REINFORCE蒙特卡罗策略梯度算法详解:python从零实现
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
好的!我会按照你的要求,认真完成翻译任务,确保内容完整、准确且符合要求。以下是翻译后的 Markdown 文档:
引言
强化学习(Reinforcement Learning, RL)的目标是训练智能体(agent),使其能够在环境中做出一系列决策,以最大化累积奖励。虽然基于价值的方法(如 Q-learning 和 DQN)会学习状态-动作对的价值,但基于策略的方法会直接学习策略,即从状态到动作(或动作概率)的映射。REINFORCE,也称为蒙特卡洛策略梯度,是一种基础的策略梯度算法。
文章目录
- 🧠 向所有学习者致敬!
- 🌐 欢迎[点击加入AI人工智能社区](https://bbs.csdn.net/forums/b8786ecbbd20451bbd20268ed52c0aad?joinKey=bngoppzm57nz-0m89lk4op0-1-315248b33aafff0ea7b)!
- 引言
- REINFORCE 是什么?
- 为什么选择策略梯度?
- REINFORCE 的应用场景和使用方式
- REINFORCE 的数学基础
- 策略梯度定理回顾(直觉)
- REINFORCE 的目标函数
- REINFORCE 的梯度估计器
- 计算折扣回报(蒙特卡洛)
- REINFORCE 的逐步解释
- REINFORCE 的关键组件
- 策略网络
- 动作选择(采样)
- 轨迹收集
- 折扣回报计算
- 损失函数(策略梯度目标)
- 超参数
- 实践示例:自定义网格世界
- 设置环境
- 创建自定义环境
- 实现 REINFORCE 算法
- 定义策略网络
- 动作选择(从策略中采样)
- 计算回报
- 优化步骤(策略更新)
- 运行 REINFORCE 算法
- 超参数设置
- 初始化
- 训练循环
- 可视化学习过程
- 分析学习到的策略(可选可视化)
- REINFORCE 中的常见挑战及解决方案
- 结论
REINFORCE 是什么?
REINFORCE 是一种直接学习参数化策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ) 的算法,而无需先显式学习一个价值函数。它的原理如下:
- 执行当前策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ),生成完整的经验轨迹(episode): ( s 0 , a 0 , r 1 , s 1 , a 1 , r 2 , . . . , s T ) (s_0, a_0, r_1, s_1, a_1, r_2, ..., s_T) (s0,a0,r1,s1,a1,r2,...,sT)。
- 对于轨迹中的每一步 t t t,计算从该步开始直到结束的总折扣回报 G t = ∑ k = t T γ k − t r k + 1 G_t = \sum_{k=t}^T \gamma^{k-t} r_{k+1} Gt=∑k=tTγk−trk+1。
- 使用梯度上升更新策略参数 θ \theta θ,以增加导致高回报 G t G_t Gt 的动作 a t a_t at 的概率,并减少导致低回报的动作的概率。
它被称为蒙特卡洛方法,因为它使用整个轨迹的完整回报 G t G_t Gt 来更新策略,而不是像 Q-learning 或 Actor-Critic 方法那样从估计值中进行引导(bootstrapping)。
为什么选择策略梯度?
策略梯度方法相比纯基于价值的方法(如 DQN)具有以下优势:
- 连续动作空间:它们可以自然地处理连续动作空间,而 DQN 主要用于离散动作。
- 随机策略:它们可以学习随机策略( π ( a ∣ s ) \pi(a|s) π(a∣s) 给出概率),在部分可观测环境或需要鲁棒性时非常有用。
- 概念上更简单(在某些方面):直接优化策略有时比估计价值函数更直接,尤其是当价值函数复杂时。
然而,像 REINFORCE 这样的基础策略梯度方法通常由于蒙特卡洛采样而导致梯度估计的方差较高,这可能导致收敛速度比 DQN 或 Actor-Critic 方法更慢或更不稳定。
REINFORCE 的应用场景和使用方式
REINFORCE 是理解更高级的策略梯度和 Actor-Critic 方法的基础。由于其高方差限制了其在复杂、大规模问题中的直接应用,相比最先进的算法,它更适合以下场景:
- 简单的强化学习基准问题:例如 CartPole、Acrobot 或自定义网格世界,这些场景的轨迹较短,方差可控。
- 学习随机策略:当需要概率性动作选择时。
- 教学目的:它为理解策略梯度学习的核心概念提供了一个清晰的入门。
REINFORCE 适用于以下情况:
- 目标是直接学习策略。
- 环境允许在更新之前生成完整的轨迹。
- 动作空间可以是离散的或连续的(尽管我们的示例使用离散动作)。
- 可以接受高方差的更新,或者可以通过基线(baseline)等方法进行管理(尽管这里没有实现)。
- 它是在线策略,即生成数据的策略与正在改进的策略相同。旧策略的数据不能轻易重用(与 DQN 的离线策略性质不同,DQN 使用重放缓冲区)。
REINFORCE 的数学基础
策略梯度定理回顾(直觉)
目标是找到策略参数 θ \theta θ,以最大化期望的总折扣回报,通常记为 J ( θ ) J(\theta) J(θ)。策略梯度定理提供了一种计算该目标关于策略参数的梯度的方法:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t | s_t) Q^{\pi_\theta}(s_t, a_t) \right] ∇θJ(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)Qπθ(st,at)]
其中 τ \tau τ 是使用策略 π θ \pi_\theta πθ 采样的轨迹, Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t, a_t) Qπθ(st,at) 是在策略 π θ \pi_\theta πθ 下的动作价值函数。
REINFORCE 的目标函数
REINFORCE 使用蒙特卡洛回报 G t = ∑ k = t T γ k − t r k + 1 G_t = \sum_{k=t}^T \gamma^{k-t} r_{k+1} Gt=∑k=tTγk−trk+1 作为 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t, a_t) Qπθ(st,at) 的无偏估计。梯度则变为:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T G t ∇ θ log π θ ( a t ∣ s t ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T G_t \nabla_\theta \log \pi_\theta(a_t | s_t) \right] ∇θJ(θ)=Eτ∼πθ[t=0∑TGt∇θlogπθ(at∣st)]
我们希望对 J ( θ ) J(\theta) J(θ) 进行梯度上升。这相当于对负目标函数进行梯度下降,从而得到实现中常用的损失函数:
L ( θ ) = − E τ ∼ π θ [ ∑ t = 0 T G t log π θ ( a t ∣ s t ) ] L(\theta) = - \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T G_t \log \pi_\theta(a_t | s_t) \right] L(θ)=−Eτ∼πθ[t=0∑TGtlogπθ(at∣st)]
在实践中,我们通过当前策略生成的样本(轨迹)来近似期望。
REINFORCE 的梯度估计器
对于单个轨迹 τ \tau τ,梯度估计为 ∑ t = 0 T G t ∇ θ log π θ ( a t ∣ s t ) \sum_{t=0}^T G_t \nabla_\theta \log \pi_\theta(a_t | s_t) ∑t=0TGt∇θlogπθ(at∣st)。其中 ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta(a_t | s_t) ∇θlogπθ(at∣st) 通常被称为“资格向量”(eligibility vector)。它表示在参数空间中增加在状态 s t s_t st 下采取动作 a t a_t at 的对数概率的方向。这个方向通过回报 G t G_t Gt 进行缩放。如果 G t G_t Gt 很高,我们就会显著朝这个方向移动;如果 G t G_t Gt 很低(或为负),我们会远离这个方向。
计算折扣回报(蒙特卡洛)
在完成一个轨迹后,我们得到了奖励序列 r 1 , r 2 , . . . , r T r_1, r_2, ..., r_T r1,r2,...,rT,然后计算每个时间步 t t t 的折扣回报:
G t = r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . + γ T − t r T G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + ... + \gamma^{T-t} r_T Gt=rt+1+γrt+2+γ2rt+3+...+γT−trT
通常可以通过从轨迹的末尾向后迭代来高效计算:
G T = 0 G_T = 0 GT=0(假设 r T + 1 = 0 r_{T+1}=0 rT+1=0 或取决于问题设置)
G T − 1 = r T + γ G T G_{T-1} = r_T + \gamma G_T GT−1=rT+γGT
G T − 2 = r T − 1 + γ G T − 1 G_{T-2} = r_{T-1} + \gamma G_{T-1} GT−2=rT−1+γGT−1
……依此类推,直到 G 0 G_0 G0。
方差降低(基线):一种常见的技术(尽管在这个基础示例中没有实现)是从回报中减去一个依赖于状态的基线 b ( s t ) b(s_t) b(st)(通常是状态价值函数 V ( s t ) V(s_t) V(st)):
∇ θ J ( θ ) ≈ ∑ t ( G t − b ( s t ) ) ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta J(\theta) \approx \sum_t (G_t - b(s_t)) \nabla_\theta \log \pi_\theta(a_t|s_t) ∇θJ(θ)≈t∑(Gt−b(st))∇θlogπθ(at∣st)
这不会改变期望梯度,但可以显著降低其方差。
REINFORCE 的逐步解释
- 初始化:策略网络 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ),带有随机权重 θ \theta θ,折扣因子 γ \gamma γ,学习率 α \alpha α。
