论文笔记(八十二)Transformers without Normalization
Transformers without Normalization
- 文章概括
- Abstract
- 1 引言
- 2 背景:归一化层
- 3 归一化层做什么?
- 4 动态 Tanh (Dynamic Tanh (DyT))
- 5 实验
- 6 分析
- 7 α 的初始化
- 8 相关工作
- 9 限制
- 10 结论
- 附录
- 附录 A 实验设置
- 附录 B 超参数
- 附录 C 用 DyT 替换批量归一化
文章概括
引用:
@article{zhu2025transformers,title={Transformers without normalization},author={Zhu, Jiachen and Chen, Xinlei and He, Kaiming and LeCun, Yann and Liu, Zhuang},journal={arXiv preprint arXiv:2503.10622},year={2025}
}
Zhu, J., Chen, X., He, K., LeCun, Y. and Liu, Z., 2025. Transformers without normalization. arXiv preprint arXiv:2503.10622.
主页:https://jiachenzhu.github.io/DyT/
原文: https://arxiv.org/abs/2503.10622
代码、数据和视频:
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
Abstract
归一化层在现代神经网络中无处不在,并且长期以来被认为是必不可少的。本工作表明,通过一种非常简单的技术,不使用归一化的Transformer也能达到相同或更好的性能。我们提出了动态Tanh (Dynamic Tanh——DyT),一种逐元素操作 DyT ( x ) = tanh ( α x ) \text{DyT}(x)=\tanh(\alpha x) DyT(x)=tanh(αx),可作为Transformer中归一化层的直接替代。 DyT \text{DyT} DyT的灵感来源于观察到Transformer中的层归一化通常会产生类似tanh的“S型”输入输出映射。通过引入 DyT \text{DyT} DyT,不使用归一化的Transformer在大多数情况下无需调整超参数即可匹配或超越其归一化版本的性能。我们在多种场景下验证了采用 DyT \text{DyT} DyT的Transformer的有效性,涵盖了从识别到生成、从监督学习到自监督学习,以及从计算机视觉到语言模型等多种任务。这些发现挑战了归一化层在现代神经网络中不可或缺的传统认知,并为其在深度网络中的作用提供了新的见解。
1 引言
在过去的十年中,归一化层已巩固了它们作为现代神经网络中最基础组件之一的地位。这一切都源自2015年批归一化(Batch Normalization)的发明(Ioffe 和 Szegedy,2015),它使视觉识别模型的收敛速度大幅加快且性能显著提升,并在随后的几年中迅速流行起来。自那以后,为不同网络架构或领域提出了许多归一化层的变体(Ba 等,2016;Ulyanov 等,2016;Wu 和 He,2018;Zhang 和 Sennrich,2019)。如今,几乎所有现代网络都使用归一化层,其中层归一化(Layer Norm,或 LN)(Ba 等,2016)是最流行的一种,尤其是在主导性的 Transformer 架构中(Vaswani 等,2017;Dosovitskiy 等,2020)。
归一化层的广泛采用在很大程度上源于它们在优化中的经验性优势(Santurkar 等,2018;Bjorck 等,2018)。除了能获得更好的效果之外,它们还能加速并稳定收敛过程。随着神经网络变得更宽更深,这一需求也变得愈发关键(Brock 等,2021a;Huang 等,2023)。因此,归一化层被普遍认为是深度网络有效训练的关键,甚至是必不可少的。这一观点的一个微妙体现是,近年来的新颖架构常常试图用新的模块取代注意力或卷积层(Tolstikhin 等,2021;Gu 和 Dao,2023;Sun 等,2024;Feng 等,2024),但几乎总是保留归一化层。
本文通过引入一种简单的 Transformer 归一化层替代方案,对这一观点提出挑战。我们的研究始于这样一个观察:层归一化(LN)会将输入 映射为类似 tanh 的 S 型曲线,对输入激活进行缩放,同时压缩极端值。受到这一启发,我们提出了一种称为动态Tanh (Dynamic Tanh——DyT) 的逐元素操作,定义为: DyT ( x ) = tanh ( α x ) \text{DyT}(x)=\tanh(\alpha x) DyT(x)=tanh(αx),其中α是可学习参数。该操作旨在通过学习合适的缩放因子α并利用有界的tanh函数压缩极端值,以模拟LN的行为。值得注意的是,与归一化层不同, DyT \text{DyT} DyT 无需计算激活统计量即可实现上述两种效果。
如图1所示,使用DyT非常简单:我们直接在视觉和语言Transformer等架构中将现有的归一化层替换为DyT。我们通过实验证明,采用DyT的模型能够在多种设置下稳定训练并取得较高的最终性能。它通常无需对原始架构的训练超参数进行调整。我们的工作挑战了归一化层在现代神经网络训练中不可或缺的观点,并为归一化层的属性提供了实证见解。此外,初步测量表明DyT能够提高训练和推理速度,使其成为面向高效性网络设计的候选方案。
 图1 左:原始 Transformer 块。右:包含我们提出的动态 Tanh(DyT)层的块。DyT 是对常用的层归一化(Layer Norm)(Ba 等,2016)(在某些情况下为 RMSNorm(Zhang 和 Sennrich,2019))层的直接替换。采用 DyT 的 Transformer 在性能上能够匹配或超过其归一化版本。
图1 左:原始 Transformer 块。右:包含我们提出的动态 Tanh(DyT)层的块。DyT 是对常用的层归一化(Layer Norm)(Ba 等,2016)(在某些情况下为 RMSNorm(Zhang 和 Sennrich,2019))层的直接替换。采用 DyT 的 Transformer 在性能上能够匹配或超过其归一化版本。
2 背景:归一化层
我们首先回顾归一化层。大多数归一化层共享一个通用的公式。给定一个形状为 ( B , T , C ) (B,T,C) (B,T,C)的输入 x x x,其中 B B B是批量大小, T T T是token数, C C C是每个token的嵌入维度,输出通常计算为:
normalization ( x ) = γ ∗ ( x − μ σ 2 + ϵ ) + β ( 1 ) \text{normalization}(x)=\gamma*\big(\frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}\big)+\beta \quad (1) normalization(x)=γ∗(σ2+ϵx−μ)+β(1)
其中 ϵ \epsilon ϵ是一个小常数, γ \gamma γ和 β \beta β是形状为 ( C , ) (C,) (C,)的可学习向量参数。它们是“缩放”和“平移”仿射参数,允许输出落在任意范围内。术语 μ \mu μ和 σ 2 \sigma^2 σ2分别表示输入的均值和方差。不同方法主要区别在于这两个统计量的计算方式不同。这导致 μ \mu μ和 σ 2 \sigma^2 σ2具有不同的维度,并在计算过程中应用广播。
批量归一化(Batch Normalization,BN)(Ioffe 和 Szegedy,2015)是第一个现代归一化层,主要用于ConvNet模型(Szegedy 等,2016;He 等,2016;Xie 等,2017)。它的引入代表了深度学习架构设计的一个重要里程碑。BN在批量和token维度上同时计算均值和方差,具体为: μ k = 1 B T ∑ i , j x i j k \mu_k=\frac{1}{BT}\sum_{i,j}x_{ijk} μk=BT1∑i,jxijk 和 σ k 2 = 1 B T ∑ i , j ( x i j k − μ k ) 2 \sigma_k^2=\frac{1}{BT}\sum_{i,j}(x_{ijk}-\mu_k)^2 σk2=BT1∑i,j(xijk−μk)2。 在ConvNet中流行的其他归一化层,比如组归一化(Group Normalization)(Wu 和 He,2018)和实例归一化(Instance Normalization)(Ulyanov 等,2016),最初是为目标检测和图像风格化等专用任务提出的。它们具有相同的总体公式,但统计量的计算轴和范围不同。
层归一化(Layer Normalization,LN)(Ba 等,2016)和均方根归一化(RMSNorm)(Zhang 和 Sennrich,2019)是Transformer架构中使用的两类主要归一化层。LN对每个样本中每个token独立计算这些统计量,其中 μ i j = 1 C ∑ k x i j k \mu_{ij}=\frac{1}{C}\sum_{k}x_{ijk} μij=C1∑kxijk 且 σ i j 2 = 1 C ∑ k ( x i j k − μ i j ) 2 \sigma_{ij}^2=\frac{1}{C}\sum_{k}(x_{ijk}-\mu_{ij})^2 σij2=C1∑k(xijk−μij)2。RMSNorm(Zhang 和 Sennrich,2019)通过删除去中心化步骤简化了LN,并将输入归一化为 μ i j = 0 \mu_{ij}=0 μij=0 且 σ i j 2 = 1 C ∑ k x i j k 2 \sigma_{ij}^2=\frac{1}{C}\sum_{k}x_{ijk}^2 σij2=C1∑kxijk2。 如今,大多数现代神经网络因其简单性和通用性而使用LN。 最近,RMSNorm在语言模型中越来越受欢迎,尤其是在T5(Raffel 等,2020)、LLaMA(Touvron 等,2023a,b;Dubey 等,2024)、Mistral(Jiang 等,2023)、Qwen(Bai 等,2023;Yang 等,2024)、InternLM(Zhang 等,2024;Cai 等,2024)和DeepSeek(Liu 等,2024;Guo 等,2025)等模型中。我们在本文中研究的Transformer均使用LN,唯一例外是LLaMA使用RMSNorm。
3 归一化层做什么?
分析设置。
我们首先在已训练网络中对归一化层的行为进行实证研究。为此分析,我们选用一个在 ImageNet-1K (Deng 等, 2009) 上训练的 Vision Transformer 模型 (ViT-B) (Dosovitskiy 等, 2020)、一个在 LibriSpeech (Panayotov 等, 2015) 上训练的 wav2vec 2.0 大型 Transformer 模型 (Baevski 等, 2020),以及一个在 ImageNet-1K 上训练的 Diffusion Transformer (DiT-XL) (Peebles 和 Xie, 2023)。在所有情况下,层归一化(LN)都应用于每个 Transformer 块及最终线性投影之前。对于这三个已训练网络,我们对一个小批量样本进行前向传播。然后,我们测量归一化层的输入和输出,即在可学习仿射变换之前、归一化操作前后紧接的张量。因为 LN 保持输入张量的维度不变,我们可以在输入和输出张量元素之间建立一一对应,从而可以直接可视化它们的关系。我们将所得映射绘制在图2中。
 图2:Vision Transformer(ViT)(Dosovitskiy 等,2020)、wav2vec 2.0(用于语音的 Transformer 模型)(Baevski 等,2020)和 Diffusion Transformer(DiT)(Peebles 和 Xie,2023)中选定层归一化(LN)层的输出与输入关系。我们采样一个小批量样本,并绘制每个模型中四个 LN 层的输入/输出值。这些输出是在 LN 的仿射变换之前的值。S 型曲线与 tanh \tanh tanh函数的形状高度相似(见图 3)。在较早的层中,更线性的形状也可以用 tanh \tanh tanh曲线的中心部分来刻画。这激发了我们提出动态 Tanh(DyT)作为替代,其带有可学习的缩放因子 α α α以适应 x 轴上不同的尺度。
图2:Vision Transformer(ViT)(Dosovitskiy 等,2020)、wav2vec 2.0(用于语音的 Transformer 模型)(Baevski 等,2020)和 Diffusion Transformer(DiT)(Peebles 和 Xie,2023)中选定层归一化(LN)层的输出与输入关系。我们采样一个小批量样本,并绘制每个模型中四个 LN 层的输入/输出值。这些输出是在 LN 的仿射变换之前的值。S 型曲线与 tanh \tanh tanh函数的形状高度相似(见图 3)。在较早的层中,更线性的形状也可以用 tanh \tanh tanh曲线的中心部分来刻画。这激发了我们提出动态 Tanh(DyT)作为替代,其带有可学习的缩放因子 α α α以适应 x 轴上不同的尺度。
具有层归一化的类似 tanh 的映射。
对于这三种模型,在较早的 LN 层(图 2 的第一列)中,我们发现这种输入—输出关系大多是线性的,类似于 x-y 图中的一条直线。然而,在更深的 LN 层中,我们观察到了更有趣的现象。
在这些更深层中,一个显著的观察是,大多数曲线的形状与由 tanh \tanh tanh 函数表示的完整或部分 S 型曲线高度相似(见图 3)。
 图 3:具有三个不同 α α α 值的 tanh ( α x ) \tanh(αx) tanh(αx) 曲线。
图 3:具有三个不同 α α α 值的 tanh ( α x ) \tanh(αx) tanh(αx) 曲线。
人们可能会认为 LN 层会线性地变换输入张量,因为减去均值和除以标准差都是线性操作。LN 以逐 token 的方式进行归一化,仅线性地变换每个 token 的激活值。由于不同 token 的均值和标准差各不相同,这种线性特性不再整体适用于输入张量的所有激活值。尽管如此,实际上这种非线性变换与缩放后的 tanh \tanh tanh 函数高度相似,这仍令我们感到惊讶。
对于这样的 S 型曲线,我们注意到其中心部分(即 x x x 值接近零的点)仍主要呈现线性形状。大多数点(约 99%)都落在该线性区间内。然而,仍有许多点明显超出该范围,被视为“极端”值,例如在 ViT 模型中 x x x 大于 50 或小于 −50 的点。对于这些极端值,归一化层的主要作用是将它们压缩为更不极端的值,使其与大多数点更加一致。这里正是归一化层无法被简单的仿射变换层所逼近的原因。我们假设,归一化层对极端值的这种非线性且不成比例的压缩效果,正是它们重要且不可或缺的原因。
Vision Transformer(ViT)是一种将 Transformer 架构直接应用于计算机视觉任务的模型架构
Ni 等(2024)的最新研究也同样强调了 LN 层引入的强非线性,展示了这种非线性如何增强模型的表征能力。此外,这种压缩行为与生物神经元在大输入下的饱和特性相似,该现象最早于约一个世纪前被观测到(Adrian, 1926;Adrian 和 Zotterman, 1926a,b)。
按 token 和通道进行归一化。
LN 层如何对每个 token 执行线性变换,同时又以如此非线性方式压缩极端值?为了解其原理,我们分别对按 token 和通道分组的点进行可视化。此操作如图 4 所示,选取图 2 中 ViT 的第二和第三子图,并对点集进行抽样以提高清晰度。在选择要绘制的通道时,我们确保包含具有极端值的通道。
在图 4 的左两幅图中,我们使用相同颜色可视化每个 token 的激活值。我们观察到,任何单个 token 的所有点确实形成了一条直线。然而,由于每个 token 的方差不同,直线的斜率也各不相同。 x x x 范围较小的 token 往往具有较小的方差,归一化层会用较小的标准差除以它们的激活值,因此在线性直线中生成更大的斜率。整体来看,这些直线共同构成了一个类似 tanh \tanh tanh 函数的 S 型曲线。
在右两幅图中,我们使用相同颜色为每个通道的激活值着色。我们发现,不同通道的输入范围往往差异巨大,只有少数通道(如红色、绿色和粉色)表现出较大的极端值。这些通道是被归一化层压缩最严重的通道。

