【论文阅读】Attentive Collaborative Filtering:
Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention
Attentive Collaborative Filtering (ACF)、隐式反馈推荐、注意力机制、贝叶斯个性化排序
标题翻译:注意力协同过滤:基于项目和组件级注意力的多媒体推荐
原文地址:点这里
摘要
多媒体内容正主导着当今网络信息。用户与多媒体项目之间的互动通常是二值的隐式反馈(例如照片点赞、视频观看、歌曲下载等),相比显式反馈(如商品评分),这种隐式反馈能以更低的成本、大规模地收集。然而,大多数现有的协同过滤(CF)系统在多媒体推荐场景中并不理想,因为它们忽略了用户与多媒体内容互动中的“隐式性”。我们认为,在多媒体推荐中,存在两层“隐式”——项目层面(item-level)和组件层面(component-level),它们模糊了用户真实的偏好。项目层面隐式性指用户对整个项目(照片、视频、歌曲等)的偏好强度未知;组件层面隐式性指用户对项目内部不同组成部分(例如图像的不同区域、视频的不同帧)的偏好也未知。比如一次“观看”操作既不告诉我们用户到底多喜欢这段视频,也不告诉我们他对视频哪个部分感兴趣。
为了解决这两层隐式反馈带来的挑战,论文提出了一种将**注意力机制(Attention)**引入协同过滤的新框架——Attentive Collaborative Filtering (ACF)。该方法由两个子模块组成:
- 组件级注意力模块:以任意内容特征提取网络(如用于图像/视频的 CNN)为基础,自动学习为项目中的各个组成部分分配权重,从而挑选出最有信息量的部分;
- 项目级注意力模块:根据用户和项目的特征,为不同项目分配权重,以建模用户对各项目的真实兴趣强度。
ACF 能无缝集成到经典的隐式反馈 CF 模型(如 BPR、SVD++)中,并可通过随机梯度下降高效训练。实验证明,在 Vine 和 Pinterest 两个真实的多媒体网络服务数据集上,ACF 显著优于现有最先进的 CF 方法。
一、引言
当我们登录多媒体网络服务(例如 YouTube)时,就像其他数十亿用户一样,我们可以随时浏览和分享线上数十亿条内容。同时,随着移动设备的发展,数以百万计的新图片和视频正不断涌入这些网站。以 Snapchat 为例——这是最受欢迎的视频社交应用之一——在您阅读此段文字的过程中,约有 5 万段视频片段被分享,2.4 百万次视频被观看。毫无疑问,日益占据主导地位的网页多媒体内容,需要尤其是基于协同过滤(CF)的现代推荐系统,在高度动态的环境中为用户筛选出海量内容。
协同过滤(CF)通过分析用户之间的关系和项目之间的相互依赖,以发现新的用户–项目关联【21, 23, 37】。在多媒体推荐中,“项目”指用户消费的各种多媒体内容,如视频、照片或歌曲。大多数 CF 系统依赖显式的用户兴趣作为输入,例如商品的星级评分,这提供了显式反馈【19, 25, 38】。然而,在许多应用场景中并不总能获得显式评分。由于多媒体内容的规模庞大且类型多样【15】,多媒体推荐系统中固有的用户–项目交互通常基于隐式反馈,如**视频的“观看”、照片的“点赞”、歌曲的“播放”**等。由于隐式反馈缺少用户不喜欢哪些项目(即负反馈)的直接证据,现有基于隐式反馈的 CF 方法【20, 21, 30】通常侧重于如何将缺失的用户–项目交互纳入偏好建模。但很少有方法深入挖掘用户偏好的“隐式”特征。我们认为,在多媒体推荐中存在两层隐式反馈,这一点在大多数现有 CF 方法中尚未得到充分考虑。
项目层面的隐式反馈(Item-Level Implicit Feedback)。通过追踪用户的消费行为,每位用户都会关联上一组项目(即正向反馈)。然而,这组正反馈的项目并不意味着用户对它们的喜好程度是相同的。这种现象在多媒体服务中尤为普遍,因为大多数此类服务具有社交属性。例如,一些被用户“点赞”的图片可能仅仅是因为拍摄者是朋友,而并非出于用户的真实兴趣。即便是那些确实符合用户兴趣的图片,用户对它们的喜好程度也可能不同。这种无法获取每个项目具体偏好程度的情形,被称为项目层面的隐式性(item-level implicitness)。为了更好地刻画用户的偏好画像,针对项目层面的隐式反馈,需要对不同项目给予不同的“注意力”权重。然而,据我们所知,现有的协同过滤模型通常使用统一权重【23】或预设的启发式权重【21】,因此基于这些固定加权方式得到的邻域上下文,难以有效建模项目层面的隐式反馈。
通俗地说,项目层面的隐式反馈就是:
用户给了一批“喜欢”或“看过”的东西,但这些标记并不告诉我们他们到底有多喜欢每一件——有的只是随手点点赞,有的是真心喜欢。
举个例子:你在朋友圈里点了好几张朋友的照片“赞”,可你并不一定真正喜欢每一张,也可能只是礼貌或因为对方是好友。
换到推荐系统里,就是说系统知道你看过或点过赞的项目,但不知道你对它们的真实偏爱度。所以,为了更准确地推荐,就需要给不同项目分配不同“重要度”——也就是给真正喜欢的项目更高的“注意力”权重,而不是把它们都当成一样。
组件层面的隐式反馈(Component-Level Implicit Feedback)。对多媒体内容的反馈通常只在整体项目层面,而多媒体内容本身往往蕴含多种语义和多个组成部分。我们将组件层面的隐式性定义为无法获得针对各个组件的单独反馈的情形。以一场篮球比赛视频为例,整段视频包含多名球员和丰富的动作。一位用户对该视频的“播放”反馈,不一定意味着他喜欢视频的全部内容,可能只是因为对视频最后展示比赛最终比分的片段感兴趣。因此,与仅把多媒体内容视为整体的传统基于内容的协同过滤方法【4, 12】不同,我们应当建模用户对低层次内容组件的偏好,比如图像中不同位置的特征【39】或视频中各帧的特征【6, 10, 41】。
通俗地说,组件层面的隐式反馈就是:
- 系统知道你看过、听过或点过赞一个多媒体项目(比如一段视频或一张图片),
- 但它不知道你到底是因为哪个“部分”才感兴趣——可能是视频里的某个精彩片段,或者图片里一个小细节,
- 换句话说,就是你对项目整体做了“喜欢”或“播放”,却没有对项目中的各个组成部分(帧、区域、音段等)打标签,系统只能把整段内容一起看,无法针对最吸引你的那部分做出更精准的推荐。
然而,直接对项目层面和组件层面的隐式反馈进行建模以改进推荐并非易事,因为这两层隐式反馈的真实标签(ground truth)是不可得的。为了解决这一问题,我们提出了一种新颖的协同过滤框架——Attentive Collaborative Filtering(ACF),它能够以远程监督的方式,自动为两层隐式反馈分配权重。
ACF 基于潜在因子模型,将用户和项目映射到同一隐空间以便进行直接比较;同时,它结合了邻域模型,通过对用户历史交互项目的加权求和来刻画用户的兴趣画像,其中项目的权重即反映了两层隐式反馈的重要性。
- 项目层面建模(Section 4.2):我们设计了一个多层神经网络作为加权函数,输入包括用户特征、项目特征及多媒体内容特征,输出项目的注意力权重。
- 组件层面建模(Section 4.3):多媒体内容特征本身由对项目中多个组件(如图像区域或视频帧)进行加权求和而来;对应的组件注意力模块也是一个多层神经网络,输入为用户特征和组件特征。所有被赋予注意力的组件共同组成了项目的内容特征向量,作为项目层面注意力网络的输入之一。
ACF 可通过随机梯度下降(SGD)在大规模图像和视频的用户–项目交互数据上高效训练(Section 4.4)。我们在代表两类多媒体的真实数据集——Pinterest(图像)和 Vine(视频)上对 ACF 进行了全面评估。实验结果表明,ACF 在各类方法(包括基于 CF 的、基于内容的【28, 35】及混合方法【9, 33】)中均取得了显著领先(Section 5)。
本文贡献总结
- 提出首个专门面向多媒体推荐中的隐式反馈问题、引入注意力机制的协同过滤框架 ACF。
- 针对项目层面与组件层面两种隐式反馈,设计了两套可无缝嵌入任意邻域模型、并可端到端通过 SGD 高效训练的注意力子模块。
- 在两个真实多媒体数据集上的广泛实验证明了 ACF 相较于多种先进隐式反馈 CF 方法的一致性能提升。
二、相关工作
