故障诊断——复现github代码ClassBD-CNN(BDCNN)
刚好看到这篇文献有github代码,而且也比较新,感觉可以当作自己论文中的对比方法。
https://www.sciencedirect.com/science/article/pii/S0888327024006484 (论文地址)

(看到4090,有点想劝退自己......)
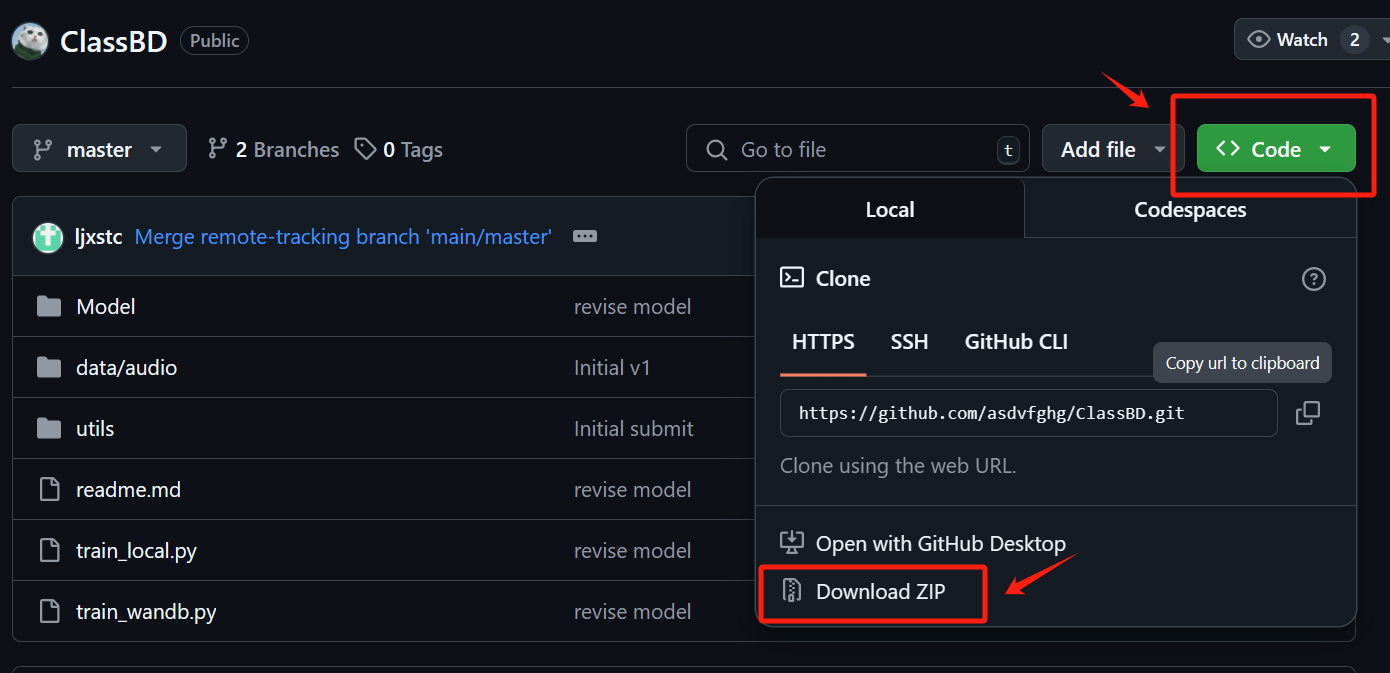
算了,来都来了,试试吧。https://github.com/asdvfghg/ClassBD
[还好没劝退,其实在4060上也能用]
一. 准备工作
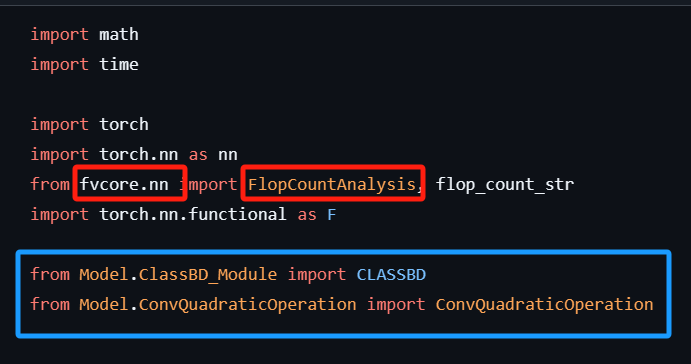
这篇文献是在python 3.8和pytorch 2.1中运行。
然后观察我想运行的BDCNN的代码,除了torch外,还得看我有没有下载fvcore。
蓝色的框是Github代码包里就自带的。
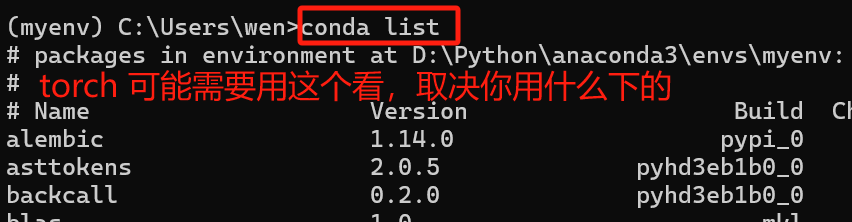
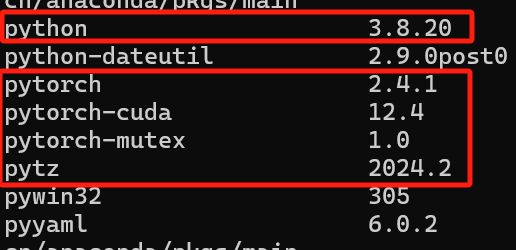 (注:建立环境按照论文写的来,python3.8)
(注:建立环境按照论文写的来,python3.8)
{不会建立环境和下pytorch的小伙伴看这里:计算生物学习——Code_PyTorch(06.15-06.19)_libcupti.so.11.8-CSDN博客}
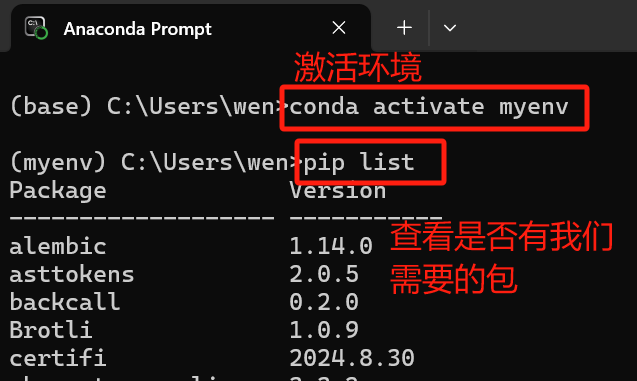
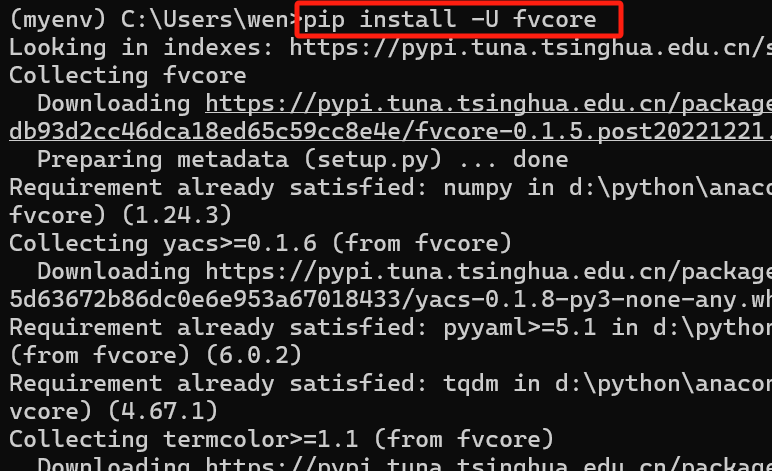
没有fvcore,下一个。官网:GitCode - 全球开发者的开源社区,开源代码托管平台
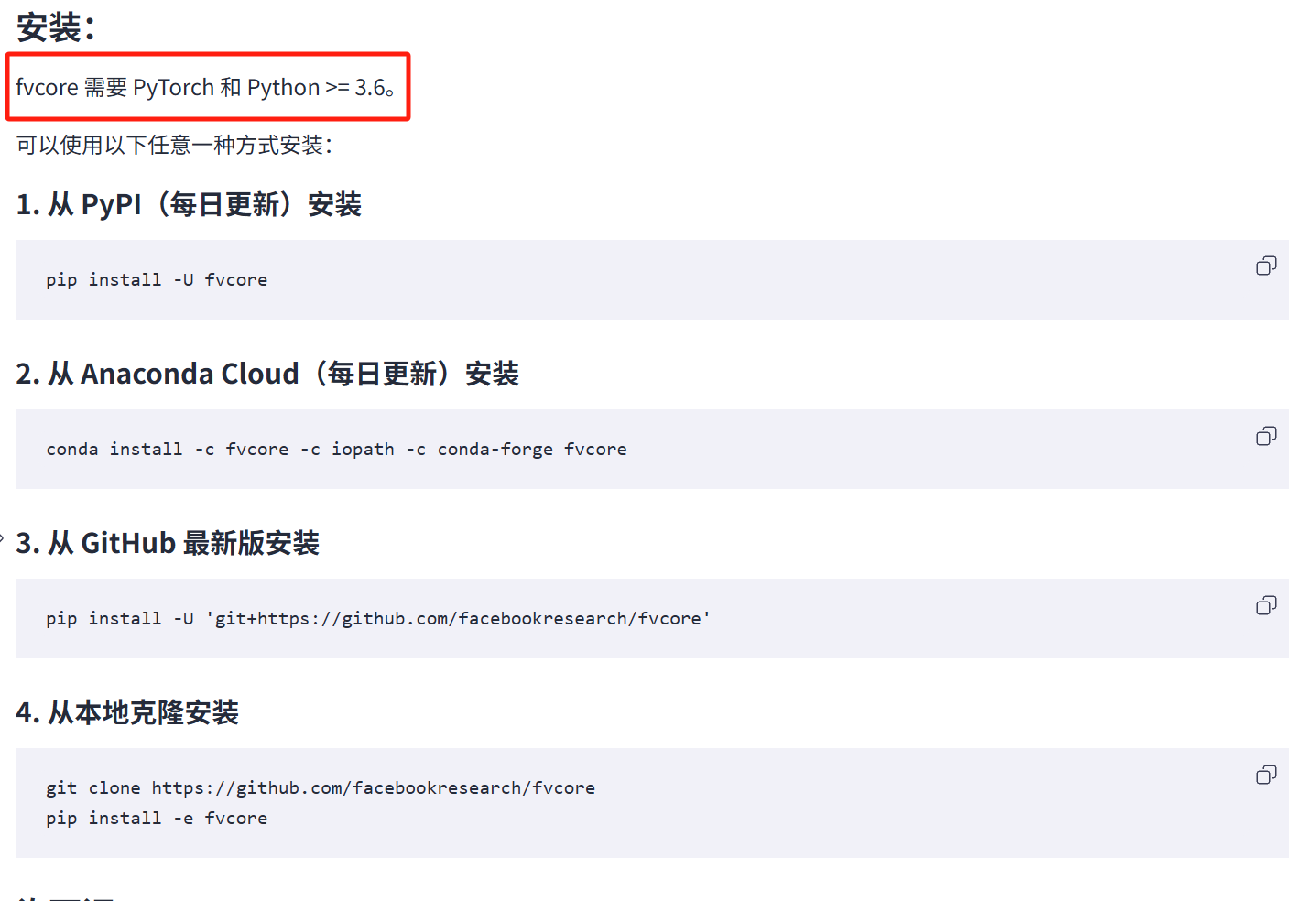
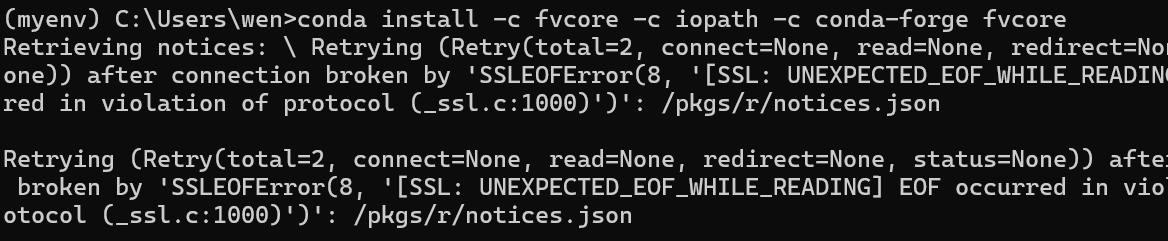
可能因为当时正在用梯子,没下成功。
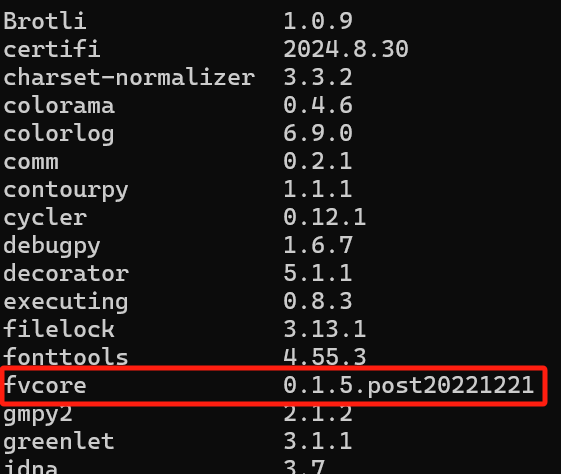
关了梯子,用代码:pip install -U fvcore,就可以成功啦~~~(再用pip list确认一下,fvcore下好了)
二. 调用 BDWDCNN
① 下载的压缩包,解压打开,创建一个新的文件。(确保的代码运行目录在这个包里)
② 尝试调用包
三. 模型应用
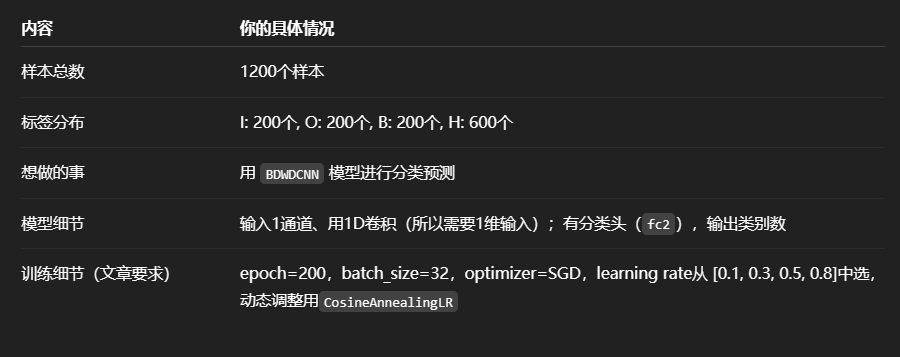
1.准备数据
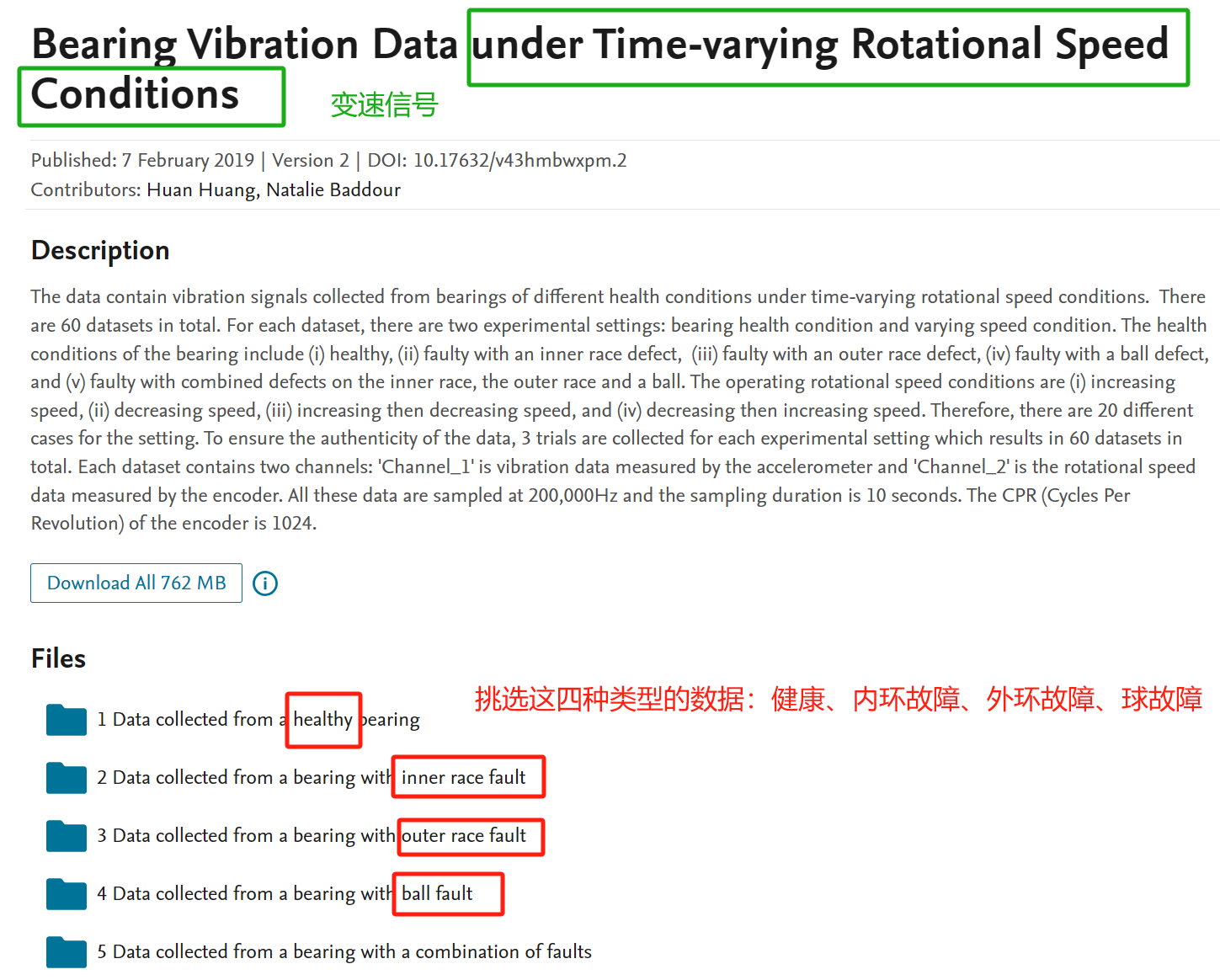
