二叉树与优先级队列
1.树
树是由n个数据构成的非线性结构,它是根朝上,叶朝下。
注意:树形结构之中,子树之间不能连接,不然就不构成树形结构
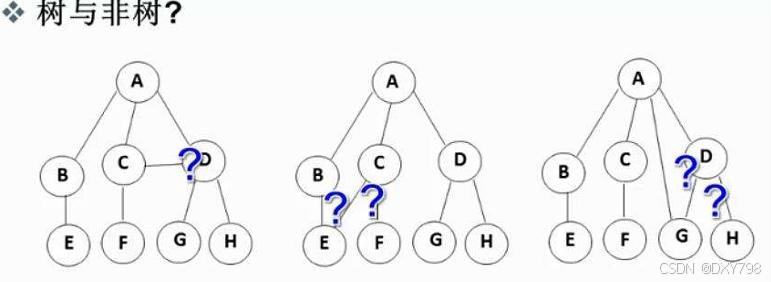
1.子树之间没有交集
2.除了根节点以外,每一个节点有且只有一个父亲节点
3.一个n个节点的树,有n-1条边
1.1树的一些概念
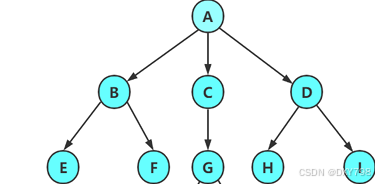
结点的度:一个结点含有子树的个数称为该结点的度; 如上图:A的度为6
树的度:一棵树中,所有结点度的最大值称为树的度; 如上图:树的度为6
叶子结点或终端结点:度为0的结点称为叶结点; 如上图:B、C、H、I...等节点为叶结点 双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点; 如上图:A是B的父结点
孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点; 如上图:B是A的孩子结点
根结点:一棵树中,没有双亲结点的结点;如上图:A
结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推
树的高度或深度:树中结点的最大层次; 如上图:树的高度为4 树的以下概念只需了解,
非终端结点或分支结点:度不为0的结点; 如上图:D、E、F、G...等节点为分支结点
兄弟结点:具有相同父结点的结点互称为兄弟结点; 如上图:B、C是兄弟结点
堂兄弟结点:双亲在同一层的结点互为堂兄弟;如上图:H、I互为兄弟结点
结点的祖先:从根到该结点所经分支上的所有结点;如上图:A是所有结点的祖先
子孙:以某结点为根的子树中任一结点都称为该结点的子孙。如上图:所有结点都是A的子孙
森林:由m(m>=0)棵互不相交的树组成的集合称为森林
2.二叉树
2.1概念
一棵二叉树的节点是有限集合
对于任意的二叉树,都是由下列情况组合而成
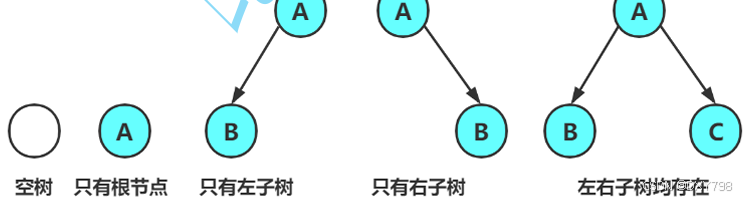
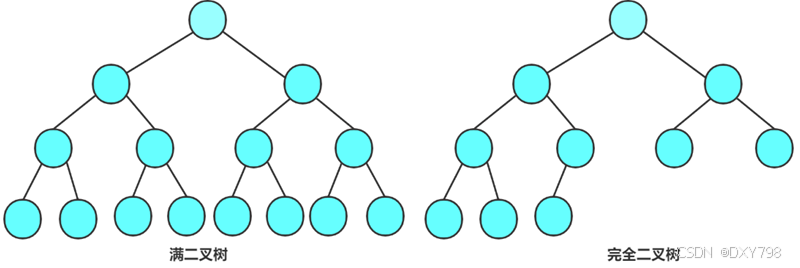
2.2两种特殊的二叉树
1.满二叉树:一棵二叉树树,每一层的节点数都到达了最大值,那么这就是满二叉树。也就是说如果一棵二叉树是k层,那么这棵树的节点树,且结点总数是-1,则它就是满二叉树。
2.完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n 个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从0至n-1的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
2.3二叉树的性质
1. 若规定根结点的层数为1,则一棵非空二叉树的第i层上最多有(i>0)个结点
2. 若规定只有根结点的二叉树的深度为1,则深度为K的二叉树的最大结点数是-1(k>=0)
3. 对任何一棵二叉树, 如果其叶结点个数为 n0, 度为2的非叶结点个数为 n2,则有n0=n2+1
4. 具有n个结点的完全二叉树的深度k为上取整
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的顺序对所有节点从0开始编号,则对于序号为i 的结点有:
若i>0,双亲序号:(i-1)/2;i=0,i为根结点编号,无双亲结点
若2i+1<n 左孩子序号:2i+1,否则没有左孩子
若2i+2<n 右孩子序号:2i+1,否则没有右孩子
2.4二叉树的存储
二叉树的存储结构分为:顺序存储和类似于链表的链式存储。
二叉树的链式存储是通过一个一个的节点引用起来的,常见的表示方式有二叉和三叉表示方式,具体如下
//孩子表示法
class Node {int val; //用于储存数据Node left; //表示左孩子,通常为以左子树为根节点的二叉树Node right; //表示右孩子,通常为右子树为根节点的二叉树
}
// 孩子双亲表示法
class Node {int val; // 数据域Node left; // 左孩子的引用,常常代表左孩子为根的整棵左子树Node right; // 右孩子的引用,常常代表右孩子为根的整棵右子树Node parent; // 当前节点的根节点
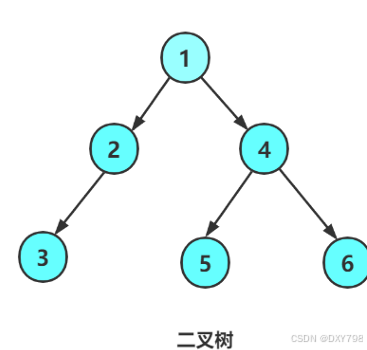
}2.2二叉树的基本操作
存储方式是孩子表示方法
BinaryTree类
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;public class BinaryTree {public static class TreeNode {public int val;public TreeNode left;//储存左子树public TreeNode rigth;//储存右子树public TreeNode(int val) {this.val = val;}@Overridepublic String toString() {return "TreeNode{" +"val=" + val +'}';}}//创建一个二叉树public TreeNode createbinarytree() {TreeNode A = new TreeNode(1);TreeNode B = new TreeNode(2);TreeNode C = new TreeNode(3);TreeNode D = new TreeNode(4);TreeNode E = new TreeNode(5);TreeNode F = new TreeNode(6);TreeNode G = new TreeNode(7);TreeNode H = new TreeNode(8);//连接数的结构A.left = B;A.rigth = C;B.left = D;B.rigth = E;C.left = F;C.rigth = G;E.rigth = H;return A;}//先实现三种遍历方法// 前序遍历public void preOrder(TreeNode root) {//NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点--->根的左子树--->根的右子树。//递归的结束条件if (root == null) {return;}System.out.print(" " + root.val);preOrder(root.left);preOrder(root.rigth);//走到结尾这个循环结束}//不使用递归的的方法实现前序遍历public void preOrder1(TreeNode root){//借用栈来实现if(root==null){return ;}Stack<TreeNode> stack=new Stack<>();TreeNode cur=root;while(cur!=null||!stack.isEmpty()){while(cur!=null){stack.push(cur);System.out.print(cur.val+" ");cur=cur.left;}TreeNode top=stack.pop();cur=top.rigth;}}// 中序遍历public void inOrder(TreeNode root) {//LNR:中序遍历(Inorder Traversal)——根的左子树--->根节点--->根的右子树。