RAG工程-基于LangChain 实现 Advanced RAG(预检索-查询优化)(下)
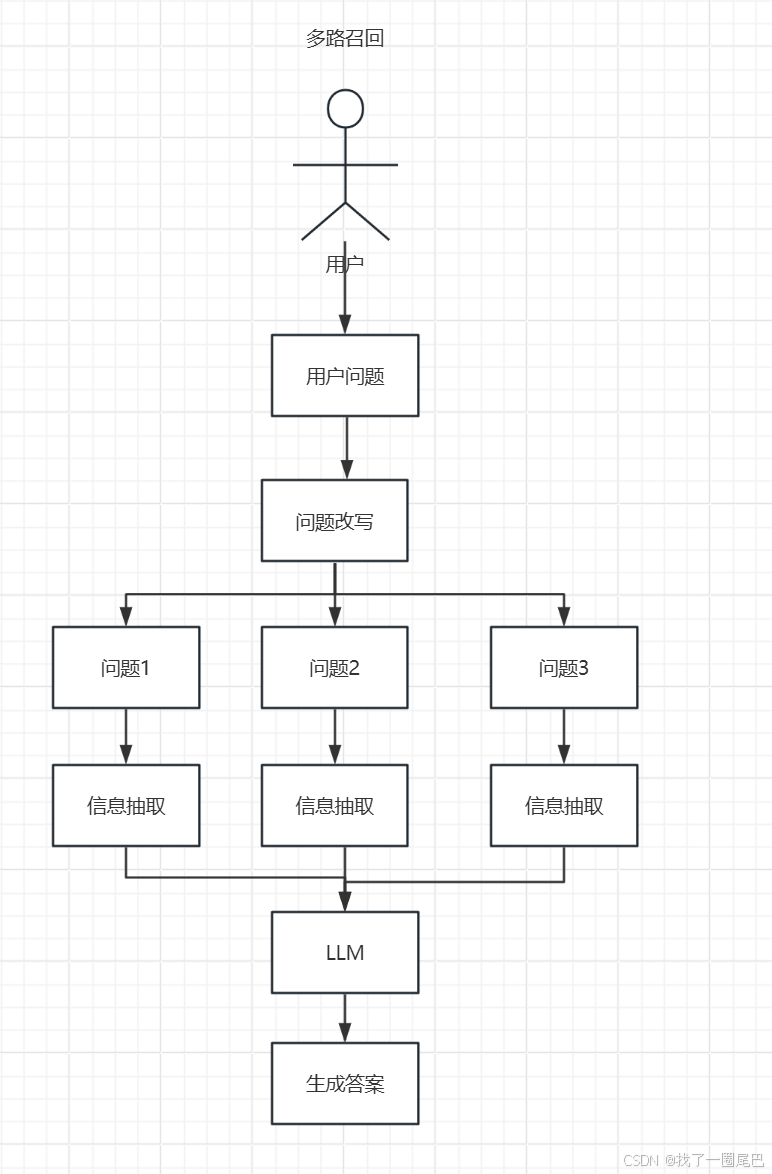
Multi-Query 多路召回
多路召回流程图
多路召回策略利用大语言模型(LLM)对原始查询进行拓展,生成多个与原始查询相关的问题,再将原始查询和生成的所有相关问题一同发送给检索系统进行检索。它适用于用户查询比较宽泛、模糊或者需要从多个角度获取信息的场景。当用户提出一个较为笼统的问题时,通过多路召回可以从不同维度去检索相关信息,以全面满足用户需求。
多路召回的实现流程
-
利用 LLM 生成相关问题:当用户输入原始查询时,LLM 会对查询进行深度语义解析,识别其中的关键词、主题和潜在需求。
-
将所有问题发送给检索系统:完成相关问题的生成后,原始查询与 LLM 生成的 N 个相关问题会一同被发送至检索系统。
-
获取更多检索文档:通过 Multi-Query 多路召回,检索系统能够从向量库中获取到更多与用户需求相关的文档。传统单一查询检索受限于用户输入的表述方式和详细程度,可能会遗漏一些关键信息。而 Multi-Query 多路召回利用多个问题进行多次检索,每个问题都能检索到一批相关文档,这些文档集合相互补充,涵盖了更广泛的内容和角度。
基于LangChain 框架的多路召回代码实现
import logging
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import MultiQueryRetriever
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI# 加载文档
def load_documents(file_path):try:loader = TextLoader(file_path, encoding='utf-8')return loader.load()except FileNotFoundError:print(f"错误:未找到文件 {file_path}")return []except Exception as e:print(f"加载文件时出现错误: {e}")return []# 分割文档
def split_documents(docs, chunk_size=600, chunk_overlap=100):text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)return text_splitter.split_documents(docs)# 创建向量数据库
def create_vectorstore(chunks, embedding_model):return Chroma.from_documents(documents=chunks, embedding=embedding_model, collection_name="multi-query")# 初始化检索器
def initialize_retriever(vectorstore, llm):retriever = vectorstore.as_retriever()QUERY_PROMPT = PromptTemplate(input_variables=["question"],template="""You are an AI language model assistant. Your task is to generate 5 different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}""")return MultiQueryRetriever.from_llm(prompt=QUERY_PROMPT,retriever=retriever,llm=llm,include_original=True)# 打印文档
def pretty_print_docs(docs):for doc in docs:print(doc.page_content)if __name__ == "__main__":# 定义文件路径TXT_DOCUMENT_PATH = "your_text_file.txt"# 初始化日志logging.basicConfig()logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)# 初始化嵌入模型embeddings_model = HuggingFaceEmbeddings()# 初始化大语言模型,这里使用 ChatOpenAI 作为示例,你可以根据需要替换llm = ChatOpenAI()# 加载文档docs = load_documents(TXT_DOCUMENT_PATH)if docs:# 分割文档chunks = split_documents(docs)# 创建向量数据库vectorstore = create_vectorstore(chunks, embeddings_model)# 初始化检索器retrieval_from_llm = initialize_retriever(vectorstore, llm)# 执行检索unique_docs = retrieval_from_llm.invoke("详细介绍DeepSeek")# 打印文档pretty_print_docs(unique_docs)在 LangChain 框架中,MultiQueryRetriever 是实现多路召回功能的强大工具。它的核心原理是通过与精心设计的多路召回提示词相结合,突破传统单一检索的局限。
具体来说,当用户输入查询时,MultiQueryRetriever 会将该查询传递给语言模型,在多路召回提示词的引导下,语言模型会从多个维度和视角对原始查询进行拓展,生成一系列相关的衍生问题。这些衍生问题与原始查询一同组成查询集合,随后被发送至检索系统。检索系统基于这个查询集合,在向量数据库中执行多次检索操作,每次检索都对应一个查询,如同从不同方向探索信息宝库,从而从向量库中召回更多与用户需求潜在相关的文档。这种方式能够有效弥补用户原始查询可能存在的表述模糊、语义局限等问题,极大地丰富了检索结果的数量和多样性,为后续的信息处理和答案生成提供更全面、充足的素材,显著提升了整个检索增强生成系统的性能和用户体验,尤其适用于复杂、模糊或需要深度信息挖掘的查询场景。
