【PostgreSQL数据分析实战:从数据清洗到可视化全流程】7.2 PostgreSQL与Python数据交互(psycopg2库使用)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL与Python数据交互:psycopg2库实战指南
- 一、引言:数据交互的桥梁
- 1.1 psycopg2核心优势
- 二、环境准备与基础连接
- 2.1 安装配置
- 2.1.1 安装psycopg2
- 2.1.2 连接参数说明
- 2.2 建立连接实例
- 三、数据交互核心操作
- 3.1 创建示例表
- 3.2 插入数据
- 3.2.1 单条插入
- 3.2.2 批量插入(性能提升50%+)
- 3.3 查询数据
- 3.3.1 基础查询
- 3.3.2 结果处理方式对比
- 3.4 更新数据
- 3.5 删除数据
- 四、事务管理与异常处理
- 4.1 事务控制原理
- 4.2 安全操作模板
- 4.3 常见异常类型
- 五、高级特性与最佳实践
- 5.1 参数化查询(防止SQL注入)
- 5.2 处理复杂数据类型
- 5.2.1 日期时间类型
- 5.2.2 JSON类型(PostgreSQL 9.4+支持)
- 5.3 连接池优化(高并发场景)
- 5.4 性能优化策略
- 六、实战案例:销售数据交互
- 6.1 数据清洗:过滤无效数据
- 6.2 数据分析:区域销售汇总
- 七、总结与最佳实践
- 7.1 核心价值总结
- 7.2 最佳实践清单
PostgreSQL与Python数据交互:psycopg2库实战指南

一、引言:数据交互的桥梁
在数据驱动的时代,PostgreSQL以其强大的关系型数据管理能力和开放性,成为企业级数据分析的核心数据库。
- Python作为
数据分析领域的首选语言,两者的高效交互是实现数据清洗、分析到可视化全流程的关键环节。 psycopg2作为Python生态中最成熟的PostgreSQL适配器,提供了稳定、高效的数据交互解决方案。- 本文将从基础连接到高级特性,结合具体数据案例,全面解析
psycopg2的实战应用。
1.1 psycopg2核心优势
| 特性 | 优势说明 |
|---|---|
| 原生支持 | 直接调用PostgreSQL C API,确保最佳性能和功能完整性 |
| 参数化查询 | 内置SQL注入防护机制,提升数据操作安全性 |
| 事务管理 | 支持完整ACID事务控制,确保数据一致性 |
| 类型适配 | 自动映射PostgreSQL数据类型与Python类型,减少类型转换成本 |
| 批量操作 | 支持批量数据插入/更新,显著提升大数据量处理效率 |
二、环境准备与基础连接
2.1 安装配置
2.1.1 安装psycopg2
# 常规安装(适用于已安装PostgreSQL开发包的环境)
pip install psycopg2-binary# 源码安装(适用于需要自定义配置的场景)
pip install psycopg2 -i https://pypi.tuna.tsinghua.edu.cn/simple
2.1.2 连接参数说明
建立数据库连接前,需准备以下核心参数:
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
| dbname | str | 数据库名称 | “postgres” |
| user | str | 数据库用户名 | “postgres” |
| password | str | 数据库密码 | “postgres” |
| host | str | 数据库主机地址(本地为"localhost") | “192.168.1.100” |
| port | int | 数据库端口(默认5432) | 5432 |
2.2 建立连接实例
import psycopg2
from psycopg2 import OperationalErrordef list_all_databases(config):"""查询PostgreSQL所有数据库清单(过滤系统模板库)"""try:# 建立数据库连接(使用上下文管理器自动关闭连接)with psycopg2.connect(**config) as conn:# 使用游标执行查询(with语句自动关闭游标)with conn.cursor() as cur:# 查询所有非模板数据库(排除template0/template1)# pg_database是PostgreSQL系统表,存储数据库元数据# datistemplate为false表示非模板库(用户创建的库)query_sql = """SELECT datname FROM pg_database WHERE datistemplate = false ORDER BY datname;"""cur.execute(query_sql)# 获取所有查询结果(返回格式:[(dbname1,), (dbname2,), ...])db_list = cur.fetchall()# 转换为纯数据库名列表(去除元组结构)return [db[0] for db in db_list]except OperationalError as e:print(f"连接或查询失败: {str(e)}")return Noneif __name__ == "__main__":# 数据库连接配置(根据实际环境修改)db_config = {"dbname": "postgres", # 连接默认数据库以执行系统表查询"user": "postgres","password": "postgres","host": "localhost","port": 5432}# 执行查询并打印结果databases = list_all_databases(db_config)if databases:print("PostgreSQL数据库清单(非模板库):")for idx, db in enumerate(databases, 1):print(f"{idx}. {db}")else:print("未获取到数据库列表")# 注意:with语句已自动关闭连接,无需手动调用conn.close()

