基于DQN的自动驾驶小车绕圈任务
1.任务介绍
任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现
任务原始代码: self-driving car
最终效果:
以下所有内容,都是对上面DQN代码的改进,在与deepseek的不断提问交互中学习理解代码,并且对代码做出改进,让小车能够尽可能的跑的远。
这个DQN代码依然有很多可改进的地方,受限于个人精力,没有再继续探索下去,欢迎指正交流。
后续会更新DDPG算法和PPO算法在此任务上的应用调试记录的代码。
2.调试记录
问题:使用原始DQN代码,小车很难学习到正确的策略去绕圈,并且跑的距离也很短
2.1 更改学习率(lr)和探索率(eps_end)
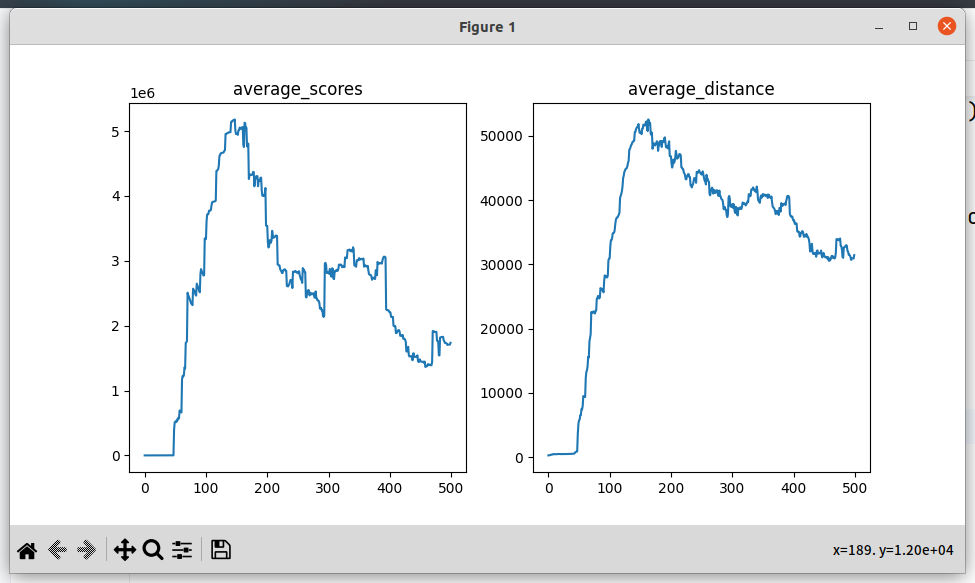
记录:图片为最初设置的average_score,增大减小都没有显著效果;
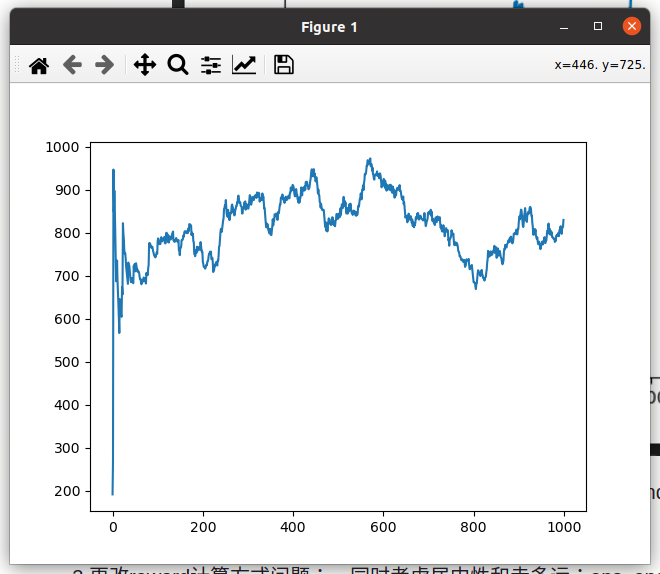
2.2 增加模型层数
记录:型采用三层,中间增加256*256的隐藏层;模型增加一层之后,效果显著提升,训练到400次的时候,average_score已经能够达到5.3w
原因:模型太简单了,这样的结构可能不足以捕捉复杂的状态空间,导致训练的效果差;
现阶段问题:横向是不太稳定的,小车跑起来方向频繁抖动,且整体流畅度不够
2.3 横纵向action细化,同时更改max_mem_size=1000000
记录:[5,0],[2,1],[2,-1],[0,1],[0,0],[0,-1],[-2,1],[-2,-1],[-5,0],一共9中组合;修改完之后流畅度有较大提升,avg_score也有很大提升;
2.4 奖励函数优化