Decomposition 问题分解
问题分解(Decomposition)策略通过将复杂、模糊的用户查询拆解为多个更易处理的子问题,能够显著提升检索的准确性与全面性,进而为生成高质量答案奠定基础。问题分解策略的核心目标是:
-
提升召回率:通过子问题覆盖更多相关文档片段
-
降低处理难度:每个子问题聚焦单一语义单元
-
增强可解释性:明确展示问题解决路径
典型适用场景:
-
多条件复合问题("同时满足A和B的方案")
-
多步骤推理问题("实现X需要哪些步骤")
-
对比分析问题("A与B的优劣比较")
常见分解策略
逻辑结构分解
将问题拆分为逻辑关联的子模块:
示例:
原问题:
"如何设计一个支持高并发支付的电商系统?"子问题分解:
电商支付系统的核心组件有哪些?
高并发场景下的数据库选型建议
支付接口的限流熔断方案
分布式事务一致性保障方法
时间序列分解
按时间维度拆分阶段性问题:
示例:
原问题:
"从立项到上线的APP开发全流程"子问题分解:
移动应用立项阶段的需求分析方法
敏捷开发中的迭代管理实践
APP上线前的测试验收标准
应用商店发布审核注意事项
多视角分解
从不同角度生成互补性问题:
示例:
原问题:
"深度学习在医疗影像中的应用"子问题分解:
(技术视角)医疗影像分析的常用深度学习模型架构
(临床视角)三甲医院实际部署案例中的准确率数据
(合规视角)医学AI模型的法律监管要求
分解流程
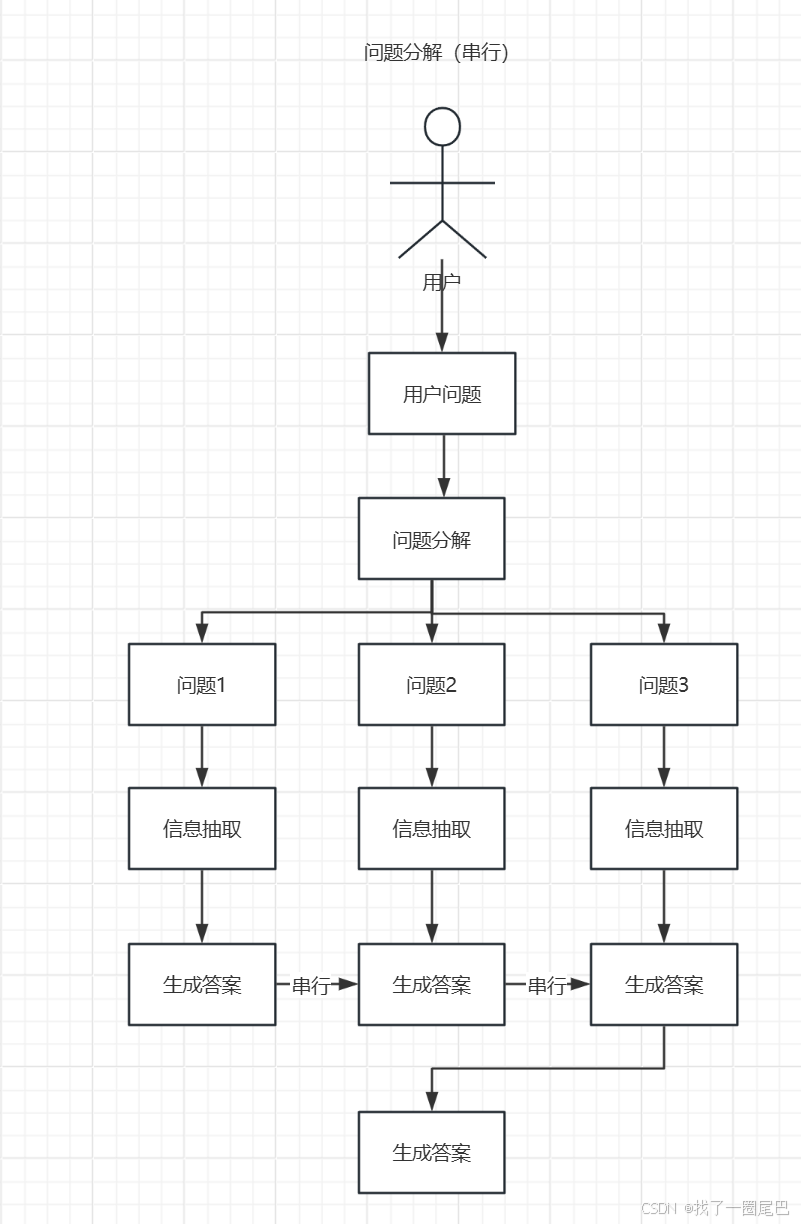
串行分解流程
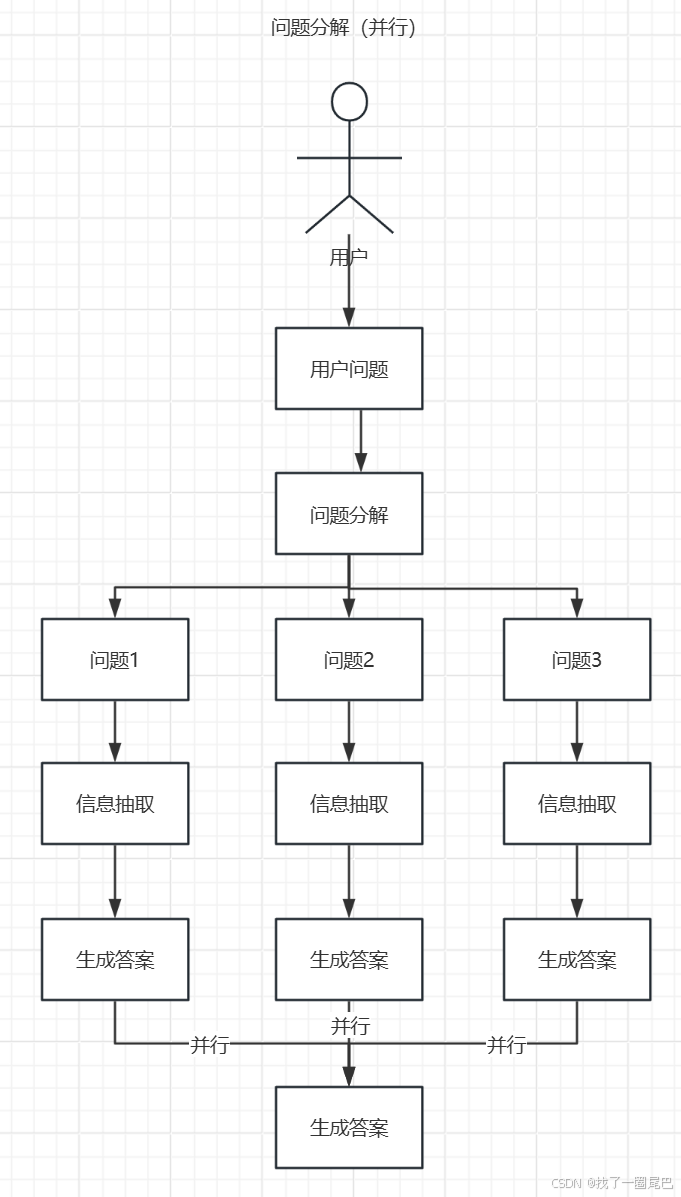
并行分解流程
技术实现方案
基于规则模板的分解
根据不同领域和问题类型,预先制定规则和模板。这种方式适用于结构化程度高、问题模式相对固定的场景,优点是简单直接、执行效率高,但灵活性较差,难以应对复杂多变或新型的问题。
# 定义分解规则模板
DECOMPOSE_RULES = {"设计类问题": ["核心组件", "架构模式", "技术选型"],"比较类问题": ["优势分析", "劣势分析", "适用场景"]
}def rule_based_decompose(query, category):return [f"{query}的{aspect}" for aspect in DECOMPOSE_RULES.get(category, [])]基于LLM的智能分解
借助自然语言处理(NLP)技术,尤其是深度学习模型(如 Transformer 架构),对用户问题进行深度语义分析。这种方法能够处理复杂语义,适应性强,但对模型的训练和计算资源要求较高。
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplatedecompose_prompt = PromptTemplate.from_template("""将复杂问题拆分为3-5个原子子问题:要求:1. 每个子问题可独立检索2. 覆盖原始问题的所有关键方面3. 使用明确的问题句式4. 你的目标是帮助用户克服基于距离的相似性搜索的一些局限性输入问题:{query}生成子问题:"""
)decompose_chain = LLMChain(llm=llm, prompt=decompose_prompt)# 执行分解
sub_questions = decompose_chain.run("如何构建企业级数据中台?").split("\n")
# 输出:["数据中台的核心架构组成?", "数据治理的最佳实践?", "..."]混合分解策略
结合规则与LLM的优势:
def hybrid_decomposition(query):# 第一步:分类问题类型classifier_chain = LLMChain(...) category = classifier_chain.run(query)# 第二步:根据类型选择策略if category in DECOMPOSE_RULES:return rule_based_decompose(query, category)else:return decompose_chain.run(query)层次化多阶段分解
对于极其复杂的问题,采用分层次、多阶段的分解策略。首先进行宏观层面的初步分解,得到几个主要的子问题方向,然后针对每个子问题再进行进一步细化分解。通过这种逐步细化的方式,确保问题的每个方面都能得到充分考虑,检索也更加精准。
在这里,我让DeepSeek 帮我生成了一个基于LangChain ,构建小说的代码,使用的就是层次化多阶段分解的策略。具体代码如下:
from langchain.chains import SequentialChain, TransformChain
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
from typing import Dict, List# 第一阶段:生成小说大纲
def create_outline_chain(llm):outline_template = """你是一个专业小说家,根据用户需求创作小说大纲。
用户需求:{user_input}
请按以下格式生成包含5个章节的小说大纲:
1. 章节标题:章节核心事件
2. 章节标题:章节核心事件
...
输出示例:
1. 命运相遇:主角在拍卖会意外获得神秘古剑
2. 真相初现:发现古剑与失传王朝的关联"""return LLMChain(llm=llm,prompt=PromptTemplate.from_template(outline_template),output_key="outline")# 第二阶段:章节分解器
def chapter_decomposer(outline: str) -> List[Dict]:"""将大纲解析为章节结构"""chapters = []for line in outline.split("\n"):if "." in line:num, rest = line.split(".", 1)title, event = rest.split(":", 1) if ":" in rest else (rest.strip(), "")chapters.append({"chapter_num": num.strip(),"title": title.strip(),"core_event": event.strip()})return chapters# 第三阶段:分章节内容生成