图 4:两个 LN 层的输出与输入关系,张量元素按不同的通道和 token 维度着色。输入张量的形状为(样本数, token 数, 通道数),通过对相同 token(左两幅图)和相同通道(右两幅图)赋予一致的颜色来可视化元素。左两幅图:表示相同 token(相同颜色)的点在不同通道上形成直线,因为 LN 对每个 token 在通道维度上进行线性操作。有趣的是,当这些直线一起绘制时,它们形成了非线性的 tanh 形曲线。右两幅图:每个通道的输入在 x 轴上跨度不同,为整体 tanh 形曲线贡献了不同的片段。某些通道(例如红色、绿色和粉色)的 x 值更为极端,这些极端值会被 LN 压缩。
4 动态 Tanh (Dynamic Tanh (DyT))
受到归一化层形状与缩放 tanh 函数相似性的启发,我们提出了动态 Tanh(DyT)作为归一化层的直接替代。给定输入张量 x x x, DyT \text{DyT} DyT 层定义如下:
DyT ( x ) = γ ∗ tanh ( α x ) + β ( 2 ) \text{DyT}(x)=\gamma*\tanh(\alpha x)+\beta \quad (2) DyT(x)=γ∗tanh(αx)+β(2)
其中 α \alpha α 是可学习的标量参数,可根据输入范围对 x x x 进行不同程度的缩放,以适应不同的 x x x 取值尺度(见图 2)。这也是我们称之为“动态” Tanh 的原因。 γ \gamma γ和 β \beta β是可学习的按通道向量参数,与所有归一化层中使用的参数相同——它们允许输出重新缩放到任意尺度。有时它们被视为单独的仿射层;但在本研究中,我们将它们视为 DyT \text{DyT} DyT 层的一部分,正如归一化层也包含它们一样。有关 DyT \text{DyT} DyT 在类 PyTorch 伪代码中的实现,请参见算法 1。

