注意力机制(Attention)
1. 注意力认知和应用
AM: Attention Mechanism,注意力机制。
根据眼球注视的方向,采集显著特征部位数据:

注意力示意图:
注意力机制是一种让模型根据任务需求动态地关注输入数据中重要部分的机制。通过注意力机制,模型可以做到对图像中不同区域、句子中的不同部分给予不同的权重,从而增强感兴趣特征,并抑制不感兴趣区域。
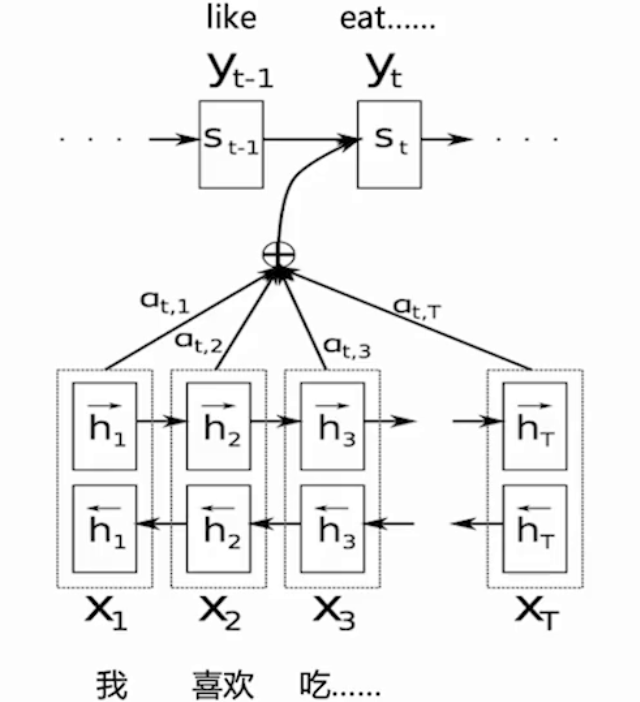
注意力机制最初应用于机器翻译(如Transformer),后逐渐被广泛应用于各类任务,包括:
1. NLP:如机器翻译、文本生成、摘要、问答系统等。
|
|
|
|---|---|
| 机器翻译 | 关键词提取,摘要生成:输入句和参考摘要之间的重叠关键词(红色)涵盖了输入句的重要信息,可根据这些关键字生成摘要 |

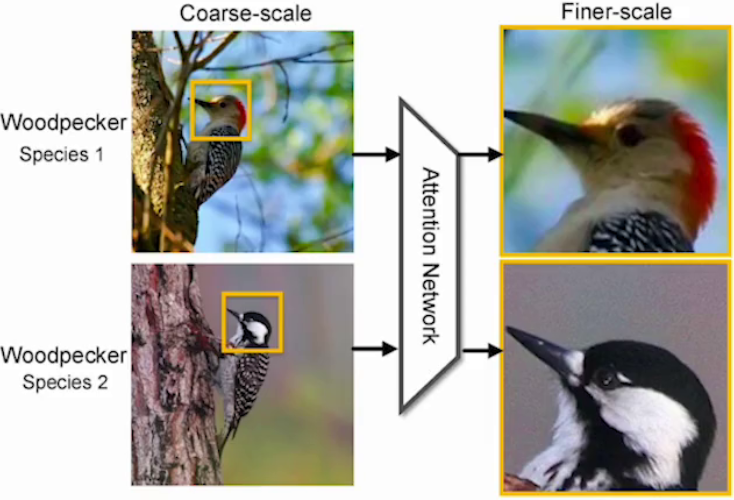
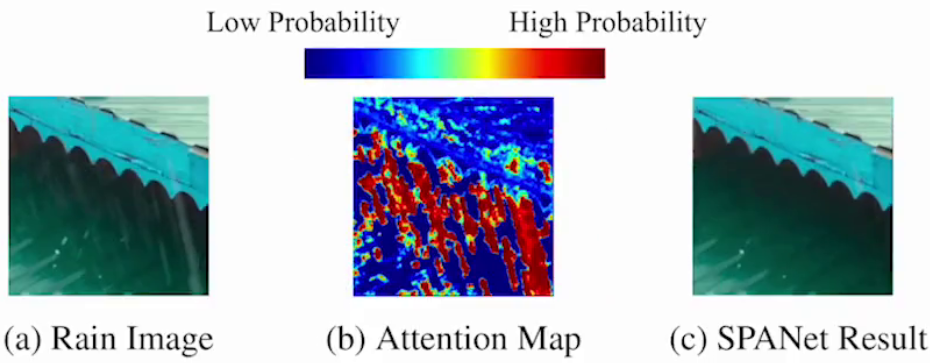
2. 计算机视觉:如图像分类(细粒度识别)、目标检测(显著目标检测)、图像分割(图像修复)等。
|
|
|
| 细粒度识别 | 图像修复:监控摄像头去除雨线、雨滴等 |
3. 跨模态任务:如图文生成、视频描述等。
这里我们学习下视觉处理中常见的典型注意力机制,如特征注意力、空间注意力以及混合注意力。
2. 通道注意力
对不同的特征通道进行增强或抑制,也就是赋予不同的权重参数。96个卷积核卷之后会得到不同的96个特征图谱:边缘、形状、颜色等,不同的通道关注不同的特征

2.1 SENet
Squeeze-and-Excitation Networks:挤压 - 和 - 激活、激发。
SENet模型论文: https://arxiv.org/pdf/1709.01507
2.1.1 基本认知
Filter SENet采用具有全局感受野的池化操作进行特征压缩,并使用全连接层学习不同特征图的权重,模型流程图如下:
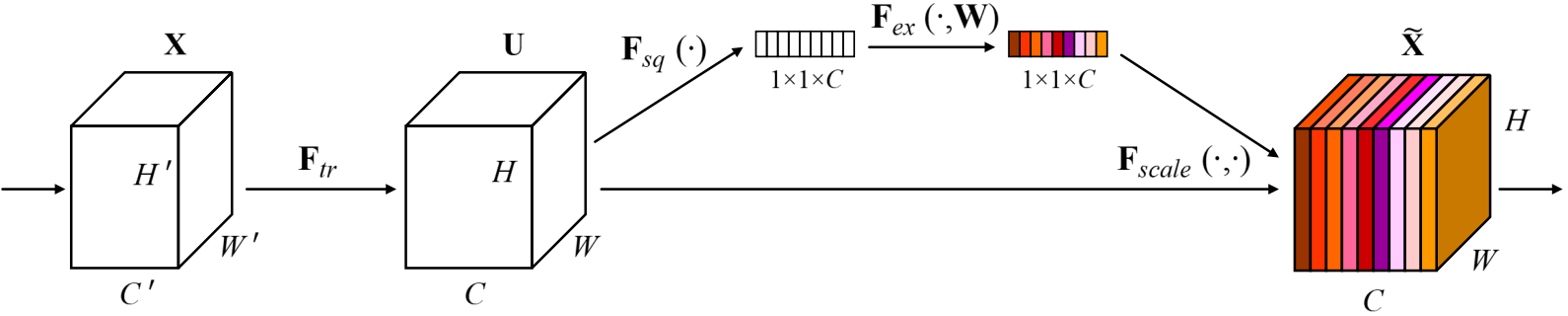
2.1.2 流程详解
1. Squeeze阶段:该阶段通过全局平均池化完成全局信息提取,公式如下:
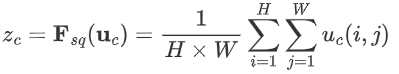
示意图如下:

# Squeeze:压缩、降维、挤压
self.sq = nn.AdaptiveAvgPool2d(1)2. Excitation阶段:Squeeze的输出作为Excitation阶段的输入,经过两个全连接层,动态地为每个通道生成权重,公式如下:
![]()
示意图如下:
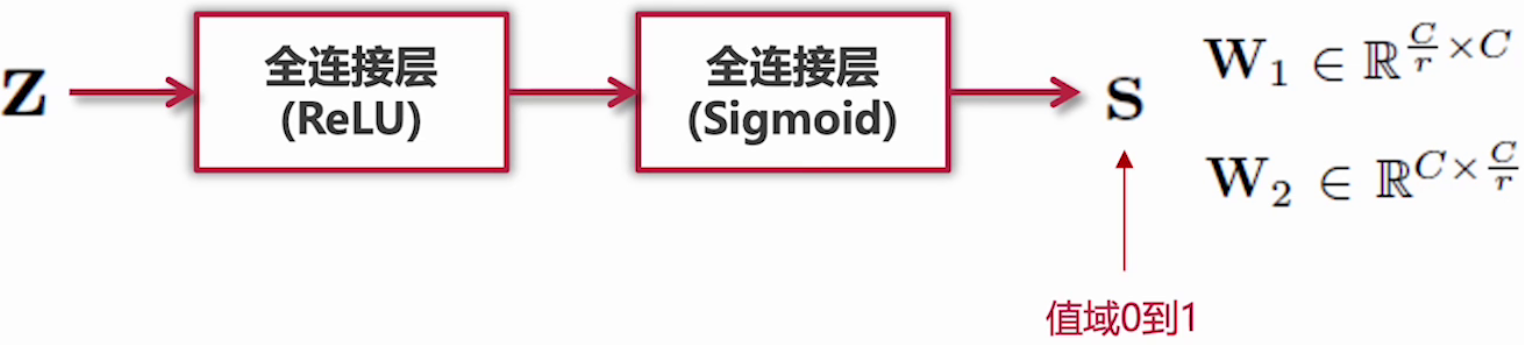
全连接层加入激活函数,用于引入非线性变化:
-
第一个全连接层(ReLU),将通道数从C降维为C/r。
-
r 是缩放因子,Ratio,比例的意思,用以减少运算量和防止过拟合。
-
通过第二个全连接层(si4)将维度恢复为C,输出一个1 \times 1 \times C的权重向量。
-
权重归一化:使用sigmoid确保权重在0~1之间。
-
该向量代表每个通道的重要性,也就是注意力的权重。
# Excitation:激活
self.ex = nn.Sequential(nn.Linear(inplanes, inplanes // r),nn.ReLU(),nn.Linear(inplanes // r, inplanes),nn.Sigmoid(),
) 3. 输出阶段:特征和 Excitation阶段产出的
进行相乘操作,用于对不同的通道添加权重:
![]()