三、数据交互核心操作
3.1 创建示例表
我们以员工信息表employees为例,演示完整的数据操作流程:
import psycopg2
from psycopg2 import OperationalError, ProgrammingErrordb_config = {"dbname": "postgres","user": "postgres","password": "postgres","host": "192.168.232.128","port": 5432
}try:conn = psycopg2.connect(**db_config)conn.autocommit = True # 关闭自动事务(建表是DDL,自动提交)# ======================================# 步骤1:执行建表语句(确保表结构正确)# ======================================create_table_sql = """CREATE TABLE IF NOT EXISTS employees (emp_id SERIAL PRIMARY KEY,name VARCHAR(50) NOT NULL,age INTEGER,department VARCHAR(30),salary NUMERIC(10,2),hire_date DATE);"""with conn.cursor() as cur:cur.execute(create_table_sql)print("表创建/验证成功!")# ======================================# 步骤2:执行数据插入(确保表结构正确后再执行)# ======================================insert_data_sql = """INSERT INTO employees (name, age, department, salary, hire_date)SELECT name,age,department,CASE WHEN department = '技术部' THEN round( (10000 + random() * 15000)::numeric, 2 )ELSE round( (6000 + random() * 12000)::numeric, 2 )END AS salary,'2020-01-01'::date + (random() * (CURRENT_DATE - '2020-01-01'::date))::int AS hire_dateFROM (SELECT'员工_' || generate_series AS name,floor(random() * 43) + 18 AS age,CASE floor(random() * 5)WHEN 0 THEN '技术部'WHEN 1 THEN '市场部'WHEN 2 THEN '财务部'WHEN 3 THEN '人力资源部'WHEN 4 THEN '运营部'END AS departmentFROM generate_series(1, 100)) AS subquery;"""with conn.cursor() as cur:cur.execute(insert_data_sql)print("数据插入成功!")except (OperationalError, ProgrammingError) as e:print(f"执行错误: {str(e)}")
finally:if conn:conn.close()print("数据库连接已关闭")

3.2 插入数据
3.2.1 单条插入
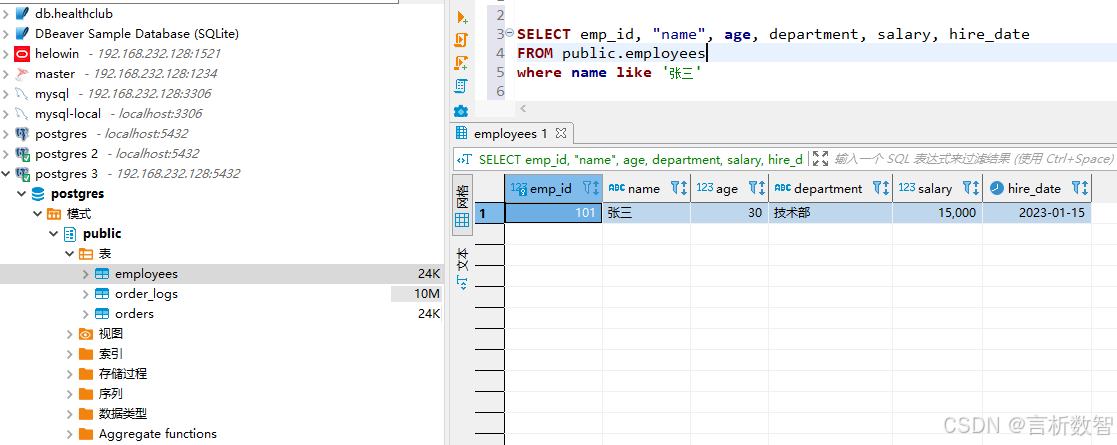
insert_single_sql = """
INSERT INTO employees (name, age, department, salary, hire_date)
VALUES (%s, %s, %s, %s, %s);