挑选加拿大渥太华的变速轴承数据集
Bearing Vibration Data under Time-varying Rotational Speed Conditions - Mendeley Data
import scipy.io as sio
import numpy as np
import random
import os# 定义基础路径
base_path = 'D:/0A_Gotoyourdream/00_BOSS_WHQ/A_Code/A_Data/'# 定义各类别对应的mat文件
file_mapping = {'H': 'H-B-1.mat','I': 'I-B-1.mat','B': 'B-B-1.mat','O': 'O-B-2.mat'
}# 定义每个类别需要抽取的数量
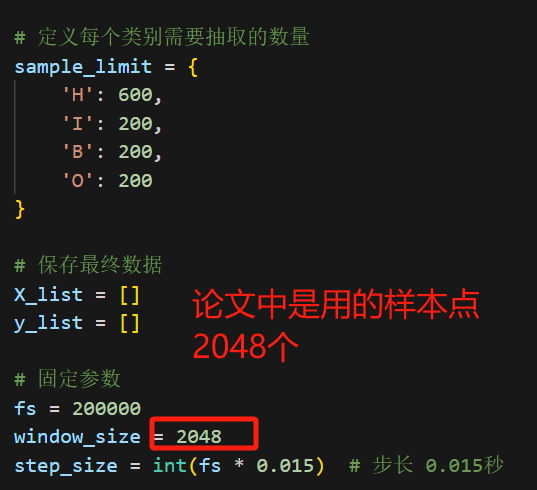
sample_limit = {'H': 600,'I': 200,'B': 200,'O': 200
}# 保存最终数据
X_list = []
y_list = []# 固定参数
fs = 200000
window_size = 2048
step_size = int(fs * 0.015) # 步长 0.015秒# 类别编码
label_mapping = {'H': 0, 'I': 1, 'B': 3, 'O': 2} # 注意和你之前保持一致# 创建保存目录(可选)
output_dir = os.path.join(base_path, "ClassBD-Processed_Samples")
os.makedirs(output_dir, exist_ok=True)# 遍历每一类数据
for label_name, file_name in file_mapping.items():print(f"正在处理类别 {label_name}...")mat_path = os.path.join(base_path, file_name)dataset = sio.loadmat(mat_path)# 提取振动信号并去直流分量vib_data = np.array(dataset["Channel_1"].flatten().tolist()[:fs * 10])vib_data = vib_data - np.mean(vib_data)# 滑窗切分样本vib_samples = []start = 0while start + window_size <= len(vib_data):sample = vib_data[start:start + window_size].astype(np.float32) # 降低内存占用vib_samples.append(sample)start += step_sizevib_samples = np.array(vib_samples)print(f"共切分得到 {vib_samples.shape[0]} 个样本")# 抽样if vib_samples.shape[0] < sample_limit[label_name]:raise ValueError(f"类别 {label_name} 样本不足(仅 {vib_samples.shape[0]}),无法抽取 {sample_limit[label_name]} 个")selected_indices = random.sample(range(vib_samples.shape[0]), sample_limit[label_name])selected_X = vib_samples[selected_indices]selected_y = np.full(sample_limit[label_name], label_mapping[label_name], dtype=np.int64)# 保存save_path_X = os.path.join(output_dir, f"X_{label_name}.mat")save_path_y = os.path.join(output_dir, f"y_{label_name}.mat")sio.savemat(save_path_X, {'X': selected_X})sio.savemat(save_path_y, {'y': selected_y})print(f"已保存类别 {label_name} 的数据:{save_path_X}, {save_path_y}")
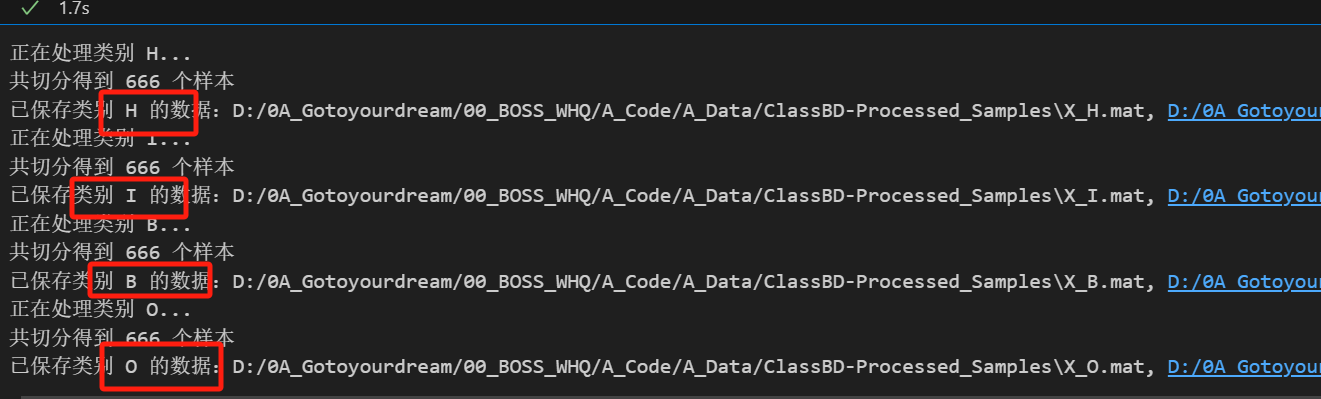
2. 读取并合并数据
import os
import scipy.io as sio
import numpy as np
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader# ========== 1. 读取四类数据 ==========
