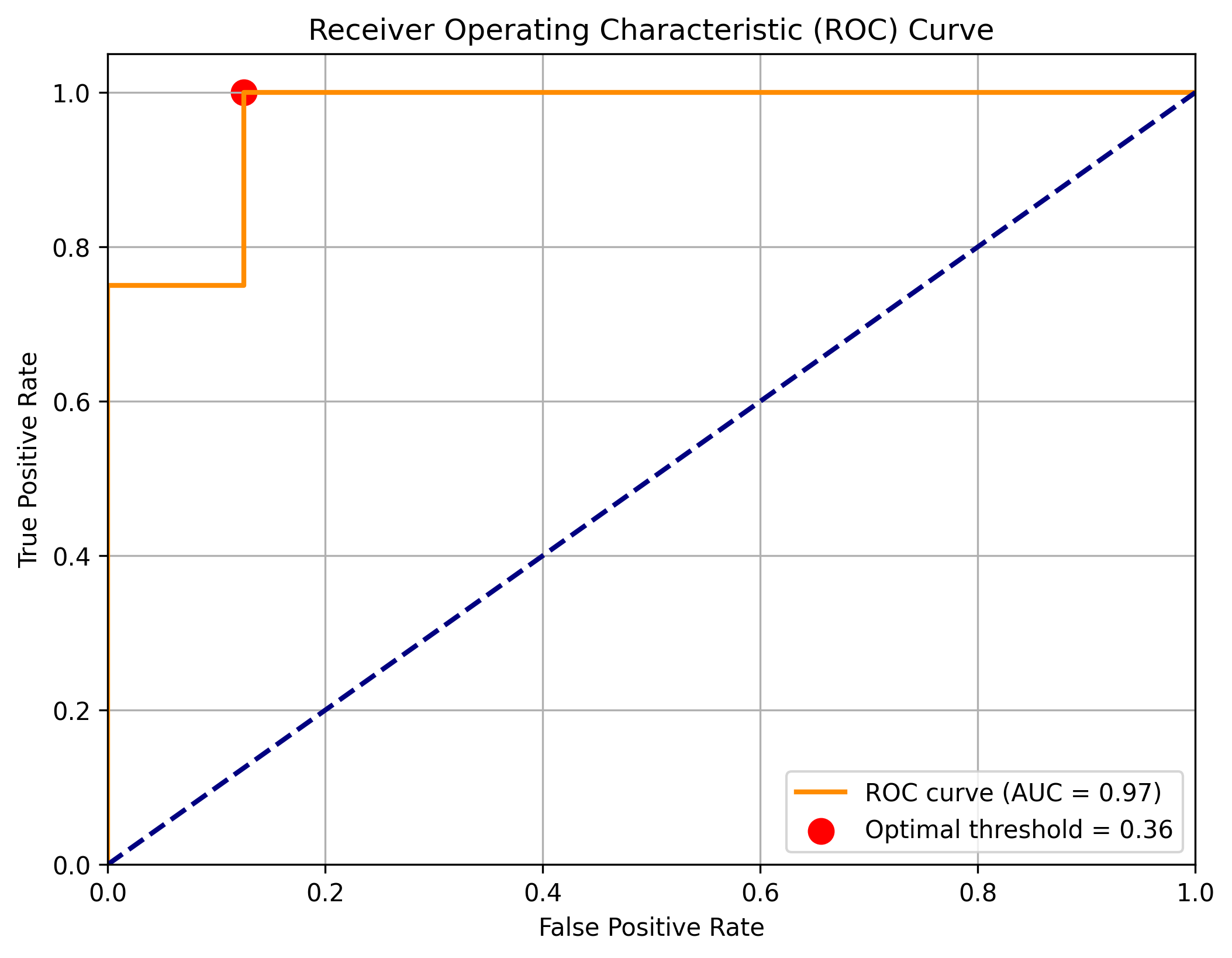
AUC = 0.97,模型性能优异
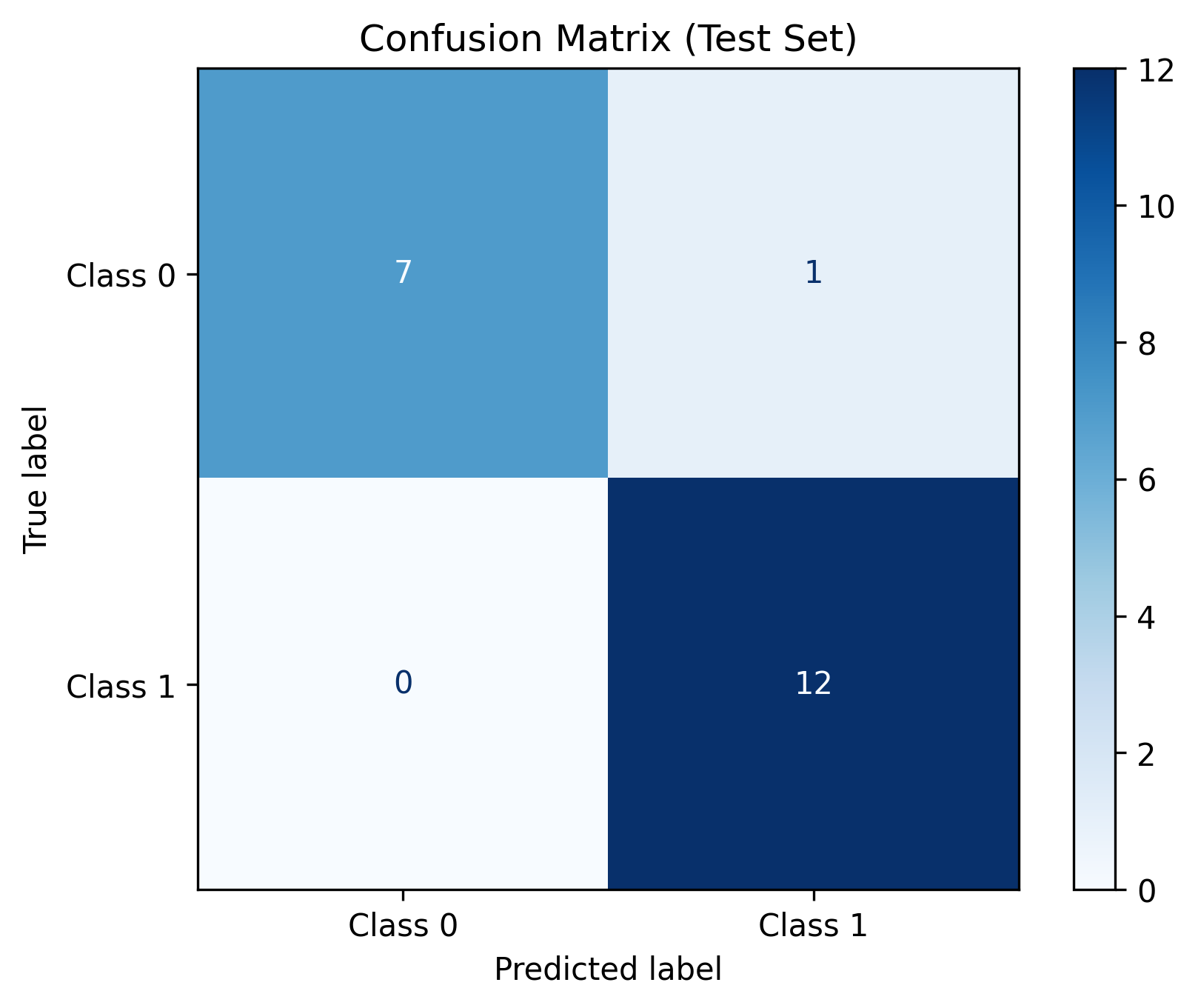
4.3 混淆矩阵 (基于测试集测试结果)
七、学习总结
逻辑回归是一种用于二分类问题的机器学习算法,通过sigmoid函数将线性回归的输出映射到0到1之间,表示样本属于正类的概率。其核心是利用最大似然估计优化参数,构建损失函数(通常为对数损失),通过梯度下降等方法最小化损失来拟合模型。逻辑回归假设数据特征与目标变量之间存在线性关系,适合处理线性可分的数据。它简单高效,广泛应用于分类任务,如垃圾邮件检测、疾病预测等,但对非线性关系和多类问题需扩展处理。
相关文章:

【机器学习】Logistic 回归
Logistic 回归虽然名字中带有“回归”,但它实际上是一种广泛应用于 二分类问题 的线性分类算法。 Logistic 回归的核心任务是预测一个样本属于正类的概率,而概率必须在 [ 0 , 1 ] 范围内。 Logistic回归 通过将输入特征的线性组合映射到概率空间&…...

ClimateCatcher专用CDS配置教程
文章目录 API获取官网账号注册CDSAPI本地化配置 API获取官网 首先需要访问CDS官方网站,点我蓝色字直接到官网how-to-api点我蓝色字直接到官网 目前API的网页是这样的 账号注册 如果有账号的小伙伴可以直接登录自己的账号并跳转到CDSAPI本地化配置,如…...

拆解 Prompt 工程:五大场景驱动 DeepSeek 超越 ChatGPT
同样的模型、不一样的答案,差距往往发生在一行 Prompt 里。本文围绕五大高频实战场景,给出可直接复制的 DeepSeek 提问框架,并穿插《DeepSeek 行业应用大全》中 64 个行业模板精华,帮助读者迅速跑赢 ChatGPT。🌟 剧透…...

【解决方案】CloudFront VPC Origins 实践流程深入解析 —— 安全高效架构的实战之道
目录 引言一、VPC Origins 的核心价值(一)安全性提升(二)运维效率优化(三)成本节约(四)全球分发能力的保留 二、VPC Origins 的架构解析(一)流量路径设计&…...
)
软考 系统架构设计师系列知识点 —— 黑盒测试与白盒测试(2)
接前一篇文章:软考 系统架构设计师系列知识点 —— 黑盒测试与白盒测试(1) 本文内容参考: 黑盒测试和白盒测试详解-CSDN博客 软件测试中的各种覆盖(Coverage)详解-CSDN博客 特此致谢! 二、白…...
)
【背包dp----01背包】例题三------(标准的01背包+变种01背包1【恰好装满背包体积 产生的 最大价值】)
【模板】01背包 题目链接 题目描述 : 输入描述: 输出描述: 示例1 输入 3 5 2 10 4 5 1 4输出 14 9说明 装第一个和第三个物品时总价值最大,但是装第二个和第三个物品可以使得背包恰好装满且总价值最大。 示例2 输入 3 8 12 6 11 8 6 8输出 8 0说明 装第三个物…...

设计模式之状态模式
在日常开发中,我们经常会遇到这样的场景:一个对象在不同时刻有不同的状态,不同状态下它的行为也会发生变化。此时,使用大量if...else或switch语句会让代码变得混乱而难以维护。为了更优雅地应对这种问题,状态模式(Stat…...

arXiv论文 MALOnt: An Ontology for Malware Threat Intelligence
文章讲恶意软件威胁情报本体。 作者信息 作者是老美的,单位是伦斯勒理工学院,文章是2020年的预印本,不知道后来发表在哪里(没搜到,或许作者懒得投稿,也可能是改了标题)。 中心思想 介绍开源…...

Spark处理过程-转换算子和行动算子
计算时机 转换算子 转换算子是惰性执行的,这意味着在调用转换算子时,系统不会立即进行数据处理。这种惰性计算的方式可以让 Spark 对操作进行优化,例如合并多个转换操作,减少数据的传输和处理量。行动算子 行动算子是立即执行的。…...

使用 pgrep 杀掉所有指定进程
使用 pgrep 杀掉所有指定进程 pgrep 是一个查找进程 ID 的工具,结合 pkill 或 kill 命令可以方便地终止指定进程。以下是几种方法: 方法1:使用 pkill(最简单) pkill 进程名例如杀掉所有名为 “firefox” 的进程&…...
)
Android学习总结之MMKV(代替SharedPreferences)
Q1:SharedPreferences 为什么会导致 ANR?MMKV 如何从根本上解决? 高频考察点:Android 主线程阻塞原理、SP 同步 / 异步机制缺陷、MMKV 内存映射技术 SP 导致 ANR 的三大元凶: 同步提交(commit ()…...

