机器学习朴素贝叶斯算法
1.朴素贝叶斯算法
1.1基本概念
其分类原理是利用贝叶斯公式根据某特征的先验概率计算出其后验概率,然后选择具有最大后验概率作为该特征所属的类。之所以称之为“朴素”,是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是相对独立的。
其核心思想是通过考虑各个特征的概率来预测分类(即对于给出的待分类样本,计算该样本在每个类别下出现的概率,最大的就被认为是该分类样本所属于的类别
朴素贝叶斯被广泛地应用在文本分类、垃圾邮件过滤、情感分析等场合
1.2朴素贝叶斯的优缺点
优点:
具有稳定的分类效率
在数据较少时仍然有效,可以处理多类别的问题
对缺失数据不太敏感
进行分类时对时间和空间的开销都比较小
缺点:
对于输入数据的准备方式比较敏感,需要对数据进行适当的预处理
需要假设属性之间相互独立,这在实际情况中往往不太现实
需要知道先验概率,但是由于先验概率大多取决于假设,故很容易因此导致预测效果不佳
1.3 朴素贝叶斯的一般过程
准备数据:收集并预处理数据,将数据分为特征和标签
特征选择:选择对分类有帮助的特征
模型训练:使用训练数据计算每个类别的先验概率和条件概率
预测:对新数据进行分类,选择概率最大的类别作为预测结果
2.算法实现
先验概率
P(cj)代表还没有训练模型之前,根据历史数据/经验估算cj拥有的初始概率。P(cj)常被称为cj的先验概率(prior probability) ,它反映了cj的概率分布,该分布独立于样本。通常可以用样例中属于cj的样例数|cj|比上总样例数|D|来近似,即:
