【大模型系列篇】Qwen3开源全新一代大语言模型来了,深入思考,更快行动
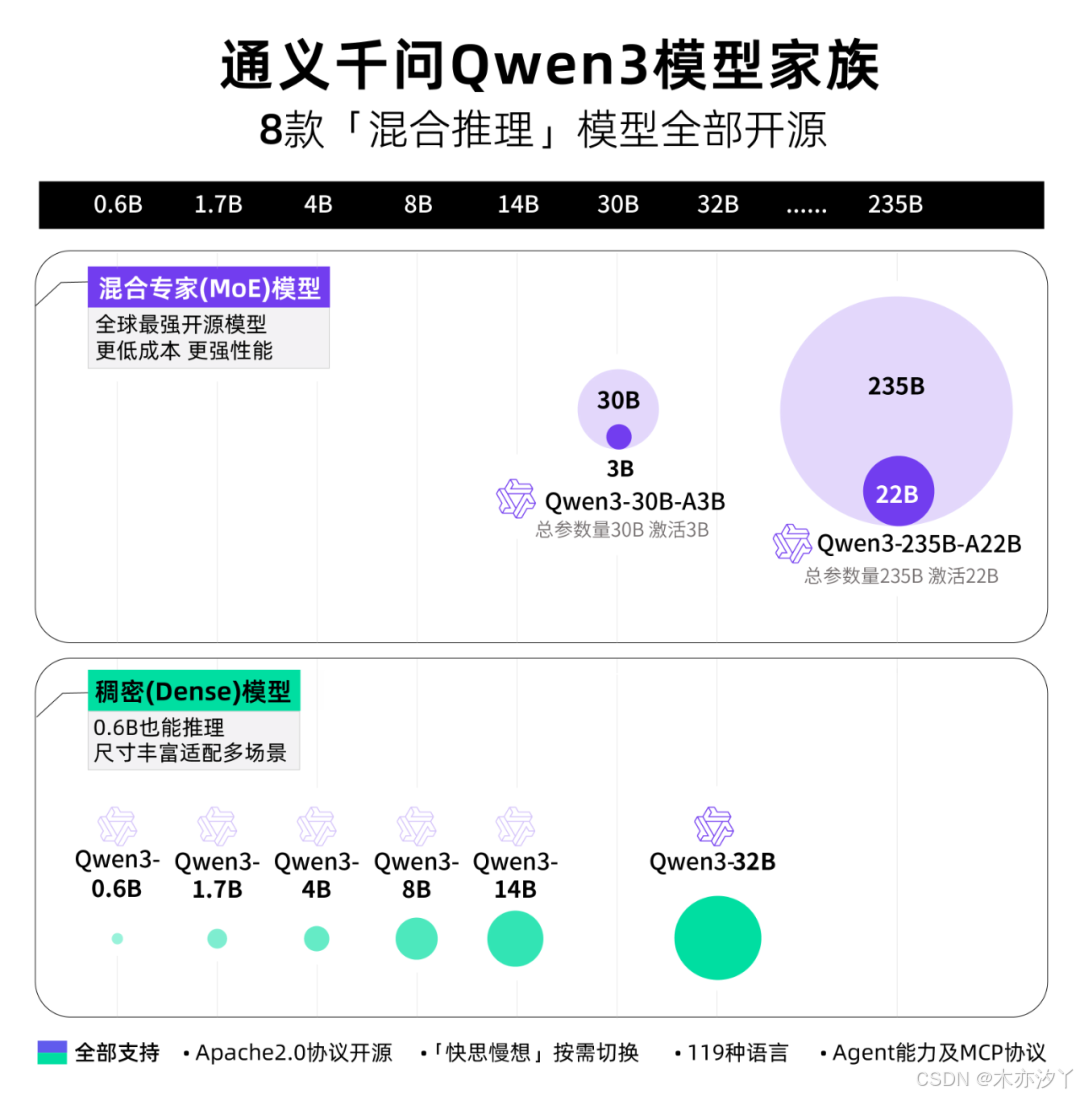
Qwen3开源模型全览
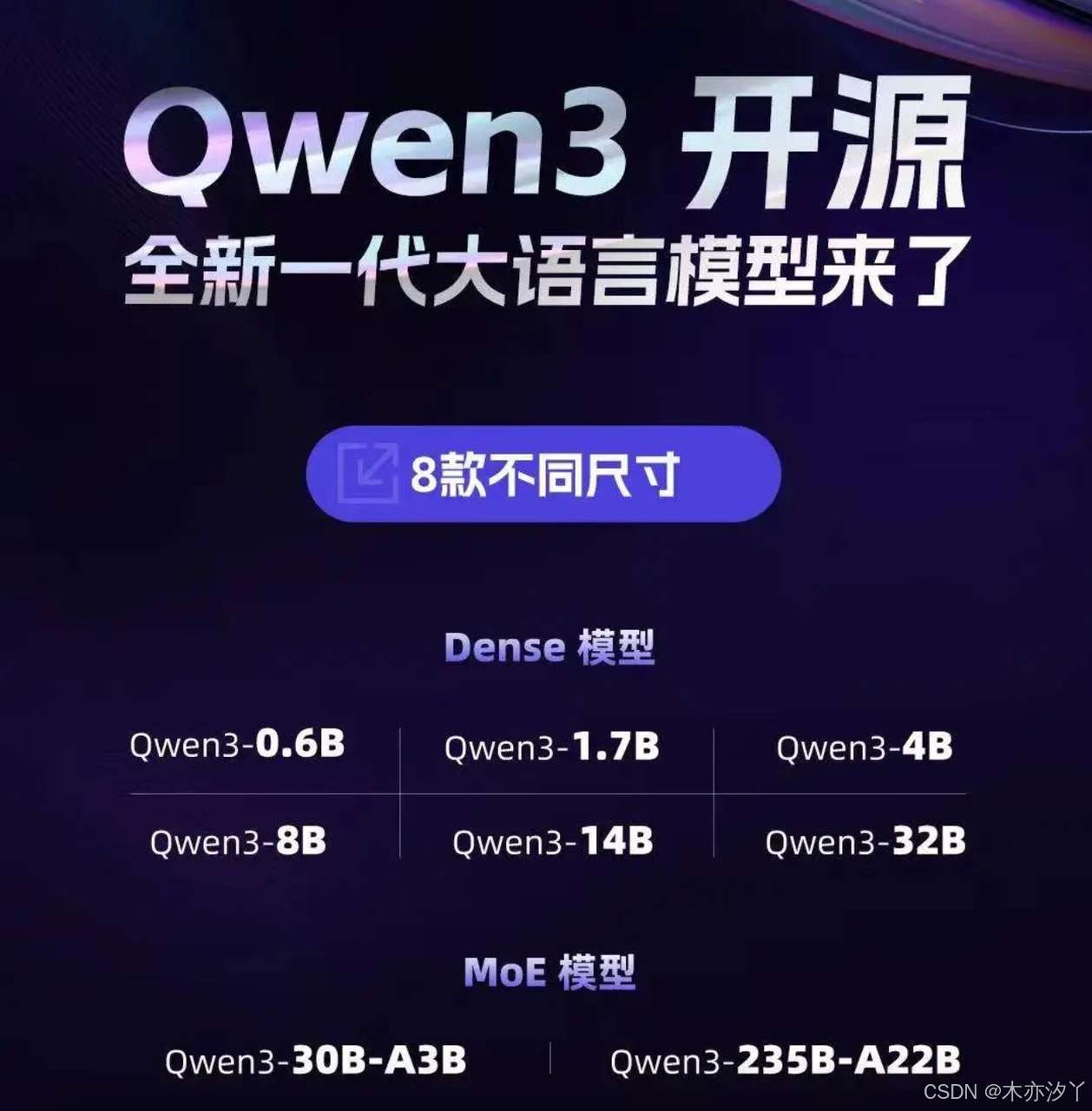
Qwen3是全球最强开源模型(MoE+Dense)
Qwen3 采用混合专家(MoE)架构,总参数量 235B,激活仅需 22B。
Qwen3 预训练数据量达 36T,并在后训练阶段多轮强化学习,将非思考模式无缝整合到思考模型中。
Qwen3 在推理、指令遵循、工具调用、多语言能力等方面均大幅增强,即创下所有国产模型及全球开源模型的性能新高:
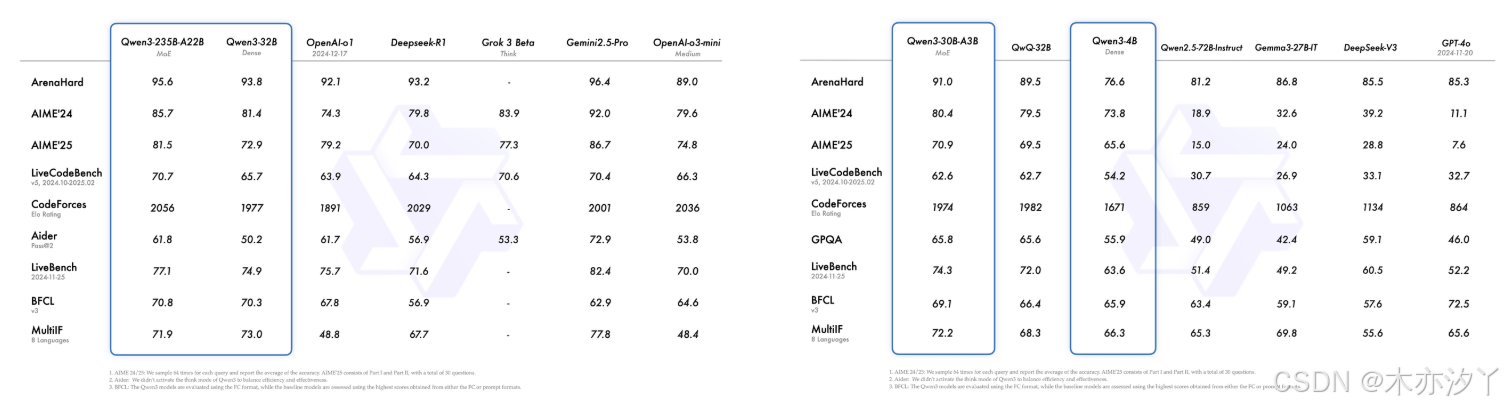
- 在奥数水平的 AIME25 测评中,Qwen3 斩获 81.5 分,刷新开源纪录;
- 在考察代码能力的 LiveCodeBench 评测中,Qwen3 突破 70 分大关,表现甚至超过 Grok3;
- 在评估模型人类偏好对齐的 ArenaHard 测评中,Qwen3 以 95.6 分超越 OpenAI-o1 及 DeepSeek-R1。
性能大幅提升的同时,Qwen3 的部署成本还大幅下降,仅需 4 张 H20 即可部署 Qwen3 满血版,显存占用仅为性能相近模型的三分之一。
Qwen3 还提供了丰富的模型版本,包含 2 款 30B、235B 的 MoE 模型,以及 0.6B、1.7B、4B、8B、14B、32B 等 6 款密集模型。
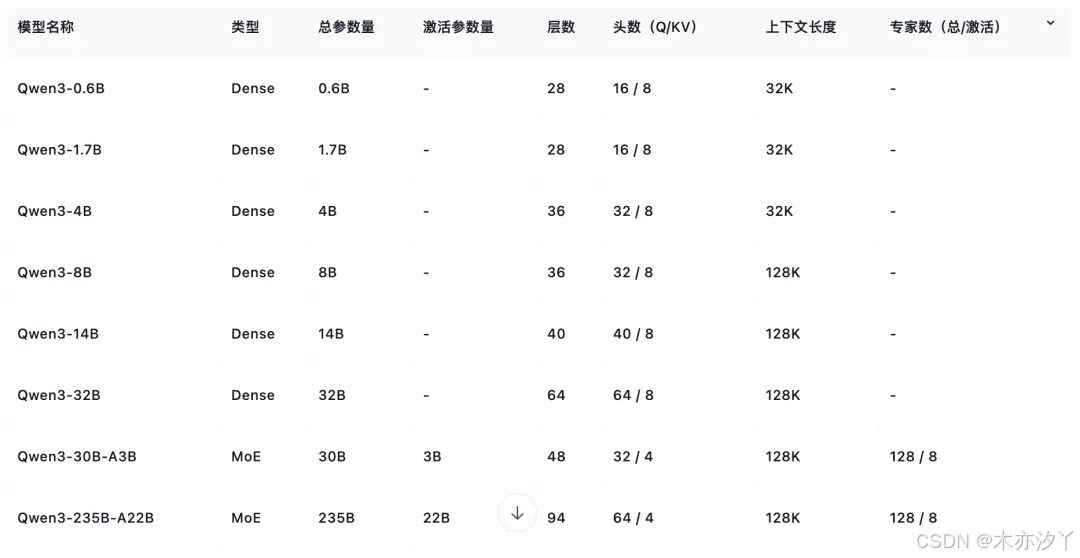
每款模型均斩获同尺寸开源模型 SOTA(最佳性能):
Qwen3 的 30B 参数 MoE 模型实现了 10 倍以上的模型性能杠杆提升,仅激活 3B 就能媲美上代 Qwen2.5-32B 模型性能;
Qwen3 的稠密模型性能继续突破,一半的参数量可实现同样的高性能,如 32B 版本的 Qwen3 模型可跨级超越 Qwen2.5-72B 性能。
同时,所有 Qwen3 模型都是混合推理模型,API 可按需设置「思考预算」(即预期最大深度思考的 tokens 数量),进行不同程度的思考,灵活满足 AI 应用和不同场景对性能和成本的多样需求。
比如,4B 模型是手机端的绝佳尺寸;8B 可在电脑和汽车端侧丝滑部署应用;32B 最受企业大规模部署欢迎,有条件的开发者也可轻松上手。
比如让它做一款记忆配对卡牌的 Web 小游戏,效果如下:
Qwen3的主要特点
Qwen3 是国内首个支持“混合推理”模型
Qwen3 原生支持思考模式与非思考模式两种工作方式,意味着既能在简单问题上快思考,秒出答案;又能在复杂问题上慢思考,展开多步推理和深入分析。这种设计让用户可以根据不同任务,轻松调整花多少费用,既省成本又保证推理效果。
- 思考模式:在这种模式下,模型在提供最终答案之前需要时间逐步推理。这对于需要深入思考的复杂问题来说是理想的选择。
- 非思考模式:在这里,该模型提供快速、近乎即时的回答,适用于速度比深度更重要的简单问题。
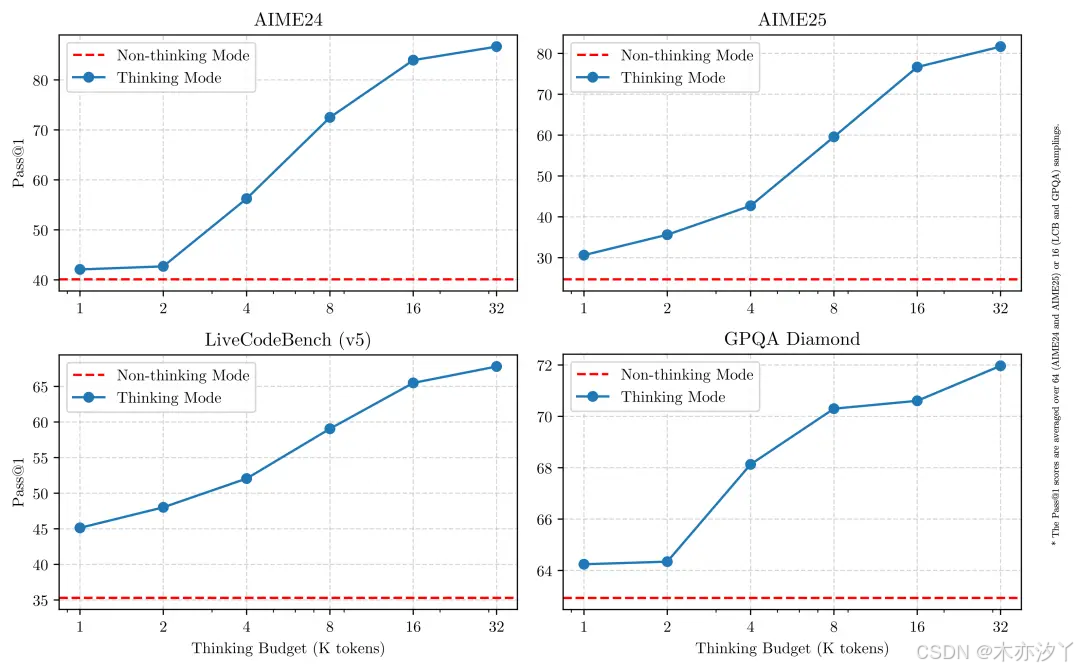
这种灵活性允许用户根据手头的任务控制模型执行多少 “思考”。例如,较难的问题可以通过扩展推理来解决,而较简单的问题可以毫不拖延地直接回答。至关重要的是,这两种模式的融合极大地增强了模型实施稳定高效的思维预算控制的能力。如上所述,Qwen3 表现出可扩展且流畅的性能改进,这与分配的计算推理预算直接相关。这种设计使用户能够更轻松地配置特定于任务的预算,从而在成本效率和推理质量之间实现更理想的平衡。
Qwen3 原生支持 MCP 协议
Qwen3 为即将到来的智能体 Agent 和大模型应用爆发提供了更好的支持。在大模型从“聊天”走向“动手做事”的关键时刻,Qwen3 的设计也跟着升级了,不再只是回答问题那么简单,而是专门为 Agent 架构做了优化,提升了执行任务的效率、响应的结构化程度,还有对各种工具的适配能力。