def create_chapter_chain(llm):chapter_template = """根据以下大纲创作小说章节内容:
整体大纲:
{outline}当前章节:{chapter_num} {title}
核心事件:{core_event}
要求:
1. 包含3个关键场景
2. 保持文学性描写
3. 字数800-1000字章节内容:"""return LLMChain(llm=llm,prompt=PromptTemplate.from_template(chapter_template),output_key="chapter_content")# 构建完整工作流
class NovelGenerator:def __init__(self, llm):self.outline_chain = create_outline_chain(llm)self.chapter_chain = create_chapter_chain(llm)# 定义转换链处理章节分解self.decompose_chain = TransformChain(input_variables=["outline"],output_variables=["chapters"],transform=chapter_decomposer)# 构建主流程self.master_chain = SequentialChain(chains=[self.outline_chain,self.decompose_chain,self._build_chapter_expansion()],input_variables=["user_input"],output_variables=["final_novel"])def _build_chapter_expansion(self):"""构建章节扩展子链"""def expand_chapters(inputs: Dict) -> Dict:full_novel = []for chapter in inputs["chapters"]:# 合并上下文context = {"outline": inputs["outline"],**chapter}# 生成单章内容result = self.chapter_chain(context)full_novel.append(f"## {chapter['chapter_num']} {chapter['title']}\n{result['chapter_content']}")return {"final_novel": "\n\n".join(full_novel)}return TransformChain(input_variables=["outline", "chapters"],output_variables=["final_novel"],transform=expand_chapters)def generate(self, user_input: str) -> str:"""执行完整生成流程"""return self.master_chain({"user_input": user_input})["final_novel"]# 使用示例
if __name__ == "__main__":from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(model="gpt-4", temperature=0.7)generator = NovelGenerator(llm)novel = generator.generate("创作一部以民国古玩商人为背景的悬疑爱情小说")# 保存生成结果with open("novel_draft.md", "w", encoding="utf-8") as f:f.write(novel)基于知识图谱的分解
我们可以利用知识图谱中实体与关系的结构化信息,辅助问题分解。借助知识图谱的语义关联,使分解结果更具逻辑性和针对性。代码示例如下:
from langchain.chains import LLMChain, TransformChain
from langchain.prompts import PromptTemplate
from typing import Dict, List# 示例知识图谱(实际应用时可替换为Neo4j等图数据库接口)
MEDICAL_KNOWLEDGE_GRAPH = {"nodes": {"糖尿病": {"type": "疾病","properties": {"别名": ["消渴症"],"分类": ["代谢性疾病"]},"relationships": [{"type": "治疗方法", "target": "胰岛素治疗", "properties": {"有效性": "高"}},{"type": "并发症", "target": "糖尿病肾病", "properties": {"概率": "30%"}},{"type": "检查项目", "target": "糖化血红蛋白检测"}]},"胰岛素治疗": {"type": "治疗方法","properties": {"给药方式": ["注射"],"副作用": ["低血糖"]}}}