base_path = "D:/0A_Gotoyourdream/00_BOSS_WHQ/A_Code/A_Data/ClassBD-Processed_Samples"def load_data(label):X = sio.loadmat(os.path.join(base_path, f"X_{label}.mat"))["X"]y = sio.loadmat(os.path.join(base_path, f"y_{label}.mat"))["y"].flatten()return X.astype(np.float32), y.astype(np.int64)X_H, y_H = load_data("H")
X_I, y_I = load_data("I")
X_B, y_B = load_data("B")
X_O, y_O = load_data("O")# ========== 2. 合并数据 + reshape ==========
X_all = np.concatenate([X_H, X_I, X_B, X_O], axis=0)
y_all = np.concatenate([y_H, y_I, y_B, y_O], axis=0)
X_all = X_all[:, np.newaxis, :] # (N, 1, 200000)
3.划分训练集/测试集
我这里定义的训练集70%,测试集30%。可以随意更改。
# ========== 3. 划分训练/测试集 ==========
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=0.3, stratify=y_all, random_state=42)
4.DataLoader
文献里的batch_size是128,想想自己的笔记本,还是调小一点...
# ========== 4. DataLoader ==========
train_dataset = TensorDataset(torch.tensor(X_train), torch.tensor(y_train))
test_dataset = TensorDataset(torch.tensor(X_test), torch.tensor(y_test))train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
5. 定义模型结构
# ========== 5. 定义模型结构 ==========
from Model.BDCNN import BDWDCNN # 确保你能import成功model = BDWDCNN(n_classes=4)6. 定义损失函数、优化器、调度器
# ========== 6. 定义损失函数、优化器、调度器 ==========
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=200)7. 开始训练
