【深度好文】4、Milvus 存储设计深度解析
引言
作为一款主流的云原生向量数据库,Milvus 通过其独特的存储架构设计来保证高效的查询性能。本文将深入剖析 Milvus 的核心存储机制,特别是其最小存储单元 Segment 的完整生命周期,包括数据写入、持久化、合并以及索引构建等关键环节。
1. 数据写入流程
Milvus 中的每个 Collections 指定若干分片,每个分片对应一个虚拟通道(vchannel)。如下图所示,Milvus 会为日志代理中的每个 vchannel 分配一个物理通道(pchannel)。任何传入的插入/删除请求都会根据主键的哈希值路由到分片。
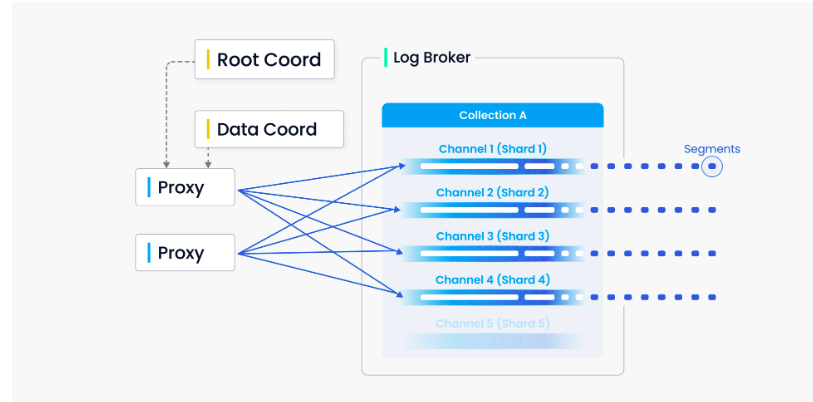
1.1 Insert 请求处理
当 Milvus 启动后,系统会在消息队列(Pulsar/Kafka)中创建数据接收管道,具体数量由 milvus.yaml 中的 rootCoord.dmlChannelNum 配置决定。数据写入流程如下:
-
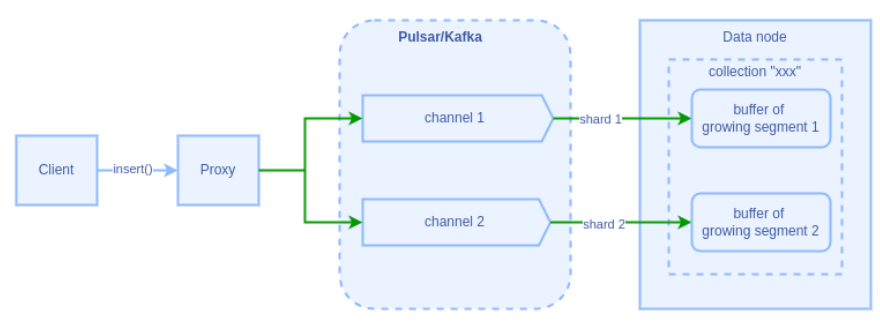
请求接收与分片
- Proxy 接收 insert 请求
- 根据数据的 primary key 计算 hash 值
- 将 hash 值对 collection 的 shards_num 取模,确定数据分片
-
数据传输机制
- 每个 shard 的数据通过指定管道传输 ,多个 shard 可共享同一管道实现负载均衡
- Data node 订阅对应 shard 数据 , 并尽可能把不同的 shard 分配到多个 data node 上。如果只有一个 data node ,那么就订阅所有的 shard 数据。
-
Growing Segment 处理
- 每个 partition 中的每个 shard 对应一个 growing segment
- Data node 为每个 growing segment 维护缓存
- 缓存用于存储未落盘的数据
下图展示了在 shards_num=2 的情况下,数据经由管道传输至 data node 的流程示意图:
2. 数据持久化机制
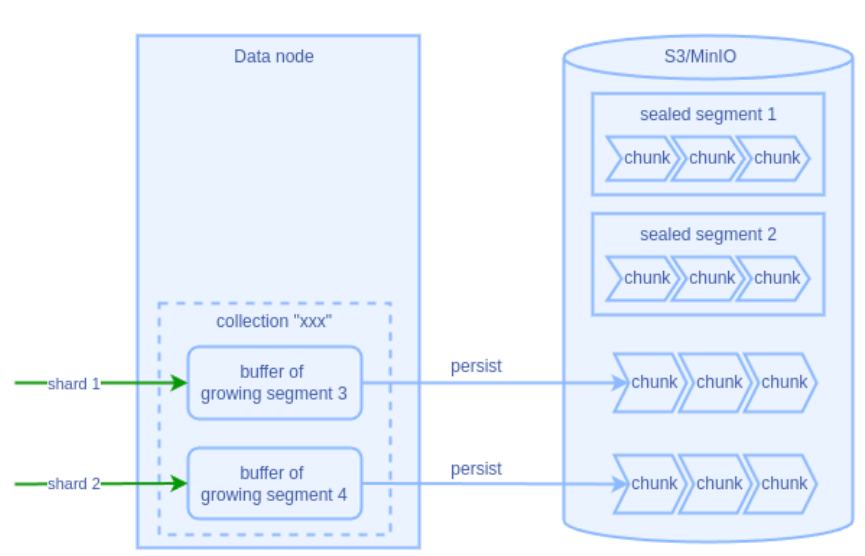
2.1 Growing Segment 持久化
Growing segment 的数据持久化受以下参数控制:
dataNode.segment.insertBufSize: 缓存最大容量(默认16MB)dataNode.segment.syncPeriod: 数据最长停留时间(默认600秒)
当满足以下任一条件时,数据会被写入 S3/MinIO:
- 缓存数据量超过 insertBufSize
- 数据在缓存中停留时间超过 syncPeriod
为什这么设计:
1、减少 data node 内存占用,避免growing segment 内存占用过多。
2、如果系统发生故障之后 ,无需从mq 中重新拉取growing segment 的全部数据,已持久化的数据直接从S3/MinIO读取。
2.2 Sealed Segment 转换
Growing segment 在达到特定条件后会转换为 sealed segment:
- 触发条件:数据量达到