基于隐式反馈的推荐问题也被称为单类别问题(one-class problem)【27】,这是因为缺乏负反馈,系统中通常只存在正向反馈(例如点击、观看等)。除了这些正反馈之外,剩余的数据既包含了真实的负反馈,也可能只是缺失值。因此,仅凭隐式反馈,很难可靠地判断用户到底不喜欢哪些项目。
为了解决负样本缺失的问题,已有若干方法被提出,大致可分为两类:基于采样的方法【20, 27, 30】和基于全数据的方法【21, 23】。前者从缺失数据中随机抽取部分作为负样本进行学习;后者则将所有缺失条目一律视为负反馈。因此,基于采样的方法在效果上通常更佳,而基于全数据的方法则能覆盖更多数据。
传统的全数据方法假设所有未观测到的交互都是负样本,且赋予相同权重【23】。然而,这种做法并不真实,因为未观测到的数据中可能包含“伪负”——其实只是缺失的正例。为此,最近一些工作【21, 27】着重于设计更精细的加权方案,根据对未观测样本是否真正为负例的“置信度”来分配权重。例如,提出了基于用户偏好程度的非均匀加权【27】和基于项目流行度的非均匀加权【21】,它们已被证明比统一权重效果更好。但这种非均匀加权方法的一大局限在于:权重的设定依赖于作者的主观假设,这些假设在真实数据中未必成立。
正如前文所述,大多数现有方法都集中在负反馈的采样或加权方案上,以应对缺乏负反馈的问题,而对于两层正反馈——即项目层面的注意力和组件层面的注意力——关注较少,这两者其实相当于对正向样本进行加权。为弥补正向样本加权的空白,我们提出了一种新颖的注意力机制,能够基于用户–项目交互矩阵及项目内容,自动为正向隐式信号分配权重。
三、预备知识
我们先来定义一些符号:
- 令 R ∈ R M × N R \in \mathbb{R}^{M \times N} R∈RM×N 为用户–项目交互矩阵,其中 M M M 是用户数, N N N 是项目数。
- 矩阵中的第 ( i , j ) (i,j) (i,j) 个元素记作 R i j R_{ij} Rij。
- 对于隐式反馈,若用户 i i i 与项目 j j j 之间存在交互(例如点击、观看等),则 R i j = 1 R_{ij} = 1 Rij=1;否则 R i j = 0 R_{ij} = 0 Rij=0。
- 我们用集合 R = { ( i , j ) ∣ R i j = 1 } \mathcal{R} = \{(i,j)\mid R_{ij} = 1\} R={(i,j)∣Rij=1} 表示所有有过交互的用户–项目对。
在隐式反馈的协同过滤任务中,目标是利用已知的 R \mathcal{R} R 信息,对那些未观测到的 ( i , j ) (i,j) (i,j) 对预测一个分数 R ^ i j \hat{R}_{ij} R^ij,以便进行推荐排序。
3.1 潜在因子模型(Latent Factor Models)
潜在因子模型将用户和项目同时映射到一个共同的低维隐空间中,并通过向量内积来估计用户对项目的偏好得分。我们重点讨论基于对用户–项目评分矩阵进行奇异值分解(SVD)的模型。
-
令用户的隐向量矩阵为
U = [ u 1 , … , u M ] ∈ R D × M , U = [u_1, \dots, u_M] \in \mathbb{R}^{D \times M}, U=[u1,…,uM]∈RD×M,
其中 u i u_i ui 表示第 i i i 个用户的 D D D 维隐向量。
-
令项目的隐向量矩阵为
V = [ v 1 , … , v N ] ∈ R D × N , V = [v_1, \dots, v_N] \in \mathbb{R}^{D \times N}, V=[v1,…,vN]∈RD×N,
其中 v j v_j vj 表示第 j j j 个项目的 D D D 维隐向量, D ≤ min ( M , N ) D\le\min(M,N) D≤min(M,N) 是设定的隐特征维度。
用户 i i i 对项目 j j j 的预测偏好得分为两者向量的内积:
R ^ i j = ⟨ u i , v j ⟩ = u i T v j . \hat R_{ij} = \langle u_i, v_j \rangle = u_i^T v_j. R^ij=⟨ui,vj⟩=uiTvj.
模型的目标是通过最小化观测到的评分的正则化平方损失来学习 U U U 和 V V V:
min U , V ∑ ( i , j ) ∈ R ( R i j − R ^ i j ) 2 λ ( ∥ U ∥ 2 2 + ∥ V ∥ 2 2 ) , \min_{U,V} \sum_{(i,j)\in\mathcal{R}} (R_{ij} - \hat R_{ij})^2 \lambda \bigl(\|U\|_2^2 + \|V\|_2^2\bigr), U,Vmin(i,j)∈R∑(Rij−R^ij)2λ(∥U∥22+∥V∥22),
1其中 λ \lambda λ 是正则化系数,一般采用 L2 范数以防止过拟合。模型训练完成后,就可以根据预测得分 R ^ i j \hat R_{ij} R^ij 对所有项目进行排序,进而为用户生成推荐列表。
但是,当直接将 SVD 应用于隐式反馈场景时会遇到挑战:未观测到的条目数量非常大,如果不加区分地将它们都当作负样本,会为训练带来大量的“伪负”——本来可能只是未点击或遗漏的正样本。
3.2 贝叶斯个性化排序(BPR)
BPR 是一个著名的框架,用于解决协同过滤中隐式反馈的“隐式”问题【30】。与 SVD 中的逐点(point-wise)学习不同,BPR 针对一个用户和两项物品构建三元组:其中一项是该用户已交互(正例)的项目,另一项则是未交互(负例)的项目。具体地,若用户 i i i 在交互矩阵 R R R 中对项目 j j j 进行了“查看”或其他正向操作,则假设用户 i i i 更偏好项目 j j j 而非任意未交互的项目。
BPR 的优化目标基于最大后验估计。结合上述潜在因子模型,常见的 BPR 损失函数为:
min U , V ∑ ( i , j , k ) ∈ R B − ln σ ( R ^ i j − R ^ i k ) + λ ( ∥ U ∥ 2 2 + ∥ V ∥ 2 2 ) , \min_{U,V} \sum_{(i,j,k)\in \mathcal{R}_B} -\ln\sigma\bigl(\hat R_{ij} - \hat R_{ik}\bigr) \;+\;\lambda\bigl(\|U\|_2^2 + \|V\|_2^2\bigr), U,Vmin(i,j,k)∈RB∑−lnσ(R^ij−R^ik)+λ(∥U∥22+∥V∥22),
其中
- σ ( x ) = 1 / ( 1 + e − x ) \sigma(x) = 1/(1+e^{-x}) σ(x)=1/(1+e−x) 是 logistic sigmoid 函数,
- λ \lambda λ 是正则化参数,
- R ^ i j = u i T v j \hat R_{ij} = u_i^T v_j R^ij=uiTvj 如前所述,
- R B = { ( i , j , k ) ∣ j ∈ R ( i ) ∧ k ∈ I ∖ R ( i ) } \mathcal{R}_B = \{(i,j,k)\mid j\in \mathcal{R}(i)\;\wedge\;k\in \mathcal{I}\setminus\mathcal{R}(i)\} RB={(i,j,k)∣j∈R(i)∧k∈I∖R(i)}。
这里, I \mathcal{I} I 表示数据集中所有项目的集合, R ( i ) \mathcal{R}(i) R(i) 表示用户 i i i 曾交互过的项目集合。每个三元组 ( i , j , k ) ∈ R B (i,j,k)\in\mathcal{R}_B (i,j,k)∈RB 表明“用户 i i i 偏好项目 j j j 胜过项目 k k k”。由于 BPR 能有效利用未观测的用户–项目反馈进行模型训练,我们在本工作中以 BPR 作为基础学习框架。
四、ACF(注意力协同过滤)
图1
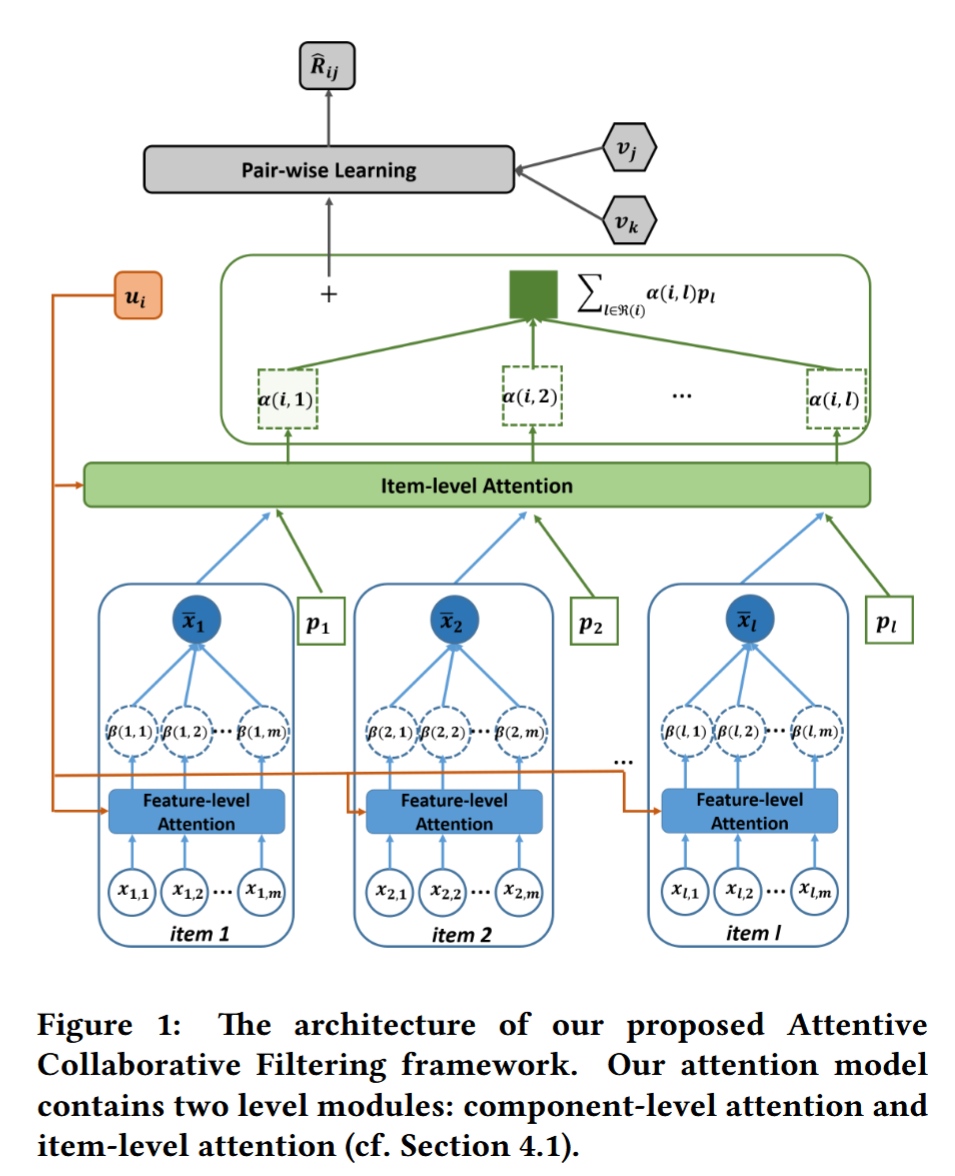
图 1 展示了 ACF 的整体流程。首先,对第 i i i 位用户,他交互过的一组项目构成了输入集。对于每个项目 l l l:
-
组件特征提取
取出该项目的多个组件特征集合 { x l m } \{x_{lm}\} {xlm}(图中蓝色实心圆),其中 x l m x_{lm} xlm 可以是第 m m m 个空间位置的图像区域特征【39】,也可以是视频中第 m m m 帧的帧特征【41】。 -