if (root == null) {return;}inOrder(root.left);System.out.print(" " + root.val);inOrder(root.rigth);}//不使用递归的的方法实现中序遍历public void inOrder1(TreeNode root){//借用栈来实现iif(root==null){return ;}Stack<TreeNode> stack=new Stack<>();TreeNode cur=root;while(cur!=null||!stack.isEmpty()){while(cur!=null){stack.push(cur);cur=cur.left;}TreeNode top=stack.pop();System.out.print(top.val+" ");cur=top.rigth;}}// 后序遍历public void postOrder(TreeNode root) {//LRN:后序遍历(Postorder Traversal)——根的左子树--->根的右子树--->根节点。if (root == null) {return;}postOrder(root.left);postOrder(root.rigth);System.out.print(" " + root.val);}//使用不递归的方法使用后序遍历public void postOrder1(TreeNode root){//借用栈来实现if(root==null){return ;}Stack<TreeNode> stack=new Stack<>();TreeNode cur=root;TreeNode prve=null;while(cur!=null||!stack.isEmpty()){while(cur!=null){stack.push(cur);cur=cur.left;}TreeNode top=stack.peek();if(top==null||top.rigth==prve){System.out.println(top.val+" ");prve= stack.pop();}else{cur=top.rigth;}}}//获取数中节点个数public int nodesize;//第一种遍历式获取public void Nodesize1(TreeNode root) {//采用前序遍历if (root == null) {return;}//遇见节点将打印改成nodesize++nodesize++;Nodesize1(root.left);Nodesize1(root.rigth);}//第二种获取节点个数方法//左子树节点个数+右子树节点个数+根节点个数public int Nodesize2(TreeNode root) {if (root == null) {return 0;}return Nodesize2(root.left) + Nodesize2(root.rigth) + 1;}// 获取叶子节点的个数//依旧两种方法//第一遍种历二叉树public int getLeafNodeCount;public void getLeafNodeCount1(TreeNode root) {if (root == null) {return;}if (root.left == null && root.rigth == null) {getLeafNodeCount++;}getLeafNodeCount1(root.left);getLeafNodeCount1(root.rigth);}//第二种获取叶子节点个数//左子树叶子+右子树叶子节点个数public int getGetLeafNodeCount2(TreeNode root) {if (root == null) {return 0;}if (root.left == null && root.rigth == null) {return 1;}return getGetLeafNodeCount2(root.left) + getGetLeafNodeCount2(root.rigth);}// 获取第K层节点的个数public int getKLevelNodeCount(TreeNode root, int k) {//统计k层的节点个数,先找到第k-1层if (k == 1) {if (root == null) {return 0;} else {return 1;}}return getKLevelNodeCount(root.left, k - 1) + getKLevelNodeCount(root.rigth, k - 1);}// 获取二叉树的高度public int getHeight(TreeNode root) {//二叉树的高度等于左子树高度和右子树高度的最大值if(root==null) {return 0;}return getHeight(root.left)>getHeight(root.rigth)?getHeight(root.left)+1:getHeight(root.rigth)+1;}// 检测值为value的元素是否存在public TreeNode find(TreeNode root, int val){if(root.val==val){return root;}if(root.left!=null){TreeNode leftT=find(root.left,val);if(leftT!=null){return leftT;}}if(root.rigth!=null){TreeNode rigthT =find(root.rigth,val);if(rigthT!=null){return rigthT;}}return null;}//层序遍历public void levelOrder(TreeNode root){if(root==null){return;}//创建一个队列Queue<TreeNode> queue=new LinkedList<>();queue.offer(root);TreeNode cur=root;while(!queue.isEmpty()){//先将队列元素弹出cur=queue.poll();System.out.print(cur.val+" ");if(cur.left!=null){queue.offer(cur.left);}if(cur.rigth!=null){queue.offer(cur.rigth);}}System.out.println();}// 判断一棵树是不是完全二叉树public boolean isCompleteTree(TreeNode root){//完全二叉树从左到右依次填满Queue<TreeNode> queue=new LinkedList<>();TreeNode cur=root;queue.offer(cur);while(queue.peek()!=null){cur=queue.poll();queue.offer(cur.left);queue.offer(cur.rigth);}while(!queue.isEmpty()){if(queue.poll()!=null){return false;}}return true;}public static void main(String[] args) {}