dataCoord.segment.maxSize(默认1024MB) ×dataCoord.segment.sealProportion(默认0.12) - 转换后会创建新的 growing segment 继续接收数据。
数据在 S3/MinIO 中的存储路径由 milvus.yaml 中 minio.bucketName(默认值 a-bucket)以及 minio.rootPath(默认值 files)共同决定。segment 数据的完整路径格式为:
[minio.bucketName]/[minio.rootPath]/insert_log/[collection ID]/[partition ID]/[segment ID]
在 docker 里面的显示如下:
3. 性能优化建议
3.1 避免频繁调用 flush()
- 频繁调用 flush() 可能导致大量碎片化的小 segment
- 建议依赖系统自动落盘机制
- 仅在需要确认全量数据落盘时手动调用
3.2 Segment 管理优化
-
监控 Segment 数量
- 使用 attu 工具监控 segment 分布
- 适当调整 segment_size 参数
- 根据数据量设置合理的 shards_num:
- 百万级数据:shards_num=1
- 千万级数据:shards_num=2
- 亿级数据:shards_num=4或8
-
Partition 规划
- 合理控制 partition 数量
- 避免过多 partition 影响系统性能
3.3 Clustering Key 设计
- 针对范围查询场景优化
- 优化批量数据删除性能
- 提升 compaction 效率
3.4 Segment 合并与 Compaction
在持续执行 insert 请求时,sealed segment 的数量会随着新数据不断写入而增加。如果数据被拆分成过多小尺寸(如小于 100MB)的 segment,会影响系统的数据管理和查询效率。为此,data node 会通过 compaction 将若干较小的 sealed segment 合并成更大的 sealed segment。理想情况下,合并后 segment 大小会尽量接近 dataCoord.segment.maxSize(默认 1GB)。
Compaction 主要包括以下三种场景:
(1) 小文件合并(系统自动)
- 触发条件:存在多个体积较小的 sealed segment,其总大小接近 1GB。
- 优化效果:减少元数据开销,提高批量查询的性能。
(2) 删除数据清理(系统自动)
- 触发条件:segment 中的被删除数据占比 ≥ dataCoord.compaction.single.ratio.threshold(默认 20%)。
- 优化效果:释放存储空间,减少无效数据的重复扫描。
(3) 按聚类键(Clustering Key)重组(手动触发)
- 使用场景:面向特定查询模式(如地域或时间范围检索)优化数据分布。
- 调用方式:通过 SDK 调用 compaction,并按照指定的 Clustering Key 对 Segment 进行重组。
4. 索引构建机制
4.1 索引构建流程
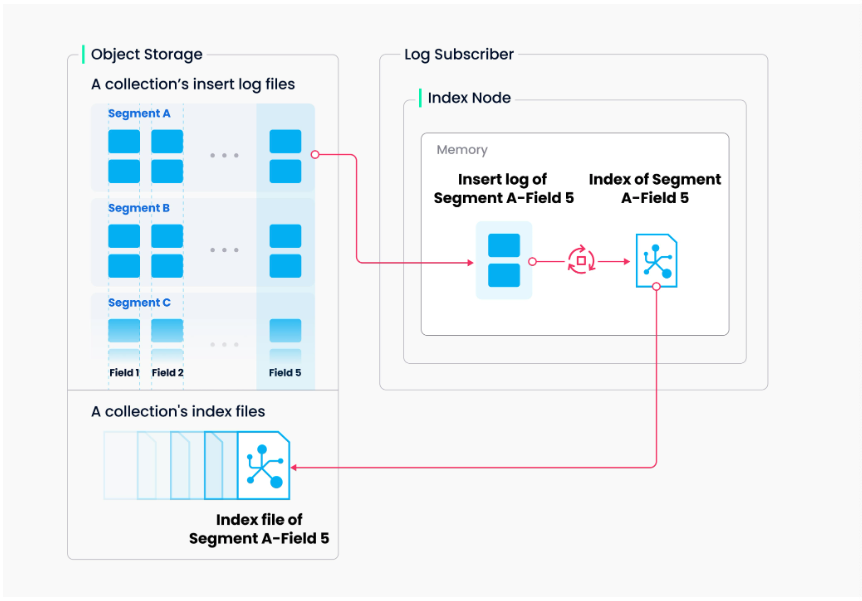
