数据结构学习笔记
第 1 章 绪论
【考纲内容】
(一)数据结构的基本概念
(二)算法的基本概念
算法的时间复杂度和空间复杂度
【知识框架】
【复习提示】
本章内容是数据结构概述,并不在考研大纲中。读者可通过对本章的学习,初步了解数据结构的基本内容和基本方法。分析算法的时间复杂度和空间复杂度是本章重点,需要熟练掌握,算法设计题通常都会要求分析时间复杂度、空间复杂度,同时会出现考查时间复杂度的选择题。
1.1 数据结构的基本概念
1.1.1 基本概念和术语
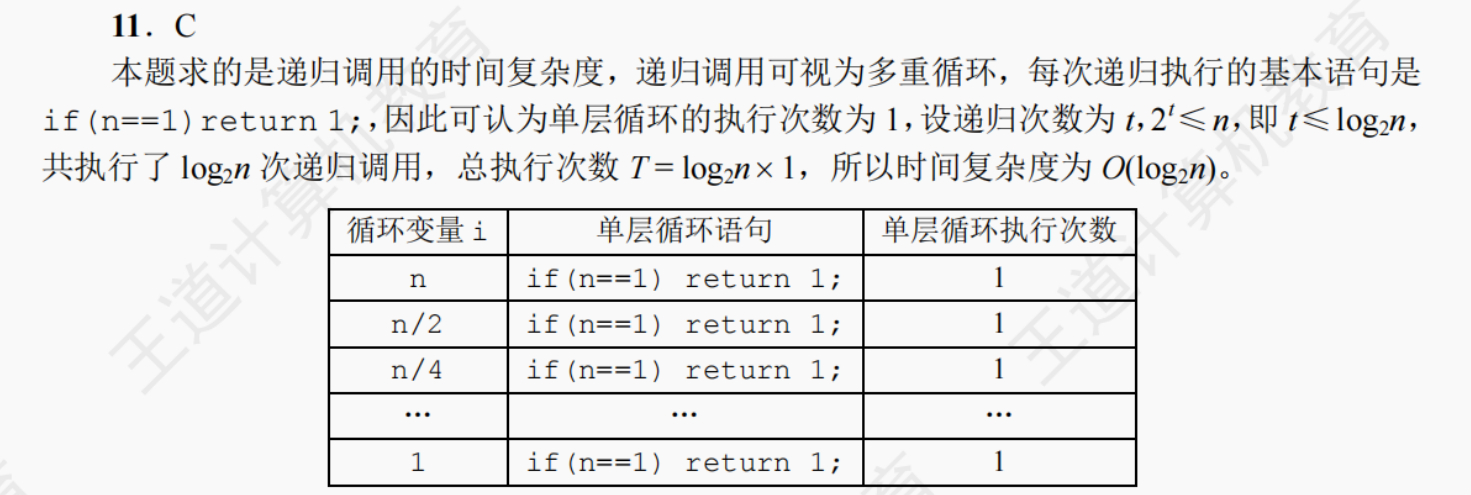
1.数据
数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。数据是计算机程序加工的原料。
2.数据元素
数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。一个数据元素可由若干数据项组成,数据项是构成数据元素的不可分割的最小单位。例如,学生记录就是一个数据元素,它由学号、姓名、性别等数据项组成。
3.数据对象
数据对象是具有相同性质的数据元素的集合,是数据的一个子集。例如,整数数据对象是集合 N={0,±1,±2,⋯}。
4.数据类型
数据类型是一个值的集合和定义在此集合上的一组操作的总称。
1)原子类型。其值不可再分的数据类型。
2)结构类型。其值可以再分解为若干成分(分量)的数据类型。
3)抽象数据类型(ADT)。一个数学模型及定义在该数学模型上的一组操作。它通常是对数据的某种抽象,定义了数据的取值范围及其结构形式,以及对数据操作的集合。
5.数据结构
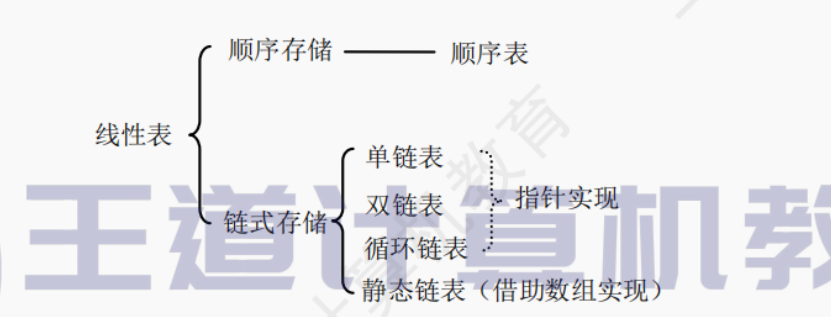
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。在任何问题中,数据元素都不是孤立存在的,它们之间存在某种关系,这种数据元素相互之间的关系称为结构(Structure)。数据结构包括三方面的内容:逻辑结构、存储结构和数据的运算。
数据的逻辑结构和存储结构是密不可分的两个方面,一个算法的设计取决于所选定的逻辑结构,而算法的实现依赖于所采用的存储结构①。
①读者应通过后续章节的学习,逐步理解设计与实现的概念与区别。
1.1.2 数据结构三要素
1.数据的逻辑结构
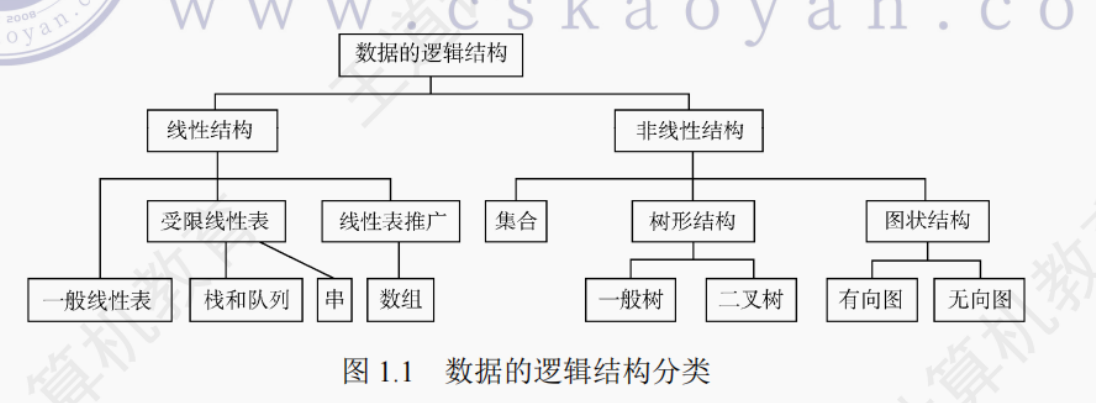
逻辑结构是指数据元素之间的逻辑关系,即从逻辑关系上描述数据。它与数据的存储无关,是独立于计算机的。数据的逻辑结构分为线性结构和非线性结构,线性表是典型的线性结构;集合、树和图是典型的非线性结构。数据的逻辑结构分类如图1.1所示:
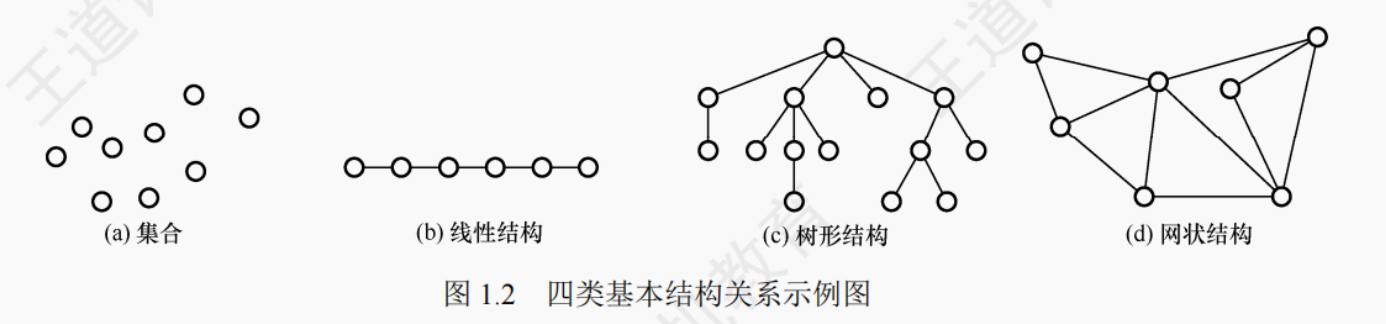
1)集合:结构中的数据元素之间除 “同属一个集合” 外,别无其他关系,如图 1.2 (a) 所示。
2)线性结构:结构中的数据元素之间只存在一对一的关系,如图 1.2 (b) 所示。
3)树形结构:结构中的数据元素之间存在一对多的关系,如图 1.2 (c) 所示。
4)图状结构或网状结构:结构中的数据元素之间存在多对多的关系,如图 1.2 (d) 所示。
2.数据的存储结构
存储结构是指数据结构在计算机中的表示(也称映像),也称物理结构。它包括数据元素的表示和关系的表示。数据的存储结构是用计算机语言实现的逻辑结构,它依赖于计算机语言。数据的存储结构主要有顺序存储、链式存储、索引存储和散列存储。
1)顺序存储:把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现。其优点是可以实现随机存取,每个元素占用最少的存储空间;缺点是只能使用相邻的一整块存储单元,因此可能产生较多的外部碎片。
2)链式存储:不要求逻辑上相邻的元素在物理位置上也相邻,借助指示元素存储地址的指针来表示元素之间的逻辑关系。其优点是不会出现碎片现象,能充分利用所有存储单元;缺点是每个元素因存储指针而占用额外的存储空间,且只能实现顺序存取。
3)索引存储:在存储元素信息的同时,还建立附加的索引表。索引表中的每项称为索引项,索引项的一般形式是(关键字,地址)。其优点是检索速度快;缺点是附加的索引表额外占用存储空间。另外,增加和删除数据时也要修改索引表,因而会花费较多的时间。
4)散列存储:根据元素的关键字直接计算出该元素的存储地址,也称哈希(Hash)存储。其优点是检索、增加和删除结点的操作都很快;缺点是若散列函数不好,则可能出现元素存储单元的冲突,而解决冲突会增加时间和空间开销。
3.数据的运算
施加在数据上的运算包括运算的定义和实现。运算的定义是针对逻辑结构的,指出运算的功能;运算的实现是针对存储结构的,指出运算的具体操作步骤。
1.1.3 本节试题精选
一、单项选择题
01. 可以用 ( ) 定义一个完整的数据结构。
A. 数据元素
B. 数据对象
C. 数据关系
D. 抽象数据类型
01.D
抽象数据类型(ADT)描述了数据的逻辑结构和抽象运算,通常用(数据对象、数据关系、基本操作集)这样的三元组来表示,从而构成一个完整的数据结构定义。02. 下列四种数据结构中,( ) 是非线性数据结构。
A. 树
B. 字符串
C. 队列
D. 栈
02.A
树和图是典型的非线性数据结构,其他选项都属于线性数据结构。03. 下列选项中,属于逻辑结构的是 ( )。
A. 顺序表
B. 哈希表
C. 有序表
D. 单链表
03.C
顺序表、哈希表和单链表是三种不同的数据结构,既描述逻辑结构,又描述存储结构和数据运算。而有序表是指关键字有序的线性表,仅描述元素之间的逻辑关系,它既可以链式存储,又可以顺序存储,所以属于逻辑结构。04. 下列关于数据结构的说法中,正确的是 ( )。
A. 数据的逻辑结构独立于其存储结构
B. 数据的存储结构独立于其逻辑结构
C. 数据的逻辑结构唯一定决定其存储结构
D. 数据结构仅由其逻辑结构和存储结构决定
04.A
数据的逻辑结构是从面向实际问题的角度出发的,只采用抽象表达方式,独立于存储结构,数据的存储方式有多种不同的选择;而数据的存储结构是逻辑结构在计算机上的映射,它不能独立于逻辑结构而存在。数据结构包括三个要素,缺一不可。05. 在存储数据时,通常不仅要存储各数据元素的值,而且要存储 ( )。
A. 数据的操作方法
B. 数据元素的类型
C. 数据元素之间的关系
D. 数据的存取方法
05.C
在存储数据时,不仅要存储数据元素的值,而且要存储数据元素之间的关系。二、综合应用题
01. 对于两种不同的数据结构,逻辑结构或物理结构一定不相同吗?
01【解答】
应该注意到,数据的运算也是数据结构的一个重要方面。
对于两种不同的数据结构,它们的逻辑结构和物理结构完全有可能相同。比如二叉树和二叉排序树,二叉排序树可以采用二叉树的逻辑表示和存储方式,前者通常用于表示层次关系,而后者通常用于排序和查找。虽然它们的运算都有建立树、插入结点、删除结点和查找结点等功能,但对于二叉树和二叉排序树,这些运算的定义是不同的,以查找结点为例,二叉树的平均时间复杂度为 O(n),而二叉排序树的平均时间复杂度为 O(log2n)。02. 试举一例,说明对相同的逻辑结构,同一种运算在不同的存储方式下实现时,其运算效率不同。
02.【解答】
线性表既可以用顺序存储方式实现,又可以用链式存储方式实现。在顺序存储方式下,在线性表中插入和删除元素,平均要移动近一半的元素,时间复杂度为 O(n);而在链式存储方式下,插入和删除的时间复杂度都是 O(1)。1.2 算法和算法评价
1.2.1 算法的基本概念
算法(Algorithm)是对特定问题求解步骤的一种描述,它是指令的有限序列,其中的每条指令表示一个或多个操作。此外,一个算法还具有下列五个重要特性:
1)有穷性:一个算法必须总在执行有穷步之后结束,且每一步都可在有穷时间内完成。
2)确定性:算法中每条指令必须有确切的含义,对于相同的输入只能得出相同的输出。
3)可行性:算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
4)输入:一个算法有零个或多个输入,这些输入取自于某个特定的对象的集合。
5)输出:一个算法有一个或多个输出,这些输出是与输入有着某种特定关系的量。
通常,设计一个 “好” 的算法应考虑达到以下目标:
1)正确性:算法应能够正确地解决求解问题。
2)可读性:算法应具有良好的可读性,以帮助人们理解。
3)健壮性:算法能对输入的非法数据做出反应或处理,而不会产生莫名其妙的输出。
4)高效率与低存储量需求:效率是指算法执行的时间,存储量需求是指算法执行过程中所需要的最大存储空间,这两者都与问题的规模有关。
1.2.2 算法效率的度量
算法效率的度量是通过时间复杂度和空间复杂度来描述的。
1.时间复杂度
命题追踪 分析算法的时间复杂度(2011-2014、2017、2019、2022)
一个语句的频度是指该语句在算法中被重复执行的次数。算法中所有语句的频度之和记为 T(n),它是该算法问题规模 n 的函数,时间复杂度主要分析 T(n) 的数量级。算法中基本运算(最深层循环中的语句)的频度与 T(n) 同数量级,因此通常将算法中基本运算的执行次数的数量级作为该算法的时间复杂度。于是,算法的时间复杂度记为:
T(n)=O(f(n))
式中,O 的含义是 T(n) 的数量级,其严格的数学定义是:若 T(n) 和 f(n) 是定义在正整数集合上的两个函数,则存在正常数 C 和 n0,使得当 n≥n0 时,都满足 0≤T(n)≤Cf(n)。算法的时间复杂度不仅依赖于问题的规模 n,也取决于待输入数据的性质(如输入数据元素的初始状态)。例如,在数组 A[0..n−1] 中,查找给定值 k 的算法大致如下:
(1) i=n-1; (2) while(i>=0 && A[i]!=k ) (3) i--; (4) return i;该算法中语句 3(基本运算)的频度不仅与问题规模 n 有关,而且与下列因素有关:
① 若 A 中没有与 k 相等的元素,则语句 3 的频度 f(n)=n。
② 若 A 的最后一个元素等于 k,则语句 3 的频度 f(n) 是常数 0。最坏时间复杂度是指在最坏情况下,算法的时间复杂度。
平均时间复杂度是指所有可能输入实例在等概率出现的情况下,算法的期望运行时间。
最好时间复杂度是指在最好情况下,算法的时间复杂度。
一般总是考虑在最坏情况下的时间复杂度,以保证算法的运行时间不会比它更长。在分析一个程序的时间复杂性时,有以下两条规则:
① 加法规则:T(n)=T1(n)+T2(n)=O(f(n))+O(g(n))=O(max(f(n),g(n)))
② 乘法规则:T(n)=T1(n)×T2(n)=O(f(n))×O(g(n))=O(f(n)×g(n))例如,设 a{ }、b{ }、c{ } 三个语句块的时间复杂度分别为 O(1)、O(n)、O(n^2),则
① a{b{}c{} }//时间复杂度为O(n^2),满足加法规则 ② a{b{c{}} }//时间复杂度为O(n^3),满足乘法规则常见的渐近时间复杂度为:
O(1)<O(log2n)<O(n)<O(nlog2n)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n)2.空间复杂度
算法的空间复杂度 S(n) 定义为该算法所需的存储空间,它是问题规模 n 的函数,记为:
S(n)=O(g(n))一个程序在执行时除需要存储空间来存放本身所用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为实现计算所需信息的辅助空间。若输入数据所占空间只取决于问题本身,和算法无关,则只需分析除输入和程序之外的额外空间。例如,若算法中新建了几个与输入数据规模 n 相同的辅助数组,则空间复杂度为 O(n)。
算法原地工作是指算法所需的辅助空间为常量,即 O(1)。
1.2.3 本节试题精选
一、单项选择题
01. 一个算法应该具有 ( ) 等重要特性。
A. 可维护性、可读性和可行性
B. 可行性、确定性和有穷性
C. 确定性、有穷性和可靠性
D. 可读性、正确性和可行性01.B
一个算法应具有五个重要特性:有穷性、确定性、可行性、输入和输出。选项 A、C 和 D 中提到的特性(如可维护性、可读性、可靠性、正确性等)是很重要的,但它们并不是算法定义的重要特性,更多的是关于软件开发中的附加要求。
02. 下列关于算法的说法中,正确的是 ( )。
A. 算法的时间效率取决于算法执行所花的 CPU 时间
B. 在算法设计中不允许用牺牲空间效率的方式来换取好的时间效率
C. 算法必须具备有穷性、确定性等五个特性
D. 通常用时间效率和空间效率来衡量算法的优劣02.C
算法的时间效率是指算法的时间复杂度,即执行算法所需的计算工作量,选项 A 错误。算法设计会综合考虑时间效率和空间效率两个方面,若某些应用场景对时间效率要求很高,而对空间效率要求不高,则可用牺牲空间效率的方式来换取好的时间效率,选项 B 错误。评价一个算法的 “优劣” 不仅要考虑算法的时空效率,还要从正确性、可读性、健壮性等方面来综合评价。03. 某算法的时间复杂度为 O(n^2),则表示该算法的 ( )。
A. 问题规模是 n^2
B. 执行时间等于 n^2
C. 执行时间与 n^2 成正比
D. 问题规模与 n^2 成正比03.C
时间复杂度为 O(n^2),说明算法的时间复杂度 T(n) 满足 T(n)≤cn^2(其中 c 为比例常数),即 T(n)=O(n^2),时间复杂度 T(n) 是问题规模 n 的函数,其问题规模仍然是 n 而不是 n^2。04. 若某算法的空间复杂度为 O(1),则表示该算法 ( )。
A. 不需要任何辅助空间
B. 所需辅助空间大小与问题规模 n 无关
C. 不需要任何空间
D. 所需空间大小与问题规模 n 无关04.B
算法的空间复杂度为 O(1),表示执行该算法所需的辅助空间大小相比输入数据的规模来说是一个常量,而不表示该算法执行时不需要任何空间或辅助空间。05. 下列关于时间复杂度的函数中,时间复杂度最小的是 ( )。
A. T1(n)=nlog2n+5000n
B. T2(n)=n^2−8000n
C. T3(n)=nlog2n−6000n
D. T4(n)=20000log2n05.D
A 的最高阶是 nlog2n,时间复杂度是 O(nlog2n)。B 的最高阶是 n^2,时间复杂度是 O(n^2)。C 的最高阶是 nlog2n,时间复杂度是 O(nlog2n)。D 的最高阶是 log2n,时间复杂度是 O(log2n)。06. 下列算法的时间复杂度为 ( )。
void fun(int n){int i=1;while(i<=n)i=i*2; }A. O(n)
B. O(n^2)
C. O(nlog2n)
D. O(log2n)
07. 下列算法的时间复杂度为 ( )。void fun(int n){int i=0;while(i*i*i<=n)i++; }A. O(n)
B. O(nlog2n)
C. O()
D. O()
08. 某个程序段如下:
for(i=n-1;i>1;i--)for(j=1;j<i;j++)if(A[j]>A[j+1])A[j]与A[j+1]对换;其中 n 为正整数,则最后一行语句的频度在最坏情况下是 ( )。
A. O(n)
B. O(nlog2n)
C. O(n^3)
D. O(n^2)08.D
这是冒泡排序的算法代码,考查最坏情况下的元素交换次数(若觉得理解起来有困难,则可在学完第 8 章后再回顾)。当所有相邻元素都为逆序时,则最后一行的语句每次都会执行。此时,