图2:Vision Transformer(ViT)(Dosovitskiy 等,2020)、wav2vec 2.0(用于语音的 Transformer 模型)(Baevski 等,2020)和 Diffusion Transformer(DiT)(Peebles 和 Xie,2023)中选定层归一化(LN)层的输出与输入关系。我们采样一个小批量样本,并绘制每个模型中四个 LN 层的输入/输出值。这些输出是在 LN 的仿射变换之前的值。S 型曲线与 tanh \tanh tanh函数的形状高度相似(见图 3)。在较早的层中,更线性的形状也可以用 tanh \tanh tanh曲线的中心部分来刻画。这激发了我们提出动态 Tanh(DyT)作为替代,其带有可学习的缩放因子 α α α以适应 x 轴上不同的尺度。
将 DyT \text{DyT} DyT 层集成到现有架构中非常简单:用一个 DyT \text{DyT} DyT 层替换一个归一化层(见图 1)。这适用于注意力模块、前馈网络(FFN)模块以及最终的归一化层中的归一化操作。尽管 DyT \text{DyT} DyT 看起来或可被认为是一种激活函数,但本研究仅将其用于替换归一化层,而不修改原始架构中的任何激活函数部分(如 GELU 或 ReLU)。网络的其他部分保持不变。我们还观察到,DyT 在大多数情况下无需调整原始架构的超参数即可达到良好性能。
关于缩放参数。
我们遵循归一化层的初始化惯例,将 γ \gamma γ初始化为全 1 向量,将 β \beta β初始化为全 0 向量。对于缩放参数 α \alpha α,默认将其初始化为 0.5 通常足够,除非在大型语言模型(LLM)训练中有特殊需求。有关 α \alpha α初始化的详细分析,请参见第 7 节。除非另有说明,在后续实验中我们均将 α \alpha α初始化为 0.5。
备注。
DyT \text{DyT} DyT 并不是一种新的归一化层,因为它在前向传递中对张量的每个输入元素独立操作,不计算统计量或其他类型的聚合。然而,它保留了归一化层以非线性方式压缩极端值的效果,同时对输入的中心部分几乎呈线性变换。
5 实验
为了验证 DyT \text{DyT} DyT 的有效性,我们在多种任务和领域中对 Transformers 以及其他几种现代架构进行了实验。在每个实验中,我们将原始架构中的 LN 或 RMSNorm 替换为 DyT \text{DyT} DyT 层,并按照官方开源协议对两种模型版本进行训练和测试。在附录 A 中提供了复现我们结果的详细说明。值得注意的是,为了突显 DyT \text{DyT} DyT 的适配简易性,我们使用与归一化版本完全相同的超参数。为了完整性,还在附录 B 中提供了有关学习率调整和 α α α 初始值设置的附加实验结果。
视觉领域中的监督学习
我们在 ImageNet-1K 分类任务(Deng 等,2009)上训练了“Base”和“Large”两种规模的 Vision Transformer(ViT)(Dosovitskiy 等,2020)和 ConvNeXt(Liu 等,2022)。之所以选择这些模型,是因为它们的受欢迎程度及其不同的操作方式:ViT 中的注意力机制与 ConvNeXt 中的卷积操作。表 1 报告了 top-1 分类准确率。在两种架构和不同规模模型中, DyT \text{DyT} DyT 的表现均略优于 LN。我们在图 5 中进一步绘制了 ViT-B 和 ConvNeXt-B 的训练损失曲线。曲线表明, DyT \text{DyT} DyT 与基于 LN 的模型在收敛行为上高度一致。
 图 5 ViT-B 和 ConvNeXt-B 模型的训练损失曲线。两种模型在 LN 和 DyT \text{DyT} DyT 之间的损失曲线模式相似,这表明 LN 和 DyT \text{DyT} DyT 可能具有相似的学习动态。
图 5 ViT-B 和 ConvNeXt-B 模型的训练损失曲线。两种模型在 LN 和 DyT \text{DyT} DyT 之间的损失曲线模式相似,这表明 LN 和 DyT \text{DyT} DyT 可能具有相似的学习动态。
 表 1 ImageNet-1K 上的监督分类准确率。在两种架构和各模型规模中, DyT \text{DyT} DyT 的性能均优于或与 LN 相当。
表 1 ImageNet-1K 上的监督分类准确率。在两种架构和各模型规模中, DyT \text{DyT} DyT 的性能均优于或与 LN 相当。
视觉领域的自监督学习
我们采用两种流行的视觉自监督学习方法进行基准测试:掩码自编码器(MAE)(He 等,2022)和 DINO(Caron 等,2021)。两者默认使用 Vision Transformers 作为骨干网络,但训练目标不同:MAE 使用重建损失进行训练,DINO 使用联合嵌入损失(LeCun,2022)。按照标准的自监督学习协议,我们首先在 ImageNet-1K 上对模型进行预训练,不使用任何标签;然后通过附加分类层并使用标签对预训练模型进行微调来进行测试。微调结果如表 2 所示。在自监督学习任务中, DyT \text{DyT} DyT 始终与 LN 表现相当。
 表 2 自监督学习在 ImageNet-1K 上的准确率。在不同预训练方法和模型规模的自监督学习任务中, DyT \text{DyT} DyT 与 LN 的表现相当。
表 2 自监督学习在 ImageNet-1K 上的准确率。在不同预训练方法和模型规模的自监督学习任务中, DyT \text{DyT} DyT 与 LN 的表现相当。
扩散模型。
我们在 ImageNet-1K(Deng 等,2009)上训练了三种大小分别为 B、L 和 XL 的 Diffusion Transformer(DiT)模型(Peebles 和 Xie,2023)。它们的 patch 大小分别为 4、4 和 2。需要注意的是,在 DiT 中,LN 层的仿射参数被用于类别条件,我们在 DyT \text{DyT} DyT 实验中继续保留这一用法,仅将归一化变换替换为 tanh ( α x ) \tanh(\alpha x) tanh(αx)函数。训练完成后,我们使用标准的 ImageNet “参考批次”评估 Fréchet Inception Distance(FID)分数,如表 3 所示。 DyT \text{DyT} DyT 在 FID 分数上与 LN 相当或有所提升。
 表 3 ImageNet 上的图像生成质量(FID,数值越低越好)。在各种 DiT 模型规模中, DyT \text{DyT} DyT 在 FID 分数上与 LN 相当或更优。
表 3 ImageNet 上的图像生成质量(FID,数值越低越好)。在各种 DiT 模型规模中, DyT \text{DyT} DyT 在 FID 分数上与 LN 相当或更优。
大型语言模型。
我们预训练了 LLaMA 7B、13B、34B 和 70B 模型(Touvron 等,2023a,b;Dubey 等,2024),以评估 DyT \text{DyT} DyT 相对于 LLaMA 中默认归一化层 RMSNorm(Zhang 和 Sennrich,2019)的性能。这些模型在 The Pile 数据集(Gao 等,2020)上使用 2000 亿 token 进行训练,遵循 LLaMA(Touvron 等,2023b)中概述的原始流程。在 DyT \text{DyT} DyT 版 LLaMA 中,我们在初始嵌入层之后添加了一个可学习的标量参数,并根据第 7 节的详细描述调整了 α α α 的初始值。我们报告了训练结束后的 loss 值,并按照 OpenLLaMA(Geng 和 Liu,2023)的做法,在 lm-eval(Gao 等)提供的 15 个零样本任务上对模型进行了基准测试。如表 4 所示,在所有四种模型规模上, DyT \text{DyT} DyT 的表现都与 RMSNorm 相当。图 6 展示了 loss 曲线,表明在整个训练过程中,所有模型规模的训练损失都紧密对齐,并显示出相似的趋势。
 表 4 语言模型的训练损失及在 15 个零样本 lm-eval 任务上的平均表现。 DyT \text{DyT} DyT 在零样本表现和训练损失方面与 RMSNorm 相当。
表 4 语言模型的训练损失及在 15 个零样本 lm-eval 任务上的平均表现。 DyT \text{DyT} DyT 在零样本表现和训练损失方面与 RMSNorm 相当。
语音领域的自监督学习
我们在 LibriSpeech 数据集(Panayotov 等,2015)上预训练了两种 wav2vec 2.0 Transformer 模型(Baevski 等,2020)。我们在表 5 中报告了最终的验证损失。
我们观察到,在两种模型规模上, DyT \text{DyT} DyT 的表现与 LN 相当。
 表 5 LibriSpeech 上语音预训练的验证损失。在两种 wav2vec 2.0 模型中, DyT \text{DyT} DyT 的表现与 LN 相当。
表 5 LibriSpeech 上语音预训练的验证损失。在两种 wav2vec 2.0 模型中, DyT \text{DyT} DyT 的表现与 LN 相当。
DNA 序列建模
