【现代深度学习技术】现代循环神经网络07:序列到序列学习(seq2seq)

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、编码器
- 二、解码器
- 三、损失函数
- 四、训练
- 五、预测
- 六、预测序列的评估
- 小结
正如我们在机器翻译与数据集中看到的,机器翻译中的输入序列和输出序列都是长度可变的。为了解决这类问题,我们在编码器-解码器架构中设计了一个通用的”编码器-解码器“架构。本节,我们将使用两个循环神经网络的编码器和解码器,并将其应用于序列到序列(sequence to sequence,seq2seq)类的学习任务。
遵循编码器-解码器架构的设计原则,循环神经网络编码器使用长度可变的序列作为输入,将其转换为固定形状的隐状态。换言之,输入序列的信息被编码到循环神经网络编码器的隐状态中。为了连续生成输出序列的词元,独立的循环神经网络解码器是基于输入序列的编码信息和输出序列已经看见的或者生成的词元来预测下一个词元。图1演示了如何在机器翻译中使用两个循环神经网络进行序列到序列学习。

在图1中,特定的'<eos>'表示序列结束词元。一旦输出序列生成此词元,模型就会停止预测。在循环神经网络解码器的初始化时间步,有两个特定的设计决定:首先,特定的'<bos>'表示序列开始词元,它是解码器的输入序列的第一个词元。其次,使用循环神经网络编码器最终的隐状态来初始化解码器的隐状态。正是基于这种设计将输入序列的编码信息送入到解码器中来生成输出序列的。在其他一些设计中,如图1所示,编码器最终的隐状态在每一个时间步都作为解码器的输入序列的一部分。类似于语言模型和数据集中语言模型的训练,可以允许标签成为原始的输出序列,从源序列词元'<bos>'、'Ils'、'regardent'、'.'到新序列词元'Ils'、'regardent'、'.'、'<eos>'来移动预测的位置。
下面,我们动手构建图1的设计,并将基于机器翻译与数据集中介绍的“英-法”数据集来训练这个机器翻译模型。
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
一、编码器
从技术上讲,编码器将长度可变的输入序列转换成形状固定的上下文变量 c \mathbf{c} c,并且将输入序列的信息在该上下文变量中进行编码。如图所示,可以使用循环神经网络来设计编码器。
考虑由一个序列组成的样本(批量大小是 1 1 1)。假设输入序列是 x 1 , … , x T x_1, \ldots, x_T x1,…,xT,其中 x t x_t xt是输入文本序列中的第 t t t个词元。在时间步 t t t,循环神经网络将词元 x t x_t xt的输入特征向量 x t \mathbf{x}_t xt和 h t − 1 \mathbf{h} _{t-1} ht−1(即上一时间步的隐状态)转换为 h t \mathbf{h}_t ht(即当前步的隐状态)。使用一个函数 f f f来描述循环神经网络的循环层所做的变换:
h t = f ( x t , h t − 1 ) (1) \mathbf{h}_t = f(\mathbf{x}_t, \mathbf{h}_{t-1}) \tag{1} ht=f(xt,ht−1)(1)
总之,编码器通过选定的函数 q q q,将所有时间步的隐状态转换为上下文变量:
c = q ( h 1 , … , h T ) (2) \mathbf{c} = q(\mathbf{h}_1, \ldots, \mathbf{h}_T) \tag{2} c=q(h1,…,hT)(2) 比如,当选择 q ( h 1 , … , h T ) = h T q(\mathbf{h}_1, \ldots, \mathbf{h}_T) = \mathbf{h}_T q(h1,…,hT)=hT时(就像图1中一样),上下文变量仅仅是输入序列在最后时间步的隐状态 h T \mathbf{h}_T hT。
到目前为止,我们使用的是一个单向循环神经网络来设计编码器,其中隐状态只依赖于输入子序列,这个子序列是由输入序列的开始位置到隐状态所在的时间步的位置(包括隐状态所在的时间步)组成。我们也可以使用双向循环神经网络构造编码器,其中隐状态依赖于两个输入子序列,两个子序列是由隐状态所在的时间步的位置之前的序列和之后的序列(包括隐状态所在的时间步),因此隐状态对整个序列的信息都进行了编码。
现在,让我们实现循环神经网络编码器。注意,我们使用了嵌入层(embedding layer)来获得输入序列中每个词元的特征向量。嵌入层的权重是一个矩阵,其行数等于输入词表的大小(vocab_size),其列数等于特征向量的维度(embed_size)。对于任意输入词元的索引 i i i,嵌入层获取权重矩阵的第 i i i行(从 0 0 0开始)以返回其特征向量。另外,本文选择了一个多层门控循环单元来实现编码器。
#@save
class Seq2SeqEncoder(d2l.Encoder):"""用于序列到序列学习的循环神经网络编码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):super(Seq2SeqEncoder, self).__init__(**kwargs)# 嵌入层self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)def forward(self, X, *args):# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X)# 在循环神经网络模型中,第一个轴对应于时间步X = X.permute(1, 0, 2)# 如果未提及状态,则默认为0output, state = self.rnn(X)# output的形状:(num_steps,batch_size,num_hiddens)# state的形状:(num_layers,batch_size,num_hiddens)return output, state