}class KnowledgeGraphDecomposer:def __init__(self, llm):# 实体识别链self.entity_chain = LLMChain(llm=llm,prompt=PromptTemplate.from_template("""从医疗问题中提取医学实体:问题:{question}输出格式:["实体1", "实体2", ...]"""),output_key="entities")# 子问题生成链self.decompose_chain = LLMChain(llm=llm,prompt=PromptTemplate.from_template("""基于知识图谱关系生成子问题:原始问题:{question}相关实体:{entities}知识关联:{kg_info}请生成3-5个逻辑递进的子问题,要求:1. 覆盖诊断、治疗、预防等方面2. 使用明确的医学术语3. 体现知识图谱中的关联关系输出格式:- 子问题1- 子问题2"""),output_key="sub_questions")def query_kg(self, entity: str) -> Dict:"""知识图谱查询"""return MEDICAL_KNOWLEDGE_GRAPH["nodes"].get(entity, {})def build_pipeline(self):"""构建处理管道"""return TransformChain(input_variables=["question"],output_variables=["sub_questions"],transform=self._process)def _process(self, inputs: Dict) -> Dict:# 步骤1:实体识别entities = eval(self.entity_chain.run(inputs["question"]))# 步骤2:知识图谱查询kg_info = {}for entity in entities:node_info = self.query_kg(entity)if node_info:kg_info[entity] = {"属性": node_info.get("properties", {}),"关联": [rel["type"]+"→"+rel["target"] for rel in node_info.get("relationships", [])]}# 步骤3:子问题生成return {"sub_questions": self.decompose_chain.run({"question": inputs["question"],"entities": str(entities),"kg_info": str(kg_info)})}# 使用示例
if __name__ == "__main__":from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.5)decomposer = KnowledgeGraphDecomposer(llm)pipeline = decomposer.build_pipeline()# 执行问题分解result = pipeline.invoke({"question": "糖尿病患者应该如何进行治疗?"})print("生成的子问题:")print(result["sub_questions"])混合检索
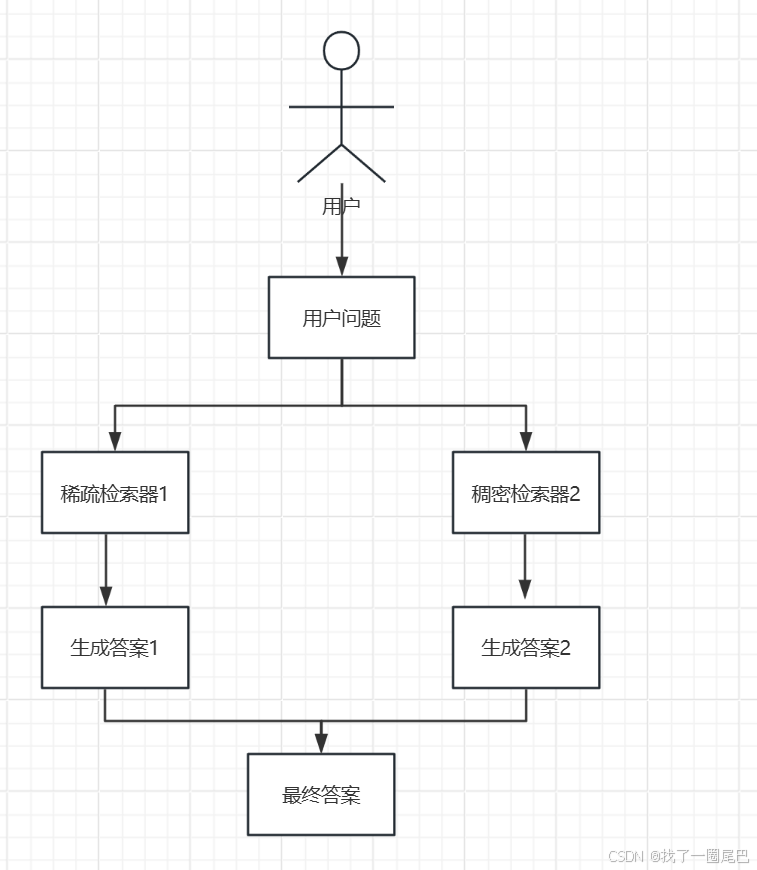
混合检索流程
混合检索策略是一种将不同检索方式优势相结合的检索方法,在实际应用中展现出强大的灵活性与高效性。其核心在于融合向量检索(稠密检索)和关键字检索(稀疏检索),常见的是以 BM25 关键词检索等稀疏检索策略与向量检索搭配使用。
向量检索(稠密检索)基于深度学习模型,将文本转化为高维向量,通过计算向量之间的相似度,检索出语义相近的文本。它擅长捕捉文本的语义信息,能理解用户查询背后的含义,即使查询语句与文档表述不完全一致,只要语义相似,也能实现精准检索,适合处理语义复杂、模糊的查询场景。而关键字检索(稀疏检索),如 BM25 关键词检索,依据用户输入的关键词在文本中进行匹配,通过统计关键词在文档中的出现频率、位置等信息,评估文档与查询的相关性。这种方式简单直接,对结构化数据、精确匹配的检索需求有很好的效果,能够快速定位包含特定关键词的文档。
以下是一段基于BM25 检索结合向量检索的代码示例:
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever# 假设这些函数和变量已经定义
def pretty_print_docs(docs):for doc in docs:print(doc.page_content)def perform_hybrid_retrieval(chunks, vector_retriever, query):try:# BM25关键词检索BM25_retriever = BM25Retriever.from_documents(chunks, k=3)BM25Retriever_doc = BM25_retriever.invoke(query)print("BM25关键词检索结果:")pretty_print_docs(BM25Retriever_doc)# 向量检索vector_retriever_doc = vector_retriever.invoke(query)print("\n向量检索结果:")pretty_print_docs(vector_retriever_doc)# 向量检索和关键词检索的权重各0.5,两者赋予相同的权重retriever = EnsembleRetriever(retrievers=[BM25_retriever, vector_retriever], weights=[0.5, 0.5])ensemble_result = retriever.invoke(query)print("\n混合检索结果:")pretty_print_docs(ensemble_result)except Exception as e:print(f"检索过程中出现错误: {e}") 在这里,我们运用EnsembleRetriever方法实现了高效的混合检索策略。具体而言,通过将基于 BM25 算法的关键词检索器BM25_retriever与向量检索器vector_retriever相结合,并为二者赋予相等的权重 0.5,使得检索过程既能发挥 BM25 关键词检索在精确匹配方面的优势,快速定位包含目标关键词的文档;又能借助向量检索在语义理解层面的特长,捕捉语义相近的相关内容。这种强强联合的方式,最终整合出兼具准确性和全面性的混合检索结果,有效提升了检索系统对复杂查询的处理能力和响应质量。
相关文章:
(下))
RAG工程-基于LangChain 实现 Advanced RAG(预检索-查询优化)(下)
Multi-Query 多路召回 多路召回流程图 多路召回策略利用大语言模型(LLM)对原始查询进行拓展,生成多个与原始查询相关的问题,再将原始查询和生成的所有相关问题一同发送给检索系统进行检索。它适用于用户查询比较宽泛、模糊或者需要…...

