基于常微分方程的神经网络(Neural ODE)
参考资料:B站的视频解析
知乎神经常微分方程总结
论文链接:论文
什么是常微分方程?
微分方程式包含未知函数及其导数的方程,未知函数导数的最高阶数称为给i微分方程的阶。
常微分方程(ordinary differential equation,简称ODE)是未知函数只含有一个自变量的微分方程
F ( x , y , y ′ , y ′ ′ , . . . , y ( n ) ) = 0 F(x,y,y^{^{\prime}},y^{^{\prime\prime}},...,y^{(n)})=0 F(x,y,y′,y′′,...,y(n))=0
f ′ ( x ) − 7 f ( x ) = 0 f^{^{\prime}}(x)-7f(x)=0 f′(x)−7f(x)=0
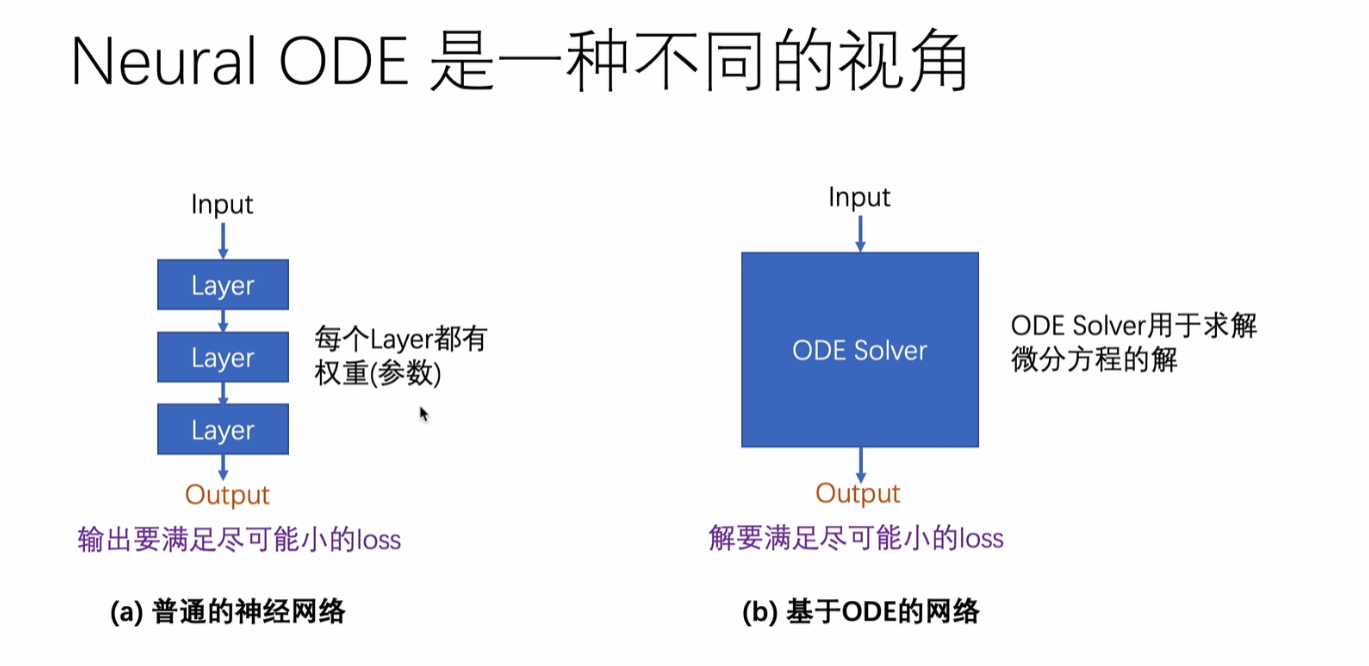
对输入求解一个为微分方程的解的值。
Neural ODE的核心思想
Neural ODE将神经网络的前向传播视为微分方程的求解过程。具体来说,它用微分方程描述隐藏状态随"时间"的变化:
d h ( t ) d t = f ( h ( t ) , t , θ ) \frac {dh(t)}{dt} = f(h(t), t, θ) dtdh(t)=f(h(t),t,θ)
- h(t)是时间t的隐藏状态
- f是由神经网络参数化的函数(通常是MLP)
- θ是可学习参数
用ODE表示有什么优势
1.Powerful representation:微分方程可以用数值法求解,因此对于任何连续函数都有良好的逼近能力。
2.Memory efficiency:不需要用到反向传播,因此训练上节约内存
3.Simplicity:不需要考虑复杂的调参和网络设计,形式简洁
4.Abstraction:让网络不需要考虑每层需要做什么,只需要考虑怎么计算结果
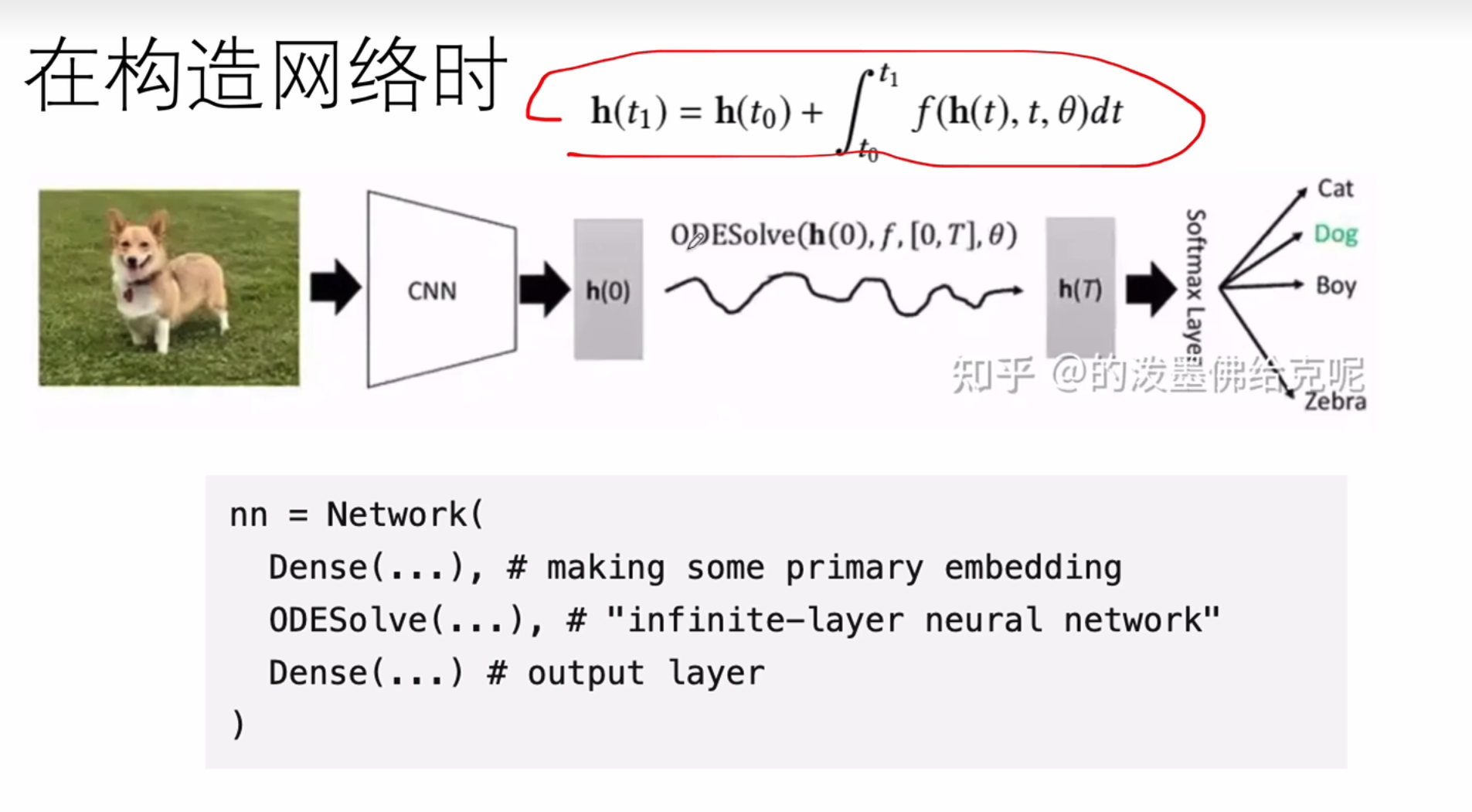
求解微分方程
因为解析解并不总是好计算的

