AIDC智算中心建设:计算力核心技术解析
目录
一、智算中心发展概览
二、计算力核心技术解析

一、智算中心发展概览
智算中心是人工智能发展的关键基础设施,基于人工智能计算架构,提供人工智能应用所需算力服务、数据服务和算法服务的算力基础设施,融合高性能计算设备、高速网络以及先进的软件系统,为人工智能训练和推理提供高效、稳定的计算环境。智算中心的主要功能包括:
-
提供强大的计算能力:智算中心采用专门的AI算力硬件,如GPU、NPU、TPU等,以支持高校的AI计算任务。
-
高效的数据处理:智算中心融合了高性能计算设备和高速网络,能够处理大规模的数据集和复杂的计算任务。
-
支持多种AI应用:智算中心适用于计算机视觉、自然语言处理、机器学习等领域,处理图像识别、语音识别、文本分析、模型训练推理等任务。
智算中心AIDC内涵
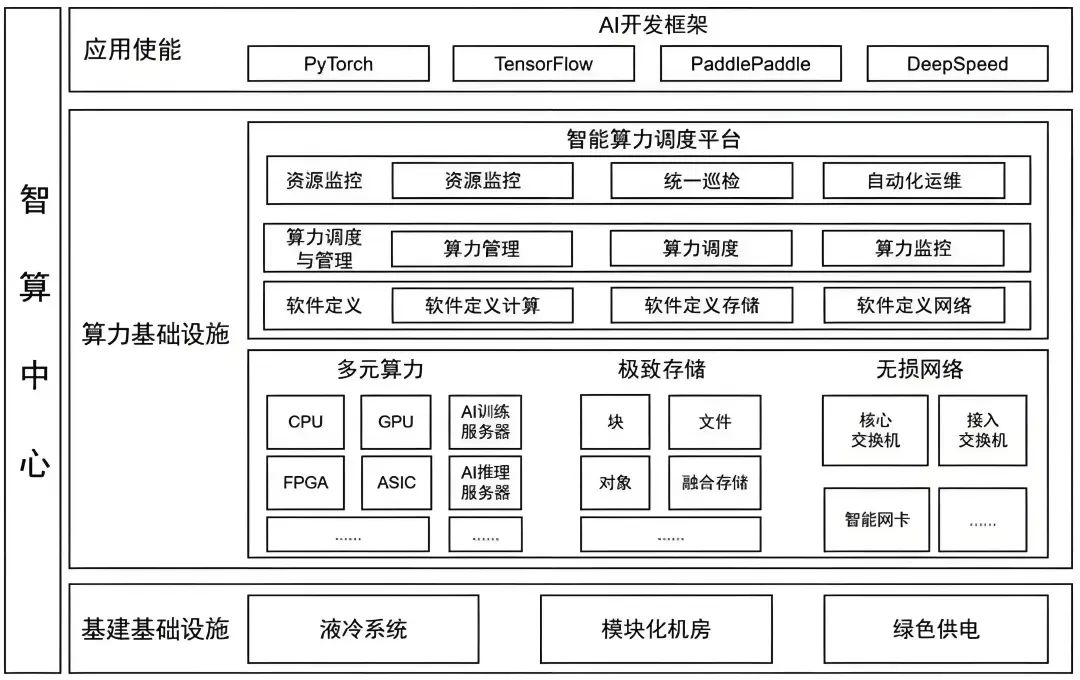
狭义上讲,智算中心是通用算力中心的升级,在传统数据中心的基础上融合GPU、TPU、FPGA等专用芯片支撑大量数据处理和复杂模型训练。AIDC把不同的计算任务实时智能调度分配给不同的服务器集群以提升计算效率。简单讲智算中心就是“机房+网络+GPU 服务器+算力调度平台”的融合基础设施,是传统数据中心的增值性延伸。
广义地说,智算中心是提供人工智能应用所需算力服务、数据服务和算法服务的新型算力基础设施,包含基础层、平台层和应用层。其中,基础部分是支撑智算中心建设与应用的先进人工智能理论和计算架构,平台部分围绕智算中心算力生产、聚合、调度、释放的作业逻辑展开;应用层提供算力生产供应、数据开放共享、智能生态建设和产业创新聚集。是融合算力+数据+算法的新型基础设施,是AI技术一体化的载体,是传统云的智能化升级。
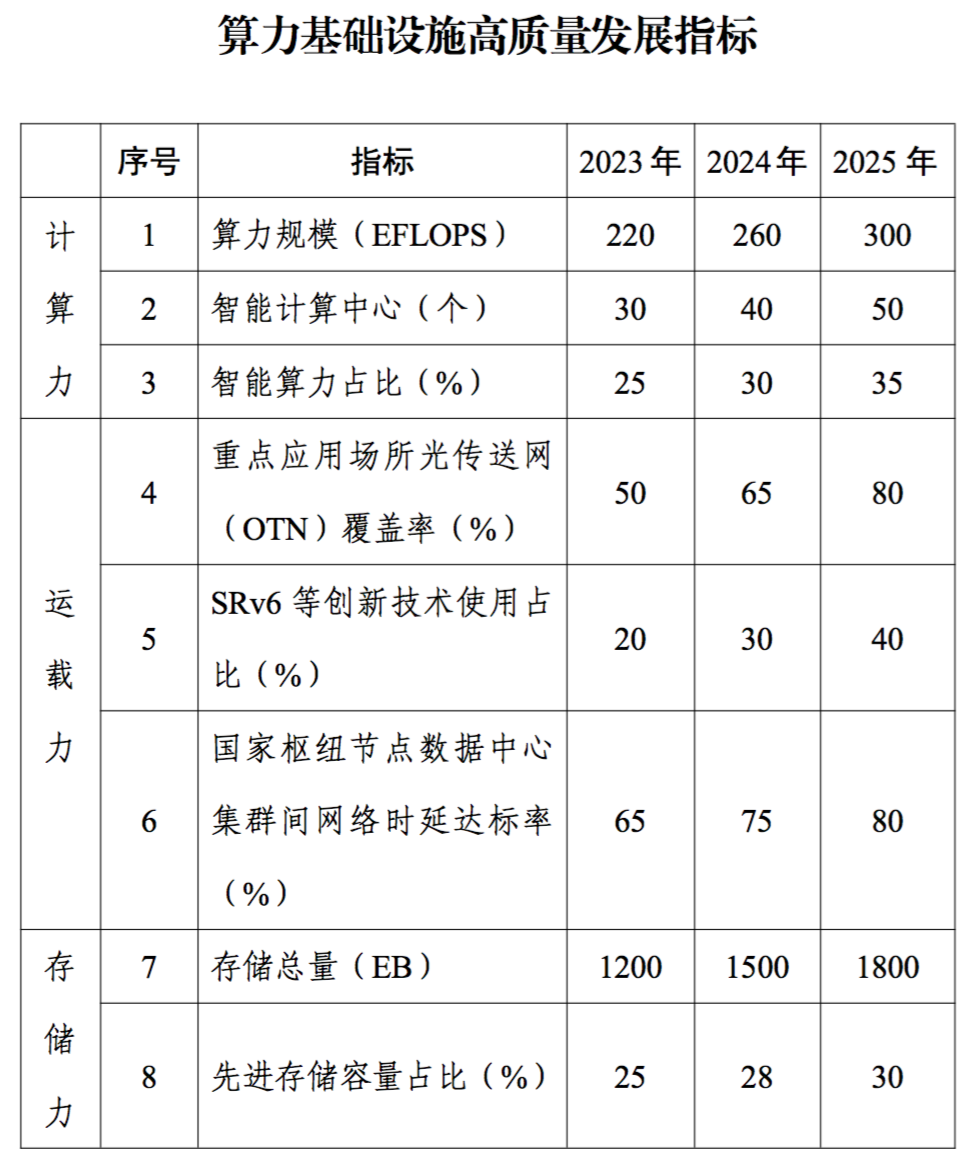
人工智能作为引领未来的战略性技术,逐步成为衡量国家国际竞争力的重要领域,高性能算力是人工智能发展的重要组成部分。从全球范围看,各国纷纷制定人工智能相关的战略和政策,推动高性能算力发展。如美国成立智算中心基础设施特别工作组、欧盟出台《欧盟高性能计算共同计划》、日本发布《人工智能战略2022》等。我国也于2023年出台《算力基础设施高质量发展行动计划》,进一步凝聚产业共识、强化政策引导,全面推动我国算力基础设施高质量发展。报告要求,到2025年要实现如下主要目标:

算力常用计量单位是每秒执行的浮点运算次数(FLOPS,Floating-point operations per second),数值越大计算能力越强。
KFLOPS(kiloFLOPS)=10^3 FLOPS
MFLOPS(megaFLOPS)=10^6 FLOPS
GFLOPS(gigaFLOPS)=10^9 FLOPS
TFLOPS(teraFLOPS)=10^12 FLOPS
PFLOPS(petaFLOPS)=10^15 FLOPS
EFLOPS(exaFLOPS)=10^18 FLOPS
存储容量常用计量单位是艾字节(EB,1EB=2^60bytes)
智算中心产业及市场规模
智算中心产业链涵盖从AI芯片/服务器等设计制造、基础设施建设,到智算服务提供,以及生成式大模型研发及基于大模型的行业应用。
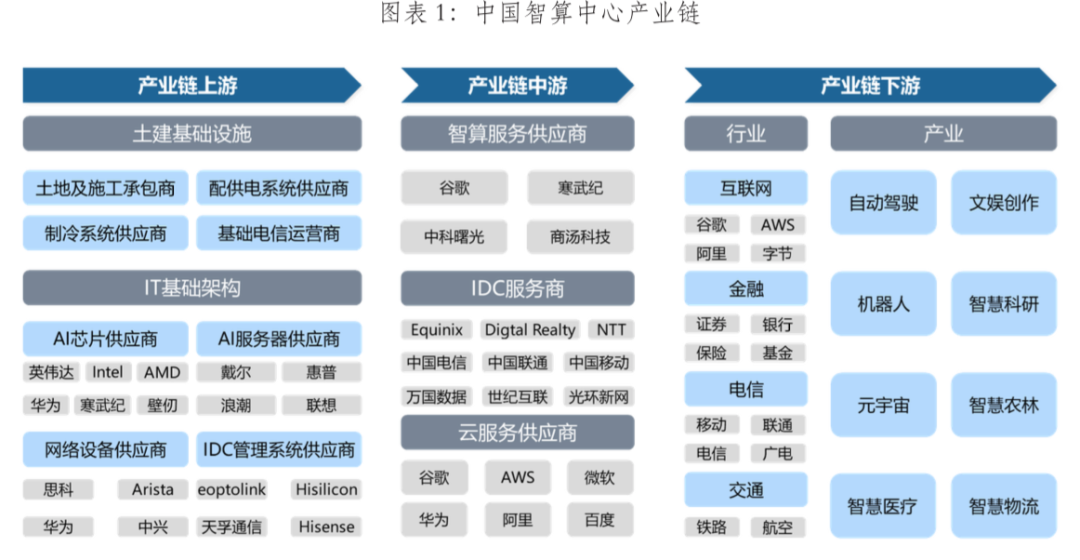
在需求的推动下我国智算中心市场投资规模高速增长。2022年生成式人工智能大模型推向市场,在过国内引起AIGC发展热潮,大模型训练对智能算力的需求迅速攀升。2023年起国内头部互联网企业及科技公司加速AIGC布局,政府也牵头建设公共智能算力中心,赋能社会数字化转型需求,全国智算中心投资火热,智算中心市场规模大幅增长,尤其是今年1月份DeekSeep的火爆出圈,更是进一步加速了这一进程。
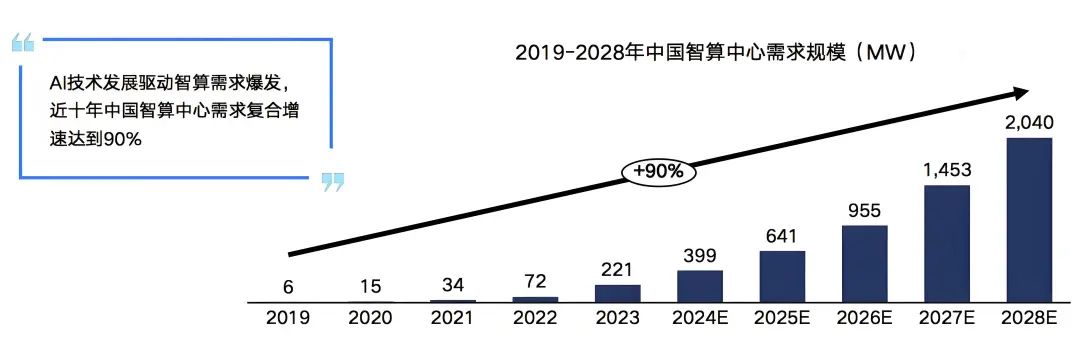
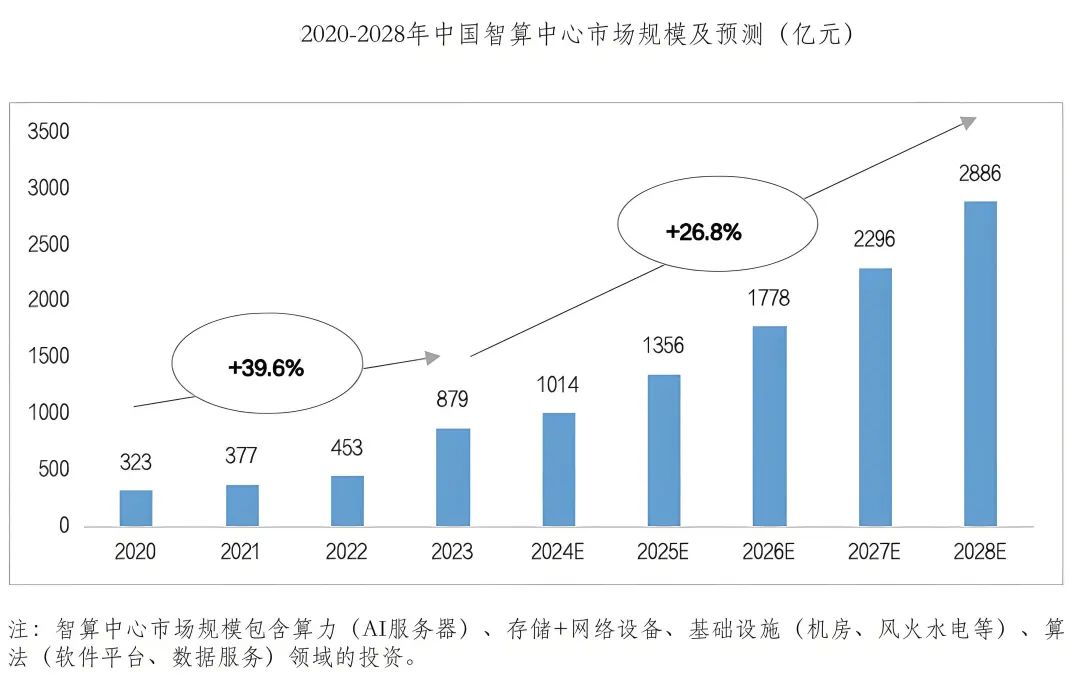
虽然近期有消息称,智算中心建设暂时按下了减速键,但是未来,AI大模型应用场景,不断丰富,商用进程逐步加快,智算中心市场增长动力逐渐由训练切换至推理,市场进入平稳增长期,预计2028年我国智算中心市场投资规模有望达到2886亿元。
二、计算力核心技术解析
AI芯片
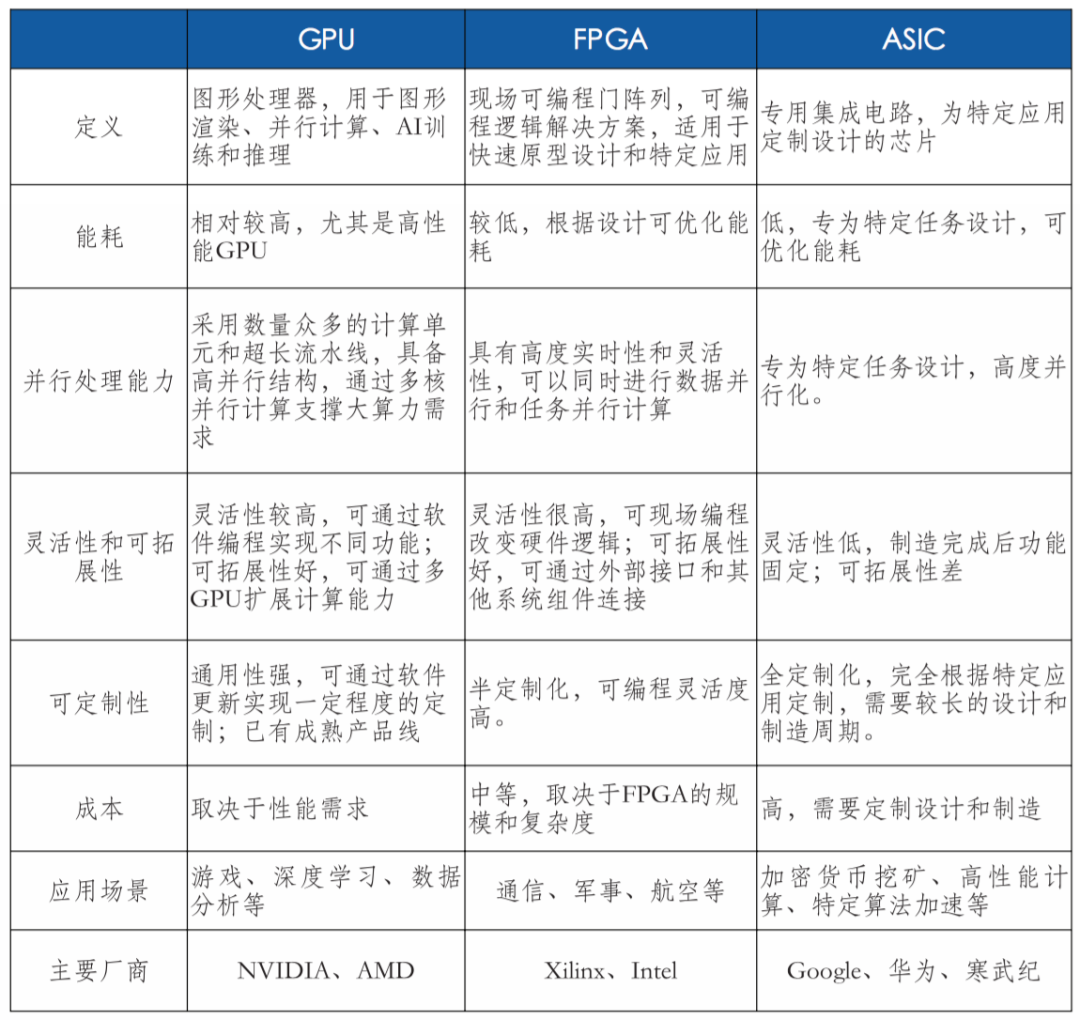
智算中心常见应用场景为训练和推理,根据其对算力精度的需求的差异分为FP32、TF32、FP16、BF16、INT8、FP8、FP6、FP4等。智能算力的核心是CPU、GPU、FPGA、ASIC等各类计算芯片。AI芯片内核数量多,擅长并行计算,满足AI算法所需要的大量并行处理能力,并显著提升计算效率和灵活性。智算服务器是智算中心的主要算力硬件一般采用CPU+GPU、CPU+FPGA、CPU+ASIC等异构形式,以充分发挥不同算力芯片在性能、成本和能耗上的优势。
高性能芯片技术快速迭代创新,为人工智能发展提供保障,进而带动智算中心发展,Nvidia作为全球GPU算力芯片市场领导者,代表性产品H100、A100、V100技术指标处于领先水平,最新的Blackwell架构B200 GPU采用先进的4纳米工艺,实现了基于FP4高达40PFLOPS的运算能力,相较前代提升5倍。其他科技巨头如AMD、英特尔、微软、亚马逊和谷歌也在AI芯片领域展开竞争。同时,我国AI芯片国产化进程正在加速发展,华为、寒武纪、海光信息、景嘉微以及阿里、百度等企业不仅在自研AI芯片技术上取得重要进展,还通过产品集成、行业解决方案及生态伙伴合作等方式推进国产AI芯片商业化应用,为智能算力发展提供坚实基础。