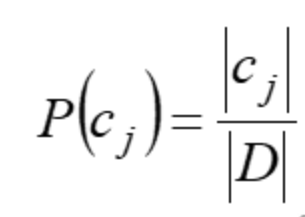
后验概率
给定数据样本x时cj成立的概率P(cj | x )被称为后验概率(posterior probability),因为它反映了在看到数据样本 x后 cj 成立的置信度。
注:大部分机器学习模型尝试得到后验概率
贝叶斯定理
朴素贝叶斯算法的核心是贝叶斯公式,公式如下:
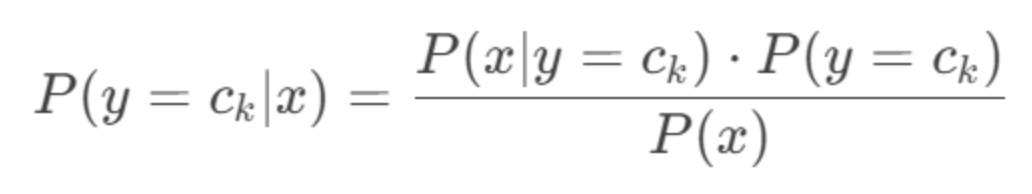
条件独立性假设
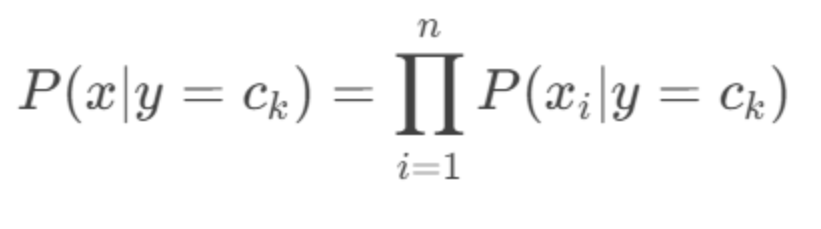
最终选择使后验概率最大的类别:
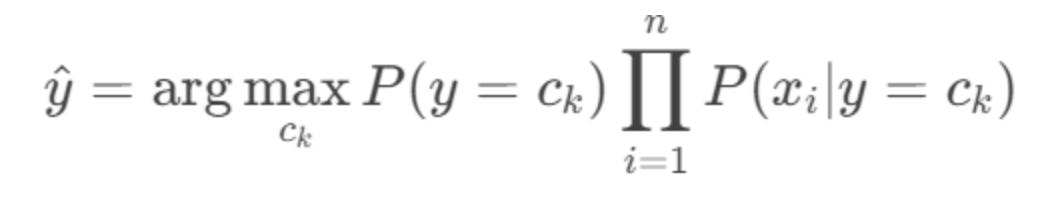
计算步骤
接下来我们通过一个例子来说明计算步骤
判断是否能够PlayTennis
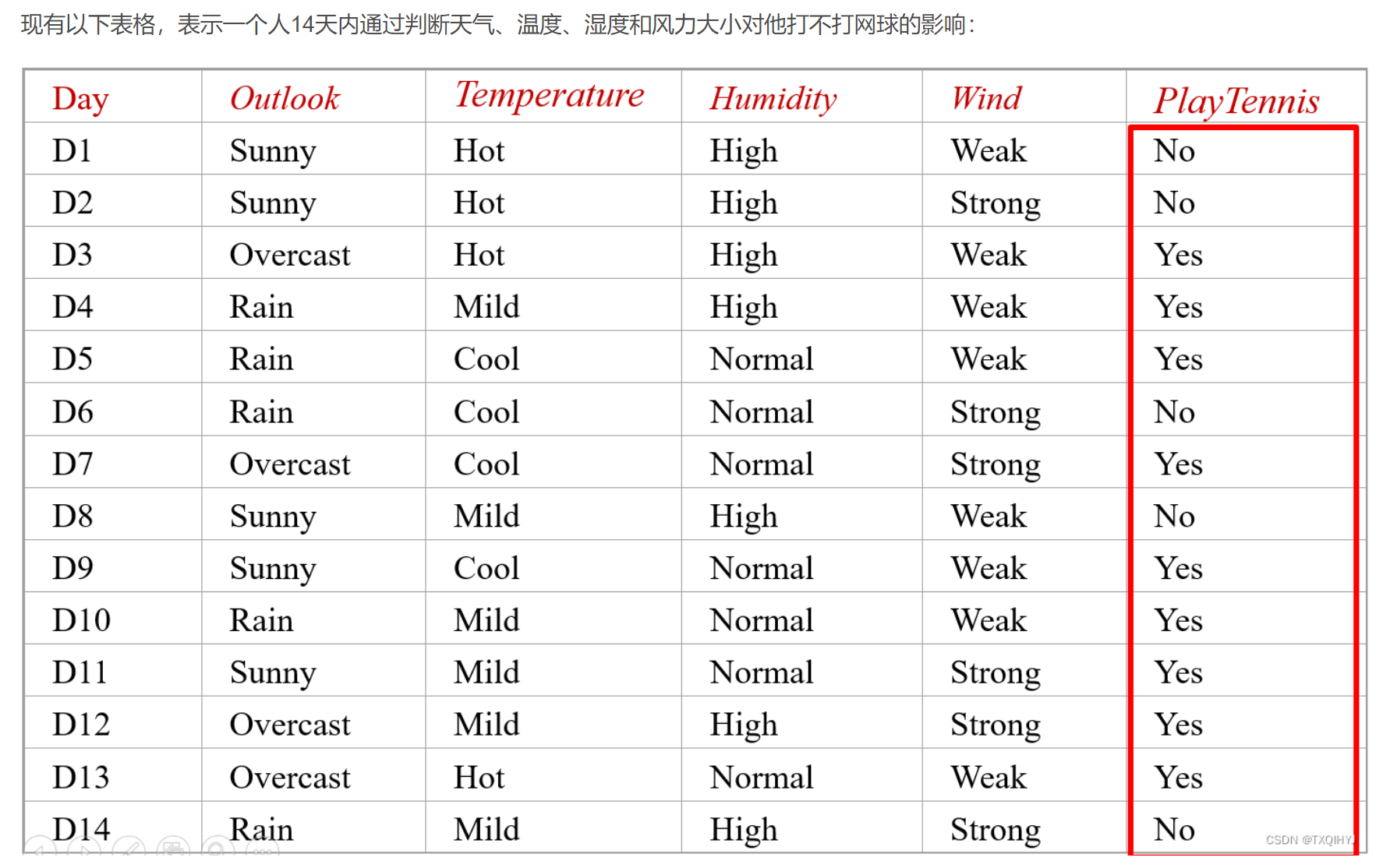
我们需要通过已有数据计算出,如果给出一个天气情况,这个人去不去打网球。
如
现在假设有一个样例 x
x = {Sunny, Hot, High,Weak}
它应该属于类别Yes?No?
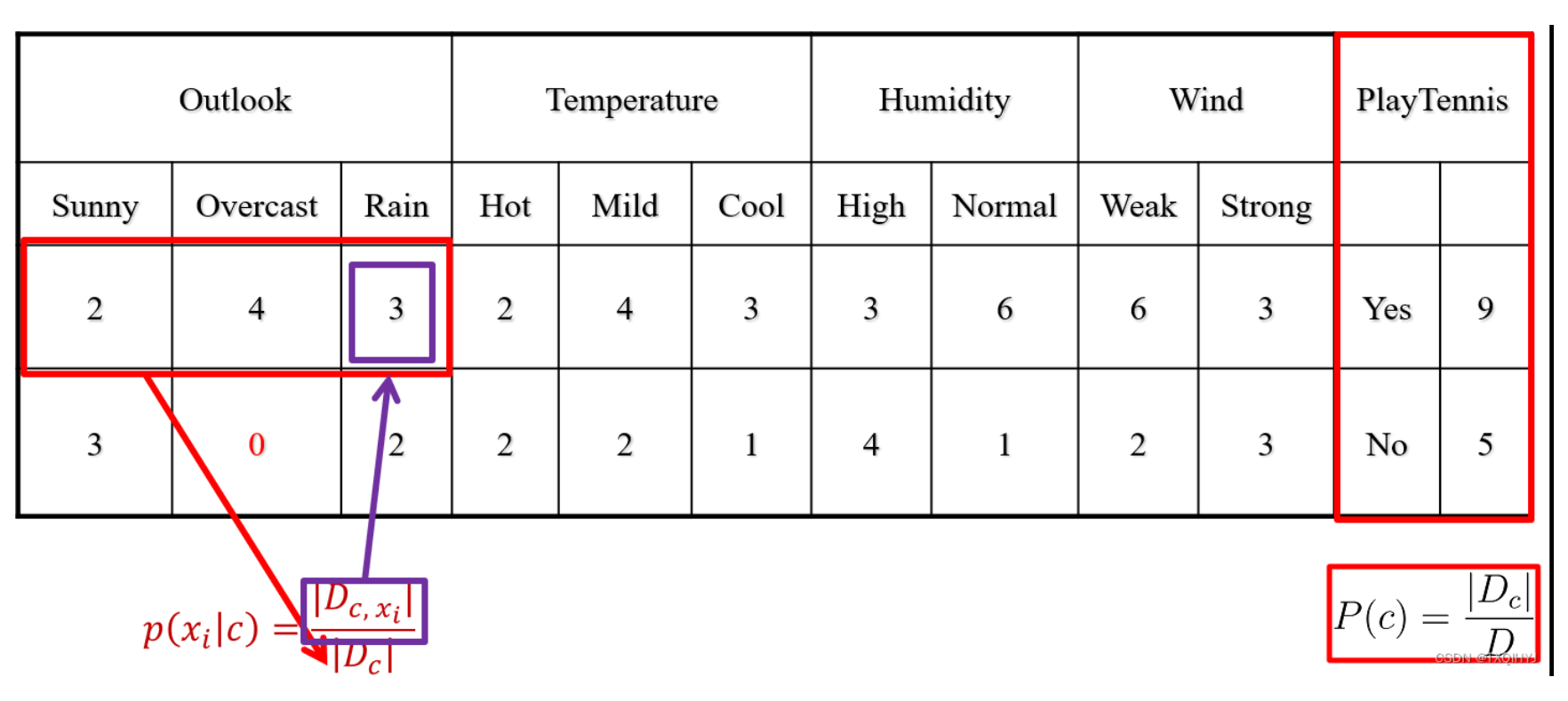
1.统计个计算先验概率
统计在各个条件下出去Yes和No的天数