数值分析的内容。
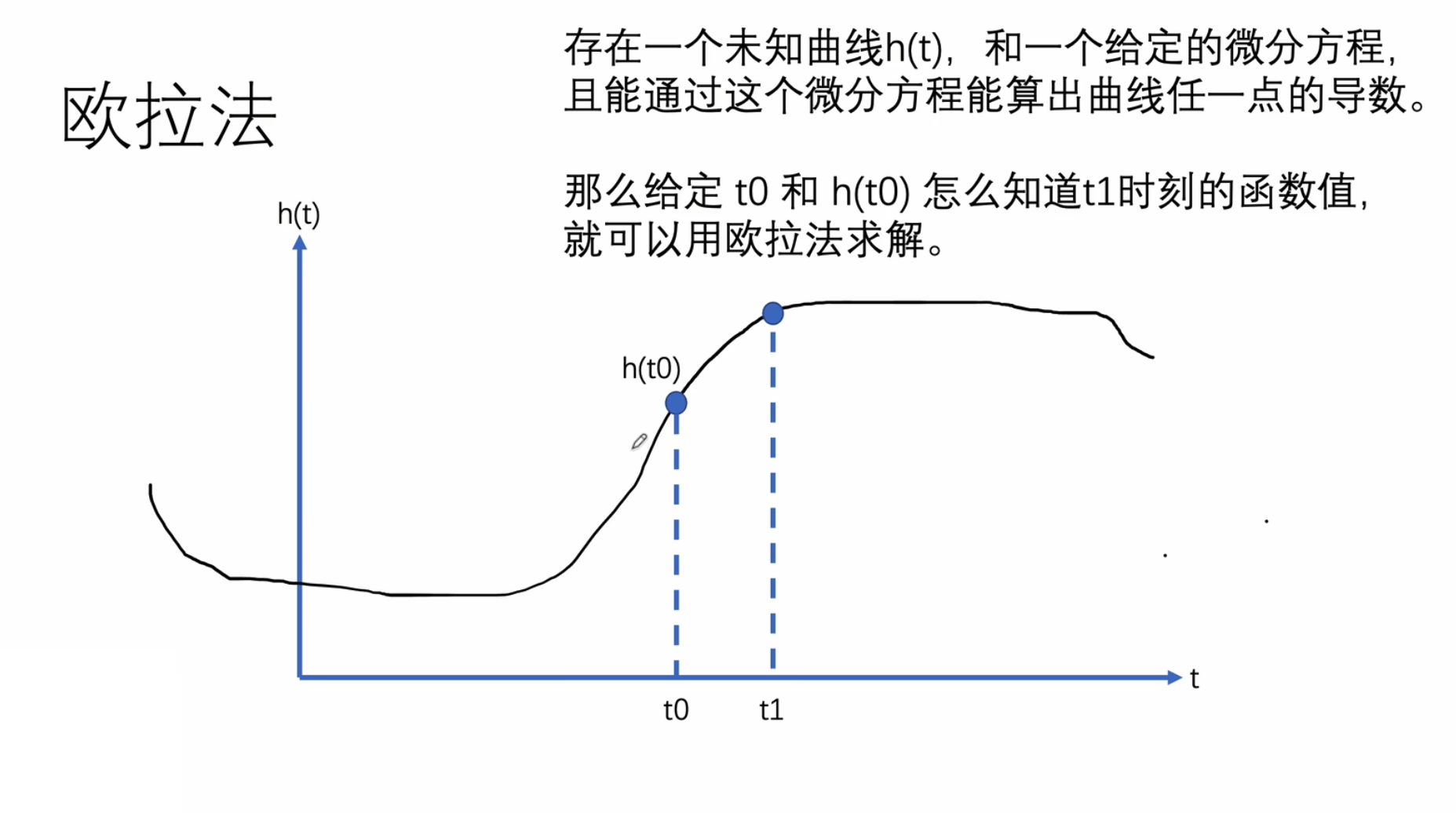
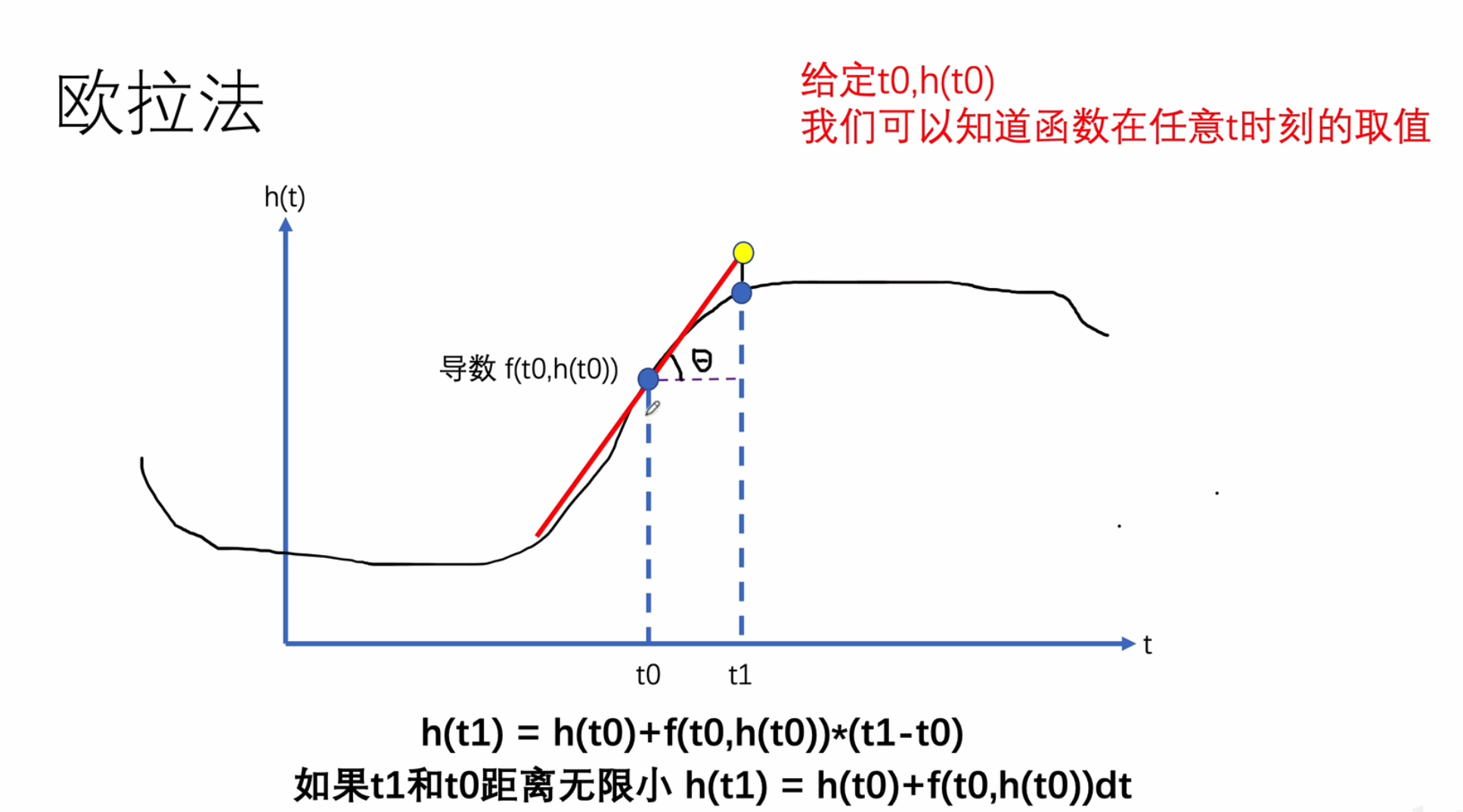
欧拉法
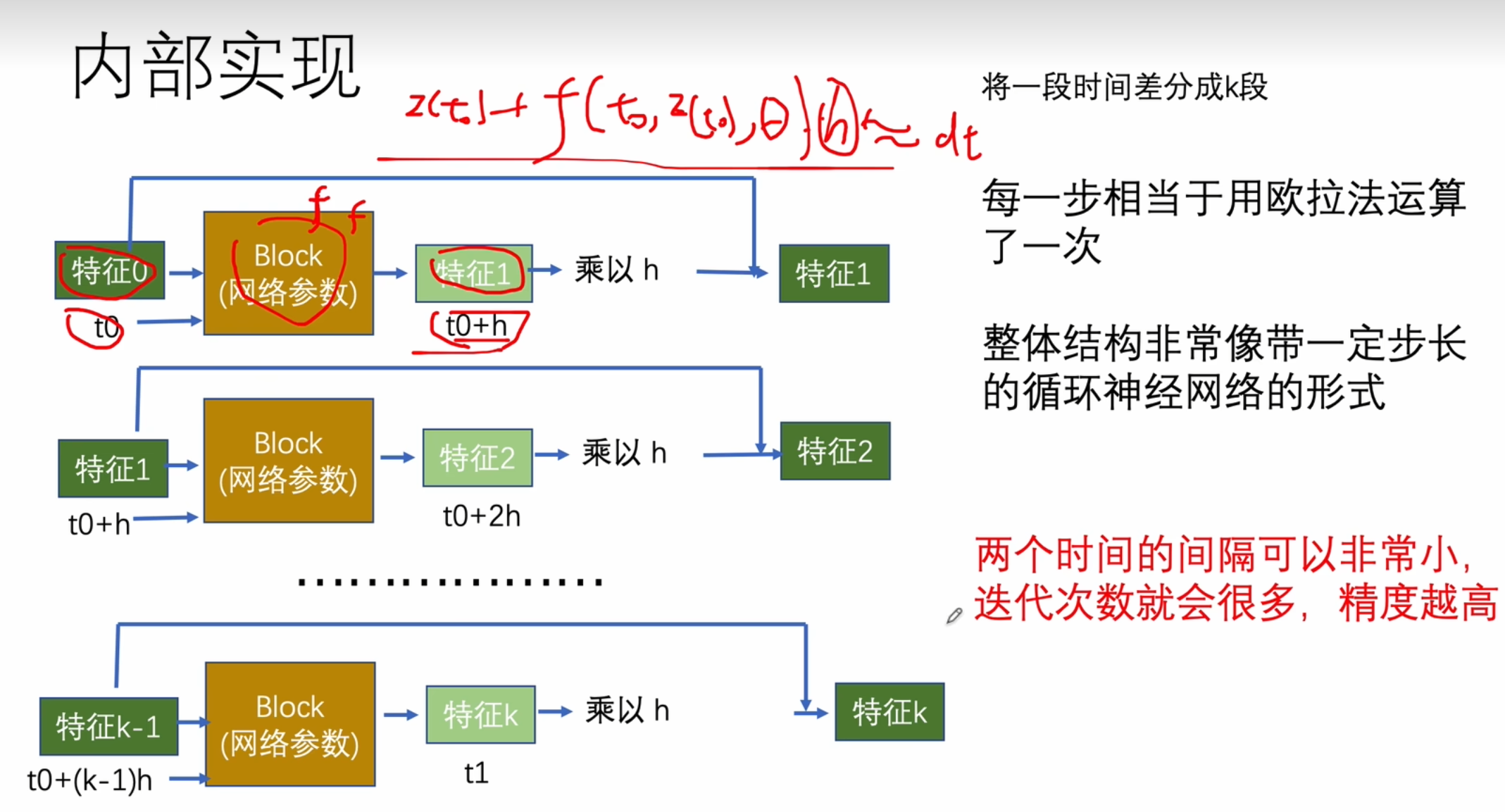
ResNet与欧拉法的关系
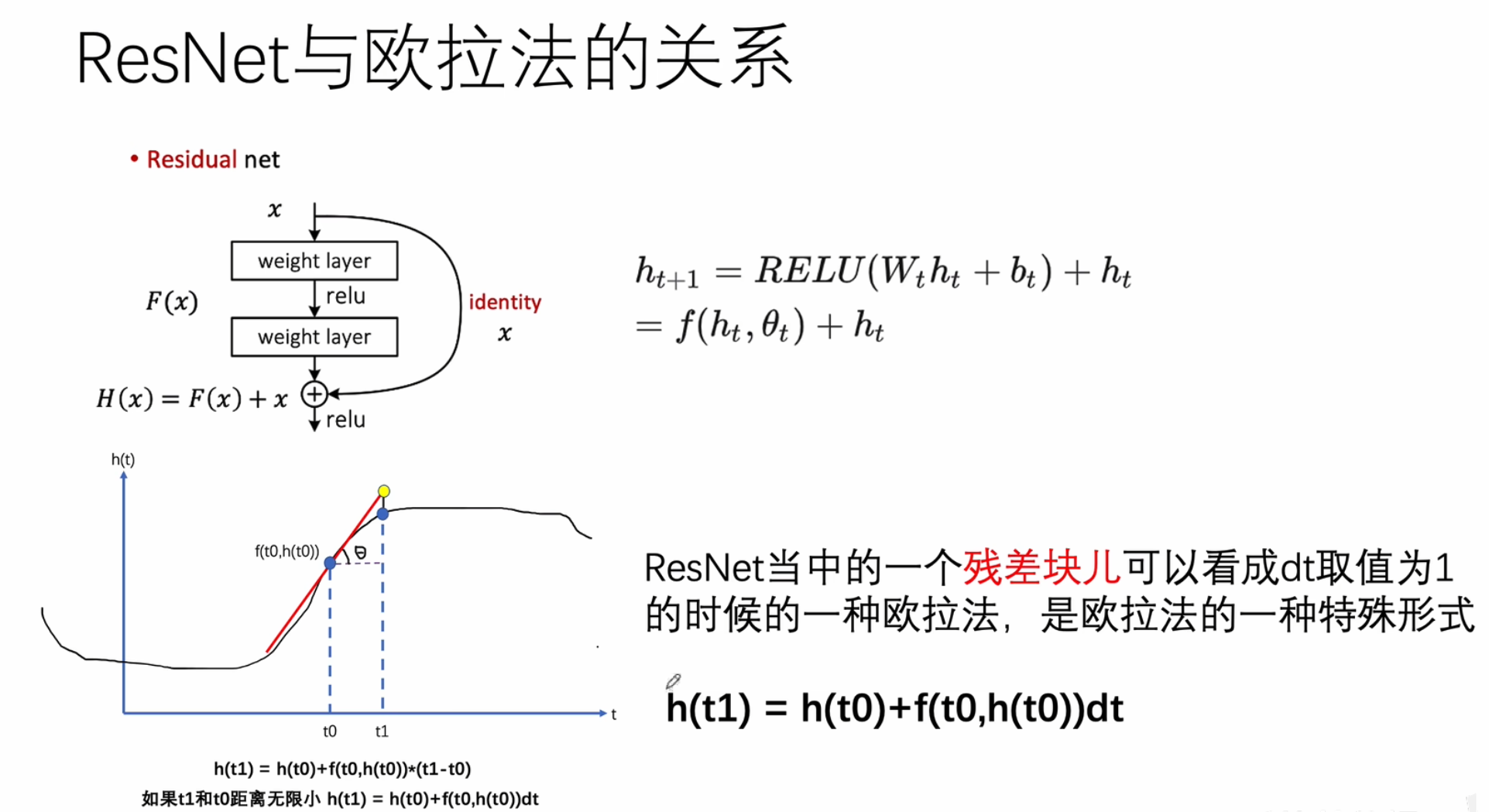