"""data = ("张三", 30, "技术部", 15000.00, "2023-01-15")with conn.cursor() as cur:cur.execute(insert_single_sql, data)
conn.commit()
3.2.2 批量插入(性能提升50%+)
insert_batch_sql = """
INSERT INTO employees (name, age, department, salary, hire_date)
VALUES %s;
"""batch_data = [("李四", 28, "市场部", 12000.50, "2023-03-20"),("王五", 35, "研发部", 20000.00, "2022-05-10"),("赵六", 25, "财务部", 8000.75, "2023-08-01")
]# 导入psycopg2的sql模块(用于安全构建SQL语句,本示例未直接使用)
from psycopg2 import sql
# 从psycopg2扩展模块导入execute_values函数(关键批量插入工具)
from psycopg2.extras import execute_values# 使用上下文管理器创建游标(自动关闭游标,避免资源泄露)
with conn.cursor() as cur:# 执行批量插入(核心操作)execute_values(cur, # 数据库游标(用于执行SQL)insert_batch_sql, # 插入的SQL模板(需包含%s占位符,如"INSERT INTO table VALUES %s")batch_data, # 待插入的数据列表(格式:[(val1, val2), (val3, val4), ...])template=None, # 数据行的模板(默认None,自动生成%s占位符;可自定义如"(%s::int, %s::date)")page_size=100 # 分页大小(每次发送到数据库的行数,默认100;大数据量时可调整优化))# 注意:execute_values不会自动提交事务,需手动提交# 提交事务(将内存中的修改持久化到数据库)
conn.commit()
3.3 查询数据
3.3.1 基础查询
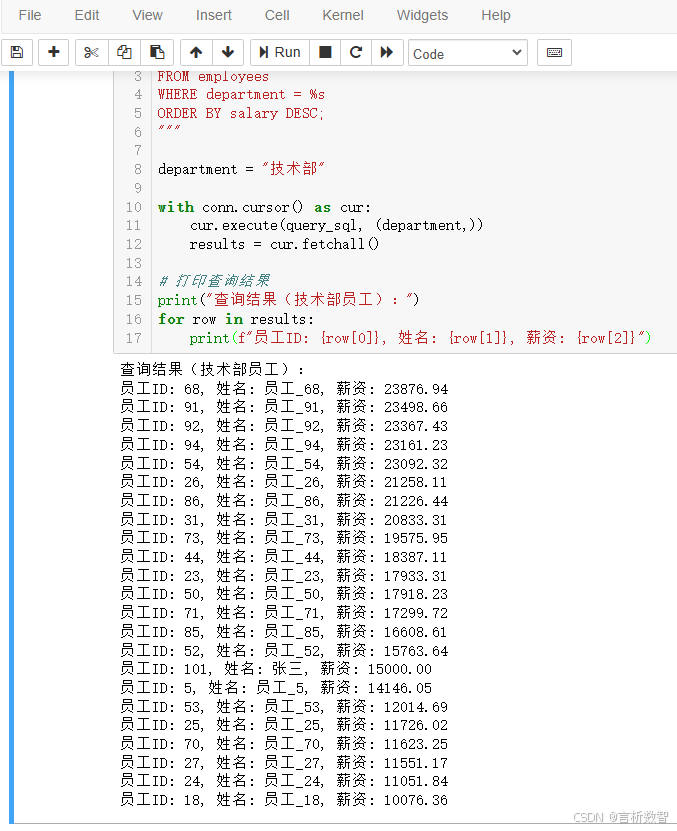
query_sql = """SELECT emp_id, name, salary FROM employees WHERE department = %s ORDER BY salary DESC;
"""department = "技术部"with conn.cursor() as cur:cur.execute(query_sql, (department,))results = cur.fetchall()# 打印查询结果
print("查询结果(技术部员工):")
for row in results:print(f"员工ID: {row[0]}, 姓名: {row[1]}, 薪资: {row[2]}")
3.3.2 结果处理方式对比
| 方法 | 说明 | 内存占用 | 适用场景 |
|---|---|---|---|
fetchone() | 获取下一行记录 | 最小 | 逐条处理大量数据 |
fetchmany(size) | 获取指定数量的记录(默认size=100) | 中等 | 分页处理 |
fetchall() | 获取所有记录 | 最大 | 小数据集一次性处理 |
3.4 更新数据
update_sql = """UPDATE employees SET salary = salary * 1.1 WHERE department = %s AND age > %s;
"""params = ("研发部", 30)with conn.cursor() as cur:cur.execute(update_sql, params)print(f"更新行数:{cur.rowcount}") # 获取受影响的行数
conn.commit()