所以在最坏情况下该语句的频度是 O(n^2)。09. 下列程序段的时间复杂度是 ( )。
if(n>=0){for(int i=0;i<n;i++)for(int j=0;j<n;j++)printf("输入数据大于或等于零\n"); } else{for(int j=0;j<n;j++)printf("输入数据小于零\n"); }A. O(n^2)
B. O(n)
C. O(1)
D. O(nlog2n)9.A
当程序段中有条件判断语句时,取分支路径上的最大时间复杂度。10. 下列算法中加下画线的语句的执行次数为 ( )。
int m=0,i,j; for(i=1;i<n;i++)for(j=1;j<2*i;j++)m++;A. n(n+1)
B. n
C. n+1
D. n^2
11. 下列函数代码的时间复杂度是 ( )。
int Func(int n){if(n==1) return 1;else return 2*Func(n/2)+n; }A. O(n)
B. O(nlog2n)
C. O(log2n)
D. O(n^2)
12. 【2011 统考真题】设 n 是描述问题规模的非负整数,下列程序段的时间复杂度是 ( )。
x=2; while(x<n/2)x=2*x;A. O(log2n)
B. O(n)
C. O(nlog2n)
D. O(n^2)
13. 【2012 统考真题】求整数 () 的阶乘的算法如下,其时间复杂度是 ( )。
int fact(int n){if(n<=1) return 1;return n*fact(n-1); }A. O(log2n)
B. O(n)
C. O(nlog2n)
D. O(n^2)
14. 【2014 统考真题】下列程序段的时间复杂度是 ( )。
count=0; for(k=1;k<=n;k*=2)for(j=1;j<=n;j++)count++;A. O(log2n)
B. O(n)
C. O(nlog2n)
D. O(n^2)
15. 【2017 统考真题】下列函数的时间复杂度是 ( )。
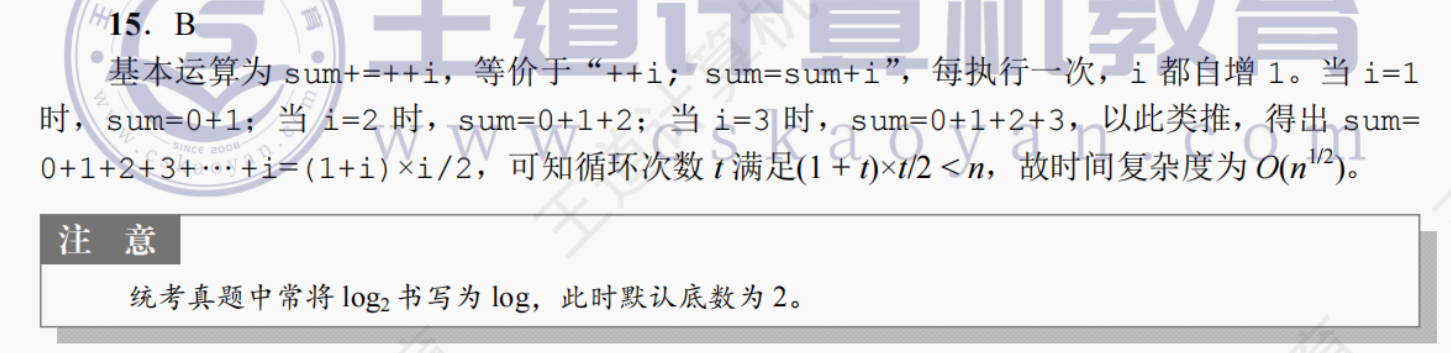
int func(int n){int i=0, sum=0;while(sum<n) sum += ++i;return i; }A. O(log2n)
B. O(n^1/2)
C. O(n)
D. O(nlog2n)
16. 【2019 统考真题】设 n 是描述问题规模的非负整数,下列程序段的时间复杂度是 ( )。
x=0; while (n>=(x+1)*(x+1))x=x+1;A. O(log2n)
B. O(n^1/2)
C. O(n)
D. O(n^2)
17. 【2022 统考真题】下列程序段的时间复杂度是 ( )。
int sum=0; for(int i=1;i<n;i*=2)for(int j=0;j<i;j++)sum++;A. O(log2n)
B. O(n)
C. O(nlog2n)
D. O(n^2)
二、综合应用题
01. 分析下列各程序段,求出算法的时间复杂度。
① i=1;k=0; while(i<n-1){k=k+10*i;i++; } ② y=0; while((y+1)*(y+1)<=n)y=y+1; ③ for(i=0;i<n;i++)for(j=0;j<m;j++)a[i][j]=0;
归纳总结
本章的重点是分析程序的时间复杂度。一定要掌握分析时间复杂度的方法和步骤,很多读者在做题时一眼就能看出程序的时间复杂度,但就是无法规范地表述其推导过程。为此,编者查阅众多资料,总结出了此类题型的两种形式,供大家参考。
1.循环主体中的变量参与循环条件的判断
在用于递推实现的算法中,首先找出基本运算的执行次数 x 与问题规模 n 之间的关系式,解得 x=f(n),f(n) 的最高次幂为 k,则算法的时间复杂度为 O(n^k)。例如,1. int i=1; while(i<=n)i=i*2;2. int y=5; while((y+1)*(y+1)<n)y=y+1;在例 1 中,设基本运算 i=i*2 的执行次数为 t,则 2*t≤n,解得 t≤log2n,故 T(n)=O(log2n)。
在例 2 中,设基本运算 y=y+1 的执行次数为 t,则 t=y−5,且 (t+5+1)(t+5+1)<n,解得 t<
2. 循环主体中的变量与循环条件无关
此类题可采用数学归纳法或直接累计循环次数。多层循环时从内到外分析,忽略单步语句、条件判断语句,只关注主体语句的执行次数。此类问题又可分为递归程序和非递归程序:
- 递归程序:一般使用公式进行递推。时间复杂度的分析如下:
T(n)=1+T(n−1)=1+1+T(n−2)=⋯=n−1+T(1)
即 T(n)=O(n)。
- 非递归程序:分析比较简单,可以直接累计次数。本节前面给出了相关的习题。
思维拓展
求解斐波那契数列
有两种常用的算法:递归算法和非递归算法。试分别分析两种算法的时间复杂度。提示:请结合归纳总结中的两种方法进行解答。
递归算法时间复杂度分析
递归算法实现斐波那契数列的代码(C++ 示例)如下:
int FibonacciRecursive(int n) {if (n == 0) return 0;if (n == 1) return 1;return FibonacciRecursive(n - 1) + FibonacciRecursive(n - 2); }设 T(n) 表示计算 F(n) 所需的时间。
当 n=0 或 n=1 时,算法执行一次判断和一次返回,时间复杂度为 O(1),即 T(0)=T(1)=O(1) 。
当 n>1 时,计算 F(n) 需要分别计算 F(n−1) 和 F(n−2) ,然后将结果相加,所以 T(n)=T(n−1)+T(n−2)+O(1) 。
通过递归树来分析,该递归树的高度近似为 O(2^n) (因为每一层的节点数近似是上一层的 2 倍 ),所以递归算法的时间复杂度为 O(2^n) 。这是因为随着 n 的增大,计算量呈指数级增长。
非递归算法时间复杂度分析
非递归算法实现斐波那契数列的代码(C++ 示例)如下:
int FibonacciIterative(int n) {if (n == 0) return 0;if (n == 1) return 1;int a = 0, b = 1, c;for (int i = 2; i <= n; i++) {c = b;b = a + b;a = c;}return b; }在这个非递归算法中,使用了一个 for 循环,循环次数为 n−1 次(从 i=2 到 i=n ) ,每次循环内执行的操作都是固定的几个赋值语句,时间复杂度为 O(1) 。根据算法时间复杂度的计算方法,当循环次数为 n ,每次循环内操作时间复杂度为常数时,整个算法的时间复杂度为 O(n) 。所以非递归算法计算斐波那契数列的时间复杂度为 O(n) 。
第 2 章 线性表
【考纲内容】
(一)线性表的基本概念
(二)线性表的实现
顺序存储;链式存储
(三)线性表的应用【知识框架】
【复习提示】
线性表是算法题命题的重点。这类算法题的实现比较容易且代码量较少,但是要求具有最优的性能(时间 / 空间复杂度),才能获得满分。因此,应牢固掌握线性表的各种基本操作(基于两种存储结构),在平时的学习中多注重培养动手能力。另需提醒的是,算法最重要的是思想!考场上的时间紧迫,在试卷上不一定要求代码具有实际的可执行性,因此应尽力表达出算法的思想和步骤,而不必过于拘泥所有细节。此外,采用时间 / 空间复杂度较差的方法也能拿到大部分分数,因此在时间紧迫的情况下,建议直接采用暴力法。注意,算法题只能用 C/C++ 语言实现。
2.1 线性表的定义和基本操作
2.1.1 线性表的定义
线性表是具有相同数据类型的 n(n>=0) 个数据元素的有限序列,其中 n 为表长,当 n=0 时线性表是一个空表。若用 L 命名线性表,则其一般表示为
L=(a1,a2,⋯,ai,ai+1,⋯,an)
式中,a1 是唯一的 “第一个” 数据元素,也称表头元素;an 是唯一的 “最后一个” 数据元素,也称表尾元素。除第一个元素外,每个元素有且仅有一个直接前驱。除最后一个元素外,每个元素有且仅有一个直接后继(“直接前驱” 和 “前驱”、“直接后继” 和 “后继” 通常被视为同义词)。以上就是线性表的逻辑特性,这种线性有序的逻辑结构正是线性表名字的由来。
由此,我们得出线性表的特点如下:
1.表中元素的个数有限。
2.表中元素具有逻辑上的顺序性,表中元素有其先后次序。
3.表中元素都是数据元素,每个元素都是单个元素。
4.表中元素的数据类型都相同,这意味着每个元素占有相同大小的存储空间。
5.表中元素具有抽象性,即仅讨论元素间的逻辑关系,而不考虑元素究竟表示什么内容。
注意:线性表是一种逻辑结构,表示元素之间一对一的相邻关系。顺序表和链表是指存储结构,两者属于不同层面的概念,因此不要将其混淆。
2.1.2 线性表的基本操作
一个数据结构的基本操作是指其最核心、最基本的操作。其他较复杂的操作可通过调用其基本操作来实现。线性表的主要操作如下。
InitList(&L):初始化表。构造一个空的线性表。 Length(L):求表长。返回线性表 L 的长度,即 L 中数据元素的个数。 LocateElem(L, e):按值查找操作。在表 L 中查找具有给定关键字值的元素。 GetElem(L, i):按位查找操作。获取表 L 中第 i 个位置的元素的值。 ListInsert(&L, i, e):插入操作。在表 L 中的第 i 个位置上插入指定元素 e。 ListDelete(&L, i, &e):删除操作。删除表 L 中第 i 个位置的元素,并用 e 返回删除元素的值。 PrintList(L):输出操作。按前后顺序输出线性表 L 的所有元素值。 Empty(L):判空操作。若 L 为空表,则返回 true,否则返回 false。 DestroyList(&L):销毁操作。销毁线性表,并释放线性表 L 所占用的内存空间。注意:
① 基本操作的实现取决于采用哪种存储结构,存储结构不同,算法的实现也不同。② 符号 “&” 表示 C++ 语言中的引用调用,在 C 语言中采用指针也可达到同样的效果。2.1.3 本节试题精选
单项选择题
01. 线性表是具有 n 个 ( ) 的有限序列。
A. 数据表
B. 字符
C. 数据元素
D. 数据项01. C
线性表是由具有相同数据类型的有限数据元素组成的,数据元素是由数据项组成的。02. 下列几种描述中,( ) 是一个线性表。
A. 由 n 个实数组成的集合
B. 由 100 个字符组成的序列
C. 所有整数组成的序列
D. 邻接表02. B
线性表定义的要求为:相同数据类型、有限序列。选项 C 的元素个数是无穷个,错误;选项 A 集合中的元素没有前后驱关系,错误;选项 D 属于一种存储结构,本题要求选出的是一个具体的线性表,不要将二者混为一谈。只有选项 B 符合线性表定义的要求。03. 在线性表中,除开始元素外,每个元素 ( )。
A. 只有唯一的前驱元素
B. 只有唯一的后继元素
C. 有多个前驱元素
D. 有多个后继元素03. A
线性表中,除最后一个(或第一个)元素外,每个元素都只有一个后继(或前驱)元素。04. 若非空线性表中的元素既没有直接前驱,又没有直接后继,则该表中有 ( ) 个元素。
A. 1
B. 2
C. 3
D. n04. A
线性表中的第一个元素没有直接前驱,最后一个元素没有直接后继;当线性表中仅有一个元素时,该元素既没有直接前驱,又没有直接后继。2.2 线性表的顺序表示
2.2.1 顺序表的定义
命题追踪 (算法题)顺序表的应用(2010、2011、2018、2020)
线性表的顺序存储也称顺序表。它是用一组地址连续的存储单元依次存储线性表中的数据元素,从而使得逻辑上相邻的两个元素在物理位置上也相邻。第 1 个元素存储在顺序表的起始位置,第 i 个元素的存储位置后面紧接着存储的是第 i+1 个元素,称 i 为元素 ai 在顺序表中的位序。因此,顺序表的特点是表中元素的逻辑顺序与其存储的物理顺序相同。假设顺序表 L 存储的起始位置为 LOC(A),sizeof(ElemType)是每个数据元素所占用存储空间的大小,则表 L 所对应的顺序存储结构如图 2.1 所示。
每个数据元素的存储位置都和顺序表的起始位置相差一个和该数据元素的位序成正比的常数,因此,顺序表中的任意一个数据元素都可以随机存取,所以线性表的顺序存储结构是一种随机存取的存储结构。通常用高级程序设计语言中的数组来描述线性表的顺序存储结构。
注意:线性表中元素的位序是从 1 开始的,而数组中元素的下标是从 0 开始的。
假定线性表的元素类型为 ElemType,则静态分配的顺序表存储结构描述为
#define MaxSize 50 //定义线性表的最大长度typedef struct{ElemType data[MaxSize]; //顺序表的元素int length; //顺序表的当前长度 }SqList; //顺序表的类型定义一维数组可以是静态分配的,也可以是动态分配的。对数组进行静态分配时,因为数组的大小和空间先已经给定,所以一旦空间占满,再加入新数据就会产生溢出,进而导致程序崩溃。
而在动态分配时,存储数组的空间是在程序执行过程中通过动态存储分配语句分配的,一旦数据空间占满,就另外开辟一块更大的存储空间,将原表中的元素全部拷贝到新空间,从而达到扩充数组存储空间的目的,而不需要为线性表一次性地划分所有空间。
动态分配的顺序表存储结构描述为
#define InitSize 100 //表长度的初始定义typedef struct{ElemType *data; //指示动态分配数组的指针int MaxSize,length; //数组的最大容量和当前个数 }SeqList; //动态分配数组顺序表的类型定义C 的初始动态分配语句为
L.data=(ElemType*)malloc(sizeof(ElemType)*InitSize);C++ 的初始动态分配语句为
L.data=new ElemType[InitSize];注意:动态分配并不是链式存储,它同样属于顺序存储结构,物理结构没有变化,依然是随机存取方式,只是分配的空间大小可以在运行时动态决定。
顺序表的主要优点:① 可进行随机访问,即可通过首地址和元素序号可以在 O(1) 时间内找到指定的元素;② 存储密度高,每个结点只存储数据元素。顺序表的缺点也很明显:① 元素的插入和删除需要移动大量的元素,插入操作平均需要移动 n/2 个元素,删除操作平均需要移动 (n−1)/2 个元素;② 顺序存储分配需要一段连续的存储空间,不够灵活。
2.2.2 顺序表上基本操作的实现
命题追踪 顺序表上操作的时间复杂度分析(2023)
这里仅讨论顺序表的初始化、插入、删除和按值查找,其他基本操作的算法都很简单。注意:在各种操作的实现中(包括严蔚敏老师撰写的教材),往往可以忽略边界条件判断、变量定义、内存分配不足等细节,即不要求代码具有可执行性,而重点在于算法的思想。
1.顺序表的初始化
静态分配和动态分配的顺序表的初始化操作是不同的。静态分配在声明一个顺序表时,就已为其分配了数组空间,因此初始化时只需将顺序表的当前长度设为 0。//SqList L; //声明一个顺序表 void InitList(SqList &L){L.length=0; //顺序表初始长度为0 }动态分配的初始化为顺序表分配一个预定义大小的数组空间,并将顺序表的当前长度设为 0。MaxSize 指示顺序表当前分配的存储空间大小,一旦因插入元素而空间不足,就进行再分配。
