【LLM】deepseek R1之GRPO训练笔记(持续更新)
note
- 相关框架对比:
- 需微调模型且资源有限 → Unsloth;
- 本地隐私优先的小规模推理 → Ollama;
- 复杂逻辑或多模态任务 → SGLang;
- 高并发生产环境 → vLLM
- 微调SFT和GRPO是确实能学到新知识的
- 四种格式(
messages、sharegpt、alpaca、query-response)在AutoPreprocessor处理下都会转换成ms-swift标准格式中的messages字段,即都可以直接使用--dataset <dataset-path>接入,即可直接使用json数据
文章目录
- note
- 一、Swift框架
- 数据集定义
- 奖励函数
- GRPO公式
- 训练参数
- 二、unsloth框架
- 1. Unsloth框架介绍
- 2. 使用
- 3. 训练参数
- 三、open r1项目
- 数据生成
- 模型训练
- 模型评估
- 四、GRPO经验总结
- 关于DeepseekR1的17个观点
- Reference
一、Swift框架
数据集定义
Coundown Game任务:给定几个数字,进行加减乘除后得到目标数值。
数据量:5w条
[INFO:swift] train_dataset: Dataset({features: ['nums', 'messages', 'target'],num_rows: 49500
})
[INFO:swift] val_dataset: Dataset({features: ['nums', 'messages', 'target'],num_rows: 500
})
通过 template, 使用 numbers 和 target 完成任务定义,并给到 query 字段供模型采样使用。同时,我们需要保留 nums 和 target 两个字段,用于后续的奖励函数计算。
class CoundownTaskPreprocessor(ResponsePreprocessor):def preprocess(self, row: Dict[str, Any]) -> Dict[str, Any]:numbers = row['nums']target = row.pop('response', None)query = f"""Using the numbers {numbers}, create an equation that equals {target}.You can use basic arithmetic operations (+, -, *, /) and each number can only be used once.Show your work in <think> </think> tags. And return the final equation and answer in <answer> </answer> tags,for example <answer> (1 + 2) / 3 * 4 = 4 </answer>."""row.update({'target': target, 'query': query})return super().preprocess(row)register_dataset(DatasetMeta(ms_dataset_id='zouxuhong/Countdown-Tasks-3to4',subsets=['default'],preprocess_func=CoundownTaskPreprocessor(),tags=['math']))
奖励函数
- 格式奖励函数:Deepseek-R1 中提到的格式奖励函数,已经在swift中内置,通过 --reward_funcs format 可以直接使用
- 准确性奖励函数:使用 external_plugin 的方式定义准确性奖励函数,将代码放在
swift/examples/train/grpo/plugin/plugin.py中。- 奖励函数的输入包括 completions、target 和 nums 三个字段,分别表示模型生成的文本、目标答案和可用的数字。
- 每个都是list,支持多个 completion 同时计算。注意这里除了 completions 之外的参数都是数据集中定义的字段透传而来,如果有任务上的变动,可以分别对数据集和奖励函数做对应的改变即可。
class CountdownORM(ORM):def __call__(self, completions, target, nums, **kwargs) -> List[float]:"""Evaluates completions based on Mathematical correctness of the answerArgs:completions (list[str]): Generated outputstarget (list[str]): Expected answersnums (list[str]): Available numbersReturns:list[float]: Reward scores"""rewards = []for completion, gt, numbers in zip(completions, target, nums):try:# Check if the format is correctmatch = re.search(r"<answer>(.*?)<\/answer>", completion)if match is None:rewards.append(0.0)continue# Extract the "answer" part from the completionequation = match.group(1).strip()if '=' in equation:equation = equation.split('=')[0]# Extract all numbers from the equationused_numbers = [int(n) for n in re.findall(r'\d+', equation)]# Check if all numbers are used exactly onceif sorted(used_numbers) != sorted(numbers):rewards.append(0.0)continue# Define a regex pattern that only allows numbers, operators, parentheses, and whitespaceallowed_pattern = r'^[\d+\-*/().\s]+$'if not re.match(allowed_pattern, equation):rewards.append(0.0)continue# Evaluate the equation with restricted globals and localsresult = eval(equation, {"__builti'ns__": None}, {})# Check if the equation is correct and matches the ground truthif abs(float(result) - float(gt)) < 1e-5:rewards.append(1.0)else:rewards.append(0.0)except Exception as e:# If evaluation fails, reward is 0rewards.append(0.0)return rewards