- 对于每个轨迹:
a. 按照策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ) 生成完整的轨迹 τ = ( s 0 , a 0 , r 1 , s 1 , a 1 , . . . , s T − 1 , a T − 1 , r T , s T ) \tau = (s_0, a_0, r_1, s_1, a_1, ..., s_{T-1}, a_{T-1}, r_T, s_T) τ=(s0,a0,r1,s1,a1,...,sT−1,aT−1,rT,sT):
i. 对于 t = 0 , 1 , . . . , T − 1 t=0, 1, ..., T-1 t=0,1,...,T−1:
- 观察状态 s t s_t st。
- 从 π ( ⋅ ∣ s t ; θ ) \pi(\cdot | s_t; \theta) π(⋅∣st;θ) 中采样动作 a t a_t at。
- 执行 a t a_t at,观察奖励 r t + 1 r_{t+1} rt+1 和下一个状态 s t + 1 s_{t+1} st+1。
- 存储 s t , a t , r t + 1 s_t, a_t, r_{t+1} st,at,rt+1,以及 log π θ ( a t ∣ s t ) \log \pi_\theta(a_t | s_t) logπθ(at∣st)。
b. 计算回报:对于 t = 0 , 1 , . . . , T − 1 t=0, 1, ..., T-1 t=0,1,...,T−1:
- 计算折扣回报 G t = ∑ k = t T − 1 γ k − t r k + 1 G_t = \sum_{k=t}^{T-1} \gamma^{k-t} r_{k+1} Gt=∑k=tT−1γk−trk+1。
c. 更新策略:执行梯度上升(或对负目标函数进行梯度下降):
- 计算损失 L = − ∑ t = 0 T − 1 G t log π θ ( a t ∣ s t ) L = -\sum_{t=0}^{T-1} G_t \log \pi_\theta(a_t | s_t) L=−∑t=0T−1Gtlogπθ(at∣st)。
- 更新权重: θ ← θ + α ∇ θ J ( θ ) \theta \leftarrow \theta + \alpha \nabla_\theta J(\theta) θ←θ+α∇θJ(θ)(或使用优化器对 L L L 进行优化)。 - 重复:直到收敛或达到最大轨迹数。
REINFORCE 的关键组件
策略网络
- 核心函数逼近器。学习将状态映射到动作概率。
- 架构取决于状态表示(对于向量使用 MLP,对于图像使用 CNN)。
- 在隐藏层中使用非线性激活函数(如 ReLU)。
- 输出层通常使用 Softmax 激活函数,用于离散动作空间,以产生动作的概率分布。
动作选择(采样)
- 从策略网络 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ) 输出的概率分布中采样动作。
- 这种方法本身就提供了探索性。随着学习的进行,更好动作的概率会增加,从而导致更多的利用性。
- 需要存储所选动作的对数概率( log π ( a t ∣ s t ; θ ) \log \pi(a_t|s_t; \theta) logπ(at∣st;θ)),以便进行梯度计算。
轨迹收集
- REINFORCE 是在线策略且基于轨迹的。
- 它需要使用当前策略收集完整的轨迹(状态、动作、奖励序列),然后才能进行更新。
- 存储每个步骤的奖励、状态、动作和对数概率。
折扣回报计算
- 在一个轨迹完成后,计算每个时间步 t t t 的 G t G_t Gt。
- 该值表示从该点开始在该特定轨迹中实际收到的累积奖励。
损失函数(策略梯度目标)
- 通常是 − ∑ t G t log π ( a t ∣ s t ; θ ) -\sum_t G_t \log \pi(a_t|s_t; \theta) −∑tGtlogπ(at∣st;θ)。
- 最大化导致高回报的动作的概率。
- 通常会对回报 G t G_t Gt 进行标准化(减去均值,除以标准差),以稳定学习。
超参数
- 关键超参数包括学习率、折扣因子 γ \gamma γ 和网络架构。
- 性能可能对这些参数敏感,尤其是学习率,因为梯度估计的方差较高。
实践示例:自定义网格世界
我们将使用与 DQN 示例相同的简单自定义网格世界环境来进行比较,并保持风格一致。
环境描述:
- 网格大小:10x10。
- 状态:代理的
(row, col)位置。表示为归一化向量[row/10, col/10],用于网络输入。 - 动作:4 个离散动作:0(上),1(下),2(左),3(右)。
- 起始状态:(0, 0)。
- 目标状态:(9, 9)。
- 奖励:
- 到达目标状态 (9, 9) 时 +10。
- 碰到墙壁(试图移出网格)时 -1。
- 其他步骤 -0.1(小成本,鼓励效率)。
- 终止:当代理到达目标或达到最大步数时,轨迹结束。
设置环境
导入必要的库并设置环境。
# 导入用于数值计算、绘图和实用功能的库
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque # Deque 在 REINFORCE 中可能不需要
from itertools import count
from typing import List, Tuple, Dict, Optional# 导入 PyTorch 用于构建和训练神经网络
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical # 用于采样动作# 设置设备,如果可用则使用 GPU,否则回退到 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")# 设置随机种子以确保运行结果可复现
seed = 42
random.seed(seed) # Python 随机模块的种子
np.random.seed(seed) # NumPy 的种子
torch.manual_seed(seed) # PyTorch(CPU)的种子
if torch.cuda.is_available():torch.cuda.manual_seed_all(seed) # PyTorch(GPU)的种子# 为 Jupyter Notebook 启用内联绘图
%matplotlib inline
使用设备:cpu
创建自定义环境
我们重用了 DQN 笔记本中的完全相同的 GridEnvironment 类。这确保了可比性,并符合参考风格。
# 自定义网格世界环境(与 DQN 笔记本中的完全相同)
class GridEnvironment:"""一个简单的 10x10 网格世界环境。状态:(row, col),表示为归一化向量 [row/10, col/10]。动作:0(上),1(下),2(左),3(右)。奖励:到达目标 +10,碰到墙壁 -1,每步 -0.1。"""def __init__(self, rows: int = 10, cols: int = 10) -> None:"""初始化网格世界环境。参数:- rows (int): 网格的行数。- cols (int): 网格的列数。"""self.rows: int = rowsself.cols: int = colsself.start_state: Tuple[int, int] = (0, 0) # 起始位置self.goal_state: Tuple[int, int] = (rows - 1, cols - 1) # 目标位置self.state: Tuple[int, int] = self.start_state # 当前状态self.state_dim: int = 2 # 状态由 2 个坐标(row, col)表示self.action_dim: int = 4 # 4 个离散动作:上、下、左、右# 动作映射:将动作索引映射到 (row_delta, col_delta)self.action_map: Dict[int, Tuple[int, int]] = {0: (-1, 0), # 上1: (1, 0), # 下2: (0, -1), # 左3: (0, 1) # 右}def reset(self) -> torch.Tensor:"""将环境重置到起始状态。返回:torch.Tensor:初始状态作为归一化张量。"""self.state = self.start_statereturn self._get_state_tensor(self.state)def _get_state_tensor(self, state_tuple: Tuple[int, int]) -> torch.Tensor:"""将 (row, col) 元组转换为网络所需的归一化张量。参数:- state_tuple (Tuple[int, int]): 状态表示为元组 (row, col)。返回:torch.Tensor:归一化后的状态作为张量。"""# 将坐标归一化到 0 和 1 之间(根据 0 索引调整归一化)normalized_state: List[float] = [state_tuple[0] / (self.rows - 1) if self.rows > 1 else 0.0,state_tuple[1] / (self.cols - 1) if self.cols > 1 else 0.0]return torch.tensor(normalized_state, dtype=torch.float32, device=device)def step(self, action: int) -> Tuple[torch.Tensor, float, bool]:"""根据给定的动作执行一步。参数:action (int): 要执行的动作(0:上,1:下,2:左,3:右)。返回:Tuple[torch.Tensor, float, bool]:- next_state_tensor (torch.Tensor):下一个状态作为归一化张量。- reward (float):该动作的奖励。- done (bool):是否结束轨迹。"""# 如果已经到达目标状态,则返回当前状态,奖励为 0,done=Trueif self.state == self.goal_state:return self._get_state_tensor(self.state), 0.0, True# 获取该动作对应的行和列增量dr, dc = self.action_map[action]current_row, current_col = self.statenext_row, next_col = current_row + dr, current_col + dc# 默认步进成本reward: float = -0.1hit_wall: bool = False# 检查该动作是否会导致移出边界if not (0 <= next_row < self.rows and 0 <= next_col < self.cols):# 保持在相同状态并受到惩罚next_row, next_col = current_row, current_colreward = -1.0hit_wall = True# 更新状态self.state = (next_row, next_col)next_state_tensor: torch.Tensor = self._get_state_tensor(self.state)# 检查是否到达目标状态done: bool = (self.state == self.goal_state)if done:reward = 10.0 # 到达目标的奖励return next_state_tensor, reward, donedef get_action_space_size(self) -> int:"""返回动作空间的大小。返回:int:可能的动作数量(4)。"""return self.action_dimdef get_state_dimension(self) -> int:"""返回状态表示的维度。返回:int:状态的维度(2)。"""return self.state_dim
