【学习笔记】机器学习(Machine Learning) | 第六周|过拟合问题
机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- 机器学习(Machine Learning)
- 简要声明
- 摘要
- 过拟合与欠拟合问题
- 一、回归问题中的过拟合
- 1. 欠拟合(Underfit)
- 2. 刚好拟合(Just right)
- 3. 过拟合(Overfit)
- 二、分类问题中的过拟合
- 1. 欠拟合(Underfit)
- 2. 刚好拟合(Just right)
- 3. 过拟合(Overfit)
- 三、过拟合的原因及解决方法
- 过拟合原因
- 解决方法
- 解决过拟合问题
- 一、收集更多训练数据
- 二、选择特征
- 三、正则化
- 四、过拟合解决方法总结
- 正则化的应用
- 一、带正则化的代价函数
- 二、正则化线性回归
- 三、正则化逻辑回归
- 四、正则化参数的选择
- 五、正则化方法对比
摘要
本文介绍了机器学习中的过拟合和欠拟合问题,通过回归和分类问题展示了不同拟合程度的表现。针对过拟合问题,提出了增加训练数据、特征选择、正则化等解决方法,并讨论了正则化在线性回归和逻辑回归中的应用,包括带正则化的代价函数和梯度下降更新规则。最后,对比了正则化方法的优缺点,强调合理应用正则化技术对提高模型泛化能力的重要性。
过拟合与欠拟合问题
在机器学习中,过拟合是一个常见的问题,它导致模型在训练数据上表现很好,但在新的、未见过的数据上表现不佳。以下是对过拟合问题的详细探讨。
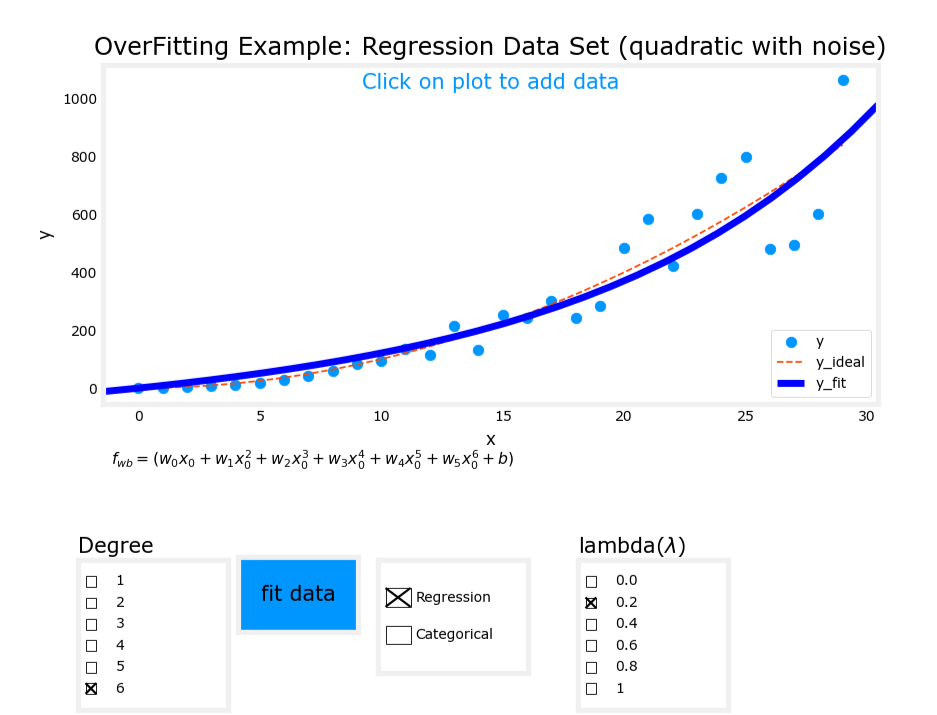
一、回归问题中的过拟合
考虑一个简单的回归问题,尝试用不同复杂度的模型来拟合数据。
1. 欠拟合(Underfit)
- 模型表达式: y = w 1 x + b y = w_1x + b y=w1x+b
- 特征:仅使用输入变量的一次项。
- 表现:模型无法很好地拟合训练数据,存在高偏差(high bias)。
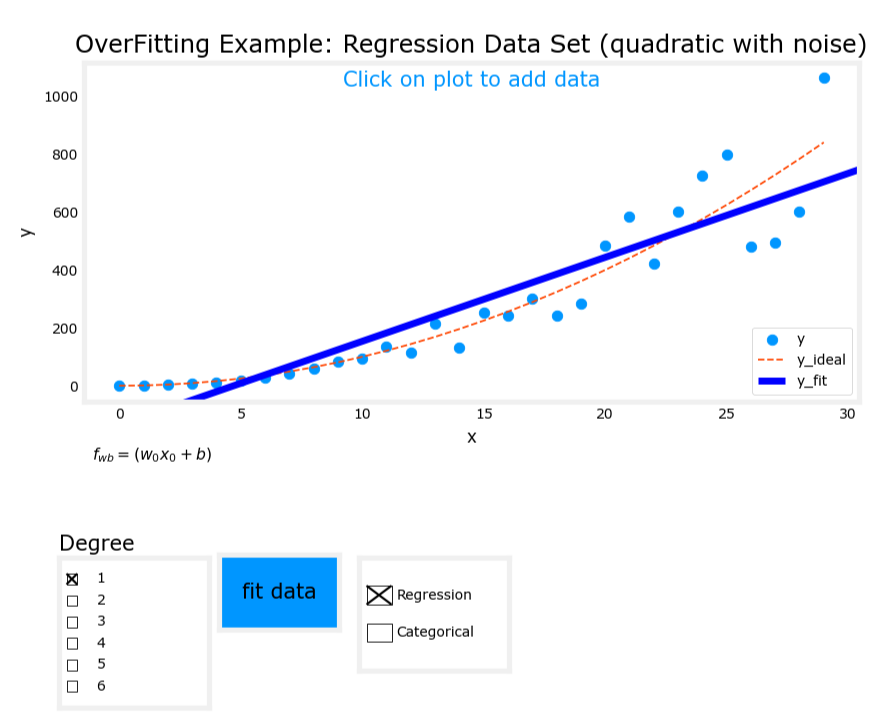
2. 刚好拟合(Just right)
- 模型表达式: y = w 1 x + w 2 x 2 + b y = w_1x + w_2x^2 + b y=w1x+w2x2+b
- 特征:使用输入变量的一次项和二次项。
- 表现:模型很好地拟合了训练数据,具有良好的泛化能力(generalization)。
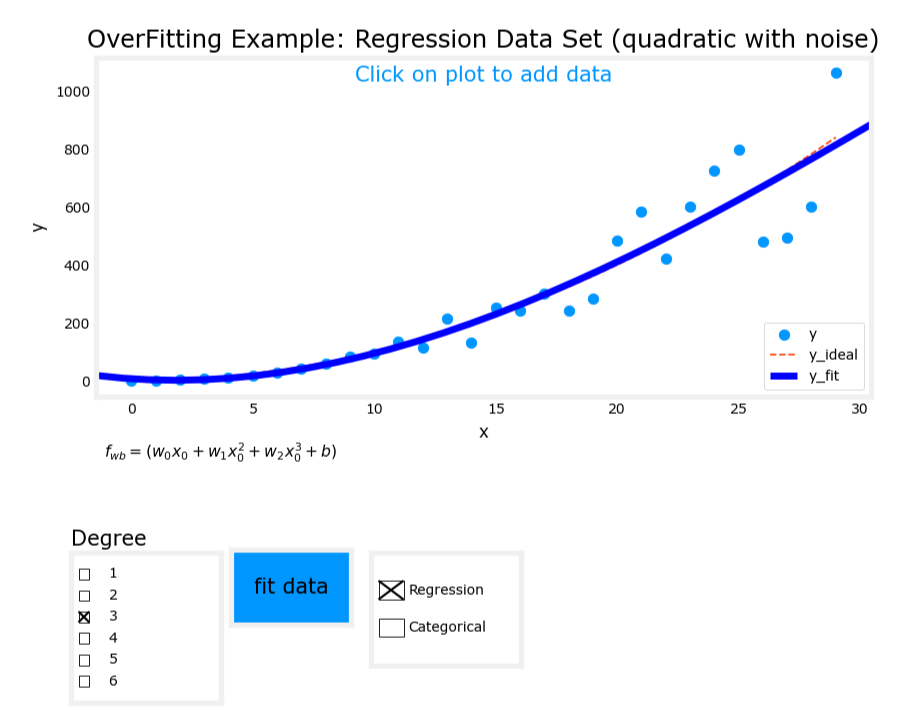
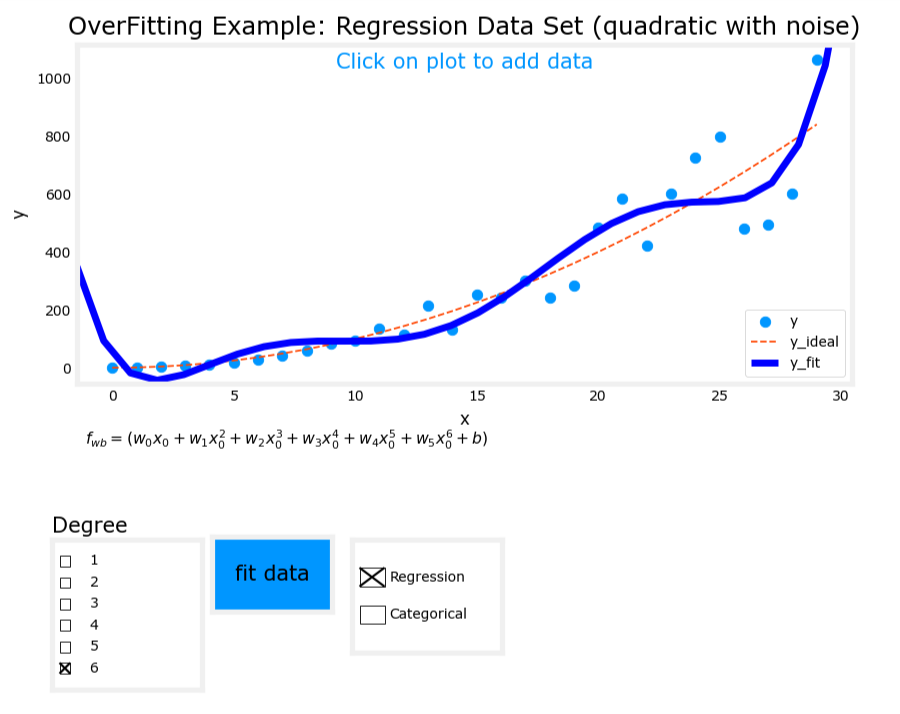
3. 过拟合(Overfit)
- 模型表达式: y = w 1 x + w 2 x 2 + w 3 x 3 + w 4 x 4 + b y = w_1x + w_2x^2 + w_3x^3 + w_4x^4 + b y=w1x+w2x2+w3x3+w4x4+b
- 特征:使用了过多的高次项。
- 表现:模型在训练数据上拟合得非常好,但存在高方差(high variance),泛化能力差。
图像对比
欠拟合
刚好拟合
过拟合
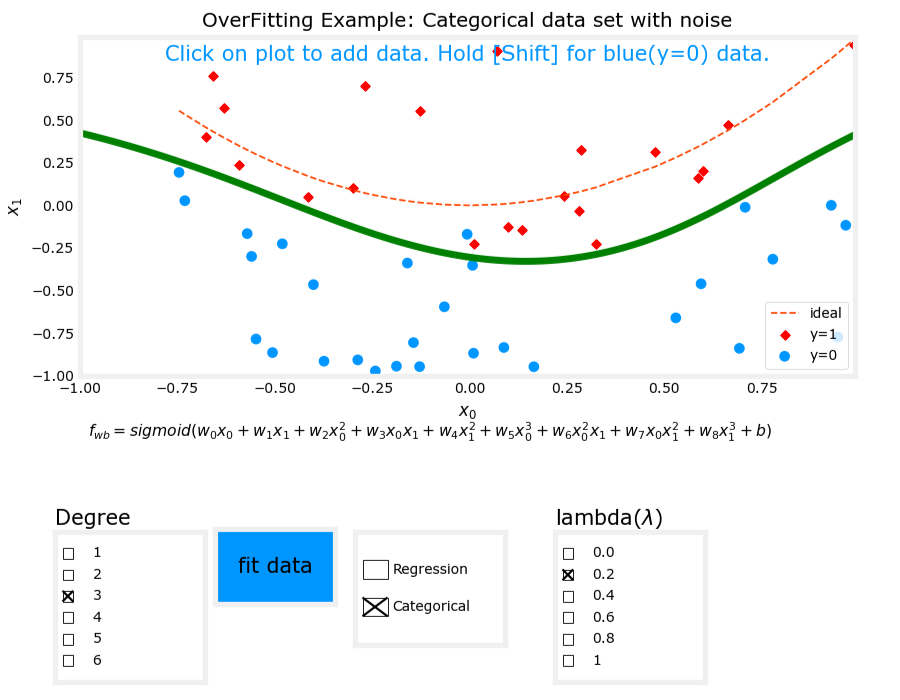
二、分类问题中的过拟合
在分类问题中,过拟合问题同样存在。
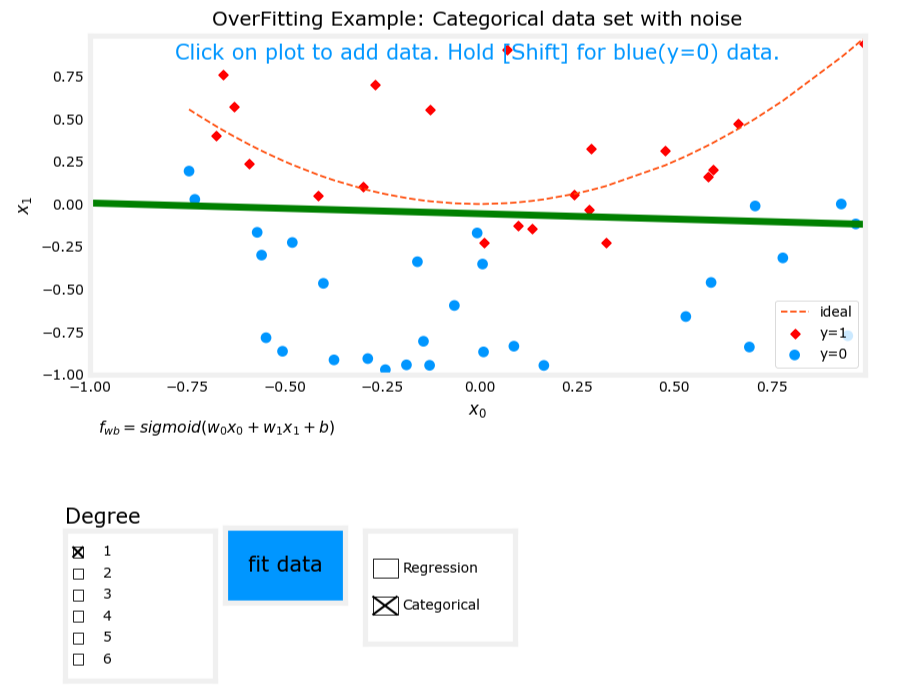
1. 欠拟合(Underfit)