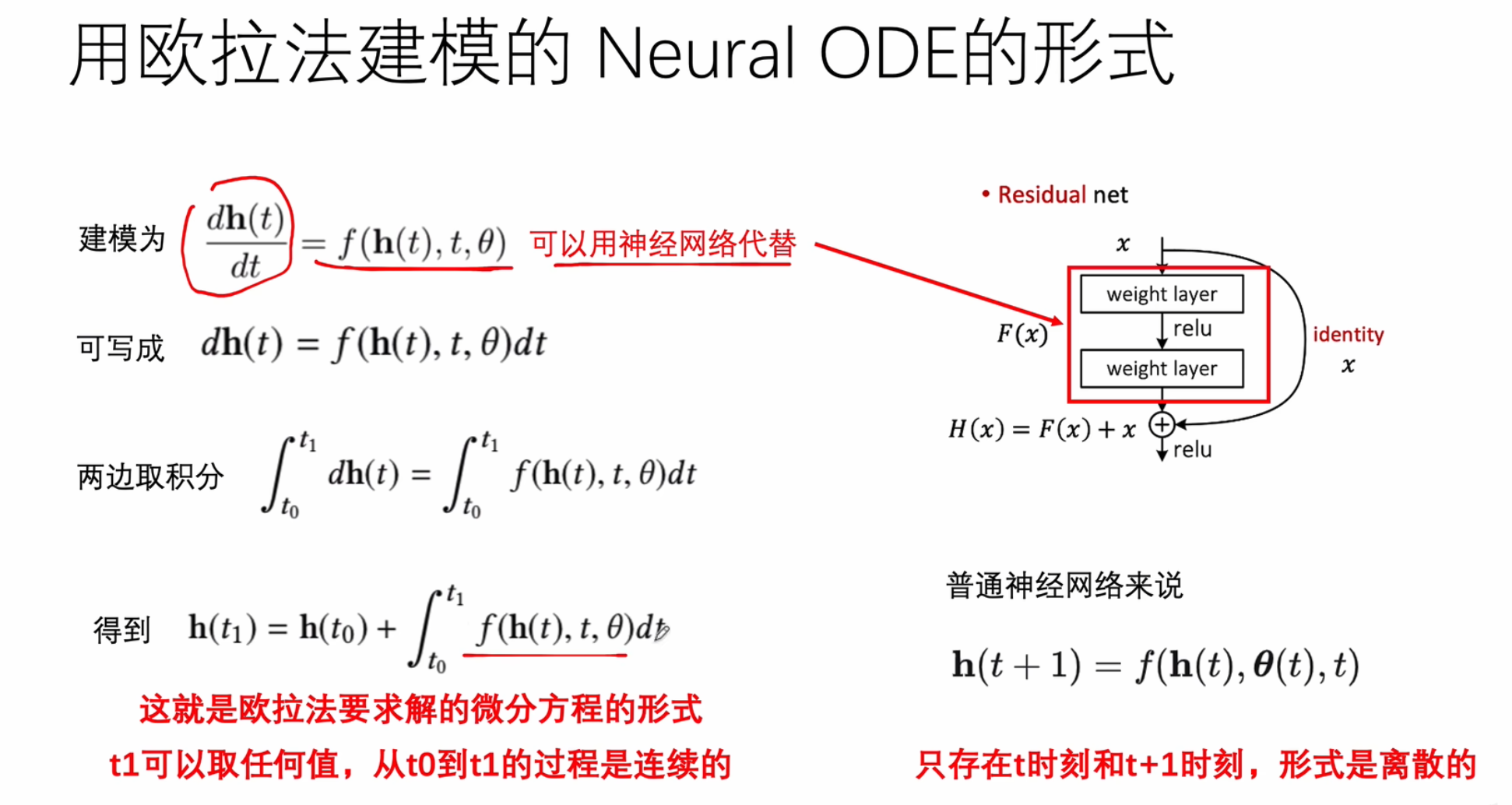
一个是离散的,一个是连续的
.
求解的最大距离,计算步长,迭代更新方程
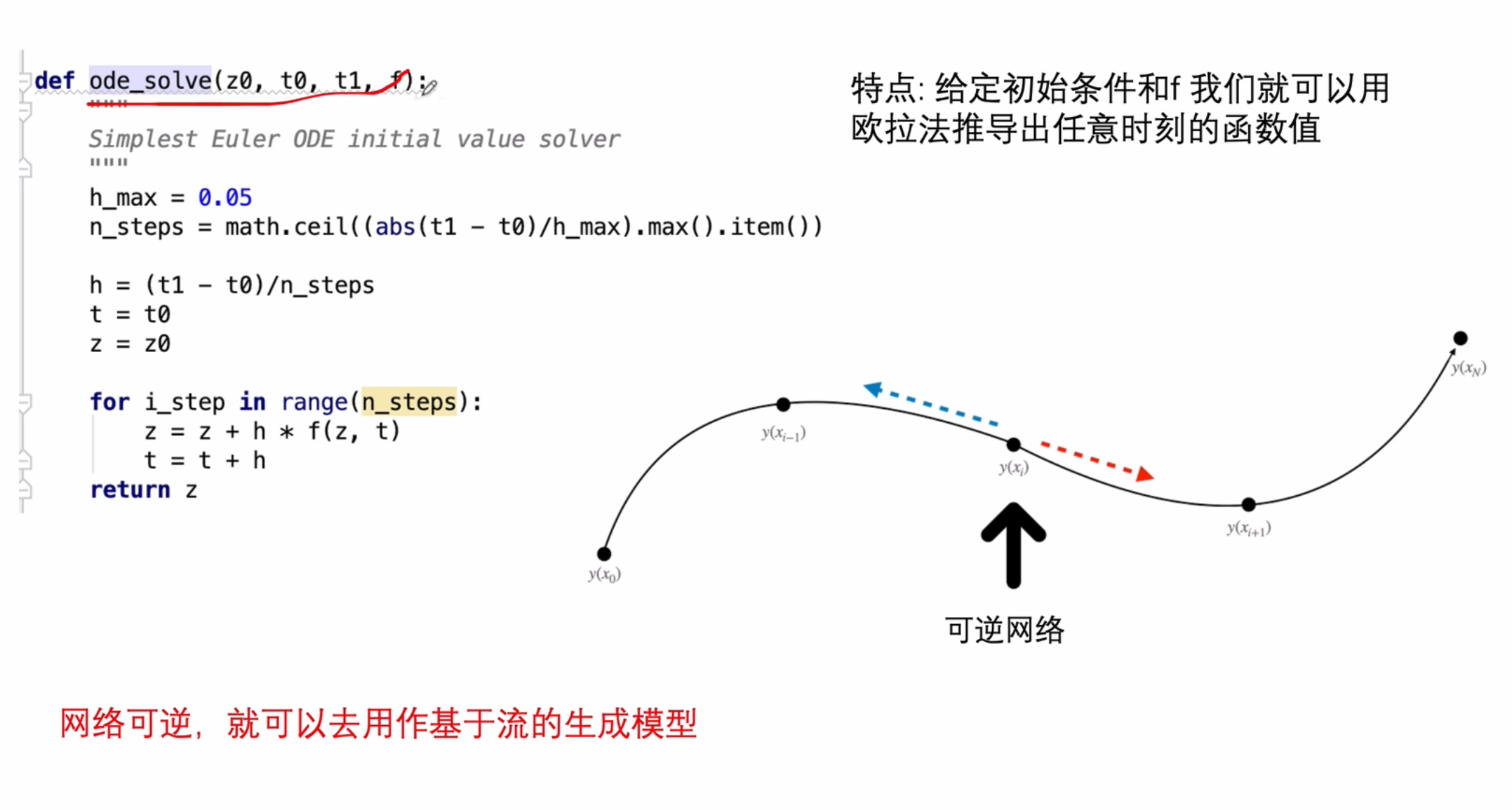
网络参数更新
不适用反向传播,因为相当于从把离散的值,用连续的值来进行扩散,数值太多了。
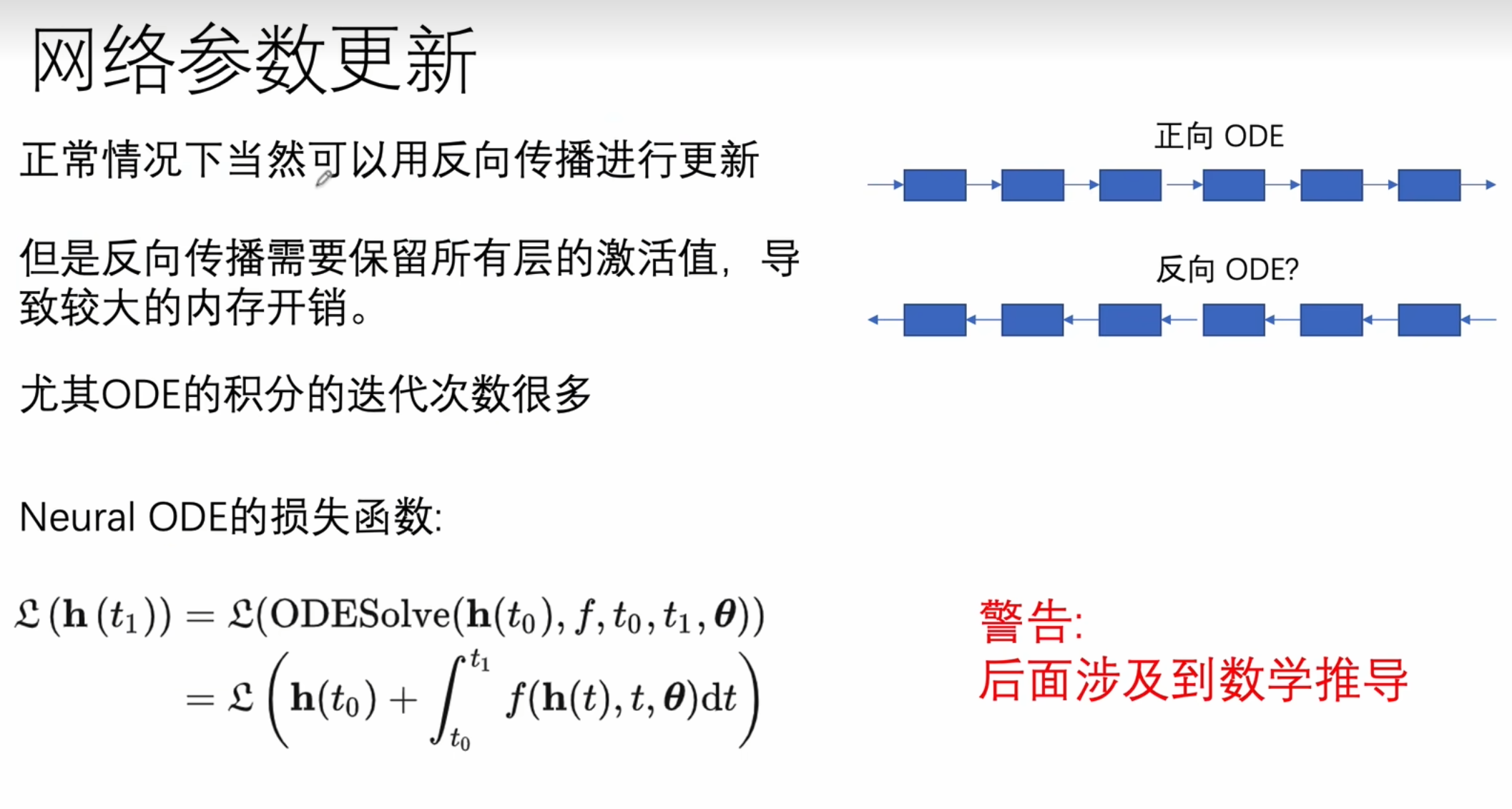