orms['external_countdown'] = CountdownORM
GRPO公式
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ] − β D K L [ π θ ∣ ∣ π r e f ] } \begin{aligned} \mathcal{J}_{G R P O}(\theta) & =\mathbb{E}\left[q \sim P(Q),\left\{o_i\right\}_{i=1}^G \sim \pi_{\theta_{o l d}}(O \mid q)\right] \\ & \frac{1}{G} \sum_{i=1}^G \frac{1}{\left|o_i\right|} \sum_{t=1}^{\left|o_i\right|}\left\{\min \left[\frac{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{o l d}}\left(o_{i, t} \mid q, o_{i,<t}\right)} \hat{A}_{i, t}, \operatorname{clip}\left(\frac{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{o l d}}\left(o_{i, t} \mid q, o_{i,<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) \hat{A}_{i, t}\right]-\beta \mathbb{D}_{K L}\left[\pi_\theta| | \pi_{r e f}\right]\right\} \end{aligned} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∣∣πref]}
训练参数
选取 Qwen2.5-3B-Instruct 作为基础模型进行训练,选取 Instruct 而不是基模的主要原因是可以更快地获取 format reward。我们在三卡 GPU 上进行实验,因此vllm的推理部署在最后一张卡上,而进程数设置为2,在剩下两张卡上进行梯度更新。
由于任务较为简单,我们设置 max_completion_length 和 vllm_max_model_len 为1024,如果有更复杂的任务,可以适当加大模型输出长度。注意,这两个参数越大,模型训练需要的显存越多,训练速度越慢,单个step的训练时间与max_completion_length呈现线性关系。
在我们的实验中,总batch_size为 n u m _ p r o c e s s e s × p e r _ d e v i c e _ t r a i n _ b a t c h _ s i z e × g r a d i e n t _ a c c u m u l a t i o n _ s t e p s = 2 × 8 × 8 = 128 num\_processes \times per\_device\_train\_batch\_size \times gradient\_accumulation\_steps = 2 \times 8 \times 8 = 128 num_processes×per_device_train_batch_size×gradient_accumulation_steps=2×8×8=128 而参数设置有一个限制,即: n u m _ p r o c e s s e s × p e r _ d e v i c e _ t r a i n _ b a t c h _ s i z e num\_processes \times per\_device\_train\_batch\_size num_processes×per_device_train_batch_size 必须整除 n u m _ g e n e r a t i o n s num\_generations num_generations,其中, n u m _ g e n e r a t i o n s num\_generations num_generations就是GRPO公式中的 G G G,故我们设置为8。
注意:
- 这里单卡batch_size设置也与显存息息相关,请根据显存上限设置一个合适的值。
- 总的steps数量 : n u m _ s t e p s = e p o c h s × l e n ( d a t a s e t s ) × n u m _ g e n e r a t i o n s ÷ b a t c h _ s i z e num\_steps = epochs \times len(datasets) \times num\_generations \div batch\_size num_steps=epochs×len(datasets)×num_generations÷batch_size,需要根据这个来合理规划训练的学习率和warmup设置。
- 设置是学习率和 beta,学习率比较好理解,而beta则是是以上公式的 β \beta β,即KL散度的梯度的权重。这两个参数设置的越大,模型收敛原则上更快,但训练往往会不稳定。经过实验,我们分别设置为
5e-7和0.001。在实际训练中,请根据是否出现不稳定的震荡情况适当调整这两个参数。 - 对于KL散度,社区有很多的讨论,可以参考为什么GRPO坚持用KL散度。
- 具体的参数介绍:https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html
CUDA_VISIBLE_DEVICES=0,1,2 \
WANDB_API_KEY=your_wandb_key \
NPROC_PER_NODE=2 \