在评估模型 Agent 能力的 BFCL 评测中,Qwen3 创下 70.8 的新高,超越 Gemini2.5-Pro、OpenAI-o1 等顶尖模型,将大幅降低 Agent 调用工具的门槛。
同时,Qwen3 原生支持 MCP 协议,并具备强大的工具调用(function calling)能力,结合封装了工具调用模板和工具调用解析器的 Qwen-Agent 框架,将大大降低编码复杂性,实现高效的手机及电脑 Agent 操作等任务。
此外
Qwen3 系列模型依旧采用宽松的 Apache2.0 协议开源,并首次支持 119 多种语言。
全球开发者、研究机构和企业均可免费在魔搭社区、HuggingFace 等平台下载模型并商用,也可以通过阿里云百炼调用千问 3 的 API 服务。
个人用户可立即通过通义 APP 直接体验 Qwen3,夸克也即将全线接入Qwen3。
据悉,阿里通义已开源 200 余个模型,全球下载量超 3 亿次,千问衍生模型数超 10 万个,已超越美国 Llama,成为全球第一开源模型。
Qwen3的预训练与后训练
Qwen3-预训练数据与三阶段流程
Qwen3使用了近36万亿token的超大规模多语种数据集进行预训练,是Qwen2.5时期数据量的约2倍。
训练过程分为三个阶段:
- Stage 1:在超30万亿token上进行初步预训练,具备通用语言理解与生成能力(上下文长度4K)。
- Stage 2:引入大量STEM(科学、技术、工程、数学)数据和代码数据,在额外5万亿token上继续训练。
- Stage 3:使用高质量长文本扩展上下文窗口至32K,优化长文档处理能力。
在数据构建过程中,还引入了模型辅助的数据增强技术,如使用Qwen2.5-Math、Qwen2.5-Coder生成高质量数学与代码数据,进一步强化了模型在专业领域的推理与表达能力。
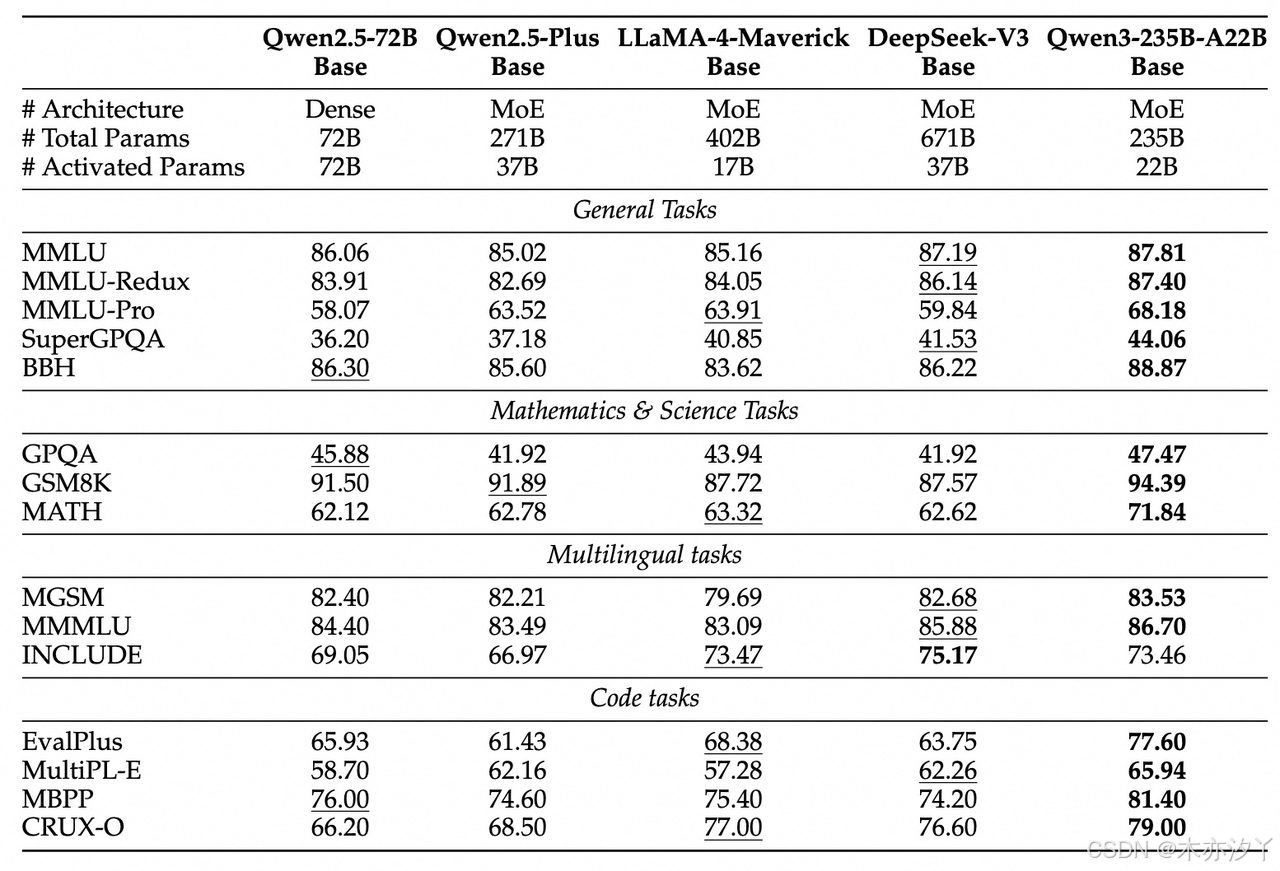
在相同或更少激活参数数量下,Qwen3基础模型性能全面优于同等规模Qwen2.5 Dense模型。
Qwen3-后训练强化学习与思考模式融合
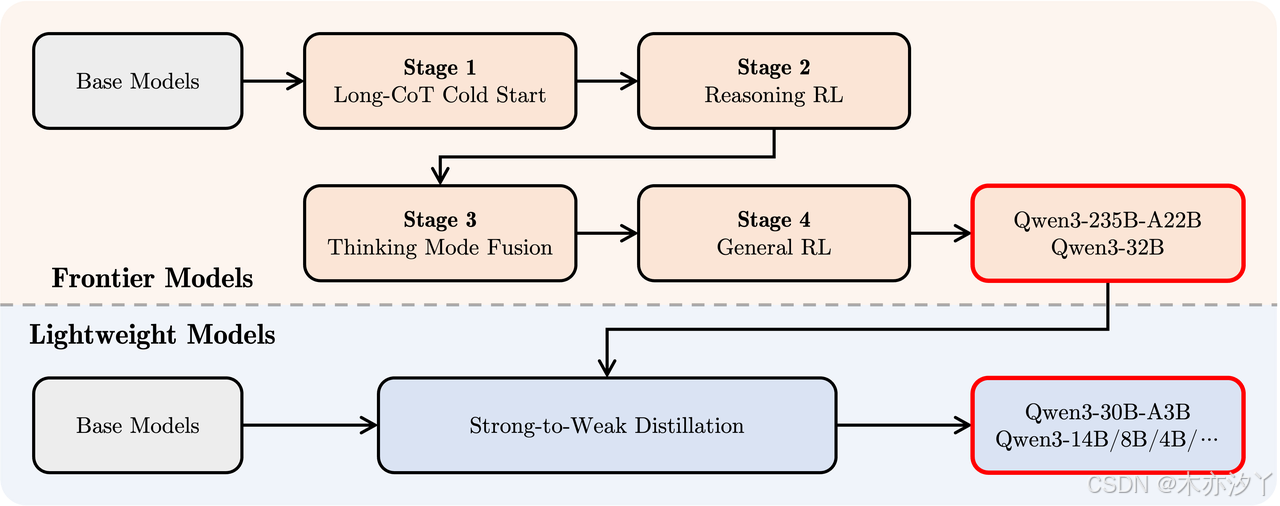
为了进一步优化推理链条质量与控制思考模式,Qwen3在后训练阶段设计了四阶段强化学习流程:
- Stage 1:长推理链冷启动(Long-CoT Cold Start): 微调模型在复杂任务(如数学、代码、逻辑推理)中的长推理链条。
- Stage 2:推理强化学习(Reasoning RL): 基于规则奖励机制,强化模型的推理深度与探索能力。
- Stage 3:思考模式融合(Thinking Mode Fusion): 融合思考模式与快速模式,打通推理链条与即时响应路径。
- Stage 4:通用强化学习(General RL):在指令跟随、格式遵循、工具调用等领域进一步微调,提升通用任务完成能力。
同时,针对中小尺寸模型,还引入了Strong-to-Weak蒸馏技术,将大型模型的推理能力高效迁移至轻量级模型中,保证小模型也能具备优秀的推理与交互表现。
Qwen3部署与开发
本地部署
对于部署,可以使用 sglang>=0.4.6.post1 或 vllm>=0.8.4 创建兼容 OpenAI 的 API 终端节点:
- SGLang:
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3- vLLM:
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1如果你用它来本地开发,你可以通过运行一个简单的命令 ollama run qwen3:30b-a3b 来使用 ollama 来玩转模型,或者你可以使用 LMStudio 或 llama.cpp 和 ktransformers 在本地构建。
开发示例
以 Qwen3-30B-A3B 为例