统计各个特征出现的次数
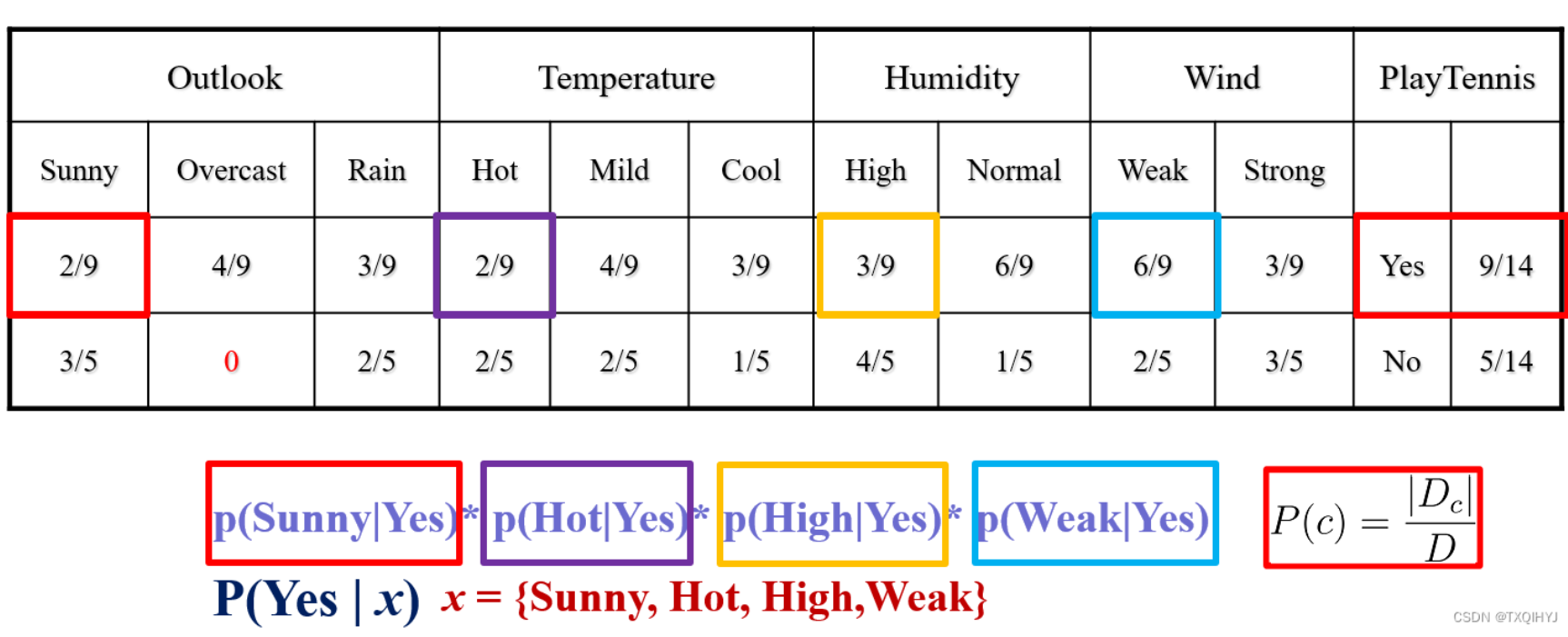
2.计算条件概率
计算在Yes和No的条件下各个特征出现的概率
离散特征:

连续特征(假设服从高斯分布):

对于多个特征:
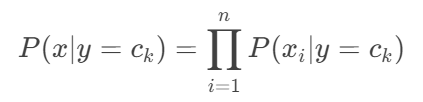
3.计算在已知该特征下Yes和No发生的条件概率
现在 假设有一个样例 x
x = {Sunny, Hot, High,Weak}
Y es的概率 P(Yes | x )
∝ p(Yes)*p(Sunny|Yes)* p(Hot|Yes)* p(High|Yes)* p(Weak|Yes)
=9/14*2/9*2/9*3/9*6/9
=0.007039
No的概率 P(No | x )
∝ p(No)*p(Sunny| No)* p(Hot| No)* p(High| No)* p(Weak| No)
=5/14*3/5*2/5*4/5*2/5
=0.027418
max (P(Yes| x ), P(No| x ) ) = P(No| x ) 所以可以把 x 分类为No
拉普拉斯修正
避免零概率事件,适用于离散特征
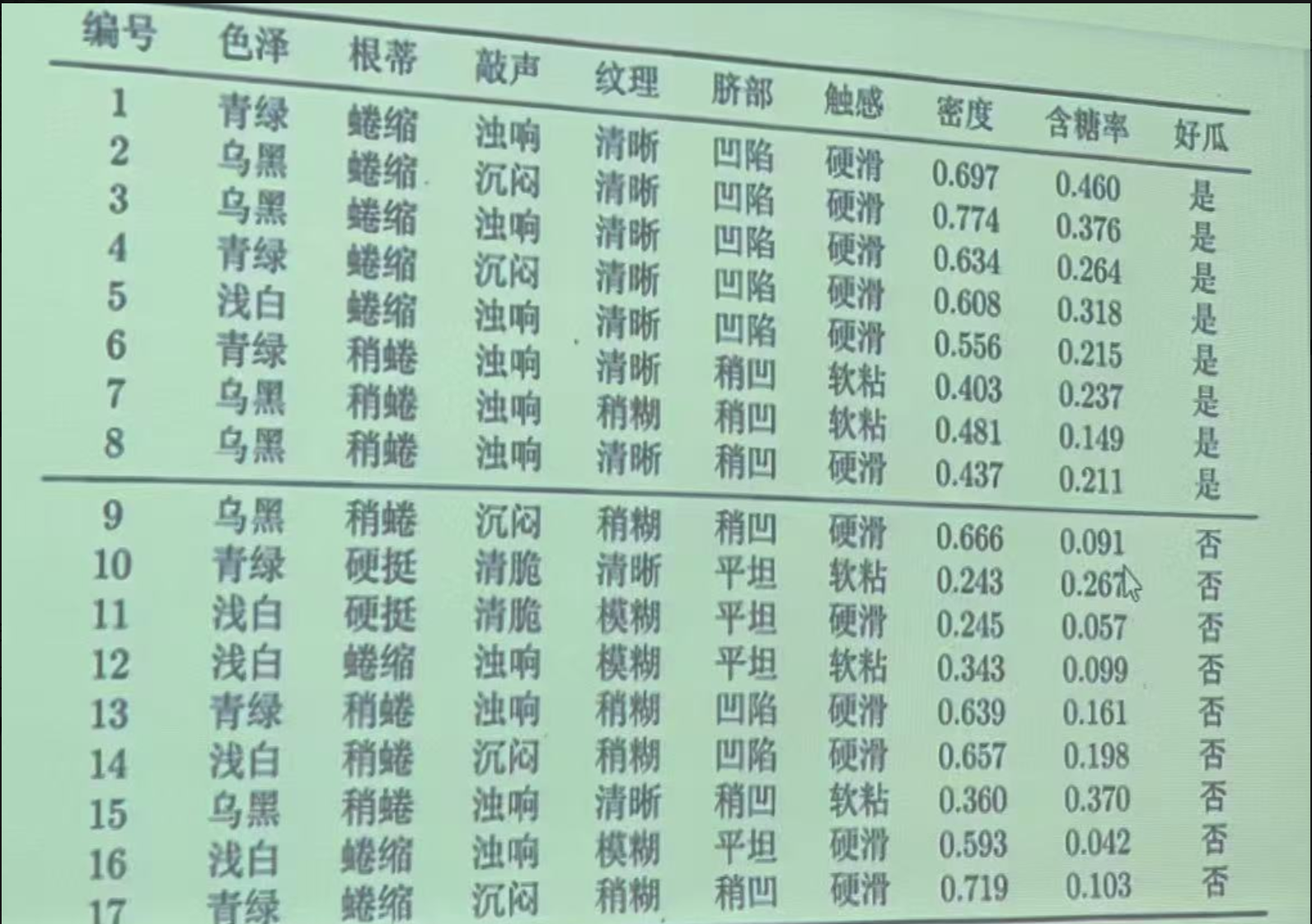
若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现 over-fitting 现象。比如“敲声=清脆”测试例,训练集中没有该样例,因此连乘式计算的概率值为0,无论其他属性上明显像好瓜,分类结果都是“好瓜=否”,这显然不合理。
为了避免其他属性携带的信息,被训练集中未出现的属性值“抹去”,在估计概率值时通常要进行“拉普拉斯修正”:
令 N 表示训练集 D 中可能的类别数,𝑁𝑖N_i表示第i个属性可能的取值数,则贝叶斯公式可修正为:


3.实例:判断西瓜好坏
训练集:
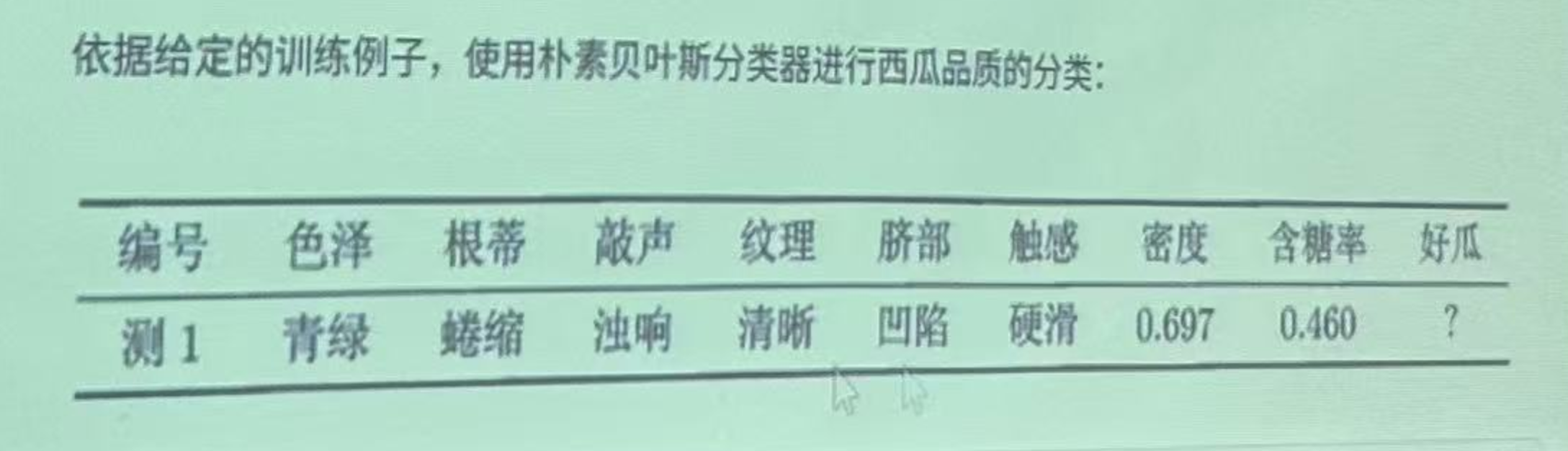
待测样本
代码实现:
data_preprocessing.py
该文件封装了数据预处理的逻辑,包括数据读取、特征编码和数据划分等操作,最后返回处理好的训练数据、测试数据和标签编码器。
import pandas as pd
from sklearn.preprocessing import LabelEncoderdef preprocess_data():# 假设从第一张图训练集读取数据到DataFrametrain_data = pd.DataFrame({'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿', '浅白', '浅白', '青绿', '浅白', '乌黑', '浅白', '青绿'],'根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍蜷', '硬挺', '硬挺', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '蜷缩', '蜷缩'],'敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '浊响', '沉闷', '清脆', '清脆', '浊响', '浊响', '沉闷', '浊响', '浊响', '沉闷'],'纹理': ['清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '清晰', '稍糊', '清晰', '模糊', '模糊', '稍糊', '稍糊', '清晰', '模糊', '稍糊'],'脐部': ['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '稍凹', '稍凹', '平坦', '平坦', '平坦', '凹陷', '凹陷', '稍凹', '平坦', '稍凹'],'触感': ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '硬滑'],'密度': [0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.481, 0.437, 0.666, 0.243, 0.245, 0.343, 0.639, 0.657, 0.360, 0.593, 0.719],'含糖率': [0.460, 0.376, 0.264,0.318, 0.215, 0.237, 0.149, 0.211, 0.091, 0.267, 0.057, 0.099, 0.161, 0.198, 0.370, 0.042, 0.103],'好瓜': ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否']})# 假设第二张图预测样本读取到DataFrametest_data = pd.DataFrame({'色泽': ['青绿'],'根蒂': ['蜷缩'],'敲声': ['浊响'],'纹理': ['清晰'],'脐部': ['凹陷'],'触感': ['硬滑'],'密度': [0.697],'含糖率': [0.460]})# 对类别型特征进行编码label_encoders = {}for col in ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜']:le = LabelEncoder()train_data[col] = le.fit_transform(train_data[col])label_encoders[col] = leif col in test_data.columns:test_data[col] = label_encoders[col].transform(test_data[col])# 提取特征和标签X = train_data.drop('好瓜', axis=1)y = train_data['好瓜']test_sample = test_datareturn X, y, test_sample, label_encodersmain.py
作为主程序文件,调用data_preprocessing.py中的preprocess_data函数获取预处理后的数据,再调用model_training_and_prediction.py中的train_and_predict函数完成模型训练和预测任务。
from data_preprocessing import preprocess_data
from model_training_and_prediction import train_and_predictif __name__ == "__main__":X, y, test_sample, label_encoders = preprocess_data()train_and_predict(X, y, test_sample, label_encoders) model_training_and_prediction.py
此文件负责模型的训练和预测工作,接收预处理后的数据和标签编码器,创建高斯朴素贝叶斯分类器,进行训练和预测,并将预测结果解码输出。
from sklearn.naive_bayes import GaussianNBdef train_and_predict(X, y, test_sample, label_encoders):# 创建高斯朴素贝叶斯分类器clf = GaussianNB()# 训练模型clf.fit(X, y)# 预测prediction = clf.predict(test_sample)# 解码预测结果predicted_class = label_encoders['好瓜'].inverse_transform(prediction)print("预测结果:", predicted_class[0])
运行结果:

相关文章:

机器学习朴素贝叶斯算法
1.朴素贝叶斯算法 1.1基本概念 其分类原理是利用贝叶斯公式根据某特征的先验概率计算出其后验概率,然后选择具有最大后验概率作为该特征所属的类。之所以称之为“朴素”,是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是相对独立…...