swift rlhf \--rlhf_type grpo \--model Qwen/Qwen2.5-3B-Instruct \--external_plugins examples/train/grpo/plugin/plugin.py \--reward_funcs external_countdown format \--use_vllm true \--vllm_device auto \--vllm_gpu_memory_utilization 0.6 \--train_type full \--torch_dtype bfloat16 \--dataset 'zouxuhong/Countdown-Tasks-3to4#50000' \--max_length 2048 \--max_completion_length 1024 \--num_train_epochs 1 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 8 \--learning_rate 5e-7 \--gradient_accumulation_steps 8 \--eval_steps 500 \--save_steps 100 \--save_total_limit 20 \--logging_steps 1 \--output_dir output/GRPO_COUNTDOWN \--warmup_ratio 0.01 \--dataloader_num_workers 4 \--num_generations 8 \--temperature 1.0 \--system 'You are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer.' \--deepspeed zero3 \--log_completions true \--vllm_max_model_len 1024 \--report_to wandb \--beta 0.001 \--num_iterations 1
二、unsloth框架
链接:https://docs.unsloth.ai/basics/reasoning-grpo-and-rl/tutorial-train-your-own-reasoning-model-with-grpo
1. Unsloth框架介绍
- 开源项目Unsloth AI实现重大突破,通过优化GRPO训练方法,将内存使用减少80%,让7GB显存GPU就能本地运行DeepSeek-R1级别的推理模型;
- Unsloth实现了与vLLM的深度整合,可将模型吞吐量提升20倍,同时仅需一半VRAM,使单张48GB GPU就能微调Llama 3.3 70B;
- 该项目在GitHub获2万多星,其核心团队仅由两兄弟组成,成功大幅降低了AI推理模型的部署门槛。本地也能体验「Aha」 时刻:现在可以在本地设备上复现DeepSeek-R1的推理!只需7GB VRAM,你就能体验到「Aha」时刻。Unsloth把GRPO训练需要的内存减少了80%。15GB VRAM就可以把Llama-3.1(8B)和Phi-4(14B)转变为推理模型。
2. 使用
unsloth是推理、微调一体式框架,unsloth将Llama 3.3、Mistral、Phi-4、Qwen 2.5和Gemma的微调速度提高2倍,同时节省80%的内存。官网地址:GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memoryhttps://github.com/unslothai/unsloth
使用如下命令快速安装:
pip install unslothpip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
3. 训练参数
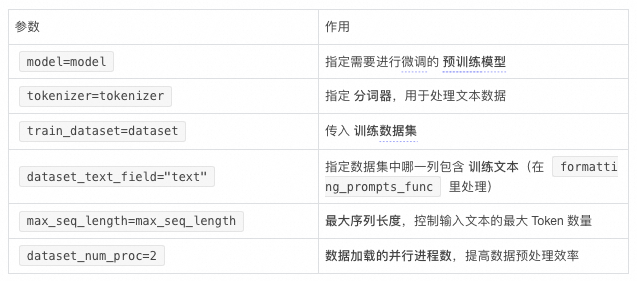
SFTTTrainer 进行监督微调(Supervised Fine-Tuning, SFT),适用于 transformers 和 Unsloth 生态中的模型微调:1. 相关库
-
SFTTrainer(来自 trl 库):
- trl(Transformer Reinforcement Learning)是 Hugging Face 旗下的 trl 库,提供监督微调(SFT)和强化学习(RLHF)相关的功能。
- SFTTrainer 主要用于有监督微调(Supervised Fine-Tuning),适用于 LoRA 等低秩适配微调方式。
-
TrainingArguments(来自 transformers 库):
- 这个类用于定义训练超参数,比如批量大小、学习率、优化器、训练步数等。
-
is_bfloat16_supported(来自 unsloth):- 这个函数检查当前 GPU 是否支持 bfloat16(BF16),如果支持,则返回 True,否则返回 False
- bfloat16 是一种更高效的数值格式,在新款 NVIDIA A100/H100 等GPU上表现更优。
SFTTrainer 部分
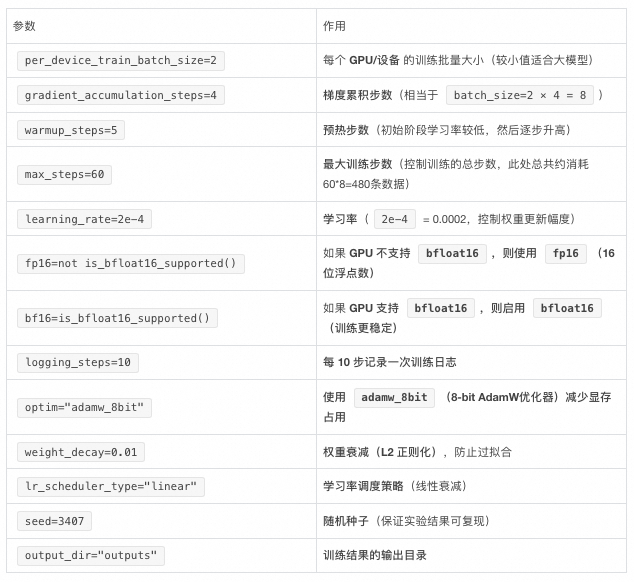
TrainingArguments 部分
参考:从零开始的DeepSeek微调训练实战(SFT)阿里云开发社区
三、open r1项目
一个parquet文件:/root/paddlejob/workspace/env_run/gtest/rl_train/data/OpenR1-Math-220k/open-r1/OpenR1-Math-220k/all/train-00001-of-00020.parquet
SFT训练:
# Train via command line
accelerate launch --config_file=recipes/accelerate_configs/zero3.yaml src/open_r1/sft.py \--model_name_or_path Qwen/Qwen2.5-1.5B-Instruct \--dataset_name open-r1/OpenR1-Math-220k \--learning_rate 1.0e-5 \--num_train_epochs 1 \--packing \--max_seq_length 16384 \--per_device_train_batch_size 16 \--gradient_checkpointing \--bf16 \--output_dir data/Qwen2.5-1.5B-Open-R1-Distill# Train via YAML config
accelerate launch --config_file recipes/accelerate_configs/zero3.yaml src/open_r1/sft.py \--config recipes/Qwen2.5-1.5B-Instruct/sft/config_demo.yaml
GRPO训练:
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/zero2.yaml \--num_processes=7 src/open_r1/grpo.py \--config recipes/DeepSeek-R1-Distill-Qwen-1.5B/grpo/config_demo.yaml
数据生成
数据生成:为了构建 OpenR1-220k,我们使用 DeepSeek R1 大语言模型生成 NuminaMath 1.5 中 40 万个问题的解决方案。我们遵循模型卡的推荐参数,并在用户提示词前添加以下指令:“请逐步推理,并将最终答案放在 \boxed{} 中。”
