【网络原理】 《TCP/IP 协议深度剖析:从网络基础到协议核心》
文章目录
- 一、网络基础
- 1. 认识IP地址
- 概念
- 作用
- 格式
- 组成
- 子网掩码
- 2、认识Mac地址
- 一跳一跳的网络数据传输
- 3. 网络设备及相关技术
- 集线器:转发所有端口
- 交换机:MAC地址转换表+转发对应端口
- 主机:网络分层从上到下封装
- 主机&路由器:ARP缓存表+ARP寻址
- 路由器:路由+NAPT
- 冲突域
- 广播域
- 二、网络数据传输流程
- 1. 局域网传输流程:集线器
- 局域网传输流程:交换机
- 局域网传输流程:交换机+路由器
- 广域网数据传输流程
- 三、应用层重点协议
- 1. DNS
- 2.NAT
- 3. NAPT
- 四、传输层重点协议
- 1. TCP协议
- TCP协议段格式
- TCP原理
- **确认应答机制(安全机制)**
- 超时重传机制(安全机制)
- 连接管理机制(安全机制):
- 滑动窗口(效率机制)
- 流量控制(安全机制)
- 拥塞控制(安全机制)
- 延迟应答(效率机制)
- 捎带应答(效率机制)
- 粘包问题
- TCP异常情况
- TCP小结
- 2. UDP协议
- UDP协议端格式
- UDP的特点:
- TCP/UDP对比
- 五、网络层重点协议
- 1.IP协议
- 总结

一、网络基础
1. 认识IP地址
概念
IP地址(Internet Protocol Address)是指互联网协议地址,又译为网际协议地址。
作用
IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
格式
IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节),如:01100100.00000100.00000101…00000110。
通常用“点分十进制”的方式来表示,即 a.b.c.d 的形式(a,b,c,d都是0~255之间的十进制整数)。如:100.4.5.6。
IP协议有两个版本,IPv4和IPv6。我们整个的课程,凡是提到IP协议,没有特殊说明的,默认都是指IPv4。
IPv4数量=2^32,大约43亿左右,而TCP/IP协议规定,每个主机都需要有一个IP地址。对于全世界计算机来说,这个数量是不够的,所以后来推出了IPv6(长度128位,是IPv4的4倍)。但因为目前IPv4还广泛的使用,且可以使用其他技术来解决IP地址不足的问题,所以IPv6也就没有普及。
组成
IP地址分为两个部分,网络号和主机号
网络号:标识网段,保证相互连接的两个网段具有不同的标识;
主机号:标识主机,同一网段内,主机之间具有相同的网络号,但是必须有不同的主机号;
通过合理设置网络号和主机号,就可以保证在相互连接的网络中,每台主机的IP地址都是唯一的。那么,如何划分网络号和主机号呢?
过去曾经提出一种划分网络号和主机号的方案,把所有IP 地址分为五类,如下图所示:
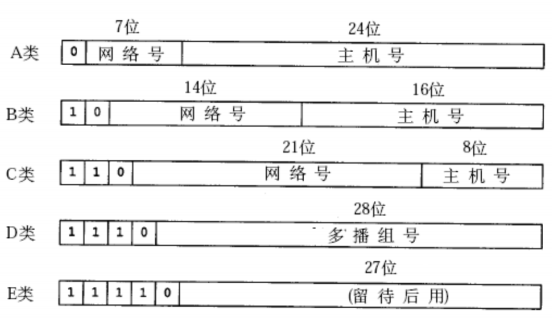
各类地址的表示范围是:

备注:主机最大连接数减去2,是扣除主机号为全0和全1的特殊IP地址。
特殊的IP地址:
将IP地址中的主机地址全部设为0,就成为了网络号,代表这个局域网;
将IP地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包;
127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1本机环回主要用于本机到本机的网络通信(系统内部为了性能,不会走网络的方式传输),对于开发网络通信的程序(即网络编程)而言,常见的开发方式都是本机到本机的网络通
信。
在上述的分类中,存在IP地址浪费的问题:
(1)单位一般会申请B类网络(C类连接主机数量有限),但实际网络架设时,连接的主机数量又常远小于65534(B类连接主机数),造成IP地址浪费;同理,A类网络的IP地址也会造成大量的浪费。
(2)当一个单位申请了一个网络号。他想将该网络能表示的IP地址再分给它下属的几个小单位时,如果在申请新的网络就会造成浪费。
为了解决以上问题,引入子网掩码来进行子网划分.
子网掩码
格式
子网掩码格式和IP地址一样,也是一个32位的二进制数。其中左边是网络位,用二进制数字“1”表示,1的数目等于网络位的长度;右边是主机位,用二进制数字“0”表示,0的数目等于主机位的长度。子网掩码也可以使用二进制所有高位1相加的数值来表示,如以上子网掩码也可以表示为24。
作用:
(1)划分A,B,C三类 IP 地址子网:如一个B类IP地址:191.100.0.0,按A ~ E类分类来说,网络号二进制数为16位网络号+16位主机号。假设使用子网掩码 255.255.128.0(即17) 来划分子网,意味着划分子网后,高17位都是网络位/网络号,也就是将原来16位主机号,划分为1位子网号+15位主机号。
此时,IP地址组成为:网络号+子网号+主机号,网络号和子网号统一为网络标识(划分子网后的网络号/网段)
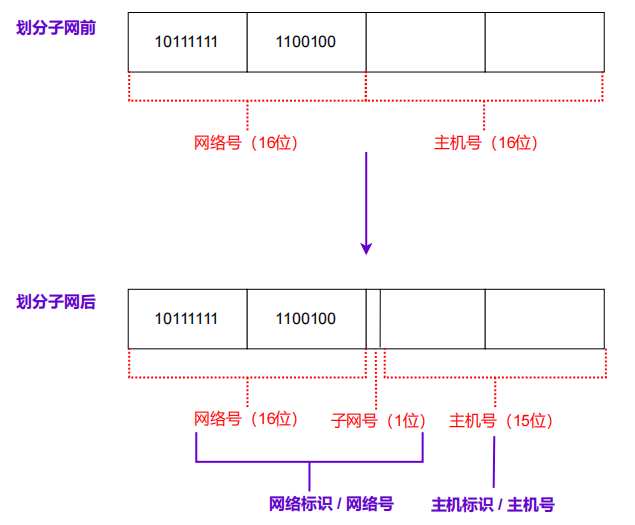
(2)网络通信时,子网掩码结合IP地址,可以计算获得网络号(划分子网后的网络号)及主机号(划分子网后的主机号)。一般用于判断目的IP与本IP是否为同一个网段。
对于网络通信来说,发送数据报时,目的主机与发送端主机是否在同一个网段,流程是不一样的。
计算方式:
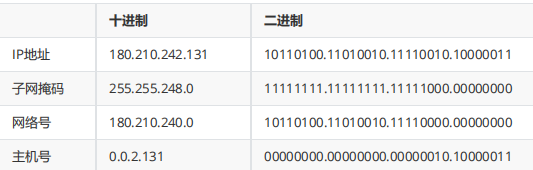
将 IP 地址和子网掩码进行“按位与”操作(二进制相同位,与操作,两个都是1结果为1,否则为0),得到的结果就是网络号。 将子网掩码二进制按位取反,再与 IP 地址位与计算,得到的就是主机号。
示例:
2、认识Mac地址
MAC地址,即 Media Access Control Address,用于标识网络设备的硬件物理地址。主机具有一个或多个网卡,路由器具有两个或两个以上网卡;其中每个网卡都有唯一的一个MAC地址。
网络通信,即网络数据传输,本质上是网络硬件设备,将数据发送到网卡上,或从网卡接收数据。
硬件层面,只能基于MAC地址识别网络设备的网络物理地址。MAC地址用来识别数据链路层中相连的节点;长度为48位,及6个字节。一般用16进制数字加上冒号的形式来表示(例如:08:00:27:03:fb:19)
在网卡出厂时就确定了,不能修改。虚拟机中的MAC地址不是真实的MAC地址,可能会冲突;也有些网卡支持用户配置MAC地址。
特殊的MAC地址:
广播数据报:发送一个广播数据报,表示对同网段所有主机发送数据报。广播数据报的MAC地址为:FF:FF:FF:FF:FF:FF
一跳一跳的网络数据传输
以下为主机B传输数据到主机C经过的网络设备:
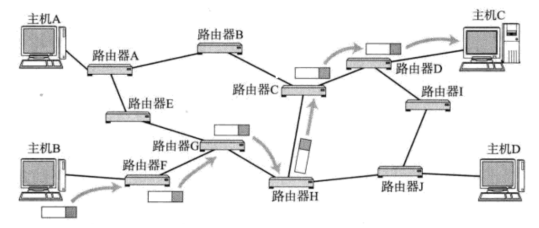
对于以上经过的网络设备:
主机:配有IP地址,但是不进行路由控制的设备;
路由器:即配有IP地址,又能进行路由控制;
节点:主机和路由器的统称;
对于网络数据传输,不是想象中那样,数据直接从源主机到达目的主机,而是类似在地图中,从A到B的
过程:
唐僧去西天取经,行程为长安、五指山、黑风山、女儿国……大雷音寺。
IP地址描述的是路途总体的起点和终点:
源IP就是整个行程的起点:长安;
目的IP对应为整个行程的终点:大雷音寺
而行进也必须一个地点一个地点的前进,由MAC地址来描述路途上每一个区间的起点和终点:从长安到五指山,为一跳的区间,源MAC为长安,目的MAC为五指山;从五指山到黑风山,为下一跳的区间,源MAC为五指山,目的MAC为黑风山。
总结IP地址和MAC地址:
IP地址描述的是路途总体的起点和终点;是给人使用的网络逻辑地址。
MAC地址描述的是路途上的每一个区间的起点和终点,即每一跳的起点和终点;是给网络硬件设备使用的网络物理地址。
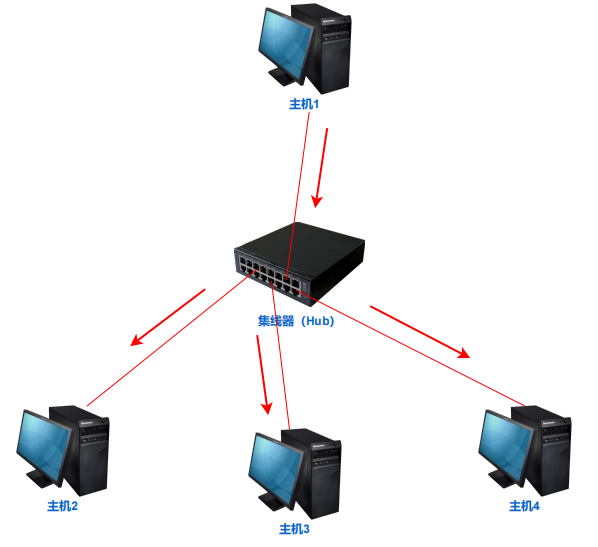
3. 网络设备及相关技术
集线器:转发所有端口
集线器是工作在物理层的网络设备,发送到集线器的任何数据,都只是简单的将数据复制并转发到其他所有端口。(端口指集线器后边的物理端口)
交换机:MAC地址转换表+转发对应端口
交换机工作在数据链路层,交换机内部会记录并维护一张MAC地址转换表:
- MAC地址转换表主要记录MAC地址与端口之间的映射。(端口指交换机后边的物理端口)
- 主机连接到交换机,及主机发送数据的时候,交换机可以学习并记录该主机MAC地址与端口信息。
- 交换机接收到数据报以后,在MAC地址转换表中,通过目的MAC查找到对应的端口,则目的主机为该端口相连接的主机。只需要将数据报转发到对应端口上即可。
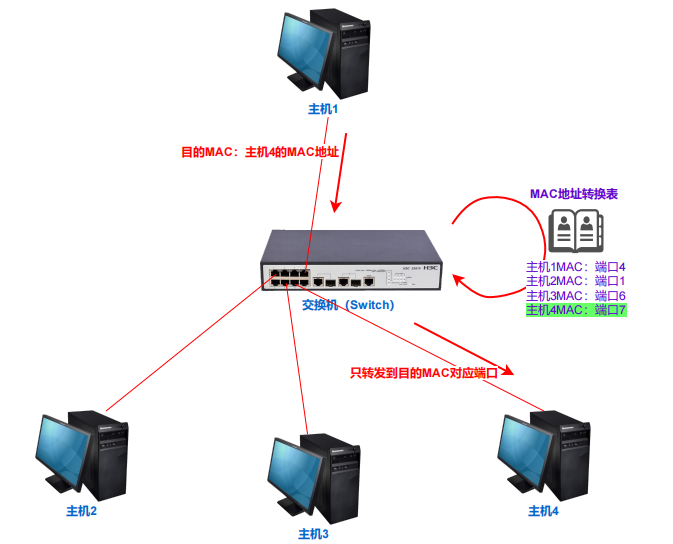
以上是使用MAC地址转换表,通过目的MAC能找到对应端口的情况;如果找不到,交换机设置数据报目的MAC为广播地址FF:FF:FF:FF:FF:FF,发送到其他所有端口,目的主机返回响应后,交换机再记录该主机MAC与端口的映射信息。
主机:网络分层从上到下封装
发送数据报时,发送端主机都需要先根据网络分层从上到下封装:
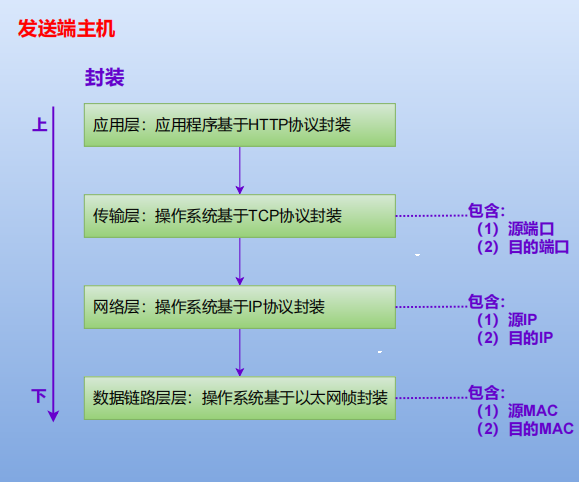
由“一跳一跳的网络数据传输”可知,以上:
源IP与目的IP标识整个路途的起点和终点;
源MAC与目的MAC标识了每一跳的起点和终点;
此时,需要根据发送端主机(源主机)与接收端主机(目的主机)是否在同一网段,来设置下一跳设备:
源主机和目的主机在同一个网段时,下一跳设备就是目的主机;
发送端主机和接收端主机在不同网段时,发送端主机是无法知道目的主机在哪,此时会设置下一跳设备为网关设备;
所谓网关,我们这里可以简单理解为,不同网段的网络互连时,需要使用网关设备。通常的网关设备是路由器,可以划分公网和局域网(内网),同时还可以把局域网划分为多个子网(不同网段)Windows中,可以在网络设置中,更改适配器设置查看网关IP:
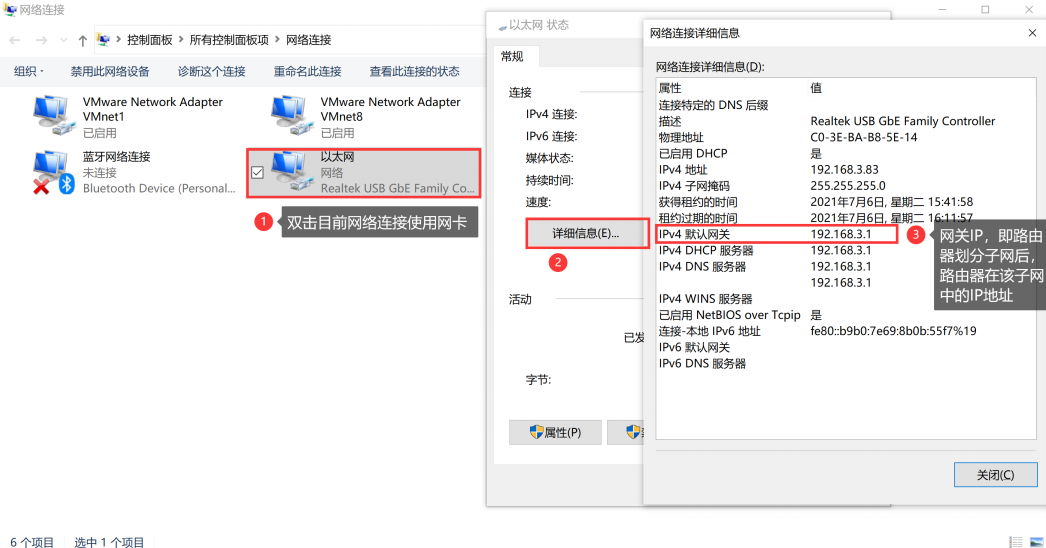
以上两种情况,下一跳设备IP地址都可以获取到,但该设备的MAC地址(即目的MAC)可能不知道,就需要使用以下ARP寻址:
主机&路由器:ARP缓存表+ARP寻址
首先,ARP是一个介于数据链路层和网络层之间的协议;ARP协议建立了IP地址与MAC地址的映射关系。
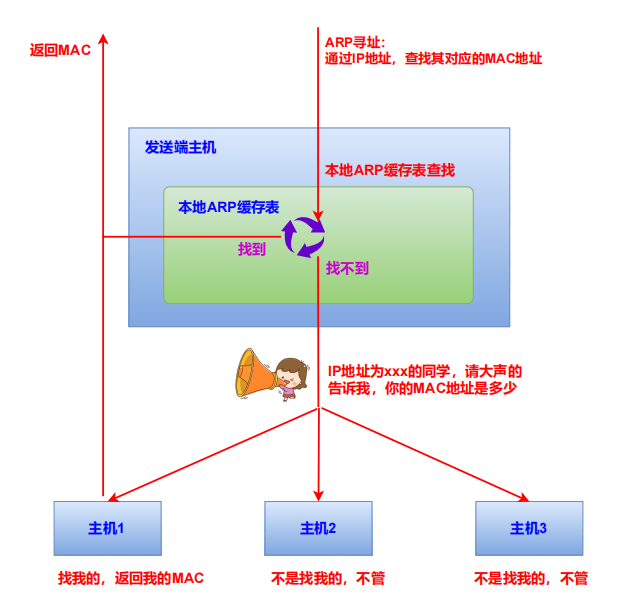
在数据链路层,寻找下一跳设备MAC地址的过程,称为ARP寻址:
(1)主机和路由器中都保存了一张ARP缓存表:通过IP地址可以找到对应的MAC地址。
(2)根据下一跳设备的IP地址,在ARP缓存表中能找到对应的MAC地址,则可以设置目的MAC并发送数据报。
(3)如果找不到,则发送ARP广播数据报:目的MAC为广播地址,询问下一跳设备的MAC地址。这个过程类似于QQ群喊话:张三(下一跳设备IP地址),我要给你发快递(发送数据报),请告诉我你的收货地址(MAC地址)。
参见以下流程:
路由器:路由+NAPT
路由器主要有两个作用:
(1)网关
路由器作为网关,可以划分公网和局域网,某些路由器还可以将局域网划分为多个子网(不同网段)
公网端口即WAN口,为单独的网卡,具有公网IP地址和公网MAC地址。划分的多个子网,是由局域网端口即LAN口划分,每个端口都有单独的网卡,具有该网段IP地址和MAC地址。
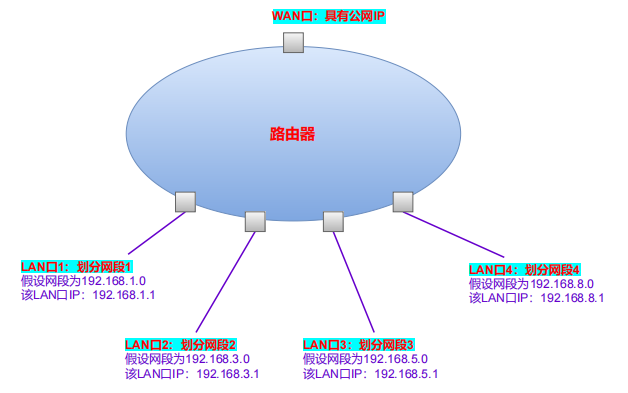
路由器作为网关:
- 划分局域网多个子网时,可以直接通过ARP寻址找到局域网任意主机。(这里的局域网就是路由器下的多个子网组成的局域网)。