SWiRL:数据合成、多步推理与工具使用
SWiRL:数据合成、多步推理与工具使用 在大语言模型(LLMs)蓬勃发展的今天,其在复杂推理和工具使用任务上却常遇瓶颈。本文提出的Step-Wise Reinforcement Learning(SWiRL)技术,为解决这些难题带…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】7.2 PostgreSQL与Python数据交互(psycopg2库使用)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL与Python数据交互:psycopg2库实战指南一、引言:数据交互的桥梁1.1 psycopg2核心优势 二、环境准备与基础连接2.1 安装配置2.1.1 安装psyco…...

【Prompt工程—文生图】案例大全
目录 一、人物绘图 二、卡通头像 三、风景图 四、logo设计图 五、动物形象图 六、室内设计图 七、动漫风格 八、二次元图 九、日常场景图 十、古风神化图 十一、游戏场景图 十二、电影大片质感 本文主要介绍了12种不同类型的文生图技巧,通过加入不同的图像…...

NVM完全指南:安装、配置与最佳实践
发布于 2025年5月7日 • 阅读时间:10分钟 💡 TL;DR: 本文详细介绍了如何完整卸载旧版Node.js,安装NVM,配置阿里云镜像源,以及设置node_global与node_cache目录,打造高效Node.js开发环境。 📋 目…...

成都养老机器人“上岗”,机器人养老未来已至还是前路漫漫?
近日,成都养老机器人“上岗”引发关注,赛博养老这一概念再次成为人们讨论的焦点,究竟赛博养老未来已来,还是仍需漫长等待,引发诸多思考。 成都研发的养老机器人“上岗”确实标志着智慧养老领域的又一进步,…...

数据中心 第十五次CCF-CSP计算机软件能力认证
总结一下图树算法比如krusal 迪杰斯特拉 prim算法喜欢改变距离定义 或者求别的东西 而拓扑排序喜欢大模拟 本题使用kerusal算法求出最后一条边就可以。 ac代码: #include <iostream> #include <vector> #include <algorithm>using namespac…...

【面试 · 一】vue大集合
目录 vue2 基础属性 组件通信 全局状态管理 vueX 路由 路由守卫 vue3 基础属性 组件通信 全局状态管理 Pinia 路由 路由守卫 vue2、vue3生命周期 setup vue2 基础属性 data:用于定义组件的初始数据,必须是一个函数,返回一个对…...
)
Java 常用的 ORM框架(对象关系映射)
Java 常用的 ORM(对象关系映射)框架有以下几种,每种都有其特点和使用场景: Hibernate ● 特点: ○ 完整的 ORM 框架,功能强大。 ○ 支持缓存机制(一级缓存、二级缓存)。 ○ 支持多种…...

自动化创业机器人:现状、挑战与Y Combinator的启示
自动化创业机器人:现状、挑战与Y Combinator的启示 前言 AI驱动的自动化创业机器人,正逐步从科幻走向现实。我们设想的未来是:商业分析、PRD、系统设计、代码实现、测试、运营,全部可以在monorepo中由AI和人类Co-founder协作完成…...

支持向量机
支持向量机(Support Vector Machine,SVM)是一种有监督的机器学习算法,可用于分类和回归任务,尤其在分类问题上表现出色。下面将从原理、数学模型、核函数、优缺点和应用场景等方面详细介绍。 原理 支持向量机的基本思…...

华为昇腾910B通过vllm部署InternVL3-8B教程
前言 本文主要借鉴:VLLM部署deepseek,结合自身进行整理 下载模型 from modelscope import snapshot_download model_dir snapshot_download(OpenGVLab/InternVL3-8B, local_dir"xxx/OpenGVLab/InternVL2_5-1B")环境配置 auto-dl上选择单卡…...

ZArchiver解压缩工具:高效解压,功能全面
在使用智能手机的过程中,文件管理和压缩文件的处理是许多用户常见的需求。无论是解压下载的文件、管理手机存储中的文件,还是进行日常的文件操作,一款功能强大且操作简便的文件管理工具都能极大地提升用户体验。今天,我们要介绍的…...

ETL介绍
(一)ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较…...

2025.05.07-华为机考第三题300分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 城市紧急救援队伍协同规划 问题描述 智慧城市建设中,卢小姐负责设计一套紧急救援队伍协同系统。城市被规划为一个 n n n \times n...