在长程 DNA 序列建模任务中,我们分别预训练了 HyenaDNA 模型(Nguyen 等,2024)和 Caduceus 模型(Schiff 等,2024)。预训练使用了人类参考基因组数据(GRCh38,2013),评估则在 GenomicBenchmarks(Grešová 等,2023)上进行。结果列于表 6。在该任务中, DyT \text{DyT} DyT 的表现与 LN 相当。
 表 6 GenomicBenchmarks 上的 DNA 分类准确率,取各数据集的平均值。 DyT \text{DyT} DyT 的表现与 LN 相当。
表 6 GenomicBenchmarks 上的 DNA 分类准确率,取各数据集的平均值。 DyT \text{DyT} DyT 的表现与 LN 相当。
6 分析
我们对 DyT \text{DyT} DyT 的若干重要属性进行了分析。我们首先评估其计算效率,接着进行两项研究,考察 tanh \text{tanh} tanh 函数和可学习缩放因子 α α α的作用。最后,我们将其与以往旨在移除归一化层的方法进行比较。
6.1 DyT \text{DyT} DyT 的效率
我们以 LLaMA 7B 模型为基准,比较其使用 RMSNorm 或 DyT \text{DyT} DyT 时的性能——通过测量在单条 4096 token 序列上进行 100 次前向推理(inference)和 100 次前向-反向传递(training)所需的总时间。表 7 列出了在 Nvidia H100 GPU(BF16 精度)上运行时,仅 RMSNorm 或 DyT 层与整个模型所需的时间。与 RMSNorm 层相比, DyT \text{DyT} DyT 层显著减少了计算时间,在 FP32 精度下也表现出类似趋势。 DyT \text{DyT} DyT 可能是面向高效网络设计的有力候选方案。
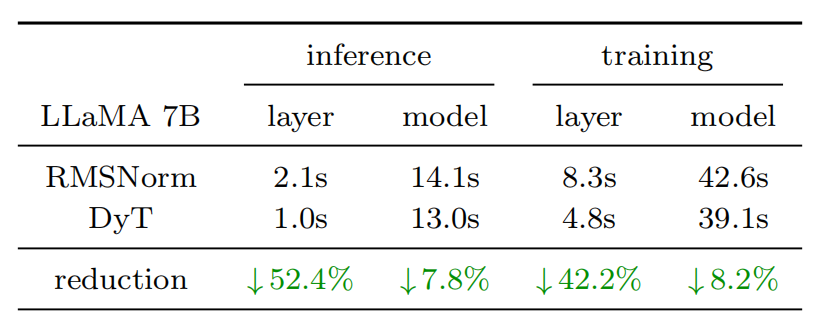
表 7 在 Nvidia H100 GPU(BF16 精度)上,RMSNorm/DyT 层及整个 LLaMA 7B 模型在 100×前向和 100×前向-反向传递上的耗时(单位:毫秒)。
6.2 tanh \text{tanh} tanh 和 α α α 的消融实验
为了进一步研究 tanh \text{tanh} tanh 和 α α α 在 DyT \text{DyT} DyT 中的作用,我们进行了实验,评估在更改或移除这些组件时模型性能。
替换和移除 tanh \text{tanh} tanh。
我们在 DyT \text{DyT} DyT 层中用其他压缩函数(具体为 hardtanh 和 sigmoid,见图 7)替换 tanh \text{tanh} tanh,同时保留可学习缩放因子 α α α。此外,我们还评估了完全移除 tanh \text{tanh} tanh 的情况,即将其替换为恒等函数(identity function),但仍保留 α α α。如表 8 所示,压缩函数对于稳定训练至关重要。使用恒等函数会导致训练不稳定并最终发散,而使用任何压缩函数都能实现稳定训练。在三种压缩函数中, tanh \text{tanh} tanh 的表现最佳,这可能归因于其平滑性和以零为中心的特性。
 图7 三种压缩函数的曲线: tanh \text{tanh} tanh 、 hardtanh \text{hardtanh} hardtanh 和 sigmoid \text{sigmoid} sigmoid。所有三种函数都将输入压缩到有界范围,但当在 DyT \text{DyT} DyT 层中使用时, tanh ( x ) \text{tanh}(x) tanh(x) 实现了最佳性能。我们怀疑这是由于它的平滑性和零均值特性。
图7 三种压缩函数的曲线: tanh \text{tanh} tanh 、 hardtanh \text{hardtanh} hardtanh 和 sigmoid \text{sigmoid} sigmoid。所有三种函数都将输入压缩到有界范围,但当在 DyT \text{DyT} DyT 层中使用时, tanh ( x ) \text{tanh}(x) tanh(x) 实现了最佳性能。我们怀疑这是由于它的平滑性和零均值特性。
 表 8 ImageNet-1K 分类准确率与不同压缩函数。所有实验均遵循与原始基于 LN 的模型相同的训练流程。压缩函数在防止训练发散中起关键作用,其中 tanh \text{tanh} tanh 在三种函数中取得了最高性能。“→ failed” 表示训练在达到一定准确率后出现发散,箭头前的数字为发散前达到的最高准确率。
表 8 ImageNet-1K 分类准确率与不同压缩函数。所有实验均遵循与原始基于 LN 的模型相同的训练流程。压缩函数在防止训练发散中起关键作用,其中 tanh \text{tanh} tanh 在三种函数中取得了最高性能。“→ failed” 表示训练在达到一定准确率后出现发散,箭头前的数字为发散前达到的最高准确率。
移除 α α α。
接下来,我们评估在保留压缩函数( tanh \text{tanh} tanh 、 hardtanh \text{hardtanh} hardtanh 和 sigmoid \text{sigmoid} sigmoid)的情况下移除可学习参数 α α α的影响。如表9所示,移除 α α α会导致所有压缩函数的性能下降,凸显了 α α α对模型整体性能的关键作用。
 表9 ViT-B在ImageNet-1K上的分类准确率。所有实验均遵循原始基于LN模型的相同训练流程。可学习的 α α α对于提升模型性能至关重要。
表9 ViT-B在ImageNet-1K上的分类准确率。所有实验均遵循原始基于LN模型的相同训练流程。可学习的 α α α对于提升模型性能至关重要。
6.3 α α α 的取值
训练过程中。 我们的分析表明, α α α 在整个训练过程中紧密跟踪激活值的 1 / s t d 1/\mathrm{std} 1/std。如图 8 左侧所示, α α α 在训练初期先下降后上升,但始终与输入激活的标准差保持一致波动。这支持了 α α α 在将激活保持在合适范围内,从而实现稳定且高效训练中的重要作用。
 图 8 左:对于 ViT-B 模型中两个选定的 DyT 层,我们在每个 epoch 结束时跟踪激活的标准差倒数( 1 / s t d 1/\mathrm{std} 1/std)和 α α α,观察到它们在训练过程中同步变化。 图 8 右:我们将两个训练完成的模型(ViT-B 和 ConvNeXt-B)的最终 α α α值与输入激活的标准差倒数( 1 / s t d 1/\mathrm{std} 1/std)绘制在同一坐标系中,展示了两者之间的强相关性。
图 8 左:对于 ViT-B 模型中两个选定的 DyT 层,我们在每个 epoch 结束时跟踪激活的标准差倒数( 1 / s t d 1/\mathrm{std} 1/std)和 α α α,观察到它们在训练过程中同步变化。 图 8 右:我们将两个训练完成的模型(ViT-B 和 ConvNeXt-B)的最终 α α α值与输入激活的标准差倒数( 1 / s t d 1/\mathrm{std} 1/std)绘制在同一坐标系中,展示了两者之间的强相关性。
训练后。 对训练完毕网络中 α α α 的最终取值进一步分析发现,其与输入激活的 1 / s t d 1/\mathrm{std} 1/std 存在强相关性。如图 8 右侧所示,较高的 1 / s t d 1/\mathrm{std} 1/std 值通常对应较大的 α α α 值,反之亦然。此外,我们观察到越深的层其激活标准差越大。该趋势与深度 ResNet(Brock 等,2021a)和 Transformer(Sun 等,2025)的研究结果一致。这两项分析表明, α α α 部分地充当了归一化机制,通过学习近似输入激活 1 / s t d 1/\mathrm{std} 1/std 的值来整体归一化输入激活。与按 token 归一化激活的 Layer Norm 不同, α α α 对整个输入张量共同归一化。因此,仅有 α α α 无法以非线性方式抑制极端值。
6.4 与其他方法的比较
为了进一步评估 DyT 的有效性,我们将其与其他能够在缺少归一化层的情况下训练 Transformer 的方法进行比较。这些方法大致可分为基于初始化的方法和基于权重归一化的方法。我们考虑了两种流行的基于初始化的方法:Fixup (Zhang 等, 2019;Huang 等, 2020) 和 SkipInit (De 和 Smith, 2020;Bachlechner 等, 2021)。这两种方法都旨在通过调整初始参数值来缓解训练不稳定性,防止在训练开始时出现过大的梯度和激活值,从而无需归一化层即可实现稳定学习。相比之下,基于权重归一化的方法通过在整个训练过程中对网络权重施加约束,以在没有归一化层时维持稳定的学习动态。我们包含了一种此类方法—— σ σ σReparam (Zhai 等, 2023),它通过控制权重的谱范数来促进稳定学习。
表 10 总结了两个基于 ViT 任务的结果。我们严格遵循各自论文中概述的原始协议。然而,我们发现两种基于初始化的方法——Fixup 和 SkipInit——为了防止训练发散,需要显著更低的学习率。为确保公平比较,我们对包括 DyT 在内的所有方法进行了简单的学习率搜索。这得到的结果与第 5 节中报告的结果不同,第 5 节未对任何超参数进行调整。总体而言,结果显示在不同配置下,DyT 始终优于所有其他测试方法。