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen3-30B-A3B"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# conduct text completion
generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)
关闭思考模式
如果需要禁用思考模式,只需修改 enable_thinking=False
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False # 禁用思考模式
)
高级用法
Qwen3提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以将 /think 和 /no_think 添加到用户提示或系统消息中,以将模型的思维模式从轮次切换到轮次。该模型将遵循多轮次对话中的最新指令。
多轮次对话的示例
from transformers import AutoModelForCausalLM, AutoTokenizerclass QwenChatbot:def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.history = []def generate_response(self, user_input):messages = self.history + [{"role": "user", "content": user_input}]text = self.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = self.tokenizer(text, return_tensors="pt")response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()response = self.tokenizer.decode(response_ids, skip_special_tokens=True)# Update historyself.history.append({"role": "user", "content": user_input})self.history.append({"role": "assistant", "content": response})return response# Example Usage
if __name__ == "__main__":chatbot = QwenChatbot()# First input (without /think or /no_think tags, thinking mode is enabled by default)user_input_1 = "How many r's in strawberries?"print(f"User: {user_input_1}")response_1 = chatbot.generate_response(user_input_1)print(f"Bot: {response_1}")print("----------------------")# Second input with /no_thinkuser_input_2 = "Then, how many r's in blueberries? /no_think"print(f"User: {user_input_2}")response_2 = chatbot.generate_response(user_input_2)print(f"Bot: {response_2}") print("----------------------")# Third input with /thinkuser_input_3 = "Really? /think"print(f"User: {user_input_3}")response_3 = chatbot.generate_response(user_input_3)print(f"Bot: {response_3}")