组件级注意力
将用户隐向量 u i u_i ui 和每个组件特征 x l m x_{lm} xlm 一同输入组件级注意力子网络,输出该组件的注意力权重 β ( i , l , m ) \beta(i,l,m) β(i,l,m)(图中蓝色虚线圆)。通过对所有组件特征做加权求和x l = ∑ m β ( i , l , m ) x l m x_l = \sum_m \beta(i,l,m)\,x_{lm} xl=m∑β(i,l,m)xlm
(图中蓝色实心圆),得到项目 l l l 的最终内容表示 x l x_l xl。
-
项目级注意力
将用户隐向量 u i u_i ui、项目隐向量 v l v_l vl、辅助项目向量 p l p_l pl 以及刚得到的内容表示 x l x_l xl 一同输入项目级注意力子网络,计算用户 i i i 对项目 l l l 的注意力权重 α ( i , l ) \alpha(i,l) α(i,l)(图中绿色虚线方框)。 -
邻域聚合
类似地,对所有历史项目做加权求和∑ l ∈ R ( i ) α ( i , l ) p l \sum_{l\in\mathcal{R}(i)} \alpha(i,l)\,p_l l∈R(i)∑α(i,l)pl
(图中绿色实心方块),得到用户的邻域表示。
- 优化训练
将上述邻域表示与基础用户隐向量 u i u_i ui 相加,构成用户的最终表征,并通过随机梯度下降优化 BPR 的成对学习目标(参见式 (5))。
这两级注意力机制使模型能够自适应地从用户–项目互动和多媒体内容中提取最具信息量的部分,进而提升推荐效果。
4.1 整体框架
ACF 是一个分层的神经网络模型,用于同时在项目层面和组件层面刻画用户的偏好得分。设用户为 i i i,项目为 l l l,项目 l l l 的第 m m m 个组件为该项目的一个子部分,我们分别用
- α ( i , l ) \alpha(i, l) α(i,l) 表示用户 i i i 对项目 l l l 的整体偏好程度,
- β ( i , l , m ) \beta(i, l, m) β(i,l,m) 表示用户 i i i 对项目 l l l 中第 m m m 个组件的偏好程度。
为此,ACF 设计了两个注意力子网络:
- 组件级注意力模块:先对项目的各个组件(如视频帧或图像区域)分配权重,再生成该项目的内容表示;
- 项目级注意力模块:以生成的内容表示(以及用户和项目本身的特征)为输入,进一步为不同项目分配注意力权重,从而构建对用户的最终表征。
这两个模块协同工作,使模型能够自适应地从“项目 → 组件”两个层次抽取用户的真实偏好信号。
目标函数 除了使用显式参数向量 u i u_i ui 来表示每个用户 i i i 之外,ACF 还根据用户 i i i 的历史交互项目集合 R ( i ) \mathcal{R}(i) R(i) 来对用户进行建模。因此,每个项目 l l l 有两组隐向量:
- 基本项目向量 v l v_l vl:作为潜在因子模型中项目本身的表示。
- 辅助项目向量 p l p_l pl:用于根据用户已经交互的项目集合来刻画用户的兴趣画像。
用户 i i i 的最终表示由其个人向量 u i u_i ui 与加权求和的辅助项目向量共同组成:
u i + ∑ l ∈ R ( i ) α ( i , l ) p l , u_i \;+\; \sum_{l \in \mathcal{R}(i)} \alpha(i, l)\,p_l, ui+l∈R(i)∑α(i,l)pl,
其中 α ( i , l ) \alpha(i,l) α(i,l) 是用户 i i i 对项目 l l l 的项目级注意力权重。
ACF 在 BPR(Bayesian Personalized Ranking)的成对学习目标下进行优化,旨在最大化用户对正例项目与负例项目之间的排序差距。其数学形式为:
min U , V , P , Θ ∑ ( i , j , k ) ∈ R B − ln σ ( ( u i + ∑ l ∈ R ( i ) α ( i , l ) p l ) T v j − ( u i + ∑ l ∈ R ( i ) α ( i , l ) p l ) T v k ) + λ ( ∥ U ∥ 2 2 + ∥ V ∥ 2 2 + ∥ P ∥ 2 2 ) , \min_{U,V,P,\Theta}\ \sum_{(i,j,k)\in \mathcal{R}_B} -\,\ln \sigma\!\Bigl( \bigl(u_i + \!\!\sum_{l\in \mathcal{R}(i)}\alpha(i,l)\,p_l\bigr)^{\!T}v_j \;-\; \bigl(u_i + \!\!\sum_{l\in \mathcal{R}(i)}\alpha(i,l)\,p_l\bigr)^{\!T}v_k \Bigr) \;+\;\lambda\bigl(\|U\|_2^2 + \|V\|_2^2 + \|P\|_2^2\bigr), U,V,P,Θmin (i,j,k)∈RB∑−lnσ((ui+l∈R(i)∑α(i,l)pl)Tvj−(ui+l∈R(i)∑α(i,l)pl)Tvk)+λ(∥U∥22+∥V∥22+∥P∥22),
- R ( i ) \mathcal{R}(i) R(i) 是用户 i i i 交互过的项目集合;
- α ( i , l ) \alpha(i,l) α(i,l) 由项目级注意力模块计算,表示用户 i i i 对项目 l l l 的偏好权重;
- p l p_l pl 是项目 l l l 的辅助隐向量,用于聚合用户历史项目;
- u ^ i = u i + ∑ l ∈ R ( i ) α ( i , l ) p l \hat u_i = u_i + \sum_{l\in \mathcal{R}(i)}\alpha(i,l)\,p_l u^i=ui+∑l∈R(i)α(i,l)pl 为用户 i i i 的最终隐表示;
- ( i , j , k ) ∈ R B (i,j,k)\in \mathcal{R}_B (i,j,k)∈RB 表示正例 j j j 已被 i i i 交互,负例 k k k 未被交互;
- σ ( x ) = 1 / ( 1 + e − x ) \sigma(x)=1/(1+e^{-x}) σ(x)=1/(1+e−x) 是 sigmoid 函数;
- Θ \Theta Θ 包含所有注意力网络的参数;
- λ \lambda λ 是 L2 正则化系数,作用于 U , V , P U,V,P U,V,P 的范数。
组件级注意力也被整合到 α ( i , l ) \alpha(i,l) α(i,l) 的计算中,从而共同影响用户最终表示和排序优化。
推断(Inference) 在学习得到用户、项目及辅助项目的隐向量 U U U、 V V V、 P P P 以及注意力网络参数后,我们可以基于以下预测得分对所有项目进行排序,生成推荐:
R ^ i j = ( u i + ∑ l ∈ R ( i ) α ( i , l ) p l ) T v j . \hat R_{ij} = \Bigl(u_i + \sum_{l\in \mathcal{R}(i)} \alpha(i,l)\,p_l\Bigr)^T v_j. R^ij=(ui+l∈R(i)∑α(i,l)pl)Tvj.
也就是说,用户 i i i 对项目 j j j 的预测偏好得分 R ^ i j \hat R_{ij} R^ij 就是用户最终隐表示与项目隐向量 v j v_j vj 的内积。
与邻域模型的关系
我们可以将式 (6) 展开成两部分之和:
R ^ i j = u i T v j ⏟ 潜在因子模型 + ∑ l ∈ R ( i ) α ( i , l ) p l T v j ⏟ 邻域模型 , \hat R_{ij} = \underbrace{u_i^T v_j}_{\text{潜在因子模型}} \;+\; \underbrace{\sum_{l\in\mathcal{R}(i)}\alpha(i,l)\,p_l^T v_j}_{\text{邻域模型}}, R^ij=潜在因子模型 uiTvj+邻域模型 l∈R(i)∑α(i,l)plTvj,