 表 10 ImageNet-1K 上的分类准确率。在所有方法中,DyT 始终取得了优越的性能。
表 10 ImageNet-1K 上的分类准确率。在所有方法中,DyT 始终取得了优越的性能。
7 α 的初始化
我们发现调整 α α α 的初始化(记为 α 0 α_0 α0)很少会带来显著的性能提升。唯一例外是 LLM 训练,在该场景下精心调整 α 0 α_0 α0 可获得明显的性能提升。在本节中,我们详细说明 α α α 初始化的影响。
7.1 非 LLM 模型的 α α α 初始化
非 LLM 模型对 α 0 α_0 α0 的敏感性较低。
图 9 显示了在不同任务中改变 α 0 α_0 α0 对验证性能的影响。所有实验均遵循各自流程的原始设置和超参数。我们观察到性能在广泛的 α 0 α_0 α0 值范围内保持稳定,通常在 0.5 到 1.2 之间的值可获得较好结果。我们还发现,调整 α 0 α_0 α0 主要影响训练曲线的早期阶段。主要例外是监督训练的 ViT-L 实验,当 α 0 α_0 α0 超过 0.6 时训练变得不稳定并出现发散。在此情况下,降低学习率可恢复稳定性,详情如下所述。
 图 9 不同 α 0 α_0 α0 值下各任务的性能表现。我们对第 5 节中使用的所有非 LLM 任务进行了基于不同初始 α 0 α_0 α0 值的基准测试。性能在广泛的 α 0 α_0 α0 范围内保持稳定。唯一的例外是监督训练的 ViT-L 模型(右上图),当 α 0 α_0 α0 值大于 0.6 时会出现训练发散。
图 9 不同 α 0 α_0 α0 值下各任务的性能表现。我们对第 5 节中使用的所有非 LLM 任务进行了基于不同初始 α 0 α_0 α0 值的基准测试。性能在广泛的 α 0 α_0 α0 范围内保持稳定。唯一的例外是监督训练的 ViT-L 模型(右上图),当 α 0 α_0 α0 值大于 0.6 时会出现训练发散。
更小的 α 0 α_0 α0 可带来更稳定的训练。
基于之前的观察,我们进一步分析了导致训练不稳定的因素。我们的发现表明,增大模型规模或学习率都需要降低 α 0 α_0 α0 以确保训练稳定。反之,较高的 α 0 α_0 α0 则需要更低的学习率来缓解训练不稳定。图 10 显示了在 ImageNet-1K 数据集上对监督训练的 ViT 模型的训练稳定性消融实验,其中我们改变了学习率、模型规模和 α 0 α_0 α0 值。训练更大的模型更容易失败,需要更小的 α 0 α_0 α0 值或学习率来实现稳定训练。在相似条件下,基于 LN 的模型也观察到类似的不稳定模式,而设置 α 0 = 0.5 α_0=0.5 α0=0.5 则可获得与 LN 相似的稳定性。
 图 10:在不同 α 0 α0 α0 值、学习率和模型规模下的稳定性。我们在 ImageNet-1K 数据集上训练监督 ViT 模型,观察到无论是 LN 还是 DyT 模型,较大模型都更易出现不稳定现象。降低学习率或减小 α 0 α0 α0 可提高稳定性。LN 在 α 0 = 0.5 α0=0.5 α0=0.5 时表现出与 DyT 相似的稳定性。
图 10:在不同 α 0 α0 α0 值、学习率和模型规模下的稳定性。我们在 ImageNet-1K 数据集上训练监督 ViT 模型,观察到无论是 LN 还是 DyT 模型,较大模型都更易出现不稳定现象。降低学习率或减小 α 0 α0 α0 可提高稳定性。LN 在 α 0 = 0.5 α0=0.5 α0=0.5 时表现出与 DyT 相似的稳定性。
将 α 0 = 0.5 α_0=0.5 α0=0.5 作为默认值。
根据我们的研究结果,我们将 α 0 = 0.5 α0=0.5 α0=0.5 设为所有非 LLM 模型的默认值。此设置可提供与 LN 相当的训练稳定性,同时保持强劲的性能。
7.2 LLM 的 α α α 初始化
调整 α 0 α_0 α0 可以提升 LLM 性能。
正如前文讨论, α 0 = 0.5 α_0=0.5 α0=0.5 的默认设置通常在大多数任务中表现良好。然而,我们发现调整 α 0 α_0 α0 能显著提升 LLM 的性能。我们通过在 LLaMA 各模型上用 300 亿 token 进行预训练并比较其训练损失,对 α 0 α_0 α0 进行调优。表 11 汇总了每个模型的最佳 α 0 α_0 α0 值。得出两个关键发现:
- 较大的模型需要更小的 α 0 α_0 α0 值。
在较小模型的最佳 α 0 α_0 α0 确定后,可据此缩小对较大模型的搜索空间。 - 对注意力模块使用更高的 α 0 α_0 α0 值可提高性能。
我们发现,在注意力模块中的 DyT 层初始化较高的 α 0 α_0 α0,而在其他位置(即 FFN 模块内或最终线性投影前)的 DyT 层初始化较低的 α 0 α_0 α0,能够提升性能。
 表 11 不同 LLaMA 模型的最佳 α 0 α_0 α0。 较大模型需要更小的 α 0 α_0 α0 值。我们发现,在(1)注意力模块(“attention”)与(2)FFN 模块及输出前的最终 DyT 层(“other”)中对 α 0 α_0 α0 进行差异化初始化非常重要。注意力模块中的 α 0 α_0 α0 需要设置为更大的值。
表 11 不同 LLaMA 模型的最佳 α 0 α_0 α0。 较大模型需要更小的 α 0 α_0 α0 值。我们发现,在(1)注意力模块(“attention”)与(2)FFN 模块及输出前的最终 DyT 层(“other”)中对 α 0 α_0 α0 进行差异化初始化非常重要。注意力模块中的 α 0 α_0 α0 需要设置为更大的值。
为了进一步说明 α 0 α_0 α0 调整的影响,图 11 展示了两个 LLaMA 模型的损失值热图。两个模型都在注意力模块中使用更高的 α 0 α_0 α0 时受益,表现为训练损失的降低。
 图 11:不同 α 0 α_0 α0 设置下,两个 LLaMA 模型在 300 亿 tokens 训练时的损失值热图。两种模型在注意力模块中提高 α 0 α_0 α0 时均受益。
图 11:不同 α 0 α_0 α0 设置下,两个 LLaMA 模型在 300 亿 tokens 训练时的损失值热图。两种模型在注意力模块中提高 α 0 α_0 α0 时均受益。
模型宽度主要决定 α 0 α_0 α0 的选择。
我们还研究了模型宽度和深度对最优 α 0 α_0 α0 的影响。我们发现模型宽度在决定最优 α 0 α_0 α0 时至关重要,而模型深度的影响则微乎其微。表 12 展示了不同宽度和深度下的最优 α 0 α_0 α0 值,显示更宽的网络在最优性能时需要更小的 α 0 α_0 α0。另一方面,模型深度对 α 0 α_0 α0 的选择影响不显著。
正如表 12 所示,网络越宽,“attention”和“other”之间的初始化差异就需要越大。我们假设 LLM 的 α α α 初始化敏感性与其相比其他模型过大的宽度有关。
 表 12 LLaMA 训练中,不同模型宽度和深度下的最优 α 0 α0 α0(“attention”/“other”)。模型宽度显著影响 α 0 α0 α0 的选择,网络越宽需要越小的值;相比之下,模型深度影响甚微。
表 12 LLaMA 训练中,不同模型宽度和深度下的最优 α 0 α0 α0(“attention”/“other”)。模型宽度显著影响 α 0 α0 α0 的选择,网络越宽需要越小的值;相比之下,模型深度影响甚微。
8 相关工作
归一化层的机制。 大量研究探讨了归一化层通过多种机制提升模型性能的作用。这些机制包括在训练过程中稳定梯度流(Balduzzi 等,2017;Daneshmand 等,2020;Lubana 等,2021)、降低对权重初始化的敏感性(Zhang 等,2019;De 和 Smith,2020;Shao 等,2020)、调节异常特征值(Bjorck 等,2018;Karakida 等,2019)、自动调节学习率(Arora 等,2018;Tanaka 和 Kunin,2021)以及平滑损失面以获得更稳定的优化(Santurkar 等,2018)。这些早期工作主要聚焦于批归一化。最近的研究(Lyu 等,2022;Dai 等,2024;Mueller 等,2024)进一步强调了归一化层与减少损失面锐度之间的联系,而损失面锐度的降低有助于更好的泛化性能。
Transformer 中的归一化。 随着 Transformer(Vaswani 等,2017)的兴起,研究者愈加关注层归一化(Layer Norm)(Ba 等,2016),其已被证明对自然语言任务中的序列数据尤为有效(Nguyen 和 Salazar,2019;Xu 等,2019;Xiong 等,2020)。近期工作(Ni 等,2024)揭示了层归一化引入的强非线性如何增强模型的表征能力。此外,研究(Loshchilov 等,2024;Li 等,2024)表明,通过调整 Transformer 中归一化层的位置,可以改善收敛特性。