循环层返回变量的说明可以参考循环神经网络的简洁实现。
下面,我们实例化上述编码器的实现:我们使用一个两层门控循环单元编码器,其隐藏单元数为 16 16 16。给定一小批量的输入序列X(批量大小为 4 4 4,时间步为 7 7 7)。在完成所有时间步后,最后一层的隐状态的输出是一个张量(output由编码器的循环层返回),其形状为(时间步数,批量大小,隐藏单元数)。
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
output.shape
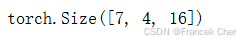
由于这里使用的是门控循环单元,所以在最后一个时间步的多层隐状态的形状是(隐藏层的数量,批量大小,隐藏单元的数量)。如果使用长短期记忆网络,state中还将包含记忆单元信息。
state.shape
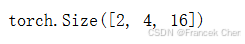
二、解码器
正如上文提到的,编码器输出的上下文变量 c \mathbf{c} c对整个输入序列 x 1 , … , x T x_1, \ldots, x_T x1,…,xT进行编码。来自训练数据集的输出序列 y 1 , y 2 , … , y T ′ y_1, y_2, \ldots, y_{T'} y1,y2,…,yT′,对于每个时间步 t ′ t' t′(与输入序列或编码器的时间步 t t t不同),解码器输出 y t ′ y_{t'} yt′的概率取决于先前的输出子序列 y 1 , … , y t ′ − 1 y_1, \ldots, y_{t'-1} y1,…,yt′−1和上下文变量 c \mathbf{c} c,即 P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c}) P(yt′∣y1,…,yt′−1,c)。
为了在序列上模型化这种条件概率,我们可以使用另一个循环神经网络作为解码器。在输出序列上的任意时间步 t ′ t^\prime t′,循环神经网络将来自上一时间步的输出 y t ′ − 1 y_{t^\prime-1} yt′−1和上下文变量 c \mathbf{c} c作为其输入,然后在当前时间步将它们和上一隐状态 s t ′ − 1 \mathbf{s}_{t^\prime-1} st′−1转换为隐状态 s t ′ \mathbf{s}_{t^\prime} st′。因此,可以使用函数 g g g来表示解码器的隐藏层的变换:
s t ′ = g ( y t ′ − 1 , c , s t ′ − 1 ) (3) \mathbf{s}_{t^\prime} = g(y_{t^\prime-1}, \mathbf{c}, \mathbf{s}_{t^\prime-1}) \tag{3} st′=g(yt′−1,c,st′−1)(3) 在获得解码器的隐状态之后,我们可以使用输出层和softmax操作来计算在时间步 t ′ t^\prime t′时输出 y t ′ y_{t^\prime} yt′的条件概率分布 P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) P(y_{t^\prime} \mid y_1, \ldots, y_{t^\prime-1}, \mathbf{c}) P(yt′∣y1,…,yt′−1,c)。
根据图1,当实现解码器时,我们直接使用编码器最后一个时间步的隐状态来初始化解码器的隐状态。这就要求使用循环神经网络实现的编码器和解码器具有相同数量的层和隐藏单元。为了进一步包含经过编码的输入序列的信息,上下文变量在所有的时间步与解码器的输入进行连接(concatenate)。为了预测输出词元的概率分布,在循环神经网络解码器的最后一层使用全连接层来变换隐状态。
class Seq2SeqDecoder(d2l.Decoder):"""用于序列到序列学习的循环神经网络解码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):super(Seq2SeqDecoder, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, *args):return enc_outputs[1]def forward(self, X, state):# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X).permute(1, 0, 2)# 广播context,使其具有与X相同的num_stepscontext = state[-1].repeat(X.shape[0], 1, 1)X_and_context = torch.cat((X, context), 2)output, state = self.rnn(X_and_context, state)output = self.dense(output).permute(1, 0, 2)# output的形状:(batch_size,num_steps,vocab_size)# state的形状:(num_layers,batch_size,num_hiddens)return output, state
下面,我们用与前面提到的编码器中相同的超参数来实例化解码器。如我们所见,解码器的输出形状变为(批量大小,时间步数,词表大小),其中张量的最后一个维度存储预测的词元分布。
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
output.shape, state.shape