我这里定义的是90次,原文是200次
# ========== 7. 开始训练 ==========
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)for epoch in range(1, 91):model.train()running_loss = 0.0correct = 0total = 0for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs, _, _ = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()scheduler.step()train_acc = correct / total * 100# 测试集评估model.eval()correct_test = 0total_test = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs, _, _ = model(inputs)_, predicted = outputs.max(1)total_test += labels.size(0)correct_test += predicted.eq(labels).sum().item()test_acc = correct_test / total_test * 100print(f"Epoch {epoch:03d}: Loss={running_loss:.4f}, Train Acc={train_acc:.2f}%, Test Acc={test_acc:.2f}%")出来结果比我想象中快很多。
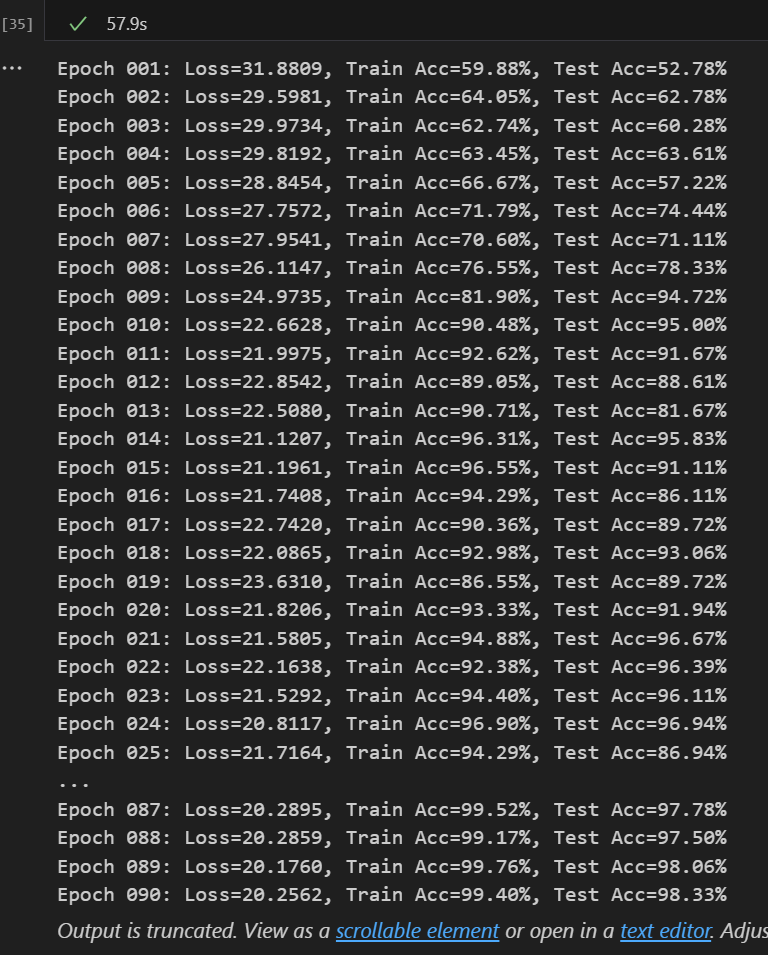
如果训练集比较足够的时候有用,准确率很高。
因为之后想针对少样本、跨数据集的研究。所以我也顺便试了一下在少样本的情况下的表现。
(训练集只有10%,迭代次数增加到200)
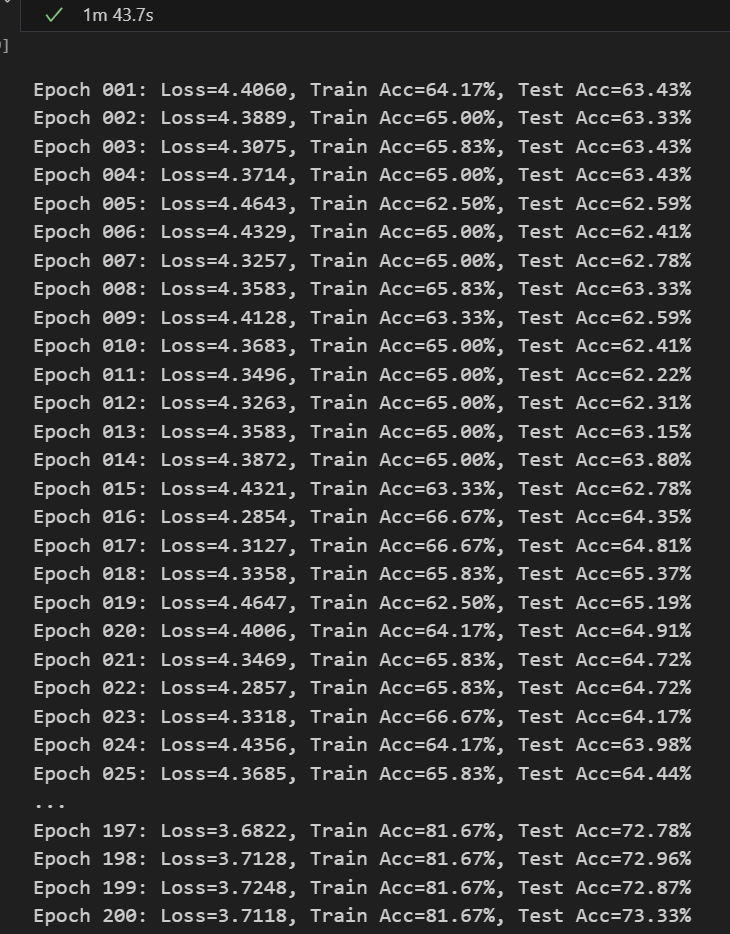
【可以加在论文里当作对比了,嘿嘿】
相关文章:
)
故障诊断——复现github代码ClassBD-CNN(BDCNN)
刚好看到这篇文献有github代码,而且也比较新,感觉可以当作自己论文中的对比方法。 https://www.sciencedirect.com/science/article/pii/S0888327024006484 (论文地址) (看到4090,有点想劝退自己......&…...