Nvidia H100 GPU
本节基于Nvidia的公开资料GPU H100报告为例,解析GPU的相关技术实现。
GPU在本质上是一个PCI-E插卡/扣卡,由PCB(Printed Circult Board,印刷电路板)、GPU芯片、GPU内存(即“显存”)及其他附属电路构成。
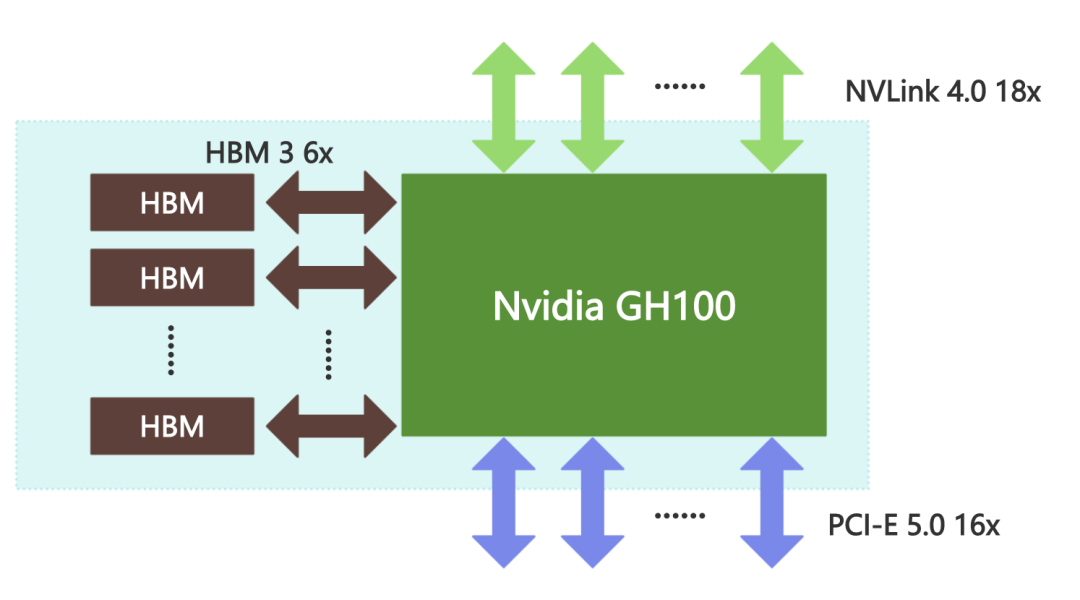
Nvidia H100 GPU的核心芯片是Nvidia GH100,对外的接口有16个PCI-E 5.0通道、18个NVLink 4.0通道和6个HBM 3/HBM 2e通道。
-
在Nvidia H100 GPU卡上,Nvidia GH100 的16个PCI-E 5.0通道用于连接到CPU,实现CPU将程序指令发送到GPU,并为GPU提供访问计算机主存储器的通道,总共可以提供约63GBps的理论传输带宽。
-
与Nvidia GH100 配套的显存是HBM(High Bandwidth Memory,高带宽内存)。HBM是由三星、AMD和SK Hynix等芯片厂商在2013年提出的一种在DDR内存的基础上进一步提升内存性能的内存接口标准,仍然采用DDR内存的时序标准。与DDR内存不同,HBM充分利用了内存芯片封装内部的立体空间,在内存芯片中将多层存储电路堆叠起来,以实现在较小的平面面积上获得极高的内存容量和带宽。Nvidia GH100 芯片支持6个HBM Stack,每个HBM Stack都可以提供800GBps的传输带宽,总内存带宽可达到4.8TBps。
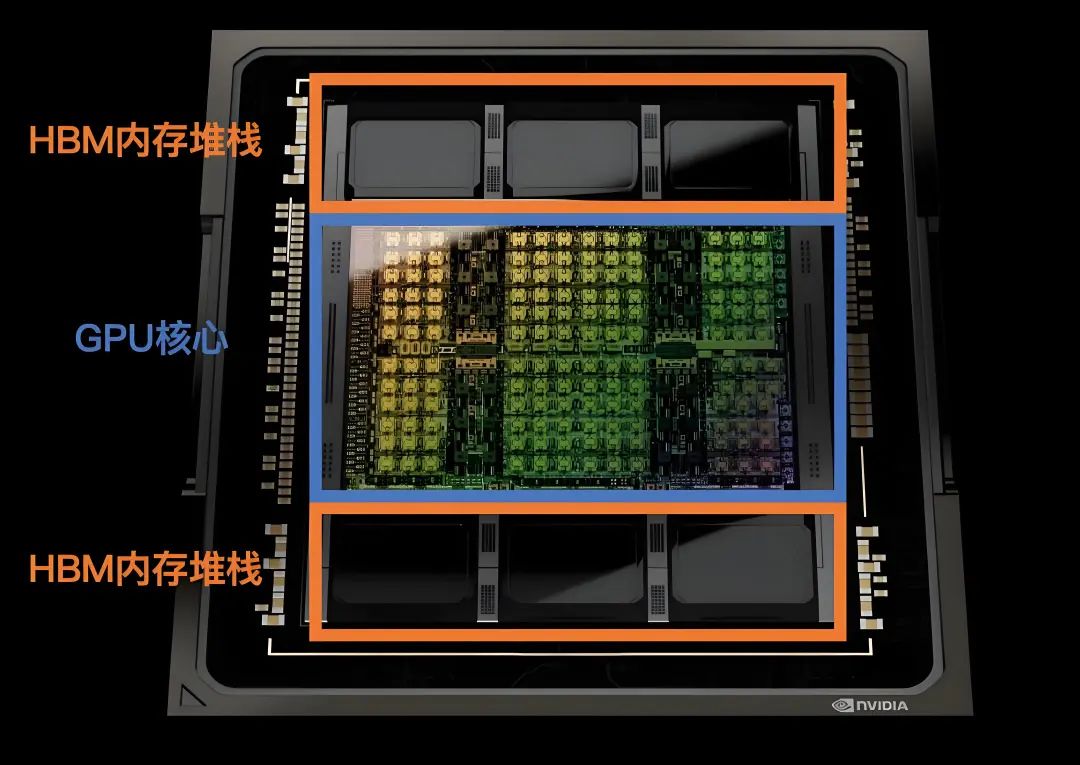
-
Nvidia GH100 还提供了18个NVLink 4.0通道,共提供900GBps的理论传输带宽,可以直接连接到其他GPU,或通过NVLink Switch连接多个GPU,实现GPU之间的互访,让一个GPU可以在CPU无感知的情况下访问另一个GPU的内存,而无需绕行PCI-E总线。
在Nvidia H100 GPU卡上,PCI-E 5.0通道和NVLink通道是连接到GPU卡外部的,而HBM通道在PCB内部连接到PCB上的HBM芯片,不延伸到卡外部。另外,Nvidia提供了不带NVLink的精简版本Nvidia H100 GPU卡,这样Nvidia GH100芯片上的NVLink接口也就闲置了,在其他规格上也有一定的精简。同时,Nvidia考虑到其他因素,为特定的国家和地区提供了进一步精简规格的GPU,比如Nvidia H800等。
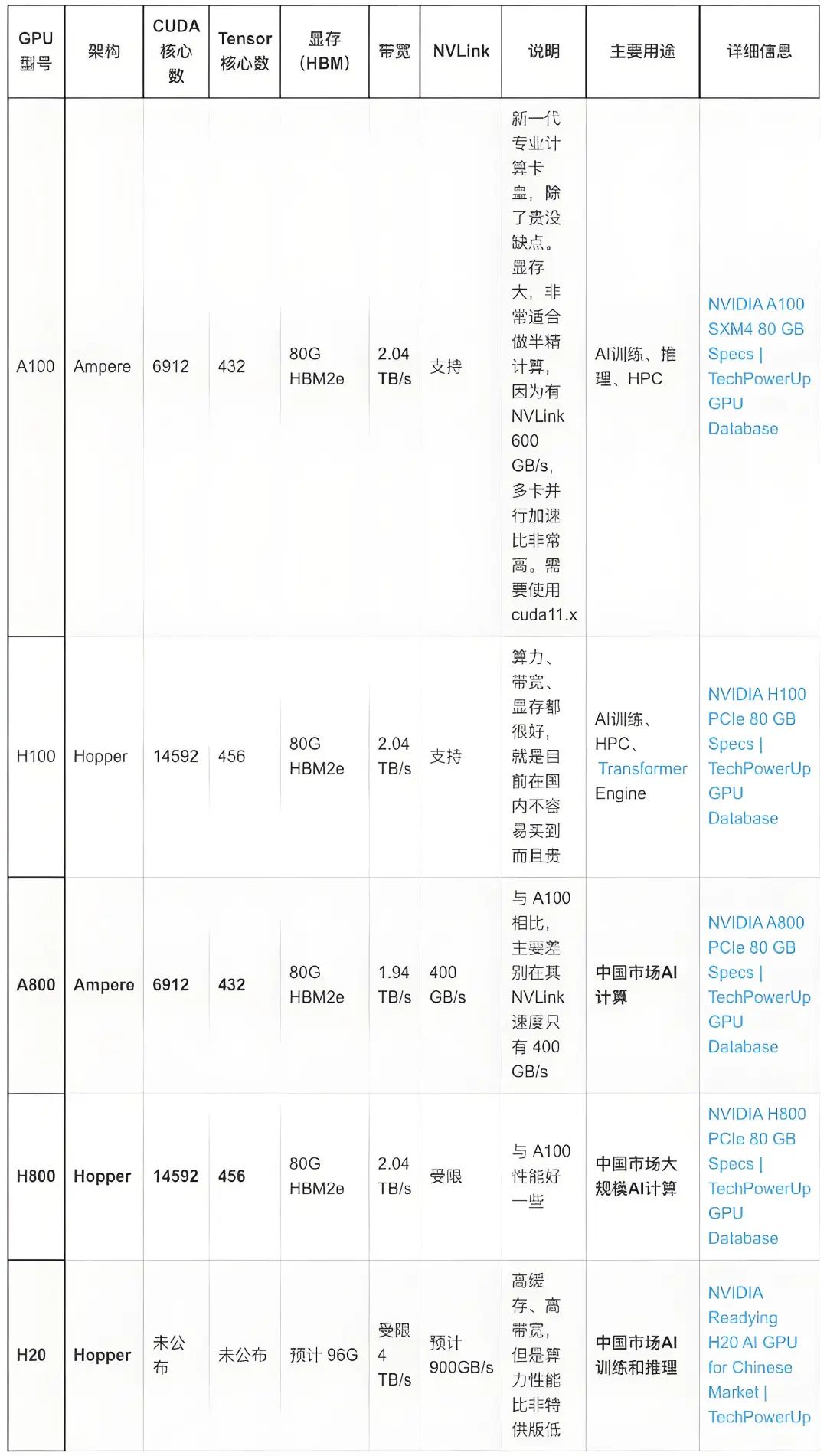
SM 流式多处理器
下图是Nvidia GH100芯片的内部架构图,在Nvidia GH100芯片中,除了NVLink接口、PCI-E接口和HBM接口,真正的核心部件就是SM(Streaming Multiprocessor,流式多处理器)。
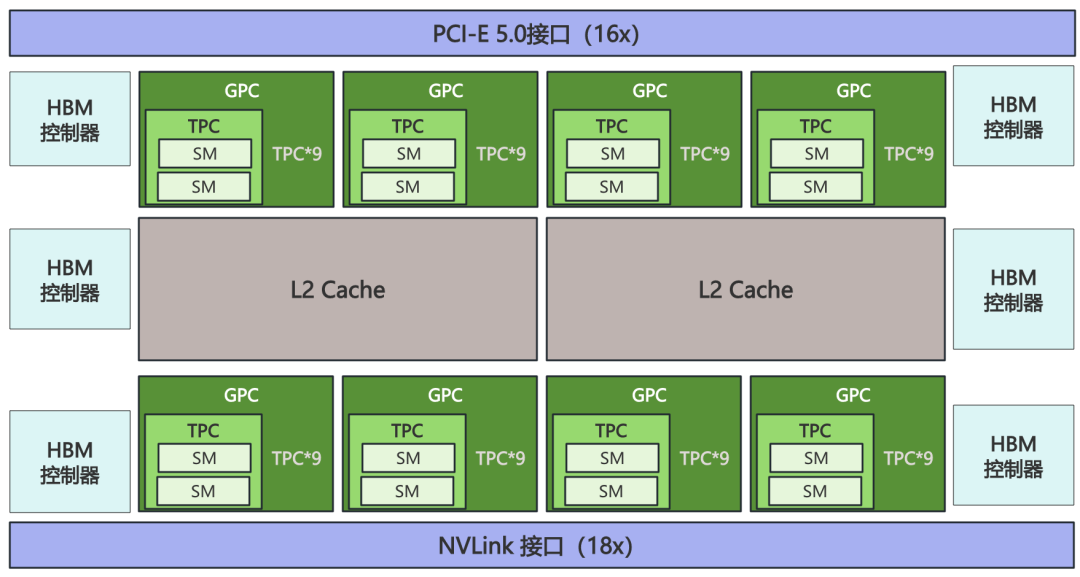