3.5 删除数据
delete_sql = """DELETE FROM employees WHERE hire_date < %s;
"""six_months_ago = "2023-01-01"with conn.cursor() as cur:cur.execute(delete_sql, (six_months_ago,))print(f"删除行数:{cur.rowcount}")
conn.commit()

四、事务管理与异常处理
4.1 事务控制原理
PostgreSQL通过事务保证数据操作的原子性,psycopg2的事务管理遵循以下流程:
-
- 自动提交模式:默认关闭(
conn.autocommit = False)
- 自动提交模式:默认关闭(
-
- 手动提交:通过
conn.commit()确认变更
- 手动提交:通过
-
- 回滚机制:通过
conn.rollback()撤销未提交变更
- 回滚机制:通过
4.2 安全操作模板
try:with conn.cursor() as cur:cur.execute("危险操作SQL", params)conn.commit()
except psycopg2.Error as e:conn.rollback()print(f"操作失败:{str(e)}")raise # 可选:向上抛出异常
finally:if conn:conn.close()
4.3 常见异常类型
| 异常类 | 说明 | 处理建议 |
|---|---|---|
| OperationalError | 连接失败、SQL语法错误等 | 检查连接参数和SQL语句 |
| IntegrityError | 唯一约束冲突、外键约束失败等 | 验证数据完整性 |
DataError | 数据类型不匹配、值超出范围等 | 检查数据格式和范围 |
ProgrammingError | 参数数量不匹配、未定义的表/列等 | 检查SQL语句结构 |
五、高级特性与最佳实践
5.1 参数化查询(防止SQL注入)
- 错误示例(直接拼接SQL):
# 危险!存在SQL注入风险
user_input = "'; DROP TABLE employees; --"cur.execute(f"SELECT * FROM employees WHERE name = '{user_input}'")
- 安全实践(使用%s占位符):
cur.execute("SELECT * FROM employees WHERE name = %s", (user_input,))
5.2 处理复杂数据类型
5.2.1 日期时间类型
from datetime import datehire_date = date(2023, 10, 1)
cur.execute("INSERT INTO employees (hire_date) VALUES (%s)", (hire_date,))
5.2.2 JSON类型(PostgreSQL 9.4+支持)
import jsonmetadata = {"title": "高级工程师", "level": "资深"}
cur.execute("INSERT INTO employees (metadata) VALUES (%s)", (json.dumps(metadata),))
5.3 连接池优化(高并发场景)
from psycopg2.pool import SimpleConnectionPool# ======================================
# 1. 配置连接池(最小2连接,最大10连接)
# ======================================
pool = SimpleConnectionPool(minconn=2, # 连接池最小保持的空闲连接数maxconn=10, # 连接池最大允许的连接数dbname="postgres", # 数据库名称user="postgres", # 数据库用户password="postgres", # 数据库密码host="192.168.232.128",# 数据库主机地址port=5432 # 数据库端口(默认5432,可省略)
)# ======================================
# 2. 从连接池获取连接并执行查询
# ======================================
try:# 获取一个数据库连接(如果池中有空闲连接则直接获取,否则新建直到maxconn)conn = pool.getconn()# 使用上下文管理器创建游标(自动关闭游标)with conn.cursor() as cur:# 执行SQL查询(统计employees表的记录数)cur.execute("SELECT COUNT(*) FROM employees")# 获取查询结果(COUNT(*)返回一行一列,使用fetchone())# fetchone()返回元组,例如:(100,),[0]获取第一个元素count_result = cur.fetchone()[0]# 打印结果print(f"employees表记录数:{count_result}")finally:# 关键:无论是否出错,都要将连接归还给连接池(而非关闭!)if conn:pool.putconn(conn)print("连接已归还至连接池")# ======================================
# 3. 关闭连接池(程序结束时执行,释放所有资源)
# ======================================
pool.closeall()
print("连接池已关闭")