其中 p l T v j p_l^T v_j plTvj 可以看作是项目 l l l 与项目 j j j 之间的相似度度量【24】。
-
第一项 u i T v j u_i^T v_j uiTvj 对应经典的潜在因子模型;
-
第二项 ∑ l α ( i , l ) p l T v j \sum_{l}\alpha(i,l)\,p_l^T v_j ∑lα(i,l)plTvj 则是邻域模型:用用户历史交互过的项目对目标项目加权求和。
-
当我们将注意力权重 α ( i , l ) \alpha(i,l) α(i,l) 简化为统一的归一化常数 1 ∣ R ( i ) ∣ \tfrac1{|\mathcal{R}(i)|} ∣R(i)∣1 时,ACF 退化为 SVD++【25】;
-
若将其换成某种启发式权重函数,则类似于 FISM【24】。
然而,这些方法忽略了多媒体推荐中两层隐式反馈的重要性,固定或预设的权重假设所有历史项目对预测贡献相同。实际上,权重理应高度依赖于用户特征和项目内容,我们将在 4.2 节和 4.3 节详细介绍如何学习自适应的注意力权重。
4.2 项目级注意力(Item-Level Attention)
项目级注意力的目标是从用户历史交互的项目中挑选对其喜好最具代表性的项目,并聚合这些关键项目的表示来刻画用户。给定:
- 用户的基础隐向量 u i u_i ui,
- 历史项目 l l l 的隐向量 v l v_l vl,
- 辅助项目向量 p l p_l pl,以及
- 项目内容特征 x l x_l xl(第 4.3 节详述),
我们使用一个两层前馈网络来计算注意力分数 a ( i , l ) a(i,l) a(i,l):
a ( i , l ) = w 1 T ϕ ( W 1 u u i + W 1 v v l + W 1 p p l + W 1 x x l + b 1 ) + c 1 , a(i, l) = w_1^{T}\,\phi\bigl(W_{1u}\,u_i \;+\; W_{1v}\,v_l \;+\; W_{1p}\,p_l \;+\; W_{1x}\,x_l \;+\; b_1\bigr) \;+\; c_1, a(i,l)=w1Tϕ(W1uui+W1vvl+W1ppl+W1xxl+b1)+c1,
其中:
- W 1 u , W 1 v , W 1 p , W 1 x W_{1u}, W_{1v}, W_{1p}, W_{1x} W1u,W1v,W1p,W1x 以及偏置 b 1 b_1 b1 是第一层的参数,
- 向量 w 1 w_1 w1 和标量 c 1 c_1 c1 是第二层的参数,
- ϕ ( x ) = max ( 0 , x ) \phi(x)=\max(0,x) ϕ(x)=max(0,x) 是 ReLU 激活函数,它比带 tanh \tanh tanh 的单层感知机效果更好。
接着,用 Softmax 对所有历史项目的注意力分数进行归一化,得到项目级注意力权重 α ( i , l ) \alpha(i,l) α(i,l),它可以理解为项目 l l l 对用户 i i i 偏好画像的贡献度:
α ( i , l ) = exp ( a ( i , l ) ) ∑ n ∈ R ( i ) exp ( a ( i , n ) ) . \alpha(i, l) = \frac{\exp\bigl(a(i,l)\bigr)} {\sum_{n \in \mathcal{R}(i)} \exp\bigl(a(i,n)\bigr)}. α(i,l)=∑n∈R(i)exp(a(i,n))exp(a(i,l)).
4.3 组件级注意力(Component-Level Attention)
多媒体项目包含丰富且复杂的信息,而不同用户可能对同一项目中的不同部分感兴趣。设项目 l l l 的组件特征集合为 { x l m } \{x_{lm}\} {xlm},集合大小记为 ∣ { x l ∗ } ∣ \bigl|\{x_{l*}\}\bigr| {xl∗} ,其中 x l m x_{lm} xlm 表示第 m m m 个组件的特征。与通常采用平均池化【6, 33】来提取统一内容表示的做法不同,组件级注意力的目标是根据用户偏好为各组件分配不同权重,再通过加权求和构建内容表示。
-
注意力打分
对于用户 i i i、项目 l l l 的第 m m m 个组件 x l m x_{lm} xlm,其注意力分数由一个两层网络计算:b ( i , l , m ) = w 2 T ϕ ( W 2 u u i + W 2 x x l m + b 2 ) + c 2 , b(i,l,m) = w_2^{T}\,\phi\bigl(W_{2u}\,u_i \;+\; W_{2x}\,x_{lm} \;+\; b_2\bigr) \;+\; c_2, b(i,l,m)=w2Tϕ(W2uui+W2xxlm+b2)+c2,
其中 W 2 u , W 2 x W_{2u}, W_{2x} W2u,W2x 及偏置 b 2 b_2 b2 是第一层参数,向量 w 2 w_2 w2 和偏置 c 2 c_2 c2 是第二层参数, ϕ ( x ) = max ( 0 , x ) \phi(x)=\max(0,x) ϕ(x)=max(0,x) 是 ReLU 激活。
-
归一化权重
对所有组件分数做 Softmax 归一化,得到注意力权重:β ( i , l , m ) = exp ( b ( i , l , m ) ) ∑ n = 1 ∣ { x l ∗ } ∣ exp ( b ( i , l , n ) ) . \beta(i,l,m) = \frac{\exp\bigl(b(i,l,m)\bigr)} {\sum_{n=1}^{|\{x_{l*}\}|} \exp\bigl(b(i,l,n)\bigr)}. β(i,l,m)=∑n=1∣{xl∗}∣exp(b(i,l,n))exp(b(i,l,m)).
-
加权求和
最终,结合用户偏好的组件注意力,计算项目 l l l 的内容表示:x l = ∑ m = 1 ∣ { x l ∗ } ∣ β ( i , l , m ) ⋅ x l m . x_l = \sum_{m=1}^{|\{x_{l*}\}|}\beta(i,l,m)\,\cdot x_{lm}. xl=m=1∑∣{xl∗}∣β(i,l,m)⋅xlm.
这使得模型能够聚焦于对用户最具吸引力的组件,从而更精确地表达多媒体内容。
4.4 算法
我们提出了一种基于训练三元组自助采样(bootstrap sampling)的随机梯度下降(SGD)算法来优化整个网络。训练流程如算法 1 所示。为简化符号,我们将 ACF 划分为三大子过程:
- ACFcomp(第 5–7 行):计算组件级注意力并汇总成内容表示(图像为区域特征,视频为帧特征)。
- ACFitem(第 4–9 行):基于内容表示、用户向量和项目向量计算项目级注意力并汇总成邻域表示。
- BPR-OPT:在第 12 行,根据式 (5) 对所有参数进行反向传播和更新。
我们用 Θ \Theta Θ 表示项目级和组件级注意力网络的所有参数,用 R ^ i j k \hat R_{ijk} R^ijk 表示 R ^ i j − R ^ i k \hat R_{ij}-\hat R_{ik} R^ij−R^ik。在第 12 行中,按照链式法则计算每个参数的梯度,并沿着负梯度方向更新。每次迭代中,算法随机选取一个训练三元组 ( i , j , k ) (i,j,k) (i,j,k),再执行上述三个子过程并更新参数
划分为三大子过程:
- ACFcomp(第 5–7 行):计算组件级注意力并汇总成内容表示(图像为区域特征,视频为帧特征)。
- ACFitem(第 4–9 行):基于内容表示、用户向量和项目向量计算项目级注意力并汇总成邻域表示。
- BPR-OPT:在第 12 行,根据式 (5) 对所有参数进行反向传播和更新。
我们用 Θ \Theta Θ 表示项目级和组件级注意力网络的所有参数,用 R ^ i j k \hat R_{ijk} R^ijk 表示 R ^ i j − R ^ i k \hat R_{ij}-\hat R_{ik} R^ij−R^ik。在第 12 行中,按照链式法则计算每个参数的梯度,并沿着负梯度方向更新。每次迭代中,算法随机选取一个训练三元组 ( i , j , k ) (i,j,k) (i,j,k),再执行上述三个子过程并更新参数
相关文章:

【论文阅读】Attentive Collaborative Filtering:
Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention Attentive Collaborative Filtering (ACF)、隐式反馈推荐、注意力机制、贝叶斯个性化排序 标题翻译:注意力协同过滤:基于项目和组件级注意力的…...

如何使用极狐GitLab 软件包仓库功能托管 maven?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 Maven 包 (BASIC ALL) 在项目的软件包库中发布 Maven 产物。然后,在需要将它们用作依赖项时安装它…...

Notion Windows桌面端快捷键详解
通用导航 这些快捷键帮助用户在 Notion 的界面中快速移动。 打开 Notion:Ctrl T 打开一个新的 Notion 窗口或标签页,方便快速进入工作空间。返回上一页:Ctrl [ 导航回之前查看的页面。前进到下一页:Ctrl ] 跳转到导航历史中的…...

企业智能化第一步:用「Deepseek+自动化」打造企业资源管理的智能中枢
随着Deepseek乃至AI人工智能技术在企业中得到了广泛的关注和使用,多数企业开始了AI探索之旅,迅易科技也不例外,且在不断地实践中强化了AI智能应用创新的强大能力。 为解决企业知识管理碎片化、提高内部工作效率等问题,迅易将目光放…...
)
GoFly企业版框架升级2.6.6版本说明(框架在2025-05-06发布了)
前端框架升级说明: 1.vue版本升级到^3.5.4 把"vue": "^3.2.40",升级到"vue": "^3.5.4",新版插件需要时useTemplateRef,所以框架就对齐进行升级。 2.ArcoDesign升级到2.57.0(目前最新2025-02-10&a…...