代理用法
Qwen3 在工具调用功能方面表现出色。这里推荐使用 Qwen-Agent 来充分利用 Qwen3 的代理能力。Qwen-Agent 在内部封装了工具调用模板和工具调用解析器,大大降低了编码复杂度。
要给代理定义可用的工具,可以使用 MCP 配置文件,使用 Qwen-Agent 的集成工具,或自行集成其他工具。
from qwen_agent.agents import Assistant# Define LLM
llm_cfg = {'model': 'Qwen3-30B-A3B',# Use the endpoint provided by Alibaba Model Studio:# 'model_type': 'qwen_dashscope',# 'api_key': os.getenv('DASHSCOPE_API_KEY'),# Use a custom endpoint compatible with OpenAI API:'model_server': 'http://localhost:8000/v1', # api_base'api_key': 'EMPTY',# Other parameters:# 'generate_cfg': {# # Add: When the response content is `<think>this is the thought</think>this is the answer;# # Do not add: When the response has been separated by reasoning_content and content.# 'thought_in_content': True,# },
}# Define Tools
tools = [{'mcpServers': { # You can specify the MCP configuration file'time': {'command': 'uvx','args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']},"fetch": {"command": "uvx","args": ["mcp-server-fetch"]}}},'code_interpreter', # Built-in tools
]# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):pass
print(responses)如何选择适合的模型?
- 本地测试及科研:Qwen3-0.6B/1.7B,硬件要求低,适合快速实验;
- 手机端侧应用:Qwen3-4B,性能与效率兼顾,适合移动端部署;
- 电脑或汽车端:Qwen3-8B,适用于对话系统、语音助手等场景;
- 企业落地:Qwen3-14B/32B性能更强,适合复杂任务;
- 云端高效部署:MoE模型,Qwen3-30B-A3B速度快;Qwen3-235B-A22B性能强劲且显存占用低;
无论你是开发者、科研人员还是普通用户,Qwen3都能满足你的需求!
结束语
Qwen3 代表了阿里迈向通用人工智能 (AGI) 和人工智能超级智能 (ASI) 之旅的一个重要里程碑。通过扩展预训练和强化学习 (RL),实现了更高水平的智能。Qwen3拥有无缝整合的思考和非思考模式,为用户提供了控制思考预算的灵活性。此外,Qwen3还扩展了对多种语言的支持,增强了全球可访问性。
展望未来,千问的目标是在多个维度上增强模型。这包括改进模型架构和训练方法以实现几个关键目标:扩展数据、增加模型大小、扩展上下文长度、拓宽模态以及利用环境反馈推进 RL 以进行长期推理。
我们正在从一个专注于训练模型的时代过渡到一个以训练代理为中心的时代。下一次将为每个人的工作和生活带来有意义的进步。