- 划分公网和局域网时,局域网内主机发送数据报到公网主机时,需要基于NAPT协议,将局域网主机的IP地址和端口号,转换为路由器公网IP和端口号(指路由器中运行的程序的端口)。局域网IP+端口需要转换为公网IP+端口,原因是接收端返回的响应数据报,目的IP和目的端口无法使用局域网IP和端口。
(2)路由
所谓路由,即在复杂的网络结构中,找出一条通往终点的路线;
网络通信(网络数据传输),路由器中的路由功能,就类似于规划路线,往哪个方向行进能更快到达目
的地
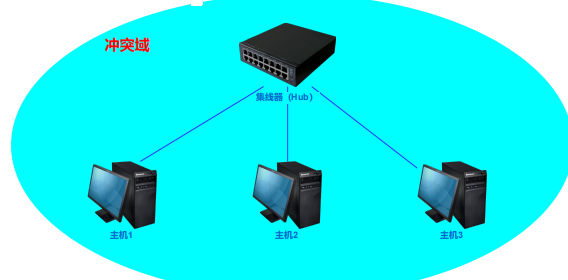
冲突域
主机之间通过网络设备(集线器、交换机)的物理端口、网线相连时,两个主机在同一时刻同时发送数据报,如果存在冲突,则该网络范围为一个冲突域。
冲突域是基于第一层物理层,又称为碰撞域。
所谓的冲突,类似两个人(主机)在一个房间(网络范围)同时说话,导致房间内其他人无法听清讲话的内容,即产生了冲突。
冲突域中的网络通信,要解决冲突,就得按时间顺序来发送多个数据报:同一时刻,网络设备只能接收并转发一个数据报,多余的会丢弃,让发送端主机重新发送。
集线器接收到数据报后,是将数据报简单的复制、转发到其他所有端口,如果有两个数据报要同时转发,就会出现冲突。整个集线器,即集线器的所有端口为一个冲突域。
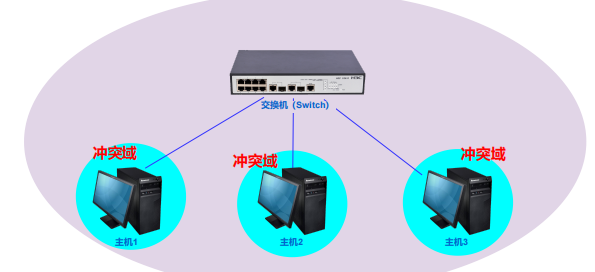
交换机接收到数据报后,是将数据报转发到对应的一个端口:两个数据报同时转发到不同端口不存在冲突,但同时转发到一个端口就出现冲突。即交换机可以分割冲突域,分割后,一个端口为一个冲突域。
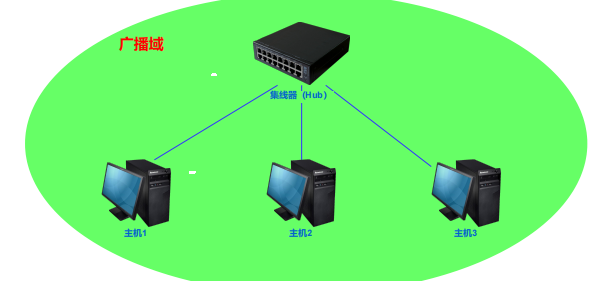
广播域
广播是指某个网络中的主机同时向网络中其它所有主机发送数据(IP、MAC地址设置为广播地址),这个数据所能传播到的范围即为广播域 。
广播域基于第二层数据链路层。
集线器接收到广播数据报,仍是简单的复制、转发到其他所有端口,所以集线器的所有端口为一个广播域。
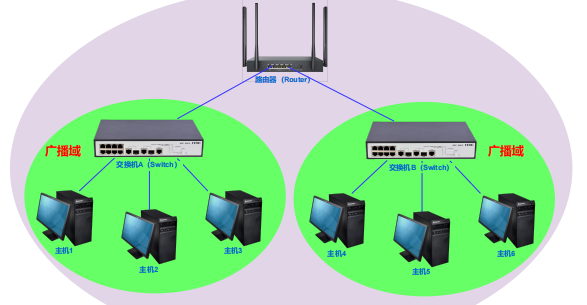
交换机接收到广播数据报,会转发到其他所有端口;而路由器可以隔离广播域
路由器某个LAN口网卡接收到广播数据报,如果发现是同网段,则丢弃,即广播数据不会扩散到路由器以外。
二、网络数据传输流程
1. 局域网传输流程:集线器
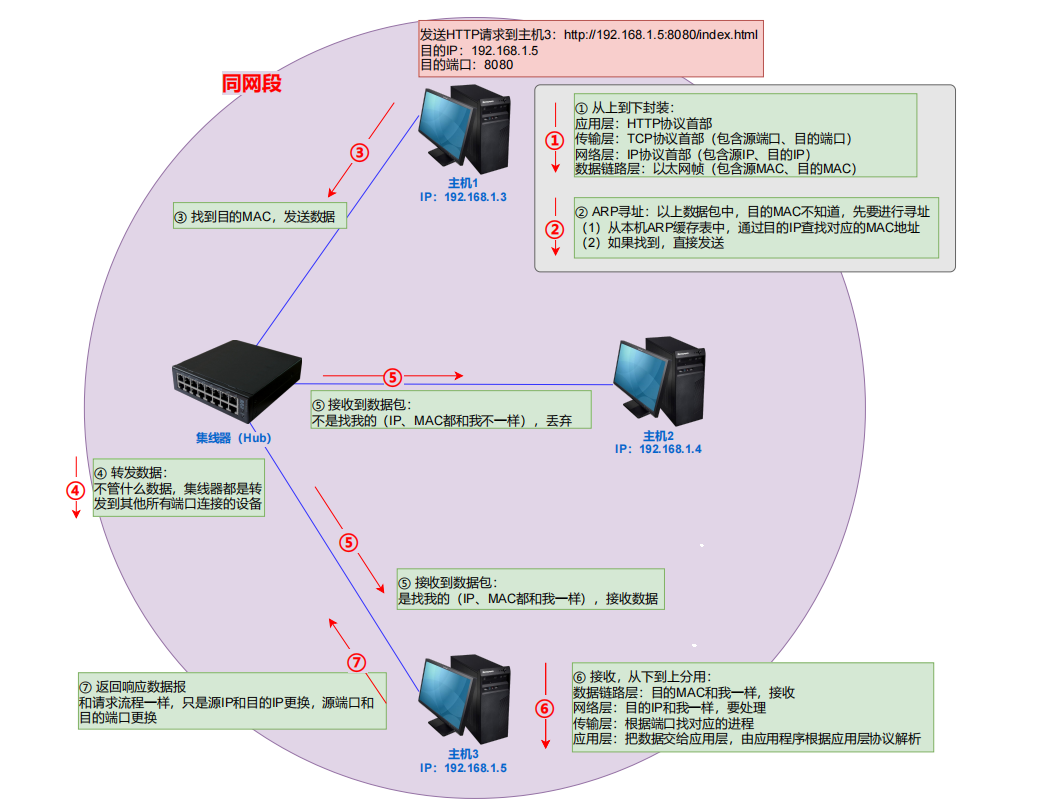
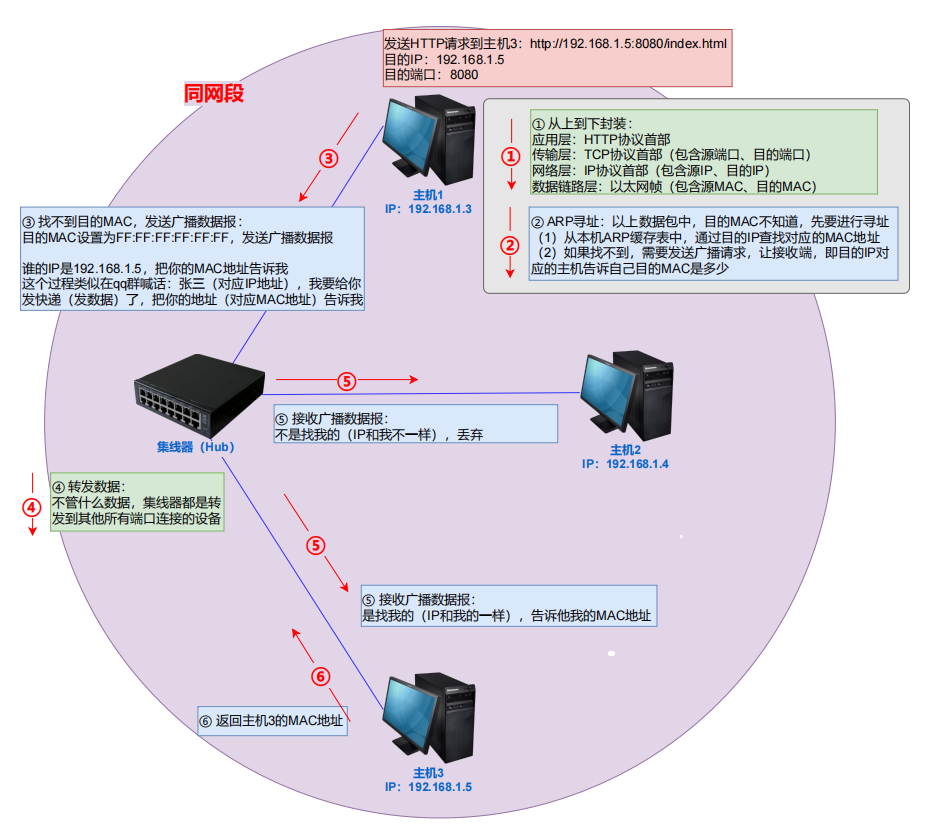
使用集线器网络互联的情况下,发送端主机发送数据包时,需要先从上到下封装数据报。但封装时,目的MAC可能并不知道,需要先进行ARP寻址:
(1)发送端在本机ARP缓存表中,根据目的IP查找对应的MAC地址
(2)如果找到,则可以在数据链路层以太网帧头中,设置目的MAC并发送数据包
(3)如果没有找到,需要先发送ARP广播请求,让接收端,即目的主机告诉自己,目的MAC是多少
(4)发送端更新本机ARP缓存表:保存目的IP与目的MAC的映射
(5)有了目的MAC,就可以按照第(2)个步骤发送数据了。
以下为本机ARP缓存表能找到目的MAC的流程:
涉及的知识:封装,集线器转发,ARP寻址
如果本机ARP缓存表中找不到目的MAC,则需要先发送广播请求:
涉及的知识:ARP寻址,ARP广播
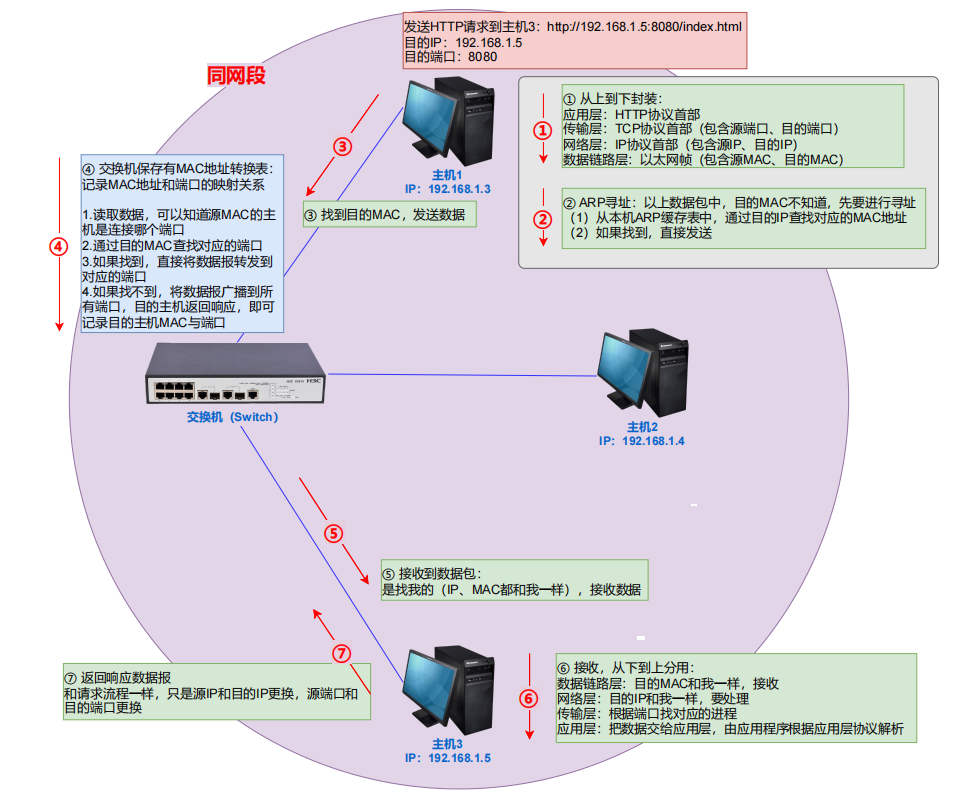
局域网传输流程:交换机
涉及的知识:交换机MAC地址转换表
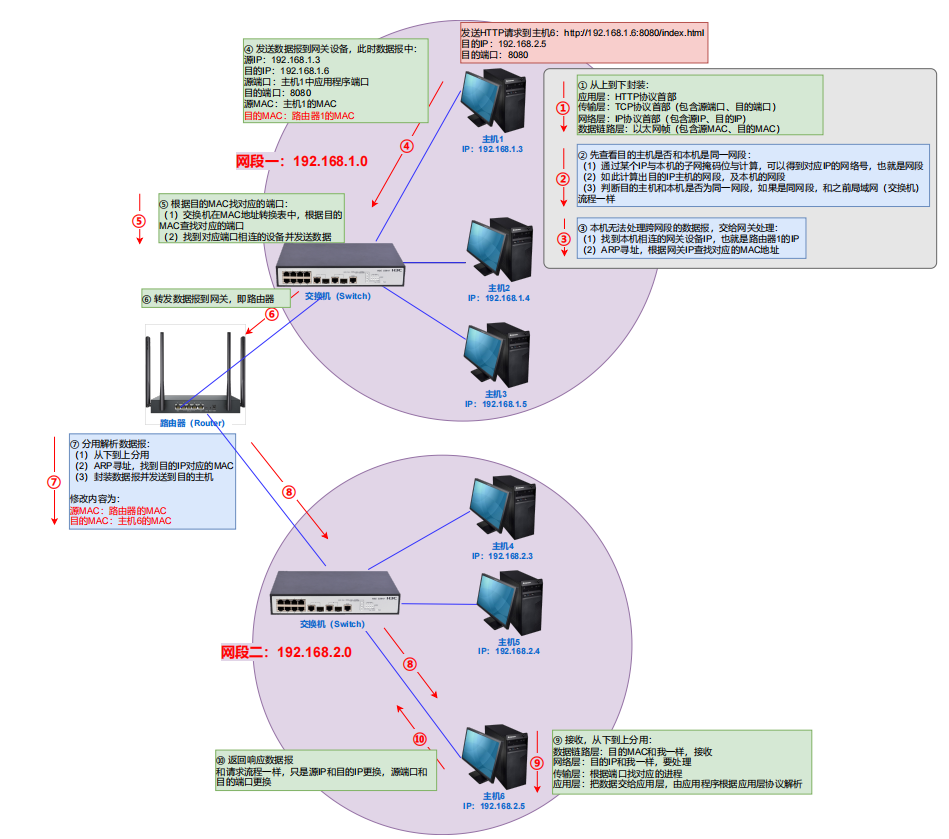
局域网传输流程:交换机+路由器
涉及的知识:子网掩码,网关
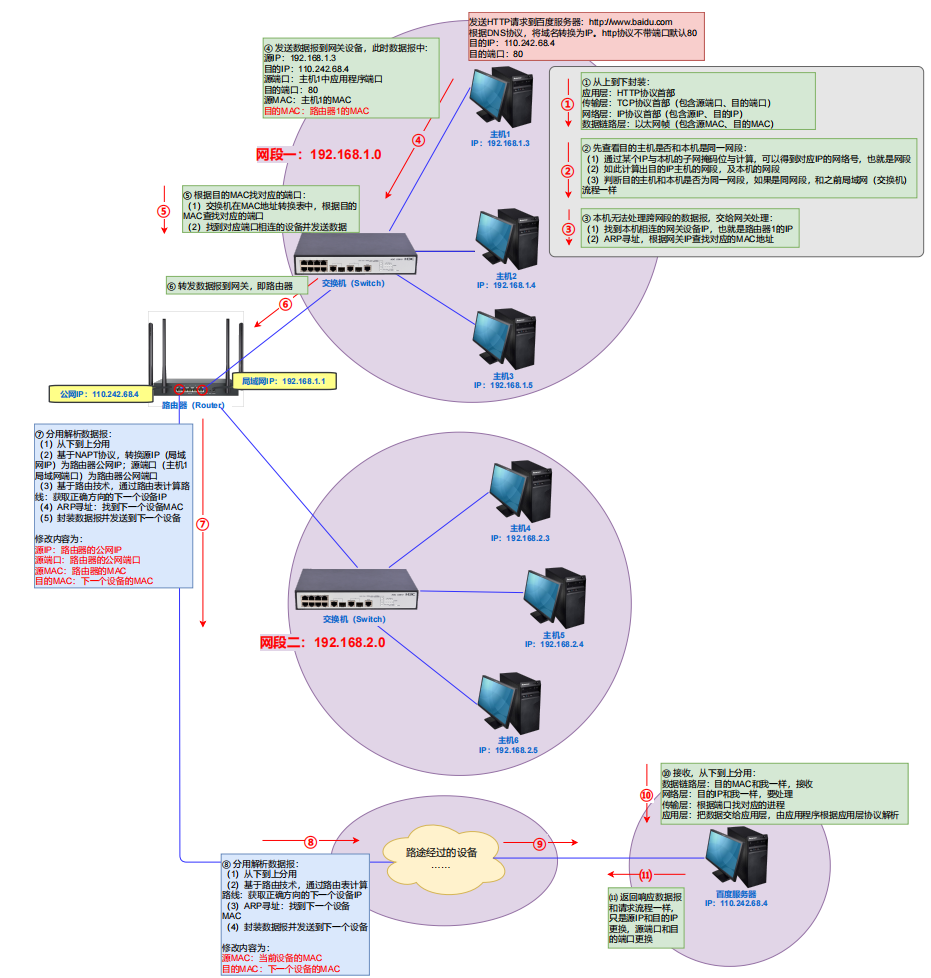
广域网数据传输流程
涉及的知识:DNS,NAPT,路由
三、应用层重点协议
下面我们主要学习TCP/IP四层模型中的重点网络协议:
1. DNS
DNS,即Domain Name System,域名系统。DNS是一整套从域名映射到IP的系统。TCP/IP中使用IP地址来确定网络上的一台主机,但是IP地址不方便记忆,且不能表达地址组织信息,于是人们发明了域名,并通过域名系统来映射域名和IP地址。
这里是引用
域名是一个字符串,如 www.baidu.com , hr.nowcoder.com 域名系统为一个树形结构的系统,包含多个根节点。其中:
1 . 根节点即为根域名服务器,最早IPv4的根域名服务器全球只有13台,IPv6在此基础上扩充了数量。
2 . 子节点主要由各级DNS服务器,或DNS缓存构成。
DNS域名服务器,即提供域名转换为IP地址的服务器。
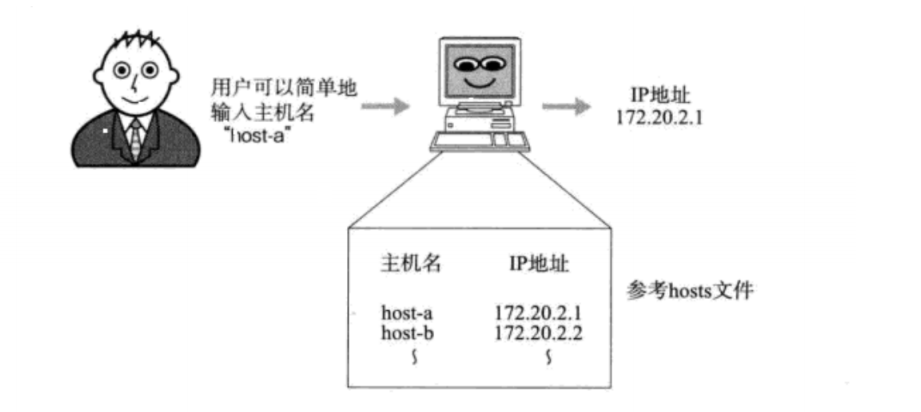
浏览器、主机系统、路由器中都保存有DNS缓存。
Windows系统的DNS缓存在 C:\Windows\System32\drivers\etc\hosts 文件中,
Mac/Linux系统的DNS缓存在 /etc/hosts 文件中
网络通信发送数据时,如果使用目的主机的域名,需要先通过域名解析查找到对应的IP地址:
1 .域名解析的过程,可以简单的理解为:发送端主机作为域名系统树形结构的一个子节点,通过域名信息,从下到上查找对应IP地址的过程。如果到根节点(根域名服务器)还找不到,即找不到该主机。
2 .域名解析使用DNS协议来传输数据。DNS协议是应用层协议,基于传输层UDP或TCP协议来实现。
2.NAT
技术背景
之前我们讨论了,IPv4协议中,IP地址数量不充足的问题 。NAT技术当前解决IP地址不够用的主要手段,是路由器的一个重要功能;
NAT能够将私有IP对外通信时转为全局IP。也就是就是一种将私有IP和全局IP相互转化的技术方法:
很多学校,家庭,公司内部采用每个终端设置私有IP,而在路由器或必要的服务器上设置全局IP;
全局IP要求唯一,但是私有IP不需要;在不同的局域网中出现相同的私有IP是完全不影响的;
NAT IP转换过程:
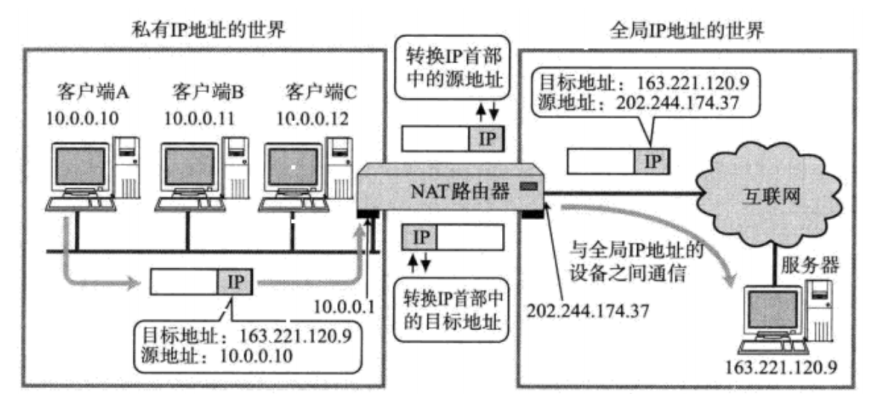
NAT路由器将源地址从10.0.0.10替换成全局的IP 202.244.174.37;
NAT路由器收到外部的数据时,又会把目标IP从202.244.174.37替换回10.0.0.10;
在NAT路由器内部,有一张自动生成的,用于地址转换的表;
当 10.0.0.10 第一次向 163.221.120.9 发送数据时就会生成表中的映射关系;
3. NAPT
那么问题来了,如果局域网内,有多个主机都访问同一个外网服务器,那么对于服务器返回的数据中,目的IP都是相同的。那么NAT路由器如何判定将这个数据包转发给哪个局域网的主机?
这时候NAPT来解决这个问题了。使用IP+port来建立这个关联关系:
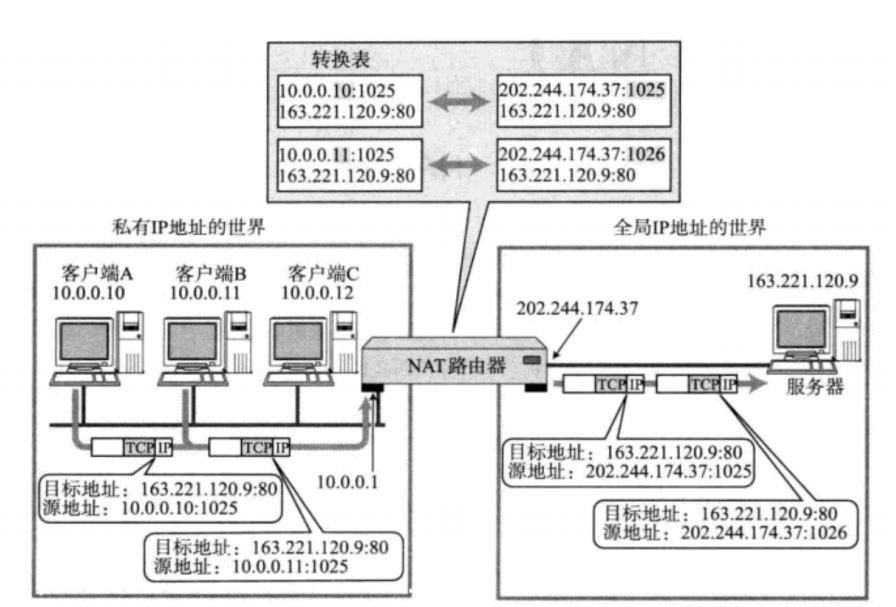
这种关联关系也是由NAT路由器自动维护的。例如在TCP的情况下,建立连接时,就会生成这个表项;在断开连接后,就会删除这个表项。
NAT技术的缺陷
由于NAT依赖这个转换表,所以有诸多限制:
无法从NAT外部向内部服务器建立连接;
转换表的生成和销毁都需要额外开销;
通信过程中一旦NAT设备异常,即使存在热备,所有的TCP连接也都会断开;
四、传输层重点协议
负责数据能够从发送端传输接收端。
1. TCP协议
TCP,即Transmission Control Protocol,传输控制协议。人如其名,要对数据的传输进行一个详细的控制。
TCP协议段格式
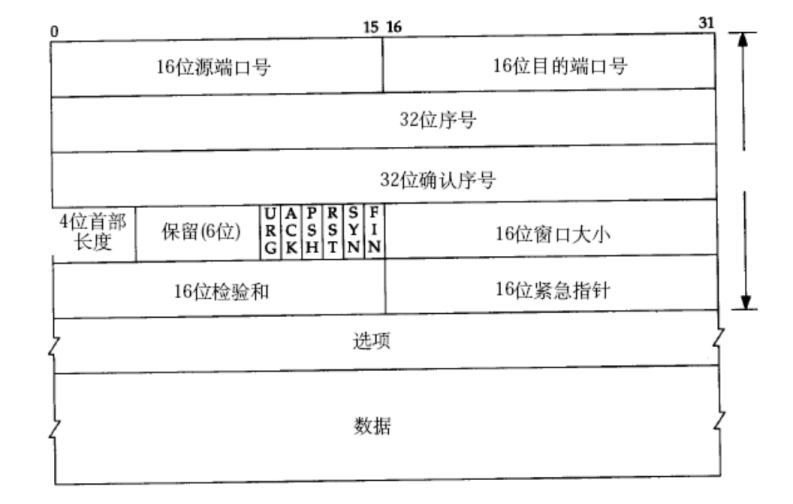
源/目的端口号:表示数据是从哪个进程来,到哪个进程去;
32位序号/32位确认号:下文会为大家详细讲解
4位TCP报头长度:表示该TCP头部有多少个32位bit(有多少个4字节);所以TCP头部最大长度是15 * 4 = 60
6位标志位:
URG:紧急指针是否有效
ACK:确认号是否有效
PSH:提示接收端应用程序立刻从TCP缓冲区把数据读走
RST:对方要求重新建立连接;我们把携带RST标识的称为复位报文段
SYN:请求建立连接;我们把携带SYN标识的称为同步报文段
FIN:通知对方,本端要关闭了,我们称携带FIN标识的为结束报文段
16位窗口大小:后面为大家讲解
16位校验和:发送端填充,CRC校验。接收端校验不通过,则认为数据有问题。此处的检验和不光包含TCP首部,也包含TCP数据部分。