总之,上述循环神经网络“编码器-解码器”模型中的各层如图2所示。

三、损失函数
在每个时间步,解码器预测了输出词元的概率分布。类似于语言模型,可以使用softmax来获得分布,并通过计算交叉熵损失函数来进行优化。回想一下机器翻译与数据集中,特定的填充词元被添加到序列的末尾,因此不同长度的序列可以以相同形状的小批量加载。但是,我们应该将填充词元的预测排除在损失函数的计算之外。
为此,我们可以使用下面的sequence_mask函数通过零值化屏蔽不相关的项,以便后面任何不相关预测的计算都是与零的乘积,结果都等于零。例如,如果两个序列的有效长度(不包括填充词元)分别为 1 1 1和 2 2 2,则第一个序列的第一项和第二个序列的前两项之后的剩余项将被清除为零。
#@save
def sequence_mask(X, valid_len, value=0):"""在序列中屏蔽不相关的项"""maxlen = X.size(1)mask = torch.arange((maxlen), dtype=torch.float32, device=X.device)[None, :] < valid_len[:, None]X[~mask] = valuereturn XX = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
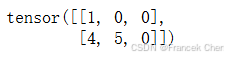
我们还可以使用此函数屏蔽最后几个轴上的所有项。如果愿意,也可以使用指定的非零值来替换这些项。
X = torch.ones(2, 3, 4)
sequence_mask(X, torch.tensor([1, 2]), value=-1)
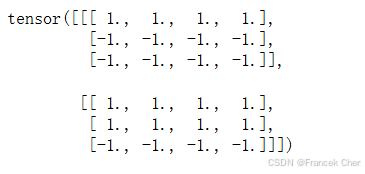
现在,我们可以通过扩展softmax交叉熵损失函数来遮蔽不相关的预测。最初,所有预测词元的掩码都设置为1。一旦给定了有效长度,与填充词元对应的掩码将被设置为0。最后,将所有词元的损失乘以掩码,以过滤掉损失中填充词元产生的不相关预测。
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):"""带遮蔽的softmax交叉熵损失函数"""# pred的形状:(batch_size,num_steps,vocab_size)# label的形状:(batch_size,num_steps)# valid_len的形状:(batch_size,)def forward(self, pred, label, valid_len):weights = torch.ones_like(label)weights = sequence_mask(weights, valid_len)self.reduction='none'unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred.permute(0, 2, 1), label)weighted_loss = (unweighted_loss * weights).mean(dim=1)return weighted_loss
我们可以创建三个相同的序列来进行代码健全性检查,然后分别指定这些序列的有效长度为 4 4 4、 2 2 2和 0 0 0。结果就是,第一个序列的损失应为第二个序列的两倍,而第三个序列的损失应为零。
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long), torch.tensor([4, 2, 0]))
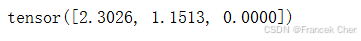
四、训练
在下面的循环训练过程中,如图所示,特定的序列开始词元('<bos>')和原始的输出序列(不包括序列结束词元'<eos>')连接在一起作为解码器的输入。这被称为强制教学(teacher forcing),因为原始的输出序列(词元的标签)被送入解码器。或者,将来自上一个时间步的预测得到的词元作为解码器的当前输入。
#@save
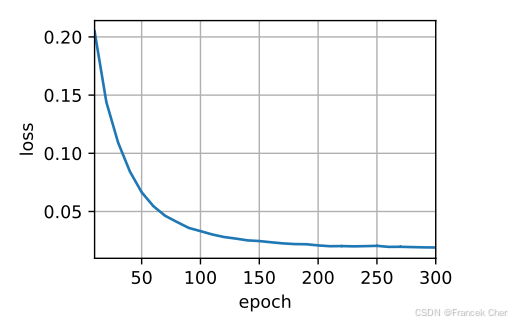
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):"""训练序列到序列模型"""def xavier_init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)if type(m) == nn.GRU:for param in m._flat_weights_names:if "weight" in param:nn.init.xavier_uniform_(m._parameters[param])net.apply(xavier_init_weights)net.to(device)optimizer = torch.optim.Adam(net.parameters(), lr=lr)loss = MaskedSoftmaxCELoss()net.train()animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[10, num_epochs])for epoch in range(num_epochs):timer = d2l.Timer()metric = d2l.Accumulator(2) # 训练损失总和,词元数量for batch in data_iter:optimizer.zero_grad()X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0], device=device).reshape(-1, 1)dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学Y_hat, _ = net(X, dec_input, X_valid_len)l = loss(Y_hat, Y, Y_valid_len)l.sum().backward() # 损失函数的标量进行“反向传播”d2l.grad_clipping(net, 1)num_tokens = Y_valid_len.sum()optimizer.step()with torch.no_grad():metric.add(l.sum(), num_tokens)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, (metric[0] / metric[1],))print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} 'f'tokens/sec on {str(device)}')
现在,在机器翻译数据集上,我们可以创建和训练一个循环神经网络“编码器-解码器”模型用于序列到序列的学习。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
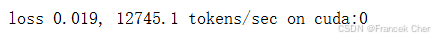
五、预测
为了采用一个接着一个词元的方式预测输出序列,每个解码器当前时间步的输入都将来自于前一时间步的预测词元。与训练类似,序列开始词元('<bos>')在初始时间步被输入到解码器中。该预测过程如图3所示,当输出序列的预测遇到序列结束词元('<eos>')时,预测就结束了。