实例化自定义环境并验证其属性。
# 实例化 10x10 网格的自定义环境
custom_env = GridEnvironment(rows=10, cols=10)# 获取动作空间大小和状态维度
n_actions_custom = custom_env.get_action_space_size()
n_observations_custom = custom_env.get_state_dimension()# 打印环境的基本信息
print(f"自定义网格环境:")
print(f"大小:{custom_env.rows}x{custom_env.cols}")
print(f"状态维度:{n_observations_custom}")
print(f"动作维度:{n_actions_custom}")
print(f"起始状态:{custom_env.start_state}")
print(f"目标状态:{custom_env.goal_state}")# 重置环境并打印起始状态的归一化状态张量
print(f"(0,0) 的示例状态张量:{custom_env.reset()}")# 执行一个示例动作:向右移动(动作=3)并打印结果
next_s, r, d = custom_env.step(3) # 动作 3 对应向右移动
print(f"动作结果(动作=右):下一个状态={next_s.cpu().numpy()},奖励={r},结束={d}")# 再执行一个示例动作:向上移动(动作=0)并打印结果
# 这将碰到墙壁,因为代理在最上面一行
next_s, r, d = custom_env.step(0) # 动作 0 对应向上移动
print(f"动作结果(动作=上):下一个状态={next_s.cpu().numpy()},奖励={r},结束={d}")
自定义网格环境:
大小:10x10
状态维度:2
动作维度:4
起始状态:(0, 0)
目标状态:(9, 9)
(0,0) 的示例状态张量:tensor([0., 0.])
动作结果(动作=右):下一个状态=[0. 0.11111111],奖励=-0.1,结束=False
动作结果(动作=上):下一个状态=[0. 0.11111111],奖励=-1.0,结束=False
实现 REINFORCE 算法
现在,让我们实现核心组件:策略网络、动作选择机制(采样)、回报计算和策略更新步骤。
定义策略网络
我们使用 PyTorch 的 nn.Module 定义一个简单的多层感知机(MLP)。与 DQN 网络的主要区别在于输出层,它使用 nn.Softmax 产生动作概率。
# 定义策略网络架构
class PolicyNetwork(nn.Module):""" 用于 REINFORCE 的简单 MLP 策略网络 """def __init__(self, n_observations: int, n_actions: int):"""初始化策略网络。参数:- n_observations (int): 状态空间的维度。- n_actions (int): 可能的动作数量。"""super(PolicyNetwork, self).__init__()# 定义网络层(与 DQN 示例类似)self.layer1 = nn.Linear(n_observations, 128) # 输入层self.layer2 = nn.Linear(128, 128) # 隐藏层self.layer3 = nn.Linear(128, n_actions) # 输出层(动作对数几率)def forward(self, x: torch.Tensor) -> torch.Tensor:"""通过网络进行前向传播以获取动作概率。参数:- x (torch.Tensor): 表示状态的输入张量。返回:- torch.Tensor:输出张量,表示动作概率(经过 Softmax)。"""# 确保输入是浮点张量if not isinstance(x, torch.Tensor):x = torch.tensor(x, dtype=torch.float32, device=device)elif x.dtype != torch.float32:x = x.to(dtype=torch.float32)# 应用带有 ReLU 激活函数的层x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))# 从输出层获取动作对数几率action_logits = self.layer3(x)# 应用 Softmax 以获取动作概率action_probs = F.softmax(action_logits, dim=-1) # 使用 dim=-1 以确保对批次通用return action_probs
动作选择(从策略中采样)
此函数通过从策略网络输出的概率分布中采样来选择动作。它还返回所选动作的对数概率,这是 REINFORCE 更新所需的。
# REINFORCE 的动作选择
def select_action_reinforce(state: torch.Tensor, policy_net: PolicyNetwork) -> Tuple[int, torch.Tensor]:"""通过从策略网络输出的分布中采样来选择动作。参数:- state (torch.Tensor):当前状态作为张量,形状为 [state_dim]。- policy_net (PolicyNetwork):用于估计动作概率的策略网络。返回:- Tuple[int, torch.Tensor]:- action (int):所选动作的索引。- log_prob (torch.Tensor):所选动作的对数概率。"""# 如果网络有 dropout 或 batchnorm 层,则确保其处于评估模式(这里可选)# policy_net.eval() # 从策略网络获取动作概率# 如果状态是单个实例 [state_dim],则添加批次维度 [1, state_dim]if state.dim() == 1:state = state.unsqueeze(0)action_probs = policy_net(state)# 创建一个动作的分类分布# 如果之前添加了批次维度,则通过 squeeze(0) 获取单个状态的概率m = Categorical(action_probs.squeeze(0)) # 从分布中采样一个动作action = m.sample()# 获取所采样动作的对数概率(用于梯度计算)log_prob = m.log_prob(action)# 如果需要,将网络恢复为训练模式# policy_net.train()# 返回动作索引(作为 int)及其对数概率(作为张量)return action.item(), log_prob
计算回报
此函数计算每个时间步 t t t 的折扣回报 G t G_t Gt,给定奖励列表。它可以选择性地标准化回报。
def calculate_discounted_returns(rewards: List[float], gamma: float, standardize: bool = True) -> torch.Tensor:"""计算每个时间步 $t$ 的折扣回报 $G_t$。参数:- rewards (List[float]):在轨迹中收到的奖励列表。- gamma (float):折扣因子。- standardize (bool):是否标准化(归一化)回报(减去均值,除以标准差)。返回:- torch.Tensor:包含每个时间步的折扣回报的张量。"""n_steps = len(rewards)returns = torch.zeros(n_steps, device=device, dtype=torch.float32)discounted_return = 0.0# 从后向前迭代奖励以计算折扣回报for t in reversed(range(n_steps)):discounted_return = rewards[t] + gamma * discounted_returnreturns[t] = discounted_return# 标准化回报(可选但通常有帮助)if standardize:mean_return = torch.mean(returns)std_return = torch.std(returns) + 1e-8 # 添加小 epsilon 以防止除以零returns = (returns - mean_return) / std_returnreturn returns
优化步骤(策略更新)
此函数在完成一个轨迹后执行策略更新。它使用收集到的对数概率和计算出的回报来计算损失并执行反向传播。
def optimize_policy(log_probs: List[torch.Tensor], returns: torch.Tensor, optimizer: optim.Optimizer
) -> float:"""使用 REINFORCE 更新规则对策略网络执行一步优化。参数:- log_probs (List[torch.Tensor]):在轨迹中采取的动作的对数概率列表。- returns (torch.Tensor):轨迹中每个时间步的折扣回报张量。- optimizer (optim.Optimizer):用于更新策略网络的优化器。返回:- float:轨迹的计算损失值。"""# 将对数概率堆叠成一个张量log_probs_tensor = torch.stack(log_probs)# 计算 REINFORCE 损失:- (returns * log_probs)# 我们希望最大化 $E[G_t \cdot \log(\pi)]$,因此最小化 $-E[G_t \cdot \log(\pi)]$# 对整个轨迹步骤求和loss = -torch.sum(returns * log_probs_tensor)# 执行反向传播和优化optimizer.zero_grad() # 清除之前的梯度loss.backward() # 计算梯度optimizer.step() # 更新策略网络参数return loss.item() # 返回损失值以便记录