VBA数据库解决方案第二十讲:Select From Where条件表达式
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...

Linux架构篇、第1章_02源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62
Linux_基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62 版本号: 1.0,0 作者: 老王要学习 日期: 2025.05.01 适用环境: Centos7 文档说明 本文…...

【Machine Learning Q and AI 读书笔记】- 03 小样本学习
Machine Learning Q and AI 中文译名 大模型技术30讲,主要总结了大模型相关的技术要点,结合学术和工程化,对LLM从业者来说,是一份非常好的学习实践技术地图. 本文是Machine Learning Q and AI 读书笔记的第3篇,对应原…...
)
Webug4.0靶场通关笔记08- 第11关万能密码登录(SQL注入漏洞)
目录 第13关 万能密码登录 1.打开靶场 2.源码分析 3.渗透方法1 4.渗透方法2 第13关 万能密码登录 本文通过《webug靶场第13关 万能密码登录》来进行渗透实战。 万能密码是利用 SQL 注入漏洞,构造出能够绕过登录验证的特殊密码字符串。通常,登录验…...

terraform中statefile文件的实现原理及作用
Terraform 的 State 文件(terraform.tfstate)是其基础设施即代码(IaC)机制的核心组件,用于记录和管理云资源的实际状态。以下是其实现原理及核心作用的详细分析: 一、State 文件的实现原理 1. 数据结构与…...