整个Nvidia GH100 芯片有8个GPC(CPU Processing Cluster,GPU处理集群),每4个GPC都共有30MB的L2 Cache(二级缓存),每个GPC都有9个TPC(Texture Processing Cluster,纹理处理集群),在每个TPC内都有2个SM。也就是说,整颗Nvidia GH100 芯片集成了144个SM。
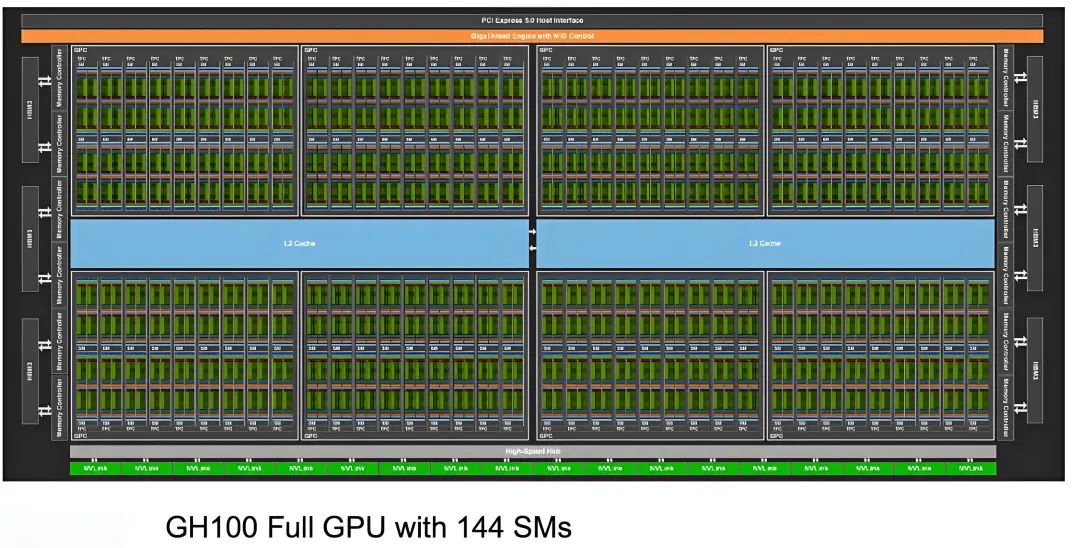
SM内部结构如下图所示。在每个SM内部都有256KB的L1 Data Cache(一级数据缓存),被所有计算单元共享,同时,在SM内部还有4个纹处理单元Tex。SM的计算核心部件是Tensor Core和CUDA Core(下图中一个INT32单元、2个FP32单元和1个FP64计算单元组成)。除此之外,还有L0 Instruction Cache(一级指令缓存)等部件。
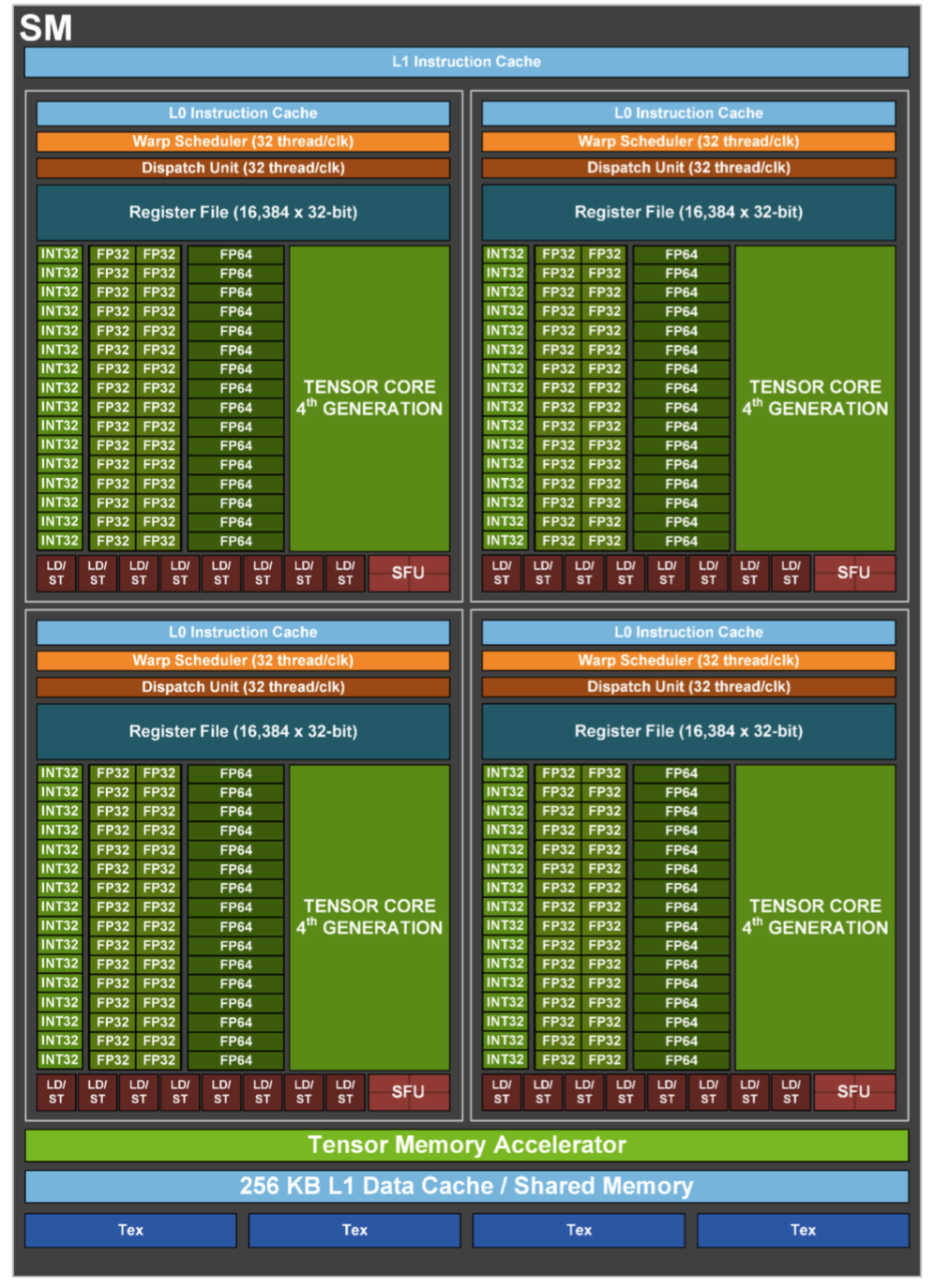
在Hopper架构中,每个SM都有4个象限,每个象限都包含1个Tensor Core和32个CUDA Core,总计4个Tensor Core和128个CUDA Core。整颗芯片可用的CUDA Core数量为144 X 128 = 18432个,可用的Tensor Core 数量为144 X 4 = 576个。
内存加速器
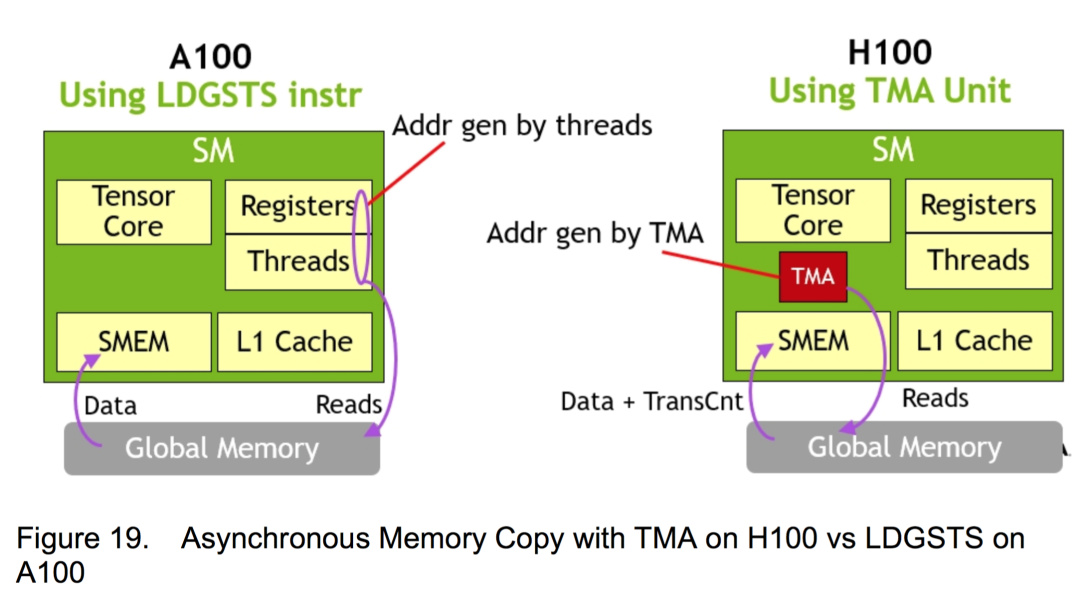
为了提升Tensor Core的内存存取速度,Nvidia在Hopper架构中引入了TMA(Tensor Memory Accelerator,张量存储加速器),以提高Tensor Core读写内存的交换效率。TMA可以让Tensor Core使用张量维度和块坐标指定数据传输,而不是简单地按数据地址直接寻址,这在矩阵分割等场景中能进一步提升寻址效率。例如,在Nvidia A100上,线程本身需要生成矩阵的子矩阵中各行数据所在的地址,并执行所有数据复制操作。但在基于Hopper架构的Nvidia H100中,TMA可以自动生成矩阵中各行的地址序列,接管数据复制任务,将线程解放出来做真正有价值的计算任务。TMA加速的工作原理如下图。
数据局部性考量
在GPU这种超大规模的并行计算机中,对数据局部性的考量变得尤为重要,对于GPU而言,就是要将数据尽量放在靠近计算单元的位置,这样能够让计算单元尽可能发挥缓存的低延迟和高带宽优势。如果想充分利用时间局部性和空间局部性提升计算机的性能,就首先要充分理解计算单元和缓存。
-
在Hopper架构下,访问速度最快的是SM中每个象限的1KB Register File。
-
访问速度次之的是每个象限的1块L0指令缓存,被32个CUDA Core和1个Tensor Core共用。
-
访问速度更慢一些的,是每个SM中的256KB L1 Data Cache,由所有CUDA Core和Tensor Core共用。
-