相关文章:

【大模型系列篇】Qwen3开源全新一代大语言模型来了,深入思考,更快行动
Qwen3开源模型全览 Qwen3是全球最强开源模型(MoEDense) Qwen3 采用混合专家(MoE)架构,总参数量 235B,激活仅需 22B。 Qwen3 预训练数据量达 36T,并在后训练阶段多轮强化学习,将非思…...
)
DeepSeek-Prover-V2-671B 简介、下载、体验、微调、数据集:专为数学定理自动证明设计的超大垂直领域语言模型(在线体验地址)
DeepSeek-Prover-V2-671B 最新发布:专为数学定理自动证明设计的超大语言模型 体验地址:Hugging Face 在线体验 推荐入口:Novita 平台直达链接(含邀请码) 一、模型简介 DeepSeek-Prover-V2-671B 是 DeepSeek 团队于 2…...

Gupta-Sproull 抗据此画线算法
本文源自于:从https://www.inf.ed.ac.uk/teaching/courses/cg/lectures/cg4_2012.pdf Gupta-Sproull是在Brensenham的画线算法基础上得到。 为了防止之前的链接失效,特地搬运一下...

idea写spark程序
使用IntelliJ IDEA编写Spark程序的完整指南 一、环境准备 安装必要软件 IntelliJ IDEA (推荐Ultimate版,Community版也可) JDK 8或11 Scala插件(在IDEA中安装) Spark最新版本(本地开发可以用embedded模式) 创建项目 打开IDEA → New Project 选择"Maven…...