记录:奖励函数去掉距离的概念,主要考虑居中性、速度的连续性、转角的连续性;可以看到avg_score已经可以达到非常大的值,变化趋势都是先持续增加,然后在迭代次数达到200-300次左右时震荡下降
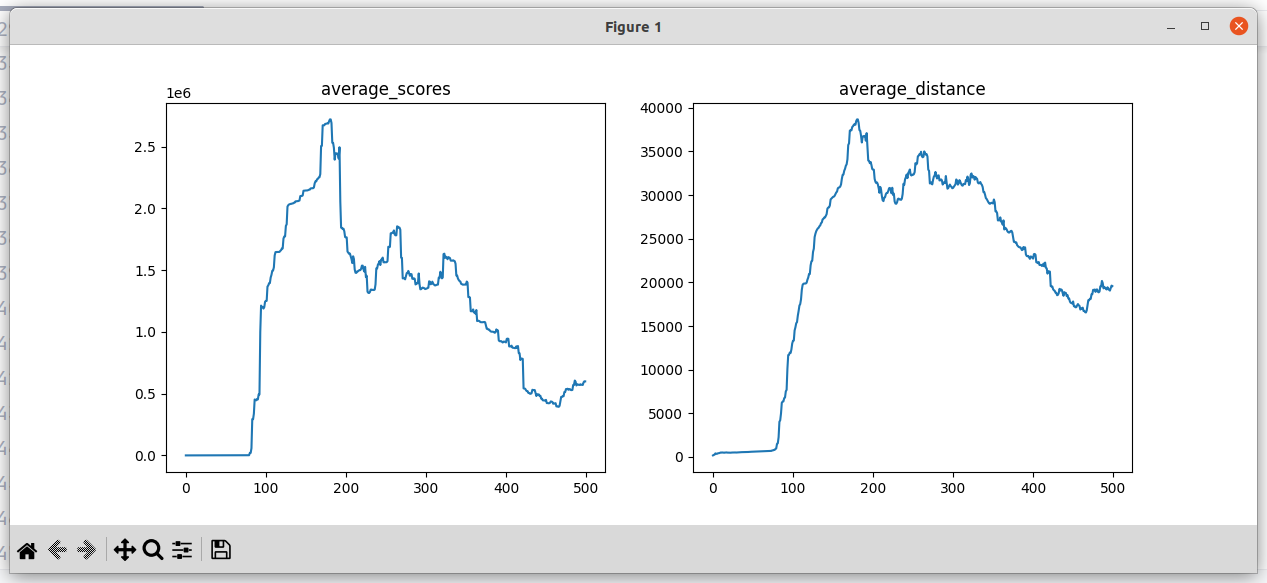
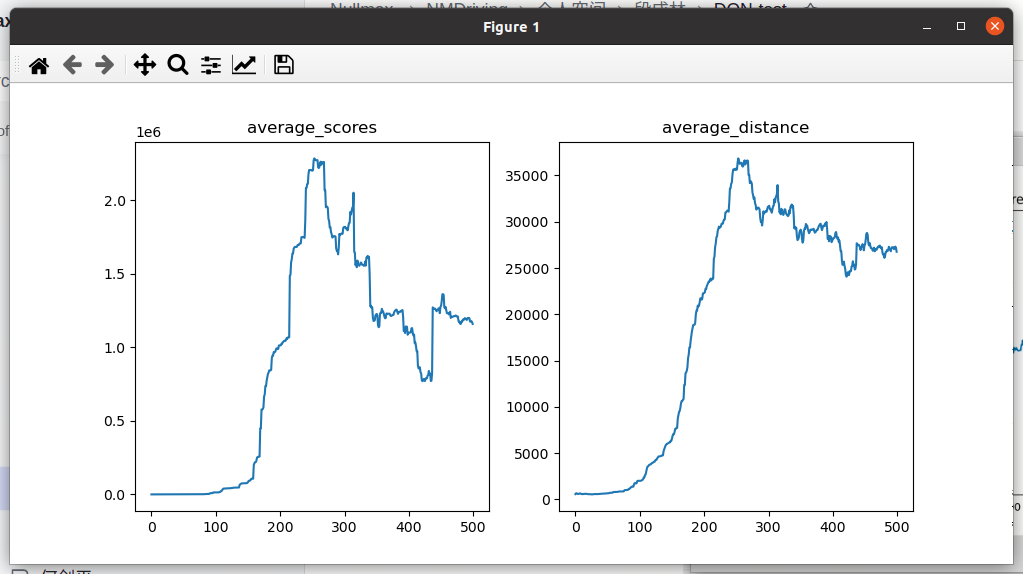
现阶段问题:avg_score变化趋势都是先持续增加,然后在迭代次数达到200-300次左右时震荡下降
2.5 增加目标网络,且目标网络更新用软更新
记录:原始DNQ代码中是没有目标网络的,训练震荡会比较大,增加目标网络可以稳定训练; 小车在行驶过程中频繁的小幅度左右摇头的情况变少了,不过感觉纵向的加减速比较频繁,目标网络用软更新之后明显感觉在两台电脑上训练起来性能提升都很快,70次左右的时候都达到了百万级别,前期分数异常高,后期分数抖动很大
2.6 状态中增加最小距离,自车车速,自车转角,使得问题符合MDP
记录:这一点其实早该考虑到的,原来的状态返回之后雷达距离,是缺少一些自车相关的信息
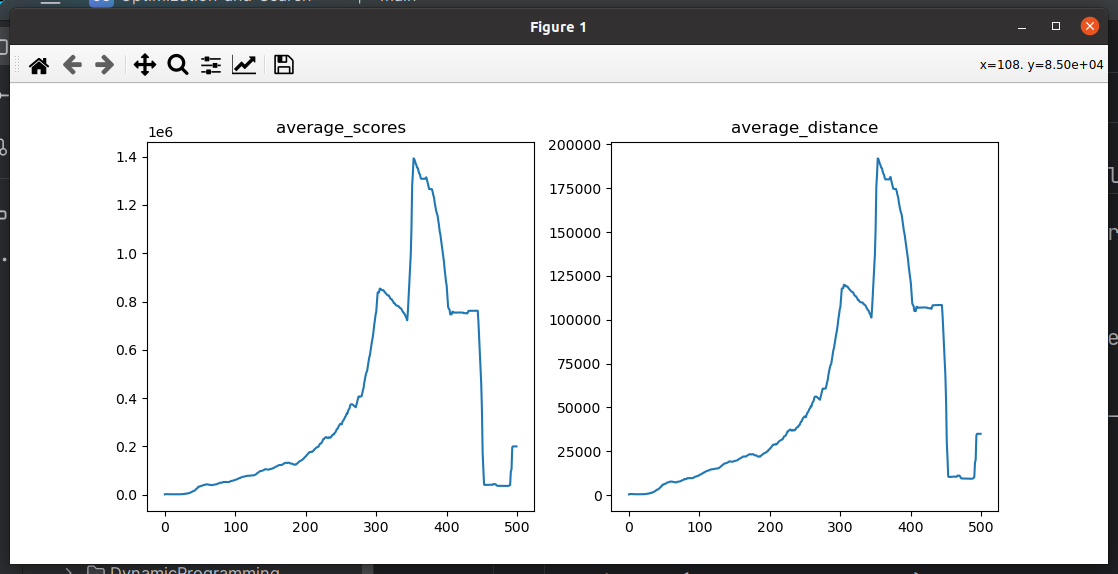
现阶段问题:模型在290次左右的时候score达到峰值,后面越训练得分越低
原因:核心原因应该还是之前的经验被遗忘导致的,memory_size由100W改为1000W就有很大改善了
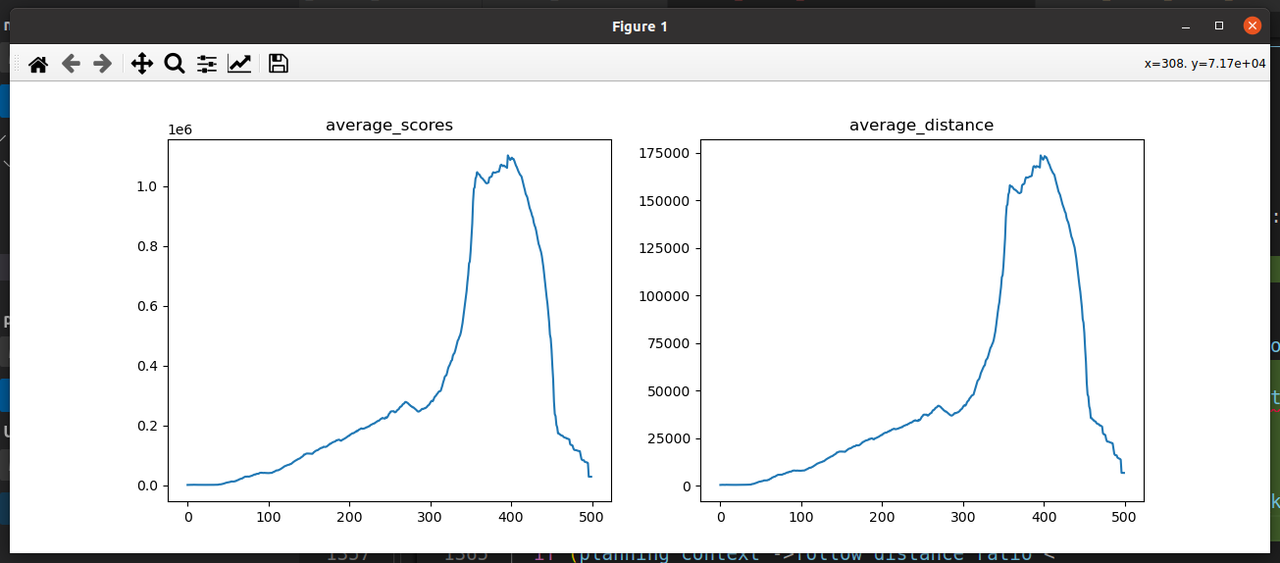
2.7 状态中雷达数据去掉强制int转换,防止丢失精度影响模型策略学习和泛化能力
记录:最大score能到250W了,并且mem_cntr已经远远超过100W,证明有帮助,不过仍然存在越训练score越低的情况,大概在sp355次左右;在去掉雷达int的强制转换之后,训练效果有很大提升;