void InitList(SeqList &L){L.data=(ElemType *)malloc(InitSize*sizeof(ElemType));//分配存储空间L.length=0; //顺序表初始长度为0L.MaxSize=InitSize; //初始存储容量 }2.插入操作
在顺序表 L 的第 i(1<=i<=L.length+1) 个位置插入新元素 e。若 i 的输入不合法,则返回 false,表示插入失败;否则,将第 i 个元素及其后的所有元素依次往后移动一个位置,腾出一个空位置插入新元素 e,顺序表长度增加 1,插入成功,返回 true。bool ListInsert(SqList &L,int i,ElemType e){if(i<1||i>L.length+1) //判断i的范围是否有效return false;if(L.length>=MaxSize) //当前存储空间已满,不能插入return false;for(int j=L.length;j>=i;j--) //将第i个元素及之后的元素后移L.data[j]=L.data[j-1];L.data[i-1]=e; //在位置i处放入eL.length++; //线性表长度加1return true; }注意:区别顺序表的位序和数组下标。为何判断插入位置是否合法时 if 语句中用 length + 1,而移动元素的 for 语句中只用 length?
1. 顺序表的位序与数组下标的本质区别
位序:顺序表的位序是从 1 开始计数的逻辑位置标识。它反映的是元素在顺序表中的逻辑顺序,是从用户视角、逻辑层面去看待元素位置,例如第一个元素位序为 1 ,第二个元素位序为 2 ,以此类推。
数组下标:在计算机语言(如 C、C++ )中,数组下标是从 0 开始计数的。它是计算机在内存中对数组元素进行寻址和操作的依据,第一个元素下标为 0 ,第二个元素下标为 1 等。
2. if 语句中用 length + 1 判断插入位置合法性的原因
顺序表的插入操作,从逻辑上看,合法的插入位置有两种情况:
在已有元素之间插入:可以在顺序表中已存在的 n 个元素的任意两个元素之间插入新元素,即第 1 个位置到第 n 个位置(这里的位置用位序表示 )。
在表尾插入:可以在顺序表的末尾添加新元素,也就是第 n+1 个位置(位序 )。这里的 n 就是顺序表当前的长度 length ,所以判断插入位置 i 是否合法时,需要判断 i 是否在 1 到 length + 1 这个范围内 ,即 if(i < 1 || i > L.length + 1) ,如果超出这个范围,插入位置就是非法的。
3. for 语句中只用 length 移动元素的原因
在顺序表中插入元素时,需要将插入位置及之后的元素向后移动。由于顺序表是用数组来实现存储的,数组下标从 0 开始 。顺序表中最后一个元素对应的数组下标是 length - 1 。
当进行插入操作时,从最后一个元素(下标为 length - 1 )开始向后移动,一直移动到插入位置对应的下标(如果插入位置 i 对应的数组下标为 i - 1 ) ,所以移动元素的循环是 for(int j = L.length; j >= i; j--) ,这里 j 从 L.length 开始,是因为 L.length 对应的是数组中最后一个元素的下一个位置(从数组下标角度 ),从这里开始往前移动元素,直到移动到插入位置对应的下标位置。最好情况:在表尾插入(i=n+1),元素后移语句将不执行,时间复杂度为 O(1)。
最坏情况:在表头插入(i=1),元素后移语句将执行 n 次,时间复杂度为 O(n)。
平均情况:假设 pi(pi=1/(n+1)) 是在第 i 个位置上插入一个结点的概率,则在长度为 n 的线性表中插入一个结点时,所需移动结点的平均次数为
因此,顺序表插入算法的平均时间复杂度为 O(n)。
3.删除操作
删除顺序表 L 中第 i(1<=i<=L.length+1) 个位置的元素,用引用变量 e 返回。若 i 的输入不合法,则返回 false;否则,将被删元素赋给引用变量 e,并将第 i+1 个元素及其后的所有元素依次往前移动一个位置,返回 true。bool ListDelete(SqList &L,int i,ElemType &e){if(i<1||i>L.length) //判断i的范围是否有效return false;e=L.data[i-1]; //将被删除的元素赋值给efor(int j=i;j<L.length;j++) //将第i个位置后的元素前移L.data[j-1]=L.data[j];L.length--; //线性表长度减1return true; }最好情况:删除表尾元素(i=n),无须移动元素,时间复杂度为 O(1)。
最坏情况:删除表头元素(i=1),需移动除表头元素外的所有元素,时间复杂度为 O(n)。
平均情况:假设 () 是删除第 i 个位置上结点的概率,则在长度为 n 的线性表中删除一个结点时,所需移动结点的平均次数为
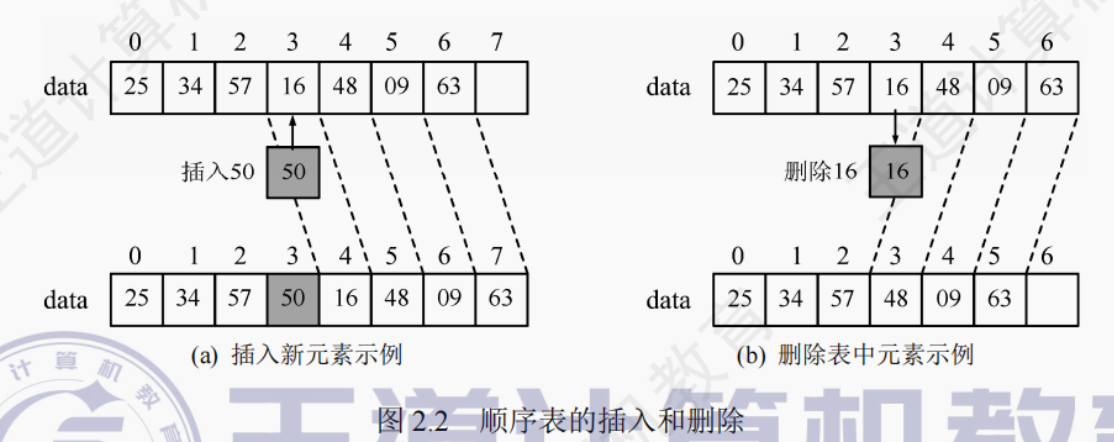
因此,顺序表删除算法的平均时间复杂度为 O(n)。可见,顺序表中插入和删除操作的时间主要耗费在移动元素上,而移动元素的个数取决于插入和删除元素的位置。图 2.2 所示为一个顺序表在进行插入和删除操作前、后的状态,以及其数据元素在存储空间中的位置变化和表长变化。在图 2.2 (a) 中,将第 4 个至第 7 个元素从后往前依次后移一个位置,在图 2.2 (b) 中,将第 5 个至第 7 个元素从前往后依次前移一个位置。
4.按值查找(顺序查找)
在顺序表 L 中查找第一个元素值等于 e 的元素,并返回其位序。int LocateElem(SqList L,ElemType e){int i;for(i=0;i<L.length;i++)if(L.data[i]==e)return i+1; //下标为i的元素值等于e,返回其位序i+1return 0; //退出循环,说明查找失败 }最好情况:查找的元素就在表头,仅需比较一次,时间复杂度为 O(1)。
最坏情况:查找的元素在表尾(或不存在)时,需要比较 n 次,时间复杂度为 O(n)。
平均情况:假设 pi(pi=1/n) 是查找的元素在第 i(1<=i<=L.length) 个位置上的概率,则在长度为 n 的线性表中查找值为 e 的元素所需比较的平均次数为
因此,顺序表按值查找算法的平均时间复杂度为 O(n)。顺序表的按序号查找非常简单,即直接根据数组下标访问数组元素,其时间复杂度为 O(1)。
2.2.3 本节试题精选
一、单项选择题
01. 下列叙述中,( ) 是顺序存储结构的优点。
A. 存储密度大
B. 插入运算方便
C. 删除运算方便
D. 方便地运用于各种逻辑结构的存储表示01.A
顺序表不像链表那样要在结点中存放指针域,因此存储密度大,选项 A 正确。选项 B 和 C 是链表的优点。选项 D 是错误的,比如对于树形结构,顺序表显然不如链表表示起来方便。02.下列关于顺序表的叙述中,正确的是 ( ) 。
A. 顺序表可以利用一维数组表示,因此顺序表与一维数组在逻辑结构上是相同的
B. 在顺序表中,逻辑上相邻的元素物理位置上不一定相邻
C. 顺序表和一维数组一样,都可以进行随机存取
D. 在顺序表中,每个元素的类型不必相同02.C
顺序表是顺序存储的线性表,表中所有元素的类型必须相同,且必须连续存放。一维数组中的元素可以不连续存放;此外,栈、队列和树等逻辑结构也可利用一维数组表示,但它与顺序表不属于相同的逻辑结构。在顺序表中,逻辑上相邻的元素物理位置上也相邻。03.线性表的顺序存储结构是一种 ( ) 。
A. 随机存取的存储结构
B. 顺序存取的存储结构
C. 索引存取的存储结构
D. 散列存取的存储结构03.A
本题易误选选项 B。注意,存取方式是指读 / 写方式。顺序表是一种支持随机存取的存储结构,根据起始地址加上元素的序号,可以很方便地访问任意一个元素,这就是随机存取的概念。04.通常说顺序表具有随机存取的特性,指的是 ( ) 。
A. 查找值为 x 的元素的时间与顺序表中元素个数 n 无关
B. 查找值为 x 的元素的时间与顺序表中元素个数 n 有关
C. 查找序号为 i 的元素的时间与顺序表中元素个数 n 无关
D. 查找序号为 i 的元素的时间与顺序表中元素个数 n 有关04.C
随机存取是指在 O(1) 的时间访问下标为 i 的元素,所需时间与顺序表中的元素个数 n 无关。05.一个顺序表所占用的存储空间大小与 ( ) 无关。
A. 表的长度
B. 元素的存放顺序
C. 元素的类型
D. 元素中各字段的类型05.B
顺序表所占的存储空间 = 表长 ×sizeof(元素的类型),表长和元素的类型显然会影响存储空间的大小。若元素为结构体类型,则元素中各字段的类型也会影响存储空间的大小。06.若线性表最常用的操作是存取第 i 个元素及其前驱和后继元素的值,为了提高效率,应采用 ( ) 的存储方式。
A. 单链表
B. 双链表
C. 循环单链表
D. 顺序表06.D
题干实际要求能最快存取第 i−1、i 和 i+1 个元素值。选项 A、B、C 都只能从头结点依次顺序查找,时间复杂度为 O(n);只有顺序表可以按序号随机存取,时间复杂度为 O(1)。07.一个线性表最常用的操作是存取任意一个指定序号的元素并在最后进行插入、删除操作,则利用 ( ) 存储方式可以节省时间。
A. 顺序表
B. 双链表
C. 带头结点的循环双链表
D. 循环单链表07.A
只有顺序表可以按序号随机存取,且在最后进行插入和删除操作时不需要移动任何元素。08.在 n 个元素的线性表的数组表示中,时间复杂度为 O(1) 的操作是 ( ) 。
I. 访问第 i(1<=i<=n) 个结点和求第 i(2<=i<=n) 个结点的直接前驱
II. 在最后一个结点后插入一个新的结点
III. 删除第 1 个结点
IV. 在第 i(1<=i<=n) 个结点后插入一个结点
A. I
B. II、III
C. I、II
D. I、II、III08.C
对于 I,解析略;对于 II,在最后位置插入新结点不需要移动元素,时间复杂度为 O(1);对于 III,被删结点后的结点需要依次前移,时间复杂度为 O(n);对于 IV,需要后移 n−i 个结点,时间复杂度为 O(n)。09.设线性表有 n 个元素,严格说来,以下操作中,( ) 在顺序表上实现要比在链表上实现的效率高。
I. 输出第 i(1<=i<=n) 个元素值
II. 交换第 3 个元素与第 4 个元素的值
III. 顺序输出这 n 个元素的值
A. I
B. I、III
C. I、II
D. II、III09.C
对于 II,顺序表只需要 3 次交换操作;链表则需要分别找到两个结点前驱,第 4 个结点断链后再插入到第 2 个结点后,效率较低。对于 III,需依次顺序访问每个元素,时间复杂度相同。10.在一个长度为 n 的顺序表中删除第 () 个元素时,需向前移动 ( ) 个元素。
A. n
B. i−1
C. n−i
D. n−i+110.C
需要将元素 ai+1∼an 依次前移一位,共移动 n−(i+1)+1=n−i 个元素。11.对于顺序表,访问第 i 个位置的元素和在第 i 个位置插入一个元素的时间复杂度为 ( ) 。
A. O(n),O(n)
B. O(n),O(1)
C. O(1),O(n)
D. O(1),O(1)11.C
在第 i 个位置插入一个元素,需要移动 n−i+1 个元素,时间复杂度为 O(n)。12.对于顺序存储的线性表,其算法时间复杂度为 O(1) 的运算应该是 ( ) 。
A. 将 n 个元素从小到大排序
B. 删除第 i(1<=i<=n) 个元素
C. 改变第 i(1<=i<=n) 个元素的值
D. 在第 i(1<=i<=n) 个元素后插入一个新元素12.C
对 n 个元素进行排序的时间复杂度最小也要 O(n)(初始有序时),通常为 O(nlog2n) 或 O(n2),通过第 8 章学习后会更理解。选项 B 和 D 显然错误。顺序表支持按序号的随机存取方式。13.若长度为 n 的非空线性表采用顺序存储结构,在表的第 i 个位置插入一个数据元素,则 i 的合法值应该是 ( ) 。
A. 1≤i≤n
B. 1≤i≤n+1
C. 0≤i≤n−1
D. 0≤i≤n13.B
线性表元素的序号是从 1 开始,而在第 n+1 个位置插入相当于在表尾追加。14.顺序表的插入算法中,当 n 个空间已满时,可再申请增加分配 m 个空间,若申请失败,则说明系统没有 ( ) 可分配的存储空间。
A. m 个
B. m 个连续
C. n+m 个
D. n+m 个连续14.D
顺序存储需要连续的存储空间,在申请时需申请 n+m 个连续的存储空间,然后将线性表原来的 n 个元素复制到新申请的 n+m 个连续的存储空间的前 n 个单元。15.【2023 统考真题】在下列对顺序存储的有序表(长度为 n )实现给定操作的算法中,平均时间复杂度为 O(1) 的是 ( ) 。
A. 查找包含指定值元素的算法
B. 插入包含指定值元素的算法
C. 删除第 () 个元素的算法
D. 获取第 () 个元素的算法15.D
对于顺序存储的有序表,查找指定值元素可以采用顺序查找法或折半查找法,平均时间复杂度最少为 O(log2n)。插入指定值元素需要先找到插入位置,然后将该位置及之后的元素依次后移一个位置,最后将指定值元素插入到该位置,平均时间复杂度为 O(n)。删除第 i 个元素需要将该元素之后的全部元素依次前移一个位置,平均时间复杂度为 O(n)。获取第 i 个元素只需直接根据下标读取对应的数组元素即可,时间复杂度为 O(1)。二、综合应用题
01.从顺序表中删除具有最小值的元素(假设唯一)并由函数返回被删元素的值。空出的位置由最后一个元素填补,若顺序表为空,则显示出错信息并退出运行。
01.【解答】
算法思想:搜索整个顺序表,查找最小值元素并记住其位置,搜索结束后用最后一个元素填补空出的原最小值元素的位置。本题代码如下:
bool Del_Min(SqList &L, ElemType &value) {//删除顺序表L中最小值元素结点,并通过引用型参数value返回其值//若删除成功,则返回true;否则返回falseif (L.length == 0)return false; //表空,中止操作返回value = L.data[0]; //假定0号元素的值最小int pos = 0;for (int i = 1; i < L.length; i++) //循环,寻找具有最小值的元素if (L.data[i] < value) { //让value记忆当前具有最小值的元素value = L.data[i];pos = i;}L.data[pos] = L.data[L.length - 1]; //空出的位置由最后一个元素填补L.length--;return true; //此时,value为最小值 }注意:本题也可用函数返回值返回,两者的区别是:函数返回值只能返回一个值,而参数返回(引用传参)可以返回多个值。
02.设计一个高效算法,将顺序表 L 的所有元素逆置,要求算法的空间复杂度为 O(1)。
02.【解答】
算法思想:扫描顺序表 L 的前半部分元素,对于元素 L.data[i](0<=i<L.length/2),将其与后半部分的对应元素 L.data[L.length−i−1] 进行交换。本题代码如下:
void Reverse(SqList &L) {ElemType temp; //辅助变量for (int i = 0; i < L.length / 2; i++) {temp = L.data[i]; //交换L.data[i]与L.data[L.length - i - 1]L.data[i] = L.data[L.length - i - 1];L.data[L.length - i - 1] = temp;} }03.对长度为 n 的顺序表 L,编写一个时间复杂度为 O(n)、空间复杂度为 O(1) 的算法,该算法删除顺序表中所有值为 x 的数据元素。
03.【解答】
解法 1:用 k 记录顺序表 L 中不等于 x 的元素个数(需要保存的元素个数),扫描时将不等于 x 的元素移动到下标 k 的位置,并更新 k 值。扫描结束后修改 L 的长度。本题代码如下:
void del_x_1(SqList &L, ElemType x) {//本算法实现删除顺序表L中所有值为x的数据元素int k = 0, i; //记录值不等于x的元素个数for (i = 0; i < L.length; i++)if (L.data[i] != x) {L.data[k] = L.data[i];k++; //不等于x的元素增1}L.length = k; //顺序表L的长度等于k }解法 2:用 k 记录顺序表 L 中等于 x 的元素个数,一边扫描 L,一边统计 k,并将不等于 x 的元素前移 k 个位置。扫描结束后修改 L 的长度。
本题代码如下:
void del_x_2(SqList &L, ElemType x) {int k = 0, i = 0; //k记录值等于x的元素个数while (i < L.length) {if (L.data[i] == x)k++;elseL.data[i - k] = L.data[i]; //当前元素前移k个位置i++;}L.length = L.length - k; //顺序表L的长度递减 }此外,本题还可以考虑设头、尾两个指针(i=1,j=n),从两端向中间移动,在遇到最左端值 x 的元素时,直接将最右端值非 x 的元素左移至值为 x 的数据元素位置,直到两指针相遇。但这种方法会改变原表中元素的相对位置。
04.从顺序表中删除其值在给定值 s 和 t 之间(包含 s 和 t,要求 s<t)的所有元素,若 s 或 t 不合理或顺序表为空,则显示出错信息并退出运行。
04.【解答】
算法思想:从前向后扫描顺序表 L,用 k 记录值在 s 和 t 之间的元素个数(初始时 k=0)。对于当前扫描的元素,若其值不在 s 和 t 之间,则前移 k 个位置;否则执行 k++。每个不在 s 和 t 之间的元素仅移动一次,因此算法效率高。本题代码如下:
bool Del_s_t(SqList &L, ElemType s, ElemType t) {//删除顺序表L中值在给定值s和t(要求s<t)之间的所有元素int i, k = 0;if (L.length == 0 || s >= t)return false; //线性表为空或s、t不合法,返回for (i = 0; i < L.length; i++) {if (L.data[i] >= s && L.data[i] <= t)k++;elseL.data[i - k] = L.data[i]; //当前元素前移k个位置} //forL.length -= k; //长度减小return true; }注意:本题也可从后向前扫描顺序表,每遇到一个值在 s 和 t 之间的元素,就删除该元素,其后的所有元素全部前移。但移动次数远大于前者,效率不够高。
05.从有序顺序表中删除所有其值重复的元素,使表中所有元素的值均不同。
05.【解答】
算法思想:注意是有序顺序表,值相同的元素一定在连续的位置上,用类似于直接插入排序的思想,初始时将第一个元素视为非重复的有序表。之后依次判断后面的元素是否与前面非重复有序表的最后一个元素相同,若相同,则继续向后判断,若不同,则插入前面的非重复有序表的最后,直至判断到表尾为止。本题代码如下:
bool Delete_Same(SeqList& L) {if (L.length == 0)return false;int i = 0, j = 1; //i存储第一个不相同的元素,j为工作指针for (; j < L.length; j++)if (L.data[i] != L.data[j]) //查找下一个与上一个元素值不同的元素L.data[++i] = L.data[j]; //找到后,将元素前移L.length = i + 1;return true; }对于本题的算法,请读者用序列 1,2,2,2,2,3,3,3,4,4,5 来手动模拟算法的执行过程,在模拟过程中要标注 i 和 j 所指示的元素。
思考:若将本题中的有序表改为无序表,你能想到时间复杂度为 O(n) 的方法吗?(提示:使用散列表。)
06.将两个有序顺序表合并为一个新的有序顺序表,并由函数返回结果顺序表。
06.【解答】
算法思想:首先,按顺序不断取下两个顺序表表头较小的结点存入新的顺序表中。然后,看哪个表还有剩余,将剩下的部分加到新的顺序表后面。本题代码如下:
bool Merge(SeqList A, SeqList B, SeqList &C) {//将有序顺序表A与B合并为一个新的有序顺序表Cif (A.length + B.length > C.MaxSize) //大于顺序表的最大长度return false;int i = 0, j = 0, k = 0;while (i < A.length && j < B.length) { //循环,两两比较,小者存入结果表if (A.data[i] <= B.data[j])C.data[k++] = A.data[i++];elseC.data[k++] = B.data[j++];}while (i < A.length) //还剩一个没有比较完的顺序表C.data[k++] = A.data[i++];while (j < B.length)C.data[k++] = B.data[j++];C.length = k;return true; }注意:本算法的方法非常典型,需牢固掌握。
07.已知在一维数组 A[m+n] 中依次存放两个线性表 (a1,a2,a3,⋯,am) 和 (b1,b2,b3,⋯,bn)。编写一个函数,将数组中两个顺序表的位置互换,即将 (b1,b2,b3,⋯,bn) 放在 (a1,a2,a3,⋯,am) 的前面。
07.【解答】
算法思想:首先将数组 A[m+n] 中的全部元素 (a1,a2,a3,⋯,am,b1,b2,b3,⋯,bn) 原地逆置为 (bn,bn−1,bn−2,⋯,b1,am,am−1,am−2,⋯,a1),然后对前 n 个元素和后 m 个元素分别使用逆置算法,即可得到 (b1,b2,b3,⋯,bn,a1,a2,a3,⋯,am),
从而实现顺序表的位置互换。
本题代码如下:
typedef int DataType; void Reverse(DataType A[], int left, int right, int arraySize) {//逆转(a[left],a[left+1],a[left+2],…,a[right])为(a[right],a[right-1],…,a[left])if (left > right || right >= arraySize)return;int mid = (left + right) / 2;for (int i = 0; i <= mid - left; i++) {DataType temp = A[left + i];A[left + i] = A[right - i];A[right - i] = temp;} } void Exchange(DataType A[], int m, int n, int arraySize) {/*数组 A[m+n]中,从 0到m-1存放顺序表(a1,a2,a3,⋯,am),从m到m+n-1存放顺序表(b1,b2,b3,⋯,bn),算法将这两个表的位置互换*/Reverse(A, 0, m + n - 1, arraySize);Reverse(A, 0, n - 1, arraySize);Reverse(A, n, m + n - 1, arraySize); }08.线性表 (a1,a2,a3,⋯,an) 中的元素递增有序且按顺序存储于计算机内。要求设计一个算法,完成用最少时间在表中查找数值为 x 的元素,若找到,则将其与后继元素位置相交换,若找不到,则将其插入表中并使表中元素仍递增有序。
08.【解答】
算法思想:顺序存储的线性表递增有序,可以顺序查找,也可以折半查找。题目要求 “用最少的时间在表中查找数值为 x 的元素”,这里应使用折半查找法。本题代码如下:
void SearchExchangeInsert(ElemType A[], ElemType x) {int low = 0, high = n - 1, mid; //low和high指向顺序表下界和上界的下标while (low <= high) {mid = (low + high) / 2; //找中间位置if (A[mid] == x) break; //找到x,退出while循环else if (A[mid] < x) low = mid + 1; //到中点mid的右半部去查else high = mid - 1; //到中点mid的左半部去查//下面两个if语句只会执行一个}if (A[mid] == x && mid != n - 1) { //若最后一个元素与x相等,则不存在与其后//继交换的操作ElemType t = A[mid]; A[mid] = A[mid + 1]; A[mid + 1] = t;}if (low > high) { //查找失败,插入数据元素xfor (int i = n - 1; i > high; i--) A[i + 1] = A[i]; //后移元素A[high + 1] = x; //插入x} }本题的算法也可写成三个函数:查找函数、交换后继函数与插入函数。写成三个函数的优点是逻辑清晰、易读。
09.给定三个序列 A、B、C,长度均为 n,且均为无重复元素的递增序列,请设计一个时间上尽可能高效的算法,逐行输出同时存在于这三个序列中的所有元素。例如,数组 A 为 {1,2,3},数组 B 为 {2,3,4},数组 C 为 {−1,0,2},则输出 2。要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用 C 或 C++ 语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。09.【解析】
1)算法的基本设计思想。
使用三个下标变量从小到大遍历数组。当三个下标变量指向的元素相等时,输出并向前推进指针,否则仅移动小于最大元素的下标变量,直到某个下标变量移出数组范围,即可停止。
2)算法的实现。void samekey(int A[], int B[], int C[], int n) {int i = 0, j = 0, k = 0; //定义三个工作指针while (i < n && j < n && k < n) { //相同则输出,并集体后移if (A[i] == B[j] && B[j] == C[k]) {printf("%d\n", A[i]);i++; j++; k++;}else {int maxNum = max(A[i], max(B[j], C[k]));if (A[i] < maxNum) i++;if (B[j] < maxNum) j++;if (C[k] < maxNum) k++;}} }3)每个指针移动的次数不超过 n 次,且每次循环至少有一个指针后移,所以时间复杂度为 O(n),算法只用到了常数个变量,空间复杂度为 O(1)。
10.【2010 统考真题】设将 () 个整数存放到一维数组 R 中。设计一个在时间和空间两方面都尽可能高效的算法。将 R 中保存的序列循环左移 () 个位置,即将 R 中的数据由 (X0,X1,⋯,Xn−1) 变换为 (Xp,Xp+1,⋯,Xn−1,X0,X1,⋯,Xp−1)。要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用 C 或 C++ 或 Java 语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。10.【解答】
1)算法的基本设计思想:
可将问题视为把数组 ab 转换成数组 ba(a 代表数组的前 p 个元素,b 代表数组中余下的 n−p 个元素),先将 a 逆置得到 a^−1b,再将 b 逆置得到 a^−1b^−1,最后将整个 a^−1b^−1 逆置得到 (a^−1b^−1)^−1=ba。设 Reverse 函数执行将数组逆置的操作,对 abcdefgh 向左循环移动 3(p=3)个位置的过程如下:
Reverse(0, p - 1) 得到 cbadefgh;
Reverse(p, n - 1) 得到 cbahgfed;
Reverse(0, n - 1) 得到 defghabc。
注:在 Reverse 中,两个参数分别表示数组中待转换元素的始末位置。
2)使用 C 语言描述算法如下:void Reverse(int R[], int from, int to) {int i, temp;for (i = 0; i < (to - from + 1) / 2; i++){ temp = R[from + i]; R[from + i] = R[to - i]; R[to - i] = temp; } } void Converse(int R[], int n, int p) {Reverse(R, 0, p - 1);Reverse(R, p, n - 1);Reverse(R, 0, n - 1); }3)上述算法中三个 Reverse 函数的时间复杂度分别为 O(p/2)、O((n−p)/2) 和 O(n/2),故所设计的算法的时间复杂度为 O(n),空间复杂度为 O(1)。
【另解】借助辅助数组来实现。算法思想:创建大小为 p 的辅助数组 S,将 R 中前 p 个整数依次暂存在 S 中,同时将 R 中后 n−p 个整数左移,然后将 S 中暂存的 p 个数依次放回到 R 中的后续单元。时间复杂度为 O(n),空间复杂度为 O(p)。11.【2011 统考真题】一个长度为 () 的升序序列 S,处在 ⌈L/2⌉ 个位置的数称为 S 的中位数。例如,若序列 S1={11,13,15,17,19},则 S1 的中位数是 15,两个序列的中位数是含它们所有元素的升序序列的中位数。例如,若 S2={2,4,6,8,20},则 S1 和 S2 的中位数是 11。现在有两个等长升序序列 A 和 B,试设计一个在时间和空间两方面都尽可能高效的算法,找出两个序列 A 和 B 的中位数。要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用 C 或 C++ 或 Java 语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。11.【解答】