我们将在束搜索中介绍不同的序列生成策略。
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps, device, save_attention_weights=False):"""序列到序列模型的预测"""# 在预测时将net设置为评估模式net.eval()src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]enc_valid_len = torch.tensor([len(src_tokens)], device=device)src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])# 添加批量轴enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)enc_outputs = net.encoder(enc_X, enc_valid_len)dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)# 添加批量轴dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)output_seq, attention_weight_seq = [], []for _ in range(num_steps):Y, dec_state = net.decoder(dec_X, dec_state)# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入dec_X = Y.argmax(dim=2)pred = dec_X.squeeze(dim=0).type(torch.int32).item()# 保存注意力权重(稍后讨论)if save_attention_weights:attention_weight_seq.append(net.decoder.attention_weights)# 一旦序列结束词元被预测,输出序列的生成就完成了if pred == tgt_vocab['<eos>']:breakoutput_seq.append(pred)return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
六、预测序列的评估
我们可以通过与真实的标签序列进行比较来评估预测序列。虽然提出的BLEU(bilingual evaluation understudy)最先是用于评估机器翻译的结果,但现在它已经被广泛用于测量许多应用的输出序列的质量。原则上说,对于预测序列中的任意 n n n元语法(n-grams),BLEU的评估都是这个 n n n元语法是否出现在标签序列中。
我们将BLEU定义为
exp ( min ( 0 , 1 − l e n label l e n pred ) ) ∏ n = 1 k p n 1 / 2 n (4) \exp\left(\min\left(0, 1 - \frac{\mathrm{len}_{\text{label}}}{\mathrm{len}_{\text{pred}}}\right)\right) \prod_{n=1}^k p_n^{1/2^n} \tag{4} exp(min(0,1−lenpredlenlabel))n=1∏kpn1/2n(4) 其中, l e n label \mathrm{len}_{\text{label}} lenlabel表示标签序列中的词元数和 l e n pred \mathrm{len}_{\text{pred}} lenpred表示预测序列中的词元数, k k k是用于匹配的最长的 n n n元语法。另外,用 p n p_n pn表示 n n n元语法的精确度,它是两个数量的比值:第一个是预测序列与标签序列中匹配的 n n n元语法的数量,第二个是预测序列中 n n n元语法的数量的比率。具体地说,给定标签序列 A A A、 B B B、 C C C、 D D D、 E E E、 F F F和预测序列 A A A、 B B B、 B B B、 C C C、 D D D,我们有 p 1 = 4 / 5 p_1 = 4/5 p1=4/5、 p 2 = 3 / 4 p_2 = 3/4 p2=3/4、 p 3 = 1 / 3 p_3 = 1/3 p3=1/3和 p 4 = 0 p_4 = 0 p4=0。
根据式(4)中BLEU的定义,当预测序列与标签序列完全相同时,BLEU为 1 1 1。此外,由于 n n n元语法越长则匹配难度越大,所以BLEU为更长的 n n n元语法的精确度分配更大的权重。具体来说,当 p n p_n pn固定时, p n 1 / 2 n p_n^{1/2^n} pn1/2n会随着 n n n的增长而增加(原始论文使用 p n 1 / n p_n^{1/n} pn1/n)。而且,由于预测的序列越短获得的 p n p_n pn值越高,所以式(4)中乘法项之前的系数用于惩罚较短的预测序列。例如,当 k = 2 k=2 k=2时,给定标签序列 A A A、 B B B、 C C C、 D D D、 E E E、 F F F和预测序列 A A A、 B B B,尽管 p 1 = p 2 = 1 p_1 = p_2 = 1 p1=p2=1,惩罚因子 exp ( 1 − 6 / 2 ) ≈ 0.14 \exp(1-6/2) \approx 0.14 exp(1−6/2)≈0.14会降低BLEU。
BLEU的代码实现如下。
def bleu(pred_seq, label_seq, k): #@save"""计算BLEU"""pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')len_pred, len_label = len(pred_tokens), len(label_tokens)score = math.exp(min(0, 1 - len_label / len_pred))for n in range(1, k + 1):num_matches, label_subs = 0, collections.defaultdict(int)for i in range(len_label - n + 1):label_subs[' '.join(label_tokens[i: i + n])] += 1for i in range(len_pred - n + 1):if label_subs[' '.join(pred_tokens[i: i + n])] > 0:num_matches += 1label_subs[' '.join(pred_tokens[i: i + n])] -= 1score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))return score
最后,利用训练好的循环神经网络“编码器-解码器”模型,将几个英语句子翻译成法语,并计算BLEU的最终结果。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, attention_weight_seq = predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device)print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')