16位紧急指针:标识哪部分数据是紧急数据;
TCP原理
TCP对数据传输提供的管控机制,主要体现在两个方面:安全和效率。
这些机制和多线程的设计原则类似:保证数据传输安全的前提下,尽可能的提高传输效率。
确认应答机制(安全机制)
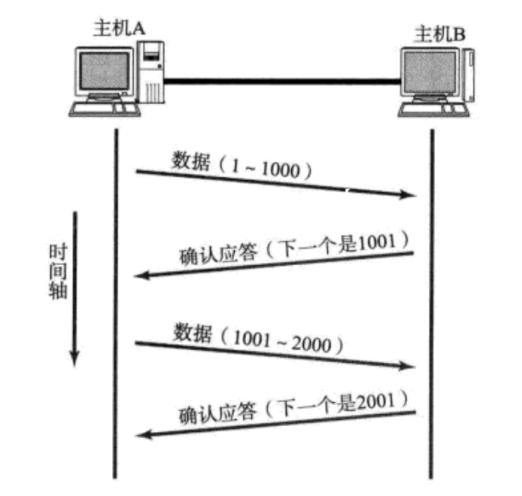
TCP将每个字节的数据都进行了编号。即为序列号。
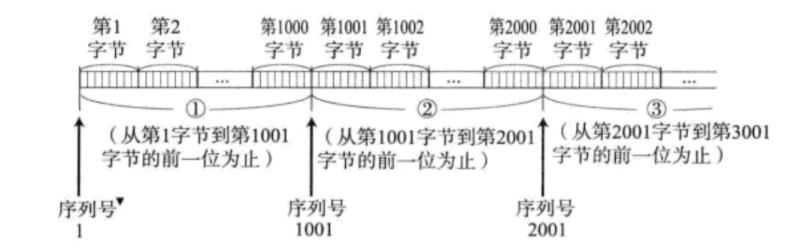
每一个ACK都带有对应的确认序列号,意思是告诉发送者,我已经收到了哪些数据;下一次你从哪里开始发。
超时重传机制(安全机制)
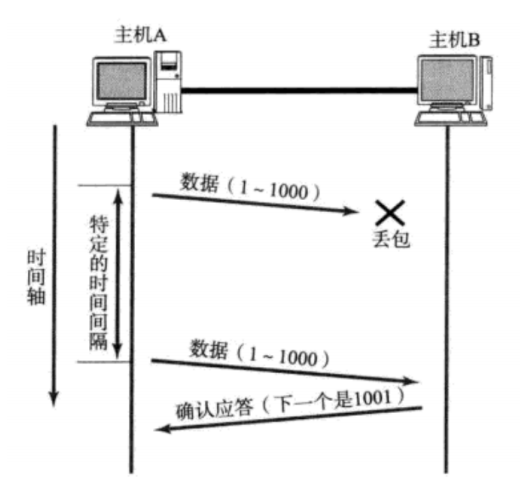
主机A发送数据给B之后,可能因为网络拥堵等原因,数据无法到达主机B;
如果主机A在一个特定时间间隔内没有收到B发来的确认应答,就会进行重发;
但是,主机A未收到B发来的确认应答,也可能是因为ACK丢失了;
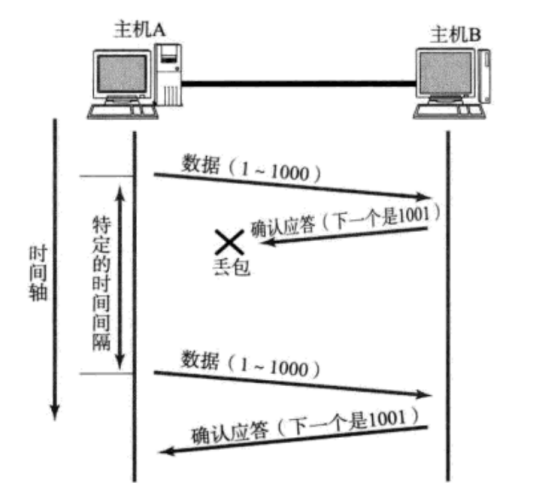
因此主机B会收到很多重复数据。那么TCP协议需要能够识别出那些包是重复的包,并且把重复的丢弃掉。这时候我们可以利用前面提到的序列号,就可以很容易做到去重的效果。那么,如果超时的时间如何确定?
最理想的情况下,找到一个最小的时间,保证 “确认应答一定能在这个时间内返回”。
但是这个时间的长短,随着网络环境的不同,是有差异的。
如果超时时间设的太长,会影响整体的重传效率;
如果超时时间设的太短,有可能会频繁发送重复的包;
TCP为了保证无论在任何环境下都能比较高性能的通信,因此会动态计算这个最大超时时间。
Linux中(BSD Unix和Windows也是如此),超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍。
如果重发一次之后,仍然得不到应答,等待 2500ms 后再进行重传。
如果仍然得不到应答,等待 4500ms 进行重传。依次类推,以指数形式递增。
累计到一定的重传次数,TCP认为网络或者对端主机出现异常,强制关闭连接。
连接管理机制(安全机制):
在正常情况下,TCP要经过三次握手建立连接,四次挥手断开连接:
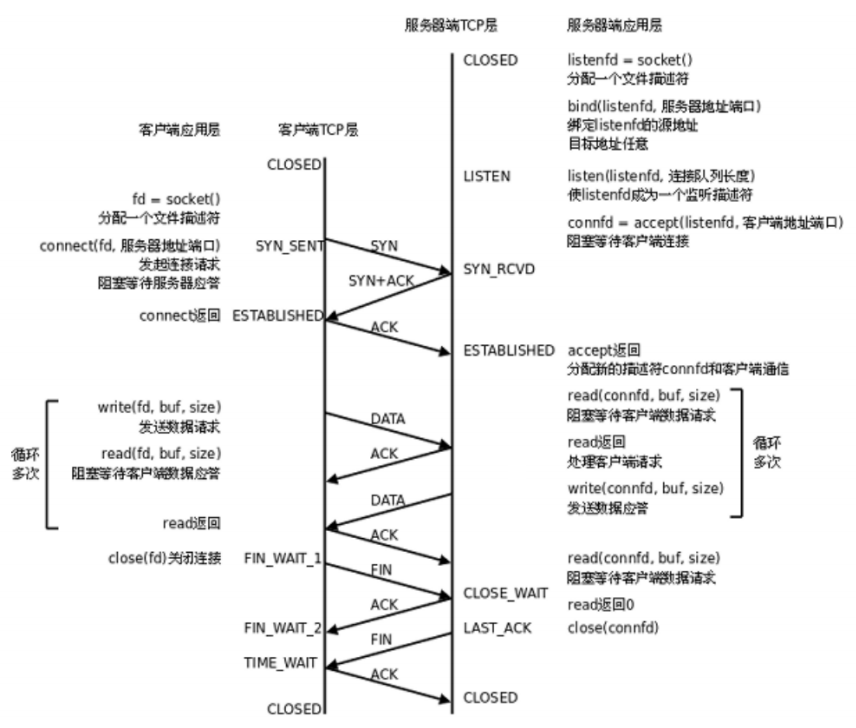
服务端状态转化:
[CLOSED -> LISTEN] 服务器端调用listen后进入LISTEN状态,等待客户端连接;
[LISTEN -> SYN_RCVD] 一旦监听到连接请求(同步报文段),就将该连接放入内核等待队列中,并向客户端发送SYN确认报文。
[SYN_RCVD -> ESTABLISHED] 服务端一旦收到客户端的确认报文,就进入ESTABLISHED状态,可以进行读写数据了。
[ESTABLISHED -> CLOSE_WAIT] 当客户端主动关闭连接(调用close),服务器会收到结束报文段,服务器返回确认报文段并进入CLOSE_WAIT;
[CLOSE_WAIT -> LAST_ACK] 进入CLOSE_WAIT后说明服务器准备关闭连接(需要处理完之前的数据);当服务器真正调用close关闭连接时,会向客户端发送FIN,此时服务器进入LAST_ACK状态,等待最后一个ACK到来(这个ACK是客户端确认收到了FIN)
[LAST_ACK -> CLOSED] 服务器收到了对FIN的ACK,彻底关闭连接。
客户端状态转化:
[CLOSED -> SYN_SENT] 客户端调用connect,发送同步报文段;
[SYN_SENT -> ESTABLISHED] connect调用成功,则进入ESTABLISHED状态,开始读写数据;
[ESTABLISHED -> FIN_WAIT_1] 客户端主动调用close时,向服务器发送结束报文段,同时进入FIN_WAIT_1;
[FIN_WAIT_1 -> FIN_WAIT_2] 客户端收到服务器对结束报文段的确认,则进入FIN_WAIT_2,开始等待服务器的结束报文段;
[FIN_WAIT_2 -> TIME_WAIT] 客户端收到服务器发来的结束报文段,进入TIME_WAIT,并发出LAST_ACK;
[TIME_WAIT -> CLOSED] 客户端要等待一个2MSL(Max Segment Life,报文最大生存时间)的时间,才会进入CLOSED状态。
TIME_WAIT
想一想,为什么是TIME_WAIT的时间是2MSL?
MSL是TCP报文的最大生存时间,因此TIME_WAIT持续存在2MSL的话就能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失(否则服务器立刻重启,可能会收到来自上一个进程的迟到的数据,但是这种数据很可能是错误的);同时也是在理论上保证最后一个报文可靠到达(假设最后一个ACK丢失,那么服务器会再重发一个FIN。这时虽然客户端的进程不在了,但是TCP连接还在,仍然可以重发
LAST_ACK);
CLOSE_WAIT
一般而言,对于服务器上出现大量的 CLOSE_WAIT 状态,原因就是服务器没有正确的关闭 socket,导致四次挥手没有正确完成。这是一个 BUG。只需要加上对应的 close 即可解决问题。
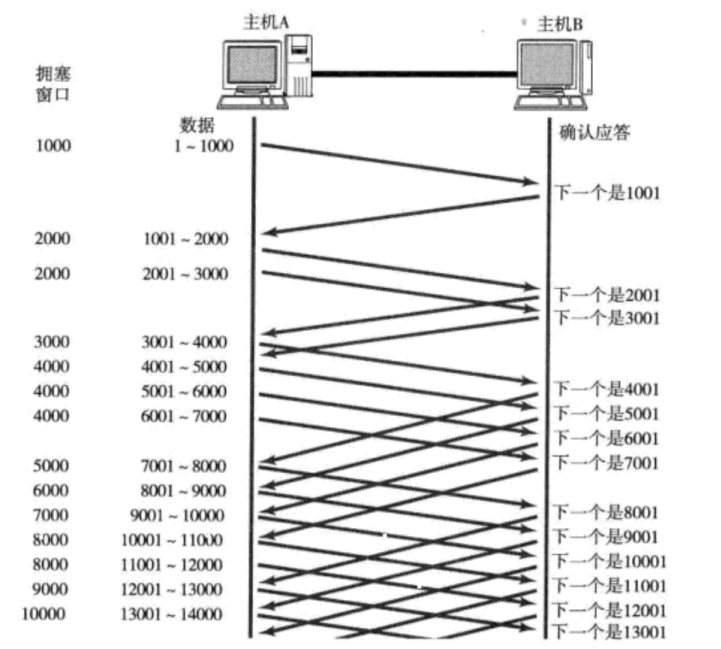
滑动窗口(效率机制)
刚才我们讨论了确认应答策略,对每一个发送的数据段,都要给一个ACK确认应答。收到ACK后再发送下一个数据段。这样做有一个比较大的缺点,就是性能较差。尤其是数据往返的时间较长的时候。
既然这样一发一收的方式性能较低,那么我们一次发送多条数据,就可以大大的提高性能(其实是将多个段的等待时间重叠在一起了)。
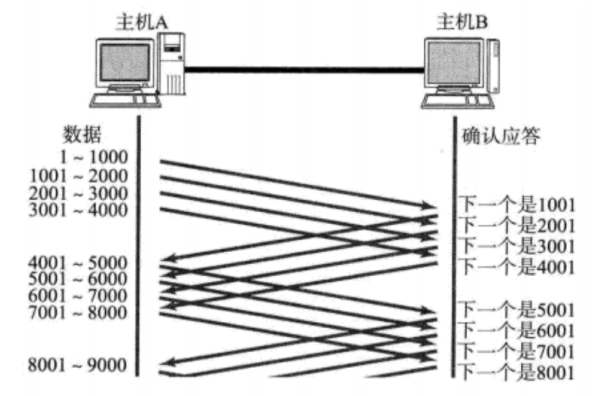
窗口大小指的是无需等待确认应答而可以继续发送数据的最大值。上图的窗口大小就是4000个字节(四个段)。
发送前四个段的时候,不需要等待任何ACK,直接发送;
收到第一个ACK后,滑动窗口向后移动,继续发送第五个段的数据;依次类推;
操作系统内核为了维护这个滑动窗口,需要开辟 发送缓冲区 来记录当前还有哪些数据没有应
答;只有确认应答过的数据,才能从缓冲区删掉;
窗口越大,则网络的吞吐率就越高;
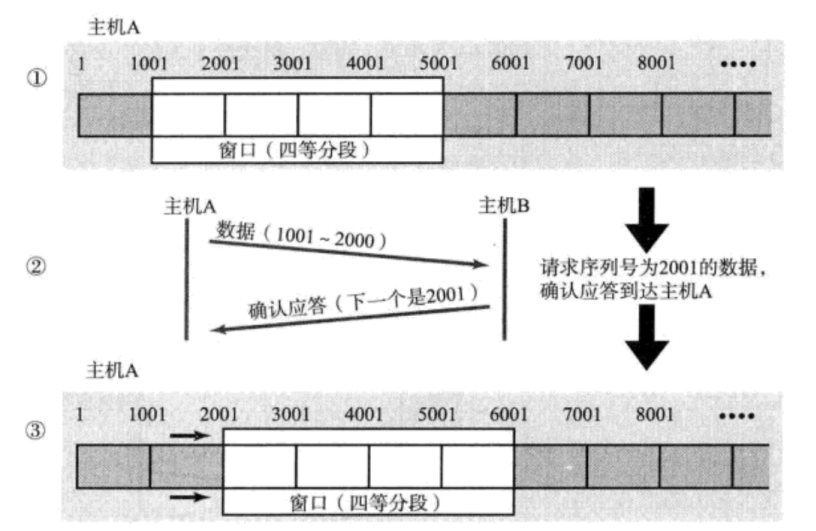
那么如果出现了丢包,如何进行重传?这里分两种情况讨论。
情况一:数据包已经抵达,ACK被丢了。
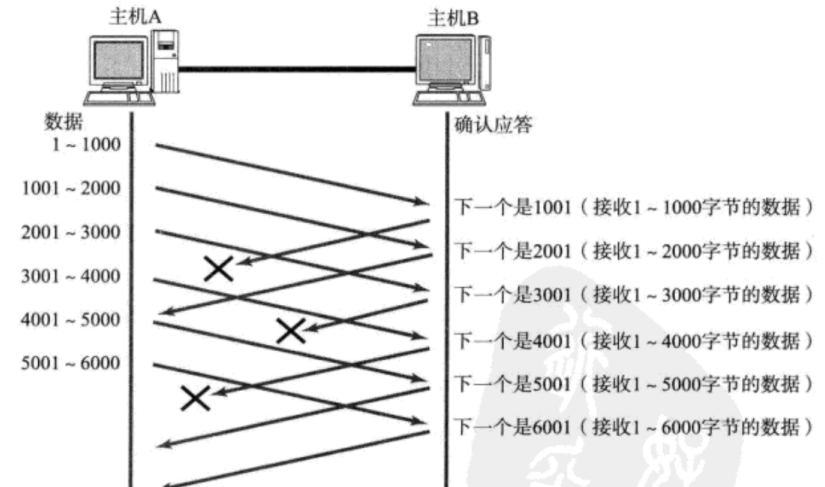
这种情况下,部分ACK丢了并不要紧,因为可以通过后续的ACK进行确认;
情况二:数据包就直接丢了:
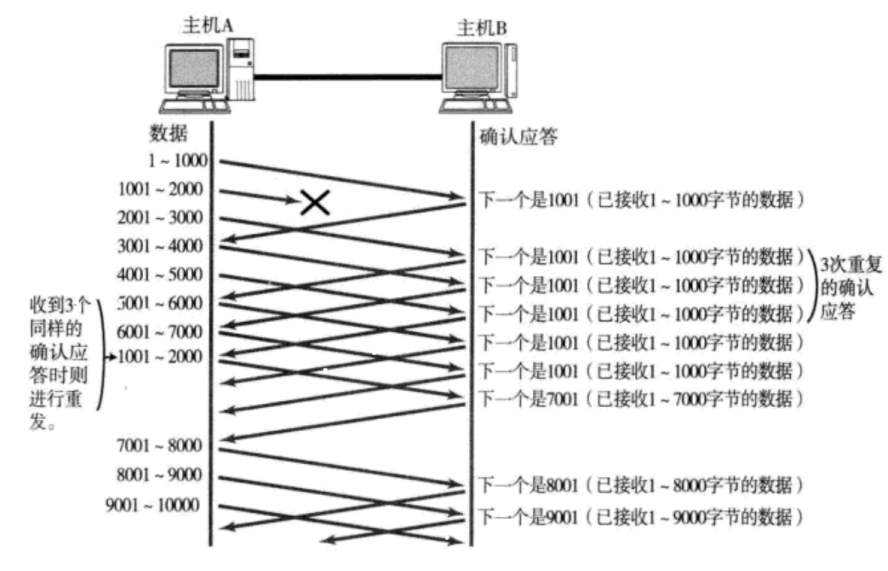
当某一段报文段丢失之后,发送端会一直收到 1001 这样的ACK,就像是在提醒发送端 “我想要的是 1001” 一样;
如果发送端主机连续三次收到了同样一个 “1001” 这样的应答,就会将对应的数据 1001 - 2000 重新发送;
这个时候接收端收到了 1001 之后,再次返回的ACK就是7001了(因为2001 - 7000)接收端其实之前就已经收到了,被放到了接收端操作系统内核的接收缓冲区中;
这种机制被称为 “高速重发控制”(也叫 “快重传”)。
流量控制(安全机制)
接收端处理数据的速度是有限的。如果发送端发的太快,导致接收端的缓冲区被打满,这个时候如果发送端继续发送,就会造成丢包,继而引起丢包重传等等一系列连锁反应。
因此TCP支持根据接收端的处理能力,来决定发送端的发送速度。这个机制就叫做流量控制(Flow Control)
接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 “窗口大小” 字段,通过ACK端通知发送端;
窗口大小字段越大,说明网络的吞吐量越高;
接收端一旦发现自己的缓冲区快满了,就会将窗口大小设置成一个更小的值通知给发送端;
发送端接受到这个窗口之后,就会减慢自己的发送速度;
如果接收端缓冲区满了,就会将窗口置为0;这时发送方不再发送数据,但是需要定期发送一个窗口探测数据段,使接收端把窗口大小告诉发送端。
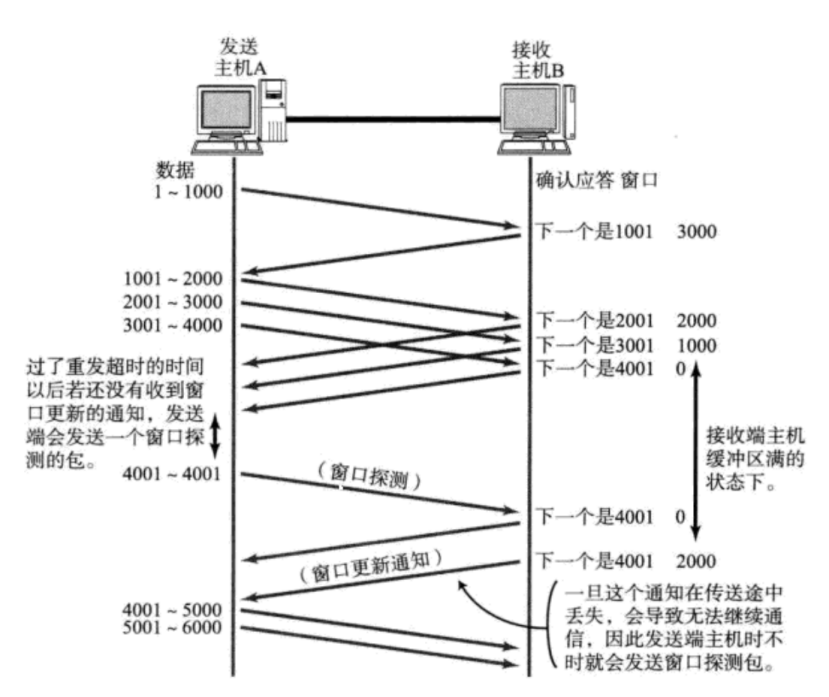
接收端如何把窗口大小告诉发送端呢?回忆我们的TCP首部中,有一个16位窗口字段,就是存放了窗口大小信息;那么问题来了,16位数字最大表示65535,那么TCP窗口最大就是65535字节么?实际上,TCP首部40字节选项中还包含了一个窗口扩大因子M,实际窗口大小是 窗口字段的值左移 M 位;