运行 REINFORCE 算法
设置超参数,初始化策略网络和优化器,然后运行主训练循环。
超参数设置
为应用于自定义网格世界的 REINFORCE 算法定义超参数。
# REINFORCE 在自定义网格世界的超参数
GAMMA_REINFORCE = 0.99 # 折扣因子
LR_REINFORCE = 1e-3 # 学习率(通常低于 DQN,较为敏感)
NUM_EPISODES_REINFORCE = 1500 # REINFORCE 通常需要更多轨迹,因为方差较高
MAX_STEPS_PER_EPISODE_REINFORCE = 200 # 每个轨迹的最大步数
STANDARDIZE_RETURNS = True # 是否标准化回报
初始化
初始化策略网络和优化器。
# 重新实例化自定义 GridEnvironment
custom_env: GridEnvironment = GridEnvironment(rows=10, cols=10)# 获取动作空间大小和状态维度
n_actions_custom: int = custom_env.get_action_space_size() # 4 个动作
n_observations_custom: int = custom_env.get_state_dimension() # 2 个状态维度# 初始化策略网络
policy_net_reinforce: PolicyNetwork = PolicyNetwork(n_observations_custom, n_actions_custom).to(device)# 初始化策略网络的优化器
optimizer_reinforce: optim.Adam = optim.Adam(policy_net_reinforce.parameters(), lr=LR_REINFORCE)# 用于存储轨迹统计数据以便绘图的列表
episode_rewards_reinforce = []
episode_lengths_reinforce = []
episode_losses_reinforce = []
训练循环
在自定义网格世界环境中训练 REINFORCE 代理。注意与 DQN 的工作流程差异:我们需要先收集一个完整的轨迹,然后计算回报并更新策略。
print("开始在自定义网格世界上训练 REINFORCE...")# 训练循环
for i_episode in range(NUM_EPISODES_REINFORCE):# 重置环境并获取初始状态张量state = custom_env.reset()# 用于存储当前轨迹数据的列表episode_log_probs: List[torch.Tensor] = []episode_rewards: List[float] = []# --- 生成一个轨迹 ---for t in range(MAX_STEPS_PER_EPISODE_REINFORCE):# 根据当前策略选择动作并存储对数概率action, log_prob = select_action_reinforce(state, policy_net_reinforce)episode_log_probs.append(log_prob)# 在环境中执行动作next_state, reward, done = custom_env.step(action)episode_rewards.append(reward)# 转移到下一个状态state = next_state# 如果轨迹结束,则退出if done:break# --- 轨迹结束,现在更新策略 ---# 计算轨迹的折扣回报returns = calculate_discounted_returns(episode_rewards, GAMMA_REINFORCE, STANDARDIZE_RETURNS)# 执行策略优化loss = optimize_policy(episode_log_probs, returns, optimizer_reinforce)# 存储轨迹统计数据total_reward = sum(episode_rewards)episode_rewards_reinforce.append(total_reward)episode_lengths_reinforce.append(t + 1)episode_losses_reinforce.append(loss)# 定期打印进度(例如,每 100 个轨迹)if (i_episode + 1) % 100 == 0:avg_reward = np.mean(episode_rewards_reinforce[-100:])avg_length = np.mean(episode_lengths_reinforce[-100:])avg_loss = np.mean(episode_losses_reinforce[-100:])print(f"轨迹 {i_episode+1}/{NUM_EPISODES_REINFORCE} | "f"最近 100 个轨迹的平均奖励:{avg_reward:.2f} | "f"平均长度:{avg_length:.2f} | "f"平均损失:{avg_loss:.4f}")print("自定义网格世界训练完成(REINFORCE)。")
开始在自定义网格世界上训练 REINFORCE...
轨迹 100/1500 | 最近 100 个轨迹的平均奖励:0.31 | 平均长度:43.90 | 平均损失:-2.5428
轨迹 200/1500 | 最近 100 个轨迹的平均奖励:5.83 | 平均长度:21.42 | 平均损失:-1.5049
轨迹 300/1500 | 最近 100 个轨迹的平均奖励:6.93 | 平均长度:20.16 | 平均损失:-1.6836
轨迹 400/1500 | 最近 100 个轨迹的平均奖励:7.20 | 平均长度:19.39 | 平均损失:-1.2332
轨迹 500/1500 | 最近 100 个轨迹的平均奖励:7.34 | 平均长度:19.16 | 平均损失:-1.0108
轨迹 600/1500 | 最近 100 个轨迹的平均奖励:7.43 | 平均长度:19.23 | 平均损失:-1.1386
轨迹 700/1500 | 最近 100 个轨迹的平均奖励:7.66 | 平均长度:18.73 | 平均损失:-0.2648
轨迹 800/1500 | 最近 100 个轨迹的平均奖励:7.96 | 平均长度:18.52 | 平均损失:-0.4335
轨迹 900/1500 | 最近 100 个轨迹的平均奖励:7.93 | 平均长度:18.57 | 平均损失:0.6314
轨迹 1000/1500 | 最近 100 个轨迹的平均奖励:7.95 | 平均长度:18.42 | 平均损失:1.5364
轨迹 1100/1500 | 最近 100 个轨迹的平均奖励:7.87 | 平均长度:18.45 | 平均损失:2.0860
轨迹 1200/1500 | 最近 100 个轨迹的平均奖励:7.95 | 平均长度:18.42 | 平均损失:1.9074
轨迹 1300/1500 | 最近 100 个轨迹的平均奖励:7.91 | 平均长度:18.44 | 平均损失:1.6792
轨迹 1400/1500 | 最近 100 个轨迹的平均奖励:7.85 | 平均长度:18.63 | 平均损失:1.1213
轨迹 1500/1500 | 最近 100 个轨迹的平均奖励:7.74 | 平均长度:18.60 | 平均损失:1.5478
自定义网格世界训练完成(REINFORCE)。
可视化学习过程
绘制 REINFORCE 代理在自定义网格世界环境中的学习结果(奖励、轨迹长度)。
# 绘制 REINFORCE 在自定义网格世界的训练结果
plt.figure(figsize=(20, 4))# 奖励
plt.subplot(1, 3, 1)
plt.plot(episode_rewards_reinforce)
plt.title('REINFORCE 自定义网格:轨迹奖励')
plt.xlabel('轨迹')
plt.ylabel('总奖励')
plt.grid(True)
# 添加移动平均线
rewards_ma_reinforce = np.convolve(episode_rewards_reinforce, np.ones(100)/100, mode='valid')
if len(rewards_ma_reinforce) > 0: plt.plot(np.arange(len(rewards_ma_reinforce)) + 99, rewards_ma_reinforce, label='100-轨迹移动平均', color='orange')
plt.legend()# 长度
plt.subplot(1, 3, 2)
plt.plot(episode_lengths_reinforce)
plt.title('REINFORCE 自定义网格:轨迹长度')
plt.xlabel('轨迹')
plt.ylabel('步数')
plt.grid(True)
# 添加移动平均线
lengths_ma_reinforce = np.convolve(episode_lengths_reinforce, np.ones(100)/100, mode='valid')
if len(lengths_ma_reinforce) > 0:plt.plot(np.arange(len(lengths_ma_reinforce)) + 99, lengths_ma_reinforce, label='100-轨迹移动平均', color='orange')
plt.legend()# 损失
plt.subplot(1, 3, 3)
plt.plot(episode_losses_reinforce)
plt.title('REINFORCE 自定义网格:轨迹损失')
plt.xlabel('轨迹')
plt.ylabel('损失')
plt.grid(True)
# 添加移动平均线
losses_ma_reinforce = np.convolve(episode_losses_reinforce, np.ones(100)/100, mode='valid')
if len(losses_ma_reinforce) > 0:plt.plot(np.arange(len(losses_ma_reinforce)) + 99, losses_ma_reinforce, label='100-轨迹移动平均', color='orange')
plt.legend()plt.tight_layout()
plt.show()