视觉问答论文解析:《Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning》
《Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning》论文解析 一、研究背景与动机 近年来,“慢思考”多模态模型(如 OpenAI-o1、GeminiThinking、Kimi-1.5 和 Skywork-R1V)在数学和科学领域的复杂推理任务中取得了显…...

修改linux账号名
修改linux账号名 结论是步骤1.临时创建一个辅助账户执行操作2.注销当前账户,登录 tempadmin 用户。3.使用它修改 旧用户名olduser:4.(可选)删除临时用户: 结论是 不可以直接修改,要么需要创建一个临时用户来打辅助. …...
MVP变换示例)
计算机图形学:(二)MVP变换示例
前言 当在阅读计算机图形学系列的书籍时,会发现大部分图书每章内容都如出一辙。从个人实际体会来讲,虽然能理解书中大部分的知识,但到了实际使用时却有点抓耳挠腮。因此,在写了计算机图形学:(一)…...
)
PostgreSQL中的SSL(2)
PGSQL数据库的默认隔离级别是读提交,并且同时支持可重复读和序列化模式。但是在9.1之前的版本中,序列化模式是采用快照隔离来实现,并非是真正的序列化模式。 这样的话就会存在一个问题,那就是写偏序(Write Skew&#…...

Linux 部署以paddle Serving 的方式部署 PaddleOCR CPU版本
强烈建议您在Docker内构建Paddle Serving,更多镜像请查看Docker镜像列表。 提示-1:Paddle Serving项目仅支持Python3.6/3.7/3.8/3.9,接下来所有的与Python/Pip相关的操作都需要选择正确的Python版本。 提示-2:以下示例中GPU环境均…...
)
苏德战争前期苏联损失惨重(马井堂)
苏德战争前期(1941年6月22日德国发动“巴巴罗萨行动”至1941年底至1942年初)是苏联在二战中损失最惨重的阶段之一。以下是主要方面的损失概述: 一、军事损失 人员伤亡与俘虏 至1941年底,苏军伤亡约300万人ÿ…...
)
SI5338-EVB Usage Guide(LVPECL、LVDS、HCSL、CMOS、SSTL、HSTL)
目录 1. 简介 1.1 EVB 介绍 1.2 Si5338 Block Diagram 2. EVB 详解 2.1 实物图 2.2 基本配置 2.2.1 Universal Pin 2.2.2 IIC I/F 2.2.3 Input Clocks 2.2.4 Output Frequencies 2.2.5 Output Driver 2.2.6 Freq and Phase Offset 2.2.7 Spread Spectrum 2.2.8 快…...

LeetCode LCP40 心算挑战题解
看似一道简单的题目,实则不然,没有看评论的话,实在想不出来怎么写。 现在则由我来转述思想供大家参考理解,还是先给出示例,供大家更好的理解这个题目。 输入:cards [1,2,8,9], cnt 3输出:18解…...

Smart Link+Monitor Link组网
1.技术背景及原理 一般情况下,Smart Link只能感知与其接口直连的链路故障。将Monitor Link配置在Smart Link的上游设备上,可使Smart Link迅速感知上游链路故障,进行链路切换。Smart Link与Monitor Link配合使用,扩大了Smart Link…...
套接字,多线程远程执行命令编程)
【计算机网络】TCP(传输控制协议)套接字,多线程远程执行命令编程
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:UDP套接字编程(英汉字典以及多线程聊天室编写)…...

PostgreSQL 中 VACUUM FULL 对索引的影响
PostgreSQL 中 VACUUM FULL 对索引的影响 是的,VACUUM FULL 会重建表上的所有索引。这是它与普通 VACUUM 命令的一个重要区别。 一、VACUUM FULL 的工作原理 表重建过程: 创建表的全新副本只将有效数据写入新存储删除原始表文件将新文件重命名为原表名…...

DeepSeek本地部署及WebUI可视化完全指南
以下是为您整理的DeepSeek本地部署及WebUI可视化完全指南,整合了官方文档及社区实践的最佳方案: 一、环境准备 1. 硬件需求 CPU:推荐支持AVX2指令集的Intel i7或AMD Ryzen 7及以上处理器 。 GPU(可选但推荐)…...