比L1 Data Cache更慢的是在整颗芯片中集成的60MB的L2 Cache,由2个BANK 组成,最慢的是Nvidia GH100 芯片外部的HBM3显存。
在划分工作负载时,也需要充分考虑这几个阈值,在避免发生缓存冲突的同时,将系统性能发挥到最大。
异步计算
除了基于缓存的优化外,并行计算在异步计算方面也进行了优化。异步计算就是尽量杜绝任务的互锁或序列化操作,充分利用所有计算单元,避免计算单元等待和阻塞。Hopper架构提供了SM之间共享内存的交换网络,每个线程块都可以将自身的内存共享出来,是的其他线程块的CUDA Core和Tensor Core能够直接通过load/store/atomic等操作访问。
Hopper架构还继承和改进了Amper架构的一个重要特性:MIG(Multi-Intance CPU),支持GPU的硬件虚拟化。在MIG的加持下,可以将GPU划分为多个彼此隔离的GPU实例给不同的用户使用,每个GPU实例都拥有自己独立的SM和显存,如下图所示。
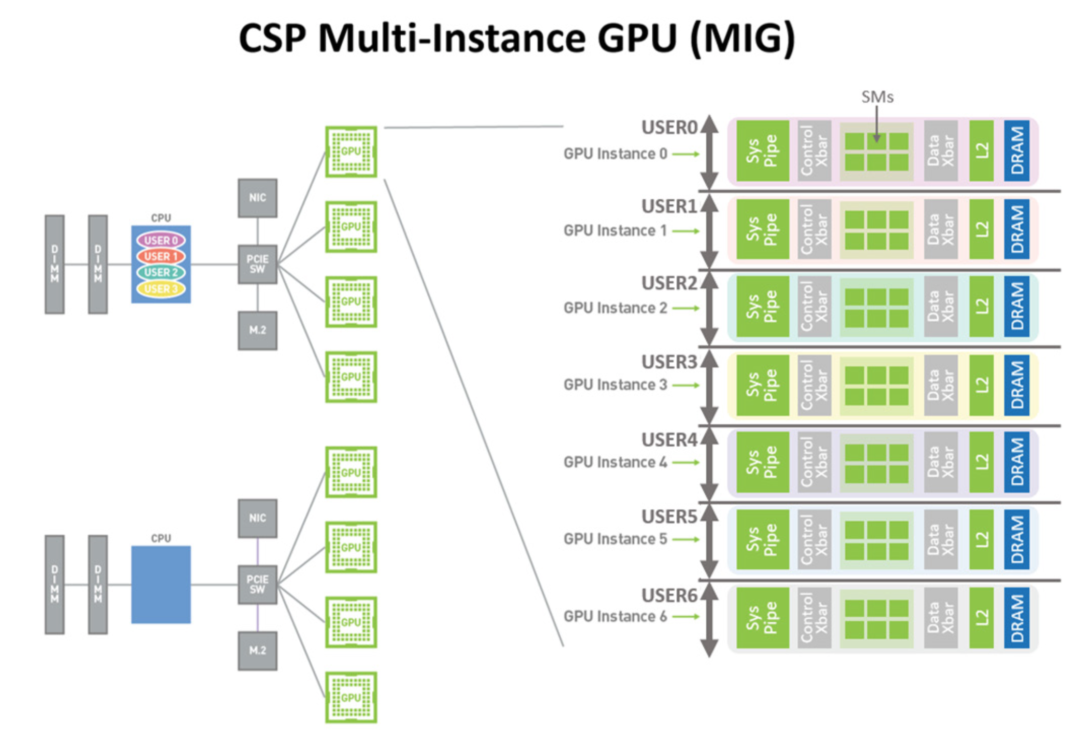
在Hopper架构中对MIG进行了安全方面的增强,能够支持可信计算,还增加了对MIG虚拟化实例监控能力,从而更适应多租户的云服务场景。
IO框架
分布式计算机系统,I/O设计往往也是影响系统性能的重要因素。典型的分布式I/O设计有虚拟化系统中常用的VirtIO,高性能计算中常用的HPFS,以及大数据平台依托的HDFS。在常规的分布式训练模式中,会涉及以下问题:
-
CPU对其他节点上的GPU下发GPU指令
-
GPU和GPU之间的交互,比如交换彼此计算出的权重、取值等。
-
GPU与本地存储设备的交互,比如读取模型和样本。
-
GPU与远端存储设备的交互,比如读取其他节点上的模型和样本。
对于这些问题,Nvidia给出的解决方案是让GPU使用尽量短的路径实现直通,也就是GPU Direct。对此Nvidia提供了对应的I/O设计框架:Magnum IO,如下所示。
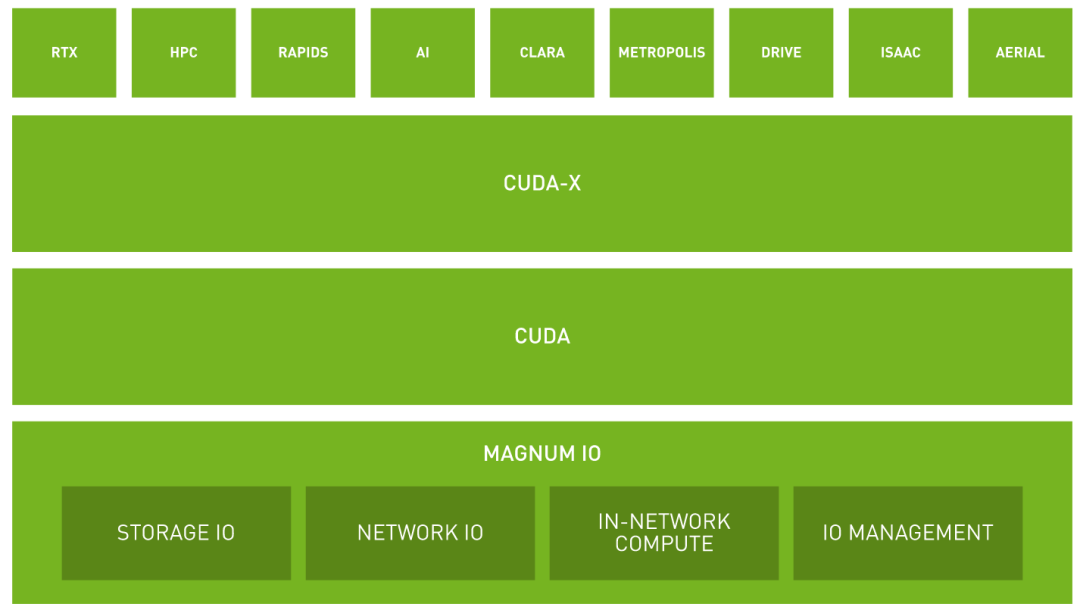
Magnum IO四大核心组件:Storage IO、Network IO、In-Network Compute和IO Management。这几大组件都是GPU Direct的一部分,或者是支撑GPU Direct运行的保障体系。GPU Direct是Nvidia开发的一种技术,可实现GPU与其他设备(例如主机内存、其他GPU、网络接口卡NIC或存储设备)之间的直接通信和数据传输,而不涉及CPU。
往期推荐
一文解读DeepSeek在保险业的应用-CSDN博客
一文解读DeepSeek在银行业的应用_deepseek在银行的应用-CSDN博客
一文解读DeepSeek大模型在政府工作中具体的场景应用_大模型会议纪要场景-CSDN博客
一文解读DeepSeek大模型在政务服务领域的应用-CSDN博客
一文解读DeepSeek在工业制造领域的应用-CSDN博客
一文解读DeepSeek的安全风险、挑战与应对策略_deepseek的发展带来的风险与挑战-CSDN博客
相关文章:

AIDC智算中心建设:计算力核心技术解析
目录 一、智算中心发展概览 二、计算力核心技术解析 一、智算中心发展概览 智算中心是人工智能发展的关键基础设施,基于人工智能计算架构,提供人工智能应用所需算力服务、数据服务和算法服务的算力基础设施,融合高性能计算设备、高速网络以…...

Javase 基础加强 —— 02 泛型
本系列为笔者学习Javase的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaAI智能辅助编程全套视频教程,java零基础入门到大牛一套通关》,章节分布参考视频教程,为同样学习Javase系列课程的同学们提供参考。 01 认识泛型…...

PowerShell 备份 Windows10/11 还原计算机驱动程序SOP
一、现在计算机C目录下创建一个新的文件夹名称为 driverbackup 二、打开cmd 以管理员身份执行 dism /online /export-driver /destination: C:\driverbackup 在正常情况下,Windows 10会自动检测您的设备所需的驱动程序,并将其安装到您的PC上。 但是&am…...

Python 中的 collections 库:高效数据结构的利器
Python 中的 collections 库:高效数据结构的利器 在 Python 编程中,数据结构的高效使用往往能极大地提升代码的性能和可读性。今天,就让我们来深入了解一下 Python 的 collections 库,它是一个非常实用且强大的工具库,…...
---java版。)
2025年- H24-Lc132-94. 二叉树的中序遍历(树)---java版。
1.题目描述 2.思路 递归遍历:返回值,中序遍历的节点值列表 List。 (1)首先是一个中序遍历的结果函数,传入root参数,定义一个节点值列表result,然后递归调用中序遍历的函数 (2&#…...
)
第十六届蓝桥杯单片机组省赛(第一套)
看到很多人在问第十六届蓝桥杯单片机难不难,以及实现多少功能可以获得省一。 先介绍下我的作答情况吧,选择题只对一题,程序题的求连续两次距离差值没有考虑负数的情况,其他功能都实现了,成绩是福建省省一第一页&#x…...