from datasets import load_dataset
from distilabel.models import vLLM
from distilabel.pipeline import Pipeline
from distilabel.steps.tasks import TextGenerationprompt_template = """\
You will be given a problem. Please reason step by step, and put your final answer within \boxed{}:
{{ instruction }}"""dataset = load_dataset("AI-MO/NuminaMath-TIR", split="train").select(range(10))model_id = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B" # Exchange with another smol distilled r1with Pipeline(name="distill-qwen-7b-r1",description="A pipeline to generate data from a distilled r1 model",
) as pipeline:llm = vLLM(model=model_id,tokenizer=model_id,extra_kwargs={"tensor_parallel_size": 1,"max_model_len": 8192,},generation_kwargs={"temperature": 0.6,"max_new_tokens": 8192,},)prompt_column = "problem"text_generation = TextGeneration(llm=llm, template=prompt_template,num_generations=4,input_mappings={"instruction": prompt_column} if prompt_column is not None else {})if __name__ == "__main__":distiset = pipeline.run(dataset=dataset)distiset.push_to_hub(repo_id="username/numina-deepseek-r1-qwen-7b")
提示词:
You are a mathematical answer validator. You will be provided with a mathematical problem and you need to compare the answer in the reference solution, and the final answer in a model's solution to determine if they are equivalent, even if formatted differently.PROBLEM:{problem}REFERENCE SOLUTION:{answer}MODEL'S SOLUTION:{generation}Focus ONLY on comparing the final mathematical answer provided by the model while ignoring differences in:- Formatting (e.g., \\boxed{{}} vs plain text)
- Multiple choice formatting (e.g., "A" vs full solution)
- Order of coordinate pairs or solutions
- Equivalent mathematical expressions or notation variations
- If the model's answer is nonsense, return "Verdict: AMBIGUOUS"Start with a brief explanation of your comparison (2-3 sentences). Then output your final answer in one of the following formats:- "Verdict: EQUIVALENT"
- "Verdict: DIFFERENT"
- "Verdict: AMBIGUOUS"
模型训练
模型评估
在几个经典benchmark上评估:
MODEL=deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
MODEL_ARGS="pretrained=$MODEL,dtype=bfloat16,max_model_length=32768,gpu_memory_utilization=0.8,generation_parameters={max_new_tokens:32768,temperature:0.6,top_p:0.95}"
OUTPUT_DIR=data/evals/$MODEL# AIME 2024
TASK=aime24
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \--custom-tasks src/open_r1/evaluate.py \--use-chat-template \--output-dir $OUTPUT_DIR# MATH-500
TASK=math_500
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \--custom-tasks src/open_r1/evaluate.py \--use-chat-template \--output-dir $OUTPUT_DIR# GPQA Diamond
TASK=gpqa:diamond
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \--custom-tasks src/open_r1/evaluate.py \--use-chat-template \--output-dir $OUTPUT_DIR# LiveCodeBench
lighteval vllm $MODEL_ARGS "extended|lcb:codegeneration|0|0" \--use-chat-template \--output-dir $OUTPUT_DIR
四、GRPO经验总结
关于DeepseekR1的17个观点