小结
- 根据“编码器-解码器”架构的设计,
我们可以使用两个循环神经网络来设计一个序列到序列学习的模型。 - 在实现编码器和解码器时,我们可以使用多层循环神经网络。
- 我们可以使用遮蔽来过滤不相关的计算,例如在计算损失时。
- 在“编码器-解码器”训练中,强制教学方法将原始输出序列(而非预测结果)输入解码器。
- BLEU是一种常用的评估方法,它通过测量预测序列和标签序列之间的 n n n元语法的匹配度来评估预测。
相关文章:
)
【现代深度学习技术】现代循环神经网络07:序列到序列学习(seq2seq)
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

【Linux我做主】进度条小程序深度解析
Linux下C语言进度条程序深度解析 进度条小程序GitHub地址 前言前置知识回车换行(CR/LF)的深度解析历史渊源与技术规范在进度条/倒计时中的应用 缓冲区机制的全面剖析缓冲区引入缓冲类型对比进度条开发中的关键控制 进度条实现以小见大——倒计时倒计时最…...

Vue项目安全实践指南:从输入验证到状态管理的全方位防护
一、项目背景 在Vue2项目开发过程中,我们遇到了一些需要优化的安全实践问题。本文将分享我们在项目中的一些安全优化经验,希望能帮助到其他开发者。 主要优化点: 输入输出安全处理请求安全防护数据存储安全路由访问控制文件上传处理表单数…...

Pinocchio导入URDF关节为continuous的问题及详细解释
视频讲解: Pinocchio导入URDF关节为continuous的问题及详细解释 仓库地址:GitHub - LitchiCheng/mujoco-learning 问题背景:打算测试将之前的panda的urdf换成so-arm100的urdf,发现pinocchio的代码不能用,很奇怪&#…...

《Python星球日记》第30天:Flask数据库集成
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、数据库…...
)
GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)
GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab) 目录 GAF-CNN-SSA-LSSVM故障诊断/分类预测,附带模型研究报告(Matlab)效果一览基本描述程序设计参考资料 效果一览 基本描述 本研究提出的GA…...

轻松养生:让健康融入生活
养生不是负担,而是可以轻松融入日常的生活方式。掌握以下要点,就能开启健康之旅。 清晨醒来,先喝一杯常温水,唤醒沉睡的肠胃。早餐选择富含膳食纤维的燕麦片搭配新鲜水果,补充能量又促进消化。午餐和晚餐做到荤素搭配&…...

工业主义与民主的兴衰:历史逻辑与未来危机
一、工业主义催生大众民主的机制 经济基础变革 非技术工人崛起:工业革命后,机器生产替代传统手工业,非熟练工人(包括妇女、儿童)收入提升,财富分配趋于平等,形成新兴中产阶级。 政府财政能力增…...
 PyTorch版)
从代码学习深度学习 - 目标检测前置知识(二) PyTorch版
文章目录 前言一、多尺度目标检测1.1 多尺度锚框1.2 绘图工具函数 (`utils_for_huitu.py`)1.3 可视化多尺度锚框1.4 多尺度检测(理论)二、自定义目标检测数据集2.1 读取数据2.2 创建 Dataset 类2.3 创建 DataLoader2.4 验证数据加载2.5 可视化数据集样本总结前言 大家好!欢…...