- 模型表达式: z = w 1 x 1 + w 2 x 2 + b z = w_1x_1 + w_2x_2 + b z=w1x1+w2x2+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b(x)=g(z),其中(g)是Sigmoid函数。
- 特征:仅使用线性特征。
- 表现:模型无法很好地划分数据,存在高偏差(high bias)。
2. 刚好拟合(Just right)
- 模型表达式: z = w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 x 2 + b z = w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1x_2 + b z=w1x1+w2x2+w3x12+w4x22+w5x1x2+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b(x)=g(z)。
- 特征:使用二次项特征。
- 表现:模型能够很好地划分不同类别的数据。
3. 过拟合(Overfit)
- 模型表达式: z = w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 3 x 2 + w 6 x 1 3 x 2 2 + ⋯ + b z = w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1^3x_2 + w_6x_1^3x_2^2 + \cdots + b z=w1x1+w2x2+w3x12+w4x22+w5x13x2+w6x13x22+⋯+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b(x)=g(z)。
- 特征:使用了过多的高次交叉项。
- 表现:模型在训练数据上表现完美,但在新数据上表现不佳,存在高方差(high variance)。
图像对比
欠拟合
刚好拟合
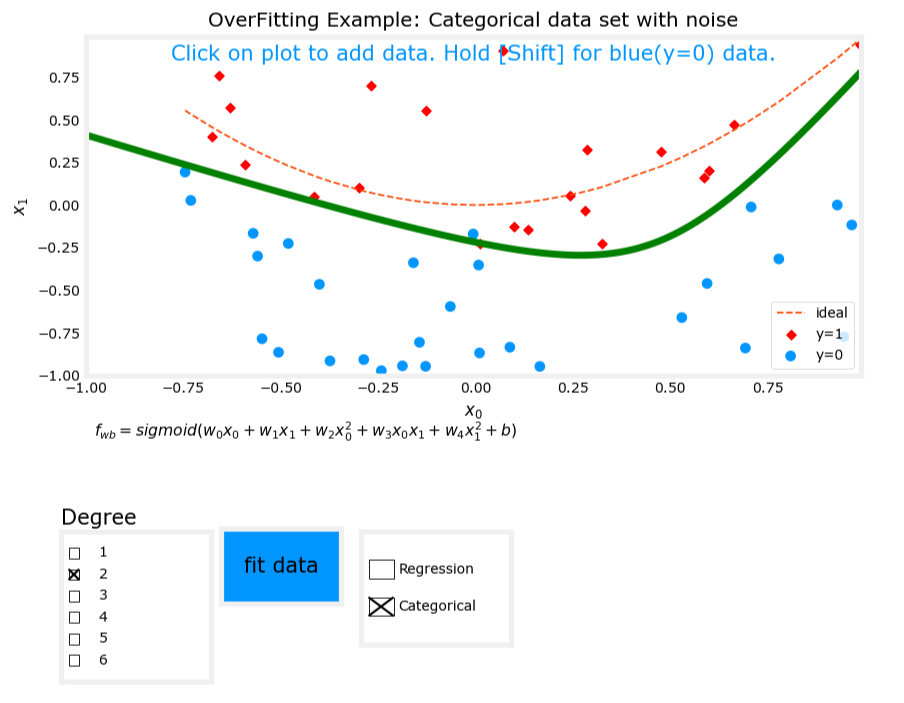
过拟合
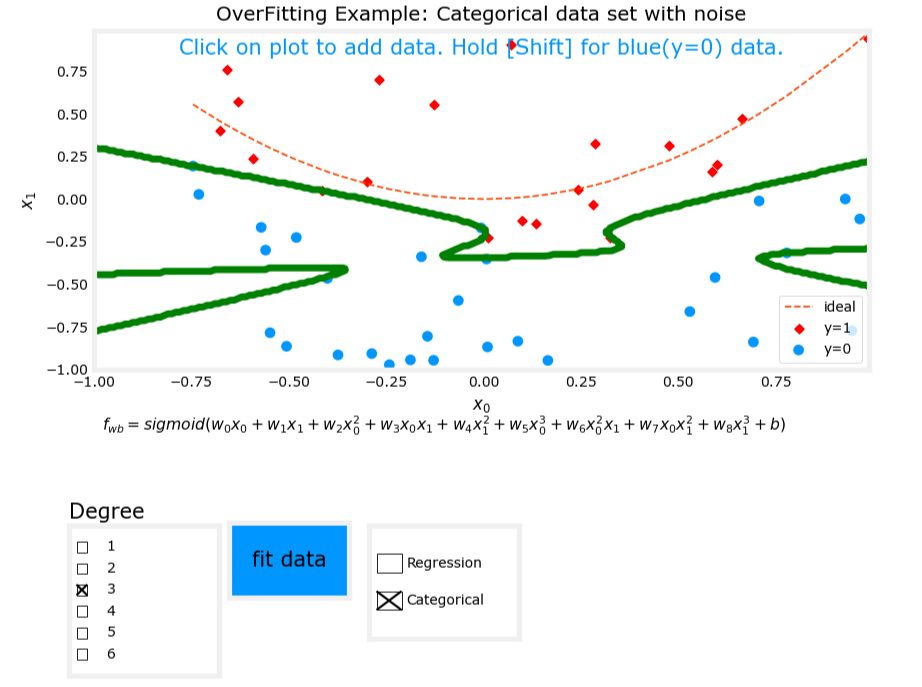
三、过拟合的原因及解决方法
过拟合原因
- 模型复杂度过高
- 训练数据量不足
- 特征过多或噪声特征
解决方法
| 方法 | 说明 |
|---|---|
| 增加训练数据 | 更多样化的数据有助于模型学习到更通用的模式。 |
| 减少特征数量 | 通过特征选择或降维技术减少输入特征的数量。 |
| 正则化 | 通过在损失函数中添加正则化项(如L1或L2正则化)来限制模型复杂度。 |
| 交叉验证 | 使用交叉验证技术评估模型在不同数据集上的表现,避免过拟合。 |
| 早停 | 在训练过程中,当验证集性能不再提升时提前停止训练。 |
解决过拟合问题
一、收集更多训练数据
增加训练数据量是解决过拟合的一种有效方法。更多的数据可以帮助模型学习到更通用的模式,减少过拟合的风险。
- 原理:更多的训练样本可以提供更全面的信息,使模型更好地泛化。
- 示例:如果模型在有限的房屋价格数据上过拟合,增加更多不同大小、价格的房屋数据可以使模型更准确地预测新数据。
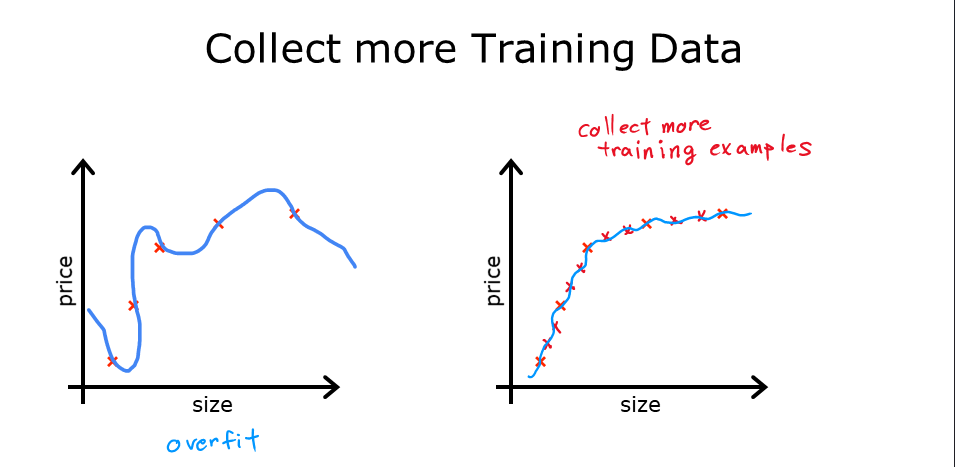
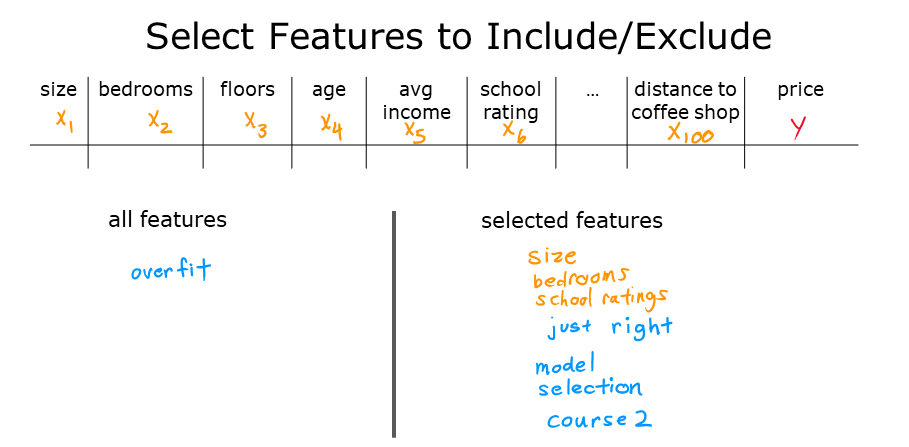
二、选择特征
选择合适的特征可以减少模型的复杂度,从而降低过拟合的可能性。
- 特征选择:从众多特征中选择最相关的特征,去除无关或冗余的特征。
- 优点:减少模型复杂度,提高训练速度。
- 缺点:可能丢失一些有用的信息。
| 特征选择方法 | 说明 |