5.4 性能优化策略
-
- 批量操作:使用
execute_values替代循环单条插入,性能提升约300%
- 批量操作:使用
-
- 游标优化:对大数据集使用
named cursor(cur = conn.cursor(name="large_cursor"))
- 游标优化:对大数据集使用
-
- 连接复用:使用连接池减少连接创建开销
-
- 预处理语句:通过
PREPARE和EXECUTE减少SQL解析时间
- 预处理语句:通过
六、实战案例:销售数据交互
假设我们有一张销售记录表sales_records,包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| sale_id | BIGINT | 销售记录ID(主键) |
| product_name | VARCHAR(50) | 产品名称 |
| sale_date | DATE | 销售日期 |
| amount | NUMERIC(10,2) | 销售金额 |
| region | VARCHAR(20) | 销售区域 |
6.1 数据清洗:过滤无效数据
raw_sales建表语句,并构建测试数据
-- 创建原始销售数据表(含可能不规范的数据,用于清洗)
CREATE TABLE IF NOT EXISTS raw_sales (id SERIAL PRIMARY KEY, -- 自增主键(唯一标识每条记录)product_name VARCHAR(100) NOT NULL, -- 产品名称(如"手机","笔记本电脑"等)sale_date DATE NOT NULL, -- 销售日期(格式:YYYY-MM-DD)amount NUMERIC(10,2), -- 销售金额(可能为正/负,模拟退货或错误数据)region VARCHAR(20) -- 销售区域(可能包含无效值,如"西北","国外")
);-- 向raw_sales表插入100条测试数据(包含有效和无效数据,用于验证清洗逻辑)
INSERT INTO raw_sales (product_name, sale_date, amount, region)
SELECT-- 产品名称:从预设列表中随机选择(模拟真实产品)CASE floor(random() * 5) -- 0-4对应5种产品WHEN 0 THEN '智能手机'WHEN 1 THEN '笔记本电脑'WHEN 2 THEN '平板电脑'WHEN 3 THEN '智能手表'WHEN 4 THEN '无线耳机'END AS product_name,-- 销售日期:过去1年内的随机日期(2024-05-01至2025-05-01)'2024-05-01'::date + floor(random() * 365)::int AS sale_date,-- 关键修正:将随机金额转换为numeric类型后再round(保留2位小数)CASE WHEN random() > 0.5 THEN round( (100 + random() * 4900)::numeric, 2 ) -- 正数:100-5000元(保留2位小数)ELSE round( (-100 - random() * 4900)::numeric, 2 ) -- 负数:-5000至-100元(保留2位小数)END AS amount,-- 销售区域:30%概率为有效区域(华北/华东/华南),70%为无效区域(模拟需要清洗的场景)CASE floor(random() * 10) -- 0-9共10种可能WHEN 0 THEN '华北'WHEN 1 THEN '华东'WHEN 2 THEN '华南'ELSE '无效区域' -- 包括"西北","西南","国外"等(简化为统一描述)END AS region
FROM generate_series(1, 100); -- 生成1-100的序号(控制数据量)
cleaned_sales建表语句
-- 创建清洗后销售数据表(若不存在)
CREATE TABLE IF NOT EXISTS cleaned_sales (product_name VARCHAR(100) NOT NULL, -- 产品名称(与raw_sales的product_name类型一致,假设长度100)sale_date DATE NOT NULL, -- 销售日期(与raw_sales的sale_date类型一致,日期类型)amount NUMERIC(10,2) NOT NULL, -- 销售金额(与raw_sales的amount类型一致,保留2位小数)region VARCHAR(20) NOT NULL -- 销售区域(与raw_sales的region类型一致,假设常用区域名长度20)
);
clean_sql = """
INSERT INTO cleaned_sales (product_name, sale_date, amount, region)
SELECT product_name, sale_date, amount, region
FROM raw_sales
WHERE amount > 0 AND region IN ('华北', '华东', '华南');
"""with conn.cursor() as cur:cur.execute(clean_sql)
conn.commit()
6.2 数据分析:区域销售汇总
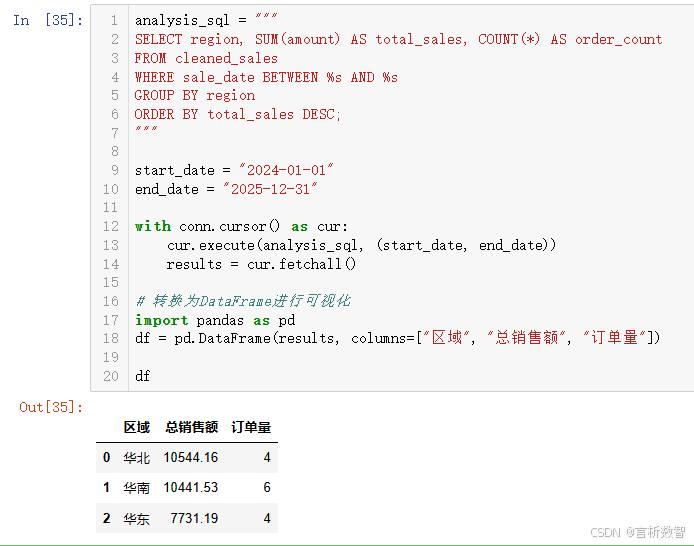
analysis_sql = """
SELECT region, SUM(amount) AS total_sales, COUNT(*) AS order_count
FROM cleaned_sales
WHERE sale_date BETWEEN %s AND %s
GROUP BY region
ORDER BY total_sales DESC;
"""start_date = "2024-01-01"
end_date = "2025-12-31"with conn.cursor() as cur:cur.execute(analysis_sql, (start_date, end_date))results = cur.fetchall()# 转换为DataFrame进行可视化
import pandas as pd
df = pd.DataFrame(results, columns=["区域", "总销售额", "订单量"])df
七、总结与最佳实践
7.1 核心价值总结
-
- 无缝集成:实现
PostgreSQL与Python的高效数据流转
- 无缝集成:实现
-
- 安全可靠:通过
参数化查询和事务管理保障数据安全
- 安全可靠:通过
-
- 性能卓越:支持
批量操作和连接池技术应对大数据量场景
- 性能卓越:支持
-
- 生态兼容:无缝对接Pandas、Matplotlib等数据分析库
7.2 最佳实践清单
-
- 始终使用参数化查询:避免SQL注入风险
-
- 合理管理连接:
使用with语句自动释放资源,高并发场景用连接池
- 合理管理连接:
-
- 明确事务边界:复杂操作使用显式事务控制
-
- 处理类型转换:对JSON、日期等复杂类型使用官方推荐转换方法
-
- 监控与日志:记录关键操作的错误信息和执行时间
这篇文章全面介绍了psycopg2库在PostgreSQL与Python数据交互中的应用。
- 你可以说说对内容的看法,比如是否需要增加更多案例或调整讲解深度,以便我进一步优化。
- 通过掌握
psycopg2的核心功能和最佳实践,数据分析师和开发人员能够高效构建从PostgreSQL到Python的数据管道,为后续的数据可视化和深度分析奠定坚实基础。无论是小规模的数据探索,还是千万级数据的批量处理,psycopg2都能提供稳定可靠的解决方案,成为PostgreSQL数据交互的首选工具。
相关文章:
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】7.2 PostgreSQL与Python数据交互(psycopg2库使用)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL与Python数据交互:psycopg2库实战指南一、引言:数据交互的桥梁1.1 psycopg2核心优势 二、环境准备与基础连接2.1 安装配置2.1.1 安装psyco…...

【Prompt工程—文生图】案例大全
目录 一、人物绘图 二、卡通头像 三、风景图 四、logo设计图 五、动物形象图 六、室内设计图 七、动漫风格 八、二次元图 九、日常场景图 十、古风神化图 十一、游戏场景图 十二、电影大片质感 本文主要介绍了12种不同类型的文生图技巧,通过加入不同的图像…...

NVM完全指南:安装、配置与最佳实践
发布于 2025年5月7日 • 阅读时间:10分钟 💡 TL;DR: 本文详细介绍了如何完整卸载旧版Node.js,安装NVM,配置阿里云镜像源,以及设置node_global与node_cache目录,打造高效Node.js开发环境。 📋 目…...