}Test类
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;public class Test {public static void main(String[] args) {//调用创建二叉树BinaryTree binaryTree=new BinaryTree();//调用类中2的成员变量BinaryTree.TreeNode root=binaryTree.createbinarytree();//测试前序遍历打印binaryTree.preOrder(root);System.out.println();// //测试前序遍历打印1binaryTree.preOrder1(root);System.out.println();System.out.println("==============================");System.out.println();//测试中序遍历binaryTree.inOrder(root);System.out.println();//测试中序遍历的非递归方法binaryTree.inOrder1(root);System.out.println("===============================");System.out.println();//测试后序遍历binaryTree.postOrder(root);System.out.println();//测试后续遍历的非递归方法binaryTree.postOrder1(root);System.out.println("=========================");System.out.println();//打印节点个数binaryTree.Nodesize1(root);System.out.println("二叉树结点个数:"+binaryTree.nodesize);//测试第二种打印节点个数方法System.out.println("二叉树结点个数:"+binaryTree.Nodesize2(root));//测试第一种叶子节点个数binaryTree.getLeafNodeCount1(root);System.out.println("二叉树叶子节点个数:"+binaryTree.getLeafNodeCount);//测试第二种叶子节点个数System.out.println("二叉树叶子节点个数:"+binaryTree.getGetLeafNodeCount2(root));//测试统计第k层的节点个数System.out.println("第1层的节点个数为"+binaryTree.getKLevelNodeCount(root, 1));System.out.println("第2层的节点个数为"+binaryTree.getKLevelNodeCount(root, 2));System.out.println("第3层的节点个数为"+binaryTree.getKLevelNodeCount(root, 3));System.out.println("第4层的节点个数为"+binaryTree.getKLevelNodeCount(root, 4));//测试计算二叉树的高度System.out.println("二叉树的高度为:"+binaryTree.getHeight(root));//测试二叉树的是否存在的元素List<List<Integer>> llist=new ArrayList<List<Integer>>();List<Integer> list1=new ArrayList<>();llist.add(list1);Queue<Integer> queue=new LinkedList<>();queue.offer(1);System.out.println(queue.poll());System.out.println("元素1存在节点"+binaryTree.find(root, 1)+"中");System.out.println("元素4存在节点"+binaryTree.find(root, 4)+"中");System.out.println("元素8存在节点"+binaryTree.find(root, 8)+"中");System.out.println("元素7存在节点"+binaryTree.find(root, 7)+"中");//测试二叉树的层序遍历binaryTree.levelOrder(root);//判断二叉树是否是完全二叉树System.out.println("判断这棵树是否是完全二叉树 "+binaryTree.isCompleteTree(root));}
}
3.优先队列(PriorityQueue)
3.1堆的性质
堆逻辑上是一颗完全二叉树,物理上是存储在数组中
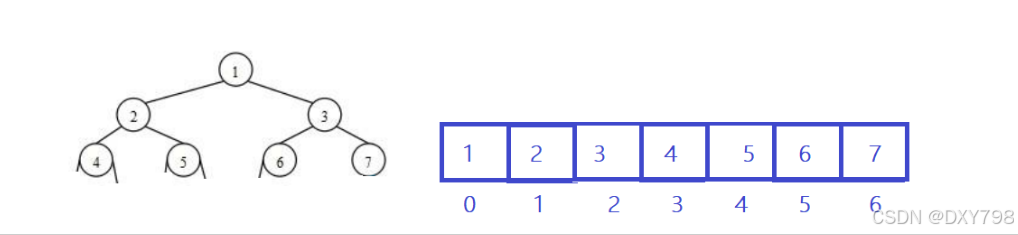
总结:一颗完全二叉树以层序遍历方式放入数组中存储,这种方式的主要用法就是堆的表示。
关于堆下标位置的计算
如果已知父亲(parent) 的下标,
则: 左孩子(left) 下标 = 2 * parent + 1;
右孩子(right) 下标 = 2 * parent + 2;
已知孩子(不区分左右)(child)下标,
则: 双亲(parent) 下标 = (child - 1) / 2;
3.2堆的分类
大堆:根节点大于左右两个子节点的完全二叉树 (父亲节点大于其子节点),叫做大堆,或者大根堆,或者最大堆 。
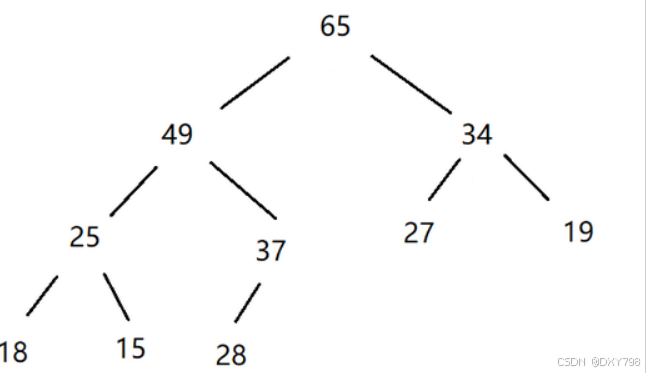
小堆:根节点小于左右两个子节点的完全二叉树叫 小堆(父亲节点小于其子节点),或者小根堆,或者最小堆。
3.3堆的底层代码实现
创建小根堆
创建大根堆
向上调整
现在有一个堆,我们需要在堆的末尾插入数据,再对其进行调整,使其仍然保持堆的结构,这就是向上调整。
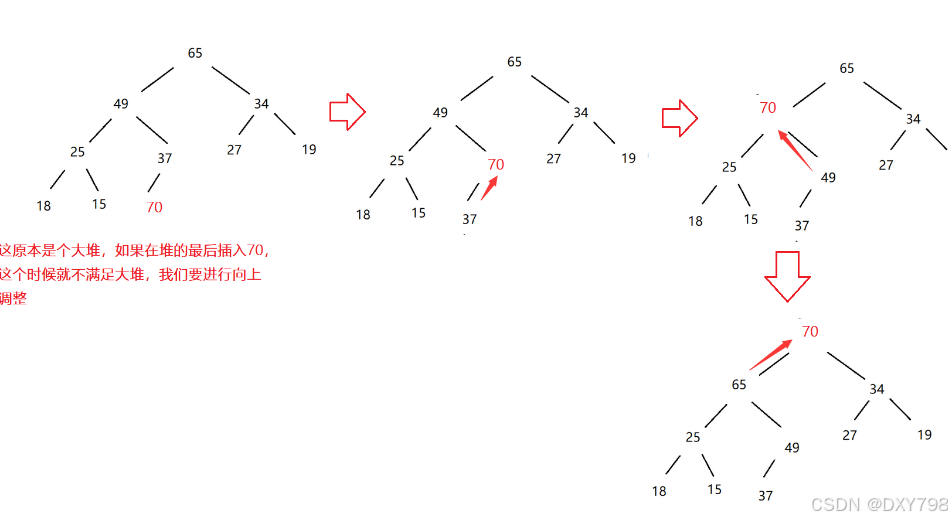
以大堆为例:
向下调整
堆的删除和添加
PriorityQueue类
import java.lang.reflect.Array;