DeepseekR1总结,在 DeepSeek-R1 发布 100 天后,我们学到了什么?,100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models,https://arxiv.org/pdf/2505.00551,DeepSeek-R1模型发布后的100天内,学术界对其复制研究的进展和未来发展方向。
17个观点:
1、高质量、经过验证的思维链(Chain-of-Thought, CoT)数据对于监督微调(Supervised Fine-Tuning, SFT)是有效的。
2、为 SFT 挑选更难的问题(例如,基于较弱模型的低通过率筛选)能显著提升模型性能。
3、开放数据集中混杂有基准测试样本,需要仔细进行数据去污染(decontamination)以保证公平评估。
4、倾向于包含更长 CoT(通常意味着问题更复杂)的数据集,在 SFT 后往往能带来更好的推理性能。
5、SFT 能有效地赋予模型推理结构,为后续的强化学习(Reinforcement Learning, RL)奠定必要基础。
6、相较于基础模型,已经过指令微调的模型在 SFT 阶段能更有效地学习推理模式。
7、强化学习(RL)数据集受益于严格的验证过程(例如使用数学求解器、代码执行)以及筛选掉模型可能出错的“不确定性”样本。
8、使用简单的、可验证的、基于结果的奖励(例如,判断对错)是有效的,并且能降低奖励操纵(reward hacking)的风险。
9、在推理模型的强化学习(RL for Verification/Reasoning)中,明确的格式或长度奖励的必要性和益处尚存争议,有时模型可以隐式地学习这些方面。
10、PPO 和 GRPO 是最常用的 RL 算法,但它们的变体(如 DAPO、Dr. GRPO、VC-PPO、VAPO)被设计用于解决偏差(如长度偏差、难度偏差)和训练不稳定性问题。
11、KL 损失虽然常用于提升训练稳定性,但在推理模型的 RL 训练中有时会被省略,或者发现它会限制模型的探索能力和最终的性能提升。
12、在 RL 训练过程中,逐步增加训练样本的难度或模型允许的最大响应长度,有助于提升性能和稳定性。
13、将训练重点放在更难的样本上,或者剔除模型已经“学会解决”的简单样本,这类策略可以提升 RL 的训练效率。
14、集成了价值函数的方法(如 VC-PPO、VAPO)在处理长 CoT 问题时,其表现可能优于无价值函数的方法(如 GRPO)。
15、RL 训练能够提升模型的域外泛化能力,其效果可能超越单独使用 SFT,甚至能泛化到看似不相关的任务上(例如,通过数学/代码训练提升写诗能力)。
16、推理模型带来了新的安全挑战,例如奖励操纵(reward hacking)、过度思考(overthinking)以及特定的越狱(jailbreaking)漏洞。
17、对于较小规模的模型(例如 <32B 参数),相比于使用蒸馏得到的检查点(distilled checkpoints),单纯依靠 RL 来复现最佳性能通常更具挑战性。
Reference
[1] Open R1 项目 第二周总结与展望
[2] 摸着Logic-RL,复现7B - R1 zero
[3] https://huggingface.co/blog/open-r1/update-2
[4] 用极小模型复现R1思维链的失败感悟
[5] https://github.com/Unakar/Logic-RL
[6] 【LLM-RL】强化对齐之GRPO算法和微调实践
[7] 官方文档:https://docs.unsloth.ai/get-started/fine-tuning-guide
[8] https://huggingface.co/datasets/yahma/alpaca-cleaned/viewer
[9] 官方文档跑GRPO:https://docs.unsloth.ai/basics/reasoning-grpo-and-rl/tutorial-train-your-own-reasoning-model-with-grpo
[10] R1复现小记:在业务场景的两类NLP任务上有显著效果 NLP工作站
[11] 批判性视角看待 R1 训练(基础模型和强化学习)中的坑
[12] MLNLP社区发布《动画中学强化学习笔记》项目!
[13] 【LLM】R1复现项目(SimpleRL、OpenR1、LogitRL、TinyZero)持续更新
[14] 项目地址:https://github.com/MLNLP-World/Reinforcement-Learning-Comic-Notes
[15] 笔记:https://github.com/MLNLP-World/Reinforcement-Learning-Comic-Notes/tree/main/note
[16] unsloth官方微调指南:https://docs.unsloth.ai/get-started/fine-tuning-guide
[17] unsloth官方GRPO指南:https://docs.unsloth.ai/basics/reasoning-grpo-and-rl
[18] 基于unsloth框架完成7B规模模型SFT微调训练(10GB显存占用) bookname,某乎
[19] 使用Unsloth训练自己的R1模型.中科院计算所
[20] GRPO中的KL Loss实现细节问题
[21] 个性训练(2)-借助GRPO提升多轮对话能力
[22] 个性训练-借助GRPO塑造一个有个性且智商在线的大模型
[23] 为什么大家都在吹deepseek的GRPO?某乎
[24] Datasets Guide 数据集指南
[25] 基于qwen2.5进行GRPO训练:https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2.5_(3B)-GRPO.ipynb
[26] DeepSeek同款GRPO训练大提速!魔搭开源全流程方案,支持多模态训练、训练加速和评测全链路
[27] 聊聊DeepSeek-R1-Distilled-QWen32B基于GRPO算法下的训练记录——基于ms-swift训推框架
[28] 多模态GRPO完整实验流程- swift 小健
[29] swift官方文档GRPO训练过程:https://swift.readthedocs.io/zh-cn/latest/BestPractices/GRPO%E5%AE%8C%E6%95%B4%E6%B5%81%E7%A8%8B.html
[30] [Wandb] api key怎么查看
[31] 多模态GRPO完整实验流程.swift官方文档
[32] AI大模型ms-swift框架实战指南(十):自定义数据集微调实践大全
[33] 大模型团队搞GRPO强化学习,一些小Tips2
相关文章:
)
【LLM】deepseek R1之GRPO训练笔记(持续更新)
note 相关框架对比: 需微调模型且资源有限 → Unsloth;本地隐私优先的小规模推理 → Ollama;复杂逻辑或多模态任务 → SGLang;高并发生产环境 → vLLM 微调SFT和GRPO是确实能学到新知识的四种格式(messages、sharegpt…...