1)算法的基本设计思想如下。
分别求两个升序序列 A、B 的中位数,设为 a 和 b,求序列 A、B 的中位数过程如下:
① 若 a=b,则 a 或 b 为所求中位数,算法结束。
② 若 a<b,则舍弃序列 A 中较小的一半,同时舍弃序列 B 中较大的一半,要求两次舍弃的长度相等。
③ 若 a>b,则舍弃序列 A 中较大的一半,同时舍弃序列 B 中较小的一半,要求两次舍弃的长度相等。
在保留的两个升序序列中,重复过程①、②、③,直到两个序列中均只含一个元素时为止,较小者为所求的中位数。
2)本题代码如下:int M_Search(int A[], int B[], int n) {int s1 = 0, d1 = n - 1, m1, s2 = 0, d2 = n - 1, m2;while (s1 != d1 || s2 != d2) {m1 = (s1 + d1) / 2;m2 = (s2 + d2) / 2;if (A[m1] == B[m1] == B[m2]) //满足条件①return A[m1];if (A[m1] < B[m2]) { //满足条件②if ((s1 + d1) % 2 == 0) { //若元素个数为奇数s1 = m1; //舍弃A中间点以前的部分,且保留中间点d2 = m2; //舍弃B中间点以后的部分,且保留中间点}else { //元素个数为偶数s1 = m1 + 1; //舍弃A的前半部分d2 = m2; //舍弃B的后半部分}}else { //满足条件③if ((s1 + d1) % 2 == 0) { //若元素个数为奇数d1 = m1; //舍弃A中间点以后的部分,且保留中间点s2 = m2; //舍弃B中间点以前的部分,且保留中间点}else { //元素个数为偶数d1 = m1; //舍弃A的后半部分s2 = m2 + 1; //舍弃B的前半部分}}}return A[s1] < B[s2]? A[s1] : B[s2]; }3)算法的时间复杂度为 O(log2n),空间复杂度为 O(1)。
【另解】对两个长度为 n 的升序序列 A 和 B 中的元素按从小到大的顺序依次访问,这里访问的含义只是比较序列中两个元素的大小,并不实现两个序列的合并,因此空间复杂度为 O(1)。按照上述规则访问第 n 个元素时,这个元素为两个序列 A 和 B 的中位数。12.【2013 统考真题】已知一个整数序列 A=(a0,a1,⋯,an−1),其中 ()。若存在 ap1=ap2=⋯=apm=x 且 (),则称 x 为 A 的主元素。例如 A={0,5,5,3,5,7,5,5},则 5 为主元素;又如 A={0,5,5,3,5,1,5,7},则 A 中没有主元素。假设 A 中的 n 个元素保存在一个一维数组中,请设计一个尽可能高效的算法,找出 A 的主元素。若存在主元素,则输出该元素;否则输出 −1。要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用 C 或 C++ 或 Java 语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。12. 【解答】
1)算法的基本设计思想:算法的策略是从前向后扫描数组元素,标记出一个可能成为主元素的元素 Num。然后重新计数,确认 Num 是否是主元素。
算法可分为以下两步:
① 选取候选的主元素。依次扫描所给数组中的每个整数,将第一个遇到的整数 Num 保存到 c 中,记录 Num 的出现次数为 1;若遇到的下一个整数仍等于 Num,则计数加 1,否则计数减 1;当计数减到 0 时,将遇到的下一个整数保存到 c 中,计数重新记为 1,开始新一轮计数,即从当前位置开始重复上述过程,直到扫描完全部数组元素。
② 判断 c 中元素是否是真正的主元素。再次扫描该数组,统计 c 中元素出现的次数,若大于 n/2,则为主元素;否则,序列中不存在主元素。
2)算法实现如下:int Majority(int A[], int n) {int i, c, count = 1; //c用来保存候选主元素,count用来计数c = A[0]; //设置A[0]为候选主元素for (i = 1; i < n; i++) //查找候选主元素if (A[i] == c)count++; //对A中的候选主元素计数elseif (count > 0)count--; //处理不是候选主元素的情况else { //更换候选主元素,重新计数c = A[i];count = 1;}if (count > 0)for (i = count = 0; i < n; i++) //统计候选主元素的实际出现次数if (A[i] == c)count++;if (count > n / 2) return c; //确认候选主元素else return -1; //不存在主元素 }3)实现的程序的时间复杂度为 O(n),空间复杂度为 O(1)。
说明:本题若采用先排序再统计的方法 [时间复杂度为 O(nlog2n) ],则只要解答正确,最高可拿 11 分。即便是写出 O(n^2) 的算法,最高也能拿 10 分,因此对于统考算法题,花费大量时间去思考最优解法是得不偿失的。本算法的方法非常典型,需牢固掌握。
13.【2018 统考真题】给定一个含 () 个整数的数组,请设计一个在时间上尽可能高效的算法,找出数组中未出现的最小正整数。例如,数组 {−5,3,2,3} 中未出现的最小正整数是 1;数组 {1,2,3} 中未出现的最小正整数是 4。要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用 C 或 C++ 语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。13. 【解答】
1)算法的基本设计思想:
要求在时间上尽可能高效,因此采用空间换时间的办法。分配一个用于标记的数组 B[n],用来记录 A 中是否出现了 1∼n 中的正整数,B[0] 对应正整数 1,B[n - 1] 对应正整数 n,初始化 B 中全部为 0。A 中含有 n 个整数,因此可能返回的值是 1∼n+1,当 A 中 n 个数恰好为 1∼n 时返回 n+1。当数组 A 中出现了小于或等于 0 或大于 n 的值时,会导致 1∼n 中出现空余位置,返回结果必然在 1∼n 中,因此对于 A 中出现了小于或等于 0 或大于 n 的值,可以不采取任何操作。
经过以上分析可以得出算法流程:从 A[0] 开始遍历 A,若 0<A[i]<=n,则令 B[A[i] - 1] = 1;否则不做操作。对 A 遍历结束后,开始遍历数组 B,若能查找到第一个满足 B[i] == 0 的下标 i,返回 i + 1 即为结果,此时说明 A 中未出现的最小正整数在 1 和 n 之间。若 B[i] 全部不为 0,返回 i + 1(跳出循环时 i = n,i + 1 等于 n + 1),此时说明 A 中未出现的最小正整数是 n + 1。
2)算法实现:int findMissMin(int A[], int n) {int i, *B; //标记数组B = (int *)malloc(sizeof(int) * n); //分配空间memset(B, 0, sizeof(int) * n); //赋初值为0for (i = 0; i < n; i++)if (A[i] > 0 && A[i] <= n) //若A[i]的值介于1~n,则标记数组BB[A[i] - 1] = 1;for (i = 0; i < n; i++) //扫描数组B,找到目标值if (B[i] == 0) break;return i + 1; //返回结果 }3)时间复杂度:遍历 A 一次,遍历 B 一次,两次循环内操作步骤为 O(1) 量级,因此时间复杂度为 O(n)。空间复杂度:额外分配了 B[n],空间复杂度为 O(n)。
14.【2020 统考真题】定义三元组 (a,b,c)(a、b、c 均为整数)的距离 D=∣a−b∣+∣b−c∣+∣c−a∣。给定 3 个非空整数集合 S1、S2 和 S3,按升序分别存储在 3 个数组中。请设计一个尽可能高效的算法,计算并输出所有可能的三元组 (a,b,c)(a∈S1,b∈S2,c∈S3)中的最小距离。例如 S1={−1,0,9},S2={−25,−10,10,11},S3={2,9,17,30,41},则最小距离为 2,相应的三元组为 (9,10,9)。要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用 C 语言或 C++ 语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。14. 【解答】
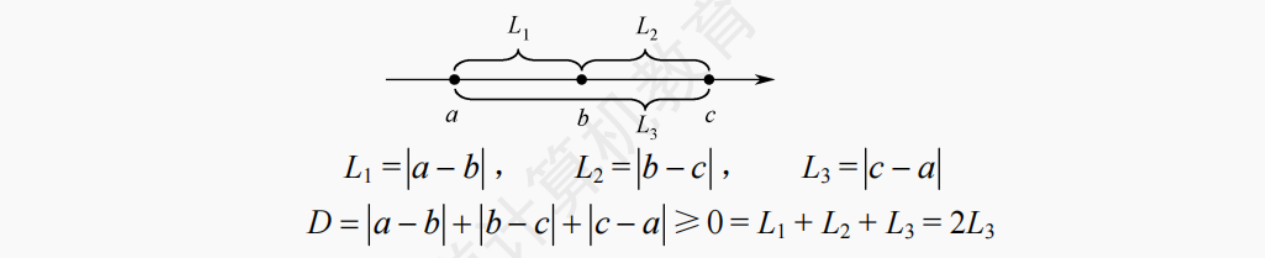
分析:由 D=∣a−b∣+∣b−c∣+∣c−a∣≥0 有如下结论。
① 当 a=b=c 时,距离最小。
② 其余情况。不失一般性,假设 a≤b≤c,观察下面的数轴:
由 D 的表达式可知,事实上决定 D 大小的关键是 a 和 c 之间的距离,于是问题就可以简化为每次固定 c 找一个 a,使得 L3=∣c−a∣ 最小。
1)算法的基本设计思想:
① 使用 D_min 记录所有已处理的三元组的最小距离,初值为一个足够大的整数。
② 集合 S1、S2 和 S3 分别保存在数组 A、B、C 中。数组的下标变量 i=j=k=0,当 i<∣S1∣,j<∣S2∣ 且 k<∣S3∣ 时(∣S∣ 表示集合 S 中的元素个数),循环执行下面的 a)~c)。
a)计算 (A[i], B[j], C[k]) 的距离 D;(计算 D)
b)若 D < D_min,则 D_min = D;(更新 D)
c)将 A[i]、B[j]、C[k] 中的最小值的下标 +1;(对照分析:最小值为 a,最大值为 c,这里 c 不变而更新 a,试图寻找更小的距离 D)
③ 输出 D_min,结束。
2)算法实现:#define INT_MAX 0x7fffffff int abs_(int a) { //计算绝对值if (a < 0) return -a;else return a; } bool xls_min(int a, int b, int c) { //a是否是三个数中的最小值if (a <= b && a <= c) return true;return false; } int findMinTrip(int A[], int n, int B[], int m, int C[], int p) {//D_min用于记录三元组的最小距离,初值赋为INT_MAXint i = 0, j = 0, k = 0, D_min = INT_MAX, D;while (i < n && j < m && k < p && D_min > 0) {D = abs_(A[i] - B[j]) + abs_(B[j] - C[k]) + abs_(C[k] - A[i]); //计算Dif (D < D_min) D_min = D; //更新Dif (xls_min(A[i], B[j], C[k])) i++; //更新aelse if (xls_min(B[j], C[k], A[i])) j++;else k++;}return D_min; }3)设 n=(∣S1∣+∣S2∣+∣S3∣),时间复杂度为 O(n),空间复杂度为 O(1)。
2.3 线性表的链式表示
顺序表的存储位置可以用一个简单直观的公式表示,它可以随机存取表中任一元素,但插入和删除操作需要移动大量元素。链式存储线性表时,不需要使用地址连续的存储单元,即不要求逻辑上相邻的元素在物理位置上也相邻,它通过 “链” 建立元素之间的逻辑关系,因此插入和删除操作不需要移动元素,而只需修改指针,但也会失去顺序表可随机存取的优点。
2.3.1 单链表的定义
命题追踪 单链表的应用(2009、2012、2013、2015、2016、2019)
线性表的链式存储也称单链表,它是指通过一组任意的存储单元来存储线性表中的数据元素。为了建立数据元素之间的线性关系,对每个链表结点,除存放元素自身的信息外,还需要存放一个指向其后继的指针。单链表结点结构如图2.3所示,其中 data 为数据域,存放数据元素;next 为指针域,存放其后继结点的地址。
单链表中结点类型的描述如下:
typedef struct LNode{ //定义单链表结点类型ElemType data; //数据域struct LNode *next; //指针域 }LNode, *LinkList;利用单链表可以解决顺序表需要大量连续存储单元的缺点,但附加的指针域,也存在浪费存储空间的缺点。单链表的元素离散地分布在存储空间中,因此是非随机存取的存储结构,即不能直接找到表中某个特定结点。查找特定结点时,需要从表头开始遍历,依次查找。
通常用头指针 L(或 head 等)来标识一个单链表,头指针为 NULL 时表示一个空表。此外,为了操作上的方便,在单链表第一个数据结点之前附加一个结点,称为头结点。头结点的数据域可以不设任何信息,但也可以记录表长等信息。单链表带头结点时,头指针 L 指向头结点,如图2.4(a)所示。单链表不带头结点时,头指针 L 指向第一个数据结点,如图2.4(b)所示。表尾结点的指针域为 NULL(用 “^” 表示)。
头结点和头指针的关系:不管带不带头结点,头指针都始终指向链表的第一个结点,而头结点是带头结点链表中的第一个结点,结点内通常不存储信息。
引入头结点后,可以带来两个优点:
① 第一个数据结点的位置被存放在头结点的指针域中,因此在链表的第一个位置上的操作和在表的其他位置上的操作一致,无须进行特殊处理。
② 无论链表是否为空,其头指针都是指向头结点的非空指针(空表中头结点的指针域为空),因此空表和非空表的处理也就得到了统一。2.3.2 单链表上基本操作的实现
带头结点单链表的操作代码书写较为方便,如无特殊说明,本节均默认链表带头结点。
1.单链表的初始化
带头结点和不带头结点的单链表的初始化操作是不同的。带头结点的单链表初始化时,需要创建一个头结点,并让头指针指向头结点,头结点的 next 域初始化为 NULL。bool InitList(LinkList &L){ //带头结点的单链表的初始化L = (LNode*)malloc(sizeof(LNode)); //创建头结点①L->next = NULL; //头结点之后暂时还没有元素结点return true; }① 执行L
=(LNode*)malloc(sizeof(LNode))的作用是由系统生成一个 LNode 型的结点,并将该结点的起始位置赋给指针变量 L。不带头结点的单链表初始化时,只需将头指针 L 初始化为 NULL。
bool InitList(LinkList &L){ //不带头结点的单链表的初始化L = NULL;return true; }注意:设 p 为指向链表结点的结构体指针,则 *p 表示结点本身,因此可用 p->data 或 (*p).data 访问 *p 这个结点的数据域,二者完全等价。成员运算符 . 左边是一个普通的结构体变量,而指向运算符 -> 左边是一个结构体指针。通过 (*p).next 可以得到指向下一个结点的指针,因此 (*(*p).next).data 就是下一个结点中存放的数据,或者直接用 p->next->data。


