Linux《进程概念(中)》
在之前的Linux《进程概念(上)》当中我们已经了解了进程的基本概念以及如何去创建对应的子进程,那么接下来在本篇当中我们就继续来进程的学习,在本篇当中我们要学习到进程的状态、进程的优先级、进程切换、Linux真实的调度算法——O(1)调度算法。一起加油吧!!!

1.进程状态
我们知道在不同的情况下人是处于不同的状态下的,就例如在上课、在打球、出去玩等。和人的状态类似进程其实也有不同的状态,并且描述进程的状态就是使用一个整数来实现的,这个整数是存储在task_struct内的。
在此在详细了解Linux当中进程的具体的状态之前我们先要来了解操作系统抽象的进程状态有哪些
以下就是进程各个状态的转换图
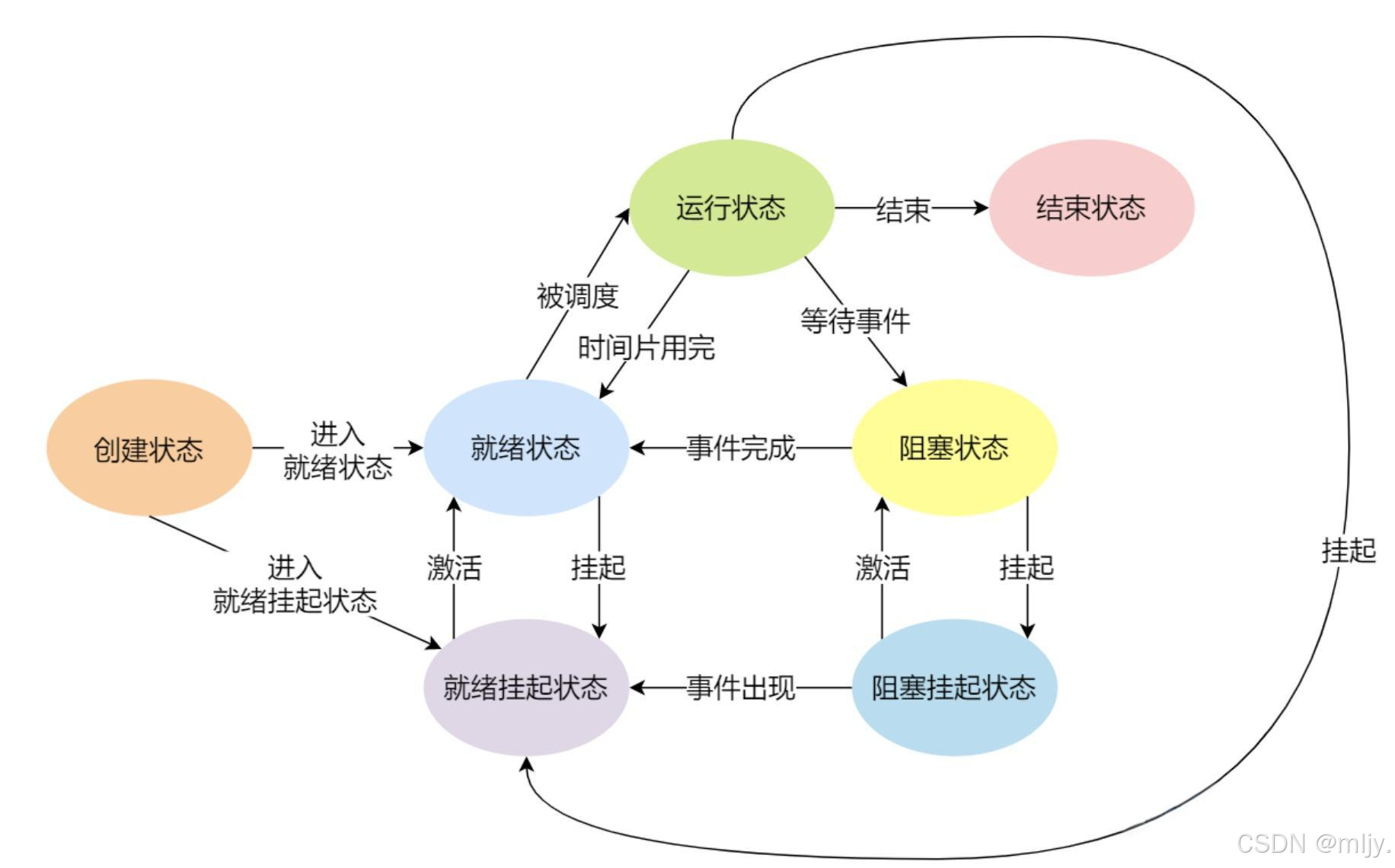
以上大致的描述出了各个进程状态之间的转换图,不过以上图示当中的进程转换其实不是我们要重点学习的,接下来我们要了解以上所示的进程运行状态、阻塞状态、挂起状态具体是什么样的。
1.1 了解各个状态
由于接下来我们会详细的了解Linux当中进程的调度,因此关于进程如何运行接下来就来大致的了解。
由于CPU的资源是有限的,而进程在一些情况下又是多个的,那么此时就会有一个调度队列来管理进程。要让一个CPU来选择一个进程来运行其实选择的不是进程的代码和数据去运行;而是选择特定进程的PCB去运行,这是因为在通过PCB内的指针就可以找到特定进程的代码和数据。
当多个进程同时存在时就会如下所示
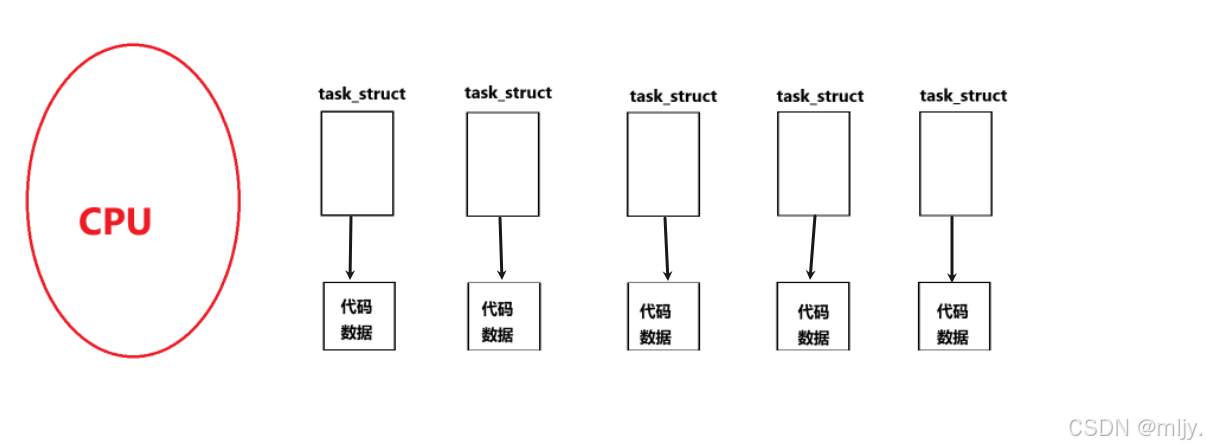
其实在一个CPU当中会有对应的一个调度队列,而调度队列其实就是将各个进程连接成一个队列。
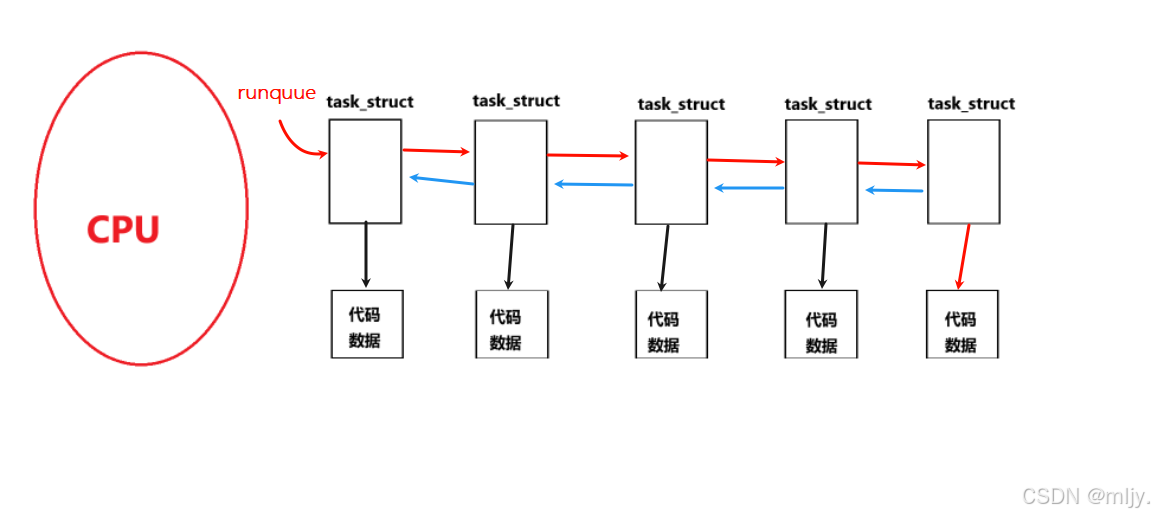
在操作系统学科当中就存在一个FIFO算法就是按照先进先出的顺序来将调度队列内的进程依次进行执行

在此就将只要在调度队列当中的进程都称当前的进程状态为运行状态,而以进程状态转换图当中的运行状态和就绪状态其实是对运行状态的再一细化,在此我们现在不需要了解的那么深,可以将这两种状态统称为运行状态。
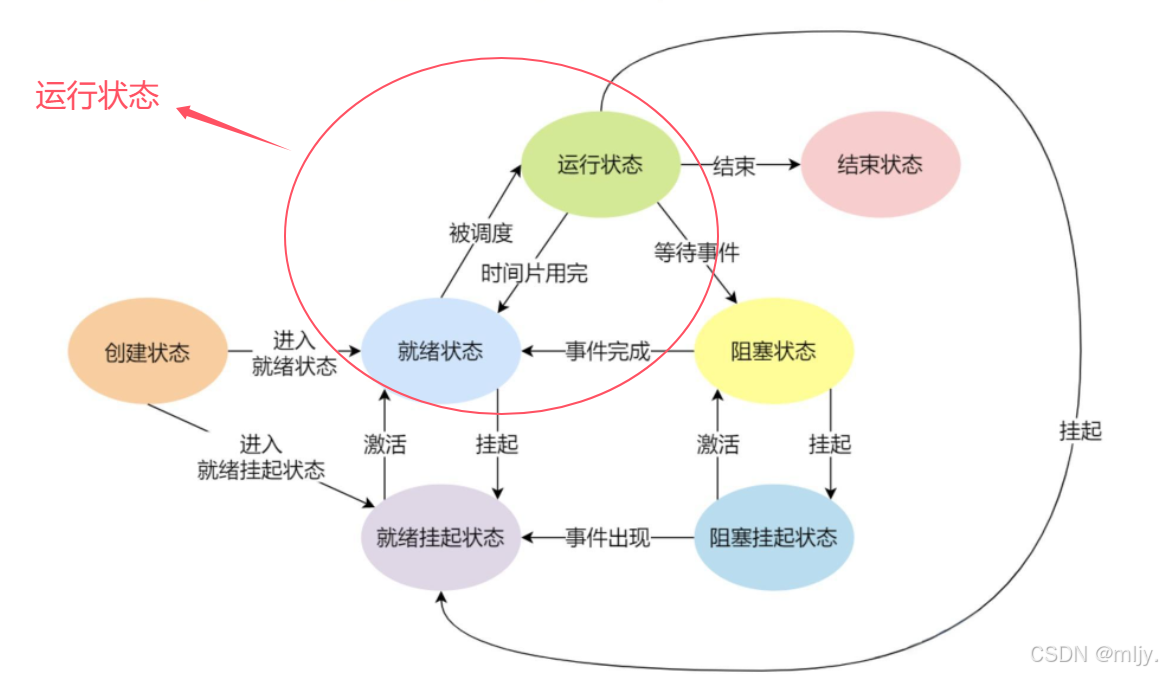
那么在了解了什么是进程运行状态,那么接下来就来了解进程的另外一个状态——阻塞状态。
在了解进行阻塞状态之前我们先来回想一下之前的C/C++的学习当中有什么情况进程会出现阻塞
其实很容易想到的就是之前在C使用scanf和C++当中使用cin的时候,进程就会停在需要用户输入的位置,在此只有用户输入之后才会接着运行下去。但其实在使用scanf的时候其实进程不是等待用户输入而是等待键盘硬件就绪。
因此阻塞的意义就是等待某种设备或者资源就绪
在此在了解进程的阻塞状态是如何产生的那么在此之前就要先来了解在计算机当中是如何对硬件资源进行管理的。在计算机当中硬件是有硬盘、显示器、键盘、网卡、摄像头、话筒等,在此操作系统要对这些硬件进行管理其实和进程一样也是通过先描述再组织完成的。
因此和进程一样硬件也会有对应的PCB内核的结构体来存储对应硬件的状态信息,在结构体内部就如下所示:

在此将这些PCB结构体进行连接就形成了设备队列
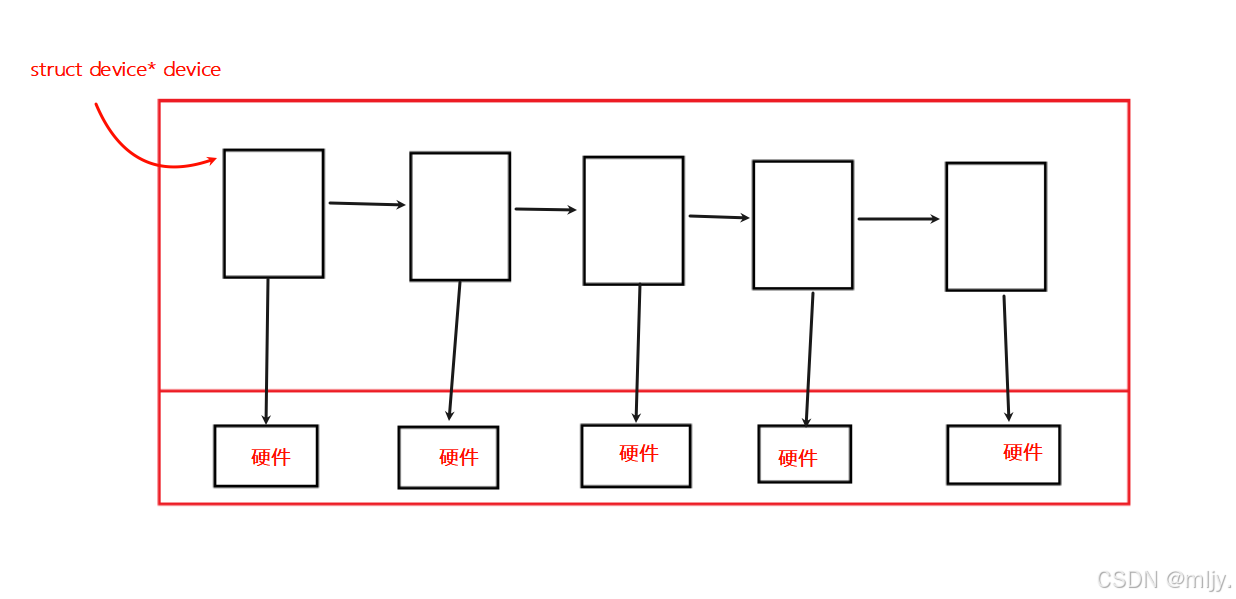
此时你可能就会有疑问了,不同的设备内进行访问的操作方式或者是进行数据的读取都是不一样的,那么是如何使用一个相同类型的结构体来进行管理的。
其实解决这种情况是很简单的,这需要使结构体内的指针指向不同的数据就可以实现个性化的需求。
以上我们就了解了操作系统是如何对硬件进行管理的,其实简单来时对硬件的管理就与对进程的管理类似,本质都是先描述再组织。
那么了解了以上的知识之后接下来就要思考进程阻塞具体的表现形式究竟是什么样的呢?进行阻塞和之前提到的进程运行之间又是怎么进行转换的的呢?
其实当多个进程PCB同时运行时会先后插入到调度队列当中,当轮到对应的进程要被CPU处理时,如果当前的进程还未获取到对应硬件的相应的资源,此时进程PCB就会从调度队列当中转换到阻塞队列当中。
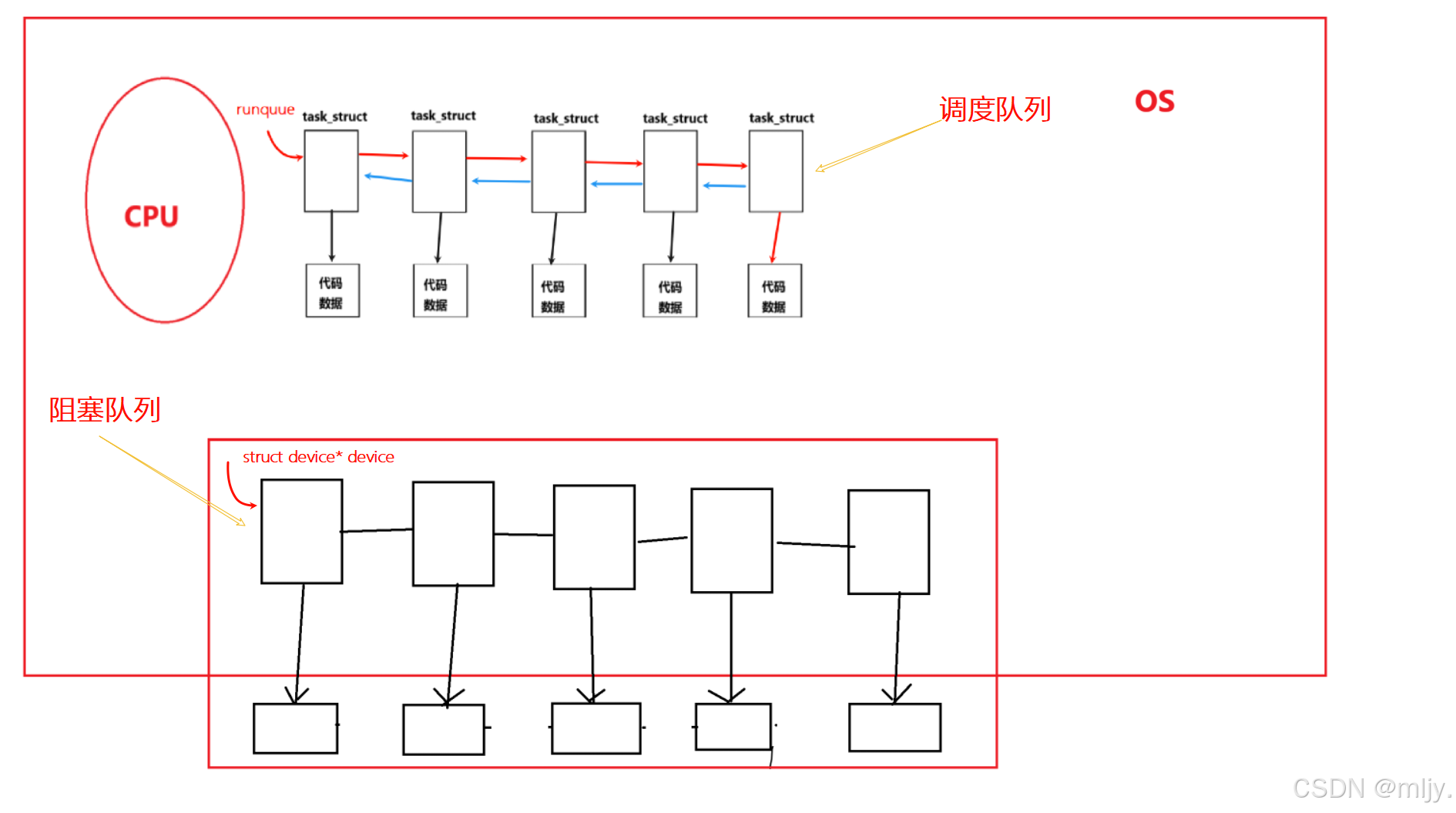
当前运行的进程此时还无法运行就会按照以下的形式将进程从调度队列当中连接到对应硬件的阻塞队列当中。
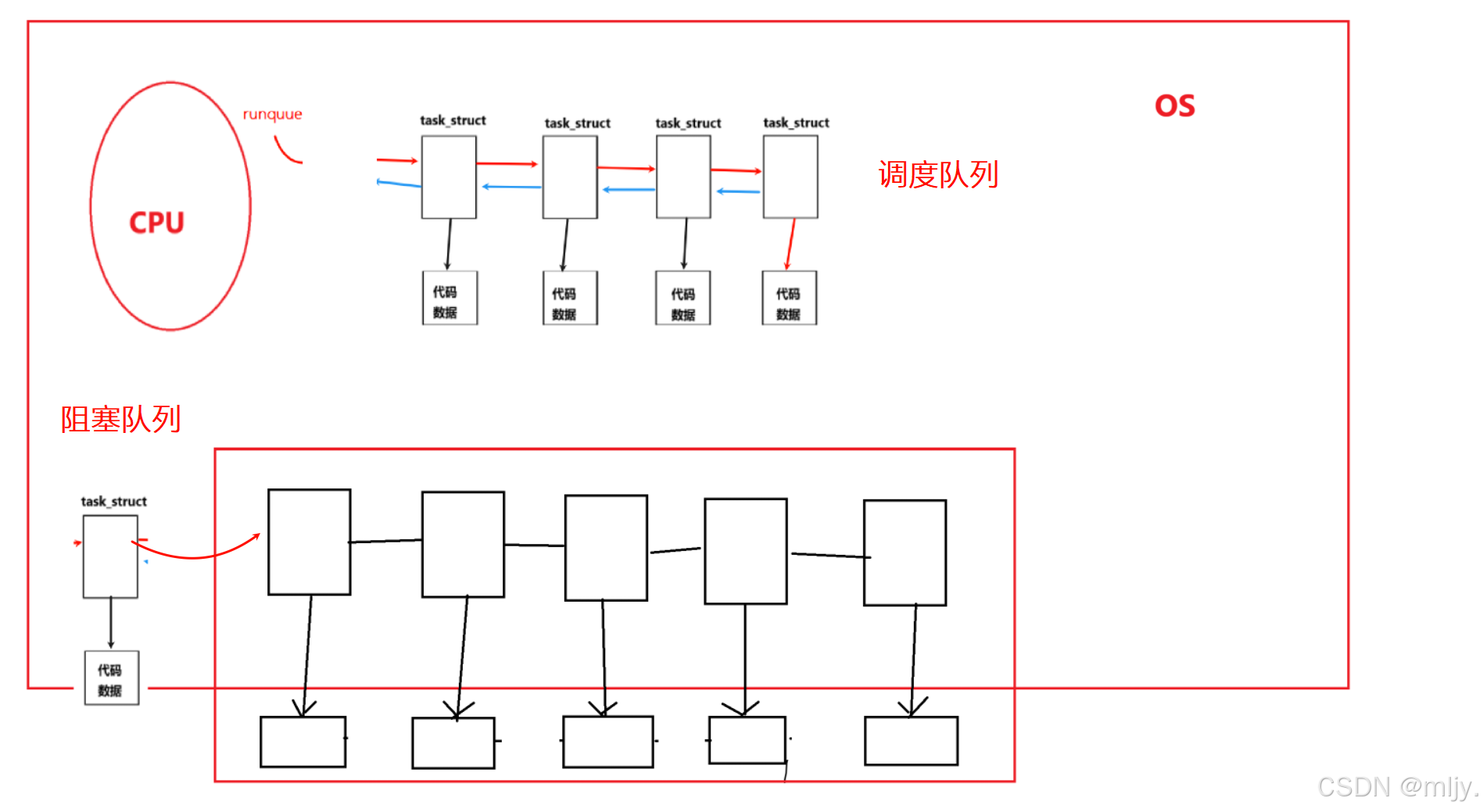
当在阻塞队列当中的进程等待到了相应的等待的设备或者资源就绪,由于操作系统是硬件的管理者因此一旦进程对应硬件就绪了,那么此时操作系统就会将此时该进程的PCB从设备的等待队列当中重新链路到到调度队列当中,并且将该进程的状态从阻塞变为运行。
通过了解进程的运行状态和进程的阻塞状态就可以了解到进程状态的变化表现形式之一就是在不同的队列当中流动,其实本质就是数据结构的增删查改。
其实以上进程在调度队列和等待队列当中进行转换的情况就和我们在投递简历的时候一样,如果当HR一开始觉得你的虽然不是很符合他们的要求但是又觉得你的能力还可以,此时可能就会将你的简历放到待定区内,之后再看了其他的人时候突然觉得你还是挺符合公司的要求的,那么此时就会将你的简历从待定区重新捞出来。在此其实进程的PCB被链路到等待队列的过程就可以类别HR将你的简历放到待定区,进程的PCB从阻塞队列重新链路到调度队列就可以类比HR将你的简历从待定区当中捞出来。
以上我们就了解了进程阻塞状态的概念,那么接下来继续来了解进程的另外一种状态——挂起状态
通过以上的学习我们知道当进程被链路到等待队列的时候对应的硬件没有就绪时对应的进程是一定不会被调度的,那么在这种情况下如果当前的进程内存资源严重不足的时候,那么此时操作系统会怎么做呢?
对应出现以上的情况时,由于有一些数据不会立即被访问,但是这些代码和数据对应的进程如果是在等待队列当中时,此时操作系统就会使用磁盘当中的swap分区。此时就会将阻塞状态的进程的代码和数据直接置换到磁盘的swap分区上,在操作系统当中只保存这些进程的PCB,当这些进程重新被调度的时候再从swap分区当中将代码和数据重新连接到对应进程的PCB上。以上通过这样的方式就可以在内存资源严重不足的时候,释放当前内存的压力。
注:swap分区是磁盘的一个存储块,大小一般和内存大小一直
在此就将等待队列当中数据或者代码被置换到swap只剩下PCB的进程状态称为阻塞挂起状态。
除了以上的情况之外如果已经将等待队列当中的进程当中的代码和数据置换到磁盘的swap分区之后内存的资源还是严重的不足,那么此时操作系统就会将调度队列当中末端的进程的代码和数据置换到磁盘的swap分区当中。将这种在调度队列当中只省下PCB的进程状态称为运行挂起状态。
以上无论是阻塞挂起还是运行挂起其实挂起本质都是将对应的进程的代码和数据唤入到磁盘的swap分区当中,之后从挂起状态恢复回原来的状态就是将进程的代码和数据从swap分区当中唤出。
1.2 理解内核链表
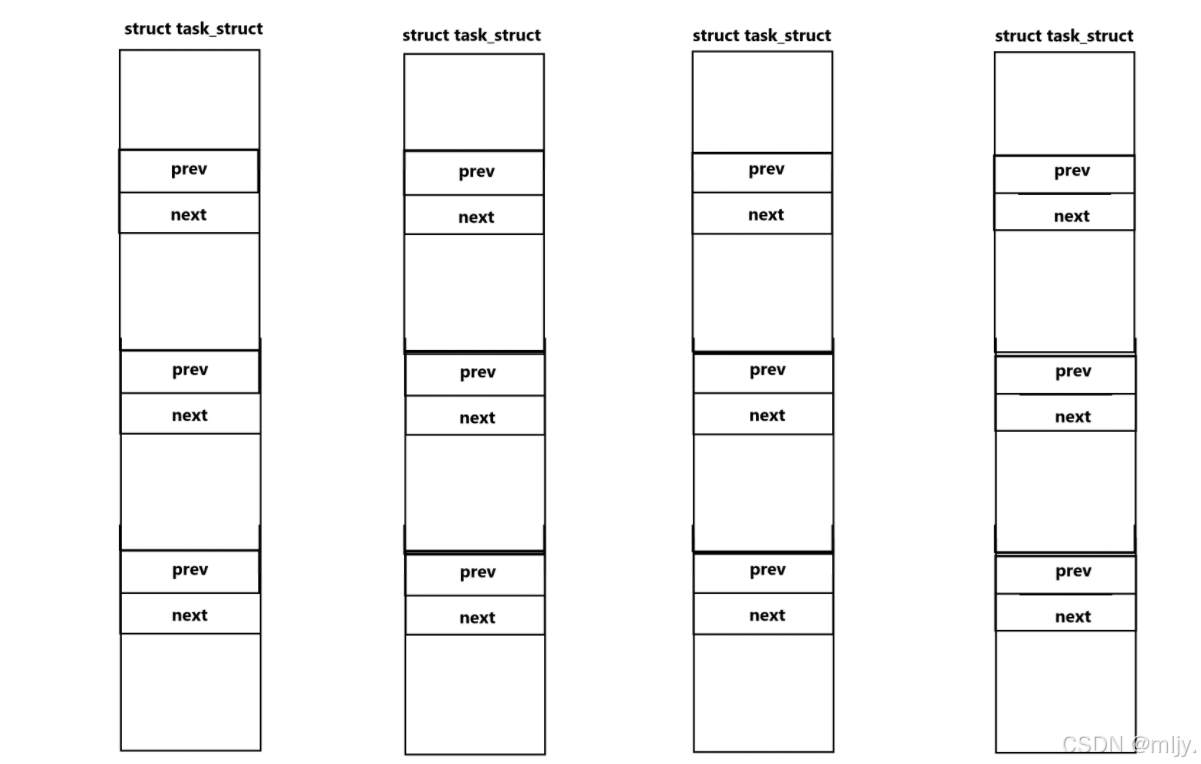
其实进程的PCB之间是通过双链表连接起来的,但是此时就有问题了,以上提到的进程的PCB是存放到调度队列当中的,这时不会会出现同一个节点同时存在在两个数据结构当中了吗,这不就和之前我们学习一个节点只能存在一个数据结构相违背了吗?
要解答这个问题就需要我们来查看Linux的内核源代码,查看之后对比我们实现的数据结构看有什么区别。
在Linux当中就是将存储当前节点前后节点的指针单独存放在list_head的结构体当中的,再将该结构体存放到节点数据的节点当中。