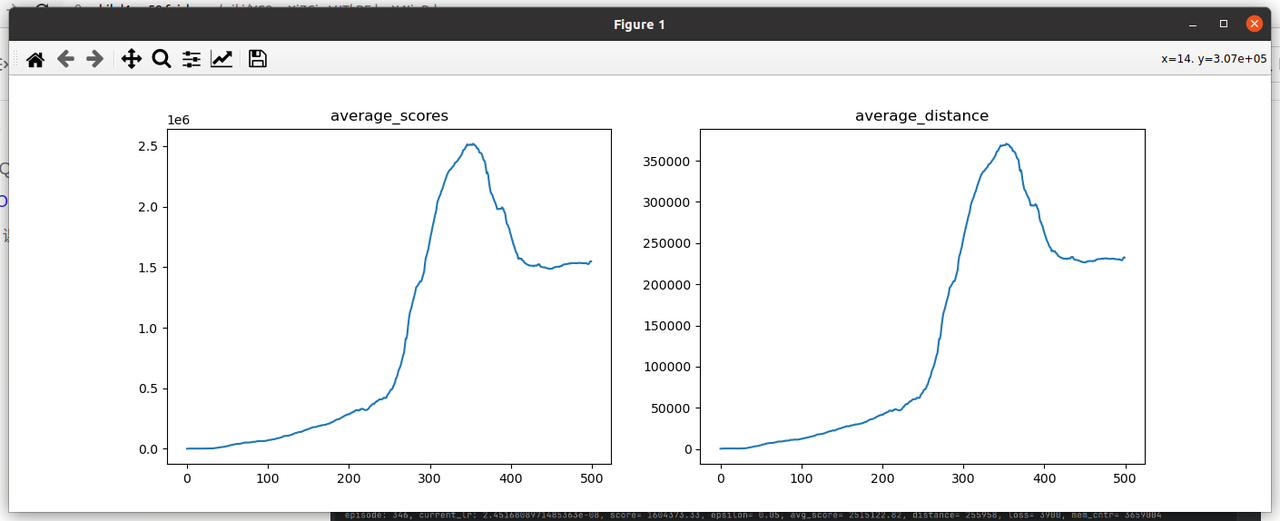
2.8 observation归一化
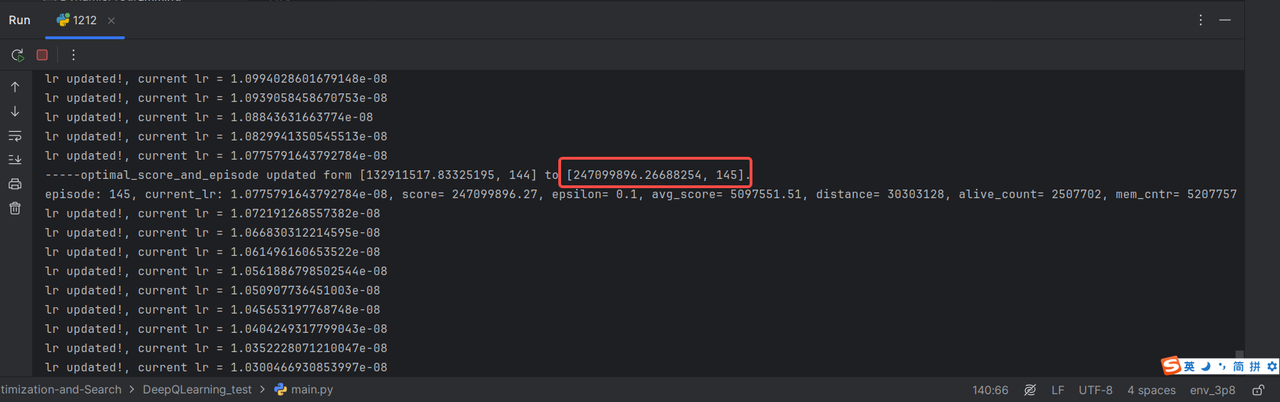
记录:episode 145,单次score已经能够达到2.5亿左右,平均score达到500W
3.代码主要改进点
3.1 DeepQNetwork
1.网络增加一层;
class DeepQNetwork(nn.Module):def __init__(self, lr, input_dims, n_actions):...# 网络增加一层self.fc1 = nn.Linear(*input_dims, 256)self.fc2 = nn.Linear(256, 256)self.fc3 = nn.Linear(256, n_actions)...
2.网络激活函数改变;
class DeepQNetwork(nn.Module):def forward(self, state):# 激活函数也做了一定的尝试变更x = F.relu(self.fc1(state))x = F.tanh(self.fc2(x))...
3.输出action做对应适配;
class DeepQNetwork(nn.Module):def forward(self, state):...# 输出action也做对应适配actions = self.fc3(x)return actions
3.2 Agent
1.增加目标网络,用于稳定训练;
class Agent:def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):...self.Q_eval = DeepQNetwork(lr, input_dims, n_actions)# 增加目标网络,用于稳定训练self.Q_target = DeepQNetwork(lr, input_dims, n_actions)...def learn_dqp(self, n_game):...# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]# 直接调self.Q_target(new_state_batch)和self.Q_eval.forward(new_state_batch)的效果是一样的q_next = self.Q_target(new_state_batch)...
2.增加学习率调度器(指数衰减);
class Agent:def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):...self.lr_min = 1e-6self.loss_value = 0# 新增学习率调度器(指数衰减)self.lr_scheduler = optim.lr_scheduler.ExponentialLR(self.Q_eval.optimizer,gamma=0.995 # 每episode学习率衰减0.5%)self.action_memory = np.zeros(self.mem_size, dtype=np.int32)...def learn_dqp(self, n_game):...self.Q_eval.optimizer.step()# 学习率调整必须在参数更新之后if self.mem_cntr % 2000 == 0:if self.lr_scheduler.get_last_lr()[0] > self.lr_min:self.lr_scheduler.step() # 调整学习率print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))...
3.目标网络参数更新采用软更新;
class Agent:def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):...self.Q_target = DeepQNetwork(lr, input_dims, n_actions)self.update_target_freq = 1000 # 每1000步同步一次self.tau = 0.05 # 软更新系数...def soft_update_target(self):for target_param, param in zip(self.Q_target.parameters(),self.Q_eval.parameters()):target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)def learn_dqp(self, n_game):...# 软更新目标网络self.soft_update_target()...
4.增加了double-DQN的实现方式;
class Agent:def learn_double_dqp(self, n_game):# TODO: 看一下这一块是不是论文中提到的每间几千步更新一下?# 这一块他设定了一个batch_size=64,即每64个为一批,然后通过模型更新一下参数if self.mem_cntr < self.batch_size:returnself.Q_eval.optimizer.zero_grad()max_mem = min(self.mem_cntr, self.mem_size)batch = np.random.choice(max_mem, self.batch_size, replace=False)batch_index = np.arange(self.batch_size, dtype=np.int32)state_batch = torch.tensor(self.state_memory[batch]).to(self.Q_eval.device)new_state_batch = torch.tensor(self.new_state_memory[batch]).to(self.Q_eval.device)reward_batch = torch.tensor(self.reward_memory[batch]).to(self.Q_eval.device)terminal_batch = torch.tensor(self.terminal_memory[batch]).to(self.Q_eval.device)action_batch = self.action_memory[batch]# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]# ========== Double DQN修改部分 ==========q_eval_next = self.Q_eval(new_state_batch)max_actions = torch.argmax(q_eval_next, dim=1)# 输出为[batch_size,action_size],每一行对应随机选取的state,每一列对应当前state对应的每个action估计的Q值# print(q_eval_next)# 输出为每个state下能够得到最大Q值的action,dim为1*batch_size# print(max_actions)# 输出为每个state下能够得到最大Q值的action,不过将dim转换为了batch_size*1# print(max_actions.unsqueeze(1))# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,dim=batch_size*1# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)))# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,不过将dim转换为了1*batch_size# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1))q_next = self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1)q_next[terminal_batch] = 