所以使用了反向的梯度扩散
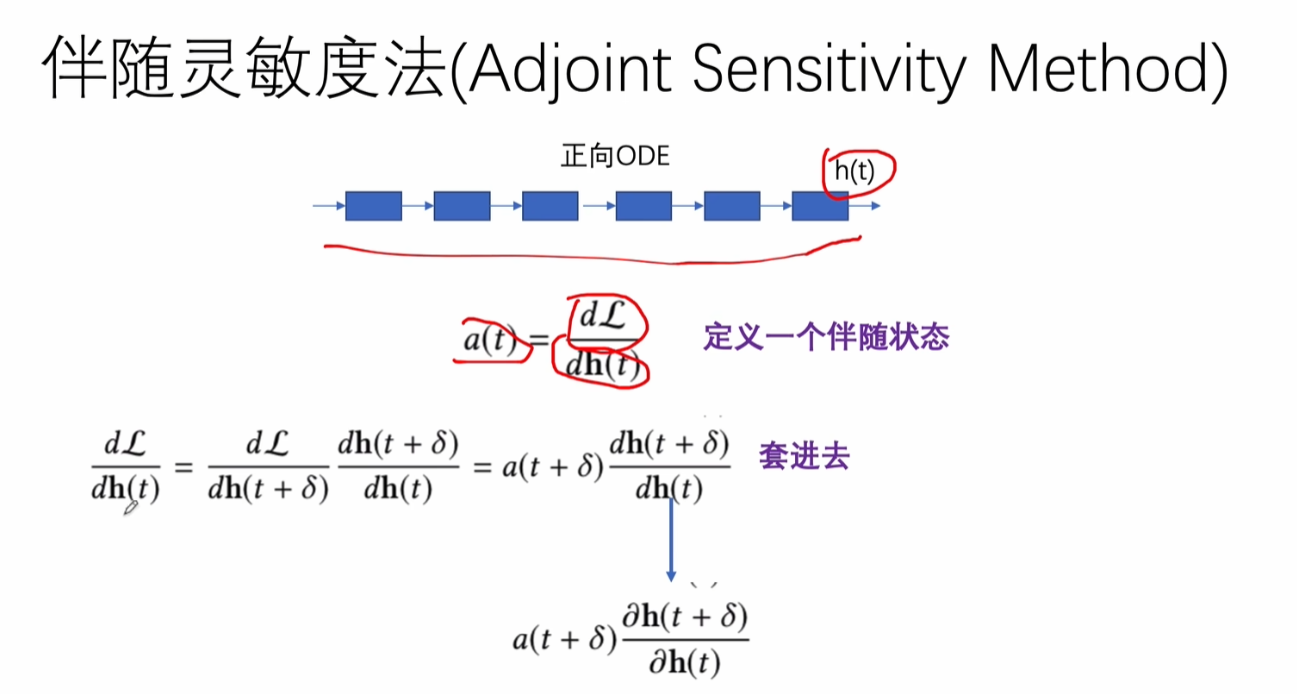
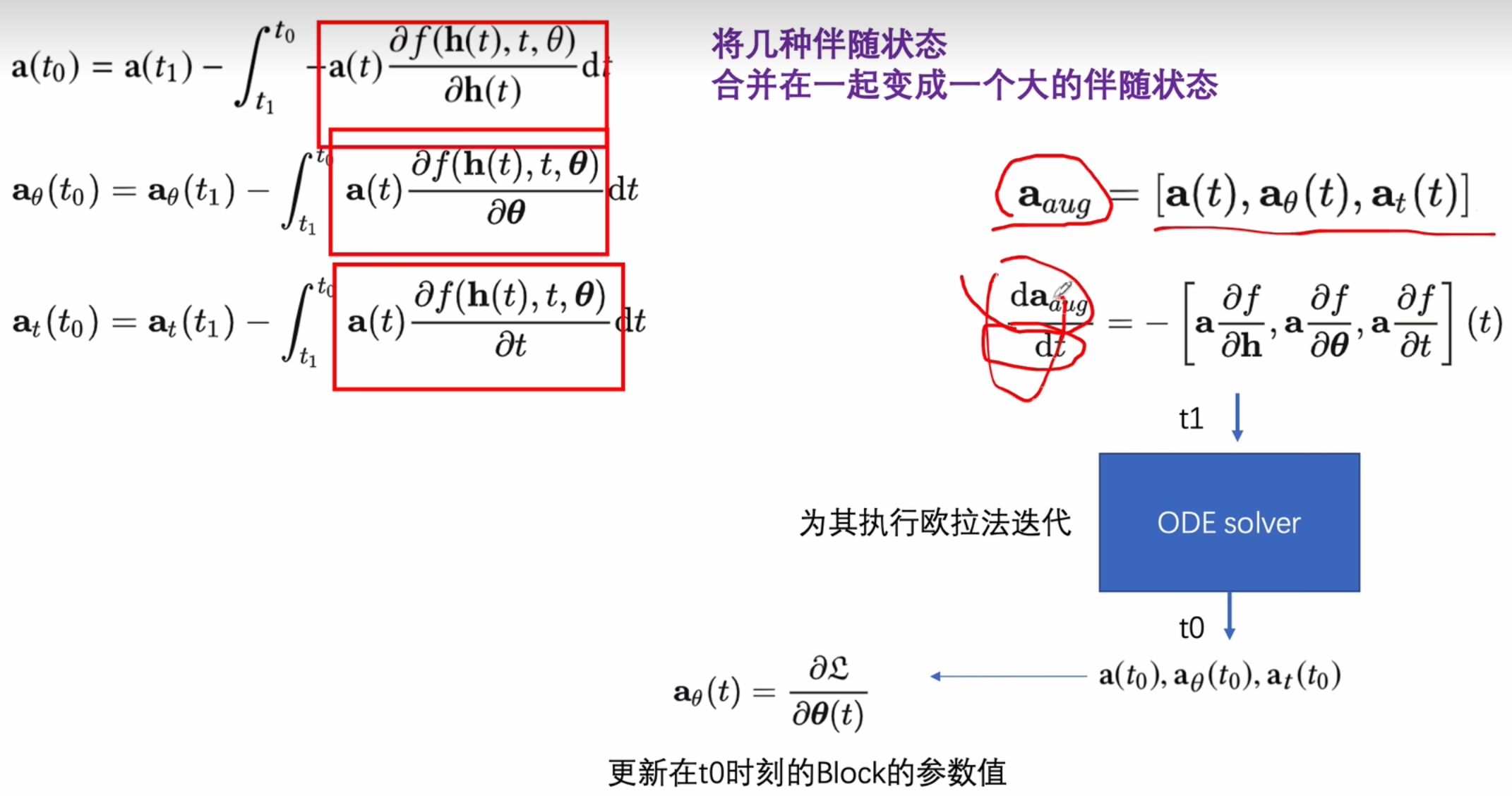
伴随灵敏度法
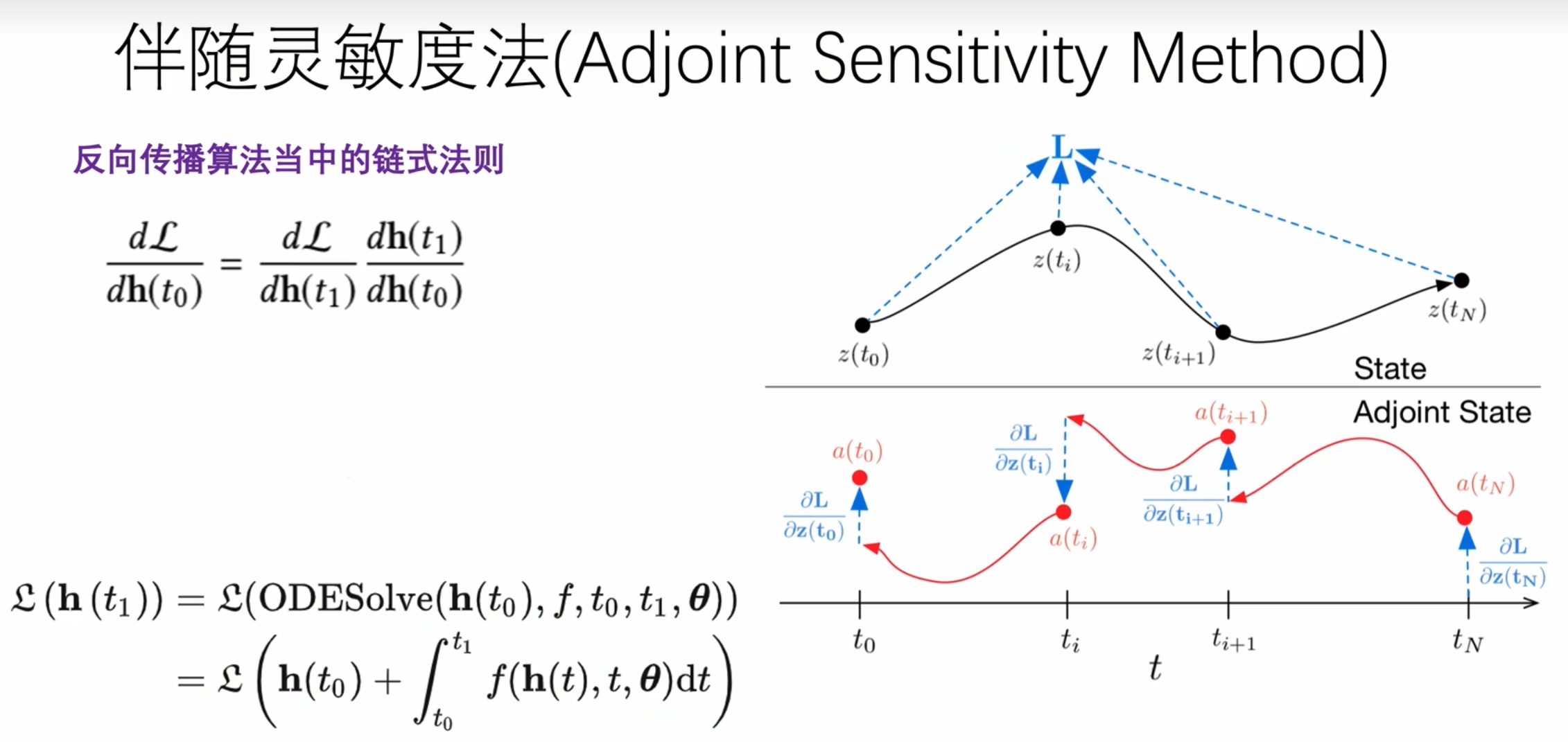
反向,建立和正向相同数量的state
构建中间的状态