|---|---|
| Filter Methods | 通过相关性分析等方法预选特征 |
| Wrapper Methods | 通过模型性能评估选择特征组合 |
| Embedded Methods | 在模型训练过程中自动选择特征 |
三、正则化
正则化是一种通过在损失函数中添加惩罚项来限制模型复杂度的方法。
- L1正则化:添加参数的绝对值之和。公式为: λ ∑ j = 1 n ∣ w j ∣ \lambda \sum_{j=1}^{n} |w_j| λj=1∑n∣wj∣
- L2正则化:添加参数的平方和。公式为: λ ∑ j = 1 n w j 2 \lambda \sum_{j=1}^{n} w_j^2 λj=1∑nwj2
- 作用:使参数值更小,减少模型对单个特征的依赖。
| 正则化方法 | 优点 | 缺点 |
|---|---|---|
| L1正则化 | 可进行特征选择,稀疏性好 | 收敛速度较慢 |
| L2正则化 | 收敛速度快,稳定性好 | 无法进行特征选择 |
四、过拟合解决方法总结
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 收集更多数据 | 训练数据量不足时 | 提高模型泛化能力 | 数据收集成本高 |
| 特征选择 | 特征数量多且存在冗余特征时 | 减少模型复杂度,提高训练速度 | 可能丢失有用信息 |
| 正则化 | 模型参数量大,容易过拟合时 | 有效控制模型复杂度,提高泛化能力 | 需要调整正则化参数 |
| 交叉验证 | 数据集有限,需要充分利用数据进行模型评估时 | 减少数据浪费,提高模型评估准确性 | 计算成本高 |
| 早停 | 模型训练时间长,容易过拟合时 | 防止模型在训练集上过优化,保存较好的泛化能力 | 需要确定合适的停止点 |
正则化的应用
一、带正则化的代价函数
在带正则化的代价函数中,我们在原始代价函数的基础上添加了一个正则化项。对于线性回归模型,其带正则化的代价函数形式如下:
J ( w , b ) = 1 2 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = \frac{1}{2m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right)^2 + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=2m1i=1∑m(fw,b(x(i))−y(i))2+2mλj=1∑nwj2
其中:
- m m m是训练样本的数量
- n n n 是特征的数量
- λ \lambda λ 是正则化参数,用于控制正则化的强度
正则化项 λ 2 m ∑ j = 1 n w j 2 \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 2mλ∑j=1nwj2 会惩罚过大的参数值,使模型更倾向于学习较小的参数,从而降低模型的复杂度。
二、正则化线性回归
在正则化线性回归中,我们通过梯度下降算法来最小化带正则化的代价函数。其梯度下降的更新规则如下:
w j = w j − α [ 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m w j ] w_j = w_j - \alpha \left[ \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} + \frac{\lambda}{m} w_j \right] wj=wj−α[m1i=1∑m(fw,b(x(i))−y(i))xj(i)+mλwj]