import java.util.Arrays;public class PriorityQueue {public int[] elem;public int usedsize;public PriorityQueue() {this.elem=new int[10];}public void initelem(int [] array){for(int i=0;i<array.length;i++){this.elem[i]=array[i];usedsize++;}}public void elempeek(){for(int i=0;i<this.usedsize;i++){System.out.print(elem[i]+" ");}}//创建小根堆public void Smallrootpiles(){//小根堆的节点数要大于子树//第一步先确定有多少个树,利用最后一个节点来找到父亲节点for(int parent=(usedsize-1-1)/2;parent>=0;parent--){//也是一样采用向下调整的方法siftDown2(parent,usedsize);}}public void siftDown2(int parent,int usedsize){//parent:代表调整子树的起始位置//usedsize:判断子树是否还需要调整//1.根据父亲节点,找到左子树孩子节点int child=parent*2+1;//2.找到孩子之间的最小值while(child<usedsize){if(child+1<usedsize&&elem[child]>elem[child+1]){child++;}if(elem[child]<elem[parent]){int num=elem[parent];elem[parent]=elem[child];elem[child]=num;parent=child;child=child*2+1;}else{break;}}}//创建大根堆public void createhead(){//大根堆的节点数要大于子树//第一步先确定有多少个树,利用最后一个节点来找到父亲节点for(int parent=(usedsize-1-1)/2;parent>=0;parent--){//采用向下调整siftDown1(parent,usedsize);}}//parent:代表调整子树的起始位置//usedsize:判断子树是否还需要调整public void siftDown1(int parent,int usedsize){//根据父亲节点找到左子树节点int child=parent*2+1;while(child<usedsize){if(child+1<usedsize&&elem[child]<elem[child+1]){child++;}if(elem[child]>elem[parent]){int num=elem[parent];elem[parent]=elem[child];elem[child]=num;
// elem[child]=elem[child]^elem[parent];
// elem[parent]=elem[child]^elem[parent];
// elem[child]=elem[child]^elem[child];parent=child;child=child*2+1;}else{break;}}}//向堆中增加元素public void push(int val) {//先进行判满处理if (isFull()) {//进行扩容elem = Arrays.copyOf(elem, elem.length * 2);}elem[usedsize] = val;usedsize++;siftUp(usedsize - 1);}//向上调整public void siftUp(int child) {//孩子节点找到父亲节点int parent=(child-1)/2;//向上调整while(parent>=0){if(elem[child]>elem[parent]){int num=elem[parent];elem[parent]=elem[child];elem[child]=num;child=parent;parent=(parent-1)/2;}else{break;}}}public boolean isFull(){if(usedsize==this.elem.length){return true;}return false;}//删除堆的元素public int poll(){if(isEmpty()){return -1;}int val=elem[0];//交换0位置和最后一个节点位置elem[0]=elem[usedsize-1];elem[usedsize-1]=val;//对0节点位置进行向下调整siftDown1(0,usedsize-1);usedsize--;return val;}//判段是否为空public boolean isEmpty(){if (usedsize==0){return true;}return false;}//对节点进行排从小到大排序(再节点本身上排序)public void headsort(){//先对数据进行建大堆this.createhead();int end=usedsize-1;while(end>0){int num=elem[0];elem[0]=elem[end];elem[end]=num;siftDown1(0,end);end--;}}public static void main(String[] args) {}
}
Test类
public class Test {public static void main(String[] args) {//对队进行初始化PriorityQueue priorityQueue=new PriorityQueue();int[] array={ 27,15,19,18,28,34,65,49,25,37 };priorityQueue.initelem(array);//测试建立小根堆priorityQueue.Smallrootpiles();priorityQueue.elempeek();System.out.println();//测试大根堆的实现priorityQueue.createhead();priorityQueue.elempeek();//测试插入一个元素priorityQueue.push(80);System.out.println();priorityQueue.elempeek();//测试删除一个元素priorityQueue.poll();System.out.println();priorityQueue.elempeek();System.out.println();//测试堆排序priorityQueue.headsort();priorityQueue.elempeek();//}
}
3.4堆的问题
3.4.1topk问题
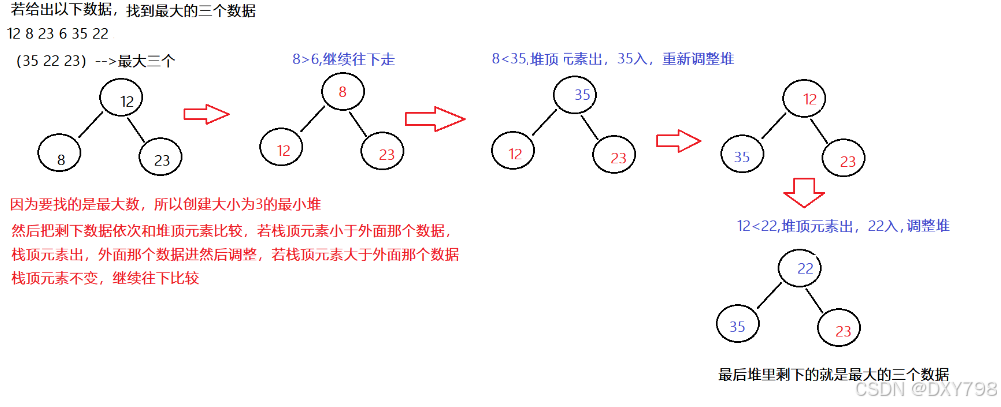
给你6个数据,求前3个最大数据。这时候我们用堆怎么做的?
解题思路:
1、如果求前K个最大的元素,要建一个小根堆。
2、如果求前K个最小的元素,要建一个大根堆。
3、第K大的元素。建一个小堆,堆顶元素就是第K大的元素。
4、第K小的元素。建一个大堆,堆顶元素就是第K大的元素。
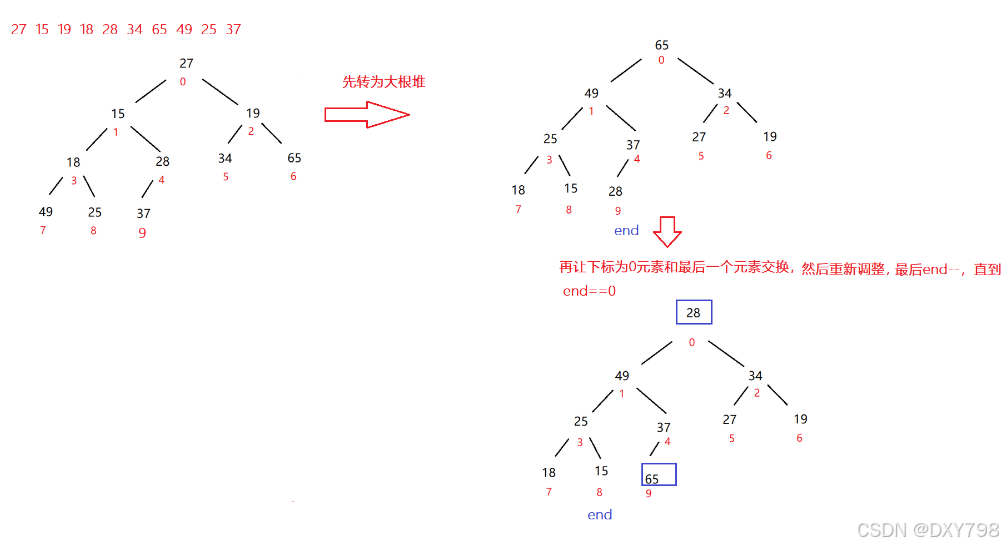
3.4.2数组的排序
再者说如果要对一个数组进行从小到大排序,要借助大根堆还是小根堆呢?
---->大根堆
3.5PriorityQueue
使用注意:
1. 使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue; 2. PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出 ClassCastException异常
3. 不能插入null对象,否则会抛出NullPointerException
4. 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
5. 插入和删除元素的时间复杂度为
6. PriorityQueue底层使用了堆数据结构
7. PriorityQueue默认情况下是小堆---即每次获取到的元素都是最小的元素
1.优先级队列的构造