LeapVAD:通过认知感知和 Dual-Process 思维实现自动驾驶飞跃——论文阅读
《LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking》2025年1月发表,来自浙江大学、上海AI实验室、慕尼黑工大、同济大学和中科大的论文。 尽管自动驾驶技术取得了显著进步,但由于推理能力有限,数…...

ps信息显示不全
linux执行ps是默认宽度是受限制的,例如: ps -aux 显示 遇到这种情况,如果显示的信息不是很长可以添加一个w参数来放宽显示宽度 ps -auxw 显示 再添加一个w可以接触宽度限制,有多长就显示多长 ps -auxww 显示...

性能比拼: Redis Streams vs Pub/Sub
本内容是对知名性能评测博主 Anton Putra Redis Streams vs Pub/Sub: Performance 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 在这个视频中,我们首先将介绍 Redis Streams 和 Redis Pub/Sub 之间的区别。然后,我们将在 AWS 上运行一个基准…...

实践004-Gitlab CICD部署应用
文章目录 Gitlab CICD部署应用部署设计集成Kubernetes后端Java项目部署创建gitlab部署项目创建部署文件创建流水线提交流水线 前端Web项目部署创建gitlab部署项目创建部署文件创建流水线提交流水线 Gitlab CICD部署应用 部署设计 对于前后端服务都基于 Kubernetes 进行部署&a…...

二叉树与优先级队列
1.树 树是由n个数据构成的非线性结构,它是根朝上,叶朝下。 注意:树形结构之中,子树之间不能连接,不然就不构成树形结构 1.子树之间没有交集 2.除了根节点以外,每一个节点有且只有一个父亲节点 3.一个n个…...

如何使用极狐GitLab 软件包仓库功能托管 npm?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 npm 包 (BASIC ALL) npm 是 JavaScript 和 Node.js 的默认包管理器。开发者使用 npm 共享和重用代码ÿ…...

uniapp自定义底部导航栏h5有效果小程序无效的解决方案
在使用 uni-app 开发跨端应用时,常见问题之一是自定义底部导航栏(tabbar)在H5端有效,但在小程序端无效。这是因为小程序端的页面结构和生命周期与H5有差异,且小程序端的原生tabbar有更高的优先级,覆盖了自定…...
)
开发搭载阿里云平台的物联网APP(支持数据接收与发送)
一、开发环境准备 工具安装 HBuilderX:下载并安装最新版(支持Vue.js和uni-app框架)阿里云IoT SDK:使用JavaScript版SDK(如aliyun-iot-mqtt或mqtt.js)插件安装:HBuilderX插件市场搜索安装mqtt相关…...