什么是“系统调用”
一、什么是“系统调用”?用生活中的比喻理解 可以把“系统调用”比作你(用户)向“管理员”请求帮助完成某件事情的过程。 举个例子: 你想借书,去图书馆(操作系统)找管理员(内核&a…...
识别与重构指南)
代码异味(Code Smell)识别与重构指南
1、引言:什么是“代码异味”? 在软件开发中,“代码异味(Code Smell)”是指那些虽然不会导致程序编译失败或运行错误,但暗示着潜在设计缺陷或可维护性问题的代码结构。它们是代码演进过程中的“信号灯”,提示我们某段代码可能需要优化。 1.1 ✅ 为什么关注代码异味? 预…...

005-nlohmann/json 基础方法-C++开源库108杰
《二、基础方法》:节点访问、值获取、显式 vs 隐式、异常处理、迭代器、类型检测、异常处理……一节课搞定C处理JSON数据85%的需求…… JSON 字段的简单类型包括:number、boolean、string 和 null(即空值);复杂类型则有…...
)
java学习之数据结构:四、树(代码补充)
这部分主要是用代码实现有序二叉树、树遍历、删除节点 目录 1.构建有序二叉树 1.1原理 1.2插入实现 2.广度优先遍历--队列实现 3.深度优先遍历--递归实现 3.1先序遍历 3.2中序遍历 3.3后序遍历 4.删除 4.1删除叶子节点 4.2删除有一棵子树的节点 4.3删除有两棵子树的节…...

Java面试场景分析:从音视频到安全与风控的技术探讨
Java面试场景分析:从音视频到安全与风控的技术探讨 在一个阳光明媚的早晨,互联网大厂的面试室里,面试官李老师坐在桌前,严肃认真;而程序员小张则显得有些紧张,甚至有些搞笑。 第一轮提问: 李老…...

《OmniMeetProTrack 全维会议链智能追录系统 软件设计文档》
撰稿人:wjz 一、引言 1.1 目的 本软件设计文档详细描述了 OmniMeetProTrack 全维会议链智能追录系统的架构、组件、模块设计及实现细节,旨在为开发人员、利益相关者和维护人员提供系统的全面设计蓝图。本文档基于需求定义文档,确保系统实现…...

C 语言逻辑运算符:组合判断,构建更复杂的条件
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 在 C 语言编程中,我们已经学习了如何使用比较运算符(如 ==, <, >)来判断两个值之间的关系,从而得到“真”或“假”的结果。但很多时候,我们需要根据多个条件的组合…...

大模型推理框架简介
概述 通常需要大量的计算资源,高效运行LLMs仍然是一个挑战, 推理框架作为LLM高效部署的关键组件,直接关系到应用的性能、成本和开发效率。 高性能框架 vLLM GitHub,由SKYPILOT构建的推理优化框架,旨在提高在GPU上…...

《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-《5G通信速成:MATLAB毫米波信道建模仿真指南》
《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-5G通信速成:MATLAB毫米波信道建模仿真指南 🚀📡 大家好!今天我将带大家进入5G通信的奇妙世界,我们一起探索5G通信中最激动人心的部分之一——毫米波信…...

word导出pdf带有目录导航栏-error记
1、打开word文档——>点击"视图"选项卡——>勾选"导航窗格" 2、点击"文件"——>导出——>创建PDF/XPS 3、点击"选项"——>勾选"创建书签时使用(C)" "标题(H)" 4、点击"确定"——>点击…...

word怎么删除空白页?word最后一页删不掉怎么办
在使用word的过程中,有时出现空白页就可能会给大家带来一些困扰。到底怎么样才能把这些空白页删除,又应该如何解决最后也删不掉的问题呢? 要想删除普通的空白页,那就需要将光标直接放在空白页,然后按【Delete】键&…...

虚幻基础:硬件输入
文章目录 triggered:按下一直触发 等于tickcompleted:必须等到triggered结束后 才触发松下triggered结束 默认按键触发顺序按下:触发两个先 Started后 Triggered 松开Completed 触发器:用于修改triggered 触发和结束驱动阈值&…...
)
【Java ee初阶】多线程(5)
一、wait 和 notify wait notify 是两个用来协调线程执行顺序的关键字,用来避免“线程饿死”的情况。 wait 和 notify 其实都是 Object 这个类的方法,而 Object这个类是所有类的“祖宗类”,也就是说明,任何一个类,都…...