索引构建由专门的 index node 负责执行。为了避免频繁的数据更新导致重复建索引,Milvus 采用了基于 segment 的索引构建策略:
4.1 临时索引 vs 持久化索引
对于每个 growing segment,query node 会在内存中为其建立临时索引,这些临时索引并不会持久化。
同理,当 query node 加载未建立索引的 sealed segment 时,也会创建临时索引。
关于临时索引的相关配置,可在 milvus.yaml 中通过 queryNode.segcore.interimIndex 进行调整。
当 data coordinator 监测到新的 sealed segment 生成后,会指示 index node 为其构建并持久化索引。然而,如果该 sealed segment 的数据量小于 indexCoord.segment.minSegmentNumRowsToEnableIndex (默认 1024 行) ,index node 将不会为其创建索引。
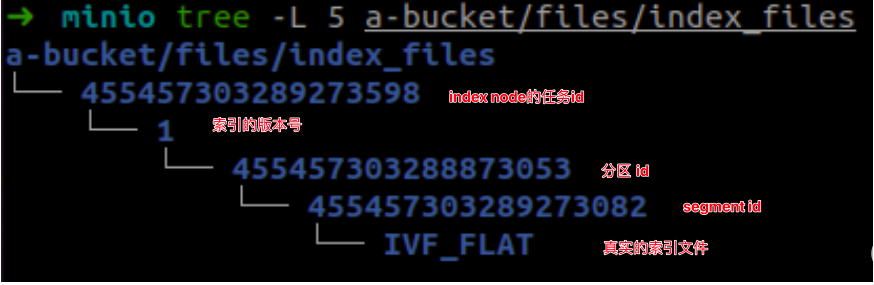
所有索引数据都被保存在以下路径:
[minio.bucketName]/[minio.rootPath]/index_files
5. 数据查询处理
5.1 查询执行流程
Milvus 支持两种主要的查询模式:
- K 近邻搜索:返回与目标向量最接近的 K 个向量
- 范围搜索:返回与目标向量距离在指定范围内的所有向量
查询流程如下:
-
查询请求广播
- 搜索请求广播至所有 query node
- 各节点并发执行搜索
- 对本地 segment 进行剪枝和搜索
- 汇总并返回结果
-
查询节点职责
- 按照 query coord 指令加载或释放 segment
- 在本地 segment 中执行搜索
- Query node 之间相互独立
- Proxy 负责归并各节点结果
5.2 数据一致性管理
Milvus 通过 handoff 机制管理数据一致性:
-
Segment 状态转换
- Growing segment:用于增量数据
- Sealed segment:用于历史数据
- Query node 通过订阅 vchannel 接收最新更新
-
Handoff 流程
- Growing segment 达到阈值后被 data coord 封存
- 开始构建索引
- Query coord 触发 handoff 操作 ,只有等新的 segment 创建之后,索引也可以使用了。旧的数据才从内存中进行删除。
- 增量数据转换为历史数据
-
负载均衡
- Query coord 根据多个指标分配 sealed segment:
- 内存使用情况
- CPU 负载
- Segment 数量
- Query coord 根据多个指标分配 sealed segment:
总结
通过深入理解 Milvus 的存储设计,特别是 Segment 的生命周期管理,开发者可以更好地:
- 设计合理的数据写入策略
- 优化系统配置参数
- 确保系统在复杂场景下保持稳定的高性能表现
本文详细介绍了 Milvus 存储架构的核心组件和关键概念,希望能帮助开发者更好地使用和优化 Milvus 系统。
相关文章:

【深度好文】4、Milvus 存储设计深度解析
引言 作为一款主流的云原生向量数据库,Milvus 通过其独特的存储架构设计来保证高效的查询性能。本文将深入剖析 Milvus 的核心存储机制,特别是其最小存储单元 Segment 的完整生命周期,包括数据写入、持久化、合并以及索引构建等关键环节。 …...
 2025年4月27日19:23:32)
航顺 芯片 开发记录 (一) 2025年4月27日19:23:32
芯片型号: HK32F030MF4P6 第一步:创建工程目录 inc :头文件目录 MDK-ARM : 工程根目录 (新建工程选择该目录) src :相关资源存放位置 官方函数库相关内容 官方函数库大致结构图 ├─HK32F030MLib ├─CMSIS │ ├─CM0 │ │ └─Core │ │ arm_common_table…...

Java 设计模式
Java后端常用设计模式总览表 模式核心思想Spring / Spring Boot应用手写实现核心单例模式 (Singleton)一个类只有一个实例,提供全局访问点Spring容器中的默认Bean都是单例管理volatile synchronized 双重检查锁定,懒加载单例工厂模式 (Factory)统一管理…...

Milvus如何实现关键词过滤和向量检索的混合检索
Milvus 可以实现关键词过滤和向量检索的混合检索,具体来说,可以结合向量搜索与其他属性字段(如关键词、类别标签等)进行联合查询。这样,在检索时不仅考虑向量的相似度,还能根据特定的关键词或标签等条件对数据进行筛选,从而提高检索的精度和灵活性。 1. 理解混合检索的…...

基于Qt5的蓝牙打印开发实战:从扫描到小票打印的全流程
文章目录 前言一、应用案例演示二、开发环境搭建2.1 硬件准备2.2 软件配置 三、蓝牙通信原理剖析3.1 实现原理3.2 通信流程3.3 流程详解3.4 关键技术点 四、Qt蓝牙核心类深度解析4.1 QBluetoothDeviceDiscoveryAgent4.2 QBluetoothDeviceInfo4.3 QBluetoothSocket 五、功能实现…...