Linux:深入理解数据链路层
实际上一台主机中,报文并没有通过网络层直接发送出去,而是交给了自己的下一层协议——数据链路层!! 一、理解数据链路层 网络层交付给链路层之前,会先做决策再行动(会先查一下路由表,看看目标网…...

健康养生:从生活点滴启航
养生并非遥不可及的高深学问,只需把握生活中的细微之处,就能为健康保驾护航。 清晨睁眼,先在床上做简单的搓脸动作,从下巴到额头轻柔按摩,促进面部血液循环,唤醒肌肤活力。随后空腹喝一杯温水,可…...

【向量数据库】用披萨点餐解释向量数据库:一个美味的技术类比
文章目录 前言场景设定:披萨特征向量化顾客到来:生成查询向量相似度计算实战1. 欧氏距离计算(值越小越相似)2. 余弦相似度计算(值越大越相似) 关键发现:度量选择影响结果现实启示结语 前言 想象…...

CloudCompare 中 ccDrawableObject
CloudCompare 中 ccDrawableObject 类的主要内容与使用 1. ccDrawableObject 概述 在 CloudCompare 中,ccDrawableObject 是一个基类,主要用于管理 3D 可绘制对象 的显示属性,如颜色、可见性、LOD(层次细节)、光照等…...

【Linux】进程控制
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 目录 前言 一、什么是进程控制 二、进程创建 三、进程终止(进程退出) 退出码 main函数返回 _exit() exit() 测试 四、进…...
)
设计模式-基础概念学习总结(继承、多态、虚方法、方法重写)
概念使用例子的方式介绍(继承,多态,虚方法,方法重写),实现代码python 1. 继承(Inheritance) 概念:子类继承父类的属性和方法,可以直接复用父类的代码&#…...
和srand()函数的功能)
分析rand()和srand()函数的功能
rand()和srand()函数原型: int rand(void) 返回一个范围在 0 到 RAND_MAX 之间的伪随机数。 void srand(unsigned int seed)用来给rand() 设置随机数发生器,随机数发生器输出不同的数值,rand() 就会生成不同的随机数 1)、在“D:\Keil_v5\AR…...

架构师如何构建个人IP:职业规划与业务战略的双重提升
在数字化时代,软件架构师的角色已从单纯的技术专家转变为兼具技术领导力和业务影响力的复合型人才。如何构建个人IP,提升行业影响力,成为架构师职业发展的关键课题。本文从个人认知、业务战略、架构决策、产品思维四个维度,探讨架…...

CSS知识总结
一、CSS核心概念解析 1.1 选择器体系(重点) 基础选择器: /* ID选择器 */ #header { background: #333; }/* 类选择器 */ .btn-primary { color: white; }/* 属性选择器 */ input[type"text"] { border: 1px solid #ccc; } 组合…...

CRS 16 slot 设备硬件架构
目录 1. 核心组件 1.1 线路卡与物理接口模块 1.2 交换结构与容量 1.3 控制与管理 1.4 风扇与散热 1.5 电源与告警 2. 插槽编号与机箱布局 2.1 前侧(PLIM 面) 2.2 后侧(MSC 面) 2.3 插槽配对 1. 核心组件 1.1 线路卡与物…...

人工智能浪潮中Python的核心作用与重要地位
在人工智能(Artificial Intelligence,AI)蓬勃发展的时代,Python已然成为推动这一技术进步的关键编程语言。从复杂的机器学习算法实现,到前沿的深度学习模型构建,再到智能系统的部署,Python无处不…...
)
【了解】数字孪生网络(Digital Twin Network,DTN)
目录 一、为什么?二、是什么?三、什么架构?四、如何应用?参考 一、为什么? 一方面,网络负载不断增加,,网络规模持续扩大带来的网络复杂性,使得网络的运行和维护变得越来越复杂。另一…...

[C语言]第一章-初识
目录 一.引言 二.MinGW 下载与安装 1.什么是 MinGW 2.下载 MinGW 3.安装 MinGW 4.配置 MinGW 环境变量 三.VS Code 下载与安装 1.什么是 VS Code 2.下载 VS Code 3.安装 VS Code 4.汉化 5.安装扩展插件 C/C 截图 四.编写并运行 Hello World 程序 代码解释 运行…...

如何用git将项目上传到github
步骤 1.创建仓库 2.记下仓库的url 3.在本地初始化仓库 路径要在项目下 cd /path/to/your/vue-project git init 4.创建touch .gitignore文件 在项目根目录下创建 .gitignore 文件,用于指定 Git 忽略哪些文件或文件夹 5.添加和提交项目文件 将文件提交到版本控…...
--《Hello C++ World!》(1)(C/C++))
C++入门(上)--《Hello C++ World!》(1)(C/C++)
文章目录 前言命名空间域命名空间的用法 C的输入和输出缺省参数函数重载auto关键字(C11)范围for 前言 C不是C# C兼容大部分C的东西,但不是完全(98%的样子,除非遇到了不兼容的,那就记一下,不然就认为自己在C里面写的那些可以写到C里…...

架构思维:构建高并发读服务_基于流量回放实现读服务的自动化测试回归方案
文章目录 引言一、升级读服务架构,为什么需要自动化测试?二、自动化回归测试系统:整体架构概览三、日志收集1. 拦截方式2. 存储与优化策略3. 架构进化 四、数据回放技术实现关键能力 五、差异对比对比方式灵活配置 六、三种回放模式详解1. 离…...
)
代码随想录第33天:动态规划6(完全背包基础)
一、完全平方数(Leetcode 279) 本题与“零钱兑换”基本一致。 1.确定dp数组以及下标的含义 dp[j]:和为j的完全平方数的最少数量为dp[j] 2.确定递推公式 dp[j] 可以由dp[j - i * i]推出, dp[j - i * i] 1 便可以凑成dp[j]。 …...