REINFORCE 学习曲线分析(自定义网格世界):
-
轨迹奖励(左图):
- 代理在初期学习非常迅速,轨迹奖励在大约 150 个轨迹内迅速增加到接近最优水平。移动平均线确认了策略收敛到高奖励策略。然而,原始奖励在整个训练过程中仍然高度波动,这展示了由于使用噪声蒙特卡洛回报进行更新,基础 REINFORCE 算法的高方差特性。
-
轨迹长度(中图):
- 该图强烈证实了高效学习,与奖励曲线的趋势一致。轨迹长度在初期急剧下降,迅速收敛到一个稳定的接近最优平均值(10x10 网格中最短路径为 18 步)。这表明代理成功地学习了一致地找到通往目标状态的高效路径。
-
轨迹损失(右图):
- 策略梯度损失表现出极端的方差,直接反映了 REINFORCE 更新中使用的噪声蒙特卡洛回报估计。与 MSE 损失不同,它不会收敛到零,而是在初始学习阶段后趋于稳定。这种梯度估计的高方差是导致奖励曲线波动的主要原因。
总体结论:
REINFORCE 成功且迅速地解决了自定义网格世界任务,学习到了高效的策略以最大化奖励。图表清晰地展示了快速收敛的特性,但也突出了算法固有的高方差问题,尤其是在奖励信号和梯度估计方面。这种高方差是 REINFORCE 相比更先进的策略梯度或 Actor-Critic 方法的主要局限性。
分析学习到的策略(可选可视化)
我们将从 DQN 笔记本中改编策略网格可视化代码,以使用策略网络。它展示了每个状态的最可能动作(取策略输出的 argmax)。
def plot_reinforce_policy_grid(policy_net: PolicyNetwork, env: GridEnvironment, device: torch.device) -> None:"""绘制由 REINFORCE 策略网络导出的贪婪策略。注意:显示的是最可能的动作,而不是采样动作。参数:- policy_net (PolicyNetwork):训练好的策略网络。- env (GridEnvironment):自定义网格环境。- device (torch.device):设备(CPU/GPU)。返回:- None:显示策略网格图。"""rows: int = env.rowscols: int = env.colspolicy_grid: np.ndarray = np.empty((rows, cols), dtype=str)action_symbols: Dict[int, str] = {0: '↑', 1: '↓', 2: '←', 3: '→'}fig, ax = plt.subplots(figsize=(cols * 0.6, rows * 0.6))for r in range(rows):for c in range(cols):state_tuple: Tuple[int, int] = (r, c)if state_tuple == env.goal_state:policy_grid[r, c] = 'G'ax.text(c, r, 'G', ha='center', va='center', color='green', fontsize=12, weight='bold')else:state_tensor: torch.Tensor = env._get_state_tensor(state_tuple)with torch.no_grad():state_tensor = state_tensor.unsqueeze(0)# 获取动作概率action_probs: torch.Tensor = policy_net(state_tensor)# 选择最高概率的动作(贪婪动作)best_action: int = action_probs.argmax(dim=1).item()policy_grid[r, c] = action_symbols[best_action]ax.text(c, r, policy_grid[r, c], ha='center', va='center', color='black', fontsize=12)ax.matshow(np.zeros((rows, cols)), cmap='Greys', alpha=0.1)ax.set_xticks(np.arange(-.5, cols, 1), minor=True)ax.set_yticks(np.arange(-.5, rows, 1), minor=True)ax.grid(which='minor', color='black', linestyle='-', linewidth=1)ax.set_xticks([])ax.set_yticks([])ax.set_title("REINFORCE 学习到的策略(最可能的动作)")plt.show()# 绘制训练网络学习到的策略
print("\n绘制 REINFORCE 学习到的策略:")
plot_reinforce_policy_grid(policy_net_reinforce, custom_env, device)
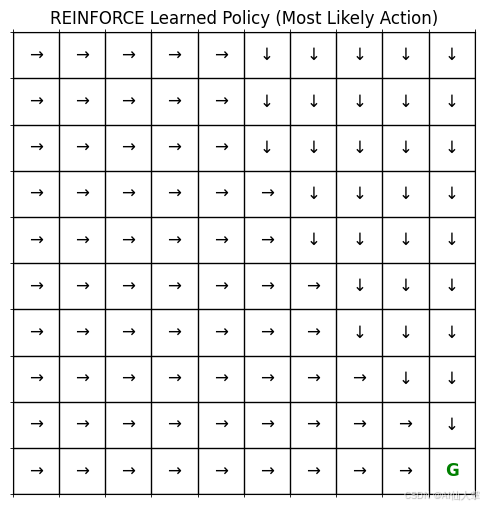
REINFORCE 学习到的策略可视化:
通过可视化策略网格,我们可以直观地看到代理在每个状态下的最可能动作。从图中可以看出,策略在大部分状态下都指向目标位置(右下角),并且在靠近目标时,策略能够正确地引导代理避开墙壁并快速到达目标。
REINFORCE 中的常见挑战及解决方案
挑战 1:梯度估计的高方差
- 问题:使用完整的蒙特卡洛回报 G t G_t Gt 会使梯度估计变得嘈杂,因为一个轨迹中早期的一个好动作或坏动作可能会不当地影响所有前面动作的更新,即使这些动作与最终回报无关。
- 解决方案:
- 基线减法:从 G t G_t Gt 中减去一个依赖于状态的基线(如状态价值 V ( s t ) V(s_t) V(st)):更新公式为 ( G t − V ( s t ) ) ∇ log π (G_t - V(s_t)) \nabla \log \pi (Gt−V(st))∇logπ。这种方法不会改变梯度的期望值,但可以显著降低方差。不过,这需要学习 V ( s t ) V(s_t) V(st),从而引出了 Actor-Critic 方法。
- 标准化回报:在轨迹或批次内对回报进行归一化(减去均值,除以标准差)。这有助于稳定更新。
- 增加批次大小:在更新之前对多个轨迹的梯度进行平均(尽管这需要更多内存)。
挑战 2:收敛速度慢
- 问题:高方差和可能较小的学习步长会导致学习速度变慢。
- 解决方案:
- 调整学习率:仔细调整学习率至关重要。使用自适应学习率的优化器(如 Adam)可能会有所帮助。
- 使用基线:如上所述,降低方差可以加速收敛。
- Actor-Critic 方法:用从学习到的 critic(价值函数)中引导的 TD 误差代替蒙特卡洛回报 G t G_t Gt,从而实现更快、方差更低的更新(例如 A2C、A3C)。
挑战 3:在线策略数据效率低
- 问题:REINFORCE 必须在每次策略更新后丢弃数据,使其不如 DQN 等离线策略方法那样样本高效。
- 解决方案:
- 重要性采样:在离线策略策略梯度方法(如 PPO)中使用的技术可以在一定程度上重用旧数据,但会增加复杂性。
- 接受这一局限性:对于交互成本较低或问题较简单的情况,简单在线策略更新的优点可能更为突出。
结论
REINFORCE 是强化学习中一种基础的策略梯度算法。它通过根据轨迹中获得的完整折扣回报调整动作概率,直接优化参数化的策略。其核心优势在于概念简单,能够处理各种动作空间并学习随机策略。
正如在自定义网格世界中所展示的,REINFORCE 可以学习到有效的策略。然而,由于其蒙特卡洛梯度估计的固有高方差特性,其实际应用通常受到限制,可能导致不稳定或收敛速度慢。通过使用基线减法和回报标准化等技术可以缓解这一问题。REINFORCE 为理解更先进且广泛使用的策略梯度和 Actor-Critic 方法(如 A2C、A3C、DDPG、PPO、SAC)奠定了基础,这些方法在保持其核心原理的同时,解决了其局限性,尤其是在方差和样本效率方面。
相关文章:

REINFORCE蒙特卡罗策略梯度算法详解:python从零实现
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

模拟SIP终端向Freeswitch注册用户
1、简介 使用go语言编写一个程序,模拟SIP-T58终端在Freeswitch上注册用户 2、思路 以客户端向服务端Freeswitch发起REGISTER请求,告知服务器当前的联系地址构造SIP REGISTER请求 创建UDP连接,连接到Freeswitch的5060端口发送初始的REGISTER请…...

Elasticsearch 中的索引模板:如何使用可组合模板
作者:来自 Elastic Kofi Bartlett 探索可组合模板以及如何创建它们。 更多阅读: Elasticsearch:可组合的 Index templates - 7.8 版本之后 想获得 Elastic 认证吗?查看下一期 Elasticsearch Engineer 培训的时间! El…...

一篇文章看懂时间同步服务
Linux 系统时间与时区管理 一、时间与时钟类型 时钟类型说明管理工具系统时钟由 Linux 内核维护的软件时钟,基于时区配置显示时间timedatectl硬件时钟 (RTC)主板上的物理时钟,通常以 UTC 或本地时间存储,用于系统启动时初始化时间hwclock …...

Mysql常用语句汇总
Mysql语句分类 DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML: 数据操作语言,用来对数据库表中的数据进行增删改DQL: 数据查询语言,用来查询数据库中表的记录DCL: 数据控制语言,用来创建数据…...

迭代器的思想和实现细节
1. 迭代器的本质 迭代器是一种行为类似指针的对象,它可能是指针(如 std::vector 的迭代器),也可能是封装了指针的类(如 std::list 的迭代器)。如果是指针那天然就可以用下面的运算,如果是类&am…...

[Vue]编程式导航
在 Vue 中,编程式导航是通过 JavaScript 代码(而非 <router-link> 标签)动态控制路由跳转的核心方式。这个方法依赖于 Vue Router 提供的 API,能更灵活地处理复杂场景(如异步操作、条件跳转等)。 一、…...

使用Node.js搭建https服务器
一、引言 https是是http的安全版本,在http的基础上通过传输加密和身份认证保证了传输过程中的安全性。可以认为:https http tls/ssl。本文讲述使用Node.js搭建https服务器的方法。 二、编译OpenSSL 按照《Openssl在Linux下编译/交叉编译》࿰…...

网络安全:sql注入练习靶场——sqli_labs安装保姆级教程
网络安全:sql注入练习靶场——sqli_labs安装保姆级教程 前言 sqli-labs靶场是一个开源的sql注入练习的综合靶场,包含大部分sql注入漏洞以及注入方式 网络安全学习者可以通过在sqli-labs靶场练习提升对sql注入的理解,以及学习各种绕过姿势。…...

rfsoc petalinux适配调试记录
1。安装虚拟机 2.设置共享文件夹 https://xinzhi.wenda.so.com/a/1668239544201149先设置文件夹路径 vmware 12 下安装 ubuntu 16.04 后,按往常的惯例安装 vmware-tools,安装时提示建议使用 open-vm-tools,于是放弃 vmware-tools 的安装&am…...