b = b − α 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) b=b−αm1i=1∑m(fw,b(x(i))−y(i))
其中:
- α \alpha α是学习率
- w j w_j wj 是特征 ( j ) 的参数
- b b b是偏置项
在梯度下降过程中,正则化项会使得参数 w j w_j wj在每次更新时都乘以一个因子 ( 1 − α λ m ) (1 - \alpha \frac{\lambda}{m}) (1−αmλ),从而实现参数的“收缩”。
| 正则化线性回归与普通线性回归对比 | 正则化线性回归 | 普通线性回归 |
|---|---|---|
| 更新规则 | 包含正则化项 | 不包含正则化项 |
| 参数变化 | 参数逐渐收缩 | 参数无收缩 |
| 泛化能力 | 更强 | 较弱 |
三、正则化逻辑回归
正则化逻辑回归与正则化线性回归类似,其代价函数也包含一个正则化项。对于逻辑回归模型,其带正则化的代价函数形式如下:
J ( w , b ) = − 1 m ∑ i = 1 m [ y ( i ) log ( f w , b ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(f_{\mathbf{w},b}(\mathbf{x}^{(i)})) + (1 - y^{(i)}) \log(1 - f_{\mathbf{w},b}(\mathbf{x}^{(i)})) \right] + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=−m1i=1∑m[y(i)log(fw,b(x(i)))+(1−y(i))log(1−fw,b(x(i)))]+2mλj=1∑nwj2
其中:
- ( f w , b ( x ( i ) ) ) ( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) ) (fw,b(x(i))) 是逻辑回归模型的预测输出,使用Sigmoid函数计算得到
正则化逻辑回归的梯度下降更新规则与正则化线性回归类似,也是在原始梯度的基础上添加了正则化项。
四、正则化参数的选择
正则化参数 λ \lambda λ 的选择对模型的性能有重要影响:
- λ \lambda λ 过小:正则化效果不明显,模型可能仍然过拟合
- λ \lambda λ 过大:过度正则化,模型可能欠拟合
可以通过交叉验证的方法来选择合适的 λ \lambda λ 值。
五、正则化方法对比
| 正则化方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| L1正则化 | 特征稀疏 | 可进行特征选择 | 收敛速度较慢 |
| L2正则化 | 参数平滑 | 收敛速度快 | 无法进行特征选择 |
通过合理应用正则化技术,可以有效防止模型过拟合,提高模型的泛化能力和实际应用效果。
正则化后图像
线性回归
分类
end
相关文章:
 | 第六周|过拟合问题)
【学习笔记】机器学习(Machine Learning) | 第六周|过拟合问题
机器学习(Machine Learning) 简要声明 基于吴恩达教授(Andrew Ng)课程视频 BiliBili课程资源 文章目录 机器学习(Machine Learning)简要声明 摘要过拟合与欠拟合问题一、回归问题中的过拟合1. 欠拟合(Underfit&#x…...