7.0/Q1,GBD数据库最新文章解读
文章题目:Cardiovascular disease s mortality in Brazilian municipalities: estimates from the Global Burden of Disease study, 2000-2018 DOI:10.1016/j.lana.2025.101106 中文标题:巴西城市的心血管疾病死亡率:来自2000-20…...

linux 使用nginx部署next.js项目,并使用pm2守护进程
前言 本文基于:操作系统 CentOS Stream 8 使用工具:Xshell8、Xftp8 服务器基础环境: node - 请查看 linux安装node并全局可用pm2 - 请查看 linux安装pm2并全局可用nginx - 请查看 linux 使用nginx部署vue、react项目 所需服务器基础环境&…...

0基础 | Proteus电路仿真 | 电机使用
目录 电机类型 51单片机对直流电机的控制 基于89C51主控的直流电机控制电路仿真 代码《基于Keil C51》 51单片机对步进电机的控制 控制代码《基于Keil C51》 基于89C51主控的步进电机控制电路仿真 电机类型 直流电机 步进电机 51单片机对直流电机的控制 直流电机&#…...
有何区别?)
人工智能100问☞第14问:人工智能的三大流派(符号主义、联结主义、行为主义)有何区别?
目录 一、通俗解释 二、专业解析 三、权威参考 一、通俗解释 人工智能的三大流派,就像三位不同性格的工程师用各自的方法造机器人: 1、符号主义(逻辑派) 核心:用“教科书式规则”教机器思考。比如教计算机下棋,先写一本《国际象棋必胜法则》,机器…...

油气人工地震资料信号处理中,机器学习和AI应用
在油气人工地震资料信号处理中,机器学习和AI可以应用于多个环节,显著提升数据质量、解释效率和勘探准确性。以下是主要应用场景及对应的开源工具推荐: 1. 数据预处理 应用场景: 噪声压制(如随机噪声、多次波、面波&am…...

Python数据分析课程实验-1
1.1数据分析简介 当今世界对信息技术的依赖程度日渐加深,每天都会产生和存储海量的数据。数据的来源多种多样一自 动检测系统、传感器和科学仪器等。不知你有没有意识到,你每次从银行取钱、买东西、写博客、发微博也会产生新的数据。 什么是数据呢?数据实际上不同于…...

算法--模拟题目
算法–模拟问题 1576. 替换所有的问号 思路:遍历字符串,找到?, 然后遍历字符a 到 z 找到不等于前后字符,替换即可 class Solution { public:string modifyString(string s) {for(int i 0; i < s.size(); i){if(s[i] ?){//替换for(char a a; a < z; a){//当字符不等…...

PDF24 Tools:涵盖20+种PDF工具,简单高效PDF工具箱,支持一键编辑/转换/合并
一、软件介绍 PDF 24 Tools是一款由德国公司开发的PDF编辑工具,拥有18年的历史,并且一直免费使用,这在同类软件中非常难得。 早在许久之前,我就推荐过这款工具的免费网页版,但由于网页使用起来可能不太方便且速度较慢…...
 : Fisk‘s proof)
12.多边形的三角剖分 (Triangulation) : Fisk‘s proof
目录 1.Fisks proof Trangulation Coloring Domination Pigeon-Hold Principle Generation 2.Orthogonal Polygons (正交多边形) Necessity of floor(n4) Sufficiency by convex Quadrilateralization Generalization 1.Fisks proof Trangulation 引入内对角线&…...

数据库基本概念:数据库的定义、特点、分类、组成、作用
一:数据库相关概念 1.1 定义 (1)数据库:存储数据的仓库 (2)数据库管理系统:模拟和管理数据库的大型软件 (3)SQL:操作关系型数据库的编程语言,定义…...

PostgreSQL 数据库下载和安装
官网: PostgreSQL: Downloads 推荐下载网站:EDB downloads postgresql 我选了 postgresql-15.12-1-windows-x64.exe 鼠标双击,开始安装: 安装路径: Installation Directory: D:\Program Files\PostgreSQL\15 Serv…...

【c++】【STL】queue详解
目录 queue的作用什么是容器适配器queue的接口构造函数emptysizefrontback queue类的实现 queue的作用 queue是stl库提供的一种容器适配器,也就是我们数据结构中学到的队列,是非常常用的数据结构,特点是遵循LILO(last in last ou…...

循环插入数据库行
文章目录 循环插入数据库行 循环插入数据库行 -- 声明变量 DECLARE i INT 201;-- 开始循环 WHILE i < 200 BEGIN-- 插入数据INSERT INTO T_AGVPOS (POS) VALUES (i);SET i i 1; END;...