局部和整体的关系
Prompt:为什么要研究局部和整体的关系呢?是因为很多情况下,局部就能表达出整体? 这是一个非常本质的问题,其实你已经接近数学和物理中“几何本质”的核心了。我们研究局部和整体的关系,是因为:…...

1.5 点云数据获取方式——双目立体相机
图1-5-1 双目立体相机 双目相机通过模拟人眼立体视觉,利用两个摄像头的视差信息计算物体深度,进而生成 3D 点云,具有成本低、体积小、信息丰富等优势,成为中...

Flume启动报错
报错1: 报错2: File Channel transaction capacity cannot be greater than the capacity of the channel capacit... 解决方案:删除配置...
)
leetcode 21. 合并两个有序链表(c++解法+相关知识点复习)
目录 题目 所需知识点复习 1.链表 1.1单链表 1.2哑结点(Dummy Node) 解答过程 1.循环双指针解法 2.递归解法 2025.4.29想到其他知识点会后续再继续补充。 题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表…...

链表反转_leedcodeP206
P206反转链表 原题 反转思路 将链表反转的过程分为两个区域: 🟦 未反转区(待处理) 原链表中还没有处理(还没有反转指针方向)的部分,从 current 开始一直到链表尾部。 🟩 已反转…...

Laravel+API 接口
LaravelAPI 接口 网课连接:BIlibili. 中文文档. 1.RestFul Api编码风格 一、API设计 修改hosts,C:\Windows\System32\drivers\etc\hosts,增加127.0.0.1 api.lv8.com # Laravel 框架 用这个域名来测试(推荐规范) 在…...

在 Ubuntu 上离线安装 ClickHouse
在 Ubuntu 上离线安装 ClickHouse 的步骤如下: 一.安装验证 # 检查服务状态 sudo systemctl status clickhouse-server #删除默认文件 sudo rm /etc/clickhouse-server/users.d/default-password.xml # 使用客户端连接 clickhouse-client --password...
)
【AI微信小程序开发】掷骰子小程序项目代码:自设骰子数量和动画(含完整前端代码)
系列文章目录 【AI微信小程序开发】AI减脂菜谱小程序项目代码:根据用户身高/体重等信息定制菜谱(含完整前端+后端代码)【AI微信小程序开发】AI菜谱推荐小程序项目代码:根据剩余食材智能生成菜谱(含完整前端+后端代码)【AI微信小程序开发】图片工具小程序项目代码:图片压…...

Linux-02-VIM和VI编辑器
第一节:什么是VI和VIM编辑器: VI是Unix和类Unix操作系统中出现的通用的文本编辑器。VIM是从VI发展出来的一个性能更强大的文本编辑器可以主动的以字体颜色辨别语法的正确性,方便程序设计,VIM和VI编辑器完全兼容。使用:vi xxx文件 或者vim xxx文件,简单来说就是用来编辑文件的一…...

同为科技 智能PDU产品选型介绍-EN10/G801FR
随着各行业对数据中心机房重视程度的不断提高, 加强机柜微环境及电源计量、监控和管理则十分必要。在新型微模块化数据中心供配电系统建设中,UPS电源、智能PDU、监控管理系统、资产管理等产品早已成为IDC机房不可或缺的部分。其中,智能PDU通过…...

NS-SWIFT微调Qwen3
目录 一、NS-SWIFT简介 二、Qwen3简介 三、微调Qwen3 1、安装NS-SWIFT环境 2、准备训练数据 3、Lora微调 4、GROP训练 5、Megatron并行训练 一、NS-SWIFT简介 SWIFT(Scalable lightWeight Infrastructure for Fine-Tuning)是魔搭ModelScope开源社…...

借 AI 热潮,深挖 [风车 AI ] 为跨境电商打造的图片翻译黑科技
家人们,这几年 AI 技术简直像坐了火箭一样飞速发展,生活里、工作中到处都能看到它的身影。对咱们跨境行业来说,语言翻译一直是个让人头疼的大问题。今天咱就借着这股 AI 热潮,好好深挖一下风车 AI 为跨境打造的那些超厉害的翻译黑…...

uni-app 中封装全局音频播放器
在开发移动应用时,音频播放功能是一个常见的需求。无论是背景音乐、音效还是语音消息,音频播放都需要一个稳定且易于管理的解决方案。在 uni-app 中,虽然原生提供了 uni.createInnerAudioContext 方法用于音频播放,但直接使用它可…...