序列到序列学习
seq2seq 就是把一个句子翻译到另外一个句子。 机器翻译 给定一个源语言的句子,自动翻译成目标语言这两个句子可以有不同的长度 seq2seq 是一个 Encoder - Decoder 的架构 编码器是一个 RNN , 读取输入句子(可以是双向) 解码…...

去打印店怎么打印手机文件,网上打印平台怎么打印
在数字化时代,手机已成为我们存储和传输文件的重要工具。然而,当需要将手机中的文件转化为纸质文档时,许多人会面临选择:是前往线下打印店,还是利用线上打印平台?本文将为您解析这两种方式的优劣࿰…...

LeetCode每日一题5.4
1128. 等价多米诺骨牌对的数量 问题 问题分析 等价的定义为:两个骨牌 [a, b] 和 [c, d] 等价,当且仅当 (a c 且 b d) 或者 (a d 且 b c)。 思路 标准化骨牌表示: 为了方便比较,我们可以将每个骨牌 [a, b] 标准化为 [min(a…...

前端小练习————表白墙+猜数字小游戏
1,猜数字游戏 实现一个这个样式的 要猜的目标数字 点击重新开始游戏之后: 代码实现 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widt…...

五年级数学知识边界总结思考-上册
目录 一、背景二、过程1.小数乘法和除法小学五年级小数乘除法的知识点、由来、作用与意义解析**一、核心知识点梳理****二、知识点的由来****三、作用与意义****四、教学意义** **总结** 2.位置小学五年级“位置”知识点、由来、作用与意义解析**一、核心知识点梳理****二、知识…...

C与指针——内存操作与动态内存
1、内存常用操作 void* memcpy(void* dst,const void* src,size_t length); \\内存不允许重叠 void* memmove(void* dst,const void* src,size_t length); \\内存允许重叠 int memcmp(const void* dst,const void* src,size_t length); \\相等返回0 void* memset(void* dst,in…...

P3469 [POI 2008] BLO-Blockade
P3469 [POI 2008] BLO-Blockade 题目描述 B 城有 n n n 个城镇(从 1 1 1 到 n n n 标号)和 m m m 条双向道路。 每条道路连结两个不同的城镇,没有重复的道路,所有城镇连通。 把城镇看作节点,把道路看作边&…...

Linux网络编程 day3 五一结假
基本概念 三次握手 主动发起连接请求端,发送SYN标志位,请求建立连接。携带数据包包号、数据字节数(0)、滑动窗口大小。 被动接收连接请求端,发送ACK标志位,同时携带SYN请求标志位。携带序号、确认序号、数据包包号、数据字节数…...

解释一下NGINX的反向代理和正向代理的区别?
大家好,我是锋哥。今天分享关于【解释一下NGINX的反向代理和正向代理的区别?】面试题。希望对大家有帮助; 解释一下NGINX的反向代理和正向代理的区别? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 NGINX 作为一个高效的反向代理服务器&a…...

Coco AI 入驻 GitCode:打破数据孤岛,解锁智能协作新可能
在信息爆炸时代,企业正面临前所未有的挑战: 企业数据和信息分散,数据孤岛现象严重,员工往往浪费大量时间跨平台检索;跨部门协作困难,团队因信息隔阂导致项目延期;数据安全问题严峻,…...
)
【QT】QT中的网络编程(TCP 和 UDP通信)
QT中的网络编程(TCP 和 UDP通信) 1.tcp1.1 tcp通信1.1.1 相比linux中tcp通信:1.1.2 QT中的tcp通信: 1.2 tcp通信流程1.2.1 服务器流程:1.2.1.1 示例代码1.2.1.2 现象 1.2.2 客户端流程:1.2.2.1 示例代码1.2.2.2 现象: …...

个性化推荐:大数据引领电子商务精准营销新时代
个性化推荐:大数据引领电子商务精准营销新时代 引言 在电子商务的时代,个性化推荐系统已经成为提升用户体验、增强平台竞争力的重要技术。随着大数据技术的迅猛发展,传统的推荐方法已经无法满足用户日益增长的需求。为了精准地把握用户兴趣和消费倾向,商家们依赖大数据分析…...

【前端】【总复习】HTML
一、HTML(结构) HTML 是网页的骨架,主要负责网页的结构与语义表达,为 CSS 和 JavaScript 提供承载基础。 1.1 HTML 基本结构与语义化标签 1.1.1 HTML 基本结构 <!DOCTYPE html> <html lang"en"> <hea…...

Android 输入控件事件使用示例
一 前端 <EditTextandroid:id="@+id/editTextText2"android:layout_width="match_parent"android:layout_height="wrap_content"android:ems="10"android:inputType="text"android:text="Name" />二 后台代…...

JVM happens-before 原则有哪些?
理解Java Memory Model (JMM) 中的 happens-before 原则对于编写并发程序有很大帮助。 Happens-before 关系是 JMM 用来描述两个操作之间的内存可见性以及执行顺序的抽象概念。如果一个操作 A happens-before 另一个操作 B (记作 A hb B),那么 JMM 向你保证&#x…...

Python实例题:Python获取NBA数据
目录 Python实例题 题目 方式一:使用网页爬虫获取数据 代码解释 get_nba_schedule 函数: 主程序: 方式二:使用专业 API 获取数据 代码解释 运行思路 方式一 方式二 注意事项 以下是完整的 doubaocanvas 代码块&#…...

【中间件】brpc_基础_remote_task_queue
文章目录 remote task queue1 简介2 核心功能2.1 任务提交与分发2.2 无锁或低锁设计2.3 与 bthread 深度集成2.4 流量控制与背压 3 关键实现机制3.1 数据结构3.2 任务提交接口3.3 任务窃取(Work Stealing)3.4 同步与唤醒 4 性能优化5 典型应用场景6 代码…...
)
React-router v7 第七章(导航)
导航 在React-router V7中,大致有四种导航方式: 使用Link组件 link使用NavLink组件 navlink使用编程式导航useNavigate usenavigate使用redirect重定向 redirect Link Link组件是一个用于导航到其他页面的组件,他会被渲染成一个<a>…...

Terraform 中的 external 数据块是什么?如何使用?
在 Terraform 中,external 数据块(Data Block) 是一种特殊的数据源,允许你通过调用外部程序或脚本获取动态数据,并将结果集成到 Terraform 配置中。它适用于需要从 Terraform 外部的系统或工具获取信息的场景。 一、e…...