成都养老机器人“上岗”,机器人养老未来已至还是前路漫漫?
近日,成都养老机器人“上岗”引发关注,赛博养老这一概念再次成为人们讨论的焦点,究竟赛博养老未来已来,还是仍需漫长等待,引发诸多思考。 成都研发的养老机器人“上岗”确实标志着智慧养老领域的又一进步,…...

数据中心 第十五次CCF-CSP计算机软件能力认证
总结一下图树算法比如krusal 迪杰斯特拉 prim算法喜欢改变距离定义 或者求别的东西 而拓扑排序喜欢大模拟 本题使用kerusal算法求出最后一条边就可以。 ac代码: #include <iostream> #include <vector> #include <algorithm>using namespac…...

【面试 · 一】vue大集合
目录 vue2 基础属性 组件通信 全局状态管理 vueX 路由 路由守卫 vue3 基础属性 组件通信 全局状态管理 Pinia 路由 路由守卫 vue2、vue3生命周期 setup vue2 基础属性 data:用于定义组件的初始数据,必须是一个函数,返回一个对…...
)
Java 常用的 ORM框架(对象关系映射)
Java 常用的 ORM(对象关系映射)框架有以下几种,每种都有其特点和使用场景: Hibernate ● 特点: ○ 完整的 ORM 框架,功能强大。 ○ 支持缓存机制(一级缓存、二级缓存)。 ○ 支持多种…...

自动化创业机器人:现状、挑战与Y Combinator的启示
自动化创业机器人:现状、挑战与Y Combinator的启示 前言 AI驱动的自动化创业机器人,正逐步从科幻走向现实。我们设想的未来是:商业分析、PRD、系统设计、代码实现、测试、运营,全部可以在monorepo中由AI和人类Co-founder协作完成…...

支持向量机
支持向量机(Support Vector Machine,SVM)是一种有监督的机器学习算法,可用于分类和回归任务,尤其在分类问题上表现出色。下面将从原理、数学模型、核函数、优缺点和应用场景等方面详细介绍。 原理 支持向量机的基本思…...

华为昇腾910B通过vllm部署InternVL3-8B教程
前言 本文主要借鉴:VLLM部署deepseek,结合自身进行整理 下载模型 from modelscope import snapshot_download model_dir snapshot_download(OpenGVLab/InternVL3-8B, local_dir"xxx/OpenGVLab/InternVL2_5-1B")环境配置 auto-dl上选择单卡…...

ZArchiver解压缩工具:高效解压,功能全面
在使用智能手机的过程中,文件管理和压缩文件的处理是许多用户常见的需求。无论是解压下载的文件、管理手机存储中的文件,还是进行日常的文件操作,一款功能强大且操作简便的文件管理工具都能极大地提升用户体验。今天,我们要介绍的…...

ETL介绍
(一)ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较…...

2025.05.07-华为机考第三题300分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 城市紧急救援队伍协同规划 问题描述 智慧城市建设中,卢小姐负责设计一套紧急救援队伍协同系统。城市被规划为一个 n n n \times n...

缓存菜品-04.功能测试
一.功能测试 redis中的数据已缓存 查询数据时并没有发sql 修改鸡蛋汤价格为5元。 缓存数据没有了 价格修改成功 停售启售是一样的。修改后清理,再次查询又被缓存到redis中。...

跨境电商生死局:动态IP如何重塑数据生态与运营效率
凌晨三点的深圳跨境电商产业园,某品牌独立站运营总监李明(化名)正盯着突然中断的广告投放系统。后台日志显示,过去24小时内遭遇了17次IP封禁,直接导致黑五促销期间损失23%的预期流量。这并非个案——2023年跨境电商行业…...

day 14 SHAP可视化
一、原理——合作博弈论 SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法,它基于合作博弈论中的 Shapley 值概念。Shapley 值最初用于解决合作博弈中的利益分配问题。假设有 n 个参与者共同合作完成一项任务并…...

处理PostgreSQL数据库事务死锁过程
查询pg_locks表,获取未得到满足的锁信息: select * from pg_locks where granted is false ; --查询得不到锁的,那就是两个互相等待对方持有的锁查询活动的事务会话进程,和上一步的锁的事务对应起来: select * from …...
、平台架构与设计重构大模型应用)
大数据、物联网(IoT)、平台架构与设计重构大模型应用
结合大数据、物联网(IoT)、平台架构与设计重构大模型应用,需构建一个数据驱动、实时响应、弹性扩展的智能系统。以下从技术架构、数据流、核心模块设计三个维度展开: 一、整体架构设计 分层架构(基于云-边-端协同): [物联网设备层] → [边缘计算层] → [大数据平台层]…...
)
开发 Chrome 扩展中的侧边栏图标设置实录(Manifest V3)
在开发自己的 Chrome 扩展 Pocket Bookmarks(口袋书签) 的过程中,我遇到了一个看似简单却颇具挑战的问题:如何在扩展的侧边栏显示自定义图标? 这篇文章记录一下我踩过的坑,以及最终的解决方案。 这里说的侧…...
)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK在Linux系统下设置多个USB相机(C++)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK在Linux系统下设置多个USB相机(C) Baumer工业相机Baumer工业相机BGAPI SDK在Linux系统下设置USB相机的技术背景Linux系统内核 USB 模块内存的修改内存限制的确定使用 GRUB 引导加载程序修改内存限制使用 U-B…...

zst-2001 历年真题 知识产权
知识产权 - 第1题 发表权有时间限制 其他下面3个没有 c 知识产权 - 第2题 bd是财产权 c 知识产权 - 第3题 b 知识产权 - 第4题 d 知识产权 - 第5题 d 知识产权 - 第6题 d 知识产权 - 第7题 d 知识产权 - 第8题 b是国务院发布的 d没有复制权…...