那么Linux内核当中将各个节点设计未为这样有什么好处呢?
我们之前实现数据结构的节点时无论是链表还是队列等,都是将各个节点的前后节点指针同时和节点的数据存放到同一个结构体当中,这样就会使每个节点只能属于一种数据结构。

而在Linux内核当中使用节点前后指针与节点数据分离的方式就可以让各个节点通过专门的结构体连接起来,此时就能实现一个节点属于多个数据结构。
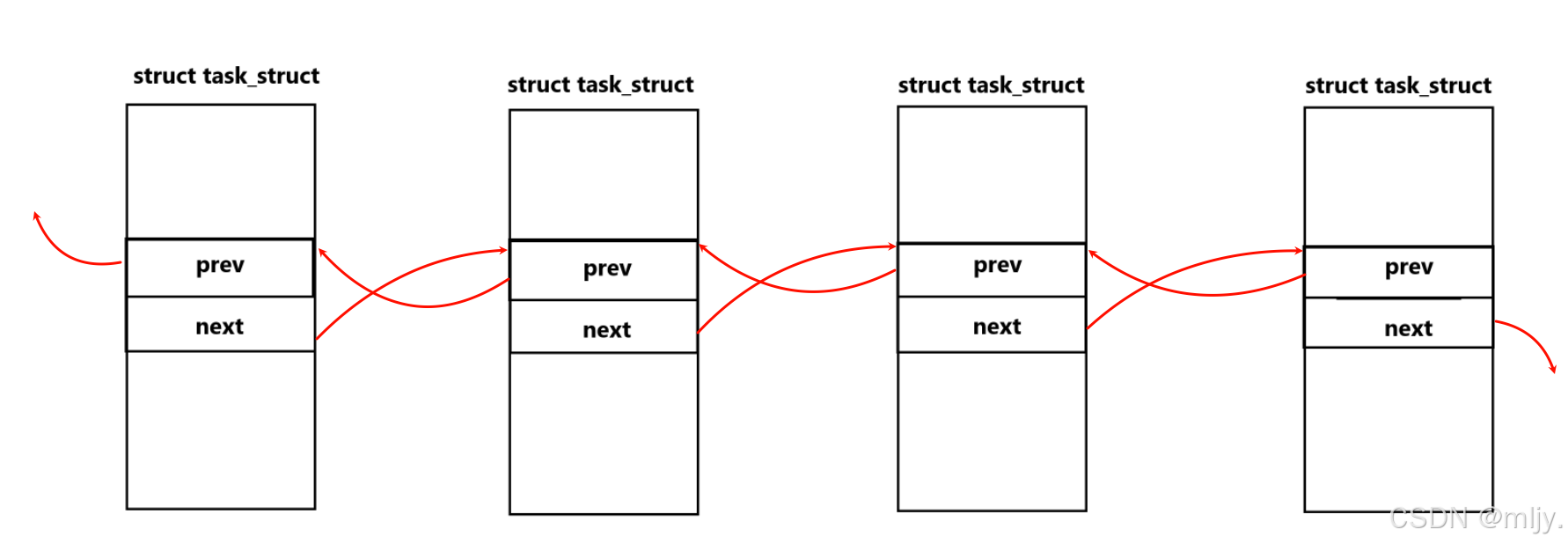
那么此时也就可以解释为什么一个进程的PCB能属于多个数据结构,其实就是按照以上的形式实现的。这就使得Linux当中的许多的数据结构是网状的。
因此操作系统当中的一个进程的PCB在操作系统当中也是只有一份的,当从调用队列从调整到阻塞队列其实是将其内部的相应的结构体的指针指向改变。
接下来我们还要思考一个问题就是使用以上这种结构时如果在得到一个节点的指针时,要怎么样得到对应的节点内的数据呢?
和我们之前实现的链表不同,我们实现的链表对应的结构体的指针就是其节点的起始地址,接下来就可以直接对节点的地址进行加减得到对应的数据,而在以上的结构当中得到的是节点内存储其前后指针的结构体地址;这就会使得得到的地址不是节点的起始地址,因此要解决该问题就要将得到的地址计算出对应节点的起始地址。
我们知道在结构体当中成员变量的地址是依次增长的,当前我们得到的是结构体内一个成员的地址,那么此时就可以先来计算该成员与结构体起始地址的偏移量。
假设在地址为0出就存在对应的结构体,强转为结构体指针之后再得到其内部对应指针结构体的地址,计算形式如下
&((struct tast_struct*)0->list_head)以上就得到了对应节点起始地址到list_head成员的偏移量,接下来将之前得到的指针减去偏移量就可以得到结构体的起始地址,之后就可以进行该结构体内成员的访问了。
(struct task_struct)(list_head-&((struct tast_struct*)0->list_head))1.3 Linux进程状态
以上我们了解的都是操作系统理论的进程状态,那么接下来在了解了基本的概念之后接下来就来学习Linux当中具体的进程状态有哪些
• 为了弄明⽩正在运⾏的进程是什么意思,我们需要知道进程的不同状态。⼀个进程可以有⼏个状
态(在Linux内核⾥,进程有时候也叫做任务)。
下⾯的状态在kernel源代码⾥定义:
/*
*The task state array is a strange "bitmap" of
*reasons to sleep. Thus "running" is zero, and
*you can test for combinations of others with
*simple bit tests.
*/
static const char *const task_state_array[] = {
"R (running)", /*0 */
"S (sleeping)", /*1 */
"D (disk sleep)", /*2 */
"T (stopped)", /*4 */
"t (tracing stop)", /*8 */
"X (dead)", /*16 */
"Z (zombie)", /*32 */
};从以上的代码可以看出在Linux当中进程的状态具体是有7种的,那么这些状态对应的进程具体的表示形式又是怎么样的呢?这就需要接下来我们来了解看看
S状态和R状态
在此我们创建一个test.c的文件之后在其内部写入以下的代码
#include<stdio.h> int main()
{ while(1) { printf("hello\n"); } return 0;
}
接下来再使用gcc编译生成对应的可执行文件mytest,接下来运行该可执行程序,再开一个Xshell的窗口使用ps命令监视我们运行的mytest程序
之后运行mytest
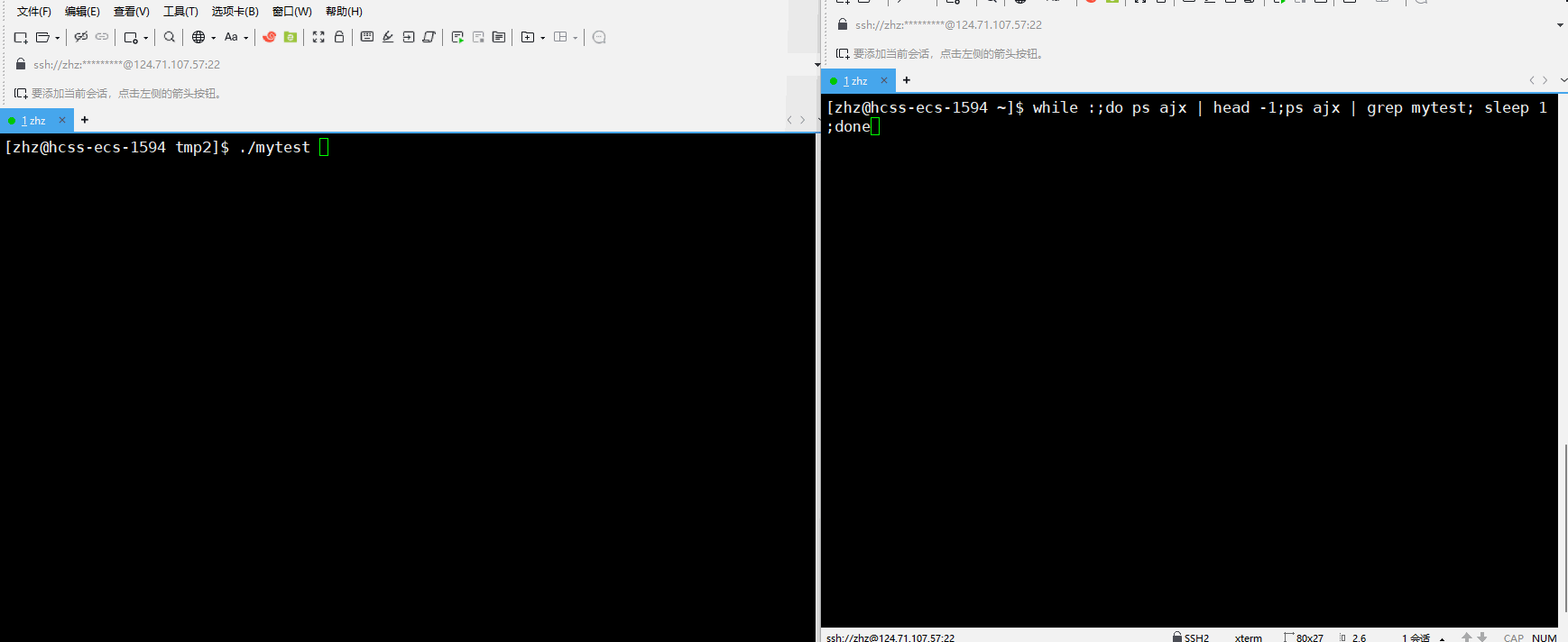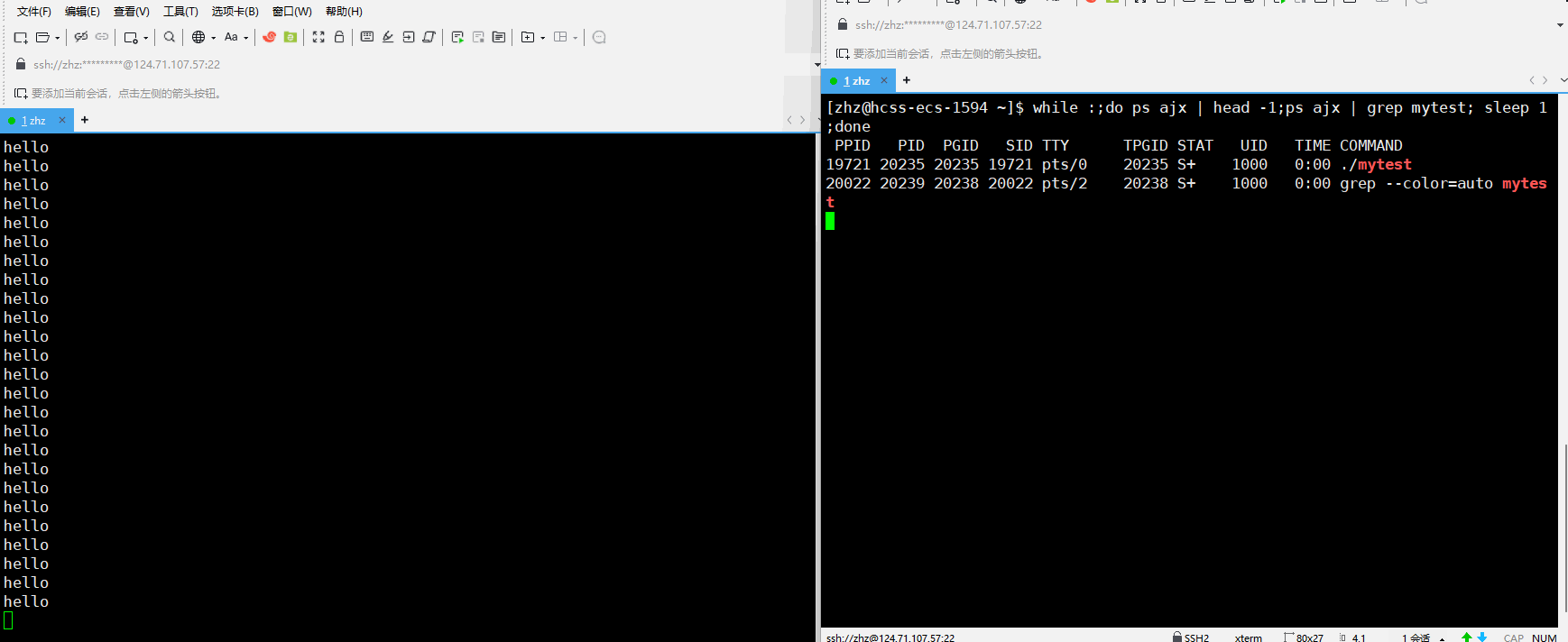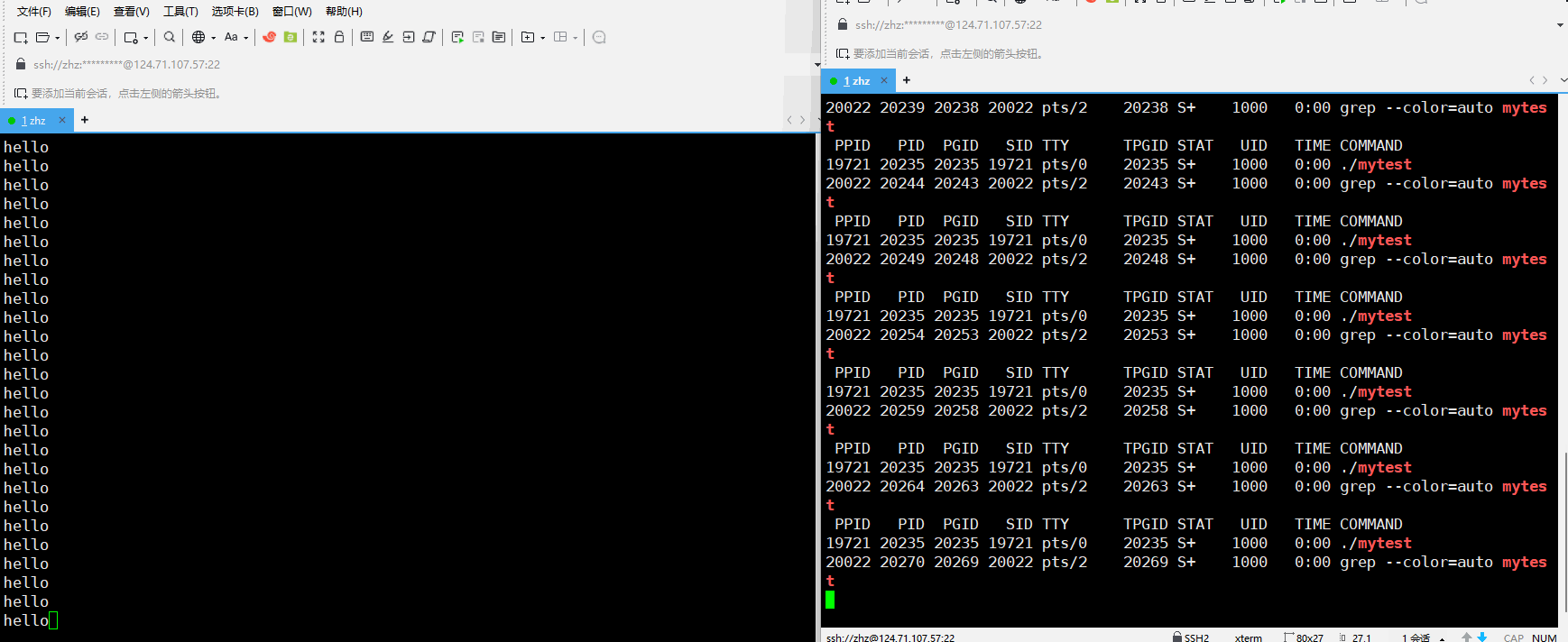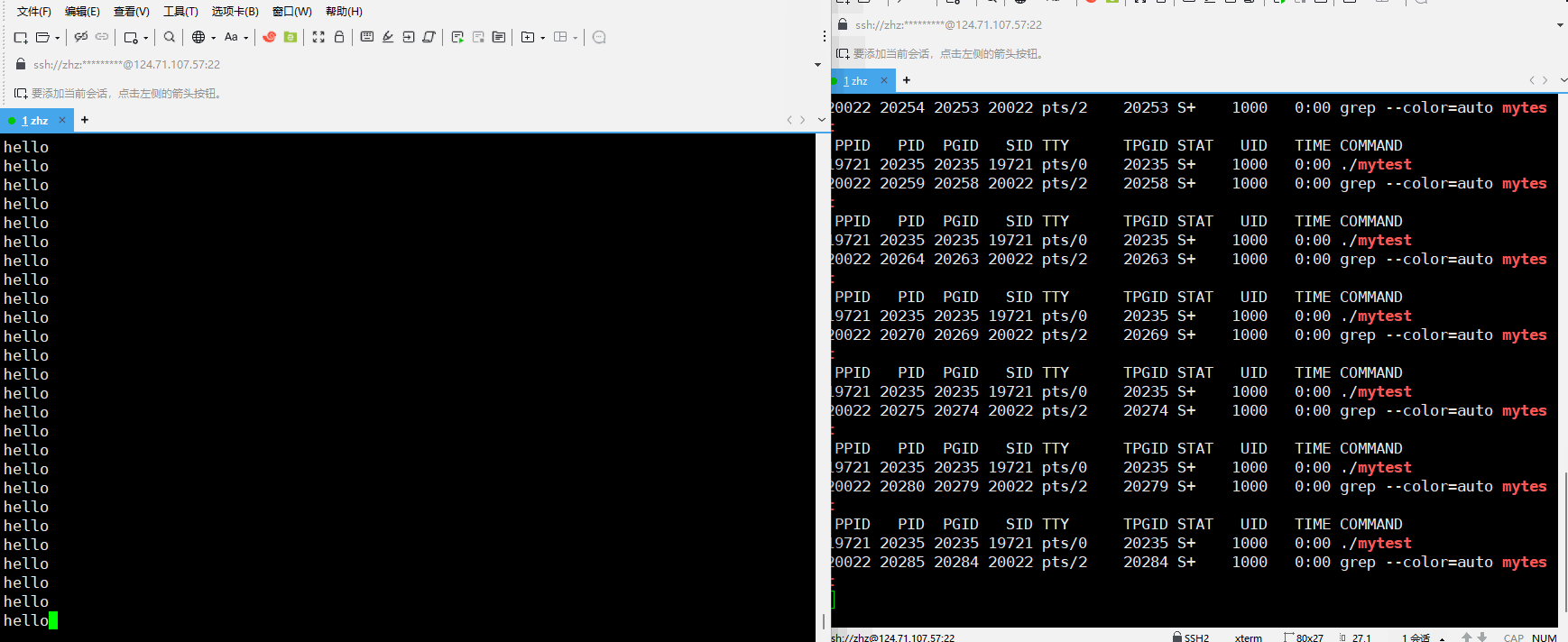
在以上就会看出在运行mytest程序之后当我们使用ps每隔一秒进行监视时就可以看到对应的进程的状态一直是S,那么是不是就是说明进程在运行的时候在Linux当中状态表示就是S呢?
其实不是这样的在,在Linux当中进程运行的时状态应该是R,以上运行程序的时候一直输出的是S,这是因为在程序当中使用的是printf,在此只有当printf在向显示器输入的时候进程会真正的运行,其他时间进程都是在休眠的,而printf在执行的时间是非常的短的,而我们监视的程序是每隔一秒才查看一次的,这就使得我们大概念看到的是S状态。
因此我们要对我们的test.c内的代码进行修改,不再使用printf,而是直接在死循环内进行变量的++。代码如下所示:
#include<stdio.h> int main()
{ int cnt=0;while(1) { cnt++;//printf("hello\n"); } return 0;
}
之后重新编译生成mytest之后执行程序并进行监视
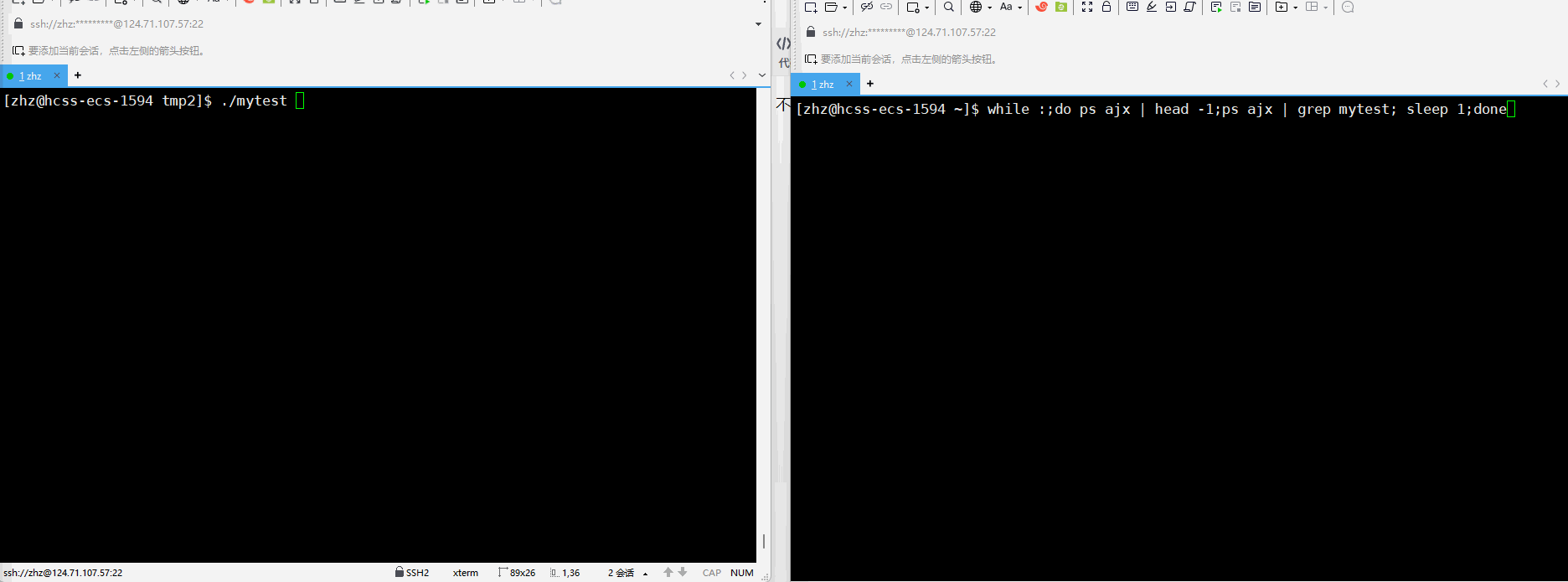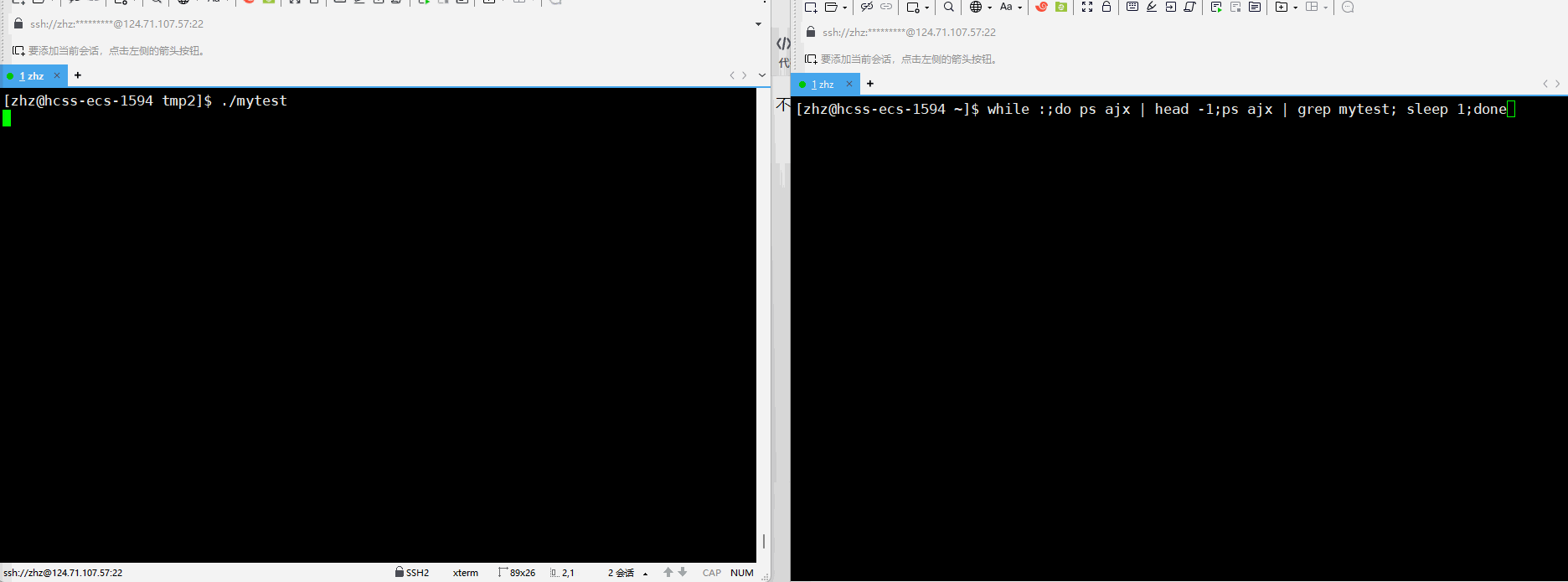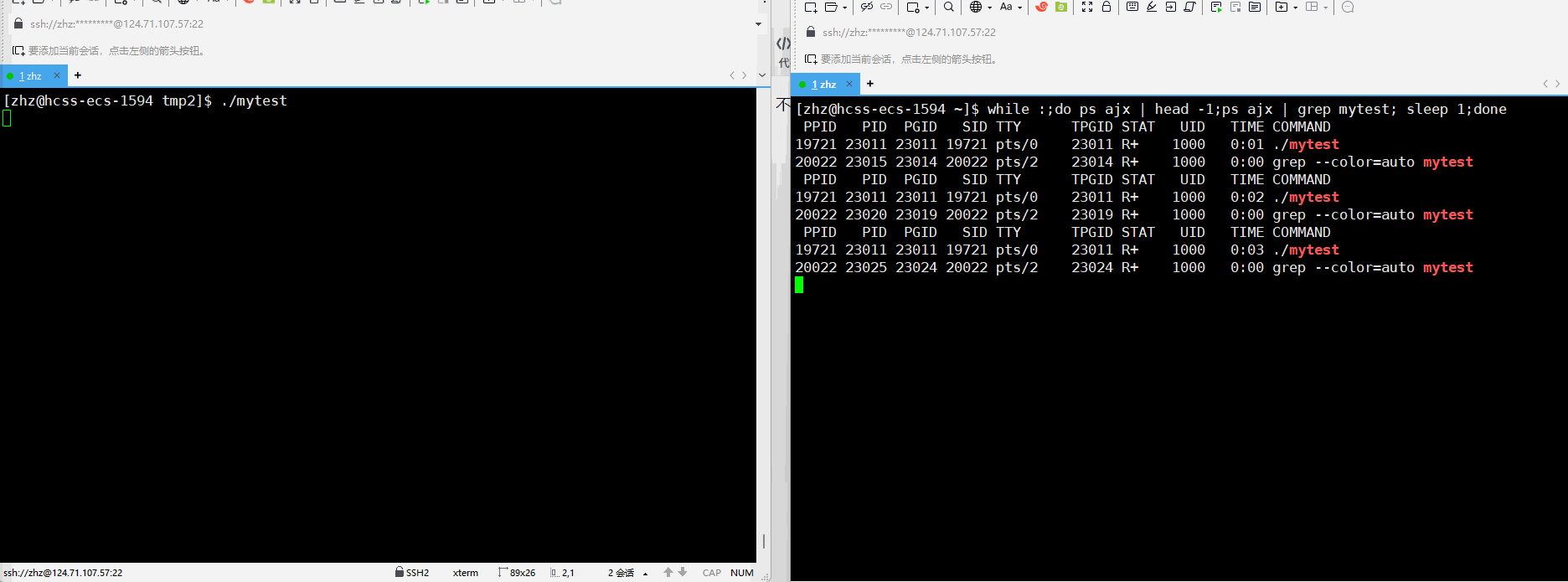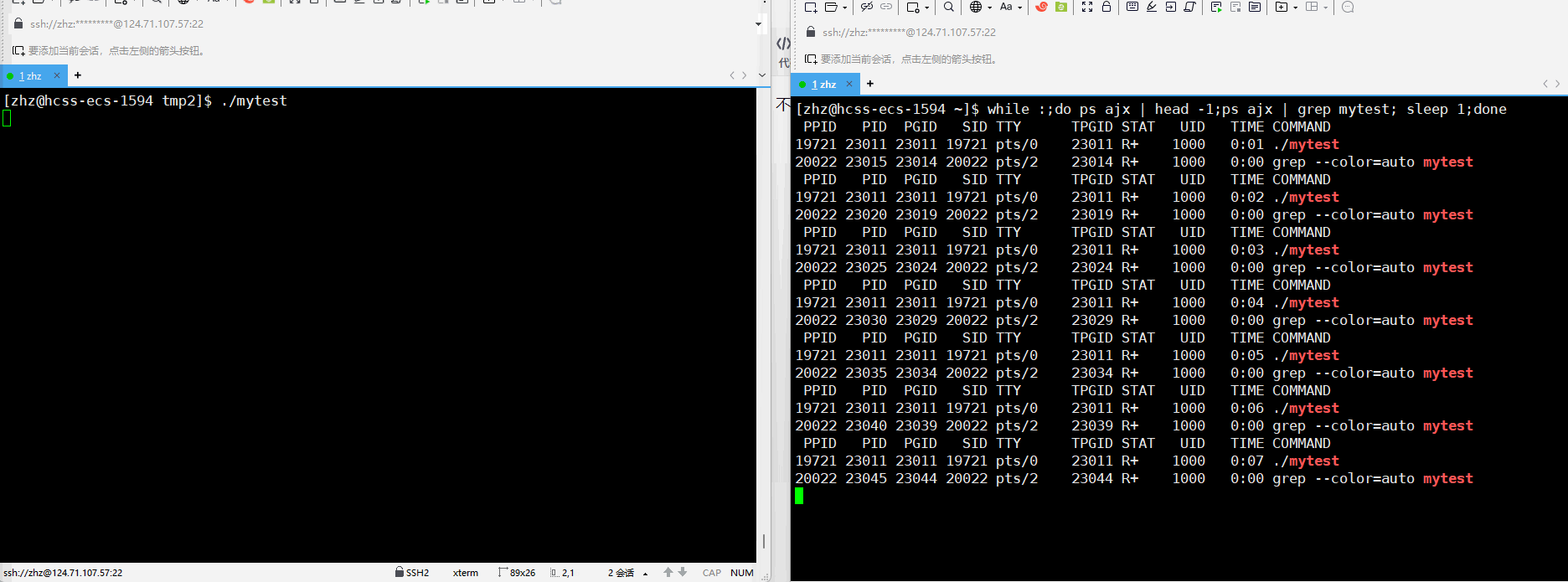
此时同ps监视输出的结果就可以看出进程在运行的时候进程的状态确实是R。
那么S状态具体的表示形式又是什么样的呢?
其实在使用scanf的时候就会直到键盘输入之前会使得进程的状态一直保持在S在此我们再将以上的代码修改为以下的形式:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h> int main()
{ printf("pid:%d",getpid());scanf("%d",&cnt); int cnt=0; while(1) { cnt++; //printf("hello\n"); } return 0;
}
之后重新编译生成mytest之后执行程序并进行监视
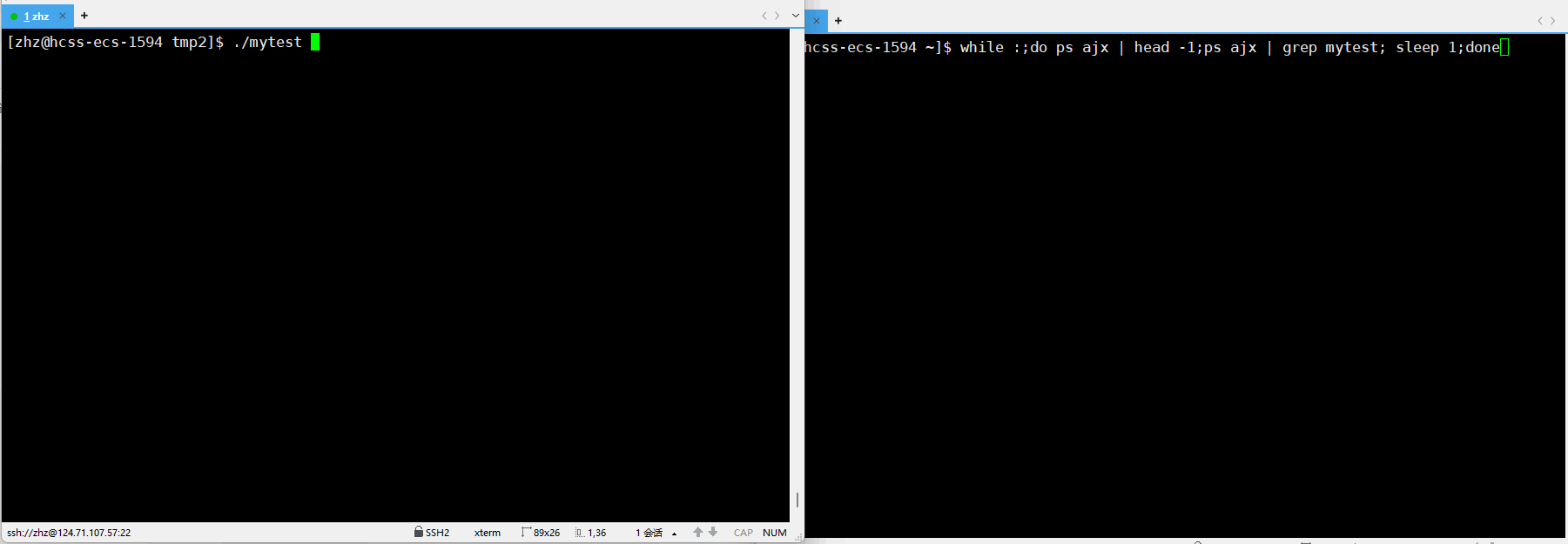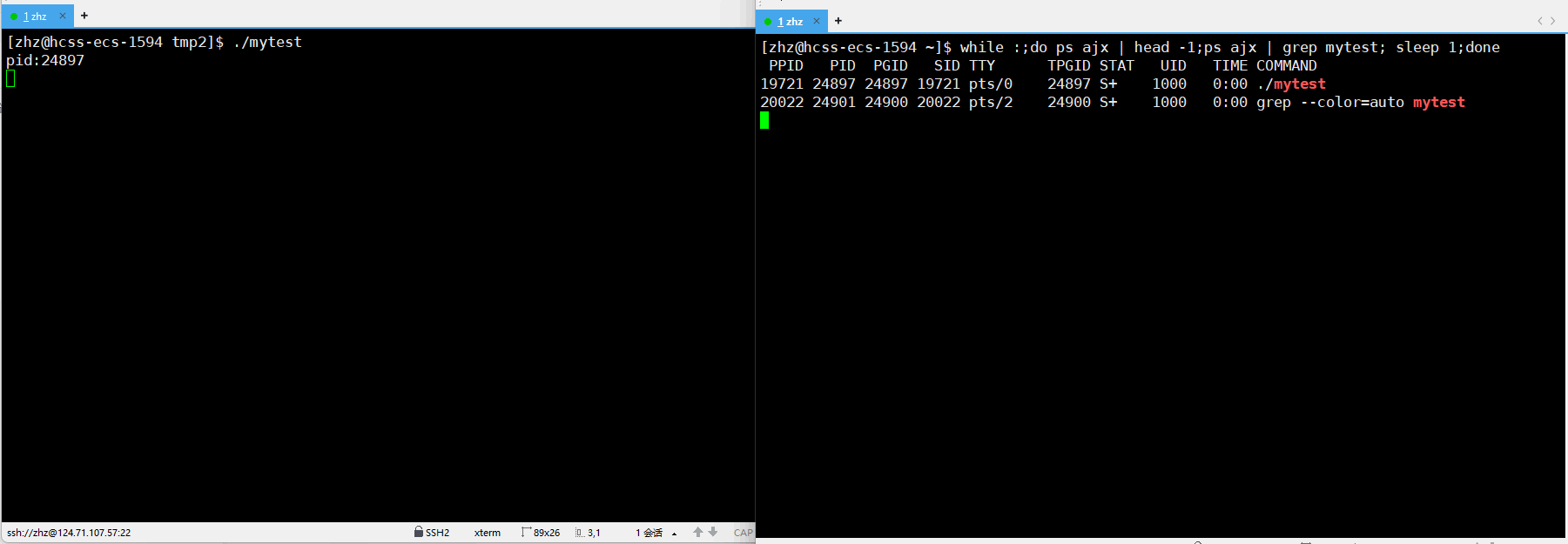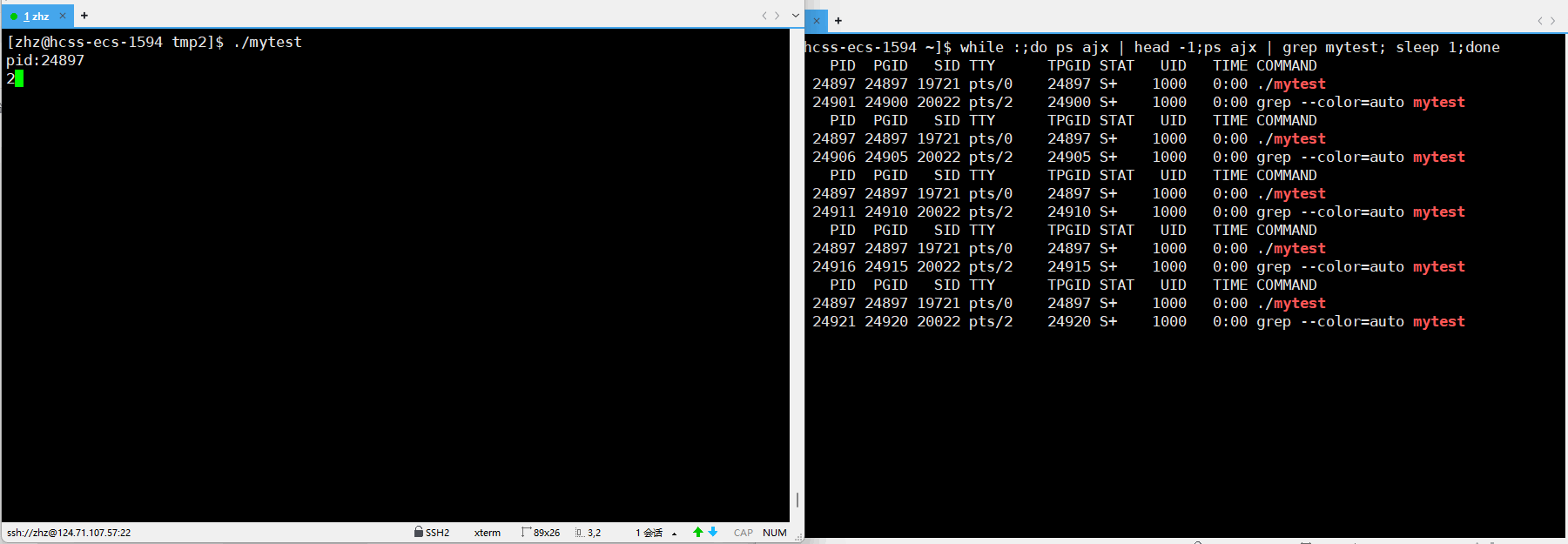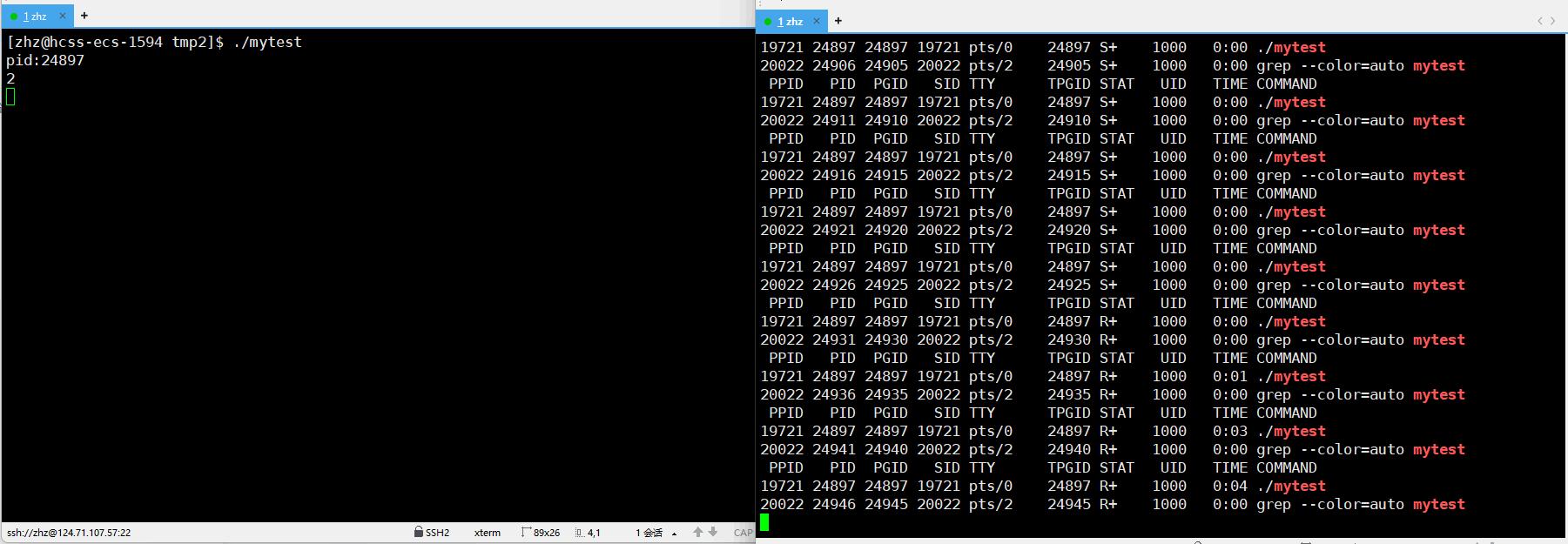
此时通过以上的使用p后的显示就可以就看出在使用了scanf之后在没有输入之前进程的状一直是S,当我们使用键盘输入之后进程的状态就变为了R