利用了可变积分的定义形式。
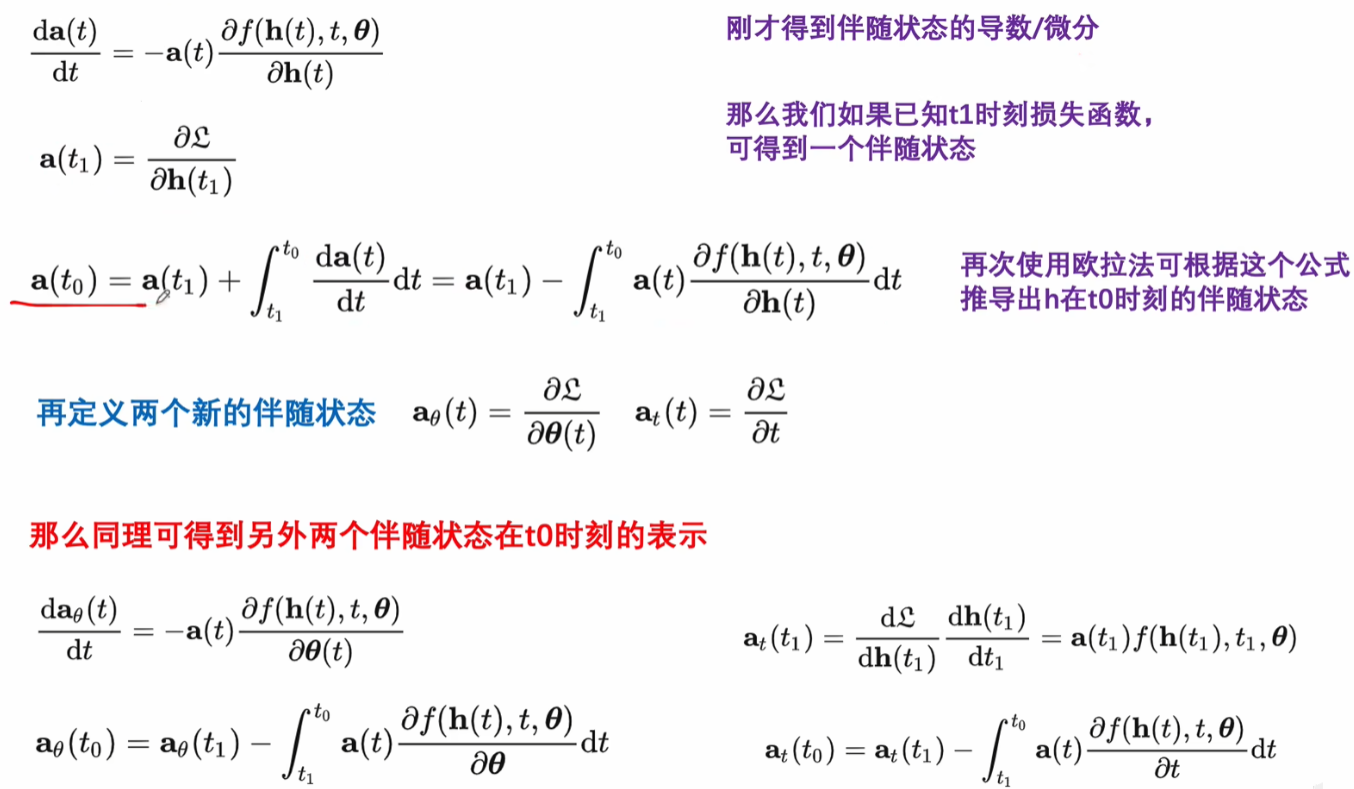
和a相关的两个参数的偏微分

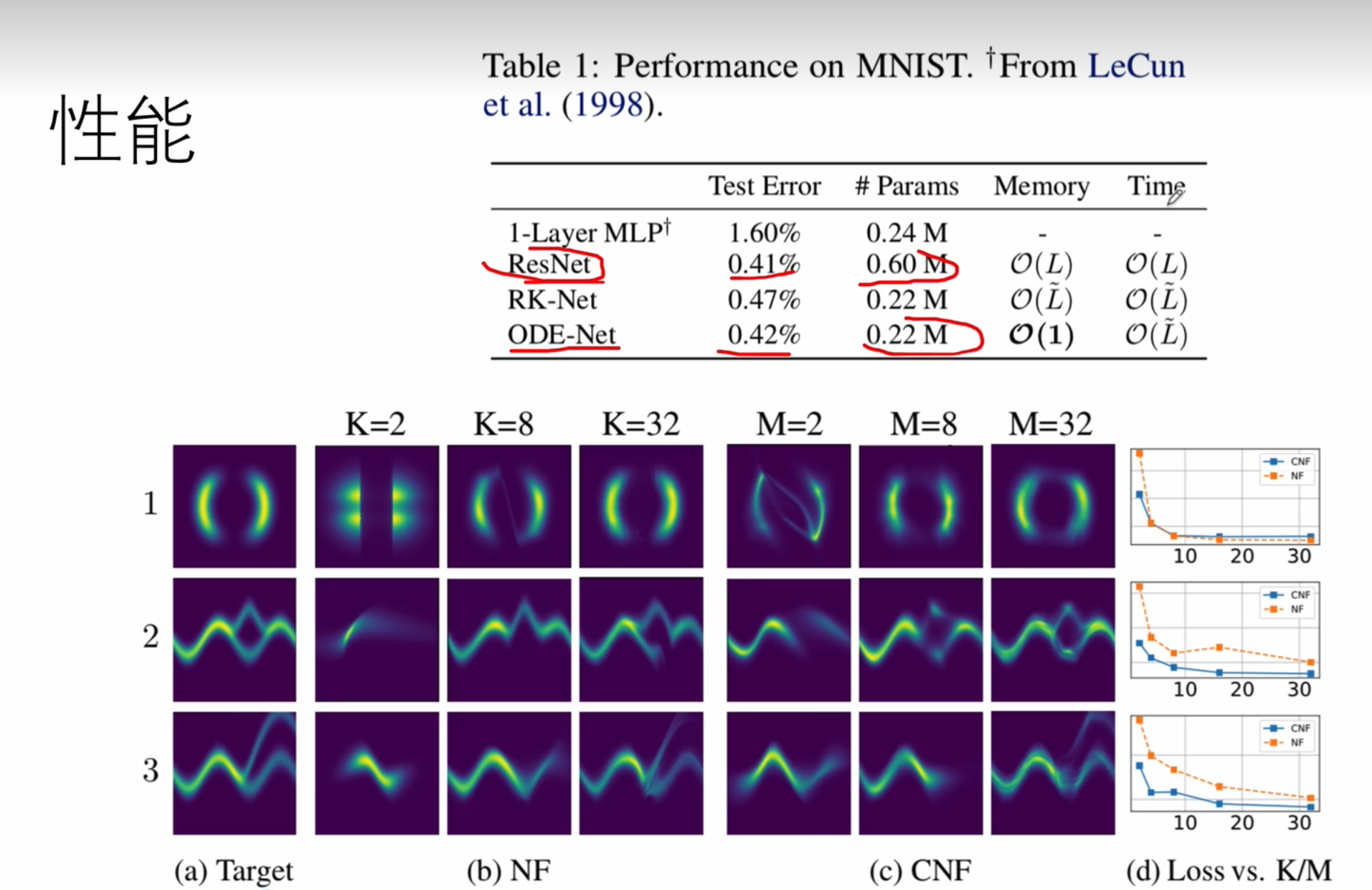
性能的对比
code example
ai生成的代码
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from torchdiffeq import odeint
matplotlib.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 定义ODE函数
class ODEFunc(nn.Module):def __init__(self, hidden_dim):super(ODEFunc, self).__init__()self.net = nn.Sequential(nn.Linear(hidden_dim, 2*hidden_dim),nn.Tanh(),nn.Linear(2*hidden_dim, hidden_dim))def forward(self, t, x):return self.net(x)# 2. 定义ODE块
class ODEBlock(nn.Module):def __init__(self, odefunc):super(ODEBlock, self).__init__()self.odefunc = odefuncself.integration_times = torch.tensor([0, 1], dtype=torch.float32)def forward(self, x):out = odeint(self.odefunc, x, self.integration_times, method='dopri5')return out[-1] # 返回最终状态# 3. 定义完整的Neural ODE模型
class NeuralODE(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(NeuralODE, self).__init__()self.encoder = nn.Linear(input_dim, hidden_dim)self.ode_block = ODEBlock(ODEFunc(hidden_dim))self.decoder = nn.Linear(hidden_dim, output_dim)def forward(self, x):x = self.encoder(x)x = self.ode_block(x)x = self.decoder(x)return x# 4. 创建一个简单的螺旋数据集作为示例
def generate_spiral_data(n_samples=1000, noise=0.2):theta = np.sqrt(np.random.rand(n_samples)) * 2 * np.pi# 两个不同的螺旋r_a = theta + np.pidata_a = np.stack([r_a * np.cos(theta) + np.random.randn(n_samples) * noise,r_a * np.sin(theta) + np.random.randn(n_samples) * noise], axis=1)label_a = np.zeros(n_samples)r_b = -theta - np.pidata_b = np.stack([r_b * np.cos(theta) + np.random.randn(n_samples) * noise,r_b * np.sin(theta) + np.random.randn(n_samples) * noise], axis=1)label_b = np.ones(n_samples)data = np.vstack([data_a, data_b])label = np.hstack([label_a, label_b])indices = np.random.permutation(len(data))return data[indices], label[indices]# 5. 准备数据
X, y = generate_spiral_data(n_samples=1000, noise=0.2)
X_train = torch.tensor(X, dtype=torch.float32)
y_train = torch.tensor(y, dtype=torch.float32).reshape(-1, 1)# 6. 初始化模型、损失函数和优化器
input_dim = 2
hidden_dim = 16
output_dim = 1
model = NeuralODE(input_dim, hidden_dim, output_dim)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)# 7. 训练模型
n_epochs = 100
losses = []print("开始训练Neural ODE模型...")
for epoch in range(n_epochs):optimizer.zero_grad()# 前向传播outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化loss.backward()optimizer.step()losses.append(loss.item())if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{n_epochs}], Loss: {loss.item():.4f}')# 8. 可视化训练过程
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(losses)
plt.title('训练损失')
plt.xlabel('Epoch')
plt.ylabel('Loss')# 9. 可视化决策边界
def plot_decision_boundary(model, X, y):# 创建网格点x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))# 对网格点进行预测with torch.no_grad():grid = torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)Z = torch.sigmoid(model(grid)).numpy().reshape(xx.shape)# 绘制决策边界和数据点plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdBu)plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdBu, edgecolors='k')plt.title('Neural ODE 决策边界')plt.xlabel('Feature 1')plt.ylabel('Feature 2')# 可视化决策边界
plt.subplot(1, 2, 2)
plot_decision_boundary(model, X, y)
plt.tight_layout()
plt.savefig('neural_ode_results.png')
plt.show()# 10. 可视化ODE轨迹
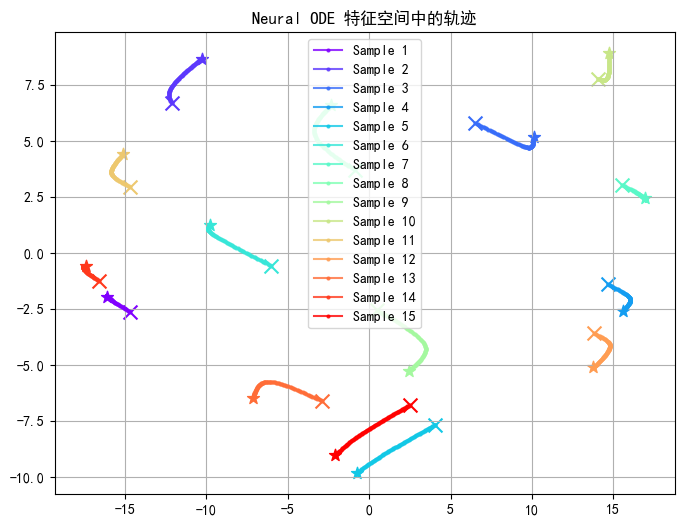
def plot_trajectories(model, X, n_samples=5):# 选择几个样本indices = np.random.choice(len(X), n_samples, replace=False)samples = torch.tensor(X[indices], dtype=torch.float32)# 获取起始隐藏状态with torch.no_grad():h0 = model.encoder(samples)# 创建更多的时间点以可视化轨迹t = torch.linspace(0, 1, 100)# 计算轨迹with torch.no_grad():trajectories = odeint(model.ode_block.odefunc, h0, t)# 轨迹形状应该是 [时间点数, 样本数, 隐藏维度]# 首先转换为正确的形状进行处理trajectories = trajectories.permute(1, 0, 2) # [样本数, 时间点数, 隐藏维度]n_samples, n_times, hidden_dim = trajectories.shape# 降维以便可视化 (使用简化的PCA)trajectories_flat = trajectories.reshape(-1, hidden_dim) # 展平所有时间点和样本# 计算协方差矩阵mean = trajectories_flat.mean(dim=0, keepdim=True)centered = trajectories_flat - meancov = centered.T @ centered / (centered.shape[0] - 1)# 特征值分解e, v = torch.linalg.eigh(cov)# 选择最大的两个特征值/向量indices = torch.argsort(e, descending=True)proj_matrix = v[:, indices[:2]] # 投影矩阵使用前两个主成分# 投影到2Dtrajectories_2d = trajectories_flat @ proj_matrixtrajectories_2d = trajectories_2d.reshape(n_samples, n_times, 2) # [样本数, 时间点数, 2]# 绘制轨迹plt.figure(figsize=(8, 6))colors = plt.cm.rainbow(np.linspace(0, 1, n_samples))for i in range(n_samples):# 获取当前样本的轨迹sample_traj = trajectories_2d[i] # [时间点数, 2]# 绘制完整轨迹plt.plot(sample_traj[:, 0], sample_traj[:, 1], 'o-', color=colors[i], alpha=0.8, markersize=2,label=f'Sample {i+1}')# 标记起点和终点plt.scatter(sample_traj[0, 0], sample_traj[0, 1], color=colors[i], s=80, marker='*', label='_')plt.scatter(sample_traj[-1, 0], sample_traj[-1, 1], color=colors[i], s=100, marker='x', label='_')plt.title('Neural ODE 特征空间中的轨迹')plt.legend()plt.grid(True)plt.savefig('neural_ode_trajectories.png')plt.show()# 可视化部分样本的ODE轨迹
plot_trajectories(model, X, n_samples=5)# 11. 评估模型性能
with torch.no_grad():y_pred = torch.sigmoid(model(X_train))preds = (y_pred > 0.5).float()accuracy = (preds == y_train).float().mean()print(f"模型准确率: {accuracy.item():.4f}")# 12. 可视化不同时间步的状态演变
def visualize_state_evolution(model, X, sample_idx=0):# 选择一个样本sample = torch.tensor(X[sample_idx:sample_idx+1], dtype=torch.float32)# 获取起始隐藏状态with torch.no_grad():h0 = model.encoder(sample)# 创建更多的时间点以可视化演变t = torch.linspace(0, 1, 10)# 计算在不同时间点的状态with torch.no_grad():states = odeint(model.ode_block.odefunc, h0, t)outputs = [model.decoder(state) for state in states]probs = [torch.sigmoid(output).item() for output in outputs]# 绘制不同时间步的输出概率plt.figure(figsize=(8, 5))plt.plot(t.numpy(), probs, 'o-', linewidth=2)plt.axhline(y=0.5, color='r', linestyle='--', alpha=0.7)plt.title(f'样本 {sample_idx} 在ODE求解过程中的输出演变')plt.xlabel('时间 t')plt.ylabel('预测概率')plt.grid(True)plt.savefig('neural_ode_evolution.png')plt.show()# 可视化一个样本的状态演变
visualize_state_evolution(model, X, sample_idx=42)print("Neural ODE 示例运行完成!")解读
ode函数的定义
ODE函数(通常表示为f(t, x, θ))代表状态随时间的变化率
1. 神经网络参数化
class ODEFunc(nn.Module):def __init__(self, hidden_dim):super(ODEFunc, self).__init__()self.net = nn.Sequential(nn.Linear(hidden_dim, 2*hidden_dim),nn.Tanh(),nn.Linear(2*hidden_dim, hidden_dim))def forward(self, t, x):return self.net(x)
这个神经网络接收当前状态x,输出状态的变化率dx/dt。关键点在于:
输入维度和输出维度必须相同(因为它代表同一状态空间中的变化率)
通常使用简单的MLP结构,但也可以使用更复杂的网络
激活函数的选择会影响ODE流的平滑性,常用Tanh或Softplus等光滑函数
2. 基于物理模型
对于某些领域特定问题,ODE函数可以基于已知的物理规律来定义,例如:
胡克定律:
d 2 x d t 2 = − k m x \frac{d^2x}{dt^2}=-\frac{k}{m}x dt2d2x=−mkx
拆分为两个方程:
{ d x d t = v d v d t = − k m x \begin{cases}\frac{dx}{dt}=v\\\frac{dv}{dt}=-\frac{k}{m}x&\end{cases} {dtdx=vdtdv=−mkx
def f(t, x, params):# 例如简谐振动的微分方程# 分解状态变量:位置(position)和速度(velocity)position, velocity = x[..., 0], x[..., 1] # 使用 ... 处理批量维度# 计算加速度:a = -k/m * xacceleration = -params['k'] * position / params['m']# 返回导数 [dx/dt, dv/dt]return torch.stack([velocity, acceleration], dim=-1)
使用示例
params = {'k': 2.0, 'm': 1.0} # 弹性系数和质量
x0 = torch.tensor([1.0, 0.0]) # 初始状态 [位置, 速度]