Android控件View、ImageView、WebView用法
一 控件清单 View、ImageView、WebView 二 控件UI代码 <?xml version="1.0" encoding="utf-8"?> <androidx.coordinatorlayout.widget.CoordinatorLayoutxmlns:android="http://schemas.android.com/apk/res/android"xmlns:app=&qu…...

关于浏览器页面自动化操作
Selenium 是一个用于自动化浏览器操作的强大框架,广泛应用于Web应用程序的测试自动化。它主要由以下几个核心组件组成: Selenium WebDriver: WebDriver 是 Selenium 的核心组件,它提供了一组API,允许开发者编写程序来…...

P5739 计算阶乘详解
此题目,对于会递归的很简单很简单,但作者是野人不会,只能是边刷边学,且题解比较有意思,所有我这次的重心不是题目,而是题解里面创作者展示的不一样的东西,先看题目 题目要求不用for循环…...

把Android设备变成“国标摄像头”:GB28181移动终端实战接入指南
把Android设备变成“国标摄像头”:GB28181移动终端实战接入指南 ——执法记录仪、巡检终端、布控球,如何通过大牛直播SDK直接挂到GB28181平台? 在过去,GB28181 通常用于固定摄像头、NVR等“设备端”。但在政务、安防、应急等行业…...

机器学习项目流程极简入门:从数据到部署的完整指南
前言 本文将通过一个简单案例(根据水果外观特征判断是否为橘子),逐步拆解机器学习项目的完整流程,帮助读者掌握从数据收集到模型部署的全流程方法论。 通常,一个完整的机器学习项目可以分为以下几个步骤: …...

PrivKV: Key-Value Data Collection with Local Differential Privacy论文阅读
文献阅读课需要制作ppt但是感觉选的这篇论文都是公式,决定做点动画直观展示一下。还没有完成会继续更新这个笔记 manim动画代码 需要下载ffmpeg下载latex https://docs.manim.org.cn/getting_started/installation.html ffmpeg下载教程 texlive官网 但是其实不需要…...
的配置文件(moveitcpp))
RViz(机器人可视化工具)的配置文件(moveitcpp)
1. Panels(面板设置) 面板是RViz界面中的各个功能区域,用于显示和操作不同的数据。 Displays(显示面板) Class: rviz_common/Displays 指定面板的类型,这里是显示面板。 Help Height: 78 帮助区域的高度…...

kotlin 01flow-StateFlow 完整教程
一 Android StateFlow 完整教程:从入门到实战 StateFlow 是 Kotlin 协程库中用于状态管理的响应式流,特别适合在 Android 应用开发中管理 UI 状态。本教程将带全面了解 StateFlow 的使用方法。 1. StateFlow 基础概念 1.1 什么是 StateFlow? StateF…...
基于qt5.15.2+mingw64+opengl绘制三角形)
OpenGl实战笔记(1)基于qt5.15.2+mingw64+opengl绘制三角形
一、实现效果 二、实现原理 (1)各函数作用与原理 initialize() 作用: 初始化 OpenGL 函数(initializeOpenGLFunctions()) 设置背景清除颜色为 rgba(0.2, 0.3, 0.4, 1.0)。 原理: initializeOpenGLFunctio…...

S100平台调试RS485/RS232
提供一个C语言的测试程序Demo #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h>...

蓝桥杯 19. 植树
植树 题目描述 小明和朋友们一起去郊外植树,他们带了一些在实验室中精心研究出的小树苗。 一共有 n 个人,每个人挑选了一个适合植树的位置,一共 n 个位置。每人准备在自己的位置种下一棵树苗。 但他们遇到一个问题:有的树苗比…...

Spring Boot 中 @Bean 注解详解:从入门到实践
在 Spring Boot 开发中,Bean注解是一个非常重要且常用的注解,它能够帮助开发者轻松地将 Java 对象纳入 Spring 容器的管理之下,实现对象的依赖注入和生命周期管理。对于新手来说,理解并掌握Bean注解,是深入学习 Spring…...

git项目迁移,包括所有的提交记录和分支 gitlab迁移到gitblit
之前git都是全新项目上传,没有迁移过,因为迁移的话要考虑已有项目上的分支都要迁移过去,提交记录能迁移就好;分支如果按照全新项目上传的方式需要新git手动创建好老git已有分支,在手动一个一个克隆老项目分支代码依次提…...

前端面试每日三题 - Day 25
这是我为准备前端/全栈开发工程师面试整理的第25天每日三题练习,涵盖了: CSS中如何实现一个保持宽高比的自适应正方形元素Angular的变更检测(Change Detection)机制项目实战 - 设计一个微前端架构的前端应用。 ✅ 题目1ÿ…...