Flowchart 流程图的基本用法
以下是 Flowchart 流程图 的基本用法整理,涵盖核心概念、符号含义、绘制步骤及注意事项,助你高效表达流程逻辑: 一、流程图的核心作用 可视化流程:将复杂步骤转化为直观图形,便于理解和分析。梳理逻辑:明确…...

Excel模版下载文件导入
工作中经常遇到Excel模板下载,然后填好后再导入的情况,简单记录下,方便下次使用 Excel模版下载(返回Base64) 模板文件存放位置 import java.util.Base64; import org.apache.commons.io.IOUtils; import org.sprin…...

深入了解linux系统—— 进程控制
进程创建 fork函数 在Linux操作系统中,我们可以通过fork函数来创建一个子进程; 这是一个系统调用,创建子进程成功时,返回0给子进程,返回子进程的pid给父进程;创建子进程失败则返回-1给父进程。 我们就可…...
)
【前端基础】7、CSS的字体属性(font相关)
一、font-size:设置字体大小 设置方法: 具体数值单位 例如:100px 也可以用em为单位:1em代表100%,2em代表200%……0.5em代表50%。 px方式: em方式: 但是设置em的时候具体是多大呢?…...

学习整理使用php将SimpleXMLElement 对象解析成数组格式的方法
学习整理使用php将SimpleXMLElement 对象解析成数组格式的方法 要将 SimpleXMLElement 对象解析成数组格式,您可以使用 PHP 的 json_decode 和 json_encode 函数。首先,将 SimpleXMLElement 对象转换为 JSON 字符串,然后将这个字符串解码成数…...
免杀混淆)
MSF(3)免杀混淆
声明!本文章所有的工具分享仅仅只是供大家学习交流为主,切勿用于非法用途,如有任何触犯法律的行为,均与本人及团队无关!!! 一、前言 前面说了木马的捆绑,dll,exe,hta等密…...

经典密码学算法实现
# AES-128 加密算法的规范实现(不使用外部库) # ECB模式S_BOX [0x63, 0x7C, 0x77, 0x7B, 0xF2, 0x6B, 0x6F, 0xC5, 0x30, 0x01, 0x67, 0x2B,0xFE, 0xD7, 0xAB, 0x76, 0xCA, 0x82, 0xC9, 0x7D, 0xFA, 0x59, 0x47, 0xF0,0xAD, 0xD4, 0xA2, 0xAF, 0x9C, 0x…...

idea里maven自定义的setting.xml文件不生效问题
问题描述: 内网环境中:maven选择选择自定义的maven文件夹时,使用的是自定义的setting.xml和本地仓库,怎么都读取不到仓库的依赖; 分析: 1.可能是setting.xml文件里没有配置本地仓库的路径; 2…...
)
注意力机制(Attention)
1. 注意力认知和应用 AM: Attention Mechanism,注意力机制。 根据眼球注视的方向,采集显著特征部位数据: 注意力示意图: 注意力机制是一种让模型根据任务需求动态地关注输入数据中重要部分的机制。通过注意力机制&…...

【java】使用iText实现pdf文件增加水印功能
maven依赖 <dependencies><dependency><groupId>com.itextpdf</groupId><artifactId>itext7-core</artifactId><version>7.2.5</version><type>pom</type></dependency> </dependencies>实现代码 前…...

TextIn ParseX重磅功能更新:支持切换公式输出形式、表格解析优化、新增电子档PDF去印章
ParseX重要版本更新内容速读 - 新增公式解析参数 formula_level,支持 LaTeX / Text 灵活切换; - 表格解析优化单元格内换行输出; - 导出excel时,图片链接放在单元格内; - 新增电子档pdf去印章功能。 体验文档解析…...

禁止idea联网自动更新通过防火墙方式
防火墙方式禁止idea更新检测,解决idea无限循环触发密钥填充流程。 1.首先打开控制面板找到高级设置 2.点击出站规则 3.新建规则 4.选择程序 5.找到idea路径 6.下一步 7.阻止连接 8.全选 9.输入禁止idea的名称 10.至此idea自动更新禁用完成...

面向智能体开发的声明式语言:可行性分析与未来图景
面向智能体开发的声明式语言:可行性分析与未来图景 一、技术演进的必然性:从“脚本化AI”到“声明式智能体” 当前AI开发仍停留在“脚本化AI”阶段:开发者通过Python/Java编写条件判断调用LLM API,如同用汇编语言编写操作系统。…...
)
【Bug经验分享】SourceTree用户设置必须被修复/SSH 主机密钥未缓存(踩坑)
文章目录 配置错误问题原因配置错误问题解决主机密钥缓存问题原因主机密钥缓存问题解决 更多相关内容可查看 配置错误问题原因 电脑太卡,曾多次强制关机,在关机前没有关闭SourceTree,导致配置错误等问题 配置错误问题解决 方式一ÿ…...

http Status 400 - Bbad request 网站网页经常报 HTTP 400 错误,清缓存后就好了的原因
目录 一、HTTP 400 错误的常见成因(一)问题 URL(二)缓存与 Cookie 异常(三)请求头信息错误(四)请求体数据格式不正确(五)文件尺寸超标(六)请求方法不当二、清缓存为何能奏效三、其他可以尝试的解决办法(一)重新检查 URL(二)暂时关闭浏览器插件(三)切换网络环…...

六个仓库合并为一个仓库,保留master和develop分支的bat脚本
利用git subtree可以实现多个仓库合并为一个仓库,手动操作起来太麻烦了,今天花了点时间写了一个可执行的脚本,现在操作起来就方便多了。 1、本地新建setup.bat文件 2、用编辑器打开(我用的是Notepad) 3、把下面代码…...

新能源汽车中的NVM计时与RTC计时:区别与应用详解
在新能源汽车的电子控制系统中,时间管理至关重要,而NVM计时(Non-Volatile Memory Timing)和RTC计时(Real-Time Clock)是两种不同的时间记录机制。虽然它们都与时间相关,但在工作原理、应用场景和…...

✨WordToCard使用分享✨
家人们,今天发现了一个超好用的工具——WordToCard!😜 它可以把WordToCard文档转换成漂亮的知识卡片,学习笔记、知识整理和内容分享都变得超轻松~🤗 支持各种WordToCard语法,像标题、列表、代…...