t = 0.0 # 当前时间(方程不显含时间t)dxdt = f(t, x0, params) # 输出应为 [0.0, -2.0]
3. 混合方法
将物理先验与神经网络结合:
def f(t, x, params, nn_params):known_dynamics = physical_model(t, x, params) unknown_dynamics = neural_network(x, nn_params)return known_dynamics + unknown_dynamics
ODE函数的设计原则
ODE函数的设计不是完全随意的,而是需要满足以下几个要点:
-
维度匹配:输入和输出维度必须相同,确保它真正表示变化率
-
平滑性:ODE求解器需要函数具有一定的平滑性,所以通常使用光滑的激活函数
-
稳定性:函数设计应当避免数值不稳定,例如避免输出极大的值
-
表达能力:函数应当具有足够的能力来表达所需的动态系统
如何选择ODE函数结构
选择ODE函数的结构通常基于以下考虑:
-
问题复杂度:对于简单问题,使用较小的网络;复杂问题则需要更强的表达能力
-
计算效率:复杂的ODE函数会增加求解器的计算负担
-
领域知识:当有领域先验知识时,可以将其编码到ODE函数中
-
实验验证:不同的ODE函数结构可以通过实验比较性能
实践中的调整
在实践中,ODE函数的确定往往遵循以下步骤:
- 从简单的MLP开始
- 调整网络宽度(隐藏层大小)
- 尝试不同的激活函数
- 根据验证集性能进行调整
- 如有领域知识,尝试将其整合到函数中
总结来说,Neural ODE中的函数不是随便定义的,而是根据问题特性、计算考虑和理论要求精心设计的。这个函数需要平衡表达能力、计算效率和数值稳定性。
odeblock
记录了一个odefunc,还有 integration_times积分的时间区间
forward方法中调用odeint进行求解,返回最后一个时间点的结果
表示使用自适应步长的Dormand-Prince 5(4)算法。
时间区间:[0, 1] 是抽象的时间跨度,可以理解为“虚拟时间”上的变换过程,与物理时间无关。
# 2. 定义ODE块
class ODEBlock(nn.Module):def __init__(self, odefunc):super(ODEBlock, self).__init__()self.odefunc = odefunc## 观察多个时间点(t=0, 0.5, 1)self.integration_times = torch.tensor([0, 1], dtype=torch.float32)def forward(self, x):out = odeint(self.odefunc, x, self.integration_times, method='dopri5')return out[-1] # 返回最终状态
NeuralODE
# 3. 定义完整的Neural ODE模型
class NeuralODE(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(NeuralODE, self).__init__()self.encoder = nn.Linear(input_dim, hidden_dim)# 编码器self.ode_block = ODEBlock(ODEFunc(hidden_dim))# ODE动力学层self.decoder = nn.Linear(hidden_dim, output_dim) # 解码器def forward(self, x):x = self.encoder(x)# 输入 → 隐藏空间x = self.ode_block(x)# 通过ODE动力学演化x = self.decoder(x)# 隐藏空间 → 输出return x
组件功能:
| 组件 | 功能 |
|---|---|
| Encoder | 将输入数据 x 从 input_dim 维度映射到 hidden_dim 的隐藏空间。 |
| ODEBlock | 在隐藏空间中通过微分方程定义的连续动力学系统对特征进行非线性变换。 |
| Decoder | 将演化后的隐藏状态映射回目标输出维度 output_dim。 |
3. 关键设计思想
① 连续深度模型
- 与传统神经网络的区别:
- 传统网络:离散的层(如
nn.Linear+nn.ReLU)堆叠,深度固定。 - Neural ODE:用ODE求解器替代离散层,形成连续深度,允许动态调整“深度”(通过调整积分时间步长)。
- 传统网络:离散的层(如
② 参数效率
- 动力学共享:所有时间步共享同一个
odefunc定义的动力学方程,参数数量与“深度”无关。 - 隐式正则化:ODE的平滑性天然避免过拟合。
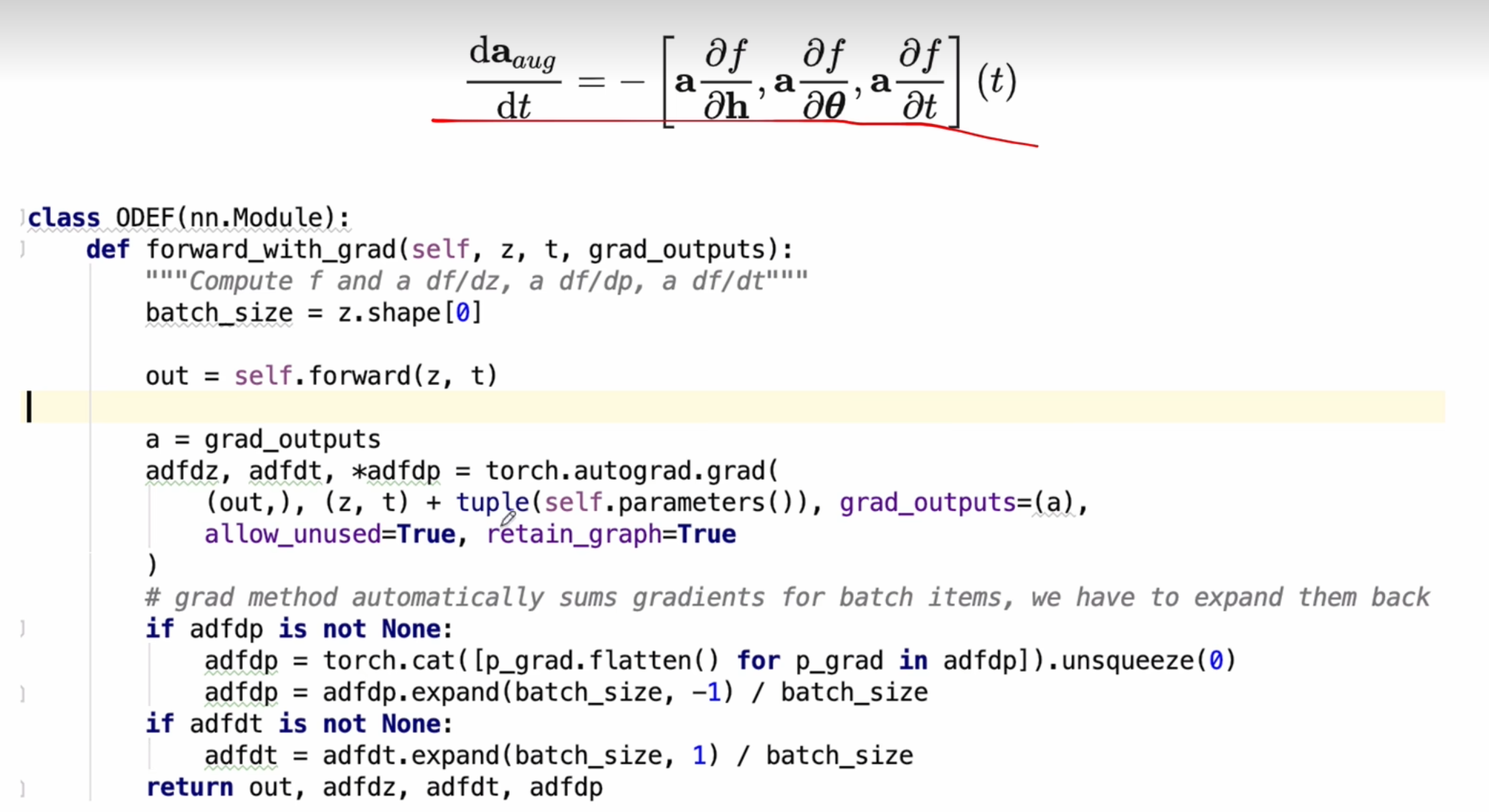
③ 反向传播机制
- 伴随方法 (Adjoint Method):通过求解伴随ODE反向传播梯度,无需存储中间状态,内存复杂度为
O(1)(与积分步数无关)。
4. 工作流程示例
假设输入数据维度为 input_dim=3,隐藏层 hidden_dim=5,输出 output_dim=2:
- 编码阶段:
encoder将输入x(维度3)映射到隐藏空间(维度5)。 - ODE演化:隐藏状态在ODE定义的向量场中从时间
0演化到1。 - 解码阶段:最终隐藏状态通过
decoder映射到输出(维度2)。
5. 与物理ODE的类比
如果将隐藏状态视为物理系统的状态:
odefunc:类似物理定律(如牛顿方程),定义状态如何随时间变化。ODEBlock:类似模拟器,根据物理定律演化系统状态。integration_times:模拟的时间跨度,控制演化“深度”。
6. 潜在扩展方向
- 复杂动力学:在
ODEFunc中设计更复杂的微分方程(如引入非线性、外部控制项)。 - 可变时间跨度:动态调整
integration_times实现自适应深度。 - 混合架构:将ODEBlock与传统神经网络层结合。
通过这种设计,Neural ODE 提供了一种连续、可逆且参数高效的建模方式,特别适合处理时序数据或需要连续变换的任务。
data
使用一个生成的数据集
# 4. 创建一个简单的螺旋数据集作为示例
def generate_spiral_data(n_samples=1000, noise=0.2):theta = np.sqrt(np.random.rand(n_samples)) * 2 * np.pi# 两个不同的螺旋r_a = theta + np.pidata_a = np.stack([r_a * np.cos(theta) + np.random.randn(n_samples) * noise,r_a * np.sin(theta) + np.random.randn(n_samples) * noise], axis=1)label_a = np.zeros(n_samples)r_b = -theta - np.pidata_b = np.stack([r_b * np.cos(theta) + np.random.randn(n_samples) * noise,r_b * np.sin(theta) + np.random.randn(n_samples) * noise], axis=1)label_b = np.ones(n_samples)data = np.vstack([data_a, data_b])label = np.hstack([label_a, label_b])indices = np.random.permutation(len(data))return data[indices], label[indices]# 5. 准备数据
X, y = generate_spiral_data(n_samples=1000, noise=0.2)
X_train = torch.tensor(X, dtype=torch.float32)
y_train = torch.tensor(y, dtype=torch.float32).reshape(-1, 1)
模型的初始化
# 6. 初始化模型、损失函数和优化器
input_dim = 2 # 模型输入维度(如二维特征)
hidden_dim = 16 # ODE隐藏状态维度
output_dim = 1 # 模型输出维度(如二分类概率)
model = NeuralODE(input_dim, hidden_dim, output_dim)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
类似于传统深度学习中的“编码-处理-解码”范式,但用ODEBlock替代了离散的中间层。
# 测试数据
x = torch.randn(32, input_dim) # batch_size=32, input_dim=2# 前向传播
h = model.encoder(x) # 输出形状: (32, 16)
h_ode = model.ode_block(h) # 输出形状: (32, 16)
output = model.decoder(h_ode) # 输出形状: (32, 1)
训练过程
# 7. 训练模型
n_epochs = 50
losses = []print("开始训练Neural ODE模型...")
for epoch in range(n_epochs):optimizer.zero_grad()# 前向传播outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化loss.backward()optimizer.step()losses.append(loss.item())if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{n_epochs}], Loss: {loss.item():.4f}')
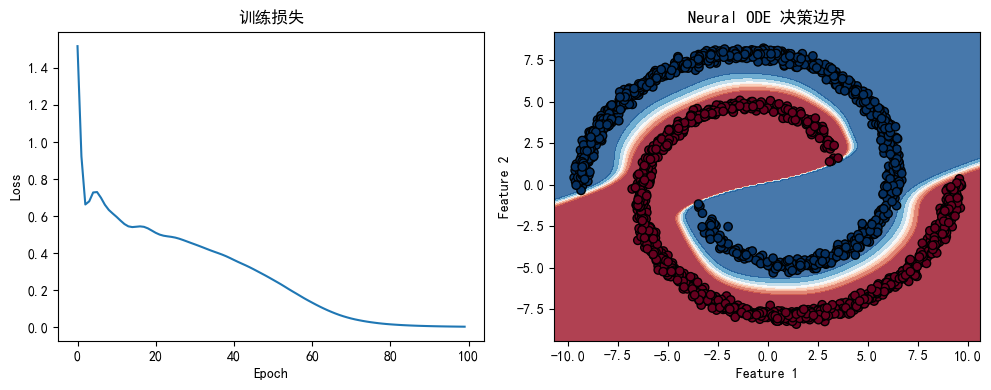
# 8. 可视化训练过程
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(losses)
plt.title('训练损失')
plt.xlabel('Epoch')
plt.ylabel('Loss')
决策边界
预测出来的是坐标(x,y)在这个里面的分类
# 9. 可视化决策边界
def plot_decision_boundary(model, X, y):# 创建网格点x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))# 对网格点进行预测with torch.no_grad():grid = torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)Z = torch.sigmoid(model(grid)).numpy().reshape(xx.shape)# 绘制决策边界和数据点plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdBu)plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdBu, edgecolors='k')plt.title('Neural ODE 决策边界')plt.xlabel('Feature 1')plt.ylabel('Feature 2')# 可视化决策边界
plt.subplot(1, 2, 2)
plot_decision_boundary(model, X, y)
plt.tight_layout()
plt.savefig('neural_ode_results.png')
plt.show()
可视化ODE轨迹
这个的意义不是很清晰。随着批次进行,某个样本点的hidden层的特征的主要部分的值变化。
# 10. 可视化ODE轨迹
def plot_trajectories(model, X, n_samples=5):# 选择几个样本indices = np.random.choice(len(X), n_samples, replace=False)samples = torch.tensor(X[indices], dtype=torch.float32)# 获取起始隐藏状态with torch.no_grad():h0 = model.encoder(samples)# 创建更多的时间点以可视化轨迹t = torch.linspace(0, 1, 100)# 计算轨迹with torch.no_grad():trajectories = odeint(model.ode_block.odefunc, h0, t)# 轨迹形状应该是 [时间点数, 样本数, 隐藏维度]# 首先转换为正确的形状进行处理trajectories = trajectories.permute(1, 0, 2) # [样本数, 时间点数, 隐藏维度]n_samples, n_times, hidden_dim = trajectories.shape# 降维以便可视化 (使用简化的PCA)trajectories_flat = trajectories.reshape(-1, hidden_dim) # 展平所有时间点和样本# 计算协方差矩阵mean = trajectories_flat.mean(dim=0, keepdim=True)centered = trajectories_flat - meancov = centered.T @ centered / (centered.shape[0] - 1)# 特征值分解e, v = torch.linalg.eigh(cov)# 选择最大的两个特征值/向量indices = torch.argsort(e, descending=True)proj_matrix = v[:, indices[:2]] # 投影矩阵使用前两个主成分# 投影到2Dtrajectories_2d = trajectories_flat @ proj_matrixtrajectories_2d = trajectories_2d.reshape(n_samples, n_times, 2) # [样本数, 时间点数, 2]# 绘制轨迹plt.figure(figsize=(8, 6))colors = plt.cm.rainbow(np.linspace(0, 1, n_samples))for i in range(n_samples):# 获取当前样本的轨迹sample_traj = trajectories_2d[i] # [时间点数, 2]# 绘制完整轨迹plt.plot(sample_traj[:, 0], sample_traj[:, 1], 'o-', color=colors[i], alpha=0.8, markersize=2,label=f'Sample {i+1}')# 标记起点和终点plt.scatter(sample_traj[0, 0], sample_traj[0, 1], color=colors[i], s=80, marker='*', label='_')plt.scatter(sample_traj[-1, 0], sample_traj[-1, 1], color=colors[i], s=100, marker='x', label='_')plt.title('Neural ODE 特征空间中的轨迹')plt.legend()plt.grid(True)plt.savefig('neural_ode_trajectories.png')plt.show()# 可视化部分样本的ODE轨迹
plot_trajectories(model, X, n_samples=5)
先学习到这里。有应用的话,在进行补充。
相关文章:
)
基于常微分方程的神经网络(Neural ODE)
参考资料:B站的视频解析 知乎神经常微分方程总结 论文链接:论文 什么是常微分方程? 微分方程式包含未知函数及其导数的方程,未知函数导数的最高阶数称为给i微分方程的阶。 常微分方程(ordinary differential equation࿰…...