static void TestPriorityQueue(){// 1.创建一个空的优先级队列,底层默认容量是11PriorityQueue<Integer> q1 = new PriorityQueue<>();// 2.创建一个空的优先级队列,底层的容量为initialCapacityPriorityQueue<Integer> q2 = new PriorityQueue<>(100);ArrayList<Integer> list = new ArrayList<>();list.add(4);list.add(3);list.add(2);list.add(1);// 用ArrayList对象来构造一个优先级队列的对象// q3中已经包含了三个元素PriorityQueue<Integer> q3 = new PriorityQueue<>(list);System.out.println(q3.size());System.out.println(q3.peek());}//注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器// 用户自己定义的比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可
class IntCmp implements Comparator<Integer>{@Overridepublic int compare(Integer o1, Integer o2) {return o2-o1;}}public class TestPriorityQueue {public static void main(String[] args) {PriorityQueue<Integer> p = new PriorityQueue<>(new IntCmp());p.offer(4);p.offer(3);p.offer(2);p.offer(1);p.offer(5)自定义排序规则
1.该改变升序降序

2.根据HashMap的value值对HashMap的键值对排序
方法摘要
System.out.println(p.peek());}}static void TestPriorityQueue2(){int[] arr = {4,1,9,2,8,0,7,3,6,5};// 一般在创建优先级队列对象时,如果知道元素个数,建议就直接将底层容量给好// 否则在插入时需要不多的扩容// 扩容机制:开辟更大的空间,拷贝元素,这样效率会比较低PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);for (int e: arr) {q.offer(e);}System.out.println(q.size()); // 打印优先级队列中有效元素个数System.out.println(q.peek()); // 获取优先级最高的元素// 从优先级队列中删除两个元素之和,再次获取优先级最高的元素q.poll();q.poll();System.out.println(q.size()); // 打印优先级队列中有效元素个数System.out.println(q.peek()); // 获取优先级最高的元素q.offer(0);System.out.println(q.peek()); // 获取优先级最高的元素// 将优先级队列中的有效元素删除掉,检测其是否为空q.clear();if(q.isEmpty()){System.out.println("优先级队列已经为空!!!")}else{System.out.println("优先级队列不为空");}}相关文章:

二叉树与优先级队列
1.树 树是由n个数据构成的非线性结构,它是根朝上,叶朝下。 注意:树形结构之中,子树之间不能连接,不然就不构成树形结构 1.子树之间没有交集 2.除了根节点以外,每一个节点有且只有一个父亲节点 3.一个n个…...

如何使用极狐GitLab 软件包仓库功能托管 npm?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 npm 包 (BASIC ALL) npm 是 JavaScript 和 Node.js 的默认包管理器。开发者使用 npm 共享和重用代码ÿ…...

uniapp自定义底部导航栏h5有效果小程序无效的解决方案
在使用 uni-app 开发跨端应用时,常见问题之一是自定义底部导航栏(tabbar)在H5端有效,但在小程序端无效。这是因为小程序端的页面结构和生命周期与H5有差异,且小程序端的原生tabbar有更高的优先级,覆盖了自定…...
)
开发搭载阿里云平台的物联网APP(支持数据接收与发送)
一、开发环境准备 工具安装 HBuilderX:下载并安装最新版(支持Vue.js和uni-app框架)阿里云IoT SDK:使用JavaScript版SDK(如aliyun-iot-mqtt或mqtt.js)插件安装:HBuilderX插件市场搜索安装mqtt相关…...

Flowchart 流程图的基本用法
以下是 Flowchart 流程图 的基本用法整理,涵盖核心概念、符号含义、绘制步骤及注意事项,助你高效表达流程逻辑: 一、流程图的核心作用 可视化流程:将复杂步骤转化为直观图形,便于理解和分析。梳理逻辑:明确…...

Excel模版下载文件导入
工作中经常遇到Excel模板下载,然后填好后再导入的情况,简单记录下,方便下次使用 Excel模版下载(返回Base64) 模板文件存放位置 import java.util.Base64; import org.apache.commons.io.IOUtils; import org.sprin…...

深入了解linux系统—— 进程控制
进程创建 fork函数 在Linux操作系统中,我们可以通过fork函数来创建一个子进程; 这是一个系统调用,创建子进程成功时,返回0给子进程,返回子进程的pid给父进程;创建子进程失败则返回-1给父进程。 我们就可…...
)
【前端基础】7、CSS的字体属性(font相关)
一、font-size:设置字体大小 设置方法: 具体数值单位 例如:100px 也可以用em为单位:1em代表100%,2em代表200%……0.5em代表50%。 px方式: em方式: 但是设置em的时候具体是多大呢?…...

学习整理使用php将SimpleXMLElement 对象解析成数组格式的方法
学习整理使用php将SimpleXMLElement 对象解析成数组格式的方法 要将 SimpleXMLElement 对象解析成数组格式,您可以使用 PHP 的 json_decode 和 json_encode 函数。首先,将 SimpleXMLElement 对象转换为 JSON 字符串,然后将这个字符串解码成数…...
免杀混淆)
MSF(3)免杀混淆
声明!本文章所有的工具分享仅仅只是供大家学习交流为主,切勿用于非法用途,如有任何触犯法律的行为,均与本人及团队无关!!! 一、前言 前面说了木马的捆绑,dll,exe,hta等密…...

经典密码学算法实现
# AES-128 加密算法的规范实现(不使用外部库) # ECB模式S_BOX [0x63, 0x7C, 0x77, 0x7B, 0xF2, 0x6B, 0x6F, 0xC5, 0x30, 0x01, 0x67, 0x2B,0xFE, 0xD7, 0xAB, 0x76, 0xCA, 0x82, 0xC9, 0x7D, 0xFA, 0x59, 0x47, 0xF0,0xAD, 0xD4, 0xA2, 0xAF, 0x9C, 0x…...

idea里maven自定义的setting.xml文件不生效问题
问题描述: 内网环境中:maven选择选择自定义的maven文件夹时,使用的是自定义的setting.xml和本地仓库,怎么都读取不到仓库的依赖; 分析: 1.可能是setting.xml文件里没有配置本地仓库的路径; 2…...
)
注意力机制(Attention)
1. 注意力认知和应用 AM: Attention Mechanism,注意力机制。 根据眼球注视的方向,采集显著特征部位数据: 注意力示意图: 注意力机制是一种让模型根据任务需求动态地关注输入数据中重要部分的机制。通过注意力机制&…...

【java】使用iText实现pdf文件增加水印功能
maven依赖 <dependencies><dependency><groupId>com.itextpdf</groupId><artifactId>itext7-core</artifactId><version>7.2.5</version><type>pom</type></dependency> </dependencies>实现代码 前…...

TextIn ParseX重磅功能更新:支持切换公式输出形式、表格解析优化、新增电子档PDF去印章
ParseX重要版本更新内容速读 - 新增公式解析参数 formula_level,支持 LaTeX / Text 灵活切换; - 表格解析优化单元格内换行输出; - 导出excel时,图片链接放在单元格内; - 新增电子档pdf去印章功能。 体验文档解析…...

禁止idea联网自动更新通过防火墙方式
防火墙方式禁止idea更新检测,解决idea无限循环触发密钥填充流程。 1.首先打开控制面板找到高级设置 2.点击出站规则 3.新建规则 4.选择程序 5.找到idea路径 6.下一步 7.阻止连接 8.全选 9.输入禁止idea的名称 10.至此idea自动更新禁用完成...