def forward(self, x):# 缓存xintifi = xx = self.sq(x)x = x.view(x.size(0), -1)x = self.ex(x).unsqueeze(2).unsqueeze(3)return intifi * x2.1.3 融入模型
作为一种即插即用模块,可以添加到任意的层后,只要保证输出通道不变即可,如把SE融入到ResNet模型,如下:
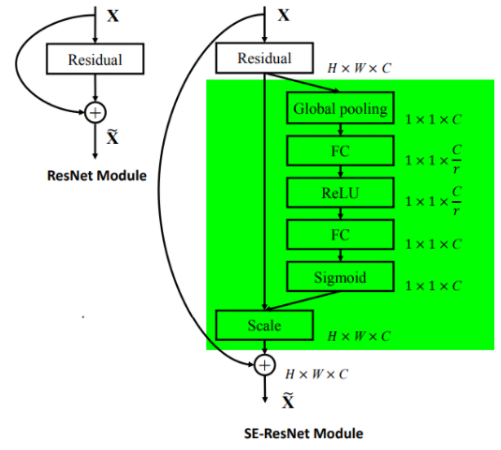
给ResNet-50加入SE注意力:
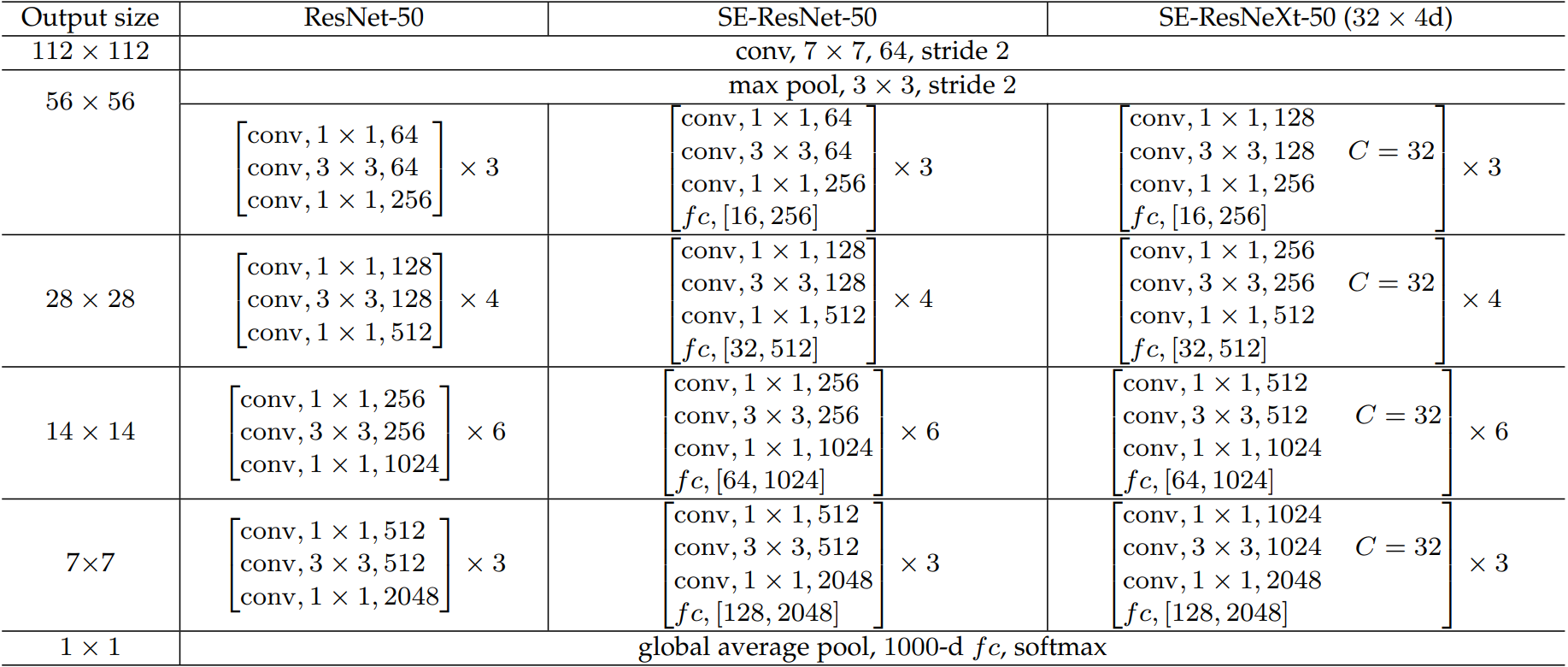
注解:表格中的 fc 后面的值,如 (16, 256) 或 (32, 512),表示在SE模块中的两个全连接层的维度变化。
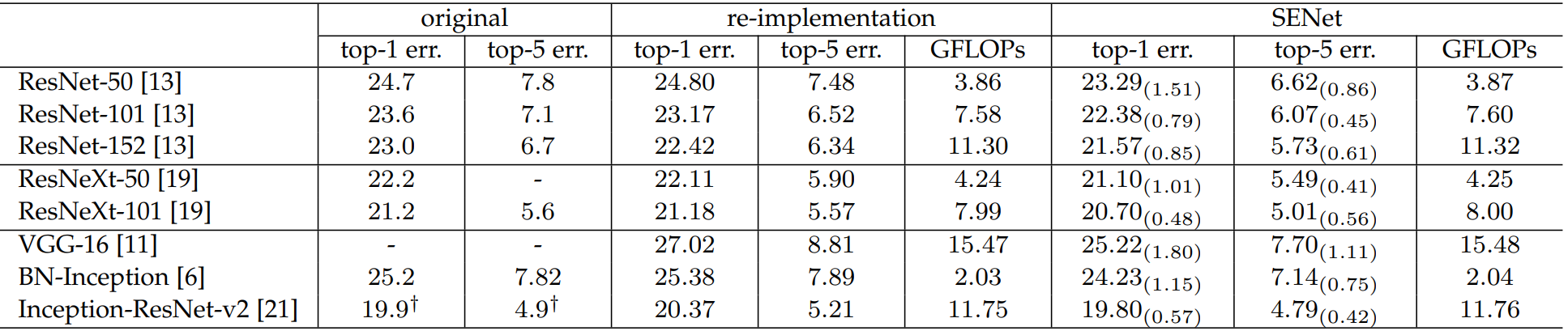
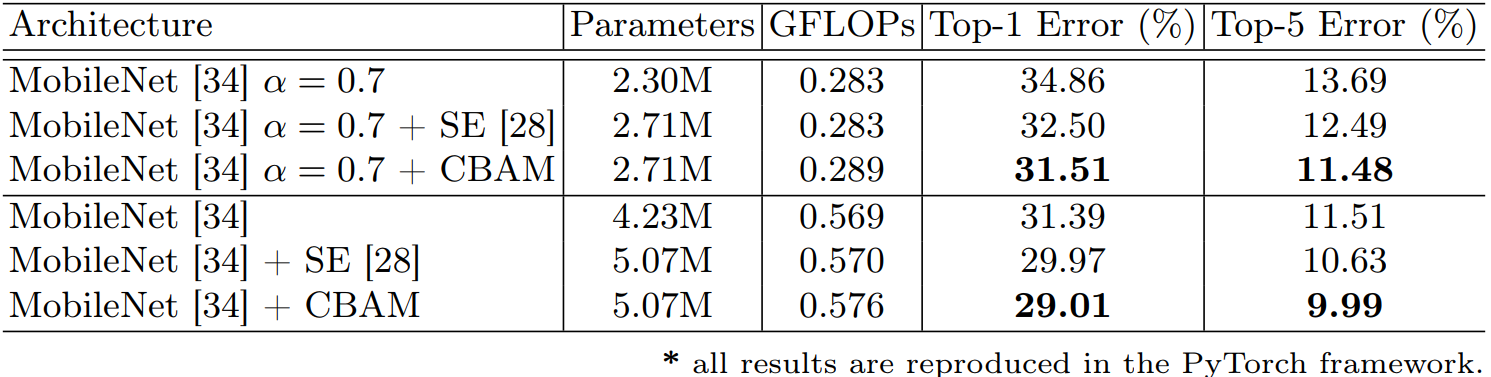
2.1.4 性能对比
加入SE后的性能对比表:re-implementation是SE作者复现效果
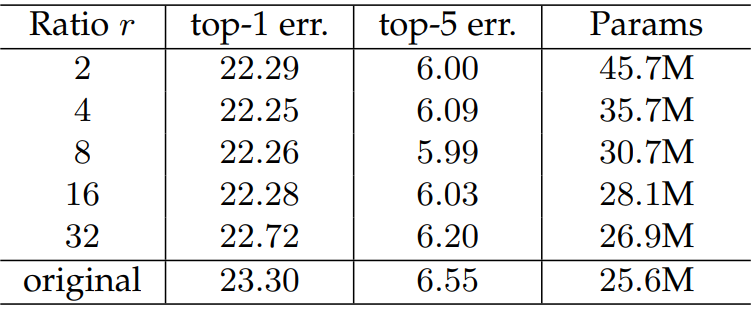
2.1.5 缩放因子
太小参数量大,容易过拟合。太大的话特征丢失严重,整体看8或16是比较不错的选择,具体的还是根据业务来定。
2.1.6 有无Squeeze
我们可以考虑不要Squeeze做平均池化,直接在Excitation阶段进行卷积操作。从下标看的出来,这个Squeeze阶段还是很有必要的。