拥塞控制(安全机制)
虽然TCP有了滑动窗口这个大杀器,能够高效可靠的发送大量的数据。但是如果在刚开始阶段就发送大量的数据,仍然可能引发问题。
因为网络上有很多的计算机,可能当前的网络状态就已经比较拥堵。在不清楚当前网络状态下,贸然发送大量的数据,是很有可能引起雪上加霜的。
TCP引入 慢启动 机制,先发少量的数据,探探路,摸清当前的网络拥堵状态,再决定按照多大的速度传输数据;
此处引入一个概念程为拥塞窗口发送开始的时候,定义拥塞窗口大小为1;每次收到一个ACK应答,拥塞窗口加1;每次发送数据包的时候,将拥塞窗口和接收端主机反馈的窗口大小做比较,取较小的值作为实际发送的窗口;
像上面这样的拥塞窗口增长速度,是指数级别的。“慢启动” 只是指初使时慢,但是增长速度非常快。
为了不增长的那么快,因此不能使拥塞窗口单纯的加倍。此处引入一个叫做慢启动的阈值。当拥塞窗口超过这个阈值的时候,不再按照指数方式增长,而是按照线性方式增长
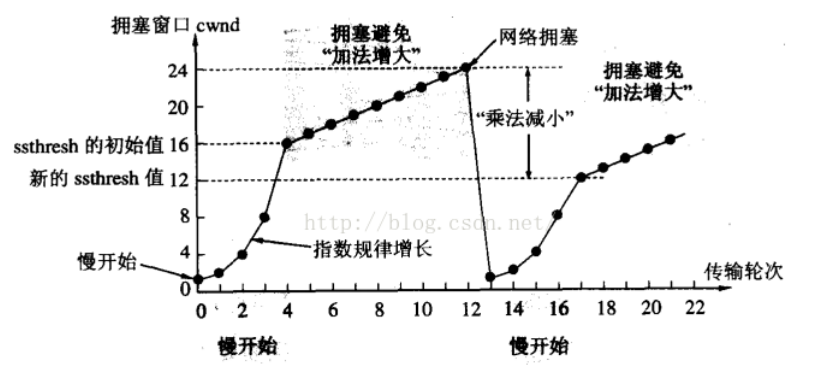
当TCP开始启动的时候,慢启动阈值等于窗口最大值;在每次超时重发的时候,慢启动阈值会变成原来的一半,同时拥塞窗口置回1;
少量的丢包,我们仅仅是触发超时重传;大量的丢包,我们就认为网络拥塞;
当TCP通信开始后,网络吞吐量会逐渐上升;随着网络发生拥堵,吞吐量会立刻下降;拥塞控制,归根结底是TCP协议想尽可能快的把数据传输给对方,但是又要避免给网络造成太大压力的折中方案
延迟应答(效率机制)
如果接收数据的主机立刻返回ACK应答,这时候返回的窗口可能比较小。
假设接收端缓冲区为1M。一次收到了500K的数据;如果立刻应答,返回的窗口就是500K;
但实际上可能处理端处理的速度很快,10ms之内就把500K数据从缓冲区消费掉了;在这种情况下,接收端处理还远没有达到自己的极限,即使窗口再放大一些,也能处理过来;如果接收端稍微等一会再应答,比如等待200ms再应答,那么这个时候返回的窗口大小就是
1M;
一定要记得,窗口越大,网络吞吐量就越大,传输效率就越高。我们的目标是在保证网络不拥塞的情况下尽量提高传输效率;
那么所有的包都可以延迟应答么?肯定也不是;
数量限制:每隔N个包就应答一次;
时间限制:超过最大延迟时间就应答一次;
具体的数量和超时时间,依操作系统不同也有差异。
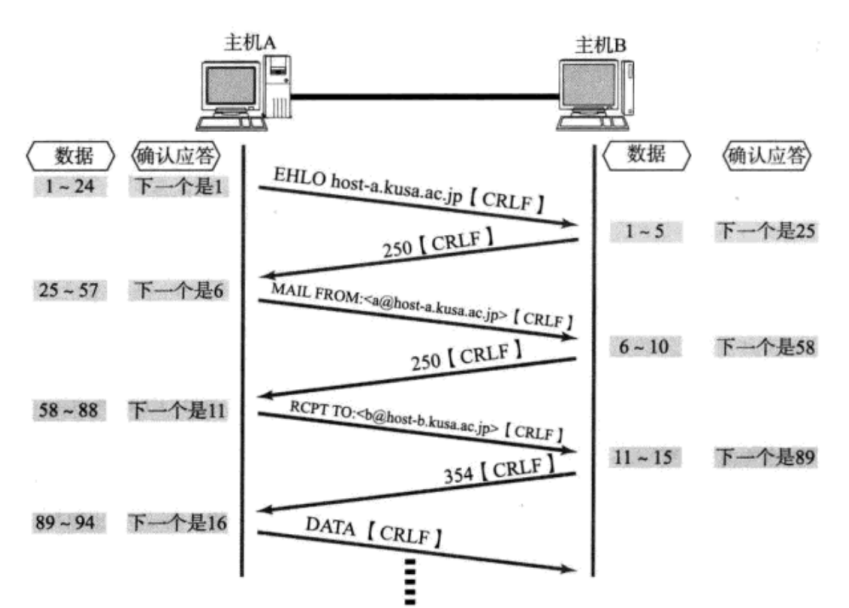
捎带应答(效率机制)
在延迟应答的基础上,我们发现,很多情况下,客户端服务器在应用层也是 “一发一收” 的。意味着客户端给服务器说了 “How are you”,服务器也会给客户端回一个 “Fine, thank you”;那么这个时候ACK就可以搭顺风车,和服务器回应的 “Fine,thank you” 一起回给客户端
其他特性:面向字节流
其他特性:缓冲区
其他特性:大小限制
创建一个TCP的socket,同时在内核中创建一个 发送缓冲区 和一个 接收缓冲区;
调用write时,数据会先写入发送缓冲区中;如果发送的字节数太长,会被拆分成多个TCP的数据包发出;如果发送的字节数太短,就会先在缓冲区里等待,等到缓冲区长度差不多了,或者其他合适的时机发送出去;接收数据的时候,数据也是从网卡驱动程序到达内核的接收缓冲区;然后应用程序可以调用read从接收缓冲区拿数据;
另一方面,TCP的一个连接,既有发送缓冲区,也有接收缓冲区,那么对于这一个连接,既可以读数据,也可以写数据。这个概念叫做 全双工
由于缓冲区的存在,TCP程序的读和写不需要一一匹配,例如:
写100个字节数据时,可以调用一次write写100个字节,也可以调用100次write,每次写一个字节;
读100个字节数据时,也完全不需要考虑写的时候是怎么写的,既可以一次read 100个字节,也可以一次read一个字节,重复100次;
粘包问题
首先要明确,粘包问题中的 “包” ,是指的应用层的数据包。在TCP的协议头中,没有如同UDP一样的 “报文长度” 这样的字段,但是有一个序号这样的字段。站在传输层的角度,TCP是一个一个报文过来的。按照序号排好序放在缓冲区中。站在应用层的角度,看到的只是一串连续的字节数据。那么应用程序看到了这么一连串的字节数据,就不知道从哪个部分开始到哪个部分,是一个完整的应用层数据包。
那么如何避免粘包问题呢?归根结底就是一句话,明确两个包之间的边界。
对于定长的包,保证每次都按固定大小读取即可;例如上面的Request结构,是固定大小的,那么就从缓冲区从头开始按sizeof(Request)依次读取即可;
对于变长的包,可以在包头的位置,约定一个包总长度的字段,从而就知道了包的结束位置;
对于变长的包,还可以在包和包之间使用明确的分隔符。
思考:对于UDP协议来说,是否也存在 “粘包问题” 呢?
对于UDP,如果还没有上层交付数据,UDP的报文长度仍然在。同时,UDP是一个一个把数据交付给应用层。就有很明确的数据边界。
站在应用层的站在应用层的角度,使用UDP的时候,要么收到完整的UDP报文,要么不收。不会出现"半个"的情况。
TCP异常情况
进程终止:进程终止会释放文件描述符,仍然可以发送FIN。和正常关闭没有什么区别。
机器重启:和进程终止的情况相同。
机器掉电/网线断开:接收端认为连接还在,一旦接收端有写入操作,接收端发现连接已经不在了,就会进行reset。即使没有写入操作,TCP自己也内置了一个保活定时器,会定期询问对方是否还在。如果对方不在,也会把连接释放。另外,应用层的某些协议,也有一些这样的检测机制。例如HTTP长连接中,也会定期检测对方的状态。例如QQ,在QQ断线之后,也会定期尝试重新连接。
TCP小结
为什么TCP这么复杂?因为要保证可靠性,同时又尽可能的提高性能。
可靠性:
校验和
序列号(按序到达)
确认应答
超时重发
连接管理
流量控制
拥塞控制
提高性能:
快速重传
延迟应答
滑动窗口
捎带应答
其他:
定时器(超时重传定时器,保活定时器,TIME_WAIT定时器等)
基于TCP应用层协议
HTTP HTTPS SSH Telnet FTP SMTP
当然,也包括你自己写TCP程序时自定义的应用层协议;
2. UDP协议
UDP协议端格式
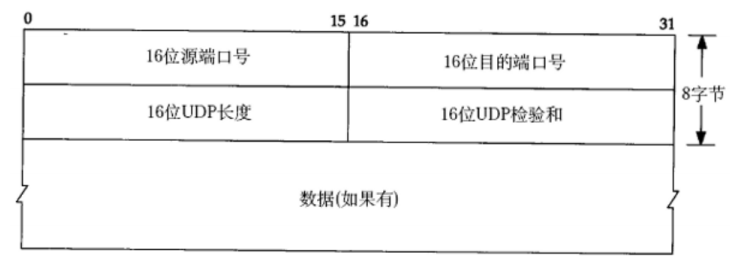
16位UDP长度,表示整个数据报(UDP首部+UDP数据)的最大长度;
如果校验和出错,就会直接丢弃;
UDP的特点:
UDP传输的过程类似于寄信
无连接:知道对端的IP和端口号就直接进行传输,不需要建立连接;
不可靠:没有任何安全机制,发送端发送数据报以后,如果因为网络故障该段无法发到对方,UDP协议层也不会给应用层返回任何错误信息;
面向数据报:应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并;
用UDP传输100个字节的数据:如果发送端一次发送100个字节,那么接收端也必须一次接收100个字节;而不能循环接收10次,每次接收10个字节。
缓冲区:UDP只有接收缓冲区,没有发送缓冲区:
UDP没有真正意义上的 发送缓冲区。发送的数据会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作;
UDP具有接收缓冲区,但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致;如果缓冲区满了,再到达的UDP数据就会被丢弃;
UDP的socket既能读,也能写,这个概念叫做 全双工每次接收10个字节。
大小受限:UDP协议首部中有一个16位的最大长度。也就是说一个UDP能传输的数据最大长度是64K(包含UDP首部);
基于UDP的应用层协议
NFS:网络文件系统
TFTP:简单文件传输协议
DHCP:动态主机配置协议
BOOTP:启动协议(用于无盘设备启动)
DNS:域名解析协议
当然,也包括你自己写UDP程序时自定义的应用层协议。
TCP/UDP对比
我们说了TCP是可靠连接,那么是不是TCP一定就优于UDP呢?TCP和UDP之间的优点和缺点,不能简单,绝对的进行比较:
TCP用于可靠传输的情况,应用于文件传输,重要状态更新等场景;
UDP用于对高速传输和实时性要求较高的通信领域,例如,早期的QQ,视频传输等。另外 UDP可以用于广播;
归根结底,TCP和UDP都是程序员的工具,什么时机用,具体怎么用,还是要根据具体的需求场景去判定。
五、网络层重点协议
1.IP协议
协议头格式如下:

4位版本号(version):指定IP协议的版本,对于IPv4来说,就是4。
4位头部长度(header length):IP头部的长度是多少个32bit,也就是 length * 4 的字节数。4bit表示最大的数字是15,因此IP头部最大长度是60字节。
8位服务类型(Type Of Service):4位TOS字段,和1位保留字段(必须置为0)。4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。这四者相互冲突,只能选择一个。对于ssh/telnet这样的应用程序,最小延时比较重要;对于
ftp这样的程序,最大吞吐量比较重要。
16位总长度(total length):IP数据报整体占多少个字节。
16位标识(id):唯一的标识主机发送的报文。如果IP报文在数据链路层被分片了,那么每一个片里面的这个id都是相同的。
3位标志字段:第一位保留(保留的意思是现在不用,但是还没想好说不定以后要用到)。第二位置为1表示禁止分片,这时候如果报文长度超过MTU,IP模块就会丢弃报文。第三位表示"更多分片",如果分片了的话,最后一个分片置为1,其他是0。类似于一个结束标记。
13位分片偏移(framegament offset):是分片相对于原始IP报文开始处的偏移。其实就是在表示当前分片在原报文中处在哪个位置。实际偏移的字节数是这个值 * 8 得到的。因此,除了最后一个报文之外,其他报文的长度必须是8的整数倍(否则报文就不连续了)。8位生存时间(Time To Live,TTL):数据报到达目的地的最大报文跳数。一般是64。每次经过一个路由,TTL -= 1,一直减到0还没到达,那么就丢弃了。这个字段主要是用来防止出现路由循环。
8位协议:表示上层协议的类型。
16位头部校验和:使用CRC进行校验,来鉴别头部是否损坏。
32位源地址和32位目标地址:表示发送端和接收端。选项字段(不定长,最多40字节)。
总结
网络层:
网络层的作用:在复杂的网络环境中确定一个合适的路径。
理解IP地址,理解IP地址和MAC地址的区别。
理解IP协议格式。
了解网段划分方法
理解如何解决IP数目不足的问题,掌握网段划分的两种方案。理解私有IP和公网IP
理解网络层的IP地址路由过程。理解一个数据包如何跨越网段到达最终目的地。
理解IP数据包分包的原因。
了解NAT设备的工作原理
传输层:
传输层的作用:负责数据能够从发送端传输接收端。
理解端口号的概念。
认识UDP协议,了解UDP协议的特点。
认识TCP协议,理解TCP协议的可靠性。理解TCP协议的状态转化。
掌握TCP的连接管理,确认应答,超时重传,滑动窗口,流量控制,拥塞控制,延迟应答,
捎带应答特性。
理解TCP面向字节流,理解粘包问题和解决方案。
能够基于UDP实现可靠传输。
理解MTU对UDP/TCP的影响
应用层
应用层的作用:满足我们日常需求的网络程序,都是在应用层
能够根据自己的需求,设计应用层协议。
理解DNS的原理和工作流程。
本文主要介绍了IP地址、mac地址等网络基础,到网络传输流程,再到对应用层、传输层的重点协议的讲解。内容量较大。
以上就是本文全部内容,感谢各位能够看到最后,如有问题,欢迎各位大佬在评论区指正,希望大家可以有所收获!创作不易,希望大家多多支持!
最后,大家再见!祝好!我们下期见!
相关文章:

【网络原理】 《TCP/IP 协议深度剖析:从网络基础到协议核心》
文章目录 一、网络基础1. 认识IP地址概念作用格式组成子网掩码 2、认识Mac地址一跳一跳的网络数据传输 3. 网络设备及相关技术集线器:转发所有端口交换机:MAC地址转换表转发对应端口主机:网络分层从上到下封装主机&路由器:ARP…...

Windows系统编译支持GPU的llama.cpp
Windows系统编译支持GPU的llama.cpp git clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp mkdir build cd buildcmake .. -G "Visual Studio 17 2022" -DGGML_CUDAON -DCMAKE_BUILD_TYPERelease -DCMAKE_CUDA_ARCHITECTURES"86"cmake --b…...

Unity编辑器扩展之导出项目中所有预制体中文本组件文字内容
一、最后导出的Excel文件效果如下图所示: 二、在Unity的Editor目录下,新建一个名为FindChineseInPrefabs的C#脚本,Copy以下代码到你新建的名为FindChineseInPrefabs的C#脚本中去,最后一定要保存文件哈。 using UnityEditor; using UnityEngine; using UnityEngine.UI; usi…...

高效管理远程服务器Termius for Mac 保姆级教程
以下是 Termius for Mac 保姆级教程,涵盖安装配置、核心功能、实战案例及常见问题解决方案,助你高效管理远程服务器(如Vultr、AWS等)。 一、Termius 基础介绍 1. Termius 是什么? 跨平台SSH客户端:支持Ma…...

WPF框架中常用算法
WPF框架中常用算法与实现 一、排序算法 1. 快速排序 (Quick Sort) 应用场景:大数据集合排序、性能敏感场景 public static void QuickSort(IList<int> list, int left, int right) {if (left < right){int pivotIndex Partition(list, left, r…...

【Java函数式编程-58】Java函数式编程深度解析
函数式编程(Functional Programming)作为一种编程范式,近年来在Java生态中获得了越来越多的关注和应用。自Java 8引入Lambda表达式和Stream API以来,函数式编程风格在Java开发中逐渐普及。本文将深入探讨Java中函数式编程的核心概念、实践技巧以及在实际…...

解决vscode cmake提示检测到 #include 错误
一、问题 cmake已经包含了动态库文件,依然提示“检测到 #include 错误。请更新 includePath。” 二、解决方案 Ctrl Shift P进入CPP编辑配置,然后在JSON中加入下面一行: "configurationProvider": "ms-vscode.cmake-tools&…...

Microsoft .NET Framework 4.8 离线安装包 下载
简介Microsoft .NET Framework 4.8 是对 Microsoft .NET Framework 4、4.5、4.5.1、4.5.2、4.6、4.6.1、4.6.2、4.7、4.7.1 和 4.7.2 的高度兼容的就地更新。 脱机程序包可用于因无法连接 Internet 而导致 Web 安装程序无法使用的情况。 此包比 Web 安装程序大,并且…...

部署若依项目到服务器遇到的问题
以下是本次部署遇到的问题及解决方法 1、问题:docker一直出现“> ERROR [internal] load metadata for docker.io/library/xxx“的问题 ERROR: failed to solve: openjdk:8-jdk-alpine: failed to resolve source metadata for docker.io/libran y/ope…...

Elasticsearch--自带“搜索引擎“的数据库
一、核心原理 1. 倒排索引(Inverted Index) 基本概念 将文档中的每个词条(term)映射到包含它的文档列表上,正如图书馆目录将关键词映射到书籍编号。工作流程 分词(Analysis):文本切…...

malloc的实现原理
malloc 是 C 语言中动态内存分配的核心函数,其实现原理涉及操作系统内存管理、数据结构和算法设计。以下是其核心实现原理的简化分析: 1. 内存池管理 基本思想:malloc 通过管理一个 内存池(堆)动态分配内存。操作系统…...

垃圾收集GC的基本理解
垃圾收集的基本理解 GC 的基本算法 标记清除 从根开始将可能被引用的对象用递归的方式进行标记(标记阶段),然后再从根开始将全部对象按顺序扫描一遍,将没有被标记的对象进行回收(清除阶段)。 大多数情况…...

JVM——Java的基本类型的实现
Java 基本类型在 JVM 中的实现 Java 作为一种广泛使用的编程语言,其在虚拟机(JVM)上的实现细节对于开发者来说至关重要。本文将详细讲解 Java 基本类型在 JVM 中的实现,去深入理解 Java 编程语言的底层工作机制。 Java 基本类型…...