缓存菜品-04.功能测试
一.功能测试 redis中的数据已缓存 查询数据时并没有发sql 修改鸡蛋汤价格为5元。 缓存数据没有了 价格修改成功 停售启售是一样的。修改后清理,再次查询又被缓存到redis中。...

跨境电商生死局:动态IP如何重塑数据生态与运营效率
凌晨三点的深圳跨境电商产业园,某品牌独立站运营总监李明(化名)正盯着突然中断的广告投放系统。后台日志显示,过去24小时内遭遇了17次IP封禁,直接导致黑五促销期间损失23%的预期流量。这并非个案——2023年跨境电商行业…...

day 14 SHAP可视化
一、原理——合作博弈论 SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法,它基于合作博弈论中的 Shapley 值概念。Shapley 值最初用于解决合作博弈中的利益分配问题。假设有 n 个参与者共同合作完成一项任务并…...

处理PostgreSQL数据库事务死锁过程
查询pg_locks表,获取未得到满足的锁信息: select * from pg_locks where granted is false ; --查询得不到锁的,那就是两个互相等待对方持有的锁查询活动的事务会话进程,和上一步的锁的事务对应起来: select * from …...
、平台架构与设计重构大模型应用)
大数据、物联网(IoT)、平台架构与设计重构大模型应用
结合大数据、物联网(IoT)、平台架构与设计重构大模型应用,需构建一个数据驱动、实时响应、弹性扩展的智能系统。以下从技术架构、数据流、核心模块设计三个维度展开: 一、整体架构设计 分层架构(基于云-边-端协同): [物联网设备层] → [边缘计算层] → [大数据平台层]…...
)
开发 Chrome 扩展中的侧边栏图标设置实录(Manifest V3)
在开发自己的 Chrome 扩展 Pocket Bookmarks(口袋书签) 的过程中,我遇到了一个看似简单却颇具挑战的问题:如何在扩展的侧边栏显示自定义图标? 这篇文章记录一下我踩过的坑,以及最终的解决方案。 这里说的侧…...
)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK在Linux系统下设置多个USB相机(C++)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK在Linux系统下设置多个USB相机(C) Baumer工业相机Baumer工业相机BGAPI SDK在Linux系统下设置USB相机的技术背景Linux系统内核 USB 模块内存的修改内存限制的确定使用 GRUB 引导加载程序修改内存限制使用 U-B…...

zst-2001 历年真题 知识产权
知识产权 - 第1题 发表权有时间限制 其他下面3个没有 c 知识产权 - 第2题 bd是财产权 c 知识产权 - 第3题 b 知识产权 - 第4题 d 知识产权 - 第5题 d 知识产权 - 第6题 d 知识产权 - 第7题 d 知识产权 - 第8题 b是国务院发布的 d没有复制权…...

设备与驱动:UART设备
大部分的嵌入式系统都包括一些I/O设备,例如仪器上的数据显示屏、工业设备上的串口通信、数据采集设备上模拟数据采样、用于保存数据的Flash/SD卡以及网络设备上的以太网接口等,都是嵌入式系统中容易找到的I/O设备例子。 本专栏主要是分享RT-Thread是如何…...

Linux 服务器静态 IP 配置初始化指南
✅ 第一步:确认网络管理方式 运行以下命令判断系统使用的网络管理服务: # 检查 NetworkManager 是否活跃 systemctl is-active NetworkManager# 检查 network(旧服务)是否活跃 systemctl is-active network或者检查配置路径&…...

【ROS2】Nav2源码之行为树定义、创建、加载
1、简述 在 Navigation2 里,机器人的导航是一项复杂的任务,包含路径规划、避障、恢复机制等多个子任务。行为树能把这些子任务组织成清晰的层次结构,让机器人可以依据不同的情况做出合理的决策。例如,当机器人在导航途中碰到障碍物时,行为树可以决定是重新规划路径、尝试…...

Redis持久化存储介质评估:NFS与Ceph的适用性分析
#作者:朱雷 文章目录 一、背景二、Redis持久化的必要性与影响1. 持久化的必要性2. 性能与稳定性问题 三、NFS作为持久化存储介质的问题1. 性能瓶颈2. 数据一致性问题3. 存储服务单点故障4. 高延迟影响持久化效率.5. 吞吐量瓶颈 四、Ceph作为持久化存储介质的问题1.…...