对VTK中的Volume Data体数据进行二维图像处理
文章目录 概要Cpp代码处理前效果处理后效果 概要 在 VTK 中对体数据进行二维图像处理的过程通常涉及从三维体数据中提取二维切片,并对这些切片进行处理。然后,可以选择性地将处理后的切片数据重新合并成新的体数据。 以下是对 VTK 中的体数据进行二维图…...

阿里云ftp服务器登录要怎么做?如何访问ftp服务器?
阿里云ftp服务器登录要怎么做?如何访问ftp服务器? 访问FTP服务器通常需要以下步骤,具体方法取决于您使用的工具和操作系统: 一、FTP服务器登录所需信息 服务器地址:通常是IP地址(如 ftp.example.com 或 192…...

中国的国产化进程
中国的国产化进程是一个涉及国家安全、经济发展和技术自主的长期战略,其历史进程和动因可以从以下几个关键阶段和核心原因来理解: 一、国产化的历史进程 1. 建国初期(1949–1978):自力更生与基础工业建设 背景:新中国成立后,面临西方国家的技术…...

突破语言藩篱:从Seq2Seq到智能翻译的范式革命
## 一、语言之桥的智能进化:超越字面转换的深层理解 在慕尼黑工业大学实验室的深夜,一个搭载最新神经网络的翻译系统正逐字解析着歌德诗句的韵律。这并非简单的词语替换,而是一场跨越时空的文化解码——机器首次在《浮士德》的英译本中保留了德文诗歌特有的头韵结构。这个突…...
)
Java写项目前的准备工作指南(技术栈选择 环境搭建和工具配置 项目结构设计与模块划分)
前言 📝 在开始编写一个 Java 项目之前,做好充分的准备工作是至关重要的。很多初学者可能在没有清晰规划的情况下就开始编写代码,导致项目开发进度缓慢、结构混乱,甚至最终无法按预期完成。而事实上,项目的成功不仅仅…...

如何使用 Redis 缓存验证码
目录 🧠 Redis 缓存验证码的工作原理 🧰 实现流程 1. 安装 Redis 和 Python 客户端 2. 生成并缓存验证码 示例代码:生成并存储验证码 3. 发送验证码(以短信为例) 4. 校验验证码 示例代码:校验验证码…...
RestAPI 毛子(Unit Testing))
(八)RestAPI 毛子(Unit Testing)
文章目录 项目地址一、Unit Testing1.1 创建X unit 测试项目1. 创建项目目录2. 管理包 1.2 创建CreateEntryDtoValidator测试1.3 创建CreateEntryDtoValidator测试 二、Integration test2.1 创建Integration test环境1. 安装所需要的包 2.2 配置基础设置1. 数据库链接DevHabitW…...
—TDA4VM芯片详解(2)—产品应用和介绍)
德州仪器(TI)—TDA4VM芯片详解(2)—产品应用和介绍
写在前面 本系列文章主要讲解德州仪器(TI)TDA4VM芯片的相关知识,希望能帮助更多的同学认识和了解德州仪器(TI)TDA4VM芯片。 若有相关问题,欢迎评论沟通,共同进步。(*^▽^*) 错过其他章节的同学…...

vue2,3:v-model的语法糖
Vue2的v-model 语法糖 **1. **v-model 的作用 v-model 是 Vue 中用于实现双向数据绑定的指令,主要用于表单元素(如 、、)和自定义组件。它简化了数据与视图之间的同步,使得开发者可以方便地处理用户输入。 **2. **v-model 的语…...

【深度学习】#10 注意力机制
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 目录 注意力提示生物学中的注意力提示查询、键和值 注意力汇聚注意力评分函数掩蔽softmax操作加性注意力缩放点积注意力 Bahdanau注意力多头注意力自注意力和位…...

Modbus总线协议智能网关协议转换案例解析:提升系统兼容性
Modbus是一种串行通信协议,是Modicon公司(现在的施耐德电气,Schneider Electic)于1979年为使用可编程逻辑控制器(PLC)通信而发表。Modbus已经成为工业领域通信协议的业界标准(Defacto),并日现在是工业电子设备之间常用的连接方式 Modbus是一种串行通信协…...

echarts自定义图表--仪表盘
基于仪表盘类型的自定义表盘 上图为3层结构组成 正常一个仪表盘配置要在外圈和内圈之间制造一条缝隙间隔 再创建一个仪表盘配置 背景透明 进度条拉满 进度条颜色和数据的背景相同开始处的线 又一个仪表盘配置 数值固定一个比较小的值 <!DOCTYPE html> <html><h…...

第五章:Execution Flow Framework
Chapter 5: Execution Flow Framework 从消息记忆到执行流程:如何让多个AI“同事”协同完成复杂任务? 在上一章的消息与记忆系统中,我们已经能让AI记住之前的对话内容。但你是否想过:如果用户要求“预订从北京到上海的高铁&#…...

01 C++概述
一、C语言发展史 起源与演进 • 1960s:剑桥大学Martin Richards开发BCPL语言,用于系统软件开发。 • 1970年:贝尔实验室Ken Thompson在BCPL基础上发明B语言。 • 1972年:Dennis Ritchie和Brian Kernighan设计出C语言,兼…...