t状态和T状态
以上我们就了解了进程R和S的状态具体是什么样的,接下来继续来了解两个进程状态t和T
在此t状态和T状态其实都是进程被暂停了,不过这两个是不同的暂停导致的,接下来就来了解看看。
当我们使用gcc编译源代码的时候使用-g就可以使用gdb进行调试,在此当我们打断点之后再运行对应的程序就会看到对应的进程状态变为t
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h> int main()
{ int cnt=0; while(1) { cnt++; } return 0;
}
gcc test.c -o mytest -g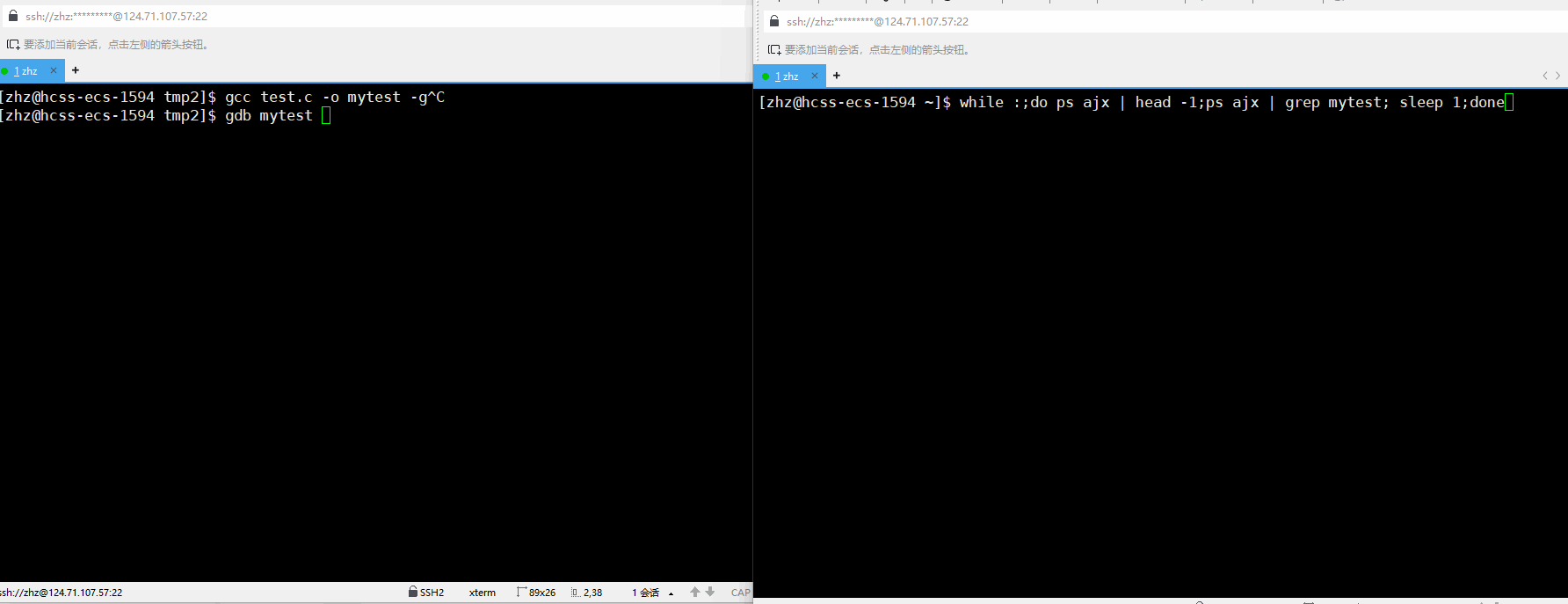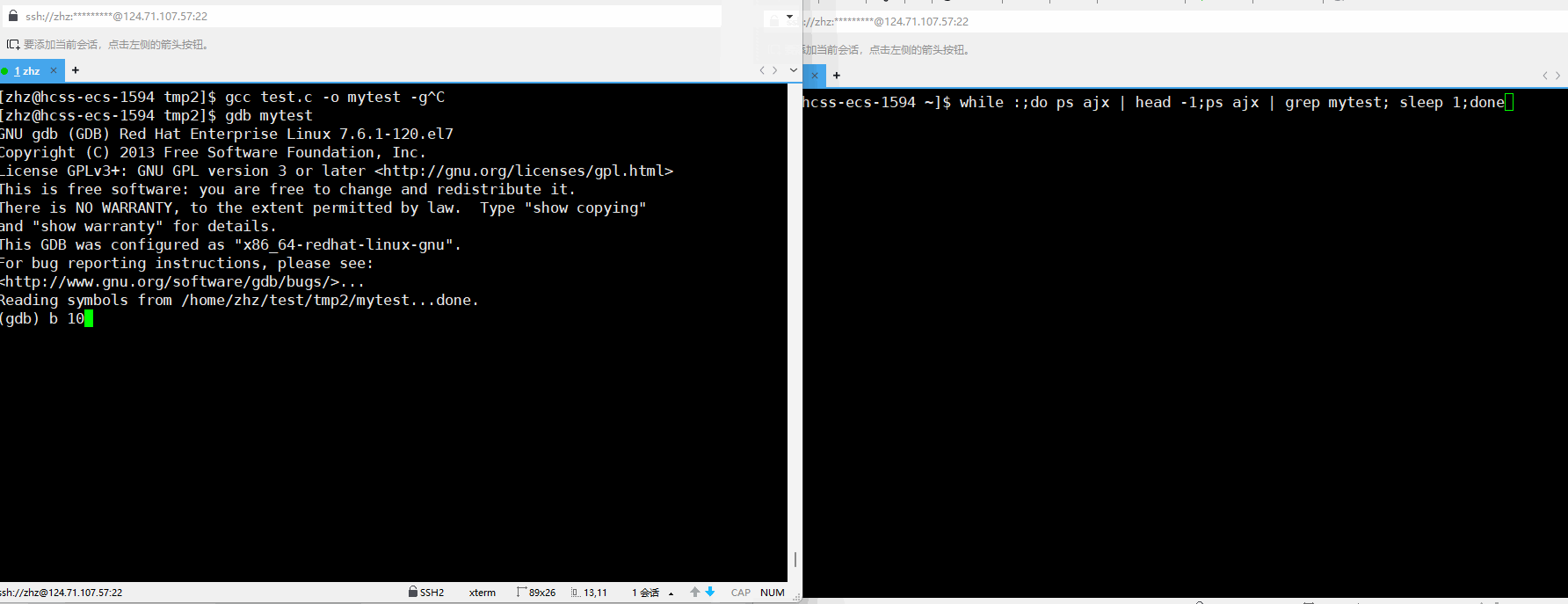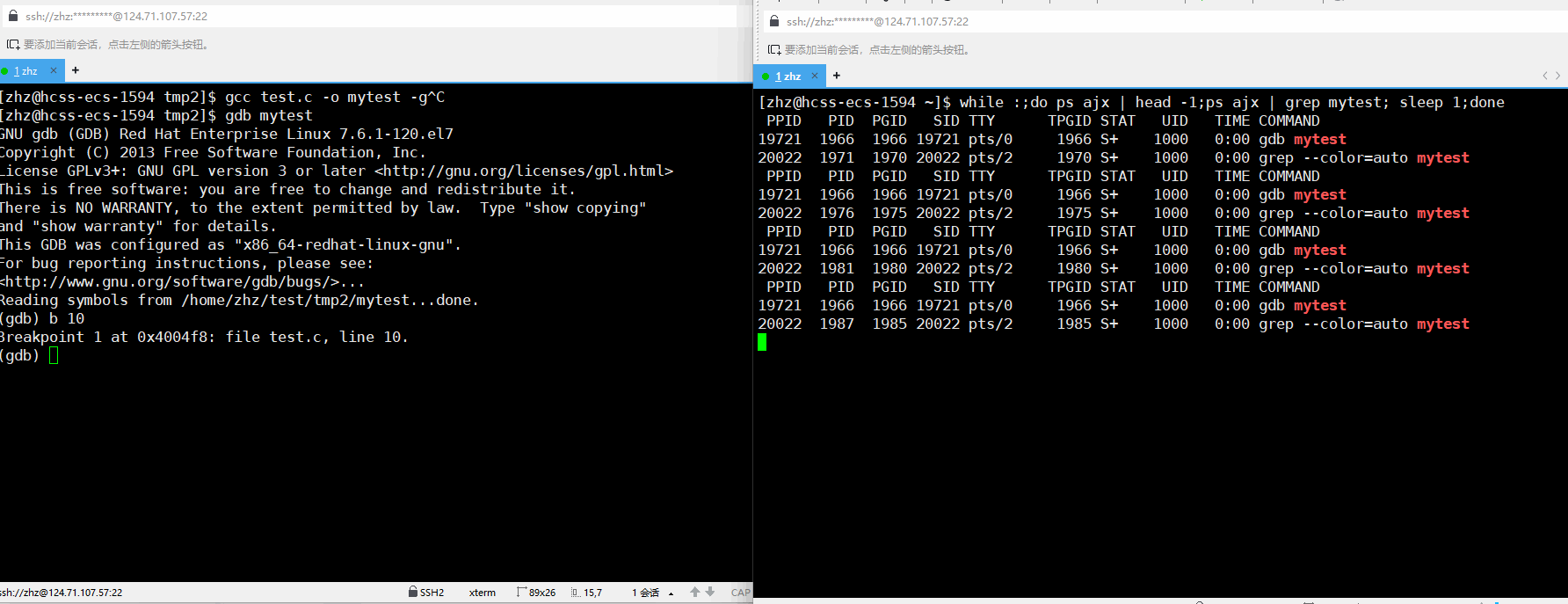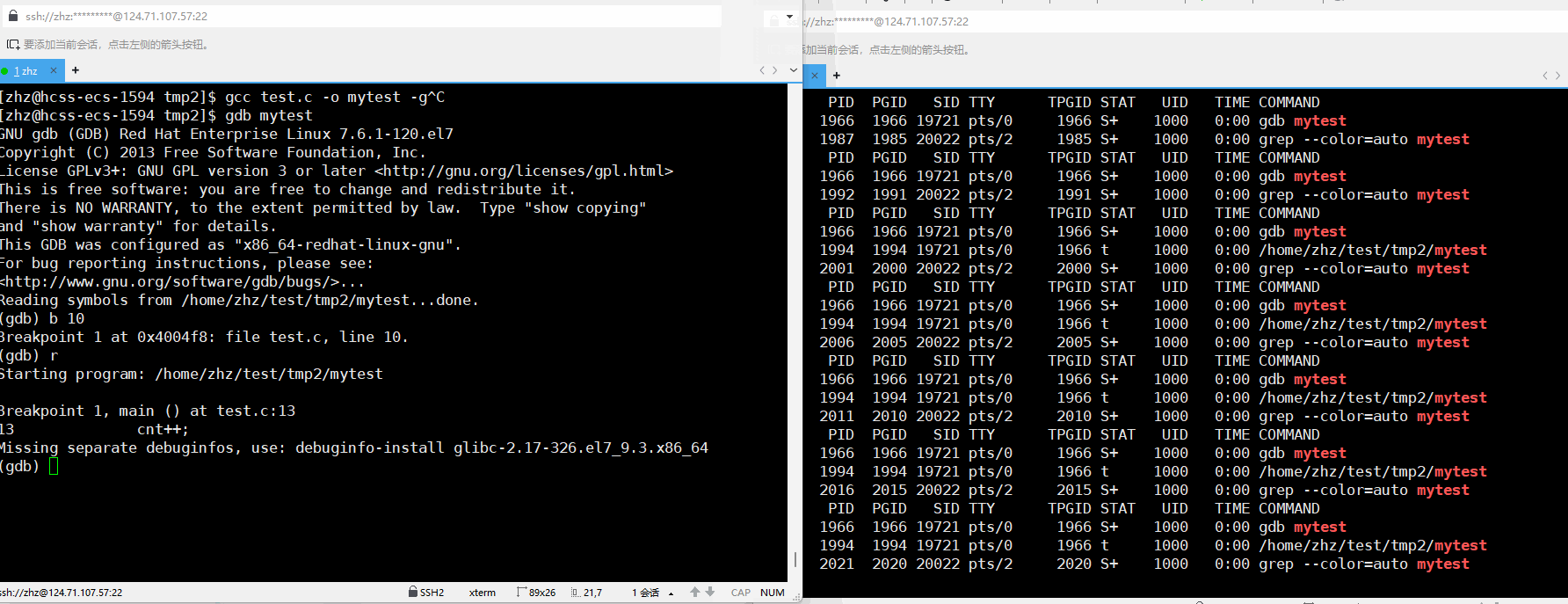
通过以上的使用ps时的输出就可以看到当我们使用调试的时候打了断点之后再运行程序就会出现t状态。
在此其实小t状态就是追踪状态,当进程在debug时,打断点的之后再运行程序就会使得进程被暂停
接下来来了解另外的一个进程状态T
当test.c内的代码是如下所示时:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h> int main()
{ while(1) { printf("hello\n"); } return 0;
}
当我们运行的时候用户在键盘当中输入CTRL+z之后就会看到对应进程的状态变为了T
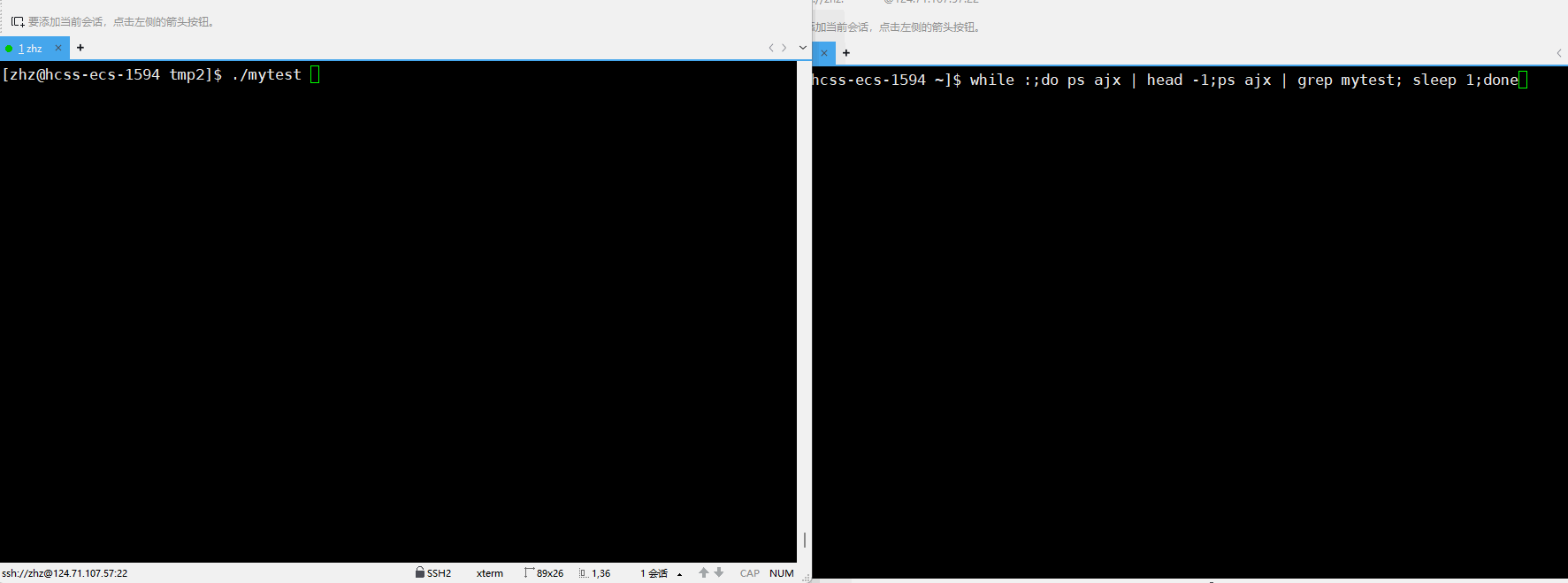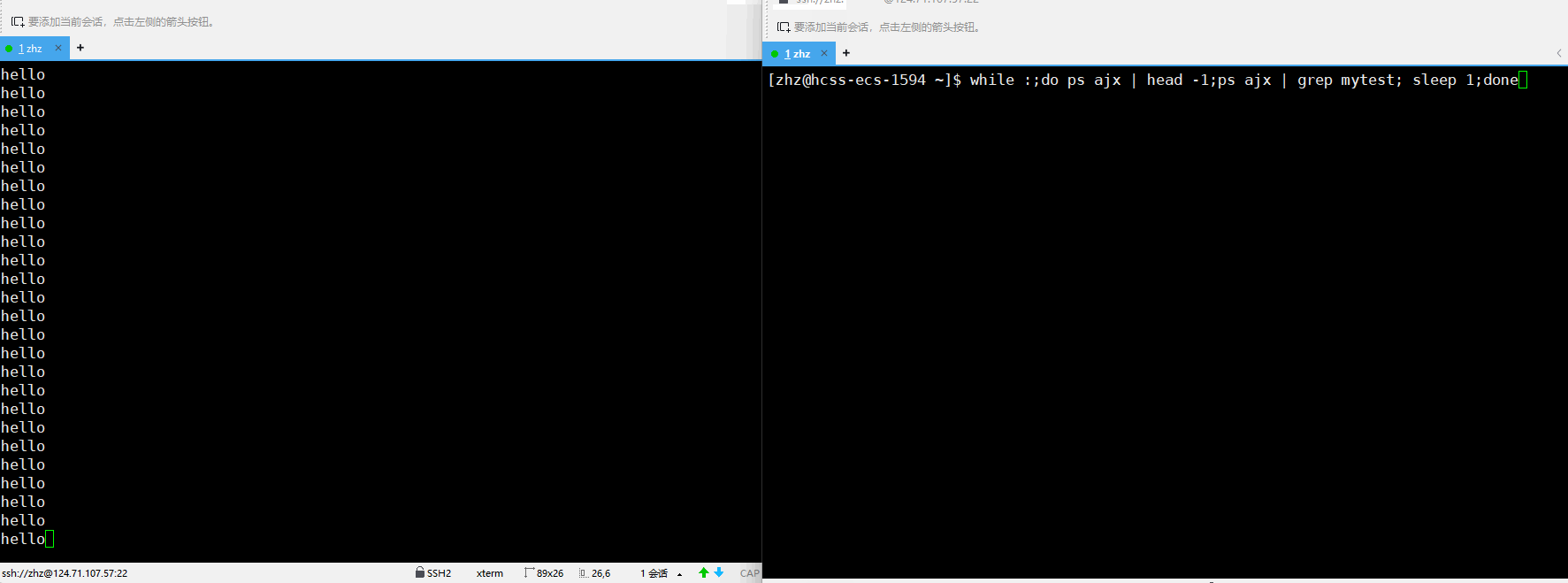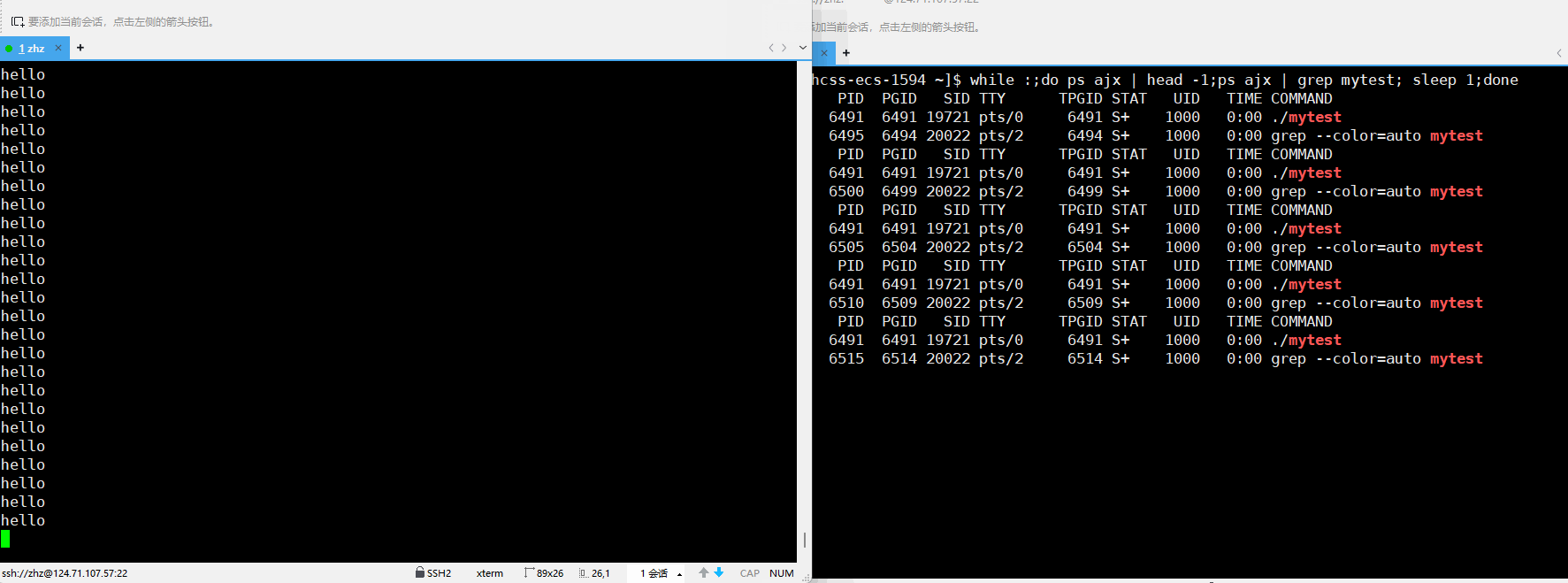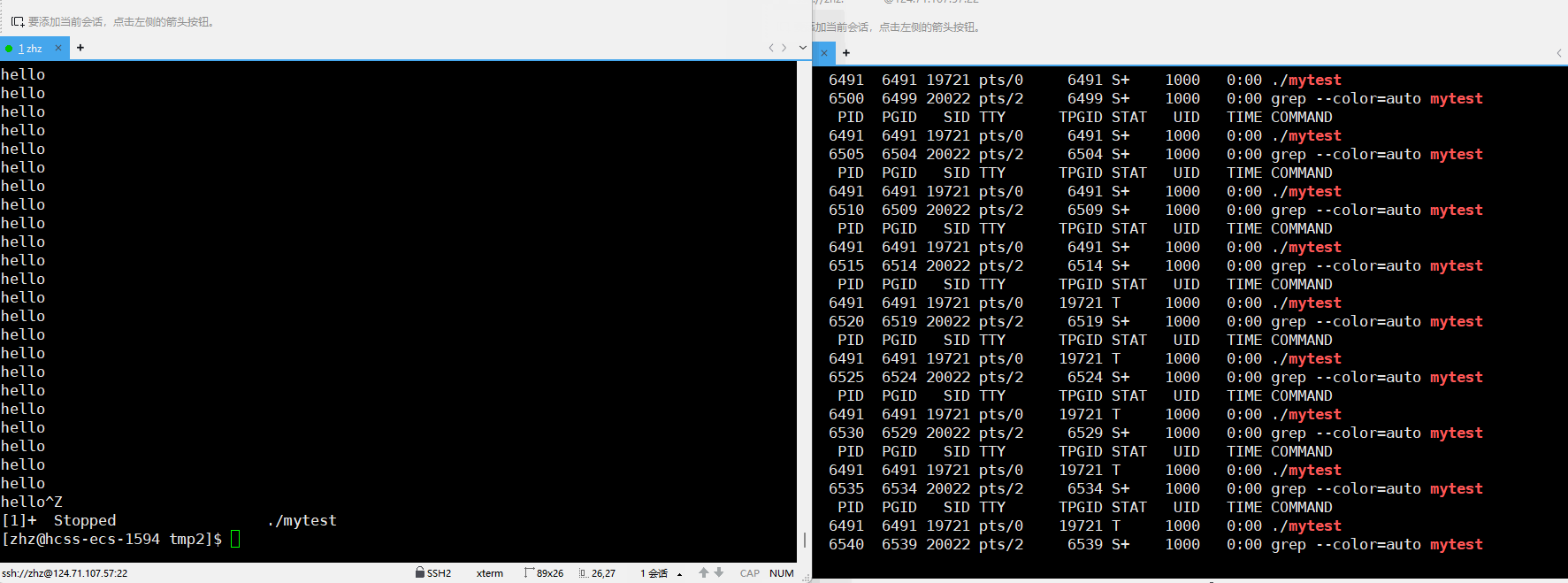
以上我们就看到了T和t状态的进程,那么此时我们就要思考了暂停状态的进程和我们之前了解的阻塞状态有什么区别呢?暂停状态的作用是什么呢?
进程阻塞是在等待某种资源,而暂停不同是条件不具备或者当中进程进行了非法操作,此时操作系统就会将对应的进程暂停,该进程是Linux当中特有的,其他的进程可能也会有这种状态当时在操作系统学科当中一般不对该状态进行说明。当操作系统检查到当中的进程有问题时但是又无法决定是否要将该进程杀掉就会将该进程的状态设置为暂停状态,这样就可以让用户来决定时候继续运行。
以上我们了解的是使用键盘的输入来让对应的进程的状态变为T,其实除了使用键盘输入还可以使用kill指令来使得对应的进程暂停下来。
在此使用kill -l指令就可以查看kill指令详细的选项。
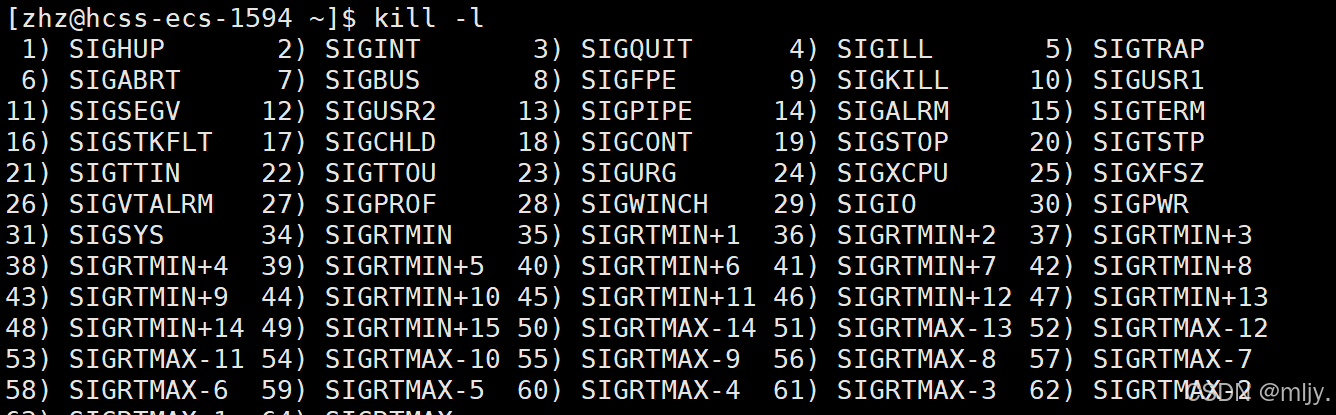
在此以上当中的选项-19就可以将对应的进程暂停
![]()
在此我们将test.c编译之后形成mytest可执行程序之后再运行,此时使用kill -9 对应的进程号就可以将该进程暂停下来
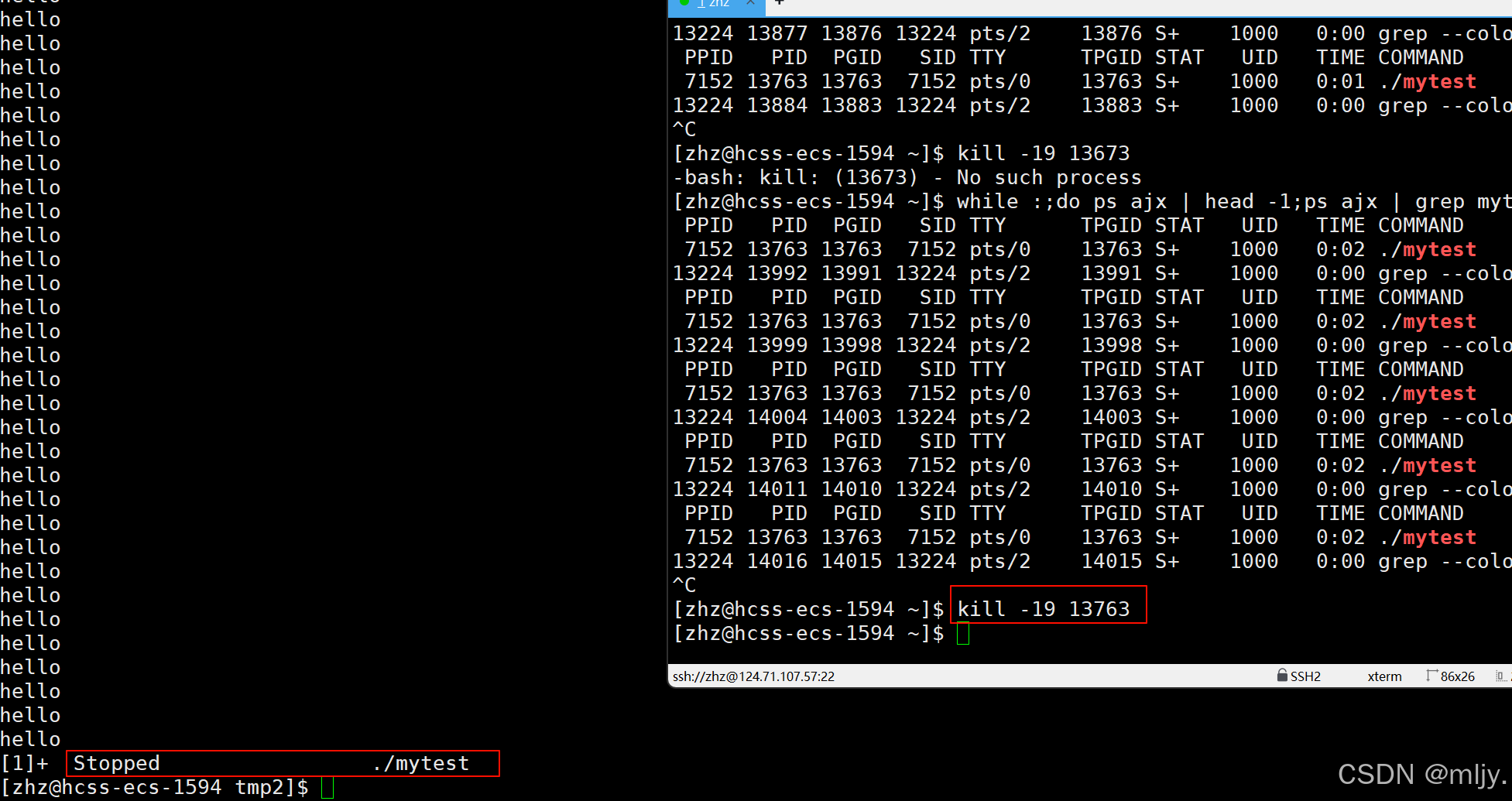
接下来要将暂停的进程再重新运行就需要使用到kill当中的-18 选项
![]()
在此如果要杀掉对应的进程可以使用kill -9 来实现
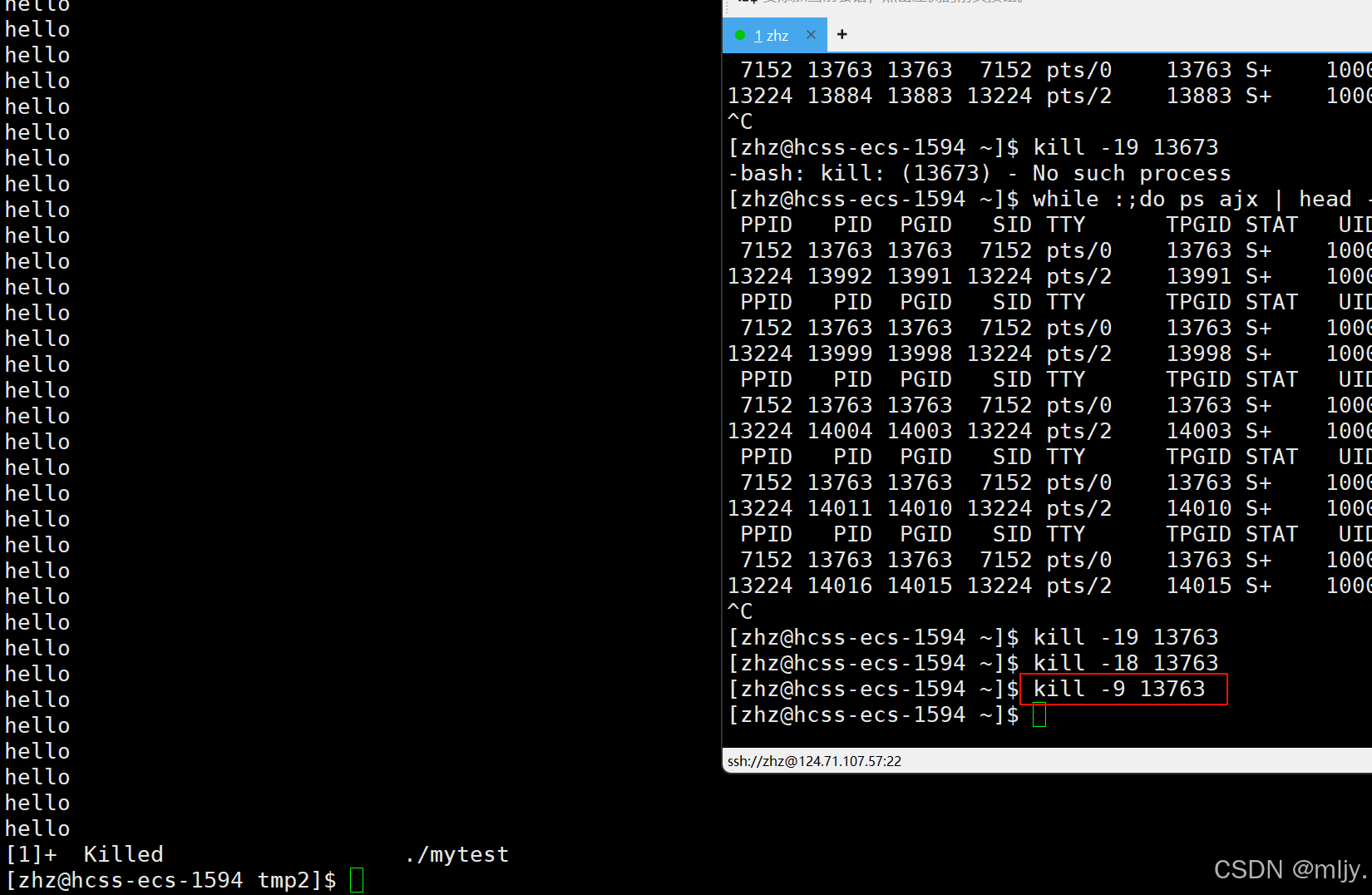
注:在此我们只是先了解kill的使用,详细的讲解到之后Linux信号部分会进行
D状态
其实在Linux当中以上我们提到的S状态其实本质是可中断休眠,而接下来要提到的D状态就是不可中断休眠也就是深度睡眠。
那么该如何去理解D状态呢,在此就通过一个IO的示例来解释D状态的具体表现形式是什么样的,例如当前在操作系统当中有一个进程要在磁盘当中读取大小为100MB的数据,那么此时进程就先找到磁盘当中对应的数据之后接下来就等待对应的数据写入到对应的内存当中。假设当中的磁盘进行IO的效率较低,那么要将写入完成就需要一定的时间,这时操作系统看到了进程占据的系统的资源但是却没有进行任何的操作,如果这时系统的资源严重的不足,那么此时操作系统可能就会将闲置的进程给杀掉,此时操作系统看之前要完成在磁盘当中进行数据读取的进程是闲置的,那么此时就会把对应的进程给杀掉。那么接下来问题就来了,那就是将进行磁盘数据读取的进程杀掉之后,就会使得无法得到磁盘读取是否成功,此时假设磁盘进行完了对应的工作之后,它就无法向操作系统告知操作的结果,这时磁盘就会认为对应的数据是无用的就会直接将对应的磁盘资源直接清除。这时就会造成数据的丢失。
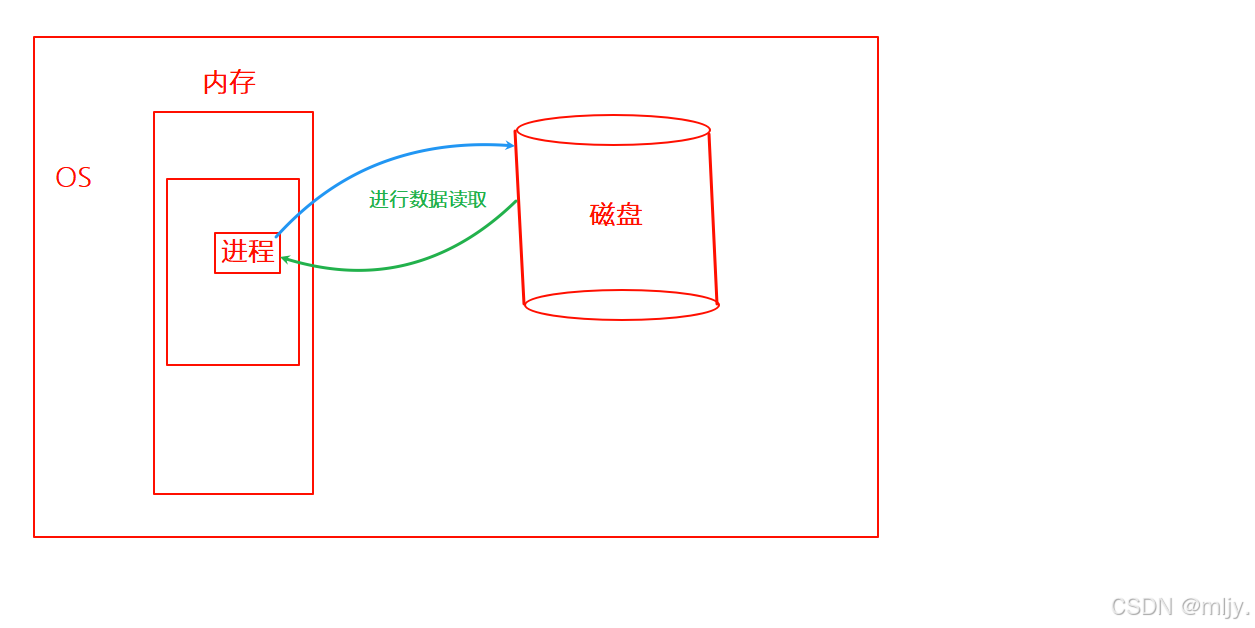
假设整个计算机就是一个银行,那么操作系统、进程、磁盘就是银行当中三个不同的员工,如果以上丢失的数据是银行一天的流水记录,此时银行就来找出现问题的地方,就将操作系统、进程以及磁盘来拷打,要找出现以上的问题是谁的责任。
此时实现就是进程来解释了,它说它一直在等待磁盘进行读取的操作,磁盘没有完成它的操作我肯定要等待磁盘啊,谁知道之后操作系统就把我给杀了,这我有什么办法。接下来磁盘就要解释了,它说我进行的读取的操作之后进程人就没了,那我肯定不知道要把这部分的数据要存储还是丢失啊,我看进程都不管我了那么就觉得数据是没有的,就把它给丢弃了啊,出现问题不能怪我。最后操作系统就来解释了,说你知道的我是你最信任的,你给了我这么大的权力,那么我看内存资源已经完全不足了,那么这时候我肯定要把闲置的内存进程给杀掉啊,要不让之后内存完全满了,那就不只是一个进程被杀掉这个小问题了,可能之后整个操作系统都会奔溃,那不是我呢提就更严重了吗?所以这个问题不能怪我。
这样看了一圈之后就就发现操作系统、进程、磁盘好像说的都没问题啊,但是问题就是出现了,那么就要思考接下来如何避免再出现以上的问题呢?
在此就引入了D状态,当进程的状态为D状态的时候操作系统就无权将D状态的进程杀掉,操作系统只能将S进程杀掉来解决内存资源不足的问题。
因此在操作系统内凡是涉及对磁盘这样的关键存储设备进行IO的时候,都将进程的状态设置为D,这样就可以避免数据的丢失。
注:在Linux当中S状态的进程和D状态的进程其实都属于阻塞状态的进程,只不过这两个状态的进程是Linux当中特有的。
操作系统要杀掉阻塞状态的进程时 ,是只能将S状态的进程杀掉的,是无法将D状态的进程杀掉的,D状态的进程要结束只有当对应的进程自己恢复或者将计算机关闭才会停止。
X状态和Z状态
在Linux当中X状态是死亡状态,Z状态是僵尸状态,那么接下来我们就来了解这两个状态
首先在了解Z状态之前先通过一个场景来带出为什么在Linux当中要存在僵尸状态