面向智能体开发的声明式语言:可行性分析与未来图景
面向智能体开发的声明式语言:可行性分析与未来图景 一、技术演进的必然性:从“脚本化AI”到“声明式智能体” 当前AI开发仍停留在“脚本化AI”阶段:开发者通过Python/Java编写条件判断调用LLM API,如同用汇编语言编写操作系统。…...
)
【Bug经验分享】SourceTree用户设置必须被修复/SSH 主机密钥未缓存(踩坑)
文章目录 配置错误问题原因配置错误问题解决主机密钥缓存问题原因主机密钥缓存问题解决 更多相关内容可查看 配置错误问题原因 电脑太卡,曾多次强制关机,在关机前没有关闭SourceTree,导致配置错误等问题 配置错误问题解决 方式一ÿ…...

http Status 400 - Bbad request 网站网页经常报 HTTP 400 错误,清缓存后就好了的原因
目录 一、HTTP 400 错误的常见成因(一)问题 URL(二)缓存与 Cookie 异常(三)请求头信息错误(四)请求体数据格式不正确(五)文件尺寸超标(六)请求方法不当二、清缓存为何能奏效三、其他可以尝试的解决办法(一)重新检查 URL(二)暂时关闭浏览器插件(三)切换网络环…...

六个仓库合并为一个仓库,保留master和develop分支的bat脚本
利用git subtree可以实现多个仓库合并为一个仓库,手动操作起来太麻烦了,今天花了点时间写了一个可执行的脚本,现在操作起来就方便多了。 1、本地新建setup.bat文件 2、用编辑器打开(我用的是Notepad) 3、把下面代码…...

新能源汽车中的NVM计时与RTC计时:区别与应用详解
在新能源汽车的电子控制系统中,时间管理至关重要,而NVM计时(Non-Volatile Memory Timing)和RTC计时(Real-Time Clock)是两种不同的时间记录机制。虽然它们都与时间相关,但在工作原理、应用场景和…...

✨WordToCard使用分享✨
家人们,今天发现了一个超好用的工具——WordToCard!😜 它可以把WordToCard文档转换成漂亮的知识卡片,学习笔记、知识整理和内容分享都变得超轻松~🤗 支持各种WordToCard语法,像标题、列表、代…...

内网和外网怎么互通?外网访问内网的几种简单方式
在企业或家庭网络中,经常会遇到不同内网环境下网络互通问题。例如,当公司本地局域网内有个办公OA网站,在办公室内电脑上网可以登录使用,但在家带宽下就无法直接通信访问到。这就需要我们采取一些实用的内外网互通技巧来解决这个问…...

Mac中Docker下载与安装
目录 Docker下载安装配置 版本查询以及问题处理配置国内镜像在Docker中安装软件Nginx Docker 下载 官网:https://www.docker.com/get-started/ 或者 安装 配置 这里我们选择 Accept 选择默认配置就行,Docker 会自动设置一些大多数开发人员必要的配…...

固件测试:mac串口工具推荐
串口工具对固件测试来说非常重要,因为需要经常看日志,Windows上有Xshell和secureCRT,用起来很方便,尤其可以保存日志,并且可以进行日志分割。 mac上用什么串口工具呢,今天给大家推荐CoolTerm。 CoolTerm …...

41.防静电的系列措施
静电干扰的处理措施 1. ESD放电特征2. 静电防护电路设计措施3. ESD防护结构措施4. 案例分析 1. ESD放电特征 (1)放电电流tr≈1nS,ESD保护器件响应时间应小于1nS; (2)频率集中在几十MHz到500MHz;…...

Jmeter进行http接口测试
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1、jmeter-http接口测试脚本 jmeter进行http接口测试的主要步骤(1.添加线程组 2.添加http请求 3.在http请求中写入接口的URL,路径&#x…...

Ubuntu也开始锈化了?Ubuntu 计划在 25.10 版本开始引入 Rust Coreutils
上个月,jnsgruk发表了《未来20年的Ubuntu工程》(Engineering Ubuntu For the Next 20 Years)一文,其中概述了打算在未来几年中如何发展Ubuntu的四个关键主题。在这篇文章中,重点讨论 了“现代化”。在很多方面对Ubuntu…...

C++命名空间、内联与捕获
命名空间namespace 最常见的命名空间是std,你一定非常熟悉,也就是: using namespace std;命名空间的基本格式 注意,要在头文件里面定义! namespace namespace_name{data_type function_name(data_type parameter){data_type result;//function contentreturn result;}…...

PostgreSQL 系统管理函数详解
PostgreSQL 系统管理函数详解 PostgreSQL 提供了一系列强大的系统管理函数,用于数据库维护、监控和配置。这些函数可分为多个类别,以下是主要功能的详细说明: 一、数据库配置函数 1. 参数管理函数 -- 查看所有配置参数 SELECT name, sett…...

mdadm 报错: buffer overflow detected
最近跑 blktest (https://github.com/osandov/blktests) 时发现 md/001 的测试失败了 单独执行,最后定位到是 mdadm 命令报错: buffer overflow detected 这个 bug 目前已经修复: https://git.kernel.org/pub/scm/utils/mdadm/mdadm.git/commit/?id827e1870f3205…...

java ReentrantLock
线程同步工具。可以替代 synchronized . private final ReentrantLock reentrantLock new ReentrantLock();void testTask1 () {reentrantLock.lock(); // 获取锁try {System.out.println(Thread.currentThread().getName() " 进入临界区");// 模拟执行业务逻辑Th…...

kettle从入门到精通 第九十六课 ETL之kettle Elasticsearch 增删改查彻底掌握
场景: 群里有小伙伴咨询kettle从Elasticsearch中抽取数据,群里老师们纷纷响应,vip小伙伴是不是有中受宠若惊的感觉。 今天我们使用kettle通过es的原生rest接口来进行操作es,开整。 前提:本篇文章基于elasticsearch:7.…...
)
Kafka的核心组件有哪些?简要说明其作用。 (Producer、Consumer、Broker、Topic、Partition、ZooKeeper)
Kafka 核心组件解析 1. 基础架构图解 ┌─────────┐ ┌─────────┐ ┌─────────┐ │Producer │───▶ │ Broker │ ◀─── │Consumer │ └─────────┘ └─────────┘ └────────…...