2.1.7 池化方式
我们也可以考虑采用最大池化,不过效果不如平均池化。因为对注意力来讲更多的是维持原始信息,而不是强化特征。

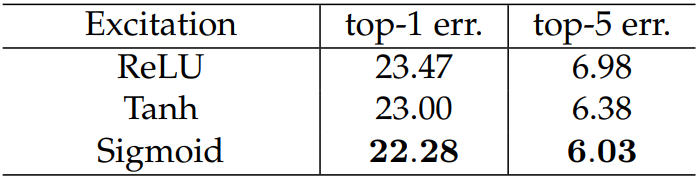
2.1.8 激活函数
这里是针对第二个全连接层,我们想要的是一个概率向量,无疑返回值在(0 ~ 1)之间的Sigmoid是最好的选择。
2.1.9 网络位置
SE模块灵活度较高,如下:
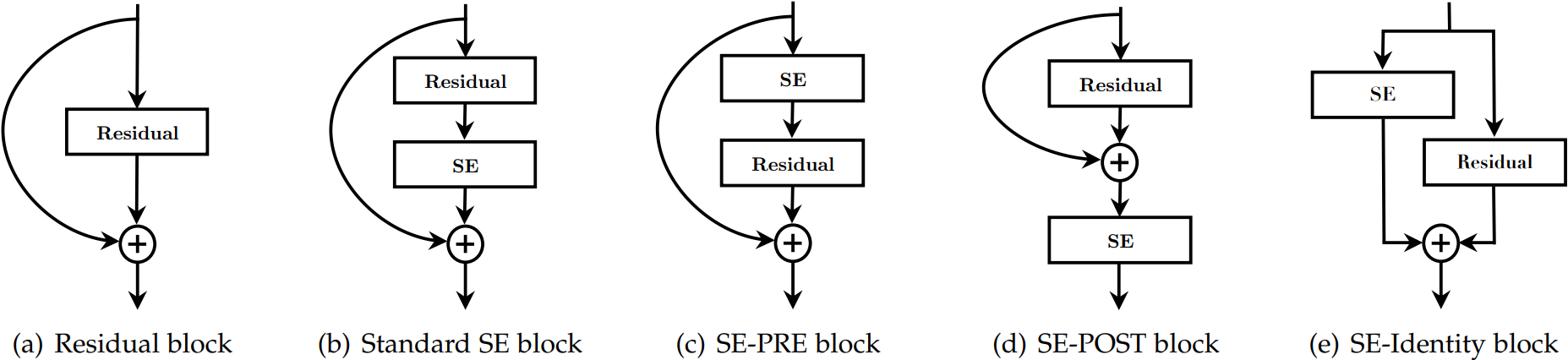
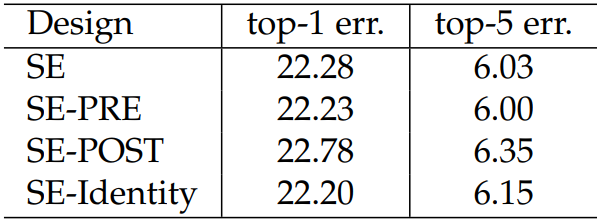
性能对比如下:POST模式最差
2.1.10 不同阶段添加
比如ResNet是分很多个阶段的,不同的阶段添加SE模块效果是不一样的。
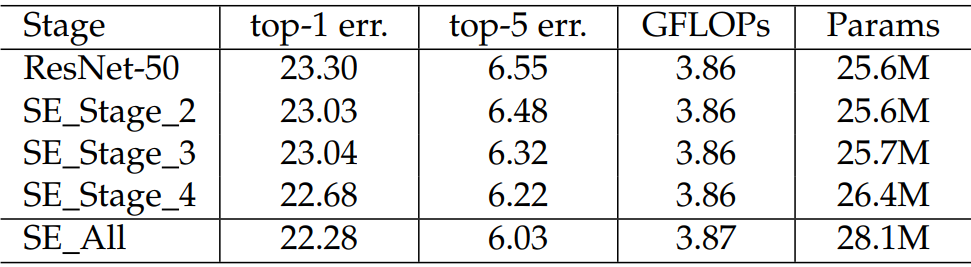
看的出来,越靠后的位置效果越好,因为越靠后特征学习的越好,此时加入效果就越好。当然全加SE的效果最好,不过参数量也不小。
2.2 SKNet
Selective Kernel Networks:可选择的 卷积核尺寸
目的:bSKNet中的神经元可以捕获不同尺度的目标物体,这验证了神经元根据输入自适应调整其感受野大小的能力。
SKNet论文地址:https://arxiv.org/pdf/1903.06586
2.2.1 基本认知
SK是对SE的改进版,可以动态调整感受野大小,分为Split-Fuse-Select共3个阶段,模型流程图如下:
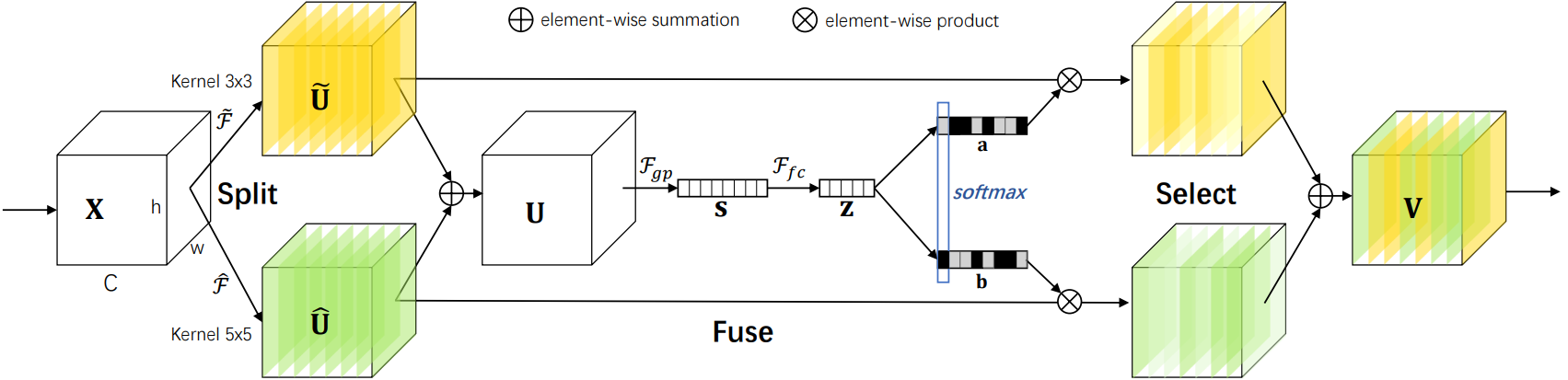
2.2.2 Split阶段
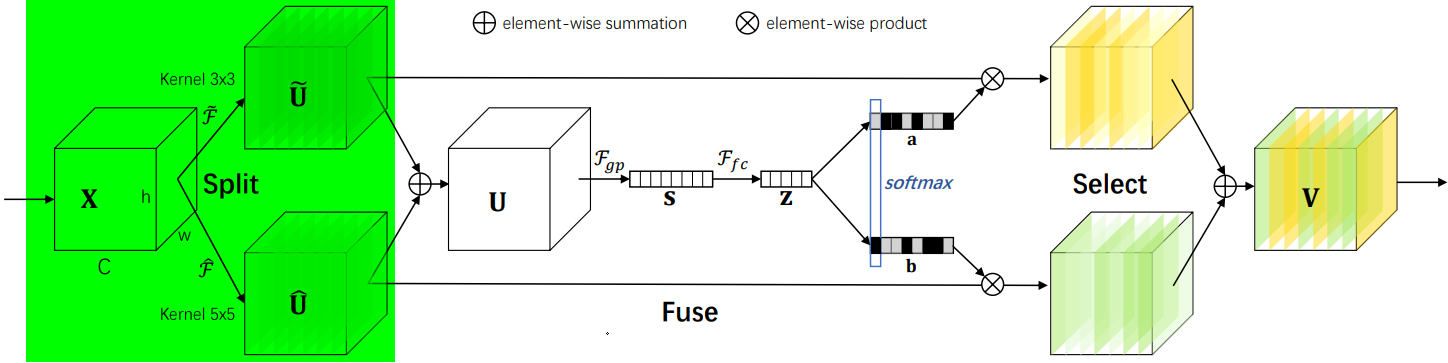
- 在Split阶段会分出多个分支,每个分支实现不同大小的感受野,从而捕获不同的特征。
- 为提高效率,传统的5×5卷积被替换为带有3×3卷积核和膨胀大小为2的膨胀卷积。
- 具体公式如下:
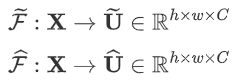
2.2.3 Fuse阶段
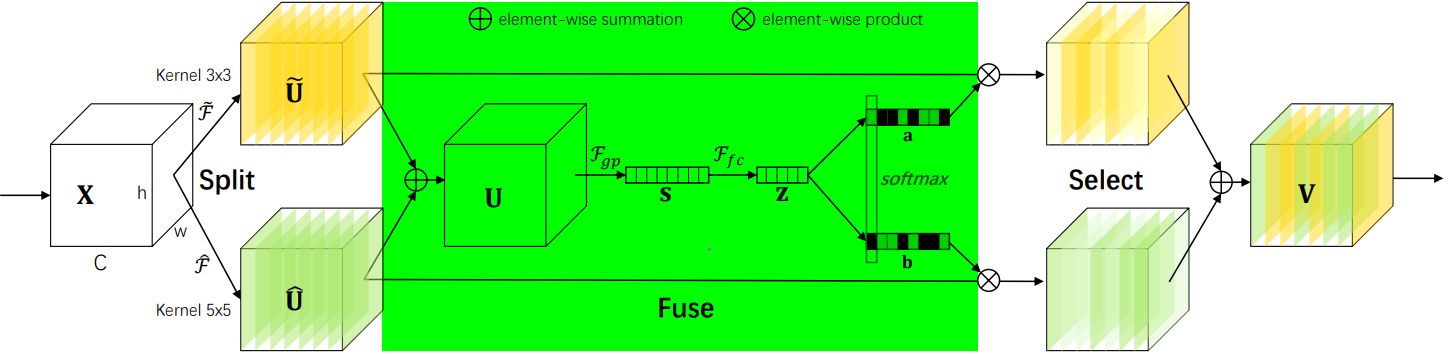
该阶段会整合分支信息,具体步骤如下:
1. 通过element-wise summation得到 U:
2. 通过global average pooling得到特征s:就是一个平均池化操作。
3. 通过FC全连接层得到:
,其中
是batch normalization,
是ReLU,
。注意这里通过reduction ratio r 和阈值 L 两个参数控制 z 的输出通道 d:
,L 默认值为32。
4. 通过两个不同的FC层(即矩阵A、B)分别得到 a 和 b,这里将通道从 d 又映射回原始通道数 C。
5. 对 a,b 对应通道 c 处的值进行 softmax 处理。
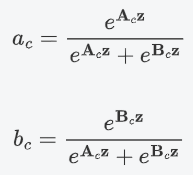
在公式中,,
和
分别代表不同(3×3、5×5)的卷积核经过全局池化(
)和全连接层(
)后得到的特征。a,b分别表示
和
的注意力系数。
2.2.4 Select阶段
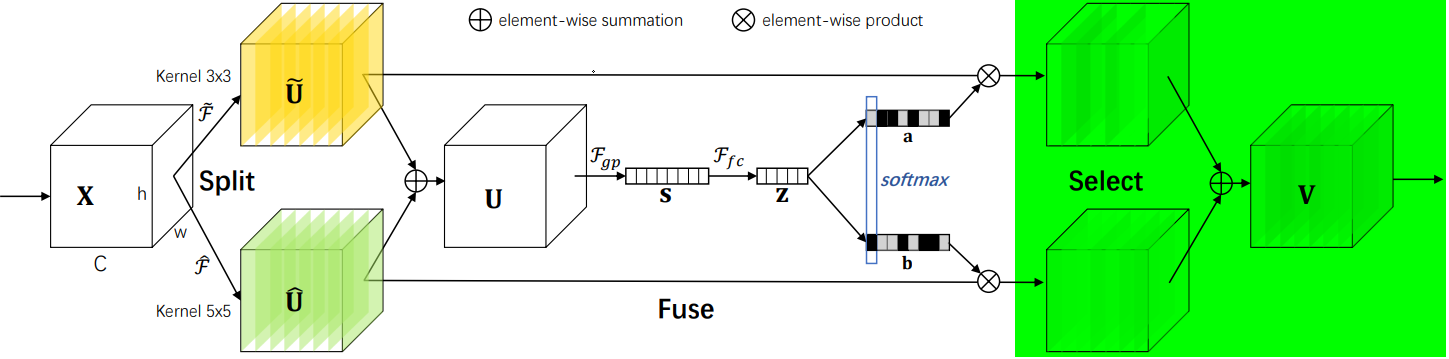
具体步骤如下:
1. 和
分别与 sofmax 处理后的 a,b 相乘,再相加,得到最终输出的 V 和原始输入 X 的维度一致。
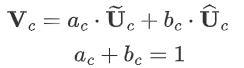
其中
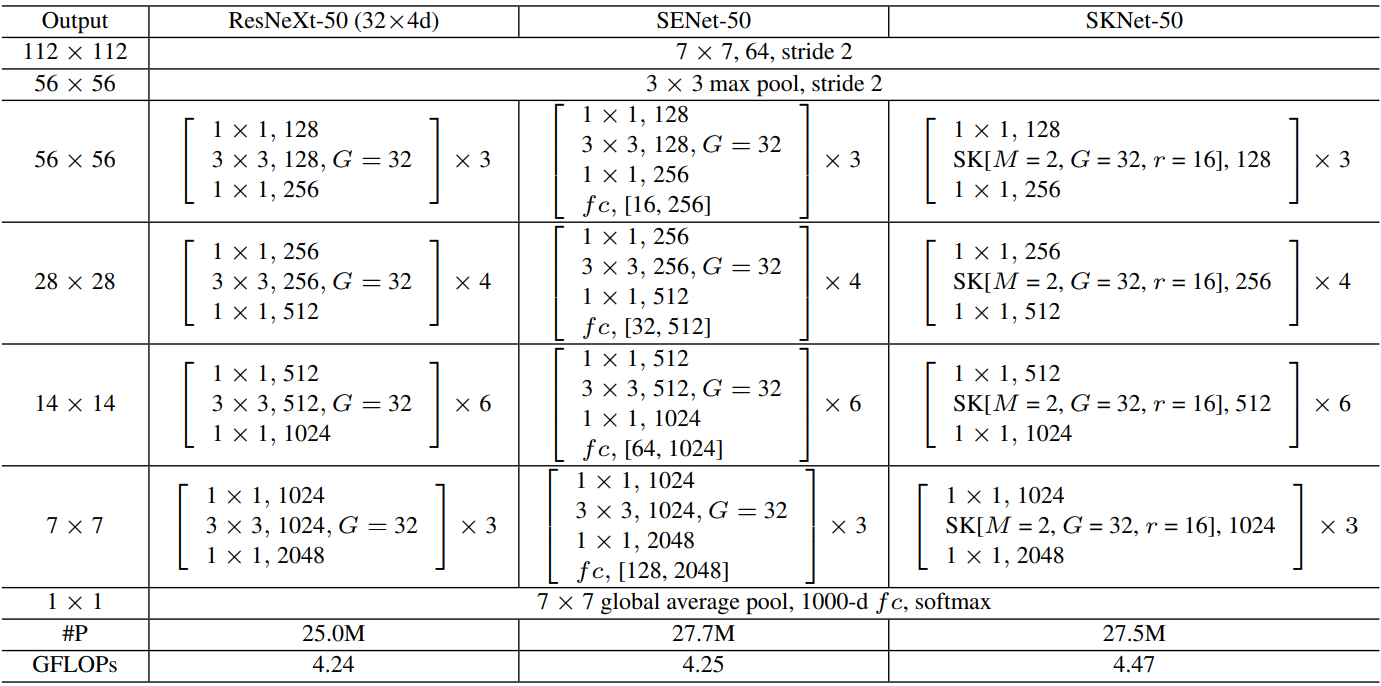
2.2.5 融入模型
ResNeXt加入SE和SK:
2.2.6 注意力权重分析
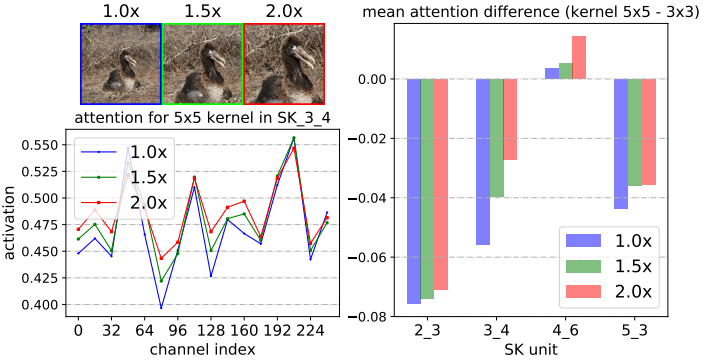
图标注解:
-
通过中心裁剪和随后的调整大小,逐步将中心对象从1.0× 扩大到2.0×
-
SK_X_Y 中的 X 代表网络的不同层级(Stage),数字越大表示层越深。
-
Y 代表该层级中的第几个SK模块。
-
不同的SK模块在不同的层级负责提取不同尺度、不同语义的特征。
-
从第2层到第5层,特征从低级(如边缘、纹理)逐渐过渡到高级语义信息(如物体、场景等)。
-
channel index(32、64、96等) 表示不同通道编号。
-
activation表示每个通道上的注意力权重值。这个值越高,表明网络对该通道上的特征越重视。
结论:
1. 当目标物体增大时,对大核(5×5) 的关注权值增大,这表明神经元自适应地变大。
2. 我们发现了一个关于自适应选择跨深度作用的令人惊讶的模式:目标对象越大,越会将更多的注意力分配给更大的对象。
3. 随着网络加深,5x5卷积核的权重值也逐渐在变大,但在更高层时又不同。
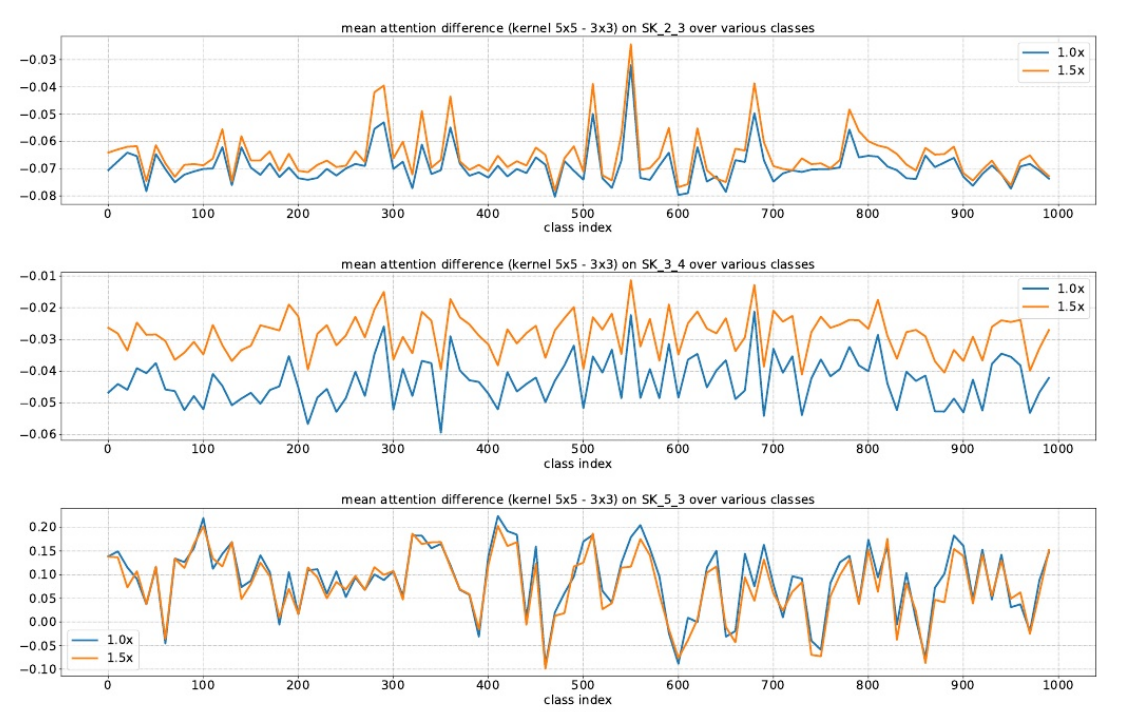
对于使用ImageNet上所有验证样本的1000个类别中的每一个,在SKNet-50的SK单元上的平均注意差(内核的平均注意值5×5减去内核的平均 注意值3×3)。在低级或中级SK单元(例如,SK 2.3, SK 34 4)上,如果目标对象变大(1.0x→1.5x),则明显更强调5×5核。
结论:在低级和中级阶段(例如,SK 23 3, SK 34 4),通过选择性核机制的核。然而,在更高的层次(例如,SK 53 3),所有的尺度信息都丢失了,这样的模式消失了。
这表明在网络的前期,可以根据对象大小的语义感知选择合适的核大小,从而有效地调整这些神经元的RF大小。然而,这种模式不存在于像SK 5.3这样的非常高层中,因为对于高层表示, “尺度”部分编码在特征向量中,与低层的情况相比, 内核大小的影响较小。
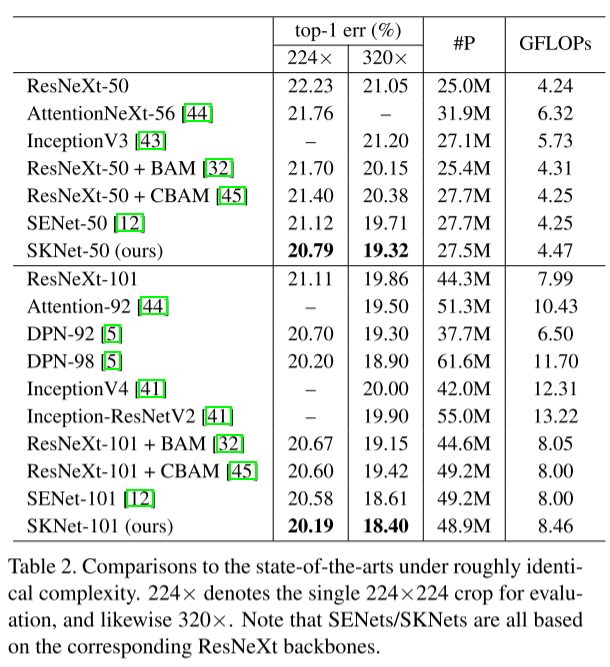
2.2.7 性能对比
3. 空间注意力
空间注意力(Spatial Attention)是一种专注于特征图的空间维度的重要性分配的机制。它通过对特征图中的特定空间位置进行加权,从而突出对任务最有贡献的区域,抑制无关或冗余的区域,以提高模型的性能
3.1 Spatial Attention Module
这里介绍的空间注意力是 CBAM 中的组成模块。
论文地址:https://arxiv.org/pdf/1807.06521
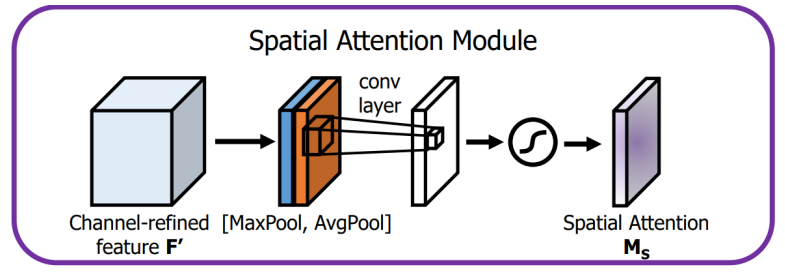
空间注意力模块通过卷积操作为特征图的每个空间位置生成权重,聚焦在图像中的关键区域,这是对通道注意力的补充。
-
空间注意力模块计算公式如下:
-
表示通道中的平均池化特征
-
表示通道中的最大池化特征
-
表示滤波器大小为 7×7 的卷积操作
-
表示 sigmoid 激活函数
-
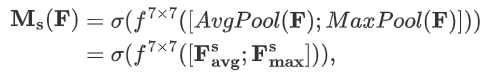
-
空间注意力模块布局如下:
-
输入特征:通道注意力模块的输出 F' 就是空间注意力模块的输入。
-
池化操作:
-
在 F' 的通道维度上进行全局的 MaxPool 和 AvgPool,生成 2 个二维特征图,维度为 1 × H × W。
-
-
卷积层:
-
把池化得到的特征图连接起来
。
-
使用一个
的卷积核对拼接后的特征图进行卷积操作,经 Sigmoid 激活后,生成空间注意力图
,维度为
。
-
-
输出:
-
空间注意力图M_S与经过通道注意力增强后的特征图 F' 逐元素相乘,输出最终的增强特征图。
-
-
3.1.1 实验结论
这个实验结论是 CBAM 论文中给出的,不仅仅是添加了空间注意力,还添加了通道注意力,可以看出都比不用(baseline)效果要好