Kotlin DSL 深度解析:从 Groovy 迁移的困惑与突破
引言 Gradle 作为现代构建工具,支持 Groovy 和 Kotlin 两种 DSL(领域特定语言)。Kotlin DSL 因其类型安全和更好的 IDE 支持逐渐流行,但它的语法设计却让许多开发者感到困惑,尤其是从 Groovy 迁移时。 本文将从 Kotl…...

2025年二级造价师考点总结
二级造价师考点总结 一、建设工程造价管理 工程造价构成:重点掌握建筑安装工程费(人工费、材料费、机械费、企业管理费、利润、规费、税金)的组成及计算。 计价依据:熟悉工程量清单计价规范,掌握定额计价与清单计价的…...

Typecho博客使用阿里云cdn和oss:handsome主题进阶版
Typecho使用阿里云cdn和oss 设置前需要保证阿里云cdn和oss已配置好且可以正常使用一、准备工作二、修改 Handsome 主题的静态资源链接方法 1:直接修改主题文件(推荐)方法 2:通过主题设置自定义(方便) 三、处…...

知识体系_用户研究_用户体验度量模型
1 用户体验度量常见模型 1.1 满意度(CSAT/PSAT) CSAT(Customer Satisfaction)指客户满意度,PAST(Product Satisfaction)指产品满意度。顾名思义,其用于衡量客户对产品或服务的体验度量指标。在用户完成某个产品或某项服务的体验后,对其进行…...

邮件分类特征维度实验分析
活动发起人小虚竹 想对你说: 这是一个以写作博客为目的的创作活动,旨在鼓励大学生博主们挖掘自己的创作潜能,展现自己的写作才华。如果你是一位热爱写作的、想要展现自己创作才华的小伙伴,那么,快来参加吧!…...

Linux服务之Nginx服务部署及基础配置
目录 一.Nginx介绍 1.Nginx功能介绍 2.基础特性 3.Web服务相关的功能 4.I/O模型相关概念 5.nginx模块 6.Nginx文件存放位置 7.Nginx事件驱动模型 二.平滑升级及信号使用 1.Nginx 程序当作命令使用 2.信号类型 3.平滑升级nginx 4.回滚 三.Nginx调优 1.隐藏版本号或…...

Centos小白之在CentOS8.5中安装Rabbitmq 3.10.8
注意事项 安装以及运行等其他操作,要使用root账号进行,否则会遇到很多麻烦的事情。 使用命令行进行远程登录 ssh root192.168.0.167 安装make 执行安装命令 yum -y install make gcc gcc-c kernel-devel m4 ncurses-devel openssl-devel这里有可能会…...

基于单片机的游泳馆智能管理系统设计与实现
标题:基于单片机的游泳馆智能管理系统设计与实现 内容:1.摘要 随着游泳馆规模的不断扩大和管理需求的日益提高,传统的管理方式已难以满足高效、精准的管理要求。本文旨在设计并实现一种基于单片机的游泳馆智能管理系统。采用单片机作为核心控制单元,结合…...
——深度相机模型及用途介绍)
深度相机(一)——深度相机模型及用途介绍
一、深度相机概述 深度相机,又称 3D 相机,是一种能够获取场景中物体深度信息(即物体到相机的距离)的设备。与传统相机只能拍摄二维平面图像不同,深度相机不仅能记录物体的颜色和纹理,还能通过特定技术手段测…...

【Torch】nn.Conv1d、nn.Conv2d、nn.Conv3d算法详解
1. nn.Conv1d 1.1 输入(Input)和输出(Output) 输入张量 形状:(batch_size, in_channels, length) batch_size:一次过网络的样本数in_channels:每个样本的通道数(特征维度࿰…...

Android WebRTC回声消除
文章目录 安卓可用的回声消除手段各种回声消除技术优缺点WebRTC回声消除WebRTC回声消除回声消除处理流程WebRTC AECM APP 安卓可用的回声消除手段 硬件回声消除 使用 AudioRecord 的 VOICE_COMMUNICATION 模式:通过 AudioRecord 的 VOICE_COMMUNICATION 音频源可以…...

[Linux运维] [Ubuntu/Debian]在Lightsail Ubuntu服务器上安装Python环境的完整指南
在之前的教程中,我们已经讲过如何开通亚马逊Lightsail服务器并安装宝塔面板。今天,我们来进一步补充:如何在Lightsail上的Ubuntu/Debian系统中安装和配置Python开发环境。 本教程不仅适用于Lightsail服务器,也适用于所有使用Ubunt…...

2025医疗领域AI发展五大核心趋势与路线研究
引言 人工智能技术正在全球范围内深刻改变医疗服务的提供方式,推动全球医疗的普惠化、技术合作、产业升级以及公共卫生防控发生巨变[0]。医疗AI的浪潮奔涌向前,从2024年开始,生成式AI的爆发式发展更是将医疗AI推到了新的十字路口[1]。在这一背景下,本报告将深入探讨医疗领…...
 | 第六周|过拟合问题)
【学习笔记】机器学习(Machine Learning) | 第六周|过拟合问题
机器学习(Machine Learning) 简要声明 基于吴恩达教授(Andrew Ng)课程视频 BiliBili课程资源 文章目录 机器学习(Machine Learning)简要声明 摘要过拟合与欠拟合问题一、回归问题中的过拟合1. 欠拟合(Underfit&#x…...

【MQ篇】RabbitMQ之惰性队列!
目录 引言:当“生产”大于“消费”,队列就“胖”了!肥宅快乐队列?🤔队列界的“躺平”大师:惰性队列(Lazy Queues)驾到!😴如何“激活”你的队列的“惰性”属性…...

计算机视觉——通过 OWL-ViT 实现开放词汇对象检测
介绍 传统的对象检测模型大多是封闭词汇类型,只能识别有限的固定类别。增加新的类别需要大量的注释数据。然而,现实世界中的物体类别几乎无穷无尽,这就需要能够检测未知类别的开放式词汇类型。对比学习(Contrastive Learning&…...
)
第二部分:网页的妆容 —— CSS(下)
目录 6 布局基础:Display 与 Position - 元素如何排列和定位6.1 小例子6.2 练习 7 Flexbox 弹性布局:一维布局利器7.1 小例子7.2 练习 8 Grid 网格布局:强大的二维布局系统8.1 小例子8.2 练习 9 响应式设计与媒体查询:适应不同设备…...

vite项目tailwindcss4的使用
1、安装taillandcss 前几天接手了一个项目,看到别人用tailwindcss节省了很多css代码的编写,所以自己也想在公司项目中接入tailwindcss。 官网教程如下: Installing Tailwind CSS with Vite - Tailwind CSS 然而,我在vite中按…...

css中:is和:where 伪函数
在 CSS 里,:is() 属于伪类函数,其作用是对一组选择器进行匹配,只要元素与其中任何一个选择器相匹配,就可以应用对应的样式规则。以下是详细介绍: 基本语法 :is() 函数的参数是一个或多个选择器,各个选择器之…...

线下零售数据采集:在精度与效率之间寻找平衡点
线下零售数据采集:在精度与效率之间寻找平衡点 为什么线下零售必须重视数据采集? 随着零售行业竞争加剧,门店执行的标准化与透明化成为供应链协作、销售提升的基础工作。 POG(陈列执行规范)的落地效果、陈列策略的调整…...

【Robocorp实战指南】Python驱动的开源RPA框架
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现案例1:网页数据抓取案例2:Excel报表生成 运行结果验证 三、性能对比测试方…...

新ubuntu物理机开启ipv6让外网访问
Ubuntu 物理机 SSH 远程连接与 IPv6 外网访问测试指南 1. 通过 SSH 远程连接 Ubuntu 物理机 1.1 安装 SSH 服务 sudo apt update sudo apt install openssh-server1.2 检查 SSH 服务状态 sudo systemctl status ssh确认出现 active (running)。 1.3 获取物理机 IP 地址 i…...

驱动开发硬核特训 │ Regulator 子系统全解
一、Regulator子系统概述 在 Linux 内核中,Regulator 子系统是专门用于管理电源开关、电压调整、电流控制的一套完整框架。 它主要解决以下问题: 设备需要的电压通常不一样,如何动态调整?有些设备休眠时需要关闭供电࿰…...
)
入门版 鸿蒙 组件导航 (Navigation)
入门版 鸿蒙 组件导航 (Navigation) 注意:使用 DevEco Studio 运行本案例,要使用模拟器,千万不要用预览器,预览器看看 Navigation 布局还是可以的 效果:点击首页(Index)跳转到页面(…...

怎样将visual studio 2015开发的项目 保存为2010版本使用
用的老旧电脑跑vs2015太慢了,实在忍不了了! 想把用 Visual Studio 2015 的做的项目保存为 Visual Studio 2010 兼容的格式,以后都使用2010写了。自己在网上搜了一下,亲测以下步骤可以的 手动修改解决方案和项目文件 修改解决方案…...

【学习笔记】软件测试流程-测试设计阶段
软件测试设计阶段这个阶段主要工作是编写测试用例。 什么是测试用例? 测试用例(TestCase)是为项目需求而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序是否满足客户需求。简而言之,测试用例是每一个测…...

Rust 学习笔记:关于切片的两个练习题
Rust 学习笔记:关于切片的两个练习题 Rust 学习笔记:关于切片的两个练习题引用和切片引用的大小以下程序能否通过编译? Rust 学习笔记:关于切片的两个练习题 参考视频: https://www.bilibili.com/video/BV1GrDQYeEzS…...

BeeWorks企业内部即时通讯软件支持国产化,已在鸿蒙系统上稳定运行
一、企业用户面临的困境与痛点 一些企业用的即时通讯软件比较旧,存在的问题不仅影响了日常工作的正常开展,也阻碍了企业信息化建设的进程: ● 国产系统与移动端不兼容:仅支持Windows和MAC系统,无法在银河麒麟、统信U…...

java对文字按照语义切分
实现目标 把一段文本按照一个完整的一句话为单元进行切分。如:以逗号,感叹号结尾看作是一个句子。 实现方案 StanfordCoreNLP切分 引入依赖 <dependency><groupId>edu.stanford.nlp</groupId><artifactId>stanford-corenlp<…...

华纳云:centos如何实现JSP页面的动态加载
JSP(JavaServer Pages)作为Java生态中常用的服务器端网页技术,具有动态内容生成、可扩展性强、与Java无缝结合等优势。 而CentOS作为一款稳定、高效、安全的Linux服务器操作系统,非常适合部署JSP应用。 想要让JSP页面实现动态更新加载,避免…...
:会话+消息过期机制,设备远程控制,批量控制实现)
Android 消息队列之MQTT的使用(二):会话+消息过期机制,设备远程控制,批量控制实现
目录 一、实际应用场景 室内温湿度数据上传设备远程控制批量控制实现 二、会话管理、消息过期设置 4.1 会话管理 Clean Session参数 新旧会话模式对比典型应用场景 4.2 消息过期设置 MQTT 5.0消息过期机制 Message Expiry Interval属性QoS级别影响 三、实际应用场景 …...

一、JVM基础概念
一、JVM的设计目标 一次编译,到处运行(跨平台) ➔ Java编译成字节码,由JVM在不同平台解释/编译执行,实现跨平台。 内存管理与垃圾回收 ➔ JVM统一负责内存分配和回收,降低内存泄漏的风险。 性能优化 ➔ JIT(即时编译…...

深度学习---Pytorch概览
一、PyTorch 是什么? 1. 定义与定位 开源深度学习框架:由 Facebook(Meta)AI 实验室开发,基于 Lua 语言的 Torch 框架重构,2017 年正式开源,主打动态计算图和易用性。核心优势:灵活…...

第33周JavaSpringCloud微服务 分布式综合应用
第33周JavaSpringCloud微服务 分布式综合应用 一、分布式综合应用概述 分布式知识体系内容广泛,主要包括分布式事务、分布式锁、RabbitMQ等消息中间件的应用以及跨域问题的解决。 1.1 课程重点内容介绍 分布式事务 :在大型项目中普遍存在,…...

Paramiko 完全指南
目录 Paramiko 概述核心功能与模块框架安装与依赖基础用法与案例详解 SSH 连接与命令执行密钥认证SFTP 文件传输交互式会话端口转发 高级功能与实战技巧常见问题与解决方案总结与资源推荐 1. Paramiko 概述 是什么? Paramiko 是一个纯 Python 实现的 SSHv2 协议库…...