设备与驱动:UART设备
大部分的嵌入式系统都包括一些I/O设备,例如仪器上的数据显示屏、工业设备上的串口通信、数据采集设备上模拟数据采样、用于保存数据的Flash/SD卡以及网络设备上的以太网接口等,都是嵌入式系统中容易找到的I/O设备例子。 本专栏主要是分享RT-Thread是如何…...

Linux 服务器静态 IP 配置初始化指南
✅ 第一步:确认网络管理方式 运行以下命令判断系统使用的网络管理服务: # 检查 NetworkManager 是否活跃 systemctl is-active NetworkManager# 检查 network(旧服务)是否活跃 systemctl is-active network或者检查配置路径&…...

【ROS2】Nav2源码之行为树定义、创建、加载
1、简述 在 Navigation2 里,机器人的导航是一项复杂的任务,包含路径规划、避障、恢复机制等多个子任务。行为树能把这些子任务组织成清晰的层次结构,让机器人可以依据不同的情况做出合理的决策。例如,当机器人在导航途中碰到障碍物时,行为树可以决定是重新规划路径、尝试…...

Redis持久化存储介质评估:NFS与Ceph的适用性分析
#作者:朱雷 文章目录 一、背景二、Redis持久化的必要性与影响1. 持久化的必要性2. 性能与稳定性问题 三、NFS作为持久化存储介质的问题1. 性能瓶颈2. 数据一致性问题3. 存储服务单点故障4. 高延迟影响持久化效率.5. 吞吐量瓶颈 四、Ceph作为持久化存储介质的问题1.…...

如何统一修改word中所有英文字母的字体格式
1.需求分析 我想让整篇论文中的所有英文字母格式都修改为Time New Roman格式。 2.直观操作流程 点击左上角开始 --> 点击替换 --> 点击更多 --> 点击特殊格式 --> 选择查找内容为任意字母(Y) --> 将光标点到替换内容 --> 点击格式 --> 点击字体 --> …...

服务器上机用到的设备
服务器上机通常需要以下硬件设备: 服务器主机: CPU:选择高性能的多核处理器,如英特尔至强(Xeon)系列或AMD EPYC系列,以满足高并发和多任务处理需求。 内存(RAM)…...
)
【Java ee 初阶】多线程(8)
Synchronized优化: 一、锁升级 锁升级时一个自适应的过程,自适应的过程如下: 在Java编程中,有一部分的人不一定能正确地使用锁,因此,Java的设计者为了让大家使用锁的门槛更低,就在synchronize…...

数字孪生大屏UI设计
近年来,5G、大数据、云计算等新一代信息技术的蓬勃发展,计算机仿真技术与拟真软件的成熟运用,让数字孪生技术开始蔓延渗透到“互联网”相关的产业中。数字孪生大屏给予了可视化的数据直观窗口,其中展现的动态映射与实时数据让业务流转效率得到了有效提升,管理、运营和决策都能高…...
上)
【Java ee 初阶】多线程(9)上
一、信号量Semaphore 本质上就是一个计数器,描述了一种“可用资源”的个数 申请资源(P操作):使得计数器-1 释放资源(V操作):使得计数器1 如果计数器为0了,继续申请资源ÿ…...

eclipse开发环境中缺少JavaEE组件如何安装
新版本eclipse去掉server了吗?在最近新版本的eclipse里面,确实找不到server模块了,无法配置tomcat等web服务器插件了。我们需要自己手工安装一下javaEE组件才行。 1 1:找到自己当前eclipse版本号码 2:去这个地址&…...

stm32之ADC
目录 1.简介2.逐次逼近型ADC3.基本结构4.输入通道5.转换模式6.触发控制7.数据对齐8.转换时间7.校准10.ADC外围电路11.api和结构体11.1 结构体11.2 api1. ADC_DeInit2. ADC_Init3. ADC_StructInit4. ADC_Cmd5. ADC_DMACmd6. ADC_ITConfig7. ADC_ResetCalibration8. ADC_GetReset…...