Uniapp:设置TabBar
目录 一、setTabBarBadge:增加文本二、removeTabBarBadge:移除文本三、showTabBarRedDot:显示红点四、hideTabBarRedDot:隐藏红点一、setTabBarBadge:增加文本 为 tabBar 某一项的右上角添加文本。 uni.setTabBarBadge({index: 0,text: 1 })参数类型必填说明indexNumber…...

如何查看k8s获取系统是否清理过docker镜像
k8s集群某个节点down掉后,pod就会漂移到其他节点,但是在该节点却又执行了拉取镜像操作,明明该节点之前部署过该容器的,不知为什么又拉取了一次镜像(镜像拉取配置的优先使用本地),所以怀疑是触发…...

【Linux网络】深入解析I/O多路转接 - Select
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

如何解决 Xcode 签名证书和 Provisioning Profile 过期问题
在 iOS 应用开发过程中,签名证书和 Provisioning Profile 是确保应用安全性和合法性的关键组件。然而,当这些证书或配置文件过期时,开发者可能会遇到编译或归档失败的问题。本文将详细介绍如何解决 Xcode 中“iOS Distribution”证书未找到和…...

[C++]C++20协程的原理
文章目录 协程的状态机Promise 对象挂起和恢复机制协程的执行流程示例代码分析 C 协程是 C20 引入的一项重要特性,它提供了一种更简洁、高效的异步编程方式。下面从协程的状态机、Promise 对象、挂起和恢复机制等方面介绍其底层实现原理。 协程的状态机 从底层角度…...

Oracle OCP证书有效期是三年?
这一段时间,网上经常传出消息Oracle OCM认证证书有效期为三年,其实这个假消息,通过博睿谷与Oracle官方人员确认,OCP认证证书有效期是永久的。 OCP证书本身永久有效,但老版本的OCP证书代表着更多的项目经验,…...

2025.4.29_STM32_看门狗WDG
1.WDG简介 大概意思就是给看门狗设置一个时间范围,在这个范围内必须喂狗(重置定时器),这个操作必须一直执行,比如看门狗的的时间范围是1-2秒,我们就必须间隔1-2秒就喂一次狗,否则它自减到0时就会重置电路,相…...

基于Java,SpringBoot,HTML水文水质监测预警系统设计
摘要 随着水资源管理需求的日益增长,构建高效、精准的水文监测预警系统至关重要。本文设计并实现了一套基于 Java、SpringBoot 和 HTML 技术的水文监测预警系统。系统采用 Java 语言与 SpringBoot 框架搭建后端服务,利用其强大的业务逻辑处理能力与高效…...

Qt开发:JSON字符串的序列化和反序列化
文章目录 一、构建和解析单个JSON对象二、JSON对象中嵌套多个JSON对象三、JSON对象中组建多个数组对象四、构建和解析数组对象 一、构建和解析单个JSON对象 1.1 JSON对象的构建 使用key-value形式生成JSON对象 #include <QJsonObject> #include <QJsonDocument> …...

第10次:电商项目配置开发环境
本次内容主要为给整个电商项目配置好开发环境,包括如下环节: 创建电商项目xiaoyu_mall,Django版本默认是最新的大版本5.2配置应用目录,因项目会涉及到多个应用,为保证项目结构清晰,将在项目下建立apps目录…...

【强化学习系列】Q-learning——从贝尔曼最优方程谈起
引言 上一篇贝尔曼最优方程中我们已经推导出动作价值形式的贝尔曼最优方程: q π ∗ ( s , a ) ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) [ r γ max a ′ q π ∗ ( s ′ , a ′ ) ] \begin{equation}q_{\pi^*}(s,a)\sum_{s\in S}\sum_{r\in R}p(s,…...

Java 基础--运算符全解析
【Java 基础】Java 运算符全解析:程序世界的“加减乘除”与“是非对错” 作者:IvanCodes 发布时间:2025年4月29日🐣 专栏:Java教程 嗨,各位 Java 探险家们!👋 掌握了变量、数据类…...

【神经网络与深度学习】改变随机种子可以提升模型性能?
引言 随机种子在机器学习和数据处理领域中至关重要,它决定了模型训练、数据划分以及参数初始化的随机性。虽然固定随机种子能确保实验的可重复性,但改变随机种子有时会意外提升模型性能。本文将探讨这一现象的潜在原因,并揭示随机性如何影响…...

一页概览:统一数据保护方案
2010年左右手绘,用的是公司的信纸,签字笔,马克笔。方案为统一数据保护。其实解释备份软件加备份硬件(支持重复数据删除)的联合解决方案。...

Python中的itertools模块常见函数用法示例
itertools ,迭代工具模块,提供了用于高效处理迭代器和组合问题的工具。 1. itertools.permutations(iterable, rNone) 功能:生成输入迭代器的所有可能排列。 参数: iterable:输入的可迭代对象。r:可选参数…...

微服务学习笔记
1 微服务 微服务:基于业务领域建模的、可独立发布的服务,把业务内聚的功能封装起来,并通过网络供其他服务访问。 好处: 技术异构性,不同服务可以使用不同的技术弹性,可以更好的处理服务不可用的问题扩展…...

实验七:基于89C51和DS18B20的温度采集与显示
一、实验目的 学习使用DS18B20数字温度传感器采集温度数据。使用4位共阳极数码管显示温度数据,显示精度到小数点后两位。熟悉89C51单片机的I/O口操作和位选控制。二、实验器材 89C51单片机开发板DS18B20数字温度传感器4位共阳极数码管三极管8550(用于位选驱动)电阻、电容等辅…...

cmake:基础
本文主要探讨cmake语法相关知识。 cmake(GUI)安装 apt install cmake-curses-gui cmake -y cmake语法 cmake_minimum_required(VERSION 版本号) 设置cmake最低版本 project(工程名) <> PROGECT_NAME/CMAKE_PROJECT_NAME 设置工程名字 add_library(库名 SHARED/STAT…...

1.8 点云数据获取方式——小结
点云,作为三维空间信息的直观载体,在各行各业都得到了广泛应用。而能够获得三维点云数据手段,也是极为丰富。本章节主要介绍了主动式手段(包括激光雷达、ToF相机、结构光相机)和被动式手段(双目立体相机、单…...