【MQ篇】RabbitMQ之惰性队列!
目录 引言:当“生产”大于“消费”,队列就“胖”了!肥宅快乐队列?🤔队列界的“躺平”大师:惰性队列(Lazy Queues)驾到!😴如何“激活”你的队列的“惰性”属性…...

计算机视觉——通过 OWL-ViT 实现开放词汇对象检测
介绍 传统的对象检测模型大多是封闭词汇类型,只能识别有限的固定类别。增加新的类别需要大量的注释数据。然而,现实世界中的物体类别几乎无穷无尽,这就需要能够检测未知类别的开放式词汇类型。对比学习(Contrastive Learning&…...
)
第二部分:网页的妆容 —— CSS(下)
目录 6 布局基础:Display 与 Position - 元素如何排列和定位6.1 小例子6.2 练习 7 Flexbox 弹性布局:一维布局利器7.1 小例子7.2 练习 8 Grid 网格布局:强大的二维布局系统8.1 小例子8.2 练习 9 响应式设计与媒体查询:适应不同设备…...

vite项目tailwindcss4的使用
1、安装taillandcss 前几天接手了一个项目,看到别人用tailwindcss节省了很多css代码的编写,所以自己也想在公司项目中接入tailwindcss。 官网教程如下: Installing Tailwind CSS with Vite - Tailwind CSS 然而,我在vite中按…...