基于windows安装MySQL8.0.40
基于windows安装MySQL8.0.40 基于windows 安装 MySQL8.0.40,解压文件到D:\mysql-8.0.40-winx64 在D:\mysql-8.0.40-winx64目录下创建my.ini文件,并更新一下内容 [client] #客户端设置,即客户端默认的连接参数 # 设置mysql客户端连接服务…...
 基于Python的数据挖掘与可视化 二手车数据处理与分析系统开发 (机器学习算法预测))
基于机器学习算法预测二手车市场数据清洗与分析平台(源码+定制+讲解) 基于Python的数据挖掘与可视化 二手车数据处理与分析系统开发 (机器学习算法预测)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

【神经网络与深度学习】普通自编码器和变分自编码器的区别
引言 自编码器(Autoencoder,AE)和变分自编码器(Variational Autoencoder,VAE)是深度学习中广泛应用的两类神经网络结构,主要用于数据的压缩、重构和生成。然而,二者在模型设计、训练…...
)
【现代深度学习技术】现代循环神经网络07:序列到序列学习(seq2seq)
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

【Linux我做主】进度条小程序深度解析
Linux下C语言进度条程序深度解析 进度条小程序GitHub地址 前言前置知识回车换行(CR/LF)的深度解析历史渊源与技术规范在进度条/倒计时中的应用 缓冲区机制的全面剖析缓冲区引入缓冲类型对比进度条开发中的关键控制 进度条实现以小见大——倒计时倒计时最…...

Vue项目安全实践指南:从输入验证到状态管理的全方位防护
一、项目背景 在Vue2项目开发过程中,我们遇到了一些需要优化的安全实践问题。本文将分享我们在项目中的一些安全优化经验,希望能帮助到其他开发者。 主要优化点: 输入输出安全处理请求安全防护数据存储安全路由访问控制文件上传处理表单数…...

Pinocchio导入URDF关节为continuous的问题及详细解释
视频讲解: Pinocchio导入URDF关节为continuous的问题及详细解释 仓库地址:GitHub - LitchiCheng/mujoco-learning 问题背景:打算测试将之前的panda的urdf换成so-arm100的urdf,发现pinocchio的代码不能用,很奇怪&#…...

《Python星球日记》第30天:Flask数据库集成
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、数据库…...
)
GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)
GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab) 目录 GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)效果一览基本描述程序设计参考资料 效果一览 基本描述 本研究提出的GA…...

轻松养生:让健康融入生活
养生不是负担,而是可以轻松融入日常的生活方式。掌握以下要点,就能开启健康之旅。 清晨醒来,先喝一杯常温水,唤醒沉睡的肠胃。早餐选择富含膳食纤维的燕麦片搭配新鲜水果,补充能量又促进消化。午餐和晚餐做到荤素搭配&…...

工业主义与民主的兴衰:历史逻辑与未来危机
一、工业主义催生大众民主的机制 经济基础变革 非技术工人崛起:工业革命后,机器生产替代传统手工业,非熟练工人(包括妇女、儿童)收入提升,财富分配趋于平等,形成新兴中产阶级。 政府财政能力增…...
 PyTorch版)
从代码学习深度学习 - 目标检测前置知识(二) PyTorch版
文章目录 前言一、多尺度目标检测1.1 多尺度锚框1.2 绘图工具函数 (`utils_for_huitu.py`)1.3 可视化多尺度锚框1.4 多尺度检测(理论)二、自定义目标检测数据集2.1 读取数据2.2 创建 Dataset 类2.3 创建 DataLoader2.4 验证数据加载2.5 可视化数据集样本总结前言 大家好!欢…...

什么是“系统调用”
一、什么是“系统调用”?用生活中的比喻理解 可以把“系统调用”比作你(用户)向“管理员”请求帮助完成某件事情的过程。 举个例子: 你想借书,去图书馆(操作系统)找管理员(内核&a…...
识别与重构指南)
代码异味(Code Smell)识别与重构指南
1、引言:什么是“代码异味”? 在软件开发中,“代码异味(Code Smell)”是指那些虽然不会导致程序编译失败或运行错误,但暗示着潜在设计缺陷或可维护性问题的代码结构。它们是代码演进过程中的“信号灯”,提示我们某段代码可能需要优化。 1.1 ✅ 为什么关注代码异味? 预…...

005-nlohmann/json 基础方法-C++开源库108杰
《二、基础方法》:节点访问、值获取、显式 vs 隐式、异常处理、迭代器、类型检测、异常处理……一节课搞定C处理JSON数据85%的需求…… JSON 字段的简单类型包括:number、boolean、string 和 null(即空值);复杂类型则有…...
)
java学习之数据结构:四、树(代码补充)
这部分主要是用代码实现有序二叉树、树遍历、删除节点 目录 1.构建有序二叉树 1.1原理 1.2插入实现 2.广度优先遍历--队列实现 3.深度优先遍历--递归实现 3.1先序遍历 3.2中序遍历 3.3后序遍历 4.删除 4.1删除叶子节点 4.2删除有一棵子树的节点 4.3删除有两棵子树的节…...

Java面试场景分析:从音视频到安全与风控的技术探讨
Java面试场景分析:从音视频到安全与风控的技术探讨 在一个阳光明媚的早晨,互联网大厂的面试室里,面试官李老师坐在桌前,严肃认真;而程序员小张则显得有些紧张,甚至有些搞笑。 第一轮提问: 李老…...

《OmniMeetProTrack 全维会议链智能追录系统 软件设计文档》
撰稿人:wjz 一、引言 1.1 目的 本软件设计文档详细描述了 OmniMeetProTrack 全维会议链智能追录系统的架构、组件、模块设计及实现细节,旨在为开发人员、利益相关者和维护人员提供系统的全面设计蓝图。本文档基于需求定义文档,确保系统实现…...