临床回归分析及AI推理
在医疗保健决策越来越受数据驱动的时代,回归分析已成为临床医生和研究人员最强大的工具之一。无论是预测结果、调整混杂因素、建模生存时间还是理解诊断性能,回归模型都为将原始数据转化为临床洞察提供了统计学基础。 AI推理 然而,随着技术…...
)
Ubuntu 22.04 的 ROS 2 和 Carla 设置指南(其一)
重点介绍适用于 Ubuntu 22.04 的全面 ROS 2 和 Carla 设置指南。我们将首先安装 Terminator 终端,然后安装 ROS 2 依赖项,然后继续安装 ROS 2 Humble。接下来,我们将介绍如何在 Ubuntu 22.04 上安装 Carla,最后通过设置 Carla ROS…...

声明:个人从未主动把文章设置为仅vip可读
之前一直在公司忙就没看csdn这边,前几天朋友看到我的博客是仅vip可读我才发现这个 给我气笑了。。。不反馈默认同意。。。。 现在都已经改回来 写文章的初衷就是记录一下自己的学习过程,本来就是一些偏基础类的东西,还需要去买vip才能看就太…...

【大模型系列篇】Qwen3开源全新一代大语言模型来了,深入思考,更快行动
Qwen3开源模型全览 Qwen3是全球最强开源模型(MoEDense) Qwen3 采用混合专家(MoE)架构,总参数量 235B,激活仅需 22B。 Qwen3 预训练数据量达 36T,并在后训练阶段多轮强化学习,将非思…...
)
DeepSeek-Prover-V2-671B 简介、下载、体验、微调、数据集:专为数学定理自动证明设计的超大垂直领域语言模型(在线体验地址)
DeepSeek-Prover-V2-671B 最新发布:专为数学定理自动证明设计的超大语言模型 体验地址:Hugging Face 在线体验 推荐入口:Novita 平台直达链接(含邀请码) 一、模型简介 DeepSeek-Prover-V2-671B 是 DeepSeek 团队于 2…...

Gupta-Sproull 抗据此画线算法
本文源自于:从https://www.inf.ed.ac.uk/teaching/courses/cg/lectures/cg4_2012.pdf Gupta-Sproull是在Brensenham的画线算法基础上得到。 为了防止之前的链接失效,特地搬运一下...

idea写spark程序
使用IntelliJ IDEA编写Spark程序的完整指南 一、环境准备 安装必要软件 IntelliJ IDEA (推荐Ultimate版,Community版也可) JDK 8或11 Scala插件(在IDEA中安装) Spark最新版本(本地开发可以用embedded模式) 创建项目 打开IDEA → New Project 选择"Maven…...

视觉问答论文解析:《Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning》
《Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning》论文解析 一、研究背景与动机 近年来,“慢思考”多模态模型(如 OpenAI-o1、GeminiThinking、Kimi-1.5 和 Skywork-R1V)在数学和科学领域的复杂推理任务中取得了显…...

修改linux账号名
修改linux账号名 结论是步骤1.临时创建一个辅助账户执行操作2.注销当前账户,登录 tempadmin 用户。3.使用它修改 旧用户名olduser:4.(可选)删除临时用户: 结论是 不可以直接修改,要么需要创建一个临时用户来打辅助. …...
MVP变换示例)
计算机图形学:(二)MVP变换示例
前言 当在阅读计算机图形学系列的书籍时,会发现大部分图书每章内容都如出一辙。从个人实际体会来讲,虽然能理解书中大部分的知识,但到了实际使用时却有点抓耳挠腮。因此,在写了计算机图形学:(一)…...
)
PostgreSQL中的SSL(2)
PGSQL数据库的默认隔离级别是读提交,并且同时支持可重复读和序列化模式。但是在9.1之前的版本中,序列化模式是采用快照隔离来实现,并非是真正的序列化模式。 这样的话就会存在一个问题,那就是写偏序(Write Skew&#…...

Linux 部署以paddle Serving 的方式部署 PaddleOCR CPU版本
强烈建议您在Docker内构建Paddle Serving,更多镜像请查看Docker镜像列表。 提示-1:Paddle Serving项目仅支持Python3.6/3.7/3.8/3.9,接下来所有的与Python/Pip相关的操作都需要选择正确的Python版本。 提示-2:以下示例中GPU环境均…...
)
苏德战争前期苏联损失惨重(马井堂)
苏德战争前期(1941年6月22日德国发动“巴巴罗萨行动”至1941年底至1942年初)是苏联在二战中损失最惨重的阶段之一。以下是主要方面的损失概述: 一、军事损失 人员伤亡与俘虏 至1941年底,苏军伤亡约300万人ÿ…...
)
SI5338-EVB Usage Guide(LVPECL、LVDS、HCSL、CMOS、SSTL、HSTL)
目录 1. 简介 1.1 EVB 介绍 1.2 Si5338 Block Diagram 2. EVB 详解 2.1 实物图 2.2 基本配置 2.2.1 Universal Pin 2.2.2 IIC I/F 2.2.3 Input Clocks 2.2.4 Output Frequencies 2.2.5 Output Driver 2.2.6 Freq and Phase Offset 2.2.7 Spread Spectrum 2.2.8 快…...

LeetCode LCP40 心算挑战题解
看似一道简单的题目,实则不然,没有看评论的话,实在想不出来怎么写。 现在则由我来转述思想供大家参考理解,还是先给出示例,供大家更好的理解这个题目。 输入:cards [1,2,8,9], cnt 3输出:18解…...

Smart Link+Monitor Link组网
1.技术背景及原理 一般情况下,Smart Link只能感知与其接口直连的链路故障。将Monitor Link配置在Smart Link的上游设备上,可使Smart Link迅速感知上游链路故障,进行链路切换。Smart Link与Monitor Link配合使用,扩大了Smart Link…...
套接字,多线程远程执行命令编程)
【计算机网络】TCP(传输控制协议)套接字,多线程远程执行命令编程
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:UDP套接字编程(英汉字典以及多线程聊天室编写)…...

PostgreSQL 中 VACUUM FULL 对索引的影响
PostgreSQL 中 VACUUM FULL 对索引的影响 是的,VACUUM FULL 会重建表上的所有索引。这是它与普通 VACUUM 命令的一个重要区别。 一、VACUUM FULL 的工作原理 表重建过程: 创建表的全新副本只将有效数据写入新存储删除原始表文件将新文件重命名为原表名…...

DeepSeek本地部署及WebUI可视化完全指南
以下是为您整理的DeepSeek本地部署及WebUI可视化完全指南,整合了官方文档及社区实践的最佳方案: 一、环境准备 1. 硬件需求 CPU:推荐支持AVX2指令集的Intel i7或AMD Ryzen 7及以上处理器 。 GPU(可选但推荐)…...

大模型时代的新燃料:大规模拟真多风格语音合成数据集
以大模型技术为核心驱动力的人工智能变革浪潮中,语音交互领域正迎来广阔的成长空间,应用场景持续拓宽与延伸。 其中,数据作为驱动语音大模型进化的关键要素,重要性愈发凸显。丰富多样的高质量数据能够让语音大模型充分学习到语音…...

单体项目到微服务的架构演变与K8s发展是否会代替微服务
单体项目到微服务的架构演变与K8s发展是否会代替微服务 在互联网大厂Java求职者的面试中,经常会被问到关于单体项目到微服务的架构演变以及Kubernetes(k8s)的发展是否会代替微服务的相关问题。本文通过一个故事场景来展示这些问题的实际解决…...
和自然语言交互式分析)
AI驱动的决策智能系统(AIDP)和自然语言交互式分析
在当今快速变化的商业环境中,以下几个企业级系统领域最有可能成为新的热点,其驱动力来自数字化转型加速、AI技术爆发、全球化协同需求以及ESG(环境、社会、治理)合规压力的叠加 1. AI驱动的决策智能系统(AIDP…...

kubernetes》》k8s》》Service 、Ingress 区别
K8S>>Service 资料 K8S >>Ingress 资料 Ingress VS Service 物理层数据链路层网络层传输层会话层表示层应用层 Ingress是一种用于暴露HTTP和HTTPS路由的资源,它提供了七层(应用层)的负载均衡功能。Ingress可以根据主机名、…...

全面接入!Qwen3现已上线千帆
百度智能云千帆正式上线通义千问团队开源的最新一代Qwen3系列模型,包括旗舰级MoE模型Qwen3-235B-A22B、轻量级MoE模型Qwen3-30B-A3B。千帆大模型平台开源模型进一步扩充,以多维开放的模型服务、全栈模型开发、应用开发工具链、多模态数据治理及安全的能力…...

Python-日志检测异常行为的详细技术方案
以下是根据行为日志检测异常行为的详细技术方案,涵盖数据收集、特征工程、模型选择、部署与优化的全流程: 1. 数据收集与预处理 1.1 数据来源 行为日志通常包括以下类型: 用户行为日志:点击、登录、交易、页面停留时间等。系统…...

DeepSeek-Prover-V2-671B最新体验地址:Prover版仅适合解决专业数学证明问题
DeepSeek-Prover-V2-671B最新体验地址:Prover版仅适合解决专业数学证明问题 DeepSeek 团队于 2025 年 4 月 30 日正式在Hugging Face开源了其重量级新作 —— DeepSeek-Prover-V2-671B,这是一款专为解决数学定理证明和形式化推理任务而设计的超大规模语…...

Java写数据结构:队列
1.概念: 队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾(Tail/Rear) 出队列…...

LeetCode 2905 找出满足差值条件的下标II 题解
示例 nums [8, 3, 12, 5, 1, 10, 7, 13] indexDifference 3 valueDifference 6答案 [maxIdx, j] [0, 4]我的思路是直接枚举写,但这题是中等题,一定不会让你好过的,所以也是喜提了超时,先说一下我的做题思路吧。 其实很简单就…...

【思考】欧洲大停电分析
当地时间4月28日中午,西班牙和葡萄牙发生了大规模停电事故,两国多个地区的电力供应中断,波及超过5000万伊比利亚半岛民众,交通、通信、医疗等关键领域受到影响,马德里网球公开赛因停电被迫暂停,周边法国、意…...

[论文精读]Agent综述—— A survey on large language model based autonomous agents
A survey on large language model based autonomous agents ⏲️年份: 2024 👀期刊: Frontiers of Computer Science 🌱影响因子:3.4 📚数字对象唯一标识符DOl: 10.1007/s11704-024-40231-1 🤵作者: Wang Lei,Ma Chen,Feng X…...

金融风控的“天眼”:遥感技术的创新应用
在金融市场的复杂博弈中,风险管控一直是金融机构的核心竞争力。然而,传统的风控手段在应对现代金融市场的快速变化时,往往显得捉襟见肘。 如今,遥感技术的创新应用为金融风控带来了全新的视角和手段。星图云开放平台的遥感金融立体…...
)
SpringMVC知识点总结(速查速记)
文章目录 前言1、MVC是什么2、SpringMVC是什么3、SpringMVC请求流程 && 环境搭建3.1 SpringMVC请求流程3.2 搭建环境3.2.1开发环境3.2.2 环境配置步骤 4. url地址映射 && 参数绑定4.1 url地址映射之RequestMapping①、映射单个url②、映射多个url③、映射url到…...

配置 Odoo 的 PostgreSQL 数据库以允许远程访问的步骤
1. 修改 PostgreSQL 配置文件 a. 修改 postgresql.conf 找到 PostgreSQL 的主配置文件 postgresql.conf,通常位于 /etc/postgresql/<版本号>/main/ 目录下。修改 listen_addresses 项的值为 *,表示允许来自任何 IP 地址的连接: sudo…...

涨薪技术|0到1学会性能测试第42课-apache监控与调优
前面的推文我们学习了操作系统性能监控与调优知识,如CPU、内存、磁盘、网络监控等,今天开始分享中间件apache监控与调优知识,后续文章都会系统分享干货,带大家从0到1学会性能测试! Apache是世界上使用最多的web服务器软件一种,它可以运行在几乎所有广泛使用的计算机平台上…...

【学习笔记】Shell编程--Bash变量
变量类型说明环境变量 与Shell的执行环境相关的一些变量。如PATH,HOME等,用户可重新定义。 一、环境变量的创建:export, export ABCD2 二、环境变量的查看 使用echo命令查看单个环境变量。如: echo $PATH 使用printenv…...

SpringBoot+Redis全局唯一ID生成器
📦 优雅版 Redis ID 生成器工具类 支持: 项目启动时自动初始化起始值获取自增 ID 方法yml 配置化起始值可灵活扩展多业务线 ID 📌 application.yml 配置 id-generator:member-start-value: 1000000000📌 配置类:IdG…...

micro-app前端微服务原理解析
一、核心设计思想 基于 WebComponents 的组件化渲染 micro-app 借鉴 WebComponents 的 CustomElement 和 ShadowDom 特性,将子应用封装为类似 WebComponent 的自定义标签(如 <micro-app>)。通过 ShadowDom 的天然隔离机制,实…...