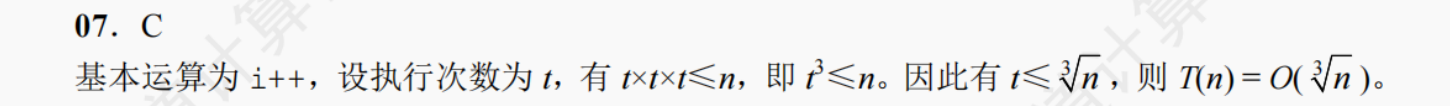
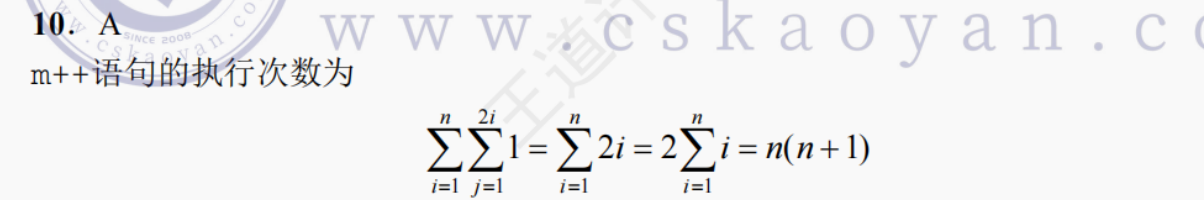
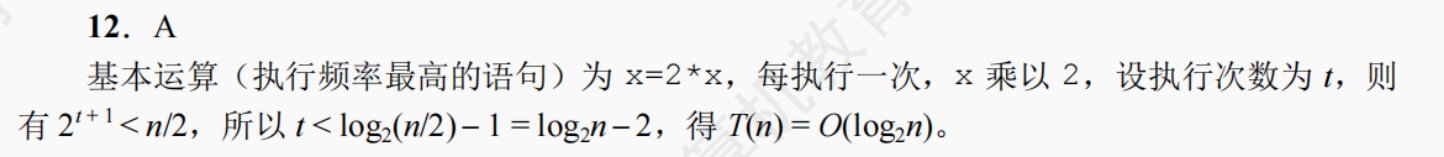