如何统一修改word中所有英文字母的字体格式
1.需求分析 我想让整篇论文中的所有英文字母格式都修改为Time New Roman格式。 2.直观操作流程 点击左上角开始 --> 点击替换 --> 点击更多 --> 点击特殊格式 --> 选择查找内容为任意字母(Y) --> 将光标点到替换内容 --> 点击格式 --> 点击字体 --> …...

服务器上机用到的设备
服务器上机通常需要以下硬件设备: 服务器主机: CPU:选择高性能的多核处理器,如英特尔至强(Xeon)系列或AMD EPYC系列,以满足高并发和多任务处理需求。 内存(RAM)…...
)
【Java ee 初阶】多线程(8)
Synchronized优化: 一、锁升级 锁升级时一个自适应的过程,自适应的过程如下: 在Java编程中,有一部分的人不一定能正确地使用锁,因此,Java的设计者为了让大家使用锁的门槛更低,就在synchronize…...

数字孪生大屏UI设计
近年来,5G、大数据、云计算等新一代信息技术的蓬勃发展,计算机仿真技术与拟真软件的成熟运用,让数字孪生技术开始蔓延渗透到“互联网”相关的产业中。数字孪生大屏给予了可视化的数据直观窗口,其中展现的动态映射与实时数据让业务流转效率得到了有效提升,管理、运营和决策都能高…...
上)
【Java ee 初阶】多线程(9)上
一、信号量Semaphore 本质上就是一个计数器,描述了一种“可用资源”的个数 申请资源(P操作):使得计数器-1 释放资源(V操作):使得计数器1 如果计数器为0了,继续申请资源ÿ…...

eclipse开发环境中缺少JavaEE组件如何安装
新版本eclipse去掉server了吗?在最近新版本的eclipse里面,确实找不到server模块了,无法配置tomcat等web服务器插件了。我们需要自己手工安装一下javaEE组件才行。 1 1:找到自己当前eclipse版本号码 2:去这个地址&…...

stm32之ADC
目录 1.简介2.逐次逼近型ADC3.基本结构4.输入通道5.转换模式6.触发控制7.数据对齐8.转换时间7.校准10.ADC外围电路11.api和结构体11.1 结构体11.2 api1. ADC_DeInit2. ADC_Init3. ADC_StructInit4. ADC_Cmd5. ADC_DMACmd6. ADC_ITConfig7. ADC_ResetCalibration8. ADC_GetReset…...

从电话到V信语音:一款App实现全场景社交脱身
作为一名资深社恐人士,我深知那些无法脱身的社交场合有多煎熬。上周参加一个行业聚会,面对滔滔不绝的陌生人,我如坐针毡却又找不到合适的离场理由。这时我突然想起之前朋友推荐的一款神器应用,它让我得以优雅脱身。今天就来分享这…...

conda init before conda activate
先conda init 然后退出命令窗口,再重新打开命令窗口再conda activate...
详细方案与部署教程)
MySQL数据库高可用(MHA)详细方案与部署教程
一:MHA简介 核心功能 二:MHA工作原理 三:MHA组件 四:MHA 架构与工具 MHA架构 Manager关键工具 Node工具 五:工作原理与流程 1: 故障检测 2: 故障切换(Failover) 3 : 切换模式 六&a…...

《Python星球日记》 第44天: 线性回归与逻辑回归
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、引言:回归方法的重要性二、线性回归原理与损失函数1. 线性回归的数学模型2. 损失函数:衡量…...

Flutter TabBar / TabBarView 详解
目录 一、引言 二、基本用法 代码解析 三、主要属性 3.1 TabBar 3.2 TabBarView 四、进阶定制:突破默认样式 4.1 视觉样式深度定制 4.2 自定义指示器与标签 4.3 动态标签管理 五、工程实践关键技巧 5.1 性能优化方案 5.2 复杂手势处理 5.3 响应式布局…...

001 环境搭建
🦄 个人主页: 小米里的大麦-CSDN博客 🎏 所属专栏: Linux_小米里的大麦的博客-CSDN博客 🎁 GitHub主页: 小米里的大麦的 GitHub ⚙️ 操作环境: Visual Studio 2022 文章目录 Linux 环境搭建全解析:从历史到实践一、Linux 的起源与…...