3.1.2 构建
import torch
import torch.nn as nn# 空间注意力模块
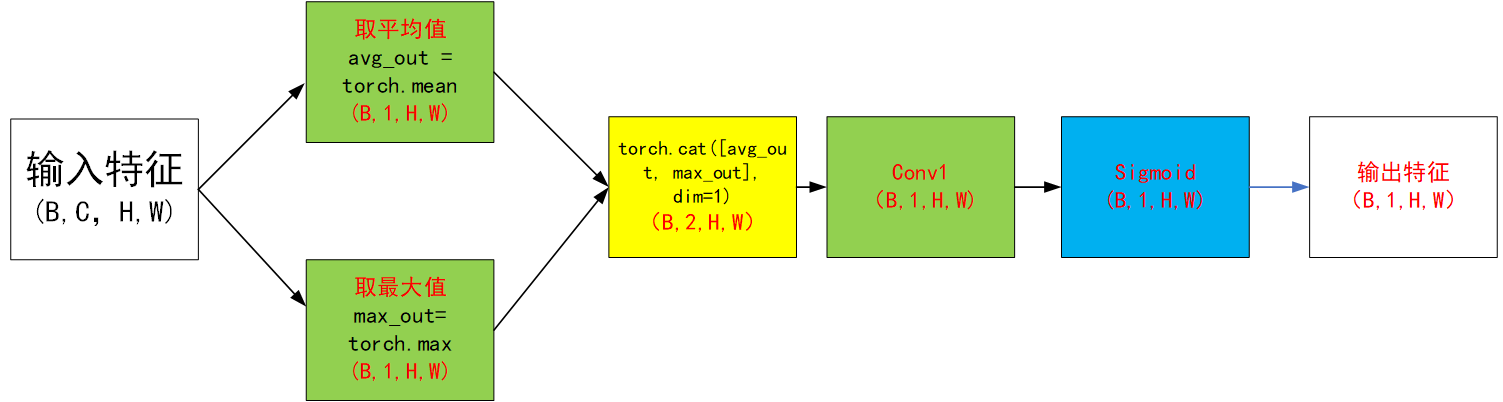
class SpatialAttentionModule(nn.Module):def __init__(self):super(SpatialAttentionModule, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3),nn.Sigmoid(),)def forward(self, x):max_pool = torch.max(x, dim=1, keepdim=True)[0]avg_pool = torch.mean(x, dim=1, keepdim=True)pool = torch.cat([max_pool, avg_pool], dim=1)out = self.conv(pool)return out3.2 Learn to Pay Attention
论文地址:https://arxiv.org/pdf/1804.02391。
源代码地址:https://github.com/SaoYan/LearnToPayAttention。
空间注意力(Spatial Attention)主要用于CV,它在空间维度上选择性地关注输入特征图的不同位置,从而提升模型对关键区域的感知能力。其实现原理是基于不同像素位置,生成对应概率掩码,是比较低层的注意力机制。
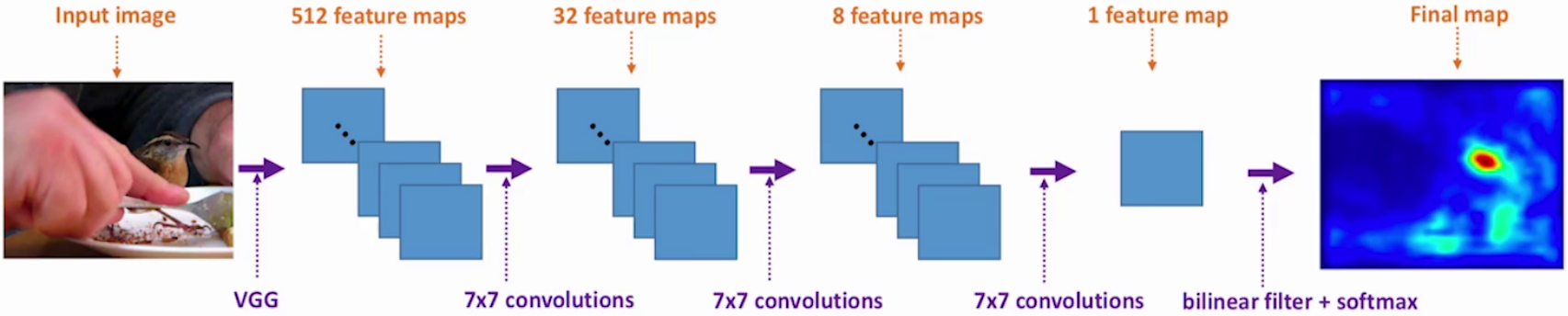
3.2.1 基本认知
结合全局特征和局部特征获得注意力机制,使用加权的局部特征来识别目标。
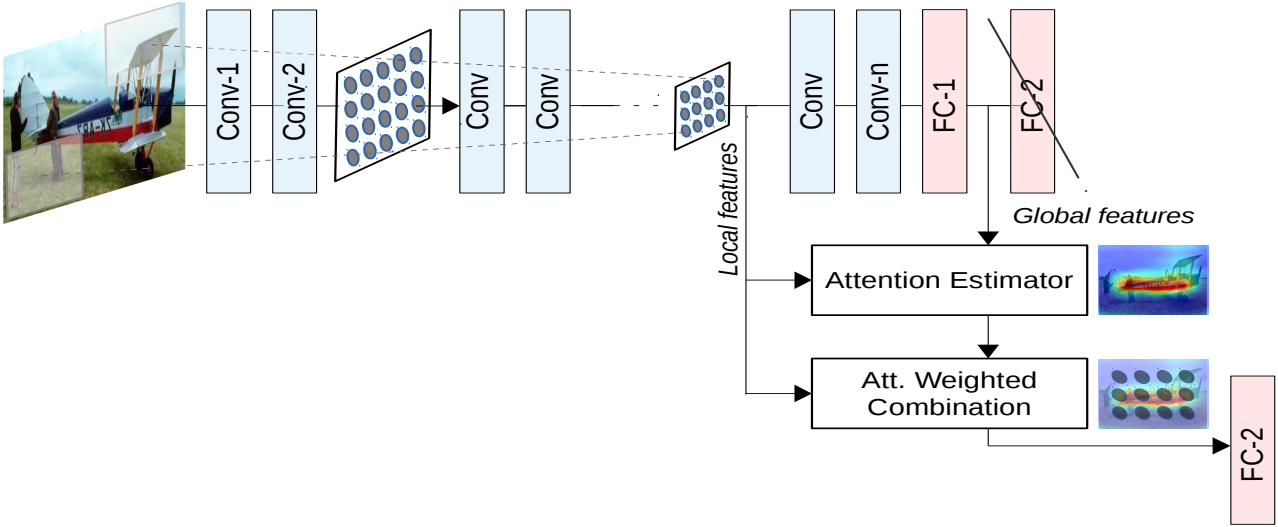
-
Local features:局部特征
如头部、轮子、尾翼、发动机、机身标志或窗户等,包含丰富的细节,对于识别飞机的具体种类、型号等非常有帮助。
-
Global features:全局特征
如整体形状、轮廓、大小、相对背景中的位置等;对于识别是什么飞机很重要,如战斗机、客机还是直升机。
-
特征融合:
在生成注意力权重前会对输入的局部和全局特征进行融合。通过全局池化(Global Average Pooling)来获得全局上下文信息。
-
Attention Estimator:
对输入特征图进行多层卷积、池化、激活等操作,用来挖掘特征之间的关系,从而生成注意力权重图。权重图的每个位置对应特征图中的一个空间位置,表示该位置的重要性。
-
Att. Weighted Combination:
将生成的注意力图与原始特征图逐点相乘,得到加权后的特征图。
3.2.2 融入模型
基于VGG16网络的多层注意力融合:是为了适配不同大小的目标。
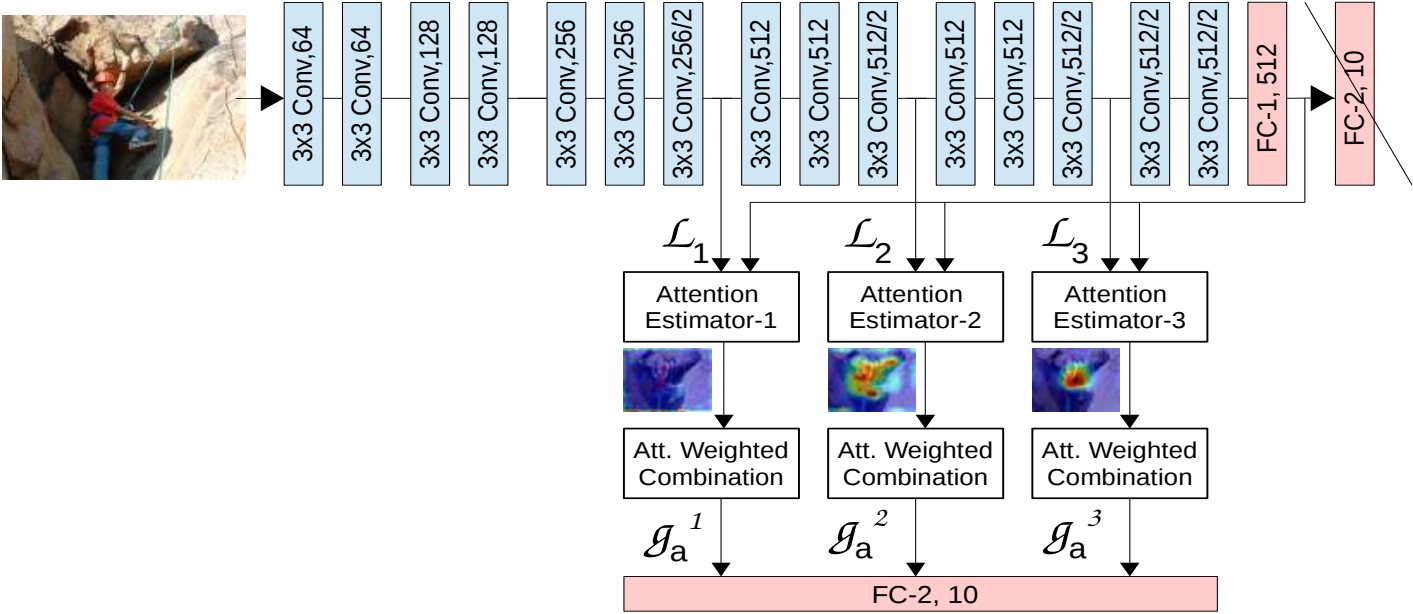
通过多层注意力估计器,模型能够学会在不同的特征层次上关注有用的信息,提升分类性能。
1)流程概述:
-
局部特征向量,s表示特征图层数:
-
(
)为VGG不同层级的局部特征向量,将
FC-1, 512的输出 G 视作全局特征,同时移除FC-2, 10层。 -
Attention Estimator 接收 L_n 和 G 作为输入,计算出注意力权重图(Attention map),挖掘特征之间的关系。
-
Attention map作用于 L_n 的每个channel得到 Weighted local feature
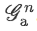 。
。 -
把各个层级下的
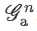 进行连接操作后得到
进行连接操作后得到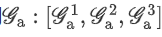
-
最后将
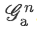 送入全连接层
送入全连接层FC-2, 10进行分类。
2)![]() 计算过程:
计算过程:
计算过程及关联数学公式如下:
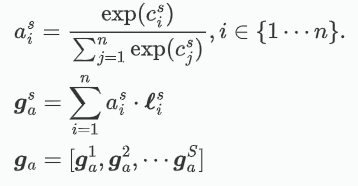
公式注解:
-
:第 s 层特征图在位置 i 处的兼容性分数(compatibility score)。
-
:通过 softmax 计算得到的第 s 层特征图在位置 i 处的注意力权重。
-
:经过注意力加权后的第 s 层特征图的全局加权特征向量。
-
:第 s 层特征图在位置 i 处的局部特征向量。
-
:注意力权重
相乘,表示该位置在注意力机制中的贡献。
-
:最终得到的全局加权特征向量,它是不同层的加权特征向量
-
2)兼容性得分计算:
兼容性得分,compatibility score,论文给出了两种方式:
-
内积法:两个特征直接做点乘得到:
-
有参法:将两个张量逐元素相加后,再经过一个全连接层进行学习, 下式中 \boldsymbol{u} 就是学习到的线性映射:
3.2.2 实验效果
从可视化和数据化两个方面进行观察。
1)效果可视化:

图阅读注解:
proposed:表示加入LTPA注意力机制。
existing:表示加入传统的注意力机制。
2)效果数据化
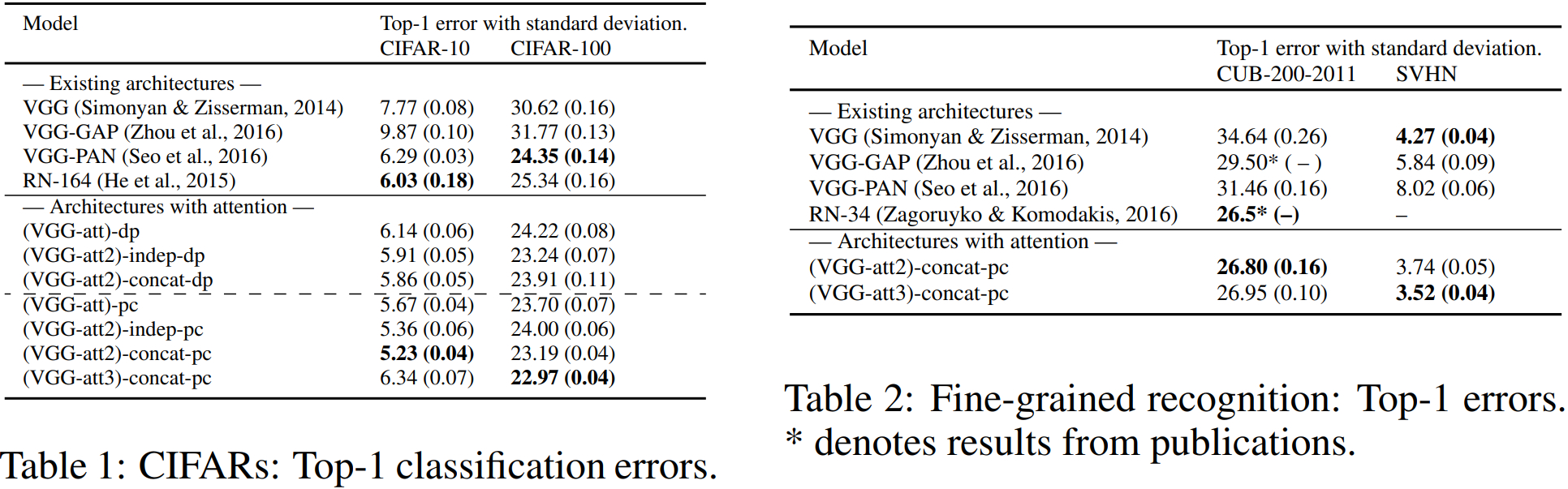
表阅读注解:注意力获取方法:pc表示有参法,dp表示内积法,最终预测策略:concat表示特征拼接后预测,indep表示多尺度独立预测结果相加
4. 混合注意力
混合注意力机制(Hybrid Attention Mechanism)是一种结合空间和通道注意力的策略,旨在提高神经网络的特征提取能力。
4.1 CBAM
Convolution Block Attention Module :卷积块注意力模块
论文地址:https://arxiv.org/pdf/1807.06521
4.1.1 基本认知
CBAM是一种轻量级的注意力模块,它通过增加空间和通道两个维度的注意力,来提高模型的性能。
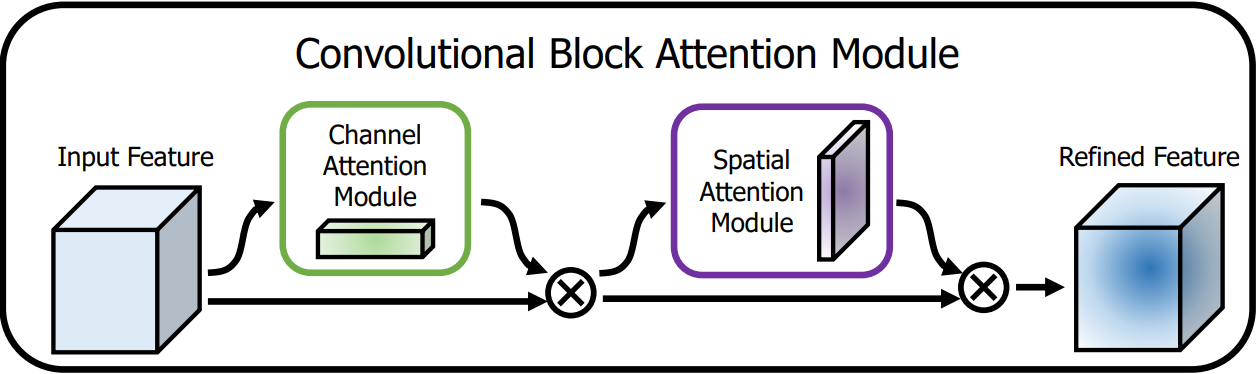
一维的通道注意力图:
二维的空间注意力图:
整个注意力过程可以概括为:
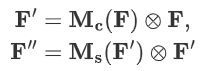
4.1.2 通道注意力模块
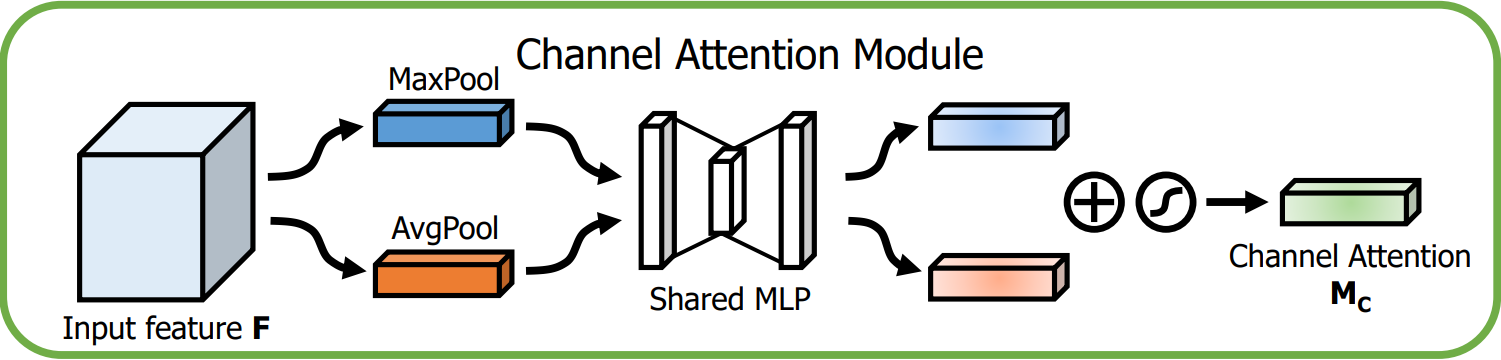
通道注意力模块的目的是为每个通道生成一个注意力权重,整体流程如下图:
通道注意力模块机制公式如下:
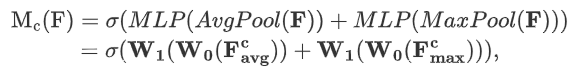
其中:r是缩放因子,用以减少参数量
通道注意力模块机制详情如下:
-
输入特征:输入特征图 F 的尺寸为 H × W × C。
-
全局池化:
-
首先对 F 进行全局的MaxPool和AvgPool,得到两个特征图,尺寸为 1×1×C。
-
MaxPool提取了局部强响应特征,AvgPool提取了全局视角。
-
-
共享多层感知器(MLP):
-
池化后的2个特征向量分别送入一个共享MLP,它包含两个全连接层,用来处理和生成通道注意力。
-
MLP的共享权重减少了参数量,同时确保两个特征向量的变换方式是一致的。
-
MLP首先会降维为 C/r,然后升维为 C。
-
-
加法与激活:
MLP输出的两个特征向量逐元素相加后经Sigmoid后,生成维度为 1 × 1 × C的通道注意力图
,表示每个通道的重要性。
-
输出:
通道注意力图
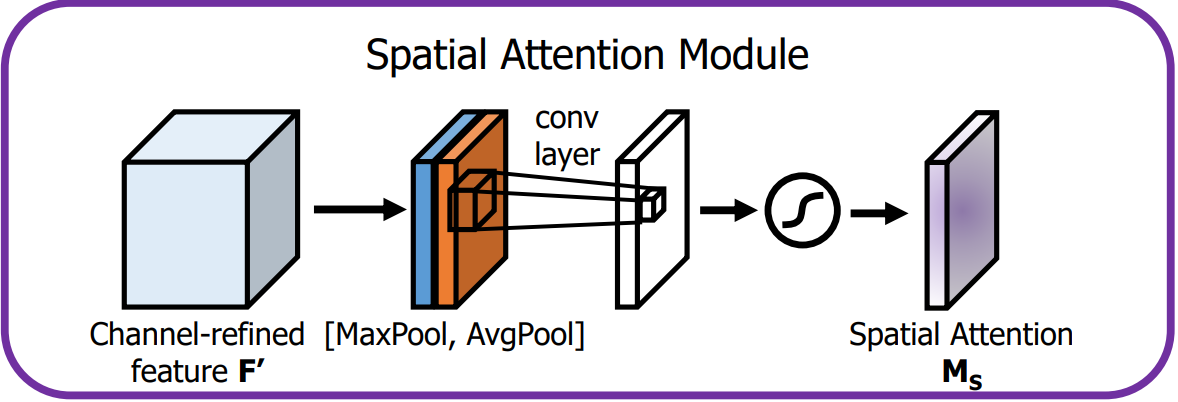
4.1.3 空间注意力模块
空间注意力模块通过卷积操作为特征图的每个空间位置生成权重,聚焦在图像中的关键区域。
空间注意力模块机制公式如下:
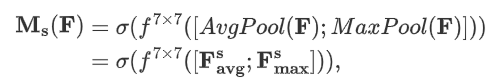
其中:
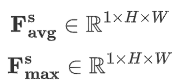
空间注意力模块机制详情如下:
-
输入特征:通道注意力模块的输出 F' 就是空间注意力模块的输入。
-
池化操作:
-
首先在 F' 的通道维度上进行全局的MaxPool和AvgPool,生成2个二维特征图,维度为 H × W × 1。
-
这样可以分别提取空间上最重要的局部和全局信息。
-
-
卷积层:
将池化得到的两个特征图按通道维度进行连接,形成一个 H × W × 2 的特征图,并通过大小为 7 × 7 的卷积层处理。
-
激活与输出:
-
卷积层的输出经Sigmoid激活后,生成单通道的空间注意力图
-
空间注意力图与经过通道注意力增强后的特征图 F' 逐元素相乘,输出最终的增强特征图。
-
4.1.4 不同策略效果对比
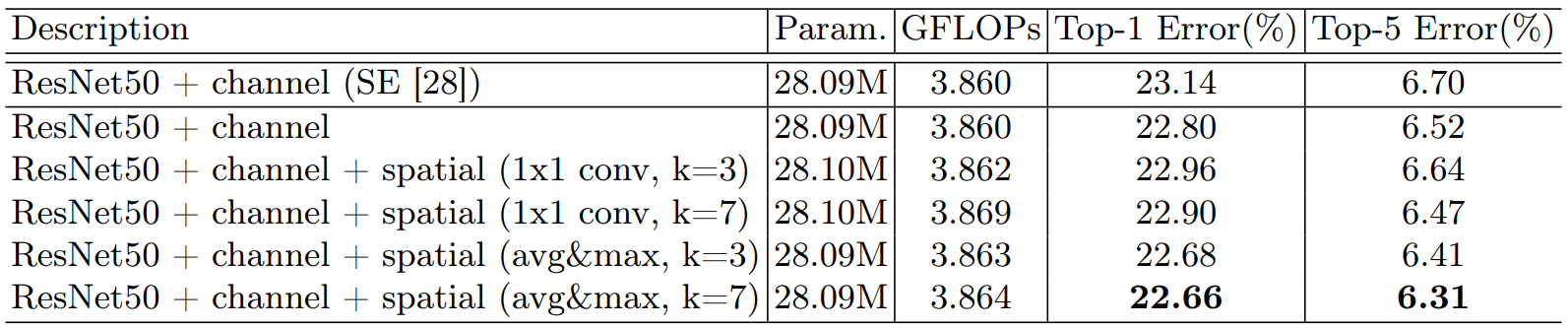
1)通道注意力:加入通道注意力:可以看的出来都比不用(baseline)效果要好。