Linux日志处理命令多管道实战应用
全文目录 1 日志处理1.1 实时日志分析1.1.1 nginx日志配置1.1.2 nginx日志示例1.1.3 日志分析示例 1.2 多文件合并分析1.3 时间范围日志提取 2 问题追查2.1 进程级问题定位2.2 网络连接排查2.3 硬件故障追踪 3 数据统计3.1 磁盘空间预警3.2 进程资源消耗排名3.3 HTTP状态码统计…...

Node.js CSRF 保护指南:示例及启用方法
解释 CSRF 跨站请求伪造 (CSRF/XSRF) 是一种利用用户权限劫持会话的攻击。这种攻击策略允许攻击者通过诱骗用户以攻击者的名义提交恶意请求,从而绕过我们的安全措施。 CSRF 攻击之所以可能发生,是因为两个原因。首先,CSRF 攻击利用了用户无法辨别看似合法的 HTML 元素是否…...
)
线性代数—向量与矩阵的范数(Norm)
参考链接: 范数(Norm)——定义、原理、分类、作用与应用 - 知乎 带你秒懂向量与矩阵的范数(Norm)_矩阵norm-CSDN博客 什么是范数(norm)?以及L1,L2范数的简单介绍_l1 norm-CSDN博客 范数(Norm…...

微服务基础-Ribbon
1. Ribbon简介: 客户端的负载均衡: 2....

移除生产环境所有console.log
大多数团队都会要求不能在生产环境输出业务侧的内容,但是往往业务开发人员会有疏漏,所以需要在工程化环境中,整体来管理console.log。我最近也是接到这样一个需求,整理了一下实现方案。 不同团队,不同场景,…...

数字人接大模型第二步:实时语音同步
接上例第一步,还是dh_live项目,增加了一个完整的实时对话样例,包含vad-asr-llm-tts-数字人全流程,以弥补之前的只有固定的问答的不足。 VAD(Voice Activity Detection,语音活动检测)VAD用于检测用户是否正在说话,从而触发后续的语音处理流程。 ASR(Automatic Speech R…...

Tomcat的安装与配置
Tomcat Tomcat是一个Java圈子中广泛使用的HTTP服务器. 后续学习Severlet内容,就是依赖Tomcat. Java程序员,要想写个网站出来,绕不开Tomcat. 我们这里使用Tomcat8 在bin目录下,这两个文件尤为重要,需要说明的是,Tomcat是那Java写的,所以在运行时需要jdk. bat后缀:是Window…...

Spring AI Alibaba - MCP连接 MySQL
先看效果 直接问他数据库有什么表。 大模型调用MySQL进行查询 搭建项目 添加依赖 创建项目后新添加Maven 依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId> …...

Spring Cloud Stream喂饭级教程【搜集全网资料整理】
文章较长,建议收藏关注,随时查看 Spring Cloud Stream 简介 Spring Cloud Stream 是 Spring 提供的一个框架,用于构建与共享消息系统相连接的高度可伸缩的事件驱动微服务,它建立在 Spring 已有的成熟组件和最佳实践之上ÿ…...

prometheus手动添加k8s集群外的node-exporter监控
1、部署node-exporter 1)helm方式部署 rootiZj6c72dzbei17o2cuksmeZ:~# helm repo add prometheus-community https://prometheus-community.github.io/helm-charts "prometheus-community" has been added to your repositories rootiZj6c72dzbei17o2cu…...
中安装Docker)
Linux(Centos版本)中安装Docker
文章目录 Linux(Centos版本)中安装Docker整体流程 Linux(Centos版本)中安装Docker整体流程 进入root权限进行安装: 下面开始安装Docker: 1、安装docker的yum管理工具:记得将yum仓库更改为国内的镜像源&…...
)
C语言-- 深入理解指针(4)
C语言-- 深入理解指针(4) 一、回调函数二、冒泡排序三、qsort函数3.1 使用qsort函数排序整型数据3.2 使用qsort函数排序double数据3.3 使用qsort来排序结构体数据 四、模仿qsort库函数实现通用的冒泡排序4.1 通用冒泡排序函数排序整型数据4.2 通用冒泡排…...