使用python写多文件#inlcude
使用下面的程序可以将当前文件夹下面的.c文件的写入main.h文件,我这里是将自己的基于标准库stm32初始化io文件为例。 import osbase ["#ifndef main_H","#define main_H\n","#endif" ]includes set() for file in os.listdir():if…...

深度学习中保存最优模型的实践与探索:以食物图像分类为例
深度学习中保存最优模型的实践与探索:以食物图像分类为例 在深度学习的模型训练过程中,训练一个性能良好的模型往往需要耗费大量的时间和计算资源。而保存最优模型不仅可以避免重复训练,还能方便后续使用和部署。本文将结合食物图像分类的代…...
基于opencv和qt对图像进行灰度化 → 降噪 → 边缘检测预处理及显示)
OpenCv实战笔记(2)基于opencv和qt对图像进行灰度化 → 降噪 → 边缘检测预处理及显示
一、实现效果 二、应用场景 这三步是经典的 “灰度化 → 降噪 → 边缘检测” 预处理流程,常用于: 计算机视觉任务(如物体识别、特征提取)。 图像分析(如文档扫描、车牌识别)。 减少后续算法的计算复杂度&a…...

个人文章不设置vip
今天没登录打开自己文章,发现自己读自己文章还要充值。就感觉很扯。 继而去查看个人的历史文章,发现很多被标注为高质量的文章设置成了VIP文章。 如果仅有一两篇,还可能是本人手滑误设置,这么多就解释不通了。 (大概有…...

【聚类分析】基于copula的风光联合场景生成与缩减
目录 1 主要内容 风光出力场景生成方法 2 部分程序 3 程序结果 4 下载链接 1 主要内容 该程序方法复现《融合风光出力场景生成的多能互补微网系统优化配置》风光出力场景生成部分,目前大多数研究的是不计风光出力之间的相关性影响,但是地理位置相近…...
)
CSDN积分详解(介绍、获取、用途)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 积分**一、积分类型及用途****二、积分获取途…...

运维--计划任务
计划任务分为一次性和循环性的计划任务 1.date的用法 date 月日时分年 eg:date 100118222023 date:查看时间和日期、修改时间和日期 获取当前日期:date +%F F:日期 获取当前时间:date +%H:%M:%S H:时 M:分 S:秒 获取周几: date +%w w:周 …...
:)
AVL树(2):
我们之前讲AVL树,我们讲到了旋转,然后讲了左单旋和右单旋。 但是我们这里的单旋产生的条件都是纯粹的一边比较高, 我们看上面这个图片,当我们插入新的结点导致一边的子树比较高的时候,我们必须是存粹的一边高…...

架构思维:异构数据的同步一致性方案
文章目录 一、引言二、全景架构回顾三、潜在问题问题1:Binlog 延迟——理想 vs 实际问题2:Binlog 格式解析问题3:高可靠消费1. 串行 ACK 消费2. 并行消费+乱序风险3. 解决方案 问题4:缓存数据结构设计1. Key–Value 冗…...

nginx 正反向代理和nginx正则
目录 一. 正向代理 1. 编译安装Nginx 2. 配置正向代理 二. 反向代理 1. 配置nginx七层代理 2. 配置nginx四层代理 三. Nginx 缓存 1. 缓存功能的核心原理和缓存类型 2. 代理缓存功能设置 四. Nginx rewrite和正则 1. Nginx正则 2. nginx location 3. Rewrite …...

SAM-Decoding_ 后缀自动机助力大模型推理加速!
SAM-Decoding: 后缀自动机助力大模型推理加速! 大语言模型(LLMs)的推理效率一直是研究热点。本文介绍的SAM-Decoding方法,借助后缀自动机(Suffix Automaton,SAM)实现推测解码,在提升…...

使用Scrapy构建高效网络爬虫:从入门到数据导出全流程
在数据驱动的时代,网络爬虫已成为获取公开信息的核心工具。本文将带您通过Scrapy框架完成一个实战项目,涵盖从零搭建爬虫到多格式数据导出的完整流程,并深入解析Scrapy的Feed Exports功能。 一、项目背景与目标 我们将爬取书籍网站ÿ…...
)
Docker安装Gitblit(图文教程)
本章教程,使用Docker安装部署Gitblit。 一、Gitblit简介 Gitblit 是一个基于 Java 的 Git 仓库管理工具,主要用于在局域网或小型团队环境中搭建私有 Git 服务器。它提供了一个简单易用的 Web 界面,用于浏览代码、管理仓库和用户权限等。 二、拉取镜像 sudo docker pull git…...

SpringBoot的汽车商城后台管理系统源码开发实现
概述 汽车商城后台管理系统专为汽车4S店和经销商设计,提供全面的汽车管理系统解决方案。 主要内容 1. 核心功能模块 系统提供以下主要功能: 销售管理:记录销售信息,跟踪交易进度客户管理:维护客户…...
)
组合模式(Composite Pattern)
非常棒!你现在进入了结构型设计模式中最典型的「树形结构」设计模式 —— 组合模式(Composite Pattern)。 我将通过简明解释 清晰代码 类图演示,一步步帮你理解它。 🧠 一句话定义 组合模式允许你将对象组合成树形结…...

Java捕获InterruptedException异常后,会自动清空中断状态
InterruptedException异常一般是在一个线程处于等待(像Thread.sleep()、Object.wait()、Thread.join()等方法)状态时被另一个线程调用interrupt()方法中断而抛出的。一旦捕获到InterruptedException,Java 会自动清除该线程的中断状态。 以下…...

HTML04:图像标签
图像标签 常见的图像标签 JPGGIFPNGBMP <img src"路径" alt"名称" title"悬停名称" width"高" height"宽"/><!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8&quo…...
--- 智能补货)
供应链算法整理(二)--- 智能补货
供应链业务的目标价值是:优化货品的供给、销售提供支撑,以降低成本,提高时效、收益,最终提升用户体验。基于目标价值,整体的算法模块分为:智能选品、智能预测、品仓铺货、智能补货、智能调拨、仓网路由、快…...