QMK机械键盘固件开发指南:从源码到实践
QMK机械键盘固件开发指南:从源码到实践 前言 QMK(Quantum Mechanical Keyboard)是一款开源的键盘固件,支持众多自定义键盘的功能配置。通过QMK,您可以完全掌控键盘的每一个按键,实现复杂的宏指令、多层按…...
Unity SpriteMask(精灵遮罩)
🏆 个人愚见,没事写写笔记 🏆《博客内容》:Unity3D开发内容 🏆🎉欢迎 👍点赞✍评论⭐收藏 🔎SpriteMask:精灵遮罩 💡作用就是对精灵图片产生遮罩,…...

AdaBoost算法详解:原理、实现与应用指南
AdaBoost算法详解:原理、实现与应用指南 1. 引言 在机器学习领域,AdaBoost(Adaptive Boosting) 是最早提出的集成学习(Ensemble Learning)**算法之一,由Yoav Freund和Robert Schapire于1995年…...

Flink流式计算核心:DataStream API与时间语义深度解析
本文将围绕Flink最核心的DataStream API展开,结合其独特的时间语义体系,深入解析Flink如何实现对无界流数据的精准控制,并通过真实业务场景案例演示其工程实践方法。 一、DataStream API:Flink处理无界流的“中枢神经” Flink的A…...

C# 方法的结构与执行详解
在编程世界里,方法是一块具有名称的代码,它就像是一个功能盒子,我们可以使用方法的名称从别的地方执行其中的代码,还能把数据传入方法并接收数据输出。方法是类的函数成员,主要由方法头和方法体两个部分构成。 方法头…...

《AI大模型应知应会100篇》第41篇:多轮对话设计:构建高效的交互式应用
第41篇:多轮对话设计:构建高效的交互式应用 摘要 在银行客服机器人突然准确回答出用户第7次追问的信用卡额度规则时,在医疗问诊系统记住患者既往病史的瞬间,多轮对话技术正在创造令人惊叹的交互体验。本文将以工业级案例为经&am…...

【Day 14】HarmonyOS分布式数据库实战
一、分布式数据库基础 1. 核心概念速记表 术语解释示例场景分布式数据库数据自动同步到同账号设备手机添加商品→平板立即显示KV数据模型键值对存储(类似JSON){"cart_item1": {"name":"牛奶","price":10}}数据…...

terraform 删除资源前先校验资源是否存在关联资源
Terraform 删除资源前校验关联资源的解决方案 在使用 Terraform 进行资源删除操作时,确实存在直接删除可能影响关联资源的风险。以下是几种在删除前校验关联资源的方法: 1. 使用 Terraform Data Sources 进行预检查 在删除主资源前,可以通…...

如何免费使用 DeepSeek-Prover-V2?
近日,Deepseek 发布了一个新模型,这是一个在数学推理方面表现卓越的模型,即 DeepSeek Prover V2。 DeepSeek-Prover-V2 是一个专门使用 Lean 4 证明助手进行形式化定理证明的高级语言模型。 简单来说, DeepSeek-Prover-V2 旨在支持数学家和计算机科学家创建和验证形式化证…...

dify+ollama+知识库 部署
这篇文章的前提是已经部署了deepseek和ollama deepseek和ollama安装 代码、配置 本地电脑如果是Windows的话,需要安装Git # 拉取Dify代码 git clone https://github.com/langgenius/dify.git复制配置 进入dify\docker目录 复制.env.example到.env 复制.middlewa…...
)
补题:K - Magic Tree (Gym - 105231K)
来源:问题 - K - Codeforceshttps://codeforces.com/gym/105231/problem/K 题目描述: 一、题目分析 本题给定一个2行m列的网格,从(1, 1)格子开始进行深度优先搜索,每个格子可到达至少一个边相邻的格子且不重复访问,…...
)
文章记单词 | 第58篇(六级)
一,单词释义 naive:英 [naɪˈiːv , nɑːˈiːv] 美 [naɪˈiːv , nɑːˈiːv],形容词,意为 “天真的;幼稚的;轻信的;易受骗的;无经验的;率真的;质朴的”…...

红利底波是什么意思?
红利低波是一种结合了红利策略和低波策略的投资策略,主要选取股息率高且波动率低的股票进行投资,具有 “高收益低风险” 的特点,适合大多数投资者的权益资产配置。以下是具体介绍: 策略构成要素 红利策略 :关注股息率…...

缓存:缓解读库压力的高效方案与应用实践
在软件开发和系统设计中,使用缓存来缓解读库压力是一种常见且有效的优化策略,以下是具体的介绍: 一、缓存的基本概念 缓存是一种临时数据存储区域,它存储了经常访问的数据副本。当应用程序需要访问数据时,首先会检查…...

17. LangChain流式响应与实时交互:打造“类ChatGPT“体验
引言:从"等待加载"到"即时对话"的革命 2025年某在线教育平台的AI助教引入流式交互后,学生平均对话轮次提升3.2倍,完课率提高47%。本文将基于LangChain的异步流式架构,揭秘如何实现毫秒级响应的自然对话体验。…...

仿腾讯会议——服务器结构讲解
总功能 1、数据库类 1、进入mysql 2、查看当前数据库 2、线程池 3、网络类 阻塞和非阻塞是通过套接字来实现的,所以不能发送和接收的阻塞状态不同...