0.0q_target = reward_batch + self.gamma * q_next# =======================================# 估计Q值,因为Q值本来就是未来的预期奖励,我们通过估计未来的预期奖励和当前实际过得的预期奖励的差值,来更新# 模型,所以你最大化你的value function,就是在最优化你的policy本身loss = self.Q_eval.loss(q_target, Q_eval).to(self.Q_eval.device)self.loss_value = loss.item()loss.backward()# 添加梯度裁剪# torch.nn.utils.clip_grad_norm_(self.Q_eval.parameters(), max_norm=1.0)self.Q_eval.optimizer.step()# 学习率调整必须在参数更新之后if self.mem_cntr % 2000 == 0:if self.lr_scheduler.get_last_lr()[0] > self.lr_min:self.lr_scheduler.step() # 调整学习率print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))# 软更新目标网络self.soft_update_target()self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_min
3.3 Agent
1.小车返回状态优化;
状态中增加最小距离,自车车速,自车转角,使得问题符合MDP;
状态中雷达数据去掉强制int转换,防止丢失精度影响模型策略学习和泛化能力;
observation归一化;
class Car:def get_data(self):# Get Distances To Borderreturn_values = [0] * len(self.radars)self.current_lateral_min_dist = 60for i, radar in enumerate(self.radars):return_values[i] = radar[1] / 300.0if radar[1] < self.current_lateral_min_dist:self.current_lateral_min_dist = radar[1]angle_rad = np.deg2rad(self.angle)return_values = return_values + [self.current_lateral_min_dist / 30,np.clip(self.speed / 20.0, 0.0, 1.0),np.sin(angle_rad), np.cos(angle_rad)]return return_values
2.奖励函数优化;
主要去掉了距离的概念,引入居中性、速度连续性、转角连续性概念,这么设计是因为只要小车始终保持居中,并且有速度,小车就可以一直跑下去;
class Car:def get_reward_optimized(self, game_map, alive_count_total):# 居中性lateral_reward = 1.0# print(self.current_lateral_min_dist)if self.current_lateral_min_dist / 60 > 0.5:lateral_reward = self.current_lateral_min_dist / 60elif self.current_lateral_min_dist / 60 < 0.4:lateral_reward = -0.5else:lateral_reward = 0.0# 速度基础speed_base_reward = self.speed / min(12 + alive_count_total / 100000, 20)# 速度连续性if len(self.speed_memory) >= 4:self.speed_memory = self.speed_memory[1:]self.speed_memory.append(self.speed)speed_up_discount = 1.0if self.speed_memory[-1] - self.speed_memory[0] >= 3 and lateral_reward > 0.0:speed_up_discount = -0.5elif self.speed_memory[-1] - self.speed_memory[0] >= 2 and lateral_reward > 0.0:speed_up_discount = 0.7# 转角连续性,写的随意了点,目的就是防止方向左右抖动angle_discount = 1.0if len(self.angle_memory) >= 5:self.angle_memory = self.angle_memory[1:]self.angle_memory.append(self.angle)aaa = [0] * 4if len(self.angle_memory) >= 5:for i in range(1, 5):aaa[i-1] = self.angle_memory[i] - self.angle_memory[i-1]bbb = [0] * 3for j in range(1, 4):bbb[j-1] = 1 if aaa[j-1] * aaa[j] < 0 else 0if sum(bbb) >= 3 and lateral_reward > 0.0:angle_discount = 0.8# print(lateral_reward, speed_up_discount, angle_discount, " ====== ", self.speed_memory)return 100 * lateral_reward * speed_up_discount * angle_discount
3.4 train
1.action优化;
def train():...agent = Agent(gamma=0.99, epsilson=1.0, batch_size=256, n_actions=9,eps_end=0.1, input_dims=[num_radar + 4], lr=0.005,max_mem_size=1000000, eps_dec=1e-4)...while not done:action = agent.choose_action(observation)# [5,0],[2,1],[2,-1],[0,1],[0,0],[0,-1],[-2,1],[-2,-1],[-5,0]if action == 0:car.angle += 5car.speed += 0elif action == 1:car.angle += 2if car.speed < 20:car.speed += 1elif action == 2:car.angle += 2if car.speed - 1 >= 12:car.speed -= 1elif action == 3:car.angle += 0if car.speed < 20:car.speed += 1elif action == 4:car.angle += 0car.speed += 0elif action == 5:car.angle += 0if car.speed - 1 >= 12:car.speed -= 1elif action == 6:car.angle -= 2if car.speed < 20:car.speed += 1elif action == 7:car.angle -= 2if car.speed - 1 >= 12:car.speed -= 1else:car.angle -= 5car.speed += 0...
4.任务思考
1.DQN为什么不能处理连续控制性问题?
DQN的核心思想是为每个可能的动作计算Q值,并选择Q值最大的动作。在连续动作空间中,动作是无限多的,连续动作空间离散化会造成维度灾难
2.DQN总是过估计的原因?