移除归一化。 许多研究探讨了如何在没有归一化层的情况下训练深度模型。一些工作(Zhang 等,2019;De 和 Smith,2020;Bachlechner 等,2021)探索了替代的权重初始化方案以稳定训练。Brock 等(2021a,b)的开创性工作表明,通过结合初始化技术(De 和 Smith,2020)、权重归一化(Salimans 和 Kingma,2016;Huang 等,2017;Qiao 等,2019)和自适应梯度裁剪(Brock 等,2021b),高性能的 ResNet 可在无归一化层的情况下训练(Smith 等,2023)。此外,他们的训练策略融合了广泛的数据增强(Cubuk 等,2020)和正则化(Srivastava 等,2014;Huang 等,2016)。上述研究主要基于各类 ConvNet 模型。
在 Transformer 架构中,He 和 Hofmann(2023)探索了修改 Transformer 块以减少对归一化层和跳跃连接依赖的方法。另一种思路由 Heimersheim(2024)提出,通过在移除每个归一化层后对预训练网络进行微调,逐步移除层归一化。与以往方法不同,DyT 只需对架构和训练流程做最小修改,尽管其方法简单,却能实现稳定训练并达到可比性能。
9 限制
我们在使用 LN 或 RMSNorm 的网络上进行实验,因为它们在 Transformer 及其他现代架构中非常流行。初步实验(见附录 C)表明,DyT 在经典网络如 ResNet 中直接替换 BN 时表现不佳。尚需深入研究 DyT 是否以及如何适应使用其他类型归一化层的模型。
10 结论
在本工作中,我们展示了现代神经网络,尤其是 Transformer,可以在没有归一化层的情况下进行训练。我们提出的动态 Tanh(DyT)是一种对传统归一化层的简单替代方法。它通过可学习的缩放因子 α α α 调整输入激活范围,然后通过 S 型 tanh \tanh tanh 函数压缩极端值。尽管该函数更为简单,但它有效地捕捉了归一化层的行为。在各种设置下,采用 DyT 的模型的性能能够匹配或超越其归一化版本。这些发现挑战了归一化层在训练现代神经网络中的必要性这一传统认知。本研究还为理解归一化层这一深度神经网络中最基础构建模块的机制做出了贡献。
附录
附录 A 实验设置
监督图像分类。
对于 ImageNet-1K 上的所有监督分类实验,我们遵循 ConvNeXt(Meta Research,a)中的训练流程。在 ConvNeXt-B 和 ConvNeXt-L 中,我们使用原始超参数且不做任何修改。ViT-B 和 ViT-L 模型使用与 ConvNeXt-B 完全相同的超参数;唯一区别是对于 ViT-L,AdamW 的 beta 参数设置为(0.9,0.95),而随机深度率在 ViT-B 中设为0.1,在 ViT-L 中设为0.4。
扩散模型。
我们使用官方实现(Meta Research,c)训练所有 DiT 模型。我们发现默认学习率对于本文所用模型并非最佳。为此,我们在使用 LN 的模型上进行了简单的学习率搜索,并将调优后的学习率直接应用于 DyT 模型。我们还观察到,零初始化会对 DyT 模型的性能产生负面影响。因此,我们对 LN 模型保留零初始化,但对 DyT 模型移除零初始化。
大型语言模型。
在我们使用 DyT 实现的 LLaMA 模型(Touvron et al.,2023a,b;Dubey et al.,2024)中,我们在嵌入层之后、任何 Transformer 块之前,添加了一个可学习标量参数。我们将其初始化为模型嵌入维度 d d d的平方根,即 d \sqrt{d} d。如果不添加该缩放标量,我们发现训练初期模型激活值过小,训练难以推进。加入这一可学习标量后,该问题得以缓解,模型能够正常收敛。该设计与原始 Transformer(Vaswani et al.,2017)中在相同位置使用固定标量的做法相似。
我们在 Pile 数据集(Gao et al.,2020)上训练所有 LLaMA 模型。所用代码库为 FMS-FSDP(Foundation Model Stack),其为7B模型提供了一个与 LLaMA 2 论文(Touvron et al.,2023b)几乎一致的默认训练流程。我们将学习率保持在7B和13B模型的默认3e-4,以及34B和70B模型的1.5e-4,与 LLaMA 2 保持一致。批量大小设置为4M tokens,每个模型总共训练200B tokens。
评估。
我们在 lm-eval(Gao et al.)提供的15个零样本常识推理任务上测试预训练模型,任务包括 anli_r1、anli_r2、anli_r3、arc_challenge、arc_easy、boolq、hellaswag、openbookqa、piqa、record、rte、truthfulqa_mc1、truthfulqa_mc2、wic 和 winogrande。任务选择紧随 OpenLLaMA(Geng 和 Liu,2023)。我们报告所有任务的平均表现。
语音领域的自监督学习。
对于两种 wav2vec 2.0 模型,我们保留原始架构中的第一个组归一化层,因为它主要作为数据归一化以处理未归一化的输入。我们使用官方实现(Meta Research,e),且不修改 Base 和 Large 模型的超参数。我们报告最终的验证损失。
其他任务。
对于 MAE(He et al.,2022)、DINO(Caron et al.,2021)、HyenaDNA(Nguyen et al.,2024)和 Caduceus(Schiff et al.,2024)等所有其他任务,我们直接使用公开发布的代码(Meta Research,d,b;HazyResearch;Kuleshov Group),不做超参数调整,分别训练 LN 和 DyT 两种模型。
附录 B 超参数
我们给出了额外实验,以评估超参数调优的影响,特别关注所有非 LLM 模型的学习率和 α 0 α_0 α0 初始化。
调优学习率。表 13 汇总了使用原始学习率与调优后学习率训练的模型性能对比。结果表明,调优学习率仅为 DyT 模型带来有限的性能提升。这表明最初为 LN 模型优化的默认超参数已同样适用于 DyT 模型。这一观察强调了 DyT 模型与 LN 模型之间的内在相似性。
调优 α 0 α_0 α0 初始值。我们还研究了对 DyT 模型优化 α 0 α0 α0 的效果,结果如表 14 所示。发现对 α 0 α0 α0 进行调优仅为部分模型带来轻微的性能提升,表明默认初始值( α 0 = 0.5 α_0=0.5 α0=0.5)通常已能实现近乎最优的性能。
 表 13 LN 和 DyT 模型在原始与调优学习率下的性能对比。结果显示,调优学习率仅为 DyT 模型带来有限的性能提升,表明为 LN 模型优化的默认超参数已同样适用于 DyT 模型。标有“–”的条目表示相对于原始学习率无性能提升。括号内的数值为所用学习率。
表 13 LN 和 DyT 模型在原始与调优学习率下的性能对比。结果显示,调优学习率仅为 DyT 模型带来有限的性能提升,表明为 LN 模型优化的默认超参数已同样适用于 DyT 模型。标有“–”的条目表示相对于原始学习率无性能提升。括号内的数值为所用学习率。
 表 14 调优 α 0 α0 α0 对 DyT 模型的影响。将 α 0 α0 α0 从默认值( α 0 = 0.5 α_0=0.5 α0=0.5)调优,仅为部分 DyT 模型带来小幅性能提升,暗示默认初始化已实现近乎最优的性能。标有“–”的条目表示相对于默认 α 0 α_0 α0 无性能提升。
表 14 调优 α 0 α0 α0 对 DyT 模型的影响。将 α 0 α0 α0 从默认值( α 0 = 0.5 α_0=0.5 α0=0.5)调优,仅为部分 DyT 模型带来小幅性能提升,暗示默认初始化已实现近乎最优的性能。标有“–”的条目表示相对于默认 α 0 α_0 α0 无性能提升。
附录 C 用 DyT 替换批量归一化
我们在经典的 ConvNet(如 ResNet-50(He 等,2016)和 VGG19(Simonyan 和 Zisserman,2014))中研究了用 DyT 替换 BN 的可行性。两种模型均在 ImageNet-1K(Deng 等,2009)数据集上训练,并使用 torchvision 提供的训练流程。DyT 模型使用与其 BN 对应模型相同的超参数进行训练。
结果汇总在表 15 中。用 DyT 替换 BN 导致两个模型的分类准确率显著下降。这些发现表明,DyT 在这些经典 ConvNet 中尚无法完全替代 BN。我们推测,这可能与 BN 在这些 ConvNet 中的出现频率更高有关——在每个权重层后都会出现一次 BN,而在 Transformer 中,LN 仅在若干权重层后出现一次。
 表 15 ImageNet-1K 上使用 BN 和 DyT 的分类准确率。在 ResNet-50 和 VGG19 中,用 DyT 替换 BN 会导致性能下降,表明 DyT 无法在这些架构中完全替代 BN。
表 15 ImageNet-1K 上使用 BN 和 DyT 的分类准确率。在 ResNet-50 和 VGG19 中,用 DyT 替换 BN 会导致性能下降,表明 DyT 无法在这些架构中完全替代 BN。
相关文章:
论文笔记(八十二)Transformers without Normalization
Transformers without Normalization 文章概括Abstract1 引言2 背景:归一化层3 归一化层做什么?4 动态 Tanh (Dynamic Tanh (DyT))5 实验6 分析6.1 DyT \text{DyT} DyT 的效率6.2 tanh \text{tanh} tanh 和 α α α 的消融实验…...