【笔记】深度学习模型训练的 GPU 内存优化之旅③:内存交换篇
开设此专题,目的一是梳理文献,目的二是分享知识。因为笔者读研期间的研究方向是单卡上的显存优化,所以最初思考的专题名称是“显存突围:深度学习模型训练的 GPU 内存优化之旅”,英文缩写是 “MLSys_GPU_Memory_Opt”。…...
2025年第二十二届五一数学建模竞赛(五一杯/五一赛)解题思路|完整代码论文集合)
(B题|矿山数据处理问题)2025年第二十二届五一数学建模竞赛(五一杯/五一赛)解题思路|完整代码论文集合
我是Tina表姐,毕业于中国人民大学,对数学建模的热爱让我在这一领域深耕多年。我的建模思路已经帮助了百余位学习者和参赛者在数学建模的道路上取得了显著的进步和成就。现在,我将这份宝贵的经验和知识凝练成一份全面的解题思路与代码论文集合…...

【2025最新】为什么用ElasticSearch?和传统数据库MySQL与什么区别?
Elasticsearch 深度解析:从原理到实践 一、为什么选择 Elasticsearch? 数据模型 Elasticsearch 是基于文档的搜索引擎,它使用 JSON 文档来存储数据。在 Elasticsearch 中,相关的数据通常存储在同一个文档中,而不是分散…...

华为云Astro大屏连接器创建操作实例:抽取物联网iotda影子设备数据的连接器创建
目录 样图(API连接器创建成功) 说明 操作场景(以Astro大屏抽取iotda影子参数为例) 实际操作步骤 新建连接器 设置基本信息。 接口鉴权方式,支持API鉴权、AK/SK、API Key和无身份验证 无身份验证 AK/SK认证(目前暂不能用) API Key认证(第三方使用) API鉴权认…...
:掌握System.Collections.Generic的核心精髓)
C#泛型集合深度解析(九):掌握System.Collections.Generic的核心精髓
一、泛型集合革命:告别装箱拆箱的性能噩梦 1.1 泛型与非泛型集合性能对比 // 非泛型集合(ArrayList) ArrayList arrayList = new ArrayList(); arrayList.Add(100); // 装箱发生 int value = (int)arrayList[0]; // 拆箱发生// 泛型集合(List<T>) List<…...

人工智能-深度学习之卷积神经网络
深度学习 mlp弊端卷积神经网络图像卷积运算卷积神经网络的核心池化层实现维度缩减卷积神经网络卷积神经网络两大特点卷积运算导致的两个问题:图像填充(padding)结构组合问题经典CNN模型LeNet-5模型AlexNet模型VGG-16模型 经典的CNN模型用于新…...
——生命周期、CMM、开发模型)
《软件设计师》复习笔记(11.1)——生命周期、CMM、开发模型
目录 一、信息系统生命周期 系统规划阶段 系统分析阶段(逻辑设计) 系统设计阶段(物理设计) 系统实施阶段 系统运行与维护阶段 二、能力成熟度模型(CMM/CMMI) CMM 五级模型 CMMI 两种表示方法 真题…...

AI大模型基础设施:主流的几款开源AI大语言模型的本地部署成本
以下是对目前主流开源AI大语言模型(如DeepSeek R1、LLaMA系列、Qwen等)本地部署成本的详细分析,涵盖计算机硬件、显卡等成本,价格以美元计算。成本估算基于模型参数规模、硬件需求(GPU、CPU、RAM、存储等)以…...

Narendra自适应控制器设计
上一篇介绍了在系统结构中引入前馈和反馈的结构,然后利用李雅普诺夫稳定性理论设计MRACS,在基于输入输出形式中,利用李雅普诺夫稳定性设计的自适应率中包含了误差的导数,这降低了系统的抗干扰性,为了避免这一缺点&…...

为什么大模型偏爱Markdown
Markdown 的简洁之美 我们常见的文档格式,比如HTML、JSON、XML或者Markdown,Markdown是最简洁的。 比如要展示一行标题,相比复杂的HTML标签,使用Markdown我们只需要在文本前加个井号: <heading level“1”>这是…...

【kafka系列】消费者组
目录 消费者组功能点 1. 动态负载均衡 2. 容错高可用 3. 消费进度管理 4. 并行消费能力 5. 消费隔离性 其他要点 1. Rebalance过程详解 2. 位移提交的精确语义 3. 消费者限速策略 4. 跨机房消费设计 消费者组功能点 1. 动态负载均衡 核心机制:通过Rebal…...

2025五一杯数学建模C题:社交媒体平台用户分析问题;思路分析+模型代码
(一)问题背景 想象一下,社交媒体平台是一个充满活力的生态系统,博主们如同才华横溢的创作者,凭借专业知识或独特兴趣,精心打造出各种高质量内容,吸引着众多用户的目光。用户则像热情的参与者&a…...

Kotlin-运算符重载函数
在 Kotlin 里,运算符重载函数允许为自定义类型重新定义现有的运算符(如 -…)行为,从而让自定义类型能像内置类型那样使用运算符 文章目录 基本语法作用场景类对象数据类型接口 注意事项 基本语法 若要重载运算符,需要定义一个带有 operato…...
Java Hashmap)
哈希表笔记(三)Java Hashmap
一、基本介绍 HashMap 是 Java 集合框架中的核心类之一,基于哈希表实现,提供了 Map 接口的主要实现。 1.1 主要特点 实现了 Map<K,V> 接口允许 null 键和 null 值(不同于 Hashtable)非同步实现(非线程安全&am…...

2025五一杯C题五一杯数学建模思路代码文章教学:社交媒体平台用户分析问题
完整内容请看文章最下面的推广群 问题一详细分析:逐步思考与建模过程 第1步:问题理解与数学建模目标明确 目标明确: 平台希望根据2024年7月11日至7月20日的用户与博主交互数据,预测2024年7月21日各博主新增的关 注数,…...