牟乃夏《ArcGIS Engine地理信息系统开发教程》学习笔记3-地图基本操作与实战案例
目录 一、开发环境与框架搭建 二、地图数据加载与文档管理 1. 加载地图文档(MXD) 2. 动态添加数据源 三、地图浏览与交互操作 1. 基础导航功能 2. 书签管理 3. 量测功能 四、要素选择与属性查询 1. 属性查询 2. 空间查询 五、视图同步与鹰眼…...

Spark Streaming实时数据处理实战:从DStream基础到自定义数据源集成
park-Streaming概述 Spark-Streaming是什么 Spark Streaming 用于流式数据的处理。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter等,以及和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:…...

微软GraphRAG的安装和在RAG中的使用体会
文章目录 0. 简介(1)**技术原理**(2)**优势**(3)**开源与演进** 1. 下载graphrag.git2.安装 poetry3.初始化项目:建立cases目录4. 修改.env5.修改settings.yaml,将两处 api_base改成中转站地址:…...
的使用指南)
Python学习记录7——集合set()的使用指南
文章目录 引言一、集合特性二、创建方式三、元素操作1、添加元素(1)add(element)(2)update(iterables) 2、删除元素(1)remove(element)(2)discard(element)(3)…...

apkpure 谷歌插件 下载的apk包
谷歌插件市场搜索 apkpure 然后直接搜索下载就行了 想看apk包中的静态资源,直接改apk 为zip后缀解压就行了 apple的ipa包也是相同的道理...

Android四大核心组件
目录 一、为什么需要四大组件? 二、Activity:看得见的界面 核心功能 生命周期图解 代码示例 三、Service:看不见的劳动者 两大类型 生命周期对比 注意陷阱 四、BroadcastReceiver:消息传递专员 两种注册方式 广播类型 …...

WSL2里手动安装Docker 遇坑
在 WSL2 里手动安装 Docker Engine 时遇坑:systemctl 和 service 命令在默认的 WSL2 Ubuntu 中 无法使用,因为 WSL2 没有 systemd。怎么办? 自己操作让 Docker Engine(dockerd)直接跑起来,挂到 /var/run/do…...

【ROS2】ROS开发环境配置——vscode和git
古月21讲-ROS2/1.系统架构/1.5_ROS2开发环境配置/ ROS机器人开发肯定离不开代码编写,课程中会给大家提供大量示例源码,这些代码如何查看、编写、编译 安Linux中安装装git sudo apt install git下载教程源码 《ROS2入门21讲》课程源码的下载方式&#x…...

django.db.models.query_utils.DeferredAttribute object
在 Django 中,当你看到 django.db.models.query_utils.DeferredAttribute 对象时,通常是因为你在查询时使用了 only() 或 defer() 方法来延迟加载某些字段。这两个方法允许你控制数据库查询中的字段加载方式,从而优化查询性能。 only() 方法…...

Linux内核中的编译时安全防护:以网络协议栈控制块校验为例
引言:内存安全的无声守卫者 在操作系统内核开发中,内存溢出引发的错误往往具有极高的隐蔽性和破坏性。Linux内核作为承载全球数十亿设备的基石,其网络协议栈的设计尤其注重内存安全性。本文通过分析一段看似简单的内核代码,揭示Linux如何通过编译时静态检查(Compile-Time…...
)
第11章 安全网络架构和组件(一)
11.1 OSI 模型 协议可通过网络在计算机之间进行通信。 协议是一组规则和限制,用于定义数据如何通过网络介质(如双绞线、无线传输等)进行传输。 国际标准化组织(ISO)在20世纪70年代晚期开发了开放系统互连(OSI)参考模型。 11.1.1 OSI模型的…...