2)叠加空间注意力:在通道注意力的基础之上加入空间注意力,就是混合注意力:效果最好的就是CBAM,并且池化不需要参数。
3)叠加顺序:空间注意力和通道注意力位置调整效果对比:还是CBAM的效果好。

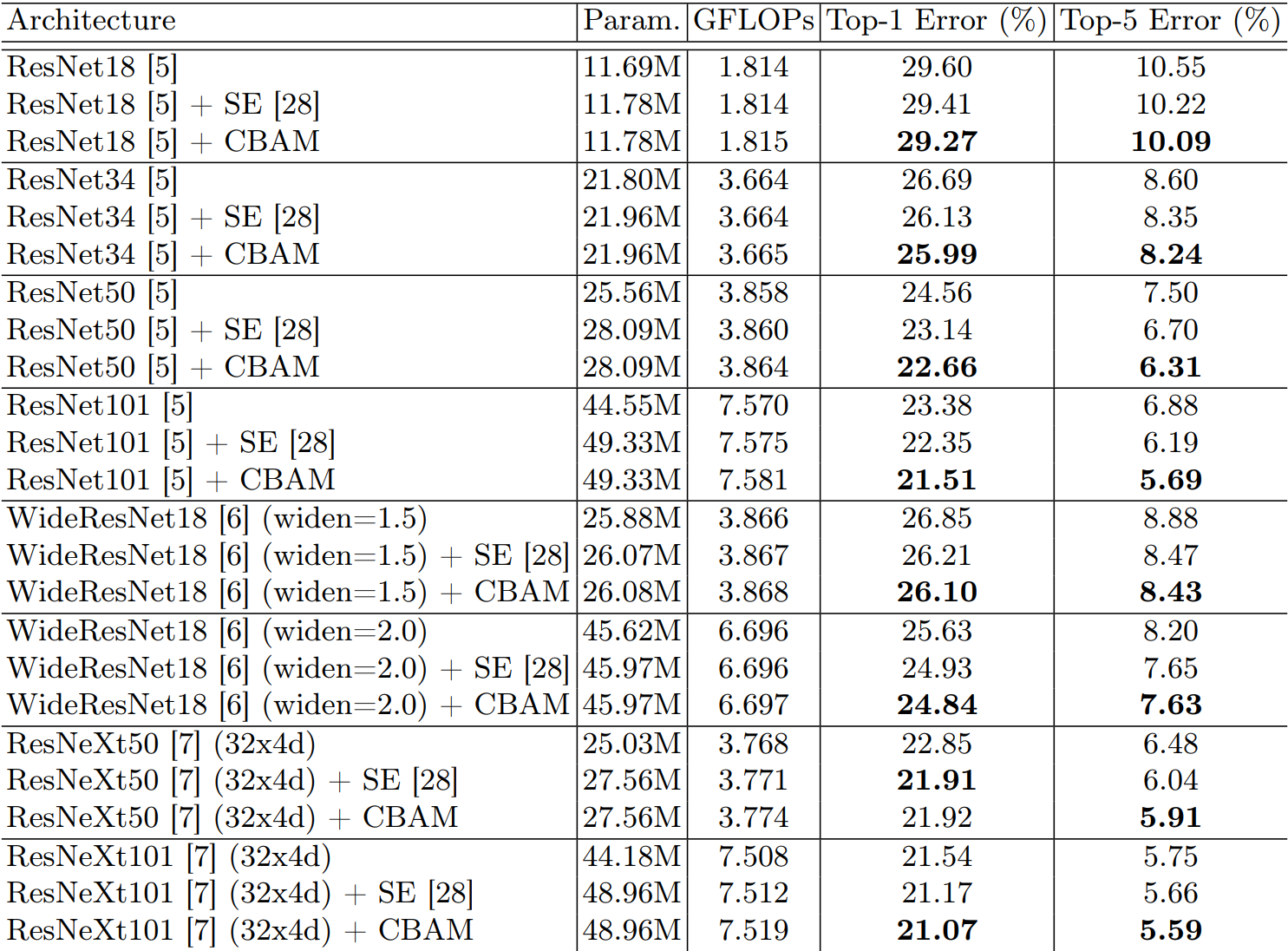
4)不同模型:不同模型对比:主打一个CBAM就是好。
5)轻量级模型:在一些轻量级模型上的效果还是很明显的。
6)注意力可视化:可视化的方式对比。