售前赢单评分是越权吗?
相关文章 软件实施工作个人看法 当前部门软件产品经理的职责涵盖售前支持工作。此前梳理工作时,计划在每个售前支持项目完成后,由支持人对项目赢单概率进行评估,旨在通过这一机制筛选重点项目,为赢单率高的项目优先配置资源。 …...

uniapp中用canvas绘制简单柱形图,小容量,不用插件——简单使用canvas
uniapp中用canvas绘制简单柱形图,小容量,不用插件——简单使用canvas 完整代码 <template><view><!-- 学习数据 --><!-- 头部选项卡 --><view class"navTab"><view :class"listIndexi?activite:"…...

SecureCRT 使用指南:安装、设置与高效操作
目录 一、SecureCRT 简介 1.1 什么是 SecureCRT? 1.2 核心功能亮点 1.3 软件特点 二、SecureCRT 安装与激活 2.1 安装步骤(Windows 系统) 2.2 激活与破解(仅供学习参考) 三、基础配置与优化 3.1 界面与编码设…...

WebRTC 服务器之SRS服务器概述和环境搭建
1.概述 SRS(Simple Realtime Server)是一款高性能、跨平台的流媒体服务器,支持多种协议,包括 RTMP、WebRTC、HLS、HTTP-FLV、SRT、MPEG-DASH 和 GB28181。本文介绍了 SRS,包括其用途、关键功能、架构和支持协议。SRS 旨…...
)
第R8周:RNN实现阿尔兹海默病诊断(pytorch)
- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rnFa-IeY93EpjVu0yzzjkw) 中的学习记录博客** - **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)** 一:前期准备工作 1.设置硬件设备 impo…...

vue+element 导航 实现例子
项目使用的是 vue 3,安装配置可以查看栏目前面的文章。 组件 导航:https://element-plus.org/zh-CN/component/menu.html 面包屑:https://element-plus.org/zh-CN/component/breadcrumb.html 安装element库 PS D:\code\my-vue3-project&g…...

金仓数据库 KingbaseES 在电商平台数据库迁移与运维中深入复现剖析
金仓数据库 KingbaseES 在电商平台数据库迁移与运维中深入复现剖析 前言 在当今数字化商业蓬勃发展的时代,电商平台的数据量呈爆发式增长,对数据库性能、稳定性和扩展性提出了极高要求。本文章基于大型电商平台原本采用 MySQL 数据库,但随着业…...
)
Go小技巧易错点100例(三十)
本期分享: 1.切片共享底层数组 2.获取Go函数的注释 切片共享底层数组 在Go语言中,切片和数组是两种不同的元素,但是切片的底层是数组,并且还有一个比较重要的机制:切片共享底层数组。 下面这段代码演示了切片&…...

LeetCode 热题 100 78. 子集
LeetCode 热题 100 | 78. 子集 大家好,今天我们来解决一道经典的算法题——子集。这道题在 LeetCode 上被标记为中等难度,要求给定一个整数数组 nums,返回该数组所有可能的子集(幂集)。解集不能包含重复的子集&#x…...

苹果公司正在与亚马逊支持的初创公司Anthropic展开合作
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
)
Python项目源码57:数据格式转换工具1.0(csv+json+excel+sqlite3)
1.智能路径处理:自动识别并修正文件扩展名,根据转换类型自动建议目标路径,实时路径格式验证,自动补全缺失的文件扩展名。 2.增强型预览功能:使用pandastable库实现表格预览,第三方模块自己安装一下&#x…...
redis持久化)
Redis总结(六)redis持久化
本文将简单介绍redis持久化的两种方式 redis提供了两种不同级别的持久化方式: RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】5.3 相关性分析(PEARSON/SPEARMAN相关系数)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 5.3 相关性分析(PEARSON/SPEARMAN相关系数)5.3.1 相关性分析理论基础5.3.1.1 相关系数定义与分类5.3.1.2 Pearson相关系数( Pearson Corr…...

C++负载均衡远程调用学习之负载均衡算法与实现
目录 01 lars 系统架构回顾 02 lars-lbAgentV0.4-route_lb处理report业务流程 03 lars-lbAgentV0.4-负责均衡判断参数配置 04 lars-lbAgentV0.4-负载均衡idle节点的失败率判断 05 lars-lbAgentV0.4-负载均衡overload节点的成功率判断 06 lars-lbAgentV0.4-负载均衡上报提交…...