假设现在在一个人在道路上突然死亡了,那么在法医法医到达之前其实所处的状态就是僵尸状态,知道法医真正的判断出他是由于什么原因死亡的才能真正的宣告其的死亡。在这里将这种处于未被法医检查的状态就称为僵尸状态,
以上提到的示例类似在操作系统当中我们知道每个进程都有其对应的父进程;其父进程可能是bash进程也可能是我们创建的进程,但其实无论是什么样的父进程创建子进程的目的都是一样的;都是为了让子进程完成某种事情,那么在子进程完成了对应的事情之后,当父进程还未获取到子进程的退出信息之前,就将该进程的状态称为僵尸状态。在此对应的子进程处于僵尸状态的目的其实就是让父进程得到其的退出信息,毕竟子进程是为了完成父进程给的任务的,那么最后肯定是要将是否完成了对应的人任务的状态告知给父进程。
那么接下来就要接着来了解一些关于进程退出时退出信息有哪些,以及退出信息是存储在什么位置的呢?
在一开始学习C语言的时候我们就被告知C语言的程序在main函数的最后要写上return 0,之后学习到函数的时候我们知道了return是用于返回当前函数的返回值的,但是直到现在我们还是没有解释为什么在main函数当中为什么月嫂有return 0,难道是有什么会接收main函数的退出信息吗?
确实是这样的,其实main函数的退出码是会被返回给其进程的父进程的,之前写的程序return 0就表示对应进程的退出码未0即表示当前进程正常执行完毕。其实在main函数当中还可以使用其他的退出码;表示的就是对应进程由于什么原因而异常的退出,具体的讲解在之后的进程控制当中会进行。
其实在进程的退出信息当中除了以上提到的退出码之外还有信号码等,这些到之后对应的章节都会进行讲解,现在我们只需要知道在退出信息当中有这些即可。
当进程退出的时候对应的代码和数据都被释放掉了,那么对应的退出信息其实就只能被存放到PCB当中,之后其父进程会通过相应的系统调用找到对应的子进程的PCB再得到对应的退出信息。
以上我们了解了Z状态具体是什么样的之后,接下来就试着在Linux当中模拟出Z状态的进程
首先在test.c的源文件当中实现以下的代码:
以下的代码当中通过fork系统调用创建了子进程,之后在子进程当中在运行五秒之后就结束,而父进程则一直执行不退出,这时我们就可以查看到子进程的状态变化。
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h> int main()
{ pid_t pid=fork(); if(pid<0) { perror("fork"); } if(pid==0) { //子进程 int cnt=5; while(cnt--) { printf("我是子进程,%d\n",cnt); sleep(1); } } else{ //父进程 while(1) { printf("我是父进程\n"); sleep(1); } } return 0;
}
以上源文件编译生成名为mytest的可执行程序之后,接下来使用ps来监视进程的状态
这时就可以看出进程子进程在5秒之后就从S状态变为了Z状态
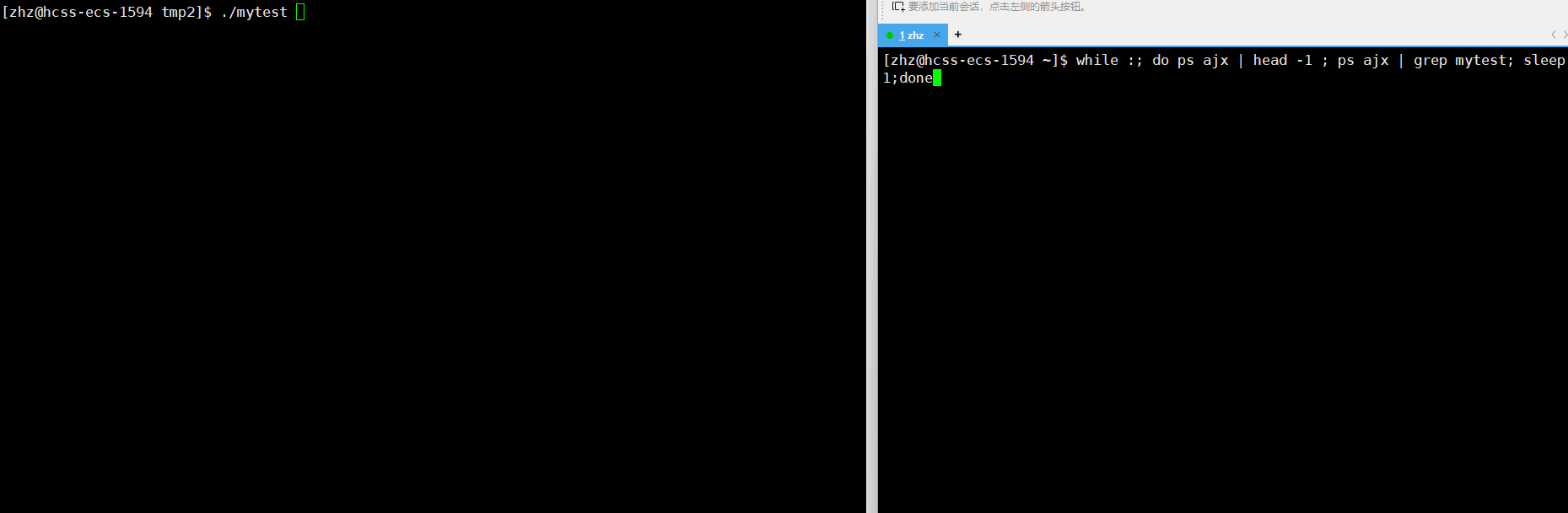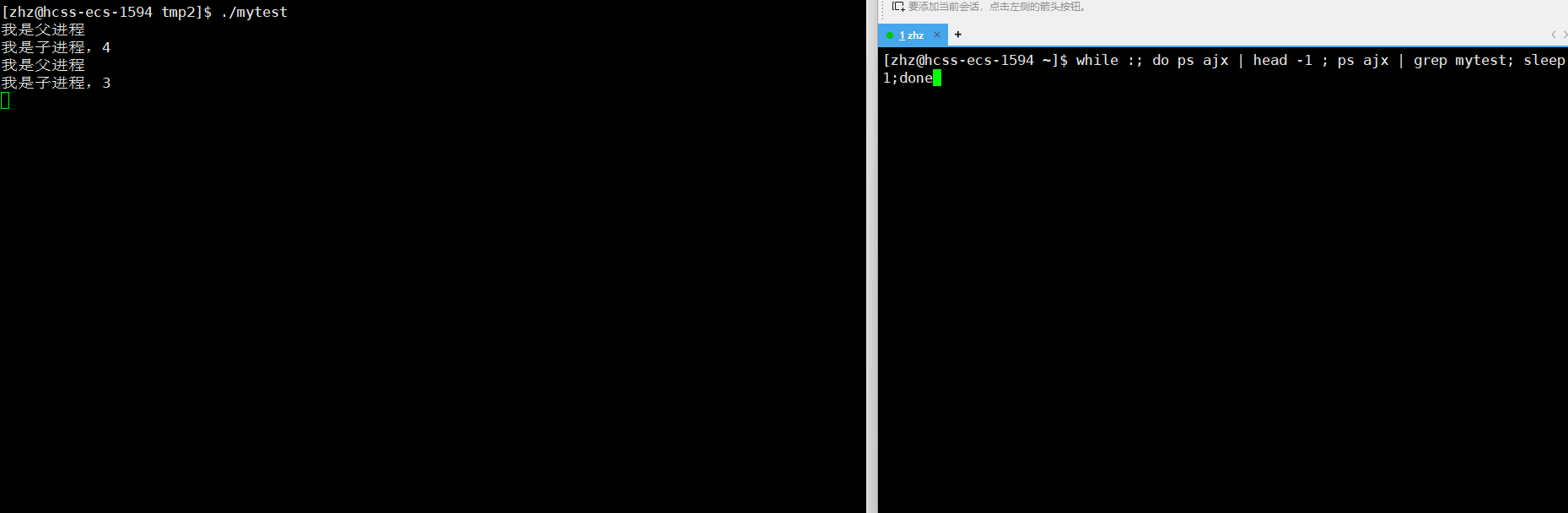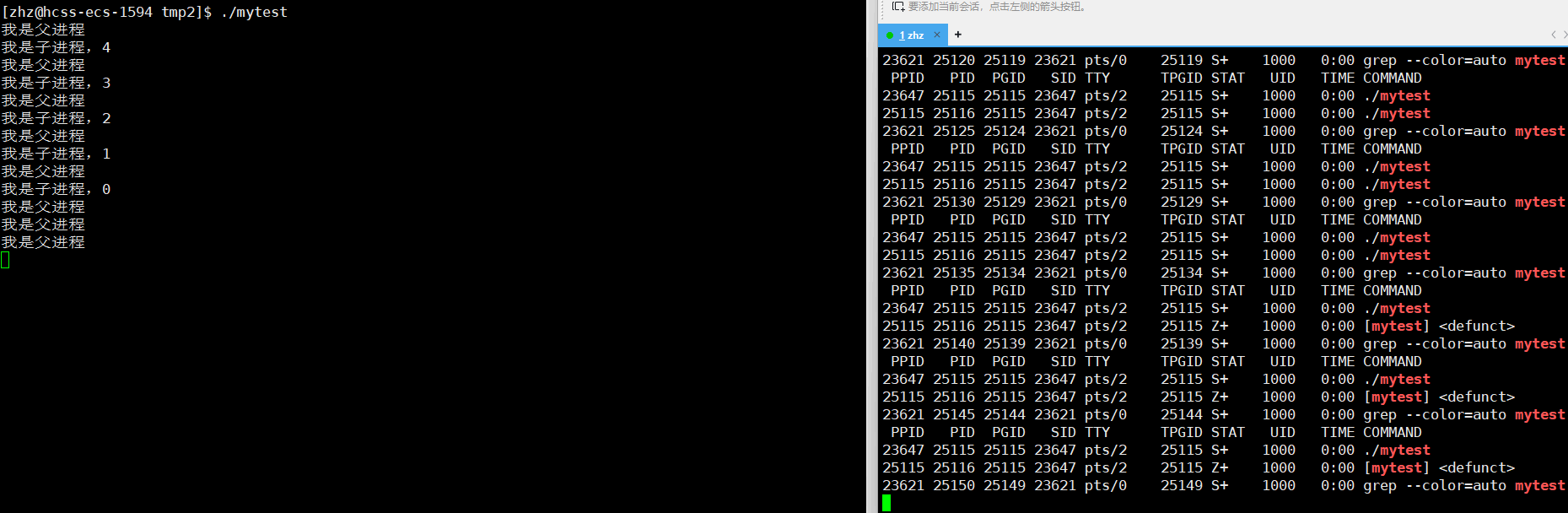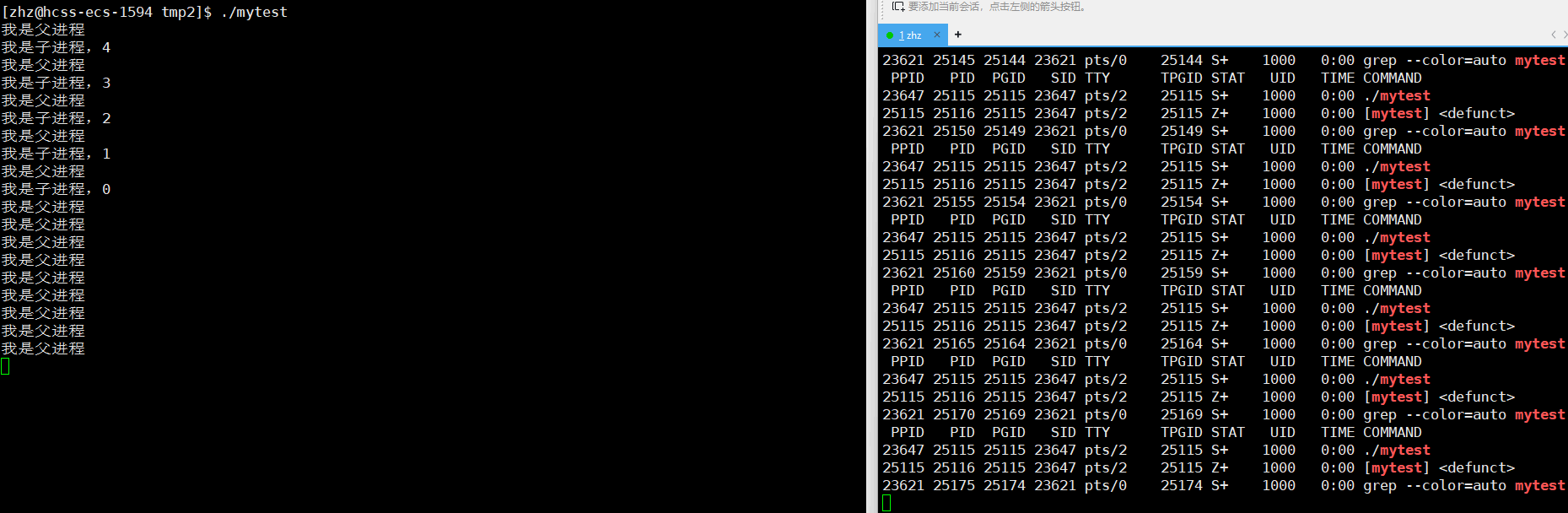
那么接下来我们就要接着思考一个问题了,那就是如果父进程一直不去获取子进程的退出信息,那么是不是Z状态会一直存在呢?
确实是这样的,如果父进程一直不去获取子进程就一直会处于僵尸状态,又因为子进程在处于僵尸状态时对应的PCB会一直存在,因为PCB是要占用资源的。那么如果子进程的PCB一直不被处理就会造成内存泄漏问题。在之前学习C/C++时我们就已经了解了在使用malloc/new时如果在不使用之后不用free/delete就会出现内存泄漏问题,现在我们就了解到了除了申请之前的原因外不对僵尸进程进行处理也会造成内存泄漏。
那么对应内存泄漏接下来就来引入以下的一个知识点,那就是在内存泄漏当中的如果对应的进程退出了,那么内存泄漏问题还会存在吗?
在此考察的进程不是以上的僵尸进程,也就是当进程退出是是不会留下PCB类似的数据结构对象的。其实只要进程退出了内存泄漏的问题也就不在了,这也就再引出了一个常识,那么就是在计算机当中其实那运行时间不长的进程引发的内存泄漏是不太可怕的,可怕的是那种从操作系统启动就一直运行的进程,那么这种进程即使内存泄漏的问题不太严重,只要经过的时间很长,那么也可能会导致系统崩溃。
僵尸进程的危害:
• 进程的退出状态必须被维持下去,因为他要告诉关⼼它的进程(⽗进程),你交给我的任务,我办的怎么样了。可⽗进程如果⼀直不读取,那⼦进程就⼀直处于Z状态?是的!
• 维护退出状态本⾝就是要⽤数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话说,Z状态⼀直不退出,PCB⼀直都要维护?是的!
• 那⼀个⽗进程创建了很多⼦进程,就是不回收,是不是就会造成内存资源的浪费?是的!因为数据结构对象本⾝就要占⽤内存,想想C中定义⼀个结构体变量(对象),是要在内存的某个位置进⾏开辟空间!
以上就了解了Z状态的进程,而X状态的进程我们是无法模拟出来观察的,这是因为进程被杀掉是在一瞬间的。其实除了以上的僵尸进程之外还有一种进程也是腰围特殊的,这就是接下来要学习的孤儿进程。
那么孤儿进程又是什么呢?
接下来先看以下的代码:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h> int main()
{ pid_t pid=fork(); if(pid<0) { perror("fork"); } if(pid==0) { //子进程 while(1) { printf("我是子进程,pid:%d,ppid:%d\n",getpid(),getppid()); sleep(1); } } else{ //父进程 int cnt=5; while(cnt--) { printf("我是父进程,pid:%d,ppid:%d,%d\n",cnt,getpid(),getppid()); sleep(1); } } return 0;
}
将以上的代码编辑成可执行程序之后接下来使用ps来监视对应的进程信息
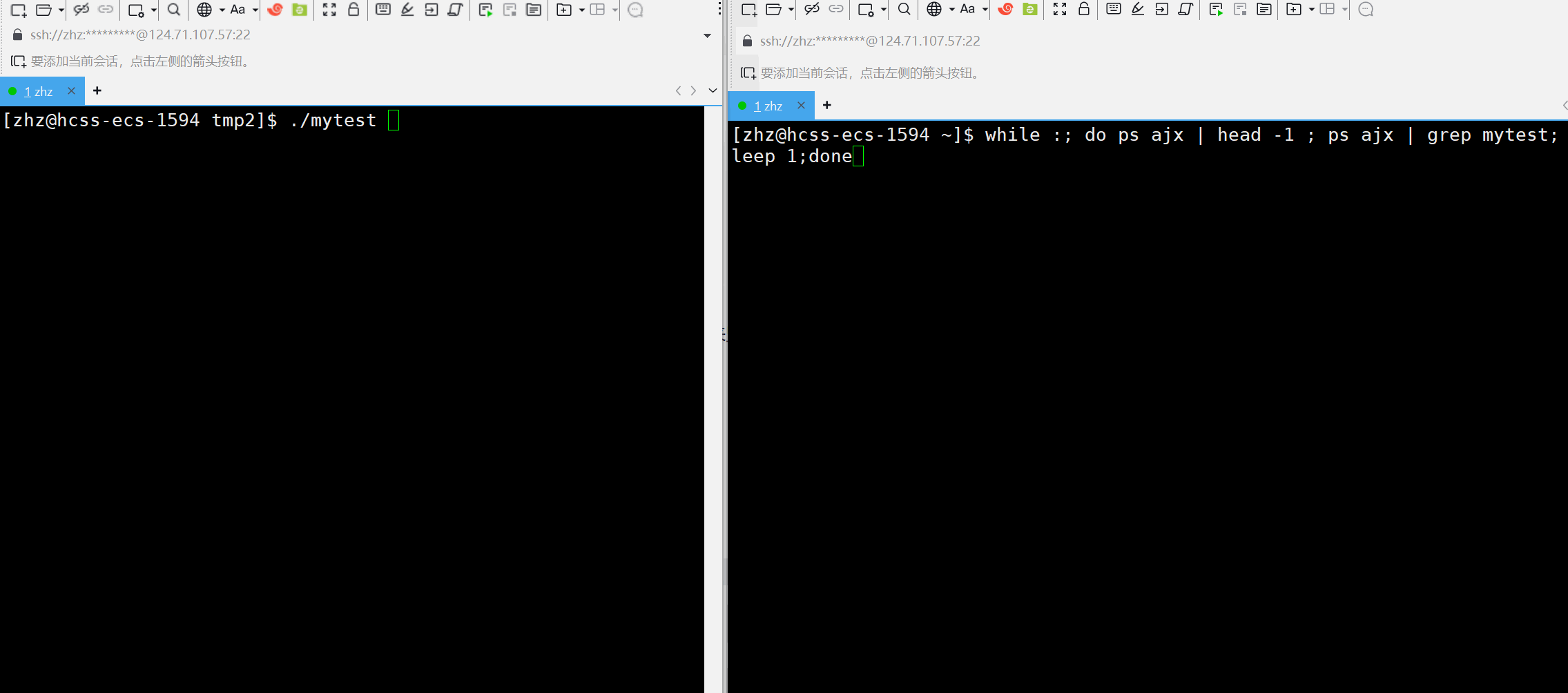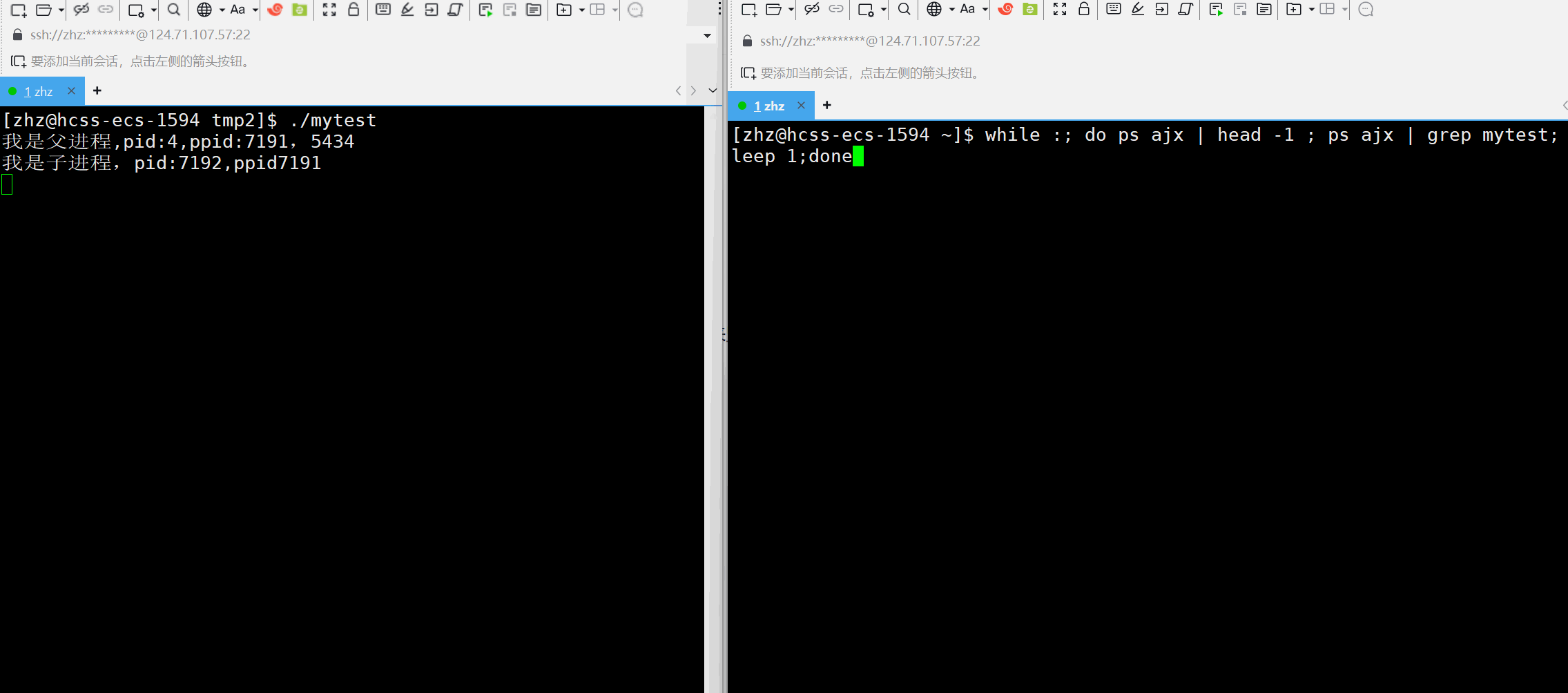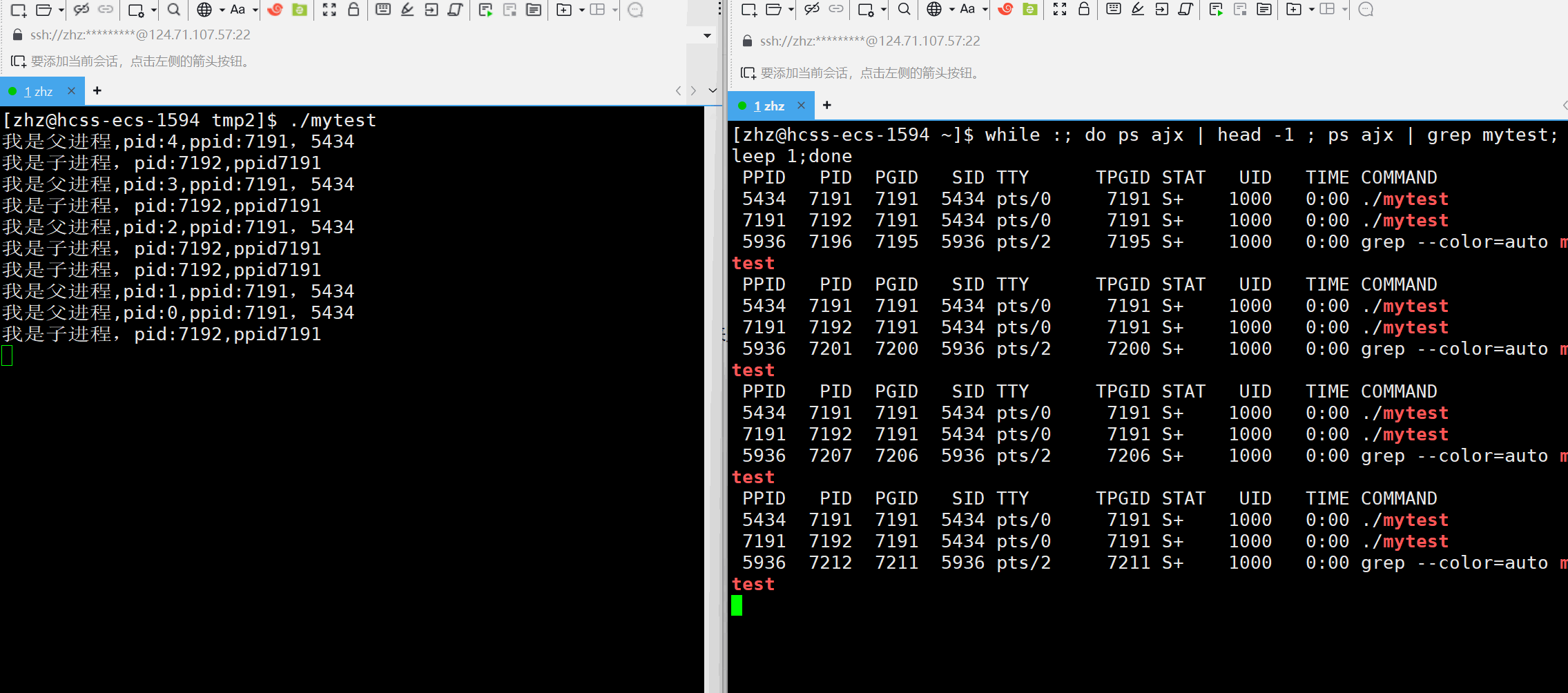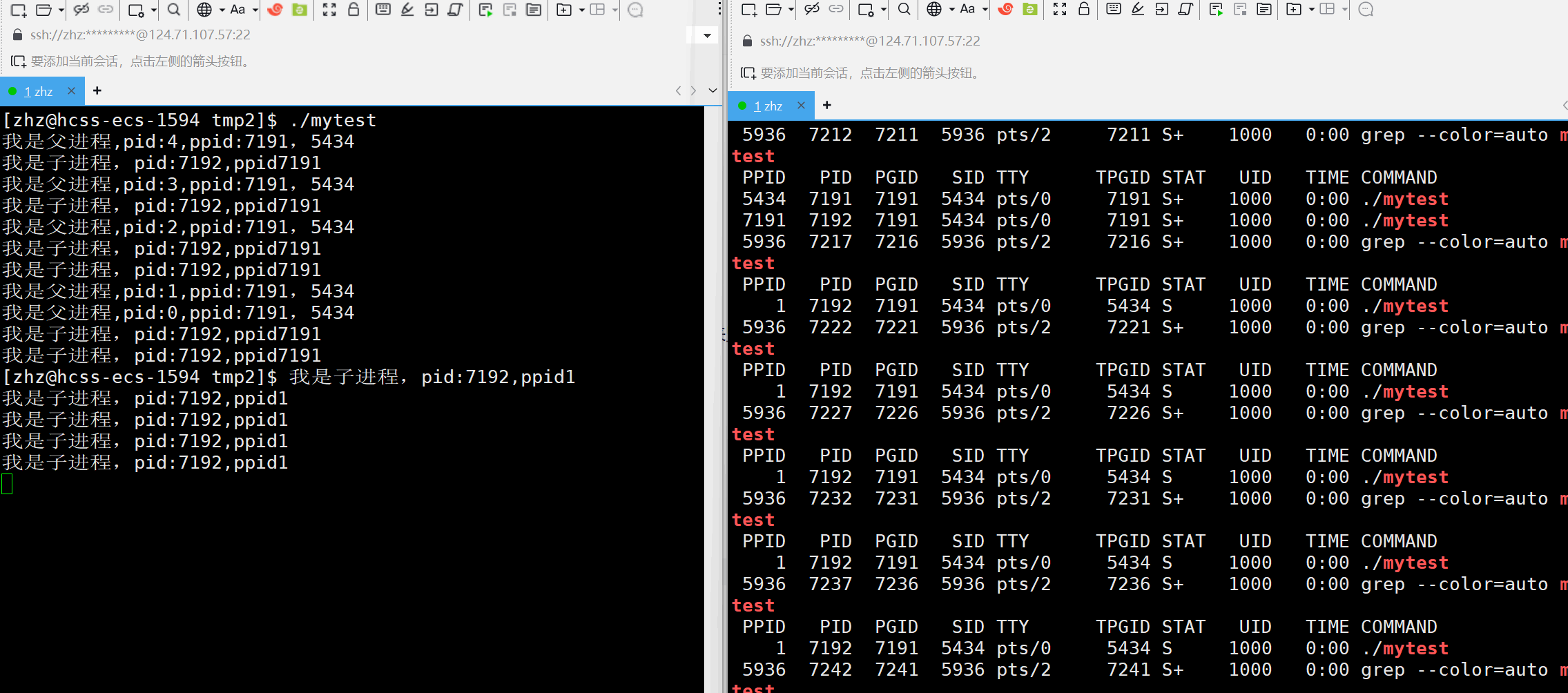
在进程运行的过程当中就可以看出子进程的父进程一开始是原来我们创建的进程,但当父进程结束之后子进程的父进程就变为了pid为1的进程,那么这个pid为1的进程是什么呢?