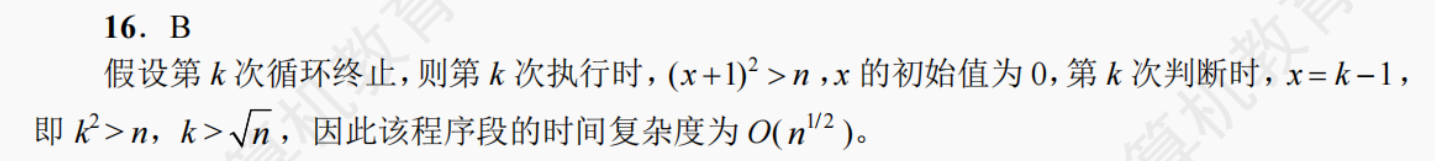


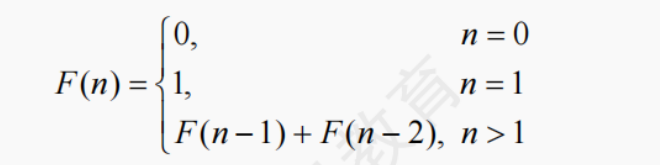

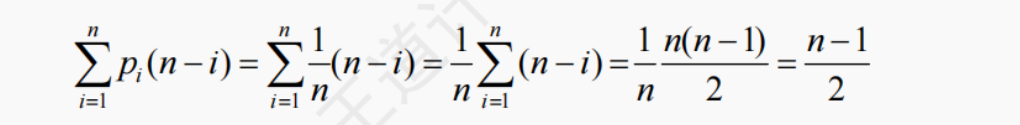
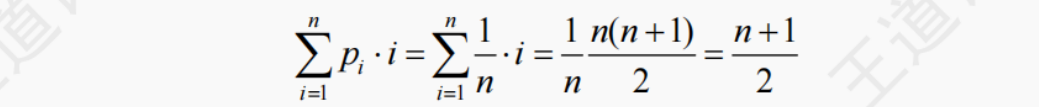


相关文章:

数据结构学习笔记
第 1 章 绪论 【考纲内容】 (一)数据结构的基本概念 (二)算法的基本概念 算法的时间复杂度和空间复杂度 【知识框架】 【复习提示】 本章内容是数据结构概述,并不在考研大纲中。读者可通过对本章的学习,初步…...

读懂 Vue3 路由:从入门到实战
在构建现代化单页应用(SPA)时,Vue3 凭借其简洁高效的特性成为众多开发者的首选。 而 Vue3 路由(Vue Router)则是 Vue3 生态中不可或缺的一部分,它就像是单页应用的 “导航地图”,帮助用户在不同…...

Aws S3上传优化
上传大约 3.4GB 的 JSON 文件,zip算法压缩后约为 395MB,上传至 S3 效率优化,有一些优化方案可以提高上传速率。下面是几种可能的优化方式,包括选择压缩算法、调整上传方式、以及其他可能的方案。 方案 1. 选择更好的压缩算法 压…...
:基于LLM的个性化营销文案)
Python 数据智能实战 (8):基于LLM的个性化营销文案
写在前面 —— 告别群发轰炸,拥抱精准沟通:用 LLM 为你的用户量身定制营销信息 在前面的篇章中,我们学习了如何利用 LLM 增强用户理解(智能分群)、挖掘商品关联(语义购物篮)、提升预测精度(融合文本特征的流失预警)。我们不断地从数据中提取更深层次的洞察。 然而,…...

html:table表格
表格代码示例: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body><!-- 标准表格。 --><table border"5"cellspacing&qu…...

2.maven 手动安装 jar包
1.背景 有的时候,maven仓库无法下载,可以手动安装。本文以pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar为例。 2.预先准备 下载文件到本地指定位置。 2.1.安装pom mvn install:install-file \-Dfile/home/wind/tmp/pentaho-aggdesigner-5.1.5-jh…...

C++ unordered_set unordered_map
上篇文章我们讲解了哈希表的实现,这节尝试使用哈希表来封装unordered_set/map 1. unordered_set/map的框架 封装的过程实际上与set/map类似,在unordered_set/map层传递一个仿函数,用于取出key值 由于我们平常使用的都是unordered_set/map&…...

第37课 绘制原理图——放置离页连接符
什么是离页连接符? 前边我们介绍了网络标签(Net Lable),可以让两根导线“隔空相连”,使原理图更加清爽简洁。 但是网络标签的使用也具有一定的局限性,对于两张不同Sheet上的导线,网络标签就不…...
)
< 自用文 Texas style Smoker > 美式德克萨斯烟熏炉 从设计到实现 (第一部分:烹饪室与燃烧室)
原因: 没钱还馋! 但有手艺。 预计目标: 常见的两种偏置式烟熏炉(Offset Smoker) 左边边是标准偏置式(Standard Offset),右边是反向流动式(Reverse Flow Offset&#x…...

【现代深度学习技术】现代循环神经网络03:深度循环神经网络
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

AimRT从入门到精通 - 03Channel发布者和订阅者
刚接触AimRT的小伙伴可能会疑惑,这个Channel和RPC(后面讲的)到底是什么呢? 但是当我们接触了之后,就会发现,其本质类似ROS的Topic通信!(其本质基于发布订阅模型) 接下来…...