css中:is和:where 伪函数
在 CSS 里,:is() 属于伪类函数,其作用是对一组选择器进行匹配,只要元素与其中任何一个选择器相匹配,就可以应用对应的样式规则。以下是详细介绍: 基本语法 :is() 函数的参数是一个或多个选择器,各个选择器之…...

线下零售数据采集:在精度与效率之间寻找平衡点
线下零售数据采集:在精度与效率之间寻找平衡点 为什么线下零售必须重视数据采集? 随着零售行业竞争加剧,门店执行的标准化与透明化成为供应链协作、销售提升的基础工作。 POG(陈列执行规范)的落地效果、陈列策略的调整…...

【Robocorp实战指南】Python驱动的开源RPA框架
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现案例1:网页数据抓取案例2:Excel报表生成 运行结果验证 三、性能对比测试方…...

新ubuntu物理机开启ipv6让外网访问
Ubuntu 物理机 SSH 远程连接与 IPv6 外网访问测试指南 1. 通过 SSH 远程连接 Ubuntu 物理机 1.1 安装 SSH 服务 sudo apt update sudo apt install openssh-server1.2 检查 SSH 服务状态 sudo systemctl status ssh确认出现 active (running)。 1.3 获取物理机 IP 地址 i…...

驱动开发硬核特训 │ Regulator 子系统全解
一、Regulator子系统概述 在 Linux 内核中,Regulator 子系统是专门用于管理电源开关、电压调整、电流控制的一套完整框架。 它主要解决以下问题: 设备需要的电压通常不一样,如何动态调整?有些设备休眠时需要关闭供电࿰…...
)
入门版 鸿蒙 组件导航 (Navigation)
入门版 鸿蒙 组件导航 (Navigation) 注意:使用 DevEco Studio 运行本案例,要使用模拟器,千万不要用预览器,预览器看看 Navigation 布局还是可以的 效果:点击首页(Index)跳转到页面(…...

怎样将visual studio 2015开发的项目 保存为2010版本使用
用的老旧电脑跑vs2015太慢了,实在忍不了了! 想把用 Visual Studio 2015 的做的项目保存为 Visual Studio 2010 兼容的格式,以后都使用2010写了。自己在网上搜了一下,亲测以下步骤可以的 手动修改解决方案和项目文件 修改解决方案…...

【学习笔记】软件测试流程-测试设计阶段
软件测试设计阶段这个阶段主要工作是编写测试用例。 什么是测试用例? 测试用例(TestCase)是为项目需求而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序是否满足客户需求。简而言之,测试用例是每一个测…...

Rust 学习笔记:关于切片的两个练习题
Rust 学习笔记:关于切片的两个练习题 Rust 学习笔记:关于切片的两个练习题引用和切片引用的大小以下程序能否通过编译? Rust 学习笔记:关于切片的两个练习题 参考视频: https://www.bilibili.com/video/BV1GrDQYeEzS…...

BeeWorks企业内部即时通讯软件支持国产化,已在鸿蒙系统上稳定运行
一、企业用户面临的困境与痛点 一些企业用的即时通讯软件比较旧,存在的问题不仅影响了日常工作的正常开展,也阻碍了企业信息化建设的进程: ● 国产系统与移动端不兼容:仅支持Windows和MAC系统,无法在银河麒麟、统信U…...

java对文字按照语义切分
实现目标 把一段文本按照一个完整的一句话为单元进行切分。如:以逗号,感叹号结尾看作是一个句子。 实现方案 StanfordCoreNLP切分 引入依赖 <dependency><groupId>edu.stanford.nlp</groupId><artifactId>stanford-corenlp<…...