打印Excel表格时单元格文字内容被下一行遮盖的解决方法
本文介绍在打印Excel表格文件时,单元格最后一行的文字内容被下一行单元格遮挡的解决方法。 最近,需要打印一个Excel表格文件。其中,已知对于表格中的单元格,都设置了自动换行,如下图所示。 并且,也都设置了…...

【Linux】命令行参数与环境变量
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 目录 前言 一、命令行参数 1. 什么是命令行参数 2. 命令行参数的作用 二、环境变量 1. 基本概念 2. 常见的环境变量 3. 环境变量相关操作 定义…...
:从零搭建开源大模型应用平台(Ollama/VLLM本地模型接入实战)》)
Dify 完全指南(一):从零搭建开源大模型应用平台(Ollama/VLLM本地模型接入实战)》
文章目录 1. 相关资源2. 核心特性3. 安装与使用(Docker Compose 部署)3.1 部署Dify3.2 更新Dify3.3 重启Dify3.4 访问Dify 4. 接入本地模型4.1 接入 Ollama 本地模型4.1.1 步骤4.1.2 常见问题 4.2 接入 Vllm 本地模型 5. 进阶应用场景6. 总结 1. 相关资源…...
 Part.3)
民法学学习笔记(个人向) Part.3
民法学学习笔记(个人向) Part.3 8. 诉讼时效🌸 概念: 是指权利主体在法定期间内不行使权利,则债务人享有抗辩权,可以导致权利人无法胜诉的法律制度(有权你不用,别人就有话说了&#…...
)
C# 方法(返回值、返回语句和void方法)
本章内容: 方法的结构 方法体内部的代码执行 局部变量 局部常量 控制流 方法调用 返回值 返回语句和void方法 局部函数 参数 值参数 引用参数 引用类型作为值参数和引用参数 输出参数 参数数组 参数类型总结 方法重载 命名参数 可选参数 栈帧 递归 返回值 方法可以向调用代码返…...

打电话玩手机检测数据集VOC+YOLO格式8061张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):8061 标注数量(xml文件个数):8061 标注数量(txt文件个数):8061 …...

详解如何压测RocketMQ
目录 1.如何设计压测 2.压测工具 3.硬件配置 4.写代码压测 5.自带压测脚本 1.如何设计压测 二八定律法则:按业务峰值的 120% 设计压测目标(若线上峰值1000TPS,压测目标至少1200TPS) 关注三个指标 吞吐量(TPS&…...

实验三 触发器及基本时序电路
1.触发器的分类?各自的特点是什么? 1 、 D 触发器 特点:只有一个数据输入端 D ,在时钟脉冲的触发沿,输出 Q 的状态跟随输入端 D 的 状态变化,即 ,功能直观,利于理解和感受…...

双列集合——map集合和三种遍历方式
双列集合的特点 键和值一一对应,每个键只能对应自己的值 一个键和值整体称为键值对或键值对对象,java中叫做entry对象。 map常见的api map接口中定义了双列集合所有的共性方法,下面三个实现类就没有什么额外新的方法要学习了。 map接口…...

WebRTC 服务器之Janus视频会议插件信令交互
1.基础知识回顾 WebRTC 服务器之Janus概述和环境搭建-CSDN博客 WebRTC 服务器之Janus架构分析-CSDN博客 2.插件使用流程 我们要使⽤janus的功能时,通常要执⾏以下操作: 1. 在你的⽹⻚引入 Janus.js 库,即是包含janus.js; <…...

LabVIEW温控系统热敏电阻滞后问题
在 LabVIEW 构建的温控系统中,热敏电阻因热时间常数大(2 秒左右)产生的滞后效应,致使控温出现超调与波动。在不更换传感器的前提下,可从算法优化、硬件调整和系统设计等维度着手解决。 一、算法优化 1. 改进 PI…...

【Unity】使用XLua进行热修复
准备工作: (1)将XLua的Tool拖入Asset (2)配置热修复 (3)运行Genrate Code (4)运行Hotfix Inject In Editor 编写脚本(注意类上带有[Hotfix]) [Hot…...

GateWay使用
首先创建一个网关服务,添加对应的依赖 <dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId&…...
)
如何使用责任链模式优雅实现功能(滴滴司机、家政服务、请假审批等)
在企业级开发中,我们经常会遇到一系列有先后顺序、逐步处理的逻辑链路,例如请假审批、报销审批、日志处理、事件处理、滴滴司机接单流程等。这些场景非常适合使用 责任链模式(Chain of Responsibility Pattern) 来优雅地实现。 本…...

opencv的contours
1.哪里来的contours: 我们常常用到这一句: contours, hierarchy cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) 输出的contours的是一个tuple类型的: 1.它的len()就是contour的个数 2.每一…...

使用 OpenCV 和 Dlib实现轮廓绘制
文章目录 引言1.准备工作2.代码解析2.1 导入必要的库2.2 定义绘制直线函数2.3 定义绘制凸包函数2.4 加载图像和模型2.5 关键点检测与绘制2.6 显示结果 3.68个关键点索引说明4.应用场景5.优化建议6. 结语 引言 人脸关键点检测是计算机视觉中的重要任务,广泛应用于人…...