一方面总是取max操作;另一方面用自己的估计再去估计自己,如果当前已经出现高估,那么下一轮的TD-target更会高估,相当于高估会累计
3.计算loss时,q_target对应的是每个状态下的最大Q值的动作,而Q_eval对应的却是从action_memory中随机选取的一批动作。这样是否会导致动作不匹配的问题,进而影响学习效果?
在DQN中,q_target的计算遵循目标策略(最大化Q值),而Q_eval基于行为策略(实际执行的动作)。这种分离是Q-learning的核心设计,不会导致动作不匹配问题,反而是算法收敛的关键。
Q_eval的作用:
估实际动评作的价值:即使动作是随机探索的,也需要知道这些动作的历史价值。
更新方向:
通过loss = (q_target - Q_eval)^2,将实际动作的Q值向更优的目标值调整。
q_target的作用:
引导策略优化:通过最大化下一状态的Q值,逐步将策略向最优方向推进。
5.完整代码
from typing import AsyncGenerator
import pygame
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import math
import osclass DeepQNetwork(nn.Module):def __init__(self, lr, input_dims, n_actions):super(DeepQNetwork, self).__init__()self.input_dims = input_dimsself.n_actions = n_actions# 网络增加一层self.fc1 = nn.Linear(*input_dims, 256)self.fc2 = nn.Linear(256, 256)self.fc3 = nn.Linear(256, n_actions)self.fc = nn.Linear(*input_dims, n_actions)self.optimizer = optim.Adam(self.parameters(), lr=lr)self.loss = nn.MSELoss()self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.to(self.device)def forward(self, state):# 激活函数也做了一定的尝试变更x = F.relu(self.fc1(state))x = F.tanh(self.fc2(x))# 输出action也做对应适配actions = self.fc3(x)return actionsclass Agent:def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):self.gamma = gammaself.epsilon = epsilsonself.eps_min = eps_endself.eps_dec = eps_decself.lr = lrself.action_space = [i for i in range(n_actions)]self.mem_size = max_mem_size # memory sizeself.batch_size = batch_sizeself.mem_cntr = 0 # memory currentself.input_dims = input_dimsself.n_actions = n_actionsself.Q_eval = DeepQNetwork(lr, input_dims, n_actions)self.Q_target = DeepQNetwork(lr, input_dims, n_actions)self.update_target_freq = 1000 # 每1000步同步一次self.tau = 0.05 # 软更新系数self.lr_min = 1e-6self.state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)self.new_state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)self.loss_value = 0# 新增学习率调度器(指数衰减)self.lr_scheduler = optim.lr_scheduler.ExponentialLR(self.Q_eval.optimizer,gamma=0.995 # 每episode学习率衰减0.5%)self.action_memory = np.zeros(self.mem_size, dtype=np.int32)self.reward_memory = np.zeros(self.mem_size, dtype=np.float32)self.terminal_memory = np.zeros(self.mem_size, dtype=bool)def store_transition(self, state_old, action, reward, state_new, done):index = self.mem_cntr % self.mem_sizeself.state_memory[index] = state_oldself.new_state_memory[index] = state_newself.reward_memory[index] = rewardself.action_memory[index] = actionself.terminal_memory[index] = doneself.mem_cntr += 1def choose_action(self, observation):if np.random.random() > self.epsilon:state = torch.tensor([observation], dtype=torch.float32).to(self.Q_eval.device)actions = self.Q_eval.forward(state)action = torch.argmax(actions).item()else:action = np.random.choice(self.action_space)return actiondef soft_update_target(self):for target_param, param in zip(self.Q_target.parameters(),self.Q_eval.parameters()):target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)def learn_dqp(self, n_game):# TODO: 看一下这一块是不是论文中提到的每间几千步更新一下?# 这一块他设定了一个batch_size=64,即每64个为一批,然后通过模型更新一下参数if self.mem_cntr < self.batch_size:returnself.Q_eval.optimizer.zero_grad()max_mem = min(self.mem_cntr, self.mem_size)batch = np.random.choice(max_mem, self.batch_size, replace=False)batch_index = np.arange(self.batch_size, dtype=np.int32)state_batch = torch.tensor(self.state_memory[batch]).to(self.Q_eval.device)new_state_batch = torch.tensor(self.new_state_memory[batch]).to(self.Q_eval.device)reward_batch = torch.tensor(self.reward_memory[batch]).to(self.Q_eval.device)terminal_batch = torch.tensor(self.terminal_memory[batch]).to(self.Q_eval.device)action_batch = self.action_memory[batch]# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]# 直接调self.Q_target(new_state_batch)和self.Q_eval.forward(new_state_batch)的效果是一样的q_next = self.Q_target(new_state_batch)# 终止状态(Terminal State):如果当前状态转移后进入终止状态(例如游戏结束、任务完成或失败),# 则没有下一个状态s′,因此未来累积奖励的期望值为0。q_next[terminal_batch] = 0.0# 目标网络对每个state对应能够得到的最大Q值的action# print(torch.max(q_next, dim=1))# 目标网络对每个state对应能够得到的最大Q值# print(torch.max(q_next, dim=1)[0])q_target = reward_batch + self.gamma * torch.max(q_next, dim=1)[0]# 估计Q值,因为Q值本来就是未来的预期奖励,我们通过估计未来的预期奖励和当前实际过得的预期奖励的差值,来更新# 模型,所以你最大化你的value function,就是在最优化你的policy本身loss = self.Q_eval.loss(q_target, Q_eval).to(self.Q_eval.device)self.loss_value = loss.item()loss.backward()# 添加梯度裁剪# torch.nn.utils.clip_grad_norm_(self.Q_eval.parameters(), max_norm=1.0)self.Q_eval.optimizer.step()# 学习率调整必须在参数更新之后if self.mem_cntr % 2000 == 0:if self.lr_scheduler.get_last_lr()[0] > self.lr_min:self.lr_scheduler.step() # 调整学习率print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))# 软更新目标网络self.soft_update_target()self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_mindef learn_double_dqp(self, n_game):# TODO: 看一下这一块是不是论文中提到的每间几千步更新一下?# 这一块他设定了一个batch_size=64,即每64个为一批,然后通过模型更新一下参数if self.mem_cntr < self.batch_size:returnself.Q_eval.optimizer.zero_grad()max_mem = min(self.mem_cntr, self.mem_size)batch = np.random.choice(max_mem, self.batch_size, replace=False)batch_index = np.arange(self.batch_size, dtype=np.int32)state_batch = torch.tensor(self.state_memory[batch]).to(self.Q_eval.device)new_state_batch = torch.tensor(self.new_state_memory[batch]).to(self.Q_eval.device)reward_batch = torch.tensor(self.reward_memory[batch]).to(self.Q_eval.device)terminal_batch = torch.tensor(self.terminal_memory[batch]).to(self.Q_eval.device)action_batch = self.action_memory[batch]# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]# ========== Double DQN修改部分 ==========q_eval_next = self.Q_eval(new_state_batch)max_actions = torch.argmax(q_eval_next, dim=1)# 输出为[batch_size,action_size],每一行对应随机选取的state,每一列对应当前state对应的每个action估计的Q值# print(q_eval_next)# 输出为每个state下能够得到最大Q值的action,dim为1*batch_size# print(max_actions)# 输出为每个state下能够得到最大Q值的action,不过将dim转换为了batch_size*1# print(max_actions.unsqueeze(1))# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,dim=batch_size*1# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)))# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,不过将dim转换为了1*batch_size# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1))q_next = self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1)q_next[terminal_batch] = 0.0q_target = reward_batch + self.gamma * q_next# =======================================# 估计Q值,因为Q值本来就是未来的预期奖励,我们通过估计未来的预期奖励和当前实际过得的预期奖励的差值,来更新# 模型,所以你最大化你的value function,就是在最优化你的policy本身loss = self.Q_eval.loss(q_target, Q_eval).to(self.Q_eval.device)self.loss_value = loss.item()loss.backward()# 添加梯度裁剪# torch.nn.utils.clip_grad_norm_(self.Q_eval.parameters(), max_norm=1.0)self.Q_eval.optimizer.step()# 学习率调整必须在参数更新之后if self.mem_cntr % 2000 == 0:if self.lr_scheduler.get_last_lr()[0] > self.lr_min:self.lr_scheduler.step() # 调整学习率print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))# 软更新目标网络self.soft_update_target()self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_minWIDTH = 1920
HEIGHT = 1080
CAR_SIZE_X = 60
CAR_SIZE_Y = 60
BORDER_COLOR = (255, 255, 255, 255) # Color To Crash on Hit