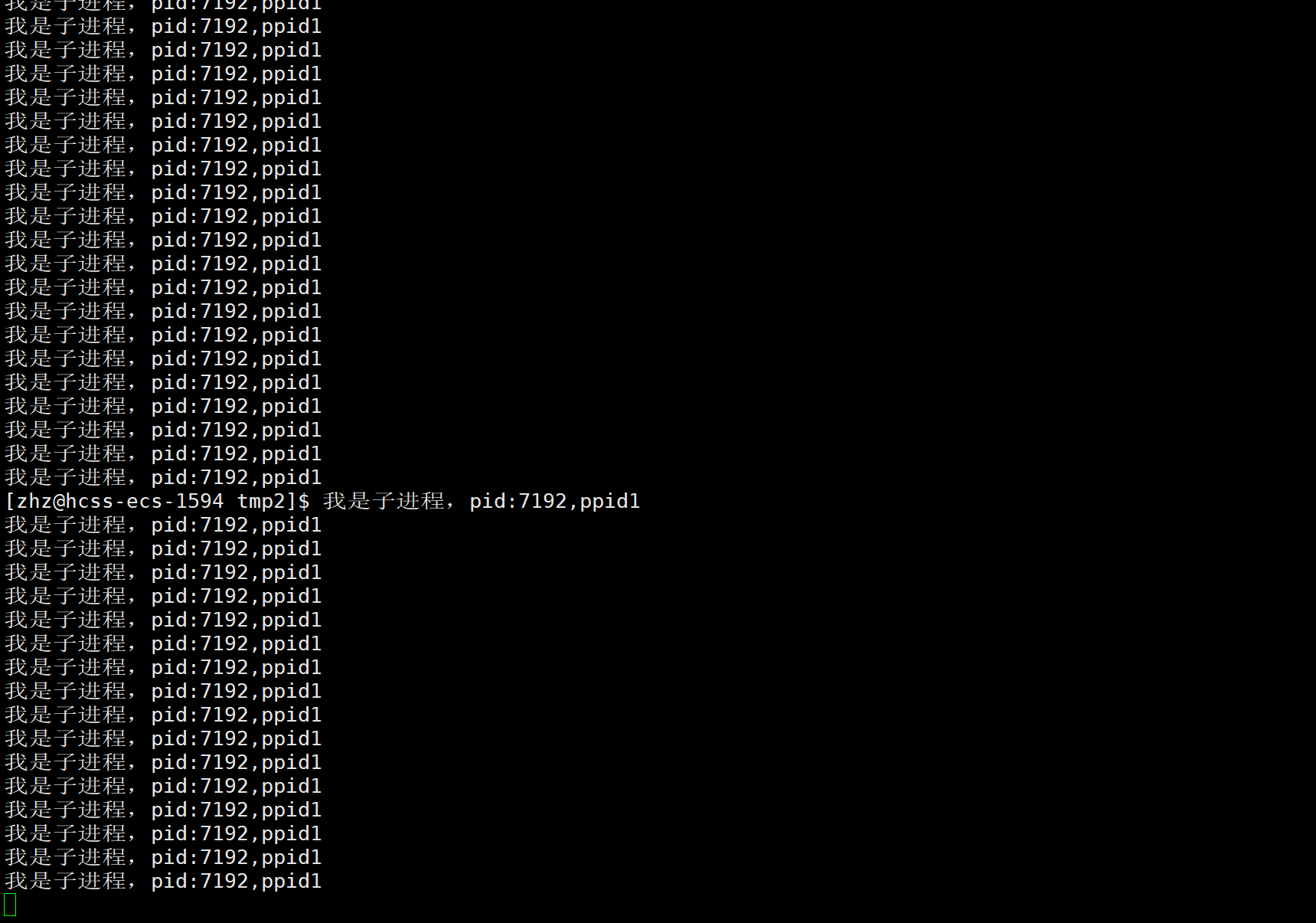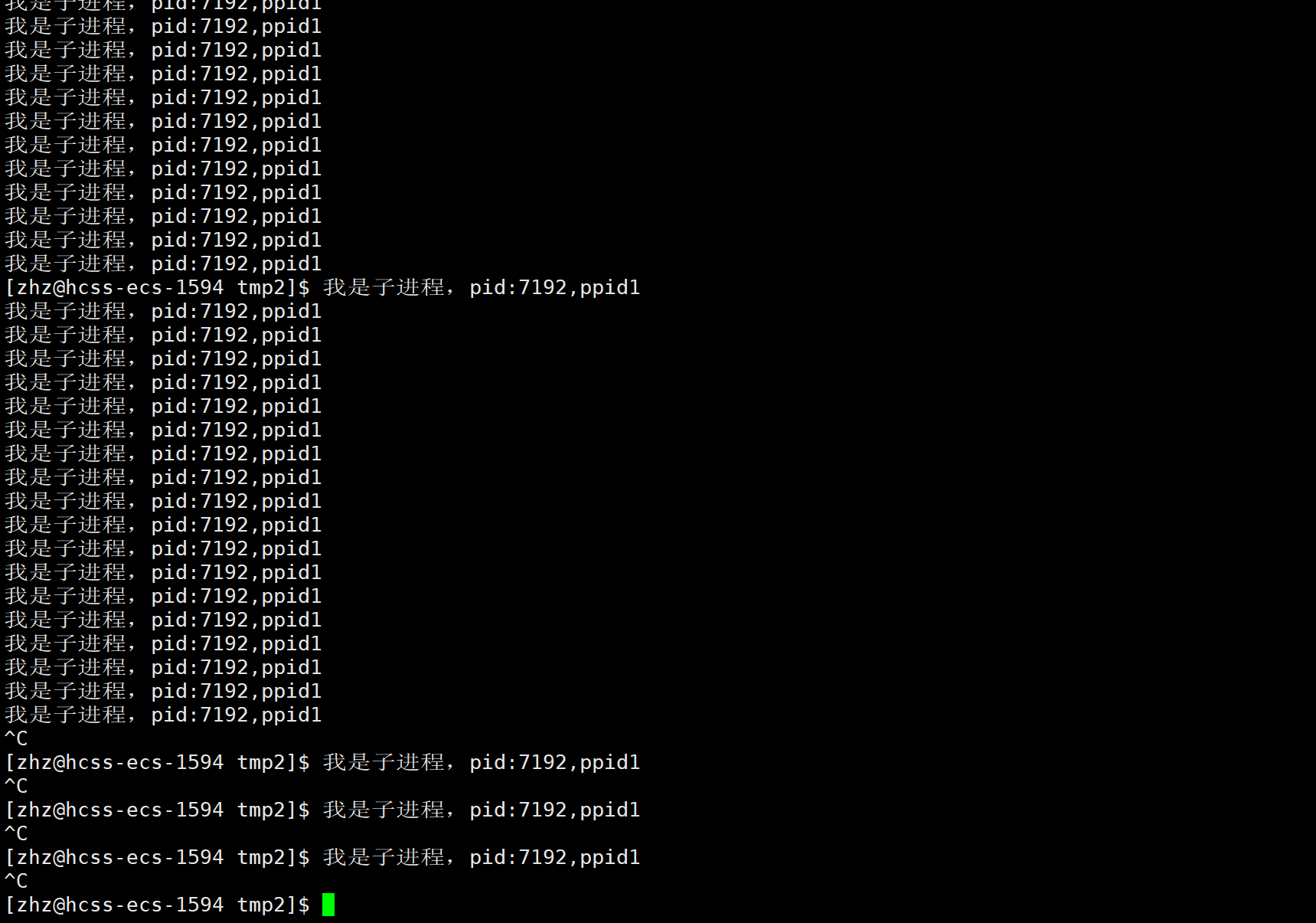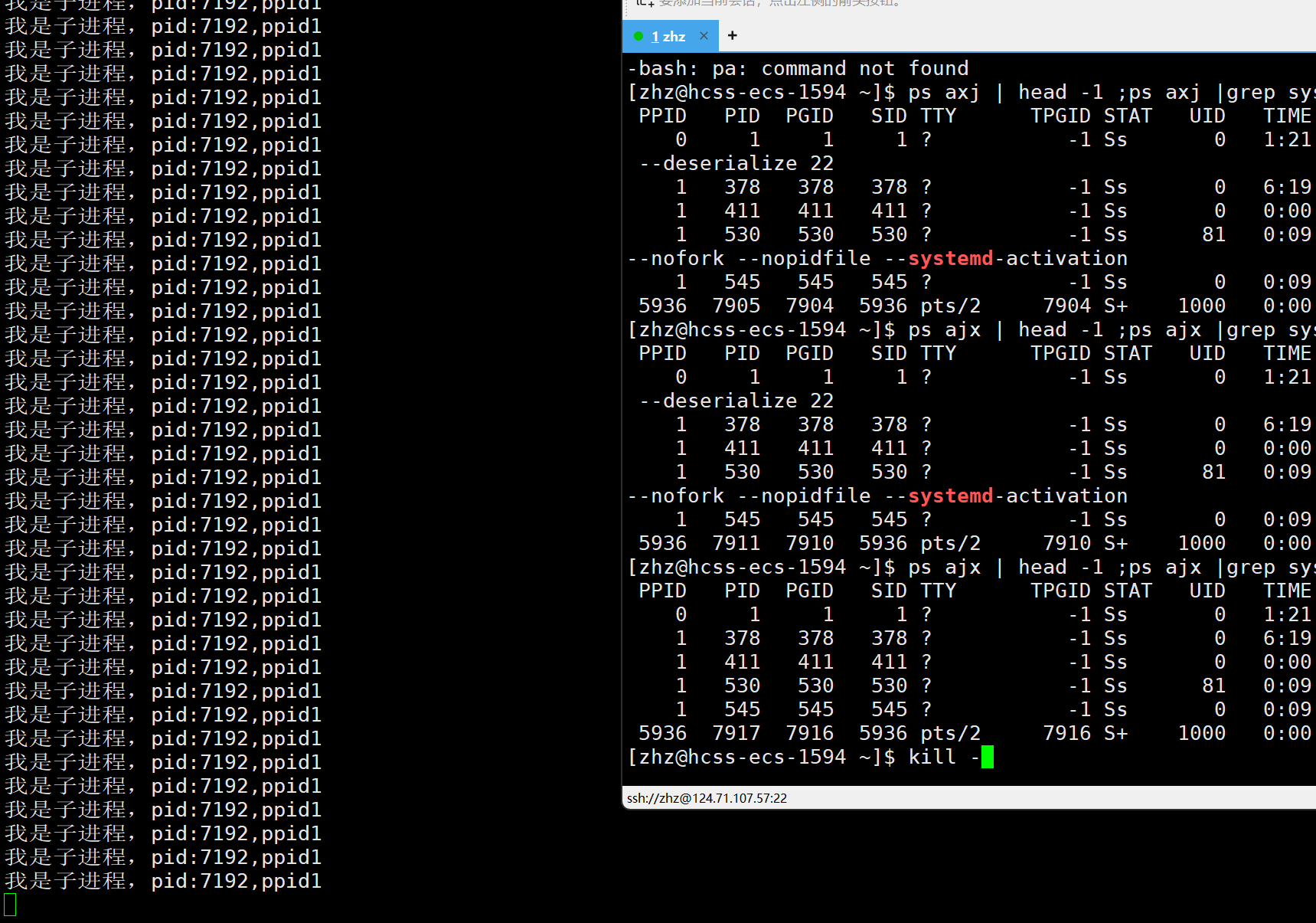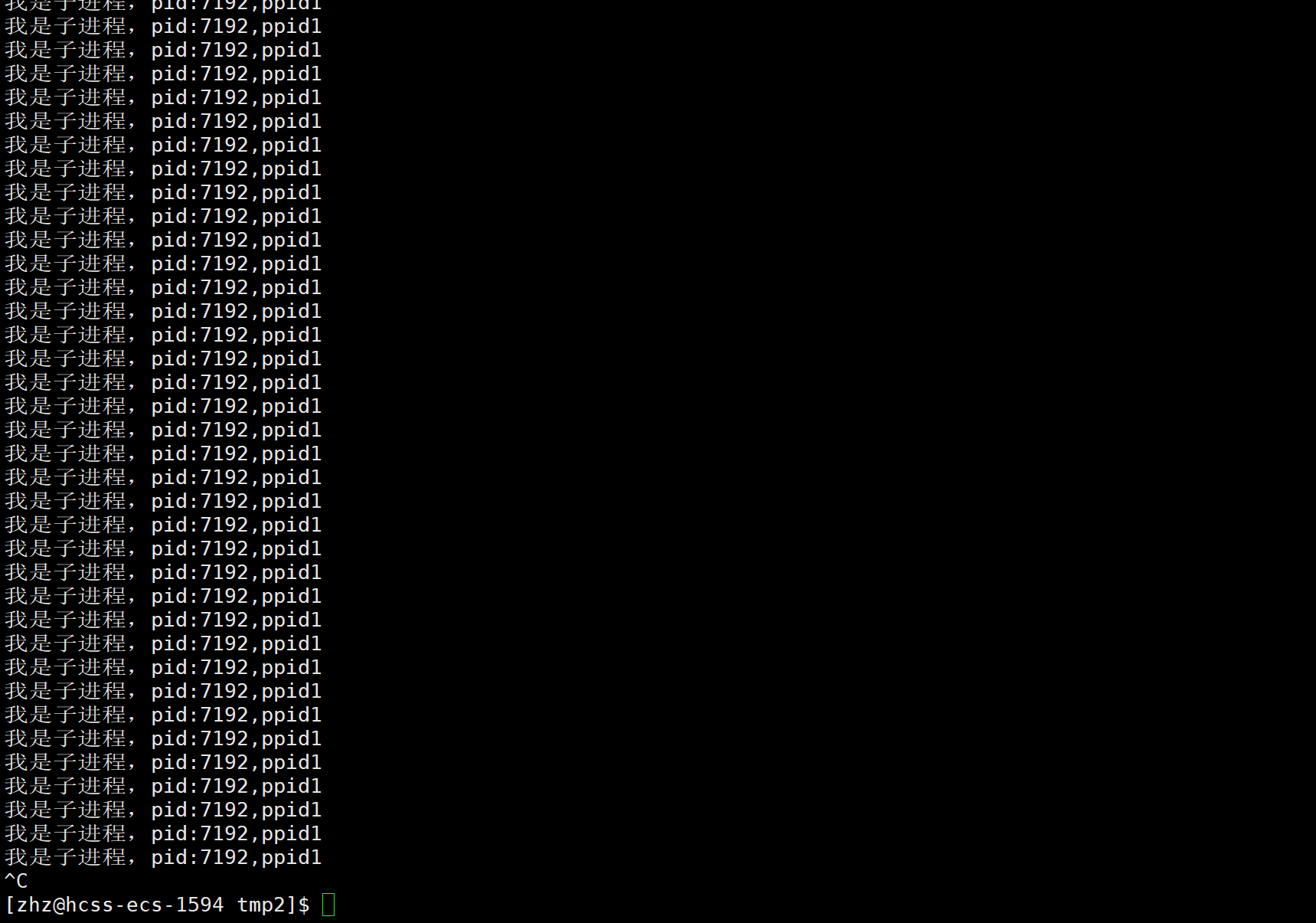
其实在Linux当中1号进程就是在操作系统一开始启动时就创建出来的进程,之后用户的bash进程就是该进程的子进程,在此就可以简单的认为该1号进程就是操作系统。当一个进程的父进程结束之后如何子进程还没有结束的话,此时子进程就变为了孤儿进程。按照Linux系统的规定,孤儿进程都会被1号进程领养,成为1号进程的子进程。
那么此时你可能就会有疑惑了,为什么要让1号进程领养孤儿进程呢?
我们知道当子进程运行结束之后如果不对子进程的退出信息做处理,那么对应的子进程就会变为僵尸进程,最终会导致内存泄漏。因此为了避免该问题就将失去父进程的子进程的父进程设置为1号进程,这样就能让1号进程来结束子进程的退出信息。
对于处于孤儿状态的进程其实是会变为后台进程的,而只有前台进程才能获取键盘的信号,这也就使得无法使用CTRL+结束当前正在运行的后台进程,这时只能使用kill -9指令。
2.进程优先级
首先来了解进程优先级的概念:
• cpu资源分配的先后顺序,就是指进程的优先权(priority)。
• 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。
• 还可以把进程运行到指定的CPU上,这样⼀来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
那么为什么在操作系统当中进程要有优先级呢?
其实这是因为在CPU内部目标资源是有限的,因此就要通过优先级来确定谁先谁后的问题。
在操作系统当中进程的优先级其实就是由数字来描述的,该数字是存储在task_struct内部的。当该进程的优先级更高的时候,其的数值就越低。但由于Linux是基于时间片的分时操作系统,为了考虑公平性,各个进程之间的优先级变化幅度不能过于大;接下来就讲解优先级值的规则。
其实体现优先级的数字就是PRI,当我们运行mytest进程的时候,mytest内进程还创建了一个子进程,那么这是使用ps带上-al选项就可以看到以下的信息