Git常用命令简明教程
本教程整合并优化了Git核心命令,涵盖初始化、配置、文件操作、分支管理、远程仓库操作及常见场景,适合快速入门和日常参考。命令按使用流程分组,简洁明了,包含注意事项和最佳实践。 1. 初始化与配置 初始化Git仓库并设置基本配置…...

在 Ubuntu 24.04 系统上安装和管理 Nginx
1、安装Nginx 在Ubuntu 24.04系统上安装Nginx,可以按照下面的步骤进行: 1.1、 更新系统软件包列表 在安装新软件之前,需要先更新系统的软件包列表,确保获取到最新的软件包信息。打开终端,执行以下命令: …...
)
数据结构——二叉树和堆(万字,最详细)
目录 1.树 1.1 树的概念与结构 1.2 树相关的术语 1.3 树的表示法 2.二叉树 2.1 概念与结构 2.2 特殊的二叉树 2.2.1 满二叉树 2.2.2 完全二叉树 2.3 二叉树存储结构 2.3.1 顺序结构 2.3.2 实现顺序结构二叉树 2.3.2.1 堆的概念与结构 2.3.2. 2 堆的插入与删除数据…...

IdeaVim 配置与使用指南
一、什么是 IdeaVim? IdeaVim 是 JetBrains 系列 IDE(如 IntelliJ IDEA, WebStorm, PyCharm 等)中的一个插件,让你在 IDE 里使用 Vim 的按键习惯,大大提升效率。 安装方法: 在 IDE 中打开 设置(Settings) →…...

前端浏览器窗口交互完全指南:从基础操作到高级控制
浏览器窗口交互是前端开发中构建复杂Web应用的核心能力,本文深入探讨23种关键交互技术,涵盖从传统API到最新的W3C提案,助您掌握跨窗口、跨标签页的完整控制方案。 一、基础窗口操作体系 1.1 窗口创建与控制 // 新窗口创建(现代浏…...

考研系列-计算机组成原理第五章、中央处理器
一、CPU的功能及结构 1.运算器的基本结构 2.控制器结构...

python+flask+flask-sockerio,部署后sockerio通信异常
前言 用python开发了一个flask web服务,前端用html,前后端通过socketio通信,开发环境,windowsminicondavscode,开发完成后本地运行没有问题,然后就开始部署,噩梦就开始了。 问题描述 程序是部…...

深度解析:TextRenderManager——Cocos Creator艺术字体渲染核心类
一、类概述 TextRenderManager 是 Cocos Creator 中实现动态艺术字体渲染的核心单例类。它通过整合资源加载、缓存管理、异步队列和自动布局等功能,支持普通字符模式和图集模式两种渲染方案,适用于游戏中的动态文本(如聊天内容、排行榜&…...

同样开源的自动化工作流工具n8n和Dify对比
n8n和Dify作为两大主流工具,分别专注于通用自动化和AI应用开发领域,选择哪个更“好用”需结合具体需求、团队能力及业务场景综合判断。以下是核心维度的对比分析: 一、核心定位与适用场景 维度n8nDify核心定位开源全场景自动化工具ÿ…...
完整讲解与实战应用)
设计模式每日硬核训练 Day 16:责任链模式(Chain of Responsibility Pattern)完整讲解与实战应用
🔄 回顾 Day 15:享元模式小结 在 Day 15 中,我们学习了享元模式(Flyweight Pattern): 通过共享对象,分离内部状态与外部状态,大量减少内存开销。适用于字符渲染、游戏场景、图标缓…...

基于边缘人工智能的AI无人机-更高效更安全的飞行任务执行
基于边缘人工智能的AI无人机-更高效更安全的飞行任务执行 人工智能有可能改变人们的生活和工作方式。人工智能和无人机是近年来发展迅速的两项技术。当这两种技术结合在一起时,它们会创造出许多以前不可能的应用。基于人工智能的无人机旨在独立执行任务,…...