华纳云:centos如何实现JSP页面的动态加载
JSP(JavaServer Pages)作为Java生态中常用的服务器端网页技术,具有动态内容生成、可扩展性强、与Java无缝结合等优势。 而CentOS作为一款稳定、高效、安全的Linux服务器操作系统,非常适合部署JSP应用。 想要让JSP页面实现动态更新加载,避免…...
:会话+消息过期机制,设备远程控制,批量控制实现)
Android 消息队列之MQTT的使用(二):会话+消息过期机制,设备远程控制,批量控制实现
目录 一、实际应用场景 室内温湿度数据上传设备远程控制批量控制实现 二、会话管理、消息过期设置 4.1 会话管理 Clean Session参数 新旧会话模式对比典型应用场景 4.2 消息过期设置 MQTT 5.0消息过期机制 Message Expiry Interval属性QoS级别影响 三、实际应用场景 …...

一、JVM基础概念
一、JVM的设计目标 一次编译,到处运行(跨平台) ➔ Java编译成字节码,由JVM在不同平台解释/编译执行,实现跨平台。 内存管理与垃圾回收 ➔ JVM统一负责内存分配和回收,降低内存泄漏的风险。 性能优化 ➔ JIT(即时编译…...

深度学习---Pytorch概览
一、PyTorch 是什么? 1. 定义与定位 开源深度学习框架:由 Facebook(Meta)AI 实验室开发,基于 Lua 语言的 Torch 框架重构,2017 年正式开源,主打动态计算图和易用性。核心优势:灵活…...

第33周JavaSpringCloud微服务 分布式综合应用
第33周JavaSpringCloud微服务 分布式综合应用 一、分布式综合应用概述 分布式知识体系内容广泛,主要包括分布式事务、分布式锁、RabbitMQ等消息中间件的应用以及跨域问题的解决。 1.1 课程重点内容介绍 分布式事务 :在大型项目中普遍存在,…...

Paramiko 完全指南
目录 Paramiko 概述核心功能与模块框架安装与依赖基础用法与案例详解 SSH 连接与命令执行密钥认证SFTP 文件传输交互式会话端口转发 高级功能与实战技巧常见问题与解决方案总结与资源推荐 1. Paramiko 概述 是什么? Paramiko 是一个纯 Python 实现的 SSHv2 协议库…...
二进制部署教程(保姆级))
夜莺监控V8(Nightingale)二进制部署教程(保姆级)
夜莺监控部署 前置工作 1. 部署好mysql 2. 部署好redis 3. 部署好prometheus夜莺压缩包下载 本教程基于Centos7系统下的二进制方式部署,先去官网进行压缩包下载 在系统创建/opt/n9etest目录,并将压缩包拖进目录 mkdir /opt/n9etest进入/opt/n9etest࿰…...

鸿蒙应用开发 知识点 官网快速定位表
ArkTS 语言介绍 ArkTS 语言介绍 基础入门 资源分类与访问 添加组件(基础组件) 显示图片 (Image) 按钮 (Button) 单选框 (Radio) 切换按钮 (Toggle) 进度条 (Progress) 视频播放 (Video) 使用文本 文本显示 (Text/Span) 文本输入 (TextInput/TextArea) 使用弹窗 使用弹…...
的差异)
【神经网络与深度学习】两种加载 pickle 文件方式(joblib、pickle)的差异
引言 从深度学习应用到数据分析的多元化需求出发,Python 提供了丰富的工具和模块,其中 pickle 和 joblib 两种方式在加载数据文件方面表现尤为突出。不同场景对性能、兼容性以及后续处理的要求不尽相同,使得这两种方式各显优势。本文将通过深…...
)
quickbi finebi 测评(案例讲解)
quickbi & finebi 测评 国产BI中入门门槛比较低的有两个,分别是quickbi和finebi。根据我的经验通过这篇文章做一个关于这两款BI的测评文章。 quickbi分为个人版、高级版、专业版、私有化部署四种。这篇文章以quickbi高级版为例,对quickbi进行分享。…...

vue的生命周期 以及钩子
最早可以在created 时调用后端接口获取数据,因为beforecreated的时候 那个data 都还还是初始化出来 修改数据的时候触发 update 案例1:create 案例2:一进来页面获取搜索框焦点 echarts 饼图渲染 初始化dom后才去准备实例,所以必须要在dom之后…...

Mariadb 防火墙服务器和端口:mysql | 3306
Centos7 Mariadb 理解:Mariadb数据库就类似于我们生活中常见的Excel。 主要工作原理就是我们创造一个数据库其中创造一个数据表再在数据表中输入内容,分为三类。在详细点就是打开Excel(数据库),我们在其中加入…...
--web请求过程)
爬虫学习笔记(二)--web请求过程
Web请求全过程(重要) 从输入完网址(如输入百度网址)到返回页面以及页面中的数据这一完整的过程发生了什么事情? 服务器端渲染 在服务器端直接把数据和html整合,统一返回给浏览器,在页面源代码…...

开发vue项目所需要安装的依赖包
在开发Vue项目时,通常需要安装以下几个核心依赖包:1、Vue CLI、2、Vue Router、3、Vuex、4、Axios。这些依赖包可以确保你的Vue项目拥有基础的功能和良好的开发体验。接下来,我们将详细介绍每个依赖包的作用、安装方法以及使用案例。 一、VUE…...
——方法详解)
Java SE(4)——方法详解
1.方法的概念&使用 1.1 什么是方法? Java中的方法类似于C语言中的函数,是用于执行特定任务的代码块。 那么用方法组织起来的代码块和普通的代码相比有什么优势呢? 1.当代码规模较大且应用场景较为复杂时,方法能够模块化地组…...
)
网络安全实战指南:从安全巡检到权限维持的应急响应与木马查杀全(命令查收表)
目录 一、安全巡检的具体内容 1. 巡检的频率与目标是什么 2. 巡检的内容是什么以及巡检后如何加固 二、Windows环境下应急响应的主要流程 1. 流程概述及每个步骤详细解释 步骤1:隔离与遏制 步骤2:识别与分析 步骤3:清除与恢复 步骤4…...