在此以上的UID其实就是用户的id,在Linux当中操作系统区分用户其实不是使用用户名的,而是根据对应的UID来区分的。
在以上当中就可以看到对于进程的PRI值,那么这个值旁边的NI又是什么呢?
在此PRI代表这个进程可被执行的优先级,而NI则表示该进程的nice值,其作用是用于修正PRI。
因此真正的优先级值=PRI(默认值80)+(NI)nice值修正
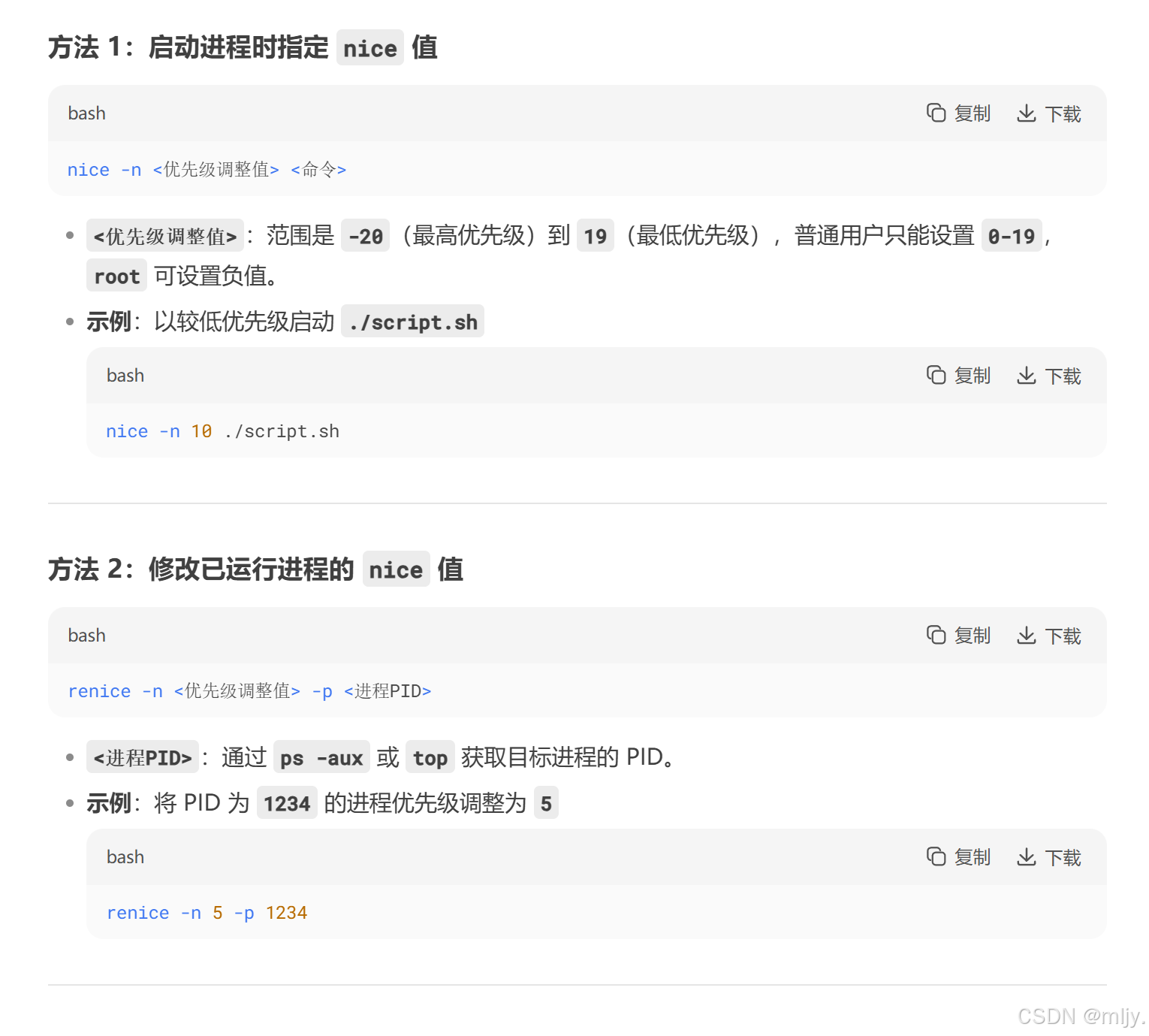
此时如果压修改进程的PRI值就可以使用道以下的指令
除了以上的指令之外还可以使用top进行nice值的修改:
• top
• 进⼊top后按“r”‒>输⼊进程PID‒>输入nice值
注:在此每次修改PRI的值都是从80的基准值上进行修改的,而不是从上一次修改的结果下修改的。并且一帮不建议盲目的修改进程的PRI值,这样不能会影响操作系统的调度。当进程的优先级设置不合理就会导致优先级低的一直得不到CPU的资源,从而导致出进程饥饿
在对进程的优先级值PRI进行修改时其实也是有范围限制的,范围是60~99,这就使得对nice值的修改只能在-20~19区间内。
补充概念-竞争、独立、并行、并发
• 竞争性: 系统进程数目众多,而CPU资源只有少量,甚⾄1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
• 独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰
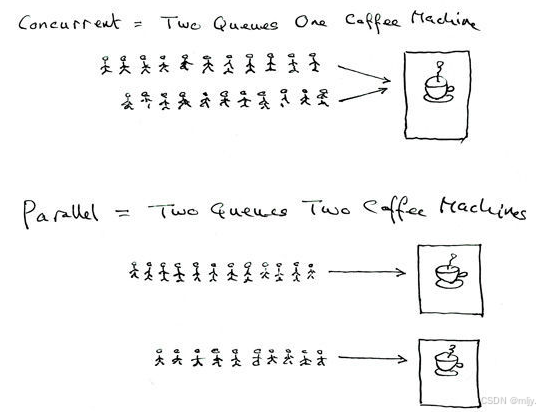
• 并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行
• 并发: 多个进程在⼀个CPU下采⽤进程切换的方式,在⼀段时间之内,让多个进程都得以推进,称之为并发
以下图示就可以简单的解释并发和并行:
3. 进程切换
在了解Linux当中进程是如何切换之前我们先来了解两个小知识点:1.死循环进程是如何运行的 2.CPU内的寄存器
首先了解的就是当运行起来一个死循环的程序,是不是CPU就会被这一个程序一直占用了呢?
其实通过之前的经验就会发现不是这样的,我们在运行死循环的程序时要是一直占用CPU,那么操作系统的内存资源应该会被一直占用啊?最后系统就会奔溃。但其实操作系统是根据时间片来调度程序的,即使是一个死循环的程序,当它的时间片到了也会被停止调度。
接下来还要来了解CPU当中是存在寄存器的
其实在CPU当中是存在非常多的寄存器的,其作用就是用于保存正在运行的程序的临时数据,就例如当我们在计算1+1的时候就会有对应的寄存器保存两个操作数,之后还会有对应的寄存器保存运算的结果,最终就可以通过该寄存器得到结果。
在此关于寄存器有两个结论:
1.寄存器就是CPU内部的临时空间
2.寄存器!=寄存器内的数据注意:寄存器是空间,而寄存器内的数据是内容是可以变化的,这两个概念是不一样的。
以上就是在学习进程的切换之前要补充的知识点,那么接下来就通过一个故事来引入进程的切换
假设你时一个上到大二的学生,最近你看到了征兵的宣传就想着最近的就业形势不怎么样要不去当兵入伍两年,还能得到退伍费,而且自己的体格也还行,说不定就通过选拔了呢?不就之后你就参加了入伍的xba果不其然你成功通过了,那么这时你就需要找你学校当中你的辅导员将你的学籍保留,这样你就可以在退伍之后再重新回学校上课。之后你就将学籍保留了。过了两年之后你重新回到了学校,那么此时你就要找学校了的辅导员将你的学籍信息恢复回来,这样你才能重新在学校立上课。
在以上的故事当中其实你就是程序;学校就是CPU;辅导员就是调度器,当你在学校上课的时候就是进程在CPU内运行,之后当你要去当兵了就是将进程从CPU上剥离下来,也就时对应的进程被替换了,那么在此你的学籍就就是正在运行的进程在CPU内寄存器内的数据也就是CPU内部当前进程的硬件上下文数据,当要保留学籍就是将进程的上下数据保存下来,之后要恢复学籍的时候就是将进程的上下文数据恢复。
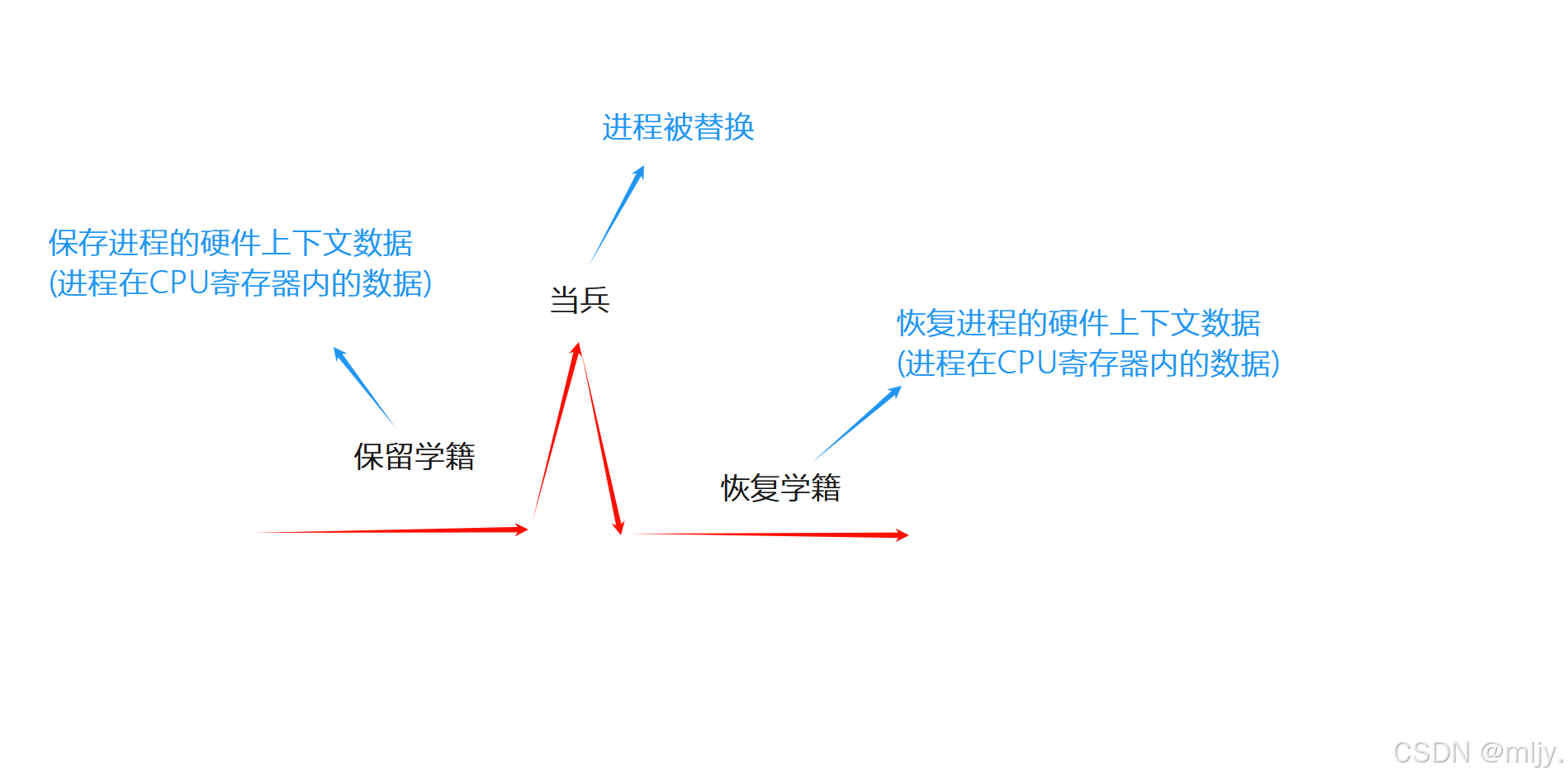
以上我们通过当兵的故事来了解进程的替换其实是感性的了解,那么接下来我们就来理性的理解看看,并且再来补充以上没有提到的一个问题,就是保存的进程德上下文数据是保存到哪里呢?
例如以下正在运行着A程序,假设当前进程运行到100行,产生了一些临时的数据在CPU的寄存器内,那么此时要将正在运行的A进程替换为B进程就其实就需要将A进程德上下文数据保存到A进程的task_struct当中
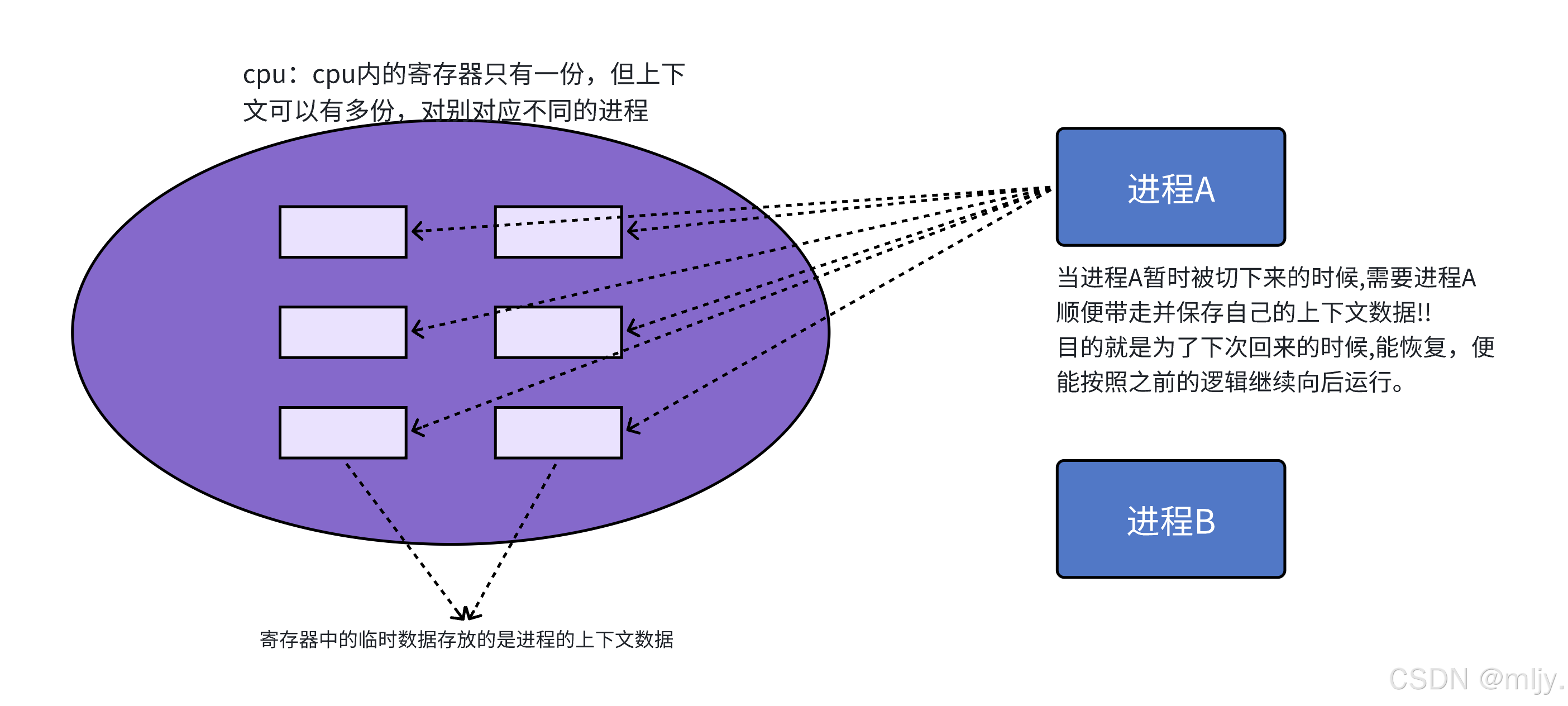
其实再进程替换的时候的上下文数据就是保存在进程的PCB也就死task_struct内的tss对象内,在此将TSS成为任务状态段。 以下我们可以通过Linux的源代码来验证