大模型时代的新燃料:大规模拟真多风格语音合成数据集
以大模型技术为核心驱动力的人工智能变革浪潮中,语音交互领域正迎来广阔的成长空间,应用场景持续拓宽与延伸。 其中,数据作为驱动语音大模型进化的关键要素,重要性愈发凸显。丰富多样的高质量数据能够让语音大模型充分学习到语音…...

单体项目到微服务的架构演变与K8s发展是否会代替微服务
单体项目到微服务的架构演变与K8s发展是否会代替微服务 在互联网大厂Java求职者的面试中,经常会被问到关于单体项目到微服务的架构演变以及Kubernetes(k8s)的发展是否会代替微服务的相关问题。本文通过一个故事场景来展示这些问题的实际解决…...
和自然语言交互式分析)
AI驱动的决策智能系统(AIDP)和自然语言交互式分析
在当今快速变化的商业环境中,以下几个企业级系统领域最有可能成为新的热点,其驱动力来自数字化转型加速、AI技术爆发、全球化协同需求以及ESG(环境、社会、治理)合规压力的叠加 1. AI驱动的决策智能系统(AIDP…...

kubernetes》》k8s》》Service 、Ingress 区别
K8S>>Service 资料 K8S >>Ingress 资料 Ingress VS Service 物理层数据链路层网络层传输层会话层表示层应用层 Ingress是一种用于暴露HTTP和HTTPS路由的资源,它提供了七层(应用层)的负载均衡功能。Ingress可以根据主机名、…...

全面接入!Qwen3现已上线千帆
百度智能云千帆正式上线通义千问团队开源的最新一代Qwen3系列模型,包括旗舰级MoE模型Qwen3-235B-A22B、轻量级MoE模型Qwen3-30B-A3B。千帆大模型平台开源模型进一步扩充,以多维开放的模型服务、全栈模型开发、应用开发工具链、多模态数据治理及安全的能力…...

Python-日志检测异常行为的详细技术方案
以下是根据行为日志检测异常行为的详细技术方案,涵盖数据收集、特征工程、模型选择、部署与优化的全流程: 1. 数据收集与预处理 1.1 数据来源 行为日志通常包括以下类型: 用户行为日志:点击、登录、交易、页面停留时间等。系统…...

DeepSeek-Prover-V2-671B最新体验地址:Prover版仅适合解决专业数学证明问题
DeepSeek-Prover-V2-671B最新体验地址:Prover版仅适合解决专业数学证明问题 DeepSeek 团队于 2025 年 4 月 30 日正式在Hugging Face开源了其重量级新作 —— DeepSeek-Prover-V2-671B,这是一款专为解决数学定理证明和形式化推理任务而设计的超大规模语…...

Java写数据结构:队列
1.概念: 队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾(Tail/Rear) 出队列…...

LeetCode 2905 找出满足差值条件的下标II 题解
示例 nums [8, 3, 12, 5, 1, 10, 7, 13] indexDifference 3 valueDifference 6答案 [maxIdx, j] [0, 4]我的思路是直接枚举写,但这题是中等题,一定不会让你好过的,所以也是喜提了超时,先说一下我的做题思路吧。 其实很简单就…...

【思考】欧洲大停电分析
当地时间4月28日中午,西班牙和葡萄牙发生了大规模停电事故,两国多个地区的电力供应中断,波及超过5000万伊比利亚半岛民众,交通、通信、医疗等关键领域受到影响,马德里网球公开赛因停电被迫暂停,周边法国、意…...

[论文精读]Agent综述—— A survey on large language model based autonomous agents
A survey on large language model based autonomous agents ⏲️年份: 2024 👀期刊: Frontiers of Computer Science 🌱影响因子:3.4 📚数字对象唯一标识符DOl: 10.1007/s11704-024-40231-1 🤵作者: Wang Lei,Ma Chen,Feng X…...

金融风控的“天眼”:遥感技术的创新应用
在金融市场的复杂博弈中,风险管控一直是金融机构的核心竞争力。然而,传统的风控手段在应对现代金融市场的快速变化时,往往显得捉襟见肘。 如今,遥感技术的创新应用为金融风控带来了全新的视角和手段。星图云开放平台的遥感金融立体…...
)
SpringMVC知识点总结(速查速记)
文章目录 前言1、MVC是什么2、SpringMVC是什么3、SpringMVC请求流程 && 环境搭建3.1 SpringMVC请求流程3.2 搭建环境3.2.1开发环境3.2.2 环境配置步骤 4. url地址映射 && 参数绑定4.1 url地址映射之RequestMapping①、映射单个url②、映射多个url③、映射url到…...

配置 Odoo 的 PostgreSQL 数据库以允许远程访问的步骤
1. 修改 PostgreSQL 配置文件 a. 修改 postgresql.conf 找到 PostgreSQL 的主配置文件 postgresql.conf,通常位于 /etc/postgresql/<版本号>/main/ 目录下。修改 listen_addresses 项的值为 *,表示允许来自任何 IP 地址的连接: sudo…...

涨薪技术|0到1学会性能测试第42课-apache监控与调优
前面的推文我们学习了操作系统性能监控与调优知识,如CPU、内存、磁盘、网络监控等,今天开始分享中间件apache监控与调优知识,后续文章都会系统分享干货,带大家从0到1学会性能测试! Apache是世界上使用最多的web服务器软件一种,它可以运行在几乎所有广泛使用的计算机平台上…...

【学习笔记】Shell编程--Bash变量
变量类型说明环境变量 与Shell的执行环境相关的一些变量。如PATH,HOME等,用户可重新定义。 一、环境变量的创建:export, export ABCD2 二、环境变量的查看 使用echo命令查看单个环境变量。如: echo $PATH 使用printenv…...