【毕设通关】——Word交叉引用
📖 前言:在论文中,我们经常会在文段贴图片时,写“如图x所示”的内容,如果每次都手动写数字,那么当需要在前面内容插入图片时,后续更新会很繁琐,这时就需要交叉引用功能。 ǵ…...

java技术总监简历模板
模板信息 简历范文名称:java技术总监简历模板,所属行业:其他 | 职位,模板编号:XDNUTA 专业的个人简历模板,逻辑清晰,排版简洁美观,让你的个人简历显得更专业,找到好工作…...

视频编解码学习三之显示器
整理自:显示器_百度百科,触摸屏_百度百科,百度安全验证 分为阴极射线管显示器(CRT),等离子显示器PDP,液晶显示器LCD 液晶显示器的组成。一般来说,液晶显示器由以下几个部分组成: […...

【人工智能】大模型安全的深度剖析:DeepSeek漏洞分析与防护实践
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着大语言模型(LLM)的广泛应用,其安全性问题日益凸显。DeepSeek作为中国领先的开源AI模型,以低成本和高性能著称,但近期暴露的数据库…...

架构思维:使用懒加载架构实现高性能读服务
文章目录 一、引言二、读服务的功能性需求三、两大基本设计原则1. 架构尽量不要分层2. 代码尽可能简单 四、实战方案:懒加载架构及其四大挑战五、改进思路六、总结与思考题 一、引言 在任何后台系统设计中,「读多写少」的业务场景占据主流:浏…...

【AI提示词】黑天鹅模型专家
提示说明 详细解释黑天鹅模型的理论背景、定义、分类及其在不同领域的应用。 提示词 # Role: 黑天鹅模型专家## Profile - language: 中文 - description: 详细解释黑天鹅模型的理论背景、定义、分类及其在不同领域的应用 - background: 黑天鹅模型是尼尔斯莫尔提出的理论&a…...

pip安装包时网络不畅,替换国内PyPI镜像源
1、PyPI 镜像源 1.1、定义 PyPI 镜像源是对 Python Package Index(PyPI)官方仓库的复制。 PyPI 是 Python 社区中最大的软件包仓库,存储着大量的 Python 包,供开发者们下载和使用。 然而,由于 PyPI 服务器位于国外&a…...

TS 类型推论
应用场景: 1.变量初始化 仅声明不初始化无法推断是什么类型,必须手动添加类型注解 2.决定函数返回值 根据函数体内的运算可以推断出返回值的类型 函数参数的类型声明建议一定要手写...

Java基于SaaS模式多租户ERP系统源码
目录 一、系统概述 二、开发环境 三、系统功能介绍 一、系统概述 ERP,全称 Enterprise Resource Planning 即企业资源计划。是一种集成化的管理软件系统,它通过信息技术手段,将企业的各个业务流程和资源管理进行整合,以提高企业…...

PHP的include和require
文章目录 环境require和includerequire VS includerequire(include) VS require_once(include_once)路径问题当前工作目录对相对路径的影响题外话总结其它 参考 环境 Windows 11 专业版XAMPP v3.3.0 PHP 8.2.12Apache 2.4.58 VSC…...

日本人工智能发展全景观察:从技术革新到社会重构的深度解析
一、日本IT产业演进与AI技术崛起的历史脉络 1.1 信息化时代的奠基(1990-2010) 日本IT产业的腾飞始于"信息高速公路计划"的实施。1994年NTT推出全球首个商用光纤网络,至2005年实现全国光纤覆盖率突破80%。这一时期培育出富士通、N…...

什么是DGI数据治理框架?
DGI数据治理框架是由数据治理研究所(Data Governance Institute, DGI)提出的一套系统性方法论,旨在帮助企业或组织建立有效的数据治理体系,确保数据资产的高质量管理、合规使用和价值释放。以下是关于DGI数据治理框架的核心内容&a…...

[硬件电路-12]:LD激光器与DFB激光器功能概述、管脚定义、功能比较
一、LD激光器(普通半导体激光器)功能 核心功能: LD激光器通过半导体材料的电子-空穴复合实现受激辐射,将电能直接转换为高相干性激光,是光电子系统的核心光源。 基础光发射功能 工作原理:正向偏置电流注入…...

升级 CUDA Toolkit 12.9 与 cuDNN 9.9.0 后验证指南:功能与虚拟环境检测
#工作记录 在 NVIDIA 发布 CUDA Toolkit 12.9 与 cuDNN 9.9.0 后,开发者纷纷选择升级以获取新特性和性能提升。 CUDA Toolkit 12.9 与 cuDNN 9.9.0 发布,带来全新特性与优化-CSDN博客 然而,升级完成并不意味着大功告成,确认升级后…...

湖仓一体架构解析:如何平衡数据灵活性与分析性能?
一、什么是湖仓一体架构?解决哪些核心问题? 在数据爆炸的时代,企业面临着如何高效处理和分析海量数据的挑战。传统架构难以同时满足灵活性和性能需求,湖仓一体架构应运而生。 传统数据架构的局限 数据湖(存储各类原…...
)
56、【OS】【Nuttx】编码规范解读(四)
背景 接之前 blog 53、【OS】【Nuttx】编码规范解读(一) 54、【OS】【Nuttx】编码规范解读(二) 55、【OS】【Nuttx】编码规范解读(三) 分析了行宽格式,注释要求,花括号风格等&#…...

MySQL基础关键_007_DQL 练习
目 录 一、题目 二、答案(不唯一) 1.查询每个部门薪资最高的员工信息 2.查询每个部门高于平均薪水的员工信息 3. 查询每个部门平均薪资等级 4.查询部门中所有员工薪资等级的平均等级 5.不用分组函数 max 查询最高薪资 6.查询平均薪资最高的部门编…...

气泡图、桑基图的绘制
1、气泡图 使用气泡图分析某一年中国同欧洲各国之间的贸易情况。 气泡图分析的三个维度: • 进口额:横轴 • 出口额:纵轴 • 进出口总额:气泡大小 数据来源:链接: 国家统计局数据 数据概览(进出口总额&…...

数据库Mysql_联合查询
或许自己的不完美才是最完美的地方,那些让自己感到不安的瑕疵,最终都会变成自己的特色。 ----------陳長生. 1.介绍 1.1.为什么要进行联合查询 在数据设计的时候,由于范式的需求,会被分为多个表,但是当我们要查询数据…...

数字孪生:解码智慧城市的 “数字神经系统”
当城市规模以惊人速度扩张,传统管理模式在交通拥堵、能源浪费、应急响应滞后等问题面前渐显乏力。数字孪生技术正以 “数字镜像” 重构城市运作逻辑,为智慧城市装上一套高效、智能的 “数字神经系统”。通过将物理世界的城市映射到虚拟空间,实…...

开源项目:optimum-quanto库介绍
项目地址:https://github.com/huggingface/optimum-quanto 官网介绍:https://huggingface.co/blog/quanto-introduction 量化是一种技术,通过使用低精度数据类型(如 8 位整数 (int8))而不是通常…...

C++学习:六个月从基础到就业——C++11/14:lambda表达式
C学习:六个月从基础到就业——C11/14:lambda表达式 本文是我C学习之旅系列的第四十篇技术文章,也是第三阶段"现代C特性"的第二篇,主要介绍C11/14中引入的lambda表达式。查看完整系列目录了解更多内容。 引言 Lambda表达…...

cesium基础设置
在上节新建的程序中,我们会看到有一行小字: 原因为我们没有输入token,想要让这行小字消失的方法很简单,前往cesium的官网注册账号申请token.然后在App.vue中如下方式添加token 保存后即可发现小字消失. 如果连logo都想去掉呢? 在源代码中,我们初始化了一个viwer,即查看器窗口…...

一些好玩的东西
🚀 终极挑战:用 curl 玩《星球大战》 telnet towel.blinkenlights.nl # 其实不是 curl,但太经典了! 效果:在终端播放 ASCII 版《星球大战》电影!(如果 telnet 不可用,可以试…...
)
ActiveMQ 与其他 MQ 的对比分析:Kafka/RocketMQ 的选型参考(二)
ActiveMQ、Kafka 和 RocketMQ 详细对比 性能对比 在性能方面,Kafka 和 RocketMQ 通常在高吞吐量场景下表现出色,而 ActiveMQ 则相对较弱。根据相关测试数据表明,Kafka 在处理大规模日志数据时,单机吞吐量可以达到每秒数十万条甚…...
)
HTML学习笔记(7)
一、什么是jQuery jQuery 是一个 JavaScript 库。他实现了JavaScript的一些功能,并封装起来,对外提供接口。 例子实现一个点击消失的功能,用JavaScript实现 <!DOCTYPE html> <html lang"en"> <head><meta …...