学习黑客Linux 命令
在操作下面的闯关题之前,给下学习资料 一图速览:20 条命令及练习手册 #命令 & 常用参数关键作用典型练习1ls -alh列文件(含隐藏 & 人类可读大小)(数字海洋)在 $HOME 统计目录数2cd / pwd切换、显示路径cd /tmp &&a…...

探秘 RocketMQ 的 DLedgerServer:MemberState 的技术解析与深度剖析
在 RocketMQ 构建高可靠、强一致性消息系统的架构中,DLedgerServer 扮演着举足轻重的角色,而 MemberState 作为 DLedgerServer 内部用于描述节点状态的核心类,更是整个分布式日志模块稳定运行的关键。深入理解 MemberState 的设计理念、功能特…...

【计算机网络】HTTP中GET和POST的区别是什么?
从以下几个方面去说明: 1.定义 2.参数传递方式 3.安全性 4.幂等性 1.定义: GET: 获取资源,通常请求数据而不改变服务器的状态。POST: 提交数据到服务器,通常会改变服务器的状态或副作用(如创建或更新资源…...

C++负载均衡远程调用学习之Agent代理模块基础构建
目录 1.课程复习 2.Lars-lbAgentV0.1-udpserver启动 3.Lars-lbAgentV0.1-dns-reporter-client-thread启动 4.Lars-lbAgentV0.1-dns-client实现 5.Lars-lbAgentV0.1-dns-client编译错误修正 6.Lars-lbAgentV0.1-reporter_client实现 1.课程复习 ### 11.2 完成Lars Reactor…...
TypeScript 的一些内置函数)
游戏开发的TypeScript(4)TypeScript 的一些内置函数
在 TypeScript 中,内置函数分为两类:JavaScript 原生函数(TypeScript 继承)和TypeScript 特有函数(类型系统相关)。以下是详细分类介绍: 一、JavaScript 原生函数 TypeScript 继承了所有 Java…...
)
软考 系统架构设计师系列知识点之杂项集萃(52)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(51) 第82题 以下关于系统性能的叙述中,不正确的是()。 A. 常见的Web服务器性能评估方法有基准测试、压力测试和可靠性测试 B. 评价Web服务器的主…...

大连理工大学选修课——图形学:第五章 二维变换及二维观察
第五章 二维变换及二维观察 二维变换 基本几何变换 图形的几何变换是指对图形的几何信息经过平移、比例、旋转等变换后产生新的图形。 基本几何变换都是相对于坐标原点和坐标轴进行的几何变换。 平移变换 推导: x ′ x T x y ′ y T y xxT_x\\ yyT_y x′xT…...
详解)
观察者模式(Observer Pattern)详解
文章目录 1. 什么是观察者模式?2. 为什么需要观察者模式?3. 观察者模式的核心概念4. 观察者模式的结构5. 观察者模式的基本实现简单的气象站示例6. 观察者模式的进阶实现推模型 vs 拉模型6.1 推模型(Push Model)6.2 拉模型(Pull Model)7. 观察者模式的复杂实现7.1 在线商…...

复刻低成本机械臂 SO-ARM100 标定篇
视频讲解: 复刻低成本机械臂 SO-ARM100 标定篇 组装完机械臂后,要进行初始标定,参考github的markdown lerobot/examples/10_use_so100.md at main huggingface/lerobot 只有从臂,所以arms里面只填follower即可 python lerobot…...

idea创建springboot工程-指定阿里云地址创建工程报错
idea创建springboot工程-指定阿里云地址创建工程报错 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是springboot的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】࿱…...

OpenStack HA高可用集群Train版-0集群环境准备
OpenStack HA高可用集群Train版-0集群环境准备 目录 主机配置1.主机名2.网卡配置网卡UUID配置主机名解析配置免密登录防火墙相关配置时间同步配置 二、基础软件安装数据库构建数据库集群设置心跳检测clustercheck准备脚本创建心跳检测用户,(任意控制节点)检测配置文件每个控制节…...
)
Python3与Dubbo3.1通讯解决方案(dubbo-python)
【文章非VIP可读,如果发现阅读限制为系统自动修改阅读权限,请留言我改回】 概述 最近AI项目需要java与python通讯,两边都是比较新的版本。因此需要双方进行通讯,在这里记录一下所采用的方案和关键点。 JAVA调用Python python通…...

深入探索 Java 区块链技术:从核心原理到企业级实践
一、Java 与区块链的天然契合 1.1 区块链技术的核心特征 区块链作为一种分布式账本技术,其核心特征包括: 去中心化:通过 P2P 网络实现节点自治,消除对中央机构的依赖。不可篡改性:利用哈希链和共识机制确保数据一旦…...

NV214NV217美光闪存固态NV218NV225
NV214NV217美光闪存固态NV218NV225 在当今数据驱动的时代,固态硬盘(SSD)的性能直接决定了计算系统的效率上限。美光科技作为全球存储解决方案的领军者,其NV系列产品凭借尖端技术持续刷新行业标准。本文将围绕NV214、NV217、NV218、…...