current_generation = 0 # Generation counterclass Car:def __init__(self, boundary_x, boundary_y, num_radar):# Load Car Sprite and Rotateself.sprite = pygame.image.load('car.png').convert() # Convert Speeds Up A Lotself.sprite = pygame.transform.scale(self.sprite, (CAR_SIZE_X, CAR_SIZE_Y))self.rotated_sprite = self.sprite# self.position = [690, 740] # Starting Positionself.position = [830, 920] # Starting Positionself.angle = 0self.angle_memory = []self.speed = 0self.speed_memory = []self.speed_set = False # Flag For Default Speed Later onself.center = [self.position[0] + CAR_SIZE_X / 2, self.position[1] + CAR_SIZE_Y / 2] # Calculate Centerself.radars = [[(0, 0), 60]] * num_radar # List For Sensors / Radarsself.drawing_radars = [] # Radars To Be Drawnself.current_lateral_min_dist = 60self.alive = True # Boolean To Check If Car is Crashedself.distance = 0 # Distance Drivenself.time = 0 # Time Passedself.width = 0self.height = 0self.boundary_x = boundary_xself.boundary_y = boundary_ydef draw(self, screen):screen.blit(self.rotated_sprite, self.position) # Draw Spriteself.draw_radar(screen) # OPTIONAL FOR SENSORSdef draw_radar(self, screen):# Optionally Draw All Sensors / Radarsfor radar in self.radars:position = radar[0]pygame.draw.line(screen, (0, 255, 0), self.center, position, 1)pygame.draw.circle(screen, (0, 255, 0), position, 5)def check_collision(self, game_map):self.alive = Truefor point in self.corners:# If Any Corner Touches Border Color -> Crash# Assumes Rectangleif game_map.get_at((int(point[0]), int(point[1]))) == BORDER_COLOR:self.alive = Falsebreakdef check_radar(self, degree, game_map):length = 0x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)# While We Don't Hit BORDER_COLOR AND length < 300 (just a max) -> go further and furtherwhile not game_map.get_at((x, y)) == BORDER_COLOR and length < 300:length = length + 1x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)# Calculate Distance To Border And Append To Radars List TODO: update dist calculatedist = int(math.sqrt(math.pow(x - self.center[0], 2) + math.pow(y - self.center[1], 2)))self.radars.append([(x, y), dist])def update(self, game_map):# Set The Speed To 20 For The First Time# Only When Having 4 Output Nodes With Speed Up and Downif not self.speed_set:self.speed = 10self.speed_set = Trueself.width, self.height = game_map.get_size()# Get Rotated Sprite And Move Into The Right X-Direction# Don't Let The Car Go Closer Than 20px To The Edgeself.rotated_sprite = self.rotate_center(self.sprite, self.angle)self.position[0] += math.cos(math.radians(360 - self.angle)) * self.speedself.position[0] = max(self.position[0], 20)self.position[0] = min(self.position[0], WIDTH - 120)# Increase Distance and Timeself.distance += self.speedself.time += 1# Same For Y-Positionself.position[1] += math.sin(math.radians(360 - self.angle)) * self.speedself.position[1] = max(self.position[1], 20)self.position[1] = min(self.position[1], WIDTH - 120)# Calculate New Centerself.center = [int(self.position[0]) + CAR_SIZE_X / 2, int(self.position[1]) + CAR_SIZE_Y / 2]# print("center: {}".format(self.center))# Calculate Four Corners# Length Is Half The Sidelength = 0.5 * CAR_SIZE_Xleft_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 30))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 30))) * length]right_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 150))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 150))) * length]left_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 210))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 210))) * length]right_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 330))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 330))) * length]self.corners = [left_top, right_top, left_bottom, right_bottom]# Check Collisions And Clear Radarsself.check_collision(game_map)self.radars.clear()# From -90 To 120 With Step-Size 45 Check Radarfor d in range(-120, 126, 15): # -90,-45,0,45,90zself.check_radar(d, game_map)def get_data(self):# Get Distances To Borderreturn_values = [0] * len(self.radars)self.current_lateral_min_dist = 60for i, radar in enumerate(self.radars):return_values[i] = radar[1] / 300.0if radar[1] < self.current_lateral_min_dist:self.current_lateral_min_dist = radar[1]angle_rad = np.deg2rad(self.angle)return_values = return_values + [self.current_lateral_min_dist / 30,np.clip(self.speed / 20.0, 0.0, 1.0),np.sin(angle_rad), np.cos(angle_rad)]return return_valuesdef is_alive(self):# Basic Alive Functionreturn self.alivedef get_reward_optimized(self, game_map, alive_count_total):# 居中性lateral_reward = 1.0# print(self.current_lateral_min_dist)if self.current_lateral_min_dist / 60 > 0.5:lateral_reward = self.current_lateral_min_dist / 60elif self.current_lateral_min_dist / 60 < 0.4:lateral_reward = -0.5else:lateral_reward = 0.0# 速度基础speed_base_reward = self.speed / min(12 + alive_count_total / 100000, 20)# 速度连续性if len(self.speed_memory) >= 4:self.speed_memory = self.speed_memory[1:]self.speed_memory.append(self.speed)speed_up_discount = 1.0if self.speed_memory[-1] - self.speed_memory[0] >= 3 and lateral_reward > 0.0:speed_up_discount = -0.5elif self.speed_memory[-1] - self.speed_memory[0] >= 2 and lateral_reward > 0.0:speed_up_discount = 0.7# 转角连续性angle_discount = 1.0if len(self.angle_memory) >= 5:self.angle_memory = self.angle_memory[1:]self.angle_memory.append(self.angle)aaa = [0] * 4if len(self.angle_memory) >= 5:for i in range(1, 5):aaa[i-1] = self.angle_memory[i] - self.angle_memory[i-1]bbb = [0] * 3for j in range(1, 4):bbb[j-1] = 1 if aaa[j-1] * aaa[j] < 0 else 0if sum(bbb) >= 3 and lateral_reward > 0.0:angle_discount = 0.8# print(lateral_reward, speed_up_discount, angle_discount, " ====== ", self.speed_memory)return 100 * lateral_reward * speed_up_discount * angle_discountdef rotate_center(self, image, angle):# Rotate The Rectanglerectangle = image.get_rect()rotated_image = pygame.transform.rotate(image, angle)rotated_rectangle = rectangle.copy()rotated_rectangle.center = rotated_image.get_rect().centerrotated_image = rotated_image.subsurface(rotated_rectangle).copy()return rotated_imagedef train():pygame.init()screen = pygame.display.set_mode((WIDTH, HEIGHT))game_map = pygame.image.load('map.png').convert() # Convert Speeds Up A Lotclock = pygame.time.Clock()num_radar = 17agent = Agent(gamma=0.99, epsilson=1.0, batch_size=256, n_actions=9,eps_end=0.1, input_dims=[num_radar + 4], lr=0.005,max_mem_size=1000000, eps_dec=1e-4)scores, eps_history = [], []average_scores = []distance = []average_distance = []alive_counts = []average_alive_counts = []n_games = 500optimal_score_and_episode = [0, 0]for i in range(n_games):car = Car([], [], num_radar)done = Falsescore = 0observation = car.get_data()alive_count = 0while not done:action = agent.choose_action(observation)# [5,0],[2,1],[2,-1],[0,1],[0,0],[0,-1],[-2,1],[-2,-1],[-5,0]if action == 0:car.angle += 5car.speed += 0elif action == 1:car.angle += 2if car.speed < 20:car.speed += 1elif action == 2:car.angle += 2if car.speed - 1 >= 12:car.speed -= 1elif action == 3:car.angle += 0if car.speed < 20:car.speed += 1elif action == 4:car.angle += 0car.speed += 0elif action == 5:car.angle += 0if car.speed - 1 >= 12:car.speed -= 1elif action == 6:car.angle -= 2if car.speed < 20:car.speed += 1elif action == 7:car.angle -= 2if car.speed - 1 >= 12:car.speed -= 1else:car.angle -= 5car.speed += 0screen.blit(game_map, (0, 0))car.update(game_map)car.draw(screen)pygame.display.flip()clock.tick(60)observation_, reward, done = car.get_data(), car.get_reward_optimized(game_map,agent.mem_cntr), not car.is_alive()score += rewardagent.store_transition(observation, action, reward, observation_, done)agent.learn_double_dqp(i)observation = observation_alive_count += 1if score > optimal_score_and_episode[0]:print("-----optimal_score_and_episode updated form {} to {}.".format(optimal_score_and_episode,[score, i]))optimal_score_and_episode = [score, i]state = {'eval_state': agent.Q_eval.state_dict(),'target_state': agent.Q_target.state_dict(),'eval_optimizer_state': agent.Q_eval.optimizer.state_dict(),'target_optimizer_state': agent.Q_target.optimizer.state_dict(),'optimal_score_and_episode': optimal_score_and_episode}torch.save(state, f'./dqn_eval.pth')# TODO:待改进,加载模型创建临时环境让小车随即初始化位置跑若干次,并且跑的时候保留最低的探索率,# 取score平均值,平均值大的模型保存下来scores.append(score)eps_history.append(agent.epsilon)avg_score = np.mean(scores[-100:])average_scores.append(avg_score)distance.append(car.distance)avg_distance = np.mean(distance[-100:])average_distance.append(avg_distance)alive_counts.append(alive_count)avg_alive_count = np.mean(alive_counts[-100:])average_alive_counts.append(avg_alive_count)# 打印当前学习率(调试用)current_lr = agent.lr_scheduler.get_last_lr()[0]print(f'episode: {i}, current_lr: {current_lr}, score= {round(score, 2)}, epsilon= {round(agent.epsilon, 3)},'f' avg_score= {round(avg_score, 2)}, distance= {round(car.distance)}, loss= {round(agent.loss_value)}, 'f'alive_count= {round(alive_count)}, mem_cntr= {agent.mem_cntr}')plt.subplot(1, 2, 1)plt.plot([i for i in range(0, n_games)], average_scores)plt.title("average_scores")plt.subplot(1, 2, 2)plt.plot([i for i in range(0, n_games)], average_distance)plt.title("average_distance")plt.show()if __name__ == '__main__':train()
相关文章:

基于DQN的自动驾驶小车绕圈任务
1.任务介绍 任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现 任务原始代码: self-driving car 最终效果: 以下所有内容,都是对上面DQN代码的改进&#…...

源码安装SRS4
Ubuntu20安装好SRS后,(源码安装) 注意:在trunk目录SRS ./objs/srs -c conf/srs.conf 以上为启动srs命令,-c 为指定配置文件, 查看SRS进程 ps aux | grep srs 查看端口: netstat -ano | gre…...

OrbitControls
OrbitControls 3D虚拟工厂在线体验 描述 Orbit controls(轨道控制器)可以使得相机围绕目标进行轨道运动。 Constructor OrbitControls( object : Camera, domElement : HTMLDOMElement ) 参数类型描述objectCamera(必须)将要…...

【数据库】四种连表查询:内连接,外连接,左连接,右连接
在数据库操作中,连表查询是处理多表关联的核心技术。以下是四种主要连接方式的详细介绍、快速掌握方法及实际应用指南: 目录 **一、四种连表查询详解****1. 内连接(INNER JOIN)****2. 左连接(LEFT JOIN / LEFT OUTER J…...

Redis怎么避免热点数据问题
使用 RedisTemplate 避免热点数据问题的解决方案、场景及示例: 1. 数据分片(Sharding) 场景:高频读写的计数器(如文章阅读量统计) 原理:将数据分散到多个子键,降低单个 Key 的压…...

完整的 VS Code + CMake + Qt + GCC 项目构建方案:EXE 程序与多个 DLL 库
完整的 VS Code CMake Qt GCC 项目构建方案:EXE 程序与多个 DLL 库 在本文中,我们将介绍如何构建一个包含 EXE 程序和多个 DLL 库的项目,适用于 VS Code CMake Qt GCC 开发环境。这个方案为一个模块化的项目结构,使得代码清…...
:智能流失预警 - 融合文本反馈)
Python 数据智能实战 (7):智能流失预警 - 融合文本反馈
写在前面 —— 不再错过关键预警!结合用户行为与 LLM 文本洞察,构建更精准的流失预测模型 在之前的探索中,我们学习了如何利用大语言模型 (LLM) 对用户评论进行深度挖掘,提取情感、发现主题,并将非结构化的文本信息转化为有价值的特征 (如 Embeddings)。 现在,我们要将…...

Flutter - 概览
Hello world ⌘ shift p 选择 Empty Application 模板 // 导入Material风格的组件包 // 位置在flutter安装目录/packages/flutter/lib/material.dart import package:flutter/material.dart;void main() {// runApp函数接收MainApp组件并将这个Widget作为根节点runApp(cons…...
及Excel表格列名操作详细分享)
Python-pandas-操作Excel文件(读取数据/写入数据)及Excel表格列名操作详细分享
Python-pandas-操作Excel文件(读取数据/写入数据) 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每…...

手写 Vue 源码 === Vue3 设计思想
1.声明式框架 Vue3 是声明式的框架,用起来简单。 命令式和声明式区别 早在 JQ 的时代编写的代码都是命令式的,命令式框架重要特点就是关注过程声明式框架更加关注结果。命令式的代码封装到了 Vuejs 中,过程靠 vuejs 来实现声明式代码更加简单,不需要关注实现,按照要求填代…...

Android WebView加载h5打开麦克风与摄像头的权限问题
目录 快速处理 app向系统申请录音与相机权限h5向app申请录音和相机权限 详细解答 app权限与h5权限录音与麦克风默许的风险最佳实践 Android webview h5 麦克风权限,摄像头(相机)权限实现与填坑。 快速处理 app向系统申请录音与相机权限 …...

三种计算最小公倍数的方法分析
三种计算最小公倍数的方法分析与比较 一.引言 最小公倍数(Least Common Multiple, LCM)是数学中的一个基本概念,指能够被两个或多个整数整除的最小的正整数。在编程中,我们有多种方法可以计算两个数的最小公倍数。本文将分析三种…...

PDF转换工具xpdf-tools-4.05
XPDF是一个开源的PDF查看、提取和转换工具套件,使用C编写,支持多种操作系统,包括Linux、Unix、OS/2、Windows和Mac OS X1。XPDF不仅是一个PDF查看器,还包含多个实用工具,如文本提取器、图像转换器和HTML转换器等&a…...
 image-content-search)
aws(学习笔记第四十课) image-content-search
aws(学习笔记第四十课) image-content-search 使用SQS Lambda集成 数据库(Aurora Serverless) Cognito(用户管理) rekognition(图像解析) 学习内容: 使用SQS Lambda Aurora Serverless Cog…...

GPT-4o 图像生成与八个示例指南
什么是GPT-4o图像生成? 简单来说,GPT-4o图像生成是集成在ChatGPT内部的一项功能。用户可以直接在对话中,通过文本描述(Prompt)来创建、编辑和调整图像。这与之前的图像生成工具相比,体验更流畅、交互性更强…...

PostgreSQL 查看表膨胀情况的方法
PostgreSQL 查看表膨胀情况的方法 表膨胀(Table Bloat)是PostgreSQL中由于MVCC机制导致的一种常见现象,当大量数据被更新或删除后,表中会积累"死元组"(dead tuples),这些死元组占据空间但不可见,导致表实际占用的磁盘空…...

从 0 到 1!深度剖析项目实施流程,开启项目管理新视野
一、项目准备 / 前期准备 (一)跟销售进行项目交接 对接人:销售人员交接会议内容: 了解项目背景、客户基本信息、项目版本、具备二次开发功能、接口、了解合同信息等。明确项目情况、客户基本情况、使用软件(版本&…...

书生实战营之沐曦专场
一:实验环境进入和启动实验容器(D.run平台) 1.1首先进入平台进行注册 D.run平台https://console.d.run/ 注册和登录环节就跳过了。 1.2 启动实验容器--详细步骤如下 1.2.1选择容器的名称、区域、镜像(注意镜像必须选择Dlinfer) 1.2.2可以选…...

在运行 Hadoop 作业时,遇到“No such file or directory”,如何在windows里打包在虚拟机里运行
最近在学习Hadoop集群map reduce分布运算过程中,经多方面排查可能是电脑本身配置的原因导致每次运行都会报“No such file or directory”的错误,最后我是通过打包文件到虚拟机里运行得到结果,具体步骤如下: 前提是要保证maven已经…...

基于YOLOV5的目标检测识别
基于YOLOV5的目标检测识别 舰船目标检测口罩目标检测飞机目标检测 舰船目标检测 口罩目标检测 飞机目标检测...

第4篇:服务层抽象与复用逻辑
在业务系统复杂度指数级增长的今天,服务层(Service Layer)的合理设计直接影响着系统的可维护性和扩展性。本文将深入剖析 Egg.js 框架中的服务层架构设计,从基础实现到高级封装,全方位讲解企业级应用的开发实践。 一、…...
)
多模态大语言模型arxiv论文略读(五十四)
RoboMP 2 ^2 2: A Robotic Multimodal Perception-Planning Framework with Multimodal Large Language Models ➡️ 论文标题:RoboMP 2 ^2 2: A Robotic Multimodal Perception-Planning Framework with Multimodal Large Language Models ➡️ 论文作者ÿ…...

中小企业MES系统详细设计
版本:V1.1 日期:2025年5月2日 一、设备协议兼容性设计 1.1 设备接入框架 #mermaid-svg-PkwqEMRIIlIBPP58 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-PkwqEMRIIlIBPP58 .error-icon{fill…...
)
第二十周:项目开发中遇到的相关问题(一)
自十九周开始,我们便开始着手写项目(关于新闻资讯类的Web项目),当然,在这之中我们也学到了很多高效且有用的好技术,在接下来的内容中将去具体的描述这些好技术,介绍它们的具体用法和应用场景。本…...

WebRtc10: 端对端1v1传输基本流程
媒体能力协商过程 RTCPeerConnection(核心类) 基本格式 pc new RTCPeerConnection([configiration]); RTCPeerConnection方法分类 媒体协商Stream/Track传输相关方法统计相关方法 媒体协商过程 协商状态变化 媒体协商方法 createOffercreateAnswe…...

【云备份】配置文件加载模块
目录 一.为什么要配置文件 二.配置文件的实现 三.单例文件配置类设计 四.源码 一.为什么要配置文件 我们将服务端程序运行中用到的一些关键信息保存到配置文件中,这样可以使程序的运行更加灵活。 这样做的好处是,未来如果我们想要修改一些关键信息&…...