超越单体:进入微服务世界与Spring Cloud概述
大家好!欢迎来到我的新系列文章——《微服务架构:Spring Cloud实战指南》。在之前的《Java服务端核心技术》系列中,我们一起深入学习了如何使用Spring Boot构建功能强大、安全可靠的单体应用程序。我们掌握了Spring的核心原理、Web开发、数据…...

深度学习篇---模型权重变化与维度分析
文章目录 前言1. 权重的作用2. 权重的维度全连接层卷积层3. 权重的变化4.实例代码(PyTorch 框架)场景代码解释模型定义数据生成优化设置初始权重设置训练循环前向传播反向传播更新权重结果输出维度与变化总结维度匹配梯度跟新5. 增加网络深度:多层感知机(MLP)代码解释6. 权…...
)
AtCoder Beginner Contest 403(题解ABCDEF)
A - Odd Position Sum #1.奇数数位和 #include<iostream> #include<vector> #include<stdio.h> #include<map> #include<string> #include<algorithm> #include<queue> #include<cstring> #include<stack> #include&l…...

计算机视觉与深度学习 | 双目立体匹配算法理论+Opencv实践+matlab实践
双目立体匹配 一、双目立体匹配算法理论与OpenCV、matlab实践一、双目立体匹配理论二、OpenCV实践三、优化建议四、算法对比与适用场景二、双目立体匹配算法理论及Matlab实践指南一、双目立体匹配理论二、Matlab实践步骤三、算法对比与优化建议四、完整流程示例五、常见问题与解…...
)
深挖Java基础之:认识Java(创立空间/先导:Java认识)
今天我要介绍的是在Java中对Java的一些基本语法的认识与他们的运用,以及拟举例子说明和运用场景,优势和劣势, 注:本篇文章是对Java的一些基本的,简单的代码块的一些内容,后续会讲解在Java中的变量类型&…...

springmvc从请求到响应的流程分析
一、创建springmvc项目 通过网盘分享的文件:hello-springmvc.zip 链接: https://pan.baidu.com/s/1VmUHurgph661ND9LWqKhaw 提取码: b36a 二、从请求到响应流程 我们先画一下流程图,如下图所示。 三、源码解析 3.1 HttpServlet接收请求 用户发送htt…...

RabbitMQ 启动报错 “crypto.app“ 的解决方法
RabbitMQ 启动报错 “crypto.app” 的解决方法 在使用 RabbitMQ 时,有时会遇到启动报错的问题,其中一种常见的报错是: {"init terminating in do_boot",{error,{crypto,{"no such file or directory","crypto.app…...
)
idm 禁止自动更新提示(修改注册表)
目前版本:v 6.42 Bulid 35 运行-regedit- 计算机\HKEY_CURRENT_USER\SOFTWARE\DownloadManager 计算机\HKEY_CURRENT_USER\SOFTWARE\DownloadManagerLstCheck -> 0 重启...

LeetCode - 02.02.返回倒数第 k 个节点
目录 题目 解法一 双指针算法 原理 详细过程 为什么它有效? 时间复杂度与空间复杂度 代码 解法二 递归算法 核心思想 执行流程详解 具体例子 代码 题目 面试题 02.02. 返回倒数第 k 个节点 - 力扣(LeetCode) 解法一 双指针算…...

<c++>使用detectMultiScale的时候出现opencv.dll冲突
最近在试着弄一下opencv,看网上很多人都是的用的python,但是python跑起来没有c快,生成的qt工程也大一些,想着试试c看能不能生成opencv。然后就用到这个函数,detectMultiScale。 出现一个问题,就是我的程序在…...

从实列中学习linux shell脚本2: shell 的变量 方法 命名和使用规则之类 比如拿:获取cpu 负载,以及负载超过2.0 以后就发生邮件为例子
以下是对 Linux Shell 中变量、方法(函数)、命名规则的详细说明,并结合 获取CPU负载并在负载超过2.0时发送邮件 的示例进行演示: 1. Shell 变量 命名规则 命名格式:变量名由字母、数字、下划线组成,不能以…...

Centos Ubuntu RedOS系统类型下查看系统信息
文章目录 一、项目背景二、页面三、说明四、代码1.SysInfo2.EmsSysConfig3.HostInformationController4.HostInfo 一、项目背景 公司项目想展示当前部署系统的:操作系统,软件版本、IP、主机名。 二、页面 三、说明 说明点1:查询系统类型及…...

【Hive入门】Hive高级特性:视图与物化视图
在大数据分析中,Hive作为Hadoop生态系统中的重要组件,提供了强大的数据查询和管理能力。除了基本表的操作,Hive还支持 视图和 物化视图,这两种特性在数据管理和查询优化中扮演着重要角色。本文将深入探讨视图的创建与性能影响&…...
的用途)
特征工程四-2:使用GridSearchCV 进行超参数网格搜索(Hyperparameter Tuning)的用途
1. GridSearchCV 的作用 GridSearchCV(网格搜索交叉验证)用于: 自动搜索 给定参数范围内的最佳超参数组合。交叉验证评估 每个参数组合的性能,避免过拟合。返回最佳模型,可直接用于预测或分析。 2. 代码逐行解析 (1…...

【Hive入门】Hive函数:内置函数与UDF开发
Apache Hive作为Hadoop生态系统中的重要组件,为大数据分析提供了强大的SQL-like查询能力。Hive不仅支持丰富的内置函数,还允许用户开发自定义函数(UDF)以满足特定需求。本文将深入探讨Hive的内置函数(包括数学函数、字…...

HTML Picture标签详细教程
HTML Picture标签详细教程 简介 <picture>标签是HTML5中引入的一个强大元素,它为开发者提供了更灵活的图像资源管理方式。该标签主要用于让浏览器根据不同条件(如设备屏幕大小、分辨率或支持的图像格式)选择最适合当前显示环境的图像…...

Html1
一,HTML概述 网页开发需要学习的知识: html css javaScript 两个框架 VUE.js ElementUI UI user interface 用户界面 HTML xml 可扩展标记语言-->存储数据 Markup Language标签语言都会提供各种标…...