Windows下编译WebRTC源码
一、开发环境要求 准备一台64位的win10或win11(我用的是win11)电脑。最好是一台纯净的、没有安装过其它软件的Windows主机,避免已安装的软件和库对编译造成影响。 然后最好预留超过100G的硬盘空间。因为编译WebRTC时会产生大量的临时文件需…...

【vscode】.dart文件没有错误波浪线
解决方法: 新建一个文件夹,在vscode里打开这个文件夹 在这个文件夹里新建.dart文件后打开即可出现错误波浪线...

OpenharmonyOS+RK3568,【编译烧录】
文章目录 1. 摘要 ✨2. 代码下载 📩3. 编译 🖥️4. 修改&适配 ✂️4.1 编译框架基本概念4.2 vendor & device 目录4.3 内核编译4.3.1 如何修改、适配自己的开发板? 4.4 修改外设驱动 5. 烧录&验证 📋参考 1. 摘要 ✨ …...

从零开始理解 C++ 后端编程中的分布式系统
一、什么是“分布式”? 简单来说,分布式系统就是由“多个计算机(或服务器)”组成的一个大系统,它们通过网络协作完成某个任务,就像一个“团队合作”一样。 想象你开了一家餐馆,最初只有 一个厨房 和 一个服务员,所有订单都在这里处理。随着生意变好,你需要: 开分店…...

基于SpringBoot的篮球竞赛预约平台设计与实现
1.1 研究背景 科学技术日新月异的如今,计算机在生活各个领域都占有重要的作用,尤其在信息管理方面,在这样的大背景下,学习计算机知识不仅仅是为了掌握一种技能,更重要的是能够让它真正地使用到实践中去,以…...
)
具身系列——PPO算法实现CartPole游戏(强化学习)
完整代码参考: https://gitee.com/chencib/ailib/blob/master/rl/ppo_cartpole.py 执行结果: 部分训练得分: (sd) D:\Dev\traditional_nn\feiai\test\rl>python ppo_cartpole_v2_succeed.py Ep: 0 | Reward: 23.0 | Running: 2…...

小程序与快应用:中国移动互联网的渐进式革命——卓伊凡的技术演进观
小程序与快应用:中国移动互联网的渐进式革命——卓伊凡的技术演进观 在知乎看到很多:“懂王”发布的要把内行笑疯了的评论,卓伊凡必须怼一下,真印证那句话,无知者无畏 一、Web与小程序的技术本质差异 1.1 浏览器渲染…...

Socket 编程 UDP
Socket 编程 UDP UDP 网络编程V1 版本 - echo serverV2 版本 - DictServerV3 版本 - 简单聊天室 补充参考内容地址转换函数关于 inet_ntoa UDP 网络编程 声明:下面代码的验证都是用Windows作为客户端的,如果你有两台云服务器可以直接粘贴我在Linux下的客…...

Lua 基础 API与 辅助库函数 中关于创建的方法用法
目录 基础 API 函数1. lua_len(L, index)2. lua_load(L, reader, data, chunkname, mode)3. lua_newstate(allocator, ud)4. lua_newtable(L)5. lua_newthread(L)6. lua_newuserdata(L, size)7. lua_next(L, index) 辅助库函数(luaL_*)8. luaL_len(L, in…...

YOLOv11改进:利用RT-DETR主干网络PPHGNetV2助力轻量化目标检测
这里写自定义目录标题 YOLOv11改进:利用RT-DETR主干网络PPHGNetV2助力轻量化目标检测1. 介绍2. 引言3. 技术背景3.1 YOLOv11概述3.2 RT-DETR与PPHGNetV23.3 相关工作 4. 应用使用场景5. 详细代码实现5.1 环境准备5.2 PPHGNetV2主干网络实现5.3 YOLOv11与PPHGNetV2集…...

centos7.0无法安装php8.2/8.3
在centos安装php8.2报错 configure: error: *** A compiler with support for C17 language features is required. 配置过程检测到你的系统编译器不支持 C17 语言特性,而 PHP 8.2 的编译需要编译器支持 C17 sudo yum update -y sudo yum install centos-releas…...

工业传动核心部件深度剖析:丝杆升降机与气缸的技术特性及选型指南
在工业自动化技术飞速发展的当下,丝杆升降机与气缸作为关键的直线传动部件,广泛应用于各类机械设备中。对于工程师而言,深入了解它们的技术特性、优缺点及适用场景,是实现高效、精准设备设计的重要前提。本文将从技术原理出发&…...

flask 获取各种请求数据:GET form-data x-www-form-urlencoded JSON headers 上传文件
在 Flask 里,能使用多种方法获取不同类型的请求数据,下面详细介绍常见请求数据的获取方式。 获取查询字符串参数(GET 请求) 查询字符串参数一般在 URL 里,以 ?key1value1&key2value2 这种形式存在。可通过 requ…...
)
c++_2011 NOIP 普及组 (1)
P1307 [NOIP 2011 普及组] 数字反转 P1307 [NOIP 2011 普及组] 数字反转 - 洛谷 # P1307 [NOIP 2011 普及组] 数字反转 ## 题目描述 给定一个整数 $N$,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零&…...

信息泄露:网站敏感文件泄漏的隐形危机与防御之道
在网络安全领域,信息泄露常被称为“沉默的杀手”。攻击者无需复杂漏洞,仅通过网站无意暴露的敏感文件(如源码备份、配置文件、版本控制记录),即可获取数据库密码、API密钥甚至服务器权限。本文将深入剖析信息泄…...
)
C++笔记-多态(包含虚函数,纯虚函数和虚函数表等)
1.多态的概念 多态(polymorphism)的概念:通俗来说,就是多种形态。多态分为编译时多态(静态多态)和运行时多态(动态多态),这里我们重点讲运行时多态,编译时多态(静态多态)和运行时多态(动态多态)。编译时多态(静态多态)主要就是我们前面讲的函…...
---java版)
2025年- H22-Lc130-206. 反转链表(链表)---java版
1.题目描述 2.思路 使用迭代法 (1)定义一个前指针 (2)然后定义两个变量 curr(head),curr.next。 (3)curr和curr.next交换位置(只要当前指针不为空,执行两两交换) 3.代码实现 /*** Definition for singly-…...

智能家居的OneNet云平台
一、声明 该项目只需要创建一个产品,然后这个产品里面包含几个设备,而不是直接创建几个产品 注意:传输数据使用到了不同的power,还有一定要手机先联网才能使用云平台 二、OneNet云平台创建 (1)Temperatur…...

二、shell脚本--变量与数据类型
1. 变量的定义与使用 定义变量:简单直接 在 Shell 里定义变量相当容易: 基本格式: variable_namevalue关键点 ❗:赋值号 的两边绝对不能有空格!这绝对是初学者最容易踩的坑之一 😨,务必留意!…...

GitHub Actions 和 GitLab CI/CD 流水线设计
以下是关于 GitHub Actions 和 GitLab CI/CD 流水线设计 的基本知识总结: 一、核心概念对比 维度GitHub ActionsGitLab CI/CD配置方式YAML 文件(.github/workflows/*.yml).gitlab-ci.yml执行环境GitHub 托管 Runner / 自托管GitLab 共享 Runner / 自托管市场生态Actions Mar…...