重构之道:识别并替换不合适使用的箭头函数
1、引言 JavaScript 自 ES6 引入了箭头函数(Arrow Function)后,因其简洁的语法和对 this 的词法绑定机制,迅速成为开发者喜爱的写法之一。然而,并不是所有场景都适合使用箭头函数。 在实际开发中,我们常常会因为追求代码简洁而忽视其潜在问题,例如: this 指向错误不适…...

git问题记录-如何切换历史提交分支,且保留本地修改
问题记录 我在本地编写了代码,突然想查看之前提交的代码,并且想保留当前所在分支所做的修改 通过git stash对本地的代码进行暂存 使用git checkout <commit-hash>切换到之前的提交记录。 查看完之后我想切换回来,恢复暂存的本地代码…...

【MySQL】事务管理
事务管理 一. 事务的概念二. 事务的特征三. 事务的版本支持四. 事务的提交方式五. 事务的常见操作六. 事务的隔离级别1. 查看与设置隔离级别2. 读未提交 (Read Uncommitted)3. 读提交 (Read Committed)4. 可重复读 (Repeatable Read)5. 串行化 (Serializable)6. 隔离级别的总结…...
全解析】从原理到工程实践)
【点对点协议(PPP)全解析】从原理到工程实践
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心配置实现案例1:基础PPP链路建立案例2:CHAP认证配置 运行结果验证 三、性能对比测试…...

环境搭建:开启 Django 开发之旅
一、环境搭建:开启 Django 开发之旅 (一)安装 Python 先确保电脑上装有 Python 3.6 及以上版本,Django 5.1 的话,至少得 Python 3.8 哦。 安装前,先查下有没有装过 Python ,终端(Wi…...

如何配置NGINX作为反向代理服务器来缓存后端服务的响应?
大家好,我是锋哥。今天分享关于【如何配置NGINX作为反向代理服务器来缓存后端服务的响应?】面试题。希望对大家有帮助; 如何配置NGINX作为反向代理服务器来缓存后端服务的响应? 1000道 互联网大厂Java工程师 精选面试题-Java资源…...

【Java IO流】File类基础详解
参考笔记:java File类基础 万字详解(通俗易懂)-CSDN博客 目录 1.前言 2. File类介绍 3. File类构造方法 4.File类常用的方法案例演示 4.1 创建文件/文件夹的方法 4.2 删除文件/文件夹的方法 4.3 判断文件/文件夹是否存在的方法 4.4 …...

《C#数据结构与算法》—201线性表
线性表的实现方式 顺序表 线性表的顺序存储是指在内存中用一块地址连续的空间依次存放线性表的数据元素,用这种方式存储的线性表叫顺序表。 特点:表中相邻的数据元素在内存中存储位置也相邻。 顺序表接口实现: 方法名参数返回值描述GetLen…...

MATLAB绘制局部放大图
今天,我将分享一段 MATLAB 代码,该代码生成了一个主副图结合的可视化展示,用于比较不同控制系统性能表现。 clc; clear; close all;% 生成时间向量 t 0:0.1:12;% 生成模拟数据 zero_feedback 0.5 * ones(size(t)); % 恒定…...

TS 常用类型
JS不会检查变量类型的变化 给变量规定特定的数据类型,错误赋值时会报错 优势:TS会标记出代码中的意外行为,尤其是typeerrors 具体实现:类型注解 JS和TS中数据类型的变化...
)
[Control-Chaos] Toxic Cascade(毒性級鏈)
信息 信息描述靶場名稱Toxic Cascade地址GitHub: Toxic Cascade難度中等人數推薦1人類型CTF、APT 攻擊模擬、故事解謎、化工工程與逆向工程描述Toxic Cascade 是一個結合 CTF、APT 攻擊模擬、故事解謎、化工工程與逆向工程的高度沉浸式靶場。該靶場具有獨特的情境背景與模擬真…...

纳米AI搜索体验:MCP工具的实际应用测试,撰写报告 / 爬虫小红书效果惊艳
1. 引言 近期测试了纳米AI搜索的MCP工具功能,重点体验了其智能体在报告生成和社交媒体数据分析方面的表现。平台整合了100多个MCP工具,通过本地化部署的方式,为用户提供了不同于云端方案的操作体验。本文将分享实际测试结果,包括智…...

React useMemo函数
第一个参数是回调函数,返回计算的结果,第二个参数是依赖项,该函数只监听count1变量的变化 import { useReducer, useState } from react; import ./App.css;// 定义一个Reducer函数 根据不同的action进行不同的状态修改 function reducer(st…...

第 1 篇:起点的选择:为何需要超越数组与链表?
大家好,欢迎来到“数据结构选型指南”系列!在软件开发中,数据是核心,而如何高效地组织和访问这些数据,则是程序性能的关键。选择合适的数据结构,就像为你的 Java 应用选择最优的“引擎零件”。今天…...

MySQL 索引不生效的情况
MySQL 索引不生效的 SQL 查询需要避免的情况 索引是提高 MySQL 查询性能的关键,但某些 SQL 写法会导致索引失效,从而影响查询效率。以下是需要避免的常见情况: 1. 使用 NOT、! 或 <> 操作符 -- 索引可能失效 SELECT * FROM users WH…...
)
【阿里云大模型高级工程师ACP学习笔记】2.9 大模型应用生产实践 (上篇)
特别说明:由于这一章节是2025年3月官方重点更新的部分,新增内容非常多,因此我不得不整理成上、下两篇,方便大家参考。 学习目标 备考阿里云大模型高级工程师ACP认证,旨在全面掌握大模型应用生产实践的专业知识,提升在该领域的实操技能与理论水平,为职业发展增添助力。具…...

STM32 ZIBEE DL-20 无线串口模块
一.配置方法 二.串口中断 u8 i; u16 buf[20],res; u8 receiving_flag 0; // 新增一个标志,用于标记是否开始接收数组 void USART1_IRQHandler(void) {if(USART_GetITStatus(USART1, USART_IT_RXNE) ! RESET) //接收中断{res USART_ReceiveData(USART1);if(receiv…...

【算法基础】选择排序算法 - JAVA
一、算法基础 1.1 什么是选择排序 选择排序是一种简单直观的排序算法,它的工作原理是:首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小…...

FastAPI 与数据库交互示例
目录 安装必要的包完整代码示例运行应用使用说明API 端点说明代码解析 下面将创建一个简单的 FastAPI 应用程序,演示如何与 SQLite 数据库进行交互。这个例子包括创建、读取、更新和删除(CRUD)操作。 安装必要的包 首先,需要安装…...
RestAPI 毛子(Http resilience/Refit/游标分页))
(六——下)RestAPI 毛子(Http resilience/Refit/游标分页)
文章目录 项目地址一、Refit1.1 安装需要的包1.2 创建接口IGitHubApi1.3 创建RefitGitHubService1. 实现接口2. 注册服务 1.4 修改使用方法 二、Http resilience2.1 安装所需要的包2.2 创建resilience pipeline简单版2.3 创建全局的resilience处理1. 创建清理全局ResilienceHan…...

Rust 学习笔记:关于枚举与模式匹配的练习题
Rust 学习笔记:关于枚举与模式匹配的练习题 Rust 学习笔记:关于枚举与模式匹配的练习题以下程序能否通过编译?若能,输出是什么?考虑这两种表示结果类型的方式,若计算成功,则包含值 T;…...

父子组件双向绑定
v-model 语法糖实现 vue中我们在input中可以直接使用v-model来完成双向绑定,这个时候 v-model 通常会帮我们完成两件事: v-bind:value的数据绑定@input的事件监听如果我们现在封装了一个组件,其他地方在使用这个组件时,是否也可以使用v-model来同时完成这两个功能呢? 当我…...

系统思考与第一性原理
最近一直有客户提到“第一性原理”,希望借此穿透纷繁复杂的现象,看清事情的本质。我第一反应是:这与系统思考中的冰山模型不谋而合。 冰山模型中提到:我们看到的只是表面事件,事件背后有趋势,趋势背后有结…...

基于Redis实现-UV统计
基于Redis实现-UV统计 本文将使用HyperLogLog来实现UV统计。 首先我们搞懂两个概念: UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录一次…...