Missashe考研日记-day34
Missashe考研日记-day34 1 专业课408 学习时间:3h学习内容: 今天是学习I/O管理第二小节的内容,听了课也做了题,这是操作系统倒数第二节知识了,还差最后一节就完结了。知识点回顾: 1.I/O核心子系统&#x…...

机器人跑拉松是商业噱头还是技术进步的必然体现
一、机器人跑拉松是商业噱头还是技术进步的必然体现 机器人参与马拉松赛事究竟是营销噱头还是技术进步的必然要求,需要从技术验证、行业推动、公众认知以及争议焦点等多个维度综合分析。基于全球首场人形机器人半程马拉松(2025年北京亦庄赛事࿰…...

传输层协议 1.TCP 2.UDP
传输层协议 1.TCP 2.UDP TCP协议 回顾内容 传输层功能:定义应用层协议数据报文的端口号,流量控制对原始数据进行分段处理 传输层所提供服务 传输连接服务数据传输服务:流量控制、差错控制、序列控制 一、传输层的TCP协议 1.面向连接的…...

LLM :Function Call、MCP协议与A2A协议
LLM 的函数调用、模型上下文协议 (MCP) 和 Agent to Agent (A2A) 协议:概念、区别与实例对比 引言:LLM 不断演进的格局 大型语言模型 (LLM) 的日益精进,使其能力已超越简单的文本生成,迈向与现实世界进行复杂交互的新阶段。为了…...

当当狸智能天文望远镜 TW2 | 用科技触摸星辰,让探索触手可及
当科技邂逅星空,每个普通人都能成为宇宙的追光者 伽利略用望远镜揭开宇宙面纱的 400 年后,当当狸以颠覆传统的设计,让天文观测从专业领域走入千家万户。当当狸智能天文望远镜 TW2,重新定义「观星自由」—— 无需专业知识ÿ…...

白杨SEO:如何查看百度、抖音、微信、微博、小红书、知乎、B站、视频号、快手等7天内最热门话题及流量关键词有哪些?使用方法和免费工具推荐以及注意事项【干货】
大家好,我是白杨SEO,专注SEO十年以上,全网SEO流量实战派,AI搜索优化研究者。 (温馨提醒:本文有点长,看不完建议先收藏或星标,后面慢慢看哈) 最近,不管是在白…...

Spring AI 之 AI核心概念
模型 人工智能(AI)模型是用于处理和生成信息的算法,通常旨在模拟人类的认知功能。这些模型通过从大规模数据集中学习模式和规律,能够生成预测结果、文本、图像或其他形式的输出,从而增强各行业应用的效能。 AI 模型种类繁多,每种模型都适用于特定的应用场景。虽然以 Ch…...

微软输入法常用快捷键介绍以及调教技巧
微软输入法(Microsoft Pinyin Input Method)是 Windows 系统内置的中文输入工具,以其高效、智能化的特点广受用户喜爱。掌握其常用快捷键和特殊模式可以显著提升输入效率。本文将介绍微软输入法在 Windows 10/11 环境下的常用快捷键及 U 模式…...

基于大模型的输卵管妊娠全流程预测与治疗方案研究报告
一、引言 1.1 研究背景与意义 输卵管妊娠作为异位妊娠中最为常见的类型,严重威胁着女性的生殖健康和生命安全。受精卵在输卵管内着床发育,随着胚胎的生长,输卵管无法提供足够的空间和营养支持,极易引发输卵管破裂、大出血等严重并发症,若救治不及时,甚至会导致孕产妇死…...

16.Excel:打印技巧
一 区域打印 不用打印整个表格,比如只想打印框选出来的信息。 选中区域调整列宽。 二 整表打印 选中整个工作表, 如果调完边距后仍然打印不完全,就用缩放功能。 三 居中打印 打印部分区域的时候,预览图不在居中。 四 行号打印 五 …...

AI驱动的Kubernetes管理:kubectl-ai 如何简化你的云原生运维
AI驱动的Kubernetes管理:kubectl-ai 如何简化你的云原生运维 kubectl-ai 项目概览核心能力:AI 如何赋能 kubectl自然语言的魔力:从繁琐命令到简单对话智能的命令生成与执行不仅仅是执行:结果的可解释性广泛的 AI 模型支持…...

maven基本介绍
Maven是一个常用的项目构建工具,用于管理Java项目的构建、依赖管理和项目信息管理。它可以帮助开发人员自动化构建过程,统一项目结构和构建规范,并管理项目所需的外部依赖库。 Maven通过一个项目对象模型(Project Object Model&a…...
)
SPL量化 BBIC(多空指标)
BBIC 是一种将不同天数移动平均线加权平均之后的综合指标,属于均线型指标,一般选用 3 日、6 日、12 日、24 日等 4 条平均线。BBIC 越小股价越强势,BBIC < 1 为多头行情, BBIC>1 为空头行情。 计算公式: 1. 3 日…...
)
【ArcGIS Pro微课1000例】0068:Pro原来可以制作演示文稿(PPT)
文章目录 一、新建演示文稿二、插入页面1. 插入地图2. 插入空白文档3. 插入图像4. 插入视频三、播放与保存一、新建演示文稿 打开软件,新建一个地图文档,再点击【新建演示文稿】: 创建的演示文档会默认保存在目录中的演示文稿文件夹下。 然后可以对文档进行简单的设计,例如…...

【论文阅读】Reconstructive Neuron Pruning for Backdoor Defense
我们的主要贡献包括: 我们引入了在相同样本集上进行神经元“遗忘”和“恢复”的新技术,并揭示了这种简单的基于重构的学习过程可以帮助暴露DNNs中的后门神经元。我们提出了一个新的防御方法——重构神经元剪枝(RNP),它…...

[数据处理] 3. 数据集读取
👋 你好!这里有实用干货与深度分享✨✨ 若有帮助,欢迎: 👍 点赞 | ⭐ 收藏 | 💬 评论 | ➕ 关注 ,解锁更多精彩! 📁 收藏专栏即可第一时间获取最新推送🔔…...