Infrared Finance:Berachain 生态的流动性支柱
在加密市场中,用户除了参与一级和二级交易,还有一种低门槛参与的就是空投。从 2021 年 DeFi 成为主流开始,空投一直都是“以小搏大”的机会,通过参与项目早期的链上交互和任务以获取空投奖励,近几年已成为一种广受欢迎…...

Hadoop和Spark大数据挖掘与实战
1.概述 本节将系统讲解大数据分析的完整流程,包括数据采集、预处理、存储管理、分析挖掘与结果可视化等核心环节。与此同时,我们还将对主流数据分析工具进行横向对比,帮助读者根据实际需求选用最合适的工具,提升数据价值挖掘的效…...
)
TCP vs UDP:核心区别、握手过程与应用场景(附对比图)
🌐 引言 在网络通信中,TCP(传输控制协议)和UDP(用户数据报协议)是两大核心传输层协议。它们各有优劣,适用于不同场景。本文将用图文对比实战示例,帮你彻底理解两者的区别࿰…...

人工智能-深度学习之多层感知器
深度学习 任务任务1任务2任务3 机器学习的弊端多层感知器 (MLP/人工神经网络)MLP实现非线性分类Keras介绍与实战准备Keras or TensorflowKeras建立MLP模型 实战(1): 建立MLP实现非线性二分类实战(2): MLP实…...

Improving Deep Learning For Airbnb Search
解决问题 问题1: 解决推荐酒店与用户实际预定酒店价格存在偏差问题,实际预定比推荐要更便宜: 所以问题为是否更低价格的list更倾向于用户偏好,应该被优先推荐? 1. 该文通过数据分析与模型演进,将模型改造为item sco…...

多模态大型模型,实现以人为中心的精细视频理解
大家看完觉得有帮助记得点赞和关注!!! 抽象 精细理解视频中人类的动作和姿势对于以人为中心的 AI 应用程序至关重要。在这项工作中,我们介绍了 ActionArt,这是一个细粒度的视频字幕数据集,旨在推进以人为中…...

向量数据库Milvus的部署与使用
Milvus介绍 Milvus是一个开源、高性能、高扩展性的向量数据库,Milvus可以用来存储文本、图像、音频等非结构化数据,本质上是用Embeddings将非结构化数据转换成能够捕捉其基本特征的数字向量,然后将这些向量存储在向量数据库中,从…...

1.文档搜索软件Everything 的使用介绍
Everything 是 Windows 文件搜索的效率天花板,通过灵活语法和极速响应,彻底告别「找文件焦虑」。 定位:一款专注于 极速文件名搜索 的 Windows 工具,免费且轻量(安装包仅几 MB)。 核心优势…...

2025系统架构师---论企业集成平台的技术与应用
摘要 本文探讨了企业集成平台的技术与应用,以某商业银行开发的绩效考核平台系统为例,分析了企业集成平台的基本功能及关键技术,并详细阐述了在表示集成、数据集成、控制集成和业务流程集成方面的应用和实施方式。通过异构系统之间的集成,绩效考核平台与其他系统实现了有机…...

STM32Cubemx-H7-16-FreeRTOS-1-创建工程,实现两个灯的基本亮灭
前言 裸机也是开发到一半快要结束了,接下来开始上操作系统,然后先能使用基本的,后面再讲理论。 Cubemx创建工程 基本打开生成就不说了,直接从界面开始 从这里开始吧 1.首先开启外部高速晶振 2.先这样选择 选择HSE时钟环ÿ…...
:更平滑的滑动窗口)
深入浅出限流算法(二):更平滑的滑动窗口
好的,接续上一篇关于固定窗口计数器的讨论,我们现在来看看它的改进版——滑动窗口算法,它旨在解决固定窗口那个恼人的“临界突变”问题。 在上一篇文章中,我们探讨了最简单的固定窗口计数器限流算法,并指出了它最大的缺…...

纷析云开源财务软件:基于Spring Boot的轻量化财务中台实践
一、技术架构与核心设计 全栈开源技术栈 后端框架:基于Spring Boot 3.x构建,集成MyBatis-Plus作为ORM层,支持JDK 17特性(如虚拟线程并发处理),确保高吞吐与稳定性。 前端框架:采用Vue 3 TypeS…...

软考-软件设计师中级备考 5、数据结构 树和二叉树
1、树的基本概念 节点的度:节点拥有的子树数目。例如,若一个节点有 3 棵子树,其度为 3。树的度:树中节点的最大度数。如树中所有节点的度最大为 4,则树的度是 4。叶子节点:度为 0 的节点,也…...

php 需要学会哪些技术栈,掌握哪些框架
作为一个「野生」程序员,我的学习过程比较急功近利。 我记得自己写的第一个 PHP 程序是留言本。一上来对 PHP 一窍不通,所以直接去网上找了个留言本的源码,下载下来后先想办法让它在自己电脑上运行起来。通过这个过程掌握了 PHP 开发环境的搭…...

短视频矩阵系统贴牌批量剪辑功能开发,支持OEM
一、引言 在短视频行业蓬勃发展的当下,短视频矩阵运营已成为企业和个人实现品牌推广、流量增长的重要策略。然而,面对大量的视频素材和多个运营账号,传统的单个视频剪辑、发布方式效率极低,难以满足矩阵运营的需求。为了提高内容…...
)
【Java EE初阶】多线程(二)
1.在图中代码,我们调用了start方法,真正让系统调用api创建了一个新线程,而在这个线程跑起来之后,就会自动执行到run。调用start方法动作本身速度非常快,一旦执行,代码就会立即往下走,不会产生任…...

分布式链路追踪理论
基本概念 分布式调用链标准-openTracing Span-节点组成跟踪树结构 有一些特定的变量,SpanName SpanId traceId spanParentId Trace(追踪):代表一个完整的请求流程(如用户下单),由多个Span组成…...

conda和bash主环境的清理
好的!要管理和清理 Conda(或 Bash)安装的包,可以按照以下步骤进行,避免冗余依赖,节省磁盘空间。 📌 1. 查看已安装的包 先列出当前环境的所有安装包,找出哪些可能需要清理ÿ…...