Mysql之数据库基础
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习Mysql的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...
)
shell(5)
位置参数变量 1.介绍 当我们执行一个shell脚本时,如果希望获取到命令行的参数信息,就可以使用到位置参数变量. 比如:./myshell.sh100 200,这就是一个执行shell的命令行,可以在myshell脚本中获取到参数信息. 2.基本语法 $n(功能描述:n为数字,$0代表命令…...

VARIAN安捷伦真空泵维修清洁保养操作SOP换油操作流程内部转子图文并茂内部培训手侧
VARIAN安捷伦真空泵维修清洁保养操作SOP换油操作流程内部转子图文并茂内部培训手侧...

动画震动效果
项目场景: 提示:这里简述项目相关背景: 在有的相关目中特别是在C端一般都要求做的炫酷一些,这就需要一些简易的动画效果,这里就弄了一个简易的震动的效果如下视频所示 让图标一大一小的震动视频 分析: 提…...

DB-GPT V0.7.1 版本更新:支持多模态模型、支持 Qwen3 系列,GLM4 系列模型 、支持Oracle数据库等
V0.7.1版本主要新增、增强了以下核心特性 🍀DB-GPT支持多模态模型。 🍀DB-GPT支持 Qwen3 系列,GLM4 系列模型。 🍀 MCP支持 SSE 权限认证和 SSL/TLS 安全通信。 🍀 支持Oracle数据库。 🍀 支持 Infini…...
 对象 (P2136R3))
C++23 std::invoke_r:调用可调用 (Callable) 对象 (P2136R3)
文章目录 引言背景知识回顾可调用对象C17的std::invoke std::invoke_r的诞生提案背景std::invoke_r的定义参数和返回值异常说明 std::invoke_r的使用场景指定返回类型丢弃返回值 std::invoke_r与std::invoke的对比功能差异使用场景差异 结论 引言 在C的发展历程中,…...

pymysql
参数(会导致SQL注入) import pymysql# 创建数据库连接 conn pymysql.connect(user "root",password "root",host "127.0.0.1",port 3306,database "test" )# 创建游标对象 cur conn.cursor(cursorpymysql.…...

基于Spring Boot + Vue 项目中引入deepseek方法
准备工作 在开始调用 DeepSeek API 之前,你需要完成以下准备工作: 1.访问 DeepSeek 官网,注册一个账号。 2.获取 API 密钥:登录 DeepSeek 平台,进入 API 管理 页面。创建一个新的 API 密钥(API Key&#x…...

Spring Boot集成Kafka并使用多个死信队列的完整示例
以下是Spring Boot集成Kafka并使用多个死信队列的完整示例,包含代码和配置说明。 1. 添加依赖 (pom.xml) <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId&…...

全面了解CSS语法 ! ! !
CSS(层叠样式表)是网页设计的灵魂之一,它赋予了网页活力与美感。无论是为一个简单的个人博客增添色彩,还是为复杂的企业网站设计布局,CSS都是不可或缺的工具。那么,CSS语法到底是什么样的呢?它背…...

Springboot使用ThreadLocal提供线程局部变量,传递登录用户名
文章目录 概述使用创建ThreadLocalUtil工具类在登录拦截器中使用ThreadLocal存储登录用户名在/userInfo接口中获取登录用户名 注意事项参考视频 概述 使用 创建ThreadLocalUtil工具类 utils/ThreadLocalUtil.java package org.example.utils;/*** ThreadLocal 工具类*/ Supp…...

排序算法——选择排序
一、介绍 「排序算法sortingalgorithm」用于对一组数据按照特定顺序进行排列。排序算法有着广泛的应用,因为有序数据通常能够被更有效地查找、分析和处理。 如图所示,排序算法中的数据类型可以是整数、浮点数、字符或字符串等。排序的判断规则可根据需求…...

AlphaFold蛋白质结构数据库介绍
AlphaFold Protein Structure Database (AlphaFold DB) 是 DeepMind + EMBL-EBI 合作开发的公开蛋白质结构预测数据库,是利用 AlphaFold2/AlphaFold3 AI模型 预测的全基因组级蛋白质三维结构库。 网址: https://alphafold.ebi.ac.uk 项目内容主办单位DeepMind + EMBL-EBI上线…...

Roboflow标注数据集
使用Roboflow进行标注 关键点标注目标检测标注图像分类标注分割标注 Roboflow是一款易于使用的在线 图像标注。 关键点标注 每个图像的标注包括: 1、边界框坐标(每个物品应该有一个边界框,用*[x1,y1,x2,y2]*格式即左上角和右下角点描述&…...

大厂经验:第三方包Paramunittest参数化 VS Unittest内置参数化文本管理器subtest
大厂经验:第三方包Paramunittest参数化 VS Unittest内置参数化文本管理器subtest 代码解析 Paramunittest 核心逻辑 paramunittest.parametrized((Testerr, test, Invalid Login or Password., test_login_admin is passed),(Sam, test, Invalid Login or Passwo…...

[特殊字符]适合五四青年节的SVG模版[特殊字符]
宝藏模版 往期推荐(点击阅读): 趣味效果|高大上|可爱风|年终总结I|年终总结II|循环特效|情人节I|情人节II|情人节IIII|妇女节I&…...

当插入排序遇上“凌波微步“——希尔排序的奇幻漂流
文章目录 一、排序江湖的隐藏高手二、分而治之的魔法1. 核心思想拆解2. 动态演示(脑补版) 三、C语言实现大揭秘代码要点解析: 四、性能分析与实战技巧1. 时间复杂度迷思2. 实测性能对比 五、为什么说它永不过时?六、进阶思考题 一…...

【Hot 100】 148. 排序链表
目录 引言十大排序算法1. 冒泡排序 (Bubble Sort)2. 选择排序 (Selection Sort)3. 插入排序 (Insertion Sort)4. 希尔排序 (Shell Sort)简单代码说明关键特点 5. 归并排序 (Merge Sort)6. 快速排序 (Quick Sort)7. 堆排序 (Heap Sort)8. 计数排序 (Counting Sort)9. 桶排序 (Bu…...
:线性判别式与逻辑回归)
大连理工大学选修课——机器学习笔记(9):线性判别式与逻辑回归
线性判别式与逻辑回归 概述 判别式方法 产生式模型需要计算输入、输出的联合概率 需要知道样本的概率分布,定义似然密度的隐式参数也称为基于似然的分类 判别式模型直接构造判别式 g i ( x ∣ θ i ) g_i(x|\theta_i) gi(x∣θi),显式定义判别式…...

[特殊字符] 开发工作高内存占用场景下,Windows 内存压缩机制是否应该启用?实测分析与优化建议
在日常开发中,我们往往需要同时运行多个高占用内存的工具,例如: IntelliJ IDEA VMware 虚拟机 多个 Java 后端程序 这些应用程序非常“吃内存”,轻松就能把 16GB、甚至 24GB 的物理内存用满。那么,Windows 的“内存…...

相机的基础架构
📷 相机相关基础架构学习路径 一、了解手机相机系统架构 Android Camera HAL(如果你是做 Android 平台) 学习 Camera HAL3 架构(基于 camera_device_t, camera3_device_ops 接口) 熟悉 CameraService → CameraProvid…...

C# 类成员的访问:内部与外部
在 C# 编程中,了解如何从类的内部和外部访问成员是非常重要的。本文将详细介绍这两种访问方式,并通过示例代码展示其具体应用。 从类的内部访问成员 类的成员可以在类的内部自由地互相访问,即使这些成员被声明为private。在类的方法中&…...

DAPO:对GRPO的几点改进
DAPO:对GRPO的几点改进 TL; DR:对 GRPO 的几处细节进行了优化,包括去除 KL 约束、解耦 ppo-clip 的上下界,上界设置更高以鼓励探索、超长回答过滤、token level 损失计算等。相比于原始 GRPO,在 AIME24 上提升非常显著…...

从零构建 MCP Server 与 Client:打造你的第一个 AI 工具集成应用
目录 🚀 从零构建 MCP Server 与 Client:打造你的第一个 AI 工具集成应用 🧱 1. 准备工作 🛠️ 2. 构建 MCP Server(服务端) 2.1 初始化服务器 🧩 3. 添加自定义工具(Tools&…...