穿越数据森林与网络迷宫:树与图上动态规划实战指南
在 C 算法的浩瀚宇宙中,树与图就像是神秘的迷宫和茂密的森林,充满了未知与挑战。而动态规划则是我们探索其中的神奇罗盘,帮助我们找到最优路径。今天,就让我们一起深入这片神秘领域,揭开树与图上动态规划的神秘面纱&am…...

Java学习手册:Spring 生态其他组件介绍
一、微服务架构相关组件 Spring Cloud 服务注册与发现 : Eureka :由 Netflix 开源,包含 Eureka Server 和 Eureka Client 两部分。Eureka Server 作为服务注册表,接收服务实例的注册请求并管理其信息;Eureka Client 负…...

[android]MT6835 Android 移植brctl指令
说明 android默认brctl不支持showmacs选项,需要移植brctl-utils软件包 移除toybox中brctl编译 mssi/external/toybox/Android.bp 将 toybox_symlinks ["[","acpi","base64","basename","blockdev","br…...
)
安卓基础(悬浮窗分级菜单和弹窗)
initializeViews() 初始化 把全部的按钮都弄出来 // 主菜单按钮ImageButton mainButton floatingMenuView.findViewById(R.id.main_button);// 二级菜单按钮subButtons new ImageButton[3];subButtons[0] floatingMenuView.findViewById(R.id.sub_button_1);subButtons[1]…...

HTTP基础介绍+OSI七层参考模型+HTTP协议介绍
图片来源于网络 图片来源于网络 浏览器 Chrome:谷歌浏览器,推荐 Safari(WebKit):苹果浏览器,iOS,macOS Firefox:火狐浏览器,开源插件特别多(FireBug) IE:Wi…...

【项目实践】boost 搜索引擎
1. 项目展示 boost搜索引擎具体讲解视频 2. 项目背景 对于boost库,官方是没有提供搜索功能的,我们这个项目就是来为它添加一个站内搜索的功能。 3. 项目环境与技术栈 • 项目环境: ubuntu22.04、vscode • 技术栈: C/C、C11、S…...
)
接口隔离原则(ISP)
非常好,**接口隔离原则(ISP: Interface Segregation Principle)是 SOLID 五大原则中的第四个,它专门解决“一个接口太臃肿”**导致的麻烦。 我来从以下几个维度详细拆解: 🧠 什么是接口隔离原则࿱…...

Leetcode刷题记录29——矩阵置零
题源:https://leetcode.cn/problems/set-matrix-zeroes/description/?envTypestudy-plan-v2&envIdtop-100-liked 题目描述: 思路一: 💡 解题思路 本题中我们采用如下策略: 第一次遍历整个矩阵,记…...
)
复刻低成本机械臂 SO-ARM100 组装篇(打螺丝喽)
视频讲解: 复刻低成本机械臂 SO-ARM100 组装篇(打螺丝喽) 组装的视频有很多,参考大佬的《手把手复刻HuggingFace开源神作之Follower机械臂组装,资料已整理》_哔哩哔哩_bilibili,跟着视频做,大体…...

[更新完毕]2025东三省B题深圳杯B题数学建模挑战赛数模思路代码文章教学:LED显示屏颜色转换设计与校正
完整内容请看文章最下面的推广群 已经更新完整的文章代码 基于非线性映射与深度模型的多通道LED显示屏色彩校正 摘要 本研究聚焦于高动态色彩空间下LED显示屏的色彩映射与逐点校正问题,结合非线性回归理论与深度学习模型,构建了一套涵盖BT.2020映射、RG…...

Easy云盘总结篇-登录注册
**说在前面:该项目是跟着B站一位大佬写的,不分享源码,支持项目付费 ** 获取图形验证码 可以看到这里有2两种图形验证码,分为: type0:如上图下面那个,是完成操作后要进行注册的验证码 type1: 如…...

04 基于 STM32 的时钟展示程序
前言 我们经常会看到 各个场合下面有 基于数码管 的时钟程序 比如 在车站, 教室, 办公室 等等 各个场合都有 然后 这里就是做一个 简单的 时钟程序 展示程序 测试用例 每一秒钟更新时间, 然后 迭代更新 天, 时, 分 等等 然后 主流程 基于 天, 时分秒 渲染数码管 #incl…...

音视频开发技术总结报告
音视频开发技术总结报告 一、音视频开发基础 1、音频基础 声音原理 声波特性:频率、振幅、波长人耳听觉范围:20Hz-20kHz声音三要素:音调、音量、音色 数字音频基础 采样率:常见44.1kHz、48kHz、96kHz量化位数:8bit、…...

FastAPI系列13:API的安全防护
API的安全防护 1、HTTPS 强制什么是HTTPS强制如何在FastAPI中实现HTTPS强制 2、CORS跨域资源共享什么是CORS在 FastAPI 中开启 CORS 3、SQL注入防护什么是SQL注入如何在FastAPI中实现SQL注入防护 4、CSRF防护什么是CSRF防护如何在FastAPI中实现CSRF防护 在 FastAPI系列12&…...

每天一道面试题@第五天
1.包装类型的缓存机制了解么? 指部分包装类在创建对象时,会将一定范围内的对象缓存起来,当再次使用相同值创建对象时,优先从缓存中获取,而不是重新创建新对象。【提高性能】【节省内存】 列举几个常见的包装类缓存机…...

Python硬核革命:从微控制器到FPGA的深度开发指南
1. 重新定义硬件开发:Python的颠覆性突破 传统硬件开发长期被C/C++和Verilog/VHDL统治,但Python正通过两条路径改变这一格局: 1.1 微控制器领域的MicroPython革命 完整Python 3.4语法支持,运行在资源受限的MCU上(最低要求:64KB ROM,16KB RAM) 直接内存访问能力,突破…...

WebRTC 服务器之Janus概述和环境搭建
1 概述 Janus 是由 Meetecho 开发的通用 WebRTC 服务器,它为构建 WebRTC 应用程序提供了一个模块化框架。服务器目标:Janus WebRTC 网关被设计为轻量级、通用的 WebRTC 服务器,除了实现以下方法外,它本身不提供任何功能࿱…...

mcp+llm+rag
MCPRAG简介 前言一、MCP是什么?二、MCP工作原理(1. MCP Hosts(主机)(2.MCP Clients(客户端)(3. MCP Servers(服务端)(4. Local Data Sources(本地数据源&…...

Seata RM的事务提交与回滚源码解析
文章目录 前言一、RM提交事务二、RM回滚事务2.1、undo校验逻辑2.2、执行回滚逻辑 总结RM 的事务提交与回滚行为说明(基于 Seata AT 模式)1. 提交阶段(Phase Two Commit)2. 回滚阶段(Phase Two Rollback) 前…...

Ubuntu 24.04 完整Docker安装指南:从零配置到实战命令大全
Ubuntu 24.04 完整Docker安装指南:从零配置到实战命令大全 文章目录 Ubuntu 24.04 完整Docker安装指南:从零配置到实战命令大全1. 安装 Docker2. 配置 Docker 镜像加速器2.1 配置 Docker 镜像源2.2 重启 Docker 服务 3. Docker 常用命令3.1 Docker 常用命…...