4.2 BAM
Bottleneck Attention Module:瓶颈注意力模块。
论文地址:https://arxiv.org/pdf/1807.06514
4.2.1 基本认知
BAM是通过在空间和通道两个维度上分别构建注意力模块,它们是**并行处理**的。
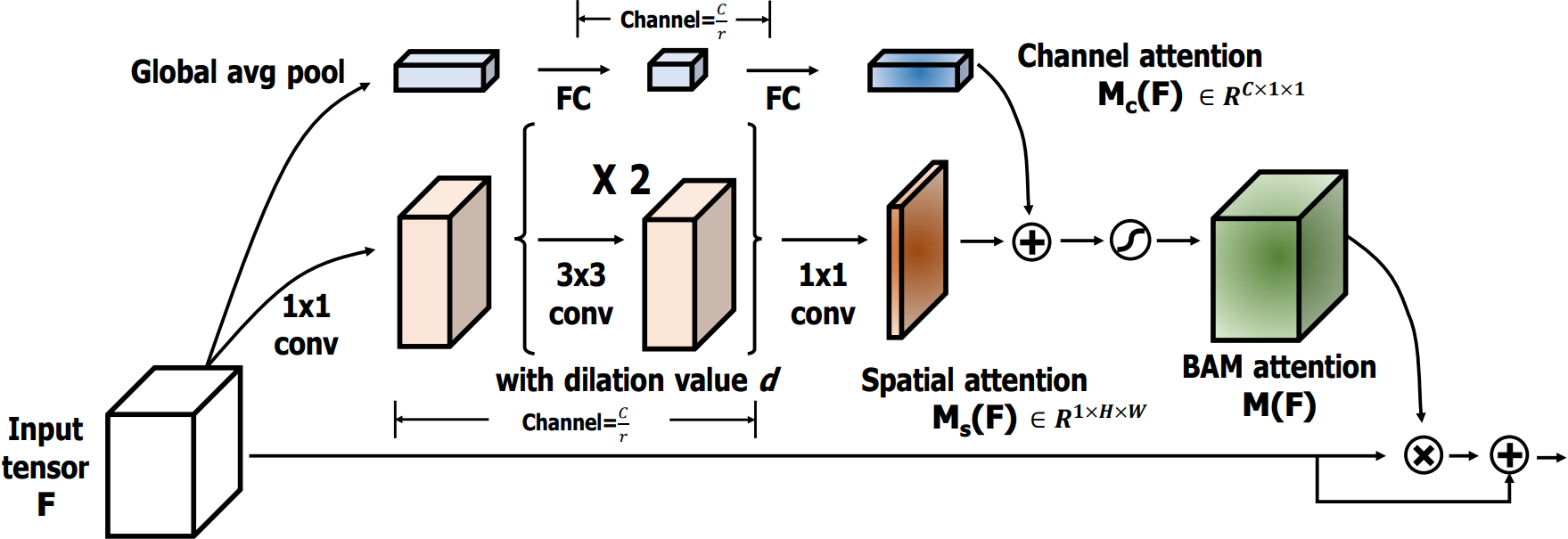
其中:形状不同的张量会自动进行广播机制。
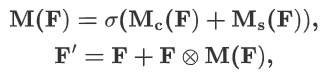
4.2.2 通道注意力模块
通道注意力公式表达如下:
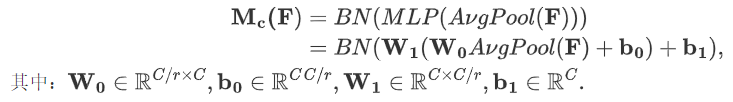
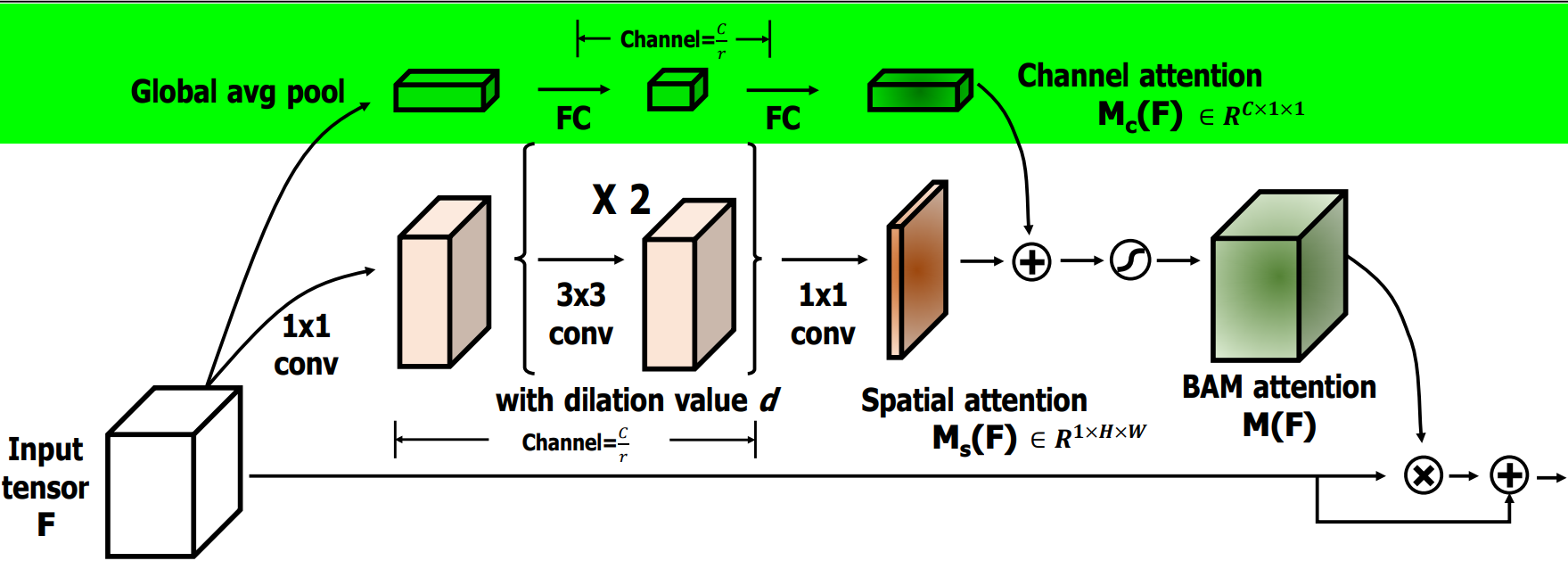
通道注意力流程如下:
-
全局平均池化:对输入特征 F 进行GlobalAvgPooling,保留通道的重要全局信息。
-
全连接层:池化后的特征通过两个FC,第一个FC降维,第二个FC则恢复到原通道数 C。这一过程可以学习通道间的依赖关系。
-
通道注意力:通过激活函数 Sigmoid 生成通道注意力图 M_c(F),用于对原始通道进行加权,强调重要通道,抑制不重要通道。
4.2.3 空间注意力模块
空间注意力公式表达如下:
![]()
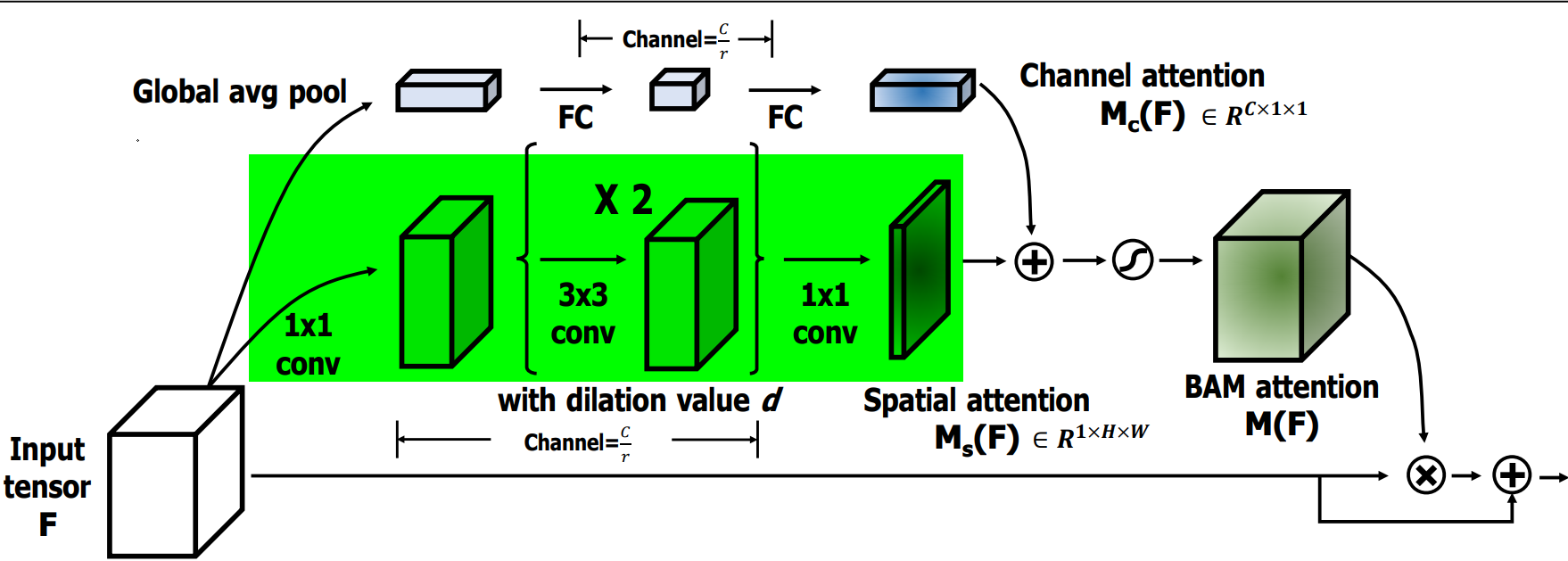
空间注意力流程如下:
-
1×1卷积:对输入特征 F 进行一次卷积操作,用于压缩通道维度并保持原始的空间信息,压缩因子是 r=16。
-
膨胀卷积:使用两层膨胀卷积(Dilated Convolution),膨胀率为 d=4。这样既扩大了感受野,又不增加参数量,帮助模型在空间维度上捕捉更广的上下文信息。
-
空间注意力生成:卷积操作生成一个空间注意力图 M_s(F),用于标识出空间维度上哪些位置更重要。
4.2.4 注意力融合
通道和空间注意力融合:和
相加后,通过Sigmoid处理,生成最终的注意力图
。
4.2.5 注意力应用
-
BAM注意力图 M(F) 应用到 F 上,从而对特征图进行重新加权。
-
残差连接:将加权后的特征图与输入特征 F 进行相加,形成残差连接。
这样不仅保留了原始特征信息,还让网络学习到重要的注意力区域。
4.2.6 实验结果
对比不同情况下的模型效果。
1)超参数配置:
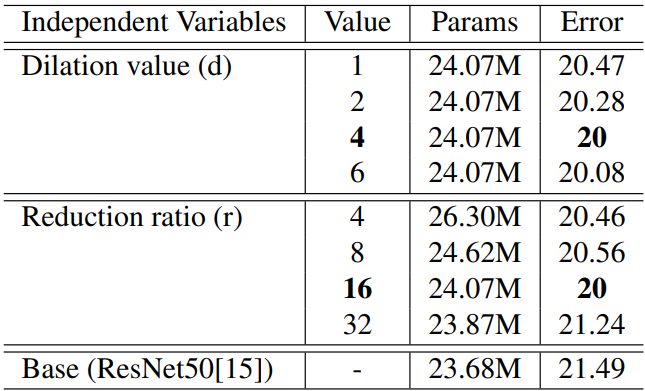
超参数:膨胀卷积的膨胀系数、FC的缩放因子
2)融合方式:
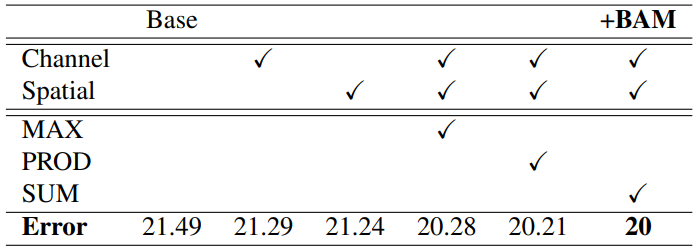
融合方式不同,效果也不同,最总就是两个注意力并行后相加效果最好。
3)模型横向对比:
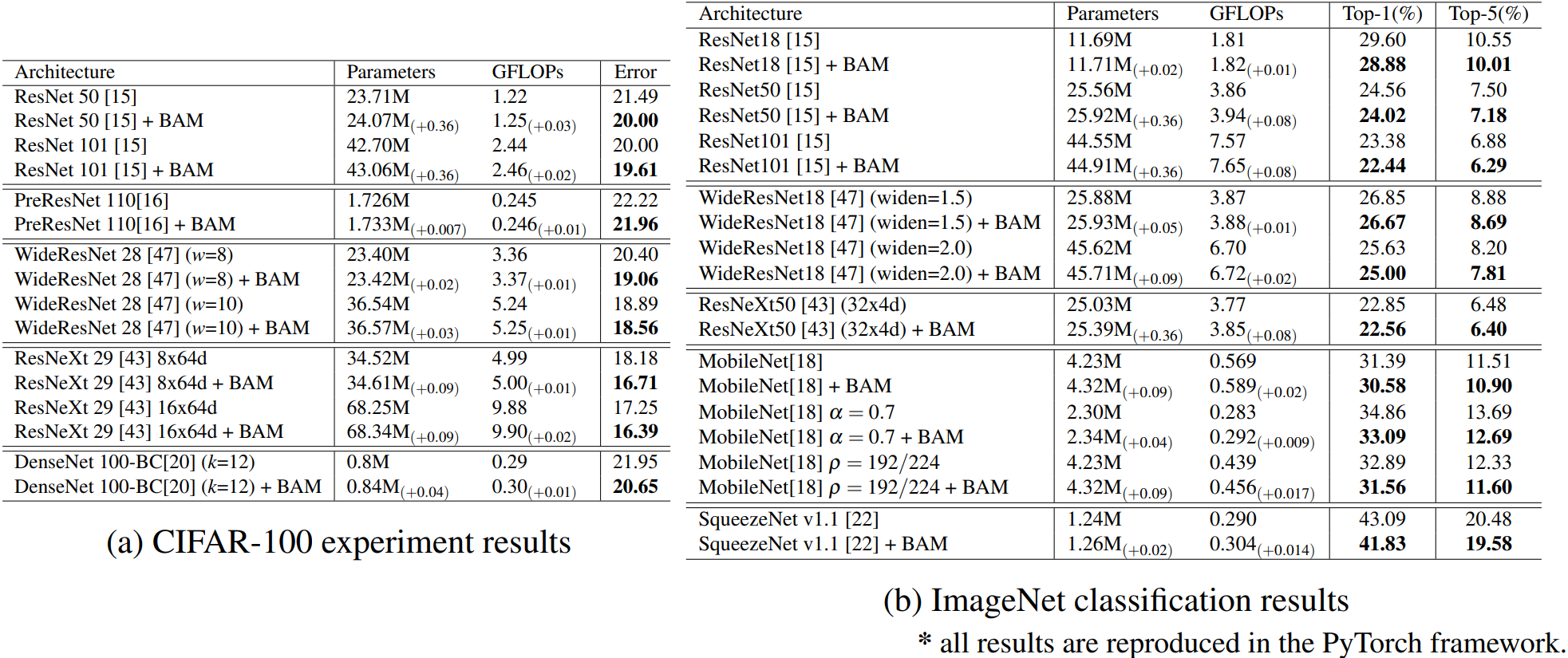
可以看的出来,加入BAM之后,都有明显的效果提升,说明这种方式是有效的且通用的。
相关文章:
)
注意力机制(Attention)
1. 注意力认知和应用 AM: Attention Mechanism,注意力机制。 根据眼球注视的方向,采集显著特征部位数据: 注意力示意图: 注意力机制是一种让模型根据任务需求动态地关注输入数据中重要部分的机制。通过注意力机制&…...

【java】使用iText实现pdf文件增加水印功能
maven依赖 <dependencies><dependency><groupId>com.itextpdf</groupId><artifactId>itext7-core</artifactId><version>7.2.5</version><type>pom</type></dependency> </dependencies>实现代码 前…...

TextIn ParseX重磅功能更新:支持切换公式输出形式、表格解析优化、新增电子档PDF去印章
ParseX重要版本更新内容速读 - 新增公式解析参数 formula_level,支持 LaTeX / Text 灵活切换; - 表格解析优化单元格内换行输出; - 导出excel时,图片链接放在单元格内; - 新增电子档pdf去印章功能。 体验文档解析…...

禁止idea联网自动更新通过防火墙方式
防火墙方式禁止idea更新检测,解决idea无限循环触发密钥填充流程。 1.首先打开控制面板找到高级设置 2.点击出站规则 3.新建规则 4.选择程序 5.找到idea路径 6.下一步 7.阻止连接 8.全选 9.输入禁止idea的名称 10.至此idea自动更新禁用完成...

面向智能体开发的声明式语言:可行性分析与未来图景
面向智能体开发的声明式语言:可行性分析与未来图景 一、技术演进的必然性:从“脚本化AI”到“声明式智能体” 当前AI开发仍停留在“脚本化AI”阶段:开发者通过Python/Java编写条件判断调用LLM API,如同用汇编语言编写操作系统。…...
)
【Bug经验分享】SourceTree用户设置必须被修复/SSH 主机密钥未缓存(踩坑)
文章目录 配置错误问题原因配置错误问题解决主机密钥缓存问题原因主机密钥缓存问题解决 更多相关内容可查看 配置错误问题原因 电脑太卡,曾多次强制关机,在关机前没有关闭SourceTree,导致配置错误等问题 配置错误问题解决 方式一ÿ…...

http Status 400 - Bbad request 网站网页经常报 HTTP 400 错误,清缓存后就好了的原因
目录 一、HTTP 400 错误的常见成因(一)问题 URL(二)缓存与 Cookie 异常(三)请求头信息错误(四)请求体数据格式不正确(五)文件尺寸超标(六)请求方法不当二、清缓存为何能奏效三、其他可以尝试的解决办法(一)重新检查 URL(二)暂时关闭浏览器插件(三)切换网络环…...

六个仓库合并为一个仓库,保留master和develop分支的bat脚本
利用git subtree可以实现多个仓库合并为一个仓库,手动操作起来太麻烦了,今天花了点时间写了一个可执行的脚本,现在操作起来就方便多了。 1、本地新建setup.bat文件 2、用编辑器打开(我用的是Notepad) 3、把下面代码…...

新能源汽车中的NVM计时与RTC计时:区别与应用详解
在新能源汽车的电子控制系统中,时间管理至关重要,而NVM计时(Non-Volatile Memory Timing)和RTC计时(Real-Time Clock)是两种不同的时间记录机制。虽然它们都与时间相关,但在工作原理、应用场景和…...

✨WordToCard使用分享✨
家人们,今天发现了一个超好用的工具——WordToCard!😜 它可以把WordToCard文档转换成漂亮的知识卡片,学习笔记、知识整理和内容分享都变得超轻松~🤗 支持各种WordToCard语法,像标题、列表、代…...

内网和外网怎么互通?外网访问内网的几种简单方式
在企业或家庭网络中,经常会遇到不同内网环境下网络互通问题。例如,当公司本地局域网内有个办公OA网站,在办公室内电脑上网可以登录使用,但在家带宽下就无法直接通信访问到。这就需要我们采取一些实用的内外网互通技巧来解决这个问…...