从电话到V信语音:一款App实现全场景社交脱身
作为一名资深社恐人士,我深知那些无法脱身的社交场合有多煎熬。上周参加一个行业聚会,面对滔滔不绝的陌生人,我如坐针毡却又找不到合适的离场理由。这时我突然想起之前朋友推荐的一款神器应用,它让我得以优雅脱身。今天就来分享这…...

conda init before conda activate
先conda init 然后退出命令窗口,再重新打开命令窗口再conda activate...
详细方案与部署教程)
MySQL数据库高可用(MHA)详细方案与部署教程
一:MHA简介 核心功能 二:MHA工作原理 三:MHA组件 四:MHA 架构与工具 MHA架构 Manager关键工具 Node工具 五:工作原理与流程 1: 故障检测 2: 故障切换(Failover) 3 : 切换模式 六&a…...

《Python星球日记》 第44天: 线性回归与逻辑回归
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、引言:回归方法的重要性二、线性回归原理与损失函数1. 线性回归的数学模型2. 损失函数:衡量…...

Flutter TabBar / TabBarView 详解
目录 一、引言 二、基本用法 代码解析 三、主要属性 3.1 TabBar 3.2 TabBarView 四、进阶定制:突破默认样式 4.1 视觉样式深度定制 4.2 自定义指示器与标签 4.3 动态标签管理 五、工程实践关键技巧 5.1 性能优化方案 5.2 复杂手势处理 5.3 响应式布局…...

001 环境搭建
🦄 个人主页: 小米里的大麦-CSDN博客 🎏 所属专栏: Linux_小米里的大麦的博客-CSDN博客 🎁 GitHub主页: 小米里的大麦的 GitHub ⚙️ 操作环境: Visual Studio 2022 文章目录 Linux 环境搭建全解析:从历史到实践一、Linux 的起源与…...

Spark-core-RDD入门
RDD基本概念 Resilient Distributed Dataset 叫做弹性分布式数据集,是Spark中最基本的数据抽象,是分布式计算的实现载体,代表一个不可变,可分区,里面的元素并行计算的集合。 - Dataset: 一个数据集合&…...

在scala中,转换算子和行动算子有什么区别
在Scala结合Spark编程中,转换算子(Transformation)和行动算子(Action)有以下区别: 执行机制 **转换算子**: 具有惰性求值(延迟计算)特性 。它对RDD(弹性分布…...

六级阅读---2024.12 卷一 仔细阅读1
文章 Imagine youre an alien sent to Earth to document the behaviour of the mammals inhabiting the planet. You stumble into a movie theatre thats showing the latest Hollywood horror film. Several dozen humans are gathered together in a dark, undercoated r…...
)
驱动开发硬核特训 · 专题篇:Vivante GPU 与 DRM 图形显示体系全解析(i.MX8MP 平台实战)
视频教程请关注 B 站:“嵌入式Jerry”。 一、背景导读:GPU 与 DRM 到底谁负责“显示”? 在嵌入式 Linux 图形系统中,“画面怎么显示出来”的问题,表面看似简单,实则涉及多个内核子系统与用户态组件的协同&…...

智慧医疗时代下的医疗设备智能控费系统解决方案
—以科技赋能医疗控费,构建精细化管理新生态 一、行业背景与现存痛点 (一)政策驱动与行业挑战 随着DRG/DIP支付改革全面落地、医保基金监管趋严,医疗机构面临“提质增效”与“成本管控”的双重压力。国家卫健委数据显示&#x…...

软件设计师2025
笔记链接 第5章:软件工程基础知识 第6章:结构化开发方法 第10章:网络和信息安全基础知识...

Umi+React+Xrender+Hsf项目开发总结
一、菜单路由配置 1.umirc.ts 中的路由配置 .umirc.ts 文件是 UmiJS 框架中的一个配置文件,用于配置应用的全局设置,包括但不限于路由、插件、样式等。 import { defineConfig } from umi; import config from ./def/config;export default defineCon…...
)
【软件设计师:数据结构】1.数据结构基础(一)
一 线性表 1.线性表定义 线性表是n个元素的有限序列,通常记为(a1,a2,…,an)。 特点: 存在惟一的表头和表尾。除了表头外,表中的每一个元素均只有惟一的直接前驱。除了表尾外,表中的每一个元素均只有惟一的直接后继。2.线性表的存储结构 (1)顺序存储 是用一组地址连续…...
)
linux_进程地址空间(虚拟地址空间)
一、进程地址空间是什么? 先看这样一个具体的例子 #include<stdlib.h> #include <stdio.h> #include<unistd.h> int main() {int a1;pid_t idfork();while(1){if(id0){printf("i am child,pid:%d,ppid:%d,a:%d ,&a:%p\n",getpid(…...

计操第四章存储管理
地址再定位...

尚硅谷-硅谷甄选项目记录
一、Vue3 1 基础配置 1.1 路径别名 vite.config.ts import { defineConfig } from vite import vue from vitejs/plugin-vue// 引入path,node提供的模块,可以获取文件或文件夹的路径 import path from pathexport default defineConfig({plugins: […...

c# LINQ-Query01
文章目录 查询数据源标准查询分两类即时查询已推迟流式处理非流式处理分类表聚合Aggregate<TSource,TAccumulate,TResult>(IEnumerable<TSource>, TAccumulate, Func<TAccumulate,TSource,TAccumulate>, Func<TAccumulate,TResult>)Aggregate<TSour…...