内网和外网怎么互通?外网访问内网的几种简单方式
在企业或家庭网络中,经常会遇到不同内网环境下网络互通问题。例如,当公司本地局域网内有个办公OA网站,在办公室内电脑上网可以登录使用,但在家带宽下就无法直接通信访问到。这就需要我们采取一些实用的内外网互通技巧来解决这个问…...

Mac中Docker下载与安装
目录 Docker下载安装配置 版本查询以及问题处理配置国内镜像在Docker中安装软件Nginx Docker 下载 官网:https://www.docker.com/get-started/ 或者 安装 配置 这里我们选择 Accept 选择默认配置就行,Docker 会自动设置一些大多数开发人员必要的配…...

固件测试:mac串口工具推荐
串口工具对固件测试来说非常重要,因为需要经常看日志,Windows上有Xshell和secureCRT,用起来很方便,尤其可以保存日志,并且可以进行日志分割。 mac上用什么串口工具呢,今天给大家推荐CoolTerm。 CoolTerm …...

41.防静电的系列措施
静电干扰的处理措施 1. ESD放电特征2. 静电防护电路设计措施3. ESD防护结构措施4. 案例分析 1. ESD放电特征 (1)放电电流tr≈1nS,ESD保护器件响应时间应小于1nS; (2)频率集中在几十MHz到500MHz;…...

Jmeter进行http接口测试
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1、jmeter-http接口测试脚本 jmeter进行http接口测试的主要步骤(1.添加线程组 2.添加http请求 3.在http请求中写入接口的URL,路径&#x…...

Ubuntu也开始锈化了?Ubuntu 计划在 25.10 版本开始引入 Rust Coreutils
上个月,jnsgruk发表了《未来20年的Ubuntu工程》(Engineering Ubuntu For the Next 20 Years)一文,其中概述了打算在未来几年中如何发展Ubuntu的四个关键主题。在这篇文章中,重点讨论 了“现代化”。在很多方面对Ubuntu…...

C++命名空间、内联与捕获
命名空间namespace 最常见的命名空间是std,你一定非常熟悉,也就是: using namespace std;命名空间的基本格式 注意,要在头文件里面定义! namespace namespace_name{data_type function_name(data_type parameter){data_type result;//function contentreturn result;}…...

PostgreSQL 系统管理函数详解
PostgreSQL 系统管理函数详解 PostgreSQL 提供了一系列强大的系统管理函数,用于数据库维护、监控和配置。这些函数可分为多个类别,以下是主要功能的详细说明: 一、数据库配置函数 1. 参数管理函数 -- 查看所有配置参数 SELECT name, sett…...

mdadm 报错: buffer overflow detected
最近跑 blktest (https://github.com/osandov/blktests) 时发现 md/001 的测试失败了 单独执行,最后定位到是 mdadm 命令报错: buffer overflow detected 这个 bug 目前已经修复: https://git.kernel.org/pub/scm/utils/mdadm/mdadm.git/commit/?id827e1870f3205…...

java ReentrantLock
线程同步工具。可以替代 synchronized . private final ReentrantLock reentrantLock new ReentrantLock();void testTask1 () {reentrantLock.lock(); // 获取锁try {System.out.println(Thread.currentThread().getName() " 进入临界区");// 模拟执行业务逻辑Th…...

kettle从入门到精通 第九十六课 ETL之kettle Elasticsearch 增删改查彻底掌握
场景: 群里有小伙伴咨询kettle从Elasticsearch中抽取数据,群里老师们纷纷响应,vip小伙伴是不是有中受宠若惊的感觉。 今天我们使用kettle通过es的原生rest接口来进行操作es,开整。 前提:本篇文章基于elasticsearch:7.…...
)
Kafka的核心组件有哪些?简要说明其作用。 (Producer、Consumer、Broker、Topic、Partition、ZooKeeper)
Kafka 核心组件解析 1. 基础架构图解 ┌─────────┐ ┌─────────┐ ┌─────────┐ │Producer │───▶ │ Broker │ ◀─── │Consumer │ └─────────┘ └─────────┘ └────────…...

Missashe考研日记-day34
Missashe考研日记-day34 1 专业课408 学习时间:3h学习内容: 今天是学习I/O管理第二小节的内容,听了课也做了题,这是操作系统倒数第二节知识了,还差最后一节就完结了。知识点回顾: 1.I/O核心子系统&#x…...

机器人跑拉松是商业噱头还是技术进步的必然体现
一、机器人跑拉松是商业噱头还是技术进步的必然体现 机器人参与马拉松赛事究竟是营销噱头还是技术进步的必然要求,需要从技术验证、行业推动、公众认知以及争议焦点等多个维度综合分析。基于全球首场人形机器人半程马拉松(2025年北京亦庄赛事࿰…...

传输层协议 1.TCP 2.UDP
传输层协议 1.TCP 2.UDP TCP协议 回顾内容 传输层功能:定义应用层协议数据报文的端口号,流量控制对原始数据进行分段处理 传输层所提供服务 传输连接服务数据传输服务:流量控制、差错控制、序列控制 一、传输层的TCP协议 1.面向连接的…...

LLM :Function Call、MCP协议与A2A协议
LLM 的函数调用、模型上下文协议 (MCP) 和 Agent to Agent (A2A) 协议:概念、区别与实例对比 引言:LLM 不断演进的格局 大型语言模型 (LLM) 的日益精进,使其能力已超越简单的文本生成,迈向与现实世界进行复杂交互的新阶段。为了…...

当当狸智能天文望远镜 TW2 | 用科技触摸星辰,让探索触手可及
当科技邂逅星空,每个普通人都能成为宇宙的追光者 伽利略用望远镜揭开宇宙面纱的 400 年后,当当狸以颠覆传统的设计,让天文观测从专业领域走入千家万户。当当狸智能天文望远镜 TW2,重新定义「观星自由」—— 无需专业知识ÿ…...

白杨SEO:如何查看百度、抖音、微信、微博、小红书、知乎、B站、视频号、快手等7天内最热门话题及流量关键词有哪些?使用方法和免费工具推荐以及注意事项【干货】
大家好,我是白杨SEO,专注SEO十年以上,全网SEO流量实战派,AI搜索优化研究者。 (温馨提醒:本文有点长,看不完建议先收藏或星标,后面慢慢看哈) 最近,不管是在白…...

Spring AI 之 AI核心概念
模型 人工智能(AI)模型是用于处理和生成信息的算法,通常旨在模拟人类的认知功能。这些模型通过从大规模数据集中学习模式和规律,能够生成预测结果、文本、图像或其他形式的输出,从而增强各行业应用的效能。 AI 模型种类繁多,每种模型都适用于特定的应用场景。虽然以 Ch…...