AIGC学术时代:DeepSeek如何助力实验与数值模拟
目录 1.实验和数值模拟工具 2.结合使用 大家好这里是AIWritePaper官方账号,官网👉AIWritePaper~ 在工程和科学研究的世界里,实验与数值模拟是探索未知、验证理论和推动创新的两大支柱。它们如同一对翅膀,让思想得以飞翔…...
、rsort()、asort()、arsort()、ksort()、krsort() 的适用场景与性能对比)
PHP数组排序深度解析:sort()、rsort()、asort()、arsort()、ksort()、krsort() 的适用场景与性能对比
在PHP开发中,数组排序是日常操作的核心技能之一。无论是处理用户数据、产品列表,还是分析日志信息,合理的排序方法能显著提升代码的效率和可维护性。PHP提供了多种数组排序函数(如 sort()、rsort()、asort() 等)&#…...

2025年企业Radius认证服务器市场深度调研:中小企业身份安全投入产出比最优解
引言:数字化转型浪潮下的身份安全新命题 在混合办公成为常态、物联网设备呈指数级增长、网络攻击手段日益隐蔽的2025年,企业网络边界正在经历前所未有的重构。据IDC预测,全球企业网络安全投入中,身份与访问管理(IAM&a…...
)
开源模型应用落地-qwen模型小试-Qwen3-8B-快速体验-批量推理(三)
一、前言 阿里云最新推出的 Qwen3-8B 大语言模型,作为国内首个集成“快思考”与“慢思考”能力的混合推理模型,凭借其 80 亿参数规模及 128K 超长上下文支持,正在重塑 AI 应用边界。该模型既可通过轻量化“快思考”实现低算力秒级响应,也能在复杂任务中激活深度推理模式,以…...

相同IP和端口的服务器ssh连接时出现异常
起因 把服务器上的一个虚拟机搞坏了,所以删除重新创建了一个,端口号和IP与之前的虚拟机相同。 ssh usernameIP -p port 时报错 WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! Someone…...

VScode中关于Copilot的骚操作
目录 1. Ctrl I 直接在工作区对话 2.Tab 党福音:写注释生成代码 3. 连续写几行函数头,Copilot 会自动“补全全函数” 4. 自动写单元测试 5. 在注释中要求它写某种风格 6. 代码重写器 7. 多语言切换无痛自动翻译 8. 在空文件中写注释,…...

linux inotify 资源详解
Linux 的 inotify 是一个强大的文件系统监控机制,允许应用程序实时监听文件和目录的变化。这对于需要响应文件系统事件的应用(如配置热加载、备份工具、文件同步服务等)至关重要。以下是对 inotify 资源的深度解析: 一、核心概念…...
——继承)
Java SE(8)——继承
1.继承的概念&作用 在Java中,继承是面向对象编程的三大基本特性之一(还有封装和多态),允许一个类(子类/继承类)继承另一个类(父类/基类)的属性和方法 继承的核心目的是…...
【论文笔记】SOTR: Segmenting Objects with Transformers
【题目】:SOTR: Segmenting Objects with Transformers 【引用格式】:Guo R, Niu D, Qu L, et al. Sotr: Segmenting objects with transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 7157-7166. 【网…...

AIDC智算中心建设:资源池化核心技术解析
目录 一、池化技术架构 二、池化核心技术 三、展望 一、池化技术架构 智能算力池化指依托云计算技术,整合 GPU/AI 芯片等异构算力资源,构建集中管理的资源池,并按上层智算业务的需求,对池化的资源进行统一调度、分配ÿ…...

flink监控指标
文章目录 一、flink yaml配置二、配置指标项情况 提示:以下是基于开源flink on k8s环境下配置监控指标(部分已实验,粗略记录) 一、flink yaml配置 配置完成后就可以在页面查询(部分 需要验证)指标 二、配置指标项情况 参考下面网址: 阿里…...

签名去背景图像处理实例
一、前言 在生活中我们经常用到电子签名,但有时候我们所获取的图像的彩色图像,我们需要获取白底黑字的电子签名,我们可以通过下面程序对彩色图像进行处理达到我们的处理目的。 原始彩色图像如下: 二、原始代码 clear all;close a…...

[人机交互]理解与概念化交互
零.本章重点(理解和分析用户问题) – 解释“问题空间”的概念和含义 – 解释如何概念化交互 – 描述什么是概念模型 – 讨论将界面隐喻作为概念模型的利弊 – 讨论界面具体化和抽象化各自的优缺点 – 概述概念设计和实际设计的关系 一.理解问题空间 简单…...

C与指针——常见库函数
字符串 #include<stdlibs.h> int abs(int); long labs(long); int rand(void);//0-RAND_MAX //字符串转值 int atoi(const char*); long atol(const char*); float atof(const char*);数学\排序 #include<math.h> \\常见三角,sqrt(); exp(); double p…...