30、不是说字符串是不可变的吗,string s=“abc“;s=“123“不就是变了吗?
一、核心概念澄清:不可变性的真实含义 1、不可变性的定义 字符串不可变性指对象内容不可修改,而非变量不可修改。 类比: 不可变字符串 装在密封信封里的信纸(内容不可更改)变量赋值 更换信封的指向(从…...

线上查询车辆出险记录:快速掌握事故情况!
在如今汽车成为人们日常不可或缺的交通工具之际,车辆出险记录成为了许多车主关注的焦点之一。为了帮助车主们快速了解车辆出险、理赔、事故记录,现在有了一种便捷的方式,那就是通过API接口在线查询。本文将介绍如何利用API接口,通…...

Python爬虫课程实验指导书
1.1Requests类库的认知 1.1.1 认识请求类库 Requests是用Python语言编写,基于,采用Apache2 Licensed开源协议的。它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。urllibHTTP库 Requests官网地址:ht…...

streamlit实现非原生的按钮触发效果 + flask实现带信息的按钮触发
目录 简介不携带信息的触发隐藏指定st.button(label, key)触发button的html代码汇总 携带信息的触发为什么需要携带信息前端JavaScript修改flask处理总代码 简介 由于streamlit可以同时在实现前后端结合,非常方便,但是这也造成了user难以方便的对页面的…...

机器学习基础——Seaborn使用
1.使用tips数据集,创建一个展示不同时间段(午餐/晚餐)账单总额分布的箱线图 import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as snstips pd.read_csv(./tips.csv)sns.boxplot(data tips,x time,y total_bill, )plt.show() 2.使用…...

Godot开发2D冒险游戏——第三节:游戏地图绘制
一、初步构建游戏地图 在游戏场景当中添加一个新的子节点:TileMapLayer 这一层称为瓦片地图层 根据提示,下一步显然是添加资源 为TileMapLayer节点添加一个TileSet 将地板添加进来,然后选择自动分割图集 自定义时要确保大小合适 让Godot自…...

Spark Mllib 机器学习
概述 机器学习是什么 根据百度百科的定义: 机器学习是一种通过算法和模型使计算机从数据中自动学习并进行预测或决策的技术。 定义比较抽象,根据常见的机器学习可以总结出三个关键字: 算法、经验、性能。 机器学习的过程可以抽象成一个pipel…...

在windows使用docker打包springboot项目镜像并上传到阿里云
1、前提:已有spring项目 2、在项目根目录下创建Dockerfile文件 FROM openjdk:11 WORKDIR /ruoyi-admin COPY ruoyi-admin/build/libs/lifecolor-web.jar lifecolor-web.jar CMD ["java", "-jar", "lifecolor-web.jar"] 3、选…...

前端高频面试题day3
JavaScript作用域理解 核心概念 作用域:定义变量/函数的可见范围及生命周期,分为 全局作用域、函数作用域、块级作用域。作用域链:变量查找从当前作用域逐级向上直至全局,遵循词法作用域(静态作用域)。闭…...

时空特征如何融合?LSTM+Resnet有奇效,SOTA方案预测准确率超91%
LSTM有着不错的时序信息提取能力,ResNet有着不错的空间特征信息提取能力。如果现在有时空特征融合的创新需求,我们是否能将LSTM和ResNet两者的优点融合起来呢? 随着这个思路下去,LSTM ResNet混合模型横空出世,在各个…...

蓝桥杯Java全攻略:从零到一掌握竞赛与企业开发实战
蓝桥杯Java软件开发竞赛已成为全国高校学生展示编程能力的重要舞台,本指南将带您从零开始构建完整的Java知识体系,不仅覆盖蓝桥杯高频考点,还延伸至企业级开发实战,助您在竞赛中脱颖而出并为未来职业发展奠定坚实基础。 一、Java基础语法与数据结构 竞赛解题流程图设计 蓝…...