MySQL初阶:数据库基础,数据库和表操作,数据库中的数据类型
1.数据库基础 数据库是一个客户端——服务器结构的程序。 服务器是真正的主体,负责保存和管理数据,数据都存储在硬盘上 数据库处理的主要内容是数据的存储,查找,修改,排序,统计等。 关系型数据库&#…...

AI 驱动的智能交通系统:从拥堵到流畅的未来出行
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。下面开始对正文内容的…...

Python清空Word段落样式的方法
在 Python 中,你可以使用 python-docx 库来操作 Word 文档,包括清空段落样式。以下是几种清空段落样式的方法: 方法一:直接设置段落样式为"Normal" from docx import Documentdoc Document(your_document.docx) # 打…...

[javaEE]网络编程
目录 socket对tcp ServerSocket ServerSocket 构造方法: ServerSocket 方法: socket 实现回显服务器和客户端 由于我们之前已经写多了socket对udq的实现,所以我们这节,主要将重心放在Tcp之上 socket对tcp ServerS…...

组件通信-mitt
mitt:与消息订阅与发布(pubsub)功能类似,可以实现任意组件间通信。 第一步:安装mitt npm i mitt 第二步:新建文件:src\utils\emitter.ts // 引入mitt import mitt from "mitt"; //调…...

微软发布了最新的开源推理模型套件“Phi-4-Reasoning
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Socat 用法详解:网络安全中的瑞士军刀
Socat 用法详解:网络安全中的强大工具 引言 socat(SOcket CAT)是一款功能强大的命令行工具,被誉为“网络瑞士军刀”,广泛应用于数据传输、端口转发和网络调试等场景。它支持多种协议和数据通道(如文件、管…...
:SaaS商业模式的指标动态与实践案例)
精益数据分析(36/126):SaaS商业模式的指标动态与实践案例
精益数据分析(36/126):SaaS商业模式的指标动态与实践案例 在创业与数据分析的学习道路上,我们不断探索各种商业模式的核心要点。今天,依旧怀揣着和大家共同进步的想法,深入研读《精益数据分析》中SaaS商业…...

2.LED灯的控制和按键检测
目录 STM32F103的GPIO口 GPIO口的作用 GPIO口的工作模式 input输入检测 -- 向内检测 output控制输出 -- 向外输出 寄存器 寄存器地址的确定 配置GPIO口的工作模式 时钟的开启和关闭 软件编程驱动 LED 灯 硬件 软件 软件编程驱动 KEY 按键 硬件 软件 按键消抖 代码 STM32F…...
:注册中心架构模式)
架构师面试(三十八):注册中心架构模式
题目 在微服务系统中,当服务达到一定数量时,通常需要引入【注册中心】组件,以方便服务发现。 大家有没有思考过,注册中心存在的最根本的原因是什么呢?注册中心在企业中的最佳实践是怎样的?注册中心的服务…...

Go-web开发之帖子功能
帖子功能 route.go r.Use(middleware.JWTAuthMiddleware()){r.POST("/post", controller.CreatePostHandler)r.GET("/post/:id", controller.GetPostDetailHandler)}post.go 定义帖子结构 type Post struct {Id int64 json:"id" …...

MYSQL-设计表
一.范式 数据库的范式是⼀组规则。在设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数 据库,这些不同的规范要求被称为不同的范式。 关系数据库有六种范式:第⼀范式(1NF)、第⼆范式(…...

动态思维——AI与思维模型【91】
一、定义 动态思维思维模型是一种强调在思考问题和分析情况时,充分考虑到事物的变化性、发展性和相互关联性,不局限于静态的、孤立的视角,而是以发展变化的眼光看待事物,能够根据不同时间、环境和条件的变化,灵活调整…...
)
文献阅读篇#7:5月一区好文阅读,BFA-YOLO,用于建筑信息建模!(下)
期刊简介:《Advanced Engineering Informatics》创刊于2002年,由Elsevier Ltd出版商出版,出版周期Quarterly。该刊已被SCIE数据库收录,在中科院最新升级版分区表中,该刊分区信息为大类学科工程技术1区,2023…...

【Linux网络编程】http协议的状态码,常见请求方法以及cookie-session
本文专栏:Linux网络编程 目录 一,状态码 重定向状态码 1,永久重定向(301 Moved Permanently) 2,临时重定向(302 Found) 二,常见请求方法 1,HTTP常见Hea…...
第六章:ARM 编程技巧与优化策略)
ARM 指令集(ubuntu环境学习)第六章:ARM 编程技巧与优化策略
在本章中,我们将介绍一些在 ARM 架构上编写高效代码的技巧和常见优化策略,帮助您在嵌入式系统中获得更低延迟、更高吞吐和更低功耗。 6.1 寄存器利用与最小化内存访问 多用寄存器 ARM 通用寄存器(r0–r12)数量充足,尽量将临时变量保留在寄存器中,减少对内存的读写。 避免…...

柔性超声耦合剂的选择与设计-可穿戴式柔性超声耦合剂面临的难题
柔性PZT压电薄膜:破解可穿戴式超声耦合剂难题的关键材料! 随着可穿戴技术的快速发展,超声设备正朝着轻量化、柔性化和高集成度方向演进。在医学诊断、健康监测和智能穿戴领域,可穿戴式超声设备因其无创、实时、动态成像等优势受到…...
)
XCTF-pwn(二)
guess_num 看一下文件信息 利用gets函数将seed[0]给覆盖掉 距离0x20 我们需要输入十次随机数产生的值 写一个c程序先预判当seed是a的时候产生的随机数分别是多少 payload from pwn import* from ctypes import* context.log_leveldebugrremote("61.147.171.105", 6…...

AI外挂RAG:大模型时代的检索增强生成技术
目录 引言 一、RAG是什么? 二、RAG为什么会出现? 三、RAG的工作原理 四、RAG的技术优势 五、RAG的应用场景 六、RAG对AI行业的影响 七、RAG面临的挑战 引言 在人工智能领域,大型语言模型(LLM)如ChatGPT、DeepSe…...

SpringTask
Spring Task是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑 应用场景:信用卡每月还款提醒、火车票售票系统处理未支付订单 fixedDelay:上一次任务执行完成后多长时间(ms)执行下一次任务 fixe…...

Sphinx 文档图片点击放大
文章目录 问题描述解决方案步骤 1:创建 JavaScript 文件步骤 2:编写 JavaScript 代码步骤 3:更新 Sphinx 配置 高级定制为所有图片添加点击功能添加缩放控制 总结 在使用 Sphinx 生成技术文档时,我们经常需要在文档中嵌入截图和示…...

菜鸟之路Day29一一MySQL之DDL
菜鸟之路Day29一一MySQL之DDL 作者:blue 时间:2025.5.2 文章目录 菜鸟之路Day29一一MySQL之DDL0.概述1.DDL之数据库操作1.1查询1.2创建1.3使用1.4删除 2.DDL之表操作2.1创建表2.2数据类型2.3查询表2.4修改表结构2.5删除表 0.概述 文章内容学习自黑马程…...
:监控系统架构模式)
架构师面试(三十七):监控系统架构模式
题目 监控是在产品生命周期的运维环节,能对产品的关键指标数据进行【实时跟踪】并对异常数据进行【实时报警】。 一句话描述,监控系统可以帮我们【主动预防和发现】业务系统中的问题。 我们常说,监控系统是 “粮草”,业务系统是…...

【Redis】Hash哈希
文章目录 注意个问题hset命令(核心)hget命令(核心)hexists命令hdel命令hkeys和hvals命令hgetall和hmget命令hlen命令hsetnx命令hincrby命令哈希命令小结哈希编码方式使用场景1.关系型数据表保存用户的信息Redis三种缓存方式对比1.…...
【SpringBoot】Spring中事务的实现:声明式事务@Transactional、编程式事务
1. 准备工作 1.1 在MySQL数据库中创建相应的表 用户注册的例子进行演示事务操作,索引需要一个用户信息表 (1)创建数据库 -- 创建数据库 DROP DATABASE IF EXISTS trans_test; CREATE DATABASE trans_test DEFAULT CHARACTER SET utf8mb4;…...
——AXI 接口MIG 使用(2))
从零开始讲DDR(9)——AXI 接口MIG 使用(2)
一、前言 在之前的文章中,我们介绍了官方DDR MIG AXI接口的例程的整体框架,在本文中,我们将着重介绍例程中关于数据产生,及驱动到AXI接口的相关逻辑实现。 二、data_gen 在例程中,有ddr4_v2_2_8_data_gen这样一个文件…...

组件通信-props
props 是使用频率最高的一种通信方式,父>子 子>父 父传子:属性值 是非函数子传父:属性值 是函数 父组件 <script setup lang"ts"> import { ref } from vue import Child from ./Child.vue const car ref(奥迪) c…...

纯原生Java实现:获取整个项目中指定接口所有的实现类
不使用第三方,不使用属性文件,不指定包名,获取整个系统中某一个接口所有的实现类,纯Java实现 /*** 类查找器,用于扫描类路径中的所有类,并找出指定类的实现类。* 该类通过递归扫描类路径下的所有 .class 文件…...

反射机制补充
不同对象实例的地址不同 在 Java 里,每当使用 new 关键字创建一个对象时,JVM 会在堆内存中为该对象分配一块新的内存空间,每个对象实例都有自己独立的内存地址。所以不同的对象实例,其内存地址是不同的。 以下是一个简单示例&am…...

计算机视觉的未来发展趋势
计算机视觉的未来发展趋势主要集中在以下几个方面: 1. 自监督学习与少样本学习 自监督学习:通过从无标签的数据中提取有用特征,克服对大量标注数据的依赖。2025年,基于大规模图像数据的自监督预训练模型将更加成熟,能…...

轻量级网页版视频播放器
用deepseek开发的轻量级,网页版视频播放器 可以选择本地文件 可以播放、暂停、全屏、有进度条和时间进度 代码如下: 新建.txt文本文档,把代码复制粘贴进去,把.txt文档后缀名改为.html,用浏览器打开即可使用 <!DO…...

18. LangChain分布式任务调度:大规模应用的性能优化
引言:从单机到万级并发的进化 2025年某全球客服系统通过LangChain分布式改造,成功应对黑五期间每秒12,000次的咨询请求。本文将基于LangChain的分布式架构,详解如何实现AI任务的自动扩缩容与智能调度。 一、分布式系统核心指标 1.1 性能基准…...

C/C++工程师使用 DeepSeek
一、使用 DeepSeek 生成 C/C 代码 在 C/C 开发中,很多时候需要编写一些常见功能的代码,如排序算法、文件读写操作、数据结构的实现等。借助 DeepSeek,工程师只需用自然语言清晰描述需求,它就能依据大量的代码数据和深度学习算法&a…...
实现)
数据结构-线性结构(链表、栈、队列)实现
公共头文件common.h #define TRUE 1 #define FALSE 0// 定义节点数据类型 #define DATA_TYPE int单链表C语言实现 SingleList.h #pragma once#include "common.h"typedef struct Node {DATA_TYPE data;struct Node *next; } Node;Node *initList();void headInser…...
:简单务实的概率性选手)
第 7 篇:跳表 (Skip List):简单务实的概率性选手
前面几篇我们都在探讨各种基于“树”结构的有序表实现,它们通过精巧的平衡策略(高度、颜色、大小)和核心的“旋转”操作来保证 O(log N) 的性能。今天,我们要介绍一位画风完全不同的选手——跳表 (Skip List)。它不依赖树形结构&a…...

sys目录介绍
文章目录 1. 前言2. 目录层次3. 目录介绍3.1 devices 目录3.2 block 目录3.3 bus 目录3.4 class 目录3.5 dev 目录3.6 firmware目录3.7 fs 目录3.8 kernel目录3.9 module 目录3.10 power 目录 sys目录介绍 1. 前言 linux 下一切皆文件,文件的类型也很多,…...

基于DQN的自动驾驶小车绕圈任务
1.任务介绍 任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现 任务原始代码: self-driving car 最终效果: 以下所有内容,都是对上面DQN代码的改进&#…...

源码安装SRS4
Ubuntu20安装好SRS后,(源码安装) 注意:在trunk目录SRS ./objs/srs -c conf/srs.conf 以上为启动srs命令,-c 为指定配置文件, 查看SRS进程 ps aux | grep srs 查看端口: netstat -ano | gre…...

OrbitControls
OrbitControls 3D虚拟工厂在线体验 描述 Orbit controls(轨道控制器)可以使得相机围绕目标进行轨道运动。 Constructor OrbitControls( object : Camera, domElement : HTMLDOMElement ) 参数类型描述objectCamera(必须)将要…...