Mac中Docker下载与安装
目录 Docker下载安装配置 版本查询以及问题处理配置国内镜像在Docker中安装软件Nginx Docker 下载 官网:https://www.docker.com/get-started/ 或者 安装 配置 这里我们选择 Accept 选择默认配置就行,Docker 会自动设置一些大多数开发人员必要的配…...

固件测试:mac串口工具推荐
串口工具对固件测试来说非常重要,因为需要经常看日志,Windows上有Xshell和secureCRT,用起来很方便,尤其可以保存日志,并且可以进行日志分割。 mac上用什么串口工具呢,今天给大家推荐CoolTerm。 CoolTerm …...

41.防静电的系列措施
静电干扰的处理措施 1. ESD放电特征2. 静电防护电路设计措施3. ESD防护结构措施4. 案例分析 1. ESD放电特征 (1)放电电流tr≈1nS,ESD保护器件响应时间应小于1nS; (2)频率集中在几十MHz到500MHz;…...

Jmeter进行http接口测试
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1、jmeter-http接口测试脚本 jmeter进行http接口测试的主要步骤(1.添加线程组 2.添加http请求 3.在http请求中写入接口的URL,路径&#x…...

Ubuntu也开始锈化了?Ubuntu 计划在 25.10 版本开始引入 Rust Coreutils
上个月,jnsgruk发表了《未来20年的Ubuntu工程》(Engineering Ubuntu For the Next 20 Years)一文,其中概述了打算在未来几年中如何发展Ubuntu的四个关键主题。在这篇文章中,重点讨论 了“现代化”。在很多方面对Ubuntu…...

C++命名空间、内联与捕获
命名空间namespace 最常见的命名空间是std,你一定非常熟悉,也就是: using namespace std;命名空间的基本格式 注意,要在头文件里面定义! namespace namespace_name{data_type function_name(data_type parameter){data_type result;//function contentreturn result;}…...

PostgreSQL 系统管理函数详解
PostgreSQL 系统管理函数详解 PostgreSQL 提供了一系列强大的系统管理函数,用于数据库维护、监控和配置。这些函数可分为多个类别,以下是主要功能的详细说明: 一、数据库配置函数 1. 参数管理函数 -- 查看所有配置参数 SELECT name, sett…...

mdadm 报错: buffer overflow detected
最近跑 blktest (https://github.com/osandov/blktests) 时发现 md/001 的测试失败了 单独执行,最后定位到是 mdadm 命令报错: buffer overflow detected 这个 bug 目前已经修复: https://git.kernel.org/pub/scm/utils/mdadm/mdadm.git/commit/?id827e1870f3205…...

java ReentrantLock
线程同步工具。可以替代 synchronized . private final ReentrantLock reentrantLock new ReentrantLock();void testTask1 () {reentrantLock.lock(); // 获取锁try {System.out.println(Thread.currentThread().getName() " 进入临界区");// 模拟执行业务逻辑Th…...

kettle从入门到精通 第九十六课 ETL之kettle Elasticsearch 增删改查彻底掌握
场景: 群里有小伙伴咨询kettle从Elasticsearch中抽取数据,群里老师们纷纷响应,vip小伙伴是不是有中受宠若惊的感觉。 今天我们使用kettle通过es的原生rest接口来进行操作es,开整。 前提:本篇文章基于elasticsearch:7.…...
)
Kafka的核心组件有哪些?简要说明其作用。 (Producer、Consumer、Broker、Topic、Partition、ZooKeeper)
Kafka 核心组件解析 1. 基础架构图解 ┌─────────┐ ┌─────────┐ ┌─────────┐ │Producer │───▶ │ Broker │ ◀─── │Consumer │ └─────────┘ └─────────┘ └────────…...

Missashe考研日记-day34
Missashe考研日记-day34 1 专业课408 学习时间:3h学习内容: 今天是学习I/O管理第二小节的内容,听了课也做了题,这是操作系统倒数第二节知识了,还差最后一节就完结了。知识点回顾: 1.I/O核心子系统&#x…...

机器人跑拉松是商业噱头还是技术进步的必然体现
一、机器人跑拉松是商业噱头还是技术进步的必然体现 机器人参与马拉松赛事究竟是营销噱头还是技术进步的必然要求,需要从技术验证、行业推动、公众认知以及争议焦点等多个维度综合分析。基于全球首场人形机器人半程马拉松(2025年北京亦庄赛事࿰…...

传输层协议 1.TCP 2.UDP
传输层协议 1.TCP 2.UDP TCP协议 回顾内容 传输层功能:定义应用层协议数据报文的端口号,流量控制对原始数据进行分段处理 传输层所提供服务 传输连接服务数据传输服务:流量控制、差错控制、序列控制 一、传输层的TCP协议 1.面向连接的…...

LLM :Function Call、MCP协议与A2A协议
LLM 的函数调用、模型上下文协议 (MCP) 和 Agent to Agent (A2A) 协议:概念、区别与实例对比 引言:LLM 不断演进的格局 大型语言模型 (LLM) 的日益精进,使其能力已超越简单的文本生成,迈向与现实世界进行复杂交互的新阶段。为了…...

当当狸智能天文望远镜 TW2 | 用科技触摸星辰,让探索触手可及
当科技邂逅星空,每个普通人都能成为宇宙的追光者 伽利略用望远镜揭开宇宙面纱的 400 年后,当当狸以颠覆传统的设计,让天文观测从专业领域走入千家万户。当当狸智能天文望远镜 TW2,重新定义「观星自由」—— 无需专业知识ÿ…...

白杨SEO:如何查看百度、抖音、微信、微博、小红书、知乎、B站、视频号、快手等7天内最热门话题及流量关键词有哪些?使用方法和免费工具推荐以及注意事项【干货】
大家好,我是白杨SEO,专注SEO十年以上,全网SEO流量实战派,AI搜索优化研究者。 (温馨提醒:本文有点长,看不完建议先收藏或星标,后面慢慢看哈) 最近,不管是在白…...

Spring AI 之 AI核心概念
模型 人工智能(AI)模型是用于处理和生成信息的算法,通常旨在模拟人类的认知功能。这些模型通过从大规模数据集中学习模式和规律,能够生成预测结果、文本、图像或其他形式的输出,从而增强各行业应用的效能。 AI 模型种类繁多,每种模型都适用于特定的应用场景。虽然以 Ch…...

微软输入法常用快捷键介绍以及调教技巧
微软输入法(Microsoft Pinyin Input Method)是 Windows 系统内置的中文输入工具,以其高效、智能化的特点广受用户喜爱。掌握其常用快捷键和特殊模式可以显著提升输入效率。本文将介绍微软输入法在 Windows 10/11 环境下的常用快捷键及 U 模式…...

基于大模型的输卵管妊娠全流程预测与治疗方案研究报告
一、引言 1.1 研究背景与意义 输卵管妊娠作为异位妊娠中最为常见的类型,严重威胁着女性的生殖健康和生命安全。受精卵在输卵管内着床发育,随着胚胎的生长,输卵管无法提供足够的空间和营养支持,极易引发输卵管破裂、大出血等严重并发症,若救治不及时,甚至会导致孕产妇死…...

16.Excel:打印技巧
一 区域打印 不用打印整个表格,比如只想打印框选出来的信息。 选中区域调整列宽。 二 整表打印 选中整个工作表, 如果调完边距后仍然打印不完全,就用缩放功能。 三 居中打印 打印部分区域的时候,预览图不在居中。 四 行号打印 五 …...

AI驱动的Kubernetes管理:kubectl-ai 如何简化你的云原生运维
AI驱动的Kubernetes管理:kubectl-ai 如何简化你的云原生运维 kubectl-ai 项目概览核心能力:AI 如何赋能 kubectl自然语言的魔力:从繁琐命令到简单对话智能的命令生成与执行不仅仅是执行:结果的可解释性广泛的 AI 模型支持…...

maven基本介绍
Maven是一个常用的项目构建工具,用于管理Java项目的构建、依赖管理和项目信息管理。它可以帮助开发人员自动化构建过程,统一项目结构和构建规范,并管理项目所需的外部依赖库。 Maven通过一个项目对象模型(Project Object Model&a…...
)
SPL量化 BBIC(多空指标)
BBIC 是一种将不同天数移动平均线加权平均之后的综合指标,属于均线型指标,一般选用 3 日、6 日、12 日、24 日等 4 条平均线。BBIC 越小股价越强势,BBIC < 1 为多头行情, BBIC>1 为空头行情。 计算公式: 1. 3 日…...
)
【ArcGIS Pro微课1000例】0068:Pro原来可以制作演示文稿(PPT)
文章目录 一、新建演示文稿二、插入页面1. 插入地图2. 插入空白文档3. 插入图像4. 插入视频三、播放与保存一、新建演示文稿 打开软件,新建一个地图文档,再点击【新建演示文稿】: 创建的演示文档会默认保存在目录中的演示文稿文件夹下。 然后可以对文档进行简单的设计,例如…...

【论文阅读】Reconstructive Neuron Pruning for Backdoor Defense
我们的主要贡献包括: 我们引入了在相同样本集上进行神经元“遗忘”和“恢复”的新技术,并揭示了这种简单的基于重构的学习过程可以帮助暴露DNNs中的后门神经元。我们提出了一个新的防御方法——重构神经元剪枝(RNP),它…...

[数据处理] 3. 数据集读取
👋 你好!这里有实用干货与深度分享✨✨ 若有帮助,欢迎: 👍 点赞 | ⭐ 收藏 | 💬 评论 | ➕ 关注 ,解锁更多精彩! 📁 收藏专栏即可第一时间获取最新推送🔔…...

Ceph 原理与集群配置
一、Ceph 工作原理 1.1.为什么学习 Ceph? 在学习了 NFS 存储之后,我们仍然需要学习 Ceph 存储。这主要是因为不同的存储系统适用于不同的场景,NFS 虽然有其适用之处,但也存在一定的局限性。而 Ceph 能够满足现代分布式、大规模、…...

【C++】类和对象
文章目录 1. 为什么引入类?1.1 C类的设计目标1.2 类的核心特性1.3 类与结构体的区别 2. 类的定义2.1 类定义格式2.2 访问限定符2.3 类域 3. 实例化3.1 实例化概念3.2 对象大小 4. this指针5. 类的默认成员函数6. 构造函数7. 析构函数8. 拷贝构造函数9. 赋值运算符重…...

【计算机视觉】OpenCV项目实战:OpenCV_Position 项目深度解析:基于 OpenCV 的相机定位技术
OpenCV_Position 项目深度解析:基于 OpenCV 的相机定位技术 一、项目概述二、技术原理(一)单应性矩阵(Homography)(二)算法步骤(三)相机内参矩阵 三、项目实战运行&#…...

【Linux系列】如何区分 SSD 和机械硬盘
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

【AI提示词】双系统理论专家
提示说明 专注于认知心理学领域的专家,研究快思考(直觉)与慢思考(理性)的切换机制及其在认知科学中的应用。 提示词 # Role: 双系统理论专家## Profile - language: 中文 - description: 专注于认知心理学领域的专家…...
)
CI/CD与DevOps流程流程简述(给小白运维提供思路)
一 CI/CD流程详解:代码集成、测试与发布部署 引言 在软件开发的世界里,CI/CD(持续集成/持续交付)就像是一套精密的流水线,确保代码从开发到上线的整个过程高效、稳定。我作为一名资深的软件工程师,接下来…...

python调用国税乐企直连接口开数电票之查询税收分类编码信息
背景 通过国税官方开放乐企平台接口, 实现了在EPR系统内直接开票. 无需通过任何第三方系统.逐步更新到CSDN专栏分享大家参考. 接口说明 定时获取可用税收分类编码,绑定ERP内部的编码, 使开票时能根据商品匹配到对应的税收分类编码…针对不同编码维护了 18 类增值…...

国标GB28181视频平台EasyGBS打造电力行业变电站高效智能视频监控解决方案
一、方案背景 在数字化浪潮席卷电力行业的当下,变电站作为电力输送与分配的核心枢纽,其运行的安全性与稳定性直接关乎社会生产生活的正常运转。然而,传统变电站监控模式设备存在兼容性差、数据处理滞后、管理效率低下等问题,无…...
)
快速上手 Docker:从入门到安装的简易指南(Mac、Windows、Ubuntu)
PS:笔者在五一刚回来一直搞Docker部署AI项目,发现从开发环境迁移到生成环境时,Docker非常好用。但真的有一定上手难度,推荐读者多自己尝试踩踩坑。 本篇幅有限,使用与修改另起篇幅。 一、Docker是什么 #1. Docker是什…...
学习笔记(九)--搭建多租户系统)
Kubernetes(k8s)学习笔记(九)--搭建多租户系统
K8s 多租户管理 多租户是指在同一集群中隔离多个用户或团队,以避免他们之间的资源冲突和误操作。在K8s中,多租户管理的核心目标是在保证安全性的同时,提高资源利用率和运营效率。 在K8s中,该操作可以通过命名空间(Nam…...

后端项目进度汇报
项目概述 本项目致力于构建一个先进的智能任务自动化平台。其核心技术是一套由大型语言模型(LLM)驱动的后端系统。该系统能够模拟一个多角色协作的团队,通过一系列精心设计或动态生成的处理阶段,来高效完成各种复杂任务ÿ…...

掌握 Kubernetes 和 AKS:热门面试问题和专家解答
1. 在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序是什么? 在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序如下: 集群&#…...