SpringBoot+Redis全局唯一ID生成器
📦 优雅版 Redis ID 生成器工具类 支持: 项目启动时自动初始化起始值获取自增 ID 方法yml 配置化起始值可灵活扩展多业务线 ID 📌 application.yml 配置 id-generator:member-start-value: 1000000000📌 配置类:IdG…...

micro-app前端微服务原理解析
一、核心设计思想 基于 WebComponents 的组件化渲染 micro-app 借鉴 WebComponents 的 CustomElement 和 ShadowDom 特性,将子应用封装为类似 WebComponent 的自定义标签(如 <micro-app>)。通过 ShadowDom 的天然隔离机制,实…...
:集成学习及随机森林)
大连理工大学选修课——机器学习笔记(7):集成学习及随机森林
集成学习及随机森林 集成学习概述 泛化能力的局限 每种学习模型的能力都有其上限 限制于特定结构受限于训练样本的质量和规模 如何再提高泛化能力? 研究新结构扩大训练规模 提升模型的泛化能力 创造性思路 组合多个学习模型 集成学习 集成学习不是特定的…...

[特殊字符] Spring Cloud 微服务配置统一管理:基于 Nacos 的最佳实践详解
在微服务架构中,配置文件众多、管理复杂是常见问题。本文将手把手演示如何将配置集中托管到 Nacos,并在 Spring Cloud Alibaba 项目中实现统一配置管理 自动刷新机制。 一、为什么要使用 Nacos 统一配置? 传统方式下,每个服务都…...

【mysql】执行过程,背诵版
sql执行再mysql的执行过程 1. 建立连接 sql通过tcp/ip发送到服务器服务器检查用户名,密码,权限创建线程处理连接 如果是sql8.0之前,select会先从缓存中查找,命中则返回,由于表结构变更会导致缓存失效,已废…...

[Survey] Image Segmentation in Foundation Model Era: A Survey
BaseInfo TitleImage Segmentation in Foundation Model Era: A SurveyAdresshttps://arxiv.org/pdf/2408.12957Journal/Time-Author北理工、上交、浙大 CCAI 、瑞士苏黎世联邦理工学院、德国慕尼黑工业大学Codehttps://github.com/stanley-313/ImageSegFM-Survey 1. Introdu…...

关于杰理ac791切换版本, git clone下来仍然是最新版本问题
在git clone 之后,在本地切换分支 常规流程:git clone →git branch →git branch -a → git checkout 分支名...

生成项目.gitignore文件的多种高效方式
在使用 Git 进行版本控制时,.gitignore 文件是不可或缺的配置文件。它可以帮助我们指定哪些文件或目录不需要被 Git 跟踪,从而避免将不必要的文件(如临时文件、编译生成的文件等)提交到仓库中。这篇文章将介绍几种生成 .gitignore…...

2025年“深圳杯”数学建模挑战赛D题-法医物证多人身份鉴定问题
法医物证多人身份鉴定问题 小驴数模 犯罪现场法医物证鉴定是关系到国家安全、公共安全、人民生命财产安全和社会稳定的重大问题。目前法医物证鉴定依赖DNA分析技术不断提升。DNA检验的核心是STR(Short Tandem Repeat,短串联重复序列)分析技术…...

嵌入式开发高频面试题全解析:从基础编程到内存操作核心知识点实战
一、数组操作:3x3 数组的对角和、偶数和、奇数和 题目 求 3x3 数组的对角元素和、偶数元素和、奇数元素和。 知识点 数组遍历:通过双重循环访问数组的每个元素,外层循环控制行,内层循环控制列。对角元素判断: 主对…...

JAVA SE 反射,枚举与lambda表达式
文章目录 📕1. 反射✏️1.1 反射相关的类✏️1.2 Class类中的相关方法✏️1.3 Field类中的相关方法✏️1.4 Method类中的相关方法✏️1.5 Constructor类中的相关方法✏️1.6 获取Class对象的三种方式✏️1.7 反射的使用 📕2. 枚举2.1 枚举的定义✏️2.2 …...

每日算法-250430
每日算法 - 2025年4月30日 记录下今天解决的两道题目。 870. 优势洗牌 (Advantage Shuffle) 题目描述 解题思路与方法 核心思想:贪心策略 (田忌赛马) 这道题的目标是对于 nums1 中的每个元素,找到 nums2 中一个比它小的元素进行配对(如果…...

MacOS 安装 cocoapods
MacOS 安装 cocoapods 下面使用 HomeBrew 安装 cocoapods 一、检测 HomeBrew 是否安装 打开终端执行命令 brew -v #如果安装,输出如 Homebrew 4.5.0如果未安装 Mac HomeBrew安装 二、检测 ruby 是否安装 系统一般自带了 ruby 但是这个升级有些麻烦,我…...
)
MATLAB绘制饼图(二维/三维)
在数据分析与展示领域,饼图是一种直观且高效的可视化工具,能够在瞬间传递各部分与整体的比例关系。今天,我将分享一段 MATLAB 绘制二维及三维饼图的代码,助你轻松将数据以饼图形式呈现于众人眼前。 无论是二维饼图的简洁明了&…...

python将字符串转成二进制数组
python将字符串转成二进制数组 功能概述: save_binary_to_json() 函数:将字符串转换为二进制数据(字节的整数表示),并保存到JSON文件中。 load_binary_from_json() 函数:从JSON文件中读取二进制数据并还原…...

防止HTTPS页面通过<iframe>标签嵌入HTTP内容
防止HTTPS页面通过<iframe>标签嵌入HTTP内容 出于安全考虑,现代浏览器实施了严格的规则来防止HTTPS页面通过<iframe>标签嵌入HTTP内容。这种行为主要是为了防止所谓的“混合内容”问题,即在一个安全(加密)的页面中…...
)
windows 使用websocket++ (C++环境)
一、简介 websocket官方网址:http://websocket.org/ websocketpp官方网址:https://www.zaphoyd.com/websocketpp websocketpp使用手册:https://www.zaphoyd.com/websocketpp/manual/ websocketpp 是 C 的 WebSocket 客户端/服务器库. 它是…...

无水印短视频素材下载网站有哪些?十个高清无水印视频素材网站分享
你知道怎么下载无水印视频素材吗?今天小编就给大家推荐十个高清无水印视频素材下载的网站,如果你也是苦于下载高清无水印的短视频素材,赶紧来看看吧~ 1. 稻虎网 首推的是稻虎网。这个网站简直就是短视频创作者的宝库。无论你需要…...