其实在当代的计算机当中由于task_struct内的数据已经很多了,如果在将进程的上下文数据直接存储到PCB内就会导致PCB十分的臃肿,所以现代的计算机都是将进程替换时的上下文数据数据保存到另外的数据结构当中,当进程要恢复的时候只需要找到对应的数据结构即可。
此时关于进程调度还有一个问题就是在操作系统当中是如何区分全新的进程和已经被调度的进程呢?
其实很简单只需要在task_struct使用一个整型变量来标识即可,当变量是全新的进程时对应的变量值为0,反之被调度之后变量的值就修改为1。
4.Linux内核进程O(1)调度队列
以上我们了解了进程的替换以及在之前学习了OS当中是存在调度队列和阻塞队列的,那么接下来就来了解Linux当中具体的进程调度算法——O(1)调度算法
其实在之前我们了解的进程的调度,也就是进程是如何在调度队列和阻塞队列当中切换的方式是操作系统学科当中描述的,而不是Linux当中具体的调度方式,在Linux当中调度算法是会体现出进程优先级不同的而导致调度过程不同。这就是接下来我们要了解的进程的O(1)调度算法。
接下来我们描述的都是单CPU的情况
在一个CPU当中都会有以下的一个运行队列,在Linux当中叫做runqueue
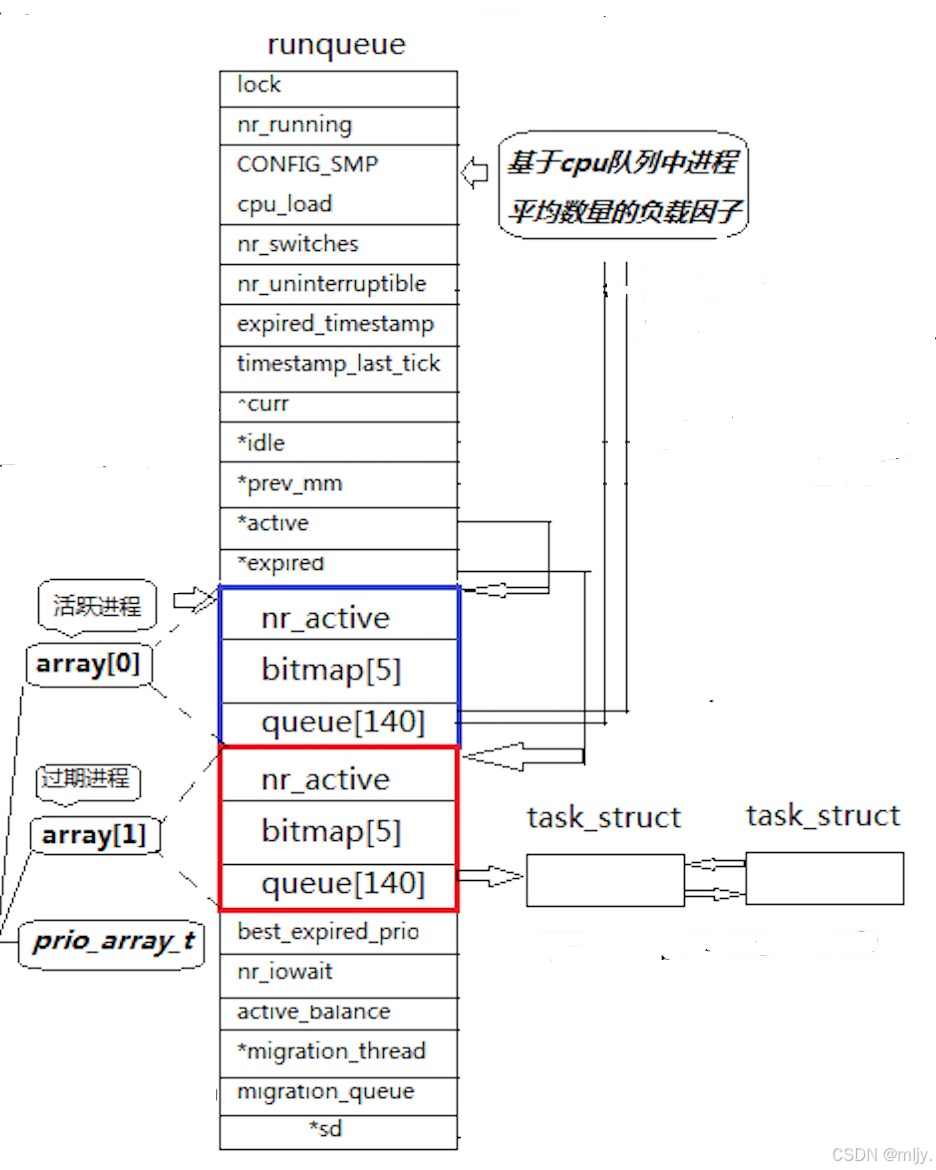
首先来看以上当中的queue[140],那么这个queue[140]是什么呢?
其实只需要将其的写完整我们就可以轻松知道,queue[140]的全名其实是struct task_struct* queue[140],也就是一个指针数组;该数组内元素有140项。
在该数组当中0~99下标其实是实时优先级,那么这时候问题就来了,那就是之前我们了解到进程的优先级的范围不是60~99吗,那这时候为什么又有140个下标;这里的实时优先级又是什么?
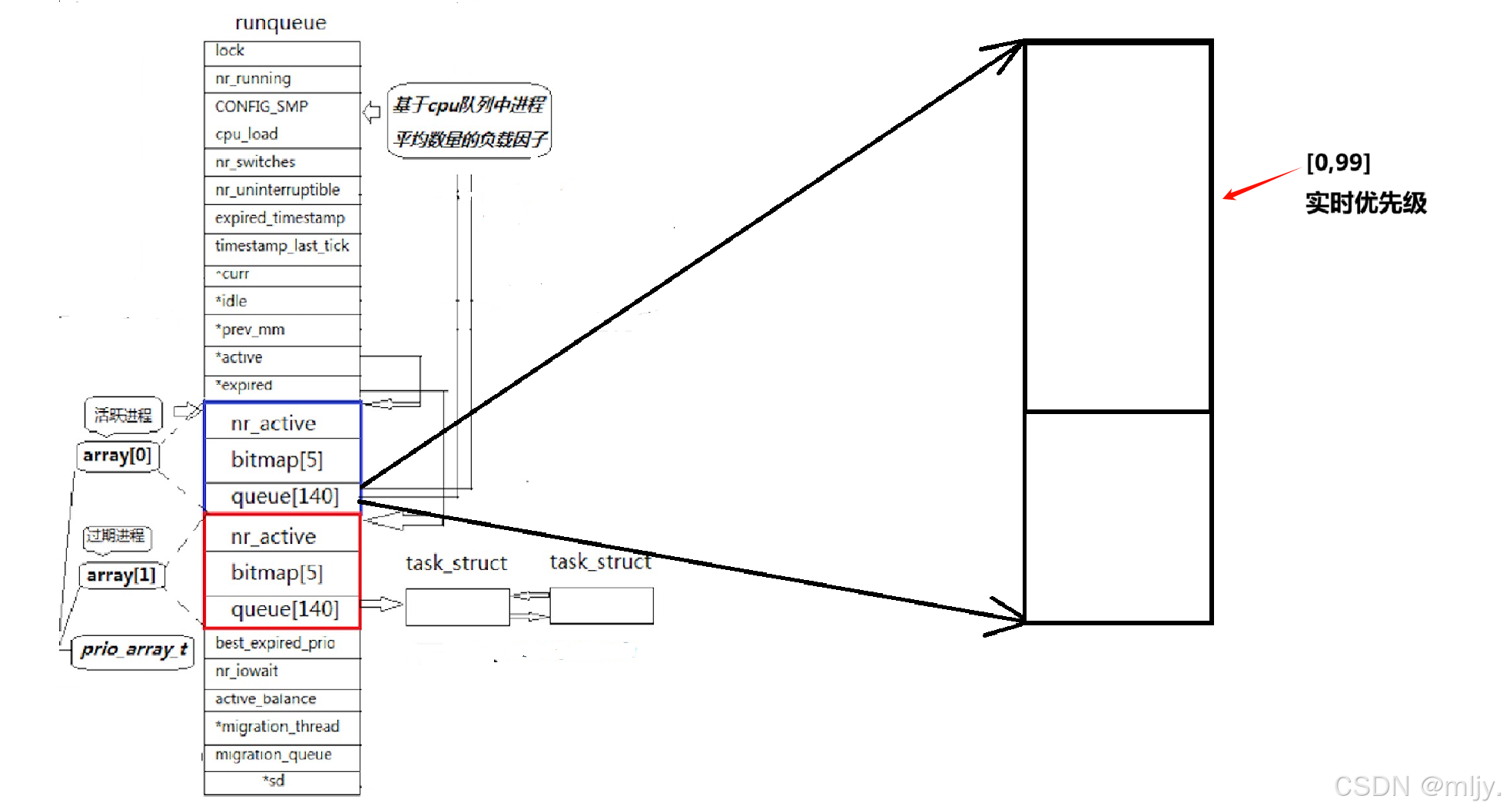
要解答以上的问题就需要来了解一下实时操作系统和分时操作系统
其实可以将操作系统是否按照时间片划分分为实时操作系统和分时操作系统,简单来说这两个的区别就是分时操作系统是会按照进程的时间片以及进程的优先级来对进程合理的调度,而实时操作系统则是完全按照进程的优先级来决定进程的运行顺序,优先级最低的进程会立刻被调用到运行。
实时操作系统更适合于工业领域,而分时操作系统更适合于计算机、手机、服务器等领域。我们使用的Windows以及Linux操作系统都是分时操作系统。
那么接下来又有问题了,那就是我们知道了Linux是分时操作系统,那么为什么在还要提供实时优先级呢?
这其实是Linux为了兼顾更多的使用场景,有了实时优先级Linux就也可以使用到工业领域当中了,更广阔的用户市场是操作系统更想看到的。但是正常情况下我们是不会使用到0~99的优先级的。而在queue数组当中剩下的下标101~140就正好对应了之前的PRI值60到99区间,此时只要通过算法就可以将PRI的值转化为相应的数组下标。
并且在queue数组当中每个数组下标内存放的都是队列的指针,这就可以让同一优先级的队列链路到同一队列当中
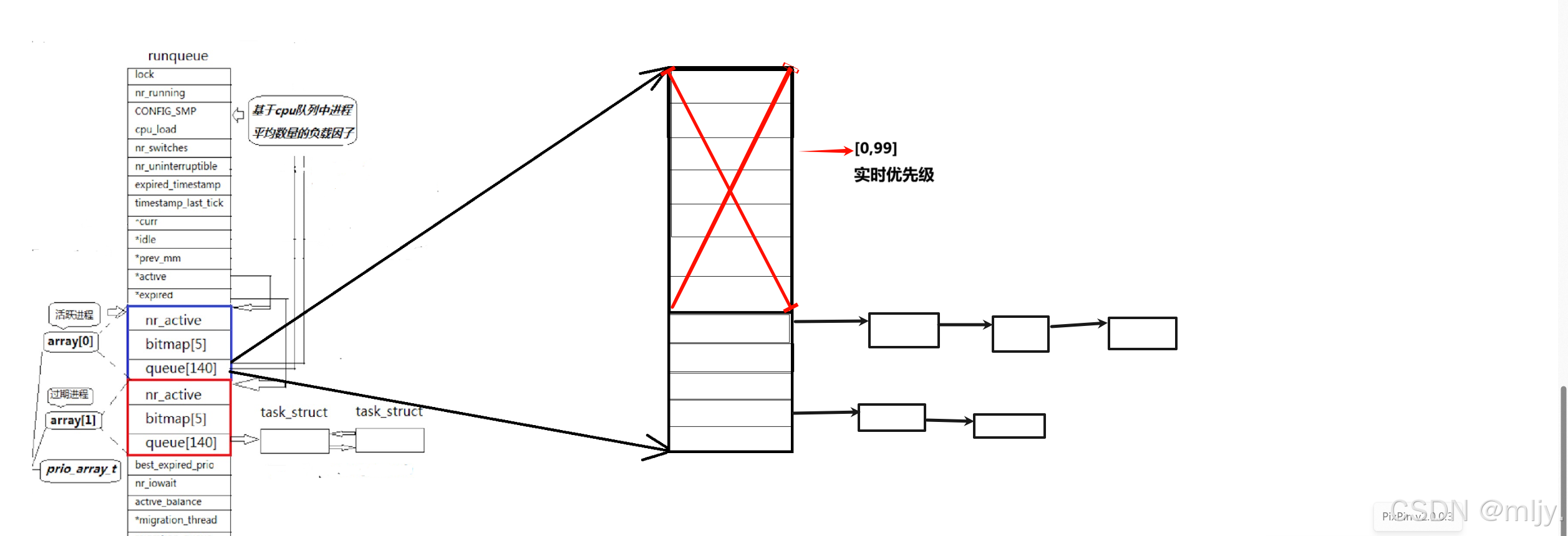 有了以上的结构就可以在queue数组当中进行调度,数组的每一个元素就指向一个队列,因此queue数组其实就是一个哈希表。那么此时在以上的queue当中查询要进行调度的进程如果只有进程优先级为99那不就要遍历一次queue数组才能查询到,这时虽然说只需要进行40个的查询,但是理论上时间复杂度还是O(n);那么这时要进行查询效率优化就在在runqueue当中添加了一个bitmap[5],在此bitmap内元素的类型为无符号整型,这5个元素总的比特位总数为32x5=160,这时就时就使用0到140的比特位来标识对应queue数组元素是否为空,是的话对应的比特位位置的值就为0;反之就为1,在此就可以使用位图来实现O(1)的查询效率。
有了以上的结构就可以在queue数组当中进行调度,数组的每一个元素就指向一个队列,因此queue数组其实就是一个哈希表。那么此时在以上的queue当中查询要进行调度的进程如果只有进程优先级为99那不就要遍历一次queue数组才能查询到,这时虽然说只需要进行40个的查询,但是理论上时间复杂度还是O(n);那么这时要进行查询效率优化就在在runqueue当中添加了一个bitmap[5],在此bitmap内元素的类型为无符号整型,这5个元素总的比特位总数为32x5=160,这时就时就使用0到140的比特位来标识对应queue数组元素是否为空,是的话对应的比特位位置的值就为0;反之就为1,在此就可以使用位图来实现O(1)的查询效率。
并且在runqueue当中还使用一个变量nr_active来统计当中所有队列的进程总数,当值为0的时候就说明当中无进程链路到队列当中。
以上的调度过程看似已经可可以满足要求了,但是其实还存在一个问题就是如果将已经调用过的进程从新链路到以上的queue当中,此时就会出现只有将高优先级的执行完才会执行低优先级的进程,这不就和我们的预期相违背了吗?
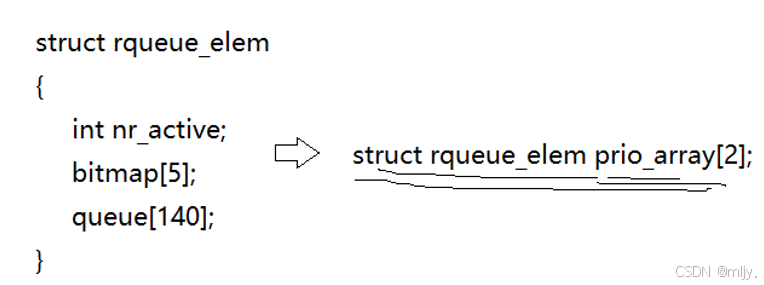
因此为了解决以上的问题在runqueue当中就再创建了一个过期队列,当进程的时间片结束之后但是进程还没有执行完就将对应的进程链路到过期队列当中。要实现这样的效果只需要在runqueue当中创建requeue_elem的结构体,在该结构体内部存在active、bitmap[5]、queue[140]。在queue当中创建两个requeue_elem的对象的数组,之前的调度队列就是下标为0的元素;而过期队列就是下标为1的元素。
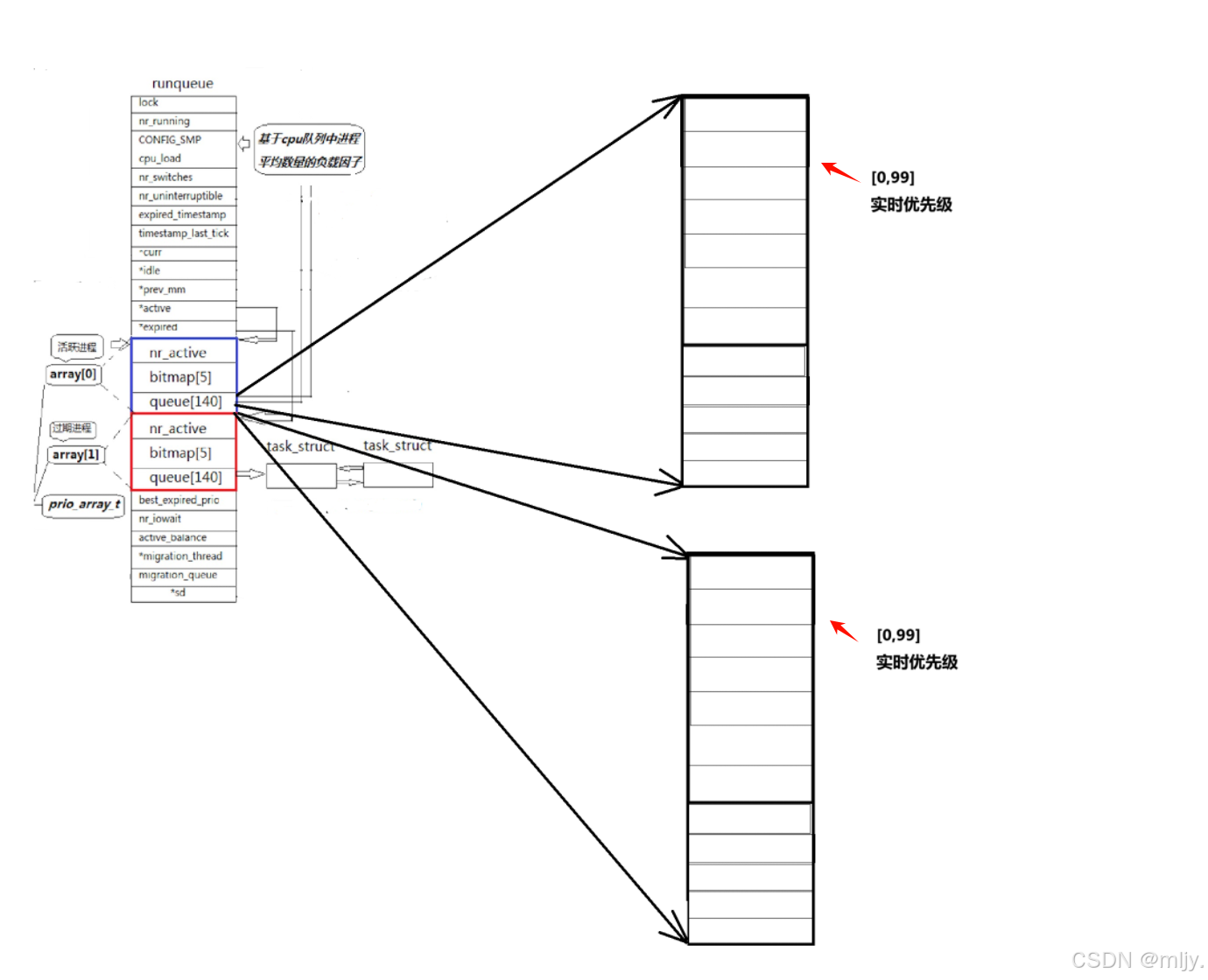
那么当运行队列上的进程都运行完了之后如何转而去运行过期队列上的进程呢,在此在runqueue当中就创建两个指针变量active和expired,active初始化的时候就指向运行队列;expired就指向过期队列,当要指向过期队列时只需要将这两个变量进行交换即可。