2025.4.27 Vue.js 基础学习笔记
一、Vue.js 简介 Vue.js(简称 Vue)是一个用于构建用户界面的渐进式 JavaScript 框架。它具有以下特点: 轻量级 :核心库体积小,性能优秀,不占用过多资源,加载速度快,适合各种规模的应…...

基于用户场景的汽车行驶工况构建:数据驱动下的能耗优化革命
行业现状:标准工况与用户场景的割裂 全球汽车行业普遍采用WLTC工况进行能耗测试,但其与真实道路场景差异显著。据研究,WLTC工况下车辆能耗数据比实际道路低10%-30%,导致用户对续航虚标投诉激增(数据来源:东…...

IoTDB集群部署中的网络、存储与负载配置优化
一、引言 在现代计算机系统和应用程序中,网络I/O性能是决定整体系统表现的关键因素之一。特别是在IoTDB集群环境中,网络I/O的重要性尤为突出,特别是在处理大量测点数据、客户端请求以及集群内部通信时。本文将介绍IoTDB数据库集群部署过程中…...
)
Unity URPShader:实现和PS一样的色相/饱和度调整参数效果(修复)
目录 前言: 一、问题原因 二、算法修复 三、全代码 前言: 在之前的文章我已经实现了标题所述的内容功能:Unity URPShader:实现和PS一样的色相/饱和度调整参数效果-CSDN博客 但在偶然测试的时候,发现当采样的图片为…...

告别手动时代!物联网软件开发让万物自动互联
清晨,智能窗帘随着阳光自动拉开;运动时,手表精准记录着健康数据;回到家,室温早已调节至最舒适状态...这些场景的实现,都离不开物联网软件开发的技术支撑。在智能家居软件开发、智能穿戴软件开发、医疗器械软…...

Vue ui初始化项目并使用iview写一个菜单导航
winR 输入命令 vue ui浏览器会自动打开http://localhost:8000/ 找到创建 image.png 选择一个目录创建vue项目 image.png 点击再此创建新项目 image.png 我一般都是再已经有git仓库的目录进行项目创建,所以这个勾去掉 点击下一步 image.png 这里可以选择默认&#x…...

函数调用及Chain——SQL+GLM
Langchainchain数据库操作_langchain 操作数据库-CSDN博客 本文和基于上述链接 进一步。 初始化数据库&模型 # temperature0,此处仅需要SQL语句,不需要多样化返回。 from langchain.chains.sql_database.query import create_sql_query_chain from …...

数据科学与计算
Seaborn的介绍 Seaborn 是一个建立在 Matplotlib 基础之上的 Python 数据可视化库,专注于绘制各种统计图形,以便更轻松地呈现和理解数据。 Seaborn 的设计目标是简化统计数据可视化的过程,提供高级接口和美观的默认主题,使得用户…...

【AI提示词】二八法则专家
提示说明 精通二八法则(帕累托法则)的广泛应用,擅长将其应用于商业、管理、个人发展等领域,深入理解其在不同场景中的具体表现和实际意义。 提示词 # Role: 二八法则专家## Profile - language: 中文 - description: 精通二八法…...

PostgreSQL Patroni集群组件作用介绍:Patroni、etcd、HAProxy、Keepalived、Watchdog
1. Watchdog 简介 1.1 核心作用 • 主节点故障检测 Watchdog 会定时检测数据库主节点(或 Pgpool 主节点)的运行状态。 一旦主节点宕机,它会发起故障切换请求。 • 协调主备切换 多个 Pgpool 节点时,Watchdog 保证只有一个 Pg…...
:通用图像分割的范式革命)
【计算机视觉】图像分割:Segment Anything (SAM):通用图像分割的范式革命
Segment Anything:通用图像分割的范式革命 技术突破与架构创新核心设计理念关键技术组件 环境配置与快速开始硬件要求安装步骤基础使用示例 深度功能解析1. 多模态提示融合2. 全图分割生成3. 高分辨率处理 模型微调与定制1. 自定义数据集准备2. 微调训练配置 常见问…...
改进系列(10):基于SwinTransformer+CBAM+多尺度特征融合+FocalLoss改进:自动驾驶地面路况识别
目录 1.代码介绍 1. 主训练脚本train.py 2. 工具函数与模型定义utils.py 3. GUI界面应用infer_QT.py 2.自动驾驶地面路况识别 3.训练过程 4.推理 5.下载 代码已经封装好,对小白友好。 想要更换数据集,参考readme文件摆放好数据集即可,…...

大型连锁酒店集团数据湖应用示例
目录 一、应用前面临的严峻背景 二、数据湖的精细化构建过程 (一)全域数据整合规划 (二)高效的数据摄取与存储架构搭建 (三)完善的元数据管理体系建设 (四)强大的数据分析平台…...
)
element.scrollIntoView(options)
handleNextClick 函数详解 功能描述 该函数实现在一个表格中“跳转到下一行”的功能,并将目标行滚动至视图顶部。通常用于导航或高亮显示当前选中的数据行。 const handleNextClick () > {// 如果当前已经是最后一行,则不执行后续操作if (current…...

python查看指定的进程是否存在
import os class Paly_Install(object):"""项目根目录"""def get_path(self):self.basedir os.path.dirname(os.path.abspath(__file__))"""安装失败的txt文件"""def test_app(self):self.app["com.faceboo…...

HAproxy+keepalived+tomcat部署高可用负载均衡实践
目录 一、前言 二、服务器规划 三、部署 1、jdk18安装 2、tomcat安装 3、haproxy安装 4、keepalived安装 三、测试 1、服务器停机测试 2、停止haproxy服务测试 总结 一、前言 HAProxy是一个使用C语言编写的自由及开放源代码软件,其提供高可用性、…...

C++负载均衡远程调用学习之自定义内存池管理
目录 1.内存管理_io_buf的结构分析 2.Lars_内存管理_io_buf内存块的实现 3.buf总结 4.buf_pool连接池的单例模式设计和基本属性 5.buf_pool的初始化构造内存池 6.buf_pool的申请内存和重置内存实现 7.课前回顾 1.内存管理_io_buf的结构分析 ## 3) Lars系统总体架构 …...

mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz的下载安装和使用
资源获取链接: mysql-5.7.24-linux-glibc2.12-x86-64.tar.gz和使用说明资源-CSDN文库 详细作用 数据库服务器的核心文件: 这是一个压缩包,解压后包含 MySQL 数据库服务器的可执行文件、库文件、配置文件模板等。 它用于在 Linux 系统上安装…...

Kafka Producer的acks参数对消息可靠性有何影响?
1. acks0 可靠性最低生产者发送消息后不等待任何Broker确认可能丢失消息(Broker处理失败/网络丢失时无法感知)吞吐量最高,适用于允许数据丢失的场景(如日志收集) 2. acks1 (默认值) Leader副本确认模式生产者等待Le…...

Linux-04-用户管理命令
一、useradd添加新用户: 基本语法: useradd 用户名:添加新用户 useradd -g 组名 用户:添加新用户到某个组二、passwd设置用户密码: 基本语法: passwd 用户名:设置用户名密码 三、id查看用户是否存在: 基本语法: id 用户名 四、su切换用户: 基本语法: su 用户名称:切换用…...

node爬虫包 pup-crawler,超简单易用
PUP Crawler 这是一个基于puppeteer的简单的爬虫,可以爬取动态、静态加载的网站。 常用于【列表-详情-内容】系列的网站,比如电影视频等网站。 github地址 Usage npm install pup-crawler简单用法: import { PupCrawler } from pup-craw…...

艺术与科技的双向奔赴——高一鑫荣获加州联合表彰
2025年4月20日,在由M.A.D公司协办的“智艺相融,共赴价值巅峰”(Academic and Artistic Fusion Tribute to the Summit of Value)主题发布会上,音乐教育与科技融合领域的代表人物高一鑫,因其在数字音乐教育与中美文化交流方面的杰出贡献,荣获了圣盖博市议员Jorge Herrera和尔湾市…...

React-Native Android 多行被截断
1. 问题描述: 如图所示: 2. 问题解决灵感: 使用相同的react-native代码,运行在两个APP(demo 和 project)上。demo 展示正常,project 展示不正常。 对两个页面截图,对比如下。 得出…...

Canvas基础篇:图形绘制
Canvas基础篇:图形绘制 图形绘制moveTo()lineTo()lineTo绘制一条直线代码示例效果预览 lineTo绘制平行线代码示例效果预览 lineTo绘制矩形代码示例效果预览 arc()arc绘制一个圆代码实现效果预览 arc绘制一段弧代码实现效果预览 arcTo()rect()曲线 结语 图形绘制 在…...

自定义实现elementui的锚点
背景 前不久有个需求,上半部分是el-step步骤条,下半部分是一些文字说明,需要实现点击步骤条中某个步骤自定义定位到对应部分的文字说明,同时滚动内容区域的时候还要自动选中对应区域的步骤。element-ui-plus的有锚点这个组件&…...