swap(&active,&expired);而新创建的进程如果直接插入到运行队列当中就实现了内核优先级抢占,如果是插入到过期队列当中就实现进程的就绪状态。
通过以上的各个模式的配合就实现了进程的O(1)调度队列。
以上就是本篇的全部内容了,接下来我们将继续学习进程的概念,接下来我们将重点学习环境变量和进程地址空间。
相关文章:
》)
Linux《进程概念(中)》
在之前的Linux《进程概念(上)》当中我们已经了解了进程的基本概念以及如何去创建对应的子进程,那么接下来在本篇当中我们就继续来进程的学习,在本篇当中我们要学习到进程的状态、进程的优先级、进程切换、Linux真实的调度算法——…...

Linux Vim 使用 显示行号、替换、查找、多文件打开等骚操作
目录 简述 vim的三种模式 概述 转换方式 文本编辑 命令模式 插入(编辑)模式 底行模式 搜索关键字 显示行号 替换 多文件打开 简述 vi编辑器是Linux系统下标准的编辑器。 那么简单的理解,就像是Windows下的记事本。 补充&a…...

AimRT 从零到一:官方示例精讲 —— 三、Executor示例.md
Executor示例 官方仓库:executor 配置文件(configuration_executor.yaml) 依据官方示例项目结构自行编写YAML配置文件: # 基础信息 base_info:project_name: Logger # 项目名称build_mode_tags: ["EXAMPLE", &quo…...

只把夜莺监控当作告警来使用:一种轻量化的运维实践
只把夜莺监控当作告警来使用:一种轻量化的运维实践 在现代的 IT 运维体系中,监控和告警是两个经常被一同提及的概念。然而,在实际工作中,很多团队对监控系统的需求并不一定全面覆盖指标采集、可视化展示、告警触发等功能…...
)
按键精灵安卓ios辅助工具脚本:实用的文件插件(lua开源)
亮点:此lua插件可再android和ios上通用 1、获取文件的属性 2、改变当前的工作路径为dirpath 3、获取当前的工作路径 4、创建文件夹,支持多级创建 5、删除文件夹 6、递归遍历文件夹 7、设置文件的访问时间和修改时间 函数原型:lfs.Attribute(…...

水库现代化建设指南-水库运管矩阵管理系统建设方案
政策背景 2023年8月24日,水利部发布的水利部关于加快构建现代化水库运行管理矩阵的指导意见中指出,在全面推进水库工程标准化管理的基础上,强化数字赋能,加快构建以推进全覆盖、全要素、全天候、全周期“四全”管理,完…...

若依后台管理系统-v3.8.8-登录模块--个人笔记
各位编程爱好者们,你们好!今天让我们来聊聊若依系统在登录模块的一些业务逻辑,以及本人的一些简介和心得,那么废话不多说,让我们现在开始吧。 以下展示的这段代码,正是若依在业务层对应的登录代码…...

Flip PDF Plus Corp7.7.22电子书制作软件
flip pdf plus corporate7.7.22中文版由FlipBuilder官方出品的一款企业级的翻页电子书制作软件,拥有丰富的模板,主题和动画场景,每本书最大页数1000页,每本书的最大大小1GB,即可以帮助企业用户制作好丰富的电子书籍。 …...

公路安全知识竞赛主持稿串词
合 :尊敬的各位领导、各位来宾 、各位选手 : 大家上午 好! 男 :安全就是生命,安全就是效益,安全是一切工作的重中之重!安全生产只有满分,没有及格。只有安全生产这个环节不出差错,我…...

vscode 配置qt
工具:vscode、qttools、qtconfigure Search Mode改成基于cmake的。 # 在项目中指定Qt的路径 set(Qt5_DIR "/home/jp/qt-everywhere-src-5.12.9/arm-qt/lib/cmake/Qt5") # 用于指定 Qt5 的安装路径 find_package(Qt5 REQUIRED COMPONENTS Widgets)这样就…...

Node.js 事件循环和线程池任务完整指南
在 Node.js 的运行体系中,事件循环和线程池是保障其高效异步处理能力的核心组件。事件循环负责调度各类异步任务的执行顺序,而线程池则承担着处理 CPU 密集型及部分特定 I/O 任务的工作。接下来,我们将结合图示,详细剖析两者的工作…...

Java之BigDecimal
BigDecimal 是 Java 中用于高精度计算的类,特别适合需要精确十进制运算的场景,如金融计算、货币运算、概率计算等。 为什么需要 BigDecimal类 解决浮点数精度问题:float 和 double 使用二进制浮点运算,无法精确表示某些十进制小数…...
X轴方向旋转60度)
Qt5与现代OpenGL学习(四)X轴方向旋转60度
把上面两张图像放到D盘1文件夹内: shader.h #ifndef SHADER_H #define SHADER_H#include <QDebug> #include <QOpenGLShader> #include <QOpenGLShaderProgram> #include <QString>class Shader { public:Shader(const QString& verte…...

基于LVS+Keepalived+NFS的高可用负载均衡集群部署
目录 项目功能 2 项目的部署 2.1 部署环境介绍 2.2 项目的拓扑结构 2.3 项目环境调试 2.4 项目的部署 2.4.1 安装软件; 2.4.2 NFS服务器配置 2.4.3 Web节点配置 2.5 项目功能的验证 2.6 项目对应服务使用的日志 项目功能 负载均衡功能 实现原理:基于LVS(D…...
:线性代数)
人工智能数学基础(四):线性代数
线性代数是人工智能领域的核心数学工具之一,广泛应用于数据表示、模型训练和算法优化等多个环节。本文将系统梳理线性代数的关键知识点,并结合 Python 实例,助力读者轻松掌握这一重要学科。资源绑定附上完整资源供读者参考学习! …...

基于C++的IOT网关和平台1:github项目ctGateway
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...

LeetCode 2962.统计最大元素出现至少 K 次的子数组:滑动窗口
【LetMeFly】2962.统计最大元素出现至少 K 次的子数组:滑动窗口 力扣题目链接:https://leetcode.cn/problems/count-subarrays-where-max-element-appears-at-least-k-times/ 给你一个整数数组 nums 和一个 正整数 k 。 请你统计有多少满足 「 nums 中…...

Nginx反向代理的负载均衡配置
Nginx 负载均衡详解 在互联网应用中,随着网站访问量的不断攀升,服务器的服务模式也需要进行相应升级。诸如分离数据库服务器、将图片作为单独服务等操作,这些都属于简单的数据负载均衡,其目的是将压力分散到不同机器上。而来自 We…...

案例速成GO+Socket,个人笔记
更多个人笔记:(仅供参考,非盈利) gitee: https://gitee.com/harryhack/it_note github: https://github.com/ZHLOVEYY/IT_note 文章目录 简单知识了解实现一个TCP 服务器与客户端(聊天室&#x…...

篮球足球体育球员综合资讯网站模板
采用帝国CMS7.5新版核心。栏目和内容模板超多变换。后台操作简单,安全可靠,性能稳定。整站浏览效果高端大气,可以帮助你快速建立一个适合自己的软件下载类型的站点! 演示地址:https://www.tmuban.com/store/620.html …...
全面总结)
HTTP(超文本传输协议)全面总结
HTTP(HyperText Transfer Protocol,超文本传输协议)是万维网(World Wide Web)应用中的基础协议,用于客户端与服务器之间的数据传输。随着互联网技术的发展,HTTP协议也经历了多个版本的更新&…...
图像与通道拼接函数-----根据指定的方式翻转图像(GMat)函数 flip())
OpenCV 图形API(72)图像与通道拼接函数-----根据指定的方式翻转图像(GMat)函数 flip()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 翻转一个2D矩阵,围绕垂直轴、水平轴或同时围绕两个轴。 该函数以三种不同的方式之一翻转矩阵(行和列的索引是从0开始的&a…...
阻止了未签名的原生模块(bcrypt_lib.node)加载)
【报错问题】 macOS 的安全策略(Gatekeeper)阻止了未签名的原生模块(bcrypt_lib.node)加载
这个错误是由于 macOS 的安全策略(Gatekeeper)阻止了未签名的原生模块(bcrypt_lib.node)加载 导致的。以下是具体解决方案: 1. 临时允许加载未签名模块(推荐先尝试) 在终端运行以下命令&#x…...

keep-alive具体使用方法
什么是 Keep-Alive <keep-alive> 是 Vue.js 提供的一个内置组件,用于缓存动态组件实例,从而避免重复渲染已加载过的组件。它的主要功能是在切换组件时保留状态和 DOM 结构,提升性能。 工作原理 <keep-alive> 的核心在于维护一个…...

【C++11】包装器:function与bind
前言: 上文我们学了C11中一个新的表达式:Lambda表达式。Lambda表达式可以在函数内部定义,其本质是仿函数【C11】Lambda表达式-CSDN博客 本文我们来学习C11的下一个新语法:包装器 function function的定义为: templat…...
)
Educational Codeforces Round 178 div2(题解ABCDE)
A. Three Decks #1.由于最后三个数会相等,提前算出来和,%3判断,再判前两个数是否大于 #include<iostream> #include<vector> #include<stdio.h> #include<map> #include<string> #include<algorithm> #…...

mermaid 序列图 解析
sequenceDiagramparticipant UI as 用户界面participant Executor as 任务执行器participant StateMgr as 状态管理器participant Repo as 数据仓库UI->>Executor: 执行任务3350c74e...Executor->>StateMgr: 更新状态为"measuring"StateMgr->>Repo…...

DTO,VO,PO,Entity
1. DTO (Data Transfer Object) 定义 DTO 是数据传输对象,用于在不同系统或层之间传输数据。 目的 简化数据传输,降低耦合,通常只包含需要传输的字段,避免暴露内部实现细节。 使用场景 Controller 和 Service 或 远程调用 之…...

Proser:重新介绍
回想Proser的定位:一款直观的【协议发送】模拟软件。 现在间断更新下来,基本成了一款通信调试助手类软件 Proser 是一款支持串口与网络的通信调试助手,其独有的协议编辑器、数据检视、标尺等功能,让指令模拟与数据分析更加易用。…...

微信小程序 首页之轮播图和搜索框 代码分享
注意!!! 只有样式,还没功能开发!!! index.wxml <!-- 搜索框 --> <view class"search"><input placeholder"请输入搜索的内容"></input><imag…...

3D可视化编辑器模版
体验地址:http://mute.turntip.cn 整个搭建平台核心模块包含如下几个部分: 3D场景渲染 组件拖拽系统 元素编辑功能 状态管理 历史记录与撤销/重做 技术栈 前端框架与库 React 18 用于构建用户界面的JavaScript库 Next.js 14 React框架,提供服…...

foc控制 - clarke变换和park变换
1. foc控制框图 下图是foc控制框图,本文主要是讲解foc控制中的larke变换和park变换clarke变换将 静止的 a b c abc abc坐标系 变换到 静止的 α β αβ αβ坐标系,本质上还是以 定子 为基准的坐标系park变换 则将 α β αβ αβ坐标系 变换到 随 转…...

DeepSeek: 探索未来的深度学习搜索引擎
深度学习驱动的下一代搜索引擎:DeepSeek 在信息爆炸的时代,搜索引擎作为连接用户与互联网世界的桥梁,其重要性不言而喻。然而,随着用户需求的日益多样化和复杂化,传统搜索引擎在理解和满足用户需求方面逐渐显现出局限…...

如何在本地部署小智服务器:从源码到全模块运行的详细步骤
小智聊天机器人本地后台服务器源码全模块部署 作者:林甲酸 -不是小女子也不是女汉子 是大女子 更新日期:2025年4月29日 🎯 前言:为什么要写这篇教程? 上周按照虾哥小智服务器的教程去部署本地后台,我用的是…...
)
基于论文的大模型应用:基于SmartETL的arXiv论文数据接入与预处理(四)
上一篇介绍了基于SmartETL框架实现arxiv采集处理的基本流程,通过少量的组件定制开发,配合yaml流程配置,实现了复杂的arxiv采集处理。 由于其业务流程复杂,在实际应用中还存在一些不足需要优化。 5. 基于Kafka的任务解耦设计 5.…...

GrapesJS 终极定制组件设计方案:扁平化对象属性编辑、多区域拖拽、多层嵌套与组件扩展实战
掌握 GrapesJS 复杂组件实用技巧,打造高复用、高交互的前端低代码组件体系 随着低代码可视化编辑需求日益提升,GrapesJS 作为优秀开源画布编辑器,灵活的组件机制是其核心优势。但在实际项目中,你可能会遇到: 如何编辑…...

Spring MVC 如何映射 HTTP 请求到 Controller 方法?
我们来详细分析一下如何在 Spring MVC 中将 HTTP 请求映射到 Controller 的处理方法(Handler Methods)上,以及 RequestMapping 注解的使用方法。 请求映射的核心:RequestMapping 注解 RequestMapping 是 Spring MVC 中最核心、最…...

vue.js中的一些事件修饰符【前端】
不要一直责怪过去的自己,他独自站在雾里也很迷茫。 目录 .stop:.prevent:.self:.once:.capture:.native:何时使用 .native? .stop: 作用:调用 event.stopPro…...

WEBSTORM前端 —— 第2章:CSS —— 第4节:盒子模型
目录 1.画盒子 2.Pxcook软件 3.盒子模型——组成 4.盒子模型 ——边框线 5.盒子模型——内外边距 6.盒子模型——尺寸计算 7.清除默认样式 8.盒子模型——元素溢出 9.外边距问题 ①合并现象 ②塌陷问题 10.行内元素——内外边距问题 11.盒子模型——圆角 12.盒子…...

Cursor —— AI编辑器 使用详解
Cursor - The AI Code Editor 一、Cursor 是什么? Cursor 是一款优秀的AI代码编辑器,它内置了 Deepseek-R1、GPT-4、Claude等 AI 模型。 简单说,就是:Cursor VS Code 编辑器 AI 大模型 Cursor 功能特性(代码补全、…...
)
故障诊断——复现github代码ClassBD-CNN(BDCNN)
刚好看到这篇文献有github代码,而且也比较新,感觉可以当作自己论文中的对比方法。 https://www.sciencedirect.com/science/article/pii/S0888327024006484 (论文地址) (看到4090,有点想劝退自己......&…...

局部和整体的关系
Prompt:为什么要研究局部和整体的关系呢?是因为很多情况下,局部就能表达出整体? 这是一个非常本质的问题,其实你已经接近数学和物理中“几何本质”的核心了。我们研究局部和整体的关系,是因为:…...

1.5 点云数据获取方式——双目立体相机
图1-5-1 双目立体相机 双目相机通过模拟人眼立体视觉,利用两个摄像头的视差信息计算物体深度,进而生成 3D 点云,具有成本低、体积小、信息丰富等优势,成为中...

Flume启动报错
报错1: 报错2: File Channel transaction capacity cannot be greater than the capacity of the channel capacit... 解决方案:删除配置...
)
leetcode 21. 合并两个有序链表(c++解法+相关知识点复习)
目录 题目 所需知识点复习 1.链表 1.1单链表 1.2哑结点(Dummy Node) 解答过程 1.循环双指针解法 2.递归解法 2025.4.29想到其他知识点会后续再继续补充。 题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表…...

链表反转_leedcodeP206
P206反转链表 原题 反转思路 将链表反转的过程分为两个区域: 🟦 未反转区(待处理) 原链表中还没有处理(还没有反转指针方向)的部分,从 current 开始一直到链表尾部。 🟩 已反转…...

Laravel+API 接口
LaravelAPI 接口 网课连接:BIlibili. 中文文档. 1.RestFul Api编码风格 一、API设计 修改hosts,C:\Windows\System32\drivers\etc\hosts,增加127.0.0.1 api.lv8.com # Laravel 框架 用这个域名来测试(推荐规范) 在…...

在 Ubuntu 上离线安装 ClickHouse
在 Ubuntu 上离线安装 ClickHouse 的步骤如下: 一.安装验证 # 检查服务状态 sudo systemctl status clickhouse-server #删除默认文件 sudo rm /etc/clickhouse-server/users.d/default-password.xml # 使用客户端连接 clickhouse-client --password...
)
【AI微信小程序开发】掷骰子小程序项目代码:自设骰子数量和动画(含完整前端代码)
系列文章目录 【AI微信小程序开发】AI减脂菜谱小程序项目代码:根据用户身高/体重等信息定制菜谱(含完整前端+后端代码)【AI微信小程序开发】AI菜谱推荐小程序项目代码:根据剩余食材智能生成菜谱(含完整前端+后端代码)【AI微信小程序开发】图片工具小程序项目代码:图片压…...

Linux-02-VIM和VI编辑器
第一节:什么是VI和VIM编辑器: VI是Unix和类Unix操作系统中出现的通用的文本编辑器。VIM是从VI发展出来的一个性能更强大的文本编辑器可以主动的以字体颜色辨别语法的正确性,方便程序设计,VIM和VI编辑器完全兼容。使用:vi xxx文件 或者vim xxx文件,简单来说就是用来编辑文件的一…...